7 第四章 经典的房室模型理论
第四章 经典的房室模型理论
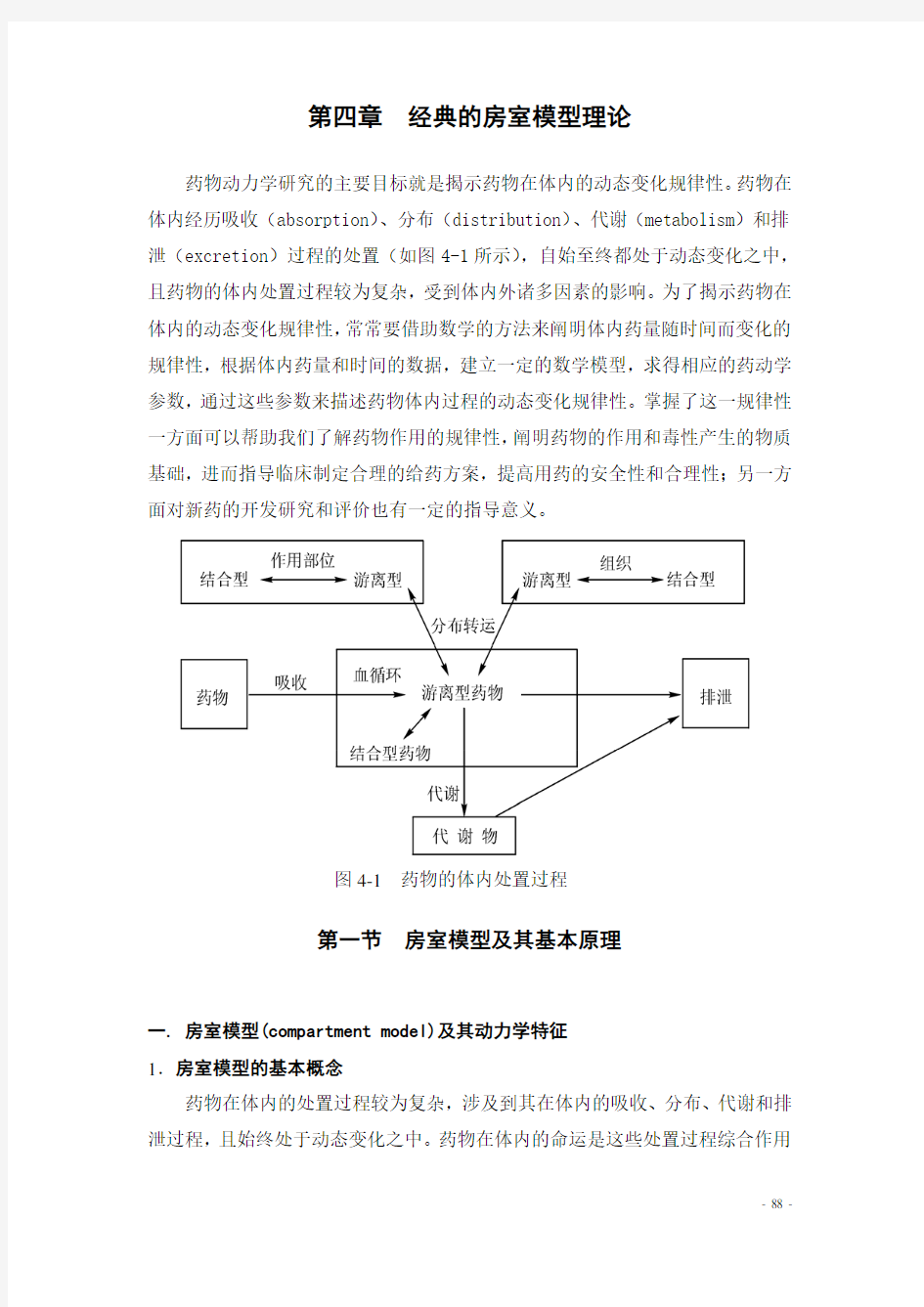
药物动力学研究的主要目标就是揭示药物在体内的动态变化规律性。药物在体内经历吸收(absorption)、分布(distribution)、代谢(metabolism)和排泄(excretion)过程的处置(如图4-1所示),自始至终都处于动态变化之中,且药物的体内处置过程较为复杂,受到体内外诸多因素的影响。为了揭示药物在体内的动态变化规律性,常常要借助数学的方法来阐明体内药量随时间而变化的规律性,根据体内药量和时间的数据,建立一定的数学模型,求得相应的药动学参数,通过这些参数来描述药物体内过程的动态变化规律性。掌握了这一规律性一方面可以帮助我们了解药物作用的规律性,阐明药物的作用和毒性产生的物质基础,进而指导临床制定合理的给药方案,提高用药的安全性和合理性;另一方面对新药的开发研究和评价也有一定的指导意义。
图4-1 药物的体内处置过程
第一节房室模型及其基本原理
一. 房室模型(compartment model)及其动力学特征
1.房室模型的基本概念
药物在体内的处置过程较为复杂,涉及到其在体内的吸收、分布、代谢和排泄过程,且始终处于动态变化之中。药物在体内的命运是这些处置过程综合作用
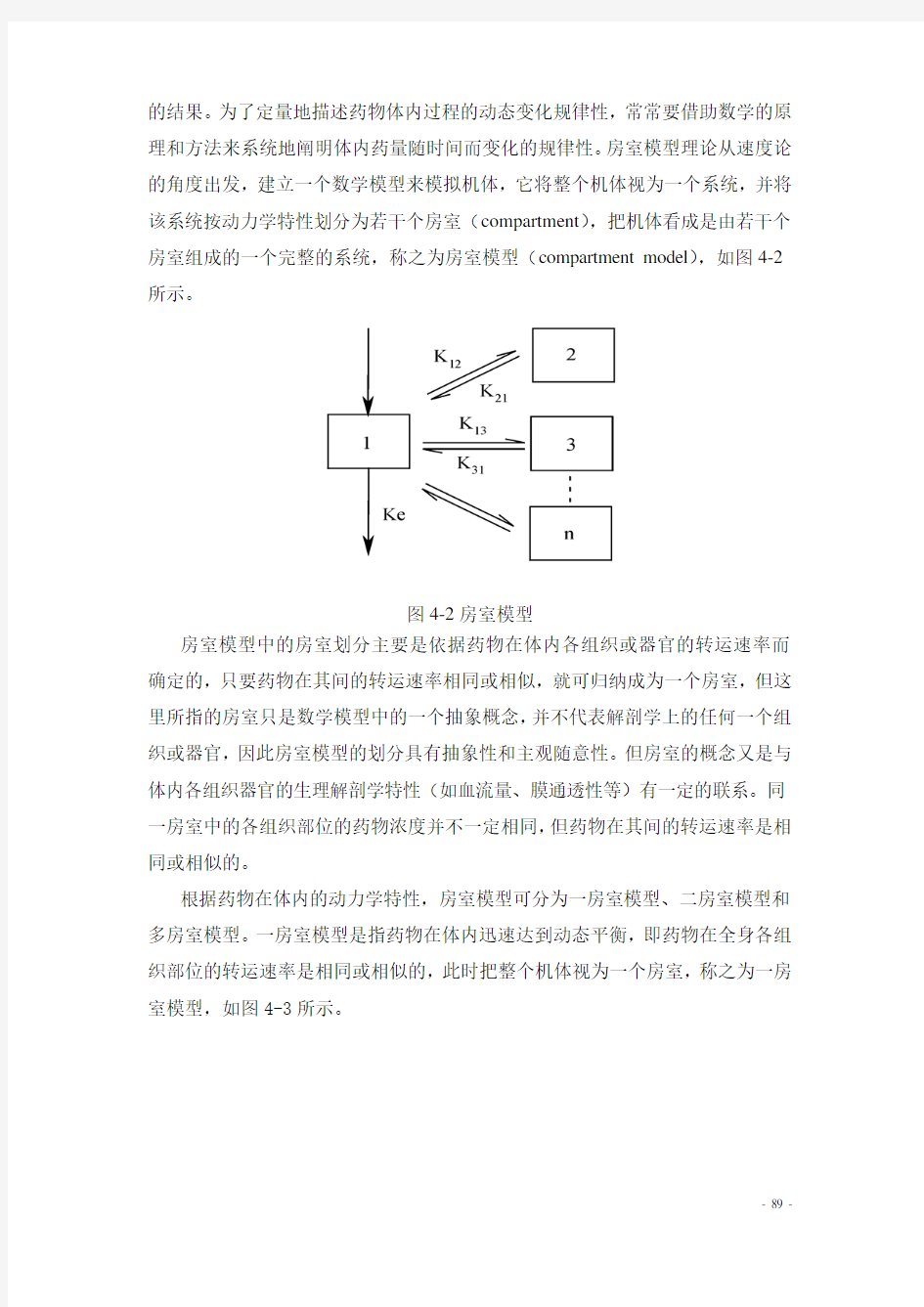
的结果。为了定量地描述药物体内过程的动态变化规律性,常常要借助数学的原理和方法来系统地阐明体内药量随时间而变化的规律性。房室模型理论从速度论的角度出发,建立一个数学模型来模拟机体,它将整个机体视为一个系统,并将该系统按动力学特性划分为若干个房室(compartment),把机体看成是由若干个房室组成的一个完整的系统,称之为房室模型(compartment model),如图4-2所示。
图4-2房室模型
房室模型中的房室划分主要是依据药物在体内各组织或器官的转运速率而确定的,只要药物在其间的转运速率相同或相似,就可归纳成为一个房室,但这里所指的房室只是数学模型中的一个抽象概念,并不代表解剖学上的任何一个组织或器官,因此房室模型的划分具有抽象性和主观随意性。但房室的概念又是与体内各组织器官的生理解剖学特性(如血流量、膜通透性等)有一定的联系。同一房室中的各组织部位的药物浓度并不一定相同,但药物在其间的转运速率是相同或相似的。
