Eviews序列相关性实验报告
实验二序列相关性
【实验目的】
掌握序列相关性问题出现的来源、后果、检验及修正的原理,以及相关的Eviews操作方法。
【实验内容】
经济理论指出,商品进口主要由进口国的经济发展水平,以及商品进口价格指数与国内价格指数对比因素决定的。由于无法取得价格指数数据,我们主要研究中国商品进口与国内生产总值的关系。
以1978-2001年中国商品进口额与国内生产总值数据为例,练习检查和克服模型的序列相关性的操作方法。
【实验步骤】
一、建立线性回归模型
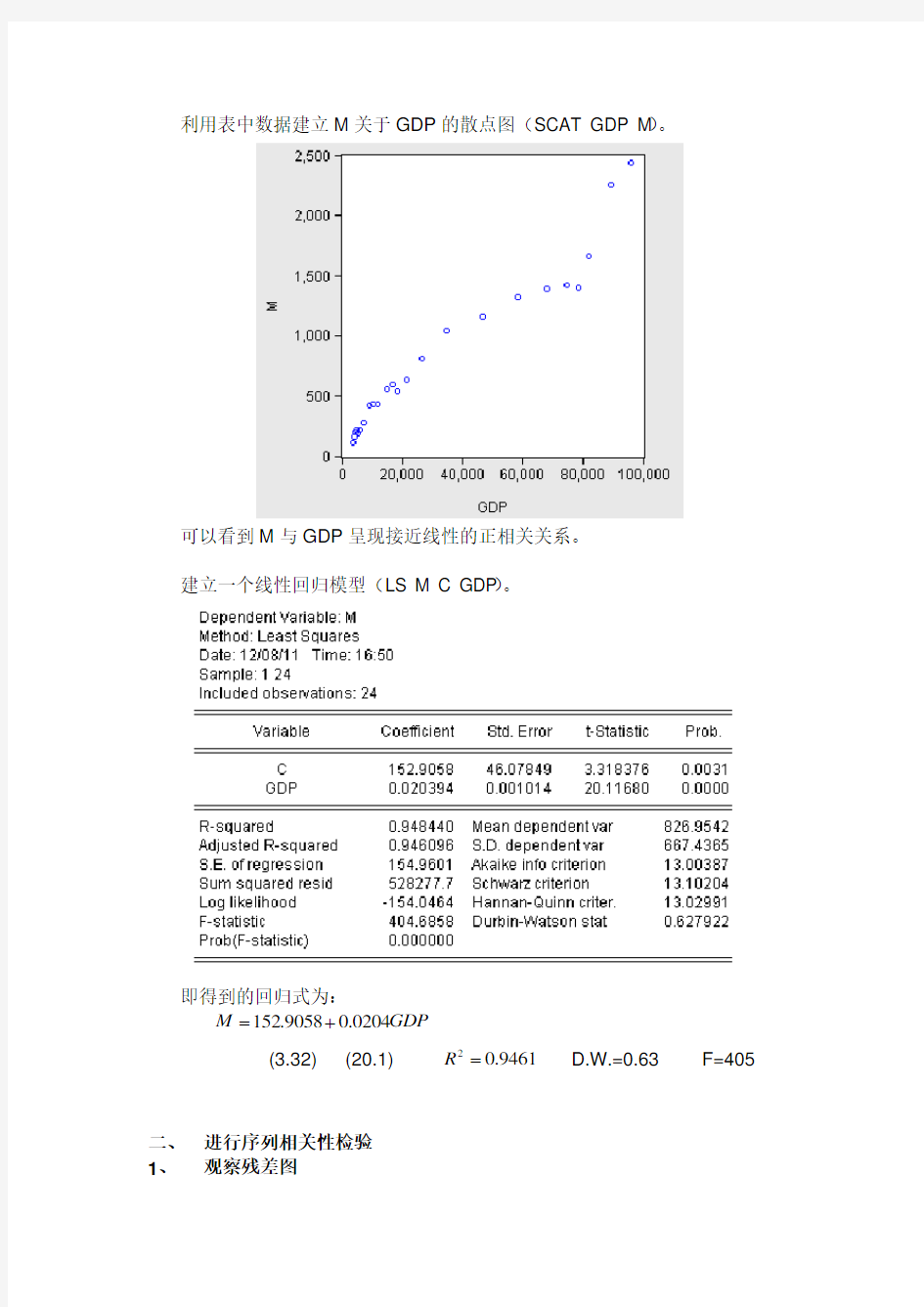
利用表中数据建立M 关于GDP 的散点图(SCAT GDP M )。
可以看到M 与GDP 呈现接近线性的正相关关系。
建立一个线性回归模型(LS M C GDP )。
即得到的回归式为:
GDP M 0204.09058.152+=
(3.32) (20.1)
9461.02=R
D.W.=0.63 F=405
二、 进行序列相关性检验 1、 观察残差图
做出残差项与时间以及与滞后一期的残差项的折线图,可以看出随机项存在正序列相关性。
2、 用D.W.检验判断
由回归结果输出D.W.=0.628。若给定05.0=α,已知n=24,k=2,查D.W.检验上下界表可得,45.1,27.1==U L d d 。由于D.W.=0.628<1.27=L d ,故存在正自相关。
3、 用LM 检验判断
在估计窗口中选择Serial Correlation LM Test,设定滞后期Lag=1,得到LM 检验结果。
由于P值为0.0027,可以拒绝原假设,表明存在自相关。
4、用回归检验法判断
对初始估计结果得到的残差序列定义为E1,首先做一阶自回归(LS E1 E1(-1))。
采用LM检验其自相关性,结果表明仍然存在自相关。
用残差项的二阶自回归形式重新建立模型(LS E1 E1(-1) E1(-2))。
再次用LM检验,此时P值达到0.7,落在接受域,认为误差项不存在自相关。
可以得到残差的二阶回归式为:
t t t t νμμμ+-=-∧
-∧∧217509.01100.1
(6.43) (-4.01)
83.90..,66.02==e s R
三、 克服自相关
用广义最小二乘法估计回归参数。根据残差二阶回归式的系数,对变量GDP 和M 作二阶广义差分,生成新变量序列:
GENR GDGDP=GDP-1.1100*GDP(-1)+0.7509*GDP(-2)
GENR GDM=M-1.1100*M(-1)+0.7509*M(-2)
以GDGDP 、GDM 为样本再次回归(LS GDM C GDGDP ),得到结果输出为:
LM 检验结果如下,已经很好地克服了自相关性。
残差图为:
广义最小二乘回归结果为:
GDGDP GDM 020.0302.107+=
(3.69) (19.6)
88.1..,32.90..,948.02===W D e s R
由于
302.107)7509.01100.11(0=+-β 得到
852.1640=β
故原模型的广义最小二乘估计为
164+
=
.
