实验三 多元回归模型
实验三多元回归模型
【实验目的】
掌握建立多元回归模型和比较、筛选模型的方法。
【实验内容】
建立我国国有独立核算工业企业生产函数。根据生产函数理论,生产函数的基本形式为:()ε,
f
t
Y=。其中,L、K分别为生产过程中投入的劳动与资金,
L
,
,K
时间变量t反映技术进步的影响。表3-1列出了我国1978-1994年期间国有独立核算工业企业的有关统计资料;其中产出Y为工业总产值(可比价),L、K分别为年末职工人数和固定资产净值(可比价)。
资料来源:根据《中国统计年鉴-1995》和《中国工业经济年鉴-1995》计算整理
【实验步骤】
一、建立多元线性回归模型
㈠建立包括时间变量的三元线性回归模型;
在命令窗口依次键入以下命令即可:
⒈建立工作文件: CREATE A 78 94
⒉输入统计资料: DATA Y L K
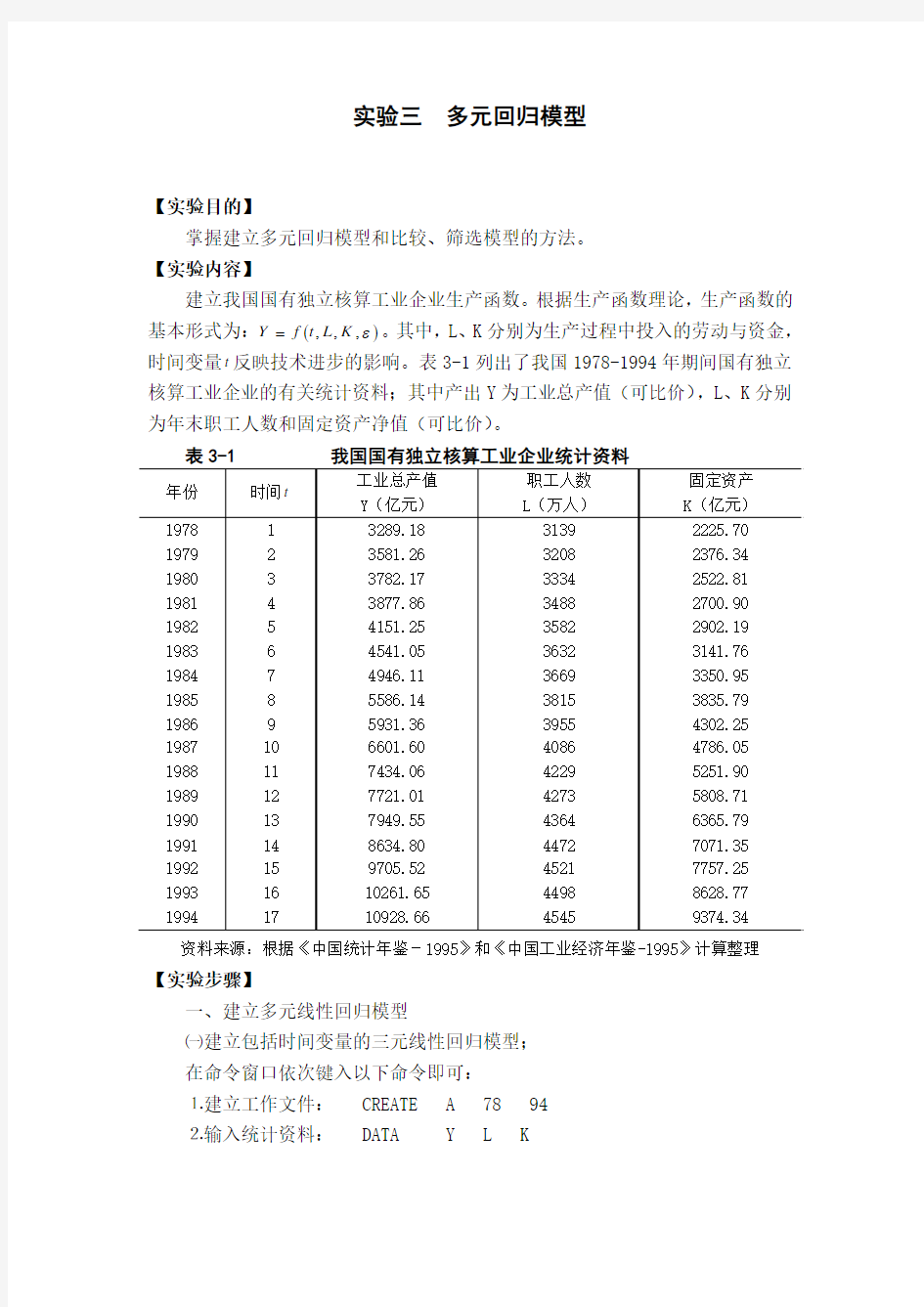
⒊生成时间变量t : GENR T=@TREND(77) ⒋建立回归模型: LS Y C T L K 则生产函数的估计结果及有关信息如图3-1所示。
图3-1 我国国有独立核算工业企业生产函数的估计结果 因此,我国国有独立工业企业的生产函数为:
K L t y
7764.06667.06789.7732.675?+++-= (模型1) t =(-0.252) (0.672) (0.781) (7.433)
9958.02
=R
9948
.02
=R
551.1018=F 模型的计算结果表明,我国国有独立核算工业企业的劳动力边际产出为0.6667,资金的边际产出为0.7764,技术进步的影响使工业总产值平均每年递增77.68亿元。回归系数的符号和数值是较为合理的。9958.02=R ,说明模型有很高的拟合优度,F 检验也是高度显著的,说明职工人数L 、资金K 和时间变量t 对工业总产值的总影响是显著的。从图3-1看出,解释变量资金K 的t 统计量值为7.433,表明资金对企业产出的影响是显著的。但是,模型中其他变量(包括常数项)的t 统计量值都较小,未通过检验。因此,需要对以上三元线性回归模型做适当的调整,按照统计检验程序,一般应先剔除t 统计量最小的变量(即时间变量)而重新建立模型。
㈡建立剔除时间变量的二元线性回归模型; 命令:LS Y C L K
则生产函数的估计结果及有关信息如图3-2所示。
图3-2 剔除时间变量后的估计结果
因此,我国国有独立工业企业的生产函数为:
K L y
8345.02085.127.2387?++-= (模型2) t =(-2.922) (4.427) (14.533)
9956.02
=R
9950
.02
=R
953.1589=F 从图3-2的结果看出,回归系数的符号和数值也是合理的。劳动力边际产出为1.2085,资金的边际产出为0.8345,表明这段时期劳动力投入的增加对我国国有独立核算工业企业的产出的影响最为明显。模型2的拟合优度较模型1并无多大变化,F 检验也是高度显著的。这里,解释变量、常数项的t 检验值都比较大,显著性概率都小于0.05,因此模型2较模型1更为合理。
㈢建立非线性回归模型——C-D 生产函数。
C-D 生产函数为:εβαe K AL Y =,对于此类非线性函数,可以采用以下两种方式建立模型。
方式1:转化成线性模型进行估计; 在模型两端同时取对数,得:
ε
βα+++=K L A y ln ln ln ln
在EViews 软件的命令窗口中依次键入以下命令:
GENR LNY=log (Y ) GENR LNL=log (L ) GENR LNK=log (K ) LS LNY C LNL LNK 则估计结果如图3-3所示。
