FLUENT中应用DPM模型时双R分布的详细说明

FLUENT中应用DPM模型时双R分布的详细说明
使用动网格的模型在应用DPM模型进行计算时,Injection Type不能使用surface。
关于rosin-rammler分布
举例说明,有一组颗粒服从这样一种粒径分布,见下表:
Diameter Mass Fraction
Range (μm ) in Range
0-70 0.05
70-100 0.10
100-120 0.35
120-150 0.30
150-180 0.15
180-200 0.05
定义一个变量Y d,其定义为:比指定粒径d 大的颗粒的质量分数。那么上面所说的颗粒的粒径分布所对应的Y d 就是:
Mass Fraction with
Diameter,d(μm) Diameter Greater than d,Y d
70 0.95
100 0.85
120 0.50
150 0.20
180 0.05
200 (0.00)
Rosin-Rammler分布函数假定粒径d和Y d只见存在这样一种指数关系:
Y d = (e-(d /dm ))n(1)
其中d[size=10.5pt]m为平均粒径(Mean Diameter );n 为传播系数(Spread Parameter)。为了获得上述两种数值,需要找到d和Y d 的关系。
Mass Fraction with
Diameter,d ( μm) Diameter Greater than d, Y d
70 0.95
100 0.85
120 0.50
150 0.20
180 0.05
200 (0.00)
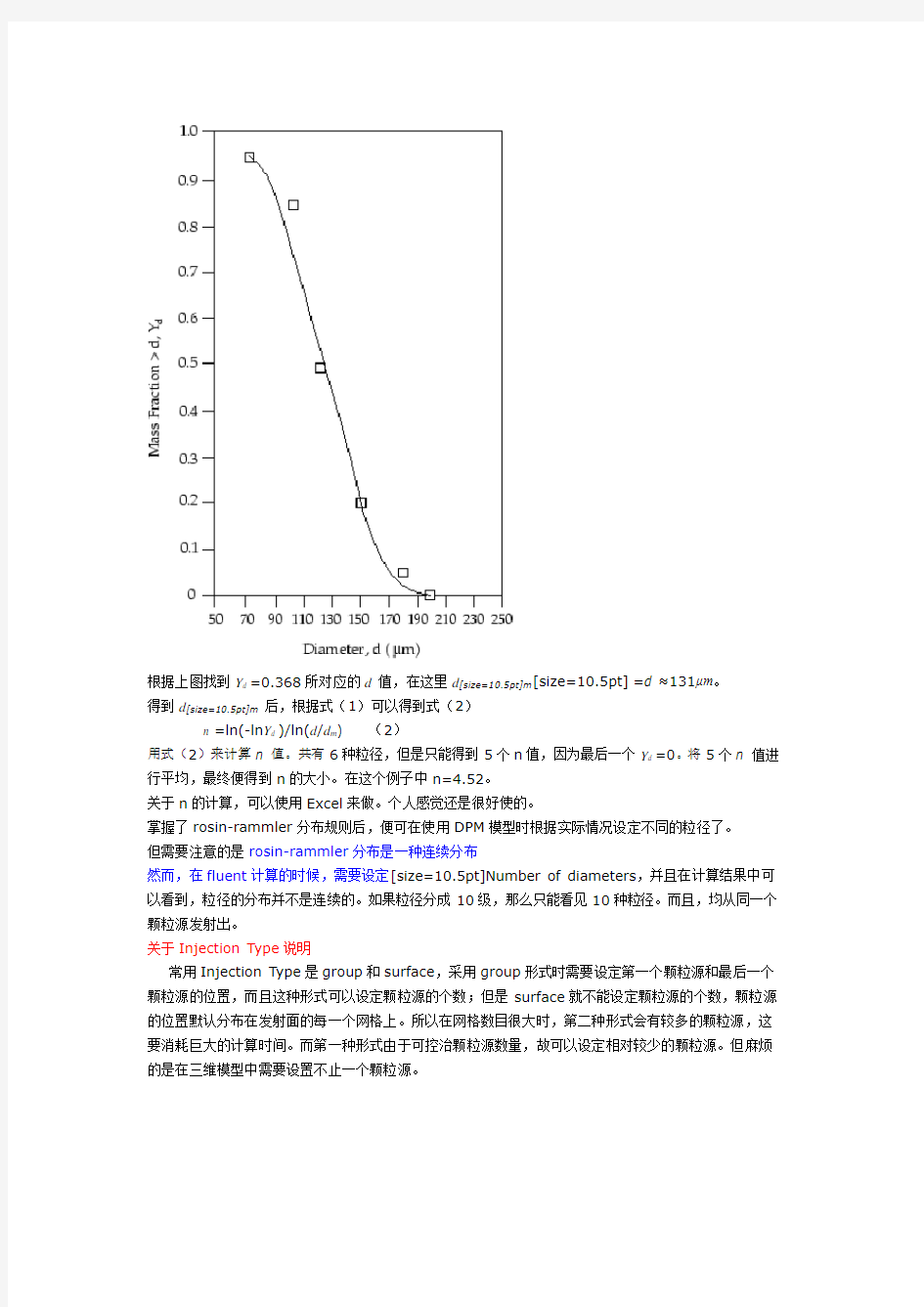
Y d = e-1≈0.368所对应的d值即为d[size=10.5pt]m,由于上表中没有0.368,所以需要根据已有数值进行拟合,得到曲线如下:
根据上图找到Y d =0.368所对应的d值,在这里d[size=10.5pt]m[size=10.5pt]=d ≈131μm。
得到d[size=10.5pt]m 后,根据式(1)可以得到式(2)
n =ln(-ln Y d )/ln(d/d m) (2)
用式(2)来计算n 值。共有6种粒径,但是只能得到5个n值,因为最后一个Y d =0。将5个n 值进行平均,最终便得到n的大小。在这个例子中n=4.52。
关于n的计算,可以使用Excel来做。个人感觉还是很好使的。
掌握了rosin-rammler分布规则后,便可在使用DPM模型时根据实际情况设定不同的粒径了。
但需要注意的是rosin-rammler分布是一种连续分布
然而,在fluent计算的时候,需要设定[size=10.5pt]Number of diameters,并且在计算结果中可以看到,粒径的分布并不是连续的。如果粒径分成10级,那么只能看见10种粒径。而且,均从同一个颗粒源发射出。
关于Injection Type说明
常用Injection Type是group和surface,采用group形式时需要设定第一个颗粒源和最后一个颗粒源的位置,而且这种形式可以设定颗粒源的个数;但是surface就不能设定颗粒源的个数,颗粒源的位置默认分布在发射面的每一个网格上。所以在网格数目很大时,第二种形式会有较多的颗粒源,这要消耗巨大的计算时间。而第一种形式由于可控治颗粒源数量,故可以设定相对较少的颗粒源。但麻烦的是在三维模型中需要设置不止一个颗粒源。
第三章,湍流模型
第三章,湍流模型 第一节, 前言 湍流流动模型很多,但大致可以归纳为以下三类: 第一类是湍流输运系数模型,是Boussinesq 于1877年针对二维流动提出的,将速度脉动的二阶关联量表示成平均速度梯度与湍流粘性系数的乘积。即: 2 1 21 x u u u t ??=-μρ 3-1 推广到三维问题,若用笛卡儿张量表示,即有: ij i j j i t j i k x u x u u u δρμρ32 -??? ? ????+ ??=''- 3-2 模型的任务就是给出计算湍流粘性系数t μ的方法。根据建立模型所需要的微分方程的数目,可以分为零方程模型(代数方程模型),单方程模型和双方程模型。 第二类是抛弃了湍流输运系数的概念,直接建立湍流应力和其它二阶关联量的输运方程。 第三类是大涡模拟。前两类是以湍流的统计结构为基础,对所有涡旋进行统计平均。大涡模拟把湍流分成大尺度湍流和小尺度湍流,通过求解三维经过修正的Navier-Stokes 方程,得到大涡旋的运动特性,而对小涡旋运动还采用上述的模型。 实际求解中,选用什么模型要根据具体问题的特点来决定。选择的一般原则是精度要高,应用简单,节省计算时间,同时也具有通用性。 FLUENT 提供的湍流模型包括:单方程(Spalart-Allmaras )模型、双方程模型(标准κ-ε模型、重整化群κ-ε模型、可实现(Realizable)κ-ε模型)及雷诺应力模型和大涡模拟。 湍流模型种类示意图 第二节,平均量输运方程 包含更多 物理机理 每次迭代 计算量增加 提的模型选 RANS-based models
