Tomcat7.0源码分析——请求原理分析(中)

Tomcat7.0源码分析——请求原理分析
(中)
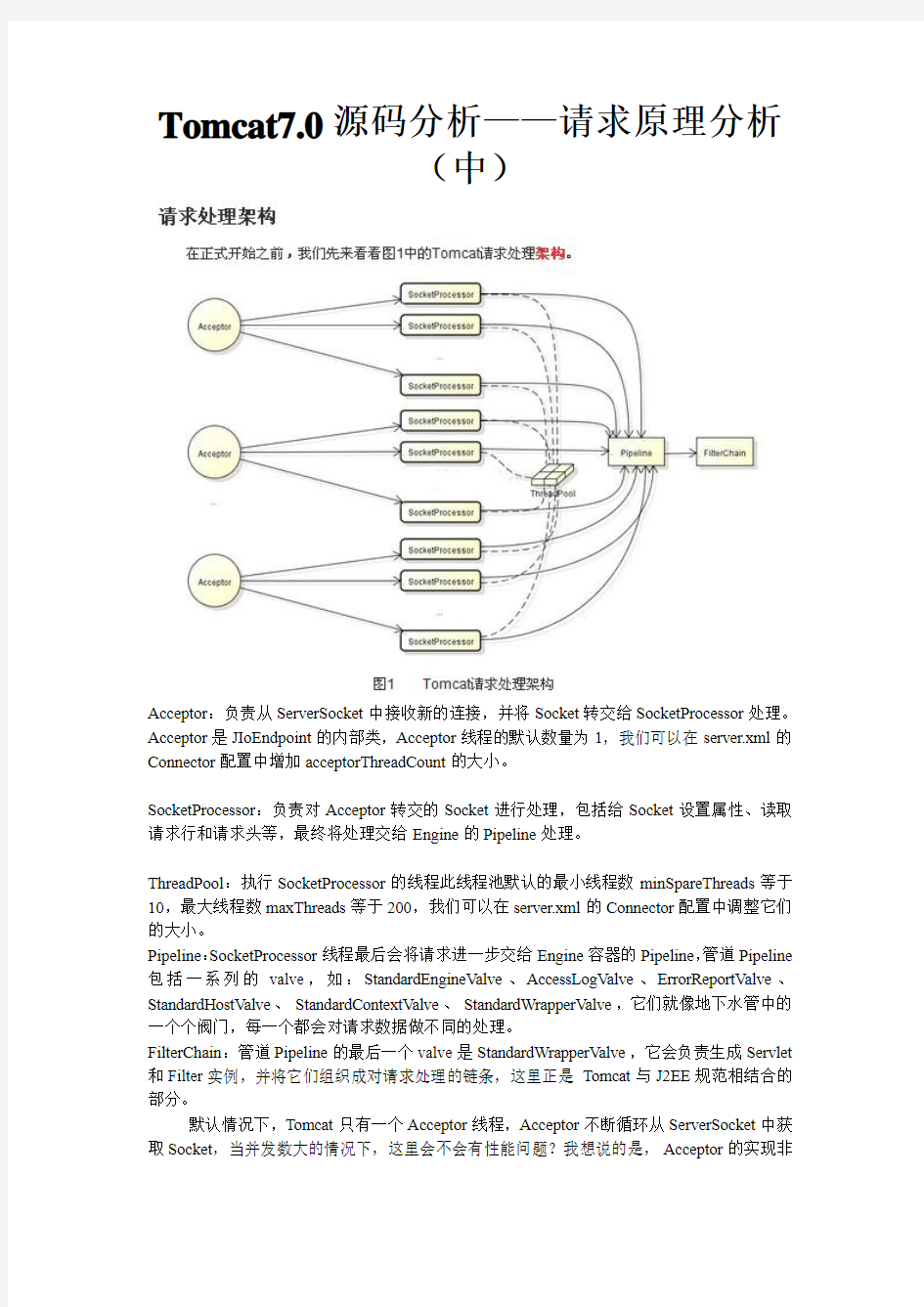
Acceptor:负责从ServerSocket中接收新的连接,并将Socket转交给SocketProcessor处理。Acceptor是JIoEndpoint的内部类,Acceptor线程的默认数量为1,我们可以在server.xml的Connector配置中增加acceptorThreadCount的大小。
SocketProcessor:负责对Acceptor转交的Socket进行处理,包括给Socket设置属性、读取请求行和请求头等,最终将处理交给Engine的Pipeline处理。
ThreadPool:执行SocketProcessor的线程此线程池默认的最小线程数minSpareThreads等于10,最大线程数maxThreads等于200,我们可以在server.xml的Connector配置中调整它们的大小。
Pipeline:SocketProcessor线程最后会将请求进一步交给Engine容器的Pipeline,管道Pipeline 包括一系列的valve,如:StandardEngineValve、AccessLogValve、ErrorReportValve、StandardHostValve、StandardContextValve、StandardWrapperValve,它们就像地下水管中的一个个阀门,每一个都会对请求数据做不同的处理。
FilterChain:管道Pipeline的最后一个valve是StandardWrapperValve,它会负责生成Servlet 和Filter实例,并将它们组织成对请求处理的链条,这里正是Tomcat与J2EE规范相结合的部分。
默认情况下,Tomcat只有一个Acceptor线程,Acceptor不断循环从ServerSocket中获取Socket,当并发数大的情况下,这里会不会有性能问题?我想说的是,Acceptor的实现非
常轻量级,它只负责两个动作:获取Socket和将Socket转交给SocketProcessor线程处理。另外,我们可以通过在server.xml的Connector配置中增加acceptorThreadCount的值,让我们同时可以拥有多个Acceptor线程。虽然我们可以修改maxThreads配置把SocketProcessor 的线程数设置的很大,但是我们需要区别对待:
如果你部署在Tomcat上的Web服务主要用于计算,那么CPU的开销势必会很大,那么线程数不宜设置的过大,一般以CPU核数*2——CPU核数*3最佳。当然如果计算量非常大,就已经超出了Tomcat的使用范畴,我想此时,选择离线计算框架Hadoop或者实时计算框架Storm、Spark才是更好的选择。
如果部署在Tomcat上的Web服务主要是为了提供数据库访问,此时I/O的开销会很大,而CPU利用率反而低,此时应该将线程数设置的大一些,但是如果设置的过大,CPU为了给成百上千个线程分配时间片,造成CPU的精力都分散在线程切换上,反而造成性能下降。具体多大,需要对系统性能调优得出。
原理就讲这么多,下面具体分析下Tomcat处理请求的具体实现。
接收请求
曾经介绍过JIoEndpoint的内部类Acceptor,Acceptor实现了Runnable接口。Acceptor作为后台线程不断循环,每次循环都会接收来自浏览器的Socket连接(用户在浏览器输入HTTP 请求地址后,浏览器底层实际使用Socket通信的),最后将Socket交给外部类JIoEndpoint 的processSocket方法(见代码清单1)处理。
代码清单1
[java] view plain copy 在CODE上查看代码片派生到我的代码片
/**
* Process given socket.
*/
protected boolean processSocket(Socket socket) {
try {
SocketWrapper
wrapper.setKeepAliveLeft(getMaxKeepAliveRequests());
getExecutor().execute(new SocketProcessor(wrapper));
} catch (RejectedExecutionException x) {
log.warn("Socket processing request was rejected for:"+socket,x);
return false;
} catch (Throwable t) {
// This means we got an OOM or similar creating a thread, or that
// the pool and its queue are full
log.error(sm.getString("endpoint.process.fail"), t);
return false;
}
return true;
}
根据代码清单1,JIoEndpoint的processSocket方法的处理步骤如下:
将Socket封装为SocketWrapper;
给SocketWrapper设置连接保持时间keepAliveLeft。这个值是通过调用父类AbstractEndpoint 的getMaxKeepAliveRequests方法(见代码清单2)获得的;
创建SocketProcessor(此类也是JIoEndpoint的内部类,而且也实现了Runnable接口,见代码清单3),并使用线程池(此线程池已在《Tomcat7.0源码分析——请求原理分析(上)》一文中启动PROTOCOLHANDLER一节介绍)执行。
代码清单2
[java] view plain copy 在CODE上查看代码片派生到我的代码片
/**
* Max keep alive requests
*/
private int maxKeepAliveRequests=100; // as in Apache HTTPD server
public int getMaxKeepAliveRequests() {
return maxKeepAliveRequests;
}
代码清单3
[java] view plain copy 在CODE上查看代码片派生到我的代码片
/**
* This class is the equivalent of the Worker, but will simply use in an
* external Executor thread pool.
