Ceph分布式存储

Ceph分布式存储系统
Ceph是根据加州大学Santa Cruz分校的Sage Weil的博士论文所设计开发的新一代自由软件分布式文件系统,其设计目标是良好的可扩展性(PB级别以上)、高性能及高可靠性。Ceph其命名和UCSC(Ceph 的诞生地)的吉祥物有关,这个吉祥物是“Sammy”,一个香蕉色的蛞蝓,就是头足类中无壳的软体动物。这些有多触角的头足类动物,是对一个分布式文件系统高度并行的形象比喻。
其设计遵循了三个原则:数据与元数据的分离,动态的分布式的元数据管理,可靠统一的分布式对象存储机制。本文将从Ceph的架构出发,综合性的介绍Ceph分布式文件系统特点及其实现方式。
一、Ceph基本架构
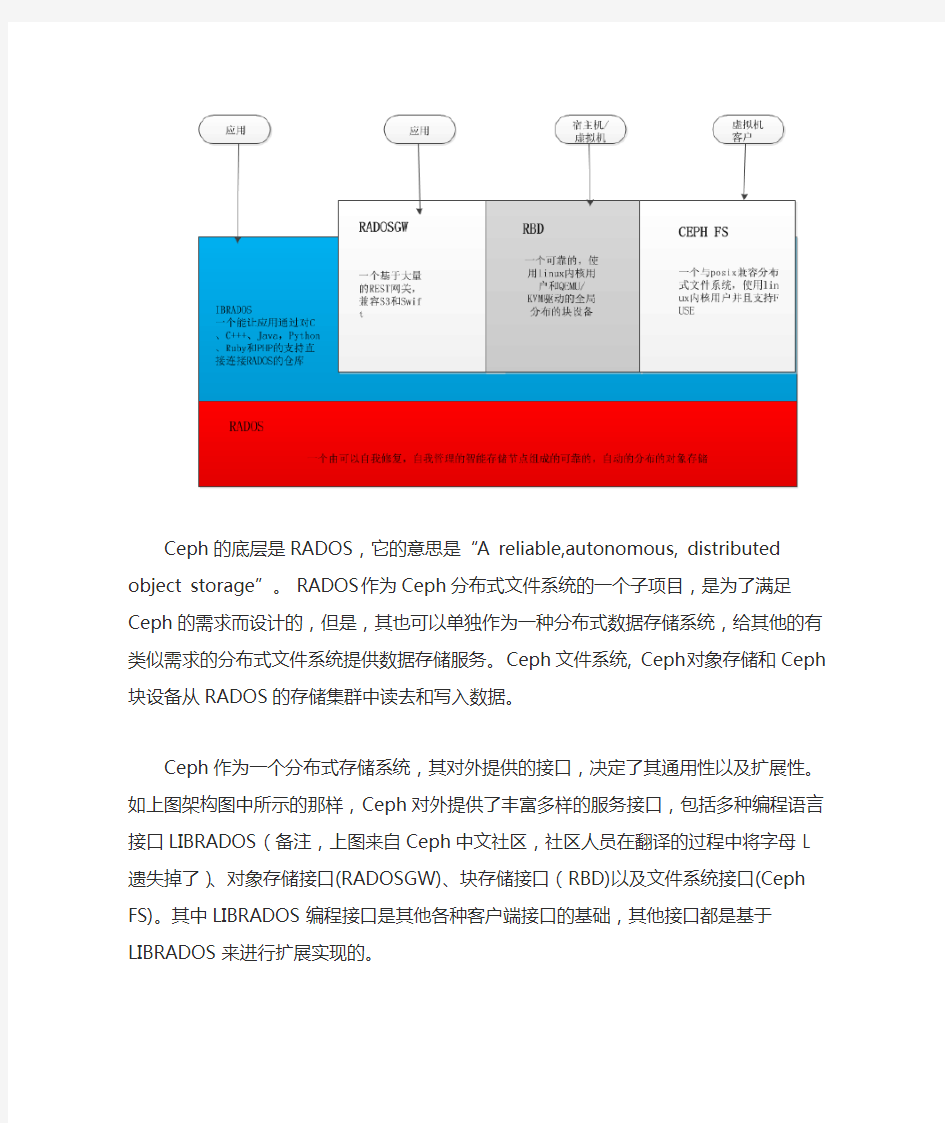
Ceph是一个高可用、易于管理、开源的分布式存储系统,可以在一套系统中同时提供对象存储、块存储以及文件存储服务。其主要由Ceph存储系统的核心RADOS以及块存取接口、对象存取接口和文件系统接口组成,如图所示
Ceph的底层是RADOS,它的意思是“A reliable,autonomous, distributed object storage”。 RADOS作为Ceph分布式文件系统的一个子项目,是为了满足Ceph的需求而
设计的,但是,其也可以单独作为一种分布式数据存储系统,给其他的有类似需求的分布式文件系统提供数据存储服务。Ceph文件系统, Ceph对象存储和Ceph块设备从RADOS的存储集群中读去和写入数据。
Ceph作为一个分布式存储系统,其对外提供的接口,决定了其通用性以及扩展性。如上图架构图中所示的那样,Ceph对外提供了丰富多样的服务接口,包括多种编程语言接口LIBRADOS(备注,上图来自Ceph中文社区,社区人员在翻译的过程中将字母L遗失掉了)、对象存储接口(RADOSGW)、块存储接口(RBD)以及文件系统接口(Ceph FS)。其中LIBRADOS编程接口是其他各种客户端接口的基础,其他接口都是基于LIBRADOS来进行扩展实现的。
1.1. RADOS
Ceph中RADOS(Reliable Autonomic Distributed Object Store)存储集群是所有其他客户端接口使用和部署的基础。RADOS由两个组件组成:
?OSD: Object StorageDevice,提供存储资源。
?Monitor:维护整个Ceph集群的全局状态。
典型的RADOS部署架构由少量的Monitor监控器以及大量的OSD存储设备组成,它能够在动态变化的基于异质结构的存储设备集群之上提供一种稳定的、可扩展的、高性能的单一逻辑对象存储接口。
RADOS系统的架构如图所示:
我们看到,RADOS不是某种组件,而是由OSD(Object Storage Device)集群和Monitor 集群组成。通常,一个RADOS系统中,OSD集群是由大量的智能化的OSD节点组成;Monitor集群是由少量的Monitor节点组成。OSD集群负责存储所有对象的数据。Monitors 集群负责管理Ceph集群中所有成员、关系、属性以及数据分发等信息。
1.2. Ceph客户端接口(Clients)
我们将Ceph架构中除了底层基础RADOS之上的LIBRADOS、RADOSGW、RBD以及Ceph FS统一称为Ceph客户端接口。而LIBRADOS又是Ceph其它如RADOSGW、RBD 以及Ceph FS的基础。简而言之就是RADOSGW、RBD以及Ceph FS根据LIBRADOS 提供的多编程语言接口开发。所以他们之间是一个阶梯级的关系。
1.2.1. RADOSGW
RADOSGW(RADOS Gmeway),又叫Ceph对象存储网关,是一个底层基于librados向客户端提供RESTful接口的对象存储接口。目前Ceph支持两种API接口:
(1)https://www.360docs.net/doc/ac14392207.html,patible:S3兼容的接口,提供与Amazon S3大部分RESTfuI API接口兼容的API接口。
(2)https://www.360docs.net/doc/ac14392207.html,patible:提供与OpenStack Swift大部分接口兼容的API接口。Ceph的对象存储使用网关守护进程(radosgw), radosgw结构图如图所示:
在实际的Ceph集群中,radosgw是一个监听RESTfulAPI访问的后台进程,s3 API和Swift APl使用同一个命名空间,即共享同一个命名空间;所以,你可以用其中一个接口写入数据而又用另外一个接口读出数据。
1.2.2. RBD
一个数据块是一个字节序列(例如,一个512字节的数据块)。基于数据块存储接口最常见的介质,如硬盘,光盘,软盘,甚至是传统的9磁道的磁带的方式来存储数据。块设备接口的普及使得虚拟块设备成为构建像Ceph海量数据存储系统理想选择。
在一个Ceph的集群中, Ceph的块设备支持自动精简配置,调整大小和存储数据。Ceph 的块设备可以充分利用RADOS功能,实现如快照,复制和数据一致性。Ceph的RADOS 块设备(即RBD)通过RADOS协议与内核模块或librbd的库进行交互。。RBD的结构如图所示:
在Ceph中,如果客户端要想使用存储集群服务提供的块存储,必须要先安装相应的Linux 内核模块Kernel Module,或者使用librbd编程接口。
1.2.3. Ceph FS
Ceph文件系统(CEPH FS)是一个POSIX兼容的文件系统,使用Ceph的存储集群来存储其数据。Ceph的文件系统使用相同的Ceph的存储集群系统比如Ceph的块设备,Ceph 的S3和SwiftAPI对象存储,或本机绑定(librados)。CEPH FS的结构图如下所示:
CEPH FS是一个符合POSIX标准的文件系统接口,同时支持用户空间文件系统FUSE。在CEPH FS中,与对象存储接口与块存储接口最大的不同就是在集群中增加了文件系统元数据服务节点MDS(Ceph Metadata Server)。MDS也支持多台机器分布式的部署,以实现系统的高可用性。文件系统客户端需要安装对应的Linux内核模块Ceph FS KernelObject或者Ceph FS FUSE组件。
二、Ceph数据存储
2.1. 数据存储过程
Ceph存储集群从客户端接收文件,每个文件都会被客户端切分成一个或多个对象,然后将这些对象进行分组,再根据一定的策略存储到集群的OSD节点中,其存储过程如图所示:
图中,对象的分发需要经过两个阶段的计算,才能得到存储该对象的OSD,然后将对象存储到OSD中对应的位置。
(1)对象到PG的映射。PG(PlaccmentGroup)是对象的逻辑集合。PG是系统向OSD节点分发数据的基本单位,相同PG里的对象将被分发到相同的OSD节点中(一个主OSD节点多个备份OSD节点)。对象的PG是由对象ID号通过Hash算法,结合其他一些修正参数得到的。
(2)PG到相应的OSD的映射,RADOS系统利用相应的哈希算法根据系统当前的状态以及PG的ID号,将各个PG分发到OSD集群中。OSD集群是根据物理节点的容错区域(比如机架、机房等)来进行划分的。
Ceph中的OSD节点将所有的对象存储在一个没有分层和目录的统一的命名空问中。每个对象都包含一个ID号、若干二进制数据以及相应的元数据。
ID号在整个存储集群中是唯一的;元数据标识了所存储数据的属性。一个对象在OSD节点中的存储方式大致如图所示。
而对存储数据的语义解释完全交给相应的客户端来完成,比如,Ceph FS客户端将文件元数据(比如所有者、创建日期、修改日期等)作为对象属性存储在Ceph中。
2.2. CRUSH算法
Ceph作为一个高可用、高性能的对象存储系统,其数据读取及写入方式是保证其高可用性及高性能的重要手段。对于已知的数据对象,Ccph通过使用CRUSH(ControlledReplication Under Scalable Hashing)算法计算出其在Ceph集群中的位置,然后直接与对应的OSD设备进行交互,进行数据读取或者写入。
