EN71-9 table
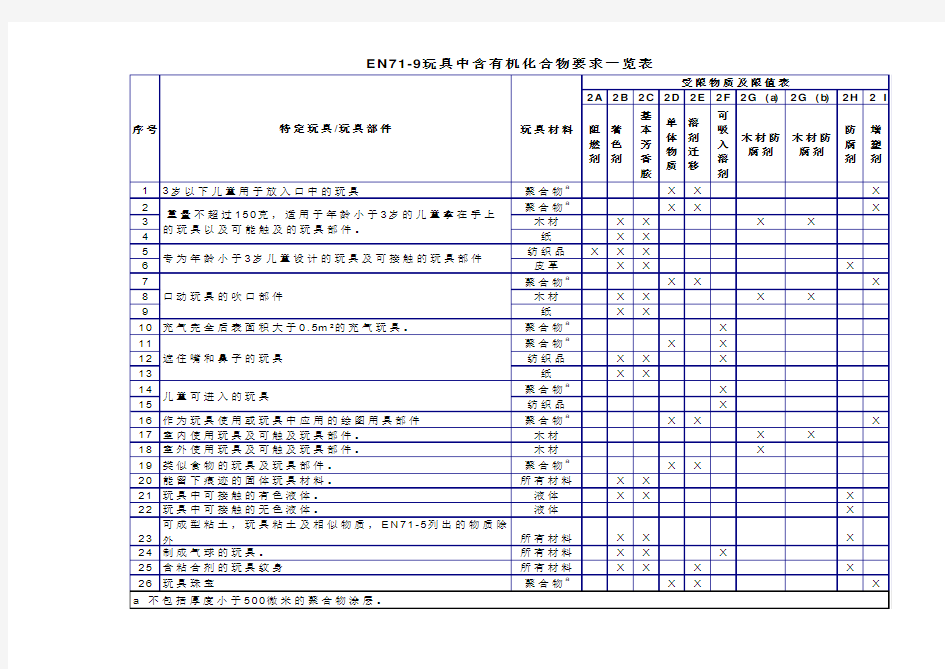

E N71-9玩具中含有机化合物要求一览表
BigTable论文笔记
BigTable论文笔记 2014年5月21日 10:01 简介 Bigtable是一个分布式结构化数据存储系统。bigtable实现为一个多维的map (可理解为一个四维的表:rowkey、 column family、 column、 timestamp):(row:string, column:string,time:int64)->string。BigtTable中数据表的一个片段如图所示: 组件 Master 1.创建表、删除表、调整表结构(列族) 2.记录活跃的tablet 3.为tablet服务器分配tablet 4.记录了哪些tablet在哪些tablet server上 5.记录还有哪些tablet没有分配 6.检测新加入的或者过期失效的Table服务器 7.对tablet服务器进行负载均衡 8.对gfs上的文件进行垃圾回收 Tablet Server 一个BigTable集群存储了很多表,每个表包含了一个Tablet的集合,而每个Tablet 包含了某个范围内的行的所有相关数据。初始状态下,一个表只有一个Tablet。随着表中数据的增长,它被自动分割成多个Tablet,缺省情况下,每个Tablet的尺寸大约是 100MB到200MB。 tablet servet的功能如下: 1.管理由master分配的一组tablet 2.处理对这些tablet的读写操作 3.当tablet过大时,进行分割(然后由master确定分割后的两个新的tablet有哪 些tablet服务器接管)。 Client 客户端使用bigtable提供的库对bigtable进行访问,有两种形式的客户端:cli (command line interface )和java api。客户端会缓存Tablet的位置信息以提高 读写效率。 对其他组件的依赖 1.bigtable依赖gfs存储数据和日志文件。
云计算_知识点2
1 云计算的计算模式为( B/C ). 2(分布式)是公有云计算基础架构的基石。 3(虚拟化)是私有云计算基础架构的基石。 4(并行计算)是一群同构处理单元的集合,这些处理单元通过通信和协作来更快地解决大规模计算问题 5(集群)在许多情况下,能够达到99.999%的可用性。 6 网格计算是利用(因特网)技术,把分散在不同地理位置的计算机组成一台虚拟超级计算机。 7 B/S网站是一种(3层架构)的计算模式。 8 云计算就是把计算资源都放到上(因特网)。 9(云用户端)提供云用户请求服务的交互界面,也是用户使用云的入口,用户通过Web浏览器可以注册、登录及定制服务、配置和管理用户。打开应用实例与本地操作桌面系统一样。 10(服务目录)帮助云用户在取得相应权限(付费或其他限制)后可以选择或定制的服务列表,也可以对已有服务进行退订的操作,在云用户端界面生成相应的图标或列表的形式展示相关的服务。 11(管理系统和部署工具)提供管理和服务,能管理云用户,能对用户授权、认证、登录进行管理,并可以管理可用计算资源和服务,接收用户发送的请求,根据用户请求并转发到相应的相应程序,调度资源智能地部署资源和应用,动态地部署、配置和回收资源。12(监控端)监控和计量云系统资源的使用情况,以便做出迅速反应,完成节点同步配置、负载均衡配置和资源监控,确保资源能顺利分配给合适的用户。 