java实现爬取指定网站的数据

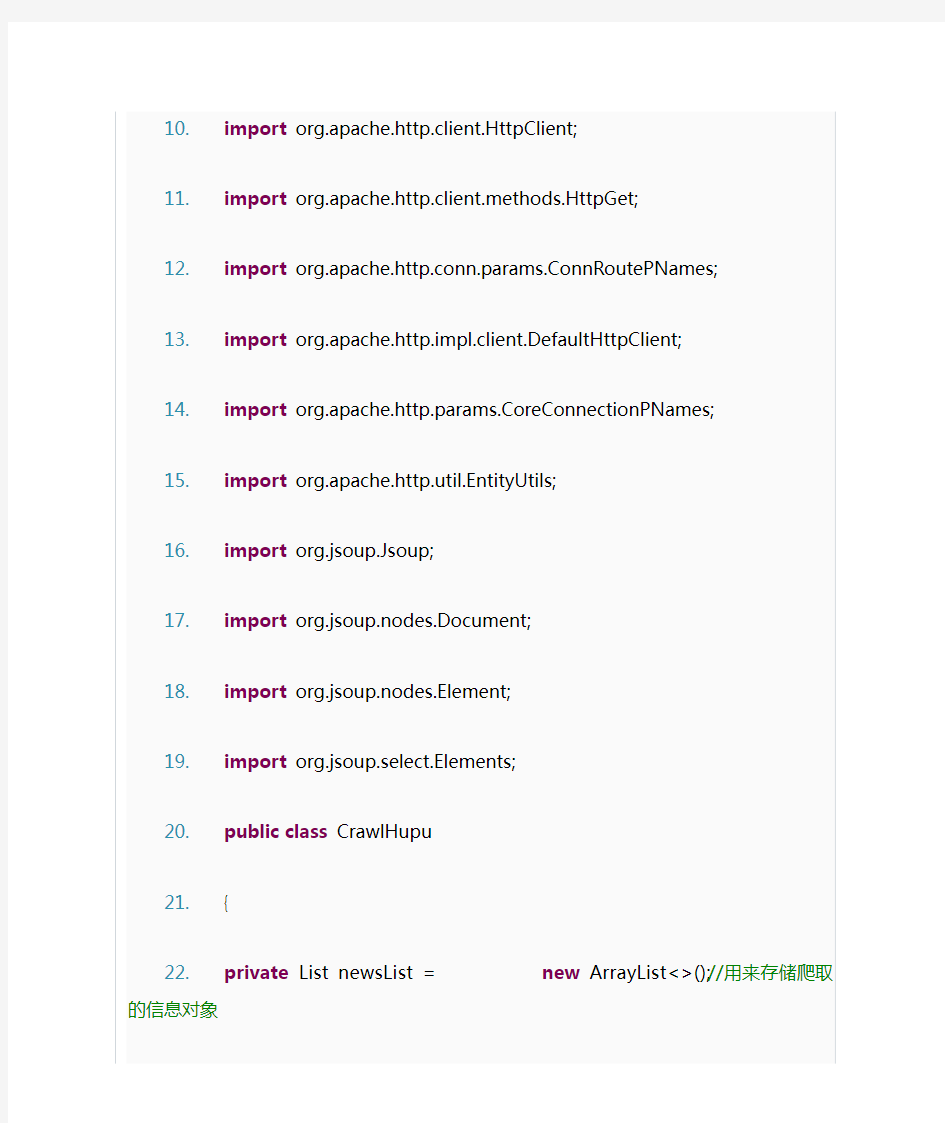
这个类是用来解析网站的内容
重点是:"div#page>div#content>div#local>div#recommend>ul>li>a";
这里用用firefox的firebug组件查看网页的代码结构,不同的网页路径也不一样。Java代码
2.这个是要获取的信息的类。不多解释。Java代码
网络爬虫工作原理
网络爬虫工作原理 1 聚焦爬虫工作原理及关键技术概述 网络爬虫是一个自动提取网页的程序,它为搜索引擎从Internet网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止,另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。 相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题: (1) 对抓取目标的描述或定义; (2) 对网页或数据的分析与过滤; (3) 对URL的搜索策略。 抓取目标的描述和定义是决定网页分析算法与URL搜索策略如何制订的基础。而网页分析算法和候选URL排序算法是决定搜索引擎所提供的服务形式和爬虫网页抓取行为的关键所在。这两个部分的算法又是紧密相关的。 2 抓取目标描述 现有聚焦爬虫对抓取目标的描述可分为基于目标网页特征、基于目标数据模式和基于领域概念3种。 基于目标网页特征的爬虫所抓取、存储并索引的对象一般为网站或网页。根据种子样本获取方式可分为: (1)预先给定的初始抓取种子样本; (2)预先给定的网页分类目录和与分类目录对应的种子样本,如Yahoo!分类结构等; (3)通过用户行为确定的抓取目标样例,分为: a) 用户浏览过程中显示标注的抓取样本; b) 通过用户日志挖掘得到访问模式及相关样本。 其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征,等等。现有的聚焦爬虫对抓取目标的描述或定义可以分为基于目标网页特征,基于目标数据模式和基于领域概念三种。 基于目标网页特征的爬虫所抓取、存储并索引的对象一般为网站或网页。具体的方法根据种子样本的获取方式可以分为:(1)预先给定的初始抓取种子样本;(2)预先给定的网页分类目录和与分类目录对应的种子样本,如Yahoo!分类结构等;(3)通过用户行为确定的抓取目标样例。其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征,等等。 基于目标数据模式的爬虫针对的是网页上的数据,所抓取的数据一般要符合一定的模式,或者可以转化或映射为目标数据模式。
网站爬虫如何爬取数据
https://www.360docs.net/doc/5e14631472.html, 网站爬虫如何爬取数据 大数据时代,用数据做出理性分析显然更为有力。做数据分析前,能够找到合适的的数据源是一件非常重要的事情,获取数据的方式有很多种,最简便的方法就是使用爬虫工具抓取。今天我们用八爪鱼采集器来演示如何去爬取网站数据,以今日头条网站为例。 采集网站: https://https://www.360docs.net/doc/5e14631472.html,/ch/news_hot/ 步骤1:创建采集任务 1)进入主界面选择,选择“自定义模式” 网站爬虫如何爬取数据图1
https://www.360docs.net/doc/5e14631472.html, 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 网站爬虫如何爬取数据图2 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容
https://www.360docs.net/doc/5e14631472.html, 网站爬虫如何爬取数据图3 步骤2:设置ajax页面加载时间 ●设置打开网页步骤的ajax滚动加载时间 ●找到翻页按钮,设置翻页循环 ●设置翻页步骤ajax下拉加载时间 1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定
https://www.360docs.net/doc/5e14631472.html, 网站爬虫如何爬取数据图4 注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量
https://www.360docs.net/doc/5e14631472.html, 网站爬虫如何爬取数据图5 步骤3:采集新闻内容 创建数据提取列表 1)如图,移动鼠标选中评论列表的方框,右键点击,方框底色会变成绿色 然后点击“选中子元素”
如何抓取网页数据,以抓取安居客举例
如何抓取网页数据,以抓取安居客举例 互联网时代,网页上有丰富的数据资源。我们在工作项目、学习过程或者学术研究等情况下,往往需要大量数据的支持。那么,该如何抓取这些所需的网页数据呢? 对于有编程基础的同学而言,可以写个爬虫程序,抓取网页数据。对于没有编程基础的同学而言,可以选择一款合适的爬虫工具,来抓取网页数据。 高度增长的抓取网页数据需求,推动了爬虫工具这一市场的成型与繁荣。目前,市面上有诸多爬虫工具可供选择(八爪鱼、集搜客、火车头、神箭手、造数等)。每个爬虫工具功能、定位、适宜人群不尽相同,大家可按需选择。本文使用的是操作简单、功能强大的八爪鱼采集器。以下是一个使用八爪鱼抓取网页数据的完整示例。示例中采集的是安居客-深圳-新房-全部楼盘的数据。 采集网站:https://https://www.360docs.net/doc/5e14631472.html,/loupan/all/p2/ 步骤1:创建采集任务 1)进入主界面,选择“自定义模式”
如何抓取网页数据,以抓取安居客举例图1 2)将要采集的网址复制粘贴到网站输入框中,点击“保存网址”
