基于SPSS的学生能力倾向聚类分析研究_罗家国

基于SPSS的学生能力倾向聚类分析研究
罗家国 罗 浩 仲佳嘉
【摘 要】 本文主要介绍了一种基于SPSS聚类分析功能的学生就业潜能评价方法,以求从教育统计学的视角探索毕业生就业咨询的新途径,为教学管理改革提供参考,进而达到改进大学生职业生涯教育、寻求增强毕业生成长后劲的最佳择业取向之目的。实验结果表明此方法快速、直观、全面且针对性较强。【关键词】 就业咨询 SPSS 聚类分析【收稿日期】 2
012年1月【作者简介】 罗家国,江西理工大学教务处教授;罗浩,江西理工大学应用科学学院讲师;仲佳嘉,江西赣州供电公司工程师。
择业是人生的重要转折点,
它在相当的程度上决定着人一生所从事的职业及今后事业的发展,
因此择业是一项非常重要和谨慎的工作。一个人在工作上能否有所作为,
最主要取决于两点:首先是兴趣、爱好和性格特点;其次是其能力倾
向,不同人的能力倾向是有差异的[
1]
。怎样根据学生的学业成绩指导学生就业?笔者通过多年的研究发现,
通过聚类分析对学生潜能进行评价,是提高学生就业能力和就业质量的一种定量分析方法。所谓“
聚类分析”,它是一种教育统计分析方法,
是数据挖掘技术的重要组成部分,它能够在不同的潜在数据中发现数据分布模式,
从而找出修正这一模式的方法[2]
。换言之,
我们可以通过采集学生的学习成绩数据,对学生的能力倾向进行“聚类分析”,从而有的放矢地对学生进行就业指导。具体操作是:首先,对学生的学业成绩进行“聚类分析”,把学生按某种能力属性分成若干小组(
类);再根据各门课程的特点分析每类学生的能力倾向;最后,根据每类学生的能力倾向和不同职业特点进行科学的就业指导。
一、数学模型及SPSS简介
本课题研究所采用的聚类分析数学模型:欧氏距离平方(Sq
uared Euclidean Distance)SEUCLID=∑k
i=1(xi-yi)
[2][3]
其中,k表示每个样本有k个变量;xi表示第一个样本在第i个变量上的取值;yi表示第二个样本在第i个变量上的取值。
SPSS的全称是Statistical Prog
ram for So-cial Sciences,即社会科学统计程序。SPSS的基本功能包括数据管理、统计分析、图表分析等,几乎无所不包。它名为社会科学统计软件包,这是为了强调其社会科学应用的一面,
而实际上它在社会科学、自然科学的各个领域都能发挥巨大的作用,并已经应用于经济学、生物学、教育学、心理学、医学以及体育、工业、农业、林业、商业和金融等各个领域。
二、用SPSS对学生学习状况进行差异分
析[
4]
用SPSS对学生学习状况进行差异分析的步骤是:
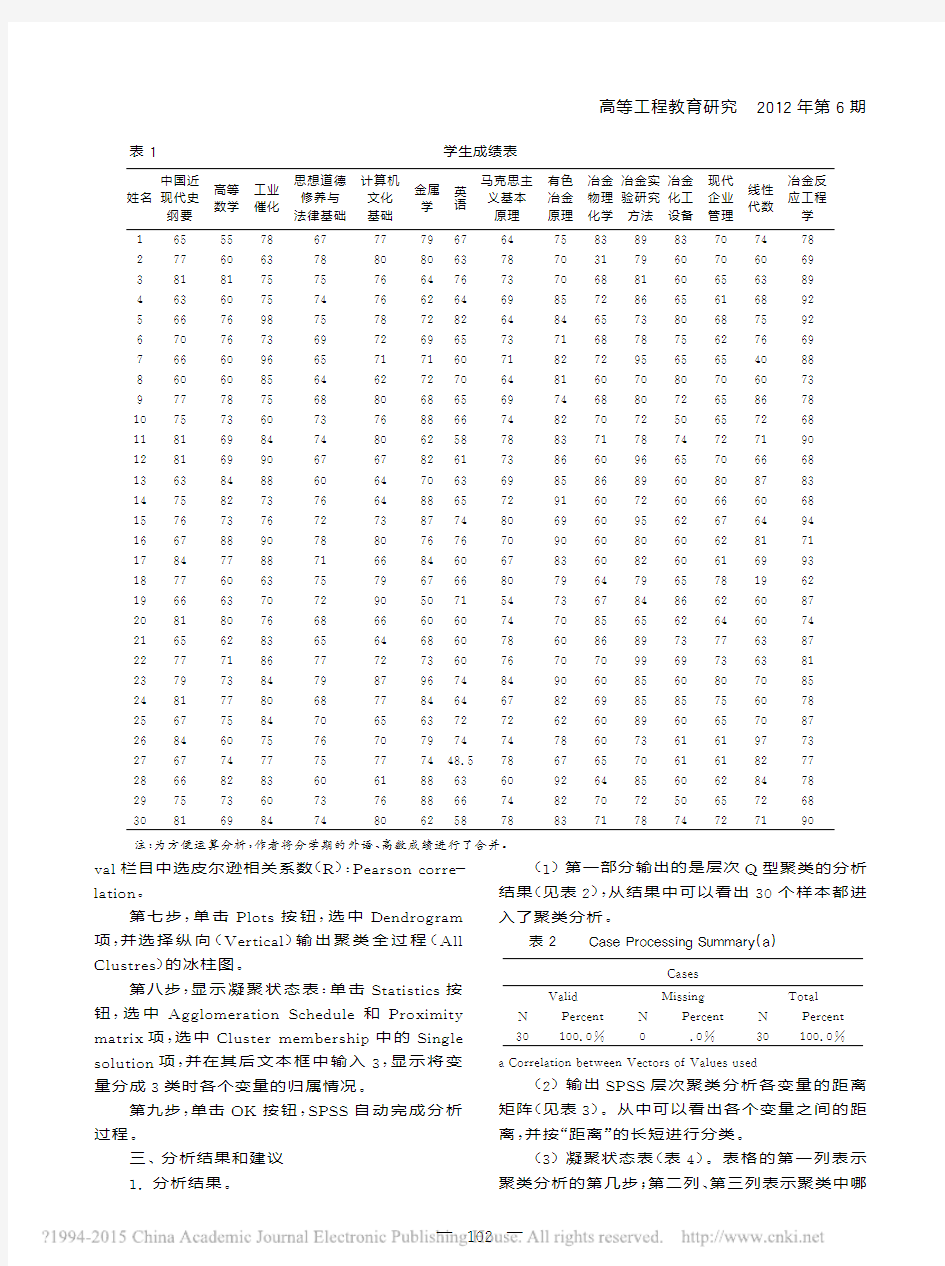
第一步,建立学生成绩EXCEL样本文档(如表1
)。第二步,启动并进入SPSS系统,将上述表中数据导入系统。
第三步,进入系统分析功能,在“Analyze”菜单“Classify
”中选择Hierarechical cluster命令。第四步,在弹出的Hierarechical cluster anal-y
sis对话框中,从对话框左侧的变量列表中选择“高等数学、工业催化、金属学、英语、有色冶金原理……”等变量,使之添加到右边的Variable(s)框中。
第五步,确定变量的Q型聚类,选择复选框:Variables
。第六步,单击Method按钮,选择聚类方法:Between-groups linkage类间平均法,即两类距离为两类元素两两之间平均平方距离。在Inter
—
101—
表1
学生成绩表
姓名中国近
现代史
纲要高等
数学工业
催化思想道德
修养与法律基础计算机
文化基础金属
学
英语
马克思主义基本原理有色
冶金原理冶金物理化学冶金实验研究方法冶金
化工设备现代
企业管理线性
代数冶金反
应工程学1 65 55 78 67 77 79 67 64 75 83 89 83 70 74 782 77 60 63 78 80 80 63 78 70 31 79 60 70 60 693 81 81 75 75 76 64 76 73 70 68 81 60 65 63 894 63 60 75 74 76 62 64 69 85 72 86 65 61 68 925 66 76 98 75 78 72 82 64 84 65 73 80 68 75 926 70 76 73 69 72 69 65 73 71 68 78 75 62 76 697 66 60 96 65 71 71 60 