例如其写入数据的其主要过程如图所示。
首先,客户端获取Ceph存储系统的状态信息Cluster Map,然后根据状态信息以及将要写入的Pool的CRUSH相关信息,获取到数据将要写入的OSD,最后
OSD将数据写入到其中相应的存储位置。其中相关概念的解释如下:
(1)集群地图(Cluster Map):Ceph依赖于客户端以及OSD进程中保存有整个集群相关的拓扑信息,来实现集群的管理和数据的读写。整个集群相关的拓扑信息就称之为“Cluster Map”。Cluster Map主要保存Monitor集群、OSD集群、MDS集群等相关的拓扑结构信息以及状态信息。
(2)存储池(P001):是对Ceph集群进行的逻辑划分,主要设置其中存储对象的权限、备份数目、PG数以及CRUSH规则等属性。
在传统的存储系统中,要查找数据通常是依赖于查找系统的的文件索引表找到对应的数据在磁盘中的位置。而在Ceph对象存储系统中,客户端与OSD节点都使用CRUSH算法来高效的计算所存储数据的相关信息。相对于传统的方式,CRUSH提供了一种更好的数据管理机制,它能够将数据管理的大部分工作都分配给客户端和OSD节点,这样为集群的扩大和存储容量的动态扩展带来了很大的方便。CRUSH是一种伪随机数据分布算法,它能够在具有层级结构的存储集群中有效的分发对象副本。
CRUSH算法是根据集群中存储设备的权重来进行数据分发的,数据在各个OSD设备上近似均匀概率分布。CRUSH中,数据在存储设备上的分布是根据一个层次化的集群地图(Cluster Map)来决定的。集群地图是由可用的存储资源以及由这些存储资源构建的集群的逻辑单元组成。比如一个Ceph存储集群的集群地图的结构可能是一排排大型的机柜,每个机柜中包含多个机架,每个机架中放置着存储设备。数据分发策略是依照数据的存放规则
(placement rules)进行定义的,存放规则是指数据在备份以及存放时应该遵循的相关约定,比如约定一个对象的三个副本应该存放在三个不同的物理机架上。
给定一个值为x的整数,CRUSH将根据相应的策略进行哈希计算输出一个
有序的包含n个存储目标的序列:
CRUSH(x)=(osd1,osd2,osd3osdn)
CRUSH利用健壮的哈希函数,其得到的结果依赖于集群地图Cluster Map、存放规贝则(placementmles)和输入x。并且CRUSH是一个伪随机算法,两个相似的输入得到的结果是没有明显的相关性的。这样就能确保Ceph中数据分布是随机均匀的。
2.3. 数据一致性
Ceph中,为了保持数据的一致性,在PG内部通常会进行对象的净化过程(scrubobjects)。数据净化通常每天进行一次(通常在数据I/O量不大,进行系统维护时进行)。OSD设备还能够通过进行数据对象bit-for-bit的对比进行深度的数据净化,用以找到普通数据净化中不易察觉的问题(比如磁盘扇区损坏等)。通过数据维护和净化,为数据的一致性提供了保障。
三、扩展性和高可用性
在传统的分布式系统中,客户端通常与一个中央节点进行交互,这样通常存在着单点故障问题,而且不利于系统的扩展。Ceph中客户端是直接与OSD节点进行交互,而不需要通过中心节点。对同一个对象,Ceph通常会在不同的OSD节点上创建多个备份,这样就保证了数据可靠性和高可用性。Ceph对元数据服务器也采用高可用的集群管理,这样也提高了系统元数据的的高可用性。Ceph的良好的高可用性和扩展性是系统设计的核心,这其中用到了很多精巧的设计和算法,下面就对实现Ceph的一些关键的实现技术进行介绍。
3.1. 高可用性的Monitor集群
在Ceph的客户端读或者写数据之前,他们必须先通过Ceph Monitor来获取最新的Cluster Map的副本。如果只有一个Monitor节点,Ceph存储集群也可以正常工作,但是这样会有单点的风险(如果这一台Monitor节点宕机了,整个Ceph
集群就无法正常工作)。Ceph中支持多台Monitor节点组成高可用的集群来提高整个Ceph 系统的高可用性。Ceph中通过Paxos算法来保持Monitor集群中各个节点的状态一致性。
3.2. 高可用性的MDS集群
在通过Ceph FS接口使用Ceph集群时,Ceph集群中需要部署MDS(Metadata Server)进程,通常也是使用集群的方式进行部署。MDS集群的主要作用是将所有的文件系统元数据(目录、文件拥有者、访问权限等)存放在高可用的内存中。这样,客户端简单的文件操作
(ls,cd等)将由MDS集群快速的响应,而不用消耗OSD设备的I/O,实现了元数据与数据的分离。为Ceph FS文件系统接口将能提供了性能上的保证。
Ccph FS旨在提供POSIX兼容的文件系统接口,依赖于MDS中运行的ceph-mds进程,该进程不仅能够作为一个单一的进程运行,还可以分布式的运行在多个服务器上,实现了高可用性和扩展性。
(1)高可用性:通常在Ceph集群中有多个ceph-mds进程在运行。当一个Ceph-mds出现运行故障时,备用的其他的ceph-mds能够立刻接替失效的ceph-mds的工作。这个过程主要依赖于Ceph中的日志机制并且通过高可用的Monitor进程来完成相关的恢复工作。(2)扩展性:Ceph集群中可以分布式的部署多个ceph-mds进程实例,他们共同完成Ceph 文件系统相关的工作,并且能够动态的实现负载均衡。
3.3. 超大规模智能守护(OSD)
在许多传统的集群架构中,往往设立一个中心节点来掌控整个集群的全部元数据信息,这样不仅会因为单点问题对系统的高可用性造成影响,而且中心节点的性能也会成为系统横向扩展的瓶颈。在Ceph就没有这样的瓶颈,在Ceph中,每个Ceph的客户端和OSD节点都保存有整个系统相关的拓扑信息。这样,客户端就能直接和存储数据的OSD节点进行交互,OSD节点相互之间也能直接进行交互。Ceph中去中心节点的架构能够带来以下一些好处:(1)OSD节点能直接为客户端提供服务:我们知道,任何网络设备都有一个并发连接的上限。中心节点结构的分布式集群中,中心节点往往是整个系统性能的瓶颈。Ceph中客户端能与存放数据的OSD节点直接通信,而不用经过任何的中心节点,这样整个系统不仅没有单点问题,而且性能就得到了很大的提升。
(2)OSD节点参与系统的维护:通常一个OSD节点加入到Ceph存储集群中,要向集群中的Monitor节点汇报自己的状态。如果OSD节点宕机,则需要系统能自动检测出来。这通常是由Monitor节点周期性的对各个OSD节点中的相关服务进行检测来实现。如果Monitor节点检测的周期间隔太短会影响系统的性能;而如果检测周期间隔太长,则会使整个系统有较长的时间处于不一致的状态。Ceph中允许OSD节点对相邻的OSD节点的状态进行检测,如果相邻的节点有状态变化,OSD节点则会主动向整个集群进行汇报,同时集群中相关的Cluster Map得到更新。这样大大减轻了Monitor节点的压力。系统的扩展性和高可用性得到很大的提升。
(3)OSD节点定期的数据清洁:数据清洁是指,一个OSD节点中存储的对象与另外一个存储该对象副本的OSD节点之间进行对象的元数据对比,依此来找出文件系统相关的错误。Ceph中OSD节点能够自动的进行数据清洁(通常是一天一次)。除了普通的数据清洁,Ceph
中OSD节点还可以通过对相同对象不同副本中的数据进行按位(bit-for-bit)的深度数据清洁(通常一周一次)。这种数据清洁机制对系统的数据一致性有很大的帮助。
(4)数据智能备份:和Ceph客户端一样,Ceph OSD节点也使用CRUSH算法。但是和客户端使用CRUSH算法来查找数据不同,Ceph OSD节点使用该算法来计算对象的备份副本应该被存储在哪个位置。数据智能备份的大致流程如图所示:
3.4. 智能负载均衡
当在Ceph集群中增加或减少OSD设备时,集群会执行负载再均衡的过程(rebalancing)。首先,集群地图(Cluster Map)会得到更新,PG ID以及OSD集群相关的信息都会得到更新。如下图,简单展示了增加OSD存储设备时数据再均衡的大致过程。其中,一些PG从其原来所处的OSD存储设备迁移到了新的OSD存储设备。在数据再均衡过程中,CRUSH 保持稳定,有许多的PG还是依然保留其原有的配置。并且由于进行了数据的迁出,原有OSD设备中的剩余容量也会相应的有所增加。整个数据再均衡过程也是利用的CRUSH算法,数据依然是均衡的分布在新的OSD集群中。
