基于Hadoop的分布式主题网络爬虫研究_李应

基于Hadoop的分布式主题网络爬虫研究
李 应
(西安工程大学计算机科学学院,陕西西安710048
)摘 要:主题网络爬虫采用集中式体系结构,
具有对单台服务器性能要求高、可扩展性差等缺点。提出了一种基于Hadoop的分布式主题网络爬虫架构,通过将主题网络爬虫部署在分布式集群中的不同机器,运用MapReduce编程模型对数据进行抓取分析,使不同机器共同完成对指定任务的抓取工作。实验证明,采用分布式架构,通过动态调节分布式集群中的节点个数,能够明显改善主题网络爬虫的抓取效果。关键词:Hadoop;Map
Reduce;分布式架构;主题网络爬虫DOI:10.11907/rj
dk.1511459中图分类号:TP301.6 文献标识码:A 文章编号:1672-7800(2016)003-0024-
03作者简介:李应(1989-)
,男,陕西礼泉人,西安工程大学计算机科学学院硕士研究生,研究方向为大数据、分布式系统、智能搜索、自然语言处理。
0 引言
互联网资源正在以指数级快速增长,
如何能够快速获取网络资源已经成为广大用户的一项基本需求。通用网络爬虫由于是对互联网全网资源的获取,因此其获取的资源范围涉及各个领域,这对于想要获得某个专业领域资源的用户带来不便。主题网络爬虫的出现使获取的网络资源具有更强的针对性,在一定程度上解决了用户的专业性需求,用户能够快速、准确地得到想要的资源。
对于拥有庞大数据量的网络资源,采用集中式服务体系结构有许多不可避免的缺点,如对于单台服务器性能要求高、数据的可维护性与可扩展性差等。分布式体系结构能够明显改善集中式体系结构中的问题,具有可扩展性强、成本低、数据不易丢失等众多优点。
本文利用分布式体系结构的优点,将主题网络爬虫与Hadoop分布式开源框架相结合,提出了一种基于Hadoop
的分布式主题网络爬虫架构。
1 相关概念介绍
1.1 Hadoop分布式文件系统(
HDFS)HDFS[
1-2]是Hadoop的核心组件之一,
是一个可扩展的分布式文件系统。HDFS可以运行在廉价的普通计
算机上,具有良好的容错能力,并且能够提供更高性能的服务。Hadoop的HD
FS对普通用户来说是透明的,用户可以像操作个人计算机一样在HDFS上添加、
删除数据等。在HDFS中有3个重要角色:NameNode、DataNode以及Client。其中,N
ameNode用来存储文件的元数据信息,包括文件名、文件所有者、文件权限等;DataNode是真正用来存放用户数据的位置,所有数据都保存在DataN-ode上,
并用冗余机制来保证数据的安全性。图1给出了HD
FS的读写数据流程
。图1 HDFS读写数据流程
1.2 Hadoop分布式计算框架(Map
Reduce)Map
Reduce[
3-4]是一种分布式编程模型,整个Ma-p
Reduce采用“分而治之”的思想。MapReduce首先将大规模数据任务进行分割,其次将分割后的子任务交给不同
的节点完成,待各个子节点完成相应的子任务分析或者计算后,将各个子节点的处理结果进行汇总,得到最终结果。在Hadoop的Map
Reduce编程模型中,包含JobTracker和TaskTracker两个重要角色。JobTracker用来进行任务分解,分解的子任务交给每个Tasktracker去完成。