图3-3 线性变换后的C-D 生产函数估计结果
即可得到C-D 生产函数的估计式为:
K L y
ln 6737.0ln 6045.09513.1?ln ++-= (模型3)
t = (-1.172) (2.217) (9.310)
9958.02
=R
9951
.02
=R
407.1641=F 即:6737.06045.01424.0?K L y
= 从模型3中看出,资本与劳动的产出弹性都是在0到1之间,模型的经济意义合理,而且拟合优度较模型2还略有提高,解释变量都通过了显著性检验。
方式2:迭代估计非线性模型,迭代过程中可以作如下控制: ⑴在工作文件窗口中双击序列C ,输入参数的初始值; ⑵在方程描述框中点击Options ,输入精度控制值。 控制过程:
①参数初值:0,0,0;迭代精度:10
-3
;
则生产函数的估计结果如图3-4所示。
图3-4 生产函数估计结果
此时,函数表达式为:
0429.10544.189.5896?K L y
-= (模型4)
t =(0.304)(-2.063)(8.606)
9835.02
=R
9811
.02
=R
可以看出,模型4中劳动力弹性α=-1.0544,资金的产出弹性β=1.0429,很显然模型的经济意义不合理,因此,该模型不能用来描述经济变量间的关系。而且模型的拟合优度也有所下降,解释变量L 的显著性检验也未通过,所以应舍弃该模型。
②参数初值:0,0,0;迭代精度:10
-5
;
图3-5 生产函数估计结果
从图3-5看出,将收敛的误差精度改为10-5后,迭代100次后仍报告不收敛,说明在使用迭代估计法时参数的初始值与误差精度或迭代次数设置不当,会直接影响模型的估计结果。
③参数初值:0,0,0;迭代精度:10
-5
,迭代次数1000;
图3-6 生产函数估计结果
此时,迭代414次后收敛,函数表达式为:
6649
.06110.01450.0?K L y
= (模型5)
t =(0.581)(2.265)(10.480)
9957.02
=R
9950
.02
=R
从模型5中看出,资本与劳动的产出弹性都是在0到1之间,模型的经济意义合理,9957.02=R ,具有很高的拟合优度,解释变量都通过了显著性检验。将模型5与通过方式1所估计的模型3比较,可见两者是相当接近的。
④参数初值:1,1,1;迭代精度:10
-5
,迭代次数1000;
图3-7 生产函数估计结果
此时,迭代129次后收敛,估计结果与模型5相同。
比较方式2的不同控制过程可见,迭代估计过程的收敛性及收敛速度与参数初始值的选取密切相关。若选取的初始值与参数真值比较接近,则收敛速度快;反之,则收敛速度慢甚至发散。因此,估计模型时最好依据参数的经济意义和有关先验信息,设定好参数的初始值。
二、比较、选择最佳模型
估计过程中,对每个模型检验以下内容,以便选择出一个最佳模型:
㈠回归系数的符号及数值是否合理;
㈡模型的更改是否提高了拟合优度;
㈢模型中各个解释变量是否显著;
㈣残差分布情况
以上比较模型的㈠、㈡、㈢步在步骤一中已有阐述,现分析步骤一中5个不同模型的残差分布情况。
分别在模型1~模型5的各方程窗口中点击View/Actual, Fitted, Residual/ Actual, Fitted, Residual Table(图3-8),可以得到各个模型相应的残差分布表(图3-9至图3-13)。
可以看出,模型4的残差在前段时期内连续取负值且不断增大,在接下来的一段时期又连续取正值,说明模型设定形式不当,估计过程出现了较大的偏差。而且,模型4的表达式也说明了模型的经济意义不合理,不能用于描述我国国有工业企业的生产情况,应舍弃此模型。
模型1的各期残差中大多数都落在σ?