71 82 72 95 65 65 40 888 60 60 85 64 62 72 70 64 81 60 70 80 70 60 739 77 78 75 68 80 68 65 69 74 68 80 72 65 86 7810 75 73 60 73 76 88 66 74 82 70 72 50 65 72 6811 81 69 84 74 80 62 58 78 83 71 78 74 72 71 9012 81 69 90 67 67 82 61 73 86 60 96 65 70 66 6813 63 84 88 60 64 70 63 69 85 86 89 60 80 87 8314 75 82 73 76 64 88 65 72 91 60 72 60 66 60 6815 76 73 76 72 73 87 74 80 69 60 95 62 67 64 9416 67 88 90 78 80 76 76 70 90 60 80 60 62 81 7117 84 77 88 71 66 84 60 67 83 60 82 60 61 69 9318 77 60 63 75 79 67 66 80 79 64 79 65 78 19 6219 66 63 70 72 90 50 71 54 73 67 84 86 62 60 8720 81 80 76 68 66 60 60 74 70 85 65 62 64 60 7421 65 62 83 65 64 68 60 78 60 86 89 73 77 63 8722 77 71 86 77 72 73 60 76 70 70 99 69 73 63 8123 79 73 84 79 87 96 74 84 90 60 85 60 80 70 8524 81 77 80 68 77 84 64 67 82 69 85 85 75 60 7825 67 75 84 70 65 63 72 72 62 60 89 60 65 70 8726 84 60 75 76 70 79 74 74 78 60 73 61 61 97 7327 67 74 77 75 77 74 48.5 78 67 65 70 61 61 82 7728 66 82 83 60 61 88 63 60 92 64 85 60 62 84 7829 75 73 60 73 76 88 66 74 82 70 72 50 65 72 6830
81
69
84
74
80
62 58
78
83
71
78
74
72
71
90
注:
为方便运算分析,作者将分学期的外语、高数成绩进行了合并。val栏目中选皮尔逊相关系数(R):Pearson corre-lation
。第七步,单击Plots按钮,选中Dendrogram项,并选择纵向(Vertical)输出聚类全过程(AllClustres
)的冰柱图。第八步,显示凝聚状态表:单击Statistics按钮,选中Agglomeration Schedule和Proximitymatrix项,选中Cluster membership中的Singlesolution项,并在其后文本框中输入3,显示将变量分成3类时各个变量的归属情况。
第九步,单击OK按钮,SPSS自动完成分析过程。
三、分析结果和建议1.分析结果。
(1
)第一部分输出的是层次Q型聚类的分析结果(见表2),从结果中可以看出30个样本都进入了聚类分析。
表2
Case Processing
Summary(a)Cases
Valid Missing
TotalN Percent N Percent N Percent30
100.0%
0
.0%
30
100.0%
a Correlation between Vectors of Values
used(2)输出SPSS层次聚类分析各变量的距离矩阵(见表3)。从中可以看出各个变量之间的距离,并按“距离”的长短进行分类。
(3
)凝聚状态表(表4)。表格的第一列表示聚类分析的第几步;
第二列、第三列表示聚类中哪—
201—
高等工程教育研究 2012年第6期
表3Proximity MatrixCase Matrix File Input
中国近现代史纲要高等数
学
工业催
化
思想道
德修养
与法律
基础
计算机
文化基
础
金属学英语
马克思
主义基
本原理
有色冶
金原理
冶金物
理化学
冶金实
验研究
方法
冶金化
工设备
现代企
业管理
线性代
数
冶金反
应工程
学
中国近现代史纲要10.
