纳米压痕实验数据图
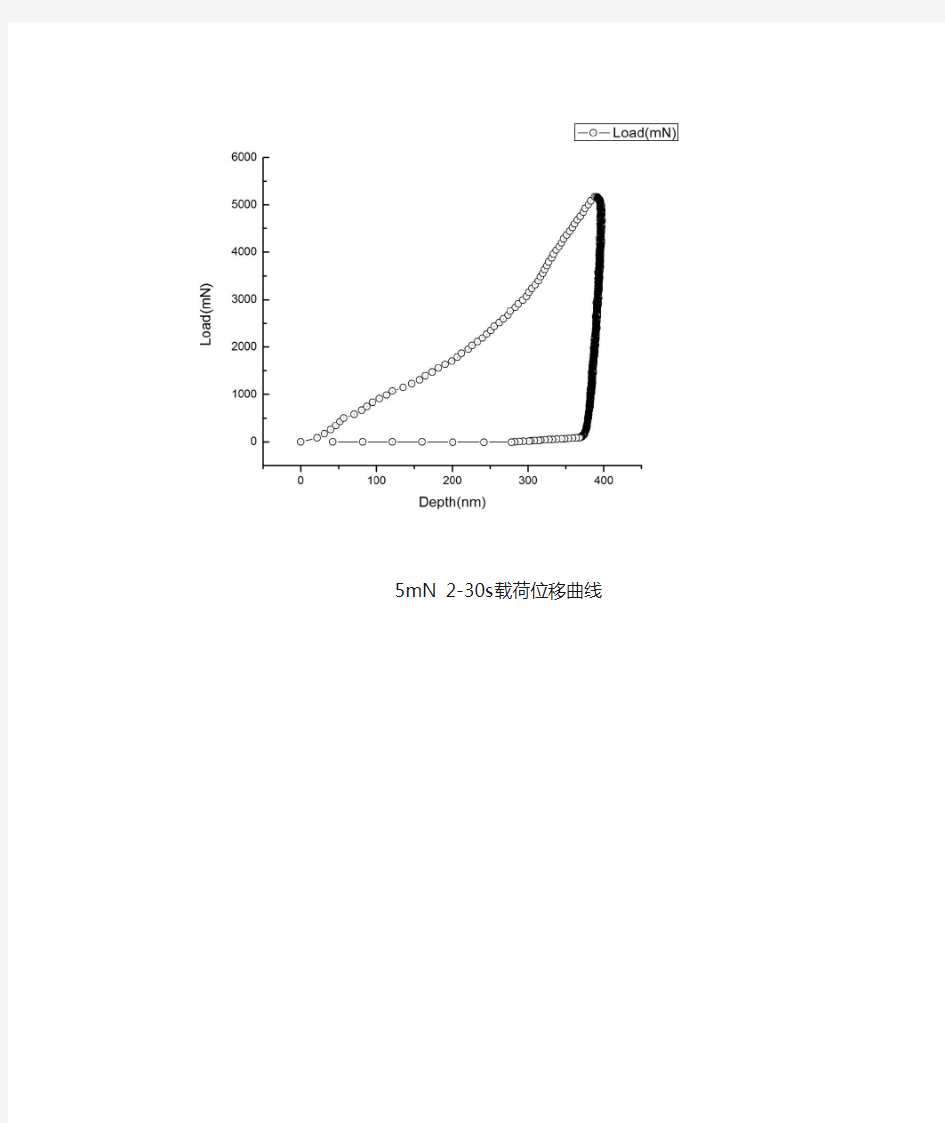

5mN 2-30s载荷位移曲线
5mN 2-30-30s载荷位移曲线
5mN 2-2s载荷位移曲线
纳米压痕实验报告讲解
纳米压痕实验报告 姓名:张永钦 学号:15120982 专业:力学 班级:15-01
一、实验目的 1. 了解材料微纳米力学测试系统的构造、工作原理。 2. 掌握载荷-位移曲线的分析手段。 3. 用纳米压痕方法测定的杨氏模量与硬度。 二、实验仪器和设备 TriboIndenter 型材料微纳米力学测试系统 三、实验原理与方法 纳米压痕技术又称深度敏感压痕技术, 它通过计算机控制载荷连续变化,并在线监 测压入深度。一个完整的压痕过程包括两个 步骤,即所谓的加载过程与卸载过程。在加 载过程中,给压头施加外载荷,使之压入样品表面,随着载荷的增大,压头压入样品的 深度也随之增加,当载荷达到最大值时,移 除外载,样品表面会存在残留的压痕痕迹。 图1为典型的载荷-位移曲线。 从图1中可以清楚地看出,随着实验载 荷的不断增大,位移不断增加,当载荷达到 最大值时,位移亦达到最大值即最大压痕深度max h ;随后卸载,位移最终回到一固定值,此时的深度叫残留压痕深度r h ,也就是压头在 样品上留下的永久塑性变形。 刚度S 是实验所测得的卸载曲线开始部分的斜率,表示为 h P S d d u = (1) 式中,u P 为卸载载荷。最初人们是选取卸载曲线上部的部分实验数据进行直线拟合来获得 刚度值的。但实际上这一方法是存在问题的,因为卸载曲线是非线性的,即使是在卸载曲线的初始部分也并不是完全线性的,这样,用不同数目的实验数据进行直线拟合,得到的刚度值会有明显的差别。因此Oliver 和Pharr 提出用幂函数规律来拟合卸载曲线,其公式如下 ()m h h A P f u -= (2) 其中,A 为拟合参数,f h 为残留深度,即为r h ,指数m 为压头形状参数。m ,A 和f h 均由最小二乘法确定。对式(2)进行微分就可得到刚度值,即 载荷 位移 图1 典型的载荷-位移曲线
数据结构课程设计图的遍历和生成树求解
数学与计算机学院 课程设计说明书 课程名称: 数据结构与算法课程设计 课程代码: 6014389 题目: 图的遍历和生成树求解实现 年级/专业/班: 学生姓名: 学号: 开始时间: 2012 年 12 月 09 日 完成时间: 2012 年 12 月 26 日 课程设计成绩: 指导教师签名:年月日
目录 摘要 (3) 引言 (4) 1 需求分析 (5) 1.1任务与分析 (5) 1.2测试数据 (5) 2 概要设计 (5) 2.1 ADT描述 (5) 2.2程序模块结构 (7) 软件结构设计: (7) 2.3各功能模块 (7) 3 详细设计 (8) 3.1结构体定义 (19) 3.2 初始化 (22) 3.3 插入操作(四号黑体) (22) 4 调试分析 (22) 5 用户使用说明 (23) 6 测试结果 (24) 结论 (26)
摘要 《数据结构》课程主要介绍最常用的数据结构,阐明各种数据结构内在的逻辑关系,讨论其在计算机中的存储表示,以及在其上进行各种运算时的实现算法,并对算法的效率进行简单的分析和讨论。进行数据结构课程设计要达到以下目的: ?了解并掌握数据结构与算法的设计方法,具备初步的独立分析和设计能力; ?初步掌握软件开发过程的问题分析、系统设计、程序编码、测试等基本方法和技能; ?提高综合运用所学的理论知识和方法独立分析和解决问题的能力; 训练用系统的观点和软件开发一般规范进行软件开发,培养软件工作者所应具备的科学的工作方法和作风。 这次课程设计我们主要是应用以前学习的数据结构与面向对象程序设计知识,结合起来才完成了这个程序。 因为图是一种较线形表和树更为复杂的数据结构。在线形表中,数据元素之间仅有线性关系,每个元素只有一个直接前驱和一个直接后继,并且在图形结构中,节点之间的关系可以是任意的,图中任意两个数据元素之间都可能相关。因此,本程序是采用邻接矩阵、邻接表、十字链表等多种结构存储来实现对图的存储。采用邻接矩阵即为数组表示法,邻接表和十字链表都是图的一种链式存储结构。对图的遍历分别采用了广度优先遍历和深度优先遍历。 关键词:计算机;图;算法。