±的虚线框内,且残差分别不存在明显的规律性。但是,由步骤一中的分析可知,模型1中除了解释变量K之外,其余变量均为通过变量显著性检验,因此,该模型也应舍弃。
模型2、模型3、模型5都具有合理的经济意义,都通过了t检验和F检验,拟合优度非常接近,理论上讲都可以描述资本、劳动的投入与产出的关系。但从图3-13看出,模型5的近期误差较大,因此也可以舍弃该模型。
最后将模型2与模型3比较发现,模型3的近期预测误差略小,拟合优度比模型2略有提高,因此可以选择模型3为我国国有工业企业生产函数。
图3-8 回归方程的残差分析
图3-9 模型1的残差分布
图3-10 模型2的残差分布
图3-11 模型3的残差分布
图3-12 模型4的残差分布
图3-13 模型5的残差分布
excel一元及多元线性回归实例
野外实习资料的数理统计分析 一元线性回归分析 一元回归处理的是两个变量之间的关系,即两个变量X和Y之间如果存在一定的关系,则通过观测所得数据,找出两者之间的关系式。如果两个变量的关系大致是线性的,那就是一元线性回归问题。 对两个现象X和Y进行观察或实验,得到两组数值:X1,X2,…,Xn和Y1,Y2,…,Yn,假如要找出一个函数Y=f(X),使它在 X=X1,X2, …,Xn时的数值f(X1),f(X2), …,f(Xn)与观察值Y1,Y2,…,Yn趋于接近。 在一个平面直角坐标XOY中找出(X1,Y1),(X2,Y2),…,(Xn,Yn)各点,将其各点分布状况进行察看,即可以清楚地看出其各点分布状况接近一条直线。对于这种线性关系,可以用数学公式表示: Y = a + bX 这条直线所表示的关系,叫做变量Y对X的回归直线,也叫Y对X 的回归方程。其中a为常数,b为Y对于X的回归系数。 对于任何具有线性关系的两组变量Y与X,只要求解出a与b的值,即可以写出回归方程。计算a与b值的公式为:
式中:为变量X的均值,Xi为第i个自变量的样本值,为因变量的均值,Yi为第i个因变量Y的样本值。n为样本数。 当前一般计算机的Microsoft Excel中都有现成的回归程序,只要将所获得的数据录入就可自动得到回归方程。 得到的回归方程是否有意义,其相关的程度有多大,可以根据相关系数的大小来决定。通常用r来表示两个变量X和Y之间的直线相关程度,r为X和Y的相关系数。r值的绝对值越大,两个变量之间的相关程度就越高。当r为正值时,叫做正相关,r为负值时叫做负相关。r 的计算公式如下: 式中各符号的意义同上。 在求得了回归方程与两个变量之间的相关系数后,可以利用F检验法、t检验法或r检验法来检验两个变量是否显著相关。具体的检验方法在后面介绍。
基于多元线性回归模型的影响居民消费水平相关因素分析
计量分析软件课程论文 论文题目:基于多元线性回归模型的影响居民消费 水平相关因素分析 姓名:学号: 学院:专业: 联系电话: 年月日 基于多元线性回归模型的影响居民消费 水平相关因素分析 一、研究背景 中国GDP总量超越日本,成为仅次于美国的第二大经济体,但我国人均GDP 依然很低,全球排名87位,这很大程度上制约了居民消费水平的提高。到2020年实现全面建成小康社会的目标,十八大明确提出提高居民人均收入和人均消费水平,共享改革开放成果。我国居民消费水平在改革开放后有了很大提高,但消费水平依然很低,消费量占GDP比重依然很小。为此,本文旨在根据全国经济宏观政策、国内生产总值、职工平均工资指数、城镇居民消费价格指数、普通中学及高等学校在校生数、卫生机构数和基本设施铁路公路货运量等因素的变化情况,来分析如何提高居民消费水平,以判断是否能使居民消费水平有很大的提高。本文通过对1978-2010年影响居民消费水平因素数据的分析,找到影响居民消费水平的主要原因,通过计量经济分析方法来建立合理的模型,探讨影响居民消费增长的长期趋势规律,并给政府提出合理的建议,以提高居民消费水平。 二、影响居民消费水平的因素 宏观经济模型) + GDP- + + =,经济发展应该紧紧抓住消费这一 I (M C X G 驾马车,而居民消费水平的高低受制于多种因素。凯恩斯消费理论认为居民消费主要受收入影响,我国居民消费一直很低,消费意愿不强,本文通过计量分析找
到影响我国居民消费水平的主要因素,从根本上改善消费不足,促进我国经济的持续稳定健康发展。 消费分为居民消费和,居民消费包括农村居民消费和城镇居民消费。本文结合居民消费水平的影响因素,列出了国内生产总值、职工平均工资指数、城镇居民消费价格指数、普通中学及高等学校在校生数、卫生机构数和基本设施铁路公路货运量等相关因素,进行计量分析,得到回归模型。 三、居民消费水平模型的总体分析框架 (1)多元线性回归法OLS 概述[1] 回归分析是计量经济分析中使用最多的方法,在现实问题研究中,因变量往往受制于多个经济变量的影响,通过统计资料,根据多个解释变量的最优组合来建立回归方程预测被解释变量的回归分析称为多元线性回归法。其模型基本形式为: 其中0β、1β、2β、3β…k β是1+k 个未知参数,称为多元回归系数。Y 称为被解释变量,t X 1、t X 2、t X 3…kt X 是k 个可以精确测量和可控的一般解释变量, t μ是随机误差项。当2≥k 时,上式为多元线性回归模型。 (2)多元回归模型的建立 定义被解释变量和解释变量,被解释变量为居民消费水平(Y 元),解释变量为国内生产总值(1X 亿元)、职工平均工资指数(2X )、城镇居民消费价格指数(3X )、普通中学及高等学校在校生数(4X 万人)、卫生机构数(5X 个)和基本设施铁路公路货运量(6X 万吨)。 (3)统计数据选取 本文所有数据均来自中国统计局和中国统计局外网中国统计年鉴。[2] 1978 184 21261 169732 195301 1979 208 175142 382929 1980 238 180553 493327 1981 264 190126 471336 1982 288 193438 492737 1983 316 196017 520197
虚拟变量回归模型
虚拟变量回归模型 以下是为大家整理的虚拟变量回归模型的相关范文,本文关键词为虚拟,变量,回归,模型,内蒙古,科技,大学,课程,计量经济学,您可以从右上方搜索框检索更多相关文章,如果您觉得有用,请继续关注我们并推荐给您的好友,您可以在综合文库中查看更多范文。 内蒙古科技大学
实验报告 课程名:计量经济学实验项目名称:单方程线性回归模型的扩展——虚拟变量回归模型 院(系):专业班级:姓名:学号: 1 内蒙古科技大学 实验地点:经管机房 实验日期:20XX年4月18日 实验目的:掌握虚拟变量回归模型的建立、参数估计和统计检验。实验内容: 1)生成趋势变量2)生成季节虚拟变量3)生成分段虚拟变量4)建立虚拟变量回归模型 5)虚拟变量回归模型的参数估计和统计检验实验方法、步骤和结果: 一、生成趋势变量 1、建立新的工作文件,导入数据并且重命名
2、点击quick,generateseries生成序列,t=@trend(1990:1)+1 2 并填写公式内蒙古科技大学 3、打开gDp,点击View,graph,line生成趋势图。 根据趋势图可以看出近似分段虚拟变量,需剔除季节的影响 3 内蒙古科技大学 二、生成季节虚拟变量 生成虚拟变量,点击quick----generateseries输入公式
