MSA 4th Edition概论

一前言
MSA (Measurement System Analysis量測系統分析)是AIAG所出版的汽車工業標準之五大核心工具之一,目的是介紹各種分析手法來找出量測的總變異(亦稱為不確定度expanded uncertainty),以便評估第一類型錯誤 (type-I error 良品判斷為不良品) 與第二類型錯誤 (type-II error 不良品判斷為良品)的風險。其中需特別關注第二類型錯誤,因其風險會直接到達客戶端,造成嚴重之客訴與品質失敗成本。
MSA手冊所介紹之分析手法皆根源於古典統計學(classic SPC),若想深入理解MSA則需先奠定古典統計學之概念。
MSA第四版已於2010年六月出來。相比於第三版並無甚麼變更,只是補充提示某些分析手法,令其讀者對理路更易瞭解,也對一些使用者的常犯錯誤做重要的觀念澄清。本文會以粗體紅字特別標出,俾令讀者能很快了解此次改版的變動。
MSA所需涵蓋的儀器範圍一般是參考管制計畫所列舉之量測儀器,最主要關注量測產品特性之儀器,因其直接和客戶要求關聯,並直接造成客戶影響。至於量測製程特性之儀器,如 溫度計,壓力計,轉速計…等則可考量其重要性或客戶要求,決定其MSA手法與允收標準,不一定是非做不可。
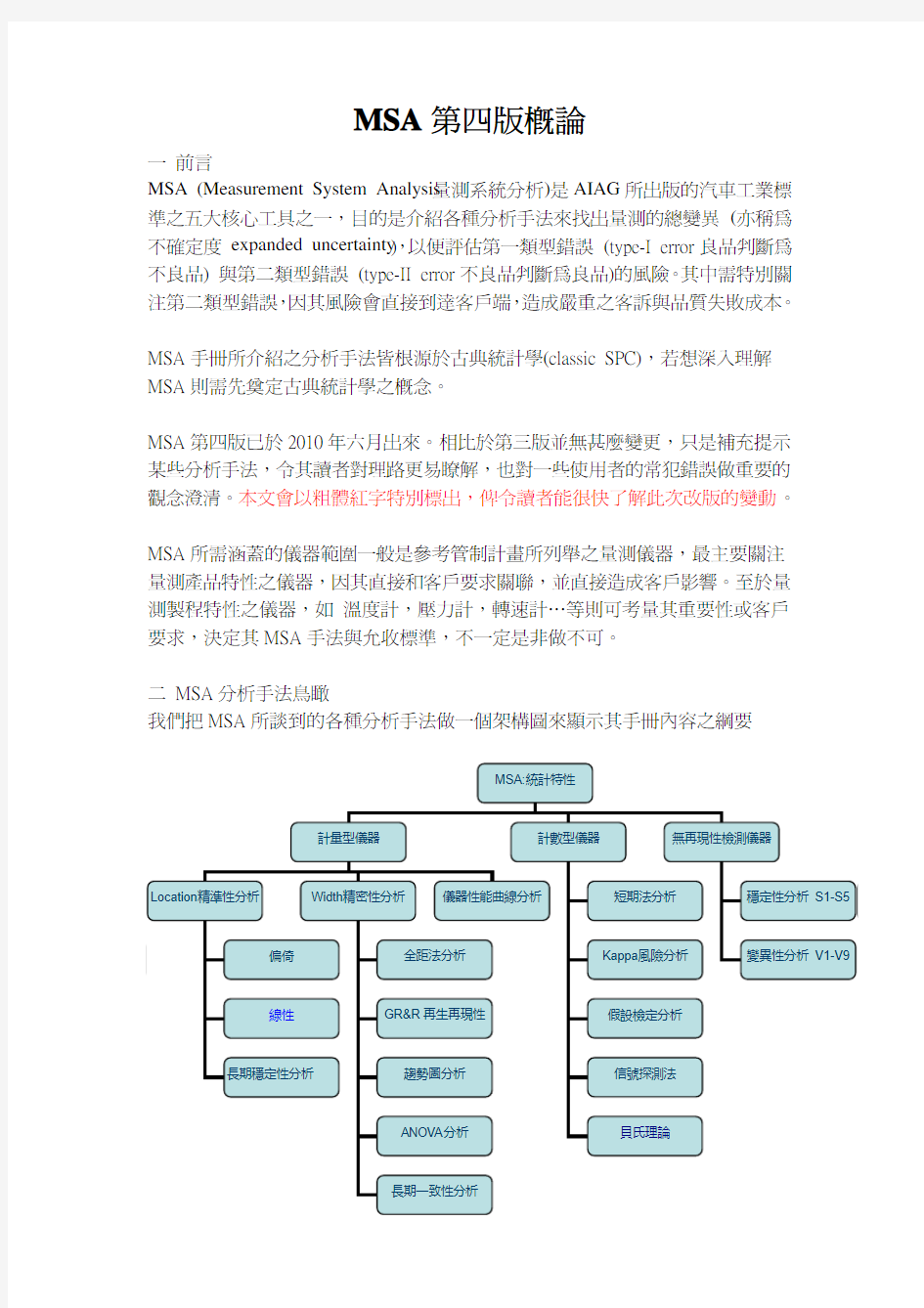
二 MSA分析手法鳥瞰
我們把MSA所談到的各種分析手法做一個架構圖來顯示其手冊內容之綱要
量測系統的統計特性:
? 理想之量測系統是一個具有零偏差、零變異的統計特性 。
? 量測系統的統計特性:
量測系統須在統計管制下,亦即量測系統的變異僅根源於共同原
因,而非特殊原因。(亦即在做MSA 之前必須確認排除所有特殊原因;例如 儀器鬆動,儀器未校準,評價人非正常生產之檢驗員,使用塊規而非使用量產之產品樣本…等。其中包括 “盲測 blind measurements”,亦即須應用客觀方式取得量測讀數,舉例來說: 評價人量測樣品的某一尺寸時,需遮蓋讀數表,當確認量測到位時,再揭開讀數表並紀錄其讀數,以避免評價人依預期心獲取讀數)。 量測系統的變異必須小於製程變異。 量測系統的變異必須小於規格界限。
量測之最小刻度必須小於製程變異或規格界限之較小者,一個通用的法則是:最小刻度應小於製程變異或規格界限較小者之1/10。(足夠的分辨率及靈敏度)
因量測項目的改變,量測系統之統計特性可能變更,但最大的量測
系統變異必須小於製程變異或規格界限較小者。
在確保統計特性之後,方能開始進行量測系統分析。
零件內變異(within part variation)必須注意,如一個圓柱體零件,不同位置所測得的外徑會有所不同。執行MSA 分析時,需做記號,將量測固定在一個位置。否則此零件內變異會跑進去附著於人員或儀器的變異。理想的零件內變異是0,在進行MSA 分析前須予以確認。
三 各種MSA 分析手法
計量型儀器:
量測能得到數值的儀器。如: 游標卡尺,三次元量測儀,三用電表,硬度計,分光儀,粗度儀…等。