13(服务器集群)提供虚拟的或物理的服务器,由管理系统管理,负责高并发量的用户请求处理、大运算量计算处理、用户Web应用服务,云数据存储时采用相应数据切割算法采用并行方式上传和下载大容量数据。 14用户可通过(云用户端)从列表中选择所需的服务,其请求通过管理系统调度相应的资源,并通过部署工具分发请求、配置Web应用。 15 在云计算技术中,(中间件)位于服务和服务器集群之间,提供管理和服务即云计算体系结构中的管理系统。 16虚拟化资源指一些可以实现一定操作具有一定功能,但其本身是(虚拟)的资源,如计算池,存储池和网络池、数据库资源等,通过软件技术来实现相关的虚拟化功能包括虚拟环境、虚拟系统、虚拟平台。 17SaaS是(软件即服务)的简称。 18 PAAS是(平台即服务)的简称。 19 IaaS是(基础设施即服务)的简称。 20虚拟化层对应(硬件即服务)结合Paas提供硬件服务,包括服务器集群及硬件检测等服务。 21虚拟机最早在(20世纪70年代)由IBM研究中心研制。 22利用公共网络来构建的私人专用网络称为(VPN)。 23OSI模型共(7 )。 24(IAAS )是指用户可通过Internet获取IT基础设施硬件资源。 25(RAID5 )有校验数据,提供数据容错能力 26基于光纤交换机的(SAN )是利用Fibre Channel Switch为主干,建成的交连网络系统。
大数据处理框架选型分析
大数据处理框架选型分析
前言 说起大数据处理,一切都起源于Google公司的经典论文:《MapReduce:Simplied Data Processing on Large Clusters》。在当时(2000年左右),由于网页数量急剧增加,Google公司内部平时要编写很多的程序来处理大量的原始数据:爬虫爬到的网页、网页请求日志;计算各种类型的派生数据:倒排索引、网页的各种图结构等等。这些计算在概念上很容易理解,但由于输入数据量很大,单机难以处理。所以需要利用分布式的方式完成计算,并且需要考虑如何进行并行计算、分配数据和处理失败等等问题。 针对这些复杂的问题,Google决定设计一套抽象模型来执行这些简单计算,并隐藏并发、容错、数据分布和均衡负载等方面的细节。受到Lisp和其它函数式编程语言map、reduce思想的启发,论文的作者意识到许多计算都涉及对每条数据执行map操作,得到一批中间key/value对,然后利用reduce操作合并那些key值相同的k-v对。这种模型能很容易实现大规模并行计算。 事实上,与很多人理解不同的是,MapReduce对大数据计算的最大贡献,其实并不是它名字直观显示的Map和Reduce思想(正如上文提到的,Map和Reduce思想在Lisp等函数式编程语言中很早就存在了),而是这个计算框架可以运行在一群廉价的PC机上。MapReduce的伟大之处在于给大众们普及了工业界对于大数据计算的理解:它提供了良好的横向扩展性和容错处理机制,至此大数据计算由集中式过渡至分布式。以前,想对更多的数据进行计算就要造更快的计算机,而现在只需要添加计算节点。 话说当年的Google有三宝:MapReduce、GFS和BigTable。但Google三宝虽好,寻常百姓想用却用不上,原因很简单:它们都不开源。于是Hadoop应运而生,初代Hadoop的MapReduce和
最新Bigtable 结构化数据的分布式存储系统 上
B i g t a b l e结构化数据的分布式存储系统 上
