总结:线性回归分析的基本步骤

线性回归分析的基本步骤
步骤一、建立模型
知识点:
1、总体回归模型、总体回归方程、样本回归模型、样本回归方程 ①总体回归模型:研究总体之中自变量和因变量之间某种非确定依赖关系的计量模型。Y X U β=+
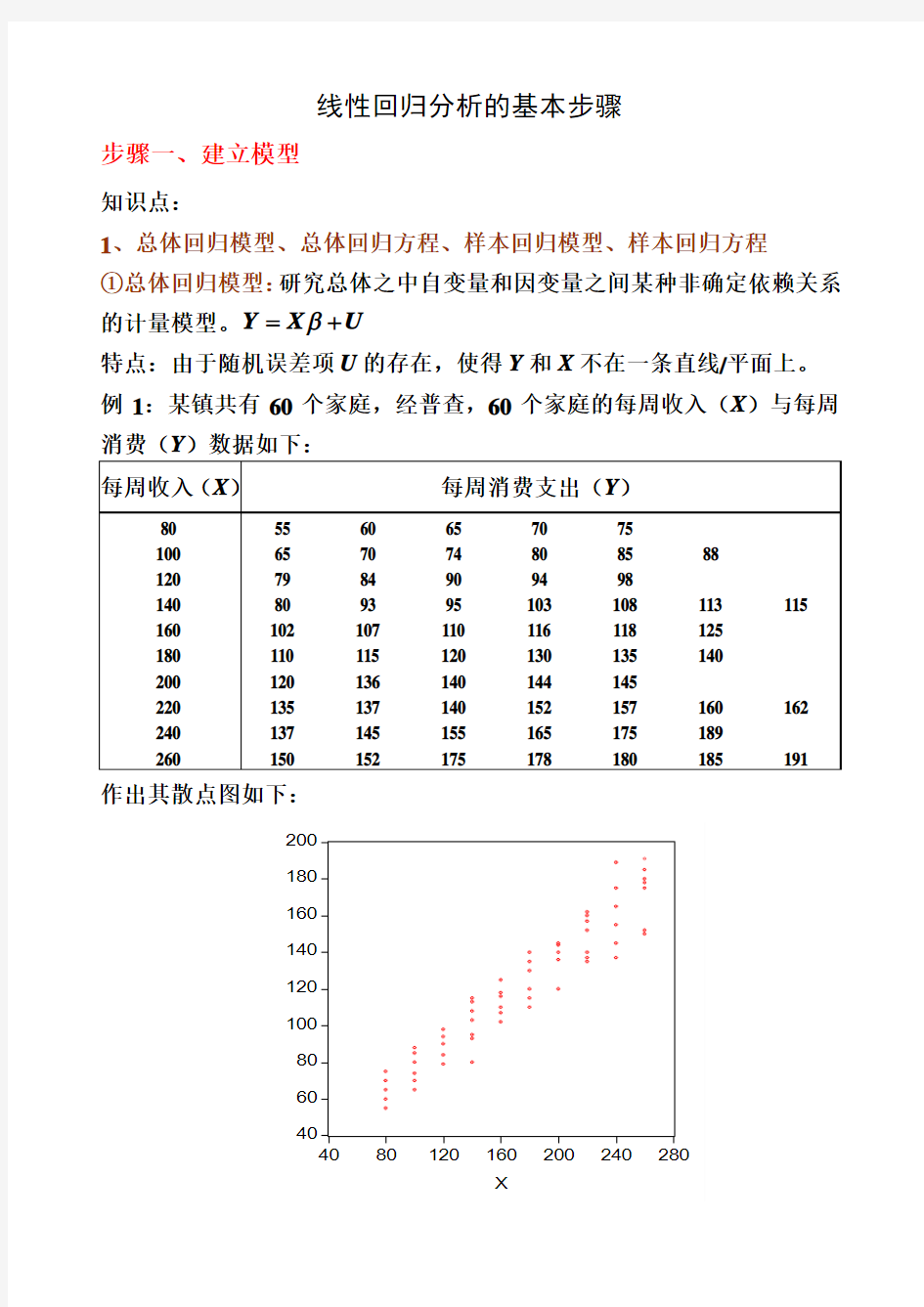
特点:由于随机误差项U 的存在,使得Y 和X 不在一条直线/平面上。 例1:某镇共有60个家庭,经普查,60个家庭的每周收入(X )与每周消费(Y )数据如下:
作出其散点图如下:
②总体回归方程(线):由于假定0EU =,因此因变量的均值与自变量总处于一条直线上,这条直线()|E Y X X β=就称为总体回归线(方程)。 总体回归方程的求法:以例1的数据为例
,求出E (Y |X 由于01|i i i E Y X X ββ=+,因此任意带入两个X i 和其对应的E (Y |X i )值,即可求出01ββ和,并进而得到总体回归方程。
如将()()22277
7100,|77200,|137X E Y X X E Y X ====和代入
()01|i i i E Y X X ββ=+可得:0100117710017
1372000.6ββββββ=+=?????=+=??