先介紹屬於精準性(accuracy)的分析,其主要在了解量測值與真值的差異是否可以接受。下分三種分析手法:
偏倚(bias): 量測值和真值(或參考值)之差距。採用古典統計裡的獨立樣本法: 抽樣誤差與信賴區間95%之水準。故只要0點座落於偏倚誤差1.96σ之內,代表量測誤差和0點相距很近,判定偏倚可以接受。
MSA 第四版提到採用假設檢定手法第四版提到採用假設檢定手法來和抽樣誤差與信賴區間法相印證來和抽樣誤差與信賴區間法相印證來和抽樣誤差與信賴區間法相印證,,一般而
言兩者所得結論會一致言兩者所得結論會一致。。此種採用各種古典統計手法來相互印證的方式,不斷出現在MSA 手冊各章節中,用以說明雖然手法有所不同,但本質相同,判斷結果就會一致。
線性線性(Line (Line (Linearity)arity): 儀器量測範圍內之偏倚的狀況,MSA 手冊中選了能代表其量測範圍的5點,得出各點之平均偏倚,利用回歸分析得出線性,也採用95%之信賴區間,得出其線性的上下兩條95%信賴區間線,故只要0點線座落於此信賴區間線之間,代表各點之0點各座落於偏倚誤差1.96σ之內,偏倚在各點可接受。整條線性即可判定接受。但MSA 手冊之案例顯示0點線跑出上下兩條95%信賴區間線,故判定線性不可接受。
線性若做過,即代表整個量測範圍的各點都偏倚都可顯示出來,不需再做某些點之偏倚了。
偏倚和線性的分析結果須先和再現性偏倚和線性的分析結果須先和再現性((re repeatability peatability peatability))對比對比,,若再現性相對於製程變異可以接受異可以接受,,代表儀器本身的變異夠小代表儀器本身的變異夠小,,不致使95%95%的信賴區間擴的太大的信賴區間擴的太大的信賴區間擴的太大,,偏倚和線性的分析才和線性的分析才算算有效。
長期穩定性長期穩定性(stability)(stability): 一般採用X -b ar R 管制圖,以了解在長時間的主軸上,其偏倚變異的狀況。分析手法則同管制圖之判讀準則,若未觀察到特殊趨勢或有任何點超出管制界限,則判定此偏倚量測無存在特殊原因,穩定性可接受。
再來介紹屬於精密性(precision)的分析,其主要在了解人員與儀器的變異下所造成每次量測值的差異是否可以接受。下分五種分析手法:
全距法分析全距法分析(range method)(range method): 若之前已做過幾次GR&R 分析,其結果都非常理想。新產品開發又使用同一儀器,或每年想確認一下其GR&R 的狀況,則可以採用此簡易型的GR&R 手法。只需兩個評價人與五個樣品,每人各量每個樣品一次。所得之GR&R 變異是揉合再生再現性的總變異,再轉化成標準差(因為需考量其抽樣誤差),與製程標準差做比對。若小於10%則可判定為可接受。
GR&R 再生再現性分析再生再現性分析(average and range method)(average and range method): 這是運用最廣的MSA 分析手法,可分離得知儀器變異,人員變異與零件變異。再轉化成標準差(因為需考量其抽樣誤差),與總標準差做比對。經常所見之錯誤有三點;