14442
-0.
21437
0.
419287
0.
177098
0.2242
-0.
09017
0.
466591
0.
043944
-0.
23304
-0.
1151
-0.
22848
0.
072441
-0.
05988
-0.
0962
高等数学0.
14442
1
0.
182042
-0.
0264
-0.
17615
0.
191957
0.
106588
-0.
04714
0.
238426
0.
059223
-0.
15851
-0.
33969
-0.
14969
0.
372153
-0.
0053
工业催化-0.
21437
0.
182042
1
-0.
28231
-0.
274
-0.
07579
0.
047708
-0.
18881
0.
229011
0.
175068
0.
388227
0.
286484
0.
139913
0.
154184
0.
509945
思想道德修养与法律基础0.
419287
-0.
0264
-0.
28231
1
0.
606054
0.
084771
0.
24613
0.
458202
0.
00747
-0.
47978
-0.
24572
-0.
21585
-0.
08891
-0.
07219
-0.
04856
计算机文化基础0.
177098
-0.
17615
-0.
274
0.
606054
1
-0.
14999
0.
204215
0.
108549
0.
029446
-0.
17773
-0.
06329
0.
23367
0.
073003
-0.
08269
0.
097417
金属学0.22420.
191957
-0.
07579
0.
084771
-0.
14999
1
0.
096161
0.
203981
0.
425077
-0.
33843
0.
040259
-0.
43129
0.
094319
0.
173089
-0.
29994
英语-0.
09017
0.
106588
0.
047708
0.
24613
0.
204215
0.
096161
1
-0.
22093
0.
121479
-0.
23046
-0.
02601
0.
054585
-0.
05243
0.
089146
0.
095956
马克思主义基本原理0.
466591
-0.
04714
-0.
18881
0.
458202
0.
108549
0.
20398
1
-0.
220931
-0.
21558
-0.
12672
-0.
0044
-0.
44456
0.
381055
-0.
17677
-0.
10659
有色冶金原理0.
043944
0.
238426
0.
229011
0.
00747
0.
029446
0.
425077
0.
121479
-0.
21558
1
-0.
09922
-0.
10136
-0.
13525
0.
053127
0.
097682
-0.
13394
冶金物理化学-0.
23304
0.
059223
0.
175068
-0.
47978
-0.
17773
-0.
33843
-0.
23046
-0.
12672
-0.
09922
1
0.
08935
0.
219066
0.
189642
0.
065486
0.
226231
冶金实验研究方法-0.
1151
-0.
15851
0.
388227
-0.
24572
-0.
06329
0.
040259
-0.
02601
-0.
0044
-0.
10136
0.
08935
1
0.
127193
0.
301409
-0.
15527
0.
38234
冶金化工设备-0.
22848
-0.
33969
0.
286484
-0.
21585
0.
23367
-0.
43129
0.
054585
-0.
44456
-0.
13525
0.
219066
0.
127193
1
0.
207093
-0.
11395
0.
24493
现代企业管理0.
072441
-0.
14969
0.
139913
-0.
08891
0.
073003
0.
094319
-0.
05243
0.
381055
0.
053127
0.
189642
0.
301409
0.
207093
1
-0.
31653
0.
005613
线性代数-0.
05988
0.
372153
0.
154184
-0.
07219
-0.
08269
0.
173089
0.
089146
-0.
17677
0.
097682
0.
065486
-0.
15527
-0.
11395
-0.
31653
1
0.
10244
冶金反应工程学-0.
0962
-0.
0053
0.
509945
-0.
04856
0.
097417
-0.
29994
0.
095956
-0.
10659
-0.
13394
0.
226231
0.
38234
0.
24493
0.
005613
0.