*/
protected class SocketProcessor implements Runnable {
protected SocketWrapper
protected SocketStatus status = null;
public SocketProcessor(SocketWrapper
if (socket==null) throw new NullPointerException();
this.socket = socket;
}
public SocketProcessor(SocketWrapper
this.status = status;
}
public void run() {
boolean launch = false;
try {
if (!https://www.360docs.net/doc/535225967.html,pareAndSet(false, true)) {
log.error("Unable to process socket. Invalid state.");
return;
}
SocketState state = SocketState.OPEN;
// Process the request from this socket
if ( (!socket.isInitialized()) && (!setSocketOptions(socket.getSocket())) ) {
state = SocketState.CLOSED;
}
socket.setInitialized(true);
if ( (state != SocketState.CLOSED) ) {
state = (status==null)?handler.process(socket):handler.process(socket,status);
}
if (state == SocketState.CLOSED) {
// Close socket
if (log.isTraceEnabled()) {
log.trace("Closing socket:"+socket);
}
try {
socket.getSocket().close();
} catch (IOException e) {
// Ignore
}
} else if (state == SocketState.OPEN){
socket.setKeptAlive(true);
socket.access();
//keepalive connection
//TODO - servlet3 check async status, we may just be in a hold pattern
launch = true;
} else if (state == SocketState.LONG) {
socket.access();
waitingRequests.add(socket);
}
} finally {
socket.processing.set(false);
if (launch) getExecutor().execute(new SocketProcessor(socket));
socket = null;
}
// Finish up this request
}
}
SocketProcessor线程专门用于处理Acceptor转交的Socket,其执行步骤如下:
调用setSocketOptions方法(见代码清单4)给Socket设置属性,从中可以看到设置属性用到了SocketProperties的setProperties方法(见代码清单5),状态更改为初始化完毕;
调用handler的process方法处理请求。在《Tomcat7.0源码分析——请求原理分析(上)》一文中我们讲过当处理Http11Protocol协议时,handler默认为Http11Protocol的内部类Http11ConnectionHandler;
请求处理完毕后,如果state等于SocketState.CLOSED,则关闭Socket;如果state等于SocketState.OPEN,则保持连接;如果state等于SocketState.LONG,则会作为长连接对待。代码清单4
[java] view plain copy 在CODE上查看代码片派生到我的代码片
/**
* Set the options for the current socket.
*/
protected boolean setSocketOptions(Socket socket) {
// Process the connection
try {
// 1: Set socket options: timeout, linger, etc
socketProperties.setProperties(socket);
} catch (SocketException s) {
//error here is common if the client has reset the connection
if (log.isDebugEnabled()) {
log.debug(sm.getString("endpoint.err.unexpected"), s);
}
// Close the socket
return false;
} catch (Throwable t) {
log.error(sm.getString("endpoint.err.unexpected"), t);
// Close the socket
return false;
}
try {
// 2: SSL handshake
serverSocketFactory.handshake(socket);
} catch (Throwable t) {
if (log.isDebugEnabled()) {
log.debug(sm.getString("endpoint.err.handshake"), t);
}
// Tell to close the socket
return false;
}
return true;
}
代码清单5
[java] view plain copy 在CODE上查看代码片派生到我的代码片
public void setProperties(Socket socket) throws SocketException{
if (rxBufSize != null)
socket.setReceiveBufferSize(rxBufSize.intValue());
if (txBufSize != null)
socket.setSendBufferSize(txBufSize.intV alue());
if (ooBInline !=null)
socket.setOOBInline(ooBInline.booleanValue());
if (soKeepAlive != null)
socket.setKeepAlive(soKeepAlive.booleanValue());
if (performanceConnectionTime != null && performanceLatency != null &&
performanceBandwidth != null)
socket.setPerformancePreferences(
performanceConnectionTime.intValue(),
performanceLatency.intValue(),
performanceBandwidth.intValue());
if (soReuseAddress != null)
socket.setReuseAddress(soReuseAddress.booleanValue());
if (soLingerOn != null && soLingerTime != null)
socket.setSoLinger(soLingerOn.booleanV alue(),
soLingerTime.intValue());
if (soTimeout != null && soTimeout.intValue() >= 0)
socket.setSoTimeout(soTimeout.intValue());
if (tcpNoDelay != null)
socket.setTcpNoDelay(tcpNoDelay.booleanValue());
if (soTrafficClass != null)
socket.setTrafficClass(soTrafficClass.intValue());
}
以Http11ConnectionHandler为例,我们重点分析它是如何进一步处理Socket的。Http11ConnectionHandler的process方法,见代码清单6。
代码清单6
[java] view plain copy 在CODE上查看代码片派生到我的代码片
public SocketState process(SocketWrapper
return process(socket,SocketStatus.OPEN);
}
public SocketState process(SocketWrapper
boolean recycle = true;
try {
if (processor == null) {
processor = recycledProcessors.poll();
}
if (processor == null) {
processor = createProcessor();
}
processor.action(ActionCode.ACTION_START, null);
if (proto.isSSLEnabled() && (proto.sslImplementation != null)) {
processor.setSSLSupport
(proto.sslImplementation.getSSLSupport(socket.getSocket()));
} else {
processor.setSSLSupport(null);
}
SocketState state = socket.isAsync()?processor.asyncDispatch(status):processor.process(socket);
if (state == SocketState.LONG) {
connections.put(socket, processor);
socket.setAsync(true);
recycle = false;
} else {
connections.remove(socket);
socket.setAsync(false);
}
return state;
} catch(https://www.360docs.net/doc/535225967.html,.SocketException e) {
// SocketExceptions are normal
Http11Protocol.log.debug
(sm.getString
("http11protocol.proto.socketexception.debug"), e);
} catch (java.io.IOException e) {
// IOExceptions are normal
Http11Protocol.log.debug
(sm.getString
("http11protocol.proto.ioexception.debug"), e);
}
// Future developers: if you discover any other
// rare-but-nonfatal exceptions, catch them here, and log as
// above.
catch (Throwable e) {
// any other exception or error is odd. Here we log it
// with "ERROR" level, so it will show up even on
// less-than-verbose logs.
