计量经济学第三版(庞浩)版课后答案全

第二章
2.2
(1)
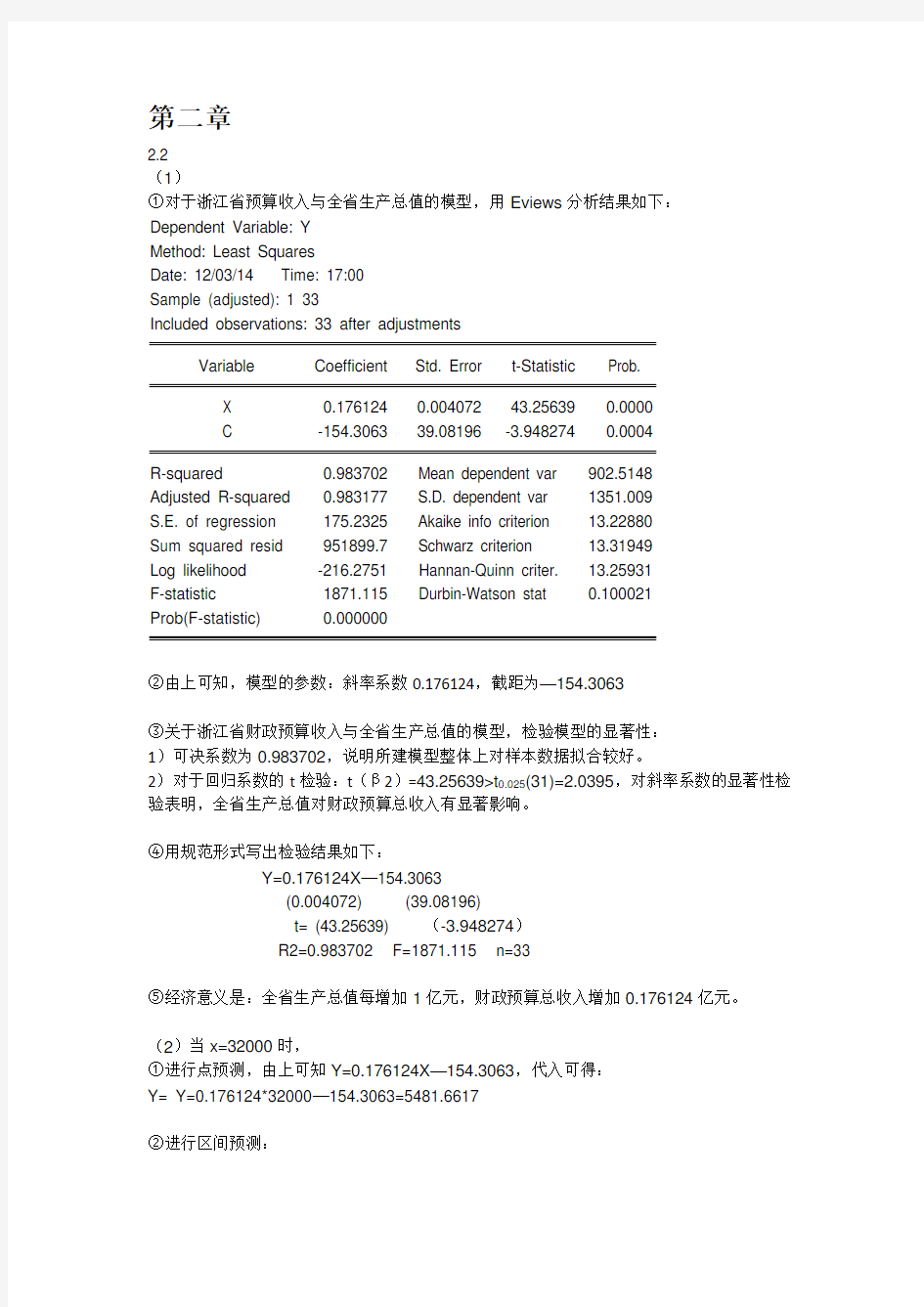
①对于浙江省预算收入与全省生产总值的模型,用Eviews分析结果如下:
Dependent Variable: Y
Method: Least Squares
Date: 12/03/14 Time: 17:00
Sample (adjusted): 1 33
Included observations: 33 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
X 0.176124 0.004072 43.25639 0.0000
C -154.3063 39.08196 -3.948274 0.0004
R-squared 0.983702 Mean dependent var 902.5148
Adjusted R-squared 0.983177 S.D. dependent var 1351.009
S.E. of regression 175.2325 Akaike info criterion 13.22880
Sum squared resid 951899.7 Schwarz criterion 13.31949
Log likelihood -216.2751 Hannan-Quinn criter. 13.25931
F-statistic 1871.115 Durbin-Watson stat 0.100021
Prob(F-statistic) 0.000000
②由上可知,模型的参数:斜率系数0.176124,截距为—154.3063
③关于浙江省财政预算收入与全省生产总值的模型,检验模型的显著性:
1)可决系数为0.983702,说明所建模型整体上对样本数据拟合较好。
2)对于回归系数的t检验:t(β2)=43.25639>t0.025(31)=2.0395,对斜率系数的显著性检验表明,全省生产总值对财政预算总收入有显著影响。
④用规范形式写出检验结果如下:
Y=0.176124X—154.3063
(0.004072) (39.08196)
t= (43.25639) (-3.948274)
R2=0.983702 F=1871.115 n=33
⑤经济意义是:全省生产总值每增加1亿元,财政预算总收入增加0.176124亿元。
(2)当x=32000时,
①进行点预测,由上可知Y=0.176124X—154.3063,代入可得:
Y= Y=0.176124*32000—154.3063=5481.6617
②进行区间预测:
先由Eviews分析:
由上表可知,
∑x2=∑(X i—X)2=δ2x(n—1)= 7608.0212 x (33—1)=1852223.473
(X f—X)2=(32000— 6000.441)2=675977068.2
当Xf=32000时,将相关数据代入计算得到:
5481.6617—2.0395x175.2325x√1/33+1852223.473/675977068.2≤
Yf≤5481.6617+2.0395x175.2325x√1/33+1852223.473/675977068.2
即Yf的置信区间为(5481.6617—64.9649, 5481.6617+64.9649)
(3) 对于浙江省预算收入对数与全省生产总值对数的模型,由Eviews分析结果如下:Dependent Variable: LNY
Method: Least Squares
Date: 12/03/14 Time: 18:00
Sample (adjusted): 1 33
Included observations: 33 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
LNX 0.980275 0.034296 28.58268 0.0000
C -1.918289 0.268213 -7.152121 0.0000
R-squared 0.963442 Mean dependent var 5.573120
Adjusted R-squared 0.962263 S.D. dependent var 1.684189
S.E. of regression 0.327172 Akaike info criterion 0.662028
Sum squared resid 3.318281 Schwarz criterion 0.752726
Log likelihood -8.923468 Hannan-Quinn criter. 0.692545
F-statistic 816.9699 Durbin-Watson stat 0.096208
Prob(F-statistic) 0.000000
①模型方程为:lnY=0.980275lnX-1.918289
②由上可知,模型的参数:斜率系数为0.980275,截距为-1.918289
③关于浙江省财政预算收入与全省生产总值的模型,检验其显著性:
1)可决系数为0.963442,说明所建模型整体上对样本数据拟合较好。
2)对于回归系数的t检验:t(β2)=28.58268>t0.025(31)=2.0395,对斜率系数的显著性检验表明,全省生产总值对财政预算总收入有显著影响。
④经济意义:全省生产总值每增长1%,财政预算总收入增长0.980275%
2.4
(1)对建筑面积与建造单位成本模型,用Eviews分析结果如下:
Dependent Variable: Y
Method: Least Squares
Date: 12/01/14 Time: 12:40
Sample: 1 12
Included observations: 12
Variable Coefficient Std. Error t-Statistic Prob.
X -64.18400 4.809828 -13.34434 0.0000
C 1845.475 19.26446 95.79688 0.0000
R-squared 0.946829 Mean dependent var 1619.333
Adjusted R-squared 0.941512 S.D. dependent var 131.2252
S.E. of regression 31.73600 Akaike info criterion 9.903792
Sum squared resid 10071.74 Schwarz criterion 9.984610
Log likelihood -57.42275 Hannan-Quinn criter. 9.873871
F-statistic 178.0715 Durbin-Watson stat 1.172407
Prob(F-statistic) 0.000000
由上可得:建筑面积与建造成本的回归方程为:
Y=1845.475--64.18400X
(2)经济意义:建筑面积每增加1万平方米,建筑单位成本每平方米减少64.18400元。
(3)
①首先进行点预测,由Y=1845.475--64.18400X得,当x=4.5,y=1556.647
②再进行区间估计:
由上表可知,
∑x2=∑(X i—X)2=δ2x(n—1)= 1.9894192 x (12—1)=43.5357
(X f—X)2=(4.5—3.523333)2=0.95387843
当Xf=4.5时,将相关数据代入计算得到:
1556.647—2.228x31.73600x√1/12+43.5357/0.95387843≤
Yf≤1556.647+2.228x31.73600x√1/12+43.5357/0.95387843
即Yf的置信区间为(1556.647—478.1231, 1556.647+478.1231)
第三章
3.2
1)对出口货物总额计量经济模型,用Eviews分析结果如下::Dependent Variable: Y
Method: Least Squares
Date: 12/01/14 Time: 20:25
Sample: 1994 2011
Included observations: 18
Variable Coefficient Std. Error t-Statistic Prob.