如何抓取网页数据,以抓取安居客举例图2 步骤2:创建翻页循环 1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。将页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”,以建立一个翻页循环
如何抓取网页数据,以抓取安居客举例图3 步骤3:创建列表循环并提取数据 1)移动鼠标,选中页面里的第一个楼盘信息区块。系统会识别此区块中的子元素,在操作提示框中,选择“选中子元素”
如何抓取网页数据,以抓取安居客举例图4 2)系统会自动识别出页面中的其他同类元素,在操作提示框中,选择“选中全部”,以建立一个列表循环
python抓取网页数据的常见方法
https://www.360docs.net/doc/5e14631472.html, python抓取网页数据的常见方法 很多时候爬虫去抓取数据,其实更多是模拟的人操作,只不过面向网页,我们看到的是html在CSS样式辅助下呈现的样子,但爬虫面对的是带着各类标签的html。下面介绍python抓取网页数据的常见方法。 一、Urllib抓取网页数据 Urllib是python内置的HTTP请求库 包括以下模块:urllib.request 请求模块、urllib.error 异常处理模块、urllib.parse url解析模块、urllib.robotparser robots.txt解析模块urlopen 关于urllib.request.urlopen参数的介绍: urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None) url参数的使用 先写一个简单的例子:
https://www.360docs.net/doc/5e14631472.html, import urllib.request response = urllib.request.urlopen(' print(response.read().decode('utf-8')) urlopen一般常用的有三个参数,它的参数如下: urllib.requeset.urlopen(url,data,timeout) response.read()可以获取到网页的内容,如果没有read(),将返回如下内容 data参数的使用 上述的例子是通过请求百度的get请求获得百度,下面使用urllib的post请求 这里通过https://www.360docs.net/doc/5e14631472.html,/post网站演示(该网站可以作为练习使用urllib的一个站点使用,可以 模拟各种请求操作)。 import urllib.parse import urllib.request data = bytes(urllib.parse.urlencode({'word': 'hello'}), encoding='utf8')
网络爬虫详解
网络爬虫详解 一、爬虫技术研究综述 引言 随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战。搜索引擎(Search Engine),例如传统的通用搜索引擎AltaVista,Yahoo!和Google等,作为一个辅助人们检索信息的工具成为用户访问万维网的入口和指南。但是,这些通用性搜索引擎也存在着一定的局限性,如: (1) 不同领域、不同背景的用户往往具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。 (2) 通用搜索引擎的目标是尽可能大的网络覆盖率,有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。 (3) 万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频/视频多媒体等不同数据大量出现,通用搜索引擎往往对这些信息含量密集且具有一定结构的数据无能为力,不能很好地发现和获取。 (4) 通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询。 为了解决上述问题,定向抓取相关网页资源的聚焦爬虫应运而生。聚焦爬虫是一个自动下载网页的程序,它根据既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所需要的信息。与通用爬虫(general purpose web crawler)不同,聚焦爬虫并不追求大的覆盖,而将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源。 1 聚焦爬虫工作原理及关键技术概述 网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件,如图1(a)流程图所示。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止,如图1(b)所示。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。 相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题: (1) 对抓取目标的描述或定义; (2) 对网页或数据的分析与过滤; (3) 对URL的搜索策略。 抓取目标的描述和定义是决定网页分析算法与URL搜索策略如何制订的基础。而网页分析算法和候选URL排序算法是决定搜索引擎所提供的服务形式和爬虫网页抓取行为的关键所在。这两个部分的算法又是紧密相关的。
如何利用爬虫爬取马蜂窝千万+数据
https://www.360docs.net/doc/5e14631472.html, 如何利用爬虫爬取马蜂窝千万+数据 最近有人爬了马蜂窝的1800万数据就刷爆了网络,惊动了互联网界和投资界,背后的数据团队也因此爆红。 你一定会想像这个团队像是电影里演的非常牛掰黑客一样的人物吧? 你以为爬数据一定要懂爬虫写代码、懂Python才能爬取网络数据是吧? 小八告诉你,过去可能是,但现在真的不!是!
