synchronized和LOCK的实现原理---深入JVM锁机制--比较好

JVM底层又是如何实现synchronized的?
目前在Java中存在两种锁机制:synchronized和Lock,Lock接口及其实现类是JDK5增加的内容,其作者是大名鼎鼎的并发专家Doug Lea。本文并不比较synchronized与Lock 孰优孰劣,只是介绍二者的实现原理。
数据同步需要依赖锁,那锁的同步又依赖谁?synchronized给出的答案是在软件层面依赖JVM,而Lock给出的方案是在硬件层面依赖特殊的CPU指令,大家可能会进一步追问:JVM底层又是如何实现synchronized的?
本文所指说的JVM是指Hotspot的6u23版本,下面首先介绍synchronized的实现:
synrhronized关键字简洁、清晰、语义明确,因此即使有了Lock接口,使用的还是非常广泛。其应用层的语义是可以把任何一个非null对象作为"锁",当synchronized作用在方法上时,锁住的便是对象实例(this);当作用在静态方法时锁住的便是对象对应的Class实例,因为Class数据存在于永久带,因此静态方法锁相当于该类的一个全局锁;当synchronized作用于某一个对象实例时,锁住的便是对应的代码块。在HotSpot JVM实现中,锁有个专门的名字:对象监视器。
1. 线程状态及状态转换
当多个线程同时请求某个对象监视器时,对象监视器会设置几种状态用来区分请求的线程:
Contention List:所有请求锁的线程将被首先放置到该竞争队列
Entry List:Contention List中那些有资格成为候选人的线程被移到Entry List
Wait Set:那些调用wait方法被阻塞的线程被放置到Wait Set
OnDeck:任何时刻最多只能有一个线程正在竞争锁,该线程称为OnDeck
Owner:获得锁的线程称为Owner
!Owner:释放锁的线程
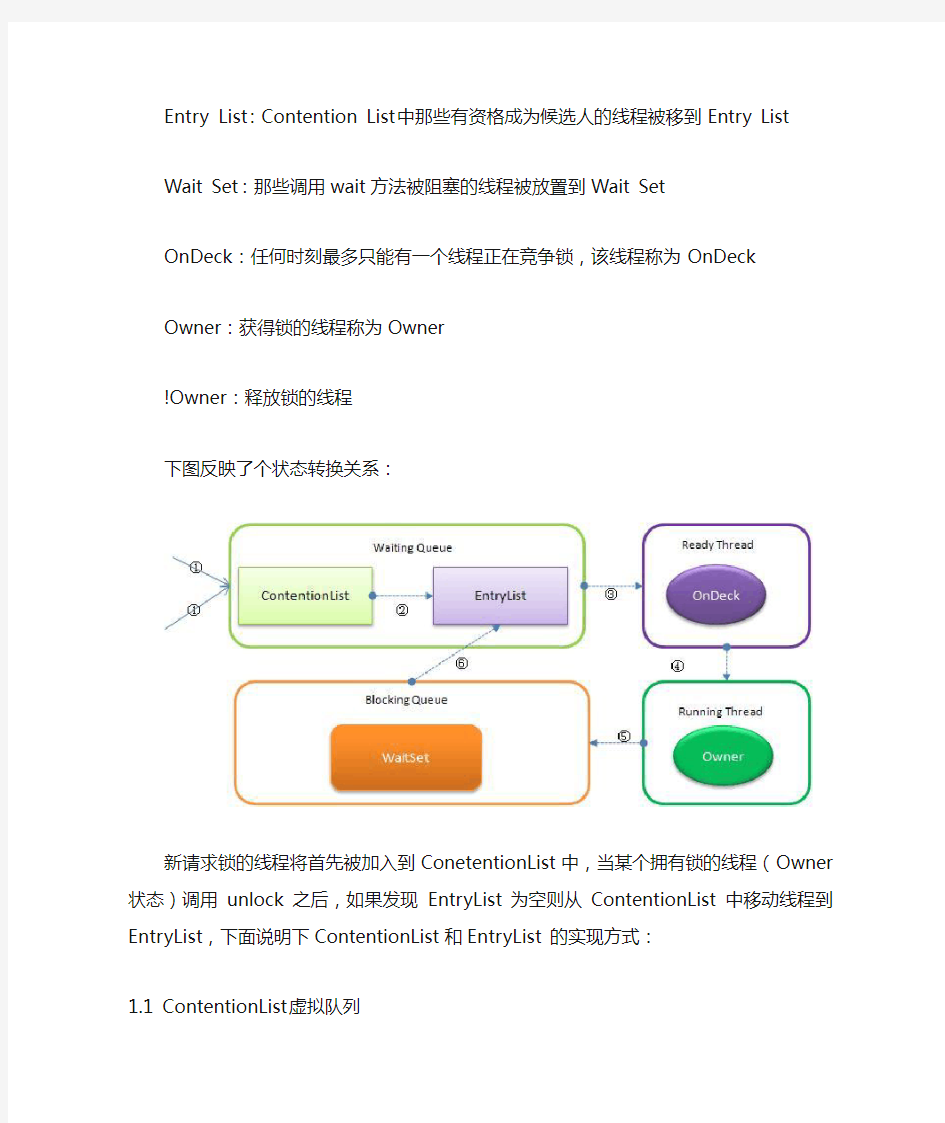
下图反映了个状态转换关系:
新请求锁的线程将首先被加入到ConetentionList中,当某个拥有锁的线程(Owner状态)调用unlock之后,如果发现EntryList为空则从ContentionList中移动线程到EntryList,下面说明下ContentionList和EntryList 的实现方式:
1.1 ContentionList虚拟队列
ContentionList并不是一个真正的Queue,而只是一个虚拟队列,原因在于ContentionList 是由Node及其next指针逻辑构成,并不存在一个Queue的数据结构。ContentionList是一个后进先出(LIFO)的队列,每次新加入Node时都会在队头进行,通过CAS改变第一个节点的的指针为新增节点,同时设置新增节点的next指向后续节点,而取得操作则发生在队尾。显然,该结构其实是个Lock- Free的队列。
因为只有Owner线程才能从队尾取元素,也即线程出列操作无争用,当然也就避免了CAS的ABA问题。
1.2 EntryList
EntryList与ContentionList逻辑上同属等待队列,ContentionList会被线程并发访问,为了降低对ContentionList队尾的争用,而建立EntryList。Owner线程在unlock时会从ContentionList中迁移线程到EntryList,并会指定EntryList中的某个线程(一般为Head)为Ready(OnDeck)线程。Owner线程并不是把锁传递给OnDeck线程,只是把竞争锁的权利交给OnDeck,OnDeck线程需要重新竞争锁。这样做虽然牺牲了一定的公平性,但极大的提高了整体吞吐量,在Hotspot中把OnDeck的选择行为称之为“竞争切换”。
OnDeck线程获得锁后即变为owner线程,无法获得锁则会依然留在EntryList中,考虑到公平性,在EntryList中的位置不发生变化(依然在队头)。如果Owner线程被wait方法阻塞,则转移到WaitSet队列;如果在某个时刻被notify/notifyAll唤醒,则再次转移到EntryList。
2. 自旋锁
那些处于ContetionList、EntryList、WaitSet中的线程均处于阻塞状态,阻塞操作由操作系统完成(在Linxu下通过pthread_mutex_lock函数)。线程被阻塞后便进入内核(Linux)调度状态,这个会导致系统在用户态与内核态之间来回切换,严重影响锁的性能
缓解上述问题的办法便是自旋,其原理是:当发生争用时,若Owner线程能在很短的时间内释放锁,则那些正在争用线程可以稍微等一等(自旋),在Owner线程释放锁后,争用线程可能会立即得到锁,从而避免了系统阻塞。但Owner运行的时间可能会超出了临界值,争用线程自旋一段时间后还是无法获得锁,这时争用线程则会停止自旋进入阻塞状态(后退)。基本思路就是自旋,不成功再阻塞,尽量降低阻塞的可能性,这对那些执行时间很短的代码块来说有非常重要的性能提高。自旋锁有个更贴切的名字:自旋-指数后退锁,也即复合锁。很显然,自旋在多处理器上才有意义。
还有个问题是,线程自旋时做些啥?其实啥都不做,可以执行几次for循环,可以执行几条空的汇编指令,目的是占着CPU不放,等待获取锁的机会。所以说,自旋是把双刃剑,如果旋的时间过长会影响整体性能,时间过短又达不到延迟阻塞的目的。显然,自旋的周期选择显得非常重要,但这与操作系统、硬件体系、系统的负载等诸多场景相关,很难选择,如果选择不当,不但性能得不到提高,可能还会下降,因此大家普遍认为自旋锁不具有扩展性。
自旋优化策略
对自旋锁周期的选择上,HotSpot认为最佳时间应是一个线程上下文切换的时间,但目前并没有做到。经过调查,目前只是通过汇编暂停了几个CPU周期,除了自旋周期选择,HotSpot还进行许多其他的自旋优化策略,具体如下:
如果平均负载小于CPUs则一直自旋
如果有超过(CPUs/2)个线程正在自旋,则后来线程直接阻塞
如果正在自旋的线程发现Owner发生了变化则延迟自旋时间(自旋计数)或进入阻塞如果CPU处于节电模式则停止自旋
自旋时间的最坏情况是CPU的存储延迟(CPU A存储了一个数据,到CPU B得知这个
数据直接的时间差)
自旋时会适当放弃线程优先级之间的差异
那synchronized实现何时使用了自旋锁?答案是在线程进入ContentionList时,也即第一步操作前。线程在进入等待队列时首先进行自旋尝试获得锁,如果不成功再进入等待队列。这对那些已经在等待队列中的线程来说,稍微显得不公平。还有一个不公平的地方是自旋线程可能会抢占了Ready线程的锁。自旋锁由每个监视对象维护,每个监视对象一个。
3. JVM1.6偏向锁
在JVM1.6中引入了偏向锁,偏向锁主要解决无竞争下的锁性能问题,首先我们看下无竞争下锁存在什么问题:
现在几乎所有的锁都是可重入的,也即已经获得锁的线程可以多次锁住/解锁监视对象,按照之前的HotSpot设计,每次加锁/解锁都会涉及到一些CAS操作(比如对等待队列的CAS 操作),CAS操作会延迟本地调用,因此偏向锁的想法是一旦线程第一次获得了监视对象,之后让监视对象“偏向”这个线程,之后的多次调用则可以避免CAS操作,说白了就是置个变量,如果发现为true则无需再走各种加锁/解锁流程。但还有很多概念需要解释、很多引入的问题需要解决:
3.1 CAS及SMP架构
CAS为什么会引入本地延迟?这要从SMP(对称多处理器)架构说起,下图大概表明了SMP的结构:
其意思是所有的CPU会共享一条系统总线(BUS),靠此总线连接主存。每个核都有自己的一级缓存,各核相对于BUS对称分布,因此这种结构称为“对称多处理器”。
而CAS的全称为Compare-And-Swap,是一条CPU的原子指令,其作用是让CPU比较后原子地更新某个位置的值,经过调查发现,其实现方式是基于硬件平台的汇编指令,就是说CAS是靠硬件实现的,JVM只是封装了汇编调用,那些AtomicInteger类便是使用了这
些封装后的接口。
Core1和Core2可能会同时把主存中某个位置的值Load到自己的L1 Cache中,当Core1在自己的L1 Cache中修改这个位置的值时,会通过总线,使Core2中L1 Cache对应的值“失效”,而Core2一旦发现自己L1 Cache中的值失效(称为Cache命中缺失)则会通过总线从内存中加载该地址最新的值,大家通过总线的来回通信称为“Cache一致性流量”,因为总线被设计为固定的“通信能力”,如果Cache一致性流量过大,总线将成为瓶颈。而当Core1和Core2中的值再次一致时,称为“Cache一致性”,从这个层面来说,锁设计的终极目标便是减少Cache一致性流量。
而CAS恰好会导致Cache一致性流量,如果有很多线程都共享同一个对象,当某个Core CAS成功时必然会引起总线风暴,这就是所谓的本地延迟,本质上偏向锁就是为了消除CAS,降低Cache一致性流量。
Cache一致性:
上面提到Cache一致性,其实是有协议支持的,现在通用的协议是MESI(最早由Intel 开始支持),具体参考:https://www.360docs.net/doc/451544023.html,/wiki/MESI_protocol,以后会仔细讲解这部分。