X2 0.135474 0.012799 10.58454 0.0000
X3 18.85348 9.776181 1.928512 0.0729
C -18231.58 8638.216 -2.110573 0.0520
R-squared 0.985838 Mean dependent var 6619.191 Adjusted R-squared 0.983950 S.D. dependent var 5767.152 S.E. of regression 730.6306 Akaike info criterion 16.17670 Sum squared resid 8007316. Schwarz criterion 16.32510 Log likelihood -142.5903 Hannan-Quinn criter. 16.19717 F-statistic 522.0976 Durbin-Watson stat 1.173432 Prob(F-statistic) 0.000000
①由上可知,模型为:
Y = 0.135474X2 + 18.85348X3 - 18231.58
②对模型进行检验:
1)可决系数是0.985838,修正的可决系数为0.983950,说明模型对样本拟合较好
2)F检验,F=522.0976>F(2,15)=4.77,回归方程显著
3)t检验,t统计量分别为X2的系数对应t值为10.58454,大于t(15)=2.131,系数是显著的,X3的系数对应t值为1.928512,小于t(15)=2.131,说明此系数是不显著的。
(2)对于对数模型,用Eviews分析结果如下:
Dependent Variable: LNY
Method: Least Squares
Date: 12/01/14 Time: 20:25
Sample: 1994 2011
Included observations: 18
Variable Coefficient Std. Error t-Statistic Prob.
LNX2 1.564221 0.088988 17.57789 0.0000
LNX3 1.760695 0.682115 2.581229 0.0209
C -20.52048 5.432487 -3.777363 0.0018
R-squared 0.986295 Mean dependent var 8.400112
Adjusted R-squared 0.984467 S.D. dependent var 0.941530
S.E. of regression 0.117343 Akaike info criterion -1.296424
Sum squared resid 0.206540 Schwarz criterion -1.148029
Log likelihood 14.66782 Hannan-Quinn criter. -1.275962
F-statistic 539.7364 Durbin-Watson stat 0.686656
Prob(F-statistic) 0.000000
①由上可知,模型为:
LNY=-20.52048+1.564221 LNX2+1.760695 LNX3
②对模型进行检验:
1)可决系数是0.986295,修正的可决系数为0.984467,说明模型对样本拟合较好。
2)F检验,F=539.7364> F(2,15)=4.77,回归方程显著。
3)t检验,t统计量分别为-3.777363,17.57789,2.581229,均大于t(15)=2.131,所以这些系数都是显著的。
(3)
①(1)式中的经济意义:工业增加1亿元,出口货物总额增加0.135474亿元,人民币汇率增加1,出口货物总额增加18.85348亿元。
②(2)式中的经济意义:工业增加额每增加1%,出口货物总额增加1.564221%,人民币汇率每增加1%,出口货物总额增加1.760695%
3.3
(1)对家庭书刊消费对家庭月平均收入和户主受教育年数计量模型,由Eviews分析结果如下:
Dependent Variable: Y
Method: Least Squares
Date: 12/01/14 Time: 20:30
Sample: 1 18
Included observations: 18
Variable Coefficient Std. Error t-Statistic Prob.
X 0.086450 0.029363 2.944186 0.0101
T 52.37031 5.202167 10.06702 0.0000
C -50.01638 49.46026 -1.011244 0.3279
R-squared 0.951235 Mean dependent var 755.1222
Adjusted R-squared 0.944732 S.D. dependent var 258.7206
S.E. of regression 60.82273 Akaike info criterion 11.20482
Sum squared resid 55491.07 Schwarz criterion 11.35321
Log likelihood -97.84334 Hannan-Quinn criter. 11.22528
F-statistic 146.2974 Durbin-Watson stat 2.605783
Prob(F-statistic) 0.000000
①模型为:Y = 0.086450X + 52.37031T-50.01638
②对模型进行检验:
1)可决系数是0.951235,修正的可决系数为0.944732,说明模型对样本拟合较好。
2)F检验,F=539.7364> F(2,15)=4.77,回归方程显著。
3)t检验,t统计量分别为2.944186,10.06702,均大于t(15)=2.131,所以这些系数都是显著的。
③经济意义:家庭月平均收入增加1元,家庭书刊年消费支出增加0.086450元,户主受教育年数增加1年,家庭书刊年消费支出增加52.37031元。
(2)用Eviews分析:
①
Dependent Variable: Y
Method: Least Squares
Date: 12/01/14 Time: 22:30
Sample: 1 18
Included observations: 18
Variable Coefficient Std. Error t-Statistic Prob.
T 63.01676 4.548581 13.85416 0.0000
C -11.58171 58.02290 -0.199606 0.8443
R-squared 0.923054 Mean dependent var 755.1222 Adjusted R-squared 0.918245 S.D. dependent var 258.7206 S.E. of regression 73.97565 Akaike info criterion 11.54979 Sum squared resid 87558.36 Schwarz criterion 11.64872 Log likelihood -101.9481 Hannan-Quinn criter. 11.56343 F-statistic 191.9377 Durbin-Watson stat 2.134043 Prob(F-statistic) 0.000000
②
Dependent Variable: X
Method: Least Squares
Date: 12/01/14 Time: 22:34
Sample: 1 18
Included observations: 18
Variable Coefficient Std. Error t-Statistic Prob.
T 123.1516 31.84150 3.867644 0.0014
C 444.5888 406.1786 1.094565 0.2899
R-squared 0.483182 Mean dependent var 1942.933 Adjusted R-squared 0.450881 S.D. dependent var 698.8325 S.E. of regression 517.8529 Akaike info criterion 15.44170 Sum squared resid 4290746. Schwarz criterion 15.54063 Log likelihood -136.9753 Hannan-Quinn criter. 15.45534 F-statistic 14.95867 Durbin-Watson stat 1.052251 Prob(F-statistic) 0.001364
以上分别是y与T,X与T的一元回归
模型分别是:
Y = 63.01676T - 11.58171
X = 123.1516T + 444.5888
(3)对残差进行模型分析,用Eviews分析结果如下:
Dependent Variable: E1
Method: Least Squares
Date: 12/03/14 Time: 20:39
Sample: 1 18
Included observations: 18
Variable Coefficient Std. Error t-Statistic Prob.
E2 0.086450 0.028431 3.040742 0.0078
C 3.96E-14 13.88083 2.85E-15 1.0000
R-squared 0.366239 Mean dependent var 2.30E-14
Adjusted R-squared 0.326629 S.D. dependent var 71.76693
S.E. of regression 58.89136 Akaike info criterion 11.09370
Sum squared resid 55491.07 Schwarz criterion 11.19264
Log likelihood -97.84334 Hannan-Quinn criter. 11.10735
F-statistic 9.246111 Durbin-Watson stat 2.605783
Prob(F-statistic) 0.007788
模型为:
E1 = 0.086450E2 + 3.96e-14
参数:斜率系数α为0.086450,截距为3.96e-14
(3)由上可知,β2与α2的系数是一样的。回归系数与被解释变量的残差系数是一样的,它们的变化规律是一致的。
第五章
5.3
(1)由Eviews软件分析得:
Dependent Variable: Y
Method: Least Squares
Date: 12/10/14 Time: 16:00
Sample: 1 31
Included observations: 31
Variable Coefficient Std. Error t-Statistic Prob.
X 1.244281 0.079032 15.74411 0.0000
C 242.4488 291.1940 0.832602 0.4119
R-squared 0.895260 Mean dependent var 4443.526
Adjusted R-squared 0.891649 S.D. dependent var 1972.072
S.E. of regression 649.1426 Akaike info criterion 15.85152
Sum squared resid 12220196 Schwarz criterion 15.94404
Log likelihood -243.6986 Hannan-Quinn criter. 15.88168
F-statistic 247.8769 Durbin-Watson stat 1.078581
Prob(F-statistic) 0.000000
由上表可知,2007年我国农村居民家庭人均消费支出(x)对人均纯收入(y)的模型为:Y=1.244281X+242.4488
(2)
①由图形法检验
由上图可知,模型可能存在异方差。
②Goldfeld-Quanadt检验
1)定义区间为1-12时,由软件分析得:
Dependent Variable: Y1
Method: Least Squares
Date: 12/10/14 Time: 11:34
Sample: 1 12
Included observations: 12
Variable Coefficient Std. Error t-Statistic Prob.
X1 1.485296 0.500386 2.968297 0.0141
C -550.5492 1220.063 -0.451247 0.6614
R-squared 0.468390 Mean dependent var 3052.950 Adjusted R-squared 0.415229 S.D. dependent var 550.5148 S.E. of regression 420.9803 Akaike info criterion 15.07406 Sum squared resid 1772245. Schwarz criterion 15.15488 Log likelihood -88.44437 Hannan-Quinn criter. 15.04414 F-statistic 8.810789 Durbin-Watson stat 2.354167 Prob(F-statistic) 0.014087
得∑e1i2=1772245.
2)定义区间为20-31时,由软件分析得:
Dependent Variable: Y1
Method: Least Squares
Date: 12/10/14 Time: 16:36
Sample: 20 31
Included observations: 12
Variable Coefficient Std. Error t-Statistic Prob.
X1 1.086940 0.148863 7.301623 0.0000
C 1173.307 733.2520 1.600141 0.1407
R-squared 0.842056 Mean dependent var 6188.329
Adjusted R-squared 0.826262 S.D. dependent var 2133.692
S.E. of regression 889.3633 Akaike info criterion 16.56990
Sum squared resid 7909670. Schwarz criterion 16.65072
Log likelihood -97.41940 Hannan-Quinn criter. 16.53998
F-statistic 53.31370 Durbin-Watson stat 2.339767
Prob(F-statistic) 0.000026
得∑e2i2=7909670.