Http11Protocol.log.error
(sm.getString("http11protocol.proto.error"), e);
} finally {
// if(proto.adapter != null) proto.adapter.recycle();
// processor.recycle();
if (recycle) {
processor.action(ActionCode.ACTION_STOP, null);
recycledProcessors.offer(processor);
}
}
return SocketState.CLOSED;
}
根据代码清单6,可见Http11ConnectionHandler的process方法的处理步骤如下:
从Socket的连接缓存connections(用于缓存长连接的Socket)中获取Socket对应的Http11Processor;如果连接缓存connections中不存在Socket对应的Http11Processor,则从可以循环使用的recycledProcessors(类型为ConcurrentLinkedQueue)中获取;如果recycledProcessors中也没有可以使用的Http11Processor,则调用createProcessor方法(见代码清单7)创建Http11Processor;
如果当前Connector配置了指定了SSLEnabled="true",那么还需要给Http11Processor设置SSL相关的属性;
如果Socket是异步的,则调用Http11Processor的asyncDispatch方法,否则调用Http11Processor的process方法;
请求处理完毕,如果Socket是长连接的,则将Socket和Http11Processor一起放入connections 缓存,否则从connections缓存中移除Socket和Http11Processor。
代码清单7
[java] view plain copy 在CODE上查看代码片派生到我的代码片
protected Http11Processor createProcessor() {
Http11Processor processor =
new Http11Processor(proto.getMaxHttpHeaderSize(), (JIoEndpoint)proto.endpoint);
processor.setAdapter(proto.adapter);
processor.setMaxKeepAliveRequests(proto.getMaxKeepAliveRequests());
processor.setKeepAliveTimeout(proto.getKeepAliveTimeout());
processor.setTimeout(proto.getTimeout());
processor.setDisableUploadTimeout(proto.getDisableUploadTimeout());
processor.setCompressionMinSize(proto.getCompressionMinSize());
processor.setCompression(proto.getCompression());
processor.setNoCompressionUserAgents(proto.getNoCompressionUserAgents());
processor.setCompressableMimeTypes(proto.getCompressableMimeTypes());
processor.setRestrictedUserAgents(proto.getRestrictedUserAgents());
processor.setSocketBuffer(proto.getSocketBuffer());
processor.setMaxSavePostSize(proto.getMaxSavePostSize());
processor.setServer(proto.getServer());
register(processor);
return processor;
}
根据之前的分析,我们知道Socket的处理方式有异步和同步两种,分别调用Http11Processor 的asyncDispatch方法或process方法,我们以同步处理为例,来看看接下来的处理逻辑。
同步处理
Http11Processor的process方法(见代码清单8)用于同步处理,由于其代码很多,所以此处在代码后面追加一些注释,便于读者理解。这里面有一些关键方法重点拿出来解释下:
InternalInputBuffer的parseRequestLine方法用于读取请求行;
InternalInputBuffer的parseHeaders方法用于读取请求头;
prepareRequest用于在正式处理请求之前,做一些准备工作,如根据请求头获取请求的版本号是HTTP/1.1还是HTTP/0.9、keepAlive是否为true等,还会设置一些输入过滤器用于标记请求、压缩等;
调用CoyoteAdapter的service方法处理请求。
代码清单8
[java] view plain copy 在CODE上查看代码片派生到我的代码片
RequestInfo rp = request.getRequestProcessor();
rp.setStage(org.apache.coyote.Constants.STAGE_PARSE);
this.socket = socketWrapper;
inputBuffer.setInputStream(socket.getSocket().getInputStream());//设置输入流
outputBuffer.setOutputStream(socket.getSocket().getOutputStream());//设置输出流
int keepAliveLeft = maxKeepAliveRequests>0?socketWrapper.decrementKeepAlive():-1;//保持连接递减
int soTimeout = endpoint.getSoTimeout();//socket超时时间
socket.getSocket().setSoTimeout(soTimeout);//设置超时时间
boolean keptAlive = socketWrapper.isKeptAlive();//是否保持连接
while (started && !error && keepAlive) {
// Parsing the request header
try {
//TODO - calculate timeout based on length in queue (System.currentTimeMills() - wrapper.getLastAccess() is the time in queue)
if (keptAlive) {//是否保持连接
if (keepAliveTimeout > 0) {
socket.getSocket().setSoTimeout(keepAliveTimeout);
}
else if (soTimeout > 0) {
socket.getSocket().setSoTimeout(soTimeout);
}
}
inputBuffer.parseRequestLine(false);//读取请求行
request.setStartTime(System.currentTimeMillis());
keptAlive = true;
if (disableUploadTimeout) {
socket.getSocket().setSoTimeout(soTimeout);
} else {
socket.getSocket().setSoTimeout(timeout);
}
inputBuffer.parseHeaders();//解析请求头
} catch (IOException e) {
error = true;
break;
} catch (Throwable t) {
if (log.isDebugEnabled()) {
log.debug(sm.getString("http11processor.header.parse"), t);
}
// 400 - Bad Request
response.setStatus(400);
adapter.log(request, response, 0);
error = true;
}
if (!error) {
// Setting up filters, and parse some request headers
rp.setStage(org.apache.coyote.Constants.STAGE_ENDED);
try {
prepareRequest();//对请求内容增加过滤器——协议、方法、请求头、host等} catch (Throwable t) {
if (log.isDebugEnabled()) {
log.debug(sm.getString("http11processor.request.prepare"), t);
}
// 400 - Internal Server Error
response.setStatus(400);
adapter.log(request, response, 0);
error = true;
}
}
if (maxKeepAliveRequests > 0 && keepAliveLeft == 0)
keepAlive = false;
// Process the request in the adapter
if (!error) {
try {
rp.setStage(org.apache.coyote.Constants.STAGE_SERVICE);
adapter.service(request, response); //将进一步处理交给CoyoteAdapter
// Handle when the response was committed before a serious
// error occurred. Throwing a ServletException should both
// set the status to 500 and set the errorException.
// If we fail here, then the response is likely already
// committed, so we can't try and set headers.
if(keepAlive && !error) { // Avoid checking twice.
error = response.getErrorException() != null ||
statusDropsConnection(response.getStatus());
}
} catch (InterruptedIOException e) {
error = true;
} catch (Throwable t) {
log.error(sm.getString("http11processor.request.process"), t);
// 500 - Internal Server Error
response.setStatus(500);
adapter.log(request, response, 0);
error = true;
}
}
// Finish the handling of the request
try {
rp.setStage(org.apache.coyote.Constants.STAGE_ENDINPUT);
// If we know we are closing the connection, don't drain input.
// This way uploading a 100GB file doesn't tie up the thread
// if the servlet has rejected it.
if(error && !async)
inputBuffer.setSwallowInput(false);
if (!async)
endRequest();
} catch (Throwable t) {
log.error(sm.getString("http11processor.request.finish"), t);
// 500 - Internal Server Error
response.setStatus(500);
adapter.log(request, response, 0);
error = true;
}
try {
rp.setStage(org.apache.coyote.Constants.STAGE_ENDOUTPUT); } catch (Throwable t) {
log.error(sm.getString("http11processor.response.finish"), t);
error = true;
}
// If there was an error, make sure the request is counted as
// and error, and update the statistics counter
if (error) {
response.setStatus(500);
}
request.updateCounters();
rp.setStage(org.apache.coyote.Constants.STAGE_KEEPALIVE);
// Don't reset the param - we'll see it as ended. Next request
// will reset it
// thrA.setParam(null);
// Next request
if (!async || error) {
inputBuffer.nextRequest();
outputBuffer.nextRequest();
}
//hack keep alive behavior
break;
}
rp.setStage(org.apache.coyote.Constants.STAGE_ENDED);
if (error) {
recycle();
return SocketState.CLOSED;
} else if (async) {
return SocketState.LONG;
} else {
if (!keepAlive) {
recycle();
return SocketState.CLOSED;
} else {
return SocketState.OPEN;
}
}
从代码清单8可以看出,最后的请求处理交给了CoyoteAdapter,CoyoteAdapter的service 方法(见代码清单9)用于真正处理请求。
代码清单9
[java] view plain copy 在CODE上查看代码片派生到我的代码片
/**
* Service method.
*/
public void service(org.apache.coyote.Request req,
org.apache.coyote.Response res)
throws Exception {
Request request = (Request) req.getNote(ADAPTER_NOTES);
Response response = (Response) res.getNote(ADAPTER_NOTES);
if (request == null) {
// Create objects
request = connector.createRequest();
request.setCoyoteRequest(req);
response = connector.createResponse();
response.setCoyoteResponse(res);
// Link objects
request.setResponse(response);
response.setRequest(request);
// Set as notes
req.setNote(ADAPTER_NOTES, request);
res.setNote(ADAPTER_NOTES, response);
// Set query string encoding
req.getParameters().setQueryStringEncoding
(connector.getURIEncoding());
}
if (connector.getXpoweredBy()) {
response.addHeader("X-Powered-By", POWERED_BY);
}
boolean comet = false;
boolean async = false;
try {
// Parse and set Catalina and configuration specific
// request parameters
req.getRequestProcessor().setWorkerThreadName(Thread.currentThread().getName());
if (postParseRequest(req, request, res, response)) {
//check valves if we support async
request.setAsyncSupported(connector.getService().getContainer().getPipeline().isAsyncSupported ());
// Calling the container
connector.getService().getContainer().getPipeline().getFirst().invoke(request, response);
if (request.isComet()) {
if (!response.isClosed() && !response.isError()) {
if (request.getAvailable() || (request.getContentLength() > 0 && (!request.isParametersParsed()))) {
// Invoke a read event right away if there are available bytes
if (event(req, res, SocketStatus.OPEN)) {
comet = true;
res.action(ActionCode.ACTION_COMET_BEGIN, null);
}
} else {
comet = true;
res.action(ActionCode.ACTION_COMET_BEGIN, null);
}
} else {
// Clear the filter chain, as otherwise it will not be reset elsewhere
// since this is a Comet request
request.setFilterChain(null);
}
}
}
AsyncContextImpl asyncConImpl = (AsyncContextImpl)request.getAsyncContext();
if (asyncConImpl!=null && asyncConImpl.getState()==AsyncContextImpl.AsyncState.STARTED) {
res.action(ActionCode.ACTION_ASYNC_START, request.getAsyncContext());
async = true;
} else if (request.isAsyncDispatching()) {
asyncDispatch(req, res, SocketStatus.OPEN);
if (request.isAsyncStarted()) {
async = true;
res.action(ActionCode.ACTION_ASYNC_START,
request.getAsyncContext());
}
} else if (!comet) {
response.finishResponse();
req.action(ActionCode.ACTION_POST_REQUEST , null);
}
} catch (IOException e) {
// Ignore
} catch (Throwable t) {
log.error(sm.getString("coyoteAdapter.service"), t);
} finally {
req.getRequestProcessor().setWorkerThreadName(null);
// Recycle the wrapper request and response
if (!comet && !async) {
request.recycle();
response.recycle();
} else {
// Clear converters so that the minimum amount of memory
// is used by this processor
request.clearEncoders();
response.clearEncoders();
}
}
}
从代码清单9可以看出,CoyoteAdapter的service方法的执行步骤如下:
创建Request与Response对象并且关联起来;
调用postParseRequest方法(见代码清单10)对请求进行解析;
将真正的请求处理交给Engine的Pipeline去处理,代码:connector.getService().getContainer().getPipeline().getFirst().invoke(request, response);
代码清单10
[java] view plain copy 在CODE上查看代码片派生到我的代码片
/**
* Parse additional request parameters.
