R 语言环境下用ARIMA模型做时间序列预测
R 语言环境下使用ARIMA模型做时间序列预测
1.序列平稳性检验
通过趋势线、自相关(ACF)与偏自相关(PACF)图、假设检验和因素分解等方法确定序列平稳性,识别周期性,从而为选择适当的模型提供依据。
1.1绘制趋势线
图1 序列趋势线图
从图1很难判断出序列的平稳性。
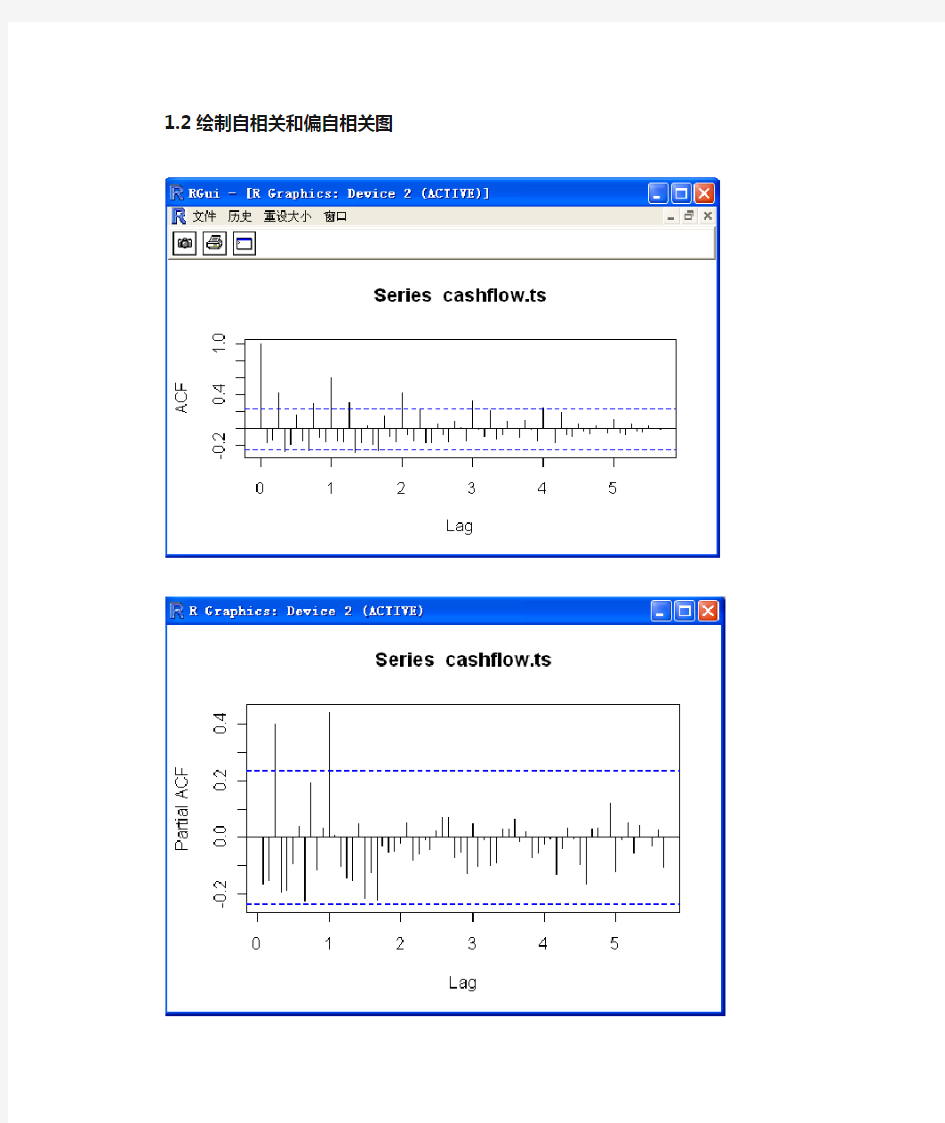
1.2绘制自相关和偏自相关图
图2 序列的自相关和偏自相关图
从图2可以看出,ACF拖尾,PACF1步截尾(p=1),说明该现金流时间序列可能是平稳性时间序列。
1.3 ADF、PP和KPSS 检验平稳性
图3 ADF、PP和KPSS检验结果
通过ADF检验,说明该现金流时间序列是平稳性时间序列(p-value for ADF test <0.02,拒绝零假设).pp test和kpss test 结果中的警告信息说明这两种检验在这里不可用。但是这些检验没有充分考虑趋势、周期和季节性等因素。下面对该序列进行趋势、季节性和不确定性因素分解来进一步确认序列的平稳性。
1.4 趋势、季节性和不确定性因素分解
R 提供了两种方法来分解时间序列中的趋势、季节性和不确定性因素。第一种是使用简单的对称过滤法,把相应时期内经趋势调整后的观察值进行平均,通过decompose()函数实现,如图4。第二种方法更为精确,它通过平滑增大规模后的观察值来寻找趋势、季节和不确定因素,利用stl()函数实现。如图5。
图4 decompose()函数分解法
图5 stl()函数分解法
两种方法得到的结果非常相似。从上图可以看出,该现金流时间序列没有很明显的长期趋势。但是有明显的季节性或周期性趋势,经分解后的不确定因素明显减少。
综上平稳性分析检验,我们选用包含季节性因素的S-ARIMA模型来预测现金流时间序列。
2.S-ARIMA模型
2.1 建立SARIMA模型
在R 软件包中包含auto.arima()、expand.grid() 等函数,针对p,d,q 众多的可能取值,可以通过expand.grid()建立所有的可能参数组合,用for()条件函数代入相应的arima()模型,把结果储存在BIC当中。其中,BIC根据AIC
是拟合原序列的最佳模型。指标来计算。结果显示,SARIMA(0,1,1)(1,1,0)
12
拟合结果如下图6所示:
图6 SARIMA(0,1,1)(1,1,0)12模型拟合结果
结果表明,ma 和sar 的系数为负数并且影响非常显著。
2.2 模型有效性检验
R 提供了tsdiag()函数来检验模型的有效性。检验结果如下图7:
图7 tsdiag()函数检验结果
图中第二行的ACF 检验说明残差没有明显的自相关性。第三行的Ljung-Box 测试显示所有的P-value>0.1,说明残差为白噪声。模型合格。
3.预测未来现金流
模通过以上模型的建立与检验,我们建立了SARIMA(0,1,1)(1,1,0)
12
型来预测未来现金流。预测结果如图8所示:
图8 模型对未来若干年现金流的预测结果
下面进行预测值与真实值的对比,如图9所示:
图9 预测值与真实值对比图(图中,蓝色代表预测值;红色代表真实值)
从图9可以看出,模型对六个月内的预测值相对准确,但是从2009年4月份开始,预测值与真实值之间出现明显偏差,说明该模型适合短期内预测。而从长期来看,由于影响现金流的不确定性因素增加,模型的预测能力下降。
基于ARIMA模型下的时间序列分析与预测
龙源期刊网 https://www.360docs.net/doc/224947685.html, 基于ARIMA模型下的时间序列分析与预测 作者:万艳苹 来源:《金融经济·学术版》2008年第09期 摘要:大多数的时间序列存在着惯性,或者说具有迟缓性。通过对这种惯性的分析,可以由时间序列的当前值对其未来值进行估计。本文以1949年到2004年江苏省社会消费品零售总额数据为研究对象,将这些数据平稳化并做分析,发现ARIMA(1,1,2)模型能比较好的对江苏省社会消费品零售总额进行市时间序列分析和预测,。 关键词:ARIMA;江苏省消费品零售总额;时间序列分析 一、引言 江苏省是一个经济大省,经济一直保持平稳较快增长,城乡居民收入都位于全国前茅,消费品需求旺盛,人们生活水平比较高。其中社会消费品零售总额是反映人民生活水平提高的一个很好的指标。所以对社会消费品零售总额做分析就比较重要。但是影响社会消费品零售总额的因素有很多,包括收入、住房、医疗、教育以及人们的预期等很多因素,而且这些因素之间又保持着错综复杂的联系。因此运用数理经济模型来分析和预测较为困难。所以本文采用ARIMA模型对江苏省的社会消费品零售总额进行分析,得出其规律性,并预测其未来值。 二、ARIMA模型的说明和构建 ARIMA模型又称为博克斯-詹金斯模型。ARIMA模型是由三个过程组成:自回归过程(AR(p));单整(I(d));移动平均过程(MA(q))。AR(p)即自回归过程,是指一个过程的当前值是过去值的线性函数。如:如果当前观测值仅与上期(滞后一期)的观测值有显著的线性函数关系,则我们就说这是一阶自回归过程,记作AR(1)。推广之,如果当前值与滞后p期的观测值都有线性关系则称p阶自回归过程,记作AR(p)。MA(q),即移动平均过程,是指模型值可以表示为过去残差项(即过去的模型拟合值与过去观测值的差)的线性函数。如:MA(1)过程,说明时间序列受到滞后一期残差项的影响。推广之,MA(q)是指时间序列受到滞后q期残差项的