(1) R p 零件變異太小(因十個樣品係從同一批挑出)造成%GR&R 過高,解決之法
可以直接將TV 總標準差總標準差= (USL = (USL = (USL--LSL) / 6 代入代入(Pp (Pp 約等於1)1),,此代表製程的一
個標準差,GR&R / TV 來得到結果,但此法是將GR&R 直接和製程一個標準差相比,條件較為嚴苛。
(2) 第二個錯誤是%R&R 之結果在10%到30%之間,卻直接判定接受,而沒有解
析對內部與客戶所造成之風險。
(3) 第三點則是MSA 第四版所提醒的: 沒有完整分析儀器的精密精沒有完整分析儀器的精密精準與長時間之準與長時間之總變異總變異,,也未解析對內部與客戶所造成之風險也未解析對內部與客戶所造成之風險,,單從單從%GR&R %GR&R 所得之結果小於10%10%就判斷此儀器之就判斷此儀器之MSA 分析可以接受分析可以接受。。 另外一個判斷重點是ND C,需大於5才可接受。其實若鑑別力(d iscri m i n atio n )夠以及%GR&R 夠小,此數據應該不會有問題。
趨勢圖分析: 這個部份沒有變動。各類趨勢圖依照GR&R 分析: 三個評價者,十個樣本,每人對每個樣品量三次。將各種分解所得之趨勢圖可以觀察到一些現象。從而解析其原因,判斷改進的方向。例如其中一個圖看出A 與B 較一致,C 與A B 較不相合,則可進一步去了解C 的量測有何問題。
ANOVA 變異數變異數分析分析: 這是比較複雜的分析,需要利用電腦軟體來計算。A NOV A 手法可拆解出: 零件,評價人,零件與評價人的相互影響以及儀器的再現性。所計算之數據跟前面之GR&R 引用相同數據,所得結果GR&R 與A NOV A 大致相同,兩者互相印證。判斷之準則和GR&R 一樣。
注意: 精準性和精密性是兩種不同類型之分析,一般情況下是互相獨立的,GR&R 結果可接受並不代表線性也會可接受。
但MSA 第四版也另提示第四版也另提示: : 若Cpk 夠高夠高,,則可則可考慮考慮考慮不須執行不須執行MSA 分析分析。。
故總結以上的計量型儀器之MSA 總變異 = 偏倚(線性)變異 + 穩定性變異(長時間) + 再生性變異 + 再現性變異 + 一致性變異(長時間)
這些變異都須以標準差的形式呈現: σ2
(總變異) =σ2
(偏倚或線性) +σ2
(穩定性) +σ2
(再生性) +σ2
(再現性) +σ2
(一致性)
得到σ(總變異)後,我們就可以來計算量測不確定性 U (un certai n ty) = kσ(總變異) 以95%信賴區間之Z 分配,可查得k 約等於2。
假設σ(總變異)=0.02,不確定性 U=2x 0.02=0.04,則我們知道在95%信賴水準下量測值21.50的結果,其實際值會介於 21.46 – 21.54。其尺寸公差若 ±0.03,則我們應該去評價有可能超出規格值0.01的情況時,我們可能判定允收,這時就要去評估當超出規格值0.01時,客戶使用後會有哪些衝擊?