以上求出01ββ和反映了E (Y |X i )和X i 之间的真实关系,即所求的总体回归方程为:()|170.6i i i E Y X X =+,其图形为:
③样本回归模型:总体通常难以得到,因此只能通过抽样得到样本数据。如在例1中,通过抽样考察,我们得到了20个家庭的样本数据:
那么描述样本数据中因变量Y 和自变量X 之间非确定依赖关系的模型
?Y X e β
=+就称为样本回归模型。 ④样本回归方程(线):通过样本数据估计出?β
,得到样本观测值的拟合值与解释变量之间的关系方程??Y X β=称为样本回归方程。如下图所示:
⑤四者之间的关系:
ⅰ:总体回归模型建立在总体数据之上,它描述的是因变量Y 和自变量X 之间的真实的非确定型依赖关系;样本回归模型建立在抽样数据基础之
上,它描述的是因变量Y 和自变量X 之间的近似于真实的非确定型依赖
关系。这种近似表现在两个方面:一是结构参数?β是其真实值β的一种近似估计;二是残差
e 是随机误差项U 的一个近似估计;
ⅱ:总体回归方程是根据总体数据得到的,它描述的是因变量的条件均值E (Y |X )与自变量X 之间的线性关系;样本回归方程是根据抽样数据得到
的,它描述的是因变量Y 样本预测值的拟合值?Y
与自变量X 之间的线性关系。
ⅲ:回归分析的目的是试图通过样本数据得到真实结构参数β的估计值,
并要求估计结果?β
足够接近真实值β。由于抽样数据有多种可能,每一次抽样所得到的估计值?β
都不会相同,即β的估计量?β是一个随机变量。因此必须选择合适的参数估计方法,使其具有良好的统计性质。 2、随机误差项U 存在的原因: ①非重要解释变量的省略 ②人的随机行为 ③数学模型形式欠妥
④归并误差(如一国GDP 的计算) ⑤测量误差等
3、多元回归模型的基本假定 ①随机误差项的期望值为零()0i E U =
②随机误差项具有同方差性2() 1,2,,i Var u i n σ==
③随机误差项彼此之间不相关(,)0 ; ,1,2,,i j Cov u u i j i j n =≠= ④解释就变量X 1,X 2,···,X k 为确定型变量,与随机误差项彼此不相关。
(,)0 1,2,, 1,2,,ij j Cov X u i k j n ===
⑤解释就变量X 1,X 2,···,X k 之间不存在精确的(完全的)线性关系,即解释变量的样本观测值矩阵X 为满秩矩阵:rank (X )=k +1 步骤二、参数估计 知识点: 1、最小二乘估计的基本原理:残差平方和最小化。 2、参数估计量: ① 一元回归:1201???i i i x y x Y X βββ?= ?? ?=-?∑∑ ② 多元回归: ()1?T X X X Y β-'= 3、最小二乘估计量的性质(Gauss-Markov 定理): 在满足基本假设的情况下,最小二乘估计量?β 是β的最优线性无偏估计量(BLUE 估计量) 步骤三、模型检验 1、经济计量检验(后三章内容) 2、统计检验 ①拟合优度检验 知识点: ⅰ:拟合优度检验的作用:检验回归方程对样本点的拟合程度 ⅱ:拟合优度的检验方法:计算(调整的)样本可决系数22/R R 21RSS ESS R TSS TSS = =-,2/1 1/1 ESS n k R TSS n --=- - 注意掌握离差平方和、回归平方和、残差平方和之间的关系以及它们 的自由度。 计算方法:通过方差分析表计算 例2:下表列出了三变量(二元)模型的回归结果: 1) 样本容量为多少? 解:由于TSS 的自由度为n -1,由上表知n -1=14,因此样本容量n =15。 2) 求ESS 解:由于TSS =ESS +RSS ,故ESS =TSS -RSS =77 3) ESS 和RSS 的自由度各为多少? 解:对三变量模型而言,k =2,故ESS 的自由度为n -k -1=12 RSS 的自由度为k =2 4) 求22R R 和 解:2 659650.998866042RSS R TSS = ==,2/1 10.9986/1 ESS n k R TSS n --=-=- ②回归方程的显著性检验(F 检验) 目的:检验模型中的因变量与自变量之间是否存在显著的线性关系 步骤:1、提出假设: 0121:...0:0 , 1,2,...,k j H H j k ββββ====≠=至少有一 2、构造统计量:/~(,1)/1 RSS k F F k n k ESS n k = ---- 3、给定显著性水平α,确定拒绝域(),1F F k n k α>-- 4、计算统计量值,并判断是否拒绝原假设 例3:就例2中的数据,给定显著性水平1%α=,对回归方程进行显著性检验。 解:由于统计量值/65965/2 5140.13/177/12 RSS k F ESS n k = ==--, 又()0.012,12 6.93F =,而()0.015140.132,12 6.93F F =>= 故拒绝原假设,即在1%的显著性水平下可以认为回归方程存在显著的线性关系。 附:2 R F 与检验的关系: 由于()()2 2 222 /1/1/1/1RSS RSS R R RSS ESS R k TSS ESS RSS R F RSS k R n k F ESS n k ?