Bigtable 结构化数据的分布式存储系 统上 转载请注明:作者phylips@bmy 摘要 Bigtable是设计用来管理那些可能达到很大大小(比如可能是存储在数千台服务器上的数PB的数据)的结构化数据的分布式存储系统。Google的很多项目都将数据存储在Bigtable中,比如网页索引,google地球,google金融。这些应用对Bigtable提出了很多不同的要求,无论是数据大小(从单纯的URL到包含图片附件的网页)还是延时需求。尽管存在这些各种不同的需求,Bigtable成功地为google的所有这些产品提供了一个灵活的,高性能的解决方案。在这篇论文中,我们将描述Bigtable所提供的允许客户端动态控制数据分布和格式的简单数据模型,此外还会描述Bigtable的设计和实现。 1.导引 在过去的2年半时间里,我们设计,实现,部署了一个称为Bigtable的用来管理google的数据的分布式存储系统。Bigtable的设计使它可以可靠地扩展到成PB的数据以及数千台机器上。Bigtable成功的实现了这几个目标:广泛的适用性,可扩展性,高性能以及高可用性。目前,Bigtable已经被包括Google分析,google金融,Orkut,个性化搜索,Writely和google地球在内的60多个google产品和项目所使用。这些产品使用Bigtable用于处理各种不同的工作负载类型,从面向吞吐率的批处理任务到时延敏感的面向终端用户的数据服务。这些产品所使用的Bigtable集群也跨越了广泛的配置规模,从几台机器到存储了几百TB数据的上千台服务器。
大数据平台技术框架选型
大数据平台框架选型分析 一、需求 城市大数据平台,首先是作为一个数据管理平台,核心需求是数据的存和取,然后因为海量数据、多数据类型的信息需要有丰富的数据接入能力和数据标准化处理能力,有了技术能力就需要纵深挖掘附加价值更好的服务,如信息统计、分析挖掘、全文检索等,考虑到面向的客户对象有的是上层的应用集成商,所以要考虑灵活的数据接口服务来支撑。 二、平台产品业务流程 三、选型思路 必要技术组件服务: ETL >非/关系数据仓储>大数据处理引擎>服务协调>分析BI >平台监管 四、选型要求 1.需要满足我们平台的几大核心功能需求,子功能不设局限性。如不满足全部,需要对未满足的其它核心功能的开放使用服务支持 2.国内外资料及社区尽量丰富,包括组件服务的成熟度流行度较高 3.需要对选型平台自身所包含的核心功能有较为深入的理解,易用其API或基于源码开发4.商业服务性价比高,并有空间脱离第三方商业技术服务 5.一些非功能性需求的条件标准清晰,如承载的集群节点、处理数据量及安全机制等 五、选型需要考虑 简单性:亲自试用大数据套件。这也就意味着:安装它,将它连接到你的Hadoop安装,集成你的不同接口(文件、数据库、B2B等等),并最终建模、部署、执行一些大数据作业。自己来了解使用大数据套件的容易程度——仅让某个提供商的顾问来为你展示它是如何工作是远远不够的。亲自做一个概念验证。 广泛性:是否该大数据套件支持广泛使用的开源标准——不只是Hadoop和它的生态系统,还有通过SOAP和REST web服务的数据集成等等。它是否开源,并能根据你的特定问题易于改变或扩展是否存在一个含有文档、论坛、博客和交流会的大社区 特性:是否支持所有需要的特性Hadoop的发行版本(如果你已经使用了某一个)你想要使用的Hadoop生态系统的所有部分你想要集成的所有接口、技术、产品请注意过多的特性可能会大大增加
HBase与BigTable的比较