https://www.360docs.net/doc/5e14631472.html, 爬这样千万级数据的工作,我们绝大部分人即使不懂写代码,都可以实现。 如何实现? 就是利用「数据爬虫工具」。 目前的爬虫工具已经趋向于简易、智能、可视化了,即使不懂代码和爬虫的小白用户都可以用。 比如在全球坐拥百万用户粉丝的八爪鱼数据采集器。 简单来说,用八爪鱼 爬取马蜂窝数据只要4个步骤。这里我们以爬取【马蜂窝景点点评数据】举例。
https://www.360docs.net/doc/5e14631472.html, ★ 第一步 打开马蜂窝,选择某城市的景点页面,(本文以采集成都景点点评为例) 第二步 用八爪鱼爬取马蜂窝的成都的top30景点页面超链接url地址
https://www.360docs.net/doc/5e14631472.html, 八爪鱼采集成都top30 景点网址url
https://www.360docs.net/doc/5e14631472.html, 第三步 用八爪鱼简易模板「蚂蜂窝国内景点点评爬虫」 第四步 导出数据到EXCEL。
https://www.360docs.net/doc/5e14631472.html, 小八只花了15分钟的时间就采集到成都TOP热门30景点的842条点评数据。如果同时运行多个客户端并使用使用云采集,将会更快。 (由于只是示例,每个景点小八只采集了842条评,如果有需要可以采集更多,这个可自己设置) 爬取结果
如何抓取网页数据
https://www.360docs.net/doc/5e14631472.html, 如何抓取网页数据 很多用户不懂爬虫代码,但是却对网页数据有迫切的需求。那么怎么抓取网页数据呢? 本文便教大家如何通过八爪鱼采集器来采集数据,八爪鱼是一款通用的网页数据采集器,可以在很短的时间内,轻松从各种不同的网站或者网页获取大量的规范化数据,帮助任何需要从网页获取信息的客户实现数据自动化采集,编辑,规范化,摆脱对人工搜索及收集数据的依赖,从而降低获取信息的成本,提高效率。 本文示例以京东评论网站为例 京东评价采集采集数据字段:会员ID,会员级别,评价星级,评价内容,评价时间,点赞数,评论数,追评时间,追评内容,页面网址,页面标题,采集时间。 需要采集京东内容的,在网页简易模式界面里点击京东进去之后可以看到所有关于京东的规则信息,我们直接使用就可以的。
https://www.360docs.net/doc/5e14631472.html, 京东评价采集步骤1 采集京东商品评论(下图所示)即打开京东主页输入关键词进行搜索,采集搜索到的内容。 1、找到京东商品评论规则然后点击立即使用
https://www.360docs.net/doc/5e14631472.html, 京东评价采集步骤2 2、简易模式中京东商品评论的任务界面介绍 查看详情:点开可以看到示例网址 任务名:自定义任务名,默认为京东商品评论 任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组 商品评论URL列表:提供要采集的网页网址,即商品评论页的链接。每个商品的链接必须以#comment结束,这个链接可以在商品列表点评论数打开后进行复制。或者自己打开商品链接后手动添加,如果没有这个后缀可能会报错。多个商品评论输入多个商品网址即可。 将鼠标移动到?号图标可以查看详细的注释信息。 示例数据:这个规则采集的所有字段信息。
网页数据抓取方法详解
https://www.360docs.net/doc/5e14631472.html, 网页数据抓取方法详解 互联网时代,网络上有海量的信息,有时我们需要筛选找到我们需要的信息。很多朋友对于如何简单有效获取数据毫无头绪,今天给大家详解网页数据抓取方法,希望对大家有帮助。 八爪鱼是一款通用的网页数据采集器,可实现全网数据(网页、论坛、移动互联网、QQ空间、电话号码、邮箱、图片等信息)的自动采集。同时八爪鱼提供单机采集和云采集两种采集方式,另外针对不同的用户还有自定义采集和简易采集等主要采集模式可供选择。
https://www.360docs.net/doc/5e14631472.html, 如果想要自动抓取数据呢,八爪鱼的自动采集就派上用场了。 定时采集是八爪鱼采集器为需要持续更新网站信息的用户提供的精确到分钟的,可以设定采集时间段的功能。在设置好正确的采集规则后,八爪鱼会根据设置的时间在云服务器启动采集任务进行数据的采集。定时采集的功能必须使用云采集的时候,才会进行数据的采集,单机采集是无法进行定时采集的。 定时云采集的设置有两种方法: 方法一:任务字段配置完毕后,点击‘选中全部’→‘采集以下数据’→‘保存并开始采集’,进入到“运行任务”界面,点击‘设置定时云采集’,弹出‘定时云采集’配置页面。
https://www.360docs.net/doc/5e14631472.html, 第一、如果需要保存定时设置,在‘已保存的配置’输入框内输入名称,再保存配置,保存成功之后,下次如果其他任务需要同样的定时配置时可以选择这个配置。 第二、定时方式的设置有4种,可以根据自己的需求选择启动方式和启动时间。所有设置完成之后,如果需要启动定时云采集选择下方‘保存并启动’定时采集,然后点击确定即可。如果不需要启动只需点击下方‘保存’定时采集设置即可。
网站数据爬取方法
https://www.360docs.net/doc/5e14631472.html, 网站数据爬取方法 网站数据主要是指网页上的文字,图像,声音,视频这几类,在告诉的信息化时代,如何去爬取这些网站数据显得至关重要。对于程序员或开发人员来说,拥有编程能力使得他们能轻松构建一个网页数据抓取程序,但是对于大多数没有任何编程知识的用户来说,一些好用的网络爬虫软件则显得非常的重要了。以下是一些使用八爪鱼采集器抓取网页数据的几种解决方案: 1、从动态网页中提取内容。 网页可以是静态的也可以是动态的。通常情况下,您想要提取的网页内容会随着访问网站的时间而改变。通常,这个网站是一个动态网站,它使用AJAX技术或其他技术来使网页内容能够及时更新。AJAX即延时加载、异步更新的一种脚本技术,通过在后台与服务器进行少量数据交换,可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