==?=??+-?=?---?= ?--? 又 ③解释变量的显著性检验(t 检验) 目的:检验模型中的自变量是否对因变量存在显著影响。 知识点: 多元回归:? i S β= 1,1i i C ++为()1 X X -'中位于第i +1行 和i +1列的元素; 一元回归: 1 ? ?S S ββ= = 变量显著性检验的基本步骤: 1、提出假设:01:0 :0i i H H ββ=≠ 2、构造统计量:??~(1)i i t t n k S β β=-- 3、给定显著性水平α,确定拒绝域/2(1)t t n k α>-- 4、计算统计量值,并判断是否拒绝原假设 例4:根据19个样本数据得到某一回归方程如下: 12?58.90.20.1 (0.0092) (0.084) Y X X se =-+- 试在5%的显著性水平下对变量12X X 和的显著性进行检验。 解:由于/20.025(1)(16) 2.12t n k t α--==,故t 检验的拒绝域为 2.12t >。对 自变量1X 而言,其t 统计量值为1 1? ?0.2 21.74 2.120.0092 t S ββ= = =>,落入 拒绝域,故拒绝10β=的原假设,即在5%的显著性水平下,可以认为自变量1X 对因变量有显著影响; 对自变量2X 而言,其t 统计量值为2 2? ?0.1 1.19 2.120.084 t S ββ= = =<,未落入拒绝域,故不能拒绝20β=的原假设,即在5%的显著性水平下,可以认为自变量2X 对因变量Y 的影响并不显著。 ④回归系数的置信区间 目的:给定某一置信水平1α-,构造某一回归参数i β的一个置信区间,使 i β落在该区间内的概率为1α- 基本步骤: 1、构造统计量? ?~(1)i i i t t n k S βββ-= -- 2、给定置信水平1α-,查表求出α水平的双侧分位数/2(1)t n k α-- 3、求出i β的置信度为1α-的置信区间() ??/2/2??,i i i i t S t S ααββ ββ-?+? 例5:根据例4的数据,求出1β的置信度为95%的置信区间。 解:由于0.025(16) 2.12t =,故1β的置信度为95%的置信区间为: ()()0.2 2.120.0092,0.2 2.120.00920.18,0.22-?+?= 3、经济意义检验 目的:检验回归参数的符号及数值是否与经济理论的预期相符。 例6:根据26个样本数据建立了以下回归方程用于解释美国居民的个人消费支出: 122?10.960.93 2.09 ( 3.33) (249.06) ( 3.09)0.9996 Y X X t R =-+---= 其中:Y 为个人消费支出(亿元);X 1为居民可支配收入(亿元);X 2为利率(%) 1) 先验估计12 ??ββ和的符号; 解:由于居民可支配收入越高,其个人消费水平也会越高,因此预期自变量X 1回归系数的符号为正;而利率越高,居民储蓄意愿越强,消费意愿 相应越低,因此个从消费支出与利率应该存在负相关关系,即2 ?β应为负。 2) 解释两个自变量回归系数的经济含义; 解:1 ?0.93β=表示,居民可支配收入每增加1亿元,其个人消费支出相应会增加0.93亿元,即居民的边际消费倾向MPC =0.93; 2 ? 2.09β=-表示,利率提高1个百分点,个人消费支出将减少2.09亿元。 截距项表示居民可支配收入和利率为零时的个人消费支出为-10.96亿元,它没有明确的经济含义。 3) 检验1β是否显著不为1;(5%α=) 解:1)提出假设:0111: 1 :1H H ββ=≠ 2)构造统计量:1 11? ?~(1)t t n k S βββ-= -- 3)给定显著性水平5%α=,查表得/20.025(1)(23) 2.07t n k t α--==,故拒绝域为 2.07t > 4)计算统计量值:由于11 11?1?1??0.93?()0.003734?249.06()t S S t ββββββ= ?=== 则1 11? ?0.07 18.75 2.070.003734 t S βββ-= = =>,落入拒绝域。故拒绝1 1 β=的原假设。 即在5%的显著性水平下,可认为边际消费倾向MPC 显著不为1。 4) 检验2β显否显著不为零;(5%α=) 解:1)提出假设:0212:0 :0H H ββ=≠ 2)构造统计量:2 2? ?~(1)t t n k S ββ= -- 3)给定显著性水平5%α=,查表得/20.025(1)(23) 2.07t n k t α--==,故拒绝域为 2.07t > 4)计算统计量值:由于2 ?() 3.09 2.07t β=>,落入拒绝域,故拒绝原假设。即在5%的显著性水平下,可以认为2β显著异于零。 5) 计算2R 值; 解:由于()()22/111 1111/111 261 110.99960.99957 2621 ESS n k ESS n n R R TSS n TSS n k n k ----=- =-?