MySQL批量SQL插入各种性能优化

MySQL批量SQL插入各种性能优化
2016-03-21one_isi_all程序人生
对于一些数据量较大的系统,数据库面临的问题除了查询效率低下,还有就是数据入库时间长。特别像报表系统,每天花费在数据导入上的时间可能会长达几个小时或十几个小时之久。因此,优化数据库插入性能是很有意义的。
经过对MySQL innodb的一些性能测试,发现一些可以提高insert效率的方法,供大家
参考参考。
1. 一条SQL语句插入多条数据。
常用的插入语句如:
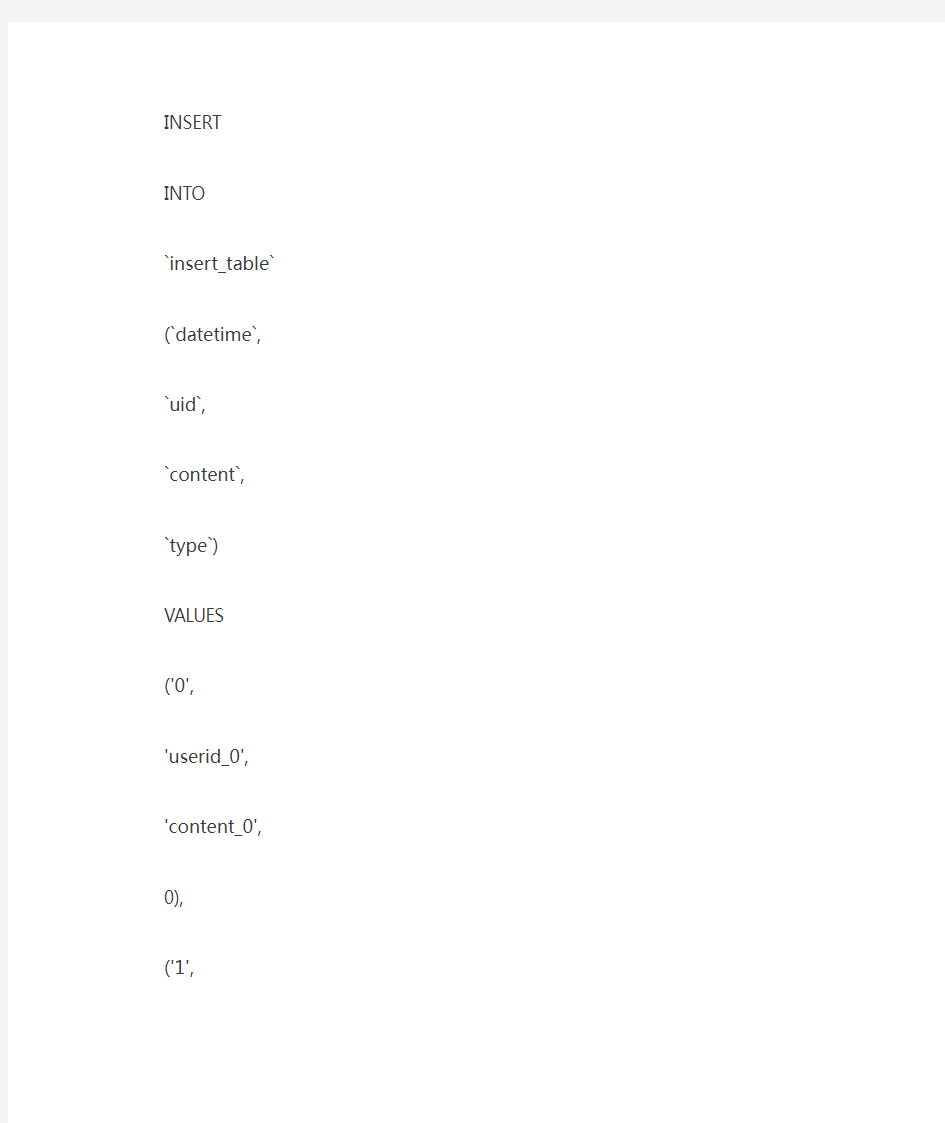
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('0', 'userid_0', 'content_0', 0);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('1', 'userid_1', 'content_1', 1);
修改成:
INSERT
INTO
`insert_table`
(`datetime`,
`uid`,
`content`,
`type`)
VALUES
('0',
'userid_0',
'content_0',
0),
('1',
'userid_1',
'content_1',
1);
修改后的插入操作能够提高程序的插入效率。这里第二种SQL执行效率高的主要原因是合并后日志量(MySQL的binlog和innodb的事务让日志)减少了,降低日志刷盘的数据量和频率,从而提高效率。通过合并SQL语句,同时也能减少SQL语句解析的次数,减少网络传输的IO。
这里提供一些测试对比数据,分别是进行单条数据的导入与转化成一条SQL语句进行导入,分别测试1百、1千、1万条数据记录。
2. 在事务中进行插入处理。
把插入修改成:
START TRANSACTION;
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('0', 'userid_0', 'content_0', 0);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('1', 'userid_1', 'content_1', 1);
...