时间序列预测模型
时间序列预测模型时间序列是指把某一变量在不同时间上的数值按时间先后顺序排列起来所形成的序列,它的时间单位可以是分、时、日、周、旬、月、季、年等。时间序列模型就是利用时间序列建立的数学模型,它主要被用来对未来进行短期预测,属于趋势预测法。一、简单一次移动平均预测法例1.某企业1月~11月的销售收入时间序列如下表所示.取n 4,试用简单一次移动平均法预测第12月的销售收入,并计算预测的标准误差. 二、加权一次移动平均预测法简单一次移动平均预测法,是把参与平均的数据在预测中所起的作用同等对待,但参与平均的各期数据所起的作用往往是不同的。为此,需要采用加权移动平均法进行预测,加权一次移动平均预测法是其中比较简单的一种。三、指数平滑预测法 1、一次指数平滑预测法一元线性回归模型 * 项数n的数值,要根据时间序列的特点而定,不宜过大或过小.n过大会降低移动平均数的敏感性,影响预测的准确性;n过小,移动平均数易受随机变动的影响,难以反映实际趋势.一般取n的大小能包含季节变动和周期变动的时期为好,这样可消除它们的影响.对于没有季节变动和周期变动的时间序列,项数n的取值可取较大的数;如果历史数据的类型呈上升或下降型的发展趋势,则项数n的数值应取较小的数,这样能取得较好的预测效果. 1102.7 1015.1 963.9 892.7 816.4 772.0 705.1 649.8 606.9 574.6 533.8 销售收入 11 10 9 8 7 6 5 4 3 2 1 月份 t 158542.7 993.6 12 12950.4 19016.4 17662.4 24617.6 27989.3
实验三:ARIMA模型建模与预测实验报告
课程论文 (2016 / 2017学年第 1 学期) 课程名称应用时间序列分析 指导单位经济学院 指导教师易莹莹 学生姓名班级学号 学院(系) 经济学院专业经济统计学
实验三ARIMA 模型建模与预测实验指导 一、实验目的: 了解ARIMA 模型的特点和建模过程,了解AR ,MA 和ARIMA 模型三者之间的区别与联系,掌握如何利用自相关系数和偏自相关系数对ARIMA 模型进行识别,利用最小二乘法等方法对ARIMA 模型进行估计,利用信息准则对估计的ARIMA 模型进行诊断,以及如何利用ARIMA 模型进行预测。掌握在实证研究如何运用Eviews 软件进行ARIMA 模型的识别、诊断、估计和预测。 二、基本概念: 所谓ARIMA 模型,是指将非平稳时间序列转化为平稳时间序列,然后将平稳的时间序列建立ARMA 模型。ARIMA 模型根据原序列是否平稳以及回归中所含部分的不同,包括移动平均过程(MA )、自回归过程(AR )、自回归移动平均过程(ARMA )以及ARIMA 过程。 在ARIMA 模型的识别过程中,我们主要用到两个工具:自相关函数ACF ,偏自相关函数PACF 以及它们各自的相关图。对于一个序列{}t X 而言,它的第j 阶自相关系数j ρ为它的j 阶自协方差除以方差,即j ρ=j 0γγ,它是关于滞后期j 的函数,因此我们也称之为自相关函数,通常记ACF(j )。偏自相关函数PACF(j )度量了消除中间滞后项影响后两滞后变量之间的相关关系。 三、实验任务: 1、实验内容: (1)根据时序图的形状,采用相应的方法把非平稳序列平稳化; (2)对经过平稳化后的1950年到2005年中国进出口贸易总额数据建立合适的(,,)ARIMA p d q 模型,并能够利用此模型进行进出口贸易总额的预测。 2、实验要求: (1)深刻理解非平稳时间序列的概念和ARIMA 模型的建模思想; (2)如何通过观察自相关,偏自相关系数及其图形,利用最小二乘法,以及信息准则建立合适的ARIMA 模型;如何利用ARIMA 模型进行预测; (3)熟练掌握相关Eviews 操作,读懂模型参数估计结果。 四、实验要求: 实验过程描述(包括变量定义、分析过程、分析结果及其解释、实验过程遇到的问题及体会)。 实验题:对经过平稳化后的1950年到2005年中国进出口贸易总额数据建立合适的(,,)ARIMA p d q 模型,并能够利用此模型进行进出口贸易总额的预测。
季节ARIMA模型建模与预测实验指导
季节ARIMA模型建模与预测实验指导
————————————————————————————————作者: ————————————————————————————————日期: ?