Hadoop中每一个MapReuce任务都要处理成一个Job,在该Job中分为Map和Reduce两个阶段,Map阶段负责各个子任务的分析处理,Reduce用来将子任务的处理结果进行合并。图2给出了Map
Reduce的处理流程
。图2 Map
Reduce处理流程1.3 主题网络爬虫
主题网络爬虫[5-6]
的爬取流程与通用爬虫流程大体
相似,主要区别在于主题网络爬虫抓取的网页都与某个主题领域有关,在网络爬虫抓取过程中,只有与设定主题相关的网页才会被抓取。主题网络爬虫的分析算法要去除与主题无关的网页,将与主题相关的链接加入待抓取URL队列中,
然后根据选取的搜索策略从待抓取队列中选择要抓取的网页,一直重复该过程,直到满足爬虫停止条件为止。图3给出了主题网络爬虫的抓取流程
。
图3 主题网络爬虫抓取流程
2 分布式主题网络爬虫设计与实现
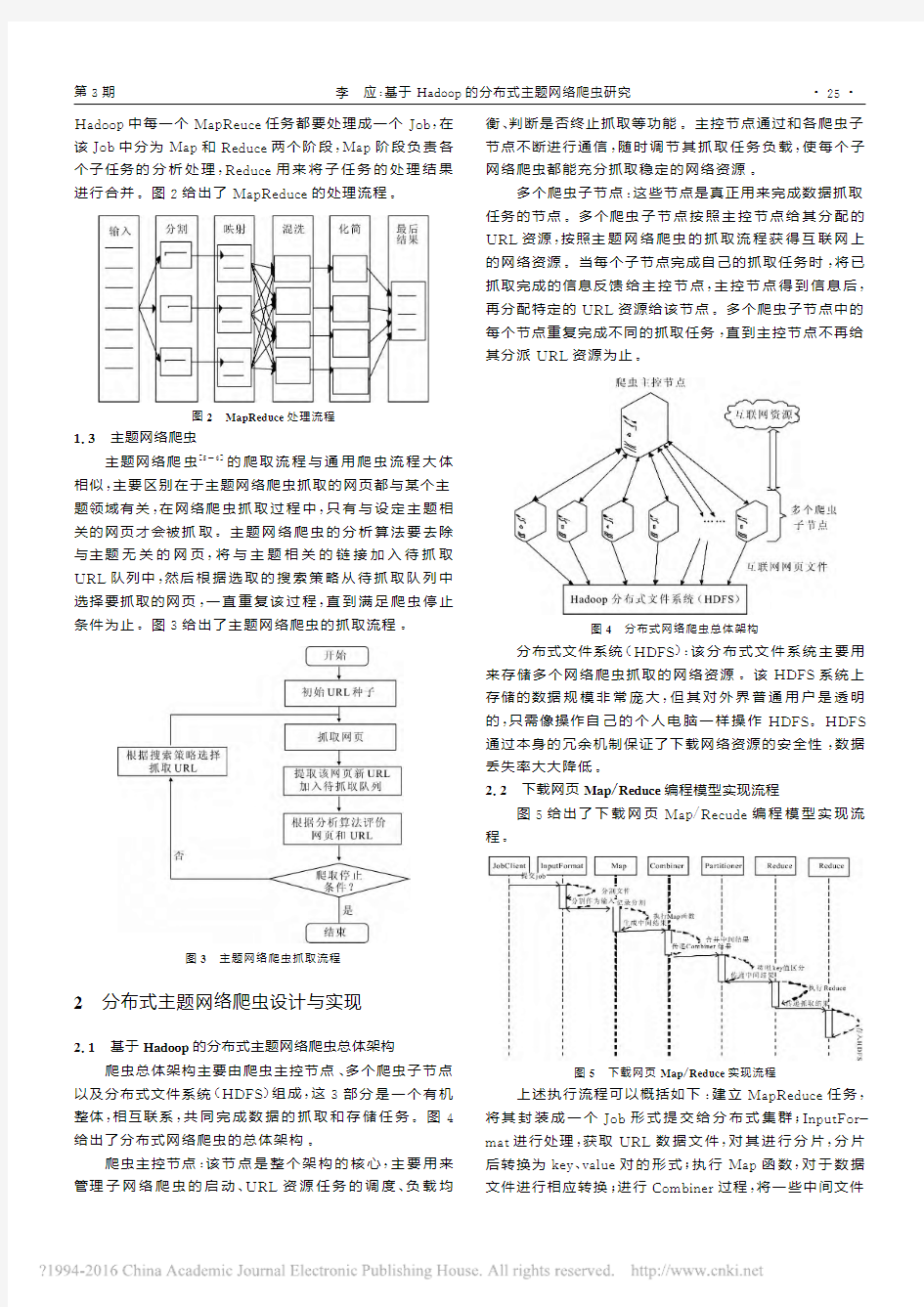
2.1 基于Hadoop的分布式主题网络爬虫总体架构
爬虫总体架构主要由爬虫主控节点、多个爬虫子节点以及分布式文件系统(HDFS)组成,这3部分是一个有机整体,相互联系,共同完成数据的抓取和存储任务。图4给出了分布式网络爬虫的总体架构。
爬虫主控节点:该节点是整个架构的核心,主要用来管理子网络爬虫的启动、UR
L资源任务的调度、负载均衡、判断是否终止抓取等功能。主控节点通过和各爬虫子节点不断进行通信,随时调节其抓取任务负载,使每个子网络爬虫都能充分抓取稳定的网络资源。
多个爬虫子节点:这些节点是真正用来完成数据抓取任务的节点。多个爬虫子节点按照主控节点给其分配的URL资源,
按照主题网络爬虫的抓取流程获得互联网上的网络资源。当每个子节点完成自己的抓取任务时,将已抓取完成的信息反馈给主控节点,主控节点得到信息后,再分配特定的URL资源给该节点。多个爬虫子节点中的每个节点重复完成不同的抓取任务,直到主控节点不再给其分派URL资源为止
。
图4 分布式网络爬虫总体架构
分布式文件系统(HDFS):该分布式文件系统主要用来存储多个网络爬虫抓取的网络资源。该HDFS系统上
存储的数据规模非常庞大,但其对外界普通用户是透明的,只需像操作自己的个人电脑一样操作HDFS。HDFS通过本身的冗余机制保证了下载网络资源的安全性,数据丢失率大大降低。
2.2 下载网页Map
/Reduce编程模型实现流程图5给出了下载网页Map/Recude编程模型实现流程
。
图5 下载网页Map
/Reduce实现流程上述执行流程可以概括如下:建立MapReduce任务,将其封装成一个Job形式提交给分布式集群;InputFor-mat进行处理,获取URL数据文件,
对其进行分片,分片后转换为key、value对的形式;执行Map函数,对于数据文件进行相应转换;进行Combiner过程,
将一些中间文件·
52·第3期 李 应:基于Hadoop的分布式主题网络爬虫研究
合并,以减少Reduce阶段的复杂度;Partitioner过程对上一步得到的结果进行分区,可以使服务器下载同一台服务器上的URL;Reduce过程对得到的数据结果进行合并,下载的最终结果保存在HDFS中;OutputFormat过程对数据的输出格式进行处理,以便数据的规范化。
3 实验结果及分析
实验环境:实验采用8台普通PC机搭建Hadoop分布式集群,每台PC机都装有64bit linux系统,机器硬盘大小都为500G,内存为4G。其中一台机器作为NameNode,另外7台作为DataNode,Hadoop版本为1.
