V7000存储自我总结硬盘更换流程
V7000 硬盘更换流程
V7000的管理IP地址,连接后,选择登入:
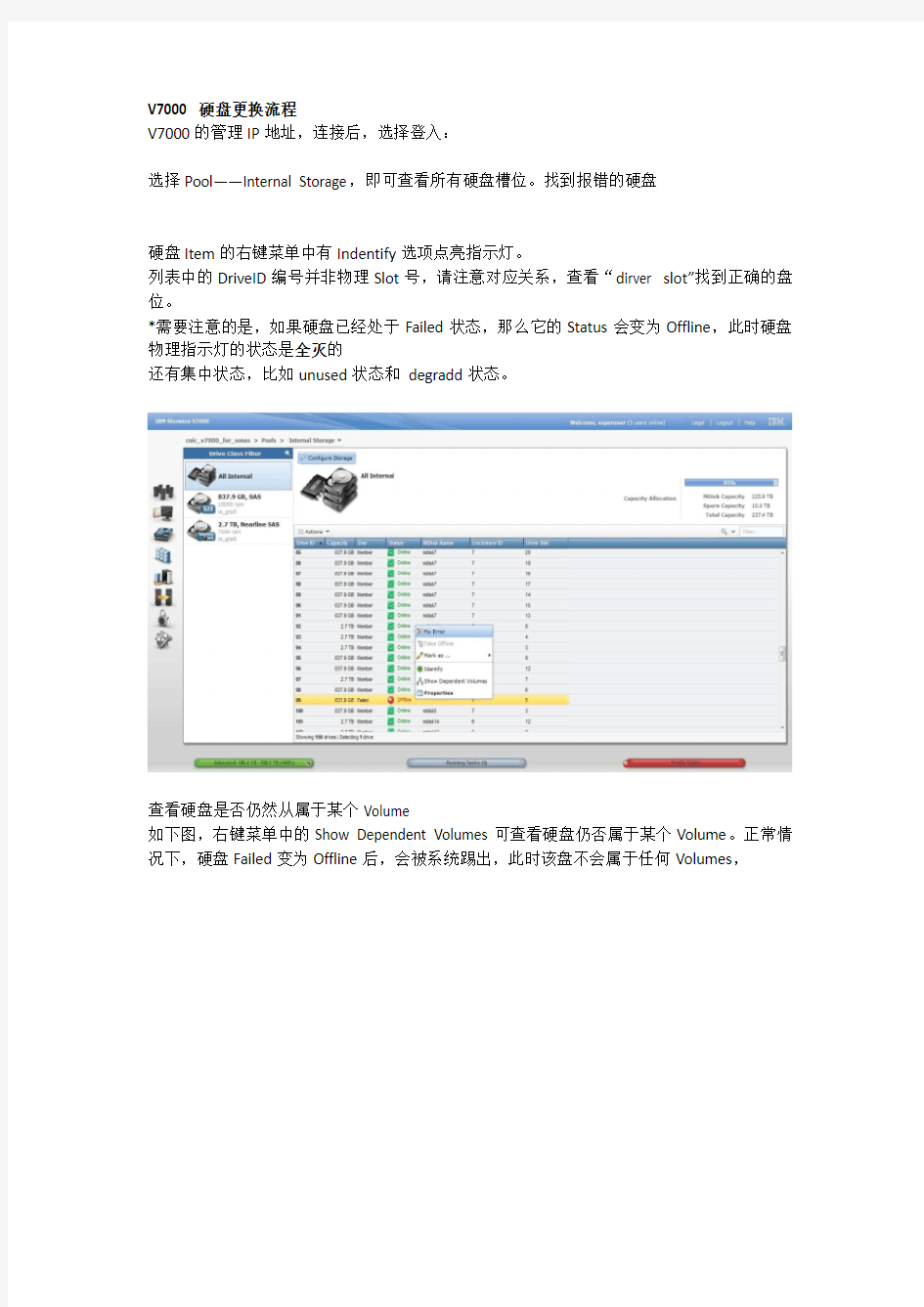
选择Pool——Internal Storage,即可查看所有硬盘槽位。找到报错的硬盘
硬盘Item的右键菜单中有Indentify选项点亮指示灯。
列表中的DriveID编号并非物理Slot号,请注意对应关系,查看“d irver slot”找到正确的盘位。
*需要注意的是,如果硬盘已经处于Failed状态,那么它的Status会变为Offline,此时硬盘物理指示灯的状态是全灭的
还有集中状态,比如unused状态和degradd状态。
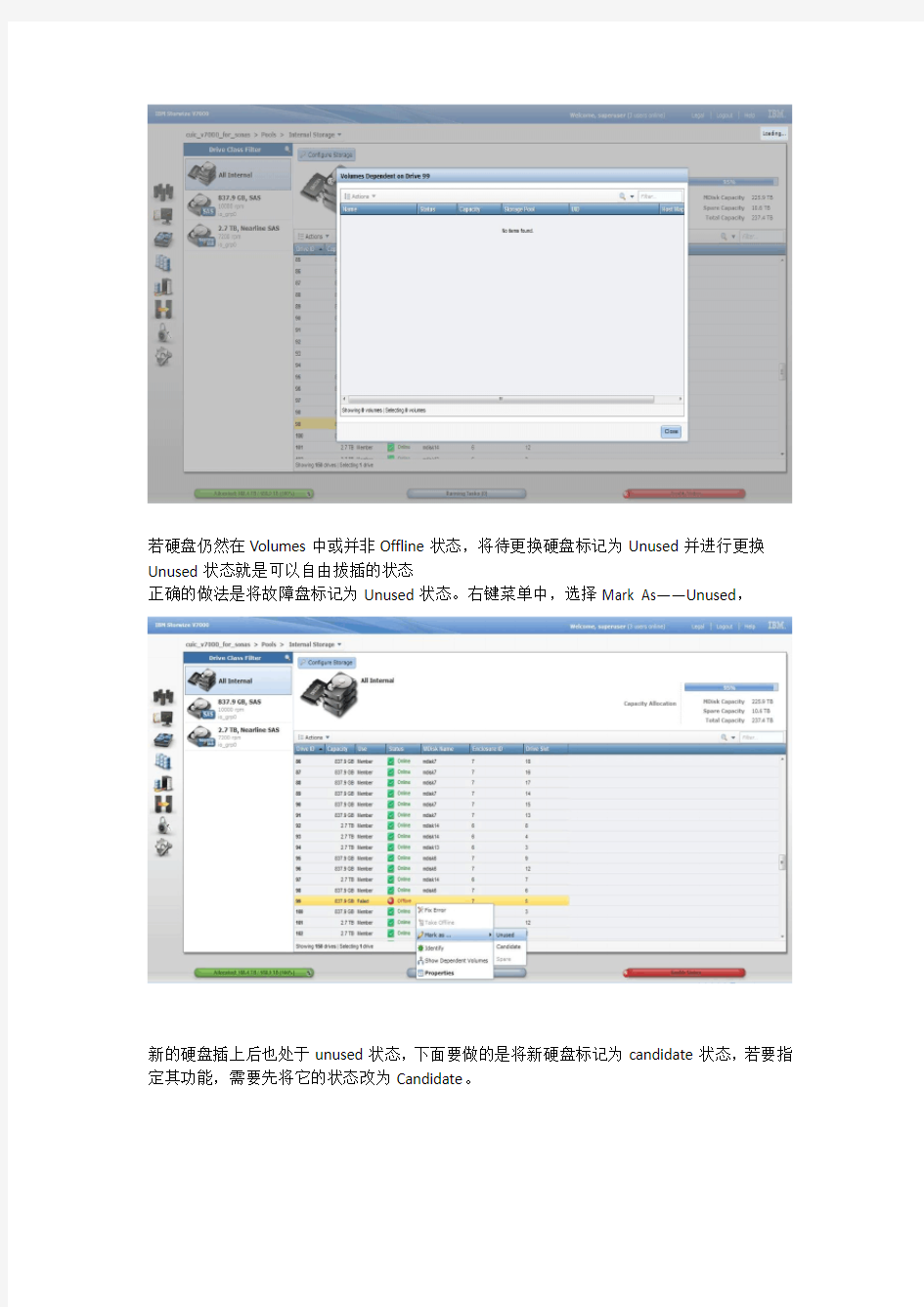
查看硬盘是否仍然从属于某个Volume
如下图,右键菜单中的Show Dependent Volumes可查看硬盘仍否属于某个Volume。正常情况下,硬盘Failed变为Offline后,会被系统踢出,此时该盘不会属于任何Volumes,
更换SSA RAID阵列中硬盘的步骤(官方)
内容提要: 建了RAID的磁盘阵列在使用过程中可能会发生硬盘出现故障需要更换的情况,本文介绍了安全更换硬盘而不破坏数据的详细步骤。 说明: 1. 首先需要从RAID定义中逻辑上删除故障硬盘。执行下面的命令: # smit ssaraid -> Change Member Disks in an SSA RAID Array -> Remove a Disk from an SSA RAID Array 2. 屏幕显示出如下的阵列列表: Change Member Disks in an SSA RAID Array Move cursor to desired item and press Enter. Remove a Disk From an SSA RAID Array Add a Disk to an SSA RAID Array Swap Members of an SSA RAID Array -------------------------------------------------------------------------------------------- SSA RAID Array Move cursor to desired item and press Enter. Use arrow keys to scroll. hdisk6 6010337B163E30K good 2.3GB RAID-5 array hdisk5 09523173A02137K good 2.3GB RAID-5 array F1=Help F2=Refresh F3=Cancel F8=Image F10=Exit Enter=Do /=Find n=Find Next -------------------------------------------------------------------------------------------- 选择要删除的硬盘所在的阵列的名称,在本例中选择hdisk6。 3. 屏幕显示如下的信息: Remove a Disk From an SSA RAID Array Type or select values in entry fields. Press Enter AFTER making all desired changes. [Entry Fields] SSA RAID Manager ssa1 SSA RAID Array hdisk6 Connection Address / Array Name 6010337B163E30K * Disk to Remove +
ai更换硬盘方法
当主机硬盘丢失 #lsvg -lp rootvg 结果 rootvg: PV_NAME PV STATE TOTAL PPs FREE PPs FREE DISTRIBUTION hdisk0 active 542 0 00..00..00..00..00 hdisk1 missing 542 0 00..00..00..00..00 #chpv -va hdisk1 看看能不能找回来 如果找不回来,则必须尽早予以跟换,跟换前必须做好备份! 先查看机器是否有磁带机,若无则 1、外置磁带机连接 #cfgmgr -v #lsdev -Cc tape 看一下 rmt0是不是avaiable 2、内置磁带机则直接备份 #smitty mksysb 3、查看硬盘的S/N,P/N号 #lscfg –vl hdisk* 查看物理卷 lspv 查看逻辑卷组 lsvg 查看在用的逻辑卷组 lsvg –o # lsvg -o
#sysdumpdev –l 4、查看所有硬盘(包括逻辑盘)的状态 # lsdev -Cc disk 查看7133磁盘柜硬盘状态 #lsdev –Cc pdisk 5、把HDISK0从ROOTVG中不做MIRROW #unmirrorvg rootvg hdisk0 (长时间40分钟) 查看物理卷 #lspv 这时HDISK0不在和HDISK1为MIRROR 把hdisk0从rootvg中去除 #reducevg rootvg hdisk0 (长时间0分2钟) 在HDISK1上创建boot image #bosboot –ad hdisk1 改变启动设备的顺序 #bootlist –m normal hdisk1 cd0 删除HDISK0 #rmdev –l hdisk0 –d #lspv #lscfg –vl hdisk0 以上2条命令不会显示HDISK0的相关信息 (如果无法unmirrorvg 和 rmdev 的话,就只能直接关机换盘了。) 6、关机后将对应的硬盘予以跟换,如果是热插拔的则可以热跟换。#shutdown –F 7、开机