852
M020
.0
GDP
异方差实验报告
附件二:实验报告格式(首页) 山东轻工业学院实验报告成绩 课程名称计量经济学指导教师实验日期 2013.5.18 院(系)商学院会计系专业班级会计实验地点实验楼二机房 学生姓名学号同组人无 实验项目名称异方差的检验 一、实验目的和要求 1、理解异方差的含义后果、 2、学会异方差的检验与加权最小二乘法要求熟悉基本操作步骤,读懂各项上机榆出结果 的含义并进行分析 3、掌握异方差性问题出现的来源、后果、检验及修正的原理,以及相关的Eviews操 作方法 4、练习检查和克服模型的异方差的操作方法。 5、掌握异方差性的检验及处理方法 6、用图示法、斯皮尔曼法、戈德菲尔德、white验证法,验证该模型是否存在异方差 二、实验原理 1、异方差的检验出消除方法 2、运用EVIEWS软件及普通最小二乘法进行模型估计 3、检验模型的异方差性并对其进行调整 三、主要仪器设备、试剂或材料 Eviews软件、课本教材、电脑 四、实验方法与步骤 一、准备工作。建立工作文件,并输入数据,用普通最小二乘法估计方程(操作步骤 与方法同前),得到残差序列。 1、CREATE U 1 31 回车 2、DATA Y X 回车 输入数据
obs Y X 1 264 8777 2 105 9210 3 90 9954 4 131 10508 5 122 10979 6 10 7 11912 7 406 12747 8 503 13499 9 431 14269 10 588 15522 11 898 16730 12 950 17663 13 779 18575 14 819 19635 15 1222 21163 16 1702 22880 17 1578 24127 18 1654 25604 19 1400 26500 20 1829 26760 21 2200 28300 22 2017 27430 23 2105 29560 24 1600 28150 25 2250 32100 26 2420 32500 27 2570 35250 28 1720 33500 29 1900 36000 30 2100 36200 31 2800 38200 3、LS Y C X 回车 用最小二乘法进行估计出现 Dependent Variable: Y Method: Least Squares Date: 05/18/13 Time: 11:19 Sample: 1 31 Included observations: 31 Variable Coefficien t Std. Error t-Statistic Prob.
Eviews时间序列分析实例
Eviews 时间序列分析实例 时间序列是市场预测中经常涉及的一类数据形式, 绍。通过第七章的学习,读者了解了什么是时间序列, 、指数平滑法实例 所谓指数平滑实际就是对历史数据的加权平均。它可以用于任何一种没有明显函数规 律,但确实存在某种前后关联的时间序列的短期预测。 由于其他很多分析方法都不具有这种 特点,指数平滑法在时间序列预测中仍然占据着相当重要的位置。 (―)一次指数平滑 一次指数平滑又称单指数平滑。它最突出的优点是方法非常简单, 甚至只要样本末期的 平滑值,就可以得到预测结果。 一次指数平滑的特点是: 能够跟踪数据变化。 这一特点所有指数都具有。 预测过程中添 加最新的样本数据后, 新数据应取代老数据的地位, 老数据会逐渐居于次要的地位, 直至被 淘汰。这样,预测值总是反映最新的数据结构。 一次指数平滑有局限性。第一,预测值不能反映趋势变动、季节波动等有规律的变动; 第二,这种方法多适用于短期预测, 而不适合作中长期的预测;第三, 由于预测值是历史数 据的均值,因此与实际序列的变化相比有滞后现象。 指数平滑预测是否理想,很大程度上取决于平滑系数。 Eviews 提供两种确定指数平滑 系数的方法:自动给定和人工确定。 选择自动给定,系统将按照预测误差平方和最小原则自 动确定系数。如果系数接近 1,说明该序列近似纯随机序列,这时最新的观测值就是最理想 的预测值。 出于预测的考虑,有时系统给定的系数不是很理想, 用户需要自己指定平滑系数值。平 滑系数取什么值比较合适呢? 一般来说,如果序列变化比较平缓,平滑系数值应该比较小, 比如小于0.1; 如果序列变化比较剧烈, 平滑系数值可以取得大一些, 如0.3?0.5。若平滑系 数值大于0.5才能跟上序列的变化,表明序列有很强的趋势,不能采用一次指数平滑进行预 测。 [例1]某企业食盐销售量预测。现在拥有最近连续 30个月份的历史资料(见表 I ), 试预测下一月份销售量。 表 某企业食盐销售量 单位:吨 解:使用对数据进行分析,第一步是建立工作文件和录入数据。有关操作在本 理和一些分析实例。本节的主要内容是说明如何使用 Eviews 软件进行分析。 本书第七章对它进行了比较详细的介 并接触到有关时间序列分析方法的原
计量经济学Eviews多重共线性实验报告
计量经济学E v i e w s多重共线性实验报告 Company Document number:WUUT-WUUY-WBBGB-BWYTT-1982GT
实验报告课程名称计量经济学 实验项目名称多重共线性 班级与班级代码 专业 任课教师 学号: 姓名: 实验日期: 2014 年 05 月 11日 广东商学院教务处制 姓名实验报告成绩 评语: 指导教师(签名) 年月日 说明:指导教师评分后,实验报告交院(系)办公室保存。 计量经济学实验报告 一、实验目的:掌握多元线性回归模型的估计方法、掌握多重共线性模型的识别和修正。 二、实验要求:应用教材第127页案例做多元线性回归模型,并识别和修正多重共线性。 三、实验原理:普通最小二乘法、简单相关系数检验法、综合判断法、逐步回归法。