Cache一致性流量的例外情况:
其实也不是所有的CAS都会导致总线风暴,这跟Cache一致性协议有关,具体参考:https://www.360docs.net/doc/451544023.html,/dave/entry/biased_locking_in_hotspot
NUMA(Non Uniform Memory Access Achitecture)架构:
与SMP对应还有非对称多处理器架构,现在主要应用在一些高端处理器上,主要特点是没有总线,没有公用主存,每个Core有自己的内存,针对这种结构此处不做讨论。
3.2 偏向解除
偏向锁引入的一个重要问题是,在多争用的场景下,如果另外一个线程争用偏向对象,拥有者需要释放偏向锁,而释放的过程会带来一些性能开销,但总体说来偏向锁带来的好处还是大于CAS代价的。
4. 总结
关于锁,JVM中还引入了一些其他技术比如锁膨胀等,这些与自旋锁、偏向锁相比影响不是很大,这里就不做介绍。
通过上面的介绍可以看出,synchronized的底层实现主要依靠Lock-Free的队列,基本思路是自旋后阻塞,竞争切换后继续竞争锁,稍微牺牲了公平性,但获得了高吞吐量。
JVM中的另一种锁Lock的实现
前文(深入JVM锁机制-synchronized)分析了JVM中的synchronized实现,本文继续分析JVM中的另一种锁Lock的实现。与synchronized不同的是,Lock完全用Java写成,在java这个层面是无关JVM实现的。
在java.util.concurrent.locks包中有很多Lock的实现类,常用的有ReentrantLock、ReadWriteLock(实现类ReentrantReadWriteLock),其实现都依赖java.util.concurrent.AbstractQueuedSynchronizer类,实现思路都大同小异,因此我们以ReentrantLock作为讲解切入点。
1. ReentrantLock的调用过程
经过观察ReentrantLock把所有Lock接口的操作都委派到一个Sync类上,该类继承了AbstractQueuedSynchronizer:
view plain
static abstract class Sync extends AbstractQueuedSynchronizer
Sync又有两个子类:
view plain
final static class NonfairSync extends Sync
view plain
final static class FairSync extends Sync
显然是为了支持公平锁和非公平锁而定义,默认情况下为非公平锁。
先理一下Reentrant.lock()方法的调用过程(默认非公平锁):
这些讨厌的Template模式导致很难直观的看到整个调用过程,其实通过上面调用过程及AbstractQueuedSynchronizer的注释可以发现,AbstractQueuedSynchronizer中抽象了绝大多数Lock的功能,而只把tryAcquire方法延迟到子类中实现。tryAcquire方法的语义在于用具体子类判断请求线程是否可以获得锁,无论成功与否AbstractQueuedSynchronizer都将处理后面的流程。
2. 锁实现(加锁)
简单说来,AbstractQueuedSynchronizer会把所有的请求线程构成一个CLH队列,当一个线程执行完毕(lock.unlock())时会激活自己的后继节点,但正在执行的线程并不在队列中,而那些等待执行的线程全部处于阻塞状态,经过调查线程的显式阻塞是通过调用LockSupport.park()完成,而LockSupport.park()则调用sun.misc.Unsafe.park()本地方法,再进一步,HotSpot在Linux中中通过调用pthread_mutex_lock函数把线程交给系统内核进行阻塞。
该队列如图:
与synchronized相同的是,这也是一个虚拟队列,不存在队列实例,仅存在节点之间的前后关系。令人疑惑的是为什么采用CLH队列呢?原生的CLH队列是用于自旋锁,但Doug Lea把其改造为阻塞锁。
当有线程竞争锁时,该线程会首先尝试获得锁,这对于那些已经在队列中排队的线程来说显得不公平,这也是非公平锁的由来,与synchronized实现类似,这样会极大提高吞吐量。
如果已经存在Running线程,则新的竞争线程会被追加到队尾,具体是采用基于CAS 的Lock-Free算法,因为线程并发对Tail调用CAS可能会导致其他线程CAS失败,解决办法是循环CAS直至成功。AbstractQueuedSynchronizer的实现非常精巧,令人叹为观止,不入细节难以完全领会其精髓,下面详细说明实现过程:
2.1 Sync.nonfairTryAcquire
nonfairTryAcquire方法将是lock方法间接调用的第一个方法,每次请求锁时都会首先调用该方法。
view plain
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
该方法会首先判断当前状态,如果c==0说明没有线程正在竞争该锁,如果不c !=0 说明有线程正拥有了该锁。
如果发现c==0,则通过CAS设置该状态值为acquires,acquires的初始调用值为1,每次线程重入该锁都会+1,每次unlock都会-1,但为0时释放锁。如果CAS设置成功,则可以预计其他任何线程调用CAS都不会再成功,也就认为当前线程得到了该锁,也作为Running线程,很显然这个Running线程并未进入等待队列。
如果c !=0 但发现自己已经拥有锁,只是简单地++acquires,并修改status值,但因为没有竞争,所以通过setStatus修改,而非CAS,也就是说这段代码实现了偏向锁的功能,并且实现的非常漂亮。
2.2 AbstractQueuedSynchronizer.addWaiter
addWaiter方法负责把当前无法获得锁的线程包装为一个Node添加到队尾:
view plain
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node);
return node;
}
其中参数mode是独占锁还是共享锁,默认为null,独占锁。追加到队尾的动作分两步:如果当前队尾已经存在(tail!=null),则使用CAS把当前线程更新为Tail
如果当前Tail为null或则线程调用CAS设置队尾失败,则通过enq方法继续设置Tail 下面是enq方法:
view plain
private Node enq(final Node node) {
for (;;) {
Node t = tail;
if (t == null) { // Must initialize
Node h = new Node(); // Dummy header
h.next = node;
node.prev = h;
if (compareAndSetHead(h)) {
tail = node;
return h;
}
}
else {
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
该方法就是循环调用CAS,即使有高并发的场景,无限循环将会最终成功把当前线程追加到队尾(或设置队头)。总而言之,addWaiter的目的就是通过CAS把当前现在追加到队尾,并返回包装后的Node实例。
把线程要包装为Node对象的主要原因,除了用Node构造供虚拟队列外,还用Node 包装了各种线程状态,这些状态被精心设计为一些数字值:
SIGNAL(-1) :线程的后继线程正/已被阻塞,当该线程release或cancel时要重新这个后继线程(unpark)
CANCELLED(1):因为超时或中断,该线程已经被取消
CONDITION(-2):表明该线程被处于条件队列,就是因为调用了Condition.await而被阻塞
PROPAGATE(-3):传播共享锁
0:0代表无状态
2.3 AbstractQueuedSynchronizer.acquireQueued
acquireQueued的主要作用是把已经追加到队列的线程节点(addWaiter方法返回值)进行阻塞,但阻塞前又通过tryAccquire重试是否能获得锁,如果重试成功能则无需阻塞,直
接返回
view plain
final boolean acquireQueued(final Node node, int arg) {
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} catch (RuntimeException ex) {
cancelAcquire(node);
throw ex;
}
}
仔细看看这个方法是个无限循环,感觉如果p == head && tryAcquire(arg)条件不满足循环将永远无法结束,当然不会出现死循环,奥秘在于第12行的parkAndCheckInterrupt会把当前线程挂起,从而阻塞住线程的调用栈。