实验六季节ARIMA模型建模与预测实验指导 学号:20131363038 姓名:阙丹凤班级:金融工程1班 一、实验目的 学会识别时间序列的季节变动,能看出其季节波动趋势。学会剔除季节因素的方法,了解ARIMA模型的特点和建模过程,掌握利用最小二乘法等方法对ARIMA模型进行估计,利用信息准则对估计的ARIMA模型进行诊断,以及如何利用ARIMA模型进行预测。掌握在实证研究如何运用Eviews软件进行ARIMA模型的识别、诊断、估计和预测。 二、实验内容及要求 1、实验内容: 根据美国国家安全委员会统计的1973-1978年美国月度事故死亡率数据,请选择适当模型拟合该序列的发展。 2、实验要求: (1)深刻理解季节非平稳时间序列的概念和季节ARIMA模型的建模思想; (2)如何通过观察自相关,偏自相关系数及其图形,利用最小二乘法,以及信息准则建立合适的ARIMA模型;如何利用ARIMA模型进行预测; (3)熟练掌握相关Eviews操作。 三、实验步骤 第一步:导入数据 第二步:画出时序图
6,000 7,000 8,000 9,000 10,000 11,000 12,000 510152025303540455055 606570 SIWANGRENSHU 由时序图可知,死亡人数虽然没有上升或者下降趋势,但由季节变动因素影响。 第三步:季节差分法消除季节变动 由时序图可知,波动的周期大约为12,所以对原序列作12步差分,得到新序列如下图所示。
股票预测模型【运用ARIMA模型预测股票价格】
股票预测模型【运用ARIMA模型预测股票价格】 [摘要]ARIMA模型是时间序列中十分常见和常用的一种模型,应用与经济的各个领域。本文基于ARIMA模型,采用了莱宝高科近67个交易日的数据,对历史数据进行分析,并且在此基础上做出一定的预测,试图为现实的投资提供一些参考信息。[关键字]ARIMA模型;股价预测;莱宝高科一、引言时间序列分析是从一段时间上的一组属性值数据中发现模式并预测未来值的过程。ARIMA模型是目前最常用的用于拟合非平稳序列的模型,对于满足有限参数线形模型的平稳时间序列的分析,ARIMA在理论上已趋成熟,它用有限参数线形模型描述时间序列的自相关结构,便于进行统计分析与数学处理。有限参数线形模型能描述的随机现象相当广泛,模型拟合的精度能达到实际工程的要求,而且由有限参数的线形模型结构可推导出适用的线形预报理论。利用ARIMA 模型描述的时间序列预报问题在金融,股票等领域具有重要的理论意义。本文将利用ARIMA模型结合莱宝高科的数据建立模型,并运用该模型对莱宝的股票日收盘价进行预测。二、ARIMA模型的建立 2.1ARIMA模型简介ARIMA是自回归移动平均结合模型的简写形式,用于平稳序列或通过差分而平稳的序列分析,简记为ARIMA(p,d,q)用公式表示为:△dZt=Xt=ψ1Xt-1+ψ2Xt-2+?+ψpXt-p+at-θ1at-1-θ2at-2-?-θqat-q 其中,p、d、q分别是自回归阶数、差分阶数和滑动平均阶数;Zt是时间序列;Xt是经过d阶差分后的时间序列值;at-q是时间为t-q的随机扰动项;ψp、θq分别是对应项前的系数。 2.2模型建立流程(1)平稳性检验以2010-3-4到2010-6-10的“莱宝高科”(002106)股票的收盘价作为模型的数据进行建立时间序列模型:做出折线图观察数据的特征:进行单位根检验,判别序列是否为平稳序列;若一阶差分后的数据为平稳序列,可以建立时间序列模型。说明原数据为一阶单整。(2)模型的选择和参数的估计根据数据的平稳性特征,初步确定建立ARIMA模型。观察一阶差分以后的序列的自相关函数和偏自相关
R 语言环境下用ARIMA模型做时间序列预测
R 语言环境下使用ARIMA模型做时间序列预测 1.序列平稳性检验 通过趋势线、自相关(ACF)与偏自相关(PACF)图、假设检验和因素分解等方法确定序列平稳性,识别周期性,从而为选择适当的模型提供依据。 1.1绘制趋势线 图1 序列趋势线图 从图1很难判断出序列的平稳性。 1.2绘制自相关和偏自相关图
图2 序列的自相关和偏自相关图
从图2可以看出,ACF拖尾,PACF1步截尾(p=1),说明该现金流时间序列可能是平稳性时间序列。 1.3 ADF、PP和KPSS 检验平稳性 图3 ADF、PP和KPSS检验结果 通过ADF检验,说明该现金流时间序列是平稳性时间序列(p-value for ADF test <0.02,拒绝零假设).pp test和kpss test 结果中的警告信息说明这两种检验在这里不可用。但是这些检验没有充分考虑趋势、周期和季节性等因素。下面对该序列进行趋势、季节性和不确定性因素分解来进一步确认序列的平稳性。 1.4 趋势、季节性和不确定性因素分解 R 提供了两种方法来分解时间序列中的趋势、季节性和不确定性因素。第一种是使用简单的对称过滤法,把相应时期内经趋势调整后的观察值进行平均,通过decompose()函数实现,如图4。第二种方法更为精确,它通过平滑增大规模后的观察值来寻找趋势、季节和不确定因素,利用stl()函数实现。如图5。
图4 decompose()函数分解法 图5 stl()函数分解法 两种方法得到的结果非常相似。从上图可以看出,该现金流时间序列没有很明显的长期趋势。但是有明显的季节性或周期性趋势,经分解后的不确定因素明显减少。
时间序列模型的构建和预测
时间序列模型的构建和预测 Box Jenkins Methodology) 步骤1:识别。观察相关图和偏相关图 步骤2:估计。估计模型中所包含的自回归系数和移动平均系数,可以用OLS 来估计 步骤3:诊断检验。选一个最适合数据的模型,检查从这模型中估计到的残差是否白噪声,如果不是的话,我们必须从头来过 步骤 4 :预测。在很多情况下,这种方法得到的预测结果要比其它计量模型得到的要准确 识别 检查时间序列是否平稳 - 如果自相关函数衰退的很慢,则序列可能是非平稳 - 如果时间序列为一非平稳过程,应该运用差分的形式使它变为平稳过程 - 在检验了一个时间序列的平稳性之后,我们应该用相