数据结构实验报告-图的遍历
数据结构实验报告 实验:图的遍历 一、实验目的: 1、理解并掌握图的逻辑结构和物理结构——邻接矩阵、邻接表 2、掌握图的构造方法 3、掌握图的邻接矩阵、邻接表存储方式下基本操作的实现算法 4、掌握图的深度优先遍历和广度优先原理 二、实验内容: 1、输入顶点数、边数、每个顶点的值以及每一条边的信息,构造一个无向图G,并用邻接矩阵存储改图。 2、输入顶点数、边数、每个顶点的值以及每一条边的信息,构造一个无向图G,并用邻接表存储该图 3、深度优先遍历第一步中构造的图G,输出得到的节点序列 4、广度优先遍历第一部中构造的图G,输出得到的节点序列 三、实验要求: 1、无向图中的相关信息要从终端以正确的方式输入; 2、具体的输入和输出格式不限; 3、算法要具有较好的健壮性,对错误操作要做适当处理; 4、程序算法作简短的文字注释。 四、程序实现及结果: 1、邻接矩阵: #include
ABAQUS模拟纳米压痕
计算固体力学 专业:固体力学 学生姓名: 学号: 2015 年4 月28 日
一、问题描述与分析 下表面固定的柱形材料被一个刚性球沿中心点压入(类似于球形硬度计实验),求刚性球所受反力与压入深度之间的关系,并画出柱形内部的Mises应力分布,找出最大应力位置。 已知参数:球半径为4mm,柱体半径为10mm,高为h=10mm,材料为线弹性,E=1MPa,v = 0.49,最大压入深度为h/10。 (1)要注意检验网格尺寸的收敛性; (2)要注意接触点造成的应力集中,接触点处要网格细化; (3)要用显式和隐式分别求解,在显式中加载时间为0.1s; (4)写出求解步骤。 二、建模过程 1.隐式分析 (1)建立几何模型 将问题简化为一个轴对称问题进行处理。进入Part模块,单击create part图标,先建立柱形材料,命名为cylinder,详细设置如图1a。再建立球体,此 处将球体处理为解析刚体,命名为rigid,详细设置如图1b。指定刚体参考点,在主菜单中选择Tools—Reference Point,然后点击圆弧圆心为参考点。 1a 1b 图1 几何模型的建立 (2)创建材料和截面属性 a.创建材料。进入property功能模块,点击create material 图标,
设置杨氏弹性模量为1MPa,泊松比为0.49。 b.创建截面属性。点击create section按钮,点击continue,然后 OK。 c.赋予截面属性。在Part中选择cylinder,然后点击assign section按 钮,选中几何模型,赋予截面属性。 (3)定义装配件 进入Assembly功能模块,单击create part按钮,在弹出对话框中,选中两个part,然后OK。再单击,将刚体移至圆柱上方,如下图2所示。 图2 组装部件 (4)设置分析步 进入Step功能模块,创建一个分析步Step-1,默认为Static,General(隐式求解),点击continue。在弹出的edit step 对话框中,选中Nlgeom On。 (5)定义接触 进入Interaction功能模块 a.定义接触面。在主菜单中选择Tools—Surface—Create,在弹出的Create Surface对话框中Name后输入Surf-Cylinder,点击Continue,点击柱形 体上表面,然后点击视图区底部的Done。同样的方式定义接触面 Surf-Sphere。 b.定义带摩擦接触属性。单击,在Name后面输入IntProp-Friction,点 击Continue。定义摩擦系数为0.1的罚函数摩擦公式,如图3。点击OK。