*/
protected boolean postParseRequest(org.apache.coyote.Request req,
Request request,
org.apache.coyote.Response res,
Response response)
throws Exception {
// 省略前边的次要代码
parsePathParameters(req, request);
// URI decoding
// %xx decoding of the URL
try {
req.getURLDecoder().convert(decodedURI, false);
} catch (IOException ioe) {
res.setStatus(400);
res.setMessage("Invalid URI: " + ioe.getMessage());
connector.getService().getContainer().logAccess(
request, response, 0, true);
return false;
}
// Normalization
if (!normalize(req.decodedURI())) {
res.setStatus(400);
res.setMessage("Invalid URI");
connector.getService().getContainer().logAccess(
request, response, 0, true);
return false;
}
// Character decoding
convertURI(decodedURI, request);
// Check that the URI is still normalized
if (!checkNormalize(req.decodedURI())) {
res.setStatus(400);
res.setMessage("Invalid URI character encoding");
connector.getService().getContainer().logAccess(
request, response, 0, true);
return false;
}
// Set the remote principal
String principal = req.getRemoteUser().toString();
if (principal != null) {
request.setUserPrincipal(new CoyotePrincipal(principal));
}
// Set the authorization type
String authtype = req.getAuthType().toString();
if (authtype != null) {
request.setAuthType(authtype);
}
// Request mapping.
MessageBytes serverName;
if (connector.getUseIPVHosts()) {
serverName = req.localName();
if (serverName.isNull()) {
// well, they did ask for it
res.action(ActionCode.ACTION_REQ_LOCAL_NAME_ATTRIBUTE, null);
}
} else {
serverName = req.serverName();
}
if (request.isAsyncStarted()) {
//TODO SERVLET3 - async
//reset mapping data, should prolly be done elsewhere
request.getMappingData().recycle();
}
connector.getMapper().map(serverName, decodedURI,
request.getMappingData()); request.setContext((Context) request.getMappingData().context); request.setWrapper((Wrapper) request.getMappingData().wrapper);
// Filter trace method
if (!connector.getAllowTrace()
&& req.method().equalsIgnoreCase("TRACE")) { Wrapper wrapper = request.getWrapper();
String header = null;
if (wrapper != null) {
String[] methods = wrapper.getServletMethods();
if (methods != null) {
for (int i=0; i if ("TRACE".equals(methods[i])) { continue; } if (header == null) { header = methods[i]; } else { header += ", " + methods[i]; } } } } res.setStatus(405); res.addHeader("Allow", header); res.setMessage("TRACE method is not allowed"); request.getContext().logAccess(request, response, 0, true); return false; } // Now we have the context, we can parse the session ID from the URL // (if any). Need to do this before we redirect in case we need to // include the session id in the https://www.360docs.net/doc/535225967.html,direct if (request.getServletContext().getEffectiveSessionTrackingModes() .contains(SessionTrackingMode.URL)) { // Get the session ID if there was one String sessionID = request.getPathParameter( ApplicationSessionCookieConfig.getSessionUriParamName( request.getContext())); if (sessionID != null) { request.setRequestedSessionId(sessionID); request.setRequestedSessionURL(true); } } // Possible redirect MessageBytes redirectPathMB = request.getMappingData().redirectPath; if (!redirectPathMB.isNull()) { String redirectPath = urlEncoder.encode(redirectPathMB.toString()); String query = request.getQueryString(); if (request.isRequestedSessionIdFromURL()) { // This is not optimal, but as this is not very common, it // shouldn't https://www.360docs.net/doc/535225967.html,tter redirectPath = redirectPath + ";" + ApplicationSessionCookieConfig.getSessionUriParamName( request.getContext()) + "=" + request.getRequestedSessionId(); } if (query != null) { // This is not optimal, but as this is not very common, it // shouldn't matter redirectPath = redirectPath + "?" + query; } response.sendRedirect(redirectPath); request.getContext().logAccess(request, response, 0, true); return false; } // Finally look for session ID in cookies and SSL session parseSessionCookiesId(req, request); parseSessionSslId(request); return true; } 从代码清单10可以看出,postParseRequest方法的执行步骤如下: 解析请求url中的参数; URI decoding的转换(为了保证URL的可移植、完整性、可读性,通过ASCII字符集的有 限子集对任意字符或数据进行编码、解码); 调用normalize方法判断请求路径中是否存在"\", "//", "/./"和"/../",如果存在则处理结束; 调用convertURI方法将字节转换为字符; 调用checkNormalize方法判断uri是否存在"\", "//", "/./"和"/../",如果存在则处理结束; 调用Connector的getMapper方法获取Mapper(已在《Tomcat7.0源码分析——请求原理分析(上)》一文中介绍),然后调用Mapper的map方法(见代码清单11)对host和context 进行匹配(比如http://localhost:8080/manager/status会匹配host:localhost,context:/manager),其实质是调用internalMap方法; 使用ApplicationSessionCookieConfig.getSessionUriParamName获取sessionid的key,然后获取sessionid; 调用parseSessionCookiesId和parseSessionSslId方法查找cookie或者SSL中的sessionid。 