2.1。实验要抓取的主题为新闻信息,以新浪官方网站ht-tp
://www.sina.com为URL种子,让主题网络爬虫去下载相关新闻网页。图6给出了网页下载速度随节点数目变化的柱状图,从图中可以看出,随着数据节点个数的增加,下载网页的速度不断加快。因此,在采用分布式架构的网络爬虫体系结构下,通过扩展数据节点,可优化爬虫系统的性能,为数据采集提供更好的服务
。
图6 网页下载速度随节点数目变化情况
4 结语
本文首先讨论了分布式开源框架Hadoop的两大核心HDFS和MapReduce,从原理上说明了其高性能的根本原因,其次介绍了主题网络爬虫的网络资源抓取机制,解释了其与通用网络爬虫的根本区别。在此基础上,本文结合Hadoop分布式开源框架及主题网络爬虫提出了基于Hadoop的分布式开源框架及其实现流程。实验结果表明,通过采用分布式主题网络爬虫架构,能够明显提高网页抓取速率,提高网络爬虫工作效率。
参考文献:
[1] 廖彬,
于炯,张陶,等.基于分布式文件系统HDFS的节能算法[J].计算机学报,2013(5):1048-
1050.[2] 余琦,
凌捷.基于HDFS的云存储安全技术研究[J].计算机工程与设计,2013(8):2701-
2702.[3] 李建江,崔健,王聃,等.Map
Reduce并行编程模型研究综述[J].电子学报,2011(11):2636-
2638.[4] 李成华,
张新访,金海,等.新型的分布式并行计算编程模型[J].计算机工程与科学,2011(3):129-
131.[5] 刘金红,
陆余良.主题网络爬虫研究综述[J].计算机应用研究,2007(10):27-
28.[6] 于娟,
刘强.主题网络爬虫研究综述[J].计算机工程与科学,2015(2):232-
234.(责任编辑:黄 健)
Research on a Distributed Topic Web Crawler Based on Hadoop
Abstract:Topic Web crawler uses a centralized architecture for a single server have high performance req
uirements,scal-ability poor shortcomings,this paper presents a distributed topic crawler Hadoop-based architecture.Topic by
differentmachines in a distributed Web crawler deployment cluster,using the MapReduce programming model for data analysiscrawl,crawl all the different machines together to complete work on a given task.Exp
eriments show that the use of a dis-tributed architecture,distributed by dynamically adjusting the number of nodes in the cluster,can significantly improvethe top
ic crawler to crawl effect.Key
Words:Hadoop;Distributed Architecture;Topic Web Crawler·62·软件导刊 2016年
hadoop2.7.2 伪分布式安装
hadoop:建立一个单节点集群伪分布式操作 安装路径为:/opt/hadoop-2.7.2.tar.gz 解压hadoop: tar -zxvf hadoop-2.7.2.tar.gz 配置文件 1. etc/hadoop/hadoop-env.sh export JAVA_HOME=/opt/jdk1.8 2. etc/hadoop/core-site.xml
hadoop伪分布式搭建2.0
1. virtualbox安装 1. 1. 安装步骤 1. 2. virtualbox安装出错情况 1. 2.1. 安装时直接报发生严重错误 1. 2.2. 安装好后,打开Vitualbox报创建COM对象失败,错误情况1 1. 2.3. 安装好后,打开Vitualbox报创建COM对象失败,错误情况2 1. 2.4. 安装将要成功,进度条回滚,报“setup wizard ended prematurely”错误 2. 新建虚拟机 2. 1. 创建虚拟机出错情况 2. 1.1. 配制好虚拟光盘后不能点击OK按钮 3. 安装Ubuntu系统 3. 1. 安装Ubuntu出错情况 3. 1.1. 提示VT-x/AMD-V硬件加速在系统中不可用 4. 安装增强功能 4. 1. 安装增强功能出错情况 4. 1.1. 报未能加载虚拟光盘错误 5. 复制文件到虚拟机 5. 1. 复制出错情况 5. 1.1. 不能把文件从本地拖到虚拟机 6. 配置无秘登录ssh 7. Java环境安装 7. 1. 安装Java出错情况 7. 1.1. 提示不能连接 8. hadoop安装 8. 1. 安装hadoop的时候出错情况 8. 1.1. DataNode进程没启动 9. 开机自启动hadoop 10. 关闭服务器(需要时才关) 1. virtualbox安装 1. 1. 安装步骤 1.选择hadoop安装软件中的VirtualBox-6.0.8-130520-Win
2.双击后进入安装界面,然后直接点击下一步 3.如果不想把VirtualBox安装在C盘,那么点击浏览
基于Hadoop的分布式搜索引擎研究与实现
太原理工大学 硕士学位论文 基于Hadoop的分布式搜索引擎研究与实现 姓名:封俊 申请学位级别:硕士 专业:软件工程 指导教师:胡彧 20100401
基于Hadoop的分布式搜索引擎研究与实现 摘要 分布式搜索引擎是一种结合了分布式计算技术和全文检索技术的新型信息检索系统。它改变了人们获取信息的途径,让人们更有效地获取信息,现在它已经深入到网络生活的每一方面,被誉为上网第一站。 目前的搜索引擎系统大多都拥有同样的结构——集中式结构,即系统所有功能模块集中部署在一台服务器上,这直接导致了系统对服务器硬件性能要求较高,同时,系统还有稳定性差、可扩展性不高的弊端。为了克服以上弊端就必须采购极为昂贵的大型服务器来满足系统需求,然而并不是所有人都有能力负担这样高昂的费用。此外,在传统的信息检索系统中,许多都采用了比较原始的字符串匹配方式来获得搜索结果,这种搜索方式虽然实现简单,但在数据量比较大时,搜索效率非常低,导致用户无法及时获得有效信息。以上这两个缺点给搜索引擎的推广带来了很大的挑战。为应对这个挑战,在搜索引擎系统中引入了分布式计算和倒排文档全文检索技术。 本文在分析当前几种分布式搜索引擎系统的基础上,总结了现有系统的优缺点,针对现有系统的不足,提出了基于Hadoop的分布式搜索引擎。主要研究工作在于对传统搜索引擎的功能模块加以改进,对爬行、索引、搜索过程中的步骤进行详细分析,将非顺序执行的步骤进一步分解为两部分:数据计算和数据合并。同时,应用Map/Reduce编程模型思想,把数据计算任务封装到Map函数中,把数据合并任务封装到Reduce函数中。经过以上改进的搜索引擎系统可以部署在廉价PC构成的Hadoop分布式环境中,并具有较高的响应速度、可靠性和扩展性。这与分布式搜索引擎中的技术需求极为符合,因此本文使用Hadoop作为系统分布式计算平台。此外,系