3)根据Goldfeld-Quanadt检验,F统计量为:
F=∑e2i2 /∑e1i2 =7909670./ 1772245=4.4631
在α=0.05水平下,分子分母的自由度均为10,查分布表得临界值F0.05(10,10)=2.98,因为F=4.4631> F0.05(10,10)=2.98,所以拒绝原假设,此检验表明模型存在异方差。(3)
1)采用WLS法估计过程中,
①用权数w1=1/X,建立回归得:
Dependent Variable: Y
Method: Least Squares
Date: 12/09/14 Time: 11:13
Sample: 1 31
Included observations: 31
Weighting series: W1
Variable Coefficient Std. Error t-Statistic Prob.
X 1.425859 0.119104 11.97157 0.0000
C -334.8131 344.3523 -0.972298 0.3389
Weighted Statistics
R-squared 0.831707 Mean dependent var 3946.082
Adjusted R-squared 0.825904 S.D. dependent var 536.1907
S.E. of regression 536.6796 Akaike info criterion 15.47102
Sum squared resid 8352726. Schwarz criterion 15.56354
Log likelihood -237.8008 Hannan-Quinn criter. 15.50118
F-statistic 143.3184 Durbin-Watson stat 1.369081
Prob(F-statistic) 0.000000
Unweighted Statistics
R-squared 0.875855 Mean dependent var 4443.526
Adjusted R-squared 0.871574 S.D. dependent var 1972.072
S.E. of regression 706.7236 Sum squared resid 14484289
Durbin-Watson stat 1.532908
对此模型进行White检验得:
Heteroskedasticity Test: White
F-statistic 0.299395 Prob. F(2,28) 0.7436
Obs*R-squared 0.649065 Prob. Chi-Square(2) 0.7229
Scaled explained SS 1.798067 Prob. Chi-Square(2) 0.4070
Test Equation:
Dependent Variable: WGT_RESID^2
Method: Least Squares
Date: 12/10/14 Time: 21:13
Sample: 1 31
Included observations: 31
Collinear test regressors dropped from specification
Variable Coefficient Std. Error t-Statistic Prob.
C 61927.89 1045682. 0.059222 0.9532
WGT^2 -593927.9 1173622. -0.506064 0.6168
X*WGT^2 282.4407 747.9780 0.377606 0.7086
R-squared 0.020938 Mean dependent var 269442.8
Adjusted R-squared -0.048995 S.D. dependent var 689166.5
S.E. of regression 705847.6 Akaike info criterion 29.86395
Sum squared resid 1.40E+13 Schwarz criterion 30.00273
Log likelihood -459.8913 Hannan-Quinn criter. 29.90919
F-statistic 0.299395 Durbin-Watson stat 1.922336
Prob(F-statistic) 0.743610
从上可知,nR2=0.649065,比较计算的统计量的临界值,因为nR2=0.649065<0.05(2)=5.9915,所以接受原假设,该模型消除了异方差。
估计结果为:
Y=1.425859X-334.8131
t=(11.97157)(-0.972298)
R2=0.875855 F=143.3184 DW=1.369081
②用权数w2=1/x2,用回归分析得:
Dependent Variable: Y
Method: Least Squares
Date: 12/09/14 Time: 21:08
Sample: 1 31
Included observations: 31
Weighting series: W2
Variable Coefficient Std. Error t-Statistic Prob.
X 1.557040 0.145392 10.70922 0.0000
C -693.1946 376.4760 -1.841272 0.0758
Weighted Statistics
R-squared 0.798173 Mean dependent var 3635.028 Adjusted R-squared 0.791214 S.D. dependent var 1029.830 S.E. of regression 466.8513 Akaike info criterion 15.19224 Sum squared resid 6320554. Schwarz criterion 15.28475 Log likelihood -233.4797 Hannan-Quinn criter. 15.22240 F-statistic 114.6875 Durbin-Watson stat 1.562975 Prob(F-statistic) 0.000000
Unweighted Statistics
R-squared 0.834850 Mean dependent var 4443.526 Adjusted R-squared 0.829156 S.D. dependent var 1972.072 S.E. of regression 815.1229 Sum squared resid 19268334 Durbin-Watson stat 1.678365
对此模型进行White检验得:
Heteroskedasticity Test: White
F-statistic 0.299790 Prob. F(3,27) 0.8252 Obs*R-squared 0.999322 Prob. Chi-Square(3) 0.8014 Scaled explained SS 1.789507 Prob. Chi-Square(3) 0.6172
Test Equation:
Dependent Variable: WGT_RESID^2
Method: Least Squares
Date: 12/10/14 Time: 21:29
Sample: 1 31
Included observations: 31
Variable Coefficient Std. Error t-Statistic Prob.
C -111661.8 549855.7 -0.203075 0.8406
WGT^2 426220.2 2240181. 0.190262 0.8505
X^2*WGT^2 0.194888 0.516395 0.377402 0.7088
X*WGT^2 -583.2151 2082.820 -0.280012 0.7816
R-squared 0.032236 Mean dependent var 203888.8
Adjusted R-squared -0.075293 S.D. dependent var 419282.0
S.E. of regression 434780.1 Akaike info criterion 28.92298
Sum squared resid 5.10E+12 Schwarz criterion 29.10801
Log likelihood -444.3062 Hannan-Quinn criter. 28.98330
F-statistic 0.299790 Durbin-Watson stat 1.835854
Prob(F-statistic) 0.825233
从上可知,nR2=0.999322,比较计算的统计量的临界值,因为nR2=0.999322<0.05
(2)=5.9915,所以接受原假设,该模型消除了异方差。
估计结果为:
Y=1.557040X-693.1946
t=(10.70922)(-1.841272)
R2=0.798173 F=114.6875 DW=1.562975
③用权数w3=1/sqr(x),用回归分析得:
Dependent Variable: Y
Method: Least Squares
Date: 12/09/14 Time: 21:35
Sample: 1 31
Included observations: 31
Weighting series: W3
Variable Coefficient Std. Error t-Statistic Prob.
X 1.330130 0.098345 13.52507 0.0000
C -47.40242 313.1154 -0.151390 0.8807
Weighted Statistics
R-squared 0.863161 Mean dependent var 4164.118
Adjusted R-squared 0.858442 S.D. dependent var 991.2079
S.E. of regression 586.9555 Akaike info criterion 15.65012
Sum squared resid 9990985. Schwarz criterion 15.74263
Log likelihood -240.5768 Hannan-Quinn criter. 15.68027
F-statistic 182.9276 Durbin-Watson stat 1.237664
Prob(F-statistic) 0.000000
Unweighted Statistics
R-squared 0.890999 Mean dependent var 4443.526
Adjusted R-squared 0.887240 S.D. dependent var 1972.072
S.E. of regression 662.2171 Sum squared resid 12717412
Durbin-Watson stat 1.314859
对此模型进行White检验得:
Heteroskedasticity Test: White
F-statistic 0.423886 Prob. F(2,28) 0.6586
Obs*R-squared 0.911022 Prob. Chi-Square(2) 0.6341
Scaled explained SS 2.768332 Prob. Chi-Square(2) 0.2505
Test Equation:
Dependent Variable: WGT_RESID^2
Method: Least Squares
Date: 12/09/14 Time: 20:36
Sample: 1 31
Included observations: 31
Collinear test regressors dropped from specification
Variable Coefficient Std. Error t-Statistic Prob.
C 1212308. 2141958. 0.565981 0.5759
WGT^2 -715673.0 1301839. -0.549740 0.5869
X^2*WGT^2 -0.015194 0.082276 -0.184677 0.8548
R-squared 0.029388 Mean dependent var 322289.8
Adjusted R-squared -0.039942 S.D. dependent var 863356.7
S.E. of regression 880429.8 Akaike info criterion 30.30597
Sum squared resid 2.17E+13 Schwarz criterion 30.44475
Log likelihood -466.7426 Hannan-Quinn criter. 30.35121
F-statistic 0.423886 Durbin-Watson stat 1.887426
Prob(F-statistic) 0.658628
从上可知,nR2=0.911022,比较计算的统计量的临界值,因为nR2=0.911022<0.05
(2)=5.9915,所以接受原假设,该模型消除了异方差。
估计结果为:
Y=1.330130X-47.40242
t=(13.52507)(-0.151390)
R2=0.863161 F=182.9276 DW=1.237664
经过检验发现,用权数w1的效果最好,所以综上可知,即修改后的结果为:
Y=1.425859X-334.8131
t=(11.97157)(-0.972298)
R2=0.875855 F=143.3184 DW=1.369081
第六章
6.1
(1)建立居民收入-消费模型,用Eviews分析结果如下:
Dependent Variable: Y
Method: Least Squares
Date: 12/20/14 Time: 14:22
Sample: 1 19
Included observations: 19
Variable Coefficient Std. Error t-Statistic Prob.