HBase与BigTable的比较 HBase是Google的BigTable架构的一个开源实现。但是我个人觉得,要做到充分了解下面两点还是有点困难的:一HBase涵盖了BigTable规范的哪些部分?二HBase与BigTable仍然有哪些区别?下面我将对这两个系统做些比较。在做比较之前,我要指出一个事实:HBase是非常接近BigTable论文描述的东西。撇开一些细微的不同,比如HBase 0.20使用ZooKeeper做它的分布式协调服务,HBase已经基本实现了BigTable所有的功能,所以我下面的篇幅重点落在它们细微的区别上,当然也可以说是HBase 小组正在努力改进的地方上。比较范围本文比较的是基于七年前发表的论文(OSDI’06)所描叙的Google BigTable系统,该系统从2005年开始运作。就在论文发表的2006年末到2007年初,作为Hadoop的子项目的HBase 也产生了。在那时,HBase的版本是0.15.0. 如今大约2年过去了,Hadoop 0.20.1和HBase 0.20.2都已发布,你当然希望有一些真正的改进。要知道我所比较的是一篇14页的技术论文和一个从头到脚都一览无余的开源项目。所以下面的比较内容里关于HBase怎么做的讲得比较多点。在文章的结尾,我也会讨论一些BigTable的如今的新功能,以及HBase跟它们比较如何。好,我们就从术语开始。术语有少
数几个不同的术语被两个系统用来描述同样的事物。最显著的莫过于HBase中的regions和BigTable中的tablet。自然地,它们各自把一连串的行(Rows)切分交给许多Region server或者tablet server管理。特性比较接下来的就是特性比较列表,列表中是BigTable跟HBase的特性比较。有的是一些实现细节,有的是可配置的选项等。让人感到有困惑的是,将这些特性分类很难。特性 BigTable HBase 说明读/ 写/ 修改的原子性 支持,每行 支持,每行 因为BigTable 不像关系型数据库,所以不支持事务。最接近事务的就是让对每行数据访问具有原子性。HBase 同样实现了”行锁”的API ,让用户访问数据时给一行或者几行数据加锁。词典顺序的行排序 支持 支持
大数据即服务DaaS以及大大数据
大数据技术发展态势跟踪 ——关于大数据的几个重要观点和产业技术路线发展 2014-8-14 11:50:31 文章来源:科技发展研究杂志 大数据(Big Data),普遍认为是指在特定行业中,超出常规处理能力、实时生成、类型多样化的数据集合体,具有海量(Volume)、快速(Velocity)、多样(Variety)和价值(Value)的4V 特征。 最早提出大数据特征的是2001 年麦塔集团(后被Gartner 公司收购)分析师道格?莱尼(Douglas Laney)发布的《3D 数据管理:控制数据容量、处理速度及数据种类》(3D Data Management: ControllingData Volume, Velocity and Variety),提出了4V 特征中的3V。最早提出词汇“Big Data”的是2011 年麦肯锡全球研究院发布的《大数据:下一个创新、竞争和生产力的前沿》研究报告。之后,经Gartner 技术炒作曲线和2012 年维克托?舍恩伯格《大数据时代:生活、工作与思维的大变革》的宣传推广,大数据概念开始风靡全球。 一、关于大数据的几个重要观点 大数据发展至今,伴随着很多争议。有人称之为“新瓶装旧酒”,也有人认为大数据的机遇被过于夸大,企业就是在这种怀疑和忐忑中抓紧推进大数据应用。客观上看,大数据在研究式、企业战略层面具有变革的潜力,但不宜过于强调其新颖性,不应同过去的数据学科领域割裂开来;21 世纪以来,大数据技术发生了革命性突破,主要体现在对3V 特性的“适应”和“运用”上,目前受益最大的是云计算产业,对其他产业和社会发展的变革作用尚未落地。 