代码清单11 [java] view https://www.360docs.net/doc/535225967.html,ain copy 在CODE上查看代码片派生到我的代码片 public void map(MessageBytes host, MessageBytes uri, MappingData mappingData) throws Exception { if (host.isNull()) { host.getCharChunk().append(defaultHostName); } host.toChars(); uri.toChars(); internalMap(host.getCharChunk(), uri.getCharChunk(), mappingData); } CoyoteAdapter的service方法最后会将请求交给Engine的Pipeline去处理. 研究 Xmodem 协议必看的 11个问题 Xmodem 协议作为串口数据传输主要的方式之一,恐怕只有做过 bootloader 的才有机会接触一下, 网上有关该协议的内容要么是英语要么讲解不详细。笔者以前写 bootloader 时研究过 1k-Xmodem ,参考了不少相关资料。这里和大家交流一下我对 Xmodem 的理解,多多指教! 1. Xmodem 协议是什么? XMODEM协议是一种串口通信中广泛用到的异步文件传输协议。分为标准Xmodem 和 1k-Xmodem 两种,前者以 128字节块的形式传输数据,后者字节块为 1k 即 1024字节,并且每个块都使用一个校验和过程来进行错误检测。在校验过程中如果接收方关于一个块的校验和与它在发送方的校验和相同时,接收方就向发送方发送一个确认字节 (ACK。由于 Xmodem 需要对每个块都进行认可, 这将导致性能有所下降, 特别是延时比较长的场合, 这种协议显得效率更低。 除了 Xmodem ,还有 Ymodem , Zmodem 协议。他们的协议内容和 Xmodem 类似,不同的是 Ymodem 允许批处理文件传输,效率更高; Zmodem 则是改进的了Xmodem ,它只需要对损坏的块进行重发,其它正确的块不需要发送确认字节。减少了通信量。 2. Xmodem 协议相关控制字符 SOH 0x01 STX 0x02 EOT 0x04 ACK 0x06 NAK 0x15 CAN 0x18 CTRLZ 0x1A 3.标准 Xmodem 协议(每个数据包含有 128字节数据帧格式 _______________________________________________________________ | SOH | 信息包序号 | 信息包序号的补码 | 数据区段 | 校验和 | |_____|____________|___________________|__________|____________| 4. 1k-Xmodem (每个数据包含有 1024字节数据帧格式 _______________________________________________________________ | STX | 信息包序号 | 信息包序号的补码 | 数据区段 | 校验和 | |_____|____________|___________________|__________|____________| 5.数据包说明 对于标准 Xmodem 协议来说,如果传送的文件不是 128的整数倍,那么最后一个数据包的有效内容肯定小于帧长,不足的部分需要用 CTRL- Z(0x1A来填充。这里可能有人会问,如果我传送的是 bootloader 工程生成的 .bin 文件, mcu 收到后遇到0x1A 字符会怎么处理?其实如果传送的是文本文件,那么接收方对于接收的内容是很容易识别的,因为 CTRL-Z 不是前 128个 ascii 码, 不是通用可见字符, 如果是二进制文件, mcu 其实也不会把它当作代码来执行。哪怕是 excel 文件等,由于其内部会有些结构表示各个字段长度等,所以不会读取多余的填充字符。否则 Xmodem太弱了。对于 1k-Xmodem ,同上理。 6.如何启动传输? 实验四汇编语言程序上机过程 实验目的: 1、掌握常用工具软件EDIT,MASM和LINK的使用。 2、伪指令: SEGMENT,ENDS,ASSUME,END,OFFSET,DUP。 3、利用的1号功能实现键盘输入的方法。 4、用INT 21H 4C号功能返回系统的方法。 程序: data segment message db 'This is a sample program of keyboard and disply' db 0dh,0ah,'Please strike the key!',0dh,0ah,'$' data ends stack segment para stack 'stack' db 50 dup(?) stack ends code segment assume cs:code,ds:data,ss:stack start: mov ax,data mov ds,ax mov dx,offset message mov ah,9 int 21h again: mov ah,1 int 21h cmp al,1bh je exit cmp al,61h jc nd cmp al,7ah ja nd and al,11011111b nd: mov dl,al mov ah,2 int 21h jmp again exit: mov ah,4ch int 21h code ends end start 实验步骤: 1、用用文字编辑工具(记事本或EDIT)将源程序输入,其扩展名为.ASM。 2、用MASM对源文件进行汇编,产生.OBJ文件和.LST文件。若汇编时提示有错,用文字编辑工具修改源程序后重新汇编,直至通过。 3、用TYPE命令显示1产生的.LST文件。 4、用LINK将.OBJ文件连接成可执行的.EXE文件。 5、在DOS状态下运行LINK产生的.EXE文件。即在屏幕上显示标题并提示你按键。每按一键在屏幕上显示二个相同的字符,但小写字母被改成大写。按ESC 键可返回DOS。若未出现预期结果,用DEBUG检查程序。 实验报告: 1、汇编,连接及调试时产生的错误,其原因及解决办法。 2、思考: 1)若在源程序中把INT 21H的'H'省去,会产生什么现象? 2)把 INT 21H 4CH号功能改为 INT 20H,行不行? 实验内容: 1. 2. ---《计算机网络与控制》论文 LWIP协议栈的分析 摘要 近些年来,随着互联网和通讯技术的迅猛发展,除了计算机之外,大量的嵌入式设备也需求接入网络。目前,互联网中使用的通讯协议基本是TCP/IP协议族,可运行于不同的网络上,本文研究的就是嵌入式TCP/IP协议栈LWIP。文章首先分析了LWIP的整体结构和协议栈的实现,再介绍协议栈的内存管理,最后讲解协议栈应用程序接口。 关键词: 嵌入式系统;协议;LWIP;以太网 Abstract With the rapid development of internet and communication technology, Not only computers but also embeded equipments are need to connect networks. At present, the basic communication protocol using in internet is TCP/IP, it can run in different network. This paper analyses the Light-Weight TCP/IP. The process model of a protocol implementation and processing of every layer are described first, and then gives the detailed management of Buffer and memory. At last, a reference lwIP API is given. Key words: Embedded System, Protocol, Light weight TCP/IP,Ethernet 引言 《微机原理及接口技术》 实验指导书 杨霞周林英编 长安大学电子与控制工程学院 2009年9月 前言 本实验指导是为适应各大、中专院校开设微机原理及应用方面的课程需做大量软硬件实验的需要而编写的,供学生编程用。完成本实验指导中的实验,可使学生基本掌握8086/8088的结构原理、接口技术、程序设计技巧。手册中详细叙述了各实验的目的、内容,列出了接线图、程序框图和实验步骤。 主要学习内容为80X86语言实验环境配置、汇编源语言格式、输出字符、循环结构、子程序调用,以及加减乘除等指令操作、通用接口芯片的接口编程与使用。所有实验都是相互独立的,次序上也没有固定的先后关系,在使用本书进行教学时,教师可根据教学要求,选择相应实验。学习结束后,要求学生能够独立编写出综合加减乘除等指令,以及循环结构、子程序调用等程序控制程序、看懂一般接口芯片电路图。 目录 实验一清零程序 (4) 实验二拆字程序 (6) 实验三数据区移动 (8) 实验四多分支程序设计 (10) 实验五多字节减法运算 (13) 实验六显示程序 (16) 实验七 8251串口实验 (20) 实验八步进电机控制 (26) 附录一汇编语言的存储模型 (36) 附录二 8279键值显示程序 (37) 实验一清零程序 一、实验目的 掌握8088汇编语言程序设计和调试方法。 二、实验设备 STAR系列实验仪一套、PC机一台。 三、实验内容 把RAM区内4000H-40FFH单元的内容清零。 四、程序框图 五、源程序清单 .MODEL TINY .STACK 100 .DATA .CODE ORG 0100H START: MOV BX,4000H MOV AX,0000H MOV CX,80H L1: MOV [BX],AX INC BX INC BX LOOP L1 JMP $ END START 六、实验步骤 微型计算机原理与应用实验指导书 上海大学通信学院 2010 年4 月 PC微机原理实验一 一、目的:掌握PC机DEBUG调试程序有关命令的操作及8086各类指令的 功能。 要求:在PC机上完成下列程序的调试运行,并写出运行结果。二、1.DEBUG的基本操作:(详细内容请参阅教材“程序的调试,P173”和“附录F 调试程序DEUBG的使用,P499”) (1)从WINDOWS进入DOS之后,输入命令启动DEBUG: C:>DEBUG 回车 (2)输入R命令,查看和记录CPU各个寄存器的内容: -R回车 看到什么 (3)输入A命令,汇编下面的字符“WINDOWS”显示程序: -A100 ;从偏移地址是0100H处开始写指令 MOV AH,2 MOV DL, 57 ;57H 是“W ”的ASCII码 INT 21 ;INT 21是DOS 功能调用,AH=2代表2号功能 ;这3句合起来的功能是:显示DL中的字符 MOV DL, 49 INT 2 1 MOV DL, 4E INT 21 MOV DL, 44 INT 2 1 MOV DL, 4F INT 2 1 MOV DL, 57 INT 2 1 MOV DL, 53 INT 2 1 INT 3 ;功能是产生一个断点,不要省略 (4)输入U 命令反汇编上面的程序: -U 100 问:这里100代表什么 (5)输入G命令连续运行上面的程序,记录运行结果: -G=100 ,57,53依次分别改为574F4E57 (6)输入E命令把上面程序中的数据,49,,44,,45:,,45,4C43,4F4D,-E 103 回车(以下同) -E 107 10B-E -E 10F 113-E 117-E 11B-E (7)输入D命令查看程序机器码的存放情况: -D 100 11E ;看从100开始到11E的机器码 (8)输入G命令再连续运行程序,并记录运行结果: -G=100 (9)依次输入下面的T命令(单步执行)和G命令(设置断点并启动运行),记录各 命令的运行结果: -T=100 回车 -G=100 106 回车 -G=100 10A 回车 -G=100 10E 回车 -G=100 11E 回车 注意: 下面第2—第8段程序是7个实用的小程序,若不小心打错指令,可以这样修改: 例如:CS:0100 B300 MOV BL,0 0102 53 PUSH BX 0103 B220 LP1: MOV DL,20 要修改“PUSH BX”,因为这条指令的IP是0102,所以按以下操作: -A 0102 回车,然后把正确的指令打入,“-A ”是汇编指令。 