10244
1
表4Agglomeration Schedule
Stage
Cluster Combined
Cluster 1Cluster 2
Coefficients
Stage Cluster First Appears
Cluster 1Cluster 2
Next Stage
1 4 5.606 0 0 72 3 15.510 0 0 53 1 8.467 0 0 74 6 9.425 0 0 105 3 11.385 2 0 86 2 14.372 0 0 107 1 4.291 3 1 138 3 12.220 5 0 119 10 13.190 0 0 1110 2 6.175 6 4 1211 3 10.170 8 9 1412 2 7.103 10 0 1313 1 2-.006 7 12 1414 1 3-.088 13 11 0
两个样本或小类聚成一类;第四列是相应的样本距离或小类距离;第五列、第六列表示本步聚类中,参与聚类的是样本还是小类。0表示样本,数据n(非0)表示由第几步聚类产生的小类参与本步聚类;第七列表示本步聚类的结果将在下面聚
类的第几步中用到。
(4)表5是变量层次聚类分析聚成3个类时变量的类归属情况。
从表5中我们可以推出表6所示的分类,并逐一定义。
—
3
0
1
—基于SPSS的学生能力倾向聚类分析研究
表5
Cluster Membership
Case
3Clusters
中国近现代史纲要
1高等数学2工业催化
3思想道德修养与法律基础
1计算机文化基础
1金属学2英语
2马克思主义基本原理
1有色冶金原理2冶金物理化学3冶金实验研究方法3冶金化工设备3现代企业管理3线性代数2冶金反应工程学
3
表6
专业课程分类
课程名称
课程分类中国近现代史纲要、
思想道德修养与法律基础、计算机文化基础、马克思主义基本原理
第1类:
我们定义为,属于偏重行政类高等数学、金属学、英语、有色冶金原理、线性代数
第2类:
我们定义为,属于偏重研究类
工业催化、
冶金物理化学、冶金实验研究方法、冶金化工设备、现代企业管理、
冶金反应工程学
第3类:
我们定义为,属于偏重工程类
(
5)由层次聚类分析的冰柱图(见表7),可以非常清楚地看到各变量按3类归属的情况。
(6)图1为聚类分析的树形图(Dendroge-am)
,表明每一步中被合并的类及其系数值,把各类之间的距离转换成1~
25间的数值。2.基于能力倾向的就业指导。
表7
Vertical
IcicleNumber
ofclusters
Case
现代
企业管理
冶金物理化学
冶金化工设备
冶金实验研究方法
冶金反应工程学
工业催化
英语
有色冶金原理
金属学
线性代数高等数学
计算机文化基础思想道德修养与法律基础马克思主义基本原理中国近现代史纲要
1XX X X X X X X X X X X X X X X X X X X X X X X X X X X X2XX X X X X X X X X X X X X X X X X X X X X X X X X X X3XX X X X X X X X X X X X X X X X X X X X X X X X X X4XX X X X X X X X X X X X X X X X X X X X X X X X X5XX X X X X X X X X X X X X X X X X X X X X X X X6XX X X X X X X X X X X X X X X X X X X X X X X7XX X X X X X X X X X X X X X X X X X X X X X8XX X X X X X X X X X X X X X X X X X X X X9XX X X X X X X X X X X X X X X X X X X X10XX X X X X X X X X X X X X X X X X X X11XX X X X X X X X X X X X X X X X X X12XX X X X X X X X X X X X X X X X X13XX X X X X X X X X X X X X X X X14
X
X
X
X
X
X
X
X
X
X
X
X X X
X
X
根据上述分析所得到的3个分类以及我们分别对每个类的定义,可以看到,一类学生在“高等数学”、“外语”、“金属学”等方面学习能力比较强,具有较强的抽象思维、逻辑推理和外语基础,适合于从事科学研究工作,因此可以建议这些学生继续深造,有条件报考研究生的应动员其报考研究生,暂时不能考研的也要抓紧学习以争取进一步提高;
一类学生行政管理和政治敏锐力较强,建议他们可以去考公务员,
将来可能会在政界取得比较大的成就;再一类学生,形象思维能力和动手能力较强,他们比较适合从事本专业的工程技术工作,建议他们进一步打好基础,深入掌握实际中的
一些技巧,以便将来能成为本专业的技术骨干和
专家。
[5]
四、结语
本研究采用教育统计原理对学生的专业课程成绩进行数据采样,并借助SPSS软件平台的因子、聚类分析方法对学生就业潜能进行客观评价,
取得了明显的效果[
6]
。尤其是通过本研究所建立的与学生就业倾向相关的数据库,
为更好实施大学生职业生涯教育、
改进大学生就业管理积累了丰富的实验数据和素材,并从数据挖掘的新视角探索出一种学生思想工作的新方法。
(下转第135页)
—
401—
高等工程教育研究 2012年第6期
[2]阳仁宇:《高校课程改革与发展趋势》,《高等理科教育》2003
年第2期。
[3
]李慧仙:《高校课程负责人制的改革建议》,《高等工程教育研究》2005年第1期。
[4]http:∥zsxx.e21.edu.cn/sqlimg/school-html-j
t/2005-06-22/article-22307.htm
[5
]叶辉:《应用型高校的生命线———访宁波高等专科学校校长高浩其》,《光明日报》2003年11月11日。
Construction of University
Core Curriculum and Its SystemQin Yanf
enAt p
resent in our country,basic trends of curriculum reform in universities are as follows:to es-tablish a curriculum system which adapts to popular higher education;to respond to the new req