=--? ------=--?=-- 6) 计算每个回归系数的标准差; 解:由于0 120 ?01???12?2?10.96 3.29? 3.33()???0.93?()0.00373??249.06()()? 2.090.6764? 3.09()i i i i i i S t t S S S t t S t βββββββββββββββ?-===?-? ??=?=?===???-?===?-? 7) 给出2β置信水平为95%的置信区间; 解:由于2 ?20.025? 2.09 , 0.6764 , (23) 2.07S t β β=-==,故2β置信水平为 95%的置信 区间为()()2.09 2.070.6764 , 2.09 2.070.6764-3.49 , -0.69--?-+?= 8) 对回归方程进行显著性检验; 解:提出假设:012112:0 :0H H ββββ==≠或 构造统计量/~(,1)/1 RSS k F F k n k ESS n k = ---- 确定拒绝域:0.05(.1)(2,23) 3.42F F k n k F α>--== 计算统计量并进行判断: 由于()() 22 /0.9996/2 28738.5 3.420.0004/231/1R k F R n k ===>--- 故拒绝原假设,即在5%的显著性水平下认为回归方程的线性关系显著成立。 步骤四:经济预测 点预测:00 ??Y X β=可以看着是Y 的条件均值()00|E Y X 和个别值0Y 的预测值,分别称为均值预测和个值预测; 性质:00 ??Y X β=是()00|E Y X 和0Y 的一个无偏估计量。 区间预测:均值()00|E Y X 的区间预测 预测步骤:1)确定统计量:()0 000 ? ?|~(1)Y Y E Y X t t n k S -= -- 其中 ?Y S = 2)给定置信水平1α-,确定()00|E Y X 的预测区间为: ()0 ??0 /2 0/2??(1),(1)Y Y Y t n k S Y t n k S αα---?+--? 个值0Y 的区间预测 预测步骤:1)确定统计量:00 000 ?~(1)e e e Y Y t t n k S S -==-- 其中0 e S = 2)给定置信水平1α-,确定0Y 的预测区间为: ()00 /2 0/2??(1),(1)e e Y t n k S Y t n k S αα---?+--? 作业: 为解释某地对酒的消费,根据20年的样本数据得到了如下回归方程: 1234 ?0.0140.3540.0180.6570.059Y X X X X =--+++ 其中:Y :每一成年人每年对酒的消费量(升); 1X :酒类的平均价格(元) ; 2X :个人可支配收入(元) 3X :酒类经营许可证数量(张) 4X :酒类广告投入(万元) 已知20.689R =,()1 X X -'对角线上的元素分别为1,10.0576C =,2,228.9014C =, 3,30.01C =,4,428.3042C =,5,50.4624C =,回归方程的残差平方和0.0375ESS = 1) 先验地,你认为各自变量回归系数的符号为什么? 2) 请完成以下方差分析表: 3) 计算2R 值 4) 对4个自变量进行显著性检验,并分析其经济含义; 5) 给出2β置信水平为95%的区间估计; 6) 对方程进行显著性检验; 回归分析的基本知识点及习题 本周题目:回归分析的基本思想及其初步应用 本周重点: (1)通过对实际问题的分析,了解回归分析的必要性与回归分析的一般步骤;了解线性回归模型与函数模型的区别; (2)尝试做散点图,求回归直线方程; (3)能用所学的知识对实际问题进行回归分析,体会回归分析的实际价值与基本思想;了解判断刻画回归模型拟合好坏的方法――相关指数和残差分析。 本周难点: (1)求回归直线方程,会用所学的知识对实际问题进行回归分析. (2)掌握回归分析的实际价值与基本思想. (3)能运用自己所学的知识对具体案例进行检验与说明. (4)残差变量的解释; (5)偏差平方和分解的思想; 本周内容: 一、基础知识梳理 1.回归直线: 如果散点图中点的分布从整体上看大致在一条直线附近,我们就称这两个变量之间具有线性相关关系,这条直线叫作回归直线。 求回归直线方程的一般步骤: ①作出散点图(由样本点是否呈条状分布来判断两个量是否具有线性相关关系),若存在线性相关关系→②求回归系数→ ③写出回归直线方程,并利用回归直线方程进行预测说明. 2.回归分析: 对具有相关关系的两个变量进行统计分析的一种常用方法。 建立回归模型的基本步骤是: ①确定研究对象,明确哪个变量是解释变量,哪个变量是预报变量; ②画好确定好的解释变量和预报变量的散点图,观察它们之间的关系(线性关系). ③由经验确定回归方程的类型. ④按一定规则估计回归方程中的参数(最小二乘法); ⑤得出结论后在分析残差图是否异常,若存在异常,则检验数据是否有误,后模型是否合适等. 3.利用统计方法解决实际问题的基本步骤: (1)提出问题; (2)收集数据; (3)分析整理数据; (4)进行预测或决策。 