四、预备知识:最小二乘法估计的原理、t检验、F检验、2R值。 五、实验步骤 1、选择数据 理论上认为影响能源消费需求总量的因素主要有经济发展水平、收入水平、产业发展、人民生活水平提高、能源转换技术等因素。为此,收集了中国能源消费标准煤总量、国民总收入、国内生产总值GDP、工业增加值、建筑业增加值、交通运输邮电业增加值、人均生活电力消费、能源加工转换效率等1985——2007年的统计数据。本题旨在通过建立这些经济变量的线性模型来说明影响能源消费需求总量的原因。主要数据如下: 1985~2007年统计数据
资料来源:《中国统计年鉴》,中国统计出版社2000、2008年版。 为分析Y 与X1、X2、X3、X4、X5、X6、X7之间的关系,做如下折线图: 能源消费Y 在1986到1996年间缓慢增长,在96至98年有短暂的下跌,但是98至02年开始缓慢回升,02年到06年开始快速增长。 国民总收入X1和国内生产总值X2以相同的趋势逐年缓慢增长。 工业增加值X3在1985年-1999年期间一直是缓慢增长,但在2000年出现了急剧下降的现象,2001年又急剧增长,达到下降前的水平,2001年以后开始缓慢增长。建筑业增长值x4、交通运输邮电业增加值x5、人均生活电力消费x6、能源加工转换效率x7数值较低,但都以较平缓的方式增长。 2、设定并估计多元线性回归模型 t t t t t t t u X X X X X Y ++++++=66554433221ββββββ () 录入数据,得到图。 2.2.1)采用OLS 估计参数 在主界面命令框栏中输入 ls y c x1 x2 x3 x4 x5 x6 x7回车,即可得到参数的估计结果。 由此可见,该模型的可决系数为,修正的可决系数为,模型拟和很好,F 统计量为,回归方程整体上显着。 可是其中的lnX3、lnX4、lnX6对lnY 影响不显着,不仅如此,lnX2、lnX5的参数为负值,在经济意义上不合理。所以这样的回归结果并不理想。 3、多重共线性模型的识别
异方差实验报告
《计量经济学》实训报告 实训项目名称异方差的检验及修正 实训时间 2011年12月13日 实训地点 班级 学号 姓名 实训(实践) 报告
实训名称异方差的检验及修正 一、实训目的 深刻理解异方差性的实质、异方差出现的原因、异方差的出现对模型的不良影响(即异方差的后果),掌握估计和检验异方差性的基本思想和修正异方差的若干方法;能够运用所学的知识处理模型中的出现的异方差问题,并要求初步掌握用EViews处理异方差的基本操作方法。 二、实训要求 使用教材第五章的数据做异方差的图形法检验、Goldfeld-Quanadt检验与White检验,使用WLS法对异方差进行修正。 三、实训内容 1、用图示法、戈德菲尔德、white验证法,验证该模型是否存在异方差。 2、用加权最小二乘法消除异方差。 四、实训步骤 练习题5.8数据1998年我国重要制造业销售收入和销售利润的数据 Y—销售利润,x—销售收入 1. 用OLS方法估计参数,建立回归模型:ls y c x
回归结果如下: Y=12.036+0.1044x; S = (19.5178) (0.00844) T= (0.6167) (12.3667) R^2=0.8547 S.E.=56.9037 2.检验是否存在异方差 (1) 图形检验:残差图形scat x e2 结果表明:
残差平方e2对解释变量的x的散点图主要分布在图形的下方,大致看出残差平方随X 的变动呈增大的趋势,因此,模型很可能出现异方差。 (2)戈德菲尔德-夸特检验 首先,对变量进行排序,在这个题目中,我选择递增型排序,这是y与x将以x按递增型排序。 然后构造子样本区间,建立回归模型。在本题目中,n=28,删除中间的1/4,的观测值,即大约8个观测值,剩余部分平分得两个样本区间:1—10和19-28,他们的样本个数均为10。 用OLS方法得到前10个数的样本结果(ls y c x): 用OLS方法得到后10个数的样本结果(ls y c x):
eviews时间序列分析实验
实验一ARMA 模型建模 一、实验目的 学会检验序列平稳性、随机性。学会分析时序图与自相关图。学会利用最小二乘法等方法对ARMA 模型进行估计,以及掌握利用ARMA 模型进行预测的方法。学会运用Eviews 软件进行ARMA 模型的识别、诊断、估计和预测和相关具体操作。 二、基本概念 1平稳时间序列: 定义:时间序列{zt}是平稳的。如果{zt}有有穷的二阶中心矩,而且满足: (a)ut= Ezt =c; (b)r(t,s) = E[(zt-c)(zs-c)] = r(t-s,0) 则称{zt}是平稳的。 2 AR 模型: AR 模型也称为自回归模型。它的预测方式是通过过去的观测值和现在的干扰值的线性组合预测。具有如下结构的模型称为P 阶自回归模型,简记为AR(P)。 x t = 0 + 1x t-1 + 2x t-2 + + p x t- p + t p0 E(t) = 0,Var(t) = 2 ,E(t s) = 0,s t Ex = 0,s t 3 MA 模型: MA 模型也称为滑动平均模型。它的预测方式是通过过去的干扰值和现在的干扰值的线性组合预测。具有如下结构的模型称为Q 阶移动平均回归模型,简记为MA(q)。 x t= +t-1t-1 -2t-2 - -q t-q q0 E() = 0,Var( ) = 2, E( ) = 0, s t 4 ARMA 模型: ARMA模型:自回归模型和滑动平均模型的组合,便构成了用于描述平稳随机过程的自回归滑动平均模型ARMA。具有如下结构的模型称为自回归移动平均回归模型,简记为ARMA(p,q)。 x t= 0 + 1x t-1 + + p x t- p+ t- 1t-1 - - q t-q