关图和偏相关图检验ARMA模型中的阶数p和q 模型 ARIMA(1,1,1) .■: x t = ■ 1. x t-1 + u t + ru t-1 自相关函数特征 缓慢地线性衰减 1.0 偏自相关函数特征 AR( 1) x t = -1 X t-1 + u t 右;1 > 0,平滑地指数衰减若-11 > 0,k=1时有正峰值然后截尾 0.8 0.6 0.4 0.2 0.0 -0.2 -0.4 -0.6 -0.8 2 - 4 6 - 8 10 12 ?14 MA ( 1) X t = U t + 71 U t- 1 AR( 2) x t = ;1 x t-1 + 2 X t-2 + u t 若;i < 0,正负交替地指数衰减 0.8 若71 > 0,k=1时有正峰值然后截尾 若71 < 0,k=1时有负峰值然后截尾 指数或正弦衰减 若-11 < 0,k=1时有负峰值然后截尾 0.8 0.6 0.4 0.2 0.0 -0.2 -0.4 -0.6 -0.8 若?冷> 0,交替式指数衰减 0.8 若3<0,负的平滑式指数衰减 k=1,2时有两个峰值然后截尾
AR,MA,ARIMA模型介绍及案例分析
BOX-JENKINS 预测法 1 适用于平稳时序的三种基本模型 (1)()AR p 模型(Auto regression Model )——自回归模型 p 阶自回归模型: 式中,为时间序列第时刻的观察值,即为因变量或称被解释变量;, 为时序的滞后序列,这里作为自变量或称为解释变量;是随机误 差项;,,,为待估的自回归参数。 (2)()MA q 模型(Moving Average Model )——移动平均模型 q 阶移动平均模型: 式中,μ为时间序列的平均数,但当{}t y 序列在0上下变动时,显然μ=0,可删除此项;t e ,1t e -,2t e -,…,t q e -为模型在第t 期,第1t -期,…,第t q -期 的误差;1θ,2θ,…,q θ为待估的移动平均参数。 (3)(,)ARMA p q 模型——自回归移动平均模型(Auto regression Moving Average Model ) 模型的形式为: 显然,(,)ARMA p q 模型为自回归模型和移动平均模型的混合模型。当q =0,时,退化为纯自回归模型()AR p ;当p =0时,退化为移动平均模型()MA q 。 2 改进的ARMA 模型 (1)(,,)ARIMA p d q 模型 这里的d 是对原时序进行逐期差分的阶数,差分的目的是为了让某些非平稳(具有一定趋势的)序列变换为平稳的,通常来说d 的取值一般为0,1,2。 对于具有趋势性非平稳时序,不能直接建立ARMA 模型,只能对经过平稳化处理,而后对新的平稳时序建立(,)ARMA p q 模型。这里的平文化处理可以是差分处理,也可以是对数变换,也可以是两者相结合,先对数变换再进行差分处理。 (2)(,,)(,,)s ARIMA p d q P D Q 模型 对于具有季节性的非平稳时序(如冰箱的销售量,羽绒服的销售量),也同样需要进行季节差分,从而得到平稳时序。这里的D 即为进行季节差分的阶数; ,P Q 分别是季节性自回归阶数和季节性移动平均阶数;S 为季节周期的长度, 如时序为月度数据,则S =12,时序为季度数据,则S =4。 在SPSS19.0中的操作如下
实验指导书ARIMA模型建模与预测范本
实验指导书ARIMA 模型建模与预测
实验指导书(ARIMA模型建模与预测) 例:中国1952- 的进出口总额数据建模及预测 1、模型识别和定阶 (1)数据录入 打开Eviews软件,选择“File”菜单中的“New--Workfile”选项,在“Workfile structure type”栏选择“Dated –regular frequency”,在“Date specification”栏中分别选择“Annual”(年数据) ,分别在起始年输入1952,终止年输入,文件名输入“im_ex”,点击ok,见下图,这样就建立了一个工作文件。 在workfile中新建序列im_ex,并录入数据(点击File/Import/Read Text-Lotus-Excel…, 找到相应的Excel数据集,打开数据集,出现如下图的窗口,
在“Data order”选项中选择“By observation-series in columns”即按照观察值顺序录入,第一个数据是从B15开始的,因此在“Upper-left data cell”中输入B15,本例只有一列数据,在“Names for series or number if named in file”中输入序列的名字im_ex,点击ok,则录入了数据): (2)时序图判断平稳性 双击序列im_ex,点击view/Graph/line,得到下列对话框:
得到如下该序列的时序图,由图形能够看出该序列呈指数上升趋势,直观来看,显著非平稳。 IM_EX 240,000 200,000 160,000 120,000 80,000 40,000 556065707580859095000510 (3 因为数据有指数上升趋势,为了减小波动,对其对数化,在Eviews命令框中输入相应的命令“series y=log(im_ex)”就得到对数序列,其时序图见下图,对数化后的序列远没有原始序列波动剧烈:
时间序列模型的建立与预测
第六节时间序列模型的建立与预测 ARIMA过程y t用 Φ (L) (Δd y t)= α+Θ(L) u t 表示,其中Φ (L)和Θ (L)分别是p, q阶的以L为变数的多项式,它们的根都在单位圆之外。α为Δd y t过程的漂移项,Δd y t表示对y t 进行d次差分之后可以表达为一个平稳的可逆的ARMA 过程。这是随机过程的一般表达式。它既包括了AR,MA 和ARMA过程,也包括了单整的AR,MA和ARMA过程。 可取 图建立时间序列模型程序图 建立时间序列模型通常包括三个步骤。(1)模型的识别,(2)模型参数的估计,(3)诊断与检验。