D2=@seas(2)D3=@seas(3)D4=@seas(4) 三、生成分段虚拟变量 1、为了研究1997年金融危机对香港经济的影响,以1997年为分界点。设d5=0,将sample改为1990第一季度到1997年第四季度。 4 内蒙古科技大学 2、设d5=1,将sample改为1998年第一季度到20XX年第四季度。 四、建立虚拟变量回归模型 gDp^=?^1+?^2t+?^3d2t+?^4d3t+?^5d4t+?^6d5t+?^7d5t*t 五、虚拟变量回归模型的参数估计和统计检验点击quick,
第三章多元线形回归模型)
第三章、经典单方程计量经济学模型:多元线性回归模型 一、内容提要 本章将一元回归模型拓展到了多元回归模型,其基本的建模思想与建模方法与一元的情形相同。主要内容仍然包括模型的基本假定、模型的估计、模型的检验以及模型在预测方面的应用等方面。只不过为了多元建模的需要,在基本假设方面以及检验方面有所扩充。 本章仍重点介绍了多元线性回归模型的基本假设、估计方法以及检验程序。与一元回归分析相比,多元回归分析的基本假设中引入了多个解释变量间不存在(完全)多重共线性这一假设;在检验部分,一方面引入了修正的可决系数,另一方面引入了对多个解释变量是否对被解释变量有显著线性影响关系的联合性F检验,并讨论了F检验与拟合优度检验的内在联系。 本章的另一个重点是将线性回归模型拓展到非线性回归模型,主要学习非线性模型如何转化为线性回归模型的常见类型与方法。这里需要注意各回归参数的具体经济含义。 本章第三个学习重点是关于模型的约束性检验问题,包括参数的线性约束与非线性约束检验。参数的线性约束检验包括对参数线性约束的检验、对模型增加或减少解释变量的检验以及参数的稳定性检验三方面的内容,其中参数稳定性检验又包括邹氏参数稳定性检验与邹氏预测检验两种类型的检验。检验都是以F检验为主要检验工具,以受约束模型与无约束模型是否有显著差异为检验基点。参数的非线性约束检验主要包括最大似然比检验、沃尔德检验与拉格朗日乘数检验。它们仍以估计无约束模型与受约束模型为基础,但以最大似然原 χ分布为检验统计量理进行估计,且都适用于大样本情形,都以约束条件个数为自由度的2 的分布特征。非线性约束检验中的拉格朗日乘数检验在后面的章节中多次使用。 二、典型例题分析 例1.某地区通过一个样本容量为722的调查数据得到劳动力受教育的一个回归方程为. .0 10+ + = - 094 36 .0 fedu sibs medu 131 .0 edu210 R2=0.214 式中,edu为劳动力受教育年数,sibs为该劳动力家庭中兄弟姐妹的个数,medu与fedu分别为母亲与父亲受到教育的年数。问 (1)sibs是否具有预期的影响?为什么?若medu与fedu保持不变,为了使预测的受教育水平减少一年,需要sibs增加多少?
eviews多元线性回归案例分析
中国税收增长的分析 一、研究的目的要求 改革开放以来,随着经济体制的改革深化和经济的快速增长,中国的财政收支状况发生了很大的变化,中央和地方的税收收入1978年为519.28亿元到2002年已增长到17636.45亿元25年间增长了33倍。为了研究中国税收收入增长的主要原因,分析中央和地方税收收入的增长规律,预测中国税收未来的增长趋势,需要建立计量经济学模型。 影响中国税收收入增长的因素很多,但据分析主要的因素可能有:(1)从宏观经济看,经济整体增长是税收增长的基本源泉。(2)公共财政的需求,税收收入是财政的主体,社会经济的发展和社会保障的完善等都对公共财政提出要求,因此对预算指出所表现的公共财政的需求对当年的税收收入可能有一定的影响。(3)物价水平。我国的税制结构以流转税为主,以现行价格计算的DGP等指标和和经营者收入水平都与物价水平有关。(4)税收政策因素。我国自1978年以来经历了两次大的税制改革,一次是1984—1985年的国有企业利改税,另一次是1994年的全国范围内的新税制改革。税制改革对税收会产生影响,特别是1985年税收陡增215.42%。但是第二次税制改革对税收的增长速度的影响不是非常大。因此可以从以上几个方面,分析各种因素对中国税收增长的具体影响。 二、模型设定 为了反映中国税收增长的全貌,选择包括中央和地方税收的‘国家财政收入’中的“各项税收”(简称“税收收入”)作为被解释变量,以放映国家税收的增长;选择“国内生产总值(GDP)”作为经济整体增长水平的代表;选择中央和地方“财政支出”作为公共财政需求的代表;选择“商品零售物价指数”作为物价水平的代表。由于税制改革难以量化,而且1985年以后财税体制改革对税收增长影响不是很大,可暂不考虑。所以解释变量设定为可观测“国内生产总值(GDP)”、“财政支出”、“商品零售物价指数” 从《中国统计年鉴》收集到以下数据 财政收入(亿元) Y 国内生产总值(亿 元) X2 财政支出(亿 元) X3 商品零售价格指 数(%) X4 1978519.283624.11122.09100.7 1979537.824038.21281.79102 1980571.74517.81228.83106
多元线性回归模型习题及答案
多元线性回归模型 一、单项选择题 1.在由30n =的一组样本估计的、包含3个解释变量的线性回归模型中,计算得多重决定 系数为,则调整后的多重决定系数为( D ) A. B. C. 下列样本模型中,哪一个模型通常是无效 的(B ) A. i C (消费)=500+i I (收入) B. d i Q (商品需求)=10+i I (收入)+i P (价格) C. s i Q (商品供给)=20+i P (价格) D. i Y (产出量)=0.6i L (劳动)0.4i K (资本) 3.用一组有30个观测值的样本估计模型01122t t t t y b b x b x u =+++后,在的显著性水平上对 1b 的显著性作t 检验,则1b 显著地不等于零的条件是其统计量t 大于等于( C ) A. )30(05.0t B. )28(025.0t C. )27(025.0t D. )28,1(025.0F 4.模型 t t t u x b b y ++=ln ln ln 10中,1b 的实际含义是( B ) A.x 关于y 的弹性 B. y 关于x 的弹性 C. x 关于y 的边际倾向 D. y 关于x 的边际倾向 5、在多元线性回归模型中,若某个解释变量对其余解释变量的判定系数接近于1,则表明 模型中存在( C ) A.异方差性 B.序列相关 C.多重共线性 D.高拟合优度 6.线性回归模型01122......t t t k kt t y b b x b x b x u =+++++ 中,检验0:0(0,1,2,...) t H b i k ==时,所用的统计量 服从( C ) (n-k+1) (n-k-2) (n-k-1) (n-k+2) 7. 