雷诺平均就是把Navier-Stokes 方程中的瞬时变量分解成平均量和脉动量两部分。对于速度,有: i i i u u u '+= 3-3 其中,i u 和i u '分别是平均速度和脉动速度(i=1,2,3) 类似地,对于压力等其它标量,我们也有: φφφ'+= 3-4 其中,φ表示标量,如压力、能量、组分浓度等。 把上面的表达式代入瞬时的连续与动量方程,并取平均(去掉平均速度i u 上的横线),我们可以把连续与动量方程写成如下的笛卡儿坐标系下的张量形式: 0)(=?? +??i i u x t ρρ 3-5 () j i j l l ij i j j i j i i u u x x u x u x u x x p Dt Du -?? +???????????? ????-??+????+??-=ρδμρ32 3-6 上面两个方程称为雷诺平均的Navier-Stokes (RANS )方程。他们和瞬时Navier-Stokes 方程有相同的形式,只是速度或其它求解变量变成了时间平均量。额外多出来的项j i u u ''-ρ是雷诺应力,表示湍流的影响。如果要求解该方程,必须模拟该项以封闭方程。 如果密度是变化的流动过程如燃烧问题,我们可以用法夫雷(Favre )平均。这样才可以求解有密度变化的流动问题。法夫雷平均就是出了压力和密度本身以外,所有变量都用密度加权平均。变量的密度加权平均定义为: ρρ/~ Φ=Φ 3-7 符号~表示密度加权平均;对应于密度加权平均值的脉动值用Φ''表示,即有: Φ''+Φ=Φ~ 。很显然,这种脉动值的简单平均值不为零,但它的密度加权平均值等于零,即: 0≠Φ'', 0=Φ''ρ Boussinesq 近似与雷诺应力输运模型 为了封闭方程,必须对额外项雷诺应力j i u u -ρ进行模拟。一个通常的方法是应用Boussinesq 假设,认为雷诺应力与平均速度梯度成正比,即: ij i i t i j j i t j i x u k x u x u u u δμρμρ)(32 ??+-??? ? ????+??=''- 3-8 Boussinesq 假设被用于Spalart-Allmaras 单方程模型和ε-k 双方程模型。Boussinesq 近似 的好处是与求解湍流粘性系数有关的计算时间比较少,例如在Spalart-Allmaras 单方程模型中,只多求解一个表示湍流粘性的输运方程;在ε-k 双方程模型中,只需多求解湍动能k 和耗散率ε两个方程,湍流粘性系数用湍动能k 和耗散率ε的函数。Boussinesq 假设的缺点是认为湍流粘性系数t μ是各向同性标量,对一些复杂流动该条件并不是严格成立,所以具有其应用限制性。
fluent计算错误分析
1. FlUENT 1.1 求解方面 1.1.1 floating point error是什么意思?怎样避免它? Floating point error已经提过很多次了并且也已经对它讨论了许多。下面是在Fluent论坛上的一些答案: 从数值计算方面看,计算机所执行的运算在计算机内是以浮点数(floating point number)来表示的。那些由于用户的非法数值计算或者所用计算机的限制所引起的错误称为floating point error。 1)非法运算:最简单的例子是使用Newton Raphson方法来求解f(x)=0的根时,如果执行第N次迭代时有,x=x(N),f’(x(N))=0,那么根据公式x(N+1)=x(N)-f(x(N))/ f’(x(N))进行下一次迭代时就会出现被0除的错误。 2)上溢或下溢:这种错误是数据太大或太小造成的,数据太大称为上溢,太小称为下溢。这样的数据在计算机中不能被处理器的算术运算单元进行计算。 3)舍入错误:当对数据进行舍入时,一些重的数字会被丢失并且不可再恢复。例如,如果对0.1进行舍入取整,得到的值为0,如果再对它又进行计算就会导致错误。 避免方法 计算和迭代我认为设一个比较小的时间步长会比较好的。或者改成小的欠松驰因子也会比较好。从我的经验来看,我把欠松驰因子设为默认值的1/3;降低欠松驰因子或使用耦合隐式求解;改变欠松驰因子,如果是非稳态问题可能是时间步长太大;改善solver-control-limits 比例或许会有帮助;你需要降低Courant数;如果仍然有错误,不选择compute from初始化求解域,然后单击init。再选择你想从哪个面初始化并迭代,这样应该会起作用。另外一个原因可能是courant数太大,就样就是说两次迭代之间的时间步太大并且计算结果变化也较大(残差高)。 网格问题当我开始缩放网格时就会发生这个错误。在Gambit中,所有的尺寸都是以mm 为单位,在fluent按scale按钮把它转换成m,然后迭代几百次时就会发生这种错误。但是当我不把网格缩放到m时,让它和在Gambit中一样,迭代就会成功;我认为你应当检查网格,你的网格数太多了,使用较少的网格问题就会解决;网格太多,计算机资源不够用,使使比较粗的网格。 边界条件在我的分析中,我设了一个wall边界条件来代迭axis边界条件,结果fluent拒绝计算并告诉我floating point error。你的边界条件不能代表真实的物理现象;错误的边界条件定义可能会导致floating point error。例如把内边界设成interior;一次我使用对称边界条件模拟2D区间时也遇到这种问题,我把symmetry设为axe symmetric,就发生了floating point error;检查你设的湍流参数,减小湍流强度,先进行50次迭代。 多处理器问题我近来在进行多处理器模拟时也遇到相似的问题。问题的解决方法是在单个处理器上运行,这样就运算得很好。 错误迭代以错误的条件来初始化,在开始迭代时就会发生floating point error。 1.1.2 coupled和segregated求解有什么区别? Coupled会同时求解所有的方程(质量守恒方程、动量守恒方程和能量守恒方程)而不是单个方程求解(方程互相分离)。当速度和压力高度耦合(高压和高速)时应该使用耦合求解,但这样会需要较长的计算时间。 在耦合求解中,能量方程中总是包含组分扩散(Species Diffusion Term)项。
Fluent性能分析
