岭回归数据
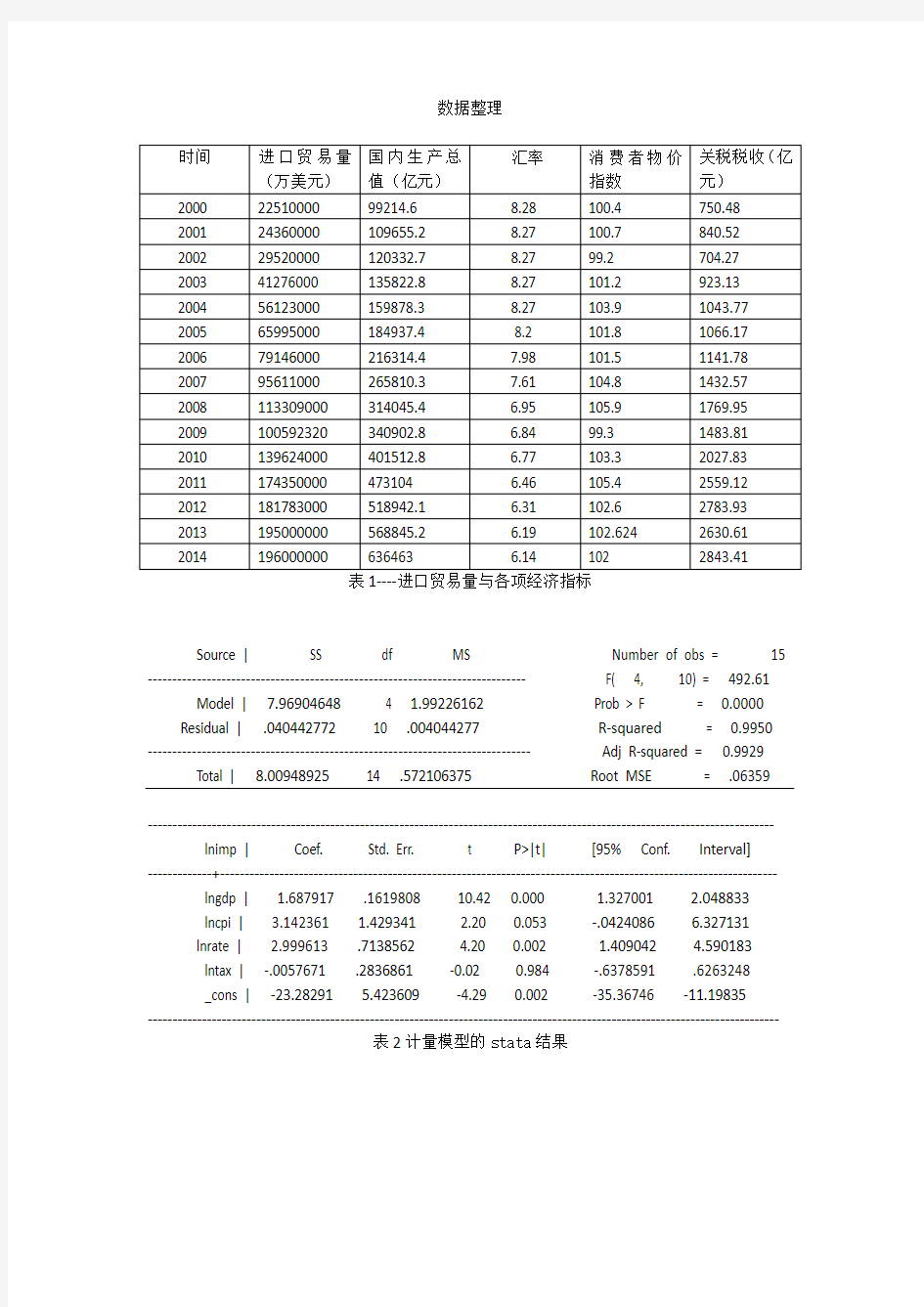
数据整理
时间进口贸易量
(万美元)国内生产总
值(亿元)
汇率消费者物价
指数
关税税收(亿
元)
2000 22510000 99214.6 8.28 100.4 750.48
2001 24360000 109655.2 8.27 100.7 840.52
2002 29520000 120332.7 8.27 99.2 704.27
2003 41276000 135822.8 8.27 101.2 923.13
2004 56123000 159878.3 8.27 103.9 1043.77
2005 65995000 184937.4 8.2 101.8 1066.17
2006 79146000 216314.4 7.98 101.5 1141.78
2007 95611000 265810.3 7.61 104.8 1432.57
2008 113309000 314045.4 6.95 105.9 1769.95
2009 100592320 340902.8 6.84 99.3 1483.81
2010 139624000 401512.8 6.77 103.3 2027.83
2011 174350000 473104 6.46 105.4 2559.12
2012 181783000 518942.1 6.31 102.6 2783.93
2013 195000000 568845.2 6.19 102.624 2630.61
2014 196000000 636463 6.14 102 2843.41
表1----进口贸易量与各项经济指标
Source | SS df MS Number of obs = 15 ----------------------------------------------------------------------------- F( 4, 10) = 492.61 Model | 7.96904648 4 1.99226162 Prob > F = 0.0000 Residual | .040442772 10 .004044277 R-squared = 0.9950 ------------------------------------------------------------------------------ Adj R-squared = 0.9929 Total | 8.00948925 14 .572106375 Root MSE = .06359
------------------------------------------------------------------------------------------------------------------------------- lnimp | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------------------------------------------------------- lngdp | 1.687917 .1619808 10.42 0.000 1.327001 2.048833
lncpi | 3.142361 1.429341 2.20 0.053 -.0424086 6.327131
lnrate | 2.999613 .7138562 4.20 0.002 1.409042 4.590183
lntax | -.0057671 .2836861 -0.02 0.984 -.6378591 .6263248
_cons | -23.28291 5.423609 -4.29 0.002 -35.36746 -11.19835
--------------------------------------------------------------------------------------------------------------------------------
表2计量模型的stata结果
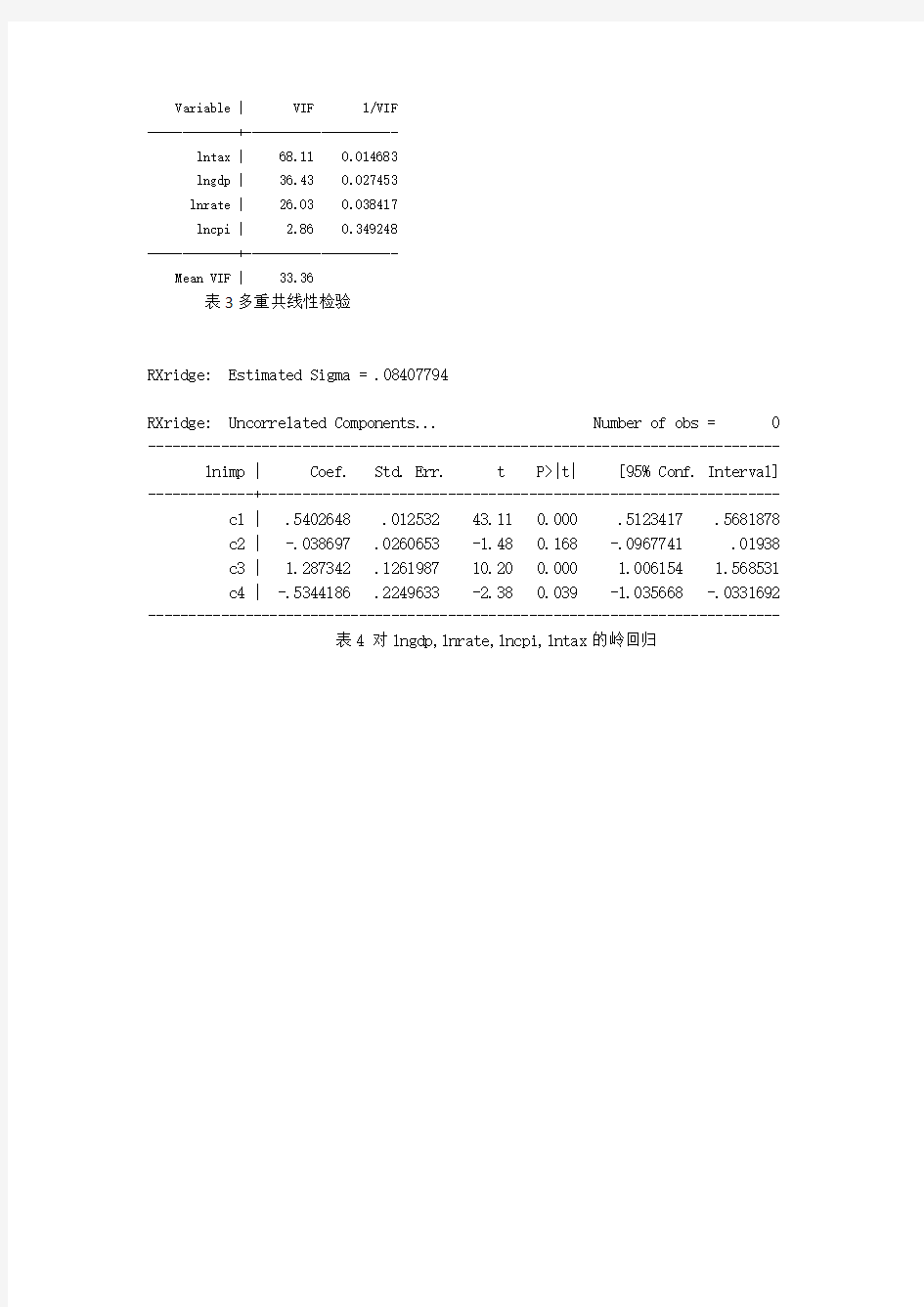
Variable | VIF 1/VIF
-------------+----------------------
lntax | 68.11 0.014683
lngdp | 36.43 0.027453
lnrate | 26.03 0.038417
lncpi | 2.86 0.349248
-------------+----------------------
Mean VIF | 33.36
表3多重共线性检验
RXridge: Estimated Sigma = .08407794
RXridge: Uncorrelated Components... Number of obs = 0 ------------------------------------------------------------------------------ lnimp | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------- c1 | .5402648 .012532 43.11 0.000 .5123417 .5681878 c2 | -.038697 .0260653 -1.48 0.168 -.0967741 .01938 c3 | 1.287342 .1261987 10.20 0.000 1.006154 1.568531 c4 | -.5344186 .2249633 -2.38 0.039 -1.035668 -.0331692 ------------------------------------------------------------------------------
表4 对lngdp,lnrate,lncpi,lntax的岭回归
SPSS—二元Logistic回归结果分析