COMMIT;
使用事务可以提高数据的插入效率,这是因为进行一个INSERT操作时,MySQL内部会建立一个事务,在事务内才进行真正插入处理操作。通过使用事务可以减少创建事务的消耗,所有插入都在执行后才进行提交操作。
这里也提供了测试对比,分别是不使用事务与使用事务在记录数为1百、1千、1万的情况。
3. 数据有序插入。
数据有序的插入是指插入记录在主键上是有序排列,例如datetime是记录的主键:INSERT
INTO
`insert_table`
(`datetime`,
`uid`,
`content`,
`type`)
VALUES
('1',
'userid_1',
'content_1',
1);
INSERT INTO
`insert_table` (`datetime`, `uid`,
`content`,
`type`)
VALUES ('0',
'userid_0', 'content_0', 0);
INSERT INTO
`insert_table` (`datetime`, `uid`,
`content`,
VALUES ('2',
'userid_2',
'content_2',2);修改成:
INSERT INTO
`insert_table` (`datetime`, `uid`,
`content`,
`type`)
VALUES ('0',
'userid_0',
'content_0', 0);
INSERT
`insert_table` (`datetime`, `uid`,
`content`,
`type`)
VALUES ('1',
'userid_1', 'content_1', 1);
INSERT INTO
`insert_table` (`datetime`, `uid`,
`content`,
`type`)
VALUES
'userid_2',
'content_2',2);
由于数据库插入时,需要维护索引数据,无序的记录会增大维护索引的成本。我们可以参照innodb使用的B+tree索引,如果每次插入记录都在索引的最后面,索引的定位效率很高,
并且对索引调整较小;如果插入的记录在索引中间,需要B+tree进行分裂合并等处理,会消耗比较多计算资源,并且插入记录的索引定位效率会下降,数据量较大时会有频繁的磁盘操作。
下面提供随机数据与顺序数据的性能对比,分别是记录为1百、1千、1万、10万、100万。
从测试结果来看,该优化方法的性能有所提高,但是提高并不是很明显。
性能综合测试:
这里提供了同时使用上面三种方法进行INSERT效率优化的测试。
从测试结果可以看到,合并数据+事务的方法在较小数据量时,性能提高是很明显的,数据量较大时(1千万以上),性能会急剧下降,这是由于此时数据量超过了innodb_buffer 的容量,每次定位索引涉及较多的磁盘读写操作,性能下降较快。而使用合并数据+事务+
有序数据的方式在数据量达到千万级以上表现依旧是良好,在数据量较大时,有序数据索引定位较为方便,不需要频繁对磁盘进行读写操作,所以可以维持较高的性能。
注意事项:
1. SQL语句是有长度限制,在进行数据合并在同一SQL中务必不能超过SQL长度限制,通过max_allowed_packet配置可以修改,默认是1M,测试时修改为8M。
2. 事务需要控制大小,事务太大可能会影响执行的效率。MySQL有
innodb_log_buffer_size配置项,超过这个值会把innodb的数据刷到磁盘中,这时,效率会有所下降。所以比较好的做法是,在数据达到这个这个值前进行事务提交。
sql语句(mysql优化)绝对经典
sql语句(mysql优化)绝对经典 误区1:count(1)和count(primary_key) 优于count(*) 很多人为了统计记录条数,就使用count(1) 和count(primary_key) 而不是count(*) ,他们认为这样性能更好,其实这是一个误区。对于有些场景,这样做可能性能会更差,应为数据库对count(*) 计数操作做了一些特别的优化。 误区2:count(column) 和count(*) 是一样的 这个误区甚至在很多的资深工程师或者是DBA 中都普遍存在,很多人都会认为这是理所当然的。实际上,count(column) 和count(*) 是一个完全不一样的操作,所代表的意义也完全不一样。count(column) 是表示结果集中有多少个column字段不为空的记录,count(*) 是表示整个结果集有多少条记录 误区3:select a,b from … 比select a,b,c from …可以让数据库访问更少的数据量 这个误区主要存在于大量的开发人员中,主要原因是对数据库的存储原理不是太了解。实际上,大多数关系型数据库都是按照行(row)的方式存储,而数据存取操作都是以一个固定大小的IO单元(被称作block 或者page)为单位,一般为4KB,8KB… 大多数时候,每个IO单元中存储了多行,每行都是存储了该行的所有字段(lob等特殊类型字段除外)。 所以,我们是取一个字段还是多个字段,实际上数据库在表中需要访问的数据量其实是一样的。当然,也有例外情况,那就是我们的这个查询在索引中就可以完成,也就是说当只取a,b两个字段的时候,不需要回表,而c这个字段不在使用的索引中,需要回表取得其数据。在这样的情况下,二者的IO量会有较大差异。(覆盖索引) 误区4:order by 一定需要排序操作 我们知道索引数据实际上是有序的,如果我们的需要的数据和某个索引的顺序一致,而且我们的查询又通过这个索引来执行,那么数据库一般会省略排序操作,而直接将数据返回,因为数据库知道数据已经满足我们的排序需求了。实际上,利用索引来优化有排序需求的SQL,是一个非常重要的优化手段。延伸阅读:MySQL ORDER BY 的实现分析,MySQL 中GROUP BY 基本实现原理以及MySQL DISTINCT 的基本实现原理。(order by null)
SQL监控及性能优化
SQL 性能监控及SQL 语句优化 性能监控 作为SQL的数据库服务器,我们可以将其比作一个人,而SQL则是他的心脏,管理员就是他的大脑。要监控心脏是否健康首先要看他这个人是否健康。这两者是相辅相成的,少了一方都是不健康的。 数据库服务器的性能监视器 性能监视器 性能工具的介绍 性能监视器是一种简单而功能强大的可视化工具,用于实时收集系统状态并从日志文件中查看性能数据。 使用性能监视器可以: 获得对诊断系统问题和规划系统资源增长有用的性能数据、了解工作负载及其对系统资源的影响、观察工作负载和资源使用情况的变化和趋势,以便计划未来的升级、通过监视结果来测试配置变化、诊断问题并确定需要优化的组件或进程。 现在,可以开始选择这些对象和要监视的计数器了。 https://www.360docs.net/doc/2e2719537.html, 应用程序性能计数器有关https://www.360docs.net/doc/2e2719537.html, 应用程序性能计数器的大部分信息最近已被合并到一个题为“改善 .NET 应用程序的性能和伸缩性”的综合文档中。下表描述了一些可用于监视和优化 https://www.360docs.net/doc/2e2719537.html, 应用程序(包括 Reporting Services)性能的重要计数器。