数据结构实验---图的储存与遍历
数据结构实验---图的储存与遍历
学号: 姓名: 实验日期: 2016.1.7 实验名称: 图的存贮与遍历 一、实验目的 掌握图这种复杂的非线性结构的邻接矩阵和邻接表的存储表示,以及在此两种常用存储方式下深度优先遍历(DFS)和广度优先遍历(BFS)操作的实现。 二、实验内容与实验步骤 题目1:对以邻接矩阵为存储结构的图进行DFS 和BFS 遍历 问题描述:以邻接矩阵为图的存储结构,实现图的DFS 和BFS 遍历。 基本要求:建立一个图的邻接矩阵表示,输出顶点的一种DFS 和BFS 序列。 测试数据:如图所示 题目2:对以邻接表为存储结构的图进行DFS 和BFS 遍历 问题描述:以邻接表为图的存储结构,实现图的DFS 和BFS 遍历。 基本要求:建立一个图的邻接表存贮,输出顶点的一种DFS 和BFS 序列。 测试数据:如图所示 V0 V1 V2 V3 V4 三、附录: 在此贴上调试好的程序。 #include
#define M 100 typedef struct node { char vex[M][2]; int edge[M ][ M ]; int n,e; }Graph; int visited[M]; Graph *Create_Graph() { Graph *GA; int i,j,k,w; GA=(Graph*)malloc(sizeof(Graph)); printf ("请输入矩阵的顶点数和边数(用逗号隔开):\n"); scanf("%d,%d",&GA->n,&GA->e); printf ("请输入矩阵顶点信息:\n"); for(i = 0;i
数据结构图的遍历
#include"stdlib.h" #include"stdio.h" #include"malloc.h" #define INFINITY 32767 #define MAX_VERTEX_NUM 20 typedef enum{FALSE,TRUE}visited_hc; typedef enum{DG,DN,UDG,UDN}graphkind_hc; typedef struct arccell_hc {int adj; int*info; }arccell_hc,adjmatrix_hc[MAX_VERTEX_NUM][MAX_VERTEX_NUM]; typedef struct {char vexs[MAX_VERTEX_NUM]; adjmatrix_hc arcs; int vexnum,arcnum; graphkind_hc kind; }mgraph_hc; typedef struct arcnode_hc {int adjvex; struct arcnode_hc *nextarc; int*info; }arcnode_hc; typedef struct vnode_hc {char data; arcnode_hc *firstarc; }vnode_hc,adjlist_hc[MAX_VERTEX_NUM]; typedef struct {adjlist_hc vertices; int vexnum,arcnum; graphkind_hc kind; }algraph_hc; int locatevex_hc(mgraph_hc*g,char v) {int i,k=0; for(i=0;i
数据结构课程设计之图的遍历和生成树求解
##大学 数据结构课程设计报告题目:图的遍历和生成树求解 院(系):计算机工程学院 学生: 班级:学号: 起迄日期: 2011.6.20 指导教师:
2010—2011年度第 2 学期 一、需求分析 1.问题描述: 图的遍历和生成树求解实现 图是一种较线性表和树更为复杂的数据结构。在线性表中,数据元素之间仅有线性关系,每个数据元素只有一个直接前驱和一个直接后继;在树形结构中,数据元素之间有着明显的层次关系,并且每一层上的数据元素可能和下一层中多个元素(及其孩子结点)相关但只能和上一层中一个元素(即双亲结点)相关;而在图形结构中,节点之间的关系可以是任意的,图中任意两个数据元素之间都可能相关。 生成树求解主要利用普利姆和克雷斯特算法求解最小生成树,只有强连通图才有生成树。 2.基本功能 1) 先任意创建一个图; 2) 图的DFS,BFS的递归和非递归算法的实现 3) 最小生成树(两个算法)的实现,求连通分量的实现 4) 要求用邻接矩阵、邻接表等多种结构存储实现 3.输入输出
输入数据类型为整型和字符型,输出为整型和字符 二、概要设计 1.设计思路: a.图的邻接矩阵存储:根据所建无向图的结点数n,建立n*n的矩阵,其中元素全是无穷大(int_max),再将边的信息存到数组中。其中无权图的边用1表示,无边用0表示;有全图的边为权值表示,无边用∞表示。 b.图的邻接表存储:将信息通过邻接矩阵转换到邻接表中,即将邻接矩阵的每一行都转成链表的形式将有边的结点进行存储。 c.图的广度优先遍历:假设从图中的某个顶点v出发,在访问了v之后依次访问v的各个未曾访问过的邻接点,然后再访问此邻接点的未被访问的邻接点,并使“先被访问的顶点的邻接点”先于“后被访问的顶点的邻接点”被访问,直至图中所有已被访问的顶点的邻接点都被访问到。若此时图中还有未被访问的,则另选未被访问的重复以上步骤,是一个非递归过程。 d.图的深度优先遍历:假设从图中某顶点v出发,依依次访问v的邻接顶点,然后再继续访问这个邻接点的系一个邻接点,如此重复,直至所有的点都被访问,这是个递归的过程。 e.图的连通分量:这是对一个非强连通图的遍历,从多个结点出发进行搜索,而每一次从一个新的起始点出发进行搜索过程中得到的顶点访问序列恰为其连通分量的顶点集。本程序利用的图的深度优先遍历算法。 2.数据结构设计: ADT Queue{ 数据对象:D={a i | a i ∈ElemSet,i=1,2,3……,n,n≥0} 数据关系:R1={| a i-1 ,a i ∈D,i=1,2,3,……,n} 基本操作: InitQueue(&Q) 操作结果:构造一个空队列Q。 QueueEmpty(Q) 初始条件:Q为非空队列。 操作结果:若Q为空队列,则返回真,否则为假。 EnQueue(&Q,e) 初始条件:Q为非空队列。 操作结果:插入元素e为Q的新的队尾元素。 DeQueue(&Q,e) 初始条件:Q为非空队列。 操作结果:删除Q的队头元素,并用e返回其值。}ADT Queue
数据结构图的遍历实验报告
实验项目名称:图的遍历 一、实验目的 应用所学的知识分析问题、解决问题,学会用建立图并对其进行遍历,提高实际编程能力及程序调试能力。 二、实验容 问题描述:建立有向图,并用深度优先搜索和广度优先搜素。输入图中节点的个数和边的个数,能够打印出用邻接表或邻接矩阵表示的图的储存结构。 三、实验仪器与设备 计算机,Code::Blocks。 四、实验原理 用邻接表存储一个图,递归方法深度搜索和用队列进行广度搜索,并输出遍历的结果。 五、实验程序及结果 #define INFINITY 10000 /*无穷大*/ #define MAX_VERTEX_NUM 40 #define MAX 40 #include
typedef struct ArCell{ int adj; }ArCell,AdjMatrix[MAX_VERTEX_NUM][MAX_VERTEX_NUM]; typedef struct { char name[20]; }infotype; typedef struct { infotype vexs[MAX_VERTEX_NUM]; AdjMatrix arcs; int vexnum,arcnum; }MGraph; int LocateVex(MGraph *G,char* v) { int c = -1,i; for(i=0;i