4.残差变量的主要来源: (1)用线性回归模型近似真实模型(真实模型是客观存在的,通常我们并不知道真实模型到底是什么)所引起的误差。 可能存在非线性的函数能够更好地描述与之间的关系,但是现在却用线性函数来表述这种关系,结果就会产生误差。这 种由于模型近似所引起的误差包含在中。 (2)忽略了某些因素的影响。影响变量的因素不只变量一个,可能还包含其他许多因素(例如在描述身高和体重 关系的模型中,体重不仅受身高的影响,还会受遗传基因、饮食习惯、生长环境等其他因素的影响),但通常它们每一个因素的影响可能都是比较小的,它们的影响都体现在中。 (3)观测误差。由于测量工具等原因,得到的的观测值一般是有误差的(比如一个人的体重是确定的数,不同的秤可 能会得到不同的观测值,它们与真实值之间存在误差),这样的误差也包含在中。 上面三项误差越小,说明我们的回归模型的拟合效果越好。 总结:线性回归分析的基本 步骤 -标准化文件发布号:(9556-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII 线性回归分析的基本步骤 步骤一、建立模型 知识点: 1、总体回归模型、总体回归方程、样本回归模型、样本回归方程 ①总体回归模型:研究总体之中自变量和因变量之间某种非确定依赖关系的计量模型。Y X U β=+ 特点:由于随机误差项U 的存在,使得Y 和X 不在一条直线/平面上。 例1:某镇共有60个家庭,经普查,60个家庭的每周收入(X )与每周消费(Y )数据如下: 作出其散点图如下: ②总体回归方程(线):由于假定0EU =,因此因变量的均值与自变量总处于一条直线上,这条直线()|E Y X X β=就称为总体回归线(方程)。 总体回归方程的求法:以例1的数据为例 由于01|i i i E Y X X ββ=+,因此任意带入两个X i 和其对应的E (Y |X i )值,即可求出01ββ和,并进而得到总体回归方程。 如将()()222777100,|77200,|137X E Y X X E Y X ====和代入 ()01|i i i E Y X X ββ=+可得:0100117710017 1372000.6ββββββ=+=?????=+=?? 以上求出01ββ和反映了E (Y |X i )和X i 之间的真实关系,即所求的总体回归方程为:()|170.6i i i E Y X X =+,其图形为: ③样本回归模型:总体通常难以得到,因此只能通过抽样得到样本数据。如在例1中,通过抽样考察,我们得到了20个家庭的样本数据: 那么描述样本数据中因变量Y 和自变量X 之间非确定依赖关系的模型 ?Y X e β =+就称为样本回归模型。 步骤一、建立模型 知识点: 1、总体回归模型、总体回归方程、样本回归模型、样本回归方程 ①总体回归模型:研究总体之中自变量和因变量之间某种非确定依赖关系的计量模型。Y X U β=+ 特点:由于随机误差项U 的存在,使得Y 和X 不在一条直线/平面上。 例1:某镇共有60个家庭,经普查,60个家庭的每周收入(X )与每周 作出其散点图如下: ②总体回归方程(线):由于假定0EU =,因此因变量的均值与自变量总处于一条直线上,这条直线()|E Y X X β=就称为总体回归线(方程)。 总体回归方程的求法:以例1的数据为例 实用标准文案 由于()01|i i i E Y X X ββ=+,因此任意带入两个X i 和其对应的E (Y |X i )值,即可求出01ββ和,并进而得到总体回归方程。 如将()()222777100,|77200,|137X E Y X X E Y X ====和代入 ()01|i i i E Y X X ββ=+可得:0100117710017 1372000.6ββββββ=+=?????=+=?? 以上求出01ββ和反映了E (Y |X i )和X i 之间的真实关系,即所求的总体回归方程为:()|170.6i i i E Y X X =+,其图形为: ③样本回归模型:总体通常难以得到,因此只能通过抽样得到样本数据。如在例1中,通过抽样考察,我们得到了20个家庭的样本数据: 那么描述样本数据中因变量Y 和自变量X 之间非确定依赖关系的模型 ?Y X e β =+就称为样本回归模型。 ④样本回归方程(线):通过样本数据估计出?β ,得到样本观测值的拟合值与解释变量之间的关系方程??Y X β=称为样本回归方程。如下图所示: ⑤四者之间的关系: ⅰ:总体回归模型建立在总体数据之上,它描述的是因变量Y 和自变量X 之间的真实的非确定型依赖关系;样本回归模型建立在抽样数据基础之上,它描述的是因变量Y 和自变量X 之间的近似于真实的非确定型依赖关系。这种近似表现在两个方面:一是结构参数?β 是其真实值β的一种近似估计;二是残差e 是随机误差项U 的一个近似估计; ⅱ:总体回归方程是根据总体数据得到的,它描述的是因变量的条件均值 线性回归分析的基本步骤 步骤一、建立模型 知识点: 1、总体回归模型、总体回归方程、样本回归模型、样本回归方程 ①总体回归模型:研究总体之中自变量和因变量之间某种非确定依赖关系的计量模型。