除了上表中介绍的这些核心监视要素之外,在您试图诊断 https://www.360docs.net/doc/2e2719537.html, 应用程序具有的特定性能问题时,下表中的性能计数器也可对您有所帮助。
Reporting Services 性能计数器 Reporting Services 包括一组它自己的性能计数器,用于收集有关报告处理和资源消耗方面的信息。可通过 Windows 性能监视器工具中出现的两个对象来监视实例和组件的状态和活动:MSRS 2005 Web Service 和 MSRS 2005 Windows Service 对象。 MSRS 2005 Web Service 性能对象包括一组用来跟踪 Report Server 处理过程的计数器,这些处理过程通常通过在线交互式报告浏览操作而引发。这些计数器在https://www.360docs.net/doc/2e2719537.html, 停止该 Web 服务后被重设。下表列出了可用于监视 Report Server 性能的计数器,并描述了它们的目的。 性能对象:RS Web Service
SQL2019系统性能优化解决方案共12页文档
SQL Server 系统性能调优解决方案 前言 近几年,医药流通市场经历了激烈的震荡,导致行业逐步成熟和企业的快速变革,差异化经营成为众多医药流通的竞争选择。时空产品在中国医药流通企业的发展过程中得到了广泛且深入应用,大量的客户化开发和定制支撑了企业管理中横向和纵向的变化,很好的适应了企业在发展过程中不断变化的需求。 对于数据库管理系统的使用,很多用户都面临着一个很棘手的问题:系统效率下降。产生效率下降的因素是多方面: 1.硬件问题 2.软件问题 3.实施问题 正因为产生效率下降的因素很多,所以如何去查找原因成为我们首要关注的问题,时空公司也处在积极探索过程中。时空公司在解决一些客户问题的过程中积累了一些方法和思路,归纳总结后呈现给体系内的技术人员,本方案就系统效率调整所必需的基础知识、方法、技巧等几个方面进行阐述,从而让技术人员能够快速定位问题,解决问题,为合作伙伴提供优质,快捷的服务。 索引简介 索引是根据数据库表中一个或多个列的值进行排序的结构。索引提供指针以指向存储在表中指定列的数据值,然后根据指定的排序次序排列这些指针。数据库使用索引的方式与使用书的目录很相似,通过搜索索引找到特定的值,然后跟随指针到达包含该值的行。 索引键:用于创建索引的列。 索引类型 ?聚集索引: 聚集索引基于数据行的键值在表内排序和存储这些数据行。由于数据行按基于聚集索引键的排序次序存储,因此聚集索引对查找行很有效。每个表只能有一个聚集索引,因为数据行本身只能按一个顺序存储。数据行本身构成聚集索引的最低级别(叶子节点)。只有当表包含聚集索引时,表内的数据行才按排序次序存储。如果表没有聚集索引,则其数据行按堆集方式存储。 聚集索引对于那些经常要搜索范围值的列特别有效。使用聚集索引找到包含第一个值的行后,便可以确保包含后续索引值的行在物理相邻。例如:如果应用程序执行的一个查询经常检索某一日期范围内的记录,则使用聚集索引可以迅速找到包含开始日期的行,然后检索表中所有相邻的行,直到到达结束日期。这样有助于提高此类查询的性能。同样,如果对从表中检索的数据进行排序时经常要用到某一列,则可以将该表在该列上聚集(物理排序),避免每次查询该列时都进行排序,从而节省成本。 ?非聚集索引 非聚集索引具有完全独立于数据行的结构。非聚集索引的最低行包含非聚集索引的键值,并且每个键值项都有指针指向包含该键值的数据行。数据行不按基于非聚集键的次序存储。如
优化mysql数据库性能
为了提高性能建议作如下优化修改: 优化mysql数据库性能的参数: (1)、max_connections: 允许的同时客户的数量。增加该值增加mysqld 要求的文件描述符的数量。这个数字应该增加,否则,你将经常看到too many connections错误。默认数值是16384,请根据实际情况设置此参数。 (2)、key_buffer_size: 索引块是缓冲的并且被所有的线程共享。key_buffer_size是用于索引块的缓冲区大小,增加它可得到更好处理的索引(对所有读和多重写),到你能负担得起那样多。如果你使它太大,系统将开始换页并且真的变慢了。默认数值是10M,请根据实际情况设置此参数。 (3)、sort_buffer: 每个需要进行排序的线程分配该大小的一个缓冲区。增加这值加速order by或group by操作。默认数值是256K,请根据实际情况设置此参数。 4)、table_cache: 为所有线程打开表的数量。增加该值能增加mysqld要求的文件描述符的数量。mysql对每个唯一打开的表需要2个文件描述符。默认数值是256,,请根据实际情况设置此参数。 (5)、thread_cache_size: 可以复用的保存在中的线程的数量。如果有,新的线程从缓存中取得,当断开连接的时候如果有空间,客户的线置在缓存中。如果有很多新的线程,为了提高性能修改这个变量值。通过比较connections 和threads_created 状态的变量,可以看到这个变量的作用。默认数值是8,请根据实际情况设置此参数。 注:以上参数的调整可以通过修改C:\AppServ\MySQL\my.ini 文件并重启mysql 实现。这是一个比较谨慎的工作,上面的结果只供参考,请根据具体主机的硬件情况(特别是内存大小)进一步修改。 优化配置文件: C:\zxin10\Was\tomcat\conf\ server.xml (6)、在server.xml中修改标红相关参数。
Oracle SQL性能优化方法研究
Oracle SQL性能优化方法探讨 Oracle性能优化方法(SQL篇) (1) 1综述 (2) 2表分区的应用 (2) 3访问Table的方式 (3) 4共享SQL语句 (3) 5选择最有效率的表名顺序 (5) 6WHERE子句中的连接顺序. (6) 7SELECT子句中幸免使用’*’ (6) 8减少访问数据库的次数 (6) 9使用DECODE函数来减少处理时刻 (7) 10整合简单,无关联的数据库访问 (8) 11删除重复记录 (8) 12用TRUNCATE替代DELETE (9) 13尽量多使用COMMIT (9) 14计算记录条数 (9) 15用Where子句替换HAVING子句 (9) 16减少对表的查询 (10) 17通过内部函数提高SQL效率 (11)
