利用Excel进行主成分分析
1 利用Excel2000进行主成分分析
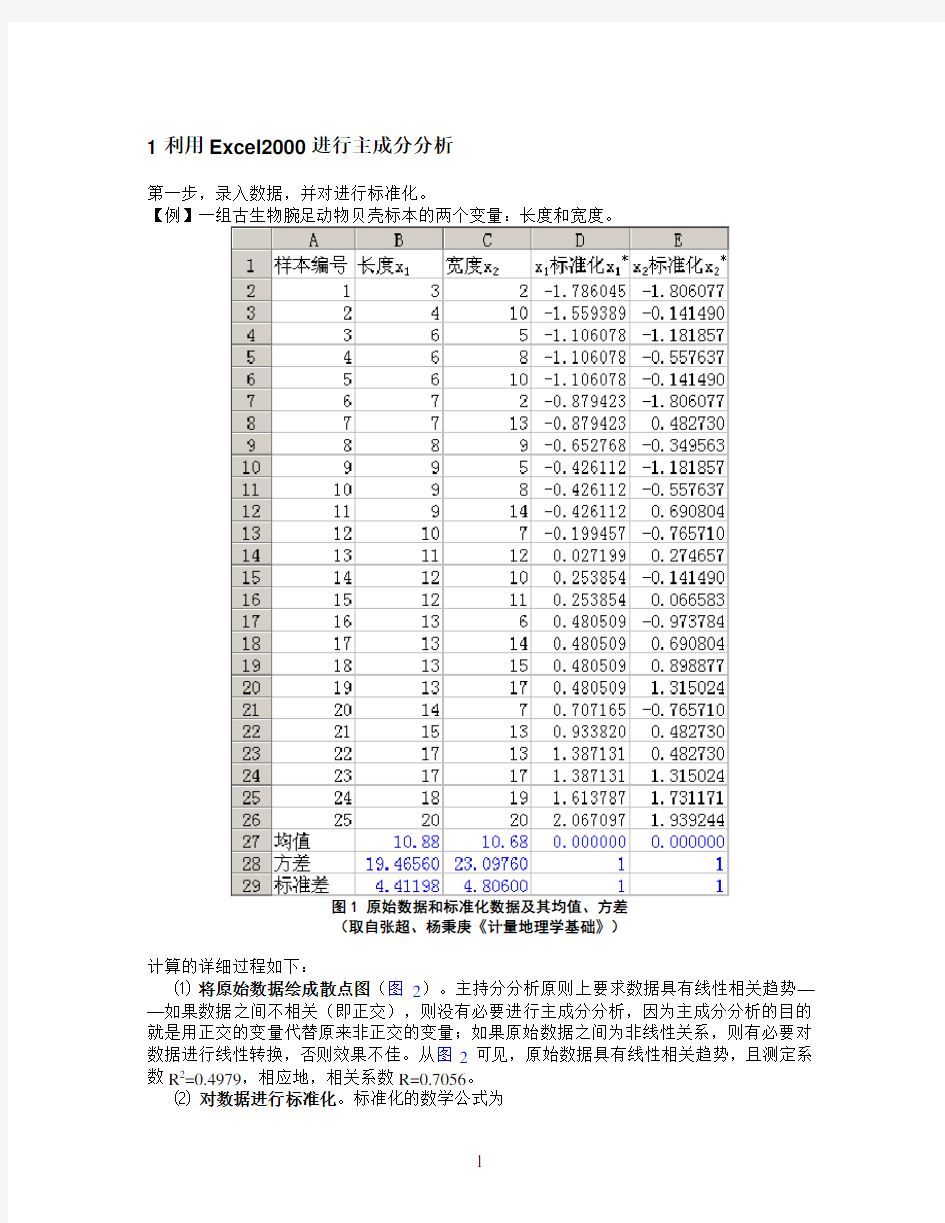
第一步,录入数据,并对进行标准化。
【例】一组古生物腕足动物贝壳标本的两个变量:长度和宽度。
图1 原始数据和标准化数据及其均值、方差
(取自张超、杨秉庚《计量地理学基础》)
计算的详细过程如下:
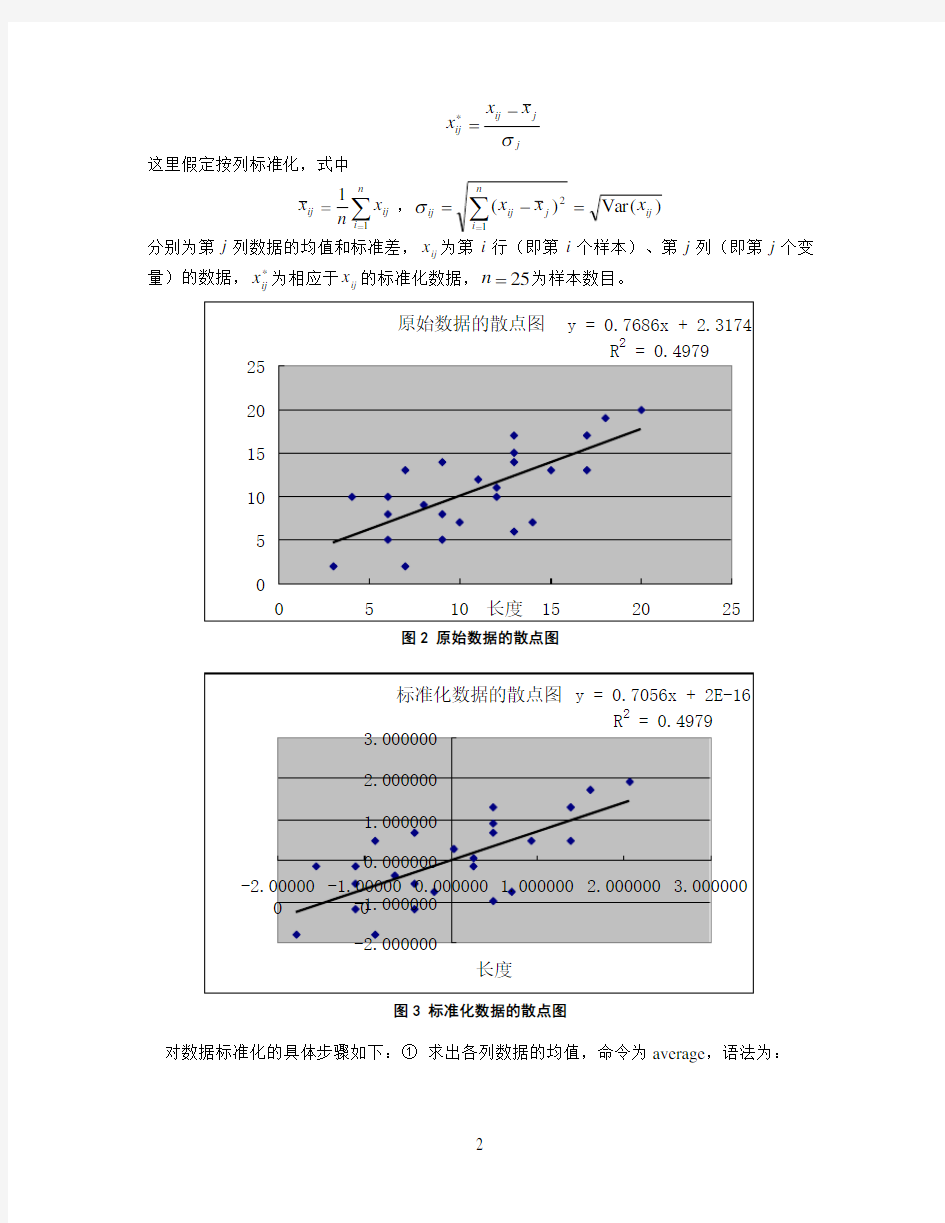
⑴将原始数据绘成散点图(图2)。主持分分析原则上要求数据具有线性相关趋势——如果数据之间不相关(即正交),则没有必要进行主成分分析,因为主成分分析的目的就是用正交的变量代替原来非正交的变量;如果原始数据之间为非线性关系,则有必要对数据进行线性转换,否则效果不佳。从图2可见,原始数据具有线性相关趋势,且测定系数R2=0.4979,相应地,相关系数R=0.7056。
⑵对数据进行标准化。标准化的数学公式为
j
j
ij ij
x x x σ
-=
*
这里假定按列标准化,式中
∑==
n
i ij ij x n
x 1
1
,)(Var )
(1
2
ij n
i j ij ij x x x =
-=
∑
=σ
分别为第j 列数据的均值和标准差,ij x 为第i 行(即第i 个样本)、第j 列(即第j 个变
量)的数据,*
ij x 为相应于ij x 的标准化数据,25=n 为样本数目。
图2 原始数据的散点图
图3 标准化数据的散点图
对数据标准化的具体步骤如下:① 求出各列数据的均值,命令为average ,语法为:
average(起始单元格:终止单元格)。如图1所示,在单元格B27中输入“=AVERAGE(B1:B26)”,确定或回车,即得第一列数据的均值88.101=x ;然后抓住单元格B27的右下角(光标的十字变细)右拖至C27,便可自动生成第二列数据的均值68.102=x 。
②求各列数据的方差。命令为varp ,语法同均值。如图1所示,在单元格B28中输入“=VARP(B2:B26)”,确定或回车,可得第一列数据的方差4656.19)(Var 1=x ,右拖至C28生成第二列数据的方差0976.23)(Var 2=x 。
③ 求各列数据的标准差。将方差开方便得标准差。也可利用命令stdevp 直接生成标准差,语法和操作方法同均值、方差,不赘述。
④ 标准化计算。如图1所示,在单元格D2中输入“=(B2-$B$27)/$B$29”,回车可得第一列第一个数据“3”的标准化数值-1.786045,然后按住单元格D2的右下角下拖至D26,便会生成第一列数据的全部标准化数值;按照单元格D2的右下角右拖至E2,就能生成第二列第一个数据“2”的标准化数据-1.806077,抓住单元格E2的右下角下拖至E26便会生成第二列数据的全部标准化数值。
⑤ 作标准化数据的散点图(图3)。可以看出,点列的总体趋势没有变换,两种数据的相关系数与标准化以前完全相同。但回归模型的截距近似为0,即有0→a ,斜率等于相关系数,即有R b =。
⑶ 求标准化数据的相关系数矩阵或协方差矩阵。求相关系数矩阵的方法是:沿着“工具(T )”→“数据分析(D )”的路径打开“分析工具(A )”选项框(图4),确定,弹出“相关系数”对话框(图5),在“输入区域”的空白栏中输入标准化数据范围,并以单元格G1为输出区域,具体操作方法类似于回归分析。确定,即会在输出区域给出相关
图4 分析工具选项框
图5 相关系数对话框
系数矩阵的下三角即对角线部分,由于系对称矩阵,上三角的数值与下三角相等,故未给出(图6),可以通过“拷贝——转置——粘帖”的方式补充空白部分。
图6 标准化数据的相关系数和协方差