调整的判定系数 与多重判定系数 之间有如下关系( D ) A.2 211n R R n k -=-- B. 22111 n R R n k -=--- C. 2211(1)1n R R n k -=-+-- D. 2211(1)1n R R n k -=---- 8.关于经济计量模型进行预测出现误差的原因,正确的说法是( C )。 A.只有随机因素 B.只有系统因素 C.既有随机因素,又有系统因素 、B 、C 都不对 9.在多元线性回归模型中对样本容量的基本要求是(k 为解释变量个数):( C ) A n ≥k+1 B n 1. 表1列出了某地区家庭人均鸡肉年消费量Y 与家庭月平均收入X ,鸡肉价格P 1,猪肉价格P 2与牛肉价格P 3的相关数据。 年份 Y/千 克 X/ 元 P 1/(元/千克) P 2/(元/千克) P 3/(元/千克) 年份 Y/千克 X/元 P 1/(元/ 千克) P 2/(元/ 千克) P 3/(元/千克) 1980 2.78 397 4.22 5.07 7.83 1992 4.18 911 3.97 7.91 11.40 1981 2.99 413 3.81 5.20 7.92 1993 4.04 931 5.21 9.54 12.41 1982 2.98 439 4.03 5.40 7.92 1994 4.07 1021 4.89 9.42 12.76 1983 3.08 459 3.95 5.53 7.92 1995 4.01 1165 5.83 12.35 14.29 1984 3.12 492 3.73 5.47 7.74 1996 4.27 1349 5.79 12.99 14.36 1985 3.33 528 3.81 6.37 8.02 1997 4.41 1449 5.67 11.76 13.92 1986 3.56 560 3.93 6.98 8.04 1998 4.67 1575 6.37 13.09 16.55 1987 3.64 624 3.78 6.59 8.39 1999 5.06 1759 6.16 12.98 20.33 1988 3.67 666 3.84 6.45 8.55 2000 5.01 1994 5.89 12.80 21.96 1989 3.84 717 4.01 7.00 9.37 2001 5.17 2258 6.64 14.10 22.16 1990 4.04 768 3.86 7.32 10.61 2002 5.29 2478 7.04 16.82 23.26 1991 4.03 843 3.98 6.78 10.48 (1) 求出该地区关于家庭鸡肉消费需求的如下模型: 01213243ln ln ln ln ln Y X P P P u βββββ=+++++ (2) 请分析,鸡肉的家庭消费需求是否受猪肉及牛肉价格的影响。 先做回归分析,过程如下: 输出结果如下: 基于多元线性回归的期权价格预测模型 王某某 (北京航空航天大学计算机学院北京100191)1 摘要:期权是国际市场成熟、普遍的金融衍生品,是金融市场极为重要的金融工具。2015年2月9日,上海证券交易所正式推出了我国首支场内交易期权——上证50ETF期权,翻开了境内场内期权市场的新篇章。50ETF期权上市以来,市场规模逐步扩大,其发展情况境外期权产品相同时期。本文以此为研究背景,以“50ETF购12月1.95”这支期权为研究对象,以今日开盘价、收盘价、最高价、最低价、结算价、成交量、成交额、持仓量、涨停价和跌停价为解释变量,通过多元线性回归模型,预测该期权的明日收盘价。本次研究以多元线性回归的全模型(模型1)为出发点,通过异方差检验、残差的独立性检验、误差的正太分布检验以及多重共线性检验,说明该模型不违反回归的基本假设条件。进而通过主成分回归(模型4)和逐步回归(模型5)进行降维,结果表明因变量与解释变量之间存在强烈的线性相关关系,且主成分回归和逐步回归相比全模型有更好的预测能力。 关键词:期权价格多元线性回归50ETF 多重共线性因子分析 一、引言 期权(option)是依据合约形态划分的一种衍生品,指赋予其购买方在规定期限内按买卖双方约定的价格(即协议价格或行权价格)购买或者出售一定数量某种金融资产(即标的资产)的权利的合约。期权购买方为了获得这个权利,必须支付给期权出售方一定的费用,称为权利金或期权价格[1]。 2015年2月9日,上海证券交易所正式推出了我国首支场内交易期权——上证50ETF,翻开了境内场内期权市场的新篇章。期权是与期货并列的基础衍生产品,是金融市场极为重要的金融工具之一。 自50ETF上市以来,市场规模逐步扩大。2015年2月日均合约成交面值为5.45亿元,12月就达到了47.69亿元,增长了7.75倍;2月日均合约成交量为2.33万张,12月就达到了19.81万张,增长了7.5倍;2月权利金总成交额为2.48亿元,12月就达到了35.98亿元,增长了13.51倍[1]。 我国股票市场有上亿的个人投资者,是一个较为典型的散户市场[1]。相较于专业投资机构讲,散户缺乏时间,精力以及专业分析,投资具有很大的投机行为。对于这些投资者来说,期权价格的变动则是他们最为关注的问题,其变化直接影响到自身的收益。在实际情况中,影响股票价格的因素很多,涉及到金融政策、利率政策以及国际市场等因素,其作用机制也相当复杂[2]。因此,对于期权价格预测的研究,则可以降低投资者的投资风险,及时调整投资结构,从而保障自身的收益。 1作者简介:王某某,北京航空航天大学研究生邮箱:bnuwjx@https://www.360docs.net/doc/7c2030060.html,。 实验四虚拟变量 【实验目的】 掌握虚拟变量的基本原理,对虚拟变量的设定和模型的估计与检验,以及相关的Eviews操作方法。 【实验内容】 试根据1998年我国城镇居民人均收入与彩电每百户拥有量的统计资料建立 【实验步骤】 1、相关图分析 根据表中数据建立人均收入X与彩电拥有量Y的相关图(SCAT X Y)。从相关图可以看出,前3个样本点(即低收入家庭)与后5个样本点(中、高收入)的拥有量存在较大差异, 因此,为了反映“收入层次”这一定性因素的影响,设置虚拟变量如下: ?? ?=低收入家庭 中、高收入家庭 1D 2、构造虚拟变量 构造虚拟变量 1D (DATA D1),并生成新变量序列: GENR XD=X*D1 3、估计虚拟变量模型 LS Y C X D1 XD 得到估计结果: 我国城镇居民彩电需求函数的估计结果为: XD D X Y 009.0873.31012.0611.571-++=∧ (16.25) (9.03) (8.32) (-6.59) 366,066.1..,9937.02===F e s R 再由t 检验值判断虚拟变量的引入方式,并写出各类家庭的需求函数。 虚拟变量的回归系数的t 检验都是显著的,且模型的拟合优度很高,说明我国城镇居民低收入家庭与中高收入家庭对彩电的消费需求,在截距和斜率上都存在着明显差异,所以以加法和乘法方式引入虚拟变量是合理的。 