年终工作总结流程5篇_个人年度总结范本
年終工作总结流程5篇_个人年度总结范本 a;工作中,我一定发扬吃苦耐劳精神和孜孜不倦的进取精神认真总结经验,克服不足,努力把工作做得更好,以对工作、对事业高度负责的态度,脚踏实地,尽职尽责地做好各项工作,不辜负领导和同志们对我的期望。下面给大家整理了关于年終总结流程表,方便大家学习。 年終总结流程表1 为了进一步提高自己的工作效率及工作能力,特制定以下工作计划: 一、对销售工作的认识: 1、不断学习行业知识、产品知识,为客户带来实用介绍内容,更好为客户服务,显得行业的专业性; 2、先友后单:与客户发展良好友谊,转换销售员角色,处处为客户着想,把客户当成自己朋友,达到思想和情感上的交融; 3、调整心态,进一步提高自己的工作激情与工作自信心;百倍认真努力地对待每一天工作、每一个潜在客户的挖掘; 4、去除任何客户拒绝的恐惧心理,对任何一个营销电话、任何一个潜在客户要自信专业性的进行交流; 二、对销售工作的提高: 1、制定工作日程表; 2、一天一小结、一周一大结、一月一总结;不断查找工作上的不足,及时纠正工作的失误,完善工作的整体效率;
3、不断挖掘潜在客户、展示产品、跟进客户;乐观积极向上自信的工作态度才能拥有很好的工作成果; 4、每天坚持打40个有效电话,挖掘潜在客户、每周至少拜访2位客户,促使潜在客户变成可持续客户: 5、拜访客户之前要对该客户做全面的了解,并准备一些必要的话题或活动去与客户进行更好的交融及相应的专业产品知识的应付方案; 6、对陕西省、山西省、江西省、河南省四大省市、县公路段单位负责人进行逐个电话销售,挖掘潜在客户,跟进并对相关重要客户进行预约拜访; 7、提高自己电话营销技巧,灵活专业地与客户进行电话交流; 8、通过电话销售过程中了解各省、市的设备仪器使用、采购情况及相关重要追踪人; 三、重要客户跟踪: 1、江西萍乡市公路管理局供机科林科长、养护科曾科长; 2、山西、陕西、江西、河南各省市级公路局养护科; 3、浙江省临安市公路局、淳安县公路段、昌化县公路段、建德县公路段的相关负责人; 4、山西省大同市北郊区公路段桥工程乐; 5、河南市政管理处的姚科长; 以上是我一年工作计划,我会严格按计划进行每一项工作。 年終总结流程表2
HDS-存储配置步骤
第1章HDS AMS存储设备总体安装步骤1.1设备到货 设备到货,开箱,进入机房 拆包前,检查包装的外观。 检查任何的损坏和不正常的指示标记。 检查是否有遗失部件。 如有任何异常,需联系相应的部门,并采取相应的措施。 货物清点,签署验货报告 1.2AMS安装和上电自检 机架的物理定位,AMS上架 AMS内部ENC连接 AMS电源连接 AMS的硬件安装 AMS上电自检 1.3安装监控PC 监控PC由客户提供,如果配置公网IP,可以同时作为Hitrack PC 确定AMS 管理端口和监控PC的IP地址 用网线将AMS和监控PC连接到交换机 根据客户需要,安装AMS管理工具软件SNM 1.4AMS客户化 根据SAN连接方案,确定AMS的客户化方案 如果需要,实施AMS初始化安装Microcode Initial Installation 输入需要使用的License 如果需要,升级AMS的微码至相应的版本 AMS磁盘系统参数设定 AMS磁盘设置,磁盘RAID及LUN划分 LUN格式化
1.5系统连接 铺设所有的光纤电缆 磁盘系统和服务器连接光纤交换机 交换机设置ZONE 设置AMS相应端口参数 设置AMS相应端口的Mapping 根据需要修改系统参数和HBA卡参数 在系统上确认识别到AMS的磁盘 根据需要修改设备参数 1.6安装多路径软件HDLM 确认系统已经安装相应的PATCH 安装HDLM软件 1.7安装和测试Hitrack呼叫功能 在客户提供Hitrack PC上安装Hitrack Monitor软件 连接Hitrack PC到Internet 设置Hitack中的客户信息 测试Hitrack的Call Home功能 1.8设备安装验收 所有设备按照客户的要求进行客户化,设备达到合同的有关规定,有关各方签署设备安装验 收报告。设备安装完成,进入售后服务阶段。
优化服务流程工作总结
优化服务流程工作总结 篇一:关于流程优化项目总结以及组织规划工作的思考 关于流程优化项目总结以及组织规划工作的思考 个人目前工作总结 流程优化项目目前推进思路: 每季度调研收集区域流程优化建议,反馈总部各体系,跟进各体系流程诊断,牵头业务及信息责任人推进流程优化的落地 目前存在问题: 1- 缺乏客观的流程评估标准,流程是否优化目前仅由总部业务单方面判断,存在由于总部业务先入为主,或缺乏与大区间的沟通而导致很多大区意见被否定,目前整体大区意见采纳率仅有50%左右;另外也会因缺少流程评估的科学标准,导致很多低效流程难以被发现; 2- 目前信息的产品设计部门多是将自己定位为被动的需求受理角色,对于业务提出的流程调整方案的合理性缺乏主动判断的意识和能力。 3- 工作方法上较为低效,组织规划牵头调研,再反馈总部各体系,会存在部分总部体系敷衍塞责,不能主动地去对自身体系予以周期性的诊断,对于大区提出的建议有很多未予以沟通或解释;另外全体系对接,组织规划仅是充当调度者角色,很多流程难以深入,方案合理性也难以判断,沦