view plain
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);
return Thread.interrupted();
}
如前面所述,LockSupport.park最终把线程交给系统(Linux)内核进行阻塞。当然也不是马上把请求不到锁的线程进行阻塞,还要检查该线程的状态,比如如果该线程处于Cancel状态则没有必要,具体的检查在shouldParkAfterFailedAcquire中:view plain
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) { int ws = pred.waitStatus;
if (ws == Node.SIGNAL)
/*
* This node has already set status asking a release
* to signal it, so it can safely park
*/
return true;
if (ws > 0) {
/*
* Predecessor was cancelled. Skip over predecessors and
* indicate retry.
*/
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
/*
* waitStatus must be 0 or PROPAGA TE. Indicate that we
* need a signal, but don't park yet. Caller will need to
* retry to make sure it cannot acquire before parking.
*/
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
检查原则在于:
规则1:如果前继的节点状态为SIGNAL,表明当前节点需要unpark,则返回成功,此时acquireQueued方法的第12行(parkAndCheckInterrupt)将导致线程阻塞规则2:如果前继节点状态为CANCELLED(ws>0),说明前置节点已经被放弃,则回溯到一个非取消的前继节点,返回false,acquireQueued方法的无限循环将递归调用该方法,直至规则1返回true,导致线程阻塞
规则3:如果前继节点状态为非SIGNAL、非CANCELLED,则设置前继的状态为SIGNAL,返回false后进入acquireQueued的无限循环,与规则2同
总体看来,shouldParkAfterFailedAcquire就是靠前继节点判断当前线程是否应该被阻塞,如果前继节点处于CANCELLED状态,则顺便删除这些节点重新构造队列。
至此,锁住线程的逻辑已经完成,下面讨论解锁的过程。
3. 解锁
请求锁不成功的线程会被挂起在acquireQueued方法的第12行,12行以后的代码必须等线程被解锁锁才能执行,假如被阻塞的线程得到解锁,则执行第13行,即设置interrupted = true,之后又进入无限循环。
从无限循环的代码可以看出,并不是得到解锁的线程一定能获得锁,必须在第6行中调用tryAccquire重新竞争,因为锁是非公平的,有可能被新加入的线程获得,从而导致刚被唤醒的线程再次被阻塞,这个细节充分体现了“非公平”的精髓。通过之后将要介绍的解锁机制会看到,第一个被解锁的线程就是Head,因此p == head的判断基本都会成功。
至此可以看到,把tryAcquire方法延迟到子类中实现的做法非常精妙并具有极强的可扩展性,令人叹为观止!当然精妙的不是这个Templae设计模式,而是Doug Lea对锁结构的精心布局。
解锁代码相对简单,主要体现在AbstractQueuedSynchronizer.release和Sync.tryRelease 方法中:
class AbstractQueuedSynchronizer
view plain
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
class Sync
view plain
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
tryRelease与tryAcquire语义相同,把如何释放的逻辑延迟到子类中。tryRelease语义很明确:如果线程多次锁定,则进行多次释放,直至status==0则真正释放锁,所谓释放锁即设置status为0,因为无竞争所以没有使用CAS。
release的语义在于:如果可以释放锁,则唤醒队列第一个线程(Head),具体唤醒代码如下:
view plain
private void unparkSuccessor(Node node) {
/*
* If status is negative (i.e., possibly needing signal) try
* to clear in anticipation of signalling. It is OK if this
* fails or if status is changed by waiting thread.
*/
int ws = node.waitStatus;
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
/*
* Thread to unpark is held in successor, which is normally
* just the next node. But if cancelled or apparently null,
* traverse backwards from tail to find the actual
* non-cancelled successor.
*/
Node s = node.next;
if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
LockSupport.unpark(s.thread);
}
这段代码的意思在于找出第一个可以unpark的线程,一般说来head.next == head,Head 就是第一个线程,但Head.next可能被取消或被置为null,因此比较稳妥的办法是从后往前找第一个可用线程。貌似回溯会导致性能降低,其实这个发生的几率很小,所以不会有性能影响。之后便是通知系统内核继续该线程,在Linux下是通过pthread_mutex_unlock 完成。之后,被解锁的线程进入上面所说的重新竞争状态。
4. Lock VS Synchronized
AbstractQueuedSynchronizer通过构造一个基于阻塞的CLH队列容纳所有的阻塞线程,而对该队列的操作均通过Lock-Free(CAS)操作,但对已经获得锁的线程而言,ReentrantLock 实现了偏向锁的功能。
synchronized 的底层也是一个基于CAS操作的等待队列,但JVM实现的更精细,把等待队列分为ContentionList和EntryList,目的是为了降低线程的出列速度;当然也实现了偏向锁,从数据结构来说二者设计没有本质区别。但synchronized还实现了自旋锁,并针对不同的系统和硬件体系进行了优化,而Lock则完全依靠系统阻塞挂起等待线程。
当然Lock比synchronized更适合在应用层扩展,可以继承AbstractQueuedSynchronizer 定义各种实现,比如实现读写锁(ReadWriteLock),公平或不公平锁;同时,Lock对应的Condition也比wait/notify要方便的多、灵活的多。
JVM原理以及JVM内存管理机制
一、 JVM简介 JVM是Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。JVM工作原理和特点主要是指操作系统装入JVM是通过jdk中Java.exe来完成, 首先来说一下JVM工作原理中的jdk这个东西, .JVM 在整个jdk中处于最底层,负责于操作系统的交互,用来屏蔽操作系统环境,提供一个完整的Java运行环境,因此也就虚拟计算机. 操作系统装入JVM是通过jdk中Java.exe来完成。 通过下面4步来完成JVM环境. 1.创建JVM装载环境和配置 2.装载JVM.dll 3.初始化JVM.dll并挂界到JNIENV(JNI调用接口)实例 4.调用JNIEnv实例装载并处理class类。 对于JVM自身的物理结构,我们可以从下图了解:
JVM的一个重要的特征就是它的自动内存管理机制,在执行一段Java代码的时候,会把它所管理的内存划分 成几个不同的数据区域,其中包括: 1. 程序计数器,众所周知,JVM的多线程是通过线程轮流切换并 分配CPU执行时间的方式来实现的,那么每一个线程在切换 后都必须记住它所执行的字节码的行号,以便线程在得到CPU 时间时进行恢复,这个计数器用于记录正在执行的字节码指令的地址,这里要强调的是“字节码”,如果执行的是Native方法,那么这个计数器应该为null; 2.