SPSS—二元Logistic回归结果分析 2011-12-02 16:48 身心疲惫,睡意连连,头不断往下掉,拿出耳机,听下歌曲,缓解我这严重的睡意吧!今天来分析二元Logistic回归的结果 分析结果如下: 1:在“案例处理汇总”中可以看出:选定的案例489个,未选定的案例361个,这个结果是根据设定的validate = 1得到的,在“因变量编码”中可以看出“违约”的两种结果“是”或者“否” 分别用值“1“和“0”代替,在“分类变量编码”中教育水平分为5类,如果选中“为完成高中,高中,大专,大学等,其中的任何一个,那么就取值为 1,未选中的为0,如果四个都未被选中,那么就是”研究生“ 频率分别代表了处在某个教育水平的个数,总和应该为489个
1:在“分类表”中可以看出:预测有360个是“否”(未违约)有129个是“是”(违约) 2:在“方程中的变量”表中可以看出:最初是对“常数项”记性赋值,B为 -1.026,标准误差为:0.103 那么wald =( B/S.E)2=(-1.026/0.103)2 = 99.2248, 跟表中的“100.029几乎接近,是因为我对数据进行的向下舍入的关系,所以数据会稍微偏小, B和Exp(B) 是对数关系,将B进行对数抓换后,可以得到:Exp(B) = e^-1.026 = 0.358, 其中自由度为1, sig为0.000,非常显著
1:从“不在方程中的变量”可以看出,最初模型,只有“常数项”被纳入了模型,其它变量都不在最初模型内 表中分别给出了,得分,df , Sig三个值, 而其中得分(Score)计算公式如下: (公式中(Xi- Xˉ) 少了一个平方) 下面来举例说明这个计算过程:(“年龄”自变量的得分为例) 从“分类表”中可以看出:有129人违约,违约记为“1”则违约总和为129,选定案例总和为489 那么: yˉ = 129/489 = 0.2638036809816 xˉ = 16951 / 489 = 34.664621676892 所以:∑(Xi-xˉ)2 = 30074.9979 yˉ(1-yˉ)=0.2638036809816 *(1-0.2638036809816 )
岭回归解决多重共线性
一、引言 回归分析是一种比较成熟的预测模型,也是在预测过程中使用较多的模型,在自然科学管理科学和社会经济中有着非常广泛的应用,但是经典的最小二乘估计,必需满足一些假设条件,多重共线性就是其中的一种。实际上,解释变量间完全不相关的情形是非常少见的,大多数变量都在某种程度上存在着一定的共线性,而存在着共线性会给模型带来许多不确定性的结果。 二、认识多重共线性 (一)多重共线性的定义 设回归模型01122p p y x x x ββββε=+++?++如果矩阵X 的列向量存在一组不全 为零的数012,,p k k k k ?使得011220i i p i p k k x k x k x +++?+=, i =1,2,…n ,则称其存在完全共线性,如果022110≈+?+++p i p i i x k x k x k k , i =1,2,…n ,则称其存在 近似的多重共线性。 (二)多重共线性的后果 1.理论后果 对于多元线性回归来讲,大多数学者都关注其估计精度不高,但是多重共线性不可 能完全消除,而是要用一定的方法来减少变量之间的相关程度。多重共线性其实是由样本容量太小所造成的后果,在理论上称作“微数缺测性”,所以当样本容量n 很小的时候,多重共线性才是非常严重的。 多重共线性的理论后果有以下几点: (1)保持OLS 估计量的BLUE 性质; (2) 戈德伯格提出了近似多重共线性其实是样本观测数刚好超过待估参数个数时出现的 情况。所以多重共线性并不是简单的自变量之间存在的相关性,也包括样本容量的大小问题。 (3)近似的多重共线性中,OLS 估计仍然是无偏估计。无偏性是一种多维样本或重复抽样 的性质;如果X 变量的取值固定情况下,反复对样本进行取样,并对每个样本计算OLS 估计量,随着样本个数的增加,估计量的样本值的均值将收敛于真实值。 (4)多重共线性是由于样本引起的。即使总体中每一个X 之间都没有线性关系,但在具体 取样时仍存在样本间的共线性。 2.现实后果 (1)虽然存在多重共线性的情况下,得到的OLS 估计是BLUE 的,但有较大的方差和协方差, 估计精度不高; (2)置信区间比原本宽,使得接受0H 假设的概率更大;
Logistic回归分析报告结果解读分析
Logistic 回归分析报告结果解读分析 Logistic 回归常用于分析二分类因变量(如存活和死亡、患病和未患病等)与多个自变量的关系。比较常用的情形是分析危险因素与是否发生某疾病相关联。例如,若探讨胃癌的危险因素,可以选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群有不同的临床表现和生活方式等,因变量就为有或无胃癌,即“是” 或“否”,为二分类变量,自变量包括年龄、性别、饮食习惯、是否幽门螺杆菌感染等。自变量既可以是连续变量,也可以为分类变量。通过Logistic 回归分析,就可以大致了解胃癌的危险因素。 Logistic 回归与多元线性回归有很多相同之处,但最大的区别就在于他们的因变量不同。多元线性回归的因变量为连续变量;Logistic 回归的因变量为二分类变量或多分类变量,但二分类变量更常用,也更加容易解释。 1. Logistic 回归的用法 一般而言,Logistic 回归有两大用途,首先是寻找危险因素,如上文的例子,找出与胃癌相关的危险因素;其次是用于预测,我们可以根据建立的Logistic 回归模型,预测在不同的自变量情况下,发生某病或某种情况的概率(包括风险评分的建立)。 2. 用Logistic回归估计危险度 所谓相对危险度(risk ratio , RR)是用来描述某一因素不同状态发生疾病(或其它结局)危险程度的 比值。Logistic回归给出的OR(odds ratio)值与相对危险度类似,常用来表示相对于某一人群,另一人群发生终点事件的风险超出或减少的程度。如不同性别的
胃癌发生危险不同,通过Logistic回归可以求出危险度的具体数值,例如1.7,
岭回归1