为计划管理工作。 工作改善建议: 1- 牵头组织流程评估标准建设,季度性要求各体系按此标准予以本体系流程的诊断,包括大区调研;组织规划监督各体系季度流程评估工作的开展,负责流程评估标准的维护; 2- 具体参与重点流程的制定与优化工作。对于各体系重点流程(重要的或者问题较严重的)予以直接关注。 关于部门工作的思考 部门定位:根据集团战略目标,设计集团组织、指导组织运行,监控组织运行过程,并及时修正组织问题。 部门工作开展思路: 1- 人员分工上。矩阵式分工。没人对接固定体系,同时每个人根据特长及专业负责不同职能块,具体包括:组织设计、流程管理、绩效评估、岗位管理等,部门工作以项目制开展,每个项目由不同模块的责任人牵头,各体系对接人配合参与。这样每个人都有专 攻的项目,又能够方便其他体系与我部门的对接,以及各类问题的汇总与协调,对于部门员工自身的发展也较好。 2- 工作开展方面。 1)干什么。干什么、怎么干和干的怎么样是我们组织的一个管理闭环,但其实是彼此两两关联的,组织规划部应
AIX 更换磁盘阵列
何看机器内的卡及硬盘的微码级别(microcode level) 用下面命令可以得到一个SSA卡的微码级别: # lscfg -vl ssa0 其中 ssa0 是此SSA卡的设备名称. 输出结果中的ROS level及ID 即是微码级别(microcode level). 用下面命令可以得到一个硬盘的微码级别: lscfg -vl pdiskX 在RS6000系统上安装RAID适配器时,一般通过重新启动系统,AIX操作系统可以自动认到该适配器。但是在某些情况下,系统会停留在启动RAID适配器的位置,LED面板显示:“0751-P1-I1/Q1”;若运行cfgmgr命令,报0514-407错误。 解答这时有一种可能是该RAID适配器微码版本过低,需要从IBM 网站下载最新的微码。如何确定该RAID适配器的微码版本是否过低呢?下面以7044-270机器上的2498 PCI 4通道Ultra3 SCSI RAID适配器为例,使用下面的命令可以读到存储在适配器中的微码版本。 1)列出系统中安装的PCI RAID适配器: lsdev -C | grep scraid 注意:设备名是所有已安装的PCI 4通道Ultra3 SCSI RAID适配器的名称。适配器设备名将是scraidX, X为0,1 或其他的数字。 2)检查当前适配器的微码版本: lscfg -vl scraidX (X为系统已安装的适配器的号码。) 命令显示如下: DEVICE LOCATION DESCRIPTION Scraid0 20-58 PCI 4-Channel Ultra3 SCSI RAID Adapter Part Number.................09P1521 EC Level....................0H10522 Serial Number (00000001) FRU Number..................37L6892 Manufacturer................IBM000 Displayable Message.........UL3RAID Diagnostic Level (03) Device Driver Level (03) Loadable Microcode Level....4.20.01
双机热备ServHA 镜像集群节点更换操作教程
ServHA镜像集群节点更换(或重新连入)操作手册一、手册目的 本手册介绍ServHA镜像集群的节点更换、节点重新连入的操作步骤,当用户部分硬件损坏、系统及其应用重新安装导致的原有集群配置丢失时,可按照本手册操作步骤对集群进行恢复。 注:如严格按照本手册操作,可以在集群对外服务不中断的情况下将重新连入的节点加入集群。 手册中我们假定原有集群中一台服务器的集群配置完全丢失(同时其应用也均未安装,如更换了硬盘、重新安装了操作系统),下文中这台配置丢失的服务器我们称之为“新节点”(因为其配置完全丢失,在集群看来,这完全是一个全新的节点),原有的正常服务的主机我们称之为“原节点”。 本手册前提为:新节点完全与集群脱离关系,原节点还在受集群管理,集群对外服务正常,只是新节点在集群看来已经完全离线。 (我们以一次MySQL镜像集群恢复全过程作为例子,至于其他应用其原理与操作步骤都与此例相同。) 二、配置前准备工作 首先镜像集群中目前对外正在服务,所以新节点连入时,其业务数据必须以原节点为准,在配置前,必须在新节点划分出一个大于等于原节点镜像盘空间的分区,这个分区作为新节点的镜像盘,这样才能在不损失数据(数据是以原节点镜像盘为准的)的同时将新节点连入镜像集群,这点非常重要。同时记得将新节点的IP地址等还原为离线前的状态(即设置新节点的IP地址为之前集群中离线节点的IP地址)。
在新节点完全脱离集群后,集群工作状态如下图(配置监控端):(此例中节点192.168.1.91 为新节点、192.168.1.92为原节点)双机连接状态 资源树状态,此时原节点正常对外服务(即192.168.1.92) 镜像包状态
写好工作总结的一般流程