Eviews虚拟变量实验报告
实验四虚拟变量 【实验目的】 掌握虚拟变量的基本原理,对虚拟变量的设定和模型的估计与检验,以及相关的Eviews操作方法。 【实验内容】 试根据1998年我国城镇居民人均收入与彩电每百户拥有量的统计资料建立 【实验步骤】 1、相关图分析 根据表中数据建立人均收入X与彩电拥有量Y的相关图(SCAT X Y)。从相关图可以看出,前3个样本点(即低收入家庭)与后5个样本点(中、高收入)的拥有量存在较大差异,
因此,为了反映“收入层次”这一定性因素的影响,设置虚拟变量如下: ?? ?=低收入家庭 中、高收入家庭 1D 2、构造虚拟变量 构造虚拟变量 1D (DATA D1),并生成新变量序列: GENR XD=X*D1 3、估计虚拟变量模型 LS Y C X D1 XD 得到估计结果:
我国城镇居民彩电需求函数的估计结果为: XD D X Y 009.0873.31012.0611.571-++=∧ (16.25) (9.03) (8.32) (-6.59) 366,066.1..,9937.02===F e s R 再由t 检验值判断虚拟变量的引入方式,并写出各类家庭的需求函数。 虚拟变量的回归系数的t 检验都是显著的,且模型的拟合优度很高,说明我国城镇居民低收入家庭与中高收入家庭对彩电的消费需求,在截距和斜率上都存在着明显差异,所以以加法和乘法方式引入虚拟变量是合理的。 低收入家庭与中高收入家庭各自的需求函数为: 低收入家庭: X Y 012.0611.57+=∧ 中高收入家庭: X X Y 003.0484.89)009.0012.0()873.31611.57(+=-++=∧ 由此可见我国城镇居民家庭现阶段彩电消费需求的特点: 对于人均年收入在3300元以下的低收入家庭,需求量随着收入水平的提高而快速上升,人均年收入每增加1000元,百户拥有量将平均增加12台;对于人均年收入在4100元以上的中高收入家庭,虽然需求量随着收入水平的提高也在增加,但增速趋缓,人均年收入每增加1000元,百户拥有量只增加3台。
计量经济学异方差实验报告材料二
实验报告2 实验目的:掌握异方差的检验及处理方法。 实验容:检验家庭人均纯收入与家庭生活消费支出可能存在的异方差性。有关数据如下:其中,收入为X,家庭生活消费支出为Y。 地区家庭人均 纯收入 家庭生活 消费支出地区 家庭人均 纯收入 家庭生活 消费支出 北京9439.63 6399.27 湖北3997.48 3090 天津7010.06 3538.31 湖南3904.2 3377.38 河北4293.43 2786.77 广东5624.04 4202.32 山西3665.66 2682.57 广西3224.05 2747.47 3953.1 3256.15 海南3791.37 2556.56 辽宁4773.43 3368.16 重庆3509.29 2526.7 吉林4191.34 3065.44 四川3546.69 2747.27 4132.29 3117.44 贵州2373.99 1913.71 上海10144.62 8844.88 云南2634.09 2637.18 江苏6561.01 4786.15 西藏2788.2 2217.62 浙江8265.15 6801.6 陕西2644.69 2559.59 安徽3556.27 2754.04 甘肃2328.92 2017.21 福建5467.08 4053.47 青海2683.78 2446.5 江西4044.7 2994.49 宁夏3180.84 2528.76 山东4985.34 3621.57 新疆3182.97 2350.58 河南3851.6 2676.41 实验步骤如下: 一、建立有关模型分析异方差检验如下。 方法一、图示法。(两种) (一)、x y 相关分析 从图中可以看出,随着收入的增加,家庭生活消费支出不断的提高,但离散程度也逐步扩大。这说明变量之间可能存在递增的异方差性。 建立模型: 1、从图中可以看出,x y不是简单的线性关系。建立线性回归方程如下, LS Y C X
eviews教程第25章时间序列截面数据模型