https://www.360docs.net/doc/5e14631472.html, 表现特征为点击网页中某个选项时,大部分网站的网址不会改变;网页不是完全加载,只是局部进行了数据加载,有所变化。这个时候你可以在八爪鱼的元素“高级选项”的“Ajax加载”中可以设置,就能抓取Ajax加载的网页数据了。 八爪鱼中的AJAX加载设置
https://www.360docs.net/doc/5e14631472.html, 2.从网页中抓取隐藏的内容。 你有没有想过从网站上获取特定的数据,但是当你触发链接或鼠标悬停在某处时,内容会出现?例如,下图中的网站需要鼠标移动到选择彩票上才能显示出分类,这对这种可以设置“鼠标移动到该链接上”的功能,就能抓取网页中隐藏的内容了。 鼠标移动到该链接上的内容采集方法
https://www.360docs.net/doc/5e14631472.html, 在滚动到网页底部之后,有些网站只会出现一部分你要提取的数据。例如今日头条首页,您需要不停地滚动到网页的底部以此加载更多文章内容,无限滚动的网站通常会使用AJAX或JavaScript来从网站请求额外的内容。在这种情况下,您可以设置AJAX超时设置并选择滚动方法和滚动时间以从网页中提取内容。
网络爬虫工具如何爬取网站数据
https://www.360docs.net/doc/5e14631472.html, 网络爬虫的基本原理是什么 目前网络爬虫已经是当下最火热的一个话题,许多新兴技术比如VR、智能机器人等等,都是依赖于底层对大数据的分析,而大数据又是从何而来呢?其中最常用的手段即是使用网络爬虫工具去获取。提起网络爬虫工具,很多小伙伴还可能没这么接触过。本文将解决以下问题:网络爬虫是什么,基本原理是什么;网络爬虫工具是什么;八爪鱼采集器是什么;三者的关系是什么。 先上重点:八爪鱼是一个网页采集器,网页采集器是一种专门的爬虫工具。 爬虫、网页采集器、八爪鱼关系图
https://www.360docs.net/doc/5e14631472.html, 一、网络爬虫是什么,原理是什么 爬虫是什么:网络爬虫,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。又被称为网页蜘蛛,聚焦爬虫,网络机器人。在FOAF社区中间,更经常的称为网页追逐者,另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。 爬虫工作原理:网络爬虫系统一般会选择一些比较重要的、出度(网页中链出超链接数)较大的网站的URL作为种子URL集合。以这些种子集合作为初始URL,开始数据抓取。 其基本工作流程如下: 1)将这些种子URL集合放入待抓取URL队列。 2)从待抓取URL队列中,取出待抓取URL,解析DNS,并且得到主机的ip,并将URL 对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。3)分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL 队列,从而进入下一个循环。如此反复进行,直到遍历了整个网络或者满足某种条件后,才会停止下来。
https://www.360docs.net/doc/5e14631472.html, 爬虫工具原理 二、网页采集器是什么八爪鱼采集器是什么 网页采集器:这里讲的网页采集器,专门指会根据用户的指令或者设置,从指定的网页上获取用户指定内容的工具软件。严格来讲,这里说的网页采集器也是爬虫的一种。 八爪鱼采集器:八爪鱼采集器就是一种网页采集器,用户可以设置从哪个网站爬取数据,爬取那些数据,爬取什么范围的数据,什么时候去爬取数据,爬取的数据如何保存等等。 八爪鱼采集的核心原理是:模拟人浏览网页,复制数据的行为,通过记录和模拟人的一系列上网行为,代替人眼浏览网页,代替人手工复制网页数据,从而实现自动化从网页采集数据,然后通过不断重复一系列设定的动作流程,实现全自动采集大量数据。 八爪鱼采集器可应对各种网页的复杂结构(AJAX页面、瀑布流等)和防采集措施(登录、
动态网页数据爬取
动态网站的抓取静态网站困难一些,主要涉及ajax和html,传统的web应用,我们提交一个表单给服务器接受请求返回一个页面给浏览器,这样每次用户的交互都需要向服务器发送请求。同时对整个网页进行刷新,这样会浪费网络宽带影响用户体验。 怎么解决? Ajax--异步JavaScript和xml。是JavaScript异步加载技术、xml及dom还有xhtml和css等技术的组合。他不必刷新整个页面只需要页面的局部进行更新。Ajax只取回一些必要数据,使用soap、xml或者支持json的web service接口。这样提高服务器的响应减少了数据交互提高了访问速度。 Dhtml动态html,他只是html、css、和客户的的一宗集合,一个页面有html、css、JavaScript 制作事事变换页面的元素效果的网页设计。 如何分辨? 最简单的就是看有没有“查看更多”字样,也可以使用response访问网页返回的response 内容和浏览器的内容不一致时就是使用了动态技术。这样我们也无法提取有效数据 如何提取? 1直接在JavaScript中采集的数据分析 2使用采集器中加载好的数据 为什么使用Phantomjs? Ajax请求太多并加密,手动分析每个ajax请求无疑愚公移山,phantomjs直接提取浏览器渲染好的结果不进行ajax请求分析,其实phantomjs就是基于webkit 的服务端JavaScript api。支持web而无需浏览器支持运行快,支持各种web标准:dom、css、json、canvas、svg。