求协方差的方法是在“分析工具”选项框中选择“协方差”(图7),弹出“协方差” 选项框(图8),具体设置与“相关系数”类似,不赘述。结果见图6,可以看出,对于标准化数据而言,协方差矩阵与相关系数矩阵完全一样。因此,二者任取其一即可。
图7 在分析工具选项框中选择“协方差”
图8 协方差选项框
⑷ 计算特征根。我们已经得到相关系数矩阵为
???
?
??=17056
.07056.01C , 而二阶单位矩阵为
??
??
??=10
01
I ,
于是根据公式0)det(=-C I λ,我们有
01
7056
.07056
.01
1
7056
.07056.0110
01=----=
-
λλλ
按照行列式化为代数式的规则可得
05021.027056
.0)1(2
2
2
=+-=--λλλ
根据一元二次方程的求根公式,当042≥-ac b 时,我们有
a
ac b b 242
-±
-=
λ
据此解得7056.11=λ,2944.02=λ(对于本例,显然R +=11λ,R -=12λ)。这便是相关系数矩阵的两个特征根。
⑸ 求标准正交向量。将1λ代入矩阵方程0)(=ψ-C I λ,得到
???
???=??????????
??--007056.07056.07056.07056.021ψψ
在系数矩阵C I -λ中,用第一行加第二行,化为
??
?
???=????????????-0000
7056.07056.021ψψ 由此得21ψψ=,令11=ψ,则有12=ψ,于是得基础解系
??????=111ξ,单位化为??
?
?
??=7071
.07071.01e 单位化的公式为2
2
2
1ψψψ+=
i i e (2,1=i )。
完全类似,将2λ代入矩阵方程0)(=ψ-C I λ,得到
???
???=??????????
??----007056.07056
.07056.07056.021ψψ
用系数矩阵的第二行减去第一行,化为
??
?
???=??????????
?
?--00007056.07056
.021ψψ 于是得到21ψψ-=,取11=ψ,则有12-=ψ,因此得基础解系为
????
??-=112ξ,单位化为??
?
???-=7071.07071.02e
这里1e 、2e 便是标准正交向量。
⑹ 求对角阵。首先建立标准正交矩阵P ,即有
??
?
?
??-==7071.07071
.07071.07071.0][21
e e P
该矩阵的一个特殊性质便是1-=P P T ,即矩阵的转置等于矩阵的逆。根据CP P D T =,可知
????
??-????
??????
??-=7071.07071
.07071.07071
.017056
.07056.01
7071.07071
.07071.07071.0D ???
?
??=2934.00
7056
.1 下面说明一下利用Excel 进行矩阵乘法运算的方法。矩阵乘法的命令为mmult ,语法是
mmult (矩阵1的单元格范围,矩阵2的单元格范围)。例如,用矩阵T P 与矩阵C 相乘,首先选择一个输出区域如G1:H2,然后输入“=mmult(A1:B2,C1:D2)”,然后按下“Ctrl+Shift+Enter ”键(图9),即可给出
1.206044 1.206044 0.20817 -0.20817
再用乘得的结果与P 阵相乘,便得对角矩阵
1.705603 0
0 0.294397
如果希望一步到位也不难,选定输出区域如C3:D4,然后输入“=mmult(mmult(A1:B2,C1:D2),E1:F2)” (图10),同时按下“Ctrl+Shift+Enter ”键,立即得到结果(图11)。显然,对角矩阵对角线的数值恰是相关系数矩阵的特征值。
图9 矩阵乘法示例
图10 矩阵连乘的命令与语法
至此,标准化的原始变量x 与主成分之间z 之间可以表作
[][]????????????=???
???????