写好工作总结的一般流程 工作总结是单位或个人对过去一个时期内的实践活动作出系统的回顾归纳、分析评价,从中得出规律性认识用以指导今后工作的事务性文书。那么,工作总结的格式是怎样的呢? (一)总结的种类 从性质、时间、形式等角度可划分出不同类型的总结,从内容分主要有综合总结和专 题总结两种。综合总结又称全面总结,它是对某一时期各项工作的全面回顾和检查,进而 总结经验与教训。专题总结是对某项工作或某方面问题进行专项的总结,尤以总结推广成 功经验为多见。总结也有各种别称,如自查性质的评估及汇报、回顾、小结等都具总结的 性质。 (二)工作总结怎么写? 1、标题 文件式标题一般由单位名称、时限、内容、文种名称构成。例:《××局19×× 年度拥军拥属工作总结》。 文章式标题以单行标题概括主要内容或基本观点,不出现总结字样,但对总结内容 有提示作用。例某高校的专题总结《我们是如何实行教学与科研相结合的》。 2020上半年工作总结的结尾 正文主体写好了,怎么收尾呢?什么都不说,直接落款走人是不是太过突然了,感觉 别扭?是的,最好的工作总结就是要有一个收尾,简单一点就好。比如我们可以这样写: 双行式标题即分别以文章式标题和文件式标题为正副标题,正标题揭示观点或概括 内容,副标题点明单位、时限、性质和总结种类。例:《知名教授上讲台教书育人放异彩——×× 大学德育工作总结》。 2、正文 一年的工作已经结束了,在即将迎来的一年中,我们会继续不断的努力的,这是一直 无法拒绝的问题,这是一直以来我们在年终时候的总结。每一年都有自己的进步,每一年 都会有自己的成长!相信大家在来年中一定会取得最圆满的成功的! 前言
服务器更换新硬盘做系统的详细操作步骤
服务器更换新硬盘做系统的详细操作步骤 当服务器系统损坏或硬盘故障需要更换新硬盘时需要重做服务器系统。以下操作主要是以服务器的一块硬盘备份到另一块的详细操作步骤: 一.关闭服务器 1.登陆服务器使用SecureCRT登录服务器 用户名:root 密码:root 即可登录服务器 2.关闭程序输入cd /export/home/tjsc20/runs/etc路径回车,反复执行scshut回车待 屏幕出现如下图字样说明应用关闭成功
3.备份文件使用winscp登录服务器,主机名为服务器IP地址,用户名密码都为tjsc20 然后点击登录 将shell.tar文件夹放入/export/home/tjsc20目录下 使用CRT登录服务器进入/export/home/tjsc20/目录下执行tar -xvf shell.tar命令用tjsc20用户解压cd /export/home/tjsc20/shell目录下执行 ./Data_Backup.sh 使用wincp将备份文件考到本地。 4.关闭监听使用su – oracle命令切换用户,密码也是oracle,成功后首先执行lsnrctl stop命令关闭监听,然后执行sqlplus / as sysdba进入数据库,最后执行shutdown immediate关闭数据库待屏幕出现如下图字样代表数据库关闭成功,最后执行exit退出
5.关机su–root命令切换超级用户,密码为rootroot切换后执行init 5关机 二.做系统 ※需要显示器,键盘,鼠标连接至服务器。 6.更换硬盘待服务器关机后0槽放置好硬盘,1槽放置需要做系统的新硬盘,后按住 开机键待听带风扇启动的声音后松开开机键 7.复制系统开机自检过程中出现ctrl+c提示,按ctrl+c进入LSI Logic Config Utility
EMC_CX存储更换硬盘过程
壹: EMC CX存储一般在二种情况下需要换盘,一为硬盘已经损坏(亮黄灯),二为频繁报DIsk soft media error错误,第一种情况很简单,直接去现场热拔插换硬盘即可,第二种情况其实硬盘还没有硬件损坏,指示灯仍正常,这种情况换硬盘需要多点步骤,下面是实际更换过程的记录: 1. 找到相应需要更换的硬盘(存储->hysical->Bus x Enclosure x->Disks),然后右键执行copy to hot Spare,即把需要更换硬盘上的数据copy 到hotspare盘上 2. 在执行第一步操作后,存储的图标会变成带一个“T”,这表示数据正在copy,还不能换盘,需继续等待,大概需要30分钟 3. 等到存储的图标从“T”变为“F”后,需要更换的硬盘指示灯变为桔黄色,这表示已经可以拔出这块坏盘了 4. 拔出坏盘,换入新盘,注意比较一下二块盘的型号是否一致,如转数,接口,容量 5. 换入新盘后,硬盘指示灯变为绿色,并快速闪烁,表示存储已经在重建数据,把数据从HotSpare盘上恢复到这块新盘上 6. 从存储的console页面上也能看到,存储的图标又变为“T”,大约30分钟后,重建完成,图标T消失,恢复正常
7. 详细过程从sp的log上也能看到。 贰: 更换EMC损坏的磁盘以后,盘阵会自动开始把hot spare备份的数据恢复过来。然后把启用的hot spare盘恢复到初始备用状态。 我们可以通过命令来观察这一过程,首先看新换上来的硬盘,注意此时的状态为Equalizing,也就是正在进行平衡的过程: # navicli -h 172.16.9.5 getdisk 1_0_1 Bus 1 Enclosure 0 Disk 1 Vendor Id: SEAGATE Product Id: ST373307 CLAR72 Product Revision: 7A0A Lun: 6 Type: 6: RAID5 State: Equalizing Hot Spare: 6: NO Prct Rebuilt: 6: 100 Prct Bound: 6: 100 Serial Number: 3HZ6TL7F Sectors: 139681792 (68204) Capacity: 68238 Private: 6: 69704 Bind Signature: 0x5cf2, 0, 1