常用于页面自动化、网络监测、网页截屏、无界面测试。 安装? 下载https://www.360docs.net/doc/5e14631472.html,/download.html解压设置环境变量phantomjs -v测试安装 下载:{l55l59〇6〇9〇} 使用 页面加载:分析创建网页对象的呈现 代码:使用webpage模块创建一个page对象,通过page对象打开url网址,如果状态为success 通过render方法将页面保存。 代码评估:利用evaluate执行沙盒它执行网页外的JavaScript代码,evaluate返回一个对象然后返回值仅限对象不包含函数 屏幕捕获: 网络监控: 页面自动化: 常用模块和方法? Phantom,webpage,system,fs 图形化? Selenium将Python和phantomjs紧密结合实现爬虫开发。Selenium是自动化测试工具,支持各种浏览器,就是浏览器驱动可以对浏览器进行控制。并且支持多种开发语言phantomjs 负责解析JavaScript,selenium负责驱动浏览器和Python对接。 安装 pip install selenium===3.0.1 或者https://https://www.360docs.net/doc/5e14631472.html,/pypi/selenium#downloads 下载源码解压python setup.py install selenium3然后下载https://https://www.360docs.net/doc/5e14631472.html,/SeleniumHQ/selenium/
如何抓取网页数据
网页源码中规则数据的获取过程: 第一步:获取网页源码。 第二步:使用正则表达式匹配抽取所需要的数据。 第三步:将结果进行保存。 这里只介绍第一步。 https://www.360docs.net/doc/5e14631472.html,.HttpWebRequest; https://www.360docs.net/doc/5e14631472.html,.HttpWebResponse; System.IO.Stream; System.IO.StreamReader; System.IO.FileStream; 通过C#程序来获取访问页面的内容(网页源代码)并实现将内容保存到本机的文件中。 方法一是通过https://www.360docs.net/doc/5e14631472.html,的两个关键的类 https://www.360docs.net/doc/5e14631472.html,.HttpWebRequest; https://www.360docs.net/doc/5e14631472.html,.HttpWebResponse; 来实现的。 具体代码如下 方案0:网上的代码,看明白这个就可以用方案一和方案二了 HttpWebRequest httpReq; HttpWebResponse httpResp; string strBuff = ""; char[] cbuffer = new char[256]; int byteRead = 0; string filename = @"c:\log.txt"; ///定义写入流操作 public void WriteStream() { Uri httpURL = new Uri(txtURL.Text); ///HttpWebRequest类继承于WebRequest,并没有自己的构造函数,需通过WebRequest 的Creat方法建立,并进行强制的类型转换 httpReq = (HttpWebRequest)WebRequest.Create(httpURL); ///通过HttpWebRequest的GetResponse()方法建立HttpWebResponse,强制类型转换 httpResp = (HttpWebResponse) httpReq.GetResponse(); ///GetResponseStream()方法获取HTTP响应的数据流,并尝试取得URL中所指定的网页内容///若成功取得网页的内容,则以System.IO.Stream形式返回,若失败则产生 ProtoclViolationException错误。在此正确的做法应将以下的代码放到一个try块中处理。这里简单处理 Stream respStream = httpResp.GetResponseStream(); ///返回的内容是Stream形式的,所以可以利用StreamReader类获取GetResponseStream的内容,并以StreamReader类的Read方法依次读取网页源程序代码每一行的内容,直至行尾(读取的编码格式:UTF8) StreamReader respStreamReader = new StreamReader(respStream,Encoding.UTF8); byteRead = respStreamReader.Read(cbuffer,0,256);
js 爬虫如何实现网页数据抓取
https://www.360docs.net/doc/5e14631472.html, js 爬虫如何实现网页数据抓取 互联网Web 就是一个巨大无比的数据库,但是这个数据库没有一个像SQL 语言可以直接获取里面的数据,因为更多时候Web 是供肉眼阅读和操作的。如果要让机器在Web 取得数据,那往往就是我们所说的“爬虫”了。有很多语言可以写爬虫,本文就和大家聊聊如何用js实现网页数据的抓取。 Js抓取网页数据主要思路和原理 在根节点document中监听所有需要抓取的事件 在元素事件传递中,捕获阶段获取事件信息,进行埋点 通过getBoundingClientRect() 方法可获取元素的大小和位置 通过stopPropagation() 方法禁止事件继续传递,控制触发元素事件 在冒泡阶段获取数据,保存数据 通过settimeout异步执行数据统计获取,避免影响页面原有内容 Js抓取流程图如下