如果要查看0100以后的指令及相应的机器代码,可以 -U 0100 回车,能够看到CS:0100开始的指令及相应的机器代码。“-U ”是反汇编 若发现有误用,用“-A XXXX 回车”,重打这条指令即可 2.编制一个能在CRT上连续显示A,B,C,D······Z大写英文字符的源程序,并在源程序下汇编调试机运行。 微机原理及应用实验 实验一开发环境的使用 一、实验目的 掌握伟福开发环境的使用方法,包括源程序的输入、汇编、修改;工作寄存器内容的查看、修改;内部、外部RAM内容的查看、修改;PSW中个状态位的查看;机器码的查看;程序的各种运行方式,如单步执行、连续执行,断点的设置。二、实验内容 在伟福开发环境中编辑、汇编、执行一段汇编语言程序,把单片机片内的 30H~7FH 单元清零。 三、实验设备 PC机一台。 四、实验步骤 用连续或者单步的方式运行程序,检查30H-7FH 执行前后的内容变化。五、实验思考 1.如果需把30H-7FH 的内容改为55H,如何修改程序? 2.如何把128B的用户RAM全部清零? 六、程序清单 文件名称:CLEAR.ASM ORG 0000H CLEAR: MOV R0,#30H ;30H 送R0寄存器 MOV R6,#50H ;50H 送R6寄存器(用作计数器) CLR1: MOV A,#00H ;00 送累加器A MOV @R0,A ;00 送到30H-7FH 单元 INC R0 ;R0 加1 DJNZ R6,CLR1 ;不到50H个字节,继续 WAIT: LJMP WAIT END 实验二数据传送 一、实验目的 掌握MCS-51指令系统中的数据传送类指令的应用,通过实验,切实掌握数据传送类指令的各种不同的寻址方式的应用。 二、实验内容 1.编制一段程序,要求程序中包含7中不同寻址方式。 2.编制一段程序,将片内RAM30H~32H中的数据传送到片内RAM38H~3AH中。 3.编制一段程序,将片内RAM30H~32H中的数据传送到片外RAM1000H~1002H 中。 4.编制一段程序,将片内RAM40H~42H中的数据与片外RAM2000H~2002H中的数据互换。 三、实验设备 PC机一台。 汇编语言程序设计实验 一、实验内容 1.学习并掌握IDE86集成开发环境的使用,包括编辑、编译、链接、 调试与运行等步骤。 2.参考书例4-8,P165 (第3版161页)以单步形式观察程序的 执行过程。 3.修改该程序,求出10个数中的最大值和最小值。以单步形式观 察,如何求出最大值、最小值。 4.求1到100 的累加和,并用十进制形式将结果显示在屏幕上。 要求实现数据显示,并返回DOS状态。 二、实验目的 1.学习并掌握IDE86集成开发环境的使用 2.熟悉汇编语言的基本算法,并实际操作 3.学会利用IDE86进行debug的步骤 三、实验方法 1.求出10个数中的最大值和最小值 (1)设计思路:利用冒泡法,先对数据段的10个数字的前2个比 较,把二者中大的交换放后面。在对第二个和第三个数比较,把 二者中较大的交换放后面,依此类推直到第十个数字。这样第十 位数就是10个数里面最大的。然后选出剩下9个数字里面最大 的,还是从头开始这么做,直到第九个数字。以此类推直到第一 个数字。 (2)流程图 2.求1到100 的累加和,并用十进制形式将结果显示在屏幕上。 要求实现数据显示,并返回DOS状态 (1)设计思路:结果存放在sum里面,加数是i(初始为1),进行 100次循环,sum=sum+I,每次循环对i加1. (2)流程图: 四、 1.求出10个数中的最大值和最小值 DSEG SEGMENT NUM DB -1,-4,0,1,-2,5,-6,10,4,0 ;待比较数字 DSEG ENDS CODE SEGMENT ASSUME DS:DSEG,CS:CODE START:MOV AX,DSEG MOV DS,AX LEA SI,NUM MOV DX,SI MOV CL,9 ;大循环计数寄存器初始化 NEXT1:MOV BL,CL ;大循环开始,小循环计数器初始化MOV SI,DX NEXT2:MOV AL,[SI+1] CMP [SI],AL ;比较 JGGONE ;如果后面大于前面跳到小循环末尾CHANGE:MOV AH,[SI] ;交换 MOV [SI+1],AH MOV [SI],AL JMP GONE GONE:add SI,1 DEC BL JNZ NEXT2 竭诚为您提供优质文档/双击可除lwip各层协议栈详解 篇一:lwip协议栈源码分析 lwip源码分析 -----caoxw 1lwip的结构 lwip(lightweightinternetprotocol)的主要模块包括:配置模块、初始化模块、netif模块、mem(memp)模块、netarp模块、ip模块、udp模块、icmp模块、igmp模块、dhcp模块、tcp模块、snmp模块等。下面主要对我们需要关心的协议处理进行说明和梳理。配置模块: 配置模块通过各种宏定义的方式对系统、子模块进行了配置。比如,通过宏,配置了mem管理模块的参数。该配置模块还通过宏,配置了协议栈所支持的协议簇,通过宏定制的方式,决定了支持那些协议。主要的文件是opt.h。 初始化模块: 初始化模块入口的文件为tcpip.c,其初始化入口函数为: voidtcpip_init(void(*initfunc)(void*),void*arg) 该入口通过调用lwip_init()函数,初始化了所有的子模块,并启动了协议栈管理进程。同时,该函数还带有回调钩子及其参数。可以在需要的地方进行调用。 协议栈数据分发管理进程负责了输入报文的处理、超时处理、api函数以及回调的处理,原型如下: staticvoidtcpip_thread(void*arg) netif模块: netif模块为协议栈与底层驱动的接口模块,其将底层的一个网口设备描述成协议栈的一个接口设备(netinterface)。该模块的主要文件为netif.c。其通过链表的方式描述了系统中的所有网口设备。 netif的数据结构描述了网口的参数,包括ip地址、mac 地址、link状态、网口号、收发函数等等参数。一个网口设备的数据收发主要通过该结构进行。 mem(memp)模块: mem模块同一管理了协议栈使用的内容缓冲区,并管理pbuf结构以及报文的字段处理。主要的文件包括mem.c、memp.c、pbuf.c。 netarp模块: netarp模块是处理arp协议的模块,主要源文件为etharp.c。其主要入口函数为: err_tethernet_input(structpbuf*p,structnetif*netif) 一、实验目的 (1)学习汇编语言循环结构语句的特点,重点掌握冒泡排序的方法。 (2)理解并掌握各种指令的功能,编写完整的汇编源程序。 (3)进一步熟悉DEBUG的调试命令,运用DEBUG进行调试汇编语言程序。 二、实验内容及要求 (1)实验内容:从键盘输入五个有符号数,用冒泡排序法将其按从小到大的顺序排序。(2)实验要求: ①编制程序,对这组数进行排序并输出原数据及排序后的数据; ②利用DEBUG调试工具,用D0命令,查看排序前后内存数据的变化; ③去掉最大值和最小值,求出其余值的平均值,输出最大值、最小值和平均值; ④用压栈PUSH和出栈POP指令,将平均值按位逐个输出; ⑤将平均值转化为二进制串,并将这组二进制串输出; ⑥所有数据输出前要用字符串的输出指令进行输出提示,所有数据结果能清晰显示。 三、程序流程图Array (1)主程序:MAIN (2)冒泡排序子程序: SORT 四、程序清单 NAME BUBBLE_SORT DATA SEGMENT ARRAY DW 5 DUP(?) ;输入数据的存储单元 COUNT DW 5 TWO DW 2 FLAG1 DW 0 ;判断符号标志 FLAG2 DB 0 ;判断首位是否为零的标志 FAULT DW -1 ;判断出错标志 CR DB 0DH,0AH,'$' STR1 DB 'Please input five numbers seperated with space and finished with Enter:','$' STR2 DB 'The original numbers:','$' STR3 DB 'The sorted numbers:','$' STR4 DB 'The Min:','$' STR5 DB 'The Max:','$' STR6 DB 'The Average:','$' STR7 DB 'The binary system of the average :','$' STR8 DB 'Input error!Please input again!''$' DATA ENDS CODE SEGMENT MAIN PROC FAR ASSUME CS:CODE,DS:DATA,ES:DATA START: PUSH DS AND AX,0 PUSH AX MOV AX,DATA MOV DS,AX LEA DX,STR1 MOV AH,09H ;9号DOS功能调用,提示输入数据 INT 21H CALL CRLF ;回车换行 REIN: CALL INPUT ;调用INPUT子程序,输入原始数据CMP AX,FAULT ;判断是否出错, JE REIN ;出错则重新输入 LEA DX,STR2 MOV AH,09H ;9号DOS功能调用,提示输出原始数据 INT 21H CALL OUTPUT ;调用OUTPUT子程序,输出原始数据 CALL SORT ;调用SORT子程序,进行冒泡排序 LEA DX,STR3 MOV AH,09H ;9号DOS功能调用,提示输出排序后的数据 INT 21H CALL OUTPUT ;调用OUTPUT子程序,输出排序后的数据 LwIP协议栈源码详解 ——TCP/IP协议的实现 Created by.. 老衲五木 at.. UESTC Contact me.. for_rest@https://www.360docs.net/doc/535225967.html, 540535649@https://www.360docs.net/doc/535225967.html, 前言 最近一个项目用到LwIP,恰好看到网上讨论的人比较多,所以有了写这篇学习笔记的冲动,一是为了打发点发呆的时间,二是为了吹过的那些NB。