Fluent性能分析 仅仅就我接触过得谈谈对fluent的认识,并说说哪些用户适合用,哪些不适合 fluent对我来说最麻烦的不在里面的设置,因为我本身解决的就是高速流动可压缩N-S方程,而且本人也是学力学的,诸如边界条件设置等概念还是非常清楚的同时我接触的流场模拟,都不会有很特别的介质,所以设置起来很简单 对我来说,颇费周折的是gambit做图和生成网格,并不是我不会,而是gambit对作图要求的条件很苛刻,也就是说,稍有不甚,就前功尽弃,当然对于计算流场很简单的用户,这不是问题。有时候好几天生成不了的图形,突然就搞定了,逐渐我也总结了一点经验,就是要注意一些小的拐角地方的图形,有时候做布尔运算在图形吻合的地方,容易产生一些小的面最终将导致无法在此生成网格, fluent里面的计算方法是有限体积法,而且我觉得它在计算过程中为了加快收敛速度,采取了交错网格,这样,计算精度就不会很高。同时由于非结构网格,肯定会导致计算精度的下降,所以我一贯来认为在fluent里面选取复杂的粘性模型和高精度的 格式没有任何意义,除非你的网格做的非常好。 而且fluent5.5以前的版本(包括5。5),其物理模型,(比如粘性流体的几个模型)都是预先设定的,所以,对于那些做探索性或者检验新方法而进行的模拟,就不适合 用。 同时gambit做网格,对于粘性流体,特别是计算湍流尺度,或者做热流计算来说其网格精度一般是不可能满足的,除非是很小的计算区域 所以,用fluent做的比较复杂一点的流场(除了经典的几个基本流场) 其计算所得热流,湍流,以及用雷诺应力模拟的粘性都不可能是准确的, 这在物理上和计算方法已经给fluent判了死刑,有时候看到很多这样讨论的文章,觉得 大家应该从物理和力学的本质上考虑问题。 但是,fluent往往能计算出量级差不多的结果,我曾经做了一个复杂的飞行器热流计算,高超音速流场,得到的壁面热流,居然在量级上是吻合的,但是,从计算热流需要的壁面网格精度来判断,gambit所做的网格比起壁面网格所满足的尺寸的要大了至少2个数量级, 我到现在还不明白fluent是怎么搞的。 综上,我觉得,如果对付老板的一些工程项目,可以用fluent对付过去但是如果真的做论文,或者需要发表文章,除非是做一些技术性工作,比如优化计算 一般用fluent是不适合的。 我感觉fluent做力的计算是很不错的,做流场结构的计算,即使得出一些涡也不是流场本身性质的反应,做低速流场计算,fluent的优势在于收敛 速度快,但是低速流场计算,其大多数的着眼点在于对流场结构的探索,所以计算得到的结果就要好好斟酌一下了,高速流场的模拟中,一般着眼点在于气动力的结果,压力分布
FLUENT 15.0 VOF模型测试报告
ANSYS 15.0 系列测试报告 FLUENT 15.0 VOF模型 测试人:崔亮安世亚太公司 测试时间:2013.12.01
1、仿真平台 HP Z820工作站,Intel Xeon E5-2690 * 2,内存64GB,2TB SATA硬盘。安装ANSYS 15.0 Preview3版本。 2、仿真模型 对某车型上带有底部隔板的油箱,在车辆加速时油箱内燃油晃动的瞬态过程进行瞬态仿真分析,网格单元数约10万,使用FLUENT的VOF模型计算空气和燃油的两相交界面。重点考察FLUENT 15.0中VOF模型的计算效率和两相交界面捕捉精度的提升。 测试案例的几何形状 测试案例的网格模型 3、试用情况 1).稳定性 在整个试用过程中,软件保持稳定,未出现任何不流畅、死机、系统崩溃等情况。2).流畅度 模型拖动、旋转、缩放等操作十分流畅,模型设定及求解过程操作十分流畅。 3).效率 该模型使用0.0005秒的时间步长进行瞬态计算,共计算了2000步,共计1.0秒时长。使用15.0 Preview3版本所用的计算时间为3693秒。之前使用13.0版本计算该模型所用计算时间为4381秒。新版本提速15.7%。 4).硬件资源调用情况 由于该模型网格数量较少,仅使用单核进行求解计算。在整个计算过程中,单核占用率达到100%,内存占用峰值约为400 MB。之前使用13.0版本计算该模型的内存占用峰值约
为450兆。新版本对内存的峰值占用约为旧版本的90%左右。 5).计算精度 VOF模型的计算精度体现在两相交界面捕捉的清晰程度,15.0版本的交界面捕捉清晰程度比旧版本略有提升,对于一些较小的气泡有着更好的捕捉能力。 t=0.45s时,15.0版本和13.0版本计算的两相交界面对比 t=0.45s时,15.0版本和13.0版本计算的两相交界面对比 4、总结 在ANSYS 15.0 Preview3版本的试用过程中,对FLUENT 15.0中VOF模型的计算效率提升感到满意,相比较于旧版本,约有15%的计算速度提升,这对缩短仿真分析的周期有极大帮助;还有约10%的内存峰值占用量下降,这对于合理利用现有硬件资源进行更大规模的模型计算有着重要意义。此外,新版本VOF模型的计算精度也有所提升,两相交界面捕捉更加锐利,对于一些较小的气泡,相对于旧版本有着更好的捕捉能力
FLUENT中常用的湍流模型
The Spalart-Allmaras模型 对于解决动力漩涡粘性,Spalart-Allmaras 模型是相对简单的方程。它包含了一组新的方程,在这些方程里不必要去计算和剪应力层厚度相关的长度尺度。Spalart-Allmaras 模型是设计用于航空领域的,主要是墙壁束缚流动,而且已经显示出很好的效果。在透平机械中的应用也愈加广泛。 在原始形式中Spalart-Allmaras 模型对于低雷诺数模型是十分有效的,要求边界层中粘性影响的区域被适当的解决。在FLUENT中,Spalart-Allmaras 模型用在网格划分的不是很好时。这将是最好的选择,当精确的计算在湍流中并不是十分需要时。再有,在模型中近壁的变量梯度比在k-e模型和k-ω模型中的要小的多。这也许可以使模型对于数值的误差变得不敏感。想知道数值误差的具体情况请看5.1.2。 需要注意的是Spalart-Allmaras 模型是一种新出现的模型,现在不能断定它适用于所有的复杂的工程流体。例如,不能依靠它去预测均匀衰退,各向同性湍流。