https://www.360docs.net/doc/5e14631472.html, 第一步:分析要爬的网站:包括是否需要登陆、点击下一页的网址变化、下拉刷新的网址变化等等 第二步:根据第一步的分析,想好爬这个网站的思路 第三步:爬好所需的内容保存 爬虫过程中用到的一些包:
https://www.360docs.net/doc/5e14631472.html, (1)const request = require('superagent'); // 处理get post put delete head 请求轻量接http请求库,模仿浏览器登陆 (2)const cheerio = require('cheerio'); // 加载html (3)const fs = require('fs'); // 加载文件系统模块将数据存到一个文件中的时候会用到 fs.writeFile('saveFiles/zybl.txt', content, (error1) => { // 将文件存起来文件路径要存的内容错误 if (error1) throw error1; // console.log(' text save '); }); this.files = fs.mkdir('saveFiles/simuwang/xlsx/第' + this.page + '页/', (e rror) => { if (error) throw error; }); //创建新的文件夹 //向新的文件夹里面创建新的文件 const writeStream = fs.createWriteStream('saveFiles/simuwang/xlsx/'
如何使用爬虫软件爬取数据
https://www.360docs.net/doc/5e14631472.html, 如何使用爬虫软件爬取数据 产品和运营在日常工作中,常常需要参考各种数据,来为决策做支持。 但实际情况是,对于日常工作中的各种小决策,内部提供的数据有时还不足给予充分支持,外部的数据大部分又往往都是机构出具的行业状况,并不能提供什么有效帮助。 于是产品和运营们往往要借助爬虫来抓取自己想要的数据。比如想要获取某个电商网站的评论数据,往往需要写出一段代码,借助python去抓取出相应的内容。 说到学写代码……额,我选择放弃。 那么问题来了,有没有什么更方便的方法呢? 今天就为大家介绍1个能适应大多数场景的数据采集工具,即使不懂爬虫代码,你也能轻松爬出98%网站的数据。 最重点是,这个软件的基础功能都是可以免费使用的 所以本次介绍八爪鱼简易采集模式下“知乎爬虫采集”的使用教程以及注意要点。步骤一、下载八爪鱼软件并登陆 1、打开/download,即八爪鱼软件官方下载页面,点击图中的下载按钮。
https://www.360docs.net/doc/5e14631472.html, 2、软件下载好了之后,双击安装,安装完毕之后打开软件,输入八爪鱼用户名密码,然后点击登陆
https://www.360docs.net/doc/5e14631472.html, 步骤二、设置知乎爬虫规则任务 1、进入登陆界面之后就可以看到主页上的网站简易采集了,选择立即使用即可。
https://www.360docs.net/doc/5e14631472.html, 2、进去之后便可以看到目前网页简易模式里面内置的所有主流网站了,需要采集知乎关键字内容的,这里选择搜狗即可。
https://www.360docs.net/doc/5e14631472.html, 3、找到知乎关键字搜索这条爬虫规则,点击即可使用。
https://www.360docs.net/doc/5e14631472.html, 4、知乎关键字搜索简易采集模式任务界面介绍 查看详情:点开可以看到示例网址 任务名:自定义任务名,默认为知乎关键字搜索 任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组 搜索关键字填写注意事项:提供要采集的关键字。多关键字搜索输入多个关键字即可(回车键分隔开,即一个关键字为一行)。 示例数据:这个规则采集的所有字段信息。
如何爬取网站数据
https://www.360docs.net/doc/5e14631472.html, 如何爬取网站数据 在这信息爆炸的时代,互联网数据就像无底洞一样,有多少都可以装下去,并且这些网站数据大多是开放的。所有人均可通过网络来爬取这些网站数据,网页上能看到的数据,99%都是可以抓取的,所见即所得,今天我们使用八爪鱼采集器来演示如何去爬取网站数据。 采集网站: https://https://www.360docs.net/doc/5e14631472.html,/ch/news_hot/ 步骤1:创建采集任务 1)进入主界面选择,选择“自定义模式”
https://www.360docs.net/doc/5e14631472.html, 网站数据抓取能抓取哪些数据图1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 网站数据抓取能抓取哪些数据图2
https://www.360docs.net/doc/5e14631472.html, 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容 网站数据抓取能抓取哪些数据图3 步骤2:设置ajax页面加载时间 ●设置打开网页步骤的ajax滚动加载时间 ●找到翻页按钮,设置翻页循环 ●设置翻页步骤ajax下拉加载时间
https://www.360docs.net/doc/5e14631472.html, 1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定 网站数据抓取能抓取哪些数据图4 注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量