有如下几个重要判断和观点: 1、大数据的核心思想本质是数据挖掘。数据挖掘(Data Mining)借助计算机从海量数据中发现隐含的知识和规律,是一门融合了计算机、统计等领域知识的交叉学科,其核心的人工智能、机器学习、模式识别等理论在上世纪90 时代推行知识管理时已有显著进展。从本质上看,大数据带来的“思维大变革”以及一些数据驱动类的商业智能(Business Intelligence)模式创新,都是数据挖掘理论的延伸,表达为“数据挖掘相对于数理统计带来的思维变革”或许更加准确。比如,因果关系是数理统计中的重要容,基于完善的数学理论,代表是回归模型;而相关关系是数据挖掘中的重要容,基于强大的机器运算能力,代表是神经网络、决策树算法,这使得人们不需要了解背后复杂的因果逻辑也可以获得良好的分析和预测结果。从某种程度上说,必须感谢大数据的宣传者,正是这样的热炒才让数据挖掘这样一门小众却极具价值的科学展现在大众眼前,起到了很好的科普作用。 2、突破主要来自技术上的“能力拓展”。表现在对多样(Variety)、海量(Volume)、快速(Velocity)特征的“适应”和“运用”上:一是存储数据从结构化向半结构化、非结构化拓展,如基于Web 异构环境下的网页、文档、报表、多媒体等,导致了一批基于非结构化数据的专有挖掘算法的产生和发展。二是数据库从关系型向非关系型、分布式拓展,关系型数据库是以行和列的形式组织起来的结构化数据表,如Excel 表格,缺点在于存储容量小、数据扩展性和多样性差,而新的非关系型、分布式数据库可以弥补上述不足。三是数据处理从静态向实时交互拓展,新的大规模分布式并行数据处理技术能够实时处理社交媒体和物联网应用产生的大量交互数据,有效应对多样(Variety)和海量(Volume)带来的复
用BigTable的原则和关系数据库的原则比较
用BigTable的原则和关系数据库的原则比较 2008-06-30 13:05 在infoq看到这一篇优化使用BigTable的原则与方针,觉得对做大规模数据库设计时有很大参考作用,特拿来与关系型数据库做一下比较。 Todd从定义BigTable的适用范围开始论述。由于BigTable引入的各种代价,只有在以下情况下使用BigTable才能带来益处: a)需要伸缩到巨量的用户数,b)更新与读取操作相比比例很小。Todd还着重强调为了“优化读取速度和可伸缩性”,所采取的理论路线与关系数据库中的做法存在根本的分歧,很可能初看起来是违背直觉甚至相当冒险的。 关系数据库的世界是以防止错误为根基的;以正规化(normalization)为工具消除重复和防止更新异常。为了提高可伸缩性,数据应该重复而非正规化。Flickr 久悬着了这种路线,决定让“评论重复出现于评论者和被评论者两个用户数据分片中,而非单独建立一个评论关系”,因为“如果把用户数据分片作为可伸缩性的单元,就没有地方放置这种关系”。因此,虽然去正规化(denormalization)违背了“关系数据的伦理”,但它是BigTable数据范式不可缺少的组成部分。 ==>其实很多时候在做系统设计时,为了应付将来可能的大规模情况,根本都不考虑数据库里面的那些范式要求,一切的目的都是为了可扩展性和性能。比如把复杂的字段合并在一起变成id=>data的结构,设计很大的数据冗余,外键约束也很少考虑,类似join这种关系型数据库特性基本不用......为了可扩展性和性能,无所不用其极,而关系型数据库本身的一些设计范式倒放到一边了。