四、小结
在本文中,我们介绍了Ceph分布式文件系统的基本架构、工作机制及原理。并且从架构和原理的基础上论述了其优良的特性。综合看来,Ceph分布式文件系统有如下的特点:(1)Ceph的核心RADOS通常是由少量的负责集群管理的Monitor进程和大量的负责数据存储的OSD进程构成,采用无中心节点的分布式架构,对数据进行分块多份存储。具有良好的扩展性和高可用性。
(1)Ceph分布式文件系统提供了多种客户端,包括对象存储接口、块存储接口以及文件系统接口,具有广泛的适用性,并且客户端与存储数据的OSD设备直接进行数据交互,大大提高了数据的存取性能。
(2)Ceph作为分布式文件系统,其能够在维护 POSIX 兼容性的同时加入了复制和容错功能。从2010 年 3 月底,以及可以在Linux 内核(从2.6.34版开始)中找到 Ceph 的身影,作为Linux的文件系统备选之一,Ceph.ko已经集成入Linux内核之中。虽然目前Ceph 可能还不适用于生产环境,但它对测试目的还是非常有用的。Ceph 不仅仅是一个文件系统,还是一个有企业级功能的对象存储生态环境。现在,Ceph已经被集成在主线 Linux 内核中,但只是被标识为实验性的。在这种状态下的文件系统对测试是有用的,但是对生产环境没有做好准备。但是考虑到Ceph 加入到 Linux内核的行列,不久的将来,它应该就能用于解决海量存储的需要了。
五、参考资料
Ceph 中文文档:https://www.360docs.net/doc/ac14392207.html,/ceph
https://www.360docs.net/doc/ac14392207.html,/ceph/ceph4e2d658765876863/ceph-1
Ceph的工作原理及流程
本节将对Ceph的工作原理和若干关键工作流程进行扼要介绍。如前所述,由于Ceph的功能实现本质上依托于RADOS,因而,此处的介绍事实上也是针对RADOS进行。对于上层的部分,特别是RADOS GW和RBD,由于现有的文档中(包括Sage的论文中)并未详细介绍,还请读者多多包涵。
首先介绍RADOS中最为核心的、基于计算的对象寻址机制,然后说明对象存取的工作流程,之后介绍RADOS集群维护的工作过程,最后结合Ceph的结构和原理对其技术优势加以回顾和剖析。
Ceph系统中的寻址流程如下图所示:
上图左侧的几个概念说明如下:
1. File——此处的file就是用户需要存储或者访问的文件。对于一个基于Ceph开发的对象存储应用而言,这个file也就对应于应用中的“对象”,也就是用户直接操作的“对象”。
2. Ojbect——此处的object是RADOS所看到的“对象”。Object与上面提到的file
的区别是,object的最大size由RADOS限定(通常为2MB或4MB),以便实现底层存储的组织管理。因此,当上层应用向RADOS存入size很大的file时,需要将file切分成统一大小的一系列object(最后一个的大小可以不同)进行存储。为避免混淆,在本文中将尽量避免使用中文的“对象”这一名词,而直接使用file或object进行说明。
3. PG(Placement Group)——顾名思义,PG的用途是对object的存储进行组织和位置映射。具体而言,一个PG负责组织若干个object(可以为数千个甚至更多),但一个object只能被映射到一个PG中,即,PG和object之间是“一对多”映射关系。同时,一个PG会被映射到n个OSD上,而每个OSD上都会承载大量的PG,即,PG和OSD 之间是“多对多”映射关系。在实践当中,n至少为2,如果用于生产环境,则至少为3。一个OSD上的PG则可达到数百个。事实上,PG数量的设置牵扯到数据分布的均匀性问题。关于这一点,下文还将有所展开。
4. OSD——即object storage device,前文已经详细介绍,此处不再展开。唯一需要说明的是,OSD的数量事实上也关系到系统的数据分布均匀性,因此其数量不应太少。在实践当中,至少也应该是数十上百个的量级才有助于Ceph系统的设计发挥其应有的优势。
5. Failure domain——这个概念在论文中并没有进行定义,好在对分布式存储系统有一定概念的读者应该能够了解其大意。
基于上述定义,便可以对寻址流程进行解释了。具体而言,Ceph中的寻址至少要经历以下三次映射:
1. File -> object映射
这次映射的目的是,将用户要操作的file,映射为RADOS能够处理的object。其映射十分简单,本质上就是按照object的最大size对file进行切分,相当于RAID中的条带化过程。这种切分的好处有二:一是让大小不限的file变成最大size一致、可以被RADOS 高效管理的object;二是让对单一file实施的串行处理变为对多个object实施的并行化处理。
每一个切分后产生的object将获得唯一的oid,即object id。其产生方式也是线性映射,极其简单。图中,ino是待操作file的元数据,可以简单理解为该file的唯一id。ono则是由该file切分产生的某个object的序号。而oid就是将这个序号简单连缀在该file id之后得到的。举例而言,如果一个id为filename的file被切分成了三个object,则其object 序号依次为0、1和2,而最终得到的oid就依次为filename0、filename1和filename2。
这里隐含的问题是,ino的唯一性必须得到保证,否则后续映射无法正确进行。
2. Object -> PG映射
在file被映射为一个或多个object之后,就需要将每个object独立地映射到一个PG中去。这个映射过程也很简单,如图中所示,其计算公式是:
hash(oid) & mask ->pgid
由此可见,其计算由两步组成。首先是使用Ceph系统指定的一个静态哈希函数计算oid
的哈希值,将oid映射成为一个近似均匀分布的伪随机值。然后,将这个伪随机值和mask 按位相与,得到最终的PG序号(pgid)。根据RADOS的设计,给定PG的总数为m(m 应该为2的整数幂),则mask的值为m-1。因此,哈希值计算和按位与操作的整体结果事实上是从所有m个PG中近似均匀地随机选择一个。基于这一机制,当有大量object
和大量PG时,RADOS能够保证object和PG之间的近似均匀映射。又因为object是由file切分而来,大部分object的size相同,因而,这一映射最终保证了,各个PG中存储的object的总数据量近似均匀。
从介绍不难看出,这里反复强调了“大量”。只有当object和PG的数量较多时,这种伪随机关系的近似均匀性才能成立,Ceph的数据存储均匀性才有保证。为保证“大量”的成立,一方面,object的最大size应该被合理配置,以使得同样数量的file能够被切分成更多的object;另一方面,Ceph也推荐PG总数应该为OSD总数的数百倍,以保证有足够数量的PG可供映射。
3. PG -> OSD映射
第三次映射就是将作为object的逻辑组织单元的PG映射到数据的实际存储单元OSD。如图所示,RADOS采用一个名为CRUSH的算法,将pgid代入其中,然后得到一组共n个OSD。这n个OSD即共同负责存储和维护一个PG中的所有object。前已述及,n的数
值可以根据实际应用中对于可靠性的需求而配置,在生产环境下通常为3。具体到每个OSD,则由其上运行的OSD deamon负责执行映射到本地的object在本地文件系统中的存储、访问、元数据维护等操作。
和“object -> PG”映射中采用的哈希算法不同,这个CRUSH算法的结果不是绝对不变的,而是受到其他因素的影响。其影响因素主要有二:
一是当前系统状态,也就是上文逻辑结构中曾经提及的cluster map。当系统中的OSD状态、数量发生变化时,cluster map可能发生变化,而这种变化将会影响到PG与OSD之间的映射。
二是存储策略配置。这里的策略主要与安全相关。利用策略配置,系统管理员可以指定承载同一个PG的3个OSD分别位于数据中心的不同服务器乃至机架上,从而进一步改善存储的可靠性。
因此,只有在系统状态(cluster map)和存储策略都不发生变化的时候,PG和OSD之
间的映射关系才是固定不变的。在实际使用当中,策略一经配置通常不会改变。而系统状态的改变或者是由于设备损坏,或者是因为存储集群规模扩大。好在Ceph本身提供了对于这种变化的自动化支持,因而,即便PG与OSD之间的映射关系发生了变化,也并不会对应用造成困扰。事实上,Ceph正是需要有目的的利用这种动态映射关系。正是利用了CRUSH 的动态特性,Ceph可以将一个PG根据需要动态迁移到不同的OSD组合上,从而自动化
地实现高可靠性、数据分布re-blancing等特性。
之所以在此次映射中使用CRUSH算法,而不是其他哈希算法,原因之一正是CRUSH具
有上述可配置特性,可以根据管理员的配置参数决定OSD的物理位置映射策略;另一方面是因为CRUSH具有特殊的“稳定性”,也即,当系统中加入新的OSD,导致系统规模增大时,大部分PG与OSD之间的映射关系不会发生改变,只有少部分PG的映射关系会发生变化并引发数据迁移。这种可配置性和稳定性都不是普通哈希算法所能提供的。因此,CRUSH算法的设计也是Ceph的核心内容之一,具体介绍可以参考。
至此为止,Ceph通过三次映射,完成了从file到object、PG和OSD整个映射过程。通观整个过程,可以看到,这里没有任何的全局性查表操作需求。至于唯一的全局性数据结构cluster map,在后文中将加以介绍。可以在这里指明的是,cluster map的维护和操作
都是轻量级的,不会对系统的可扩展性、性能等因素造成不良影响。
一个可能出现的困惑是:为什么需要同时设计第二次和第三次映射?难道不重复么?关于这一点,Sage在其论文中解说不多,而笔者个人的分析如下:
我们可以反过来想像一下,如果没有PG这一层映射,又会怎么样呢?在这种情况下,一定需要采用某种算法,将object直接映射到一组OSD上。如果这种算法是某种固定映射的哈希算法,则意味着一个object将被固定映射在一组OSD上,当其中一个或多个OSD
损坏时,object无法被自动迁移至其他OSD上(因为映射函数不允许),当系统为了扩容新增了OSD时,object也无法被re-balance到新的OSD上(同样因为映射函数不允许)。这些限制都违背了Ceph系统高可靠性、高自动化的设计初衷。
如果采用一个动态算法(例如仍然采用CRUSH算法)来完成这一映射,似乎是可以避免静态映射导致的问题。但是,其结果将是各个OSD所处理的本地元数据量爆增,由此带来的计算复杂度和维护工作量也是难以承受的。
例如,在Ceph的现有机制中,一个OSD平时需要和与其共同承载同一个PG的其他OSD 交换信息,以确定各自是否工作正常,是否需要进行维护操作。由于一个OSD上大约承载数百个PG,每个PG内通常有3个OSD,因此,一段时间内,一个OSD大约需要进行数百至数千次OSD信息交换。
然而,如果没有PG的存在,则一个OSD需要和与其共同承载同一个object的其他OSD 交换信息。由于每个OSD上承载的object很可能高达数百万个,因此,同样长度的一段时间内,一个OSD大约需要进行的OSD间信息交换将暴涨至数百万乃至数千万次。而这种状态维护成本显然过高。
综上所述,笔者认为,引入PG的好处至少有二:一方面实现了object和OSD之间的动态映射,从而为Ceph的可靠性、自动化等特性的实现留下了空间;另一方面也有效简化了数据的存储组织,大大降低了系统的维护管理开销。理解这一点,对于彻底理解Ceph的对象寻址机制,是十分重要的。
此处将首先以file写入过程为例,对数据操作流程进行说明。
为简化说明,便于理解,此处进行若干假定。首先,假定待写入的file较小,无需切分,仅被映射为一个object。其次,假定系统中一个PG被映射到3个OSD上。
基于上述假定,则file写入流程可以被下图表示:
如图所示,当某个client需要向Ceph集群写入一个file时,首先需要在本地完成5.1节中所叙述的寻址流程,将file变为一个object,然后找出存储该object的一组三个OSD。这三个OSD具有各自不同的序号,序号最靠前的那个OSD就是这一组中的Primary OSD,而后两个则依次是Secondary OSD和Tertiary OSD。
找出三个OSD后,client将直接和Primary OSD通信,发起写入操作(步骤1)。Primary OSD收到请求后,分别向Secondary OSD和Tertiary OSD发起写入操作(步骤2、3)。当Secondary OSD和Tertiary OSD各自完成写入操作后,将分别向Primary OSD发
送确认信息(步骤4、5)。当Primary OSD确信其他两个OSD的写入完成后,则自己
也完成数据写入,并向client确认object写入操作完成(步骤6)。
之所以采用这样的写入流程,本质上是为了保证写入过程中的可靠性,尽可能避免造成数据丢失。同时,由于client只需要向Primary OSD发送数据,因此,在Internet使用场景下的外网带宽和整体访问延迟又得到了一定程度的优化。
当然,这种可靠性机制必然导致较长的延迟,特别是,如果等到所有的OSD都将数据写入磁盘后再向client发送确认信号,则整体延迟可能难以忍受。因此,Ceph可以分两次向client进行确认。当各个OSD都将数据写入内存缓冲区后,就先向client发送一次确认,此时client即可以向下执行。待各个OSD都将数据写入磁盘后,会向client发送一个最
终确认信号,此时client可以根据需要删除本地数据。
分析上述流程可以看出,在正常情况下,client可以独立完成OSD寻址操作,而不必依赖于其他系统模块。因此,大量的client可以同时和大量的OSD进行并行操作。同时,如果一个file被切分成多个object,这多个object也可被并行发送至多个OSD。
从OSD的角度来看,由于同一个OSD在不同的PG中的角色不同,因此,其工作压力也
可以被尽可能均匀地分担,从而避免单个OSD变成性能瓶颈。
如果需要读取数据,client只需完成同样的寻址过程,并直接和Primary OSD联系。目前的Ceph设计中,被读取的数据仅由Primary OSD提供。但目前也有分散读取压力以提高性能的讨论。
前面的介绍中已经提到,由若干个monitor共同负责整个Ceph集群中所有OSD状态的
发现与记录,并且共同形成cluster map的master版本,然后扩散至全体OSD以及client。OSD使用cluster map进行数据的维护,而client使用cluster map进行数据的寻址。
在集群中,各个monitor的功能总体上是一样的,其相互间的关系可以被简单理解为主从
备份关系。因此,在下面的讨论中不对各个monitor加以区分。
略显出乎意料的是,monitor并不主动轮询各个OSD的当前状态。正相反,OSD需要向monitor上报状态信息。常见的上报有两种情况:一是新的OSD被加入集群,二是某个OSD发现自身或者其他OSD发生异常。在收到这些上报信息后,monitor将更新cluster map信息并加以扩散。其细节将在下文中加以介绍。
Cluster map的实际内容包括:
(1)Epoch,即版本号。Cluster map的epoch是一个单调递增序列。Epoch越大,
则cluster map版本越新。因此,持有不同版本cluster map的OSD或client可以简单地通过比较epoch决定应该遵从谁手中的版本。而monitor手中必定有epoch最大、版
本最新的cluster map。当任意两方在通信时发现彼此epoch值不同时,将默认先将cluster map同步至高版本一方的状态,再进行后续操作。
(2)各个OSD的网络地址。