18使用表的不名(Alias) (12) 19用EXISTS替代IN (12) 20用NOT EXISTS替代NOT IN (13) 21识不低效执行的SQL语句 (13) 22使用TKPROF 工具来查询SQL性能状态 (14) 23用EXPLAIN PLAN 分析SQL语句 (14) 24实时批量的处理 (16)
1综述 ORACLE数据库的性能调整是个重要,却又有难度的话题,如何有效地进行调整,需要通过反反复复的过程。在数据库建立时,就能依照顾用的需要合理设计分配表空间以及存储参数、内存使用初始化参数,对以后的数据库性能有专门大的益处,建立好后,又需要在应用中不断进行应用程序的优化和调整,这需要在大量的实践工作中不断地积存经验,从而更好地进行数据库的调优。 数据库性能调优的方法 ●调整内存 ●调整I/O ●调整资源的争用问题 ●调整操作系统参数 ●调整数据库的设计 ●调整应用程序 本文针对应用程序的调整,来讲明对数据库性能如何进行优化。 2表分区的应用 关于海量数据的表,能够考虑建立分区以提高操作效率。建
mysql服务性能优化my_cnf配置说明详解16G内存
mysql服务性能优化—https://www.360docs.net/doc/2e2719537.html,f配置说明详解 (16G内存) MYSQL服务器https://www.360docs.net/doc/2e2719537.html,f配置文档详解 硬件:内存16G [client] port = 3306 socket = /data/3306/mysql.sock [mysql] no-auto-rehash [mysqld] user = mysql port = 3306 socket = /data/3306/mysql.sock basedir = /usr/local/mysql datadir = /data/3306/data open_files_limit = 10240 back_log = 600 #在MYSQL暂时停止响应新请求之前,短时间内的多少个请求可以被存在堆栈中。如果系统在短时间内有很多连接,则需要增大该参数的值,该参数值指定到来的TCP/IP连接的监听队列的大小。默认值50。 max_connections = 3000 #MySQL允许最大的进程连接数,如果经常出现Too Many Connections的错误提示,则需要增大此值。 max_connect_errors = 6000 #设置每个主机的连接请求异常中断的最大次数,当超过该次数,MYSQL服务器将禁止host 的连接请求,直到mysql服务器重启或通过flush hosts命令清空此host的相关信息。 table_cache = 614 #指示表调整缓冲区大小。# table_cache 参数设置表高速缓存的数目。每个连接进来,都会至少打开一个表缓存。#因此, table_cache 的大小应与 max_connections 的设置有关。例如,对于 200 个#并行运行的连接,应该让表的缓存至少有 200 × N ,这里 N 是应用可以执行的查询#的一个联接中表的最大数量。此外,还需要为临时表和文件保留一些额外的文件描述符。 # 当 Mysql 访问一个表时,如果该表在缓存中已经被打开,则可以直接访问缓存;如果#还
MySQL5.1性能优化方案
MySQL5.1性能优化方案 1.平台数据库 1.1.操作系统 Red Hat Enterprise Linux Server release 5.4 (Tikanga) ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), for GNU/Linux 2.6.9, dynamically linked (uses shared libs), for GNU/Linux 2.6.9, stripped 32位Linux服务器,单独作为MySQL服务器使用。 1.2.M ySQL 系统使用的是MySQL5.1,最新的MySQL5.5较之老版本有了大幅改进。主要体现在以下几个方面: 1)默认存储引擎更改为InnoDB InnoDB作为成熟、高效的事务引擎,目前已经广泛使用,但MySQL5.1之前的版本默认引擎均为MyISAM,此次MySQL5.5终于将默认数据库存储引擎改为InnoDB,并且引进了Innodb plugin 1.0.7。此次更新对数据库的好处是显而易见的:InnoDB的数据恢复时间从过去的一个甚至几个小时,缩短到几分钟(InnoDB plugin 1.0.7,InnoDB plugin 1.1,恢复时采用红-黑树)。InnoDB Plugin 支持数据压缩存储,节约存储,提高内存命中率,并且支持adaptive flush checkpoint, 可以在某些场合避免数据库出现突发性能瓶颈。 Multi Rollback Segments:原来InnoDB只有一个Segment,同时只支持1023的并发。现已扩充到128个Segments,从而解决了高并发的限制。 2)多核性能提升
mysql性能优化-慢查询分析、优化索引和配置
mysql性能优化-慢查询分析、优化索引和配置目录 一、优化概述 二、查询与索引优化分析 1性能瓶颈定位 Show命令 慢查询日志 explain分析查询 profiling分析查询 2索引及查询优化 三、配置优化 1) max_connections 2) back_log 3) interactive_timeout 4) key_buffer_size 5) query_cache_size 6) record_buffer_size 7) read_rnd_buffer_size 8) sort_buffer_size 9) join_buffer_size 10) table_cache 11) max_heap_table_size 12) tmp_table_size