3. Java计算栈,可以说整个Java程序的执行就是一个出栈入栈 的过程,JVM会为每一个线程创建一个计算栈,用于记录线程中方法的调用和变量的创建,由于在计算栈里分配的内存出栈后立即被抛弃,因此在计算栈里不存在垃圾回收,如果线程请求的栈深度大于JVM允许的深度,会抛出StackOverflowError 异常,在内存耗尽时会抛出OutOfMemoryError异常; 4. Native方法栈,JVM在调用操作系统本地方法的时候会使用到 这个栈; 5. Java堆,由于每个线程分配到的计算栈容量有限,对于可能会 占据大量内存的对象,则会被分配到Java堆中,在栈中包含了指向该对象内存的地址;对于一个Java程序来说,只有一个Java堆,也就是说,所有线程共享一个堆中的对象;由于Java堆不受线程的控制,如果在一个方法结束之后立即回收这个方法使用到的对象,并不能保证其他线程是否正在使用该对象;因此堆中对象的回收由JVM的垃圾收集器统一管理,和某一个线程无关;在HotSpot虚拟机中Java堆被划分为三代:o新生代,正常情况下新创建的对象会被分配到新生代,但如果对象占据的内存足够大以致超过了新生代的容量限 制,也可能被分配到老年代;新生代对象的一个特点是最 新、且生命周期不长,被回收的可能性高;
JVM调优总结
JVM调优总结(一)-- 一些概念 数据类型 Java虚拟机中,数据类型可以分为两类:基本类型和引用类型。基本类型的变量保存原始值,即:他代表的值就是数值本身;而引用类型的变量保存引用值。―引用值‖代表了某个对象的引用,而不是对象本身,对象本身存放在这个引用值所表示的地址的位置。 基本类型包括:byte,short,int,long,char,float,double,Boolean,returnAddress 引用类型包括:类类型,接口类型和数组。 堆与栈 堆和栈是程序运行的关键,很有必要把他们的关系说清楚。 栈是运行时的单位,而堆是存储的单位。 栈解决程序的运行问题,即程序如何执行,或者说如何处理数据;堆解决的是数据存储的问题,即数据怎么放、放在哪儿。
在Java中一个线程就会相应有一个线程栈与之对应,这点很容易理解,因为不同的线程执行逻辑有所不同,因此需要一个独立的线程栈。而堆则是所有线程共享的。栈因为是运行单位,因此里面存储的信息都是跟当前线程(或程序)相关信息的。包括局部变量、程序运行状态、方法返回值等等;而堆只负责存储对象信息。 为什么要把堆和栈区分出来呢?栈中不是也可以存储数据吗? 第一,从软件设计的角度看,栈代表了处理逻辑,而堆代表了数据。这样分开,使得处理逻辑更为清晰。分而治之的思想。这种隔离、模块化的思想在软件设计的方方面面都有体现。 第二,堆与栈的分离,使得堆中的内容可以被多个栈共享(也可以理解为多个线程访问同一个对象)。这种共享的收益是很多的。一方面这种共享提供了一种有效的数据交互方式(如:共享内存),另一方面,堆中的共享常量和缓存可以被所有栈访问,节省了空间。 第三,栈因为运行时的需要,比如保存系统运行的上下文,需要进行地址段的划分。由于栈只能向上增长,因此就会限制住栈存储内容的能力。而堆不同,堆中的对象是可以根据需要动态增长的,因此栈和堆的拆分,使得动态增长成为可能,相应栈中只需记录堆中的一个地址即可。 第四,面向对象就是堆和栈的完美结合。其实,面向对象方式的程序与以前结构化的程序在执行上没有任何区别。但是,面向对象的引入,使得对待问题的思考方式发生了改变,而更接近于自然方式的思考。当我们把对象拆开,你会发现,对象的属性其实就是数据,存放在堆中;而对象的行为(方法),就是运行逻辑,放在栈中。我们在编写对象的时候,其实即编写了数据结构,也编写的处理数据的逻辑。不得不承认,面向对象的设计,确实很美。 在Java中,Main函数就是栈的起始点,也是程序的起始点。 程序要运行总是有一个起点的。同C语言一样,java中的Main就是那个起点。无论什么java程序,找到main就找到了程序执行的入口:) 堆中存什么?栈中存什么? 堆中存的是对象。栈中存的是基本数据类型和堆中对象的引用。一个对象的大小是不可估计的,或者说是可以动态变化的,但是在栈中,一个对象只对应了一个4btye的引用(堆栈分离的好处:))。 为什么不把基本类型放堆中呢?因为其占用的空间一般是1~8个字节——需要空间比较少,而且因为是基本类型,所以不会出现动态增长的情况——长度固定,因此栈中存储就够了,如果把他存在堆中是没有什么意义的(还会浪费空间,后面说明)。可以这么说,基本类型和对象的引用都是存放在栈中,而且都是几个字节的一个数,因此在程序运行时,他们的处理方式是统一的。但是基本类型、对象引用和对象本身就有所区别了,因为一个是栈中的数据一个是堆中的数据。最常见的一个问题就是,Java中参数传递时的问题。
Java之volatile的使用及其原理
一、volatile的作用 我们已经知道可见性、有序性及原子性问题,通常情况下我们可以通过Synchronized关键字来解决这些个问题,不过如果对Synchronized原理有了解的话,应该知道Synchronized是一个比较重量级的操作,对系统的性能有比较大的影响,所以,如果有其他解决方案,我们通常都避免使用Synchronized来解决问题。 而volatile关键字就是Java中提供的另一种解决可见性和有序性问题的方案。对于原子性,需要强调一点,也是大家容易误解的一点:对volatile变量的单次读/写操作可以保证原子性的,如long和double类型变量,但是并不能保证i++这种操作的原子性,因为本质上i++是读、写两次操作。 二、volatile的使用 关于volatile的使用,我们可以通过几个例子来说明其使用方式和场景。 1、防止重排序 我们从一个最经典的例子来分析重排序问题。大家应该都很熟悉单例模式的实现,而在并发环境下的单例实现方式,我们通常可以采用双重检查加锁(DCL)的方式来实现。其源码如下: package com.paddx.test.concurrent; public class Singleton { public static volatile Singleton singleton; /** * 构造函数私有,禁止外部实例化 */ private Singleton() {}; public static Singleton getInstance() { if (singleton == null) { synchronized (singleton) { if (singleton == null) { singleton = new Singleton(); } } } return singleton; } } 现在我们分析一下为什么要在变量singleton之间加上volatile关键字。要理解这个问题,先要了解对象的构造过程,实例化一个对象其实可以分为三个步骤: ?分配内存空间。 ?初始化对象。
java内存屏障与JVM并发详解
深入Java底层:内存屏障与JVM并发详解(1) 本文介绍了内存屏障对多线程程序的影响,同时将研究内存屏障与JVM并发机制的关系,如易变量(volatile)、同步(synchronized)和原子条件式(atomic conditional)。 AD:内存屏障,又称内存栅栏,是一组处理器指令,用于实现对内存操作的顺序限制。本文假定读者已经充分掌握了相关概念和Java内存模型,不讨论并发互斥、并行机制和原子性。内存屏障用来实现并发编程中称为可见性(visibility)的同样重要的作用。 关于JVM更多内容,请参阅:JVM详解 Java虚拟机原理与优化 内存屏障为何重要? 对主存的一次访问一般花费硬件的数百次时钟周期。处理器通过缓存(caching)能够从数量级上降低内存延迟的成本这些缓存为了性能重新排列待定内存操作的顺序。也就是说,程序的读写操作不一定会按照它要求处理器的顺序执行。当数据是不可变的,同时/或者数据限制在线程范围内,这些优化是无害的。 如果把这些优化与对称多处理(symmetric multi-processing)和共享可变状态(shared mutable state)结合,那么就是一场噩梦。当基于共享可变状态的内存操作被重新排序时,程序可能行为不定。一个线程写入的数据可能被其他线程可见,原因是数据写入的顺序不一致。适当的放置内存屏障通过强制处理器顺序执行待定的内存操作来避免这个问题。 内存屏障的协调作用 内存屏障不直接由JVM暴露,相反它们被JVM插入到指令序列中以维持语言层并发原语的语义。我们研究几个简单Java程序的源代码和汇编指令。首先快速看一下Dekker算法中的内存屏障。该算法利用volatile变量协调两个线程之间的共享资源访问。 请不要关注该算法的出色细节。哪些部分是相关的?每个线程通过发信号试图进入代码第一行的关键区域。如果线程在第三行意识到冲突(两个线程都要访问),通过turn变量的操作来解决。在任何时刻只有一个线程可以访问关键区域。 1. // code run by first thread // code run by second thread 2. 3. 1 intentFirst = true; intentSecond = true;