模型的识别就是通过对相关图的分析,初步确定适合于给定样本的ARIMA模型形式,即确定d, p, q的取值。 模型参数估计就是待初步确定模型形式后对模型参数进行估计。样本容量应该50以上。 诊断与检验就是以样本为基础检验拟合的模型,以求发现某些不妥之处。如果模型的某些参数估计值不能通过显著性检验,或者残差序列不能近似为一个白噪声过程,应返回第一步再次对模型进行识别。如果上述两个问题都不存在,就可接受所建立的模型。建摸过程用上图表示。下面对建摸过程做详细论述。 1、模型的识别 模型的识别主要依赖于对相关图与偏相关图的分析。在对经济时间序列进行分析之前,首先应对样本数据取对数,目的是消除数据中可能存在的异方差,然后分析其相关图。 识别的第1步是判断随机过程是否平稳。由前面知识可知,如果一个随机过程是平稳的,其特征方程的根都应在单位圆之外;如果 (L) = 0的根接近单位圆,自相关函数将衰减的很慢。所以在分析相关图时,如果发现其衰减很慢,即可认为该时间序列是非平稳的。这时应对该时间序列进行差分,同时分析差分序列的相关图以判断差分序列的平稳性,直至得到一个平稳的序列。对于经济时间序列,差分次数d通常只取0,1或2。 实际中也要防止过度差分。一般来说平稳序列差分得到的仍然是平稳序列,但当差分次数过多时存在两个缺点,(1)序列的样本容量减小;(2)方差变大;所以建模过程中要防止差分过度。对于一个序列,差分后若数据的极差变大,说明差分过度。 第2步是在平稳时间序列基础上识别ARMA模型阶数p, q。表1给出了不同ARMA模型的自相关函数和偏自相关函数。当然一个过程的自相关函数和偏自相关函数通常是未知的。用样本得到的只是估计的自相关函数和偏自相关函数,即相关图和偏相关图。建立ARMA模型,时间序列的相关图与偏相关图可为识别模型参数p, q提供信息。相关图和偏相关图(估计的自相关系数和偏自相关系数)通常比真实的自相关系数和偏自相关系数的方差要大,并表现为更高的自相关。实际中相关图,偏相关图的特征不会像自相关函数与偏自相关函数那样“规范”,所以应该善于从相关图,偏相关图中识别出模型的真实参数p, q。另外,估计的模型形式不是唯一的,所以在模型识别阶段应多选择几种模型形式,以供进一步选择。
实验指导书(ARIMA模型建模与预测)
实验指导书(ARIMA 模型建模与预测) 例:我国1952-2011年的进出口总额数据建模及预测 1、模型识别和定阶 (1)数据录入 打开 Eviews 软件,选择"File ”菜单中的"New--Workfile ”选项,在"Workfile structure type ”栏选择"Dated -regular frequency ”,在"Date specification ”栏中 分别选择“ Annual ” (年数据),分别在起始年输入 1952,终止年输入 2011,文件名输入 “im_ex ”,点击ok ,见下图,这样就建立了一个工作文件。 在 workfile 中新建序列im_ex , 并录入数据 (点击 File/Import/Read Text-Lotus-Excel …, File | Edit Object View 卩 iroc Quick Options Window Help New ? □pen i Save Fetch from DB... T5D Fi le Im port-. DRI Bask Economics Database... Read Text-Lctu s-Excel... 找到相应的Excel 数据集,打开数据集,出现如下图的窗口,在“ Data order ”选项中 选择“ By observation-series in columns ”即按照观察值顺序录入,第一个数据是从 B15 开始的,所以在“ Upper-left data cell ”中输入B15,本例只有一列数据,在“ Namesfor series or number if named in file ”中输入序列的名字 im_ex ,点击ok ,则录入了数据): import Ex port Print PtFrtl Setup-.,.
时间序列上机实验-ARIMA模型的建立(季节乘积模型)
实验二 ARIMA 模型的建立 一、实验目的 熟悉ARIMA 模型,掌握利用ARIMA 模型建模过程,学会利用自相关系数和偏自相关系数对ARIMA 模型进行识别,利用最小二乘法等方法对ARIMA 模型进行估计,利用信息准则对估计的ARIMA 模型进行诊断,以及学会利用ARIMA 模型进行预测。掌握在实证研究如何运用Eviews 软件进行ARIMA 模型的识别、诊断、估计和预测。 二、基本概念 ARIMA 模型,即将非平稳时间序列转化为平稳时间序列,然后将平稳的时间序列建立ARMA 模型。ARIMA 模型根据原序列是否平稳以及回归中所含部分的不同,包括移动平均过程(MA )、自回归过程(AR )、自回归移动平均过程(ARMA )以及ARIMA 过程。 在ARIMA 模型的识别过程中,主要用到两个工具:自相关函数ACF ,偏自相关函数PACF 以及它们各自的相关图。对于一个序列{}t X 而言,它的第j 阶自相关系数j ρ为它的j 阶自协方差除以方差,即j ρ=j 0γγ ,它是关于滞后期j 的函数,因此我们也称之为自相关函数,通常记ACF(j )。偏自相关函数PACF(j )度量了消除中间滞后项影响后两滞后变量之间的相关关系。 三、实验内容 (1)根据时序图的形状,采用相应的方法把非平稳序列平稳化; (2)对经过平稳化后的2000年1月到2011年10月美国的失业率数据建立ARIMA (,,p d q )模型,并利用此模型进行失业率的预测。 四、实验要求: 了解ARIMA 模型的特点和建模过程,了解AR ,MA 和ARIMA 模型三者之间的区别与联系,掌握如何利用自相关系数和偏自相关系数对ARIMA 模型进行识别,利用最小二乘法等方法对ARIMA 模型进行估计,利用信息准则对估计的ARIMA 模型进行诊断,以及如何利用ARIMA 模型进行预测。 五、实验步骤 (1) 输入原始数据 打开Eviews 软件,选择“File ”菜单中的“New--Workfile ”选项,在“Workfile structure type ”栏中选择“Dated-regular frequency ”,在“Frequency ”栏中选择“Monthly ”,分别在起始月输入1991.01,终止月输入2010.12,点击ok ,见图1。再建立一个New object ,将选取的x 的月度数据复制进去 。