eviews教程第25章时间序列截面数据模型 (3) 对转换后变量使用OLS (X 包括常数项和回归 量x ) (25.12) 其中。 EViews在输出中给 出了由(3)得到的的参数估计。使用协方差矩阵的标准估计量计算 标准差。 EViews给出了随机影响的估计值。计算公式为: (25.13) 得到的是的最优线性无偏预测值。最后, EViews 给出了加权和不加权的概括统计量。加权统计量来自(3)中的 GLS 估计方程。未加权统计量来自普通模型的残差,普通模型中包括 (3)中的参数和估计随机影响: (25.14) 三、截面加权当残差具有截面异方差性和 同步不相关时最好进行截面加权回归: (25.15) EViews进行FGLS ,并且从一阶段Pool 最小 二乘回归得出。估计方差计算公式为: (25.16) 其中是OLS 的拟合值。估计系数值和协方差矩阵 由标准GLS 估计量给出。四、SUR 加权当残差具有截 面异方差性和同步相关性时,SUR 加权最小二乘是可行的GLS 估计量: (25.17) 其中是同步相关的对称阵: (25.18) 一般项,在所有的t 时为常 数。 EViews估计SUR 模型时使用的是由一阶段Pool 最小二乘回归得到: (25.19) 分母中的最大值函数是为了解决向下加权协方差项产 生的不平衡数据情况。如果缺失值的数目可渐进忽略,这种方法生成 可逆的的一致估计量。模型的参数估计和参数协方差矩阵计 算使用标准的GLS 公式。五、怀特(White )协方差估计在Pool 估计中可计算怀特的异方差性一致协方差估计(除了SUR 和 随机影响估计)。EViews 使用堆积模型计算怀特协方差矩阵: (25.20) 其中K 是估计参数总数。这种方差估计量足以解释各截面 成员产生的异方差性,但不能解释截面成员间同步相关的可能。 * * 第二十五章时间序列/截面数据模型在经典计量经济学模型 中,所利用的数据(样本观测值)的一个特征是,或者只利用时间序
计量经济学eviews实验报告
大连海事大学 实验报告 实验名称:计量经济学软件应用 专业班级:财务管理2013-1 姓名:安妮 指导教师:赵冰茹 交通运输管理学院 二○一六年十一月 一、实验目标 学会常用经济计量软件的基本功能,并将其应用在一元线性回归模型的分析中。具体包括:Eview的安装,样本数据基本统计量计算,一元线性回归模型的建立、检验及结果输出与分析,多元回归模型的建立与分析,异方差、序列相关模型的检验与处理等。二、实验环境 WINDOWSXP或2000操作系统下,基于EVIEWS5.1平台。 三、实验模型建立与分析 案例1:
我国1995-2014年的人均国民生产总值和居民消费支出的统计资料(此资料来自中华人民共和国统计局网站)如表1所示,做回归分析。 表1我国1995-2014年人均国民生产总值与居民消费水平情况
(1)做出散点图,建立居民消费水平随人均国内生产总值变化的一元线性回归方程,并解释斜率的经济意义; 利用eviews软件输出结果报告如下: Dependent Variable: CONSUMPTION Method: Least Squares Date: 06/11/16 Time: 19:02 Sample: 1995 2014 Included observations: 20
Variable Coeffici ent Std. Error t-Statisti c Prob.?? C691.0225113.3920 6.0941040.0000 AVGDP0.3527700.00490871.880540.0000 R-squared0.996528????Mean dependent var7351.300 Adjusted R-squared0.996335????S.D. dependent var4828.765 S.E. of regression292.3118????Akaike info criterion14.28816 Sum squared resid1538032.????Schwarz criterion14.38773 Log likelihood -140.881 6 ????Hannan-Quinn criter.14.30760 F-statistic5166.811????Durbin-Watson stat0.403709 Prob(F-statistic)0.000000 由上表可知财政收入随国内生产总值变化的一元线性回归方程为:
计量经济学多元线性回归、多重共线性、异方差实验报告概要
计量经济学实验报告
多元线性回归、多重共线性、异方差实验报告 一、研究目的和要求: 随着经济的发展,人们生活水平的提高,旅游业已经成为中国社会新的经济增长点。旅游产业是一个关联性很强的综合产业,一次完整的旅游活动包括吃、住、行、游、购、娱六大要素,旅游产业的发展可以直接或者间接推动第三产业、第二产业和第一产业的发展。尤其是假日旅游,有力刺激了居民消费而拉动内需。2012年,我国全年国内旅游人数达到30.0亿人次,同比增长13.6%,国内旅游收入2.3万亿元,同比增长19.1%。旅游业的发展不仅对增加就业和扩大内需起到重要的推动作用,优化产业结构,而且可以增加国家外汇收入,促进国际收支平衡,加强国家、地区间的文化交流。为了研究影响旅游景区收入增长的主要原因,分析旅游收入增长规律,需要建立计量经济模型。 影响旅游业发展的因素很多,但据分析主要因素可能有国内和国际两个方面,因此在进行旅游景区收入分析模型设定时,引入城镇居民可支配收入和旅游外汇收入为解释变量。旅游业很大程度上受其产业本身的发展水平和从业人数影响,固定资产和从业人数体现了旅游产业发展规模的内在影响因素,因此引入旅游景区固定资产和旅游业从业人数作为解释变量。因此选取我国31个省市地区的旅游业相关数据进行定量分析我国旅游业发展的影响因素。 二、模型设定 根据以上的分析,建立以下模型 Y=β 0+β1X 1 +β2X 2 +β 3 X 3 +β 4 X 4 +Ut 参数说明: Y ——旅游景区营业收入/万元 X 1 ——旅游业从业人员/人 X 2 ——旅游景区固定资产/万元 X 3 ——旅游外汇收入/万美元 X 4 ——城镇居民可支配收入/元
Eviews时间序列分析实例.