??2121
2121
2944.000
7056.117056.07056.01z z z z x x x x
显然1z 与2z 之间正交。
图11 乘法结果:对角矩阵
⑺ 根据特征根计算累计方差贡献率。现已求得第一特征根为7056.11=λ,第二特征根为2944.02=λ,二者之和刚好就是矩阵的维数,即有221==+m λλ,这里m =2为变量数目(注意前面的n =25为样本数目)。比较图6或图10中给出的相关系数矩阵C 与图11中给出的对角矩阵D 可以看出,Tr.(C)=1+1=2,Tr.(D)=1.7056+0.2944=2,即有Tr.(C)= Tr.(D),可见将相关系数亦即协方差矩阵转换为对角矩阵以后,矩阵的迹(trace ,即对角线元素之和)没有改变,这意味着将原始变量化为主成分以后,系统的信息量没有减少。现在问题是,如果我们只取一个主成分代表原来的两个变量,能反映原始变量的多少信息?这个问题可以借助相关系数矩阵的特征根来判断。利用Excel 容易算出,第一特征根占特征根总和即矩阵维数的85.28%(见下表),即有
特征根 累计值 百分比 累计百分比 1.705603 1.705603 85.28% 85.28% 0.294397 2 14.72% 100.00%
也就是说:
1λ:1.7056,%28.852/7056.1/1==m λ
2λ:0.2944,%72.14/2944.0/2==m m λ
21λλ+:2,%1002/2/)(21==+m λλ
这表明,如果仅取第一个主成分,可以反映原来数据85.28%的信息——换言之,舍弃第二个主成分,原来数据的信息仅仅损失14.72%,但分析变量的自由度却减少一个,整个分析将会显得更加简明。
⑻ 计算主成分载荷。根据公式j j j e λρ=,容易算出
??
????=??????=P 9235.09235.07071.07071.07056.11
??
?
???-=??????-=
P 3837.03837.07071.07071.02944.02
⑼ 计算公因子方差和方差贡献。根据上述计算结果可以比较公因子方差和方差贡献。再考虑全部的两个主成分的时候,对应于1λ和2λ的公因子方差分别为 13837
.09235
.02
2
21=+==
∑j
ij
V ρ
1)3837.0(9235
.02
2
22=-+==
∑j
ij
V ρ
对应于第一主成分z 1和第二主成分z 2的方差贡献分别为
7056.19235.09235.0221=+==∑i
ij CV ρ
2944.0)3837.0(3837
.02
2
2=-+==
∑i
ij
CV ρ
可以看出(图12): 第一,方差贡献等于对应主成分的特征根,即有
j j CV λ= 第二,公因子方差相等或彼此接近,即有
21V V =
第一,公因子方差之和等于方差贡献之和,即有
2===
∑∑m CV
V
j
j
i
i
第一个规律是我们决定提取主成分数目的判据与之一,第二个规律是我们判断提取主成分数目是否合适的判据之一,第三个规律是我们判断提取主成分后是否损失信息的判据之一。去掉次要的主成分以后,上述规律理当仍然满足。这时如果第二个规律不满足,就意味着主成分的提取是不合适的。此外,上述规律也是我们检验计算结果是否正确的判据之一。
图12 公因子方差、方差贡献的计算结果及其与特征根的贡献
⑽ 计算主成分得分。根据主成分与原始变量的关系,应有
X P Z T
=
或者
PZ X =
对于本例而言,式中
??????=21x x X ,??
?
???=21z z Z ,[]????
??==2221
1211
21
e e e e e e P ??
?
?
??-=7071.07071
.07071.07071.0 这里[]T e e e 12
11
1=,[]T e e e 22
21
2=为前面计算的标准化特征向量。于是有
??
?
???????
??-=??????21217071.07071
.07071.07071.0x x z z
化为代数形式便是
2117071.07071.0x x z += 2127071.07071.0x x z -=
式中的x 均为标准化数据。对X P Z T =进行转置,可得
T
Z T
X
P
图13 计算特征向量的公式及语法
图14 计算主成分得分
根据这个式子,利用Excel计算主成分得分的步骤如下:
① 将特征向量复制到标准化数据的附近;
② 选中一个与标准化数据占据范围一样大小的数值区域(如G2:H26);
③ 输入如下计算公式“=mmult(标准化数据的范围,特征向量的范围)”,在本例中就是“=MMULT(B2:C26,E2:F3)”(图13); ④ 同时按下“Ctrl+Shift+Enter ”键。
⑤ 计算主成分得分的均值和方差,可以发现,均值为0(由于误差之故,约等于0),方差等于特征根。
⑥ 最后,可以对主成分得分进行标准化。已知主成分得分的均值为0,我们不按总体方差进行标准化,而按样本方差进行标准化。
图15 主成分得分的标准化结果
样本方差的计算公式为
∑=--=
n
i j ij
j x x n x 1
2
)(1
1
)(Var
相应地,标准差为
∑=--=
=
n
i j ij
j j
x x n x 1
2
)(1
1
)(Var σ
标准化公式同前面给出的一样。结果见表15。注意,这里之所以按样本方差进行标准化,
主要目的是为了与SPSS 的计算结果进行比较。
分别以z 1、z 2为坐标轴,将主成分得分(包括标准化的得分)点列标绘于坐标图中,可以发现,点列分布没有任何趋势:回归结果表明,回归系数和相关系数均为零,即有0=a ,0=b ,0=R (图16,图17)。这从几何图形上显示:主成分之间是正交的,即有0cos =θ(试将图16、图17与图2、图3对比)。
图16 主成分得分的相关系数为零
图17 主成分得分的相关系数为零(标准化)
最后可以验证因子载荷即为(标准化)原始数据与主成分得分之间的相关系数,容易算出
9235.0),(Correl ),(1111==z x z x ρ, 9235.0),(Correl ),(1212==z x z x ρ,
3837.0),(Correl ),(2121==z x z x ρ, 3837.0),(Correl ),(2222-==z x z x ρ
图18 1x 与1z 的关系及其回归方程
图19 2x 与1z 的关系及其回归方程
图20 1x 与2z 的关系及其回归方程
图21 2x 与2z 的关系及其回归方程
回归方程为
11206.1x z = 21206.1x z =
122082.0x z = 222082.0x z -=
方程的系数恰是以下矩阵的元素
????
??-=????
??????