uire-ments the gradually improved socialist market economy system put forward;to educate talents of highqualities and core competency
to meet the social economic development needs.In view of these trendsand missions,core curriculum construction has to be valued in curriculum reform of universities orcolleges.The internal and external relationships in the curriculum system predominated by
the corecurriculums should be well handled.At the same time,a set of system frame including curriculum di-rector sy
stem should be established in order to make concrete measures into effect.(上接第104页
)
图1 聚类分析的树形图
参考文献
[1
]佟庆伟、胡迎宾、孙青:《教育科研中的量化方法》,中国科技出版社1997年版,第153~160页。
[2
]林治:《聚类分析在学生成绩管理中的应用探析》,《福建电脑》2009年第12期。
[3]李志辉、罗平:《SPSS for
Windows统计分析教程(第2版)》,电子工业出版社2005年版,第335~365页。
[4]余建英、何旭宏:《数据统计分析与SPSS应用》
,人民邮电出版社2005年版,第251~289页。
[5]张敏强:《教育与心理统计学》,人民教育出版社2003年版,
第332~369页。
[6]罗家国:《基于SPSS的课程因子分析研究》
,《江西理工大学学报》2011年第5期。
Cluster Analysis of Students′Ap
titude Based on SPSSLuo Jiaguo,Luo Hao,Zhong Jiaj
iaThis paper mainly
introduces a method to evaluate the students′employment potentials based onSPSS clustering analysis.From the perspective of education statistics,the method is introduced to ex-plore new ways of graduates′employment counseling as well as offering references for teaching
man-agement reform,thus reaching the goal of improving university students′career education and seekingthe best way
to strengthen student′s employment potential orientation.The experimental results showthat this method is rapid,visial,comprehensive and highly
targeted.—
531—高校核心课程建设及其制度架构
完整word版,SPSS聚类分析实验报告.docx
SPSS 聚类分析实验报告 一.实验目的: 1、理解聚类分析的相关理论与应用 2、熟悉运用聚类分析对经济、社会问题进行分析、 3、熟练 SPSS软件相关操作 4、熟悉实验报告的书写 二.实验要求: 1、生成新变量总消费支出=各变量之和 2、对变量食品支出和居住支出进行配对样本T 检验,并说明检验结果 3、对各省的总消费支出做出条形图(用EXCEL做图也行) 4、利用 K-Mean法把 31 省分成 3 类 5、对聚类分析结果进行解释说明 6、完成实验报告 三.实验方法与步骤 准备工作:把实验所用数据从 Word文档复制到 Excel ,并进一步导入到 SPSS数据文件中。 分析:由于本实验中要对 31 个个案进行分类,数量比较大,用系统聚类法当然也 可以得出结果,但是相比之下在数据量较大时, K 均值聚类法更快速高效,而且准确性更高。 四、实验结果与数据处理: 1.用系统聚类法对所有个案进行聚类:
生成新变量总消费支出 =各变量之和如图所示: 2.对变量食品支出和居住支出进行配对样本 T 检验,如图所示:
得出结论: 3.对各省的总消费支出做出条形图,如图所示: 4.对聚类分析结果进行解释说明: K均值分析将这样的城市分为三类: 第一类北京、上海、广东 第二类除第一类第三类以外的 第三类天津、福建、内蒙古、辽宁、山东 第一类经济发展水平高,各项支出占总支出比重高,人民生活水平高。第二类城市位于中西部地区,经济落后,人民消费水平低。第三类城市位于中东部地区,经济发展较好。
初始聚类中心 聚类 123 食品支出7776.983052.575790.72衣着支出1794.061205.891281.25居住支出2166.221245.001606.27家庭设备及服务支出1800.19612.59972.24医疗保健支出1005.54774.89617.36交通和通信支出4076.461340.902196.88文化与娱乐服务支出3363.251229.681786.00其它商品和服务支出1217.70331.14499.30总消费支出23200.409792.6614750.02 迭代历史记录a 聚类中心内的更改 迭代123 11250.5921698.8651216.114 2416.86470.786173.731 3138.955 2.94924.819 446.318.123 3.546 5849.114319.1791362.411 6805.00415.199606.915 7161.001.72475.864 832.200.0349.483 9 6.440.002 1.185 10 1.2887.815E-5.148