Eviews时间序列分析实例 时间序列是市场预测中经常涉及的一类数据形式,本书第七章对它进行了比较详细的介绍。通过第七章的学习,读者了解了什么是时间序列,并接触到有关时间序列分析方法的原理和一些分析实例。本节的主要内容是说明如何使用Eviews软件进行分析。 一、指数平滑法实例 所谓指数平滑实际就是对历史数据的加权平均。它可以用于任何一种没有明显函数规律,但确实存在某种前后关联的时间序列的短期预测。由于其他很多分析方法都不具有这种特点,指数平滑法在时间序列预测中仍然占据着相当重要的位置。 (-)一次指数平滑 一次指数平滑又称单指数平滑。它最突出的优点是方法非常简单,甚至只要样本末期的平滑值,就可以得到预测结果。 一次指数平滑的特点是:能够跟踪数据变化。这一特点所有指数都具有。预测过程中添加最新的样本数据后,新数据应取代老数据的地位,老数据会逐渐居于次要的地位,直至被淘汰。这样,预测值总是反映最新的数据结构。 一次指数平滑有局限性。第一,预测值不能反映趋势变动、季节波动等有规律的变动;第二,这种方法多适用于短期预测,而不适合作中长期的预测;第三,由于预测值是历史数据的均值,因此与实际序列的变化相比有滞后现象。 指数平滑预测是否理想,很大程度上取决于平滑系数。Eviews提供两种确定指数平滑系数的方法:自动给定和人工确定。选择自动给定,系统将按照预测误差平方和最小原则自动确定系数。如果系数接近1,说明该序列近似纯随机序列,这时最新的观测值就是最理想的预测值。 出于预测的考虑,有时系统给定的系数不是很理想,用户需要自己指定平滑系数值。平滑系数取什么值比较合适呢?一般来说,如果序列变化比较平缓,平滑系数值应该比较小,比如小于0.l;如果序列变化比较剧烈,平滑系数值可以取得大一些,如0.3~0.5。若平滑系数值大于0.5才能跟上序列的变化,表明序列有很强的趋势,不能采用一次指数平滑进行预测。 [例1]某企业食盐销售量预测。现在拥有最近连续30个月份的历史资料(见表l),试预测下一月份销售量。 表1 某企业食盐销售量单位:吨 解:使用Eviews对数据进行分析,第一步是建立工作文件和录入数据。有关操作在本
EVIEWS实验报告1
EVIEWS实验报告 专业:金融学 班级:10907 学号:1090723 姓名:侯文隽
一、选题 自1949年新中国成立以后,我国国债发行基本分为两个阶段:20世纪50年代是第一阶段,为了支援人民解放战争,恢复和发展经济,我国先后发行过人民胜利折实公债和国家经济建设公债。80年代以来是第二阶段,进入20世纪80年代以后,随着改革开放的不断深入,我国国民收入分配格局发生了变化,国债的发行量也逐年扩大。本次实验出发点是根据1980-2005年的国债规模和可能的相关因素进行分析,同时达到掌握使用EVIEWS进行经济问题分析的目的。二、建立模型 影响国债规模的因素是多方面的、多层次的,我们暂且不去考虑微观上国债的管理水平与结构、筹资成本、期限安排、偿还方式等因素,因为这些因素的影响是个别的,并且难以计量。所以从宏观经济角度出发,引入财政赤字、国内生产总值(GDP)、年还本付息支出等指标,并建立多元线性回归模型。以国债发行量作为被解释变量Y,财政赤字、GDP、还本付息支出作为解释变量分别用X1、X2、X3表示。建立模型如下: Y=b0+b1*X1+b2*X2+b3*X3 三、数据来源 下表列出了1980-2005年间历年国债发行规模及各相关因素的具体数据表1 单位:亿元
(来源于中国统计年鉴2006,1980-2005年数据) 四、实验结果 通过普通最小二乘法对变量进行回归估计,得到结果如下: Dependent Variable: Y Method: Least Squares Date: 10/02/11 Time: 13:09 Sample: 1980 2005 Included observations: 26 Variable Coefficient Std. Error t-Statistic Prob. C -82.30505 63.20978 X1 0.816282 0.075733 X2 0.671558 0.414988 X3 0.980645 0.160403 R-squared 0.994963 Mean dependent var 2015.208 Adjusted R-squared 0.994276 S.D. dependent var 2355.453 S.E. of regression 178.2087 Akaike info criterion 13.34443 Sum squared resid 698683.5 Schwarz criterion 13.53798 Log likelihood -169.4775 F-statistic Durbin-Watson stat 1.141533 Prob(F-statistic) Y=-82.3051+0.8163X1+0.6716X2+0.9806X3 五、模型检验 1、从回归估计的结果看,可决系数R2=0.9949,模型拟合较好。方程的显著性检 验中F的伴随概率等于0,小于0.05,说明所有的待估参数不全为零,方程总体上的线性关系是显著成立的。在变量的显著性检验中,X1和X3的t检
Eviews时间序列分析
时间序列分析实验指导 A
统计与应用数学学院
随着计算机技术的飞跃发展以及应用软件的普及,对高等院校的实验教学提出了越来越高的要求。为实现教育思想与教学理念的不断更新,在教学中必须注重对大学生动手能力的培训和创新思维的培养,注重学生知识、能力、素质的综合协调发展。为此,我们组织统计与应用数学学院的部分教师编写了系列实验教学指导书。 这套实验教学指导书具有以下特点: ①理论与实践相结合,书中的大量经济案例紧密联系我国的经济发展实际,有利于提高学生分析问题解决问题的能力。 ②理论教学与应用软件相结合,我们根据不同的课程分别介绍了SPSS SAS、MATLAB、EVIEWS等软件的使用方法,有利于提高学生建立数学模型并能正确求解的能力。 这套实验教学指导书在编写的过程中始终得到财经大学教务处、实验室管理处以及统计与应用数学学院的关心、帮助和大力支持,对此我们表示衷心的感谢! 限于我们的水平,欢迎各方面对教材存在的错误和不当之处予以批评指正。 统计与数学模型分析实验中心 2007年2月
实验一EVIEWS中时间序列相关函数操作................. -1 -实验二确定性时间序列建模方法 ........................ -10 -实验三时间序列随机性和平稳性检验. (21) 实验四时间序列季节性、可逆性检验.................. -25 -实验五ARMA模型的建立、识别、检验................ -34 - 实验六ARMA模型的诊断性检验...................... -37 -实验七ARMA模型的预测............................ -38 -实验八复习ARMA建模过程 .......................... -40 -实验九时间序列非平稳性检验........................ -42 -