数据结构 图的存储、遍历与应用 源代码
实验四图的存储、遍历与应用姓名:班级: 学号:日期:一、实验目的: 二、实验内容: 三、基本思想,原理和算法描述:
四、源程序: (1)邻接矩阵的存储: #include
数据结构实验 - 图的储存与遍历
一、实验目的 掌握图这种复杂的非线性结构的邻接矩阵和邻接表的存储表示,以及在此两种常用存储方式下深度优先遍历(DFS)和广度优先遍历(BFS)操作的实现。 二、实验内容与实验步骤 题目1:对以邻接矩阵为存储结构的图进行DFS 和BFS 遍历 问题描述:以邻接矩阵为图的存储结构,实现图的DFS 和BFS 遍历。 基本要求:建立一个图的邻接矩阵表示,输出顶点的一种DFS 和BFS 序列。 测试数据:如图所示 题目2:对以邻接表为存储结构的图进行DFS 和BFS 遍历 问题描述:以邻接表为图的存储结构,实现图的DFS 和BFS 遍历。 基本要求:建立一个图的邻接表存贮,输出顶点的一种DFS 和BFS 序列。 测试数据:如图所示 三、附录: 在此贴上调试好的程序。 #include
#define M 100 typedef struct node { char vex[M][2]; int edge[M ][ M ]; int n,e; }Graph; int visited[M]; Graph *Create_Graph() { Graph *GA; int i,j,k,w; GA=(Graph*)malloc(sizeof(Graph)); printf ("请输入矩阵的顶点数和边数(用逗号隔开):\n"); scanf("%d,%d",&GA->n,&GA->e); printf ("请输入矩阵顶点信息:\n"); for(i = 0;i
数据结构实验七图的创建与遍历
实验七图的创建与遍历 实验目的: 通过上机实验进一步掌握图的存储结构及基本操作的实现。 实验内容与要求: 要求: ⑴能根据输入的顶点、边/弧的信息建立图; ⑵实现图中顶点、边/弧的插入、删除; ⑶实现对该图的深度优先遍历; ⑷实现对该图的广度优先遍历。 备注:单号基于邻接矩阵,双号基于邻接表存储结构实现上述操作。算法设计: #include 实践四:图及图的应用 1.实验目的要求 理解图的基本概念,两种主要的存储结构。掌握在邻接链表存储结构下的图的深度优先递归遍历、广度优先遍历。通过选做题"最短路径问题"认识图及其算法具有广泛的应用意义。 实验要求:正确调试程序。写出实验报告。 2.实验主要内容 2.1 在邻接矩阵存储结构下的图的深度优先递归遍历、广度优先遍历。 2.1.1 要完成图的两种遍历算法,首先需要进行图的数据初始化。为把时间主要花在遍历算法的实现上,图的初始化采用结构体声明时初始化的方法。示例代码如下: #include "stdio.h" typedef int Arcell; typedef int AdjMatrix[5][5]; typedef struct { char vexs[5]; AdjMatrix arcs; int vexnum,arcnum; }MGraph; void main(){ MGraph g={ {'a','b','c','d','e'}, {{0,1,0,1,0}, {1,0,0,0,1}, {1,0,0,1,0}, {0,1,0,0,1}, {1,0,0,0,0}} ,5,9}; } 2.1.2 深度优先遍历算法7.5中FirstAdjVex方法和NextAdjVex方法需要自己实现。 2.2 拓扑排序,求图的拓扑序列 2.3 "最短路径问题",以校园导游图为实际背景进行设计。