https://www.360docs.net/doc/5e14631472.html, 网站数据抓取能抓取哪些数据图5 步骤3:采集新闻内容 创建数据提取列表 1)如图,移动鼠标选中评论列表的方框,右键点击,方框底色会变成绿色 然后点击“选中子元素”
美团数据抓取方法
https://www.360docs.net/doc/5e14631472.html, 美团数据抓取方法 随着外卖市场的发展,很多朋友需要采集美团网站的数据,但数据采集方法又不会用。今天给大家介绍一些美团的抓取方法供大家使用。 美团数据抓取使用步骤 步骤一、下载八爪鱼软件并登陆 1、打开https://www.360docs.net/doc/5e14631472.html,/download,即八爪鱼软件官方下载页面,点击图中的下载按钮。
https://www.360docs.net/doc/5e14631472.html, 2、软件下载好了之后,双击安装,安装完毕之后打开软件,输入八爪鱼用户名密码,然后点击登陆 步骤二、设置美团数据抓取规则任务 1、进入登陆界面之后就可以看到主页上的网站简易采集了,选择立即使用即可。
https://www.360docs.net/doc/5e14631472.html, 2、进去之后便可以看到目前网页简易模式里面内置的所有主流网站了,需要采集美团内容的,这里选择第四个--美团即可。
https://www.360docs.net/doc/5e14631472.html, 3、找到美团-》商家信息-关键词搜索这条爬虫规则,点击即可使用。
https://www.360docs.net/doc/5e14631472.html, 4、美团-商家信息-关键词搜索简易采集模式任务界面介绍 查看详情:点开可以看到示例网址 任务名:自定义任务名,默认为美食商家列表信息采集 任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组城市页面地址:输入你要在美团网上采集的城市url(可放入多个)搜索关键词:设置你要搜索的关键词,填入即可 示例数据:这个规则采集到的所有字段信息。
https://www.360docs.net/doc/5e14631472.html, 5、美团数据抓取规则设置示例 例如要采集南昌市所有烧烤类的商家信息 在设置里如下图所示: 任务名:自定义任务名,也可以不设置按照默认的就行 任务组:自定义任务组,也可以不设置按照默认的就行
如何批量爬取网站数据
https://www.360docs.net/doc/5e14631472.html, 如何批量爬取网站数据 在互联网时代,网站的海量数据是重要信息的来源。如何有效快捷的提取到有效信息,批量爬取我们所需要的信息呢?今天教给大家一种简易可行的方法,帮助大家提高工作效率。八爪鱼是一款极容易上手、可视化操作、功能强大的网站数据抓取工具。以下是一个使用八爪鱼采集目标网站数据的完整示例。示例中采集的是链家网上-租房-深圳分类下的出租房屋信息。本文仅以链家网这个网站为例,其他直接可见的网站均可通过八爪鱼这个工具采集。 示例网站: 步骤1:创建采集任务 1)进入主界面选择,选择自定义模式
https://www.360docs.net/doc/5e14631472.html, 如何实现获取网站数据,以采集链家房源信息为例图1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 如何实现获取网站数据,以采集链家房源信息为例图2
https://www.360docs.net/doc/5e14631472.html, 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的列表内容,就是演示采集数据 如何实现获取网站数据,以采集链家房源信息为例图3 步骤2:创建翻页循环 找到翻页按钮,设置翻页循环 1)将页面下拉到底部,找到下一页按钮,鼠标点击,在右侧操作提示框中, 选择“循环点击下一页”
https://www.360docs.net/doc/5e14631472.html, 如何实现获取网站数据,以采集链家房源信息为例图4 步骤3:房源信息采集 ●选中需要采集的字段信息,创建采集列表 ●编辑采集字段名称 1)如图,移动鼠标选中列表中标题的名称,右键点击,需采集的内容会变成绿色
https://www.360docs.net/doc/5e14631472.html, 如何实现获取网站数据,以采集链家房源信息为例图5 注意:点击右上角的“流程”按钮,即可展现出可视化流程图。 2)移动鼠标选中红色方框里任意文本字段后,列表中所有适配内容会变成绿色,在右侧操作提示框中,查看提取的字段,可以将不需要的字段删除,然后点击“选中全部”
搜索引擎爬虫数据抓取
简单搜索引擎模型 A Simple Scratch of Search Engine 作者 史春奇, 搜索工程师, 中科院计算所毕业, chunqi.shi@https://www.360docs.net/doc/5e14631472.html, https://www.360docs.net/doc/5e14631472.html,/shichunqi 计划: 1,需求迫切07/06完成 2,搜索引擎简单模型07/08完成 3,信息导航模型07/16完成1/3 数据抓取07/30 预处理 4,商家推广模型 5,未来 本文是学习搜索引擎的涂鸦草稿,高深读者请拐弯到:https://www.360docs.net/doc/5e14631472.html,/IR-Guide.txt(北大搜索引擎小组--信息检索指南) 简单搜索引擎模型 (1) A Simple Scratch of Search Engine (1) 第一章需求迫切 (2) 一)泛信息化 (2) 二)泛商品化 (2) 第二章导航模型--草根需求信息 (3) 第一节最直观简单模型 (3) 第二节互联网简单模型 (5) 1.发展历史 (6) 2.大陆互联网现状 (7) 3.草根需求 (10) 第三节网页抓取简单模型 (10) 1.最简单Spider抓取模型 (11) 2.最简单Spider调度模型 (12) 3.最简单Spider调度质量模型 (15) 4.最简单Spider调度策略模型 (18) 5.Spider的常见问题 (23) 第四节网页预处理简单模型 (23) 1.质量筛选(Quality Selection) (24) 2.相似滤重(De-duplicate) (35) 3.反垃圾(Anti-spam) (43) 第亓节索引存储简单模型 (48)