根据药物在体内的动力学特性,房室模型可分为一房室模型、二房室模型和多房室模型。一房室模型是指药物在体内迅速达到动态平衡,即药物在全身各组织部位的转运速率是相同或相似的,此时把整个机体视为一个房室,称之为一房室模型,如图4-3所示。
X 机体
机体一房室模型
二房室模型
图4-3 一房室和二房室模型示意图
二房室模型则是将机体分为两个房室,即中央室(central compartment)和外周室(peripheral compartment),如图4-3所示。中央室由一些血流比较丰富、膜通透性较好、药物易于灌注的组织(如心、肝、肾、肺等)组成,药物往往首先进入这类组织,血液中的药物可迅速与这些组织中的药物达到动态平衡;把血流不太丰富、药物转运速度较慢的,且难于灌注的组织(如脂肪、静止状态的肌肉等)归并成一个房室,称为外周室,这些组织中的药物与血液中的药物需经一段时间方能达到动态平衡。 2.房室模型的动力学特征
在应用房室模型研究药物的动力学特征时,最常采用的方法是把机体表述为由一些房室组成的系统,并假定药物在各房室间的转运速率以及药物从房室中消除的速度均符合一级反应动力学。在这里不妨回顾一下化学反应动力学是如何将各种反应速度进行分类的。若反应速度与反应物的量(或浓度)成正比,则称为一级反应,其数学式表达为:
1kx dt dx
?= 4-1
上式中x 为反应物的量,dx/dt 表示反应速度,k 为速度常数,负号表示反应朝反应物量减少的方向进行。若反应速度不受反应物量的影响而始终恒定,则称为零级反应,其数学式表达为:
k
kx dt dx 0
?=?= 4-2
若反应速度与反应物的量的二次方成正比,则称为二级反应,其数学式表达为:
2
kx dt dx ?= 4-3
在药物动力学里把N 级速率过程简称为N 级动力学,k 为N 级速率常数。在房室模型的理论中假设药物在各房室间的转运速率以及药物从房室中消除的速率均符合一级反应动力学,因此其动力学过程属于线性动力学,故房室模型又称线性房室模型,只适合于描述属于线性动力学药物的体内过程。
00.511.520
5
10
152025
30
时间(小时)
对数浓度(u g /m l )
图 4-4静注给药后的血药浓度-时间曲线 (A) 一室模型;(B )二室模型