1、做多自变量的线性回归,在统计量面板内选:共线性诊断(L); 2、如结果中的方差膨胀系数(VIF)>5,则可做岭回归分析; 3、新建语法编辑器,输入如下命令: INCLUDE '安装目录\Ridge regression.sps'. RIDGEREG DEP=因变量名 /ENTER = 自变量名(用空格分开) /START=0 /STOP=1[或其它数值] /INC=0.05[或其它搜索步长] /K=999 . 4、选择运行全部,得到各自变量岭迹图和决定系数R2与K值的关系图,在 图上作参考线,取一岭迹平稳并且R2值较大的平衡点的K值; 5、将语法编辑器中的K值改为所选K值,再运行全部,得到详细的最终模型 参数。 岭回归分析实际上是一种改良的最小二乘法,是一种专门用于共线性数据分析的有偏估计回归方法。岭回归分析的基本思想是当自变量间存在共线性时,解释变量的相关矩阵行列式近似为零,X'X是奇异的,也就是说它的行列式的值也接近于零,此时OLS估计将失效。此时可采用岭回归估计。岭回归就是用X'X+KI代替正规方程中的X'X,人为地把最小特征根由minλi提高到min(λi+k),希望这样有助于降低均方误差。SAS可以用来做岭回归分析 岭回归分析 1 岭回归估计量 岭回归分析是一种修正的最小二乘估计法,当自变量系统中存在多重相关性时,它可以提供一个比最小二乘法更为稳定的估计,并且回归系数的标准差也比最小二乘估计的要小。 根据高斯——马尔科夫定理,多重相关性并不影响最小二乘估计量的无偏性和最小方差性。但是,虽然最小二乘估计量在所有线性无偏估计量中是方差最小的,但是这个方差却不一定小。于是可以找一个有偏估计量,这个估计量虽然有微小的偏差,但它的精度却能够大大高于无偏的估计量。 在应用岭回归分析时,它的计算大多从标准化数据出发。对于标准化变量,最小二乘的正规方程为 rXXb=ryX 式中,rXX是X的相关系数矩阵,ryX是y与所有自变量的相关系数向量。 岭回归估计量是通过在正规方程中引入有偏常数c(c≥0)而求得的。它的正规方程为+
Logistic回归分析报告结果解读分析
L o g i s t i c回归分析报告结果解读分析 Company number:【0089WT-8898YT-W8CCB-BUUT-202108】
Logistic回归分析报告结果解读分析Logistic回归常用于分析二分类因变量(如存活和死亡、患病和未患病等)与多个自变量的关系。比较常用的情形是分析危险因素与是否发生某疾病相关联。例如,若探讨胃癌的危险因素,可以选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群有不同的临床表现和生活方式等,因变量就为有或无胃癌,即“是”或“否”,为二分类变量,自变量包括年龄、性别、饮食习惯、是否幽门螺杆菌感染等。自变量既可以是连续变量,也可以为分类变量。通过Logistic回归分析,就可以大致了解胃癌的危险因素。 Logistic回归与多元线性回归有很多相同之处,但最大的区别就在于他们的因变量不同。多元线性回归的因变量为连续变量;Logistic回归的因变量为二分类变量或多分类变量,但二分类变量更常用,也更加容易解释。 回归的用法 一般而言,Logistic回归有两大用途,首先是寻找危险因素,如上文的例子,找出与胃癌相关的危险因素;其次是用于预测,我们可以根据建立的Logistic回归模型,预测在不同的自变量情况下,发生某病或某种情况的概率(包括风险评分的建立)。 2.用Logistic回归估计危险度 所谓相对危险度(risk ratio,RR)是用来描述某一因素不同状态发生疾病(或其它结局)危险程度的 比值。Logistic回归给出的OR(odds ratio)值与相对危险度类似,常用来表示相对于某一人群,另一人群发生终点事件的风险超出或减少的程度。如不同性别的胃癌发生危险不同,通过Logistic回归可以求出危险度的具体数值,例如,这样就表示,男性发生胃癌的风险是女性的倍。这里要注意估计的方向问题,以女性作为参照,男性患胃癌
Logistic回归分析报告结果解读分析
Logistic回归分析报告结果解读分析Logistic回归常用于分析二分类因变量(如存活和死亡、患病和未患病等)与多个自变量的关系。比较常用的情形是分析危险因素与是否发生某疾病相关联。例如,若探讨胃癌的危险因素,可以选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群有不同的临床表现和生活方式等,因变量就为有或无胃癌,即“是”或“否”,为二分类变量,自变量包括年龄、性别、饮食习惯、是否幽门螺杆菌感染等。自变量既可以是连续变量,也可以为分类变量。通过Logistic 回归分析,就可以大致了解胃癌的危险因素。 Logistic回归与多元线性回归有很多相同之处,但最大的区别就在于他们的因变量不同。多元线性回归的因变量为连续变量;Logistic回归的因变量为二分类变量或多分类变量,但二分类变量更常用,也更加容易解释。 回归的用法 一般而言,Logistic回归有两大用途,首先是寻找危险因素,如上文的例子,找出与胃癌相关的危险因素;其次是用于预测,我们可以根据建立的Logistic 回归模型,预测在不同的自变量情况下,发生某病或某种情况的概率(包括风险评分的建立)。 2.用Logistic回归估计危险度 所谓相对危险度(risk ratio,RR)是用来描述某一因素不同状态发生疾病(或其它结局)危险程度的 比值。Logistic回归给出的OR(odds ratio)值与相对危险度类似,常用来表示相对于某一人群,另一人群发生终点事件的风险超出或减少的程度。如不同性别的胃癌发生危险不同,通过Logistic回归可以求出危险度的具体数值,例如,这样就表示,男性发生胃癌的风险是女性的倍。这里要注意估计的方向问题,以女性作为参照,男性患胃癌的OR是。如果以男性作为参照,算出的OR将会是(1/,表示女性发生胃癌的风险是男性的倍,或者说,是男性的%。撇开了参照组,相对危险度就没有意义了。
岭回归分析