(完整版)hadoop常见笔试题答案
Hadoop测试题 一.填空题,1分(41空),2分(42空)共125分 1.(每空1分) datanode 负责HDFS数据存储。 2.(每空1分)HDFS中的block默认保存 3 份。 3.(每空1分)ResourceManager 程序通常与NameNode 在一个节点启动。 4.(每空1分)hadoop运行的模式有:单机模式、伪分布模式、完全分布式。 5.(每空1分)Hadoop集群搭建中常用的4个配置文件为:core-site.xml 、hdfs-site.xml 、mapred-site.xml 、yarn-site.xml 。 6.(每空2分)HDFS将要存储的大文件进行分割,分割后存放在既定的存储块 中,并通过预先设定的优化处理,模式对存储的数据进行预处理,从而解决了大文件储存与计算的需求。 7.(每空2分)一个HDFS集群包括两大部分,即namenode 与datanode 。一般来说,一 个集群中会有一个namenode 和多个datanode 共同工作。 8.(每空2分) namenode 是集群的主服务器,主要是用于对HDFS中所有的文件及内容 数据进行维护,并不断读取记录集群中datanode 主机情况与工作状态,并通过读取与写入镜像日志文件的方式进行存储。 9.(每空2分) datanode 在HDFS集群中担任任务具体执行角色,是集群的工作节点。文 件被分成若干个相同大小的数据块,分别存储在若干个datanode 上,datanode 会定期向集群内namenode 发送自己的运行状态与存储内容,并根据namnode 发送的指令进行工作。 10.(每空2分) namenode 负责接受客户端发送过来的信息,然后将文件存储位置信息发 送给client ,由client 直接与datanode 进行联系,从而进行部分文件的运算与操作。 11.(每空1分) block 是HDFS的基本存储单元,默认大小是128M 。 12.(每空1分)HDFS还可以对已经存储的Block进行多副本备份,将每个Block至少复制到 3 个相互独立的硬件上,这样可以快速恢复损坏的数据。 13.(每空2分)当客户端的读取操作发生错误的时候,客户端会向namenode 报告错误,并 请求namenode 排除错误的datanode 后,重新根据距离排序,从而获得一个新的的读取路径。如果所有的datanode 都报告读取失败,那么整个任务就读取失败。14.(每空2分)对于写出操作过程中出现的问题,FSDataOutputStream 并不会立即关闭。 客户端向Namenode报告错误信息,并直接向提供备份的datanode 中写入数据。备份datanode 被升级为首选datanode ,并在其余2个datanode 中备份复制数据。 NameNode对错误的DataNode进行标记以便后续对其进行处理。 15.(每空1分)格式化HDFS系统的命令为:hdfs namenode –format 。 16.(每空1分)启动hdfs的shell脚本为:start-dfs.sh 。 17.(每空1分)启动yarn的shell脚本为:start-yarn.sh 。 18.(每空1分)停止hdfs的shell脚本为:stop-dfs.sh 。 19.(每空1分)hadoop创建多级目录(如:/a/b/c)的命令为:hadoop fs –mkdir –p /a/b/c 。 20.(每空1分)hadoop显示根目录命令为:hadoop fs –lsr 。 21.(每空1分)hadoop包含的四大模块分别是:Hadoop common 、HDFS 、
Hadoop试题题库
1.以下哪一项不属于 A. 单机(本地)模式 B. 伪分布式模式 C. 互联模式 D. 分布式模式 Hadoop 可以运行的模式 2. Hado op 的作者是下面哪一位 A. Marti n Fowler B. Doug cutt ing C. Kent Beck D. Grace Hopper A. TaskTracker B. DataNode C. Secon daryNameNode D. Jobtracker 4. HDFS 默认Block Size 的大小是 A. 32MB B. 64MB C. 128MB D. 256M 5.下列哪项通常是集群的最主要瓶颈 A. CPU 8. HDFS 是基于流数据模式访问和处理超大文件的需求而开发的,具有高容错、高可靠性、 高可扩展性、高吞吐率等特征,适合的读写任务是 _D ______ o 3.下列哪个程序通常与 NameNode 在同一个节点启动 B. C. D. 网络 磁盘IO 内存 6. F 列关于 A. Map Reduce B. Map Reduce C. Map Reduce D. Map Reduce Map Reduce 说法不正确的是 _ 是一种计算框架 来源于google 的学术论文 程序只能用 java 语言编写 隐藏了并行计算的细节,方便使用
A.—次写入, B.多次写入, C.多次写入, D.—次写入,少次读少次读
7. HBase依靠 A ________ 存储底层数据。 A. HDFS B.Hadoop C.Memory D. Map Reduce 8. HBase依赖 D 提供强大的计算能力。 A. Zookeeper B.Chubby C.RPC D. Map Reduce 9. HBase依赖 A 提供消息通信机制 A.Zookeeper B.Chubby C. RPC D. Socket 10.下面与 HDFS类似的框架是 A. NTFS B. FAT32 C. GFS D. EXT3 11.关于 SecondaryNameNode 下面哪项是正确的 A.它是NameNode的热备 B.它对内存没有要求 C.它的目的是帮助 NameNode合并编辑日志,减少NameNode启动时间 D.SecondaryNameNode 应与 NameNode 部署到一个节点 12.大数据的特点不包括下面哪一项巨大 的数据量多结构化数据 A. B. C. D. 增长速度快价值密度高
Hadoop最全面试题整理(附目录)
Hadoop面试题目及答案(附目录) 选择题 1.下面哪个程序负责HDFS 数据存储。 a)NameNode b)Jobtracker c)Datanode d)secondaryNameNode e)tasktracker 答案C datanode 2. HDfS 中的block 默认保存几份? a)3 份b)2 份c)1 份d)不确定 答案A 默认3 份 3.下列哪个程序通常与NameNode 在一个节点启动? a)SecondaryNameNode b)DataNode c)TaskTracker d)Jobtracker 答案D 分析:hadoop 的集群是基于master/slave 模式,namenode 和jobtracker 属于master,datanode 和tasktracker 属于slave,master 只有一个,而slave 有多个SecondaryNameNode 内存需求和NameNode 在一个数量级上,所以通常secondaryNameNode(运行在单独的物理机器上)和NameNode 运行在不同的机器上。 