(选做) 程序代码如下: #include #include ::: Application Report 先进表面力学测试 安东帕压痕模式总结 介绍 仪器化压痕技术在当今学术和工业研究以及质量控 制等许多领域都得到了广泛的应用。这种方法通常被称 为纳米压痕,因为压痕深度通常比传统的维氏或洛氏硬 度测量要小得多。仪器化压痕技术通过施加载荷和测量 压痕深度来测量多种材料的硬度和弹性模量。由于包括 分析在内的测量是自动化的,许多测量可以在不需要操 作员干预的情况下自动执行和分析。鉴于安东帕纳米压 痕系统及其软件的多功能性,可以在特定材料上应用各 种加载方式以揭示特殊材料特性。例如,可以用循环加 载探测具有分级特性或表面涂层的材料,以测量它们的 硬度梯度; 具有时间依赖性的材料如聚合物可以以恒定 的应变速率模式或以各种压痕速率压痕以获得它们的动 态响应。可以在位移控制模式中有效地实现一些与压痕 相关的实验,例如微柱压缩,以观察滑移现象。 本应用报告总结了安东帕压痕软件中包含的各种方法。 详细描述了每种方法,并给出了应用实例。本文档的目 的是指导纳米压痕器的用户选择最佳的测试方法。 1. 标准压痕模式 标准压痕是最常见的压痕类型,用于简单有效的硬度 和弹性模量测量。 它在ISO 14577标准中定义。用户只需 输入最大压痕载荷和保载时间。载荷曲线如图.1a 所示, 载荷位移曲线如图.1b 所示。 图1-a )标准压痕载荷曲线, b )得到的载荷 - 位移压痕曲线。 1.1. 高级压痕模式(单载荷压痕) 高级压痕模式是一种仪器化压痕技术,允许执行一 次压痕测量,用户可以独立定义加载和卸载速率。由于 这种模式,可以选择不同的加载类型,从而加快总测试 时间或分析不同材料对不同加载速率的响应。此模式可 用于大多数常规压痕测试应用。 安东帕仪器压痕(纳米压痕)测试仪提供三种主要类型 的载荷加载: ? 线性加载 ? 二次方加载, ? 恒定应变率加载。 基于线性或恒定应变率加载类型的试验程序可以是力控 制器或位移控制。 1.2. 具有不同加载速率的线性加载 这种加载式的高级压痕模式可用于大多数常规压痕 测试应用。加载速率的增加会缩短测试时间,尤其是在 运行大型矩阵时。它也可用于聚合物模拟阶跃载荷(载 荷快速增加),并研究随后保载期间的蠕变或应力弛 豫。 压头的加载遵循以下公式:f =k×t (图2),其中k 是加载 速率,单位为m n/min 。假设硬度恒定,深度遵循平方根 演变与时间(f ~√h )的关系。 图 2 –线性加载实例 。 生物聚合物壳聚糖/蒙脱土纳米复合材料的表征与制备 摘要: 天然高分子壳聚糖/蒙脱土纳米复合材料已经被制备出来了。其中蒙脱土用来做纳米填充剂,稀释的醋酸用来作为溶解壳聚糖和蒙脱土的溶剂的。壳聚糖纳米聚合物材料在有醋酸滤渣和没有醋酸滤渣下的形态的性质和纯的壳聚糖做了对比研究。纳米复合材料里的醋酸滤渣和蒙脱土填充物的影响已经研究出来了。X射线衍生物和透射电镜结果显示:低MMT[蒙脱土]含量下会形成插层—剥离纳米结构,高MMT会形成插层—凝结态的纳米复合材料。纳米复合材料的热稳定性和机械性质可以通过热重量法和纳米压痕来检测。以纳米态分布的粘土能提高矩阵系统的热稳定和硬度系数随着增加粘土填充物。存在壳聚糖矩阵中的醋酸滤渣会影响它的结晶度,热稳定性和机械性能。 关键词:壳聚糖,蒙脱土,纳米复合材料,结构,热稳定性,纳米压痕 1.简介 传统的非可生物降解的聚合物来自于化石燃料,在一定程度上会扰乱和破坏自然界的生态系统。因此,我们迫切需要开发可再生的生物聚合物材料。可再生的生物聚合物材料在制造过程中不会使用有毒或者有害的成分,并且可以经自然堆肥处理降解。聚交酯和多糖是最具前景的方法,因为他们来自于自然界丰富存在的物质中,而且它们可以生物降解。