R语言文本挖掘预测模型案例分析报告 附代码数据
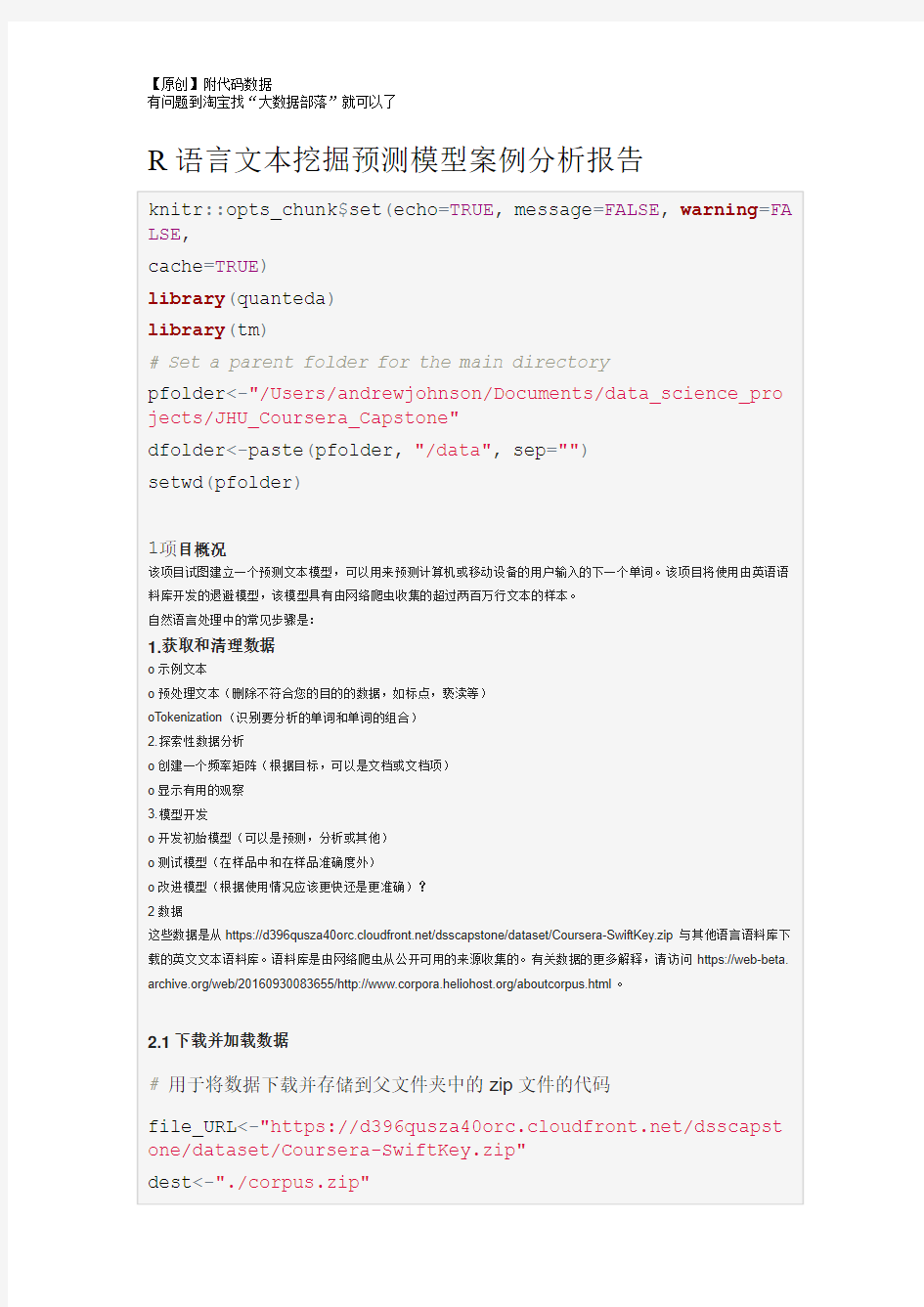

R语言文本挖掘预测模型案例分析报告
2.2数据的特点
数据的特点可以在下面看到。
2.3字数
如上所示,博客和新闻样本通常比Twitter样本长,这是有道理的,因为Twitter 限制为140个字符。有超过250个单词的可以忽略的条目,所以我删除它们来更清楚地显示大部分数据。
因为三个来源都有明确的分布模式,所以假设一个随机样本将具有相似的分布模式是合理的。
3创建和处理样本
由于语料库比较大,我只用10%的样本进行探索性数据分析,并开发出我的初始模型。
3.1选择10%的样本
3.2清理
清理过程将包括词干,也适应语法差异和错误拼写。
相关主题