13) thread_cache_size 14) thread_concurrency 15) wait_timeout 一、优化概述 MySQL数据库是常见的两个瓶颈是CPU和I/O的瓶颈,CPU在饱和的时候一般发生在数据装入内存或从磁盘上读取数据时候。磁盘I/O瓶颈发生在装入数据远大于内存容量的时候,如果应用分布在网络上,那么查询量相当大的时候那么平瓶颈就会出现在网络上,我们可以用mpstat, iostat, sar和vmstat来查看系统的性能状态。 除了服务器硬件的性能瓶颈,对于MySQL系统本身,我们可以使用工具来优化数据库的性能,通常有三种:使用索引,使用EXPLAIN分析查询以及调整MySQL的内部配置。 二、查询与索引优化分析 在优化MySQL时,通常需要对数据库进行分析,常见的分析手段有慢查询日志,EXPLAIN 分析查询,profiling分析以及show命令查询系统状态及系统变量,通过定位分析性能的瓶颈,才能更好的优化数据库系统的性能。 1 性能瓶颈定位 Show命令 我们可以通过show命令查看MySQL状态及变量,找到系统的瓶颈: Mysql> show status ——显示状态信息(扩展show status like ‘XXX’) Mysql> show variables ——显示系统变量(扩展show variables like ‘XXX’) Mysql> show innodb status ——显示InnoDB存储引擎的状态 Mysql> show processlist ——查看当前SQL执行,包括执行状态、是否锁表等
MySQL大数据量的查询提高性能优化
最近一段时间参与的项目要操作百万级数据量的数据,普通SQL查询效率呈直线下降,而且如果where中的查询条件较多时,其查询速度简直无法容忍。之前数据量小的时候,查询语句的好坏不会对执行时间有什么明显的影响,所以忽略了许多细节性的问题。 经测试对一个包含400多万条记录的表执行一条件查询,其查询时间竟然高达40几秒,相信这么高的查询延时,任何用户都会抓狂。因此如何提高sql语句查询效率,显得十分重要。以下是结合网上流传比较广泛的几个查询语句优化方法: 基本原则:数据量大的时候,应尽量避免全表扫描,应考虑在where 及order by 涉及的列上建立索引,建索引可以大大加快数据的检索速度。但是,有些情况索引是不会起效的,因此,需要下面的做法进行优化: 1、应尽量避免在where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。 2、应尽量避免在where 子句中对字段进行null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num is null 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询: select id from t where num=0 3、尽量避免在where 子句中使用or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num=10 or num=20 可以这样查询: select id from t where num=10 union all select id from t where num=20 4、下面的查询也将导致全表扫描:
千万级的mysql数据库与优化方法
千万级的mysql数据库与优化方法 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在where 及order by 涉及的列上建立索引。 2.应尽量避免在where 子句中对字段进行null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如: Sql代码 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询: Sql代码 3.应尽量避免在where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。 4.应尽量避免在where 子句中使用or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:Sql代码 可以这样查询: Sql代码 5.in 和not in 也要慎用,否则会导致全表扫描,如: 对于连续的数值,能用between 就不要用in 了: 6.下面的查询也将导致全表扫描: Sql代码
若要提高效率,可以考虑全文检索。 7.如果在where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描: Sql代码 可以改为强制查询使用索引: 8.应尽量避免在where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如: 应改为: 9.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:Sql代码 应改为: 10.不要在where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。 11.在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。 12.不要写一些没有意义的查询,如需要生成一个空表结构:
SQLServer性能优化工具
SQLServer性能优化工具 数据和工作负荷示例 使用下例说明 SQL Server 性能工具的使用。首先创建下表。 create table testtable (nkey1 int identity, col2 char(300) default 'abc', ckey1 char(1)) 接下来,在这个表中填充 10,000 行测试数据。可以为列 nkey1 中所填充的数据创建非聚集索引。可以为列 ckey1 中的数据创建聚集索引,col2 中的数据仅仅是填充内容,将每一行增加 300 字节。 declare @counter int set @counter = 1 while (@counter <= 2000) begin insert testtable (ckey1) values ('a') insert testtable (ckey1) values ('b') insert testtable (ckey1) values ('c')
insert testtable (ckey1) values ('d') insert testtable (ckey1) values ('e') set @counter = @counter + 1 end 数据库服务器将进行下面的两个查询: select ckey1,col2 from testtable where ckey1 = 'a' select nkey1,col2 from testtable where nkey1 = 5000 Profiler SQL Server Profiler 记录数据库服务器中所发生活动的详细信息。可以配置 Profiler 以便用大量的可配置性能信息监视并记录在 SQL Server 中执行查询的一个或多个用户。可在 Profiler 中记录的性能信息有:I/O 统计信息、CPU 统计信息、锁定请求、T-SQL 和 RPC 统计信息、索引和表扫描、警告和引发的错误、数据库对象的创建/除去、连接/断开、存储过程操作、游标操作等等。有关 SQL Profiler 可记录的全部信息,请在SQL Server Books Online 中搜索字符串“Profiler”。 将 Profiler 信息装载到 .trc 文件中以便用于 Index Tuning Wizard 中 Profiler 和 Index Tuning Wizard 是强大的工具组合,以帮助数