GHOST全盘镜像制作(全盘备份)教程
GHOST全盘镜像制作(全盘备份)教程. 首先您必须准备两个硬盘. 硬盘1为源硬盘也就是您要备份至其它硬盘的主硬盘.以下简称为源盘 硬盘2用来存放备份硬盘1镜像的磁盘.以下简称为目标盘. 注意事项: 创建全盘镜像时建议使用GHOST 8.2或以前版本,不建议使用GHOST 8.3,容易引起制作后出现“不是有效镜像”或制作成功后硬盘空间被占用了而找不到备份的镜像问题。 目标盘容量至少需要跟源盘一样大,或者更大。 目标盘用来存放镜像的分区容量至少需要跟源盘一样大,或者更大。 目标盘分区格式建议使用FAT32分区,如果在WINDOWS下不能分超过32G的FAT32分区,建议在MAXDOS下使用DISKGEN。或其它DOS下分区软件如:DM,GDISK,SPFDISK 等,可以支持分出无限大小的FAT32分区。 如果使用NTFS分区格式,经常会出现镜像制作成功后硬盘空间被占用了而找不到备份的镜像问题。 如果出现镜像制作成功后硬盘空间被占用了而找不到备份的镜像问题,请参见此https://www.360docs.net/doc/3b5085262.html,/bbs/read.php?tid=23699 进入正题,首先将目标盘安装到主板的IDE2接口上(请一定要注意,否则后果很严重,主板上有标),然后将目标盘整个硬盘分为一个区. 启动系统后进入MAXDOS,输入DISKGEN 后回车.出现DISKGEN菜单后如下图: 图1:
按键盘上的ALT+D (如果不熟悉键盘操作,请在运行DISKGEN前运行MOUSE加载鼠标驱动),选择“第2硬盘”回车。使用键盘上的TAB键切换至左边的圆柱形容量图上,切换过去后圆柱形容量图边框会有红色线,请注意观看。如果存在其它分区请先将这些分区删除。(请此确认此硬盘的资料已经备份)使用光标↑↓切换选择存在的分区,按DEL键将存在的分区一个一个删除。删除完毕后,再按F8存盘。 接下来在开始分区,切换到圆柱形容量图,按回车,创建新分区,出现“请输入新分区的大小”如下图 图2:
DELL PowerEdge服务器如何更换RAID上出现故障的硬盘驱动器
DELL Perc S100/S110/S300:如何更换软件 RAID 上出现故障的硬盘驱动器 本文说明如何更换Perc S100 卡中的故障磁盘。 作为提醒,Perc S100 卡是一种RAID 解决方案,仅与Windows 服务器软件兼容。此卡与Vmware Esx 或Linux 不兼容。 重要信息: 此过程仅适用于更换出现故障的硬盘驱动器(故障状态)以开始重建。 注意: Dell 建议您对数据进行完整备份,以便在您的 RAID 上执行操作。 步骤 启动服务器时(在启动操作系统之前),按Ctrl 和R 按钮可访问Perc S100/S110/S300 的BIOS。 在使用Perc S100/S110/S300 更改服务器中的磁盘时,新硬盘将显示在stauts "NO RAID" 中 此光盘无法作为RAID 的一部分被识别。在板上,Perc S100/S110/S300 应用特定签名。要将其集成到RAID 中,我们将擦除签名。 要在RAID 中集成此磁盘,您必须按如下所示操作: 向下滚动到选项:删除虚拟磁盘,然后按enter键。
选择NonRAID中的磁盘(在本例中为:1-NonRAID) 按Insert键以选择磁盘1。
按enter键,您将看到以下屏幕: 按C键确认。(驱动器将进入Ready (就绪)。)我们将此磁盘移至备份(热备用)。 向下滚动以管理全局热备用,然后按enter键。 选择分配全局热备用,然后将密钥移植:
选择我们刚刚通过就绪状态的驱动器,然后按下Insert key: 然后按enter键进行确认。 按m键返回到主菜单。 RAID 由软件管理,重建将不会启动等待服务器重启。
IBM存储DS3200更换故障硬盘步骤
IBM DS3200更换故障硬盘步骤 生产库存储Raid10上的一块硬盘故障,亮黄灯(不闪),通过存储管理软件查看得知是5号盘故障,并且热备盘已经投入使用。如下图: 需要择机更换故障盘,查阅了IBM DS3200的用户手册得知,故障硬盘可以热插拔而不影响业务。 更换的步骤: 确定要卸下的驱动器的位置。 警告:当热插拔驱动器相应的绿色活动指示灯闪烁时,切勿对它进行热插拔操 作。仅当该驱动器相应的淡黄色状态指示灯点亮并且不闪烁时,对它进行热插拔操作。 卸下驱动器: a. 按下托盘手柄右端的滑锁将其松开。 b. 将托盘手柄拉至打开位置。 c. 将驱动器从托架中拉出约12 毫米(0.5 英寸)并等待70 秒,让驱动器的内部 转子慢慢停下,并让Storage Subsystem 控制器意识到从配置中卸下了一个驱动