JobTracker 和TaskTracker JobTracker 对应于NameNode,TaskTracker 对应于DataNode,DataNode 和NameNode 是针对数据存放来而言的,JobTracker 和TaskTracker 是对于MapReduce 执行而言的。mapreduce 中几个主要概念,mapreduce 整体上可以分为这么几条执行线索:jobclient,JobTracker 与TaskTracker。 1、JobClient 会在用户端通过JobClient 类将应用已经配置参数打包成jar 文件存储到hdfs,并把路径提交到Jobtracker,然后由JobTracker 创建每一个Task(即MapTask 和ReduceTask)并将它们分发到各个TaskTracker 服务中去执行。 2、JobTracker 是一个master 服务,软件启动之后JobTracker 接收Job,负责调度Job 的每一个子任务task 运行于TaskTracker 上,并监控它们,如果发现有失败的task 就重新运行它。一般情况应该把JobTracker 部署在单独的机器上。 3、TaskTracker 是运行在多个节点上的slaver 服务。TaskTracker 主动与JobTracker 通信,接收作业,并负责直接执行每一个任务。TaskTracker 都需要运行在HDFS 的DataNode 上。 4. Hadoop 作者 a)Martin Fowler b)Kent Beck c)Doug cutting 答案C Doug cutting 5. HDFS 默认Block Size a)32MB b)64MB c)128MB 答案:B 6. 下列哪项通常是集群的最主要瓶颈 a)CPU b)网络c)磁盘IO d)内存 答案:C 磁盘 首先集群的目的是为了节省成本,用廉价的pc 机,取代小型机及大型机。小型机和大型机
Hadoop试题试题库
1. 以下哪一项不属于Hadoop可以运行的模式___C___。 A. 单机(本地)模式 B. 伪分布式模式 C. 互联模式 D. 分布式模式 2. Hadoop 的作者是下面哪一位__B____。 A. Martin Fowler B. Doug cutting C. Kent Beck D. Grace Hopper 3. 下列哪个程序通常与NameNode 在同一个节点启动__D___。 A. TaskTracker B. DataNode C. SecondaryNameNode D. Jobtracker 4. HDFS 默认Block Size 的大小是___B___。 A.32MB B.64MB C.128MB D.256M 5. 下列哪项通常是集群的最主要瓶颈____C__。 A. CPU B. 网络 C. 磁盘IO D. 内存 6. 下列关于MapReduce说法不正确的是_____C_。 A. MapReduce 是一种计算框架 B. MapReduce 来源于google 的学术论文 C. MapReduce 程序只能用java 语言编写 D. MapReduce 隐藏了并行计算的细节,方便使用 8. HDFS 是基于流数据模式访问和处理超大文件的需求而开发的,具有高容错、高可靠性、高可扩展性、高吞吐率等特征,适合的读写任务是__D____。 A.一次写入,少次读 B.多次写入,少次读 C.多次写入,多次读 D.一次写入,多次读
7. HBase 依靠__A____存储底层数据。 A. HDFS B. Hadoop C. Memory D. MapReduce 8. HBase 依赖___D___提供强大的计算能力。 A. Zookeeper B. Chubby C. RPC D. MapReduce 9. HBase 依赖___A___提供消息通信机制 A. Zookeeper B. Chubby C. RPC D. Socket 10. 下面与HDFS类似的框架是___C____? A. NTFS B. FAT32 C. GFS D. EXT3 11. 关于SecondaryNameNode 下面哪项是正确的___C___。 A. 它是NameNode 的热备 B. 它对内存没有要求 C. 它的目的是帮助NameNode 合并编辑日志,减少NameNode 启动时间 D. SecondaryNameNode 应与NameNode 部署到一个节点 12. 大数据的特点不包括下面哪一项___D___。 A. 巨大的数据量 B. 多结构化数据 C. 增长速度快 D. 价值密度高 HBase测试题 9. HBase 来源于哪一项? C
Hadoop分布式文件系统架构和设计
Hadoop分布式文件系统:架构和设计 引言....................................... 错误!未指定书签。一前提和设计目标.......................... 错误!未指定书签。 1 hadoop和云计算的关系................. 错误!未指定书签。 2 流式数据访问.......................... 错误!未指定书签。 3 大规模数据集.......................... 错误!未指定书签。 4 简单的一致性模型...................... 错误!未指定书签。 5 异构软硬件平台间的可移植性............ 错误!未指定书签。 6 硬件错误.............................. 错误!未指定书签。二HDFS重要名词解释...................... 错误!未指定书签。 1 Namenode........................... 错误!未指定书签。 2 secondary Namenode................ 错误!未指定书签。 3 Datanode............................ 错误!未指定书签。 4 jobTracker........................... 错误!未指定书签。 5 TaskTracker.......................... 错误!未指定书签。三HDFS数据存储........................... 错误!未指定书签。 1 HDFS数据存储特点..................... 错误!未指定书签。 2 心跳机制.............................. 错误!未指定书签。 3 副本存放.............................. 错误!未指定书签。 4 副本选择.............................. 错误!未指定书签。 5 安全模式.............................. 错误!未指定书签。四HDFS数据健壮性......................... 错误!未指定书签。
Hadoop云计算平台搭建最详细过程(共22页)