第六节检索框架简单模型 (48) 信息检索评价指标 (48) 第三章推广模型--商家需求客户 (49) 第四章未来 (49) 第一章需求迫切 之前说过,搜索引擎是互联网大爆炸后的新生事物,他的成功来源于两个方面高度发展,一个是泛信息化,一个是泛商品化。 一)泛信息化 分为两个方面,一方面是信息的类型呈百花齐放,另一方面是信息的数量呈海量增长。 1, 信息种类繁多。 大家切身感受到的是多媒体娱乐和社交联系在互联网上变得明显的丰富起来。信息种类繁多不可避免会导致搜索引擎的种类繁多起来。而搜索引擎种类繁多这一点,你可以看一下Google,Baidu 提供的服务是多么繁多,你就知道了。参考百度更多(https://www.360docs.net/doc/5e14631472.html,/more/),Google 更多(https://www.360docs.net/doc/5e14631472.html,/intl/en/options/),这些还不包括实验室(Lab)的产品。我们换个角度看这个问题,看看现在已经有多少种搜索引擎来满足信息繁多的各种需求了,Wiki 的搜索引擎列表(https://www.360docs.net/doc/5e14631472.html,/wiki/List_of_search_engines)有一个分类,显示了10种类型,分别是,1)论坛,2)博客,3)多媒体(音乐,视频,电视),4)源代码,5)P2P资源,6)Email,7)地图,8)价格,9)问答信息,10)自然语言。我们知道信息爆发都是由需求带动的,那么目前有多少需求已经有搜索引擎在满足了呢?下面列出了14种类型,分别是,1)普通[知识],2)地理信息,3)会计信息,4)商业信息,5)企业信息,6)手机和移动信息,7)工作信息,8)法律信息,9)医疗信息,10)新闻信息,11)社交信息,12)不动产信息,13)电视信息,14)视频游戏信息。 2,信息海量增长。 类似,我们从搜索引擎的发展,反向来看信息增长。搜索引擎的索引量是选择收录入库的网页数,肯定小于或者远小于互联网的信息量。最早Yahoo是人工编辑的目录索引,就几万和几十万的级别。到Infoseek,Google早期等的几百万的索引量。到Baidu早期的千万、上亿的索引量。到现在Google等上千亿的索引量。如果你看一个网页要1秒钟,1000亿网页要看3171年,而且不吃不喝,一秒不停地看。如果你是愚公世家,你的祖辈在大禹治水的时候就开始看网页,到现在你还没看完。 因此草根(Grassroots)用户需要搜索引擎来满足它们的信息的导航,草根用户追求免费,快捷和有效的服务。 二)泛商品化
网页内容抓取工具使用教程
https://www.360docs.net/doc/5e14631472.html, 网页内容抓取工具使用教程 目前市面上有很多种网页内容抓取工具,各有优缺点。而八爪鱼是行业内的佼佼者,不用写代码,也更为适合0基础的小白用户。但对于部分没有时间学习的用户来说,直接用自定义模式做规则可能有难度,考虑到这种情况,八爪鱼提供了网页简易模式,简易模式下放了许多现成的爬虫采集规则,涵盖国内大部分主流网站,在急需采集相关网站时可以直接使用,大大的方便了用户,节省了做规则的时间和精力。 所以本文介绍网页内容抓取工具—八爪鱼简易采集模式下“微信文章采集”的使用教程以及注意要点。 微信文章采集下来有很多作用,比如可以将自己行业中最近一个月之内发布的内容采集下来,然后分析文章标题和内容的一个方向与趋势。 微信公众号文章采集使用步骤 步骤一、下载八爪鱼软件并登陆 1、打开https://www.360docs.net/doc/5e14631472.html,/download,即八爪鱼软件官方下载页面,点击图中的下载按钮。
https://www.360docs.net/doc/5e14631472.html, 2、软件下载好了之后,双击安装,安装完毕之后打开软件,输入八爪鱼用户名密码,然后点击登陆
https://www.360docs.net/doc/5e14631472.html, 步骤二、设置微信文章爬虫规则任务 1、进入登陆界面之后就可以看到主页上的网站简易采集了,选择立即使用即可。
https://www.360docs.net/doc/5e14631472.html, 2、进去之后便可以看到目前网页简易模式里面内置的所有主流网站了,需要采集微信公众号内容的,这里选择搜狗即可。
https://www.360docs.net/doc/5e14631472.html, 3、找到搜狗公众号这条爬虫规则,点击即可使用。
https://www.360docs.net/doc/5e14631472.html, 4、搜狗公众号简易采集模式任务界面介绍 查看详情:点开可以看到示例网址 任务名:自定义任务名,默认为搜狗公众号 任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组 公众号URL列表填写注意事项:提供要采集的网页网址,即搜狗微信中相关公众号的链接。多个公众号输入多个网址即可。 采集数目:输入希望采集的数据条数 示例数据:这个规则采集的所有字段信息。