Mysql千万级别数据优化方案总结
Mysql千万级别数据优化方案 目录 目录 (1) 一、目的与意义 (2) 1)说明 (2) 二、解决思路与根据(本测试表中数据在千万级别) (2) 1)建立索引 (2) 2)数据体现(主键非索引,实际测试结果其中fid建立索引) (2) 3)MySQL分页原理 (2) 4)经过实际测试当对表所有列查询时 (2) 三、总结 (3) 1)获得分页数据 (3) 2)获得总页数:创建表记录大数据表中总数通过触发器来维护 (3)
一、目的与意义 1)说明 在MySql单表中数据达到千万级别时数据的分页查询结果时间过长,对此进行优达 到最优效果,也就是时间最短;(此统计利用的jdbc连接,其中fid为该表的主键;) 二、解决思路与根据(本测试表中数据在千万级别) 1)建立索引 优点:当表中有大量记录时,若要对表进行查询,第一种搜索信息方式是全表搜 索,是将所有记录一一取出,和查询条件进行一一对比,然后返回满足条件的记 录,这样做会消耗大量数据库系统时间,并造成大量磁盘I/O操作;第二种就是 在表中建立索引,然后在索引中找到符合查询条件的索引值,最后通过保存在索 引中的ROWID(相当于页码)快速找到表中对应的记录。 缺点:当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降 低了数据的维护速度。 2)数据体现(主键非索引,实际测试结果其中fid建立索引) 未创建索引:SELECT fid from t_history_data LIMIT 8000000,10结果:13.396s 创建索引:SELECT fid from t_history_data LIMIT 8000000,10结果:2.896s select*fromt_history_datawherefidin (任意十条数据的id )结果:0.141s 首先通过分页得到分页的数据的ID,将ID拼接成字符串利用SQL语句 select * from table where ID in (ID字符串)此语句受数据量大小的影响比较小 (如上测试); 3)MySQL分页原理 MySQL的limit工作原理就是先读取n条记录,然后抛弃前n条,读m条想要 的,所以n越大,性能会越差。 优化前SQL: SELECT * FROM v_history_data LIMIT 5000000, 1010.961s 优化后SQL: SELECT * FROM v_history_data INNER JOIN (SELECT fid FROM t_history_data LIMIT 5000000, 10) a USING (fid)1.943s 分别在于,优化前的SQL需要更多I/O浪费,因为先读索引,再读数据,然后 抛弃无需的行。而优化后的SQL(子查询那条)只读索引(Cover index)就可以了, 然后通过member_id读取需要的列 4)经过实际测试当对表所有列查询时 select * from table 会比select (所有列名)from table 快些(以查询8000000
SQL性能优化
近期因工作需要,希望比较全面的总结下SQL SERVER数据库性能优化相关的注意事项,在网上搜索了一下,发现很多文章,有的都列出了上百条,但是仔细看发现,有很多似是而非或者过时(可能对SQL SERVER6.5以前的版本或者ORACLE是适用的)的信息,只好自己根据以前的经验和测试结果进行总结了。 我始终认为,一个系统的性能的提高,不单单是试运行或者维护阶段的性能调优的任务,也不单单是开发阶段的事情,而是在整个软件生命周期都需要注意,进行有效工作才能达到的。所以我希望按照软件生命周期的不同阶段来总结数据库性能优化相关的注意事项。 一、分析阶段 一般来说,在系统分析阶段往往有太多需要关注的地方,系统各种功能性、可用性、可靠性、安全性需求往往吸引了我们大部分的注意力,但是,我们必须注意,性能是很重要的非功能性需求,必须根据系统的特点确定其实时性需求、响应时间的需求、硬件的配置等。最好能有各种需求的量化的指标。 另一方面,在分析阶段应该根据各种需求区分出系统的类型,大的方面,区分是OLTP(联机事务处理系统)和OLAP(联机分析处理系统)。 二、设计阶段 设计阶段可以说是以后系统性能的关键阶段,在这个阶段,有一个关系到以后几乎所有性能调优的过程—数据库设计。 在数据库设计完成后,可以进行初步的索引设计,好的索引设计可以指导编码阶段写出高效率的代码,为整个系统的性能打下良好的基础。 以下是性能要求设计阶段需要注意的: 1、数据库逻辑设计的规范化 数据库逻辑设计的规范化就是我们一般所说的范式,我们可以这样来简单理解范式: 第1规范:没有重复的组或多值的列,这是数据库设计的最低要求。 第2规范: 每个非关键字段必须依赖于主关键字,不能依赖于一个组合式主关键字的某些组成部分。消除部分依赖,大部分情况下,数据库设计都应该达到第二范式。 第3规范: 一个非关键字段不能依赖于另一个非关键字段。消除传递依赖,达到第三范式应该是系统中大部分表的要求,除非一些特殊作用的表。 更高的范式要求这里就不再作介绍了,个人认为,如果全部达到第二范式,大部分达到第三范式,系统会产生较少的列和较多的表,因而减少了数据冗余,也利于性能的提高。 2、合理的冗余 完全按照规范化设计的系统几乎是不可能的,除非系统特别的小,在规范化设计后,有计划地加入冗余是必要的。
MySQL数据库性能(SQL)优化方案