X 0.690488 0.012877 53.62068 0.0000
C 79.93004 12.39919 6.446390 0.0000
R-squared 0.994122 Mean dependent var 700.2747 Adjusted R-squared 0.993776 S.D. dependent var 246.4491 S.E. of regression 19.44245 Akaike info criterion 8.872095 Sum squared resid 6426.149 Schwarz criterion 8.971510 Log likelihood -82.28490 Hannan-Quinn criter. 8.888920 F-statistic 2875.178 Durbin-Watson stat 0.574663 Prob(F-statistic) 0.000000
所得模型为:
Y=0.690488X+79.93004
Se=(0.012877)(12.39919)
t=(53.62068)(6.446390)
R2=0.994122 F=2875.178 DW=0.574663
(2)
1)检验模型中存在的问题
①做出残差图如下:
Breusch-Godfrey Serial Correlation LM Test:
F-statistic 4.811108 Prob. F(2,15) 0.0243 Obs*R-squared 7.425088 Prob. Chi-Square(2) 0.0244
Test Equation:
Dependent Variable: RESID
Method: Least Squares
Date: 12/20/14 Time: 15:03
Sample: 1 19
Included observations: 19
Presample missing value lagged residuals set to zero.
Variable Coefficient Std. Error t-Statistic Prob.
X -0.003275 0.010787 -0.303586 0.7656
C 1.929546 10.35593 0.186323 0.8547
RESID(-1) 0.608886 0.292707 2.080189 0.0551 RESID(-2) 0.089988 0.291120 0.309110 0.7615
R-squared 0.390794 Mean dependent var -1.65E-13 Adjusted R-squared 0.268953 S.D. dependent var 18.89466 S.E. of regression 16.15518 Akaike info criterion 8.587023 Sum squared resid 3914.848 Schwarz criterion 8.785852 Log likelihood -77.57671 Hannan-Quinn criter. 8.620672 F-statistic 3.207406 Durbin-Watson stat 1.570723
Prob(F-statistic) 0.053468
如上表显示,LM=TR2=7.425088,其p值为0.0244,表明存在自相关。
2)对模型进行处理:
①采取广义差分法
a)为估计自相关系数ρ。对e t进行滞后一期的自回归,用EViews分析结果如下:Dependent Variable: E
Method: Least Squares
Date: 12/20/14 Time: 15:04
Sample (adjusted): 2 19
Included observations: 18 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
E(-1) 0.657352 0.177626 3.700759 0.0018
R-squared 0.440747 Mean dependent var 1.717433 Adjusted R-squared 0.440747 S.D. dependent var 17.85134
S.E. of regression 13.34980 Akaike info criterion 8.074833
Sum squared resid 3029.692 Schwarz criterion 8.124298
Log likelihood -71.67349 Hannan-Quinn criter. 8.081653
Durbin-Watson stat 1.634573
由上可知,ρ=0.657352
b)对原模型进行广义差分回归,用Eviews进行分析所得结果如下:
Dependent Variable: Y-0.657352*Y(-1)
Method: Least Squares
Date: 12/20/14 Time: 15:04
Sample (adjusted): 2 19
Included observations: 18 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
C 35.97761 8.103546 4.439737 0.0004
X-0.657352*X(-1) 0.668695 0.020642 32.39512 0.0000
R-squared 0.984983 Mean dependent var 278.1002 Adjusted R-squared 0.984044 S.D. dependent var 105.1781
S.E. of regression 13.28570 Akaike info criterion 8.115693
Sum squared resid 2824.158 Schwarz criterion 8.214623
Log likelihood -71.04124 Hannan-Quinn criter. 8.129334
F-statistic 1049.444 Durbin-Watson stat 1.830746
Prob(F-statistic) 0.000000
由上图可知回归方程为:
Y t*=35.97761+0.668695X t*
Se=(8.103546)(0.020642)
t=(4.439737)(32.39512)
R2=0.984983 F=1049.444 DW=1.830746
式中,Y t*=Y t-0.657352Y t-1,X t*=X t-0.657352X t-1
由于使用了广义差分数据,样本容量减少了1个,为18个。查5%显著水平的DW统计表可知,d L=1.158,d U=1.391模型中DW=1,830746,d u 由差分方程,β1=35.97761/(1-0.657352)=104.9987 由此最终的消费模型为: Y t=104.9987+0.668695X t ②用科克伦-奥克特迭代法,用EVIews分析结果如下: Dependent Variable: Y Method: Least Squares Date: 12/20/14 Time: 15:15 Sample (adjusted): 2 19 Included observations: 18 after adjustments Convergence achieved after 5 iterations Variable Coefficient Std. Error t-Statistic Prob. C 104.0449 23.87618 4.357687 0.0006 X 0.669262 0.020831 32.12757 0.0000 AR(1) 0.630015 0.164218 3.836462 0.0016 R-squared 0.997097 Mean dependent var 719.1867 Adjusted R-squared 0.996710 S.D. dependent var 238.9866 S.E. of regression 13.70843 Akaike info criterion 8.224910 Sum squared resid 2818.814 Schwarz criterion 8.373306 Log likelihood -71.02419 Hannan-Quinn criter. 8.245372 F-statistic 2575.896 Durbin-Watson stat 1.787878 Prob(F-statistic) 0.000000 Inverted AR Roots .63 所得方程为: Y t=104.0449+0.669262X t (3)经济意义:人均实际收入每增加1元,平均说来人均时间消费支出将增加0.669262元。 6.4 (1)针对对数模型,用Eviews分析结果如下: Dependent Variable: LNY Method: Least Squares Date: 12/27/14 Time: 16:13 Sample: 1980 2000 Included observations: 21 Variable Coefficient Std. Error t-Statistic Prob. LNX 0.951090 0.038897 24.45123 0.0000 C 2.171041 0.241025 9.007529 0.0000 R-squared 0.969199 Mean dependent var 8.039307 Adjusted R-squared 0.967578 S.D. dependent var 0.565486 S.E. of regression 0.101822 Akaike info criterion -1.640785 Sum squared resid 0.196987 Schwarz criterion -1.541307 Log likelihood 19.22825 Hannan-Quinn criter. -1.619196 F-statistic 597.8626 Durbin-Watson stat 1.159788 Prob(F-statistic) 0.000000 所得模型为: lnY=0,951090lnX+2.171041 se=(0.038897) (0.241025) t=(24.45123) (9.007529) R2=0.969199 F=597.8626 DW=1.159788 2)检验模型的自相关性 该回归方程可决系数较高,回归系数均显著。对样本量为21,一个解释变量的模型,5%的显著水平,查DW统计表可知,d L=1.221,d U=1.420,模型中DW=1.159788 (2)用广义差分法处理模型: 1)为估计自相关系数ρ。