(3)各个OSD的状态。OSD状态的描述分为两个维度:up或者down(表明OSD是否正常工作),in或者out(表明OSD是否在至少一个PG中)。因此,对于任意一个OSD,共有四种可能的状态:
—— Up且in:说明该OSD正常运行,且已经承载至少一个PG的数据。这是一个OSD
的标准工作状态;
—— Up且out:说明该OSD正常运行,但并未承载任何PG,其中也没有数据。一个新
的OSD刚刚被加入Ceph集群后,便会处于这一状态。而一个出现故障的OSD被修复后,重新加入Ceph集群时,也是处于这一状态;
—— Down且in:说明该OSD发生异常,但仍然承载着至少一个PG,其中仍然存储着数据。这种状态下的OSD刚刚被发现存在异常,可能仍能恢复正常,也可能会彻底无法工作;—— Down且out:说明该OSD已经彻底发生故障,且已经不再承载任何PG。
(4)CRUSH算法配置参数。表明了Ceph集群的物理层级关系(cluster hierarchy),位置映射规则(placement rules)。
根据cluster map的定义可以看出,其版本变化通常只会由(3)和(4)两项信息的变化触发。而这两者相比,(3)发生变化的概率更高一些。这可以通过下面对OSD工作状态
变化过程的介绍加以反映。
一个新的OSD上线后,首先根据配置信息与monitor通信。Monitor将其加入cluster map,并设置为up且out状态,再将最新版本的cluster map发给这个新OSD。
收到monitor发来的cluster map之后,这个新OSD计算出自己所承载的PG(为简化
讨论,此处我们假定这个新的OSD开始只承载一个PG),以及和自己承载同一个PG的
其他OSD。然后,新OSD将与这些OSD取得联系。如果这个PG目前处于降级状态(即承载该PG的OSD个数少于正常值,如正常应该是3个,此时只有2个或1个。这种情况通常是OSD故障所致),则其他OSD将把这个PG内的所有对象和元数据复制给新OSD。数据复制完成后,新OSD被置为up且in状态。而cluster map内容也将据此更新。这
事实上是一个自动化的failure recovery过程。当然,即便没有新的OSD加入,降级的PG也将计算出其他OSD实现failure recovery。
如果该PG目前一切正常,则这个新OSD将替换掉现有OSD中的一个(PG内将重新选出Primary OSD),并承担其数据。在数据复制完成后,新OSD被置为up且in状态,而被替换的OSD将退出该PG(但状态通常仍然为up且in,因为还要承载其他PG)。而cluster map内容也将据此更新。这事实上是一个自动化的数据re-balancing过程。
如果一个OSD发现和自己共同承载一个PG的另一个OSD无法联通,则会将这一情况上报monitor。此外,如果一个OSD deamon发现自身工作状态异常,也将把异常情况主动上报给monitor。在上述情况下,monitor将把出现问题的OSD的状态设为down且in。如果超过某一预订时间期限,该OSD仍然无法恢复正常,则其状态将被设置为down 且out。反之,如果该OSD能够恢复正常,则其状态会恢复为up且in。在上述这些状态变化发生之后,monitor都将更新cluster map并进行扩散。这事实上是自动化的failure detection过程。
由之前介绍可以看出,对于一个Ceph集群而言,即便由数千个甚至更多OSD组成,cluster map的数据结构大小也并不惊人。同时,cluster map的状态更新并不会频繁发生。即便如此,Ceph依然对cluster map信息的扩散机制进行了优化,以便减轻相关计算和通信压力。
首先,cluster map信息是以增量形式扩散的。如果任意一次通信的双方发现其epoch 不一致,则版本更新的一方将把二者所拥有的cluster map的差异发送给另外一方。
其次,cluster map信息是以异步且lazy的形式扩散的。也即,monitor并不会在每一次cluster map版本更新后都将新版本广播至全体OSD,而是在有OSD向自己上报信息时,将更新回复给对方。类似的,各个OSD也是在和其他OSD通信时,将更新发送给版本低于自己的对方。
基于上述机制,Ceph避免了由于cluster map版本更新而引起的广播风暴。这虽然是一种异步且lazy的机制,但根据Sage论文中的结论,对于一个由n个OSD组成的Ceph 集群,任何一次版本更新能够在O(log(n))时间复杂度内扩散到集群中的任何一个OSD上。一个可能被问到的问题是:既然这是一种异步和lazy的扩散机制,则在版本扩散过程中,系统必定出现各个OSD看到的cluster map不一致的情况,这是否会导致问题?答案是:不会。事实上,如果一个client和它要访问的PG内部的各个OSD看到的cluster map 状态一致,则访问操作就可以正确进行。而如果这个client或者PG中的某个OSD和其他几方的cluster map不一致,则根据Ceph的机制设计,这几方将首先同步cluster map 至最新状态,并进行必要的数据re-balancing操作,然后即可继续正常访问。
通过上述介绍,我们可以简要了解Ceph究竟是如果基于cluster map机制,并由monitor、OSD和client共同配合完成集群状态的维护与数据访问的。特别的,基于这个机制,事实上可以自然而然的完成自动化的数据备份、数据re-balancing、故障探测和故障恢复,并不需要复杂的特殊设计。这一点确实让人印象深刻。
ceph分布式存储介绍
Ceph分布式存储 1Ceph存储概述 Ceph 最初是一项关于存储系统的PhD 研究项目,由Sage Weil 在University of California, Santa Cruz(UCSC)实施。 Ceph 是开源分布式存储,也是主线Linux 内核(2.6.34)的一部分。1.1Ceph 架构 Ceph 生态系统可以大致划分为四部分(见图1):客户端(数据用户),元数据服务器(缓存和同步分布式元数据),一个对象存储集群(将数据和元数据作为对象存储,执行其他关键职能),以及最后的集群监视器(执行监视功能)。 图1 Ceph 生态系统 如图1 所示,客户使用元数据服务器,执行元数据操作(来确定数据位置)。元数据服务器管理数据位置,以及在何处存储新数据。值得注意的是,元数据存储在一个存储集群(标为―元数据I/O‖)。实际的文件I/O 发生在客户和对象存储集群之间。这样一来,更高层次的POSIX 功能(例如,打开、关闭、重命名)就由元数据服务器管理,不过POSIX 功能(例如读和
写)则直接由对象存储集群管理。 另一个架构视图由图2 提供。一系列服务器通过一个客户界面访问Ceph 生态系统,这就明白了元数据服务器和对象级存储器之间的关系。分布式存储系统可以在一些层中查看,包括一个存储设备的格式(Extent and B-tree-based Object File System [EBOFS] 或者一个备选),还有一个设计用于管理数据复制,故障检测,恢复,以及随后的数据迁移的覆盖管理层,叫做Reliable Autonomic Distributed Object Storage(RADOS)。最后,监视器用于识别组件故障,包括随后的通知。 图2 ceph架构视图 1.2Ceph 组件 了解了Ceph 的概念架构之后,您可以挖掘到另一个层次,了解在Ceph 中实现的主要组件。Ceph 和传统的文件系统之间的重要差异之一就是,它将智能都用在了生态环境而不是文件系统本身。 图3 显示了一个简单的Ceph 生态系统。Ceph Client 是Ceph 文件系统的用户。Ceph Metadata Daemon 提供了元数据服务器,而Ceph Object Storage Daemon 提供了实际存储(对数据和元数据两者)。最后,Ceph Monitor 提供了集群管理。要注意的是,Ceph 客户,对象存储端点,元数据服务器(根据文件系统的容量)可以有许多,而且至少有一对冗余的监视器。那么,这个文件系统是如何分布的呢?