往往决定做一件事是简单的,而坚持做完这件事却是漫长曲折的,但终究还是写完了,时间开销大概为四个月,内存开销无法估计。。 这篇文章覆盖了LwIP协议大部分的内容,但是并不全面。它主要讲解了LwIP协议最重要也是最常被用到的部分,包括内存管理,底层网络接口管理,ARP层,IP层,TCP层,API 层等,这些部分是LwIP的典型应用中经常涉及到的。而LwIP协议的其他部分,包括UDP,DHCP,DNS,IGMP,SNMP,PPP等不具有使用共性的部分,这篇文档暂时未涉及。 原来文章是发在空间中的,每节每节依次更新,后来又改发为博客,再后来就干脆懒得发了。现在终于搞定,于是将所有文章汇总。绞尽脑汁的想写一段空前绝后,人见人爱的序言,但越写越觉得像是猫儿抓的一样。就这样,PS:由于本人文笔有限,情商又低,下里巴人一枚,所以文中的很多语句可能让您很纠结,您可以通过邮箱与我联系。共同探讨才是进步的关键。 最后,欢迎读者以任何方式使用与转载,但请保留作者相关信息,酱紫!码字。。。世界上最痛苦的事情莫过于此。。。 ——老衲五木 目录 1 移植综述------------------------------------------------------------------------------------------------------4 2 动态内存管理------------------------------------------------------------------------------------------------6 3 数据包pbuf--------------------------------------------------------------------------------------------------9 4 pbuf释放---------------------------------------------------------------------------------------------------13 5 网络接口结构-----------------------------------------------------------------------------------------------16 6 以太网数据接收--------------------------------------------------------------------------------------------20 7 ARP表-----------------------------------------------------------------------------------------------------23 8 ARP表查询-----------------------------------------------------------------------------------------------26 9 ARP层流程-----------------------------------------------------------------------------------------------28 10 IP层输入-------------------------------------------------------------------------------------------------31 11 IP分片重装1--------------------------------------------------------------------------------------------34 12 IP分片重装2--------------------------------------------------------------------------------------------37 13 ICMP处理-----------------------------------------------------------------------------------------------40 14 TCP建立与断开----------------------------------------------------------------------------------------43 15 TCP状态转换-------------------------------------------------------------------------------------------46 16 TCP控制块----------------------------------------------------------------------------------------------49 17 TCP建立流程-------------------------------------------------------------------------------------------53 18 TCP状态机----------------------------------------------------------------------------------------------56 19 TCP输入输出函数1-----------------------------------------------------------------------------------60 20 TCP输入输出函数2-----------------------------------------------------------------------------------63 21 TCP滑动窗口-------------------------------------------------------------------------------------------66 22 TCP超时与重传----------------------------------------------------------------------------------------69 23 TCP慢启动与拥塞避免-------------------------------------------------------------------------------73 24 TCP快速恢复重传和Nagle算法-------------------------------------------------------------------76 25 TCP坚持与保活定时器-------------------------------------------------------------------------------80 26 TCP定时器----------------------------------------------------------------------------------------------84 27 TCP终结与小结----------------------------------------------------------------------------------------88 28 API实现及相关数据结构-----------------------------------------------------------------------------91 29 API消息机制--------------------------------------------------------------------------------------------94 30 API函数及编程实例-----------------------------------------------------------------------------------97 实验一两个多位十进制数相减实验 一、实验要求:将两个多位十进制数相减,要求被减数,减数均以ASCII码形式按顺序 存放在以DATAI和DATA2为首的5个内存单元中(低位在前>,结果送回 DATAI处。 二、实验目的:1.学习数据传送和算术运算指令的用法。 2.熟悉在PC机上建立、汇编、链接、调试和运行汇编语言程序的过程。 三、实验步骤:连好实验箱后接通电源,打开上位机软件88TE进入软件调试界面: 点击“文件\打开”文件路径为C: \88TE\cai\asm\Ruanjian\Rjexp1.asm。具体操作如图所示: b5E2RGbCAP 点击编译连接生成可执行的exe文件。 通过单步运行调试程序,打开寄存器查看其变量变化情况。 四、实验程序框图: 五、实验程序: 文件路径为C:\88TE\cai\asm\Ruanjian\Rjexp1.asm DATA SEGMENT DATA1 DB 33H,39H,31H,37H,38H 。第一个数据<作为被减数)DATA2 DB 36H,35H,30H,38H,32H 。第二个数据<作为减数)MES1 DB '-','$' MES2 DB '=','$'p1EanqFDPw Array DATA ENDS STACK SEGMENT STA DB 20 DUP(?> TOP EQU LENGTH STA STACK ENDS CODE SEGMENT ASSUME CS:CODE,DS:DATA,SS:STACK,ES:DATA START: MOV AX,DATA MOV DS,AX MOV ES,AX MOV AX,STACK MOV SS,AX MOV AX,TOP MOV SP,AX MOV SI,OFFSET DATA1 MOV BX,05 CALL DISPL MOV AH,09H LEA DX,MES1 INT 21H MOV SI,OFFSET DATA2 MOV BX,05 CALL DISPL MOV AH,09H LEA DX,MES2 INT 21H MOV SI,OFFSET DATA1 MOV DI,OFFSET DATA2 CALL SUBA 。减法运算 MOV SI,OFFSET DATA1 MOV BX,05 。显示结果 CALL DISPL MOV DL,0DH MOV AH,02H INT 21H MOV DL,0AH MOV AH,02H INT 21H INT 21H MOV AX,4C00H INT 21H DISPL PROC NEAR 。显示子功能 DSI: MOV AH,02 MOV DL,[SI+BX-1] 。