有时以后用数据库只是因为数据库提供了缓存、数据文件管理、并发、基本的数据格式管理、复制备份、Cluster等必不可少基础特性,即使有时候关系数据库系统不足以发挥系统的最大效能,使用它也算是性价比很高的一种方案。 在以上论述的基础上,Todd针对优化使用BigTable存储系统总结了若干必须牢记的原则: 假定数据访问是较慢的随机访问而非较快的连续访问。 因为“在BigTable里数据可能放在任何地方[……],平均读取时间可能相对较高”。 ==>在数据库里一般数据的扫描加载,原理上都是从前往后逐行筛选得到结果的,但是由于数据在物理硬盘上实际不一定连续,所以最终差不多都是随机访问数据,真正连续访问的情况很少。而按照BigTable的原则,它的数据你只能认为随机存放、随机访问,必须针对这种特性来设计。平均读取时间可能相对较高(这个我认为还是要看最终系统设计的好坏)
BigTable
1 什么是BigTable Bigtable是一个为管理大规模结构化数据而设计的分布式存储系统,可以扩展到PB级数据和上千台服务器。很多google的项目使用Bigtable存储数据,这些应用对Bigtable提出了不同的挑战,比如数据规模的要求、延迟的要求。Bigtable能满足这些多变的要求,为这些产品成功地提供了灵活、高性能的存储解决方案。 Bigtable看起来像一个数据库,采用了很多数据库的实现策略。但是Bigtable 并不支持完整的关系型数据模型;而是为客户端提供了一种简单的数据模型,客户端可以动态地控制数据的布局和格式,并且利用底层数据存储的局部性特征。Bigtable将数据统统看成无意义的字节串,客户端需要将结构化和非结构化数据串行化再存入Bigtable。 下文对BigTable的数据模型和基本工作原理进行介绍,而各种优化技术(如压缩、Bloom Filter等)不在讨论范围。 2 BigTable的数据模型 Bigtable不是关系型数据库,但是却沿用了很多关系型数据库的术语,像table (表)、row(行)、column(列)等。这容易让读者误入歧途,将其与关系型数据库的概念对应起来,从而难以理解论文。Understanding HBase and BigTable 是篇很优秀的文章,可以帮助读者从关系型数据模型的思维定势中走出来。 本质上说,Bigtable是一个键值(key-value)映射。按作者的说法,Bigtable 是一个稀疏的,分布式的,持久化的,多维的排序映射。 先来看看多维、排序、映射。Bigtable的键有三维,分别是行键(row key)、列键(column key)和时间戳(timestamp),行键和列键都是字节串,时间戳是64位整型;而值是一个字节串。可以用(row:string, column:string, time:int64)→string来表示一条键值对记录。 行键可以是任意字节串,通常有10-100字节。行的读写都是原子性的。Bigtable 按照行键的字典序存储数据。Bigtable的表会根据行键自动划分为片(tablet),片是负载均衡的单元。最初表都只有一个片,但随着表不断增大,片会自动分裂,片的大小控制在100-200MB。行是表的第一级索引,我们可以把该行的列、时间和值看成一个整体,简化为一维键值映射,类似于:
云计算第二章总结