器。 确保驱动器上贴有标签等标识,然后将驱动器从Storage Subsystem 中完全滑出。 警告:卸下驱动器后,先等待70 秒,让驱动器的内部转子慢慢停下,然后再更换或重新安装驱动器。否则可能会导致不可预测的结果。 安装新驱动器: a. 按下托盘手柄右端的滑锁将其松开。 b. 将托盘手柄拉至打开位置。 c. 将驱动器轻轻滑入空托架中,直至它停住。 d. 将托盘手柄推至闭合(锁定)位置。 检查驱动器指示灯: 当驱动器准备就绪时,绿色活动指示灯点亮并且淡黄色状态指示灯熄灭。 如果淡黄色状态指示灯点亮并且不闪烁,请从托架中卸下驱动器并等待70 秒;然后重新安装驱动器。 从安全性考虑总结了3种更换故障盘的时机。 第一种,如果很着急的情况,可以按照上述步骤直接更换。 第二种,可以在合适的时间,停止业务,并备份数据库后,在线更换故障盘。 第三种,合适的时间,停止业务,关闭数据库,关闭主机,关闭存储,然后再更换故障盘。 更换故障盘后,新硬盘的绿色活动指示灯点亮,并且黄色状态灯熄灭(但是此时存储的黄色状态灯还是点亮的,因为此时热备盘还在使用中),然后存储会自动的向新硬盘往回拷贝数据,并在回拷过程中在存储的管理软件中显示有一个操作进程。 如下图:
年终工作总结会流程(精)
阔达装饰2011年度工作总结大会流程人员安排: 总控:乔朋杰、聂雪;前台签到:王彦彦、聂雪;台上主持人:孙静文、金堃;礼仪:董杜娟、周其秀、王彦彦;首先,我宣读一下会议纪律 1、参会人员到场后,必须到前台签到处签到,签到不得由他人代签; 2、参会人员不得缺席或擅自安排他人代会及请假; 3、会议期间不得迟到、早退及会客,违者将给20元罚款; 4、参会人员因特殊情况在会议中途请假的,必须经会议总控同意后方可离开,否则按早 退处理; 5、参会人员要自觉遵守会场秩序,会议进行时,手机调振动或关机,不得在会场内抽烟、 来回走动、接打电话、交头接耳、大声喧哗、阅读与会议主题无关的报刊杂志、打瞌睡或长 时间滞留会场外等,违者给予20元罚款; 6、无故缺勤或违反会议其他纪律者将给予100元罚款. 请在场的各位都能自觉遵守会议纪律,保证大会顺利进行,谢谢大家的支持!有请主持人上台 女:尊敬的各位领导,亲爱的同事们,大家合:上午好! 男:中华大地春意浓 女:六合风调万户丰 男:在这硕果累累的一年里,我们北京阔达装饰济南唯一授权单位—济南尚层装饰设计有限公司,携着辉煌、载着收获,留下了一行行坚实的足迹,如今又迎来了阔达装饰2011年度工作总结暨表彰大会在此召开。女:新春佳节年意浓浓,远朋近邻四海升平,首先非常荣幸的向大家介绍参加本次会议 的领导及嘉宾: 阔达装饰公司总经理:王总男:阔达装饰股东:边总 阔达装饰股东:孙总女:阔达装饰总监:张总 男:阔达装饰设计部旗舰风尚殿、设计部大唐尊享殿、市场部、后勤联合部门、以及下属各位项目经理 让我们对各位领导和全体员工的到来表示热烈的欢迎。男:下面我宣布:北京阔达装饰济南唯一授权单位—济南尚层装饰设计有限公司2011年工作总结2012年计划及表彰大会现在开始。大会进行第一项 男:现在大会进行第一项,请全体起立,宣读我们2011年工作精神男:卓越是一种梦想 宣读完毕
同友存储更换硬盘步骤
环境情况:同友存储共16块盘,其中15块做RAID5 ,一块作GLOBAL SPARE。 如果坏了一块盘。那么,存储会将数据拷贝到GLOBAL SPARE上。更换故障盘就可以了 更换之后,新插上的盘的状态是NEW DRV.手动操作液晶面板,将其设置为SPARE就可以了。如果没有操作这一步的话,那么这块盘的状态将会一直是NEW DRV,而存储就此时就没有了SPARE。 注:只有NEW DRV状态的盘才可以被添加为SPARE,其他任何状态的盘都不行。 将更换的盘添加进SPARE的步骤 按住ENT(约2秒) →→ 按▽选择到view and edit drives,然后按ENT →→ 继续按▽选择到新更换的盘的位置,然后按ENT →→ 继续按▽选择到ADD GLOBAL SPARE,然后按ENT,然后再按住ENT约两秒。 之后,就可以看到添加成功。然后就可以点ESC退出了。 可以按刚才的步骤,查看此盘的状态,你会发现,它变成了。
查看RAID信息的时候。 可以看到SB=1 同友的SPARE 分为三种,只有1个逻辑驱动器,而且你没有扩展柜的话,那么下面三种都可以使用。 Logical spare (只针对某一个RAID) Global Spare (针对这个柜子的所有RAID)一般来说这个用得比较多一点。 Enclosure(大概是这词,不记得了,反正是个E开头的。)Spare(未知,也许针对某个柜子) 如果一开始发现硬盘有故障,而你查看的时候,发现已经存在一个SPARE。 你就要仔细查看RAID的状态。 比如有8块盘,,现在坏了一块,一个spare。这个时候就看DRV是否或者小于6,如果是,那么就是正常的,该存储拥有不止一块SPARE,如果是大于6,而且发现的那个SPARE没有处于recovery状态,那么该SPARE的设置一定不对,你可以尝试先将该spare删除,删除之后就变成了NEW DRV,再根据实际情况设置为上述三种SPARE中的一种。
模拟更换硬盘以及迁移lp及lv(笔记)
先介绍几个命令 第一个命令:migratelp 命令 用途 在不同的物理卷上,将已分配的逻辑分区从一个物理分区移动到另一个物理分区。 语法 migratelp LVname/LPartnumber[ /Copynumber ] DestPV[/PPartNumber] 描述 migratelp将指定的逻辑卷LVname的逻辑分区LPartnumber移动到DestPV 物理卷。如果目标物理分区PPartNumber已指定,则使用指定的分区,否则使用逻辑卷的内部区域策略来选择目标分区。在缺省情况下,迁移第一个有问题的镜像副本。可以为Copynumber指定 1、2 或 3 的值来迁移一个特殊的镜像副本。 注:在并发卷组的情况下,必须考虑其他活动的并发节点上的分区使用情况,它是由lvmstat 报告。 migratelp命令不能迁移条带化逻辑卷的分区。 安全性 要使用migratelp,必须具有 root 用户权限。 示例 1.要将逻辑卷 lv00 的第一个逻辑分区移动到 hdisk1,请输入:migratelp lv00/1 hdisk1 2.要将逻辑卷 hd2 的第三个逻辑分区的第二个镜像副本移动到 hdisk5,请 输入: migratelp hd2/3/2 hdisk5