但是为了让生物聚合物能和强度更高,更有延展性的商业聚合物【如聚乙烯或聚丙烯】竞争,我们仍需要去改进它们的性质,如耐热性,机械性能和防护性能。值得注意的是硅酸盐纳米复合材料技术已经被证明是个能显著的提高这些性能的好方法。然而,很多注意力放在了聚合物/粘土纳米复合材料上,放在生物聚合物/粘土纳米复合材料上的关注则相对很少,还包括聚交酯/粘土复合材料,棉/粘土复合材料,聚乙烯【丁烯,琥珀酸】/粘土复合材料,植物油/粘土复合材料. 壳聚糖,是一种多聚糖,由聚葡萄糖胺(1-4)-2-氨基-B-D葡萄糖单元构成,几丁质(chitin)经过脱乙酰作用得到的的产物,聚合吡喃型葡萄糖。壳聚糖和和几丁质是自然界的生物聚合物中第二丰富的,仅次于纤维素。 壳聚糖几十年来广泛的应用于分子分离,食品包装薄膜,人造皮肤,骨骼替代物,水利工程等,因为它具有良好的机械特性,生物相容性,生物降解能力,多官能团以及在水介质中的可溶性。然而,它的有些性质,如热稳定性,硬度和气体屏障能力饼不能满足那些更宽范围的使用要求。直到现在,只有有限的报告声称能够通过聚合物/层状硅酸盐纳米复合技术来加强壳聚糖的性质。艾斯拉对壳聚糖—粘土做了初步的研究,声称壳聚糖-粘土和纯壳聚糖相比可以显著的提高复合材料的伸缩性能但却有较差的热稳定性。Ruiz-Hitzky和他的伙伴合成了功能壳聚糖蒙脱土纳米复合材料。它可以在电气化学传感器检测不同的阳离子的过程中充当活跃的相位。他们通过剥离—吸附的方法来合成纳米复合材料。其中,稀释的醋酸溶液用来当作溶解粘土和壳聚糖的溶剂。但是,很少有实验报告是关于醋酸滤渣对壳聚糖的影响,而且壳聚糖和MMT之间的氢键可能是让MMT层与层聚合起来在壳聚糖矩阵中形成凝聚结构的关键推动力。考虑到这些因素,现在的研究目标是通过在纳米级上合并蒙脱土来制备高性能的壳聚糖。醋酸滤渣、壳聚糖和MMT之间的氢键作用力和粘土填充物的形态性质,热稳定性和机械性能对纳米复合材料的影响已被研究。 2.实验 2.1材料 实习报告 题目:图遍历的演示 编译环 境: Microsoft Visual Studio 2010 功能实现: 以邻接表为存储结构,演示在连通无向图上访冋全部节点的操作; 实现连通无向图的深度优先遍历和广度优先遍历; 建立深度优先生成树和广度优先生成树,按凹入表或树形打印生成树。 1.以邻接表为存储结构,演示在连通无向图上访问全部节点的操作。 该无向图为 一个交通网络,共25个节点,30条边,遍历时需要以用户指定的节点为起点, 建立深度优先生成树和广度优先生成树,再按凹入表或树形打印生成树。 2.程序的测试数据:graph.txt 文件所表示的无向交通图。 //边表结点 //邻接点域,即邻接点在顶点表中的下标 //顶点表结点 //数据域 struct TNode // 树结点 { stri ng data; struct TNode *fristchild, * nextchild; }; 2.邻接表类设计: class GraphTraverse { public: 需求分析 二、概要设计 1.主要数据结构设计: struct ArcNode { int vex In dex; ArcNode* n ext; }; struct VertexNode { stri ng vertex; ArcNode* firstArc; }; 三、详细设计 1. 主要操作函数的实现: (1) 建立深度优先生成树函数: TNode* GraphTraverse::DFSForest(i nt v) { int i,j; TNode *p,*q,*DT; j=v; for(i=O;i 微纳米力学及纳米压痕表征技术 摘要:微纳米力学为微纳米尺度力学,即特征尺度为微纳米之间的微细结构所涉及的力学问题[1] 。纳米压痕方法是通过计算机控制载荷连续变化,并在线监测压深量[2],适用于微米或纳米级的薄膜力学性能测试,本实验采用Oliver–Pharr方法研究了Al2O3薄膜,附着在ZnS 基底,得到了Al2O3薄膜的力学性能。 