Hadoop云计算平台及相关组件搭建安装过程详细教程 ——Hbase+Pig+Hive+Zookeeper+Ganglia+Chukwa+Eclipse等 一.安装环境简介 根据官网,Hadoop已在linux主机组成的集群系统上得到验证,而windows平台是作为开发平台支持的,由于分布式操作尚未在windows平台上充分测试,所以还不作为一个生产平台。Windows下还需要安装Cygwin,Cygwin是在windows平台上运行的UNIX模拟环境,提供上述软件之外的shell支持。 实际条件下在windows系统下进行Hadoop伪分布式安装时,出现了许多未知问题。在linux系统下安装,以伪分布式进行测试,然后再进行完全分布式的实验环境部署。Hadoop完全分布模式的网络拓补图如图六所示: (1)网络拓补图如六所示: 图六完全分布式网络拓补图 (2)硬件要求:搭建完全分布式环境需要若干计算机集群,Master和Slaves 处理器、内存、硬盘等参数要求根据情况而定。 (3)软件要求 操作系统64位版本:
并且所有机器均需配置SSH免密码登录。 二. Hadoop集群安装部署 目前,这里只搭建了一个由三台机器组成的小集群,在一个hadoop集群中有以下角色:Master和Slave、JobTracker和TaskTracker、NameNode和DataNode。下面为这三台机器分配IP地址以及相应的角色: ——master,namenode,jobtracker——master(主机名) ——slave,datanode,tasktracker——slave1(主机名) ——slave,datanode,tasktracker——slave2(主机名) 实验环境搭建平台如图七所示:
基于Hadoop的分布式文件系统
龙源期刊网 https://www.360docs.net/doc/0911012697.html, 基于Hadoop的分布式文件系统 作者:陈忠义 来源:《电子技术与软件工程》2017年第09期 摘要HDFS是Hadoop应用用到的一个最主要的分布式存储系统,Hadoop分布式文件系 统具有方便、健壮、可扩展性、容错性能好、操作简单、成本低廉等许多优势。。深入了解HDFS的工作原理对在特定集群上改进HDFS的运行性能和错误诊断都有极大的帮助。本文介绍了HDFS的主要设计理念、主要概念及其高可靠性的实现等。 【关键词】Hadoop 分布式文件系统 Hadoop是新一代的大数据处理平台,在近十年中已成为大数据革命的中心,它不仅仅承担存储海量数据,还通过分析从中获取有价值信息。进行海量计算需要一个稳定的,安全的数据容器,管理网络中跨多台计算机存储的文件系统称为分布式文件系统。Hadoop分布式文件系统(Hadoop Distributed File System)运应而生,它是Hadoop的底层实现部分,存储Hadoop 集群中所有存储节点上的文件。 1 HDFS的设计理念 面对存储超大文件,Hadoop分布式文件系统采用了流式数据访问模式。所谓流式数据,简单的说就是像流水一样,数据一点一点“流”过来,处理数据也是一点一点处理。如果是全部收到数据以后再进行处理,那么延迟会很大,而且会消耗大量计算机内存。 1.1 存储超大文件 这里的“超大文件”通常达到几百GB甚至达到TB大小的文件。像大型的应用系统,其存储超过PB级数据的Hadoop集群比比皆是。 1.2 数据访问模式 最高效的访问模式是一次写入、多次读取。HDFS的构建思路也是这样的。HDFS存储的数据集作为Hadoop的分析对象。在数据集生成以后,采用各种不同分析方法对该数据集进行长时间分析,而且分析涉及到该数据集的大部分数据或者全部数据。面对庞大数据,时间延迟是不可避免的,因此,Hadoop不适合运行低时间延迟数据访问的应用。 1.3 运行在普通廉价的服务器上 HDFS设计理念之一就是让它能运行在普通的硬件之上,即便硬件出现故障,也可以通过容错策略来保证数据的高可用。
07 hadoop完全分布式安装第七步:zookeeper分布式配置
实验七 zookeeper分布式的配置 tar -zxvf zookeeper-3.4.5.tar.gz mv zookeeper-3.4.5 zookeeper cd zookeeper mkdir data mkdir logs 三、集群模式 集群模式就是在不同主机上安装zookeeper然后组成集群的模式;下边以在192.168.1.1,192.168.1.2,192.168.1.3三台主机为例。 zookeeper 配置 1.Zookeeper服务集群规模不小于三个节点,要求各服务之间系统时间要保持一致。 2.在master的/home/chenlijun目录下,解压缩zookeeper(执行命令tar –zvxf zooke eper.tar.gz) 3.设置环境变量 打开/etc/profile文件!内容如下:
[html]view plain copy 1.#set java & hadoop 2. 3.export JAVA_HOME=/home/chenlijun/java/ 4. 5.export HADOOP_HOME=/home/chenlijun/hadoop 6. 7.export ZOOKEEPER_HOME=/home/chenlijun/zookeeper 8. 9.export PATH=.:$HADOOP_HOME/bin:$ZOOKEEPER_HOME/bin:$JAVA_HOME/bin:$PATH 注:修改完后profile记得执行source /etc/profile 4.在解压后的zookeeper的目录下进入conf目录修改配置文件 更名操作:mv zoo_sample.cfg zoo.cfg 5.编辑zoo.cfg (vi zoo.cfg) 修改dataDir=/home/chenlijun/zookeeper/data/ 新增server.0=master:2888:3888 server.1=slave1:2888:3888 server.2=slave2:2888:3888 文件如下:
Hadoop入门—Linux下伪分布式计算的安装与wordcount的实例展示
开始研究一下开源项目hadoop,因为根据本人和业界的一些分析,海量数据的分布式并行处理是趋势,咱不能太落后,虽然开始有点晚,呵呵。首先就是安装和一个入门的小实例的讲解,这个恐怕是我们搞软件开发的,最常见也最有效率地入门一个新鲜玩意的方式了,废话不多说开始吧。 本人是在ubuntu下进行实验的,java和ssh安装就不在这里讲了,这两个是必须要安装的,好了我们进入主题安装hadoop: 1.下载hadoop-0.20.1.tar.gz: https://www.360docs.net/doc/0911012697.html,/dyn/closer.cgi/hadoop/common/ 解压:$ tar –zvxf hadoop-0.20.1.tar.gz 把Hadoop 的安装路径添加到环/etc/profile 中: export HADOOP_HOME=/home/hexianghui/hadoop-0.20.1 export PATH=$HADOOP_HOME/bin:$PATH 2.配置hadoop hadoop 的主要配置都在hadoop-0.20.1/conf 下。 (1)在conf/hadoop-env.sh 中配置Java 环境(namenode 与datanode 的配置相同): $ gedit hadoop-env.sh $ export JAVA_HOME=/home/hexianghui/jdk1.6.0_14 3.3)配置conf/core-site.xml, conf/hdfs-site.xml 及conf/mapred-site.xml(简单配置,datanode 的配置相同) core-site.xml:
实验3 Hadoop安装与配置2-伪分布式