SPSS操作方法:聚类分析
实验指导之一 聚类分析的SPSS操作方法 系统聚类法 实验例城镇居民消费水平通常用下表中的八项指标来描述。八项指标间存在一定的线性相关。为研究城镇居民的消费结构,需将相关性强的指标归并到一起,这实际上就是对指标聚类。 实验数据表 2001年30个省。市,自治区城镇居民月平均消费数据 x1人均粮食支出(元/人) x5人均衣着商品支出(元/人) x2人均副食支出(元/人) x6人均日用品支出(元/人) x3人均烟、酒、茶支出(元/人) x7人均燃料支出(元/人) x4人均其他副食支出(元/人) x8人均非商品支出(元/人) x1x2x3x4x5x6x7x8 北京 天津 河北 山西 内蒙古 辽宁 吉林 黑龙江 上海 江苏 浙江 安徽 福建 江西 山东 河南 湖北
湖南13.23 广东 广西 海南 四川 贵州 云南 西藏 陕西 甘肃 青海 宁夏 新疆 系统聚类法的SPSS操作: 1. 从数据编辑窗口点击Analyze →Classify →Hierachical Cluster , (见图1) 图1 系统聚类法 打开层次聚类法对话如图2。 图2 系统聚类法对话框 选择需要进行聚类分析的变量进入Variable框内后,在Cluster栏中选择聚类类型,SPSS有两种层次聚类方法: Cases 对样品聚类(Q型;系统默认), Variable 对指标变量聚类(R型),本例选择。 在Display栏中选择默认的输出项。 2. 点击Statistics按钮,打开对话框如图 3. 图3 Statistics对话框 Agglomeration schedule输出凝聚状态表(聚类进度表);本例选择。
SPSS教程-聚类分析-附实例操作
各地区各行业工资水平的分析(2009年数据) 小组成员:张艺伟、赵月、陈媛、邹莉、朱海龙、曾磊、胡瑛、候银萍 1.研究背景及意义 1.1 研究背景 工资水平是指一定区域和一定时间内劳动者平均收入的高低程度。生产决定分配,只有经济发展才能提供更多的可分配的社会产品,因此一个地区的工资水平在一定程度上反映了其经济发展的水平。 1.2 研究意义 1. 通过多元统计分析方法,探究一个地区的工资水平与其经济发展水平之间的内在联系。 2. 将平均工资水平划分为3类,分析哪些地区、哪些行业的工资水平较高,可以为大学生就业提供宏观上的方向指引。 2.数据来源与描述 2.1 数据来源——《中国劳动统计年鉴─2010》 (URL:https://www.360docs.net/doc/b510136426.html,/Navi/YearBook.aspx?id=N2011010069&floor=1###) 主编单位:国家统计局人口和就业统计司,人力资源和社会保障部规划财务司 出版社:中国统计出版社 简介:《中国劳动统计年鉴─2010》是一部全面反映中华人民共和国劳动经济情况的资料性年刊。本刊收集了2009年全国和各省、自治区、直辖市、香港特别行政区、澳门特别行政区的有关劳动统计数据。本书资料的取得形式主要有国家和部门的报表统计、行政记录和抽样调查。 2.2 数据描述 本数据集记录了全国31个省市(港、澳、台除外)的工资状况,各省市分别记录了其23个主要行业的平均工资水平,这23个主要行业包括:企业、事业、机关、金融业、制造业、建筑业、房地产业、农林牧渔业等等,具体数据格式参见图-0。
图-0 3.分析方法及原理 3.1 通过描述统计分析方法,判断哪些行业平均工资水平较高 描述统计分析方法主要是从基本统计量(诸如均值、方差、标准差、极大/小值、偏度、峰度等)的计算和描述开始的,并辅助于SPSS提供的图形功能,能够把握数据的基本特征和整体的分布特征。 在本案例中,通过比较不同行业(诸如企业、事业、机关、建筑业、制造业……)工资的均值、极大/小值,可以从总体上判断哪些行业的平均工资水平较高,哪些行业的较低。 3.2 通过聚类分析方法,判断哪些地区平均工资水平较高 聚类分析是依据研究对象的个体特征,对其进行分类的方法,分类在经济、管理、社会学、医学等领域,都有广泛的应用。聚类分析能够将一批样本(或变量)数据根据其诸多特征,按照在性质上的亲疏程度在没有先验知识的情况下进行自动分类,产生多个分类结果。类内部个体特征之间具有相似性,不同类间个体特征的差异性较大。 在本案例中,我们将采用两种方法进行聚类分析:一种是系统聚类法,另一种是K-均值法(快速聚类法)。 3.2.1系统聚类法 系统聚类法的基本原理:首先将一定数量的样本或指标各自看成一类,然后根据样本(或指标)的亲疏程度,将亲疏程度最高的两类进行合并,然后考虑合并后的类与其他类之间的亲疏程度,再进行合并。重复这一过程,直到将所有的样本(或指标)合并为一类。 系统聚类分为Q型聚类和R型聚类两种:Q型聚类是对样本进行聚类,它使具有相似特征的样本聚集在一起,使差异性大的样本分离开来;R型聚类是对变量进行聚类,它使差异性大的变量分离开来,相似的变量聚集在一起,这样就可以在相似变量中选择少数具有代表性的变量参与其他分析,实现减少变量个数、降低变量维度的目的。 在本例中进行的是Q型聚类。 类与类之间距离的计算方法主要有以下几种: (1)最短距离法(Nearest Neighbor),是指两类之间每个个体距离的最小值; (2)最长距离法(Farthest Neighbor),是指两类之间每个个体距离的最大值; (3)组间联接法(Between-groups Linkage),是指两类之间个体之间距离的平均值;
聚类分析的SPSS实现
§7.5聚类分析的SPSS实现 一、系统聚类法的SPSS实现 例7.5.1利用全国30个省市自治区经济发展基本情况的八项指标数据(见数据集wyzb6_5.),用系统聚类法对这30个省市自治区作一初步的分类,并说明各类地区经济发展的特点。 操作 分析(Analyze)?分类(Classify)?系统聚类(Hierarchical Cluster)打开系统聚类分析(Hierarchical Cluster Analysis)对话框 1.变量(V ariable(s))列表框设置分析变量。 2.标志个案(Label Cases by)框设置分析对象的标志变量。3.分群(Cluster)单选择框设置聚类分析的类型。 4.输出(Display)复选择框设置聚类分析的输出结果,统计量和图都是默认选项。 5.统计量(Statistics)按钮设置输出的统计量。 合并进程表(Agglomeration schedule)默认选项,输出聚类分析的凝聚状态表; 相似性矩阵(Proximitymatrix)为复选项,输出各样品的距离矩阵。 聚类成员(Cluster Menbership)选择框: 无(None)选项:不显示类的样品构成; 单一方案(Single solution)选项:选择此项,并输入一个确定的分类数n,并输出聚成n个类时各个类的样品构成 情况。 方案范围(Range of solutions):选择此项,并输入两个数n1,n2,将显示指定聚成n1类到n2类时各个类的样品构成 情况。