岭回归分析 一、普通最小二乘估计带来的问题 当设计矩阵X 呈病态时,X 的列向量之间有较强的线性相关性,即解释变量间出现严重的多重共线性,在这种情况下,用普通最小二乘法估计模型参数,往往参 数估计的方差太大,即jj jj j L C 2)?var(σβ=很大,j β?就很不稳定,在具体取值上与真值有较大的偏差,有时会出现与实际经济意义不符的正负号。下面看一个例子,可以说明这一点。 假设已知1x ,2x 与y 的关系服从线性回归模型:ε+++=213210x x y ,给定1x ,2x 的10个值,如下表1,2行所示: 表7.1 然后用模拟的方法产生10个正态随机数,作为误差项ε,见表第3行。然后再由回归模型i i i i x x y ε+++=213210计算出10个i y 值,见表第4行。现在假设回归系数与误差项是未知的,用普通最小二乘法求回归系数的估计得:0 ?β=11.292,1?β=11.307,2 ?β=-6.591,而原模型的参数0β=10,1β=2,2β=3看来相差太大。计算1x ,2x 的样本相关系数得12r =0.986,表明1x 与2x 之间高度相关。通过这个例子可以看到解释变量之间高度相关时,普通最小二乘估计明显变坏。 二、岭回归的定义 当自变量间存在多重共线性,|X X '|≈0时,设想给X X '加上一个正常数矩阵kI (k>0)那么X X '+kI 接近奇异的程度就会比X X '接近奇异的程度小得多。考虑到变量的量纲问题,先要对数据标准化,标准化后的设计矩阵仍用X 表示,定义y X kI X X k '+'=-1)()(?β称为β的岭回归估计,其中,k 称为岭参数。由于假设X 已经标准化,所以X X '就是自变量样本相关阵。y 可以标准化也可以未标准化, 如果y 也经过标准化,那么计算的实际是标准化岭回归估计。)(?k β 作为β的估计应比最小二乘估计β ?稳定,当k=0时的岭回归估计)0(?β就是普通的最小二乘估计。因为岭参数k 不是唯一确定的,所以得到的岭回归估计)(?k β 实际是回归参数β的一个估计族。
岭回归理论知识
一、普通最小二乘估计带来的问题 当自变量间存在多重共线性时,回归系数估计的方差就很大,估计值就很不稳定。此时模型或数据的微小变化有可能造成系数估计的较大变化,对预测值产生较大影响。下面进一步用一个模拟的例子来说明这一点。 例1 假设已知1x ,2x 与y 的关系服从线性回归模型 ε+++=213210y x x 给定1x ,2x 的10个值,如下表: 表1. 二.、岭回归提出的背景 岭回归是1970年由Hoerl 和Kennard 提出的, 它是一种有偏估计,是对最小二乘估计的改进。 设有多重线性回归模型εβ+=X y ,参数β的最小二乘估计为 y )(?1X X X ''=-β
则 122)()?(-'=-X X tr E σββ 242)(2)?(-'=-X X tr D σββ 当自变量出现多重共线性时,普通最小二乘估计明显变坏。当0≈'X X 时,i λ1 就会变得很大,这时,尽管β ?是β的无偏估计,但β?很不稳定,在具体取值上与真值有较大的偏差,甚至会出现与实际意义不符的正负号。 设想给X X '加上一个正常数矩阵kI (0>k ),那么kI X X +'接近奇异的程度就会变小。先对数据作标准化,标准化后的设计阵仍用X 表示。 称 为岭回归估计。这里的k 成为岭参数。当0=k 时的岭回归估计就是普通的最小二乘估计。 因为岭参数k 不是唯一确定的,所以我们得到的岭回归估计)(?k β实际是回归参数β的一个估计族,取不同的k 值时)(?k β的取值不同。以k 为横坐标,) (?k β为纵坐标的直角坐标系,可分析β估计族的稳定性。 优点:比最小二乘估计更稳定 三、岭迹分析 在岭回归中,岭迹分析可用来了解各自变量的作用及自变量之间的相互关系。下图所反映的几种有代表性的情况来说明岭迹分析的作用。 y )()(?1X kI X X k '+'=-β
Excel求解线性回归详解(LINEST 函数)
LINEST 函数 本文介绍Microsoft Office Excel 中LINEST 函数(函数:函数是预先编写的公式,可以对一个或多个值执行运算,并返回一个或多个值。函数可以简化和缩短工作表中的公式,尤其在用公式执行很长或复杂的计算时。)的公式语法和用法。有关绘制图表和执行回归分析的详细信息,请点击“请参阅”部分中的链接。 说明 LINEST 函数可通过使用最小二乘法计算与现有数据最佳拟合的直线,来计算某直线的统计值,然后返回描述此直线的数组。也可以将LINEST 与其他函数结合使用来计算未知参数中其他类型的线性模型的统计值,包括多项式、对数、指数和幂级数。因为此函数返回数值数组,所以必须以数组公式的形式输入。请按照本文中的示例使用此函数。 直线的公式为: y = mx + b - 或- y = m1x1 + m2x2 + ... + b(如果有多个区域的x 值) 其中,因变量y 是自变量x 的函数值。m 值是与每个x 值相对应的系数,b 为常量。注意,y、x 和m 可以是向量。LINEST 函数返回的数组为{mn,mn-1,...,m1,b}。LINEST 函数还可返回附加回归统计值。 语法 LINEST(known_y's, [known_x's], [const], [stats]) LINEST 函数语法具有以下参数(参数:为操作、事件、方法、属性、函数或过程提供信息的值。): ?Known_y's必需。关系表达式y = mx + b 中已知的y 值集合。 如果known_y's 对应的单元格区域在单独一列中,则known_x's 的每一列被视为一个独立的变量。 如果known_y's 对应的单元格区域在单独一行中,则known_x's 的每一行被视为一个独立的变量。 ?Known_x's可选。关系表达式y = mx + b 中已知的x 值集合。
岭回归研究分析
岭回归分析
————————————————————————————————作者:————————————————————————————————日期:
岭回归分析 一、普通最小二乘估计带来的问题 当设计矩阵X 呈病态时,X 的列向量之间有较强的线性相关性,即解释变量间出现严重的多重共线性,在这种情况下,用普通最小二乘法估计模型参数,往往参 数估计的方差太大,即jj jj j L C 2)?var(σβ=很大,j β?就很不稳定,在具体取值上与真值有较大的偏差,有时会出现与实际经济意义不符的正负号。下面看一个例子,可以说明这一点。 假设已知1x ,2x 与y 的关系服从线性回归模型:ε+++=213210x x y ,给定 1x ,2x 的10个值,如下表1,2行所示: 表7.1 序号 1 2 3 4 5 6 7 8 9 10 (1) x 1 1.1 1.4 1.7 1.7 1.8 1.8 1.9 2.0 2.3 2.4 (2) x 2 1.1 1.5 1.8 1.7 1.9 1.8 1.8 2.1 2.4 2.5 (3) εi 0.8 -0.5 0.4 -0.5 0.2 1.9 1.9 0.6 -1.5 -1.5 (4) y i 16.3 16.8 19.2 18.0 19.5 20.9 21.1 20.9 20.3 22.0 然后用模拟的方法产生10个正态随机数,作为误差项ε,见表第3行。然后再由回归模型i i i i x x y ε+++=213210计算出10个i y 值,见表第4行。现在假设回归 系数与误差项是未知的,用普通最小二乘法求回归系数的估计得:0 ?β=11.292, 1?β=11.307,2?β=-6.591,而原模型的参数0β=10,1 β=2,2β=3看来相差太大。计算1x ,2x 的样本相关系数得12r =0.986,表明1x 与2x 之间高度相关。通过这个例子可以看到解释变量之间高度相关时,普通最小二乘估计明显变坏。 二、岭回归的定义 当自变量间存在多重共线性,|X X '|≈0时,设想给X X '加上一个正常数矩阵kI (k>0)那么X X '+kI 接近奇异的程度就会比X X '接近奇异的程度小得多。考虑到变量的量纲问题,先要对数据标准化,标准化后的设计矩阵仍用X 表示,定义 y X kI X X k '+'=-1)()(?β 称为β的岭回归估计,其中,k 称为岭参数。由于假设X 已经标准化,所以X X '就是自变量样本相关阵。y 可以标准化也可以未标准化, 如果y 也经过标准化,那么计算的实际是标准化岭回归估计。)(?k β 作为β的估计应比最小二乘估计β ?稳定,当k=0时的岭回归估计)0(?β就是普通的最小二乘估计。因为岭参数k 不是唯一确定的,所以得到的岭回归估计)(?k β 实际是回归参数β的一个估计族。
【原创】r语言收入逻辑回归分析报告附代码数据
逻辑回归对收入进行预测 1逻辑回归模型 回归是一种极易理解的模型,就相当于y=f(x),表明自变量x与因变量y的关系。最常见问题有如医生治病时的望、闻、问、切,之后判定病人是否生病或生了什么病,其中的望闻问切就是获取自变量x,即特征数据,判断是否生病就相当于获取因变量y,即预测分类。 最简单的回归是线性回归,在此借用Andrew NG的讲义,有如图1.a所示,X为数据点——肿瘤的大小,Y为观测值——是否是恶性肿瘤。通过构建线性回归模型,如h θ (x)所示,构建线性回归模型后,即可以根据肿瘤大小,预测是否为恶性肿瘤h θ(x)≥.05为恶性,h θ (x)<0.5为良性。 Zi=ln(Pi1?Pi)=β0+β1x1+..+βnxn Zi=ln(Pi1?Pi)=β0+β1x1+..+βnxn 2数据描述 该数据从美国人口普查数据库抽取而来,可以用来预测居民收入是否超过50K$/year。该数据集类变量为年收入是否超过50k$,属性变量包含年龄,工种,学历,职业,人种等重要信息,值得一提的是,14个属性变量中有7个类别型变量。 3问题描述 其实对于收入预测,主要是思考收入由哪些因素推动,再对每个因素做预测,最后得出收入预测。这其实不是一个财务问题,是一个业务问题。 对于某企业新用户,会利用大数据来分析该用户的信息来确定是否为付费用户,弄清楚用户属性,提高运营人员的办事效率。 流失预测。这方面会偏向于大额付费用户,提取额特征向量运用到应用场景的用户流失和预测里面去。 我们尝试并预测个人是否可以根据数据中可用的人口统计学变量使用逻辑回归预测收入是否超过$ 50K的资金。在这个过程中,我们将: 1.导入数据 2.检查类别偏差 3.创建训练和测试样本 4.建立logit模型并预测测试数据 5.模型诊断
岭回归数据
数据整理 时间进口贸易量 (万美元)国内生产总 值(亿元) 汇率消费者物价 指数 关税税收(亿 元) 2000 22510000 99214.6 8.28 100.4 750.48 2001 24360000 109655.2 8.27 100.7 840.52 2002 29520000 120332.7 8.27 99.2 704.27 2003 41276000 135822.8 8.27 101.2 923.13 2004 56123000 159878.3 8.27 103.9 1043.77 2005 65995000 184937.4 8.2 101.8 1066.17 2006 79146000 216314.4 7.98 101.5 1141.78 2007 95611000 265810.3 7.61 104.8 1432.57 2008 113309000 314045.4 6.95 105.9 1769.95 2009 100592320 340902.8 6.84 99.3 1483.81 2010 139624000 401512.8 6.77 103.3 2027.83 2011 174350000 473104 6.46 105.4 2559.12 2012 181783000 518942.1 6.31 102.6 2783.93 2013 195000000 568845.2 6.19 102.624 2630.61 2014 196000000 636463 6.14 102 2843.41 表1----进口贸易量与各项经济指标 Source | SS df MS Number of obs = 15 ----------------------------------------------------------------------------- F( 4, 10) = 492.61 Model | 7.96904648 4 1.99226162 Prob > F = 0.0000 Residual | .040442772 10 .004044277 R-squared = 0.9950 ------------------------------------------------------------------------------ Adj R-squared = 0.9929 Total | 8.00948925 14 .572106375 Root MSE = .06359 ------------------------------------------------------------------------------------------------------------------------------- lnimp | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+----------------------------------------------------------------------------------------------------------------- lngdp | 1.687917 .1619808 10.42 0.000 1.327001 2.048833 lncpi | 3.142361 1.429341 2.20 0.053 -.0424086 6.327131 lnrate | 2.999613 .7138562 4.20 0.002 1.409042 4.590183 lntax | -.0057671 .2836861 -0.02 0.984 -.6378591 .6263248 _cons | -23.28291 5.423609 -4.29 0.002 -35.36746 -11.19835 -------------------------------------------------------------------------------------------------------------------------------- 表2计量模型的stata结果
岭回归3
岭回归的共线性的处理 语法: INCLUDE ' C:\Program Files\SPSS\Ridge Regression.sps' ridgereg enter=自变量列表 /dep=因变量名 /start=K值起始值,默认为0 /stop= K值终止值,默认为1 /inc=K值搜索步长,默认为0.05 /k=允许搜索的K值个数,默认为999 步骤: 1、打开需要处理的数据文件; 2、执行file/new/syntax,并根据上述的语法格式写入程序; 3、点击“syntax”窗口上的播放箭头,或者执行“Run/all” 例题分析(摘自张文彤《高级教程》) 例 6.3现测得22例胎儿的身长、头围、体重和胎儿受精周龄,具体数据见文件ridgereg.sav。研究者希望能建立由前三个外形指标推测胎儿周龄的回归方程。(陈峰《医用多元统计分析方法》P46) 程序: INCLUDE ' C:\Program Files\SPSS\Ridge Regression.sps' ridgereg enter=long touwei weight /dep=y /inc=0.01. 结果分析:
可见当k=O.04~O.06时,回归系数开始趋于稳定。如选择k=0.05,则三个变量的系数分别为0.317746、O.1 113和0.537 699,可写出方程如下:zy=0.311 746 x zlong+0.111 3 x ztouwei+0.537 699 x zweight相应的决定系数为0.949 32,虽然没有原方程的0.975 42高,但方程中三个变量的系数均为正,符合专业知识。也就是说,岭回归通过丢弃少量的信息,换来了方程系数的合理估计。 图6.6为将不同k值时各变量的回归系数连成的曲线,该曲线被形象地称为岭迹(Ridge Trace),这就是岭回归名称的由来。可见当k到达0.05附近时,三条岭迹都开始变得平稳,这和前面的结论相一致。 图6.7为不同k值时决定系数的下降情况,为了便于观察,笔者在k=0.05处添加了一条参考线,可见决定系数一开始明显下降,但当k超过0.05后,决定系数一直处于缓慢下降中,没有出现明显的波动。图6.7反映出的信息也支持前面做出的结论。
【原创】在R语言中实现Logistic逻辑回归数据分析报告论文(含代码数据)
咨询QQ:3025393450 有问题百度搜索“”就可以了 欢迎登陆官网:https://www.360docs.net/doc/ae9534938.html,/datablog 在R语言中实现Logistic逻辑回归数据分析报告 来源:大数据部落| 逻辑回归是拟合回归曲线的方法,当y是分类变量时,y = f(x)。典型的使用这种模式被预测?给定一组预测的X。预测因子可以是连续的,分类的或两者的混合。 R中的逻辑回归实现 R可以很容易地拟合逻辑回归模型。要调用的函数是glm(),拟合过程与线性回归中使用的过程没有太大差别。在这篇文章中,我将拟合一个二元逻辑回归模型并解释每一步。 数据集 我们将研究泰坦尼克号数据集。这个数据集有不同版本可以在线免费获得,但我建议使用Kaggle提供的数据集,因为它几乎可以使用(为了下载它,你需要注册Kaggle)。 数据集(训练)是关于一些乘客的数据集合(准确地说是889),并且竞赛的目标是预测生存(如果乘客幸存,则为1,否则为0)基于某些诸如服务等级,性别,年龄等特征。正如您所看到的,我们将使用分类变量和连续变量。 数据清理过程