Google云计算技术包括: Google文件系统GFS、分布式计算编程模型MapReduce、分布式锁服务Chubby、分布式结构化数据表Bigtable。 简述谷歌文件系统GFS: GFS是一个大型的分布式文件系统,它为Goole云计算提供海量存储,并且与Chubby、MapReduce及Bigtable等技术结合十分紧密,处于所有核心技术的底层。 GFS将整个系统的节点分为哪几类角色: Client(客户端)、Master(主服务器)、Chunk Server(数据块服务器)。 Master是GFS的管理节点,在逻辑上只有一个,他保存系统的元数据,负责整个文件系统的管理,是GFS文件系统中的“大脑”。 Chunk Server负责具体的存储工作。数据以文件的形式存储在Chunk Server 的个数可以有多个,他的数目直接决定了GFS的规模。GFS将文件按照固定大小进行分块,默认是64MB,每一块称为一个Chunk(数据块),每个Chunk都有一个对应的索引号(Index)。 GFS具有哪些特点: 1、采用中心服务器模式:GFS采用中心服务器模式管理整个文件系统,增加新的Chunk Server是一件非常容易的事情。 2、不缓存数据:缓存机制是提升文件系统的性能的一个重要手段,通用文件系统为了提高 性能,一般需要实现复杂的缓存机制。GFS文件系统根据应用的特点,没有实现缓存,因为GFS的数据在Chunk Server上是以文件的形式存储。 3、在用户态下实现 4、只提供专用接口 GFS容错机制包含: 1、Master容错: Master上保存了GFS文件系统的三种元数据。 (1)、命名空间,也就是整个文件系统的目录结构。 (2)、Chunk与文件名的映射表 (3)、Chunk副本的位置信息,每一个Chunk默认有三个副本。 前两种GFS通过操作日志来提供容错功能。第三种直接保存各个Chunk Server上,当master发生故障时,迅速恢复以上元数据。为了防止master彻底死机,GFS提供了master 远程的实时备份。 2、Chunk Server容错: GFS采用副本的方式实现其容错。如果相关副本丢失或不可恢复,master自动将副本复制到其他Chunk Server. GFS把每一个文件划分成多个Chunk, GFS系统管理技术: 1、大规模集群安装技术 2、故障检测技术 3、节点动态加入技术 4、节能技术
云计算与大数据处理技术
云计算与大数据处理技术 今天,随着IT规模越来越大,数据规模呈几何级数增长,已经超出了传统技术方法所能解决的范畴。为此,人们把目光转向了刚刚兴起的云计算,希望通过云计算来实施海量数据处理解决方案,实现以更小的成本来处理更大规模数据的目标,并成为目前云计算应用所面对的极大挑战。本课程基本思想如下:1,目前,“云计算”已经不是一个刚刚流行的时髦概念了,在一些传统IT 方法显得无能为力的场合,云计算正在开始大展拳脚,表现了强大的解决问题的能力,海量数据存储与处理正是属于这种场合。我们如何在云计算分布式环境下正确设计大数据量数据模型?如何在设计中解决资源、效率、安全性、可靠性等一系列极难平衡的问题?如何通过云计算帮助我们解决在传统IT技术中看似解决不了的敏感问题?这些都是我们在云计算架构设计中需要深入研究的键问题。 2,理解问题最好的方法是分析成功案例,本课程分别从多个角度分析在面对海量数据处理的困难时,不同的应用体系是如何解决问题并获得成功的。研究这些已有的体系不是目的,而是希望学员能够通过学习这些解决问题的方法和思路,通过归纳整理深入理解,再根据自己所面对的领域特征,形成解决具体实际问题的方案。这也是让云计算在海量数据处理领域真正发挥作用的有效途径。 3,云计算是一种服务,在云计算应用架构设计中,就必须考虑作为服务与普通的产品设计有哪些不同?需要考虑的产品的服务特征有哪些?如何搭建面向不同层次、合适的服务平台?在这个过程中,我们需要考虑哪些问题?有哪些成功的案例?有些什么解决方案?