显示字符串中一字符 INT 21H LWIP源码分析 ----- caoxw 1 LWIP的结构 LWIP(Light weight internet protocol)的主要模块包括:配置模块、初始化模块、NetIf 模块、mem(memp)模块、netarp模块、ip模块、udp模块、icmp 模块、igmp模块、dhcp 模块、tcp模块、snmp模块等。下面主要对我们需要关心的协议处理进行说明和梳理。 配置模块: 配置模块通过各种宏定义的方式对系统、子模块进行了配置。比如,通过宏,配置了mem管理模块的参数。该配置模块还通过宏,配置了协议栈所支持的协议簇,通过宏定制的方式,决定了支持那些协议。主要的文件是opt.h。 初始化模块: 初始化模块入口的文件为tcpip.c,其初始化入口函数为: void tcpip_init(void (* initfunc)(void *), void *arg) 该入口通过调用lwip_init()函数,初始化了所有的子模块,并启动了协议栈管理进程。同时,该函数还带有回调钩子及其参数。可以在需要的地方进行调用。 协议栈数据分发管理进程负责了输入报文的处理、超时处理、API函数以及回调的处理,原型如下: static void tcpip_thread(void *arg) NetIf模块: Netif模块为协议栈与底层驱动的接口模块,其将底层的一个网口设备描述成协议栈的一个接口设备(net interface)。该模块的主要文件为netif.c。其通过链表的方式描述了系统中的所有网口设备。 Netif的数据结构描述了网口的参数,包括IP地址、MAC地址、link状态、网口号、收发函数等等参数。一个网口设备的数据收发主要通过该结构进行。 Mem(memp)模块: Mem模块同一管理了协议栈使用的内容缓冲区,并管理pbuf结构以及报文的字段处理。主要的文件包括mem.c、memp.c、pbuf.c。 netarp模块: netarp模块是处理arp协议的模块,主要源文件为etharp.c。其主要入口函数为: err_t ethernet_input(struct pbuf *p, struct netif *netif) 该入口函数通过判断输入报文p的协议类型来决定是按照arp协议进行处理还是将该报文提交到IP协议。如果报文是arp报文,该接口则调用etharp_arp_input,进行arp请求处理。 如果是ip报文,该接口就调用etharp_ip_input进行arp更新,并调用ip_input接口,将报文提交给ip层。 在该模块中,创建了设备的地址映射arp表,并提供地址映射关系查询接口。同时还提供了arp报文的发送接口。如下: 实验一初级程序的编写与调试实验 一、实验目的 (1) 掌握汇编语言程序设计的基本方法和技能; (2) 熟练掌握使用全屏幕编辑程序EDIT编辑汇编语言源程序; (3) 熟练掌握宏汇编程序MASM的使用; (4) 熟练掌握链接程序LINK的使用。 二、实验要求 (1) 掌握汇编语言程序设计上机过程; (2) 回答思考问题; (3) 记录实验结果。 三、实验内容 编写一个名字为的源程序,该程序的功能是在计算机屏幕上显示一个字符串“HELLO!”。 四、实验提示 按以下操作步骤进行实验。 (1) 编辑源程序 利用Windows XP操作系统附件中的“记事本”或者DOS编辑器编写如下源程序: DATA SEGMENT S1 DB 'HELLO!','$' DATA ENDS STACK SEGMENT PARA STACK DB 64 DUP() STACK ENDS CODE SEGMENT MAIN PROC FAR ASSUME CS:CODE,DS:DATA,SS:STACK START: PUSH DS MOV AX,0 PUSH AX MOV AX,DATA MOV DS,AX MOV AX,STACK MOV SS,AX MOV AH,09H MOV DX,OFFSET S1 INT 21H RET MAIN ENDP CODE ENDS END START 把程序保存在d:/masm5文件夹下。 (2) 汇编 windows环境下通过开始—〉运行——〉输入CMD回车(进入DOS系统)——〉输入D:回车——〉输入CD空格MASM5(进入D盘下MASM5然见的根目录)。在光标处输入MASM 文件名,回车进行编译。(例如文件名为则执行的操作为:d:\masm5>masm 执行上述操作命令之后将在屏幕上显示如下信息: Microsoft(R) Macro Assembler Version Copyright(C) Microsoft Corp 1981-1985, rights reserved Object filename[]: Source listing[]: Cross reference[]: 50678 + 410090 Bytes symbol space free 0 warning Errors 0 Severe Errors 在汇编过程中产生了三个文件,其默认的文件名显示在屏幕上,如果不需要做任何改变就直接按Enter键。 通过屏幕上的显示,可以了解到在本次汇编过程中没有发生错误和警告,因此可以继续进行链接操作。 (3) 链接 在光标处输入LINK 文件名,回车进行链接。 执行上述命令后将在屏幕上显示如下信息: Microsoft(R) Overlay Linker Version LwIP协议栈开发嵌入式网络的三种方法分析 摘要轻量级的TCP/IP协议栈LwIP,提供了三种应用程序设计方法,且很容易被移植到多任务的操作系统中。本文结合μC/OS-II这一实时操作系统,以建立TCP服务器端通信为例,分析三种方法以及之间的关系,着重介绍基于raw API的应用程序设计。最后在ST公司STM32F107微处理器平台上验证,并给出了测试结果。 关键词LwIP协议栈;μC/OS-II;嵌入式网络;STM32F107; 随着嵌入式系统功能的多样化以及网络在各个领域的中的广泛应用,具备网络功能的嵌入式设备拥有更高的使用价值和更强的通用性。然而大部分嵌入式设备使用经济型处理器,受内存和速度限制,资源有限,不需要也不可能完整实现所有的TCP/IP协议,有时只需要满足实际需求就行。LwIP是由瑞典计算机科学研究院开发的轻量型TCP/IP协议栈,其特点是保持了以太网的基本功能,通过优化减少了对存储资源的占用。LwIP是免费、开源的,任何人可以使用,能够在裸机的环境下运行,当然设计的时候也考虑了将来的移植问题,可以很容易移植到多任务操作系统中。本文介绍了以ARM微处理器STM32F107和PHY接口DP83848为平台,构建的嵌入式系统中,采用LwIP和嵌入式操作系统μC/OS-II,使用协议栈提供的三种应用程序接口,实现嵌入式设备的网络通信功能。 1LwIP和μC/OS-II介绍 1.1 LwIP协议栈 LwIP协议是瑞士计算机科学院的Adam Dunkels等开发的一套用于嵌入式系统的开放源代码TCP/IP协议栈。LwIP含义是light weight(轻型)IP协议,在实现时保持了TCP协议的主要功能基础上减少对RAM的占用,一般它只需要几十K的RAM和40K左右的ROM 就可以运行,这使LwIP协议栈很适合在低端嵌入式系统中使用。 LwIP协议栈的设计才用分层结构的思想,每一个协议都作为一个模块来实现,提供一些与其它协议的接口函数。所有的TCP/IP协议栈都在一个进程当中,这样TCP/IP协议栈就和操作系统内核分开了。而应用程序既可以是单独的进程也可以驻留在TCP/IP进程中,它们之间利用ICP机制进行通讯。如果应用程序是单独的线程可以通过操作系统的邮箱、消息队列等,与协议栈进程通讯。如果应用程序驻留在协议栈进程中,则应用程序可以通过内部回调函数和协议栈进程通讯。 1.2 μC/OS-II实时操作系统 μC/OS-II是一个源码公开、可移植、可固化、可裁剪及占先式的实时多任务操作系统,是专门为嵌入式应用设计的实时操作系统内核,已广泛的应用在各种嵌入式系统中。 μC/OS-II是多任务系统,内核负责管理各个任务,每个任务都有其优先级,μC/OS-II 最多可以管理64个任务,其每个任务都拥有自己独立的堆栈。μC/OS-II提供了非常丰富的系统服务功能,比如信号量、消息邮箱、消息队列、事件标志、内存管理和时间管理等,这些功能可以帮助用户实现非常复杂的应用。 1.3 LwIP协议栈移植到μC/OS-II LwIP协议栈在设计的时候就考虑到了将来的移植问题,因此把所有与硬件、操作系统、编译器有关的部分都全部独立起来,形成了一个操作系统模拟层。操作系统模拟层用进程间的信号量、邮箱机制处理通信问题,而μC/OS-II是一个基于任务调度的嵌入式实时操作系 实验一 MASM For Windows 的使用及顺序程序设计 一、实验目的 1、熟悉在PC机上建立、汇编、连接、调试和运行8086汇编语言程序的过程。 2、熟悉masm for windows调试环境及DEBUG常用命令的使用 二、实验内容 1.DEBUG常用命令(U、R、D、E、F、T、G、Q)的操作使用 2.编程实现两个16位无符号数的加、减、乘、除运算。 有两个两字节无符号数分别放在存储单元A、B起始的缓冲器中,求其和,结果放在A起始的缓冲区并在屏幕上显示。相加若有进位不存入存储单元。 三、实验设备 PC机一台 四、实验准备 1) 分析题目,将程序中的原始数据和最终结果的存取方法确定好。 2) 画出流程图。 3) 写出源程序。 4) 对程序中的结果进行分析,并准备好上机调试与用汇编程序及汇编调试的过程。 五、实验步骤 1) 输入源程序。 2) 汇编、连接程序,生成 .EXE文件,执行文件,检查结果。 六、学生实验报告的要求 1) 列出源程序,说明程序的基本结构,包括程序中各部分的功能。 2) 说明程序中各部分所用的算法。 3) 说明主要符号和所用到寄存器的功能。 4) 上机调试过程中遇到的问题是如何解决的。 5) 对调试源程序的结果进行分析。 4) 说明标志位CF、SF和OF的意义。 DEBUG的常用命令 1、R 显示或修改寄存器的内容 命令格式:-R 2、 D 显示存储单元的内容 命令格式:-D[地址1, 地址2] 3、E修改存储单元的内容 命令格式:-E[地址1, 地址2] 4、U反汇编 命令格式:-U[地址1, 地址2] 5、T单步执行 命令格式:-T 6、G连续执行 命令格式:-G[=起始地址, 结束地址] A小汇编 命令格式:-A 7、Q退出DEBUG,返回DOS 实验一源程序 EXAM1-2 .ASM DATA SEGMENT A D B 34H,18H,2 DUP(0),’$’ B DB 56H,83H DATA ENDS CODE SEGMENT ASSUME CS:CODE,DS:DATA START: MOV AX,DATA MOV DS,AX MOV AL,A MOV BL,B ADD AL,BL MOV AH,A+1 MOV BH, B+1 ADC AH, BH MOV A, ALXmodem协议详解以及源代码剖析
微机原理实验
LWIP协议栈的分析和设计
微机原理实验 源程序
微机原理实验指导书
微机原理及应用实验(题目)
微机原理实验报告
lwip各层协议栈详解
微机原理实验报告-冒泡排序
LwIP协议栈源码详解
微机原理实验程序
lwip协议栈源码分析
微机原理实验91036
LwIP协议栈开发嵌入式网络的三种方法分析
微机原理实验