还有要注意的是,单方程的模型经常因为对长度的不敏感而受到批评,例如当流动墙壁束缚变为自由剪切流。 标准k-e模型 最简单的完整湍流模型是两个方程的模型,要解两个变量,速度和长度尺度。在FLUENT中,标准k-e模型自从被Launder and Spalding提出之后,就变成工程流场计算中主要的工具了。适用范围广、经济,有合理的精度,这就是为什么它在工业流场和热交换模拟中有如此广泛的应用了。它是个半经验的公式,是从实验现象中总结出来的。 由于人们已经知道了k-e模型适用的范围,因此人们对它加以改造,出现了RNG k-e模型和带旋流修正k-e 模型。k-ε模型中的K和ε物理意义:k是紊流脉动动能(J),ε是紊流脉动动能的耗散率(%);k越大表明湍流脉动长度和时间尺度越大,ε越大意味着湍流脉动长度和时间尺度越小,它们是两个量制约着湍流脉动。 RNG k-e模型 RNG k-e模型来源于严格的统计技术。它和标准k-e模型很相似,但是有以下改进: ?RNG模型在e方程中加了一个条件,有效的改善了精度。 ?考虑到了湍流漩涡,提高了在这方面的精度。 ?RNG理论为湍流Prandtl数提供了一个解析公式,然而标准k-e模型使用的是用户提供的常数。 ?然而标准k-e模型是一种高雷诺数的模型,RNG理论提供了一个考虑低雷诺数流动粘性的解析公式。这些公式的效用依靠正确的对待近壁区域 这些特点使得RNG k-e模型比标准k-e模型在更广泛的流动中有更高的可信度和精度。 带旋流修正的k-e模型 带旋流修正的k-e模型是近期才出现的,比起标准k-e模型来有两个主要的不同点。 ?带旋流修正的k-e模型为湍流粘性增加了一个公式。 ?为耗散率增加了新的传输方程,这个方程来源于一个为层流速度波动而作的精确方程。 术语“realizable”,意味着模型要确保在雷诺压力中要有数学约束,湍流的连续性。带旋流修正的k-e模型直接的好处是对于平板和圆柱射流的发散比率的更精确的预测。而且它对于旋转流动、强逆压梯度的边界层流动、流动分离和二次流有很好的表现。带旋流修正的k-e模型和RNG k-e模型都显现出比标准k-e模型在强流线弯曲、漩涡和旋转有更好的表现。由于带旋流修正的k-e模型是新出现的模型,所以现在还没有确凿的证据表明它比RNG k-e模型有更好的表现。但是最初的研究表明带旋流修正的k-e模型在所有k-e模型中流动分离和复杂二次流有很好的作用。带旋流修正的k-e模型的一个不足是在主要计算旋转和静态流动区域时不能提供自然的湍流粘度。这是因为带旋流修正的k-e模型在定义湍流粘度时考虑了平均旋度的影响。这种额外的旋转影响已经在单一旋转参考系中得到证实,而且表现要好于标准k-e模型。由于这些修改,把它应用于多重参考系统中需要注意。 标准k-ω模型 标准k-ω模型是基于Wilcox k-ω模型,它是为考虑低雷诺数、可压缩性和剪切流传播而修改的。Wilcox k-ω模型预测了自由剪切流传播速率,像尾流、混合流动、平板绕流、圆柱绕流和放射状喷射,因而可以应用于墙壁束缚流动和自由剪切流动。标准k-e模型的一个变形是SST k-ω模型,它在FLUENT中也是可用的,将在10.2.9中介绍它。 剪切压力传输(SST)k-ω模型
fluent经验总结
1什么叫松弛因子?松弛因子对计算结果有什么样的影响?它对计算的收敛情况又有什 么样的影响? 1、亚松驰(Under Relaxation):所谓亚松驰就是将本层次计算结果与上一层次结果的差值作适当缩减,以避免由于差值过大而引起非线性迭代过程的发散。用通用变量来写 出时,为松驰因子(Relaxation Factors)。《数值传热学-214》 2、FLUENT中的亚松驰:由于FLUENT所解方程组的非线性,我们有必要控制的变化。一般用亚松驰方法来实现控制,该方法在每一部迭代中减少了的变化量。亚松驰最简 单的形式为:单元内变量等于原来的值加上亚松驰因子a与变化的积, 分离解算器使用亚松驰来控制每一步迭代中的计算变量的更新。这就意味着使用分离解算器解的方程,包 括耦合解算器所解的非耦合方程(湍流和其他标量)都会有一个相关的亚松驰因子。在FLUENT中,所有变量的默认亚松驰因子都是对大多数问题的最优值。这个值适合于很多问题,但是对于一些特殊的非线性问题(如:某些湍流或者高Rayleigh数自然对流问题),在计算开始时要慎重减小亚松驰因子。使用默认的亚松驰因子开始计算是很好的习惯。如 果经过4到5步的迭代残差仍然增长,你就需要减小亚松驰因子。有时候,如果发现残差 开始增加,你可以改变亚松驰因子重新计算。在亚松驰因子过大时通常会出现这种情况。 最为安全的方法就是在对亚松驰因子做任何修改之前先保存数据文件,并对解的算法做几 步迭代以调节到新的参数。最典型的情况是,亚松驰因子的增加会使残差有少量的增加, 但是随着解的进行残差的增加又消失了。如果残差变化有几个量级你就需要考虑停止计算 并回到最后保存的较好的数据文件。注意:粘性和密度的亚松驰是在每一次迭代之间的。 而且,如果直接解焓方程而不是温度方程(即:对PDF计算),基于焓的温度的更新是要进行亚松驰的。要查看默认的亚松弛因子的值,你可以在解控制面板点击默认按钮。对于 大多数流动,不需要修改默认亚松弛因子。但是,如果出现不稳定或者发散你就需要减小 默认的亚松弛因子了,其中压力、动量、k和e的亚松弛因子默认值分别为0.2,0.5,0.5和0.5。对于SIMPLEC格式一般不需要减小压力的亚松弛因子。在密度和温度强烈耦合 的问题中,如相当高的Rayleigh数的自然或混合对流流动,应该对温度和/或密度(所用 的亚松弛因子小于1.0)进行亚松弛。相反,当温度和动量方程没有耦合或者耦合较弱时,流动密度是常数,温度的亚松弛因子可以设为1.0。对于其它的标量方程,如漩涡,组分,PDF变量,对于某些问题默认的亚松弛可能过大,尤其是对于初始计算。你可以将松弛因子设为0.8以使得收敛更容易。 SIMPLE与SIMPLEC比较 在FLUENT中,可以使用标准SIMPLE算法和SIMPLEC(SIMPLE-Consistent)算法,默认是SIMPLE算法,但是对于许多问题如果使用SIMPLEC可能会得到更好的结果,尤其是可以应用增加的亚松驰迭代时,具体介绍如下: 对于相对简单的问题(如:没有附加模型激活的层流流动),其收敛性已经被压力速