6.Plots按钮设置输出图形:树状图冰状图 7.Method按钮设置聚类分析的具体方法。 聚类方法: 组间连接:类间平均法 组内连接:类内平均法 最近临元素:最短距离法 最远临元素:最长距离法 质心聚类法:重心法 中位数聚类法:中位数法 Ward法:离差平方和法 度量方法选择框:选择计算样品距离的方法转换值选择框:选择原始数据标准化的方法Z得分,最常用的方法
SPSS操作方法:聚类分析
. 实验指导之一 聚类分析的SPSS操作方法 系统聚类法 实验例城镇居民消费水平通常用下表中的八项指标来描述。八项指标间存在一定的线性相关。为研究城镇居民的消费结构,需将相关性强的指标归并到一起,这实际上就是对指标聚类。 实验数据表 2001年30个省。市,自治区城镇居民月平均消费数据 x1人均粮食支出(元/人) x5人均衣着商品支出(元/人) x2人均副食支出(元/人) x6人均日用品支出(元/人) x3人均烟、酒、茶支出(元/人) x7人均燃料支出(元/人) x4人均其他副食支出(元/人) x8人均非商品支出(元/人) x1x2x3x4x5x6x7x8 北京7.78 48.44 8.00 20.51 22.12 15.73 1.15 16.61 天津10.85 44.68 7.32 14.51 17.13 12.08 1.26 11.57 河北9.09 28.12 7.40 9.62 17.26 11.12 2.49 12.65 山西8.35 23.53 7.51 8.62 17.42 10.00 1.04 11.21 内蒙古9.25 23.75 6.61 9.19 17.77 10.48 1.72 10.51 辽宁7.90 39.77 8.49 12.94 19.27 11.05 2.04 13.29 吉林8.19 30.50 4.72 9.78 16.28 7.60 2.52 10.32 黑龙江7.73 29.20 5.42 9.43 19.29 8.49 2.52 10.00 上海8.28 64.34 8.00 22.22 20.06 15.52 0.72 22.89 江苏7.21 45.79 7.66 10.36 16.56 12.86 2.25 11.69 浙江7.68 50.37 11.35 13.30 19.25 14.59 2.75 14.87 安徽8.14 37.75 9.61 8.49 13.15 9.76 1.28 11.28 福建10.60 52.41 7.70 9.98 12.53 11.70 2.31 14.69 江西 6.25 35.02 4.72 6.28 10.03 7.15 1.93 10.39 山东8.82 33.70 7.59 10.98 18.82 14.73 1.78 10.10 河南9.42 27.93 8.20 8.14 16.17 9.42 1.55 9.76 湖北8.67 36.05 7.31 7.75 16.67 11.68 2.38 12.88
SPSS聚类分析实验报告
SPSS聚类分析实验报告 一.实验目的: 1、理解聚类分析的相关理论与应用 2、熟悉运用聚类分析对经济、社会问题进行分析、 3、熟练SPSS软件相关操作 4、熟悉实验报告的书写 二.实验要求: 1、生成新变量总消费支出=各变量之和 2、对变量食品支出和居住支出进行配对样本T检验,并说明检验结果 3、对各省的总消费支出做出条形图(用EXCEL做图也行) 4、利用K-Mean法把31省分成3类 5、对聚类分析结果进行解释说明 6、完成实验报告 三.实验方法与步骤 准备工作:把实验所用数据从Word文档复制到Excel,并进一步导入到SPSS数据文件中。 分析:由于本实验中要对31个个案进行分类,数量比较大,用系统聚类法当然也可以得出结果,但是相比之下在数据量较大时,K均值聚类法更快速高效,而且准确性更高。 四、实验结果与数据处理: 1.用系统聚类法对所有个案进行聚类:
生成新变量总消费支出=各变量之和如图所示: 2. 对变量食品支出和居住支出进行配对样本T检验,如图所示:
得出结论: 3. 对各省的总消费支出做出条形图,如图所示: 4.对聚类分析结果进行解释说明: K均值分析将这样的城市分为三类: 第一类北京、上海、广东 第二类除第一类第三类以外的 第三类天津、福建、内蒙古、辽宁、山东 第一类经济发展水平高,各项支出占总支出比重高,人民生活水平高。第二类城市位于中西部地区,经济落后,人民消费水平低。第三类城市位于中东部地区,经济发展较好。
迭代历史记录a 迭代 聚类中心内的更改 1 2 3 1 1250.592 1698.865 1216.114 2 416.864 70.786 173.731 3 138.955 2.949 24.819 4 46.318 .123 3.546 5 849.114 319.179 1362.411 6 805.004 15.199 606.915 7 161.001 .724 75.864 8 32.200 .034 9.483 9 6.440 .002 1.185 10 1.288 7.815E-5 .148 初始聚类中心 聚类 1 2 3 食品支出 7776.98 3052.57 5790.72 衣着支出 1794.06 1205.89 1281.25 居住支出 2166.22 1245.00 1606.27 家庭设备及服务支出 1800.19 612.59 972.24 医疗保健支出 1005.54 774.89 617.36 交通和通信支出 4076.46 1340.90 2196.88 文化与娱乐服务支出 3363.25 1229.68 1786.00 其它商品和服务支出 1217.70 331.14 499.30 总消费支出 23200.40 9792.66 14750.02