Java虚拟机工作原理(JVM)
As the Java V irtual Machine is a stack-based machine, almost all of its instructions involve the operand stack in some way. Most instructions push values, pop values, or both as they perform their functions. Java虚拟机是基于栈的(stack-based machine)。几乎所有的java虚拟机的指令,都与操作数栈(operand stack)有关.绝大多数指令都会在执行自己功能的时候进行入栈、出栈操作。 1Java体系结构介绍 Javaís architecture arises out of four distinct but interrelated technologies, each of which is defined by a separate specification from Sun Microsystems: 1.1 Java体系结构包括哪几部分? Java体系结构包括4个独立但相关的技术 the Java programming language →程序设计语言 the Java class file format →字节码文件格式 the Java Application Programming Interface→应用编程接口 the Java V irtual Machine →虚拟机 1.2 什么是JVM java虚拟机和java API组成了java运行时。 1.3 JVM的主要任务。 Java虚拟机的主要任务是装载class文件并执行其中的字节码。 Java虚拟机包含了一个类装载器。 类装载器的体系结构 二种类装载器 启动类装载器 用户定义的类装载器 启动类装载器是JVM实现的一部分 当被装载的类引用另外一个类时,JVM就是使用装载第一个类的类装载器装载被引用的类。 1.4 为什么java容易被反编译? ●因为java程序是动态连接的。从一个类到另一个类的引用是符号化的。在静态连接的 可执行程序中。类之间的引用只是直接的指针或者偏移量。相反在java的class文件中,指向另一个类的引用通过字符串清楚的标明了所指向的这个类的名字。
JVM调优总结:典型配置举例
JVM调优总结:典型配置举例 以下配置主要针对分代垃圾回收算法而言。 堆大小设置 年轻代的设置很关键 JVM中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制;系统的可用虚拟内存限制;系统的可用物理内存限制。32位系统下,一般限制在1.5G~2G;64为操作系统对内存无限制。在Windows Server 2003 系统,3.5G物理内存,JDK5.0下测试,最大可设置为1478m。 典型设置: java -Xmx3550m -Xms3550m -Xmn2g –Xss128k -Xmx3550m:设置JVM最大可用内存为3550M。 -Xms3550m:设置JVM促使内存为3550m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。 -Xmn2g:设置年轻代大小为2G。整个堆大小=年轻代大小+ 年老代大小+ 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。 -Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右 java -Xmx3550m -Xms3550m -Xss128k -XX:NewRatio=4 -XX:SurvivorRatio=4 -XX:MaxPermSize=16m -XX:MaxTenuringThreshold=0 -XX:NewRatio=4:设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5 -XX:SurvivorRatio=4:设置年轻代中Eden区与Survivor区的大小比值。设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6 -XX:MaxPermSize=16m:设置持久代大小为16m。 -XX:MaxTenuringThreshold=0:设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概论。 回收器选择 JVM给了三种选择:串行收集器、并行收集器、并发收集器,但是串行收集器只适用于小数据量的情况,所以这里的选择主要针对并行收集器和并发收集器。默
java虚拟机详解 免费
深入理解JVM 1 Java技术与Java虚拟机 说起Java,人们首先想到的是Java编程语言,然而事实上,Java是一种技术,它由四方面组成: Java编程语言、Java类文件格式、Java虚拟机和Java应用程序接口(Java API)。它们的关系如下图所示: 图1 Java四个方面的关系 运行期环境代表着Java平台,开发人员编写Java代码(.java文件),然后将之编译成字节码(.class文件)。最后字节码被装入内存,一旦字节码进入虚拟机,它就会被解释器解释执行,或者是被即时代码发生器有选择的转换成机器码执行。从上图也可以看出Java平台由Java虚拟机和Java应用程序接口搭建,Java 语言则是进入这个平台的通道,用Java语言编写并编译的程序可以运行在这个平台上。这个平台的结构如下图所示:
在Java平台的结构中, 可以看出,Java虚拟机(JVM) 处在核心的位置,是程序与底层操作系统和硬件无关的关键。它的下方是移植接口,移植接口由两部分组成:适配器和Java操作系统, 其中依赖于平台的部分称为适配器;JVM 通过移植接口在具体的平台和操作系统上实现;在JVM 的上方是Java的基本类库和扩展类库以及它们的API,利用Java API编写的应用程序(application) 和小程序(Java applet) 可以在任何Java平台上运行而无需考虑底层平台, 就是因为有Java虚拟机(JVM)实现了程序与操作系统的分离,从而实现了Java 的平台无关性。 那么到底什么是Java虚拟机(JVM)呢?通常我们谈论JVM时,我们的意思可能是: 1. 对JVM规范的的比较抽象的说明; 2. 对JVM的具体实现; 3. 在程序运行期间所生成的一个JVM实例。 对JVM规范的的抽象说明是一些概念的集合,它们已经在书《The Java Virtual Machine Specification》(《Java虚拟机规范》)中被详细地描述了;对JVM的具体实现要么是软件,要么是软件和硬件的组合,它已经被许多生产厂商所实现,并存在于多种平台之上;运行Java程序的任务由JVM的运行期实例单个承担。在本文中我们所讨论的Java虚拟机(JVM)主要针对第三种情况而言。它可以被看成一个想象中的机器,在实际的计算机上通过软件模拟来实现,有自己想象中的硬件,如处理器、堆栈、寄存器等,还有自己相应的指令系统。 JVM在它的生存周期中有一个明确的任务,那就是运行Java程序,因此当Java程序启动的时候,就产生JVM的一个实例;当程序运行结束的时候,该实例也跟着消失了。下面我们从JVM的体系结构和它的运行过程这两个方面来对它进行比较深入的研究。 2 Java虚拟机的体系结构 刚才已经提到,JVM可以由不同的厂商来实现。由于厂商的不同必然导致JVM在实现上的一些不同,然而JVM还是可以实现跨平台的特性,这就要归功于设计JVM时的体系结构了。 我们知道,一个JVM实例的行为不光是它自己的事,还涉及到它的子系统、存储区域、数据类型和指令这些部分,它们描述了JVM的一个抽象的内部体系结构,其目的不光规定实现JVM时它内部的体系结构,更重要的是提供了一种方式,用于严格定义实现时的外部行为。每个JVM都有两种机制,一个是装载具有合适名称的类(类或是接口),叫做类装载子系统;另外的一个负责执行包含在已装载的类或接口中的指令,叫做运行引擎。每个JVM又包括方法区、堆、Java栈、程序计数器和本地方法栈这五个部分,这几个部分和类装载机制与运行引擎机制一起组成的体系结构图为:
JVM工作原理