低收入家庭与中高收入家庭各自的需求函数为: 低收入家庭: X Y 012.0611.57+=∧ 中高收入家庭: X X Y 003.0484.89)009.0012.0()873.31611.57(+=-++=∧ 由此可见我国城镇居民家庭现阶段彩电消费需求的特点: 对于人均年收入在3300元以下的低收入家庭,需求量随着收入水平的提高而快速上升,人均年收入每增加1000元,百户拥有量将平均增加12台;对于人均年收入在4100元以上的中高收入家庭,虽然需求量随着收入水平的提高也在增加,但增速趋缓,人均年收入每增加1000元,百户拥有量只增加3台。 二、多元线性回归模型 在多要素的地理环境系统中,多个(多于两个)要素之间也存在着相互影响、相互关联的情况。因此,多元地理回归模型更带有普遍性的意义。 (一)多元线性回归模型的建立 假设某一因变量y 受k 个自变量k x x x ,...,,21的影响,其n 组观测值为(ka a a a x x x y ,...,,,21),n a ,...,2,1=。那么,多元线性回归模型的结构形式为: a ka k a a a x x x y εββββ+++++=...22110(3、2、11) 式中: k βββ,...,1,0为待定参数; a ε为随机变量。 如果k b b b ,...,,10分别为k ββββ...,,,210的拟合值,则回归方程为 ?=k k x b x b x b b ++++...22110(3、2、12) 式中: 0b 为常数; k b b b ,...,,21称为偏回归系数。 偏回归系数i b (k i ,...,2,1=)的意义就是,当其她自变量j x (i j ≠)都固定时,自变量i x 每变化一个单位而使因变量y 平均改变的数值。 根据最小二乘法原理,i β(k i ,...,2,1,0=)的估计值i b (k i ,...,2,1,0=)应该使 ()[]min (2) 1 2211012 →++++-=??? ??-=∑∑==∧ n a ka k a a a n a a a x b x b x b b y y y Q (3、2、13) 有求极值的必要条件得 ???????==??? ??--=??=??? ??--=??∑∑=∧=∧n a ja a a j n a a a k j x y y b Q y y b Q 110) ,...,2,1(0202(3、2、14) 将方程组(3、2、14)式展开整理后得: 一、邹式检验(突变点检验、稳定性检验) 1.突变点检验 1985—2002年中国家用汽车拥有量(t y ,万辆)与城镇居民家庭人均可支配收入(t x ,元),数据见表。 表 中国家用汽车拥有量(t y )与城镇居民家庭人均可支配收入(t x )数据 年份 t y (万辆) t x (元) 年份 t y (万辆) t x (元) 1985 1994 1986 1995 4283 1987 1996 1988 1997 1989 1998 1990 1999 5854 1991 2000 6280 1992 2001 1993 2002 下图是关于t y 和t x 的散点图: 从上图可以看出,1996年是一个突变点,当城镇居民家庭人均可支配收入突破元之后,城镇居民家庭购买家用汽车的能力大大提高。现在用邹突变点检验法检验1996年是不是一个突变点。 :两个字样本(1985—1995年,1996—2002年)相对应的模型回归参数相等H H :备择假设是两个子样本对应的回归参数不等。 1 在1985—2002年样本范围内做回归。 在回归结果中作如下步骤(邹氏检验): 1、 Chow 模型稳定性检验(lrtest) 用似然比作chow检验,chow检验的零假设:无结构变化,小概率发生结果变化* 估计前阶段模型 * 估计后阶段模型 * 整个区间上的估计结果保存为All * 用似然比检验检验结构没有发生变化的约束 得到结果如下; (如何解释) 2.稳定性检验(邹氏稳定性检验) 以表为例,在用1985—1999年数据建立的模型基础上,检验当把2000—2002年数据加入样本后,模型的回归参数时候出现显著性变化。 * 用F-test作chow间断点检验检验模型稳定性 * chow检验的零假设:无结构变化,小概率发生结果变化 * 估计前阶段模型 * 估计后阶段模型 * 整个区间上的估计结果保存为All 我国农民收入影响因素的回归分析 本文力图应用适当的多元线性回归模型,对有关农民收入的历史数据和现状进行分析,探讨影响农民收入的主要因素,并在此基础上对如何增加农民收入提出相应的政策建议。?农民收入水平的度量常采用人均纯收入指标。影响农民收入增长的因素是多方面的,既有结构性矛盾因素,又有体制性障碍因素。但可以归纳为以下几个方面:一是农产品收购价格水平。二是农业剩余劳动力转移水平。三是城市化、工业化水平。四是农业产业结构状况。五是农业投入水平。考虑到复杂性和可行性,所以对农业投入与农民收入,本文暂不作讨论。因此,以全国为例,把农民收入与各影响因素关系进行线性回归分析,并建立数学模型。 一、计量经济模型分析 (一)、数据搜集 根据以上分析,我们在影响农民收入因素中引入7个解释变量。即:2x -财政用于农业的支出的比重,3x -第二、三产业从业人数占全社会从业人数的比重,4x -非农村人口比重,5x -乡村从业人员占农村人口的比重,6x -农业总产值占农林牧总产值的比重,7x -农作物播种面积,8x —农村用电量。 资料来源《中国统计年鉴2006》。 (二)、计量经济学模型建立 我们设定模型为下面所示的形式: 利用Eviews 软件进行最小二乘估计,估计结果如下表所示: DependentVariable:Y Method:LeastSquares Sample: Includedobservations:19 Variable Coefficient t-Statistic Prob. C X1 X3 X4 X5 X6 X7 X8 R-squared Meandependentvar AdjustedR-squared 表1最小二乘估计结果 回归分析报告为: () ()()()()()()()()()()()()()()() 2345678 2? -1102.373-6.6354X +18.2294X +2.4300X -16.2374X -2.1552X +0.0100X +0.0634X 375.83 3.7813 2.066618.37034 5.8941 2.77080.002330.02128 -2.933 1.7558.820900.20316 2.7550.778 4.27881 2.97930.99582i Y SE t R ===---=230.99316519 1.99327374.66 R Df DW F ====二、计量经济学检验 (一)、多重共线性的检验及修正 ①、检验多重共线性 (a)、直观法 从“表1最小二乘估计结果”中可以看出,虽然模型的整体拟合的很好,但是x4x6 多元线性回归模型公式 HUA system office room 【HUA16H-TTMS2A-HUAS8Q8-HUAH1688】 二、多元线性回归模型 在多要素的地理环境系统中,多个(多于两个)要素之间也存在着相互影响、相互关联的情况。因此,多元地理回归模型更带有普遍性的意义。 (一)多元线性回归模型的建立 假设某一因变量y 受k 个自变量k x x x ,...,,21的影响,其n 组观测值为 (ka a a a x x x y ,...,,,21),n a ,...,2,1=。那么,多元线性回归模型的结构形式为: a ka k a a a x x x y εββββ+++++=...22110() 式中: k βββ,...,1,0为待定参数; a ε为随机变量。 如果k b b b ,...,,10分别为k ββββ...,,,210的拟合值,则回归方程为 ?=k k x b x b x b b ++++...22110() 式中: 0b 为常数; k b b b ,...,,21称为偏回归系数。 偏回归系数i b (k i ,...,2,1=)的意义是,当其他自变量j x (i j ≠)都固定时,自变量i x 每变化一个单位而使因变量y 平均改变的数值。 根据最小二乘法原理,i β(k i ,...,2,1,0=)的估计值i b (k i ,...,2,1,0=)应该使 ()[]min ...212211012→++++-=??? ??-=∑∑==∧n a ka k a a a n a a a x b x b x b b y y y Q () 有求极值的必要条件得 ???????==??? ??--=??=??? ??--=??∑∑=∧=∧n a ja a a j n a a a k j x y y b Q y y b Q 110),...,2,1(0202() 将方程组()式展开整理后得: ?????????????=++++=++++=++++=++++∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑===================n a a ka k n a ka n a ka a n a ka a n a ka n a a a k n a ka a n a a n a a a n a a n a a a k n a ka a n a a a n a a n a a n a a k n a ka n a a n a a y x b x b x x b x x b x y x b x x b x b x x b x y x b x x b x x b x b x y b x b x b x nb 11221211101 121221221121012111121211121011112121110)(...)()()(...)(...)()()()(...)()()()(...)()( () 方程组()式,被称为正规方程组。 如果引入一下向量和矩阵: 则正规方程组()式可以进一步写成矩阵形式 B Ab =(3.2.15’) 多元线性回归模型案例分析 ——中国人口自然增长分析一·研究目的要求 中国从1971年开始全面开展了计划生育,使中国总和生育率很快从1970年的5.8降到1980年2.24,接近世代更替水平。此后,人口自然增长率(即人口的生育率)很大程度上与经济的发展等各方面的因素相联系,与经济生活息息相关,为了研究此后影响中国人口自然增长的主要原因,分析全国人口增长规律,与猜测中国未来的增长趋势,需要建立计量经济学模型。 影响中国人口自然增长率的因素有很多,但据分析主要因素可能有:(1)从宏观经济上看,经济整体增长是人口自然增长的基本源泉;(2)居民消费水平,它的高低可能会间接影响人口增长率。(3)文化程度,由于教育年限的高低,相应会转变人的传统观念,可能会间接影响人口自然增长率(4)人口分布,非农业与农业人口的比率也会对人口增长率有相应的影响。 二·模型设定 为了全面反映中国“人口自然增长率”的全貌,选择人口增长率作为被解释变量,以反映中国人口的增长;选择“国名收入”及“人均GDP”作为经济整体增长的代表;选择“居民消费价格指数增长率”作为居民消费水平的代表。暂不考虑文化程度及人口分布的影响。 从《中国统计年鉴》收集到以下数据(见表1): 表1 中国人口增长率及相关数据 设定的线性回归模型为: 1222334t t t t t Y X X X u ββββ=++++ 三、估计参数 利用EViews 估计模型的参数,方法是: 1、建立工作文件:启动EViews ,点击File\New\Workfile ,在对 话框“Workfile Range ”。在“Workfile frequency ”中选择“Annual ” (年度),并在“Start date ”中输入开始时间“1988”,在“end date ”中输入最后时间“2005”,点击“ok ”,出现“Workfile UNTITLED ”工作框。其中已有变量:“c ”—截距项 “resid ”—剩余项。在“Objects ”菜单中点击“New Objects”,在“New Objects”对话框中选“Group”,并在“Name for Objects”上定义文件名,点击“OK ”出现数据编辑窗口。 年份 人口自然增长率 (%。) 国民总收入(亿元) 居民消费价格指数增长 率(CPI )% 人均GDP (元) 1988 15.73 15037 18.8 1366 1989 15.04 17001 18 1519 1990 14.39 18718 3.1 1644 1991 12.98 21826 3.4 1893 1992 11.6 26937 6.4 2311 1993 11.45 35260 14.7 2998 1994 11.21 48108 24.1 4044 1995 10.55 59811 17.1 5046 1996 10.42 70142 8.3 5846 1997 10.06 78061 2.8 6420 1998 9.14 83024 -0.8 6796 1999 8.18 88479 -1.4 7159 2000 7.58 98000 0.4 7858 2001 6.95 108068 0.7 8622 2002 6.45 119096 -0.8 9398 2003 6.01 135174 1.2 10542 2004 5.87 159587 3.9 12336 2005 5.89 184089 1.8 14040 2006 5.38 213132 1.5 16024 SPSS--回归-多元线性回归模型案例解析!(一) 多元线性回归,主要是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程为: 毫无疑问,多元线性回归方程应该为: 上图中的x1, x2, xp分别代表“自变量”Xp截止,代表有P个自变量,如果有“N组样本,那么这个多元线性回归,将会组成一个矩阵,如下图所示: 那么,多元线性回归方程矩阵形式为: 其中:代表随机误差,其中随机误差分为:可解释的误差和不可解释的误差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样) 1:服成正太分布,即指:随机误差必须是服成正太分别的随机变量。 2:无偏性假设,即指:期望值为0 3:同共方差性假设,即指,所有的随机误差变量方差都相等 4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。 