多元统计分析聚类分析的各种方法spss
多元统计分析 (第一次作业) 学院:信息与计算科学学院 专业: ____________ 指导老师: ____________ 小组成员:罗健水(20080560) 许志欢(20080574) 庄娜(20080595) 卓玛(20080561)
2011年4月10日
题目:某行政系统所属独立核算工业企业16个行业经济实力强弱的聚类分析 独立核算:独立核算是指对本单位的业务经营活动过程及其成果进行全面、系统的会计核算。独立核算单位的特点是:在管理上有独立的组织形式,具有一定数量的资金,在当地银行开户;独立进行经营活动,能同其他单位订立经济合同;独立计算盈亏,单独设置会计机构并配备会计人员,并有完整的会计工作组织体系。 非独立核算又称报帐制,是把本单位的业务经营活动有关的日常业务资料,逐日或定期报送上级单位,由上级单位进行核算。非独立核算单位的特点是:一般由上级拔给一定数额的周转金,从事业务活动,一切收入全面上缴,所有支出向上级报销,本身不单独计算盈亏,只记录和计算几个主要指标,进行简易核算 数据来源:上海市青浦区统计局数据链接:数据5?11.sav 固定资产原价:指企业在建造、改置、安装、改建、扩建、技固定资产计量术改造固定资产时实际支出的全部货币总额。该指标根据企业会计"资产负债表"中"固定资产原价"项的期末数填列。 固定资产净值平均余额:每月逐步减少。有部分企业单位,是按季度计提折旧,那么在没有提折旧的月 份,比如10月份,和9月份比较,固定资产净值平均余额就没有变化,也就是说,还是等于9月份的 固定资产净值平均余额 例:如09年底的固定资产净值余额为5000万元,2010年元月份完成固定资产投资1000万元,那么元月份的固定资产净值平均余额是多少?2月份又完成投资500万元,那2月份的固定资产净值平均余额是多少?(计算公式是怎样) 解:平均余额等于期初的加期末的除以2 所以一月份=(5000+6000-当月折旧)/2 二月份的=(6000+6500-两个月的折旧)/2 所有者权益(Owne' s Equities:资产扣除负债后由所有者应享的剩余利益。即一个会计主体在一定时期所拥有或可控制的具有未来经济利益资源的净额。 营业税金及附加:主营业务税金及附加”科目改名为“营业税金及附加”, “营业税金及附加”科目用法如下: 一、本科目核算企业经营活动发生的营业税、消费税、城市维护建设税、资源税和教育费附加等相关税费。 房产税、车船使用税、土地使用税、印花税在“管理费用”等科目核算,不在本科目核算。 二、企业按规定计算确定的与经营活动相关的税费,借记本科目,贷记“应交税费”等科目。企业收到的返还的消费税、营业税等原记入本科目的各种税金,应按实际收到的金额,借记“银行存款”科目,贷记本科目。
:聚类分析SPSS操作方法09
:聚类分析SPSS操作方法09 实验指导之一 聚类分析的SPSS操作方法 系统聚类法 实验例城镇居民消费水平通常用下表中的八项指标来描述。八项指标间存在一定的线性相关。为研究城镇居民的消费结构,需将相关性强的指标归并到一起,这实际上就是对指标聚类。 实验数据表 2001年30个省。市,自治区城镇居民月平均消费数据 x1人均粮食支出(元/人) x5人均衣着商品支出(元/人) x2人均副食支出(元/人) x6人均日用品支出(元/人) x3人均烟、酒、茶支出(元/人) x7人均燃料支出(元/人) x4人均其他副食支出(元/人) x8人均非商品支出(元/人) x1x2x3x4x5x6x7x8 北京7.78 48.44 8.00 20.51 22.12 15.73 1.15 16.61 天津10.85 44.68 7.32 14.51 17.13 12.08 1.26 11.57 河北9.09 28.12 7.40 9.62 17.26 11.12 2.49 12.65
系统聚类法的SPSS操作:
1. 从数据编辑窗口点击Analyze →Classify →Hierachical Cluster , (见图1) 图1 系统聚类法 打开层次聚类法对话如图2。 图2 系统聚类法对话框 选择需要进行聚类分析的变量进入Variable框内后,在Cluster栏中选择聚类类型,SPSS有两种层次聚类方法: Cases 对样品聚类(Q型;系统默认), Variable 对指标变量聚类(R型),本例选择。 在Display栏中选择默认的输出项。 2. 点击Statistics按钮,打开对话框如图 3.
手把手教你spss聚类分析和主因子分析
1.主因子分析第一步:矩阵标准化 出现如下对话框: 第二步:对标准化过的矩阵分析
聚类分析
基于SPSS的聚类分析的实用方法(层次聚类法和迭代聚类法) 层次聚类法和迭代聚类法的主要区别在于:层次聚类法的聚类结果受奇异值的影响非常大,且聚类过程是单方向的,一旦某个样本进入某一类,就不可能从该类出来,再归入其他的类;迭代聚类法的聚类结果受奇异值和不合适的聚类变量的影响较小,对于不合适的初始聚类可以进行反复调整,但其缺点是聚类结果对初始聚类非常敏感,而且它也只能得到局部最优解. (一)层次聚类 Analyze--> C1assify-->Hierachical Cluster 在“C1uster”组中选择聚类类型:要进行变量聚类选择指定“V anables”;要进行观测量聚类指定“Cases”。 指定参与分析的变量,将选定的变量通过按钮箭头转移到箭头按钮右侧的“V ariable[s]:”矩形框中;将标识变量通过下面一个箭头按钮转移到按钮右侧的“Label Cases by:”下面的矩形框中。 如果不使用系统默认值,或由于参与分析的变量量纲不一致需要指定选择项,则应该根据需要有选择性地执行下述某些步骤。 1.确定聚类方法 在主对话框中,点击“Methed”按钮,展开分层聚类分析的方法选择对话框,即“Hierachical Cluster Analysis:Method”。在对话框中根据需要指定聚类方法、距离测度的方法、对数值进行转换方法,即标准化数值的方法和对测度的转换方法。 (1)聚类方法选择 “C1uster Method:”表中列出可以选择的聚类方法: Between-groups linkage组内连接 Within-groups linkage组内连接 Nearest neighbor最近邻法