JVM工作原理 1.JVM是什么? 为java程序提供运行环境,将java字节码文件翻译成机器可执行的二进制程序。 2. JVM装入:操作系统通过jdk中的java.exe来装入JVM ①、创建JVM装载环境和配置 ②、装载JVM.dll ③、初始化JVM.dll并挂界到JNIENV(JNI调用接口)实例 ④、调用JNIEnv实例装载并处理class类 3. JVM装入环境,JVM提供的方式是操作系统的动态连接文件 基于Windows的实现的分析 ①、查找jre路径 Java是通过GetApplicationHome api来获得当前的Java.exe绝对路径 ②、查找JVM.dll F:\Java\jdk1.6.0_20\jre\bin\java.dll 或GetPublicJREHome HKEY_LOCAL_MACHINE\Software\JavaSoft\Java Runtime Environment ③、装载JVM.cfg文件 F:\Java\jdk1.6.0_20\jre\lib\i386\JVM.cfg jdk目录中jre\bin\server和jre\bin\client都有JVM.dll文件存在,而Java 正是通过JVM.cfg配置文件来管理这些不同版本的JVM.dll的 主要参数: -client KNOWN -server KNOWN -hotspot ALIASED_TO -client -classic WARN -native ERROR -green ERROR KNOWN表示JVM存在ALIASED_TO表示给别的JVM取一个别名 WARN表示不存在时找一个JVM替代ERROR表示不存在抛出异常 在运行Java XXX是,Java.exe会通过CheckJVMType来检查当前的JVM类型,Java可以通过两种参数的方式来指定具体的JVM类型,一种按照JVM.cfg文件中的JVM名称指定,第二种方法是直接指定: ①、Java –J ②、Java -XXaltJVM= 或Java -J-XXaltJVM= 如果是第一种参数传递方式,CheckJVMType函数会取参数…-J?后面的JVM名称,然后从已知的JVM配置参数中查找如果找到同名的则去掉该JVM名称前的…-?直接返回该值;而第二种方法,会直接返回“-XXaltJVM=”或“-J-XXaltJVM=”后面的JVM类型名称。如果在运行Java时未指定上面两种方法中的任一一种参数,CheckJVMType会取配置文件中
Java虚拟机的内存结构
我们都知道虚拟机的内存划分了多个区域,并不是一张大饼。那么为什么要划分为多块区域呢,直接搞一块区域,所有用到内存的地方都往这块区域里扔不就行了,岂不痛快。是的,如果不进行区域划分,扔的时候确实痛快,可用的时候再去找怎么办呢,这就引入了第一个问题,分类管理,类似于衣柜,系统磁盘等等,为了方便查找,我们会进行分区分类。另外如果不进行分区,内存用尽了怎么办呢?这里就引入了内存划分的第二个原因,就是为了方便内存的回收。如果不分,回收内存需要全部内存扫描,那就慢死了,内存根据不同的使用功能分成不同的区域,那么内存回收也就可以根据每个区域的特定进行回收,比如像栈内存中的栈帧,随着方法的执行栈帧进栈,方法执行完毕就出栈了,而对于像堆内存的回收就需要使用经典的回收算法来进行回收了,所以看起来分类这么麻烦,其实是大有好处的。 提到虚拟机的内存结构,可能首先想起来的就是堆栈。对象分配到堆上,栈上用来分配对象的引用以及一些基本数据类型相关的值。但是·虚拟机的内存结构远比此要复杂的多。除了我们所认识的(还没有认识完全)的堆栈以外,还有程序计数器,本地方法栈和方法区。我们平时所说的栈内存,一般是指的栈内存中的局部变量表。下面是官方所给的虚拟机的内存结构图
从图中可以看到有5大内存区域,按照是否被线程所共享可分为两部分,一部分是线程独占区域,包括Java栈,本地方法栈和程序计数器。还有一部分是被线程所共享的,包括方法区和堆。什么是线程共享和线程独占呢,非常好理解,我们知道每一个Java进行都会有多个线程同时运行,那么线程共享区的这片区域就是被所有线程一起使用的,不管有多少个线程,这片空间始终就这一个。而线程的独占区,是每个线程都有这么一份内存空间,每个线程的这片空间都是独有的,有多少个线程就有多少个这么个空间。上图的区域的大小并不代表实际内存区域的大小,实际运行过程中,内存区域的大小也是可以动态调整的。下面来具体说说每一个区域的主要功能。
Java架构学习【JVM与性能优化知识点整理】编写高效优雅Java程序
面向对象 构造器参数太多怎么办? 用builder模式,用在 1、5个或者5个以上的成员变量 2、参数不多,但是在未来,参数会增加 Builder模式: 属于对象的创建模式,一般有 1.抽象建造者:一般来说是个接口,包含1)建造方法,建造部件的方法(不止一 个),2)返回产品的方法 2.具体建造者 3.导演者,调用具体的建造者,创建产品对象 4.产品,需要建造的复杂对象 对于客户端,创建导演者和具体建造者,并把具体建造者交给导演者,然后由客户端通知导演者操纵建造者进行产品的创建。 在实际的应用过程中,有时会省略抽象建造者和导演者。 不需要实例化的类应该构造器私有 如,一些工具类提供的都是静态方法,这些类是不应该提供具体的实例的。可以参考JDK 中的Arrays。 不要创建不必要的对象 1.避免无意中创建的对象,如自动装箱 2.可以在类的多个实例之间重用的成员变量,尽量使用static。
但是,要记住,是不要创建不必要的对象,而不是不要创建对象。 对象池要谨慎使用,除非创建的对象是非常昂贵的操作,如数据库的连接,巨型对象等等。 避免使用终结方法 finalizer方法,jdk不能保证何时执行,也不能保证一定会执行。如果有确实要释放的资源应该用try/finally。 使类和成员的可访问性最小化 编写程序和设计架构,最重要的目标之一就是模块之间的解耦。使类和成员的可访问性最小化无疑是有效的途径之一。 使可变性最小化 尽量使类不可变,不可变的类比可变的类更加易于设计、实现和使用,而且更不容易出错,更安全。 常用的手段: 不提供任何可以修改对象状态的方法; 使所有的域都是final的。 使所有的域都是私有的。 使用写时复制机制。带来的问题:会导致系统产生大量的对象,而且性能有一定的影响,需要在使用过程中小心权衡。 复合优先于继承 继承容易破坏封装性,而且会使子类的实现依赖于父类。 复合则是在类中增加一个私有域,引用类的一个实例,这样的话就避免了依赖类的具体实现。 只有在子类确实是父类的一个子类型时,才比较适合用继承。 接口优于抽象类 java是个单继承的,但是类允许实现多个接口。
synchronized和LOCK的实现原理---深入JVM锁机制--比较好
JVM底层又是如何实现synchronized的? 目前在Java中存在两种锁机制:synchronized和Lock,Lock接口及其实现类是JDK5增加的内容,其作者是大名鼎鼎的并发专家Doug Lea。本文并不比较synchronized与Lock 孰优孰劣,只是介绍二者的实现原理。 数据同步需要依赖锁,那锁的同步又依赖谁?synchronized给出的答案是在软件层面依赖JVM,而Lock给出的方案是在硬件层面依赖特殊的CPU指令,大家可能会进一步追问:JVM底层又是如何实现synchronized的? 本文所指说的JVM是指Hotspot的6u23版本,下面首先介绍synchronized的实现: synrhronized关键字简洁、清晰、语义明确,因此即使有了Lock接口,使用的还是非常广泛。其应用层的语义是可以把任何一个非null对象作为"锁",当synchronized作用在方法上时,锁住的便是对象实例(this);当作用在静态方法时锁住的便是对象对应的Class实例,因为Class数据存在于永久带,因此静态方法锁相当于该类的一个全局锁;当synchronized作用于某一个对象实例时,锁住的便是对应的代码块。在HotSpot JVM实现中,锁有个专门的名字:对象监视器。 1. 线程状态及状态转换 当多个线程同时请求某个对象监视器时,对象监视器会设置几种状态用来区分请求的线程: Contention List:所有请求锁的线程将被首先放置到该竞争队列 Entry List:Contention List中那些有资格成为候选人的线程被移到Entry List Wait Set:那些调用wait方法被阻塞的线程被放置到Wait Set OnDeck:任何时刻最多只能有一个线程正在竞争锁,该线程称为OnDeck Owner:获得锁的线程称为Owner !Owner:释放锁的线程 下图反映了个状态转换关系:
java虚拟机的原理和作用