Fluent 湍流模型小结
Fluent 湍流模型小结湍流模型目前计算流体力学常用的湍流的数值模拟方法主要有以下三种: 直接模拟(direct numerical&Oσλαση; simulation, DNS) 直接数值模拟(DNS)特点在湍流尺度下的网格尺寸内不引入任何封闭模型的前提下对Navier-Stokes方程直接求解。这种方法能对湍流流动中最小尺度涡进行求解,要对高度复杂的湍流运动进行直接的数值计算,必须采用很小的时间与空间步长,才能分辨出湍流中详细的空间结构及变化剧烈的时间特性。基于这个原因,DNS目前仅限于相对低的雷诺数中湍流流动模型。另外,利用DNS模型对湍流运动进行直接的数值模拟对计算工具有很高的要求,计算机的内存及计算速度要非常的高,目前DNS模型还无法应用于工程数值计算,还不能解决工程实际问题。 大涡模拟(large&Oσλαση; eddy simulation, LES) 大涡模拟(LES)是基于网格尺度封闭模型及对大尺度涡进行直接求解N-S方程,其网格尺度比湍流尺度大,可以模拟湍流发展过程的一些细节,但其计算量仍很大,也仅用于比较简单的剪切流运动及管流。大涡模拟的基础是:湍流的脉动与混合主要是由大尺度的涡造成的,大尺度涡是高度的非各向同性,而且随流动的情形而异。大尺度的涡通过相互作用把能量传递给小尺度的涡,而小尺度的涡旋主要起到耗散能量的作用,几乎是各向同性的。这些对涡旋的认识基础就导致了大涡模拟方法的产生。Les大涡模拟采用非稳态的N-S方程直接模拟大尺度涡,但不计算小尺度涡,小涡对大涡的影响通过近似的模拟来考虑,这种影响称为亚格子Reynolds应力模型。大多数亚格子Reynolds模型都是将湍流脉动所造成的影响用一个湍流粘性系数,既粘涡性来描述。LES对计算机的容量和CPU的要求虽然仍然很高,但是远远低于DNS方法对计算机的要求,因而近年来的研究与应用日趋广泛。 应用Reynolds时均方程(Reynolds-averaging&Oσλαση; equations)的模拟方法 许多流体力学的研究和数值模拟的结果表明,可用于工程上现实可行的湍流模拟方法仍然是基于求解Reynolds时均方程及关联量输运方程的湍流模拟方法,即湍流的统观模拟方法。统观模拟方法的基本思想是用低阶关联量和平均流性质来模拟未知的高阶关联项,从而封闭平均方程组或关联项方程组。虽然这种方法在湍流理论中是最简单的,但是对工程应用而言仍然是相当复杂的。即便如此,在处理工程上的问题时,统观模拟方法仍然是最有效、最经济而且合理的方法。在统观模型中,使用时间最长,积累经验最丰富的是混合长度模型和K-E模型。其中混合长度模型是最早期和最简单的湍流模型。该模型是建立在层流粘性和湍流粘性的类比、平均运动与湍流的脉动的概念上的。该模型的优点是简单直观、无须增加微分方程。缺点是在模型中忽略了湍流的对流与扩散,对于复杂湍流流动混合长度难以确定。 到目前为止,工程中应用最广泛的是k-ε模型。另外针对k-ε模型的不足之处,许多学者通过对K-E模型的修正和发展,开始采用雷诺应力模型(DSM)和代数应力模型(ASM)。近年来,DSM模型已用来预报燃烧室及炉内的强旋及浮力流动。很多情况下能够给出优于k-ε模型的结果。但是该模型也有不足之处,首先它对工程预报来说太复杂,其次经验系数太多难以确定,此外,对压力应变项的模拟还有争议。更主要的是,尽管这一模型考虑了各种应变效应,但是其总精度并不总是高于其它模型,这些缺点导致了DSM模型没有得到广泛的应用。总之,虽然从本质上讲DSM模型和ASM模型比k-ε模型对湍流流场的模拟更加合理,但DSM和ASM中仍然采用精度不高的E方程,模型中常数的通用性还没有得到广泛的验证,边界条件不好给定,计算也比较复杂。正因为如此,目前用计算解决湍流问题时仍然采用比较成熟的K-E模型。 需要注意的是: 1、大涡模拟有自己的亚格子封闭模型,这和k-ε模型完全是两回事。LES的亚格子模型表
fluent湍流模型
第十章湍流模型 本章主要介绍Fluent所使用的各种湍流模型及使用方法。 各小节的具体内容是: 10.1 简介 10.2 选择湍流模型 10.3 Spalart-Allmaras 模型 10.4 标准、RNG和k-e相关模型 10.5 标准和SST k-ω模型 10.6 雷诺兹压力模型 10.7 大型艾迪仿真模型 10.8 边界层湍流的近壁处理 10.9 湍流仿真模型的网格划分 10.10 湍流模型的问题提出 10.11 湍流模型问题的解决方法 10.12 湍流模型的后处理 10.1 简介 湍流出现在速度变动的地方。这种波动使得流体介质之间相互交换动量、能量和浓度变化,而且引起了数量的波动。由于这种波动是小尺度且是高频率的,所以在实际工程计算中直接模拟的话对计算机的要求会很高。实际上瞬时控制方程可能在时间上、空间上是均匀的,或者可以人为的改变尺度,这样修改后的方程耗费较少的计算机。但是,修改后的方程可能包含有我们所不知的变量,湍流模型需要用已知变量来确定这些变量。 FLUENT 提供了以下湍流模型: ·Spalart-Allmaras 模型 ·k-e 模型 -标准k-e 模型 -Renormalization-group (RNG) k-e模型 -带旋流修正k-e模型 ·k-ω模型 -标准k-ω模型 -压力修正k-ω模型 -雷诺兹压力模型 -大漩涡模拟模型 10.2 选择一个湍流模型 不幸的是没有一个湍流模型对于所有的问题是通用的。选择模型时主要依靠以下几点:流体是否可压、建立特殊的可行的问题、精度的要求、计算机的能力、时间的限制。为了选择最好的模型,你需要了解不同条件的适用范围和限制 这一章的目的是给出在FLUENT中湍流模型的总的情况。我们将讨论单个模型对cpu 和内存的要求。同时陈述一下一种模型对那些特定问题最适用,给出一般的指导方针以便对于你需要的给出湍流模型。 10.2.1 雷诺平均逼近vs LES 在复杂形体的高雷诺数湍流中要求得精确的N-S方程的有关时间的解在近期内不太可能实现。两种可选择的方法用于把N-S方程不直接用于小尺度的模拟:雷诺平均和过滤。