MySQL数据库性能(SQL)优化方案本文探讨了提高MySQL 数据库性能的思路,并从8个方面给出了具体的解决方法。 1、选取最适用的字段属性 MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快。因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得尽可能小。例如,在定义邮政编码这个字段时,如果将其设置为CHAR(255),显然给数据库增加了不必要的空间,甚至使用VARCHAR这种类型也是多余的,因为CHAR(6)就可以很好的完成任务了。同样的,如果可以的话,我们应该使用MEDIUMINT而不是BIGIN 来定义整型字段。 另外一个提高效率的方法是在可能的情况下,应该尽量把字段设置为NOT NULL,这样在将来执行查询的时候,数据库不用去比较NULL值。 对于某些文本字段,例如“省份”或者“性别”,我们可以将它们定义为ENUM类型。因为在MySQL中,ENUM类型被当作数值型数据来处理,而数值型数据被处理起来的速度要比文本类型快得多。这样,我们又可以提高数据库的性能。 2、使用连接(JOIN)来代替子查询(Sub-Queries) MySQL从4.1开始支持SQL的子查询。这个技术可以使用SELECT语句来创建一个单列的查询结果,然后把这个结果作为过滤条件用在另一个查询中。例如,我们要将客户基本信息表中没有任何订单的客户删除掉,就可以利用子查询先从销售信息表中将所有发出订单的客户ID取出来,然后将结果传递给主查询,如下所示: DELETE FROM customerinfo WHERE CustomerID NOT in (SELECT CustomerID FROM salesinfo )
Mysql性能优化
MySQL性能优化 性能优化是通过某些有效的方法来提高MySQL的运行速度,减少占用的磁盘空间。性能优化包含很多方面,例如优化查询速度,优化更新速度和优化MySQL服务器等。本文介绍方法的主要有: 优化查询 优化数据库结构 优化MySQL服务器 数据库管理人员可以使用SHOW STATUS语句来查询MySQL数据库的性能。语法:SHOW STATUE LIKE ‘value’;其中value参数是常用的几个统计参数。 Connections:连接MySQL服务器的次数 Uptime:MySQL服务器的上线时间; Slow_queries:慢查询的次数; Com_select:查询操做的次数; Com_insert:插入操作的次数; Com_delete:删除操作的次数; Com_update:更新操作的次数; 1优化查询 查询操作是最频繁的操作,提高了查询速度可以有效提高MySQL 数据库的性能。 首先要对查询语句进行分析,分析查询语句的命令是EXPLAIN语句和DESCRIBE语句。比如 EXPLAIN SELECT * FROM student \G; 索引可以快速定位表中的某条记录。使用索引也可以提高数据库查
询的速度,从而提高数据库的性能。如果不使用索引,查询语句将 表中的所有字段。这样查询的速度会很慢。如果使用了索引,查询语句只会查询索引字段。这样就减少查询的记录数,达到提高查询效率的目的。 现在看一个查询语句中没有索引的使用情况: SELECT * FROM student WHERE name = ‘张三’;这样会对student表中的所有数据都查询一下,对比一下name的字段是否是张三。 然后我们在name字段上建立一个名为index_name的索引:CREATE INDEX index_name ON student(name); 现在name字段上面已经有索引了,再进行该select语句查询的速度就非常快了,不需要遍历整个表。 但是有些时候即使查询时使用的是索引,但索引并没有起作用。比如使用了LIKE关键字进行查询时,如果匹配字符串的第一个字符 为‘%’,索引不会被使用。如果‘%’不是在第一个位置,索引就会被使用。 另一种情况是在表的多个字段上创建一个索引,比如 CREATE INDEX index ON student(birth,department);这样只有查询语句条件中使用字段name时,索引才会被用到。因为name字段是多列索引的第一个字段,只有查询条件中使用了name字段才会使索引index起作用。 2优化子查询 很多查询中需要使用子查询。子查询可以使查询语句很灵活,但子查询的执行效率不高。MySQL需要为内层查询语句的查询结果建立一个临时表。然后外层查询语句在临时表中查询记录。查询完毕后,MySQL需要插销这些临时表。所以在MySQL中可以使用连接查询来代替子查询。连接查询不需要建立临时表,其速度比子查询要快。
Oracle_SQL性能优化技巧大总结
(1)选择最有效率的表名顺序(只在基于规则的优化器中有效): ORACLE的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表(基础表 driving table)将被最先处理,在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表。如果有3个以上的表连接查询, 那就需要选择交叉表(intersection table)作为基础表, 交叉表是指那个被其他表所引用的表. (2) WHERE子句中的连接顺序.: ORACLE采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前, 那些可以过滤掉最大数量记录的条件必须写在WHERE 子句的末尾. (3) SELECT子句中避免使用 * : ORACLE在解析的过程中, 会将'*' 依次转换成所有的列名, 这个工作是通过查询数据字典完成的, 这意味着将耗费更多的时间 (4)减少访问数据库的次数: ORACLE在内部执行了许多工作: 解析SQL语句, 估算索引的利用率, 绑定变量 , 读数据块等; (5)在SQL*Plus , SQL*Forms和Pro*C中重新设置ARRAYSIZE参数, 可以增加每次数据库访问的检索数据量 ,建议值为200 (6)使用DECODE函数来减少处理时间: 使用DECODE函数可以避免重复扫描相同记录或重复连接相同的表. (7)整合简单,无关联的数据库访问: 如果你有几个简单的数据库查询语句,你可以把它们整合到一个查询中(即使它们之间没有关系) (8)删除重复记录: 最高效的删除重复记录方法 ( 因为使用了ROWID)例子: DELETE FROM EMP E WHERE E.ROWID > (SELECT MIN(X.ROWID)FROM EMP X WHERE X.EMP_NO = E.EMP_NO); (9)用TRUNCATE替代DELETE: 当删除表中的记录时,在通常情况下, 回滚段(rollback segments ) 用来存放可以被恢复的信息. 如果你没有COMMIT事务,ORACLE会将数据恢复到删除之前的状态(准确地说是恢复到执行删除命令之前的状况) 而当运用TRUNCATE时, 回滚段不再存放任何可被恢复的信息.当命令运行后,数据不能被恢复.因此很少的资源被调用,执行时间也会很短. 译者按: TRUNCATE只在删除全表适 用,TRUNCATE是DDL不是DML) (10)尽量多使用COMMIT: 只要有可能,在程序中尽量多使用COMMIT, 这样程序的性能得到提高,需求
优化MySQL数据库性能的几个好方法