ceph源码分析之读写操作流程(2)
ceph源码分析之读写操作流程(2) 上一篇介绍了ceph存储在上两层的消息逻辑,这一篇主要介绍一下读写操作在底两层的流程。下图是上一篇消息流程的一个总结。上在ceph中,读写操作由于分布式存储的原因,故走了不同流程。 对于读操作而言: 1.客户端直接计算出存储数据所属于的主osd,直接给主osd 上发送消息。 2.主osd收到消息后,可以调用Filestore直接读取处在底层文件系统中的主pg里面的内容然后返回给客户端。具体调用函数在ReplicatedPG::do_osd_ops中实现。读操作代码流程如图:如我们之前说的,当确定读操作为主osd的消息时(CEPH_MSG_OSD_OP类型),会调用到ReplicatePG::do_osd_op函数,该函数对类型做进一步判断,当发现为读类型(CEPH_OSD_OP_READ)时,会调用FileStore中的函数对磁盘上数据进行读。 [cpp] view plain copy int ReplicatedPG::do_osd_ops(OpContext *ctx, vector<OSDOp>& ops) { …… switch (op.op) { …… case CEPH_OSD_OP_READ: ++ctx->num_read; { // read into a buffer bufferlist
bl; int r = osd->store->read(coll, soid, op.extent.offset, op.extent.length, bl); // 调用FileStore::read从底层文件系统读 取……} case CEPH_OSD_OP_WRITE: ++ctx->num_write; { ……//写操作只是做准备工作,并不实际的 写} ……} } FileStore::read 函数是底层具体的实现,会通过调用系统函数 如::open,::pread,::close等函数来完成具体的操作。[cpp] view plain copy int FileStore::read( coll_t cid, const ghobject_t& oid, uint64_t offset, size_t len, bufferlist& bl, bool allow_eio) { …… int r = lfn_open(cid, oid, false, &fd); …… got = safe_pread(**fd, bptr.c_str(), len, offset); //FileStore::safe_pread中调用了::pread …… lfn_close(fd); ……} 而对于写操作而言,由于要保证数据写入的同步性就会复杂很多: 1.首先客户端会将数据发送给主osd, 2.主osd同样要先进行写操作预处理,完成后它要发送写消息给其他的从osd,让他们对副本pg进行更改, 3.从osd通过FileJournal完成写操作到Journal中后发送消息
7种分布式文件系统介绍
FastDFS (7) Fastdfs简介 (7) Fastdfs系统结构图 (7) FastDFS和mogileFS的对比 (8) MogileFS (10) Mogilefs简介 (10) Mogilefs组成部分 (10) 0)数据库(MySQL)部分 (10) 1)存储节点 (11) 2)trackers(跟踪器) (11) 3)工具 (11) 4)Client (11) Mogilefs的特点 (12) 1. 应用层——没有特殊的组件要求 (12) 2. 无单点失败 (12) 3. 自动的文件复制 (12) 4. “比RAID好多了” (12) 5. 传输中立,无特殊协议 (13) 6.简单的命名空间 (13) 7.不用共享任何东西 (13) 8.不需要RAID (13)
9.不会碰到文件系统本身的不可知情况 (13) HDFS (14) HDFS简介 (14) 特点和目标 (14) 1. 硬件故障 (14) 2. 流式的数据访问 (14) 3. 简单一致性模型 (15) 4. 通信协议 (15) 基本概念 (15) 1. 数据块(block) (15) 2. 元数据节点(Namenode)和数据节点(datanode) . 16 2.1这些结点的用途 (16) 2.2元数据节点文件夹结构 (17) 2.3文件系统命名空间映像文件及修改日志 (18) 2.4从元数据节点的目录结构 (21) 2.5数据节点的目录结构 (21) 文件读写 (22) 1.读取文件 (22) 1.1 读取文件示意图 (22) 1.2 文件读取的过程 (23) 2.写入文件 (24) 2.1 写入文件示意图 (24)
CEPH分布式存储部署要点
CEPH分布式存储部署 PS:本文的所有操作均在mon节点的主机进行,如有变动另有注释 作者:网络技术部徐志权 日期:2014年2月10日 VERSION 1.0 更新历史: 2014.2.10:首次完成ceph部署文档,块设备及对象存储的配置随后添加。
一、部署前网络规划 1.1 环境部署 主机名公网IP(eth0)私网IP(eth1)操作系统运行服务node1 192.168.100.101 172.16.100.101 CentOS6.5 mon、mds node2 192.168.100.102 172.16.100.102 CentOS6.5 osd node3 192.168.100.103 172.16.100.103 CentOS6.5 osd ◆操作系统使用CentOS6.5,因为系统已经包含xfs的支持可以直接使用不需要再次 编译。 ◆由于CentOS6.5系统的内核为2.6.32,因此要关闭硬盘的写入缓存,若高于此版本 不需要关闭。 #hdparm -W 0 /dev/sdb 0 ◆本次部署一共有一个监控节点、一个元数据节点、两个数据节点,每个数据节点拥 有两个硬盘作为数据盘。 1.2 网络拓扑
1.3 配置服务器、安装ceph ●添加ceph的rpm库key #rpm --import 'https://https://www.360docs.net/doc/ac14392207.html,/git/?p=ceph.git;a=blob_plain;f=keys/release.asc' #rpm --import 'https://https://www.360docs.net/doc/ac14392207.html,/git/?p=ceph.git;a=blob_plain;f=keys/autobuild.asc' ●添加ceph-extras库 #vi /etc/yum.repos.d/ceph-extras [ceph-extras] name=Ceph Extras Packages baseurl=https://www.360docs.net/doc/ac14392207.html,/packages/ceph-extras/rpm/centos6/$basearch enabled=1 priority=2 gpgcheck=1 type=rpm-md gpgkey=https://https://www.360docs.net/doc/ac14392207.html,/git/?p=ceph.git;a=blob_plain;f=keys/release.asc [ceph-extras-noarch] name=Ceph Extras noarch baseurl=https://www.360docs.net/doc/ac14392207.html,/packages/ceph-extras/rpm/centos6/noarch enabled=1 priority=2 gpgcheck=1 type=rpm-md gpgkey=https://https://www.360docs.net/doc/ac14392207.html,/git/?p=ceph.git;a=blob_plain;f=keys/release.asc [ceph-extras-source] name=Ceph Extras Sources baseurl=https://www.360docs.net/doc/ac14392207.html,/packages/ceph-extras/rpm/centos6/SRPMS enabled=1 priority=2 gpgcheck=1 type=rpm-md gpgkey=https://https://www.360docs.net/doc/ac14392207.html,/git/?p=ceph.git;a=blob_plain;f=keys/release.asc ●添加ceph库 #rpm -Uvh https://www.360docs.net/doc/ac14392207.html,/rpms/el6/noarch/ceph-release-1-0.el6.noarch.rpm ●添加epel库 #rpm -Uvh https://www.360docs.net/doc/ac14392207.html,/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm ●安装ceph #yum update -y && yum install ceph -y
(完整版)Ceph分布式存储