fluent使用总结
3.1计算流体力学基础与FLUENT软件介绍 3.1.1计算流体力学基础 计算流体力学(Computational Fluid Dynamics,简称CFD)是利用数值方法通过计算机求解描述流体运动的数学方程,揭示流体运动的物理规律,研究定常流体运动的空间物理特性和非定常流体运动的时空物理特征的学科[}ss}。其基本思想可以归纳为:把原来在时间域和空间域上连续的物理量的场,如速度场和压力场,用一系列有限个离散点上的变量值的集合来代替,通过一定的原则和方式建立起关十这些离散点上场变量之间的关系的代数方程组,然后求解代数方程组获得场变量的近似值[f=}}l 计算流体力学可以看作是在流动基本方程(质量守恒方程、动量守恒方程、能量守恒方程)控制下对流动的数值仿真。通过这种数值仿真,可以得到流场内各个位置上的基本物理量(如速度、压力、温度和浓度等)的分布以及这些物理量随时间的变化规律。 还可计算出相关的其它物理量,如旋转式流体机械的转矩、水力损失和效率等。此外,与CAD联合还可进行结构优化设计等。 过去,流体力学的研究主要有实验研究和理论分析两种方法。实验研究主要以实验为研究手段,得到的结果真实可信,是理论分析和数值计算的基础,其重要性不容低估。然}fu实验往往受到模型尺寸、流场扰动和测量精度等的限制,有时可能难以通过实验的方法得到理想的结果。此外,实验往往经费投入较大、人力和物力耗费较大及周期较长;理论分析方法通常是利用简化的流动模型假设,给出所研究问题的解析解或简化方程。然}fu随着时代的发展,这些方法已不能很好地满足复杂非线性流体运动规律的研究。理论分析方法的优点是所得结果具有普遍适用性,各种影响因素清晰可见,是指导试验研究和验证新的数值计算方法的理论基础。但是,它往往要求对计算对象进行抽象和简化,才有可能得出理论解。}fU对十非线性情况,只有少数流动才能得到解析结果。 计算流体力学方法很好地克服了前面两种方法的弱点,与传统的理论分析方法、实验研究方法一同组成了研究流体流动问题的完整体系。计算流体力学的发展,先后经历 2 FLUENT软件介绍 FLUENT软件是由美国FLUENT公司开发的著名的CFD计算分析软件,在航空、航天、透平机械、汽车、船舶、机械、化工、石化、计算机、半导体、能源、医学等领域得到了广泛的应用。能够解决流动、传热、化学反应、燃烧、多相流、旋涡流动等问题。 FLUENT软件研究的流动模型包括了定常和非定常流动,层流(包括各种非牛顿流模型),紊流(包括最先进的紊流模型),不可压缩和可压缩流动,传热和化学反应等。FLUENT软件设计基于“CFD计算机软件群的概念”,针对每一种流动的物理问题的特点,采用适合于它的数值解法在计算速度、稳定性和精度等各方面达到最佳。不同领域的计算软件组合起来,成为CFD软件群,从而高效率地解决各个领域的复杂流动的计算问题,在各软件之间可以方便地进行数值交换,采用统一的前后处理工具,省去了科研工作者在计算方法、编程、前后处理等方面投入的重复、低效的劳动,而可以将主要精力用十物理问题本身的探索上。 流体有限体积法(Finite V olume Method,简称FVM)是目前计算流体动力学领域内应用最普遍的一种对偏微分方程组的离散方法。FLUENT软件就是采用C语言编写的基于非结构化网格和有限体积法的通用CFD求解器,它推出了多种优化的物理模型,如定常和非定常流动;层流(包括各种非牛顿流模型);紊流(包括最先进的紊流模型);不可压缩和可压缩流动;传热;化学反应等。对每一种物理问题的流动特点,有适合它的数值解法,用户可对显式或隐式差分格式进行选择,以期在计算速度、稳定性和精度等方面达到最佳。 在FLUENT 5.0之后的版本中,都采用GAMBIT的专用前处理软件。GAMBIT软件是面向CFD的专业前处理器软件,它包含全面的几何建模能力,也可以从主流的CAD/CAE软件导入几何体和网格,GAMBIT强大的布尔运算能力为建立复杂的几何模型提供的极大的方便。GAMBIT功能强大的网格划分工具,可以划分出包含边界层等CFD特殊要求的高质量的网格。GAMBIT中专有的网格划分算法可以保证在较为复杂的几何区域直接划分出高质量的六面体网格。GAMBIT中的TGRID方法可以在极其复杂的几何区域中划分出与相邻区域网格连续的完全非结构化的网格,GAMBIT网格划分方法的选择完全是智能化的,在选择一个几何区域后GAMBIT会自动选择最合适的网格划分算法,使网格划分过程变得极为容易。 通用CFD软件包,用来模拟从不可压缩到高度可压缩范围内的复杂流动。由于采用了多种求解方法和多重网格加速收敛技术,因而FLUENT能达到最佳的收敛速度和求解精度。灵活的非结构化网格和基于解的自适应网格技术及成熟的物理模型,使FLUENT在转捩与湍流、传热与相变、化学反应与燃烧、多相流、旋转机械、动/变形网格、噪声、材料加工、燃料电池等方面有广泛应用。
CFD讲义-湍流模型