我們可以和客戶探討功能喪失曲線(如下圖所示),並評估MSA 變異造成不良品判為良品時,客戶使用時功能喪失的程度,以了解其真實之衝擊與風險。
附注: 功能喪失曲線是指 某一產品特性在規格中心值時,其對產品所發揮之功能達到100%,隨著特性值往兩邊走,其對產品所發揮之功能遞減,每個特性遞減的幅度不盡相同所畫出來的曲線。設計者會依據此曲線來決定上下規格界線。
計數型儀器:
量測結果只有OK 或NG (例如: 環規,塞規…等),或者是不連續的幾個已定義的群組 (例如: 灰度計)。
量測誤差有兩種: (以火災煙霧偵測器為例) 沒有火
失火 沒警報 正確 第二型錯誤
有警報
第一型錯誤
正確
實務運用上,我們比
較擔心第二型錯誤,故
會將警報器調的敏感一些 (工廠檢驗設定則是將規格內縮),寧可殺錯不會放過。但如此則造成經常性的假警報 (工廠檢驗則造成很多失敗成本)。最好的作法是將儀器的誤差範圍儘量縮小,亦即下圖的II 區 (會造成第I & II 型錯誤的區域,通常會在規格界線值往兩邊延伸)。
規格上限
規格下限
60%
判定為良品
? 客戶
短期法分析(short method): 兩個人,20個樣品,每人對每個樣品各量兩次。若每樣品兩人量兩次都一致,則判定此儀器可接受。這是MSA 第二版所介紹的針對計數型儀器最簡易的方法,到現在還是有很多人在使用 (雖然第三版已刪除此手法)。但須注意的是樣品最好能包括II 區,才能更客觀的反映出MSA 結果的有效性。
Kappa 風險分析 (Kappa risk analysis): 此法最為業界廣泛使用。主要能顯示兩個群體表現的一致性的程度,若是比對兩個人量測一致性的結果 (如MSA 手冊圖表 III-C 1,A,B,C 三個評價人,有50個樣本,每人對每個樣品量三次),可整理成下表 交叉比對表:
B 評價人
A 評價人
NG
OK Total 44 6
50 NG 數 期望值 15.7 34.3 50.0 3 97 100 OK 數 期望值 31.3 68.7 100.0 47 103 150 Total 期望總數 47.0
103.0
150.0
A 和
B 一致的有44+97=141個,不一致的有6+3=9個
區域
是故P0 (判斷一致率)= 141/150=0.94
Pe (期望數機率)= (15.7+68.7)/150=0.563 光靠運氣就能猜對的機率Kappa= (P0 – Pe) / (1- Pe) = 0.86 此指數在扣掉運氣成分,所得到真實之一致性之性能指標。
將ABC三個評價人做三個交叉比對表,我們得出其Kappa指數,所代表之意義即為類似計數型之再生性 :
Kappa A B C
A - 0.86 0.78
B 0.86 - 0.79
C 0.78 0.79 -
我們也能將ABC三個評價人與樣品標準值做三個交叉比對表,算出三個Kappa 值,所代表之意義即為類似計數型之偏倚 :
A B C
Kappa 0.88 0.92 0.77
Kappa值不會超過1,允收值須為0.75以上。若低於0.4代表其一致性非常差。若此儀器所量測之特性為重要或關鍵特性,Kappa指數需列入優先之持續改善清單之中。
假設檢定分析 : 此法可和上述Kappa風險分析法相互印證。引用同一數據(MSA手冊圖表III-C 1),我們可以得出一個以95%信賴水準的誤差分布比對表:
每位評價者的score都落在彼此的信賴區間內(95% UCI與LCI之間),故原始假設H0成立,故三者具一致性,此可和之前的Kappa分析互相印證。
評價者自我的一致性評價者自我一致且與標準一致Source A B C A B C
總檢查數50 50 50 50 50 50
#Matched 42 45 40 42 45 40
一致漏失0 0 0
一致誤警報0 0 0
混合8 5 10
95% UCI 93% 97% 90% 93% 97% 90%
Score84%90%80%84%90%80%
95% LCI 71% 78% 66% 71% 78% 66%
三位評價者皆一致的次數三位評價者皆一致且和標準一
致
總檢查數50 50
一致次數39 39
95% UCI 64% 64%
Score78% 78%
95% LCI 89% 89%