时间序列分析简介与模型
第二篇 预测方法与模型 预测是研究客观事物未来发展方向与趋势的一门科学。统计预测是以统计调查资料为依据,以经济、社会、科学技术理论为基础,以数学模型为主要手段,对客观事物未来发展所作的定量推断和估计。根据社会、经济、科技的预测结论,人们可以调整发展战略,制定管理措施,平衡市场供求,进行各种各样的决策。预测也是制定政策,编制规划、计划,具体组织生产经营活动的科学基础。20世纪三四十年代以来,随着人类社会生产力水平的不断提高和科学技术的迅猛发展,特别是近年来以计算机为主的信息技术的飞速发展,更进一步推动了预测技术在国民经济、社会发展和科学技术各个领域的应用。 预测包含定性预测法、因果关系预测法和时间序列预测法三类。本篇对定性预测法不加以介绍,对后两类方法选择以下几种介绍方法的原理、模型的建立和实际应用,分别为:时间序列分析、微分方程模型、灰色预测模型、人工神经网络。 第五章 时间序列分析 在预测实践中,预测者们发现和总结了许多行之有效的预测理论和方法,但以概率统计理论为基础的预测方法目前仍然是最基本和最常用的方法。本章介绍其中的时间序列分析预测法。此方法是根据预测对象过去的统计数据找到其随时间变化的规律,建立时间序列模型,以推断未来数值的预测方法。时间序列分析在微观经济计量模型、宏观经济计量模型以及经济控制论中有广泛的应用。 第一节 时间序列简介 所谓时间序列是指将同一现象在不同时间的观测值,按时间先后顺序排列所形成的数列。时间序列一般用 ,,,,21n y y y 来表示,可以简记为}{t y 。它的时间单位可以是分钟、时、日、周、旬、月、季、年等。
一、时间序列预测法 时间序列预测法就是通过编制和分析时间序列,根据时间序列所反应出来的发展过程、方向和趋势,进行类推或延伸,借以预测下一段时间或以后若干年可能达到的水平。其容包括:收集与整理某种社会现象的历史资料;将这些资料进行检查鉴别,排成数列;分析时间序列,从中寻找该社会现象随时间变化而变化的规律,得出一定的模型,以此模型去预测该社会现象将来的情况。 二、时间序列数据的特点 通常,时间序列经过合理的函数变换后都可以看作是由三个部分叠加而成,这三个部分是趋势项部分、周期项部分和随机项部分。 1. 趋势性 许多序列的一个最主要的特征就是存在趋势。这种趋势可能是向下的也可能是向上的,也许比较陡,也许比较平缓,或者是指数增长,或者近似线性。总之,时间序列的趋势性是依据时间序列进行预测的本质所在。 2. 季节性/周期性 当数据按照月或季观测时,通常的情况是这样的:时间序列会呈现出明显的季节性。对季节性也不存在一个非常精确的定义。通常,当某个季节的观测值具有与其它季节的观测值明显不同的特征时,就称之为季节性。 3. 异常观测值 异常观测值指那些严重偏离趋势围的特殊点。异常观测值的出现往往是由于某些不可抗 1958 年自然灾害和1966年左右“文化大革命”对我国经拒的外部条件的影响。如1960 济的影响,造成经济指标陡然下降现象;1992年,我国银行紧缩政策造成的房地产业泡沫破灭,而使得房地产业的经济数据发生突然变化的例子等等。 4. 条件异方差性 所谓条件异方差性,表现出来就是异常数据观测值成群地出现,故也称为“波动积聚性”。由于方差是风险的测度,因此波动存在的积聚性的预测对于评估投资决策是很有用的,对于期权和其它金融衍生产品的买卖决策也是有益的。 5. 非线性 对非线性的最好定义就是“线性以外的一切”。非线性常常表现为“机制转换”(regime witches)或者“状态依赖”(State pendence)。其中状态依赖意味着时间序列的特征依赖于其现时的状态;不同的时刻,其特征不一样。当时间序列的特征在所有的离散状态都不一样时,就成为机制转换特性。 三、时间序列的分类 1. 按研究的对象的多少可分为单变量时间序列和多变量时间序列。 如果所研究的对象是一个变量,如某个国家的国生产总值,即为单变量时间序列。果所研究的对象是多个变量,如按年、月顺序排列的气温、气压、雨量数据,为多变量时间序列。多变量时间序列不仅描述了各个变量的变化规律,而且还表示了各变量间相互依存关系的动态规律性。 2. 按时间的连续性可将时间序列分为离散时间序列和连续时间序列。 如果某一序列中的每一个序列值所对应的时间参数为间断点,则该序列就是一个离散时间序列。如果某一序列中的每个序列值所对应的时间参数为连续函数,则该序列就是一个连续时间序列。 3. 按序列的统计特性可分为平稳时间序列和非平稳时间序列两类。
多因素时间序列的灰色预测模型
第 39卷 第 2期 2007年 4月 西 安 建 筑 科 技 大 学 ( 学 报 ( 自然科学版) ) V ol.39 No.2 Apr . 2007 J 1Xi ’an Univ . of Arch . & Tech . Natural Scie nce Editio n 多因素时间序列的灰色预测模型 苏变萍 ,曹艳平 ,王 婷 (西安建筑科技大学理学院 ,陕西 西安 710055) 摘 要:对于传统的单因素时间序列预测法在实际应用中的不足之处 ,提出采用灰色 DGM (1 ,1) 模型和多元 线性回归原理相结合的方法 ,综合各种因素建立多因素时间序列的灰色预测模型。它首先利用 DGM (1 ,1) 模 型对影响事物发展趋势的各项因素进行预测 ;然后利用多元线性回归法将各种因素综合起来 ,以预测事物的 发展趋势。最后将该模型应用于预测分析陕西省的就业状况 ,取得了较好的预测效果 ,同时也验证了此模型 的可行性。 关键词: 时间序列 ;单因素 ;多因素 ;预测模型 中图分类号:TB114 文献标识码:A 文章编号 :100627930 2007 022******* ( ) 多年以来 ,对时间序列的预测研究 ,大多是停留在对单因素时间序列上 ,对其预测通常采用的是趋 势外推法 ,而且该方法适合于原始时间序列规律性较好的情况 ,若时间序列中包含了随机因素的影 响 ,再采用这种方法得出的预测结果可能会失真. 