今天跟大家一起讨论一下,SPSS---多元线性回归的具体操作过程,下面以教程教程数据为例,分析汽车特征与汽车销售量之间的关系。通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。数据如下图所示: 点击“分析”——回归——线性——进入如下图所示的界面: 将“销售量”作为“因变量”拖入因变量框内,将“车长,车宽,耗油率,车净重等10个自变量拖入自变量框内,如上图所示,在“方法”旁边,选择“逐步”,当然,你也可以选择其它的方式,如果你选择“进入”默认的方式,在分析结果中,将会得到如下图所示的结果:(所有的自变量,都会强行进入) 如果你选择“逐步”这个方法,将会得到如下图所示的结果:(将会根据预先设定的“F统计量的概率值进行筛选,最先进入回归方程的“自变量”应该是跟“因变量”关系最为密切,贡献最大的,如下图可以看出,车的价格和车轴跟因变量关系最为密切,符合判断条件的概率值必须小于0.05,当概率值大于等于0.1时将会被剔除) 毕业论文题目基于SPSS的多元回归分析模型选取的应用 基于SPSS的多元回归分析模型选取的应用 摘要 本文不仅对于复杂的统计计算通过常用的计算机应用软件SPSS来实现,同时通过对两组数据的实证分析,来研究统计学中多元回归分析中的变量选取,让大家对统计学中的多元回归分析中模型的选取以及变量的选取和操作方法有更深层次的了解. 一组数据是对于淘宝交易额的未来发展趋势的研究,一组数据时对于我国财政收入的研究. 本文通过两个实证即淘宝交易额研究和财政收入研究从不同程度上对非线性回归模型和变量选取的研究运用通俗的语言和浅显的描述将SPSS在多元回归分析中的统计分析方法呈现在大家面前,让大家对多元回归分析以及SPSS软件都可以有更深一步的了解. 通过SPSS软件对数据进行分析,对数据进行处理的方法进行总结,找出SPSS对于数据处理和分析的优缺点,最后得在对变量的选取和软件的操作提出建议. 关键词:统计学,SPSS,变量选取,多元回归分析 Abstract This article not only for complex statistical calculations done by the commonly used computer application software of SPSS, through the empirical analysis of the two groups of data at the same time, to study the statistics of the variables in the multivariate regression analysis, let everybody in the multiple regression analysis of statistical model selection as well as the selection of variables and operation methods have a deeper understanding. Is a set of data for the future development trend of research taobao transactions, a set of data for the research of our country's fiscal revenue. In this paper, through two empirical taobao transactions and fiscal revenue research from different degree of the study of nonlinear regression model and variable selection using a common language and plain the SPSS statistical analysis method in multiple regression analysis of present in front of everyone, let everyone to multiple regression analysis and SPSS software can have a deeper understanding. Through SPSS software to analyze data, and summarizes method of data processing, find out the advantages and disadvantages of SPSS for data processing and analysis, finally had to put forward the proposal to the operation of the selection of variables and software. Keywords: Statistical, SPSS, The selection of variables, multiple regression analysis SPSS 统计分析 多元线性回归分析方法操作与分析 实验目的: 引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。 实验变量: 以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。 实验方法:多元线性回归分析法 软件:spss19.0 操作过程: 第一步:导入Excel数据文件 1.open data document——open data——open; 2. Opening excel data source——OK. 第二步: 1.在最上面菜单里面选中Analyze——Regression——Linear,Dependent (因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method选择Stepwise. 进入如下界面: 2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的Durbin-Watson、 Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue. 3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue.多元线性回归模型的案例分析
回归大作业-基于多元线性回归的期权价格预测模型
Eviews虚拟变量实验报告
多元线性回归模型公式
第三章多元线性回归模型(stata)
多元线性回归模型案例
多元线性回归模型公式定稿版
(完整word版)多元线性回归模型案例分析
多元线性回归实例分析
基于SPSS的多元回归分析模型选取的应用毕业论文
SPSS多元线性回归分析实例操作步骤