实验报告封面 课程名称: Hadoop大数据处理课程代码: JY1124 任课老师:宁穗实验指导老师: 宁穗 实验报告名称:实验3 Hadoop安装与配置2 学生: 学号: 教学班: 递交日期: 签收人: 我申明,本报告的实验已按要求完成,报告完全是由我个人完成,并没有抄袭行为。我已经保留了这份实验报告的副本。 申明人(签名): 实验报告评语与评分: 评阅老师签名:
一、实验名称:Hadoop安装与配置 二、实验日期:2015年9 月25 日 三、实验目的: Hadoop安装与配置。 四、实验用的仪器和材料: 安装环境:以下两个组合之一 1.硬件环境:存ddr3 4G及以上的x86架构主机一部 系统环境:windows 、linux或者mac os x 软件环境:运行vmware或者virtualbox (2) 存ddr 1g及以上的主机两部及以上 五、实验的步骤和方法: 本次实验重点在ubuntu中安装jdk以及hadoop。 一、关闭防火墙 sudo ufw disable iptables -F 二、jdk的安装 1、普通用户下添加grid用户
2、准备jdk压缩包,把jdk压缩包放到以上目录(此目录可自行设置) 3、将jdk压缩包解压改名 改名为jdk:mv jdk1.7.0_45 jdk 移动到/usr目录下:mv jdk /usr(此目录也可自行设置,但需与配置文件一致)4、设置jdk环境变量 此采用全局设置方法,更改/etc/profile文件 sudo gedit /etc/profile 添加(根据情况自行设置) export JA VA_HOME=/usr/jdk export JRE_HOME=/usr/ jdk/jre export CLASSPATH=.:$JA V A_HOME/lib:$JRE_HOME/lib:$CLASSPATH export PA TH=$JA V A_HOME/bin: $JRE_HOME/ bin: $PATH 然后保存。 5、检验是否安装成功 java -version 二、ssh免密码 1、退出root用户,su grid 生成密钥 ssh-keygen –t rsa
基于hadoop的分布式存储平台的搭建与验证
毕业设计(论文) 中文题目:基于hadoop的分布式存储平台的搭建与验证 英文题目:Setuping and verification distributed storage platform based on hadoop 学院:计算机与信息技术 专业:信息安全 学生姓名: 学号: 指导教师: 2018 年06 月01 日 1
任务书 题目:基于hadoop的分布式文件系统的实现与验证 适合专业:信息安全 指导教师(签名): 毕业设计(论文)基本内容和要求: 本项目的目的是要在单独的一台计算机上实现Hadoop多节点分布式计算系统。 基本原理及基本要求如下: 1.实现一个NameNode NameNode 是一个通常在 HDFS 实例中的单独机器上运行的软件。它负责管理文件系统名称空间和控制外部客户机的访问。NameNode 决定是否将文件映射到 DataNode 上的复制块上。 实际的 I/O 事务并没有经过 NameNode,只有表示 DataNode 和块的文件映射的元数据经过 NameNode。当外部客户机发送请求要求创建文件时,NameNode 会以块标识和该块的第一个副本的 DataNode IP 地址作为响应。这个 NameNode 还会通知其他将要接收该块的副本的 DataNode。 2。实现若干个DataNode DataNode 也是一个通常在 HDFS 实例中的单独机器上运行的软件。Hadoop 集群包含一个 NameNode 和大量 DataNode。DataNode 通常以机架的形式组织,机架通过一个交换机将所有系统连接起来。Hadoop 的一个假设是:机架内部节点之间的传输速度快于机架间节点的传输速度。 DataNode 响应来自 HDFS 客户机的读写请求。它们还响应来自NameNode 的创建、删除和复制块的命令。NameNode 依赖来自每个DataNode 的定期心跳(heartbeat)消息。每条消息都包含一个块报告,NameNode 可以根据这个报告验证块映射和其他文件系统元数据。如果DataNode 不能发送心跳消息,NameNode 将采取修复措施,重新复制在该节点上丢失的块。 具体设计模块如下:
hadoop安装最终版
一.在Microsoft Windows XP操作系统下,安装Ubuntu 8.04 lts server版本+ xubuntu桌面到VMware虚拟机上 1.下载ubuntu server 及xubuntu 1)Ubuntu 8.04 server: http://119.147.41.16/down?cid=A97349CDC5DF51672F26FCABACBF5BC5AF9AF89D &t=2&fmt=&usrinput=ubuntu 8.04&dt=1&ps=0_0&rt=0kbs&plt=0 2)Xubuntu: 可不下,不用桌面 http://119.147.41.16/down?cid=DADD7F929F5F442A7881C2B382865468B70B8AA5 &t=2&fmt=&usrinput=xubuntu&dt=1002002&ps=0_0&rt=0kbs&plt=0 3)VMware http://119.147.41.16/down?cid=9BAA5720718DE23B4F7312C915E8028E71779B39 &t=2&fmt=-1&usrinput=Vmware&dt=2056000&redirect=no 2.本人硬件环境(参考) CPU: 2 core 4.12G Memory: 2G ddr3 Mainboard Chip : Intel p43d3 Graphic Chip : N Geoforce 9600gs0 3.本人软件环境(参考) OS : Microsoft windows xp sp3 VM: vmware5.5.1.19175 Linux: Ubuntu linux 8.04 lts server(iso) + xubuntu (ISO) 4.设置虚拟环境 1)安装VMware :略(出现警告仍然继续,sn: E8HFE-5MD6N-F25DC-4WRNQ, 可不汉 化) 2)打开VMware Workstation软件,点击“file”菜单,选择“new”-“virtual machine” 命令 3)弹出新建虚拟机向导,点击“下一步”按钮 4)在“virtual machine configuration”中,选择第二项“custom”单选项目,点击 “下一步”按钮 5)在“virtual machine format”中,选择第一项“new - Workstation 5”单选项目, 点击“下一步”按钮 6)之后将询问虚拟机的操作系统,我们在“guest operating system”中选择“Linux”, 在下面的版本中选择“Ubuntu”,点击“下一步”按钮 7)这时询问虚拟机的名称和保存目录,请根据自己的需要进行设置。在此我使用 d:\\My Virtual Machines\Ubuntu,点击“下一步”按钮 8)虚拟处理器数,选择“one”,点击“下一步”按钮。(我是双核心处理器,所以 有这个项目) 9)这时提示分配虚拟机内存,请根据自己物理内存实际情况进行设置,建议至少 分配128MB内存,如果物理内存数量允许,推荐设置256MB内存。我的物理 内存是2GB,在此我使用虚拟机推荐的内存数量384MB,点击“下一步”按钮 10)网络连接类型。如果不想让虚拟机访问,请选择“不使用网络连接”。如果需要 访问网络,请根据自己的情况设置,在此我推荐使用第二项“NAT”,这个选项 让虚拟机使用宿主计算机的IP访问网络,宿主计算机将共享网络给虚拟机。点 击“下一步”按钮