同时 ,客观世界又是复杂多变的 ,事物的发展通常不 是由某个单个因素决定 ,往往是许多错综复杂的因素综合作用的结果 ,为了对某项事物的发展做出更加 符合实际的预测 ,这就需要来探讨多因素时间序列的预测问题 ,正是基于这些 ,本文在应用灰色 D GM (1 ,1)模型对单因素时间序列预测的基础上 ,结合多元回归原理 ,提出建立多因素时间序列的灰色预测 模型 ,这样就充分发挥了二者的优点 ,既克服了时间序列的随机因素影响 ,又综合考虑了影响事物发展 的多种因素 ,从而达到提高预测精度和增加预测结果可靠性的效果. 1 模型的建立 设 Y = (y (1) , y (2) , …, y( n)) 表示事物发展的特征因素时间序列, X i = (x i (1) , x i (2) , …, x i ( n)) (i = 1 ,2 , …, p) 表示影响事物发展的单因素时间序列. 1.1 单因素时间序列的 DGM(1 ,1) 模型 对于单因素原始时间序列{ X i } (i = 1 ,2 , …, p) ,根据灰色系统理论建模方法 ,得 D GM (1 ,1) 模 型 : x i (1) a (1 - a) + a b ,t > 1 1.2 多因素时间序列的预测模型 为了能将影响事物发展的众多因素结合起来进行综合预测和相关因素的预测分析 ,在经过多次研 究与比较后,采用多元回归的原理建立多因素时间序列的灰色预测模型: y t = a 0 + a 1 x 1 t + a 2 x 2 t + …+ a p x p t 2 式中 y t 为该事物在 t 时刻的预测值;x i t i = 1 ,2 , …, p 为第 i 个单因素 ,通过应用上述的灰色 3收稿日期 :2005201209 修改稿日期:2006204212 基金项目 :陕西省教育厅专项基金项目 01J K133( ) 作者简介 :苏变萍 19632( ) ,女 ,山西忻州人 ,副教授 ,博士研究生 ,研究方向为计量经济学. [122] (0) (0) (0) ( ) ( ) [4] (0) x (1) = x (1) ^ x (t) = (1) ( ) ^ ^ ^ ^ ^ ^
ARIMA模型预测GDP 刘春锋的论文请勿作抄袭使用
基于ARIMA模型对河南省2010年GDP预 测 摘要:ARIMA模型是对ARMA模型的差分得到的平稳时间序列模型,具有序列相关性,本文收集了1978-2009年河南省GDP数据,根据ARIMA模型的性质、利用统计软件对河南省2010年GDP进行预测。 关键字:平稳性、ARMA模型、ARIMA模型 由于2008年金融海啸的全面性的爆发,我国的整体经济水平难免呈现不良的发展趋势,4万亿的救市计划,终于达到2009年的保八目标。在这个时候如果对我国GDP进行预测,难免有些偏差,因此本文选择受金融危机影响较小、地处中原、经济持续平稳增长的河南省为例,收集改革开放30年来的数据对2010年的GDP进行预测。GDP时间序列具有明显的增长趋势,因此ARMA模型显然的不稳定的,基于ARMA模型进行差分,发现二次差分的结果不仅稳定,而且表示出良好的序列相关性,所以能用ARMIMA模型对为例GDP 进行预测。比较原始值GDP和预测值GDPF,两曲线吻合的比较好。 一、ARIMA模型的建立 时间序列模型有四种:自回归模型AR、移动平均模型MA、自回归移动平均模型ARMA、自回归差分移动平均模型ARIMA,可以
说前三种都是ARIMA 模型的特殊形式。 1. 自回归模型AR(p) p 阶自回归模型记作AR(p),满足下面的方程: t p t p t t t y y y c y εφφφ+++++=--- 2211 其中:参数 c 为常数;1,2 ,…,p 是自回归模型系数;p 为自回归模型阶数;t ε是均值为0方差为 2σ 的白噪声序列。 2. 移动平均模型MA(q) q 阶移动平均模型记作MA(q) ,满足下面的方程: q t q t t t y ---+++=εθεθεθμ 2211 其中:参数μ为常数;q θθθ,,,21 是 q 阶移动平均模型的系数; t ε是均值为0,方差为2σ 的白噪声序列。 3. ARMA(p,q)模型 q t q t t p t p t t y y c y ----++++++=εθεθεφφ 1111 显然此模型是模型AR(p)与MA(q)的组合形式,称为混合模型,常记作ARMA(p,q)。当 p=0 时,ARMA(0, q) = MA(q);当q = 0时,ARMA(p, 0) = AR(p)。 4. ARIMA (p,d,q )模型 对于非平稳序列,经过几次差分后,如果能得到平稳的时间序列,就称这样的序列为单整序列。设t y 是 d 阶单整序列,记作:t y ~ I(d),则 t d t d t y L y w )1(-=?= t w 为平稳序列,即t w ~ I(0) ,于是可以对t w 建立ARMA(p,q) 模
基于ARIMA模型的航材需求预测
摘要:为了对航材的需求进行预测,本文根据时间序列乘积季节模型,利用统计软件spss,对收集到的航材需求的历史数据进行了建模、参数估计、检验、预测,经检验预测效果较好。该方法简便实用,利于实际推广和使用。 abstract: in order to predict the uncertain demand for aircraft spareparts,a multiple arima model is used to solve this problem by time series forecasting system in spss. the prediction result and its applications are discussed. this method is simple, practical and convenient for spreading. 关键词:时间序列;需求预测;参数估计;白噪声序列 中图分类号:td176 文献标识码:a 文章编号:1006-4311(2016)24-0250-02 0 引言 随着航空兵部队的换装和飞机的更新换代,航空器材的种类越来越多,价值越来越昂贵,如何根据消耗器材的历史数据,准确预测未来器材的需求,这不仅提高了航材保障的精细化程度,减少了库存,避免了因器材具有时效性而产生的浪费,而且增加了航材保障的可预见性,为完成各种飞行任务奠定基础。