对e t进行滞后一期的自回归,用EViews分析结果如下:Dependent Variable: E Method: Least Squares Date: 12/27/14 Time: 16:18 Sample (adjusted): 1982 2000 Included observations: 19 after adjustments Variable Coefficient Std. Error t-Statistic Prob. E(-1) -0.012872 0.280581 -0.045878 0.9639 R-squared 0.000073 Mean dependent var -2.556737 Adjusted R-squared 0.000073 S.D. dependent var 397.7924 S.E. of regression 397.7778 Akaike info criterion 14.86086 Sum squared resid 2848090. Schwarz criterion 14.91057 Log likelihood -140.1782 Hannan-Quinn criter. 14.86927 Durbin-Watson stat 1.700254 由上可知,ρ=-0.012872 2)对原模型进行广义差分回归,用Eviews进行分析所得结果如下: Dependent Variable: Y+0.012872*Y(-1) Method: Least Squares Date: 12/27/14 Time: 21:06 Sample (adjusted): 1981 2000 Included observations: 20 after adjustments Variable Coefficient Std. Error t-Statistic Prob. C -104.9645 197.7928 -0.530679 0.6021 X+0.012872*X(-1) 6.653757 0.304157 21.87605 0.0000 R-squared 0.963751 Mean dependent var 3753.934 Adjusted R-squared 0.961737 S.D. dependent var 2045.606 S.E. of regression 400.1404 Akaike info criterion 14.91615 Sum squared resid 2882022. Schwarz criterion 15.01572 Log likelihood -147.1615 Hannan-Quinn criter. 14.93559 F-statistic 478.5614 Durbin-Watson stat 1.822259 Prob(F-statistic) 0.000000 由上图可知回归方程为: Y t*=-104.9645+6.653757X t* Se=(197.7928)( 0.304157) t=(-0.530679)( 21.87605) R2=0.963751 F=478.5614DW=1.8222596 式中,Y t*=Y t+0.012872Y t-1,X t*=X t+0.012872X t-1 由于使用了广义差分数据,样本容量减少了1个,为20个。查5%显著水平的DW统计表可知,d L=1.201,d U=1.411模型中DW=1.8222596,d u 由差分方程,β1=-104.9645/(1+0.012872)=-103.6306 由此最终的模型为: Y t=-103.6306+6.653757X t (3)对于此模型,用Eviews分析结果如下: Dependent Variable: LNY1 Method: Least Squares Date: 12/27/14 Time: 22:16 第二章简单线性回归模型 2.1 (1)①首先分析人均寿命与人均GDP的数量关系,用Eviews分析:Dependent Variable: Y Method: Least Squares Date: 12/27/14 Time: 21:00 Sample: 1 22 Included observations: 22 Variable Coefficient Std. Error t-Statistic Prob. C 56.64794 1.960820 28.88992 0.0000 X1 0.128360 0.027242 4.711834 0.0001 R-squared 0.526082 Mean dependent var 62.50000 Adjusted R-squared 0.502386 S.D. dependent var 10.08889 S.E. of regression 7.116881 Akaike info criterion 6.849324 Sum squared resid 1013.000 Schwarz criterion 6.948510 Log likelihood -73.34257 Hannan-Quinn criter. 6.872689 F-statistic 22.20138 Durbin-Watson stat 0.629074 Prob(F-statistic) 0.000134 有上可知,关系式为y=56.64794+0.128360x1 ②关于人均寿命与成人识字率的关系,用Eviews分析如下:Dependent Variable: Y Method: Least Squares Date: 11/26/14 Time: 21:10 Sample: 1 22 Included observations: 22 Variable Coefficient Std. Error t-Statistic Prob. C 38.79424 3.532079 10.98340 0.0000 X2 0.331971 0.046656 7.115308 0.0000 R-squared 0.716825 Mean dependent var 62.50000 Adjusted R-squared 0.702666 S.D. dependent var 10.08889 S.E. of regression 5.501306 Akaike info criterion 6.334356 Sum squared resid 605.2873 Schwarz criterion 6.433542 Log likelihood -67.67792 Hannan-Quinn criter. 6.357721 F-statistic 50.62761 Durbin-Watson stat 1.846406 Prob(F-statistic) 0.000001 由上可知,关系式为y=38.79424+0.331971x2 ③关于人均寿命与一岁儿童疫苗接种率的关系,用Eviews分析如下: 第二章简单线性回归模型 第一节回归分析与回归函数P15 (一)相关分析与回归分析 1、相关关系 2、相关系数 3、回归分析 (二)总体回归函数(条件期望) (三)随机扰动项 (四)样本回归函数 第二节简单线性回归模型参数的估计P26 (一)简单线性回归的基本假定 (二)普通最小二乘法求样本回归函数 (三)OLS回归线的性质 (四)最小二乘估计量的统计性质 1、参数估计量的评价标准(无偏性、有效性、一致性) 2、OLS估计量的统计特性(线性特性、无偏性、有效性、高斯-马尔可夫定理) 第三节拟合优度的度量(RSS、ESS、TSS)P35 (一)总变差的分解 (二)可决系数 (三)可决系数与相关系数的关系 第四节回归系数的区间估计与假设检验P38 (一)OLS估计的分布性质 (二)回归系数的区间估值 (三)回归系数的假设检验 1、Z检验 2、t检验 第五节回归模型预测P43 第六节案例分析P48 第三章多元线性回归模型 第一节多元线性回归模型及古典假定P64 一、多元线性回归模型 二、多元线性回归模型的矩阵形式 三、多元线性回归模型的古典假定 第二节多元线性回归模型的估计P68 一、多元线性回归性参数的最小二乘估计 二、参数最小二乘估计的性质(线性特性、无偏性、有效性) 三、OLS估计的分布性质 四、随机扰动项方差的估计 五、多元线性回归模型参数的区间估计 第三节多元线性回归模型的检验P74 一、拟合优度检验(多重可决系数、修正的可决系数) 二、回归方程的显著性检验(F-检验) 三、回归参数的显著性检验(t-检验) 第四节多元线性回归模型的预测P79 第五节案例分析P81 第四章多重共线性第一节什么是多重共线性P94 第二节多重共线性产生的后果 第三节多重共线性的检验 第四节多重共线性的补救措施 第五节案例分析P109 思考题答案 第一章 绪论 思考题 1.1怎样理解产生于西方国家的计量经济学能够在中国的经济理论研究和现代化建设中发挥重要作用? 答:计量经济学的产生源于对经济问题的定量研究,这是社会经济发展到一定阶段的客观需要。计量经济学的发展是与现代科学技术成就结合在一起的,它反映了社会化大生产对各种经济因素和经济活动进行数量分析的客观要求。经济学从定性研究向定量分析的发展,是经济学逐步向更加精密、更加科学发展的表现。我们只要坚持以科学的经济理论为指导,紧密结合中国经济的实际,就能够使计量经济学的理论与方法在中国的经济理论研究和现代化建设中发挥重要作用。 1.2理论计量经济学和应用计量经济学的区别和联系是什么? 答:计量经济学不仅要寻求经济计量分析的方法,而且要对实际经济问题加以研究,分为理论计量经济学和应用计量经济学两个方面。 理论计量经济学是以计量经济学理论与方法技术为研究内容,目的在于为应用计量经济学提供方法论。所谓计量经济学理论与方法技术的研究,实质上是指研究如何运用、改造和发展数理统计方法,使之成为适合测定随机经济关系的特殊方法。 应用计量经济学是在一定的经济理论的指导下,以反映经济事实的统计数据为依据,用计量经济方法技术研究计量经济模型的实用化或探索实证经济规律、分析经济现象和预测经济行为以及对经济政策作定量评价。 1.3怎样理解计量经济学与理论经济学、经济统计学的关系? 答:1、计量经济学与经济学的关系。联系:计量经济学研究的主体—经济现象和经济关系的数量规律;计量经济学必须以经济学提供的理论原则和经济运行规律为依据;经济计量分析的结果:对经济理论确定的原则加以验证、充实、完善。区别:经济理论重在定性分析,并不对经济关系提供数量上的具体度量;计量经济学对经济关系要作出定量的估计,对经济理论提出经验的内容。 2、计量经济学与经济统计学的关系。联系:经济统计侧重于对社会经济现象的描述性计量;经济统计提供的数据是计量经济学据以估计参数、验证经济理论的基本依据;经济现象不能作实验,只能被动地观测客观经济现象变动的既成事实,只能依赖于经济统计数据。区别:经济统计学主要用统计指标和统计分析方法对经济现象进行描述和计量;计量经济学主要利用数理统计方法对经济变量间的关系进行计量。 1.4在计量经济模型中被解释变量和解释变量的作用有什么不同? 答:在计量经济模型中,解释变量是变动的原因,被解释变量是变动的结果。被解释变量是模型要分析研究的对象。解释变量是说明被解释变量变动主要原因的变量。 1.5一个完整的计量经济模型应包括哪些基本要素?你能举一个例子吗? 答:一个完整的计量经济模型应包括三个基本要素:经济变量、参数和随机误差项。 例如研究消费函数的计量经济模型:u βX αY ++= 其中,Y 为居民消费支出,X 为居民家庭收入,二者是经济变量;α和β为参数;u 是随机误差项。 