貝氏理論分析(Bayes’ theorem): 運用機率來運算,可以得知若判斷結果為NG,實際上真正是NG的機率有多少,當然也可算出若判斷結果為OK,實際上真正是OK的機率有多少。故此方法能夠將第I型與第II型錯誤做數據化呈現,讓組織了解失誤風險。不過MSA手冊並未提出允收標準,主要原因是需總體考量: 對客戶之衝擊,量具性能極限,成本等,方能做出客觀判定。
信號探測法(Signal detection approach): 一種可選擇的方法是用信號探測理論來確定一個區域Ⅱ寬度近似值,並因此確定測量系統GR&R。
由MSA手冊圖表III-C8,我們可以算出兩個II區的平均距離: d=0.0237915
而d = 6σGR&R 故σGR&R = 0.003965
規格公差是 0.1,故TV= 0.1/6= 0.016667
故%GR&R=σGR&R/TV= 24%,此結果和本MSA手冊計數型GR&R分析之結
果(26.68%)差不多(也是使用GR&R的同一組數據,但改成計量型儀器)。兩者再次相互印證。
無再現性檢測儀器無再現性檢測儀器(Non (Non (Non--replicable measurement system)replicable measurement system);;包括包括破壞性破壞性破壞性與非破壞性與非破壞性與非破壞性檢檢測儀器測儀器:: 非破壞性之檢驗如: 引擎動力測試機,分析化學成分之分光儀,漏氣測試機…等。 破壞性之檢驗如: 測機械強度之萬能試驗機,鹽霧測試,剝離拉力試驗機,設置於生產線上全自動檢測機(無法從線上移出來單獨測試再生再現性)。
雖然此類檢驗無法再現,但可變通辦法,一樣可以得出偏倚與GR&R 之結果。
MSA 手冊列出二個類別:
(1) 穩定性穩定性分析分析分析(stability study)(stability study): 即類似計量型儀器之精準性分析(偏倚)與穩定性
分析(長期之偏倚變異量)。假如我們要分析萬能試驗機的拉力測試,可取同一批生產出來的鋼棒,切成數百段等長之短鋼棒,這時我們可以假設這些鋼
棒的拉伸強度應該相同(當然也須事先了解製程的長期穩定性與變異性是夠小的),但須注意: 樣品在整個MSA 研究測試期間,需確保鋼棒的拉伸強度不會變動。也要找更精準的方法先得出其相近真值(tr u e v al u e)或參考值(re f ere n ce v al u e)。每週取五件做測試,並和相近真值或參考值做比對,連續25周以上,就可畫出至少25個點的X -b ar R 管制圖。分析手法則同管制圖之判讀準則,若未觀察到特殊趨勢或有任何點超出管制界限,則判定此偏倚量測無存在特殊原因,穩定性可接受。偏倚分析之判斷則依據抽樣誤差與信賴區間95%之水準,只要0點座落於偏倚誤差1.96σ之內,代表量測誤差和0點相距很近,判定偏倚可以接受。不過偏倚的分析結果須先和其儀器再現性(repeata b ility)對比,若再現性相對於製程變異可以接受,代表儀器本身的變異夠小,不致使95%的信賴區間擴的太大,偏倚的分析才算有效。
(2) 變異性分析變異性分析(Variability study):(Variability study): 即類似計量型儀器之精密性分析(GR&R )。假如
我們要分析萬能試驗機的拉力測試,可取同一批生產出來的鋼棒,取10條鋼
棒,每條切成九段等長之短鋼棒,這時我們可以假設這些鋼棒的拉伸強度應該相同(當然也須事先了解製程的長期穩定性與變異性是夠小的)。找三個評價人,每人對每一條鋼棒所切成之短鋼棒取三個測三次,三人共九次。依此類推做完剩下的九條,共得到90個數據。依GR&R 表格依次填入,即可算出E V , A V , P V , TV , %GR&R 以及nd c 等數據。判斷方式則同GR&R 分析之允收標準。
其他不同狀況之量測特性可參考MSA 手冊,穩定性分析有S1到S 5 五種類型之分析手法,變異性有V 1到V9 九種類型之分析手法。
總結總結::
MSA 第四版雖然更新某些重要概念,但基本原則與分析手法沒有變動。對MSA 之分析不同人,不同產業會有不同之思維與看法,但都不會跑出這本MSA 所提到的原則。各種爭議都可回歸到這些原則。
我們也相信,MSA手冊會繼續依業界使用的情況,常犯錯誤以及內容仍不夠清晰之處,不斷地改版,以持續提升契入讀者的需求。