Y X U β=+ 特点:由于随机误差项U 的存在,使得Y 和X 不在一条直线/平面上。 例1:某镇共有60个家庭,经普查,60个家庭的每周收入(X )与每周消费(Y )数据如下: 作出其散点图如下: ②总体回归方程(线):由于假定0EU =,因此因变量的均值与自变量总处于一条直线上,这条直线()|E Y X X β=就称为总体回归线(方程)。 总体回归方程的求法:以例1的数据为例 ,求出E (Y |X 由于01|i i i E Y X X ββ=+,因此任意带入两个X i 和其对应的E (Y |X i )值,即可求出01ββ和,并进而得到总体回归方程。 如将()()22277 7100,|77200,|137X E Y X X E Y X ====和代入 ()01|i i i E Y X X ββ=+可得:0100117710017 1372000.6ββββββ=+=?????=+=?? 以上求出01ββ和反映了E (Y |X i )和X i 之间的真实关系,即所求的总体回归方程为:()|170.6i i i E Y X X =+,其图形为: ③样本回归模型:总体通常难以得到,因此只能通过抽样得到样本数据。如在例1中,通过抽样考察,我们得到了20个家庭的样本数据: 那么描述样本数据中因变量Y 和自变量X 之间非确定依赖关系的模型 ?Y X e β =+就称为样本回归模型。 ④样本回归方程(线):通过样本数据估计出?β ,得到样本观测值的拟合值与解释变量之间的关系方程??Y X β=称为样本回归方程。如下图所示: ⑤四者之间的关系: ⅰ:总体回归模型建立在总体数据之上,它描述的是因变量Y 和自变量X 之间的真实的非确定型依赖关系;样本回归模型建立在抽样数据基础之 stata回归分析完整步骤——吐血推荐 ****下载连乘函数prod,方法为:findit dm71 sort stkcd date //对公司和日期排序 gen r1=1+r //r为实际公司的股票收益率 gen r2=1+r_yq //r_yq为公司的预期股票收益率 egen r3=prod(r1),by(stkcd date) //求每个公司事件日的累计复合收益率 egen r4=prod(r2),by(stkcd date) //求每个公司事件日的累计预期的复合收益率 gen r=r4-r3 capture clear (清空内存中的数据) capture log close (关闭所有打开的日志文件) set mem 128m (设置用于stata使用的内存容量) set more off (关闭more选项。如果打开该选项,那么结果分屏输出,即一次只输出一屏结果。你按空格键后再输出下一屏,直到全部输完。如果关闭则中间不停,一次全部输出。)set matsize 4000 (设置矩阵的最大阶数。我用的是不是太大了?) cd D: (进入数据所在的盘符和文件夹。和dos的命令行很相似。) log using (文件名).log,replace (打开日志文件,并更新。日志文件将记录下所有文件运行后给出的结果,如果你修改了文件内容,replace选项可以将其更新为最近运行的结果。) use (文件名),clear (打开数据文件。) (文件内容) log close (关闭日志文件。) exit,clear (退出并清空内存中的数据。) 假设你清楚地知道所需的变量,现在要做的是检查数据、生成必要的数据并形成数据库供将来使用。检查数据的重要命令包括codebook,su,ta,des和list。其中,codebook提供的信息最全面,缺点是不能使用if条件限制范围,所以,有时还要用别的帮帮忙。su空格加变量名报告相应变量的非缺失的观察个数,均值,标准差,最小值和最大值。ta空格后面加一个(或两个)变量名是报告某个变量(或两个变量二维)的取值(不含缺失值)的频数,比率和按大小排列的累积比率。des后面可以加任意个变量名,只要数据中有。它报告变量的存储的类型,显示的格式和标签。标签中一般记录这个变量的定义和单位。list报告变量的观察值,可以用if或in来限制范围。所有这些命令都可以后面不加任何变量名, 教学准备 1. 教学目标 1、能根据散点分布特点,建立不同的回归模型;了解有些非线性模型通过转化可以 转化为线性回归模型 2、了解回归模型的选择,体会不同模型拟合数据的效果 2. 教学重点/难点 教学重点:通过探究使学生体会有些非线性模型通过等量变换、对数变换可以转化为 线性回归模型 教学难点:如何启发学生“对变量作适当的变换”(等量变换、对数变换),变非线 性为线性,建立线性回归模型 3. 教学用具 多媒体 4. 标签 教学过程 一、复习引入 【师】问题1:你能回忆一下建立回归模型的基本步骤? 【师】提出问题,引导学生回忆建立回归模型的基本步骤(选变量、画散点图、选模型、估计参数、分析与预测) 【生】回忆、叙述建立回归模型的基本步骤 【板演/PPT】 【师】问题2.能刻画回归模型效果的类别有哪些?它们各有什么特点? 