1.6假如你是中央银行货币政策的研究者,需要你对增加货币供应量促进经济增长提出建议, 第三章习题 3.1 (1)2011年各地区的百户拥有家用汽车量及影响因素数据图形 可以看出,2011年各地区的百户拥有家用汽车量及影响因素的差异明显,其变动的方向基本相同,相互间可能具有一定的相关性,因而将其模型设定为线性回归模型形式: Y=β1+β2X2+β3X3+β4X4 估计参数 Y=246.854+5.996865X 2-0.524027X 3-2.26568X 4 模型检验 ① R 2是0.666062,修正的R 2为0.628957,说明模型对样本拟合较好 ② F 检验,分别针对H0:βj=0(j=1,2,3,4),给定显著性水平α=0.05,在F 分布表中查出自由度为k-1=3,n-k=27的临界值F α(3,27)=3.65,由表可知,F=17.95108>F α(3,27)=3.65,应拒绝原假设,回归方程显著。 ③ t 检验,分别针对H0:βj=0(j=1,2,3,4),给定显著性水平α=0.05,查t 分布表得自由度为n-k=27临界值t 2 05.0(n-k )=2.0518。对应的t 统计量分 别为 4.749476,4.265020,-2.922950,-4.366842,其绝对值均大于t (27) =2.0518,所以这些系数都是显著的。 (2)人均GDP增加1万元,百户拥有家用汽车增加5.996865辆, 城镇人口比重增加1个百分点,百户拥有家用汽车减少0.524027辆, 交通工具消费价格指数每上升1,百户拥有家用汽车减少2.265680辆。 (3)将其模型设定为 Y=β1+β2X 2+β3LnX 3+β4LnX 4 计量经济学练习题 第一章导论 一、单项选择题 ⒈计量经济研究中常用的数据主要有两类:一类是时间序列数据,另一类是【 B 】 A 总量数据 B 横截面数据 C平均数据 D 相对数据 ⒉横截面数据是指【A 】 A 同一时点上不同统计单位相同统计指标组成的数据 B 同一时点上相同统计单位相同统计指标组成的数据 C 同一时点上相同统计单位不同统计指标组成的数据 D 同一时点上不同统计单位不同统计指标组成的数据 ⒊下面属于截面数据的是【D 】 A 1991-2003年各年某地区20个乡镇的平均工业产值 B 1991-2003年各年某地区20个乡镇的各镇工业产值 C 某年某地区20个乡镇工业产值的合计数 D 某年某地区20个乡镇各镇工业产值 ⒋同一统计指标按时间顺序记录的数据列称为【B 】 A 横截面数据 B 时间序列数据 C 修匀数据D原始数据 ⒌回归分析中定义【 B 】 A 解释变量和被解释变量都是随机变量 B 解释变量为非随机变量,被解释变量为随机变量 C 解释变量和被解释变量都是非随机变量 D 解释变量为随机变量,被解释变量为非随机变量 二、填空题 ⒈计量经济学是经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论,可以理解为数学、统计学和_经济学_三者的结合。 ⒉现代计量经济学已经形成了包括单方程回归分析,联立方程组模型,时间序列分 析三大支柱。 ⒊经典计量经济学的最基本方法是回归分析。 计量经济分析的基本步骤是:理论(或假说)陈述、建立计量经济模型、收集数据、计量经济模型参数的估计、检验和模型修正、预测和政策分析。 ⒋常用的三类样本数据是截面数据、时间序列数据和面板数据。 ⒌经济变量间的关系有不相关关系、相关关系、因果关系、相互影响关系和恒 等关系。 三、简答题 ⒈什么是计量经济学?它与统计学的关系是怎样的? 计量经济学就是对经济规律进行数量实证研究,包括预测、检验等多方面的工作。计量经济学是一种定量分析,是以解释经济活动中客观存在的数量关系为内容的一门经济学学科。 计量经济学与统计学密切联系,如数据收集和处理、参数估计、计量分析方法设计,以及参数估计值、模型和预测结果可靠性和可信程度分析判断等。可以说,统计学的知识和方法不仅贯穿计量经济分析过程,而且现代统计学本身也与计量经济学有不少相似之处。例如,统计学也通过对经济数据的处理分析,得出经济问题的数字化特征和结论,也有对经济参数的估计和分析,也进行经济趋势的预测,并利用各种统计量对分析预测的结论进行判断和检验等,统计学的这些内容与计量经济学的内容都很相似。反过来,计量经济学也经常使用各种统计分析方法,筛选数据、选择变量和检验相关结论,统计分析是计量经济分析的重要内容和主要基础之一。 计量经济学与统计学的根本区别在于,计量经济学是问题导向和以经济模型为核心的,而统计学则是以经济数据为核心,且常常是数据导向的。典型的计量经济学分析从具体经济问题出发,先建立经济模型,参数估计、判断、调整和预测分析等都是以模型为基础和出发点;典型的统计学研究则并不一定需要从具体明确的问题出发,虽然也有一些目标,但可以是模糊不明确的。虽然统计学并不排斥经济理论和模型,有时也会利用它们,但统计学通常不一定需要特定的经济理论或模型作为基础和出发点,常常是通过对经济数据的统计处理直接得出结论,统计学侧重的工作是经济数据的采集、筛选和处理。 此外,计量经济学不仅是通过数据处理和分析获得经济问题的一些数字特征,而且是借助于经济思想和数学工具对经济问题作深刻剖析。经过计量经济分析实证检验的经济理论和模型,能够对分析、研究和预测更广泛的经济问题起重要作用。计量经济学从经济理论和经济模型出发进行计量经济分析的过程,也是对经济理论证实或证伪的过程。这些是以处理数 第七章习题 7.1 (1) 1) PCE=-216.4269+1.008106PDI 2) PCE=-233.2736+0.982382PDI+0.037158PEC T-1 (2)模型一MPC=1.008106;模型二短期MPC=0.982382,长期 MPC=0.982382/(1+0.037158)=0.9472 7.2 (1) i t u X X X X X Y ++β+β+β+β=α+β4-t 43-t 32-t 21-t 1t 0 令 2 1042 103210221010 01649342 α+α+=αβα+α+=αβα+α+=αβ+α+α=αβ=αβ 模型变形为i t u Z Z Z Y ++α+α=α+α2t 21t 10t 0 其中4 -t 3-t 2-t 1-t 2t 4-t 3-t 2-t 1-t 1t 4 -t 3-t 2-t 1-t t 0t 1694432X X X X Z X X X X Z X X X X X Z +++=+++=++++= 2t 1t 0t 104392.0669904.0-891012.049234.35-Z Z Z Y t ++= 可得11833 .0-17917 .0-3123.0-3255 .0891012.043210=β=β=β=β=β,所以4 -t 3-t 2-t 1-t t 11833.0-17917.0-3123.0- 3255.0891012.049234.35-X X X X X Y t ++= 7.3 (1)估计t t u Y X Y *1-t 1*t 0**++β+β=α 1-t t 271676.0629273.010403.15-Y X Y t ++= 1)根据局部调整模型的参数关系,有δαα=*,δββ=*,δβ-1=1*,t t u u δ=* 将估计结果带入可得:728324.0=271676.0-1=-1=1*βδ 738064.20-==* δαα 864001.0==* 0δ ββ 局部调整模型估计结果为:t *864001.0738064.20X Y t += 2)经济意义:销售额每增加1亿元,未来预期最佳新增固定资产投资增加0.864001亿元。 3)运用德宾h 检验一阶自相关: 29728.1=0.114858 ×12-121 )21.518595-1(=)(-1)2d -1(=21*βnVar n h 在0.05显著水平下,临界值 1.96=h 2 α,因为h=1.29728< 1.96=h 2 α,接受原假 设,模型不存在一阶自相关性。 第二章 简单线性回归模型 2.1 (1) ①首先分析人均寿命与人均GDP 的数量关系,用Eviews 分析: Dependent Variable: Y Method: Least Squares Date: 12/27/14 Time: 21:00 Sample: 1 22 Included observations: 22 Variable Coefficient Std. Error t-Statistic Prob. C 56.64794 1.960820 28.88992 0.0000 X1 0.128360 0.027242 4.711834 0.0001 R-squared 0.526082 Mean dependent var 62.50000 Adjusted R-squared 0.502386 S.D. dependent var 10.08889 S.E. of regression 7.116881 Akaike info criterion 6.849324 Sum squared resid 1013.000 Schwarz criterion 6.948510 Log likelihood -73.34257 Hannan-Quinn criter. 6.872689 F-statistic 22.20138 Durbin-Watson stat 0.629074 Prob(F-statistic) 0.000134 有上可知,关系式为y=56.64794+0.128360x 1 ②关于人均寿命与成人识字率的关系,用Eviews 分析如下: Dependent Variable: Y Method: Least Squares Date: 11/26/14 Time: 21:10 Sample: 1 22 Included observations: 22 Variable Coefficien t Std. Error t-Statistic Prob. C 38.79424 3.532079 10.98340 0.0000 X2 0.331971 0.046656 7.115308 0.0000 R-squared 0.716825 Mean dependent var 62.50000 Adjusted R-squared 0.702666 S.D. dependent var 10.08889 S.E. of regression 5.501306 Akaike info criterion 6.334356 Sum squared resid 605.2873 Schwarz criterion 6.433542 Log likelihood -67.67792 Hannan-Quinn criter. 6.357721 计量经济学课后习题答 案汇总 标准化工作室编码[XX968T-XX89628-XJ668-XT689N] 计量经济学练习题 第一章导论 一、单项选择题 ⒈计量经济研究中常用的数据主要有两类:一类是时间序列数据,另一类是【 B 】 A 总量数据 B 横截面数据 C平均数据 D 相对数据 ⒉横截面数据是指【 A 】 A 同一时点上不同统计单位相同统计指标组成的数据 B 同一时点上相同统计单位相同统计指标组成的数据 C 同一时点上相同统计单位不同统计指标组成的数据 D 同一时点上不同统计单位不同统计指标组成的数据 ⒊下面属于截面数据的是【 D 】 A 1991-2003年各年某地区20个乡镇的平均工业产值 B 1991-2003年各年某地区20个乡镇的各镇工业产值 C 某年某地区20个乡镇工业产值的合计数 D 某年某地区20个乡镇各镇工业产值 ⒋同一统计指标按时间顺序记录的数据列称为【 B 】 A 横截面数据 B 时间序列数据 C 修匀数据 D原始数据 ⒌回归分析中定义【 B 】 A 解释变量和被解释变量都是随机变量 B 解释变量为非随机变量,被解释变量为随机变量 C 解释变量和被解释变量都是非随机变量 D 解释变量为随机变量,被解释变量为非随机变量 二、填空题 ⒈计量经济学是经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论,可以理解为数学、统计学和_经济学_三者的结合。 ⒉现代计量经济学已经形成了包括单方程回归分析,联立方程组模型,时间序列 分析三大支柱。 ⒊经典计量经济学的最基本方法是回归分析。 计量经济分析的基本步骤是:理论(或假说)陈述、建立计量经济模型、收集数据、计量经济模型参数的估计、检验和模型修正、预测和政策分析。 ⒋常用的三类样本数据是截面数据、时间序列数据和面板数据。 ⒌经济变量间的关系有不相关关系、相关关系、因果关系、相互影响关系 和恒等关系。 三、简答题 ⒈什么是计量经济学它与统计学的关系是怎样的 计量经济学就是对经济规律进行数量实证研究,包括预测、检验等多方面的工作。计量经济学是一种定量分析,是以解释经济活动中客观存在的数量关系为内容的一门经济学学科。 计量经济学与统计学密切联系,如数据收集和处理、参数估计、计量分析方法设计,以及参数估计值、模型和预测结果可靠性和可信程度分析判断等。可以说,统计学的知识和方法不仅贯穿计量经济分析过程,而且现代统计学本身也与计量经济学有不少相似之处。例如,统计学也通过对经济数据的处理分析,得出经济问题的数字化特征和结论,也有对经济参数的估计和分析,也进行经济趋势的预测,并利用各种统计量对分析预测的结论进行判断和检验等,统计学的这些内容与计量经济学的内容都很相似。反过来,计量经济学也经常使用各种统计分析方法,筛选数据、选择变量和检验相关结论,统计分析是计量经济分析的重要内容和主要基础之一。 计量经济学与统计学的根本区别在于,计量经济学是问题导向和以经济模型为核心的,而统计学则是以经济数据为核心,且常常是数据导向的。典型的计量经济学分析从具体经济问题出发,先建立经济模型,参数估计、判断、调整和预测分析等都是以模型为基础和出发点;典型的统计学研究则并不一定需要从具体明确的问题出发,虽然也有一些目标,但可以是模糊不明确的。虽然统计学并不排斥经济理论和模型,有时也会利用它们,但统计学通常不一定需要特定的经济理论或模型作为基础和出发点,常常是通过对经济数据的统计处理直接得出结论,统计学侧重的工作是经济数据的采集、筛选和处理。 此外,计量经济学不仅是通过数据处理和分析获得经济问题的一些数字特征,而且是借助于经济思想和数学工具对经济问题作深刻剖析。经过计量经济分析实证检验的经济理论和模型,能够对分析、研究和预测更广泛的经济问题起重要作用。计量经济学从 第二章练习题及参考解答 表中是1992年亚洲各国人均寿命(Y)、按购买力平价计算的人均GDP(X1)、成人识字率(X2)、一岁儿童疫苗接种率(X3)的数据 表亚洲各国人均寿命、人均GDP、成人识字率、一岁儿童疫苗接种率数据 (1)分别分析各国人均寿命与人均GDP、成人识字率、一岁儿童疫苗接种率的数量关系。 (2)对所建立的回归模型进行检验。 【练习题参考解答】 (1)分别设定简单线性回归模型,分析各国人均寿命与人均GDP、成人识字率、一岁 儿童疫苗接种率的数量关系: 1)人均寿命与人均GDP 关系 Y i 1 2 X1i u i 估计检验结果: 2)人均寿命与成人识字率关系 3)人均寿命与一岁儿童疫苗接种率关系 (2)对所建立的多个回归模型进行检验 由人均GDP、成人识字率、一岁儿童疫苗接种率分别对人均寿命回归结果的参数t 检 验值均明确大于其临界值,而且从对应的P 值看,均小于,所以人均GDP、成人识字率、一 岁儿童疫苗接种率分别对人均寿命都有显着影响. (3)分析对比各个简单线性回归模型 人均寿命与人均GDP 回归的可决系数为人均寿命与成人识字率回归的可决系数为人 均寿命与一岁儿童疫苗接种率的可决系数为 相对说来,人均寿命由成人识字率作出解释的比重更大一些 为了研究浙江省财政预算收入与全省生产总值的关系,由浙江省统计年鉴得到以下数据:表浙江省财政预算收入与全省生产总值数据 的显着性,用规范的形式写出估计检验结果,并解释所估计参数的经济意义 (2)如果2011 年,全省生产总值为32000 亿元,比上年增长%,利用计量经济模型对浙江省2011 年的财政预算收入做出点预测和区间预测 (3)建立浙江省财政预算收入对数与全省生产总值对数的计量经济模型,. 估计模型的参数,检验模型的显着性,并解释所估计参数的经济意义 【练习题参考解答】建议学生独立完成 由12对观测值估计得消费函数为: (1)消费支出C的点预测值; (2)在95%的置信概率下消费支出C平均值的预测区间。 (3)在95%的置信概率下消费支出C个别值的预测区间。 【练习题参考解答】 假设某地区住宅建筑面积与建造单位成本的有关资料如表:表某地区住 宅建筑面积与建造单位成本数据 第二章 欧阳学文 2.2 (1) ①对于浙江省预算收入与全省生产总值的模型,用Eviews 分析结果如下: Dependent Variable: Y Method: Least Squares Date: 12/03/14 Time: 17:00 Sample (adjusted): 1 33 Included observations: 33 after adjustments Variable Coefficient Std. Error t-Statistic Prob. X0.1761240.00407243.256390.0000 C-154.306339.08196-3.9482740.0004 R-squared0.983702 Mean dependent var902.5148 Adjusted R-squared0.983177 S.D. dependent var1351.009 S.E. of regression175.2325 Akaike info criterion13.22880 Sum squared resid951899.7 Schwarz criterion13.31949 Log likelihood-216.2751 Hannan-Quinn criter.13.25931 F-statistic1871.115 Durbin-Watson stat0.100021 Prob(F-statistic)0.000000 ②由上可知,模型的参数:斜率系数0.176124,截距为—154.3063 ③关于浙江省财政预算收入与全省生产总值的模型,检验模 思考题答案 第一章绪论 思考题 怎样理解产生于西方国家的计量经济学能够在中国的经济理论研究和现代化建设中发挥重要作用 答:计量经济学的产生源于对经济问题的定量研究,这是社会经济发展到一定阶段的客观需要。计量经济学的发展是与现代科学技术成就结合在一起的,它反映了社会化大生产对各种经济因素和经济活动进行数量分析的客观要求。经济学从定性研究向定量分析的发展,是经济学逐步向更加精密、更加科学发展的表现。我们只要坚持以科学的经济理论为指导,紧密结合中国经济的实际,就能够使计量经济学的理论与方法在中国的经济理论研究和现代化建设中发挥重要作用。 理论计量经济学和应用计量经济学的区别和联系是什么 答:计量经济学不仅要寻求经济计量分析的方法,而且要对实际经济问题加以研究,分为理论计量经济学和应用计量经济学两个方面。 理论计量经济学是以计量经济学理论与方法技术为研究内容,目的在于为应用计量经济学提供方法论。所谓计量经济学理论与方法技术的研究,实质上是指研究如何运用、改造和发展数理统计方法,使之成为适合测定随机经济关系的特殊方法。 应用计量经济学是在一定的经济理论的指导下,以反映经济事实的统计数据为依据,用计量经济方法技术研究计量经济模型的实用化或探索实证经济规律、分析经济现象和预测经济行为以及对经济政策作定量评价。 怎样理解计量经济学与理论经济学、经济统计学的关系 答:1、计量经济学与经济学的关系。联系:计量经济学研究的主体—经济现象和经济关系的数量规律;计量经济学必须以经济学提供的理论原则和经济运行规律为依据;经济计量分析的结果:对经济理论确定的原则加以验证、充实、完善。区别:经济理论重在定性分析,并不对经济关系提供数量上的具体度量;计量经济学对经济关系要作出定量的估计,对经济理论提出经验的内容。 2、计量经济学与经济统计学的关系。联系:经济统计侧重于对社会经济现象的描述性计量;经济统计提供的数据是计量经济学据以估计参数、验证经济理论的基本依据;经济现象不能作实验,只能被动地观测客观经济现象变动的既成事实,只能依赖于经济统计数据。区别:经济统计学主要用统计指标和统计分析方法对经济现象进行描述和计量;计量经济学主要利用数理统计方法对经济变量间的关系进行计量。 在计量经济模型中被解释变量和解释变量的作用有什么不同 答:在计量经济模型中,解释变量是变动的原因,被解释变量是变动的结果。被解释变量是模型要分析研究的对象。解释变量是说明被解释变量变动主要原因的变量。 一个完整的计量经济模型应包括哪些基本要素你能举一个例子吗 答:一个完整的计量经济模型应包括三个基本要素:经济变量、参数和随机误差项。 例如研究消费函数的计量经济模型:u + = α βX Y+ 其中,Y为居民消费支出,X为居民家庭收入,二者是经济变量;α和β为参数;u是随机误差项。 假如你是中央银行货币政策的研究者,需要你对增加货币供应量促进经济增长提 第一章绪论 参考重点: 计量经济学的一般建模过程 第一章课后题(1.4.5) 1.什么是计量经济学?计量经济学方法与一般经济数学方法有什么区别? 答:计量经济学是经济学的一个分支学科,是以揭示经济活动中客观存在的数量关系为内容的分支学科,是由经济学、统计学和数学三者结合而成的交叉学科。 计量经济学方法揭示经济活动中各个因素之间的定量关系,用随机性的数学方程加以描述;一般经济数学方法揭示经济活动中各个因素之间的理论关系,用确定性的数学方程加以描述。 4.建立与应用计量经济学模型的主要步骤有哪些? 答:建立与应用计量经济学模型的主要步骤如下:(1)设定理论模型,包括选择模型所包含的变量,确定变量之间的数学关系和拟定模型中待估参数的数值范围;(2)收集样本数据,要考虑样本数据的完整性、准确性、可比性和—致性;(3)估计模型参数;(4)检验模型,包括经济意义检验、统计检验、计量经济学检验和模型预测检验。 5.模型的检验包括几个方面?其具体含义是什么? 答:模型的检验主要包括:经济意义检验、统计检验、计量经济学检验、模型的预测检验。在经济意义检验中,需要检验模型是否符合经济意义,检验求得的参数估计值的符号与大小是否与根据人们的经验和经济理论所拟订的期望值相符合;在统计检验中,需要检验模型参数估计值的可靠性,即检验模型的统计学性质;在计量经济学检验中,需要检验模型的计量经济学性质,包括随机扰动项的序列相关检验、异方差性检验、解释变量的多重共线性检验等;模型的预测检验主要检验模型参数估计量的稳定性以及对样本容量变化时的灵敏度,以确定所建立的模型是否可以用于样本观测值以外的范围。 第二章经典单方程计量经济学模型:一元线性回归模型参考重点: 1.相关分析与回归分析的概念、联系以及区别? 2.总体随机项与样本随机项的区别与联系? 1、已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X ()() n=30 R 2= 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题: (1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义是什么。 答:(1)系数的符号是正确的,政府债券的价格与利率是负相关关系,利率的上升会引起政府债券价格的下降。 (2)i Y 代表的是样本值,而i ?Y 代表的是给定i X 的条件下i Y 的期望值,即?