B SI T ai w a n–劉昱廷(B e n so n L i u) 2010-8-6
软件测试中通用测试数据生成方法
软件测试中通用测试数据生成方法 软件测试中非常重要的一个工作就是生成和维护测试数据,而这个工作恰恰是繁琐、重复而极易出错的。无疑找到一种通用的数据生成方法是极具意义的。本文阐释了如何使用脚本语言PHP,加上简单的ini 配置文件来达到这个目的的。 测试的数据生成和维护在软件测试中是非常重要的一环。很多用例实际上就是在修改所测程序的输入数据以确保程序的逻辑是按照自己的预期进行地。 比如我们测试一个用户登录系统,我们需要测试正常用户名+ 正常密码、正常用户名+ 错误密码、错误用户名+ 错误密码等基本的用例。在执行用例之前,就需要事先在数据库中设置好相应的数据,比如有一条记录为正常用户名+ 正常密码,然后我们在登陆界面输入该用户名和密码,预期结果为正常登陆。 不同的程序有不同格式的输入数据。但不管格式千变万化,我们总可以把它们归结为基于行和列的格式,就像数据库中的表一样。一行为一条记录,每一条记录都有相同的字段组成,每一个字段有自己的数据格式,字段和字段之间可能有分隔符。 我们可以在执行每一个用例时,手工修改数据,然后再执行用例。但这样存在一些问题。 1. 重复,数据重用性差。当前用例所需的数据很有可能在下个用例中被破坏了。 2. 效率低,尤其是当数据格式比较复杂,而且又需要大量数据的时候。 3. 不灵活。但数据发生变动的时候,数据的维护成本会很高。 4. 容易出错。 那有没有一种方法来解决这个问题呢?答案是肯定的。下面我们一起来实现一个简单的工具来解决这个问题。 需要实现的基本功能 首先我们来列举一下这个软件测试工具需要实现的基本功能: 1. 通用性:能够描述各种不同格式的数据。 2. 扩展性:当需要新的数据格式时,可以任意扩展。 3. 易用性:配置文件不易复杂。 4. 跨平台:我们需要一款可以在windows、linux、FreeBSD等系统下面运行的工具。
5类软件测试工具
目前主流的测试工具主要有以下5类: 1.负载压力测试工具 这类测试工具的主要目的是度量应用系统的可扩展性和性能,是一种预测系统行为和性能的自动化测试工具。在实施并发负载过程中,通过实时性能监测来确认和查找问题,并针对所发现问题对系统性能进行优化,确保应用的成功部署。负载压力测试工具能够对整个企业架构进行测试,通过这些测试,企业能最大限度地缩短测试时间,优化性能和加速应用系统的发布周期。 2.功能测试工具 通过自动录制、检测和回放用户的应用操作,将被测系统的输出记录同预先给定的标准结果比较,功能测试工具能够有效地帮助测试人员对复杂的企业级应用的不同发布版本的功能进行测试,提高测试人员的工作效率和质量。其主要目的是检测应用程序是否能够到预期的功能并正常运行。 3.白盒测试工具 白盒测试工具一般是针对代码进行测试,测试中发现的缺陷可以定位到代码级。根据测试工具原理的不同,又可以分为静态测试工具和动态测试工具。静态测试工具直接对代码进行分析,不需要运行代码,也不需要对代码编译链接和生成可执行文件。静态测试工具一般是对代码进行语法扫描,找出不符合编码规范的地方,根据某种质量模型评价代码的质量,生成系统的调用关系图等。动态测试工具一般采用“插桩”的方式,在代码生成的可执行文件中插入一些监测代码,用来统计程序运行时的数据。它与静态测试工具最大的不同是,动态测试工具要求被测系统实际运行。 4.测试管理工具 一般而言,测试管理工具对测试需求、测试计划、测试用例、测试实施进行管理,并且测试管理工具还包括对缺陷的跟踪管理。测试管理工具能让测试人员、开发人员或其他的IT 人员通过一个中央数据仓库,在不同地方就能交互信息。 5.测试辅助工具 这些工具本身并不执行测试,例如它们可以生成测试数据,为测试提供数据准备。 参加完“2005年IT测试技术研讨会”以后,谢常君对软件测试和网络测试的主流厂商和产品有了更全面的了解。不过最让他高兴的是结识了一批企业的代表和专家。 一个阳光明媚的下午,谢常君约上某位专家在一个咖啡馆会面。“非常谢谢你能前来,我这次约你出来是希望你可以给我一些专业的建议。”谢常君说,“我们公司近期可能需要采购一些测试工具,但是我们对此了解不多,希望你可以帮我们。”