咨询QQ:3025393450 有问题百度搜索“”就可以了 欢迎登陆官网:https://www.360docs.net/doc/ae9534938.html,/datablog 在处理真实数据集时,我们需要考虑到一些数据可能丢失或损坏的事实,因此我们需要为我们的分析准备数据集。作为第一步,我们使用该函数加载csv数据read.csv()。 确保参数na.strings等于c("")使每个缺失值编码为a NA。这将帮助我们接下来的步骤。 training.data.raw < - read.csv('train.csv',header = T,na.strings = c(“”)) 现在我们需要检查缺失的值,并查看每个变量的唯一值,使用sapply()函数将函数作为参数传递给数据框的每一列。 sapply(training.data.raw,function(x)sum(is.na(x)))PassengerId生存的Pclass名称性别0 0 0 0 0 年龄SibSp Parch票价177 0 0 0 0 小屋着手687 2 sapply (training.data.raw,函数(x)长度(unique(x)))PassengerId生存的Pclass名称性别891 2 3 891 2 年龄SibSp Parch票价89 7 7 681 248 小屋着手148 4 对缺失值进行可视化处理可能会有所帮助:Amelia包具有特殊的绘图功能missmap(),可以绘制数据集并突出显示缺失值:
Logistic回归分析报告结果解读分析
Logistic回归分析报告结果解读分析 Logistic回归常用于分析二分类因变量(如存活和死亡、患病和未患病等)与多个自变量的关系。比较常用的情形是分析危险因素与是否发生某疾病相关联。例如,若探讨胃癌的危险因素,可以选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群有不同的临床表现和生活方式等,因变量就为有或无胃癌,即“是”或“否”,为二分类变量,自变量包括年龄、性别、饮食习惯、是否幽门螺杆菌
回 所谓相对危险度(risk ratio,RR)是用来描述某一因素不同状态发生疾病(或其它结局)危险程度的 比值。Logistic回归给出的OR(odds ratio)值与相对危险度类似,常用来表示相对于某一人群,另一人群发生终点事件的风险超出或减少的程度。如不同性,1.7例如回归可以求出危险度的具体数值,Logistic通过别的胃癌发生危险不同,
这里要注意估计的方向问题,1.7倍。这样就表示,男性发生胃癌的风险是女性的将OR是1.7。如果以男性作为参照,算出的以女性作为参照,男性患胃癌的OR倍,或者说,是男0.5880.588(1/1.7),表示女性发生胃癌的风险是男性的会是%。撇开了参照组,相对危险度就没有意义了。性的58.8回归在医学研究中广泛使用的原因之一,就是模型直接给出具有临Logistic床实际意义的OR 值,很大程度上方便了结果的解读与推广。 图1 相对危险度(risk ratio,RR)与OR(odds ratio)的表达 3. Logistic报告OR值或β值 值,OR回归结果汇报时,往往会遇到这样一个问题:是应该报告Logistic在.
线性回归分析在EXCEL的常用函数
线性回归分析在EXCEL的常用函数 在Excel中线性回归分析(y=ax+b)常用的函数: 详见以下说明: CORREL 函数 返回单元格区域array1 和array2 之间的相关系数。使用相关系数可以确定两种属性之间的关系。例如,可以检测某地的平均温度和空调使用情况之间的关系。 语法 CORREL(array1,array2) Array1第一组数值单元格区域。 Array2第二组数值单元格区域。 注解 如果数组或引用参数包含文本、逻辑值或空白单元格,则这些值将被忽略;但包含零值的单元格将计算在内。 如果array1 和array2 的数据点的个数不同,函数CORREL 返回错误值#N/A。 如果array1 或array2 为空,或者其数值的s(标准偏差)等于零,函数CORREL 返回错误值#DIV/0!。 SLOPE 函数 返回根据known_y's 和known_x's 中的数据点拟合的线性回归直线的斜率。斜率为直线上任意两点的重直距离与水平距离的比值,也就是回归直线的变化率。 语法
SLOPE(known_y's,known_x's) Known_y's为数字型因变量数据点数组或单元格区域。 Known_x's为自变量数据点集合。 注解 参数可以是数字,或者是包含数字的名称、数组或引用。 如果数组或引用参数包含文本、逻辑值或空白单元格,则这些值将被忽略;但包含零值的单元格将计算在内。 如果known_y's 和known_x's 为空或其数据点个数不同,函数SLOPE 返回错误值#N/A。 STEYX 函数 返回通过线性回归法计算每个x 的y 预测值时所产生的标准误差。标准误差用来度量根据单个x 变量计算出的y 预测值的误差量。 语法 STEYX(known_y's,known_x's) Known_y's为因变量数据点数组或区域。 Known_x's为自变量数据点数组或区域。 注解 参数可以是数字或者是包含数字的名称、数组或引用。 逻辑值和直接键入到参数列表中代表数字的文本被计算在内。 如果数组或引用参数包含文本、逻辑值或空白单元格,则这些值将被忽略;但包含零值的单元格将计算在内。 如果参数为错误值或为不能转换为数字的文本,将会导致错误。 如果known_y's 和known_x's 的数据点个数不同,函数STEYX 返回错误值#N/A。 如果known_y's 和known_x's 为空或其数据点个数小于三,函数STEYX 返回错误值#DIV/0!。
SPSS岭回归方法
岭回归程序调用语法(蔡国雄) 2011-12-7 1、运行:include'C:\Documents and Settings\Administrator\桌面\cgxridge.sps'. ridgereg dep=y/enter x1 x2 x3 x4 x5. ************************************** 输出结果如下:
2、运行:ridgereg dep=y/enter x2 x3 x4 x5/start=0.0/stop=0.2/INC=0.02. ******************************* 输出结果如下:
3、运行:ridgereg dep=y/enter x2 x3 x4 x5/k=0.08. ********************************************* 输出结果如下: 到此结束 附上数据: y x1 x2 x3 x4 x5 231 3010 1888 81491 14.89 180.92 298 3350 2195 86389 16 420.39 343 3688 2531 92204 19.53 570.25 401 3941 2799 95300 21.82 776.71 445 4258 3054 99922 23.27 792.43 391 4736 3358 106044 22.91 947.7 554 5652 3905 110353 26.02 1285.22 744 7020 4879 112110 27.72 1783.3
997 7859 5552 108579 32.43 2281.95 1310 9313 6386 112429 38.91 2690.23 1442 11738 8038 122645 37.38 3169.48 1283 13176 9005 113807 47.19 2450.14 1660 14384 9663 95712 50.68 2746.2 2178 16557 10969 95081 55.91 3335.65 2886 20223 12985 99693 83.66 3311.5 3383 24882 15949 105458 96.08 4152.7
如何用SPSS做logistic回归分析解读
如何用spss17.0进行二元和多元logistic回归分析 一、二元logistic回归分析 二元logistic回归分析的前提为因变量是可以转化为0、1的二分变量,如:死亡或者生存,男性或者女性,有或无,Yes或No,是或否的情况。 下面以医学中不同类型脑梗塞与年龄和性别之间的相互关系来进行二元logistic回归分析。 (一)数据准备和SPSS选项设置 第一步,原始数据的转化:如图1-1所示,其中脑梗塞可以分为ICAS、ECAS和NCAS三种,但现在我们仅考虑性别和年龄与ICAS的关系,因此将分组数据ICAS、ECAS和NCAS转化为1、0分类,是ICAS赋值为1,否赋值为0。年龄为数值变量,可直接输入到spss中,而性别需要转化为(1、0)分类变量输入到spss当中,假设男性为1,女性为0,但在后续分析中系统会将1,0置换(下面还会介绍),因此为方便期间我们这里先将男女赋值置换,即男性为“0”,女性为“1”。 图1-1 第二步:打开“二值Logistic 回归分析”对话框: 沿着主菜单的“分析(Analyze)→回归(Regression)→二元logistic (Binary Logistic)”的路径(图1-2)打开二值Logistic 回归分析选项框(图1-3)。
如图1-3左侧对话框中有许多变量,但在单因素方差分析中与ICAS 显著相关的为性别、年龄、有无高血压,有无糖尿病等(P<0.05),因此我们这里选择以性别和年龄为例进行分析。
在图1-3中,因为我们要分析性别和年龄与ICAS的相关程度,因此将ICAS选入因变量(Dependent)中,而将性别和年龄选入协变量(Covariates)框中,在协变量下方的“方法(Method)”一栏中,共有七个选项。采用第一种方法,即系统默认的强迫回归方法(进入“Enter”)。 接下来我们将对分类(Categorical),保存(Save),选项(Options)按照如图1-4、1-5、1-6中所示进行设置。在“分类”对话框中,因为性别为二分类变量,因此将其选入分类协变量中,参考类别为在分析中是以最小数值“0(第一个)”作为参考,还是将最大数值“1(最后一个)”作为参考,这里我们选择第一个“0”作为参考。在“存放”选项框中是指将不将数据输出到编辑显示区中。在“选项”对话框中要勾选如图几项,其中“exp(B)的CI(X)”一定要勾选,这个就是输出的OR和CI值,后面的95%为系统默认,不需要更改。
6、岭回归
6、岭回归(1)简单相关系数 相关性 不良贷款各项贷款余额本年累计应收贷 款贷款项目个数 本年固定资产投 资额 Pearson 相关性不良贷款 1.000 .844 .732 .700 .519 各项贷款余额.844 1.000 .679 .848 .780 本年累计应收贷款.732 .679 1.000 .586 .472 贷款项目个数.700 .848 .586 1.000 .747 本年固定资产投资额.519 .780 .472 .747 1.000 Sig. (单侧)不良贷款. .000 .000 .000 .004 各项贷款余额.000 . .000 .000 .000 本年累计应收贷款.000 .000 . .001 .009 贷款项目个数.000 .000 .001 . .000 本年固定资产投资额.004 .000 .009 .000 . N 不良贷款25 25 25 25 25 各项贷款余额25 25 25 25 25 本年累计应收贷款25 25 25 25 25 贷款项目个数25 25 25 25 25 本年固定资产投资额25 25 25 25 25 Y与四个自变量x1、x2、x3、x4的相关系数为0.844、0.732、0.700、0.519。说明y与4个变量是显著线性相关的,自变量之间也存在一定的相关性。 (2) 系数a 模型非标准化系数标准系数 t Sig. B 的 95.0% 置信区间相关性 B 标准误差试用版下限上限零阶偏部分 1 (常量) -1.02 2 .782 -1.306 .206 -2.654 .610 各项贷款余额.040 .010 .891 3.837 .001 .018 .062 .844 .651 .386 本年累计应收贷款.148 .079 .260 1.879 .075 -.016 .312 .732 .387 .189 贷款项目个数.015 .083 .034 .175 .863 -.159 .188 .700 .039 .018 本年固定资产投资额-.029 .015 -.325 -1.937 .067 -.061 .002 .519 -.397 -.195 回归方程: y=-1.022+0.040x1+0.148x2+0.015x3-0.029x4。在0.05的水平下,自变量x2、x3、 x4没有通过t检验,x4的回归系数不合理。