【生】回忆思考 【板演/PPT】 刻画回归效果的方式 (1)残差图法 作图时纵坐标为残差,横坐标可以选为的样本编号,或身高数据,或体重的估计值等,这样作出的图形称为残差图.在残差图中,残差点比较均匀地落在水平的带状区域中,说明选用的模型比较合适,这样的带状区域的宽度越窄,说明模型拟合精度越高. (2)残差平方和法 残差平方和,残差平方和越小,模型拟合效果越好. (3)利用R2刻画回归效果 ;R2表示解释变量对于预报变量变化的贡献率.R2越接近于1,表示回归的效果越好. 二、新知介绍 (1)回归模型选择比较不同模型拟合效果 【师】我国是世界产棉大国,种植棉花是我国很多地区农民的主要经济来源,棉花种植中经常会遇到一种虫害,就是红铃虫,为有效采取防止方法,有必要对红铃虫的产卵数和温度之间的关系进行研究,如图我们搜集了红铃虫的产卵数y和温度x之间的7组观测数据如下表: 【板书/PPT】 【师】试着建立y与x之间的回归方程 【生】类比前面所学过的建立线性回归方程分步骤动手实施 三、研究方法 本文采取多元线性回归的方法来设定并建立模型,再利用逐步回归来对变量予以确认和剔除。逐步回归是通过筛选,挑选偏回归平方和贡献最大的因子建立回归方程,在决定是否引入一个新的因素时,回归方程要用方差比进行显著性检验。如果判别该影响因子通过显著性检验,那么可选入方程中,否则就不应该进入到回归方程,回归方程中剔除一个变量的标准也是用方差比进行显著性检验 剔除偏回归平方和贡献最小的变量,无论是入选回归方程还是从回归方程中剔除符合条件的选入项和剔除项为止,逐步回归的方法剔除了对因变量影响小的因素 减小了分析问题的难度,提高了计算效率和回归方程的稳定性有较好的预测精度。 运用多元线性回归预测的基本思路是在确定因变量和多个自变量以及它们之间的关系后,通过设定自变量参数的回归方程对因变量进行预测。具体如下: n n 2211X a ++ X a + X a +C = Y 式中: Y 表示为粮食总产量,C 和a 为回归系数,C 、a 是待定参数,X 为所选取的影响因素.多元线性回归方法可分为强行进入法、消去法、向前选择法、向后剔除法和逐步进入法等,本文运用SPSS22.0 软件,对选择的自变量全部进入回归模型,即强行进入法进行预测。该模型的优点是方法简单、预测速度快、外推性好等。 四、分析与结果 本文选取6个解释变量,研究河南省粮食产量y ,解释变量为:X1粮食播种面积,X2农业从业人,X3农用机械总动力,X4农田有效灌溉面积,X5化肥施用折纯量,X6农村用电量。以河南省粮食产量为因变量,以如上6个解释变量为自变量做多元线性回归(数据选取2014年《河南统计年鉴》,见附录一)。 用SPSS 做变量的相关分析,从相关矩阵(表4-1)中可以看出y 与自变量的相关系数大多都在0.9以上,说明所选择变量与y 高度线性相关,用y 与自变量做多元线性回归是合适的。 表4-1相关 X1 X2 X3 X4 X5 X6 y X1 1 .687 .965 .918 .927 .970 .978 X2 .687 1 .686 .456 .448 .731 .616 X3 .965 .686 1 .946 .930 .990 .985 X4 .918 .456 .946 1 .961 .921 .960 X5 .927 .448 .930 .961 1 .901 .965 X6 .970 .731 .990 .921 .901 1 .979 . 三、研究方法 本文采取多元线性回归的方法来设定并建立模型,再利用逐步回归来对变量予以确认和剔除。逐步回归是通过筛选,挑选偏回归平方和贡献最大的因子建立回归方程,在决定是否引入一个新的因素时,回归方程要用方差比进行显著性检验。如果判别该影响因子通过显著性检验,那么可选入方程中,否则就不应该进入到回归方程,回归方程中剔除一个变量的标准也是用方差比进行显著性检验 剔除偏回归平方和贡献最小的变量,无论是入选回归方程还是从回归方程中剔除符合条件的选入项和剔除项为止,逐步回归的方法剔除了对因变量影响小的因素减小了分析问题的难度,提高了计算效率和回归方程的稳定性有较好的预测精度。运用多元线性回归预测的基本思路是在确定因变量和多个自变量以及它们之间 的关系后,通过设定自变量参数的回归方程对因变量进行预测。具体如下: Xa+?+aaX +X CY =+n121n2式中: Y 表示为粮食总产量,C和a为回归系数,C、a 是待定参数,X为所选取的影响因素.多元线性回归方法可分为强行进入法、消去法、向前选择法、向后剔除法和逐步进入法等,本文运用SPSS22.0 软件,对选择的自变量全部进入回归模型,即强行进入法进行预测。该模型的优点是方法简单、预测速度快、外推性好等。 四、分析与结果 本文选取6个解释变量,研究河南省粮食产量y,解释变量为:X1粮食播种面积, X2农业从业人,X3农用机械总动力,X4农田有效灌溉面积,X5化肥施用折纯量,X6农村用电量。以河南省粮食产量为因变量,以如上6个解释变量为自变量做 多元线性回归(数据选取2014年《河南统计年鉴》,见附录一)。 