第三章,湍流模型 第一节, 前言 湍流流动模型很多,但大致可以归纳为以下三类: 第一类是湍流输运系数模型,是Boussinesq 于1877年针对二维流动提出的,将速度脉动的二阶关联量表示成平均速度梯度与湍流粘性系数的乘积。即: 2 1 21 x u u u t ??=''-μρ 3-1 推广到三维问题,若用笛卡儿张量表示,即有: ij i j j i t j i k x u x u u u δρμρ32 -??? ? ????+ ??=''- 3-2 模型的任务就是给出计算湍流粘性系数t μ的方法。根据建立模型所需要的微分方程的数目,可以分为零方程模型(代数方程模型),单方程模型和双方程模型。 第二类是抛弃了湍流输运系数的概念,直接建立湍流应力和其它二阶关联量的输运方程。 第三类是大涡模拟。前两类是以湍流的统计结构为基础,对所有涡旋进行统计平均。大涡模拟把湍流分成大尺度湍流和小尺度湍流,通过求解三维经过修正的Navier-Stokes 方程,得到大涡旋的运动特性,而对小涡旋运动还采用上述的模型。 实际求解中,选用什么模型要根据具体问题的特点来决定。选择的一般原则是精度要高,应用简单,节省计算时间,同时也具有通用性。 FLUENT 提供的湍流模型包括:单方程(Spalart-Allmaras )模型、双方程模型(标准κ-ε模型、重整化群κ-ε模型、可实现(Realizable)κ-ε模型)及雷诺应力模型和大涡模拟。 湍流模型种类示意图 包含更多 物理机理 每次迭代 计算量增加 提的模型选 RANS-based models
第二节,平均量输运方程 雷诺平均就是把Navier-Stokes 方程中的瞬时变量分解成平均量和脉动量两部分。对于速度,有: i i i u u u '+= 3-3 其中,i u 和i u '分别是平均速度和脉动速度(i=1,2,3) 类似地,对于压力等其它标量,我们也有: φφφ'+= 3-4 其中,φ表示标量,如压力、能量、组分浓度等。 把上面的表达式代入瞬时的连续与动量方程,并取平均(去掉平均速度i u 上的横线),我们可以把连续与动量方程写成如下的笛卡儿坐标系下的张量形式: 0)(=?? +??i i u x t ρρ 3-5 () j i j l l ij i j j i j i i u u x x u x u x u x x p Dt Du ''-?? +???????????? ????-??+????+??-=ρδμρ32 3-6 上面两个方程称为雷诺平均的Navier-Stokes (RANS )方程。他们和瞬时Navier-Stokes 方程有相同的形式,只是速度或其它求解变量变成了时间平均量。额外多出来的项j i u u ''-ρ是雷诺应力,表示湍流的影响。如果要求解该方程,必须模拟该项以封闭方程。 如果密度是变化的流动过程如燃烧问题,我们可以用法夫雷(Favre )平均。这样才可以求解有密度变化的流动问题。法夫雷平均就是出了压力和密度本身以外,所有变量都用密度加权平均。变量的密度加权平均定义为: ρρ/~ Φ=Φ 3-7 符号~表示密度加权平均;对应于密度加权平均值的脉动值用Φ''表示,即有: Φ''+Φ=Φ~ 。很显然,这种脉动值的简单平均值不为零,但它的密度加权平均值等于零,即: 0≠Φ'', 0=Φ''ρ Boussinesq 近似与雷诺应力输运模型 为了封闭方程,必须对额外项雷诺应力j i u u ''-ρ进行模拟。一个通常的方法是应用Boussinesq 假设,认为雷诺应力与平均速度梯度成正比,即: ij i i t i j j i t j i x u k x u x u u u δμρμρ)(32 ??+-??? ? ????+??=''- 3-8 Boussinesq 假设被用于Spalart-Allmaras 单方程模型和ε-k 双方程模型。Boussinesq 近似 的好处是与求解湍流粘性系数有关的计算时间比较少,例如在Spalart-Allmaras 单方程模型中,只多求解一个表示湍流粘性的输运方程;在ε-k 双方程模型中,只需多求解湍动能k 和耗散率ε两个方程,湍流粘性系数用湍动能k 和耗散率ε的函数。Boussinesq 假设的缺点是认为湍
FLUENT软件学习报告
FLUENT软件学习报告 一、软件简介 CFD商业软件FLUENT,是通用CFD软件包,用来模拟从不可压缩到高度可压 FLUENT能达到最佳的收敛速度和求解精度。灵活的非结构化网格和基于解的自适应网格技术及成熟的物理模型,使FLUENT在转换与湍流、传热与相变、化学反应与燃烧、多相流、旋转机械、动/变形网格、噪声、材料加工、燃料电池等方面有广泛应用。 从本质上讲,FLUENT只是一个求解器。FLUENT本身提供的主要功能包括导入网格模型、提供计算的物理模型、施加边界条件和材料特性、求解和后处理。FLUENT支持的网格生成软件包括GAMBIT、TGRid、prePDF、GeoMesh和其他CAD/CAE软件包。 二、软件使用方法 本学习报告将以一简单算例—台阶运动演示FLUENT软件与GAMBIT及CAD 的结合使用。 2.1 物理模型 二维后台阶运动的计算区域如图2-1所示。计算区域为0.4m×1.2m,台阶长度为0.2m,高度为0.1m。 2.2在CAD中生成几何模型 在CAD中按下列步骤生成如图2-1几何模型:
(1)绘制求解区域形状。 (2)调用PEDIT命令,将构成台阶及边界的线生成多段线。 (3)调用REGION命令,将多段线形成的封闭区间生成区域。 (4)调用EXPORT命令,将绘图结果导出为ASCI格式文件命名为台阶,以便在GAMBIT中进行后续处理。 图2-2是在AUTOCAD中绘制的后台阶绕流的几何模型,该结果包含一个局域。 2.3在GAMBIT中划分网格 在AUTOCAD中生成了一个二维台阶的几何模型,该模型包含一个区域,现在转入到GAMBIT中进行网格划分。 按照导入几何模型、生成流体区域、划分网格、定义边界类型和区域类型的步骤完成GAMBIT划分网格的工作。网格划分完成后输出保存为MSH格式的网格文件。绘制结果如图2-3. 图2-3 网格