Java虚拟机 一、什么是Java虚拟机 Java虚拟机是一个想象中的机器,在实际的计算机上通过软件模拟来实现。Java虚拟机有自己想象中的硬件,如处理器、堆栈、寄存器等,还具有相应的指令系统。 1.为什么要使用Java虚拟机 Java语言的一个非常重要的特点就是与平台的无关性。而使用Java虚拟机是实现这一特点的关键。一般的高级语言如果要在不同的平台上运行,至少需要编译成不同的目标代码。而引入Java语言虚拟机后,Java语言在不同平台上运行时不需要重新编译。Java语言使用模式Java虚拟机屏蔽了与具体平台相关的信息,使得Java语言编译程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。Java虚拟机在执行字节码时,把字节码解释成具体平台上的机器指令执行。 2.谁需要了解Java虚拟机 Java虚拟机是Java语言底层实现的基础,对Java语言感兴趣的人都应对Java虚拟机有个大概的了解。这有助于理解Java语言的一些性质,也有助于使用Java语言。对于要在特定平台上实现Java虚拟机的软件人员,Java语言的编译器作者以及要用硬件芯片实现Java虚拟机的人来说,则必须深刻理解Java 虚拟机的规范。另外,如果你想扩展Java语言,或是把其它语言编译成Java语言的字节码,你也需要深入地了解Java虚拟机。 3.Java虚拟机支持的数据类型 Java虚拟机支持Java语言的基本数据类型如下: byte://1字节有符号整数的补码 short://2字节有符号整数的补码 int://4字节有符号整数的补码 long://8字节有符号整数的补码 float://4字节IEEE754单精度浮点数 double://8字节IEEE754双精度浮点数 char://2字节无符号Unicode字符 几乎所有的Java类型检查都是在编译时完成的。上面列出的原始数据类型的数据在Java执行时不需要用硬件标记。*作这些原始数据类型数据的字节码(指令)本身就已经指出了*作数的数据类型,例如iadd、ladd、fadd和dadd指令都是把两个数相加,其*作数类型别是int、long、 float和double。虚拟机没有给boolean(布尔)类型设置单独的指令。boolean型的数据是由integer指令,包括integer 返回来处理的。boolean型的数组则是用byte数组来处理的。虚拟机使用IEEE754格式的浮点数。不支持IEEE格式的较旧的计算机,在运行 Java数值计算程序时,可能会非常慢。 虚拟机支持的其它数据类型包括: object//对一个Javaobject(对象)的4字节引用 returnAddress//4字节,用于jsr/ret/jsr-w/ret-w指令 注:Java数组被当作object处理。 虚拟机的规范对于object内部的结构没有任何特殊的要求。在Sun公司的实现中,对object的引用是一个句柄,其中包含一对指针:一个指针指向该object的方法表,另一个指向该object的数据。用Java
JVM性能调优
JVM性能调优 一、引言 本文的读者是技术支持人员。阅读本文后,你将理解jboss的启动脚本文件(run.sh)中有一系列的JVM配置参数的含义,以及如何调整它们,从而使得MegaEyes中心管理服务器的性能得到优化。 MegaEyes中心管理服务器的性能调优涉及到系统的多个方面,包括MegaEyes应用本身、应用服务器(jboss)、数据库和java虚拟机(JVM)等等。本文重点介绍JVM的性能优化。 需要注意的是,JVM性能调优具有应用独特性(application specific),就是说,不同的应用情形应该有不同的调整方案,这就要求你首先要观察JVM的运行状态,然后根据观察结果调整参数。没有一个通用的调优方案可以适用于所有的MegaEyes应用。 什么是性能调优 对性能调优,不同的人有不同的理解,本文是指对下列指标最大化: ?并发用户(concurrent users),在服务请求失败或请求响应超过预期时间之前,系 统支持的最大并发用户数量。 ?系统容量(throughput),可以用每秒处理的事务(transaction)数量计算。 ?可靠性(reliability) 换句话说,我们想对更多的用户提供更快捷的、不会中断的服务。 JVM性能调优的重点 JVM的性能调优的重点是垃圾回收(gc,garbage collection)和内存管理。垃圾回收的时候会导致整个虚拟机暂停服务,因此,应该尽可能地缩短垃圾回收的处理时间。 JVM内存 JVM占用的内存称为堆(heap),它被分为三个区:年轻(young,又称为new)、老(tenured,又称为old)和永生(perm)。这三个区是按照java对象的生存期划分的,在new区的对象生存期最短,很快就会被gc回收;perm区的对象生存期最长,与JVM同生死。Perm区的对象不会被gc回收。 new区又被分为三个部分:伊甸园(eden)和两个幸存者(survivor)。对象的创建总是在eden部分(这大概就是命名该部分为eden的原因吧)。两个survivor中总有一个是空的,它作为另一个survivor的缓冲区。当gc发生时,所有eden和survivor中活下来的对象被移动到另一个survivor中。对象会在两个survivor之间不断移动,直到活得足够久,然后移动到old区。我们可以猜想,之所以如此划分使用内存,肯定是为了缩短gc的执行时间,提
java序列化原理与算法
Java序列化原理和算法 总结: java中序列化算法的顺序: 1、子类的类信息描述 2、子类的字段信息描述(如果遇到类对象的属性,暂时用string的指针表示) 3、父类的类信息描述 4、父类的字段信息描述 5、对父类的字段信息进行赋值 6、对子类的字段信息进行赋值 7、发现子类的字段为类对象时,描述该类对象,并查找该类对象的父类,以以上方式描述,然后赋值。 本文讲解了Java序列化的机制和原理。从文中你可以了解如何序列化一个对象,什么时候需要序列化以及Java序列化的算法。 有关Java对象的序列化和反序列化也算是Java基础的一部分,下面对Java序列化的机制和原理进行一些介绍。 Java序列化算法透析 Serialization(序列化)是一种将对象以一连串的字节描述的过程;反序列化deserialization 是一种将这些字节重建成一个对象的过程。Java序列化API提供一种处理对象序列化的标准机制。在这里你能学到如何序列化一个对象,什么时候需要序列化以及Java序列化的算法,我们用一个实例来示范序列化以后的字节是如何描述一个对象的信息的。 序列化的必要性 Java中,一切都是对象,在分布式环境中经常需要将Object从这一端网络或设备传递到另一端。 这就需要有一种可以在两端传输数据的协议。Java序列化机制就是为了解决这个问题而产生。如何序列化一个对象 一个对象能够序列化的前提是实现Serializable接口,Serializable接口没有方法,更像是个标记。 有了这个标记的Class就能被序列化机制处理。 import java.io.Serializable; class TestSerial implements Serializable { public byte version = 100; public byte count = 0; } 然后我们写个程序将对象序列化并输出。ObjectOutputStream能把Object输出成Byte流。 我们将Byte流暂时存储到temp.out文件里。 public static void main(String args[]) throws IOException { FileOutputStream fos = new FileOutputStream("temp.out");
JVM调优
一、 GC概要: JVM 堆相关知识 为什么先说JVM堆? JVM的堆是Java对象的活动空间,程序中的类的对象从中分配空间,其存储着正在运行着的应用程序用到的所有对象。这些对象的建立方式就是那些new一类的操作,当对象无用后,是GC来负责这个无用的对象(地球人都知道)。 JVM堆 (1) 新域:存储所有新成生的对象 (2) 旧域:新域中的对象,经过了一定次数的GC循环后,被移入旧域 (3)永久域:存储类和方法对象,从配置的角度看,这个域是独立的,不包括在JVM堆内。默认为4M。 新域会被分为3个部分:1.第一个部分叫Eden。(伊甸园??可能是因为亚当和夏娃是人类最早的活动对象?)2.另两个部分称为辅助生存空间(幼儿园),我这里一个称为A空间(From sqace),一个称为B空间(To Space)。
GC 浅谈: GC的工作目的很明确:在堆中,找到已经无用的对象,并把这些对象占用的空间收回使其可以重新利用.大多数垃圾回收的算法思路都是一致的:把所有对象组成一个集合,或可以理解为树状结构,从树根开始找,只要可以找到的都是活动对象,如果找不到,这个对象就是凋零的昨日黄花,应该被回收了。 在sun 的文档说明中,对JVM堆的新域,是采用coping算法,该算法的提出是为了克服句柄的开销和解决堆碎片的垃圾回收。它开始时把堆分成一个对象面和多个空闲面,程序从对象面为对象分配空间,当对象满了,基于 coping算法的垃圾收集就从根集中扫描活动对象,并将每个活动对象复制到空闲面(使得活动对象所占的内存之间没有空闲
洞),这样空闲面变成了对象面,原来的对象面变成了空闲面,程序会在新的对象面中分配内存。 对于新生成的对象,都放在Eden中;当Eden充满时(小孩太多了),GC将开始工作,首先停止应用程序 的运行,开始收集垃圾,把所有可找到的对象都复制到A空间中,一旦当A空间充满,GC就把在A空间中 可找到的对象都复制到B空间中(会覆盖原有的存储对象),当B空间满的时间,GC就把在B空间中可找到的 对象都复制到A空间中,AB在这个过程中互换角色,那位客官说了:拷来拷去,烦不烦啊?什么时候是头? 您别急,在活动对象经过一定次数的GC操作后,这些活动对象就会被放到旧域中。对于这些活动对象, 新域的幼儿园生活结束了。 新域为什么要这么折腾?