Ceph分布式存储系统 Ceph是根据加州大学Santa Cruz分校的Sage Weil的博士论文所设计开发的新一代自由软件分布式文件系统,其设计目标是良好的可扩展性(PB级别以上)、高性能及高可靠性。Ceph其命名和UCSC(Ceph 的诞生地)的吉祥物有关,这个吉祥物是“Sammy”,一个香蕉色的蛞蝓,就是头足类中无壳的软体动物。这些有多触角的头足类动物,是对一个分布式文件系统高度并行的形象比喻。 其设计遵循了三个原则:数据与元数据的分离,动态的分布式的元数据管理,可靠统一的分布式对象存储机制。本文将从Ceph的架构出发,综合性的介绍Ceph分布式文件系统特点及其实现方式。 一、Ceph基本架构 Ceph是一个高可用、易于管理、开源的分布式存储系统,可以在一套系统中同时提供对象存储、块存储以及文件存储服务。其主要由Ceph存储系统的核心RADOS以及块存取接口、对象存取接口和文件系统接口组成,如图所示 Ceph的底层是RADOS,它的意思是“A reliable,autonomous, distributed object storage”。 RADOS作为Ceph分布式文件系统的一个子项目,是为了满足Ceph的需求
而设计的,但是,其也可以单独作为一种分布式数据存储系统,给其他的有类似需求的分布式文件系统提供数据存储服务。Ceph文件系统, Ceph对象存储和Ceph块设备从RADOS的存储集群中读去和写入数据。 Ceph作为一个分布式存储系统,其对外提供的接口,决定了其通用性以及扩展性。如上图架构图中所示的那样,Ceph对外提供了丰富多样的服务接口,包括多种编程语言接口LIBRADOS(备注,上图来自Ceph中文社区,社区人员在翻译的过程中将字母L遗失掉了)、对象存储接口(RADOSGW)、块存储接口(RBD)以及文件系统接口(Ceph FS)。其中LIBRADOS编程接口是其他各种客户端接口的基础,其他接口都是基于LIBRADOS 来进行扩展实现的。 1.1. RADOS Ceph中RADOS(Reliable Autonomic Distributed Object Store)存储集群是所有其他客户端接口使用和部署的基础。RADOS由两个组件组成: ?OSD: Object StorageDevice,提供存储资源。 ?Monitor:维护整个Ceph集群的全局状态。 典型的RADOS部署架构由少量的Monitor监控器以及大量的OSD存储设备组成,它能够在动态变化的基于异质结构的存储设备集群之上提供一种稳定的、可扩展的、高性能的单一逻辑对象存储接口。 RADOS系统的架构如图所示: 我们看到,RADOS不是某种组件,而是由OSD(Object Storage Device)集群和Monitor集群组成。通常,一个RADOS系统中,OSD集群是由大量的智能化的OSD节点组成;Monitor集群是由少量的Monitor节点组成。OSD集群负责存储所有对象的数据。Monitors集群负责管理Ceph集群中所有成员、关系、属性以及数据分发等信息。
ceph学习资料
Ceph分布式存储 1. ceph概念 Ceph作为分布式存储,它有如下特点: ?高扩展性:普通的x86服务器组成的ceph集群,最多支持1000台以上的服务器扩展,并且可以在线扩展。 ?高可靠性:数据容错性高,没有因为单点故障造成的数据丢失;多副本技术,数据安全性更加可靠;自动修复,数据丢失或者部分磁盘故障对全局没影响,不会影响上层的应用,对用户全透明。 ?高性能:数据是均匀分布到每个磁盘上的,读写数据都是有多个osd并发完成的,集群性能理论上来说随着集群节点数和osd的增长而线性增长。 2. ceph架构 2.1 组件
Ceph的底层是RADOS,它的意思是“A reliable, autonomous, distributed object storage”(一个可靠的自治的分布式存储,字面意思哈)。 RADOS系统逻辑架构图: RADOS主要由两个部分组成。一种是大量的、负责完成数据存储和维护功能的OSD(Object Storage Device),另一种则是若干个负责完成系统状态检测和维护的monitor。osd和monitor之间相互传输节点状态信息。 而ceph集群主要包括mon、mds、osd组件 其中,mon负责维护整个集群的状态以及包括crushmap、pgmap、osdmap等一系列map 信息记录与变更。 Osd负责提供数据存储,数据的恢复均衡。 Mds(元数据服务器)主要是使用文件系统存储的时候需要,它主要负责文件数据的inode 信息,并让客户端通过该inode信息快速找到数据实际所在地。 2.2 数据映射流程 在Ceph中,文件都是以object(对象)的方式存放在众多osd上。 一个file(数据)的写入顺序: 首先mon根据map信息将file(数据)切分成多个的object;再通过hash算法决定这些个object对象分别会存放在那些pg(放置组)里面;接下来在通过crushmap再决定将pg放在底层的那些osd上,pg与osd的关系属于一对多的关系。一个osd可以包括多
分布式存储基础、Ceph、cinder及华为软件定义的存储方案
块存储与分布式存储 块存储,简单来说就是提供了块设备存储的接口。通过向内核注册块设备信息,在Linux 中通过lsblk可以得到当前主机上块设备信息列表。 本文包括了单机块存储介绍、分布式存储技术Ceph介绍,云中的块存储Cinder,以及华为软件定义的存储解决方案。 单机块存储 一个硬盘是一个块设备,内核检测到硬盘然后在/dev/下会看到/dev/sda/。因为需要利用一个硬盘来得到不同的分区来做不同的事,通过fdisk工具得到/dev/sda1, /dev/sda2等,这种方式通过直接写入分区表来规定和切分硬盘,是最死板的分区方式。 分布式块存储 在面对极具弹性的存储需求和性能要求下,单机或者独立的SAN越来越不能满足企业的需要。如同数据库系统一样,块存储在scale up的瓶颈下也面临着scale out的需要。 分布式块存储系统具有以下特性: 分布式块存储可以为任何物理机或者虚拟机提供持久化的块存储设备; 分布式块存储系统管理块设备的创建、删除和attach/detach; 分布式块存储支持强大的快照功能,快照可以用来恢复或者创建新的块设备; 分布式存储系统能够提供不同IO性能要求的块设备。 现下主流的分布式块存储有Ceph、AMS ESB、阿里云磁盘与sheepdog等。 1Ceph 1.1Ceph概述 Ceph目前是OpenStack支持的开源块存储实现系统(即Cinder项目backend driver之一) 。Ceph是一种统一的、分布式的存储系统。“统一的”意味着Ceph可以一套存储系统同时提供对象存储、块存储和文件系统存储三种功能,以便在满足不同应用需求的前提下简化部署
RedHat Ceph分布式存储指南-块设备模块
Red Hat Customer Content Services Red Hat Ceph Storage 1.3Ceph Block Device Red Hat Ceph Storage Block Device
Red Hat Ceph Storage 1.3 Ceph Block Device Red Hat Ceph Storage Block Device
Legal Notice Copyright ? 2015 Red Hat, Inc. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at https://www.360docs.net/doc/ac14392207.html,/licenses/by-sa/3.0/ . In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, JBoss, MetaMatrix, Fedora, the Infinity Logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ? is the registered trademark of Linus Torvalds in the United States and other countries. Java ? is a registered trademark of Oracle and/or its affiliates. XFS ? is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ? is a registered trademark of MySQL AB in the United States, the European Union and other countries. Node.js ? is an official trademark of Joyent. Red Hat Software Collections is not formally related to or endorsed by the official Joyent Node.js open source or commercial project. The OpenStack ? Word Mark and OpenStack Logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation's permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community. All other trademarks are the property of their respective owners. Abstract This document describes how to manage create, configure and use Red Hat Ceph Storage block devices.