3.要将逻辑卷 testlv 的第 25 个逻辑分区的第三个镜像副本移动到 hdisk7,请输入: migratelp testlv/25/3 hdisk7/100 第二个命令:migratepv [ -i] [ -l LogicalVolume] SourcePhysicalVolume DestinationPhysicalVolume... 描述 migratepv命令将已分配的物理分区和它们包含的数据从SourcePhysicalVolume移到一个或多个其他物理分区。要限制传送到特定的物理卷,请在DestinationPhysicalVolume参数中使用一个或多个物理卷的名称;否则,卷组中的所有物理卷都可以传送。所有的物理卷必须在相同的卷组中。指定的源物理卷不能包含在DestinationPhysicalVolume参数列表中。 注: 所有的“逻辑卷管理器”迁移函数都是通过创建涉及的逻辑卷的镜像,然后重新同步逻辑卷来工作的。然后删除原始的逻辑卷。如果migratepv命令用于移动包含主转储设备的逻辑卷,则在命令执行过程中系统将不能够访问主转储设备。因此,在此执行过程中的转储操作将失败。要避免这一点,可以在使用sysdumpdev命令之前重新分配一个主转储设备,或者在使用migratepv之前确保有从转储设备。 您可以使用基于 Web 的系统管理器(wsm)中的卷应用程序来更改卷特征。您也可以使用“系统管理接口工具”(SMIT)smit migratepv快速路径来运行该命令。 注: 对于并发方式卷组,在 SSA 磁盘上增强并发方式是活动的或并发方式是活动的时,migratepv才可以使用。 -i从标准输入中读取DestinationPhysicalVolume参数。 -l LogicalVolume 仅移动已分配到指定的逻辑卷和位于指定的源物理卷上的物理分区。 示例 1.要将物理分区从 hdisk1 移动到 hdisk6 和 hdisk7 上,请输入: migratepv hdisk1 hdisk6 hdisk7
RoseMirrorHA 配置替换IP的操作步骤
RoseMirrorHA配置替换IP的操作说明 由于网络访问或应用服务主动发送数据包等情况,RoseMirrorHA需要配置替换IP,以实现正常的网络访问。RoseMirrorHA配置替换IP的操作步骤说明如下。 已经创建应用服务的情况下,配置替换IP的操作说明。 1. 执行rcc命令,打开RoseMirrorHA的管理工具RCC,如下图所示。 2. 分别选中主机视图区域,右键菜单中选择“通信”,将RCC与两台主机的RoseMirrorHA服务的通信IP更换为私网心跳IP,如下图所示。两台主机都需要更换通信IP。
3. 在通信窗口中,将“主机”指定为私网心跳IP,如下所示,请根据情况输 入实际环境中的私网心跳IP。点击“确定”。 4. 将两台主机的通信IP修改为私网心跳IP后,待RCC与RoseMirrorHA 服务连接成功后,如未登录,登录后查看所创建的应用服务状态。如现为“带入”状态,选中应用服务,右键菜单中执行“带出”应用服务操作。 应用服务“带出”状态如下所示:
5. 选中已“带出”的应用服务,右键菜单选择“修改/查看”,如下图所示:
6. 在修改应用服务的窗口中,切换至“活动IP”页面,勾选“替换IP地址”,点击“确定”即可保存修改配置。 7. 修改“替换IP”配置后,选中应用服务,右键菜单选择“带入”,即可将应用服务带入。如下图所示。
8. 带入后,测试通过活动IP的网络数据是否能够正常通信。 未创建应用服务的情况下,配置替换IP的操作说明。 1. 配置RCC连接RoseMirrorHA服务时,指定私网心跳IP连接 RoseMirrorHA。 2. 在创建应用服务过程中,在“活动IP”页面,勾选“替换IP地址”即可。
部门年终总结会议流程
部门年终总结会议流程 201x年冬季姗姗到来,年底将至,各公司企业开始为年会筹备策划了!无论这一年的成果如何总要有个总结!一是对今年有个收尾,二是对来年做个计划,大家一起庆祝一番,交流下感情,活跃气氛促进公司发展和团结!事业蒸蒸日上! 沈阳超凡会展公司从事多年会议活动策划执行工作,有着丰富的经验和自己独有的一套执行计划。公司秉承客户至上的原则,以节约时间和商业成本为基准,精心做好每一次活动! 新年即将来临之时,我公司已经做好全面的准备!迎接各公司的年会策划活动!公司不单在年会流程上精心策划!还在其他如场地选择,文艺表演等方面为客户准备了参考标准等。 从接到委托开始,会与客户进行面谈,了解客户想法,从客户的角度出发,做出预案的同时给客户提出参考意见,以便方案顺利执行! 签署合同或相关法律协议后,开始按预案进行方案设计! 递交设计方案,同客户对接!确定流程 活动现场搭建,搭建过程会有专业人员现场作业和指挥! 客户验收,到现场进行对设置进行查看! 一切准备就绪,开始按方案执行! 待会议结束后,我公司工作人员会到现场进行撤场拆卸! 所有的环节都做好了部署,都有我公司专业人员实地指导、操作。能够更好的完成任务,完美达到客户的要求! 我们将呈现在客户面的是一场完美的年会! 尊敬的公司率领及同事们: 您们好! 在这新的一年里,我谨代表华南批示部的全体资料员向在座的列位致以真挚的谢意,同时给巨匠拜个晚年,祝愿列位率领同事们春节兴奋,20**事事如意;祝公司事业蒸蒸日上,更上一层楼。 我是华南批示部××项目部 的资料员兼出纳,我叫××,想必巨匠对我既熟悉又目生,熟悉的是名字,目生的是人。我是一个进公司刚满一年的员工,在曩昔的一年里深得率领的信赖和厚爱,有幸被评为优异员工,并在年关作为资料代表在此讲话,向率领们进行工作总结陈述