Java 精髓
从宏观上看,编程技术的发展在一定程度上映射了历史的发展。正如人类社会起源于极其简单的原始社会,早期的编程技术具有同样的规律;正如伟大的文明要经历萌芽、繁荣和衰落的过程,编程语言也同样会经历这些过程。国家的兴亡交替促进了人类的进步。同样,编程技术也处于不断的新旧更替之中:新的编程语言取代原来的编程语言。纵观人类历史,总不乏一些关键性事件,例如罗马帝国的颠覆、1066年的不列颠入侵,还有第一次核爆炸,它们都彻底改变了原来的世界。对于编程语言来说,虽然变革的规模较小,但同样改变了编程技术的发展进程。例如,FORTRAN语言的发明彻底改变了计算机编程的方式。Java的发明,则是另一个重大事件。 Java是标志编程进入Internet时代的里程碑。Java的设计初衷就是用来创建可以在Internet 上随处运行的应用程序,其“一次编写,随处运行”的理念定义了一种新的编程规范。Gosling 等人最初将其视为小型问题的解决方案,但后来却成为下一代程序员规划编程前景的动力。Java从根本上改变了人们对于编程的认识,因此计算机语言的发展历史可划分为两个时代:Java前时代和Java后时代。 Java前时代的程序员编写在单机上运行的程序;而Java后时代的程序员则为分布式网络环境编写程序。程序员不再只考虑单机的需求;相反,如今“网络就是计算机”的理念非常流行,程序员应该以服务器、客户端和主机的概念进行思考。 虽然Java的发展是由Internet所驱动的,但Java决不只是一种“Internet语言”。相反,它是一种特征(featuree)完备、为现代网络世界设计的通用编程语言。这意味着Java适合于几乎所有类型的编程。尽管有时候Java受限于网络性能,但它仍然包容了许多推进编程技术发展的新特征。这些特征不断影响着如今的计算模式。例如,Java提出的许多原理后来被C#所模仿。 本书将通过各种类型的应用程序来全面阐述Java语言的功能。其中一些应用程序展示了Java语言独立于网络属性(attribute)的强大功能,即所谓“纯代码”的范例,因为它们展示了Java语法的表示方法和设计思想。一些应用程序展示了如何使用Java语言及其API类简化复杂的网络编程。所有这些应用程序都说明了Java语言的强大功能和广泛应用范围。 在开始本书的Java教程之前,本章会用一些篇幅指出Java的一些特征,它们是Java作为一种优秀编程语言的标志。同时,这些特征也是将本章命名为“Java精髓”的原因所在。 1.1 简单数据类型和对象:完美的平衡 设计一种面向对象语言所面临的最大挑战,就是如何平衡对象和简单数据类型之间的抉择。从纯理论的观点来看,每种数据类型都应该是一个对象,并且都应该从一个共同的父对象派生而来。这就使得所有数据类型以相同的基本模式运作,共享一个公共的基类属性集合。现在的问题在于,如果将简单数据类型(如int和double)作为对象处理,那么对象机制所引起的额外开销会导致性能(performace)的下降。由于简单数据类型通常用于循环控制和条件语句,所以这些额外开销将带来广泛的负面影响。诀窍就是如何在“一切都是对象”的理想和“性能衡量”的现实之间找到正确的平衡点。 Java非常巧妙地解决了对象与简单数据类型之间的问题。首先,Java定义了8种简单类型:byte、short、int、long、char、float、double和boolean。这些类型能够直接转换为二进制代码。因此,CPU可以直接处理int类型的变量,而无需任何额外开销。在Java中,处理简单数据类型和其他语言一样快速高效。因此,由int类型变量所控制的for循环可以高速运行,而不受任何对象化所带来的负面影响。 除了这些简单数据类型,Java中的其他数据类型都从一个共同超类(Object类)派生而来。因此,所有这些数据类型都共享从父类继承而来的方法和属性集。例如,所有对象都有toString()方法,因为toString()是父类Object中定义的方法。 由于简单数据类型不是对象,因此Java可自由地以略有不同的方式处理对象和非对象。这
深入理解Java虚拟机(JVM)
深入理解Java虚拟机(JVM) 一、什么是Java虚拟机 当你谈到Java虚拟机时,你可能是指: 1、抽象的Java虚拟机规范 2、一个具体的Java虚拟机实现 3、一个运行的Java虚拟机实例 二、Java虚拟机的生命周期 一个运行中的Java虚拟机有着一个清晰的任务:执行Java程序。程序开始执行时他才运行,程序结束时他就停止。你在同一台机器上运行三个程序,就会有三个运行中的Java 虚拟机。 Java虚拟机总是开始于一个main()方法,这个方法必须是公有、返回void、直接受一个字符串数组。在程序执行时,你必须给Java虚拟机指明这个包换main()方法的类名。 Main()方法是程序的起点,他被执行的线程初始化为程序的初始线程。程序中其他的线程都由他来启动。Java中的线程分为两种:守护线程(daemon)和普通线程(non-daemon)。守护线程是Java虚拟机自己使用的线程,比如负责垃圾收集的线程就是一个守护线程。当然,你也可以把自己的程序设置为守护线程。包含Main()方法的初始线程不是守护线程。 只要Java虚拟机中还有普通的线程在执行,Java虚拟机就不会停止。如果有足够的权限,你可以调用exit()方法终止程序。 三、Java虚拟机的体系结构 在Java虚拟机的规范中定义了一系列的子系统、内存区域、数据类型和使用指南。这些组件构成了Java虚拟机的内部结构,他们不仅仅为Java虚拟机的实现提供了清晰的内部结构,更是严格规定了Java虚拟机实现的外部行为。 每一个Java虚拟机都由一个类加载器子系统(class loader subsystem),负责加载程序中的类型(类和接口),并赋予唯一的名字。每一个Java虚拟机都有一个执行引擎(execution engine)负责执行被加载类中包含的指令。 程序的执行需要一定的内存空间,如字节码、被加载类的其他额外信息、程序中的对象、方法的参数、返回值、本地变量、处理的中间变量等等。Java虚拟机将这些信息统统保存在数据区(data areas)中。虽然每个Java虚拟机的实现中都包含数据区,但是Java虚拟机规范对数据区的规定却非常的抽象。许多结构上的细节部分都留给了Java虚拟机实现者自己发挥。不同Java虚拟机实现上的内存结构千差万别。一部分实现可能占用很多内存,而其他以下可能只占用很少的内存;一些实现可能会使用虚拟内存,而其他的则不使用。这种比较精炼的Java虚拟机内存规约,可以使得Java虚拟机可以在广泛的平台上被实现。 数据区中的一部分是整个程序共有,其他部分被单独的线程控制。每一个Java虚拟机