(/)i i i Y E Y X =。此模型是根据样本数据得出的回归结果,左边应当是i Y 的期望值,因此是i ?Y 而不是i Y 。 (3)没有遗漏,因为这是根据样本做出的回归结果,并不是理论模型。 (4)截距项表示在X 取0时Y 的水平,本例中它没有实际意义;斜率项表明利率X 每上升一个百分点,引起政府债券价格Y 降低478美元。 2、有10户家庭的收入(X ,元)和消费(Y ,百元)数据如下表: 10户家庭的收入(X )与消费(Y )的资料 X 20 30 33 40 15 13 26 38 35 43 Y 7 9 8 11 5 4 8 10 9 10 若建立的消费Y 对收入X 的回归直线的Eviews 输出结果如下: Dependent Variable: Y Adjusted R-squared F-statistic (1)说明回归直线的代表性及解释能力。 (2)在95%的置信度下检验参数的显着性。(0.025(10) 2.2281t =,0.05(10) 1.8125t =,0.025(8) 2.3060t =,0.05(8) 1.8595t =) (3)在95%的置信度下,预测当X =45(百元)时,消费(Y )的置信区间。(其 第二章 2.2 (1) ①对于浙江省预算收入与全省生产总值的模型,用Eviews 分析结果如下: Dependent Variable: Y Method: Least Squares Date: 12/03/14 Time: 17:00 Sample (adjusted): 1 33 Included observations: 33 after adjustments Variable Coefficie nt Std. Error t-Statistic Prob. X 0.176124 0.004072 43.25639 0.0000 C -154.306 3 39.08196 -3.94827 4 0.0004 R-squared 0.983702 Mean dependent var 902.514 8 Adjusted R-squared 0.983177 S.D. dependent var 1351.00 9 S.E. of regression 175.2325 Akaike info criterion 13.2288 Sum squared resid 951899.7 Schwarz criterion 13.3194 9 Log likelihood -216.2751 Hannan-Quinn criter. 13.2593 1 F-statistic 1871.115 Durbin-Watson stat 0.10002 1 Prob(F-statistic) 0.000000 ②由上可知,模型的参数:斜率系数0.176124,截距为—154.3063 ③关于浙江省财政预算收入与全省生产总值的模型,检验模型的显著性: 1)可决系数为0.983702,说明所建模型整体上对样本数据拟合较好。 2)对于回归系数的t 检验:t (β2)=43.25639>t 0.025(31)=2.0395,对斜率系数的显著性 计量经济学第一次作业 第二章P85 8.用SPSS软件对10名同学的成绩数据进行录入,分析得r=0.875,这说明学生的课堂练习和期终考试有密切的关系,一般平时练习成绩较高者,期终成绩也高。 9.(1)一元线性回归模型如下:Y i=?0+?1X i+u i 其中,Y i表示财政收入,X i表示国民生产总值,u i为随机扰动项, ?0 ?1为待估参数。 由Eviews软件得散点图如下图: (2)Y i =-1354.856+0.179672X i Sê:(655.7254) (0.007082) t:(-2.066194) (25.37152) R2=0.958316 F=643.7141 df=28 斜率? 1 =0.179672表示国民生产总值每增加1亿元,财政收入增加0.179672亿元。(3)可决系数R2=0.958316表示在财政收入Y的总变差中由模型作出的解释部分占95.8316%,即有95.8316%由国民生产总值来解释,同时说明样本回归模型对样本数据的拟合程度较高。 R2=ESS/(ESS+RSS) ESS=RSS*R2/(1-R2)=(1.91E+08)*0.958316/(1-0.958316)=44.02E+08 F=(n-2)ESS/RSS,ESS=F*RSS/(n-2)=4.39*E09 (4)Sê(? 0)=655.7245 Sê(? 1 )=0.007082 ?1的95%的置信区间是: [?1-t 0.025(28)Sê(?1),?1+t 0.025(28)Sê(?1)] 代入数值得: [0.179672-2.048*0.007082,0.179672+2.048*0.007082] 即:[0.165,0.194] 同理可得,?0的95%置信区间为[-2697.78,-11.93] (5)①原假设H 0:?0=0 备择假设:H 1:?0≠0 则?0的t 值为:t 0=-2.066194 当ɑ=0.05时 t ɑ/2(28)=2.048 |t 0|=2.066194>t ɑ/2(28)=2.048 故拒绝原假设H 0,表明模型应保留截距项。 ②原假设H 0:?1=0 备择假设:H 1:?1≠0 当ɑ=0.05时 t ɑ/2(28)=2.048 因为|t 1|=25.37152>t ɑ/2(28)=2.048 故拒绝原假设H 0 表明国民生产总值的变动对国家财政收入有显著影响. 计量经济学第二次作业 第二章9.(10) 、建立X 与t 的趋势模型,其回归分析结果如下: Dependent Variable: X Method: Least Squares Date: 04/19/10 Time: 22:03 Sample: 1978 2008 Dependent Variable: Y Method: Least Squares Date: 04/10/10 Time: 17:31 Sample: 1978 2007 C -1354.856 655.7254 -2.066194 0.0482 R-squared 0.958316 Mean dependent var 10049.04 Adjusted R-squared 0.956827 S.D. dependent var 12585.51 S.E. of regression 2615.036 Akaike info criterion 18.64028 Sum squared resid 1.91E+08 Schwarz criterion 18.73370 Log likelihood -277.6043 F-statistic 643.7141 第二章 (1) ①对于浙江省预算收入与全省生产总值的模型,用Eviews分析结果如下:Dependent Variable: Y Method: Least Squares Date: 12/03/14 Time: 17:00 Sample (adjusted): 1 33 Included observations: 33 after adjustments Variable Coeffici ent Std. Error t-Statist ic Prob. X C R-squared Mean dependent var Adjusted R-squared. dependent var . of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood Hannan-Quinn criter. F-statistic Durbin-Watson stat Prob(F-statisti c) ②由上可知,模型的参数:斜率系数,截距为— ③关于浙江省财政预算收入与全省生产总值的模型,检验模型的显着性: 1)可决系数为,说明所建模型整体上对样本数据拟合较好。 2)对于回归系数的t检验:t(β2)=>(31)=,对斜率系数的显着性检验表明,全省生产总值对财政预算总收入有显着影响。 ④用规范形式写出检验结果如下: Y=— t= () R2= F= n=33 ⑤经济意义是:全省生产总值每增加1亿元,财政预算总收入增加亿元。 (2)当x=32000时, ①进行点预测,由上可知Y=—,代入可得: Y= Y=*32000—= ②进行区间预测: 先由Eviews分析: 第八章虚拟变量模型 1. 回归模型中引入虚拟变量的作用是什么? 答:在模型中引入虚拟变量,主要是为了寻找某(些)定性因素对解释变量的影响。加法方式与乘法方式是最主要的引入方式,前者主要适用于定性因素对截距项产生影响的情况,后者主要适用于定性因素对斜率项产生影响的情况。除此外,还可以加法与乘法组合的方式引入虚拟变量,这时可测度定性因素对截距项与斜率项同时产生影响的情况。 2. 虚拟变量有哪几种基本的引入方式? 它们各适用于什么情况? 答:在模型中引入虚拟变量的主要方式有加法方式与乘法方式,前者主要适用于定性因素对截距项产生影响的情况,后者主要适用于定性因素对斜率项产生影响的情况。除此外,还可以加法与乘法组合的方式引入虚拟变量,这时可测度定性因素对截距项与斜率项同时产生影响的情况。 3.什么是虚拟变量陷阱? 答:根据虚拟变量的设置原则,一般情况下,如果定性变量有m个类别,则需在模型中引入m-1个变量。如果引入了m个变量,就会导致模型解释变量出现完全的共线性问题,从而导致模型无法估计。这种由于引入虚拟变量个数与类别个数相等导致的模型无法估计的问题,称为“虚拟变量陷阱”。 4.在一项对北京某大学学生月消费支出的研究中,认为学生的消费支出除受其家庭的每月收入水平外,还受在学校中是否得到奖学金,来自农村还是城市,是经济发达地区还是欠发达地区,以及性别等因素的影响。试设定适当的模型,并导出如下情形下学生消费支出的平均水平: (1) 来自欠发达农村地区的女生,未得到奖学金; (2) 来自欠发达城市地区的男生,得到奖学金; (3) 来自发达地区的农村女生,得到奖学金; (4) 来自发达地区的城市男生,未得到奖学金。 解答: 记学生月消费支出为Y,其家庭月收入水平为X,则在不考虑其他因素的影响时,有如下基本回归模型: Y i=β0+β1X i+μi 有奖学金 1 来自城市 无奖学金0 来自农村 来自发达地区 1 男性 0 来自欠发达地区0 女性 Y i=β0+β1X i+α1D1i+α2D2i+α3D3i+α4D4i+μi 由此回归模型,可得如下各种情形下学生的平均消费支出: (1) 来自欠发达农村地区的女生,未得到奖学金时的月消费支出: E(Y i|= X i, D1i=D2i=D3i=D4i=0)=β0+β1X i (2) 来自欠发达城市地区的男生,得到奖学金时的月消费支出: E(Y i|= X i, D1i=D4i=1,D2i=D3i=0)=(β0+α1+α4)+β1X i计量经济学-庞皓-第三版课后答案
计量经济学第三版庞皓
计量经济学(庞皓)课后思考题答案
计量经济学第三版庞浩第三章习题
计量经济学课后习题答案
计量经济学第三版庞浩第七章习题答案
计量经济学庞皓第三版课后答案解析
计量经济学课后习题答案汇总
庞皓计量经济学第三版课后习题及答案 顶配
计量经济学第三版(庞浩)版课后答案全之欧阳学文创作
计量经济学 庞皓 课后思考题答案
《计量经济学》第三版课后题答案
计量经济学练习题答案
计量经济学第三版庞浩版课后答案
计量经济学课后答案-张龙版
计量经济学第三版庞浩版课后答案全
计量经济学课后习题答案第八章_答案