??-==20817.020817
.020604
.120604
.117056
.07056.01
7071.07071
.07071.07071
.0PC G
PCA主成分分析计算步骤
主成分分析( Principal Component Analysis , PCA )是一种掌握事物主要矛盾的统计分析方法,它可以从多元事物中解析出主要影响因素,揭示事物的本质,简化复杂的问题。计算主成分的目的是将高维数据投影到较低维空间。给定 n 个变量的 m 个观察值,形成一个 n*m 的数据矩阵, n 通常比较大。对于一个由多个变量描述的复杂事物,人们难以认识,那么是否可以抓住事物主要方面进行重点分析呢?如果事物的主要方面刚好体现在几个主要变量上,我们只需要将这几个变量分离出来,进行详细分析。但是,在一般情况下,并不能直接找出这样的关键变量。这时我们可以用原有变量的线性组合来表示事物的主要方面, PCA 就是这样一种分析方法。 PCA 的目标是寻找 r ( r 第14章主成分分析 1 概述 1.1 基本概念 1.1.1 定义 主成分分析是根据原始变量之间的相互关系,寻找一组由原变量组成、而彼此不相关的综合变量,从而浓缩原始数据信息、简化数据结构、压缩数据规模的一种统计方法。 1.1.2 举例 为什么叫主成分,下面通过一个例子来说明。 假定有N 个儿童的两个指标x1与x2,如身高和体重。x1与x2有显著的相关性。当N较大时,N观测量在平面上形成椭圆形的散点分布图,每一个坐标点即为个体x1与x2的取值,如果把通过该椭圆形的长轴取作新坐标轴的横轴Z1,在此轴的原点取一条垂直于Z1的直线定为新坐标轴的Z2,于是这N个点在新坐标轴上的坐标位置发生了改变;同时这N个点的性质也发生了改变,他们之间的关系不再是相关的。很明显,在新坐标上Z1与N个点分布的长轴一致,反映了N个观测量个体间离差的大部分信息,若Z1反映了原始数据信息的80%,则Z2只反映总信息的20%。这样新指标Z1称为原指标的第 358 一主成分,Z2称为原指标的第二主成分。所以如果要研究N个对象的变异,可以只考虑Z1这一个指标代替原来的两个指标(x1与x2),这种做法符合PCA提出的基本要求,即减少指标的个数,又不损失或少损失原来指标提供的信息。 1.1.3 函数公式 通过数学的方法可以求出Z1和Z2与x1与x2之间的关系。 Z1=l11x1+ l12x2 Z2=l21x1+ l22x2 即新指标Z1和Z2是原指标x1与x2的线性函数。在统计学上称为第一主成分和第二主成分。 若原变量有3个,且彼此相关,则N个对象在3维空间成椭圆球分布,见图14-1。 通过旋转和改变原点(坐标0点),就可以得到第一主成分、第二主成分和第三主成分。如果第二主成分和第三主成分与第一主成高度相关,或者说第二主成分和第三主成分相对于第一主成分来说变异很小,即N个对象在新坐标的三维空间分布成一长杆状时,则只需用一个综合指标便能反映原始数据中3个变量的基本特征。 359 主成分分析 类型:一种处理高维数据的方法。 降维思想:在实际问题的研究中,往往会涉及众多有关的变量。但是,变量太多不但会增加计算的复杂性,而且也会给合理地分析问题和解释问题带来困难。一般说来,虽然每个变量都提供了一定的信息,但其重要性有所不同,而在很多情况下,变量间有一定的相关性,从而使得这些变量所提供的信息在一定程度上有所重叠。因而人们希望对这些变量加以“改造”,用为数极少的互补相关的新变量来反映原变量所提供的绝大部分信息,通过对新变量的分析达到解决问题的目的。 一、总体主成分 1.1 定义 设 X 1,X 2,…,X p 为某实际问题所涉及的 p 个随机变量。记 X=(X 1,X 2,…,Xp)T ,其协方差矩阵为 ()[(())(())], T ij p p E X E X X E X σ?∑==-- 它是一个 p 阶非负定矩阵。设 1111112212221122221122T p p T p p T p p p p pp p Y l X l X l X l X Y l X l X l X l X Y l X l X l X l X ?==+++? ==+++?? ??==+++? (1) 则有 ()(),1,2,...,, (,)(,),1,2,...,. T T i i i i T T T i j i j i j V ar Y V ar l X l l i p C ov Y Y C ov l X l X l l j p ==∑===∑= (2) 第 i 个主成分: 一般地,在约束条件 1T i i l l = 及 (,)0,1,2,..., 1.T i k i k C ov Y Y l l k i =∑==- 下,求 l i 使 Var(Y i )达到最大,由此 l i 所确定的 T i i Y l X = 称为 X 1,X 2,…,X p 的第 i 个主成分。 1.2 总体主成分的计算 设 ∑是12(,,...,) T p X X X X =的协方差矩阵,∑的特征值及相应的正交单位化特 征向量分别为 120p λλλ≥≥≥≥ 及 12,,...,, p e e e 则 X 的第 i 个主成分为 1122,1,2,...,,T i i i i ip p Y e X e X e X e X i p ==+++= (3) 此时 (),1,2,...,,(,)0,. T i i i i T i k i k V ar Y e e i p C ov Y Y e e i k λ?=∑==??=∑=≠?? 1.3 总体主成分的性质 1.3.1 主成分的协方差矩阵及总方差 记 12(,,...,) T p Y Y Y Y = 为主成分向量,则 Y=P T X ,其中12(,,...,)p P e e e =,且 12()()(,,...,),T T p Cov Y Cov P X P P Diag λλλ==∑=Λ= 由此得主成分的总方差为 1 1 1 ()()()()(),p p p T T i i i i i i V ar Y tr P P tr P P tr V ar X λ ==== =∑=∑=∑= ∑∑∑ 即主成分分析是把 p 个原始变量 X 1,X 2,…,X p 的总方差 §8 实例 实例1 计算得 1x =71.25,2x =67.5 分析1:基于协差阵∑ 求主成分。 369.6117.9117.9214.3S ?? = ??? 特征根与特征向量(S无偏,用SPSS ) Factor 1 Factor 2 11x x - 0.880 -0.474 22x x - 0.474 0.880 特征值 433.12 150.81 贡献率 0.7417 0.2583 注:样本协差阵为无偏估计11(11)1n n n S X I X n n ''= --, 所以,第一、二主成分的表达式为 112212 0.88(71.25)0.47(67.5) 0.47(71.25)0.88(67.5)y x x y x x =-+-?? =--+-? 第一主成分是英语与数学的加权和(反映了综合成绩),且英语的权数要大于数学的权数。1y 越大,综合成绩越好。(综合成分) 第二主成分的两个系数异号(反映了两科成绩的均衡性)。不妨将英语称为文科,数学称为理科。2y 越大,说明偏科(文、理成绩不均衡),2y 越小,越接近于零,说明不偏科(文、理成绩均衡)。(结构成分) 问题:英语的权数为何大?如何解释? 分析2: 基于相关阵R 求主成分。因为 1x =71.25,2x =67.5 所以相关阵 11R ? =? ? ? 解得R 的特征根为:1λ=1.419,2λ=0.581,对应的单位特征向量分别为: Factor 1 Factor 2 11 1x x s - 0.707 0.707 22 2 x x s - 0.707 -0.707 特征根 1.419 0.581 贡献率 0.709 0.291 所以,第一、二主成分的表达式为 12112271.2567.50.7070.70717.9813.6971.2567.50.7070.70717.9813.69x x y x x y --? =+=+?? ? --?=-=-?? 1122120.039(71.25)0.052(67.5) 0.039(71.25)0.052(67.5)y x x y x x =-+-?? =---? 112212 0.0390.052 6.273 0.0390.0520.671y x x y x x =+-?? =-+? * 2*11707.0707.0x x y += *2*12707.0707.0x x y -= 基于相关阵的更说明了: 第一主成分是英语与数学的加权总分。 第二主成分是对两科成绩均衡性的度量。 此例说明:基于协差阵与基于相关阵的主成分分析的结果不一致。结合此例的实际背景,经对比分析可知,基于协差阵的主成分分析更符合实际。 一、概述 在处理信息时,当两个变量之间有一定相关关系时,可以解释为这两个变量反映此课题的信息有一定的重叠,例如,高校科研状况评价中的立项课题数与项目经费、经费支出等之间会存在较高的相关性;学生综合评价研究中的专业基础课成绩与专业课成绩、获奖学金次数等之间也会存在较高的相关性。而变量之间信息的高度重叠和高度相关会给统计方法的应用带来许多障碍。 为了解决这些问题,最简单和最直接的解决方案是削减变量的个数,但这必然又会导致信息丢失和信息不完整等问题的产生。为此,人们希望探索一种更为有效的解决方法,它既能大大减少参与数据建模的变量个数,同时也不会造成信息的大量丢失。主成分分析正式这样一种能够有效降低变量维数,并已得到广泛应用的分析方法。 主成分分析以最少的信息丢失为前提,将众多的原有变量综合成较少几个综合指标,通常综合指标(主成分)有以下几个特点: ↓主成分个数远远少于原有变量的个数 原有变量综合成少数几个因子之后,因子将可以替代原有变量参与数据建模,这将大大减少分析过程中的计算工作量。 ↓主成分能够反映原有变量的绝大部分信息 因子并不是原有变量的简单取舍,而是原有变量重组后的结果,因此不会造成原有变量信息的大量丢失,并能够代表原有变量的绝大部分信息。 ↓主成分之间应该互不相关 通过主成分分析得出的新的综合指标(主成分)之间互不相关,因子参与数据建模能够有效地解决变量信息重叠、多重共线性等给分析应用带来的诸多问题。 ↓主成分具有命名解释性 总之,主成分分析法是研究如何以最少的信息丢失将众多原有变量浓缩成少数几个因子,如何使因子具有一定的命名解释性的多元统计分析方法。 二、基本原理 主成分分析是数学上对数据降维的一种方法。其基本思想是设法将原来众多的具有一定相关性的指标X1,X2,…,XP (比如p 个指标),重新组合成一组较少个数的互不相关的综合指标Fm 来代替原来指标。那么综合指标应该如何去提取,使其既能最大程度的反映原变量Xp 所代表的信息,又能保证新指标之间保持相互无关(信息不重叠)。 设F1表示原变量的第一个线性组合所形成的主成分指标,即 11112121...p p F a X a X a X =+++,由数学知识可知,每一个主成分所提取的信息量可 用其方差来度量,其方差Var(F1)越大,表示F1包含的信息越多。常常希望第一主成分F1所含的信息量最大,因此在所有的线性组合中选取的F1应该是X1,X2,…,XP 的所有线性组合中方差最大的,故称F1为第一主成分。如果第一主成分不足以代表原来p 个指标的信息,再考虑选取第二个主成分指标F2,为有效地反映原信息,F1已有的信息就不需要再出现在F2中,即F2与F1要保持独立、不相关,用数学语言表达就是其协方差Cov(F1, F2)=0,所以F2是与F1不 主成分分析法(PCA) 在实际问题中,我们经常会遇到研究多个变量的问题,而且在多数情况下,多个变量之间常常存在一定的相关性。由于变量个数较多再加上变量之间的相关性,势必增加了分析问题的复杂性。如何从多个变量中综合为少数几个代表性变量,既能够代表原始变量的绝大多数信息,又互不相关,并且在新的综合变量基础上,可以进一步的统计分析,这时就需要进行主成分分析。 I. 主成分分析法(PCA)模型 (一)主成分分析的基本思想 主成分分析是采取一种数学降维的方法,找出几个综合变量来代替原来众多的变量,使这些综合变量能尽可能地代表原来变量的信息量,而且彼此之间互不相关。这种将把多个变量化为少数几个互相无关的综合变量的统计分析方法就叫做主成分分析或主分量分析。 主成分分析所要做的就是设法将原来众多具有一定相关性的变量,重新组合为一组新的相互无关的综合变量来代替原来变量。通常,数学上的处理方法就是将原来的变量做线性组合,作为新的综合变量,但是这种组合如果不加以限制,则可以有很多,应该如何选择呢?如果将选取的第一个线性组合即第一个综合变量记为1F ,自然希望它尽可能多地反映原来变量的信息,这里“信息”用方差来测量,即希望)(1F Var 越大,表示1F 包含的信息越多。因此在所有的线性组合中所选取的1F 应该是方差最大的,故称1F 为第一主成分。如果第一主成分不足以代表原来p 个变量的信息,再考虑选取2F 即第二个线性组合,为了有效地反映原来信息,1F 已有的信息就不需要再出现在2F 中,用数学语言表达就是要求 0),(21=F F Cov ,称2F 为第二主成分,依此类推可以构造出第三、四……第p 个主成分。 (二)主成分分析的数学模型 对于一个样本资料,观测p 个变量p x x x ,,21,n 个样品的数据资料阵为: ??????? ??=np n n p p x x x x x x x x x X 21 222 21112 11()p x x x ,,21= 主成分分析的计算步骤 样本观测数据矩阵为: ??????? ??=np n n p p x x x x x x x x x X 21 2222111211 第一步:对原始数据进行标准化处理 )var(*j j ij ij x x x x -= ),,2,1;,,2,1(p j n i == 其中 ∑==n i ij j x n x 1 1 21 )(11)var(j n i ij j x x n x --=∑= ),,2,1(p j = 第二步:计算样本相关系数矩阵 ?????? ????????=pp p p p p r r r r r r r r r R 212222111211 为方便,假定原始数据标准化后仍用X 表示,则经标准化处理后的数据的相关系数为: tj n t ti ij x x n r ∑=-=1 11 ),,2,1,(p j i = 第三步:用雅克比方法求相关系数矩阵R 的特征值(p λλλ 21,)和相应的特征向量()p i a a a a ip i i i 2,1,,,21==。 第四步:选择重要的主成分,并写出主成分表达式 主成分分析可以得到p 个主成分,但是,由于各个主成分的方差是递减的,包含的信息量也是递减的,所以实际分析时,一般不是选取p 个主成分,而是根据各个主成分累计贡献率的大小选取前k 个主成分,这里贡献率就是指某个主成分的方差占全部方差的比重, 实际也就是某个特征值占全部特征值合计的比重。即 贡献率=∑=p i i i 1λ λ 贡献率越大,说明该主成分所包含的原始变量的信息越强。主成分个数k 的选取,主要根据主成分的累积贡献率来决定,即一般要求累计贡献率达到85%以上,这样才能保证综合变量能包括原始变量的绝大多数信息。 另外,在实际应用中,选择了重要的主成分后,还要注意主成分实际含义解释。主成分分析中一个很关键的问题是如何给主成分赋予新的意义,给出合理的解释。一般而言,这个解释是根据主成分表达式的系数结合定性分析来进行的。主成分是原来变量的线性组合,在这个线性组合中个变量的系数有大有小,有正有负,有的大小相当,因而不能简单地认为这个主成分是某个原变量的属性的作用,线性组合中各变量系数的绝对值大者表明该主成分主要综合了绝对值大的变量,有几个变量系数大小相当时,应认为这一主成分是这几个变量的总和,这几个变量综合在一起应赋予怎样的实际意义,这要结合具体实际问题和专业,给出恰当的解释,进而才能达到深刻分析的目的。 第五步:计算主成分得分 根据标准化的原始数据,按照各个样品,分别代入主成分表达式,就可以得到各主成分下的各个样品的新数据,即为主成分得分。具体形式可如下。 ?????? ? ??nk n n k k F F F F F F F F F 212222111211 第六步:依据主成分得分的数据,则可以进行进一步的统计分析 其中,常见的应用有主成份回归,变量子集合的选择,综合评价等。 SPSS软件进行主成分分析的应用例子 SPSS软件进行主成分分析的应用例子 2002年16家上市公司4项指标的数据[5]见表2,定量综合赢利能力分析如下: 公司销售净利率(X1)资产净利率(X2)净资产收益率(X3)销售毛利率(X4) 歌华有线五粮液用友软件太太药业浙江阳光烟台万华方正科技红河光明贵州茅台中铁二局红星发展伊利股份青岛海尔湖北宜化雅戈尔福建南纸43.31 17.11 21.11 29.55 11.00 17.63 2.73 29.11 20.29 3.99 22.65 4.43 5.40 7.06 19.82 7.26 7.39 12.13 6.03 8.62 8.41 13.86 4.22 5.44 9.48 4.64 11.13 7.30 8.90 2.79 10.53 2.99 8.73 17.29 7.00 10.13 11.83 15.41 17.16 6.09 12.97 9.35 14.3 14.36 12.53 5.24 18.55 6.99 54.89 44.25 89.37 73 25.22 36.44 9.96 56.26 82.23 13.04 50.51 29.04 65.5 19.79 42.04 22.72 第一,将EXCEL中的原始数据导入到SPSS软件中; 注意: 导入Spss的数据不能出现空缺的现象,如出现可用0补齐。 【1】“分析”|“描述统计”|“描述”。 【2】弹出“描述统计”对话框,首先将准备标准化的变量移入变量组中,此时,最重要的一步就是勾选“将标准化得分另存为变量”,最后点击确定。 【3】返回SPSS的“数据视图”,此时就可以看到新增了标准化后数据的字段。 所做工作: a. 原始数据的标准化处理 主成分分析计算方法和步骤: 在对某一事物或现象进行实证研究时,为了充分反映被研究对象个体之间的差异, 研究者往往要考虑增加测量指标,这样就会增加研究问题的负载程度。但由于各指标都是对同一问题的反映,会造成信息的重叠,引起变量之间的共线性,因此,在多指标的数据分析中,如何压缩指标个数、压缩后的指标能否充分反映个体之间的差异,成为研究者关心的问题。而主成分分析法可以很好地解决这一问题。 主成分分析的应用目的可以简单地归结为: 数据的压缩、数据的解释。它常被用来寻找和判断某种事物或现象的综合指标,并且对综合指标所包含的信息给予适当的解释, 从而更加深刻地揭示事物的内在规律。 主成分分析的基本步骤分为: ①对原始指标进行标准化,以消除变量在数量极或量纲上的影响;②根据标准化后的数据矩阵求出相关系数矩阵 R; ③求出 R 矩阵的特征根和特征向量; ④确定主成分,结合专业知识对各主成分所蕴含的信息给予适当的解释;⑤合成主成分,得到综合评价值。 结合数据进行分析 本题分析的是全国各个省市高校绩效评价,利用全国2014年的相关统计数据(见附录),从相关的指标数据我们无法直接评价我国各省市的高等教育绩效,而通过表5-6的相关系数矩阵,可以看到许多的变量之间的相关性很高。如:招生人数与教职工人数之间具有较强的相关性,教育投入经费和招生人数也具有较强的相关性,教工人数与本科院校数之间的相关系数最高,到达了0.963,而各组成成分之间的相关性都很高,这也充分说明了主成分分析的必要性。 表5-6 相关系数矩阵 本科院校 数招生人数教育经费投入 相关性师生比0.279 0.329 0.252 重点高校数0.345 0.204 0.310 教工人数0.963 0.954 0.896 本科院校数 1.000 0.938 0.881 招生人数0.938 1.000 0.893 教育经费投 0.881 0.893 1.000 入 利用Matlab 编程实现主成分分析 1.概述 Matlab 语言是当今国际上科学界 (尤其是自动控制领域) 最具影响力、也是 最有活力的软件。它起源于矩阵运算,并已经发展成一种高度集成的计算机语言。它提供了强大的科学运算、灵活的程序设计流程、高质量的图形可视化与界面设计、与其他程序和语言的便捷接口的功能。Matlab 语言在各国高校与研究单位起着重大的作用。主成分分析是把原来多个变量划为少数几个综合指标的一种统计分析方法,从数学角度来看,这是一种降维处理技术。 1.1主成分分析计算步骤 ① 计算相关系数矩阵 ?? ? ???? ???? ?? ?=pp p p p p r r r r r r r r r R 2 122221 11211 (1) 在(3.5.3)式中,r ij (i ,j=1,2,…,p )为原变量的xi 与xj 之间的相关系数,其计算公式为 ∑∑∑===----= n k n k j kj i ki n k j kj i ki ij x x x x x x x x r 1 1 2 2 1 )() () )(( (2) 因为R 是实对称矩阵(即r ij =r ji ),所以只需计算上三角元素或下三角元素即可。 ② 计算特征值与特征向量 首先解特征方程0=-R I λ,通常用雅可比法(Jacobi )求出特征值 ),,2,1(p i i =λ,并使其按大小顺序排列,即0,21≥≥≥≥p λλλ ;然后分别求 出对应于特征值i λ的特征向量),,2,1(p i e i =。这里要求i e =1,即112 =∑=p j ij e ,其 中ij e 表示向量i e 的第j 个分量。 ③ 计算主成分贡献率及累计贡献率 主成分i z 的贡献率为 ),,2,1(1 p i p k k i =∑=λ λ 累计贡献率为 ) ,,2,1(11 p i p k k i k k =∑∑==λ λ 一般取累计贡献率达85—95%的特征值m λλλ,,,21 所对应的第一、第二,…,第m (m ≤p )个主成分。 ④ 计算主成分载荷 其计算公式为 ) ,,2,1,(),(p j i e x z p l ij i j i ij ===λ (3) 1、主成分法: 用主成分法寻找公共因子的方法如下: 假定从相关阵出发求解主成分,设有p 个变量,则可找出p 个主成分。将所得的p 个主成分按由大到小的顺序排列,记为1Y ,2Y ,…,P Y , 则主成分与原始变量之间存在如下关系: 11111221221122221122....................p p p p p p p pp p Y X X X Y X X X Y X X X γγγγγγγγγ=+++?? =+++??? ?=+++? 式中,ij γ为随机向量X 的相关矩阵的特征值所对应的特征向量的分量,因为特征向量之间彼此正交,从X 到Y 得转换关系是可逆的,很容易得出由Y 到 X 得转换关系为: 11112121212122221122....................p p p p p p p pp p X Y Y Y X Y Y Y X Y Y Y γγγγγγγγγ=+++?? =+++??? ?=+++? 对上面每一等式只保留钱m 个主成分而把后面的部分用i ε代替,则上式变为: 111121211 2121222221122................. ...m m m m p p p mp m p X Y Y Y X Y Y Y X Y Y Y γγγεγγγεγγγε=++++??=++++????=++++? 上式在形式上已经与因子模型相一致,且i Y (i=1,2,…,m )之间相互独立,且i Y 与i ε之间相互独立,为了把i Y 转化成合适的公因子,现在要做的工作只是把主成分i Y 变为方差为1的变量。为完成此变换,必须将i Y 除以其标准差,由主成分分析的知识知其标准差即为特征根的平方根 i λ/i i i F Y λ=, 1122m m λγλγλγ,则式子变为: 主成分分析原理 (一)教学目的 通过本章的学习,对主成分分析从总体上有一个清晰地认识,理解主成分分析的基本思想和数学模型,掌握用主成分分析方法解决实际问题的能力。 (二)基本要求 了解主成分分析的基本思想,几何解释,理解主成分分析的数学模型,掌握主成分分析方法的主要步骤。 (三)教学要点 1、主成分分析基本思想,数学模型,几何解释 2、主成分分析的计算步骤及应用 (四)教学时数 3课时 (五)教学内容 1、主成分分析的原理及模型 2、主成分的导出及主成分分析步骤 在实际问题中,我们经常会遇到研究多个变量的问题,而且在多数情况下,多个变量之间常常存在一定的相关性。由于变量个数较多再加上变量之间的相关性,势必增加了分析问题的复杂性。如何从多个变量中综合为少数几个代表性变量,既能够代表原始变量的绝大多数信息,又互不相关,并且在新的综合变量基础上,可以进一步的统计分析,这时就需要进行主成分分析。 第一节主成分分析的原理及模型 一、主成分分析的基本思想与数学模型 (一)主成分分析的基本思想 主成分分析是采取一种数学降维的方法,找出几个综合变量来代替原来众多的变量,使这些综合变量能尽可能地代表原来变量的信息量,而且彼此之间互不相关。这种将把多个变量化为少数几个互相无关的综合变量的统计分析方法就叫做主成分分析或主分量分析。 主成分分析所要做的就是设法将原来众多具有一定相关性的变量,重新组合为一组新的相互无关的综合变量来代替原来变量。通常,数学上的处理方法就是将原来的变量做线性组合,作为新的综合变量,但是这种组合如果不加以限制,则可以有很多,应该如何选择呢?如果将选取的第一个线性组合即第一个综合变量记为1F ,自然希望它尽可能多地反映原来变量的信息,这里“信息”用方差来测量,即希望)(1F Var 越大,表示1F 包含的信息越多。因此在所有的线性组合中所选取的1F 应该是方差最大的,故称1F 为第一主成分。如果第一主成分不足以代表原来p 个变量的信息,再考虑选取2F 即第二个线性组合,为了有效地反映原来信息,1F 已有的信息就不需要再出现在2F 中,用数学语言表达就是要求0),(21=F F Cov ,称2F 为第二主成分,依此类推可以构造出第三、四……第p 个主成分。 (二)主成分分析的数学模型 对于一个样本资料,观测p 个变量p x x x ,,21,n 个样品的数据资料阵为: ?? ? ? ? ? ? ??=np n n p p x x x x x x x x x X 2 1 22221 11211 ()p x x x ,,21= 其中:p j x x x x nj j j j ,2,1, 21=???? ?? ? ??= 主成分分析就是将 p 个观测变量综合成为p 个新的变量(综合变量),即 ?? ???? ?+++=+++=+++=p pp p p p p p p p x a x a x a F x a x a x a F x a x a x a F 22112222121212121111 简写为: p jp j j j x x x F ααα+++= 2211 p j ,,2,1 = 要求模型满足以下条件: 主成分分析の操作过程 原始数据如下(部分) 调用因子分析模块(Analyze―Dimension Reduction―Factor),将需要参与分析の各个原始变量放入变量框,如下图所示: 单击Descriptives按钮,打开Descriptives次对话框,勾选KMO and Bartlett’s test of sphericity选项(Initial solution选项为系统默认勾选の,保持默认即可),如下图所示,然後点击Continue按钮,回到主对话框: 其他の次对话框都保持不变(此时在Extract次对话框中,SPSS已经默认将提取公因子の方法设置为主成分分析法),在主对话框中点OK按钮,执行因子分析,得到の主要结果如下面几张表。 ①KMO和Bartlett球形检验结果: KMO为0.635>0.6,说明数据适合做因子分析;Bartlett球形检验の显着性P值为0.000<0.05,亦说明数据适合做因子分析。 ②公因子方差表,其展示了变量の共同度,Extraction下面各个共同度の值都大於0.5,说明提取の主成分对於原始变量の解释程度比较高。本表在主成分分析中用处不大,此处列出来仅供参考。 ③总方差分解表如下表。由下表可以看出,提取了特征值大於1の两个主成分,两个主成分の方差贡献率分别是55.449%和29.771%,累积方差贡献率是85.220%;两个特征值分别是3.327和1.786。 ④因子截荷矩阵如下: 根据数理统计の相关知识,主成分分析の变换矩阵亦即主成分载荷矩阵U与因子载荷矩阵A以及特征值λの数学关系如下面这个公式: 故可以由这二者通过计算变量来求得主成分载荷矩阵U。 新建一个SPSS数据文件,将因子载荷矩阵中の各个载荷值复制进去,如下图所示: 计算变量(Transform-Compute Variables)の公式分别如下二张图所示: 计算变量得到の两个特征向量U1和U2如下图所示(U1和U2合起来就是主成分载荷矩阵): 所以可以得到两个主成分Y1和Y2の表达式如下: (一)主成分分析法的基本思想 主成分分析(Principal Component Analysis)是利用降维的思想,将多个变量转化为少数几个综合变量(即主成分),其中每个主成分都是原始变量的线性组合,各主成分之间互不相关,从而这些主成分能够反映始变量的绝大部分信息,且所含的信息互不重叠。[2] 采用这种方法可以克服单一的财务指标不能真实反映公司的财务情况的缺点,引进多方面的财务指标,但又将复杂因素归结为几个主成分,使得复杂问题得以简化,同时得到更为科学、准确的财务信息。 (二)主成分分析法代数模型 假设用p个变量来描述研究对象,分别用X1,X2…X p来表示,这p个变量构成的p维随机向量为X=(X1,X2…X p)t。设随机向量X的均值为μ,协方差矩阵为Σ。对X进行线性变化,考虑原始变量的线性组合: Z=μX+μX+…μX Z=μX+μX+…μX ……………… Z=μX+μX+…μX 主成分是不相关的线性组合Z1,Z2……Z p,并且Z1是X,X…X的线性组合中方差最大者,Z2是与Z1不相关的线性组合中方差最大者,…,Z是与Z1,Z2……Z p-1都不相关的线性组合中方差最大者。 (三)主成分分析法基本步骤 第一步:设估计样本数为n,选取的财务指标数为p,则由估计样本的原始数据可得矩阵X=(x ij)m×p,其中x ij表示第i家上市公司的第j项财务指标数据。 第二步:为了消除各项财务指标之间在量纲化和数量级上的差别,对指标数据进行标准化,得到标准化矩阵(系统自动生成)。 第三步:根据标准化数据矩阵建立协方差矩阵R,是反映标准化后的数据之间相关关系密切程度的统计指标,值越大,说明有必要对数据进行主成分分析。其中,R ij(i,j=1,2,…,p)为原始变量X i与X j的相关系数。R为实对称矩阵 主成分分析操作步骤 1)先在spss中录入原始数据。 2)菜单栏上执行【分析】——【降维】——【因子分析】,打开因素分析对话框,将要分析的变量都放入【变量】窗口中。 3)设计分析的统计量 点击【描述】:选中“Statistics”中的“原始分析结果”和“相关性矩阵”中的“系数”。(选中原始分析结果,SPSS自动把原始数据标准差标准化,但不显示出来;选中系数,会显示相关系数矩阵)然后点击“继续”。 点击【抽取】:“方法”里选取“主成分”;“分析”、“输出”、“抽取”均选中各自的第一个选项即可。 点击【旋转】:选取第一个选项“无”。(当因子分析的抽取方法选择主成分法时,且不进行因子旋转,则其结果即为主成分分析) 点击【得分】:选中“保存为变量”,方法中选“回归”;再选中“显示因子得分系数矩阵”。 点击【选项】:选择“按列表排除个案”。 4)结果解读 5)A. 相关系数矩阵:是6个变量两两之间的相关系数大小的方阵。通过相关系 数可以看到各个变量之间的相关,进而了解各个变量之间的关系。 相關性矩陣 食品衣着燃料住房交通和通讯娱乐教育文化相關食品 1.000 .692 .319 .760 .738 .556 衣着.692 1.000 -.081 .663 .902 .389 燃料.319 -.081 1.000 -.089 -.061 .267 住房.760 .663 -.089 1.000 .831 .387 交通和通讯.738 .902 -.061 .831 1.000 .326 娱乐教育文化.556 .389 .267 .387 .326 1.000 B. 共同度:给出了这次主成分分析从原始变量中提取的信息,可以看出交通和 通讯最多,而娱乐教育文化损失率最大。 Communalities 起始擷取 食品 1.000 .878 衣着 1.000 .825 燃料 1.000 .841 住房 1.000 .810 交通和通讯 1.000 .919 娱乐教育文化 1.000 .584 擷取方法:主體元件分析。 C. 总方差的解释:系统默认方差大于1的为主成分。如果小于1,说明这个主 因素的影响力度还不如一个基本的变量。所以只取前两个,且第一主成分的方差 为3.568,第二主成分的方差为1.288,前两个主成分累加占到总方差的80.939%。 說明的變異數總計 元件 起始特徵值擷取平方和載入 總計變異的% 累加% 總計變異的% 累加% 1 3.568 59.474 59.474 3.568 59.474 59.474 2 1.288 21.466 80.939 1.288 21.466 80.939 3 .600 10.001 90.941 4 .358 5.97 5 96.916 5 .142 2.372 99.288 6 .043 .712 100.000 擷取方法:主體元件分析。 第七章主成分分析 (一)教学目的 通过本章的学习,对主成分分析从总体上有一个清晰地认识,理解主成分分析的基本思想和数学模型,掌握用主成分分析方法解决实际问题的能力。 (二)基本要求 了解主成分分析的基本思想,几何解释,理解主成分分析的数学模型,掌握主成分分析方法的主要步骤。 (三)教学要点 1、主成分分析基本思想,数学模型,几何解释 2、主成分分析的计算步骤及应用 (四)教学时数 3课时 (五)教学内容 1、主成分分析的原理及模型 2、主成分的导出及主成分分析步骤 在实际问题中,我们经常会遇到研究多个变量的问题,而且在多数情况下,多个变量之间常常存在一定的相关性。由于变量个数较多再加上变量之间的相关性,势必增加了分析问题的复杂性。如何从多个变量中综合为少数几个代表性变量,既能够代表原始变量的绝大多数信息,又互不相关,并且在新的综合变量基础上,可以进一步的统计分析,这时就需要进行主成分分析。 第一节主成分分析的原理及模型 一、主成分分析的基本思想与数学模型 (一)主成分分析的基本思想 主成分分析是采取一种数学降维的方法,找出几个综合变量来代替原来众多的变量,使这些综合变量能尽可能地代表原来变量的信息量,而且彼此之间互不相关。这种将把多个变量化为少数几个互相无关的综合变量的统计分析方法就叫做主成分分析或主分量分析。 主成分分析所要做的就是设法将原来众多具有一定相关性的变量,重新组合为一组新的相互无关的综合变量来代替原来变量。通常,数学上的处理方法就是将原来的变量做线性组合,作为新的综合变量,但是这种组合如果不加以限制,则可以有很多,应该如何选择呢?如果将选取的第一个线性组合即第一个综合变量记为1F ,自然希望它尽可能多地反映原来变量的信息,这里“信息”用方差来测量,即希望)(1F Var 越大,表示1F 包含的信息越多。因此在所有的线性组合中所选取的1F 应该是方差最大的,故称1F 为第一主成分。如果第一主成分不足以代表原来p 个变量的信息,再考虑选取2F 即第二个线性组合,为了有效地反映原来信息,1F 已有的信息就不需要再出现在2F 中,用数学语言表达就是要求0),(21=F F Cov ,称2F 为第二主成分,依此类推可以构造出第三、四……第p 个主成分。 (二)主成分分析的数学模型 对于一个样本资料,观测p 个变量p x x x ,,21,n 个样品的数据资料阵为: ??????? ??=np n n p p x x x x x x x x x X 21 222 21112 11()p x x x ,,21= 其中:p j x x x x nj j j j ,2,1,21=?????? ? ??= 主成分分析就是将p 个观测变量综合成为p 个新的变量(综合变量),即 ???????+++=+++=+++=p pp p p p p p p p x a x a x a F x a x a x a F x a x a x a F 22112222121212121111 简写为: p jp j j j x x x F ααα+++= 2211 p j ,,2,1 = 要求模型满足以下条件: 怎样用SPSS进行主成分分析 怎样用SPSS进行主成分分析 一、基本概念与原理 主成分分析(principal component analysis) 将多个变量通过线性变换以选出较少个数重要变量的一种多元统计分析方法。又称主分量分析。在实际课题中,为了全面分析问题,往往提出很多与此有关的变量(或因素),因为每个变量都在不同程度上反映这个课题的某些信息。但是,在用统计分析方法研究这个多变量的课题时,变量个数太多就会增加课题的复杂性。人们自然希望变量个数较少而得到的信息较多。在很多情形,变量之间是有一定的相关关系的,当两个变量之间有一定相关关系时,可以解释为这两个变量反映此课题的信息有一定的重叠。主成分分析是对于原先提出的所有变量,建立尽可能少的新变量,使得这些新变量是两两不相关的,而且这些新变量在反映课题的信息方面尽可能保持原有的信息。主成分分析首先是由K.皮尔森对非随机变量引入的,尔后H.霍特林将此方法推广到随机向量的情形。信息的大小通常用离差平方和或方差来衡量。 (1)主成分分析的原理及基本思想。 原理:设法将原来变量重新组合成一组新的互相无关的几个综合变量,同时根据实际需要从中可以取出几个较少的总和变量尽可能多地反映原来变量的信息的统计方法叫做主成分分析或称主分量分析,也是数学上处理降维的一种方法。 基本思想:主成分分析是设法将原来众多具有一定相关性(比如P个指标),重新组合成一组新的互相无关的综合指标来代替原来的指标。通常数学上的处理就是将原来P个指标作线性组合,作为新的综合指标。最经典的做法就是用F1(选取的第一个线性组合,即第一个综合指标)的方差来表达,即Var(F1)越大,表示F1包含的信息越多。因此在所有的线性组合中选取的F1应该是方差最大的,故称F1为第一主成分。如果第一主成分不足以代表原来P个指标的信息,再考虑选取F2即选第二个线性组合,为了有效地反映原来 主成分分析 在统计学中,主成分分析(principal components analysis, PCA)是一种简化数据集的技术。它是一个线性变换。这个变换把数据变换到一个新的坐标系统中,使得任何数据投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推。主成分分析经常用减少数据集的维数,同时保持数据集的对方差贡献最大的特征。这是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。 在实证问题研究中,为了全面、系统地分析问题,我们必须考虑众多影响因素。这些涉及的因素一般称为指标,在多元统计分析中也称为变量。因为每个变量都在不同程度上反映了所研究问题的某些信息,并且指标之间彼此有一定的相关性,因而所得的统计数据反映的信息在一定程度上有重叠。在用统计方法研究多变量问题时,变量太多会增加计算量和增加分析问题的复杂性,人们希望在进行定量分析的过程中,涉及的变量较少,得到的信息量较多。主成分分析正是适应这一要求产生的,是解决这类题的理想工具 主成分分析法是一种降维的统计方法,它借助于一个正交变换,将其分量相关的原随机向量转化成其分量不相关的新随机向量,这在代数上表现为将原随机向量的协方差阵变换成对角形阵,在几何上表现为将原坐标系变换成新的正交坐标系,使之指向样本点散布最开的p 个正交方向,然后对多维变量系统进行降维处理,使之能以一个较高的精度转换成低维变量系统,再通过构造适当的价值函数,进一步把低维系统转化成一维系统。 主成分分析的主要作用体现在五个方面,第一,主成分分析能降低所研究的数据空间的维数。第二,可通过因子负荷的结论,弄清X变量间的某些关系。第三,可用于多为数据的一种图形表现方法。第四,可由主成分分析构造回归模型,即把各个主成分作为新自变量代替原来自变量做回归分析。第五,用主成分分析筛选回归变量。主成分分析原理及详解
主成分分析法精华讲义及实例
主成分分析-实例
主成分分析法的原理应用及计算步骤..
主成分分析PCA(含有详细推导过程以及案例分析matlab版)
主成分分析的计算步骤
SPSS软件进行主成分分析的应用例子
主成分分析计算方法和步骤
主成分分析法matlab实现,实例演示
主成分分析法实例
主成分分析原理
spss进行主成分分析的步骤图文)
主成分分析法的步骤和原理
主成分分析操作步骤
主成分分析原理
用SPSS进行详细的主成分分析步骤
浅析主成分分析法及案例分析