关键词:微纳米力学纳米压痕杨氏模量硬度 0引言 近年来,随着工业的现代化、规模化、产业化,以及高新技术和国防技术的发展,对各种材料表面性能的要求越来越高。20世纪80年代,现代表面技术被国际科技界誉为最具发展前途的十大技术之一。薄膜、涂层和表面处理材料的极薄表层的物理、化学、力学性能和材料内部的性能常有很大差异,这些差异在摩擦磨损、物理、化学、机械行为中起着主导作用,如计算机磁盘、光盘等,要求表层不但有优良的电、磁、光性能,而且要求有良好的润滑性、摩擦小、耐磨损、抗化学腐蚀、组织稳定和优良的力学性能。因此,世界各国都非常重视材料的纳米级表层的物理、化学、机械性能及其检测方法的研究。[3]同时随着材料设计的微量化、微电子行业集成电路结构的复杂化,传统材料力学性能测试方法已难以满足微米级及更小尺度样品的测试精度,不能够准确评估薄膜材料的强度指标和寿命 ;另外在材料微结构研究领域中, 材料研究尺度逐渐缩小,材料的变形机制表现出与传统块状材料相反的规律 ,以上趋势要求测试仪器具有高的位置分辨率、位移分辨率和载荷分辨率 ,纳米压痕方法能够满足上述测试需求。[4] 现在,薄膜的厚度己经做到了微米级,甚至于纳米级,对于这样的薄膜,用传统的材料力学性能测试方法己经无法解决。纳米压痕试验方法是一种在传统的布氏和维氏硬度试验基础上发展起来的新的力学性能试验方法。它通过连续控制和记录样品上压头加载和卸载时的载荷和位移数据,并对这些数据进行分析而得出材料的许多力学性能指标,压痕深度可以非常浅,压痕深度在纳米范围,也可以得到材料的力学性能,这样该方法就成为薄膜、涂层和表面处理材料力学性能测试的首选工具,如薄膜、涂层和表面处理材料表面力学性能测试等。 1纳米力学简介 1.1纳米材料 纳米材料是指三维空间尺度至少有一维处于纳米量级(1-100nm)的材料,它是由尺寸介于原子、分子与宏观体系之间的纳米粒子所组成的材料,是把组成相或晶粒结构控制在 100nm 以下尺寸的材料。 1.2纳米材料分类 纳米材料分类:按维数,纳米材料的基本单元可以分为: 1 零维:在空间三维尺度上均在纳米尺度,如纳米尺度颗粒,原子团簇; 2 一维:在空间有两维处于纳米尺度,如纳米丝,纳米棒,纳米管等; 3 二维:在三维空间中有一维在纳米尺度,如超薄膜,多层膜,超晶格等。 1.3纳米材料特性及其基本单元 纳米材料的基本单元:团簇、纳米微粒、纳米管、纳米带、纳米薄膜、纳米结构。 图实验 一,邻接矩阵的实现 1.实验目的 (1)掌握图的逻辑结构 (2)掌握图的邻接矩阵的存储结构 (3)验证图的邻接矩阵存储及其遍历操作的实现 2.实验内容 (1)建立无向图的邻接矩阵存储 (2)进行深度优先遍历 (3)进行广度优先遍历 3.设计与编码 MGraph.h #ifndef MGraph_H #define MGraph_H const int MaxSize = 10; template { int i, j, k; vertexNum = n, arcNum = e; for(i = 0; i < vertexNum; i++) vertex[i] = a[i]; for(i = 0;i < vertexNum; i++) for(j = 0; j < vertexNum; j++) arc[i][j] = 0; for(k = 0; k < arcNum; k++) { cout << "Please enter two vertexs number of edge: "; cin >> i >> j; arc[i][j] = 1; arc[j][i] = 1; } } template数据结构 图的遍历(初始化图)
纳米压痕力学模式总结(中文)
生物聚合物壳聚糖
数据结构_图遍历的演示
微纳米力学及纳米压痕表征技术
数据结构实验报告--图实验