利用eviews实现时间序列的平稳性检验与协整检验
在对时间序列Y、X1进行回归分析时需要考虑Y与X1之间是否存在某种切实的关系,所以需要进行协整检验。 1.1利用eviews创建时间序列Y、X1: 打开eviews软件点击file-new-workfile,见对话框又三块空白处workfile structuretype处又三项选择,分别是非时间序列unstructured/undate,时间序列dated-regularfrequency,和不明英语balance panel。选择时间序列dated-regular frequency。在datespecification中选择年度,半年度或者季度等,和起始时间。右下角为工作间取名字和页数。 点击ok。 在所创建的workfile中点击object-new object,选择series,以及填写名字如Y,点击OK。 将数据填写入内。 1.2对序列Y进行平稳性检验: 此时应对序列数据取对数,取对数的好处在于可将间距很大的数据转换为间距较小的数据。 具体做法是在workfile y的窗口中点击Genr,输入logy=log(y),则生成y的对数序列logy。 再对logy序列进行平稳性检验。 点击view-United root test,test type选择ADF检验,滞后阶数中lag length 选择SIC检验,点击ok得结果如下: Null Hypothesis: LOGY has a unit root Exogenous: Constant
Lag Length: 0 (Automatic based on SIC, MAXLAG=1) t-StatisticProb.* Augmented Dickey-Fuller test statistic- 2." ."09959 Test critical values:1% level- 4."602226 5% level- 3."026225 10% level - 2."0013 当检验值Augmented Dickey-Fuller test statistic的绝对值大于临界值绝对值时,序列为平稳序列。 若非平稳序列,则对logy取一阶差分,再进行平稳性检验。直到出现平稳序列。假设Dlogy和DlogX1为平稳序列。 1.3对Dlogy和DlogX1进行协整检验 点击窗口quick-equation estimation,输入DLOGY C DLOGX1,点击ok,得到运行结果,再点击proc-make residual series进行残差提取得到残差序列,再对残差序列进行平稳性检验,若残差为平稳序列,则Dlogy与Dlogx1存在协整关系。
Eviews实验报告
江西农业大学经济贸易学院学生实验报告 课程名称:计量经济学 专业班级:经济1201班 姓名: 学号: 指导教师:徐冬梅 职称:讲师 实验日期: 2014.12.11
学生实验报告 一、实验目的及要求 1、目的 会使用EVIEWS对计量经济模型进行分析 2、内容及要求 (1)对经典线形回归模型进行参数估计、参数的检验与区间估计,对模型总体进行显著性检验; (2)异方差的检验及其处理; (3)自相关的检验及其处理; (4)多重共线性检验及其处理; 二、仪器用具 三、实验方法与步骤 (一)数据的输入、描述及其图形处理; (二)方程的估计; (三)参数的检验、违背经典假定的检验; (四)模型的处理与预测
四、实验结果与数据处理 实验一:中国城镇居民人均消费支出模型 数据散点图: 通过Eviews 估计参数方程 回归方程: Dependent Variable: Y Method: Least Squares Date: 11/27/14 Time: 15:02 Sample: 1 31 Included observations: 31 Variable Coefficien t Std. Error t-Statistic Prob. X 1.359477 0.043302 31.39525 0.0000 C -57.90655 377.7595 -0.153289 0.8792 R-squared 0.971419 Mean dependent var 11363.69 Adjusted R-squared 0.970433 S.D. dependent var 3294.469 S.E. of regression 566.4812 Akaike info criterion 15.57911 Sum squared resid 9306127. Schwarz criterion 15.67162 Log likelihood -239.4761 F-statistic 985.6616 Durbin-Watson stat 1.294974 Prob(F-statistic) 0.000000 5000 10000 15000 20000 25000 6000 800010000120001400016000 X Y
eviews时间序列分析实验
实验一ARMA 模型建模 一、实验目的 学会检验序列平稳性、随机性。学会分析时序图与自相关图。学会利用最小二乘法等方法对ARMA 模型进行估计,以及掌握利用ARMA 模型进行预测的方法。学会运用Eviews 软件进行ARMA 模型的识别、诊断、估计和预测和相关具体操作。 二、基本概念 1 平稳时间序列: 定义:时间序列{zt}是平稳的。如果{zt}有有穷的二阶中心矩,而且满足: (a )ut= Ezt =c; (b )r(t,s) = E[(zt-c)(zs-c)] = r(t-s,0) 则称{zt}是平稳的。 2 AR 模型: AR 模型也称为自回归模型。它的预测方式是通过过去的观测值和现在的干扰值的线性组合预测。具有如下结构的模型称为P 阶自回归模型,简记为AR(P)。 ? ???? ??
11222 0()0(),()0,t t t t q t q q t t t s x E Var E s t εμεθεθεθεθεεσεε---?=+----? ≠??===≠?L , 4 ARMA 模型: ARMA 模型:自回归模型和滑动平均模型的组合, 便构成了用于描述平稳随机过程的自回归滑动平均模型ARMA 。具有如下结构的模型称为自回归移动平均回归模型,简记为ARMA(p,q)。 ? ???? ??