4,云计算应用最重要的问题是安全问题。安全不是一个后期需要解决的独立问题,而是在前期就需要投入巨大精力来考虑的产品策略。可以说,安全性与可用性是云计算能否顺利实施与应用的关键点,也是云计算架构设计的关键因素。我们应该如何考虑安全问题?如何解决诸如数据安全、网络安全、主机安全、数据管理以及灾难恢复等一系列问题?如何制定合适的安全性与可用性策略?在 实践中有什么经验和教训? 5,为了把传统数据中心改造为基于云计算的服务系统,虚拟化是一个重要手段。我们必须深入研究虚拟化技术是如何实现的。虚拟化技术有哪几个层面的问题?如何正确应用虚拟化技术来实现把基础设施向服务转型?各种虚拟化技 术有些什么优点?有哪些陷阱?如何规划技术解决方案?如何正确进行云计算 体系结构设计? 本课程不是一个泛泛的理论性、概念性的介绍课程,而是针对问题讨论解决方案的深入课程。教师对于上述领域有深入的理论研究与实践经验,在课程中将会针对这些问题与学员一起进行研究,在关键点上还会搭建实验环境进行实践研究,以加深对于这些解决方案的理解。通过本课程学习,希望推动国内云计算项目开发上升到一个新水平。 云计算与大数据处理技术 第一讲云计算的概念与现状 1)云计算的概念 2)云计算发展现状 3)云计算实现机制 4)云计算的发展环境
谷歌经典论文BigTable翻译
前记 几年前在读Google的BigTable论文的时候,当时并没有理解论文里面表达的思想,因而囫囵吞枣,并没有注意到SSTable的概念。再后来开始关注HBase的设计和源码后,开始对BigTable 传递的思想慢慢的清晰起来,但是因为事情太多,没有安排出时间重读BigTable的论文。在项目里,我因为自己在学HBase,开始主推HBase,而另一个同事则因为对Cassandra比较感冒,因而他主要关注Cassandra的设计,不过我们两个人偶尔都会讨论一下技术、设计的各种观点和心得,然后他偶然的说了一句:Cassandra和HBase都采用SSTable格式存储,然后我本能的问了一句:什么是SSTable?他并没有回答,可能也不是那么几句能说清楚的,或者他自己也没有尝试的去问过自己这个问题。然而这个问题本身却一直困扰着我,因而趁着现在有一些时间深入学习HBase和Cassandra相关设计的时候先把这个问题弄清楚了。 SSTable的定义 要解释这个术语的真正含义,最好的方法就是从它的出处找答案,所以重新翻开BigTable的论文。在这篇论文中,最初对SSTable是这么描述的(第三页末和第四页初): SSTable The Google SSTable file format is used internally to store Bigtable data. An SSTable provides a persistent, ordered immutable map from keys to values, where both keys and values are arbitrary byte strings. Operations are provided to look up the value associated with a specified key, and to iterate over all key/value pairs in a specified key range. Internally, each SSTable contains a sequence of blocks (typically each block is 64KB in size, but this is configurable). A block index (stored at the end of the SSTable) is used to locate blocks; the index is loaded into memory when the SSTable is opened. A lookup can be performed with a single disk seek: we first find the appropriate block by performing a binary search in the in-memory index, and then reading the appropriate block from disk. Optionally, an SSTable can be completely mapped into memory, which allows us to perform lookups and scans without touching disk. 简单的非直译: SSTable是Bigtable内部用于数据的文件格式,它的格式为文件本身就是一个排序的、不可变的、持久的Key/Value对Map,其中Key和value都可以是任意的byte字符串。使用Key来查找Value,或通过给定Key范围遍历所有的Key/Value对。每个SSTable包含一系列的Block (一般Block大小为64KB,但是它是可配置的),在SSTable的末尾是Block索引,用于定位Block,这些索引在SSTable打开时被加载到内存中,在查找时首先从内存中的索引二分查找找到Block,然后一次磁盘寻道即可读取到相应的Block。还有一种方案是将这个SSTable加载到内存中,从而在查找和扫描中不需要读取磁盘。 这个貌似就是HFile第一个版本的格式么,贴张图感受一下: