参数估计和模型定阶 2
1、利用之前仿真的数据对MA(1)模型进行参数估计,其中的theta1=0.5。
H0:theta1=0;H1:theta^=0.
利用spss得:
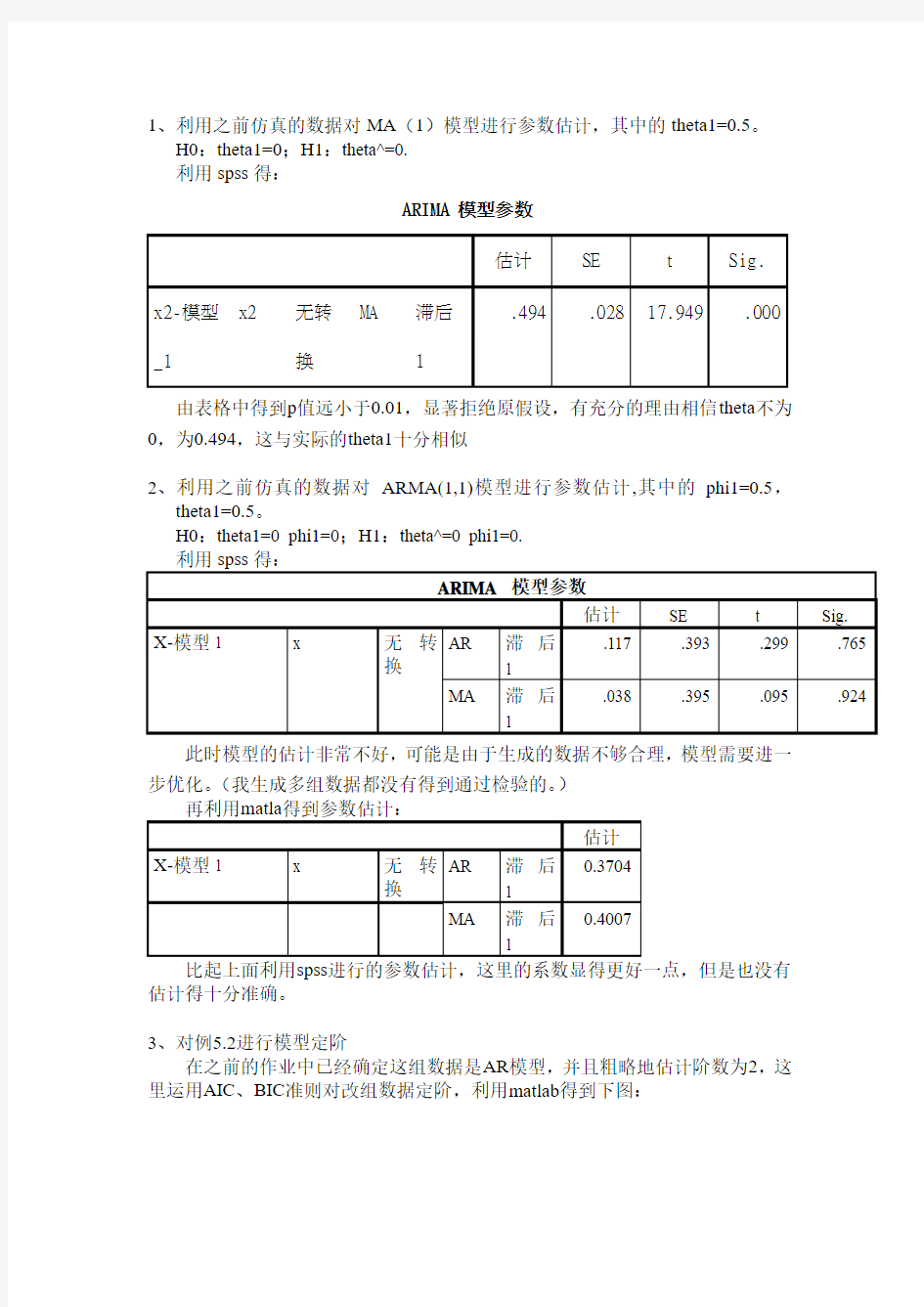
ARIMA 模型参数
估计SE t Sig.
x2-模型_1 x2 无转
换
MA 滞后
1
.494 .028 17.949 .000
由表格中得到p值远小于0.01,显著拒绝原假设,有充分的理由相信theta不为
0,为0.494,这与实际的theta1十分相似
2、利用之前仿真的数据对ARMA(1,1)模型进行参数估计,其中的phi1=0.5,
theta1=0.5。
H0:theta1=0 phi1=0;H1:theta^=0 phi1=0.
利用spss得:
ARIMA 模型参数
估计SE t Sig.
X-模型1 x 无转
换AR 滞后
1
.117 .393 .299 .765
MA 滞后
1
.038 .395 .095 .924
此时模型的估计非常不好,可能是由于生成的数据不够合理,模型需要进一步优化。(我生成多组数据都没有得到通过检验的。)
再利用matla得到参数估计:
估计
X-模型1 x 无转
换AR 滞后
1
0.3704
MA 滞后
1
0.4007
比起上面利用spss进行的参数估计,这里的系数显得更好一点,但是也没有估计得十分准确。
3、对例5.2进行模型定阶
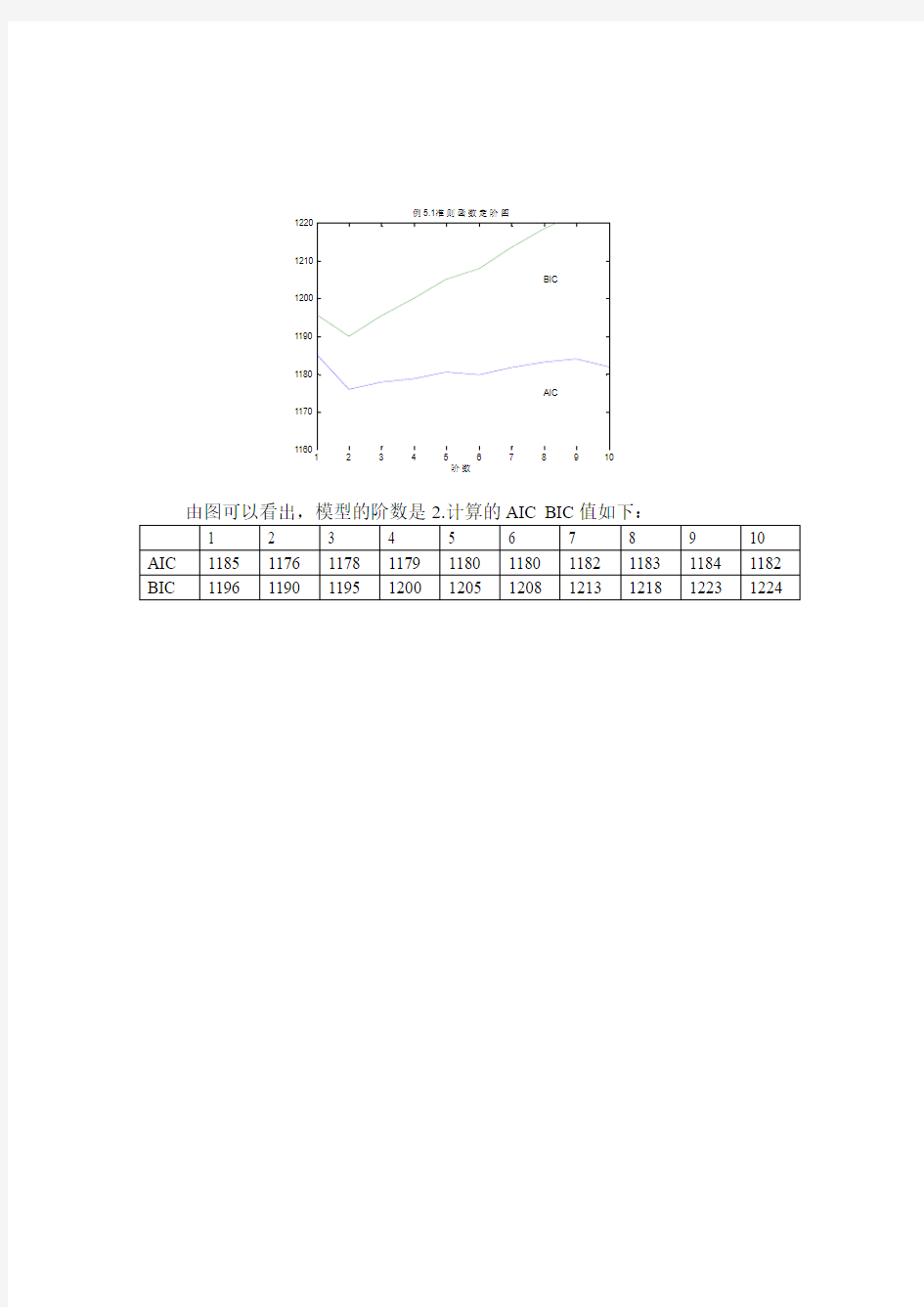
在之前的作业中已经确定这组数据是AR模型,并且粗略地估计阶数为2,这里运用AIC、BIC准则对改组数据定阶,利用matlab得到下图:
12345678910116011701180
11901200
12101220例5.1准则函数定阶图
阶数
准则函数值AIC BIC
由图可以看出,模型的阶数是2.计算的AIC BIC 值如下:
1 2 3 4 5 6 7 8 9 10 AIC 1185 1176 1178 1179 1180 1180 1182 1183 1184 1182 BIC 1196 1190 1195 1200 1205 1208 1213 1218 1223 1224
时间序列分析与综合--ARMA模型的阻尼最小二乘法
论文题目:ARMA模型的阻尼最小二乘法班级: 姓名: 学号: 指导教师:
摘要 ARMA模型是将实际问题利用时间序列建立起的模型,只要把ARMA模型的参数估计出来,实际问题就能解决了。本文只对讨论了ARMA模型参数的优化理论估计方法的一种:阻尼最小二乘法。非线性时间序列ARMA模型参数的优化估计法一阻尼最小二乘法,它结合了Newton法和最速下降法的优点,既保证了迭代计算的收敛性,又加快了收敛的速度。当初值的精度较差时,更宜采用阻尼最小二乘法。本文给出实例的MATLAB程序,并利用t统计量检验出阻尼最小二乘法要比最小二乘法的参数估计值更为显著,拟合模型更优。 关键词:非线性;阻尼最小二乘法;ARMA;MATLAB Abstract ARMA model is to establish a real problem using time series models, As long as the ARMA model parameters estimated from the actual problem can be solved. Nonlinear time series ARMA model parameter optimization estimation method—Damped least squares method, It combines the advantage of Newton method and the steepest descent method, It not only ensures the convergence of iterative calculations, but also accelerate the speed of convergence. When the accuracy of the original value is poor, it better to using qualified damped least squares method. This paper gives examples of the MATLAB program,And use the t-statistic tests the damped least squares method more significant than the method of least squares parameter estimates, and better fitting model. Keywords: Nonlinear; Damped least squares method; ARMA; MATLAB
非参数回归模型资料
非参数回归模型
精品资料 仅供学习与交流,如有侵权请联系网站删除 谢谢2 非参数回归模型 非参数回归模型也叫多元回归模型,它是一种脱离于混沌理论的多条路段分析方法。它是对当前路段和几条相邻路段的交通流信息对当前路段进行交通流预测的单条路段分析的扩展。它不需要先验知识,只需要有足够的历史数据即可。它的原理是:在历史数据库中寻找与当前点相似的近邻,并根据这些近邻来预测下一时间段的流量。该算法认为系统所有的因素之间的内在联系都蕴含在历史数据中,因此直接从历史数据中得到信息而不是为历史数据建立一个近似模型。非参数回归最为一种无参数、可移植、预测精度高的算法,它的误差比较小,且误差分布情况良好。尤其通过对搜索算法和参数调整规则的改进,使其可以真正达到实时交通流预测的要求。并且这种方法便于操作实施,能够应用于复杂环境,可在不同的路段上方便地进行预测。能够满足路网上不同路段的预测,避免路段位置和环境对预测的影响。随着数据挖掘技术左键得到人们的认可和国内外学者的大量相关研究,使得非参数回归技术在短时交通流预测领域得到广泛应用。 非参数回归的回归函数()X g Y =的估计值()X g n 一般表示为: ()()∑==n i i i i n Y X W X g 1 其中,Y 为以为广策随机变量;X 为m 维随机变量;(Xi,Yi )为第i 次观测值,i=1,...,n ;Wi(Xi)为权函数.非参数回归就是对g(X)的形状不加任何限制,即对g (X )一无所知的情况下,利用观测值(Xi,Yi ),对指定的X 值去估计Y 值。由于其不需要对系统建立精确的数学模型,因此比较适合对事变的、非线性的系统进行预测,符合对城市交通流的预测,同时可以与历史平均模型实现优缺点的互补。 K 近邻法 Friedman 于1977年提出了K 近邻法。其并不是让所有的数据都参与预 测,而是以数据点到X 点的距离为基础,甲醛是只有离X 最近的K 个数据被用来估计相应的g(X)值。可以引入欧式空间距离d ,然后按这个距离将X1,X2,...,Xn 与X 接近的程度重新排序:Xk1,...,Xkn,取权值如下: Wki(X:X1,...,Xn)=ki,i=1,..,n 将与X 最近的前K 个观测值占有最大的权K=1,其余的观测值赋予权值k=0.最终得到应用于短时交通流预测的K 近邻法可表示为:
用R语言做非参数和半参数回归笔记学习资料
用R语言做非参数和半参数回归笔记
由詹鹏整理,仅供交流和学习 根据南京财经大学统计系孙瑞博副教授的课件修改,在此感谢孙老师的辛勤付出! 教材为:Luke Keele: Semiparametric Regression for the Social Sciences. John Wiley & Sons, Ltd. 2008. ------------------------------------------------------------------------- 第一章 introduction: Global versus Local Statistic 一、主要参考书目及说明 1、Hardle(1994). Applied Nonparametic Regresstion. 较早的经典书 2、Hardle etc (2004). Nonparametric and semiparametric models: an introduction. Springer. 结构清晰 3、Li and Racine(2007). Nonparametric econometrics: Theory and Practice. Princeton. 较全面和深入的介绍,偏难 4、Pagan and Ullah (1999). Nonparametric Econometrics. 经典 5、Yatchew(2003). Semiparametric Regression for the Applied Econometrician. 例子不错 6、高铁梅(2009). 计量经济分析方法与建模:EVIEWS应用及实例(第二版). 清华大学出版社. (P127/143) 7、李雪松(2008). 高级计量经济学. 中国社会科学出版社. (P45 ch3) 8、陈强(2010). 高级计量经济学及Stata应用. 高教出版社. (ch23/24) 【其他参看原ppt第一章】 二、内容简介 方法: ——移动平均(moving average) ——核光滑(Kernel smoothing) ——K近邻光滑(K-NN) ——局部多项式回归(Local Polynormal) ——Loesss and Lowess ——样条光滑(Smoothing Spline) ——B-spline ——Friedman Supersmoother 模型: ——非参数密度估计 ——非参数回归模型 ——非参数回归模型 ——时间序列的半参数模型 ——Panel data 的半参数模型 ——Quantile Regression 三、不同的模型形式 1、线性模型linear models 2、Nonlinear in variables
非线性回归分析
SPSS—非线性回归(模型表达式)案例解析 2011-11-16 10:56 由简单到复杂,人生有下坡就必有上坡,有低潮就必有高潮的迭起,随着SPSS 的深入学习,已经逐渐开始走向复杂,今天跟大家交流一下,SPSS非线性回归,希望大家能够指点一二! 非线性回归过程是用来建立因变量与一组自变量之间的非线性关系,它不像线性模型那样有众多的假设条件,可以在自变量和因变量之间建立任何形式的模型非线性,能够通过变量转换成为线性模型——称之为本质线性模型,转换后的模型,用线性回归的方式处理转换后的模型,有的非线性模型并不能够通过变量转换为线性模型,我们称之为:本质非线性模型 还是以“销售量”和“广告费用”这个样本为例,进行研究,前面已经研究得出:“二次曲线模型”比“线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的趋势变化”,那么“二次曲线”会不会是最佳模型呢? 答案是否定的,因为“非线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的变化趋势” 下面我们开始研究: 第一步:非线性模型那么多,我们应该选择“哪一个模型呢?” 1:绘制图形,根据图形的变化趋势结合自己的经验判断,选择合适的模型 点击“图形”—图表构建程序—进入如下所示界面:
点击确定按钮,得到如下结果:
放眼望去, 图形的变化趋势,其实是一条曲线,这条曲线更倾向于"S" 型曲线,我们来验证一下,看“二次曲线”和“S曲线”相比,两者哪一个的拟合度更高! 点击“分析—回归—曲线估计——进入如下界面
在“模型”选项中,勾选”二次项“和”S" 两个模型,点击确定,得到如下结果: 通过“二次”和“S “ 两个模型的对比,可以看出S 模型的拟合度明显高于
非线性模型参数估计的遗传算法
滨江学院 毕业论文(设计)题目非线性模型参数估计的遗传算法 院系大气与遥感系 专业测绘工程 学生姓名李兴宇 学号200923500** 指导教师王永弟 职称讲师 二O一三年五月二十日
- 目录- 摘要 (3) 关键词 (3) 1.引言 (3) 1.1 课题背景 (3) 1.2 国内外研究现状 (4) 1.3 研究的目的和意义 (4) 1.4 论文结构 (5) 2.遗传算法简介 (5) 2.1 遗传算法的起源 (5) 2.2 遗传算法的基本思想 (6) 2.2.1 遗传算法求最优解的一般步骤 (7) 2.2.2 用技术路线流程图形式表示遗传算法流程 (7) 2.3 遗传算法的基本原理及设计 (8) 2.3.1 适应度设计 (8) 2.3.2 遗传算子操作 (9) 3.遗传算法的应用实例 (9) 3.1 非线性模型参数估计 (10) 3.2 实例分析 (10) 4.结语 (12) 参考文献 (12) 英文题目 (14) - 1 -
- 2 - 致谢 (15)
非线性模型参数估计的遗传算法 李兴宇 南京信息工程大学滨江学院测绘工程专业,南京 210044 摘要:关于非线性模型计算中的参数估计是十分棘手的问题,为此常常将这样的问题转化成非线性优化问题解决,遗传算法作为一种具有强适应性的全局搜索方法而被频繁的应用于非线性系统参数估计的计算当中,本文介绍了遗传算法及其理论基础,阐述了遗传算法在非线性模型参数估计中的应用的起源和发展,引入实例说明了遗传算法在非线性模型参数估计的实际运用中的实现,并概述了基于遗传算法的非线性参数模型估计具体解算过程,将使用遗传算法得到的结果与其他算法的解算结果进行比较,结果表明:遗传算法是一种行之有效的搜索算法,能有效得到全局最优解,在今后的研究中值得推广。 关键词:遗传算法非线性模型参数估计应用 1.引言 1.1课题背景 当前科学技术的发展和研究已经进入了进入各个领域、多个学科互相交叉、互相渗透和互相影响的时代,生命科学的研究与工程科学的交叉、渗透和相互补充提高便是其中一个非常典型的例子,同时也表现出了近代科学技术发展的一个新的显著特点。遗传算法研究工作的蓬勃发展以及在各个领域的广泛应用正是体现了科学发展过程的的这一明显的特点和良好的趋势。 非线性科学是一门研究复杂现象的科学,涉及到社会科学、自然科学和工程技术等诸多领域,在测绘学的研究中,尤其是在测量平差模型的研究和计算过程中,大量引入的都是非线性函数方程模型,而对于非线性模型的解算,往往过程复杂。遗传算法的出现为研究工作提供了一种求解多模型、多目标、非线性等复杂系统的优化问题的通用方法和框架。 对于非线性系统的解算,传统上常用的方法是利用其中参数的近似值将非线性系统线性化,也就是线性近似,测绘学中通常称之为线性化,经过线性化之后,将其视为线性模型并利用线性模型的解算方法得到结果,这就很大程度的简化了解算步骤,减少了工作量,但同时会带来新的问题,运用这种传统方法得到的数据结果存在的误差较大、精度不足等问题。利用线性近似方法对非线性模型进行参数估计,精度往往取决于模型的非线性强度。 - 3 -
非参数回归模型
非参数回归模型 非参数回归模型也叫多元回归模型,它是一种脱离于混沌理论的多条路段分析方法。它是对当前路段和几条相邻路段的交通流信息对当前路段进行交通流预测的单条路段分析的扩展。它不需要先验知识,只需要有足够的历史数据即可。它的原理是:在历史数据库中寻找与当前点相似的近邻,并根据这些近邻来预测下一时间段的流量。该算法认为系统所有的因素之间的内在联系都蕴含在历史数据中,因此直接从历史数据中得到信息而不是为历史数据建立一个近似模型。非参数回归最为一种无参数、可移植、预测精度高的算法,它的误差比较小,且误差分布情况良好。尤其通过对搜索算法和参数调整规则的改进,使其可以真正达到实时交通流预测的要求。并且这种方法便于操作实施,能够应用于复杂环境,可在不同的路段上方便地进行预测。能够满足路网上不同路段的预测,避免路段位置和环境对预测的影响。随着数据挖掘技术左键得到人们的认可和国内外学者的大量相关研究,使得非参数回归技术在短时交通流预测领域得到广泛应用。 非参数回归的回归函数()X g Y =的估计值()X g n 一般表示为: ()()∑==n i i i i n Y X W X g 1 其中,Y 为以为广策随机变量;X 为m 维随机变量;(Xi,Yi )为第i 次观测值,i=1,...,n ;Wi(Xi)为权函数.非参数回归就是对g(X)的形状不加任何限制,即对g (X )一无所知的情况下,利用观测值(Xi,Yi ),对指定的X 值去估计Y 值。由于其不需要对系统建立精确的数学模型,因此比较适合对事变的、非线性的系统进行预测,符合对城市交通流的预测,同时可以与历史平均模型实现优缺点的互补。 K 近邻法 Friedman 于1977年提出了K 近邻法。其并不是让所有的数据都参与预测,而是以数据点到X 点的距离为基础,甲醛是只有离X 最近的K 个数据被用来估计相应的g(X)值。可以引入欧式空间距离d ,然后按这个距离将X1,X2,...,Xn 与X 接近的程度重新排序:Xk1,...,Xkn,取权值如下: Wki(X:X1,...,Xn)=ki,i=1,..,n 将与X 最近的前K 个观测值占有最大的权K=1,其余的观测值赋予权值k=0.最终得到应用于短时交通流预测的K 近邻法可表示为: ()()()()K t V t V g t V K i i ∑=+==+111
非参数回归模型与半参数回归模型
第七章 非参数回归模型与半参数回归模型 第一节 非参数回归与权函数法 一、非参数回归概念 前面介绍的回归模型,无论是线性回归还是非线性回归,其回归函数形式都是已知的,只是其中参数待定,所以可称为参数回归。参数回归的最大优点是回归结果可以外延,但其缺点也不可忽视,就是回归形式一旦固定,就比较呆板,往往拟合效果较差。另一类回归,非参数回归,则与参数回归正好相反。它的回归函数形式是不确定的,其结果外延困难,但拟合效果却比较好。 设Y 是一维观测随机向量,X 是m 维随机自变量。在第四章我们曾引进过条件期望作回归函数,即称 g (X ) = E (Y |X ) (7.1.1) 为Y 对X 的回归函数。我们证明了这样的回归函数可使误差平方和最小,即 22)]([min )]|([X L Y E X Y E Y E L -=- (7.1.2) 这里L 是关于X 的一切函数类。当然,如果限定L 是线性函数类,那么g (X )就是线性回归函数了。 细心的读者会在这里立即提出一个问题。既然对拟合函数类L (X )没有任何限制,那么可以使误差平方和等于0。实际上,你只要作一条折线(曲面)通过所有观测点(Y i ,X i )就可以了是的,对拟合函数类不作任何限制是完全没有意义的。正象世界上没有绝对的自由一样,我们实际上从来就没有说放弃对L(X)的一切限制。在下面要研究的具体非参数回归方法,不管是核函数法,最近邻法,样条法,小波法,实际都有参数选择问题(比如窗宽选择,平滑参数选择)。 所以我们知道,参数回归与非参数回归的区分是相对的。用一个多项式去拟合(Y i ,X i ),属于参数回归;用多个低次多项式去分段拟合(Y i ,X i ),叫样条回归,属于非参数回归。 二、权函数方法 非参数回归的基本方法有核函数法,最近邻函数法,样条函数法,小波函数法。这些方法尽管起源不一样,数学形式相距甚远,但都可以视为关于Y i 的线性组合的某种权函数。也就是说,回归函数g (X )的估计g n (X )总可以表为下述形式: ∑==n i i i n Y X W X g 1 )()( (7.1.3)
非线性模型参数估计的EViews操作
非线性模型参数估计的EViews 操作 例3.5.2 建立中国城镇居民食品消费需求函数模型。根据需求理论,居民对食品的消费需求函数大致为: ()01,,f P P X Q =。 其中,Q 为居民对食品的需求量,X 为消费者的消费支出总额,P1为食品价格指数,P0为居民消费价格总指数。 表3.5.1 中国城镇居民消费支出及价格指数 单位:元 资料来源:《中国统计年鉴》(1990~2007) 估计双对数线性回归模型μββββ++++=031210n n n P L LnP X L Q L 对应的非线性模型: 3 21 1ββ βP P AX Q = 这里需要将等式右边的A 改写为0 e β。取0β,1β,2β,3β的初值均为1。
Eviews操作: 1、打开EViews,建立新的工作文档:File-New-Workfile,在Frequency选择Annual,在Start date输入“1985”,End date输入“2006”,确认OK。 2、输入样本数据:Object-New Object-Group,确认OK,输入样本数据。 图1 3、设置参数初始值:在命令窗口输入“param c(1) 1 c(2) 1 c(3) 1 c(4) 1”,回车确认。 4、非线性最小二乘法估计(NLS):Proc-Make Equation,在NLS估计的方程中写入Q=EXP(C(1))*X^C(2)*P1^C(3)*P0^C(4),方程必须写完整,不能写成Q C(1) X P1 P0。确定输出估计结果:
图2 NLS注意事项: 1).参数初始值: 如果参数估计值出现分母为0等情况将导致错误,解决办法是:手工设定参数的初始值及范围,比如生产函数中的c(2)肯定是介于0-1之间的数字。 eviews6.0中并没有start 的选项,只有iteration的次数和累进值得选择。只能通过param c(1) 0.5 c(2) 0.5来设置。 2).迭代及收敛 eviews用Gauss Seidel迭代法求参数的估计值。迭代停止的法则:基于回归函数或参数在每次迭代后的变化率,当待估参数的变化百分比的最大值小于事先给定的水平时,就会停止迭代。当迭代次数到了迭代的最大次数时也会停止,或者迭代过程中发生错误也会停止。
非线性模型参数估计方法步骤
EViews非线性模型参数估计方法步骤 1.新建EViews工作区,并将时间序列X、P1和P0导入到工作区; 2.设定参数的初始值全部为1,其方法是在工作区中其输入下列命令 并按回车键 param c(1) 1 c(2) 1 c(3) 1 c(4) 1 3.估计非线性模型参数,其方法是在工作区中其输入下列命令并按 回车键 nls q=exp(c(1))*x^c(2)*p1^c(3)*p0^c(4) 4.得到结果见table01(91页表3. 5.4结果)(案例一结束) Dependent Variable: Q Method: Least Squares Date: 03/29/15 Time: 21:44 Sample: 1985 2006 Included observations: 22 Convergence achieved after 9 iterations Q=EXP(C(1))*X^C(2)*P1^C(3)*P0^C(4) Coefficient Std. Error t-Statistic Prob. C(1) 5.567708 0.083537 66.64931 0.0000 C(2) 0.555715 0.029067 19.11874 0.0000 C(3) -0.190154 0.143823 -1.322146 0.2027 C(4) -0.394861 0.159291 -2.478866 0.0233 R-squared 0.983631 Mean dependent var 1830.000 Adjusted R-squared 0.980903 S.D. dependent var 365.1392 S.E. of regression 50.45954 Akaike info criterion 10.84319 Sum squared resid 45830.98 Schwarz criterion 11.04156 Log likelihood -115.2751 Hannan-Quinn criter. 10.88992 Durbin-Watson stat 0.672163 (92页表3.5.5结果)(案例二过程) 5.新建EViews工作区,并将时间序列X、P1和P0导入到工作区;
用R语言做非参数和半参数回归笔记
由詹鹏整理,仅供交流和学习 根据南京财经大学统计系孙瑞博副教授的课件修改,在此感谢孙老师的辛勤付出! 教材为:Luke Keele:Semiparametric Regression for the Social Sciences.John Wiley &Sons,Ltd.2008. ------------------------------------------------------------------------- 第一章introduction:Global versus Local Statistic 一、主要参考书目及说明 1、Hardle(1994).Applied Nonparametic Regresstion.较早的经典书 2、Hardle etc(2004).Nonparametric and semiparametric models:an introduction. Springer.结构清晰 3、Li and Racine(2007).Nonparametric econometrics:Theory and Practice.Princeton.较全面和深入的介绍,偏难 4、Pagan and Ullah(1999).Nonparametric Econometrics.经典 5、Yatchew(2003).Semiparametric Regression for the Applied Econometrician.例子不错 6、高铁梅(2009).计量经济分析方法与建模:EVIEWS应用及实例(第二版).清华大学出版社.(P127/143) 7、李雪松(2008).高级计量经济学.中国社会科学出版社.(P45ch3) 8、陈强(2010).高级计量经济学及Stata应用.高教出版社.(ch23/24) 【其他参看原ppt第一章】 二、内容简介 方法: ——移动平均(moving average) ——核光滑(Kernel smoothing) ——K近邻光滑(K-NN) ——局部多项式回归(Local Polynormal) ——Loesss and Lowess ——样条光滑(Smoothing Spline) ——B-spline ——Friedman Supersmoother 模型: ——非参数密度估计 ——非参数回归模型 ——非参数回归模型 ——时间序列的半参数模型 ——Panel data的半参数模型 ——Quantile Regression 三、不同的模型形式 1、线性模型linear models 2、Nonlinear in variables
ARMA模型的参数估计主要内容(精)
第六章 ARMA 模型的参数估计—主要内容 §6.1 AR(p)模型的参数估计 问题: 已知p 的AR(p): 1 ,0p t j t j t j X a X t ε-==+≥∑,2~WN(0,)t εσ.(1.1) 由12{,,,}N x x x 去估计12(,,,)T p a a a =a 和2σ. 1. AR(p)模型的Yule-Walker 估计 自回归系数p a 由自协方差函数{}k γ惟一确定.
1111210 2212 0p p p p p p a a a γγγγγγγγγγγγ----?????? ?????? ??=??????????????? ??????? 白噪声的方差2σ由2 0T p p σγ=-γa 决定. 现获12{,, ,}N x x x , N p >, 则作 (1) ,1~t t N y x x t N =-=; (2) 1 1 ?,0,1, ,N k k j j k j y y k p N γ-+== =∑;
(3) 只要12,, ,N x x x 不全同, 则?p Γ正定, 得惟一 1???p p p -=a Γγ, 2100????????T T p p p p p σγγ-=-=-γa γΓγ. 实用中, Levinson 递推公式(无需求逆, 快): (1)2 001,1 10222 1,1,11,2 1,1,101,12,2,1,,1,1,1????????(1)???????...????????...????,1,k k k k k k k k k k k k k k k k k k k j k j k k k k j a a a a a a a a a a a a a j k k p σγγγσ σγγγγγγγγ-+-++++++-?=?=??=-??----?=?----? =-≤≤≤??
非线性系统模型参数估计的算法模型
非线性系统模型参数估计的算法模型 摘要:针对非线性系统模型的多样性,提出了适用于多种非 线性模型的基于粒子群优化算法的参数估计方法。计算结果表明,粒子群优化算法是非线性系统模型参数估计的有效工具。 关键词:粒子群优化算法;非线性系统;参数估计;优化abstract: aiming at the diversity of nonlinear system model, it is proposed in this article a parameter estimation method based on particle group optimization algorithm that is applicable to a variety of nonlinear models. the result shows that the particle group optimization algorithm for parameter estimation of nonlinear system model is an effective tool. key words: particle group optimization algorithm;nonlinear system; parameter estimation; optimization 0 引言 非线性系统广泛地存在于人们的生产生活中,但是,目前我们对非线性系统的认识还不够深入,不能像线性系统那样,把所涉及的模型全部规范化,从而使辩识方法也规范化。非线性模型的表达方式相对比较复杂,目前还很少有人研究各种表达方式是否存在等效关系,因此,暂时还没有找到对所有非线性模型都适用的参数模型估计方法[1]。如果能找到一种不依赖于非线性模型的表达方式的 参数估计方法,那么,也就找到了对一般非线性模型系统进行参数
时间序列ARMA模型及分析
ARMA模型及分析 本次试验主要是通过等时间间隔,连续读取70个某次化学反应的过程数据,构成一个时间序列。试对该时间序列进行ARMA模型拟合以及模型的优化,最后进行预测。以下本次试验的数据: 表1 连续读取70个化学反应数据 47 64 23 71 38 64 55 41 59 48 71 35 57 40 58 44 80 55 37 74 51 57 50 60 45 57 50 45 25 59 50 71 56 74 50 58 45 54 36 54 48 55 45 57 50 62 44 64 43 52 38 59 55 41 53 49 34 35 54 45 68 38 50 60 39 59 40 57 54 23 资料来源:O’Donovan, Consec. Readings Batch Chemical Proces, https://www.360docs.net/doc/3b2301917.html,ler et al. 下面的分析及检验、预测均是基于上述数据进行的,本次试验是在Eviews 6.0上完成的。 一、序列预处理 由于只有对平稳的时间序列才能建立ARMA模型,因此在建立模型之前,有必要对序列进行预处理,主要包括了平稳性检验和纯随机检验。 序列时序图显示此化学反应过程无明显趋势或周期,波动稳定。见图1。
图2 化学反应过程相关图和Q统计量 从图2的序列的相关分析结果:1. 可以看出自相关系数始终在0周围波动,判定该序列为平稳时间序列2.看Q统计量的P值:该统计量的原假设为X的1期,2期……k期的自相关系数均等于0,备择假设为自相关系数中至少有一个不等于0,因此如图知,该P值在滞后2、3、4期是都为0,所以拒接原假设,即序列是非纯随机序列,即非白噪声序列(因为序列值之间彼此之间存在关联,所以说过去的行为对将来的发展有一定的影响,因此为非纯随机序列,即非白噪声序列)。 二、模型识别 由于检验出时间序列是平稳的,且是非白噪声序列,因此可以建立模型,在建立模型之前需要识别模型阶数即确定阶数。阶数确定要借助于时间序列的相关图,即序列的自相关函数和偏自相关函数,并根据他们之间的理论模式进行阶数最后的确定。 下面给出自相关函数和偏自相关函数之间的理论模式:
非参数回归模型与半参数回归模型
第七章 非参数回归模型与半参数回归模型 第一节 非参数回归与权函数法 一、非参数回归概念 前面介绍的回归模型,无论是线性回归还是非线性回归,其回归函数形式都是已知的,只是其中参数待定,所以可称为参数回归。参数回归的最大优点是回归结果可以外延,但其缺点也不可忽视,就是回归形式一旦固定,就比较呆板,往往拟合效果较差。另一类回归,非参数回归,则与参数回归正好相反。它的回归函数形式是不确定的,其结果外延困难,但拟合效果却比较好。 设Y 是一维观测随机向量,X 是m 维随机自变量。在第四章我们曾引进过条件期望作回归函数,即称 g (X ) = E (Y |X ) (7.1.1) 为Y 对X 的回归函数。我们证明了这样的回归函数可使误差平方和最小,即 22)]([min )]|([X L Y E X Y E Y E L -=- (7.1.2) 这里L 是关于X 的一切函数类。当然,如果限定L 是线性函数类,那么g (X )就是线性回归函数了。 细心的读者会在这里立即提出一个问题。既然对拟合函数类L (X )没有任何限制,那么可以使误差平方和等于0。实际上,你只要作一条折线(曲面)通过所有观测点(Y i ,X i )就可以了是的,对拟合函数类不作任何限制是完全没有意义的。正象世界上没有绝对的自由一样,我们实际上从来就没有说放弃对L(X)的一切限制。在下面要研究的具体非参数回归方法,不管是核函数法,最近邻法,样条法,小波法,实际都有参数选择问题(比如窗宽选择,平滑参数选择)。 所以我们知道,参数回归与非参数回归的区分是相对的。用一个多项式去拟合(Y i ,X i ),属于参数回归;用多个低次多项式去分段拟合(Y i ,X i ),叫样条回归,属于非参数回归。 二、权函数方法 非参数回归的基本方法有核函数法,最近邻函数法,样条函数法,小波函数法。这些方法尽管起源不一样,数学形式相距甚远,但都可以视为关于Y i 的线性组合的某种权函数。也就是说,回归函数g (X )的估计g n (X )总可以表为下述形式: ∑==n i i i n Y X W X g 1 )()( (7.1.3)
R语言实现ARMA模型的估计
基于R 的ARMA 模型的估计 首先,我们给出一个ARMA 模型:110.60.8t t t t y y εε--=-+- 随机生成一组含200个观测值的时间序列,代码如下: #ARMA(1,1) y[t]=-0.6y[t-1]+x[t]-0.8x[t-1] set.seed(10) x<-rnorm(200) y<-vector(length=2) y[1]=x[1] for(i in 2:200) { y[i]=-0.6*y[i-1]+x[i]-0.8*x[i-1] } y 事实上,在R 中有更简单的语句可以生成ARIMA 时间序列,以上述ARMA (1,1)模型为例: set.seed(10) y<-arima.sim(list(order=c(1,0,1),ar=-0.6,ma=-0.8),n=200) 在本次实验中,我们采用第一种方法生成的时间序列做估计。 时间序列图如下: ts.plot(y) ACF 和PACF 图如下: acf(y,xaxp=c(0,20,20),yaxp=c(-1,1,10)) pacf(y,xaxp=c(0,20,20),yaxp=c(-1,1,10))
下面给出三个模型的估计: 模型1:11t t t y a y ε-=+ 模型2:1111t t t t y a y b εε--=++ 模型3:1122t t t t y a y a y ε--=++ 【模型1】 a<-1;b<-0,c<-0 ARMA<-arima(y,order=c(a,b,c),method="ML") ARMA SBC 准则: #SBC=-2ln(模型中极大似然函数值)+ln(n)(模型中未知参数个数) loglike<-ARMA$loglik SBC<--2*loglike+log(200)*1 SBC 残差平方和: residual<-ARMA$residuals #残差 ssr<-0 for(i in 1:200) { ssr=ssr+(residual[i]^2)
ARMA模型建模与预测指导
实验一ARMA 模型建模与预测指导 一、实验目的 学会通过各种手段检验序列的平稳性;学会根据自相关系数和偏自相关系数来初步判断ARMA 模型的阶数p 和q ,学会利用最小二乘法等方法对ARMA 模型进行估计,学会利用信息准则对估计的ARMA 模型进行诊断,以及掌握利用ARMA 模型进行预测。掌握在实证研究中如何运用Eviews 软件进行ARMA 模型的识别、诊断、估计和预测和相关具体操作。 二、基本概念 宽平稳:序列的统计性质不随时间发生改变,只与时间间隔有关。 AR 模型:AR 模型也称为自回归模型。它的预测方式是通过过去的观测值和现在的干扰值的线性组合预测, 自回归模型的数学公式为: 1122t t t p t p t y y y y φφφε---=++++ 式中: p 为自回归模型的阶数i φ(i=1,2, ,p )为模型的待定系数,t ε为误差, t y 为一个平稳时间序列。 MA 模型:MA 模型也称为滑动平均模型。它的预测方式是通过 过去的干扰值和现在的干扰值的线性组合预测。滑动平均模型的数学公式为: 1122t t t t q t q y εθεθεθε---=---- 式中: q 为模型的阶数; j θ(j=1,2, ,q )为模型的待定系数;t ε为误差; t y 为平稳时间序列。 ARMA 模型:自回归模型和滑动平均模型的组合, 便构成了用于描述平稳随机过程的自回归滑动平均模型ARMA , 数学公式为: 11221122t t t p t p t t t q t q y y y y φφφεθεθεθε------=++ ++---- 三、实验内容及要求 1、实验内容: (1)根据时序图判断序列的平稳性; (2)观察相关图,初步确定移动平均阶数q 和自回归阶数p ; (3)运用经典B-J 方法对某企业201个连续生产数据建立合适的ARMA (,p q )模型,并能够利用此模型进行短期预测。 2、实验要求: (1)深刻理解平稳性的要求以及ARMA 模型的建模思想; (2)如何通过观察自相关,偏自相关系数及其图形,利用最小二乘法,以及信息准则建立合适的ARMA 模型;如何利用ARMA 模型进行预测; (3)熟练掌握相关Eviews 操作,读懂模型参数估计结果。 四、实验指导 1、模型识别 (1)数据录入
用R语言做非参数和半参数回归笔记.docx
由詹鹏整理 ,仅供交流和学习 根据南京财经大学统计系孙瑞博副教授的课件修改 ,在此感谢孙老师的辛勤付出! 教材为:Luke Keele: Semiparametric Regression for the Social Sciences. John Wiley & Sons, Ltd. 2008. ------------------------------------------------------------------------- 第一章 introduction: Global versus Local Statistic 一、主要参考书目及说明 1、Hardle(1994). Applied Nonparametic Regresstion. 较早的经典书 2、Hardle etc (2004). Nonparametric and semiparametric models: an introduction. Springer. 结构清晰 3、Li and Racine(2007). Nonparametric econometrics: Theory and Practice. Princeton. 较全面和深入的介绍 ,偏难 4、Pagan and Ullah (1999). Nonparametric Econometrics. 经典 5、Yatchew(2003). Semiparametric Regression for the Applied Econometrician. 例子不错 6、高铁梅(2009). 计量经济分析方法与建模:EVIEWS应用及实例(第二版). 清华大 学出版社. (P127/143) 7、李雪松(2008). 高级计量经济学. 中国社会科学出版社. (P45 ch3) 8、陈强(2010). 高级计量经济学及Stata应用. 高教出版社. (ch23/24) 【其他参看原ppt第一章】 二、内容简介 方法: ——移动平均(moving average) ——核光滑(Kernel smoothing) ——K近邻光滑(K-NN) ——局部多项式回归(Local Polynormal) ——Loesss and Lowess ——样条光滑(Smoothing Spline) ——B-spline ——Friedman Supersmoother 模型: ——非参数密度估计 ——非参数回归模型 ——非参数回归模型 ——时间序列的半参数模型 ——Panel data 的半参数模型 ——Quantile Regression 三、不同的模型形式 1、线性模型linear models 2、Nonlinear in variables
非参数计量经济学
【内容提要】 内容简介 本书分为四部分.第一部分为密度函数和条件密度函数,包括密度函 数的非参数估计、一元条件密度函数的非参数估计和多元条件密度函数的 投影追踪估计;第二部分为非参数计量经济模型,包括非参数计量经济模 型的核估计和变窗宽核估计、局部线性估计和变窗宽局部线性估计、非参 数计量经济模型的异方差问题和多重共线性问题;第三部分为非参数计 量经济联立方程模型,包括非参数计量经济联立模型的局部线性工具变量 估计和变窗宽局部线性工具变量估计、局部线性两阶段最小二乘估计和变 窗宽局部线性两阶段最小二乘估计、局部线性广义矩估计和变窗宽局部线 性广义矩估计;第四部分为半参数计量经济模型和联立方程模型,包括半 参数计量经济模型的最小二乘估计、半参数计量经济联立模型的工具变量 估计和其他工具变量估计.本书的附录包括准备知识和R软件介绍.本书适合高等院校经济、管理学科的研究生和研究人员使用. 【节选】 序言 非参数计量经济学作为现代计量经济学的一个分支,近20年来得到了迅速的
发展.从国际权威的计量经济学学术刊物的论文中,我们不难发现,关于非参数计量经济学理论方法的研究,一直是理论计量一个重要的和前沿的研究领域.在应用研究方面,将非参数、半参数模型方法与微观计量、宏观计量以及金融计量结合,也成为这些计量经济学分支领域的研究热点.在国外著名大学的经济学研究生课程表中,非参数计量经济学已经成为计量经济学高级课程重要的一部分.在国内,近年来,一批年青学者将该领域作为主要研究方向,在跟踪研究的同时,取得了一些创新成果;不少大学已经将非参数计量经济学纳入研究生高级计量经济学的教学内容,甚至为博士研究生开设了专门的课程. 但是,国内目前关于非参数计量经济学的出版物相当少.2003年7月,南开 大学出版社出版了叶阿忠教授的《非参数计量经济学二》一书,在它的序言中,我写下了如下一段话:“在国内,尚缺少全面系统的、既具有学术水平又具有应用 指导价值的著作奉献给广大读者.在这个意义上,这本《非参数计量经济学》填补了这个空白.”时隔几年,这种状况没有改变.从这个意义上说,叶阿忠教授即将出版的《非参数和半参数计量经济模型理论》专著对于推动国内的计量经济学研究与教学都具有十分重要的价值. 叶阿忠教授近10年来以非参数计量经济学模型理论为自己的主要研究方向, 取得了显著的成绩,完成了国家自然科学基金项目“半参数计量经济联立模型单 方程估计方法的理论研究”、教育部人文社会科学基金项目“非参数计量经济模 型的理论研究”和教育部人文社会科学重点研究基地重大项目“非经典计量经济