hadoop伪分布式安装方法
hadoop 伪分布式安装方法 [日期:2014-04-30] 来源:51CTO 作者:晓晓 [字体:大 中 小] 接触Hadoop 也快两年了,也一直没自己总结过安装教程,最近又要用hadoop ,需要自己搭建一个集群来进行试验,所以就利用这个机会来写个教程以备以后自己使用,也用来和大家一起探讨。 要安装Hadoop 先安装其辅助环境 java Ubuntu 下java 的安装与配置 将java 安装在指定路径方便以后查找使用。 Java 安装 1)在/home/xx (也就是当前用户)目录下,新建java1.xx 文件夹:mkdir /home/xx/java1.xx (文件名上表明版本号,方便日后了解java 版本) 2)进入/home/xx/java1.xx 目录下,运行安装指令:sudo /home/xx /jdk-6u26-linux-i586.bin ,则生成文件夹jdk1.6.0_26,如果感觉名字太长,可以对其重命名:mv jdk1.6.0_26 jdk 也可以使用sudoapt-get install 软件包来安装java 。如果想卸载java 使用命令sudo rm -rf /home/x x/java1.6/jdk1.6(安装目录) 配置环境变量 进入profile 文件添加环境配置,命令为sudo gedit /etc/profile 在文件的末尾添加 1 2 3 4 5 6 7 JAVA_HOME=/home/xx/java1.xx/jdk JRE_HOME=/home/xx /java1.xx/jdk/jre PATH=$JAVA_HOME/bin:$JRE_HOME/bin: $PATH export JAVA_HOME export JRE_HOME export CLASSPATH export PATH 完成以上配置后重启电脑然后检验java 是否安装成功在终端输入java –version 后显示 说明java 安装成功。 Java 安装成功后接着进入正题进行Hadoop 的安装,本文先进行Hadoop 的伪分布安装随后会继续更新完全分布的安装过程。 本文使用的Hadoop 版本是hadoop-0.20.2,将hadoop-0.20.2.tar.gz 移至当前用户目录下进行解压t ar –zxvf hadoop-0.20.2.tar.gz 然后配置hadoop 的环境变量,其配置方法和java 的配置方法一样,在profile 中写入HADOOP_HOME =/home/xx/hadoop Java 和hadoop 的配好的环境变量如图
hadoop完全分布式的搭建步骤
Hadoop完全分布式的搭建步骤 步骤目录: 第一步:安装虚拟机 第二步:Linux的环境配置 第三步:安装jdk并配置环境变量 第四步:建立专门运行Hadoop的专有用户abc 第五步:ssh免密码登录配置 第六步:Hadoop的安装与配置 第七步:格式化hdfs和启动守护进程 详细步骤如下 第一步:安装虚拟机 第二步:Linux的环境配置 1.修改IP(桥接模式) vim /etc/sysconfig/network-scriptps/ifcfg-eth0 (推荐使用手动的方法设置) 2.修改主机名 vim /etc/sysconfig/network 3.修改主机名和IP的映射关系 vim /etc/hosts
192.168.6.115 hadoop01 192.168.6.116 hadoop02 192.168.6.117 hadoop03 4.关闭防火墙 service iptables status//查看状态 service iptables stop//关闭防火墙 chkconfig iptables --list //查看防火墙是否开机自启 chkconfig iptables off//关闭防火墙开机自启 5.重启系统 reboot 6.查看主机名:hostname 查看IP:ifconfig 查看防火墙状态:service iptables status 7.查看各个主机之间是否能通信:互相ping IP地址 第三步:安装jdk并配置环境变量 1.上传jdk到根目录 2.创建目录mkdir /usr/java 3.解压jdk tar –zxvf jdk-7u76-linux-i586.tar.gz –C /usr/java cd /usr/java ls 4.将Java添加到环境变量(使得在任何目录下均可使用Java)
Hadoop题库
A. 单机(本地)模式 B. 伪分布式模式 C. 互联模式 D. 分布式模式 2. Hadoop的作者是下面哪一位__B____。 A. Martin Fowler B. Doug cutting C. Kent Beck D. Grace Hopper 3. 下列哪个程序通常与 NameNode 在同一个节点启动__D___。 A. TaskTracker B. DataNode C. SecondaryNameNode D. Jobtracker 4. HDFS 默认 Block Size的大小是___B___。 5. 下列哪项通常是集群的最主要瓶颈____C__。 A. CPU B. 网络 C. 磁盘IO D. 内存 6. 下列关于MapReduce说法不正确的是_____C_。 A. MapReduce是一种计算框架 B. MapReduce来源于google的学术论文 C. MapReduce程序只能用java语言编写 D. MapReduce隐藏了并行计算的细节,方便使用 8. HDFS是基于流数据模式访问和处理超大文件的需求而开发的,具有高容错、高可靠性、高可扩展性、高吞吐率等特征,适合的读写任务是 __D____。 A.一次写入,少次读 B.多次写入,少次读 C.多次写入,多次读 D.一次写入,多次读 9. HBase依靠__A____存储底层数据。
A. HDFS B. Hadoop C. Memory D. MapReduce 10. HBase依赖___D___提供强大的计算能力。 A. Zookeeper B. Chubby C. RPC D. MapReduce 11. HBase依赖___A___提供消息通信机制 A. Zookeeper B. Chubby C. RPC D. Socket 12. 下面与HDFS类似的框架是___C____? A. NTFS B. FAT32 C. GFS D. EXT3 13. 关于 SecondaryNameNode 下面哪项是正确的___C___。 A. 它是 NameNode 的热备 B. 它对内存没有要求 C. 它的目的是帮助 NameNode 合并编辑日志,减少 NameNode 启动时间 D. SecondaryNameNode 应与 NameNode 部署到一个节点 14. 大数据的特点不包括下面哪一项___D___。 A. 巨大的数据量 B. 多结构化数据 C. 增长速度快 D. 价值密度高 HBase测试题 1. HBase来源于哪一项? C A The Google File System