接下来,这位专家就首先从测试工具的分类开始讲起…… IT测试工具集锦 Radview TestView系列 Radview公司的TestView系列Web性能测试工具和WebLoad Analyzer性能分析工具,旨在测试Web应用和Web服务的功能、性能、程序漏洞、兼容性、稳定性和抗攻击性,并且能够在测试的同时分析问题原因和定位故障点。 整套Web性能测试和分析工具包含两个相对独立的子系统:Web性能测试子系统Web 性能分析子系统。其中Web性能测试子系统包含3个模块:TestView Manager、WebFT以及WebLoad。Web性能分析子系统只有WebLoad Analyzer。 左图表达了在一个完整的测试系统中,TestView Manager用来定制、管理各种测试活动;WebLoad模拟多个用户行为进行测试,所测试的是系统性能,容量,稳定性和抗攻击性;
使用PowerDesigner生成数据库测试数据
使用PowerDesigner生成数据库测试数据 1、环境 PowerDesigner15.2.0.3042-BEAN+ MySQL5.5 + mysql-connector-odbc-5.1.8 以上软件在网上都很容易找到,这里就不再给出相关链接!系统环境为WindowsXP。 2、具体流程 既然是生成测试数据,首先数据库一定存在,这里我以对MySQL的操作为例,假设我的数据库名称为db_generate_test。 流程如下: 2.1数据库反向工程 在PowerDesigner环境中,只能对PDM(物理数据模型)生成测试数据所以,首先将需要生成测试数据的数据库反向工程为PowerDesigner的PDM模型。 2.1.1配置数据源 针对MySQL5.0系列版本需要安装mysql-connector-odbc-5.1.8,这里没有什么选择项,直接“下一步”就行。安装好后,打开控制面板| 管理工具| 数据源(ODBC) 如图:
添加数据源: 创建数据源:
填完相关选项后点击“Test”连接成功,OK确定即完成数据源的创建。 2.1.2数据库反向工程 数据源建好后打开PowerDesigner,选择File | Reverse Engineer |Database…,如下图:
你可以为物理数据模型命名,确定即可,这里我命名为GenerateTestDataModel_1,接着: 点击红色箭头处配置数据源: 另外在“Options”选项下可以配置编码类型等选项:
确定后如下: 选择数据库用户,选择表,OK即可完成数据库到物理数据模型的转换
数据自动生成工具 DataFactory 的使用
数据自动生成工具DataFactory 的简单使用 一、简介: Quest DataFactory 是一种快速的、易于产生测试数据工具,它能建模复杂数据关系,且有带有GUI界面。DataFactory是一个功能强大的数据产生器,它允许开发人员和QA毫不费力地产生百万行有意义的测试数据。 二、工作原理: 首先读取数据库中表的schema,即表的定义之类的内容,以列表的形式显示;然后由用户定制要产生数据的具体内容,如数字范围、字符串长度、要产生数据记录的个数等等,最后运行工程,生成数据。 三、安装: 看到网上DataFactory有5.6版本,但是这里使用的是5.2破解版。笔者没有详细研究这两个版本的区别,有兴趣的读者可以自己查阅相关资料。 四、使用说明: DataFactory支持的数据库类型有:DB2、SQL Server、Oracle以及Sybase,最后是ODBC 数据源。本文以ODBC为例来作介绍。在产生数据之前,需要首先设置好系统ODBC数据源,即添加待操作的数据源(开始--》控制面板--》管理工具--》ODBC数据源)。简单起见,创建一个Access数据库DataFactory.accdb,并在其中创建一个customer表。设数据源名称为test,添加完成之后,如下图所示:
图1: 五、产生数据的具体操作方法: 1. 新建工程,在添加数据库时选择ODBC 图2 :
2. 在“Machine Data Source”选项卡中选择test数据源(图3),确定之后会提示输入密码来登录(图4),不填,确定即可。这样,数据库就添加成功(图5),点击OK。 图3:
c语言单元测试用例全自动生成软件wings介绍