某种型号的航材需求量,可随着时间的推移,形成一个序列,成为航材需求的时间序列。对某种型号的航材来说,需求量在一定的时间内,是不确定的,它受到飞机训练强度、环境气候、季节性等因素的影响。因此时间序列可能随着时间的推移,呈现一定的趋势性,也可能受季节因素的影响,呈现一定的季节性,如雨季训练强度减少,对器材的消耗就少,需求就相应的减少。而目前对航材需求量的预测,大多采用回归法,滑动平均法,而这些方法的处理和预测,缺少对季节性的考量,而利用时间序列arima (p,d,q)(p,d,q)s模型,可对影响航材需求的各种因素综合考虑,对于短期预测效果较好。 1 arima(p,d,q)(p,d,q)s模型 如果时间序列(yt)是平稳的,可以利用自回归移动平均模型arma(p,q)实现建模和预测,但如果时间序列具有趋势性的非平稳时序,不能直接建立arma(p,q)模型,只能对其经过平稳化处理。这里平稳化处理一般用差分处理,差分处理后的模型记为arima(p,d,q),d是差分的阶数,记bk为k阶滞后算子,即bkyt=yt-k,若k=1,则byt=yt-1。差分形式用(1-b)d表示,如果d=1,(1-b)yt=yt-yt-1,就是一阶差分。有些序列的值和季节变动有关,往往还要进行剔除季节性的影响,这样还要进行季节差分,可表示成(1-bs)d,表示d阶季节差分,若d=1,则(1-bs)yt=yt-yt-s就是一阶季节差分,如果是月度季节差分,s=12,如果是季度季节差分,s=4。为了考虑各种情况,考虑如下的模型形式:?准(b)u(b)(1-b)d(1-bs)dyt=θ(b)v(b)εt 该模型就是模型arima(p,d,q)(p,d,q)s,是自回归移动平均模型的推广。 其中,?准(b)=1-?准1b-?准2b2-…-?准pbp是p阶自回归算子,θ(b)=1-θ1b-θ2b2-…-θpbq,是q阶移动平均算子,(1-b)d是d阶差分算子,u(b)=1-u1bs-u2b2s-…-upbps是p阶季节自回归移动算子,v(b)=1-v1bs-v2b2s-…-vqbqs是q阶季节移动平均算子,(1-bs)d是d阶季节差分算子,其中?准1,?准2,…,?准p,θ1,θ2,…,θq,u1,u2,…,up,v1,v2,…,vq,都是待估参数。 2 利用arima(p,d,q)(p,d,q)s模型预测的步骤 第一步:转化成平稳序列。严格的判定序列的平稳性比较困难,可借助图像,如果图像无趋势性,无周期性,可大致认为序列平稳,也可利用自相关函数acf,若自相关函数acf 随滞后期增大,而迅速趋于0,则认为该序列是平稳的。非平稳性序列,如果具有较强的趋势性,可以通过逐期差分,逐期差分的次数,决定模型中d的取值,如果序列周期性比较明显,可以通过季节差分来实现平稳性,季节差分的阶数,就是模型中的d。
arima模型预测.doc
5 ARIMA 模型预测 5.1 模型选取 目前,学术界较为成熟的预测方法很多,各种不同的预测方法有其所面向的 特定对象,不存在一种普遍“最好”的预测方法。GM (1,1)模型预测是以灰色 系统理论为基础,通过原始数据的分析处理和建立灰色模型,对系统未来状态作 出科学的定量预测的一种方法。我们采用GM (1,1)模型是基于以下两方面的考 虑:第一,GM (1,1)模型对数据要求较低,而其他多数预测方法以数理统计为 基础,对样本量有较高要求。我们用来做预测的数据时序只有14年,预测使用 GM (1,1)模型较好;第二,GM (1,1)模型的计算量相对较小,计算方法相对简 单,适用性较好。 5.2 模型假设前提 1、假设未来重庆地区经济发展基本态势不变; 2、假设未来中央政府对重庆实施的政策方向基本不变; 3、假设未来不会出现战争、瘟疫及其它不可抗拒的自然或社会因素。 5.3 预测数据来源 预测样本为1997—2008年的重庆市农资价格指数、化学肥料价格指数、饲 料价格指数。具体预测样本数据如下: 表5.1 1997—2008年重庆部分农资价格指数 单位:% 为提高数据预测的科学性,我们以1996年(直辖前)的农资价格为基期, 假设1996年农资产品价格为100元,则以后第i 年的农资产品价格计算公式如下: i i Z Z G ???=∏ 1997100 经此换算,得到1997—2008年的预测样本。其中,NZJG 表示换算后的农资, HXFL 表示换算后的化肥,SL 表示换算后的饲料。具体见下表:
表5.2 1997—2008年转换后的预测样本 单位:元 5.4 GM (1,1)模型建立与检验 5.4.1 序列的建立 设由n 个原始数据组成的原始序列为x (0)(k)={x (0)(1),x (0)(2),…,x (0)(n)}。那么可以得到四个样本原始序列: NZJG x (0)(k)= {105.9,95.7,…,120.3}; HXFL x (0)(k)= {93.6,81.8,…,89.9}; SL x (0)(k)= {96.6,87.9,…,118.7}。 5.4.2 级比检验 级别检验是GM (1,1)建模的数据检验,经计算可得: NZJG 级比序列={ 0.904,0.932 ,…, 1.198}; HXFL 地区序列={ 0.874, 0.965,…, 1.200 }; SL 地区序列={ 0.910, 0.919,…, 1.170}; 都落在界区(0.7515,1.3307)内。这表明,以上三个样本序列均可以进行GM (1,1)模型建模。 5.4.3 模型的方程 通过一次累加生成新序列:x (1)(k)={x (1)(1),x (1)(2),…,x (1)(n)},则GM(1,1) 模型相应的微分方程为:μ=+)()(11ax dt dx 其中,a 称为发展灰度,μ为内生控制灰度,它们是方程中重要的参数。通过求解微分方程,即可得到预测模型。由于GM (1,1)预测模型种类较多,我们选取其中较常用的一种如下: a e a x x ak k μμ+????? ?-=-+.1)1( 1^ ),2,1,0(n k , =