fluent中湍流参数的定义
FLUENT 中湍流参数的定义 2011-07-28 10:46:03| 分类:默认分类|举报|字号订阅 流场的入口、出口和远场边界上,用户需要定义流场的湍流参数。在FLUENT 中可以使用的湍流模型有很多种。在使用各种湍流模型时,哪些变量需要设定,哪些不需要设定以及如何给定这些变量的具体数值,都是经常困扰用户的问题。本小节只讨论在边界上设置均匀湍流参数的方法,湍流参数在边界上不是均匀分布的情况可以用型函数和UDF (用户自定义函数)来定义,具体方法请参见相关章节的叙述。 在大多数情况下,湍流是在入口后面一段距离经过转捩形成的,因此在边界上设置均匀湍流条件是一种可以接受的选择。特别是在不知道湍流参量的分布规律时,在边界上采用均匀湍流条件可以简化模型的设置。在设置边界条件时,首先应该定性地对流动进行分析,以便边界条件的设置不违背物理规律。违背物理规律的参数设置往往导致错误的计算结果,甚至使计算发散而无法进行下去。 在Turbulence Specification Method (湍流定义方法)下拉列表中,可以简单地用一个常数来定义湍流参数,即通过给定湍流强度、湍流粘度比、水力直径或湍流特征长在边界上的值来定义流场边界上的湍流。下面具体讨论这些湍流参数的含义,以保证在设置模型时不出现违背流动规律的错误设置: (1)湍流强度(Turbulence Intensity)
湍流强度I的定义为: I=Sqrt(u’*u’+v’*v’+w’*w’)/u_avg (8-1) 上式中u',v' 和w' 是速度脉动量,u_avg是平均速度。 湍流强度小于1%时,可以认为湍流强度是比较低的,而在湍流强度大于10%时,则可以认为湍流强度是比较高的。在来流为层流时,湍流强度可以用绕流物体的几何特征粗略地估算出来。比如在模拟风洞试验的计算中,自由流的湍流强度可以用风洞的特征长度估计出来。在现代的低湍流度风洞中,自由流的湍流强度通常低于%。 内流问题进口处的湍流强度取决于上游流动状态。如果上游是没有充分发展的未受扰流动,则进口处可以使用低湍流强度。如果上游是充分发展的湍流,则进口处湍流强度可以达到几个百分点。如果管道中的流动是充分发展的湍流,则湍流强度可以用公式(8-2)计算得到,这个公式是从管流经验公式得到的: I=u’/u_avg=*Re_DH^ (8-2) 其中Re_DH是Hydraulic Diameter(水力直径)的意思,即式(8-2)中的雷诺数是以水力直径为特征长度求出的。 (2)湍流的长度尺度与水力直径 湍流能量主要集中在大涡结构中,而湍流长度尺度l则是与大涡结构相关的物理量。在充分发展的管流中,因为漩涡尺度不可能大于管道直径,
建筑群风场fluent计算分析大作业
建筑群风场fluent计算分析大作业 一、建筑群风场分析目的及计算模型的选取 1、建筑群风场分析的目的 随着城市人口的集中和建筑技术的发展,建筑物之间的间距也变得越来越小,这些建筑物对周围环境风场的影响较大,风力载荷正成为建筑群设计中必须考虑的重要因素。风对建筑物以及建筑物周围环境的影响具体表现为以下几点: (1)在建筑物比较密集的地方,建筑物改变了原来的风场,在相同条件下,建筑物周围的局部风速增大。 (2)风力载荷是一种随机载荷, 受建筑物高度、风向、风的强度以及持续时间的影响很大。高层建筑物周围的局部负压过大, 使得建筑物顶局部掀起或装饰玻璃破碎、脱 落。 (3)建筑物的外轮廓形状一般都是非流线形的, 因而流场不可避免地伴随有分离流动、涡的脱落和振荡.这些现象会在建筑物的居室产生严重的噪音, 更严重时还会引起结 构和流体的耦合震荡。 因此,研究建筑群风场的速度分布、静压分布十分有必要。 2、计算模型选择 当建筑物是钝体,空气绕过钝体时的风场和绕过流线体时存在着分离流和剪切层的非定常振动,钝体周围流场十分复杂,是由撞击、分离、再附、环绕和旋涡等确定的。另外,建筑物通常建造在大气边界层。在大气边界层中,气流质点运动杂乱无章,气流流动表现为湍流状态。湍流是由大小不同尺度的涡体叠合而成,对时间和空间都是非线性的随机运动的,因此使用湍流模型解决此问题。在湍流模型中,基于Reynolds时均的Realizable K-ε模型能
在整体上很好地反映出建筑物表面风压的变化趋势,模拟结果与试验值相差较小且计算效率高,所以选用该模型。 二、计算模型设置 1、边界条件选取 计算流域入流处采用 FLUENT 中的速度进口边界条件(velocity-inlet )。边界条件用于定义在流动进口处的流动速度及相关其它标量型流动变量。该边界条件适用于不可压缩流动,对于可压缩流动问题时会使得入口处的总温度或总压有一定的波动,导致非物理结果,所以可压缩流问题不适合采用速度进口边界条件。本文为不可压缩流,可采用以 velocity-inlet 边界。需对流动速度 v 、k 和ε定义。设建筑物所在地形为B 类地形,其风场为B 类风场,10m 高度处、10min 平均的基本风压为 w0=0.35kPa ,相应的标准高度处平均风速为u0=23.7m/s ;则人口处的湍流强度I 、湍流动能K 和湍流耗散率 ε的具体表达式如下 21.5()k u I =?; 3342 0.09k l ε=; 0.250.3150.1()5450450z I z z -≤??=?<≤?? 其中z ,u 分别是流域中任意高度和对应的平均风速,z 由模型底部开始算起。l 为湍流积分尺度,采用经验公式0.5100(l z =。平均风速剖面、湍动能,c 和耗散率 值采用Fluent 提供的UDF 编程与Fluent 作接口实现。 出口采用完全发展出流边界条件(outflow )。Outflow 边界条件用于出流边界上的压力或速度都未知的情况,适用于出口处流动是完全发展的情况。 计算流域顶部和两侧采用对称边界条件(symmetry ),适用于流动及传热场是对称的