wings是一款用于单元测试测试用例驱动框架自动生成工具,简单来说这款工具主要是全自动生成单元测试驱动代码与测试数据。 下面我们尝试使用wings来完成单元测试框架与测试数据的自动生成。 首先准备好需要测试的C语言工程,本文以大型开源软件Mysql为例。 第一步:打开wings工具,选择被测工程的主要目录。 第二步:点击工程操作中的分析生成,对工程目录下的.c文件进行解析,保存为XML 的格式,生成的文件保存在工程目录下的FunXml与GlobalXml中,分别是函数信息与全局变量的信息,点击驱动文件结构图,即可看到对应文件的函数结构信息。
上图可以查看所有.c文件的驱动函数,以及函数所对应的参数信息与全局变量的信息。 第三步:点击功能操作驱动生成,完成项目的驱动框架自动生成,驱动文件保存在wings_projects下的Driver文件夹下。点击驱动文件,即可看到对应.c文件的驱动生成代码。 点击单个函数,可以高亮定位到函数所在位置,并且双击函数参数,可以定位到每个参数的赋值单元,查看每个参数的具体驱动赋值代码。 第四步:点击值功能操作的值生成按钮,则对应生成测试数据。
界面上显示为单个函数的测试数据,可依据需要修改测试次数,重新生成测试数据文件,也可依据需要修改特定的测试数据。 第五步:将驱动文件加载到所在工程目录,与源文件一起编译,即可运行。 如果想查看对应的函数信息与全局变量信息,则右键对应打开对应的Parameter Struture Description(函数信息结构体)与Global Parameter Struture Description(全局变量结构图)。 Parameter Struture Description(函数信息结构体):显示函数的名称,参数个数,参数类型以及复杂类型的展开形式。 Global Parameter Struture Description(全局变量结构图):显示全局变量的结构信息。 使用过程中注意事项: (1)编译源文件过程中,需要手动注释调源文件中的main函数,wings将自动生成调用驱动函数的主函数。 (2)遇到特殊类型的赋值或者系统变量的驱动构造,可自行添加模板赋值方式,添加之后,再次生成驱动文件即可。 例如:遇到FILEL类型的赋值,可在模板中添加对应的赋值方式。
测试数据生成工具DataFactory的使用
DATA FACTORY的使用 Data Factor y是一个数据库测试数据生成工具。 Data Factory主要可以利用在以下两个方面:1.按照数据表中要求数据的格式,快速产生标准或不标准的测试数据,用来测试系统的功能;2.产生大量的随机数据,用来测试在海量数据的情况下的系统性能。3.从其它数据库中相关数据重新组合生成测试数据。 使用Data Factory生成测试数据,先要连接数据库,选择数据库中存在的表,根据不同的字段类型选择不同的数据生成方式:在这里,可以从文档、其他数据库、随机数据、软件自带的数据字典等多种方式生成测试的数据。然后将这些生成的测试数据添加到选择的表中。同时,Data Factory也有许多附带的功能,提供了灵活的数据生成方式。 第一章新建项目 安装好该软件后,进入系统界面: Fils new新建项目,输入项目名 称后点击add;选择数据库,输入用户名 以及密码后,系统会产生一个文件,选 择保存路径后新建项目成功. 双击数据库的图标,如下图所示 (图2),左栏是能选择数据库名和表名, 右栏则是已选中的表,确定后进入详细 的设置页面.
图2 双击表名能进入(图3)对表进行一些设置.这里能调整数据的产生量(默认是100条),右栏中的是选中的字段,可以把不需要添加数据的字段移到左栏中,对这些字段将不插入数据. 利用move up和move down对字段优先级进行设置.(优先级影响着下文中一些函数的使用。) 在output书签中可以选择将产生的测试数据直接保存到数据库 中,还是保存到新到文本中去。
图3 data factory会读入所选择的表中的所有字段名及其属性,但data factory的数据格式只有3种:text、numeric、date;所以一些例如oracle 数据库中long ,varchar等属性会统一为text属性,只是长度不同而已。 第二章数据生成 一、TEXT有6种输入方式 以下为TEXT模式中一些通用的附加设置,在后面不做介绍: (