Ceph分布式存储平台部署手册
Ceph分布式存储平台 部署手册
目录 1.CEPH的架构介绍 (5) 2.CEPH在OPENSTACK中应用的云存储的整体规划 (6) 3.CEPH集群安装在UBUNTU 12.04 (7) 3.1.配置ceph源7 3.2.依需求修改ceph.conf配置文件7 3.3.设置主机的hosts 9 3.4.设置集群节点之间无密钥访问9 3.5.创建目录10 3.6.创建分区与挂载10 3.7.执行初始化11 3.8.启动ceph 11 3.9.ceph健康检查11 4.CEPH集群安装在CENTOS6.4 (12) 4.1.安装更新源12 4.2.使用rpm安装ceph0.67.4 12 4.3.依需求修改ceph.conf配置文件13 4.4.设置主机的hosts 21 4.5.设置集群节点之间无密钥访问21 4.6.创建目录22 4.7.执行初始化22 4.8.启动ceph 22 4.9.ceph健康检查23
5.OPENSTACK GLANCE 使用CEPH集群的配置 (24) 5.1.创建卷池和图像池24 5.2.增加两个池的复制水平24 5.3.为池创建 Ceph 客户端和密钥环24 5.4.在计算节点应用密钥环24 5.4.1.创建libvirt密钥24 5.4.2.计算节点ceph安装25 5.5.更新你的 glance-api 配置文件25 6.OPENSTACK VOLUMES使用CEPH集群的配置 (27) 6.1.计算节点ceph安装27 6.2.创建临时的 secret.xml 文件27 6.3.设定 libvirt 使用上面的密钥28 6.4.更新 cinder 配置28 6.4.1.cinder.conf文件更改28 6.4.2.更改 cinder 启动脚本配置文件29 6.4.3.更改/etc/nova/nova.conf配置29 6.4.4.重启 cinder 服务29 6.5.验证cinder-volume 29 6.6.验证rdb创建volume 30 7.挂载CEPHFS (31) 7.1.配置/etc/fstab 31 7.2.挂载vm实例目录31 8.FQA (32)
SKY 分布式存储解决方案
XSKY统一存储解决方案 2017.5
研发核心?团队A :来自一线互联网,国内Ceph 社区贡献第一;?团队B :来自IT 领导厂商的存储产品研发。 关于XSKY | 星辰天合 ?总部位于北京,在上海、深圳等地有办事处和研发中心 ?启明创投、北极光创投和红点投资,A 轮前融资额¥7200万, B 轮融资额¥1亿2000万元; ?员工140+人,研发+服务~100+人; ?公司愿景:提供企业就绪的分布式软件定义存储产品,帮助客 户实现数据中心架构革新; ?产品:X-EBS 分布式块存储,X-EOS 分布式对象存储,X-EDP 统一数据平台。XSKY 公司和团队简介 Future Ready SDS 关于公司 ?Ceph 分布式存储技术中国领先者,2016年Ceph 社区中 国贡献率第一 ? 拥有近40个产品专利和软著? 中国开源云联盟理事会员?IDC 重点关注的软件定义存储创业公司
XSKY在ceph 社区的贡献度 3
XSKY如何为Ceph社区贡献源代码 XSKY开源贡献主要集中在NVMe, DPDK/SPDK/RDMA整合,BlueStore,网络 优化,OSD,MON性能优化等等方面。 XSKY为Ceph网络层AsyncMessanger的主 要贡献和维护者。 XSKY2016年10月将Ceph的 InfiniBand/RDMA互联共享给upstream。
产品以Ceph为引擎,构建企业级分布式存储产品 ?企业级接口,FC和iSCSI,多路径 ?高性能,低延时、百亿级文件对象 ?持续服务,高水平SLA和业务QoS保证 ?易运维,全图形化操作,0命令行运维 ?内置数据保护功能,一站式解决数据安全问题 ?完善的社区生态,高速增长的数据服务能力 ?成熟的数据分布算法(CRUSH) ?统一存储API,主流云平台接口 ?软件定义,硬件持续革新 5
Ceph安装部署与测试调优
Ceph安装部署及测试调优
目录 1.熟悉Ceph存储的基本原理与架构 2.掌握Ceph集群的安装部署方法 3.掌握Ceph常见的性能测试调优方法
目录 1.基本概念及架构 2.安装部署 3.测试调优
Ceph是一个统一的分布式存储系统,具有高扩展性、高可靠性、高性能,基于RADOS(reliable, autonomous, distributed object store ),可提供对象存储、块设备存储、文件系统存储三种接口 RADOS:是Ceph集群的精华,为用户实现 数据分配、Failover等集群操作。 LIBRADOS:Librados是RADOS的提供库, 上层的RBD、RGW和CephFS都是通过 LIBRADOS访问的,目前提供PHP、Ruby、 Java、Python、C和C++支持。 RBD:RBD全称RADOS block device,是 Ceph对外提供的块设备服务。 RGW:RGW全称RADOS gateway,是 Ceph对外提供的对象存储服务,接口与S3和 Swift兼容。 CephFS:CephFS全称Ceph File System, 是Ceph对外提供的文件系统服务
OSD :Ceph OSD 进程,功能是负责读写数据,处理数据的复制、恢复、回填、再均衡,并通过检查其他OSD 守护进程的心跳来向Ceph Monitors 提供一些监控信息。 Monitor :集群的管理进程,维护着展示集群状态的各种图表,包括监视器图、OSD 图、归置组 (PG )图、和CRUSH 图。 MDS :Ceph 元数据服务器,为Ceph 文件系统存储元数据(也就是说,Ceph 块存储和Ceph 对象存储不使用MDS ) 。 Ceph 存储集群
Ceph分布式存储架构深度分析
Ceph分布式存储架构深度分析
本文主要讨论Ceph架构,同时对Ceph生态、特性和企业级存储进行对比分析。 Ceph使用C++语言开发,遵循LGPL协议开源。Sage Weil(Ceph论文发表者)于2011年创立了以Inktank公司主导Ceph的开发和社区维护。2014年Redhat收购inktank公司,并发布InktankCeph 企业版(ICE)软件,业务场景聚焦云、备份和归档,支持对象和块存储应用。从此出现Ceph开源社区版本和Redhat企业版。 Cehp的基础服务架构 Cehp的基础服务架构主要包括了Object Storage Device(OSD),Monitor和MDS。基于此,Ceph提供了Librados原生对象基础库、Librbd块存储库、Librgw基于S3和Swift兼容的对象库和Libceph文件系统库。 OSD(Object Storage Device)负责存储数据,处理数据复制、数据恢复、数据再均衡以及通过心跳机制监测其它OSD状况并报告给Ceph Monitors。 Monitor负责监控集群状态,包括监控自身状态、集群OSD状态、Placement Group(存储组织和位置映射)状态、CRUSH状态(Controlled Replication Under Scalable Hashing,一种伪随机数据分布算法)。同时,Monitor还会记录它们的每一个历史状态改变版本信息,以确定集群该遵循哪个版本。 MDS负责文件系统的元数据存储和管理,也就是如前所说,块存储和对象存储服务是不需要这个模块的。MDS负责提供标准的POSIX文件访问接口。