用SPSS做变量的相关分析,从相关矩阵(表4-1)中可以看出y与自变量的相 关系数大多都在0.9以上,说明所选择变量与y高度线性相关,用y与自变量做多元线性回归是合适的。 表4-1 相关 X1 X2 X3 X4 X5 X6 y 1 / 5 . .970.965 .918 .927 .978.687 X1 1 .616 1 .448.686 .731.456X2 .687 .990.930 .946.686 X3 1 .985.965 .9611 .918.946 .456X4 .960.921 .448 1 .965.961 .901X5 .930.927 .901 .970.731 X6 .990 .9791 .921 1 .979.965.960.616 y 3.1 第一课时 回归分析的基本步骤及相关系数 一、课前准备 1.课时目标 (1) 会用散点图判断两个变量是否具备相关性; (2) 能利用公式求两个相关变量的线性回归方程; (3) 了解相关系数r 刻画回归效果. 2.基础预探 1.函数关系是一种 关系.而相关关系是一种 关系. 是对具有相关关系的两个变量进行统计分析的一种常用方法. 2.线性回归方程???y bx a =+中,?b = ,?a = ,其中x = ,y = ,______________称为(i i y x ,)(i =1,2,…,n)的中心点. 3.利用相关系数r 刻画回归效果r = = ;用它来衡量它们 之间的线性相关程度.|r |≤ ,且|r |越接近于 ,相关程度越大;|r |越接近于 ,相关程度越小. 二、学习引领 1.常见的两个变量之间的关系 常见的两个变量之间的关系有两种:①函数关系是一种确定性的关系,例如正方形的周长C=4a ,周长C 与边长a 之间就是一种确定性关系.对于自变量边长的每一个确定的值,都有唯一确定的周长的值与之相对应;②当自变量取值一定时,因变量的取值带有一定的随机性的两个变量之间的关系叫做相关关系,如人的身高与年龄之间的关系,显然,相关关系是一种非确定性关系. 2.求线性回归直线方程的步骤 第一步:列表表示x i ,y i , x i 2,x i y i ; 第二步:利用公式计算?b ; 第三步:代人??a y bx =-公式计算?a 的值; 第四步:写出回归直线方程. 3.计算线性回归方程的系数的技巧 计算线性回归方程的有关量时,由于数据运算量比较大,如果不进行系统的处理容易出 错.一般推荐利用下表计算?b 的需要的参数值. 多元回归分析的步骤 Prepared on 22 November 2020 三、研究方法 本文采取多元线性回归的方法来设定并建立模型,再利用逐步回归来对变量予以确认和剔除。逐步回归是通过筛选,挑选偏回归平方和贡献最大的因子建立回归方程,在决定是否引入一个新的因素时,回归方程要用方差比进行显着性检验。如果判别该影响因子通过显着性检验,那么可选入方程中,否则就不应该进入到回归方程,回归方程中剔除一个变量的标准也是用方差比进行显着性检验剔除偏回归平方和贡献最小的变量,无论是入选回归方程还是从回归方程中剔除符合条件的选入项和剔除项为止,逐步回归的方法剔除了对因变量影响小的因素减小了分析问题的难度,提高了计算效率和回归方程的稳定性有较好的预测精度。 运用多元线性回归预测的基本思路是在确定因变量和多个自变量以及它们之间的关系后,通过设定自变量参数的回归方程对因变量进行预测。具体如下: 式中:Y表示为粮食总产量,C和a为回归系数,C、a是待定参数,X为所选取的影响因素.多元线性回归方法可分为强行进入法、消去法、向前选择法、向后剔除法和逐步进入法等,本文运用软件,对选择的自变量全部进入回归模型,即强行进入法进行预测。该模型的优点是方法简单、预测速度快、外推性好等。 四、分析与结果 本文选取6个解释变量,研究河南省粮食产量y,解释变量为:X1粮食播种面积,X2农业从业人,X3农用机械总动力,X4农田有效灌溉面积,X5化肥施用折纯量,X6农村用电量。以河南省粮食产量为因变量,以如上6个解释变量为自变量做多元线性回归(数据选取2014年《河南统计年鉴》,见附录一)。 用SPSS做变量的相关分析,从相关矩阵(表4-1)中可以看出y与自变量的相关系数大多都在以上,说明所选择变量与y高度线性相关,用y与自变量做多元线性回归是合适的。 表4-1相关 X1 X2 X3 X4 X5 X6 y X1 1 .687 .965 .918 .927 .970 .978 X2 .687 1 .686 .456 .448 .731 .616 X3 .965 .686 1 .946 .930 .990 .985 X4 .918 .456 .946 1 .961 .921 .960 X5 .927 .448 .930 .961 1 .901 .965回归分析及独立性检验的基本知识点及习题集锦
总结:线性回归分析的基本步骤
线性回归分析报告地基本步骤
总结:线性回归分析的基本步骤
stata回归分析完整步骤-吐血推荐
1.1回归分析的基本思想及其初步应用-教学设计-教案
多元回归分析的步骤
多元回归分析的步骤
3.1 第一课时 回归分析的基本步骤及相关系数
多元回归分析的步骤