服务器磁盘阵列详细图解
服务器磁盘阵列详细图解 RAID 0 RAID 0又称为Stripe或Striping,它代表了所有RAID级别中最高的存储性能。RAID 0提高存储性能的原理是把连续的数据分散到多个磁盘上存取,这样,系统有数据请求就可以被多个磁盘并行的执行,每个磁盘执行属于它自己的那部分数据请求。这种数据上的并行操作可以充分利用总线的带宽,显著提高磁盘整体存取性能。如图1所 示: 从理论上讲,三块硬盘的并行操作使同一时间内磁盘读写速度提升了3倍。但由于总线带宽等多种因素的影响,实际的提升速率肯定会低于理论值,大量数据并行传输与串行传输比较,提速效果显著显然毋庸置疑。 RAID 0的缺点是不提供数据冗余,因此一旦用户数据损坏,损坏的数据将无法得到恢复。 RAID 0具有的特点,使其特别适用于对性能要求较高,而对数据安全不太在乎的领域,如图形工作站等。对于个人用户,RAID 0也是提高硬盘存储性能的绝佳选择。 容错性:没有冗余类型:没有 热备盘选项:没有读性能:高 随机写性能:高连续写性能:高 需要的磁盘数:一个或多个 可用容量:总的磁盘的容量 典型应用:无故障的迅速读写,要求安全性不高,如图形工作站等。 RAID 1 RAID 1又称为Mirror或Mirroring,它的宗旨是最大限度的保证用户数据的可用性和可修复性。 RAID 1的操作方式是把用户写入硬盘的数据百分之百地自动复制到另外一个硬盘上。当读取数据时,系统先从RAID 0的源盘读取数据,如果读取数据成功,则系统不去管备份
盘上的数据;如果读取源盘数据失败,则系统自动转而读取备份盘上的数据,不会造成用户工作任务的中断。当然,我们应当及时地更换损坏的硬盘并利用备份数据重新建立Mirror,避免备份盘在发生损坏时,造成不可挽回的数据损失。 由于对存储的数据进行百分之百的备份,在所有RAID级别中,RAID 1提供最高的数据安全保障。同样,由于数据的百分之百备份,备份数据占了总存储空间的一半,因而,Mirror 的磁盘空间利用率低,存储成本高。 Mirror虽不能提高存储性能,但由于其具有的高数据安全性,使其尤其适用于存放重要数据,如服务器和数据库存储等领域。 容错性:有冗余类型:复制 热备盘选项:有读性能:低 随机写性能:低连续写性能:低 需要的磁盘数:只需2个或2*N个 可用容量:只能用磁盘容量的50% 典型应用:随机数据写入,要求安全性高,如服务器、数据库存储领域。 RAID 0+1 RAID 0+1:正如其名字一样RAID 0+1是RAID 0和RAID 1的组合形式,也称为RAID 10。以四个磁盘组成的RAID 0+1为例,其数据存储方式如图所示:RAID 0+1是存储性能和数据安全兼顾的方案。它在提供与RAID 1一样的数据安全保障的同时,也提供了与RAID 0近似的存储性能。 由于RAID 0+1也通过数据的100%备份提供数据安全保障,因此RAID 0+1的磁盘空间利用率与RAID 1相同,存储成本高。
HDS 9910磁盘更换手册
HDS 9910 存储系统更换磁盘手册 Writen by: Yan Ruobing 一、流程图 1.检查损坏磁盘的状态:Normal、Warning、Block(Failed) 2.指定需要隔离(block)的磁盘 3.判断更换该部件过程中是否会影响系统操作 4.系统隔离该磁盘(block) 5.被隔离磁盘LED指示灯亮起 6.更换该磁盘 7.系统执行后续步骤(数据回拷、重建) 8.检查更换后磁盘状态(是否为Normal) 9.在SIM日志上将错误状态改为complete
二、检查磁盘状态 SVP主界面如下图,点击右上角的按钮可以切换操作模式View Mode或Modify Mode 选择Information,弹出以下窗口: 点击Log,弹出如下窗口
选择SIM可以看到当前系统日志,状态为Initial。 选择其中一项,点击content按钮,SVP会给出详细信息。 从上图中记录下“Action Code”,并通过该code可以在维护文档上查询具体更换流程。 三、找到故障磁盘 将操作模式转换为Modify Mode,然后从主界面选择Maintenance,弹出如下窗口,如果有磁盘故障,Disk按钮会闪烁。 点击Disk按钮,弹出如下窗口,故障磁盘所在的HDU组会闪烁
点击闪烁的HDU组,在该HDU组中,故障磁盘所在的图标会闪烁 点击闪烁的磁盘会出现详细信息: 查看Device Status,确认其状态是否为Failed。如果是,说明该磁盘需要更换。
四、更换磁盘 在下图的窗口中点击Replace 系统显示Checking…… 选择“YES”继续更换步骤,否则选择NO返回 系统显示Blocking……. 系统显示Spining Down…… 此时故障硬盘的LED会长亮,按下图方法拔出该硬盘 插入新磁盘