1、选取最适用的字段属性 MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快。因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得尽可能小。例如,在定义邮政编码这个字段时,如果将其设置为CHAR(255),显然给数据库增加了不必要的空间,甚至使用VARCHAR这种类型也是多余的,因为CHAR(6)就可以很好的完成任务了。同样的,如果可以的话,我们应该使用MEDIUMINT而不是BIGIN来定义整型字段。 另外一个提高效率的方法是在可能的情况下,应该尽量把字段设置为NOT NULL,这样在将来执行查询的时候,数据库不用去比较NULL值。 对于某些文本字段,例如“省份”或者“性别”,我们可以将它们定义为ENUM类型。因为在MySQL中,ENUM类型被当作数值型数据来处理,而数值型数据被处理起来的速度要比文本类型快得多。这样,我们又可以提高数据库的性能。 2、使用连接(JOIN)来代替子查询(Sub-Queries) MySQL从4.1开始支持SQL的子查询。这个技术可以使用SELECT语句来创建一个单列的查询结果,然后把这个结果作为过滤条件用在另一个查询中。例如,我们要将客户基本信息表中没有任何订单的客户删除掉,就可以利用子查询先从销售信息表中将所有发出订单的客户ID取出来,然后将结果传递给主查询,如下所示: DELETE FROM customerinfo WHERE CustomerID NOT in (SELECT CustomerID FROM salesinfo ) 使用子查询可以一次性的完成很多逻辑上需要多个步骤才能完成的SQL操作,同时也可以避免事务或者表锁死,并且写起来也很容易。但是,有些情况下,子查询可以被更有效率的连接(JOIN).. 替代。例如,假设我们要将所有没有订单记录的用户取出来,可以用下面这个查询完成:
一次TOP_SQL的性能调优经历
1.问题发现 1.1一份AWR报告 今天,收到一份100个并发用户访问下压力测试的AWR报告,并发事务数平均每秒只有6个不到。 在这个26.53分钟间隔的报告里,CPU TIME在整个TOP 事件中最突出 占了近97.6%,在8个CPU系统中,数据库给CPU造成的压力为: (5740/(26.53*60*8)*100%=45.07%,这么小的压力下,CPU就能冲得这么高,说明
系统中肯定是有问题的。下面转向TOP SQL去确认下造成资源争用最明显的SQL语句。 1.2TOP SQL 1.2.1SQL ordered by Elapsed Time 1.2.2SQL ordered by CPU Time
1.2.3SQL ordered by Gets 1.3问题发现 对一个OLTP系统来说,每一个语句的执行,都是要将其消耗的资源降到最低,这跟 OLAP系统是有差别的。对于后者来说,它需要的是短的时间返回结果,不管中间你会拿多大的成本做代价。 从上面反映的问题来看,我们的性能,无疑就是葬送在了SQL_ID为4841ajtgh43qy、1hwqh7kvxn6yg、g295mubwupf52和anyty5rts5tzf这四个语句上面,下面将对这四个SQL语句一 一做出分析,并给出相应的调优建议。
2.SQL_ID为4841ajtgh43qy的语句 2.1调整前 2.1.1语句 SELECT * FROM (SELECT TT.*, ROWNUM AS ROWNO FROM (select to_char(c.cust_id), c.password from CUST_CERTIFICATION c where c.cust_id = :CUST_ID) TT WHERE ROWNUM <= 10) TABLE_ALIAS where TABLE_ALIAS.rowno > 0 ; 2.1.2解释计划 又见全表扫
【黑马程序员】MySQL的性能调优一
【黑马程序员】MySQL的性能调优一 什么是MySQL,怎么安装,怎么使用,我这里不做说明了。 一、MySQL 与其他数据库的简单比较 1.1性能比较 性能方面,一直是MySQL 引以为自豪的一个特点。在权威的第三方评测机构多次测试较量各种数据库TPCC 值的过程中,MySQL 一直都有非常优异的表现,而且在其他所有商用的通用数据库管理系统中,仅仅只有Oracle 数据库能够与其一较高下。至于各种数据库详细的性能数据,我这里就不便记录,大家完全可以通过网上第三方评测机构公布的数据了解具体细节信息。 MySQL 一直以来奉行一个原则,那就是在保证足够的稳定性的前提下,尽可能的提高自身的处理能力。也就是说,在性能和功能方面,MySQL 第一考虑的要素主要还是性能,MySQL希望自己是一个在满足客户99%的功能需求的前提下,花掉剩下的大部分精力来性能努力,而不是希望自己是成为一个比其他任何数据库的功能都要强大的数据库产品。 1.2可靠性 关于可靠性的比较,并没有太多详细的评测比较数据,但是从目前业界的交流中可以了解到,几大商业厂商的数据库的可靠性肯定是没有太多值得怀疑的。但是做为开源数据库管理系统的代表,MySQL 也有非常优异的表现,而并不是像有些人心中所怀疑的那样,因为不是商业厂商所提供,就会不够稳定不够健壮。从当前最火的Facebook 这样大型的网站都是使用MySQL 数据库,就可以看出,MySQL 在稳定可靠性方面,并不会
比我们的商业厂商的产品有太多逊色。而且排在全球前10 位的大型网站里面,大部分都有部分业务是运行在MySQL数据库环境上,如Yahoo,Google 等。 总的来说,MySQL 数据库在发展过程中一直有自己的三个原则:简单、高效、可靠。从上面的简单比较中,我们也可以看出,在MySQL 自己的所有三个原则上面,没有哪一项是做得不好的。而且,虽然功能并不是MySQL 自身所追求的三个原则之一,但是考虑到当前用户量的急剧增长,用户需求越来越越多样化,MySQL 也不得不在功能方面做出大量的努力,来不断满足客户的新需求。比如最近版本中出现的Eent Scheduler (类似于Oracle 的Job 功能),Partition 功能,自主研发的Maria 存储引擎在功能方面的扩展,Falcon 存储引擎对事务的支持等等,都证明了MySQL 在功能方面也开始了不懈的努力。 任何一种产品,都不可能是完美的,也不可能适用于所有用户。我们只有衡量了每一种产品的各种特性之后,从中选择出一种最适合于自身的产品。 二、MySQL 的主要适用场景 据说目前MySQL 用户已经达千万级别了,其中不乏企业级用户。可以说是目前最为流行的开源数据库管理系统软件了。任何产品都不可能是万能的,也不可能适用于所有的应用场景。 那么MySQL 到底在什么场景下适用什么场景下不适用呢? 1、Web 网站系统 Web 站点,是MySQL 最大的客户群,也是MySQL 发展史上最为重要的支撑力量,这一点在最开始的MySQL Server 简介部分就已经说明过。 MySQL 之所以能成为Web 站点开发者们最青睐的数据库管理系统,是因为