多元线性回归实验报告
实验题目:多元线性回归、异方差、多重共线性 实验目的:掌握多元线性回归的最小二乘法,熟练运用Eviews软件的多元线性回归、异方差、多重共线性的操作,并能够对结果进行相应的分析。 实验内容:习题3.2,分析1994-2011年中国的出口货物总额(Y)、工业增加值(X2)、人民币汇率(X3),之间的相关性和差异性,并修正。 实验步骤: 1.建立出口货物总额计量经济模型: 错误!未找到引用源。(3.1) 1.1建立工作文件并录入数据,得到图1 图1 在“workfile"中按住”ctrl"键,点击“Y、X2、X3”,在双击菜单中点“open group”,出现数据 表。点”view/graph/line/ok”,形成线性图2。 图2 1.2对(3.1)采用OLS估计参数 在主界面命令框栏中输入ls y c x2 x3,然后回车,即可得到参数的估计结果,如图3所示。
图 3 根据图3中的数据,得到模型(3.1)的估计结果为 (8638.216)(0.012799)(9.776181) t=(-2.110573) (10.58454) (1.928512) 错误!未找到引用源。错误!未找到引用源。F=522.0976 从上回归结果可以看出,拟合优度很高,整体效果的F检验通过。但当错误!未找到引用源。=0.05时,错误!未找到引用源。=错误!未找到引用源。2.131.有重要变量X3的t检验不显著,可能存在严重的多重共线性。 2.多重共线性模型的识别 2.1计算解释变量x2、x3的简单相关系数矩阵。 点击Eviews主画面的顶部的Quick/Group Statistics/Correlatios弹出对话框在对话框中输入解释变量x2、x3,点击OK,即可得出相关系数矩阵(同图4)。 相关系数矩阵 图4 由图4相关系数矩阵可以看出,各解释变量相互之间的相关系数较高,证实解释变量之间存在多重共线性。 2.2多重共线性模型的修正
计量经济学Eviews多重共线性实验报告
实验报告 课程名称计量经济学 实验项目名称多重共线性 班级与班级代码 专业 任课教师 学号: 姓名: 实验日期:2014 年05 月11日
广东商学院教务处制 姓名实验报告成绩 评语: 指导教师(签名) 年月日
说明:指导教师评分后,实验报告交院(系)办公室保存。 计量经济学实验报告 一、实验目的:掌握多元线性回归模型的估计方法、掌握多重共线性模型的识别和修正。 二、实验要求:应用教材第127页案例做多元线性回归模型,并识别和修正多重共线性。 三、实验原理:普通最小二乘法、简单相关系数检验法、综合判断法、逐步回归法。 R值。 四、预备知识:最小二乘法估计的原理、t检验、F检验、2 五、实验步骤 1、选择数据 理论上认为影响能源消费需求总量的因素主要有经济发展水平、收入水平、产业发展、人民生活水平提高、能源转换技术等因素。为此,收集了中国能源消费标准煤总量、国民总收入、国内生产总值GDP、工业增加值、建筑业增加值、交通运输邮电业增加值、人均生活电力消费、能源加工转换效率等1985——2007年的统计数据。本题旨在通过建立这些经济变量的线性模型来说明影响能源消费需求总量的原因。主要数据如下: 1985~2007年统计数据
资料来源:《中国统计年鉴》,中国统计出版社2000、2008年版。 为分析Y 与X1、X2、X3、X4、X5、X6、X7之间的关系,做如下折线图: 能源消费Y 在1986到1996年间缓慢增长,在96至98年有短暂的下跌,但是98 至02年开始缓慢回升,02年到06年开始快速增长。 国民总收入X1和国内生产总值X2以相同的趋势逐年缓慢增长。 工业增加值X3在1985年-1999年期间一直是缓慢增长,但在2000年出现了急剧下降的现象,2001年又急剧增长,达到下降前的水平,2001年以后开始缓慢增长。建筑业增长值x4、交通运输邮电业增加值x5、人均生活电力消费x6、能源加工转换效率x7数值较低,但都以较平缓的方式增长。 2、设定并估计多元线性回归模型 t t t t t t t u X X X X X Y ++++++=66554433221ββββββ (2.1) 2.1录入数据,得到图。
EViews计量经济学实验报告异方差的诊断及修正
姓名学号实验题目异方差的诊断与修正 一、实验目的与要求: 要求目的:1、用图示法初步判断是否存在异方差,再用White检验异方差; 2、用加权最小二乘法修正异方差。
估计结果为: i Y ? = 12.03564 + 0.104393i X (19.51779) (0.008441) t=(0.616650) (12.36670) 2R =0.854696 R =0.849107 S.E.=56.89947 DW=1.212859 F=152.9353 这说明在其他因素不变的情况下,销售收入每增长1元,销售利润平均增长0.104393元。 2R =0.854696 , 拟合程度较好。在给定 =0.0时,t=12.36670 > )26(025.0t =2.056 ,拒 绝原假设,说明销售收入对销售利润有显著性影响。F=152.9353 > )6,21(F 05.0= 4.23 ,
表明方程整体显著。 (三) 检验模型的异方差 ※(一)图形法 6、判断 由图3可以看出,被解释变量Y 随着解释变量X 的增大而逐渐分散,离散程度越来越大; 同样,由图4可以看出,残差平方2 i e 对解释变量X 的散点图主要分布在图形中的下三角部分,大致看出残差平方2 i e 随i X 的变动呈增大趋势。因此,模型很可能存在异方差。但是否确实存在异方差还应该通过更近一步的检验。
※ (二)White 检验 White 检验结果 White Heteroskedasticity Test: F-statistic 3.607218 Probability 0.042036 Obs*R-squared 6.270612 Probability 0.043486 Test Equation: t 界值5.002 χ (2) =5.99147。比较计算的2χ统计量与临界值,因为n 2R = 6.270612 > 5 .002 χ(2)=5.99147 ,所以拒绝原假设,不拒绝备择假设,这表明模型存在异方差。 (四) 异方差的修正 在运用加权最小二乘法估计过程中,分别选用了权数t 1ω=1/t X ,t 2ω=1/2 t X ,t 3ω=1/t X 。 用权数t 1ω的结果