按一房室模型处置的药物静注给药后的血药浓度-时间曲线如图4-4A 所示;按二房室模型处置的药物静注给药后的血药浓度-时间曲线如图4-4B 所示。按一房室模型处置的药物静注给药后,其血药浓度-时间曲线呈单指数函数的特征,即半对数血药浓度-时间曲线呈直线关系;按二房室模型处置的药物静注给药后,其血药浓度-时间曲线呈现出双指数函数的特征,即半对数血药浓度-时间曲线呈
双指数曲线,这是我们判别一室模型和二室模型的重要的动力学特征。 二. 拉普拉氏变换(Laplace transform)
在药物动力学的研究中,速度过程多数是一级过程,即线性过程,数学模型给出线性微分方程,通常用拉普拉氏变换法求解,拉普拉氏变换把上述线性微分方程化为象函数的代数方程,再求出象函数F(s),然后经逆变换求得原微分方程的解。其过程如下:
1[()]()()[()]L f t f t F S L F s ?????
→??→????→拉氏变换拉氏逆变换
原函数象函数象原函数
其定义为:将原函数乘以e -st (s 为拉氏算子)然后从0→∞积分即得象函数,象函数再经拉氏逆变换求得原微分方程的解。下面介绍几种在药动学研究中常见函数的拉氏变换: 1.常系数A 的拉氏变换
001[]()|st st A
L A Ae dt A e s ∞
??==?∫s ∞= 4-4
2.指数函数e -st 的拉氏变换
() 0
()at at st a s t L e e e dt e dt ∞∞
????+==∫∫
()0
1
|()
1()
a s t e d t s a s a ?+∞=?
+=
+ 4-5 3.导数函数df(t)/dt 的拉氏变换
[()/]()/ ()st st L df t dt df t dt e dt e df t ∞∞
??==∫∫
0()|()(0)st
st e f t f t de SX f ∞
?∞
?=?=?∫ 4-6
上式中将定义为Lf(t)= 0
()st e f t dt ∞
?∫X
4.和的拉氏变换
L[f 1(t)+f 2(t)]=L[f 1(t)]+L[f 2(t)] 4-7
即和的拉氏变换等于拉氏变换的和。 常见函数的拉氏变换见表4-1。
表4-1 一些常用函数的拉普拉斯变换表
三. 房室模型的判别和选择
在运用房室模型估算药动学参数时所选择模型将直接影响到计算结果,某些药动学参数(如半衰期等)的估算值与所选择模型直接有关,因此模型的选择显得尤为重要。在进行药动学分析时应首先确定所研究的药物属于几室模型,一般可先用半对数图进行初步判断,但尚需计算机拟合后加以进一步的判断。在用计
算机进行药动学分析时常用的判别标准有三个,其一是残差平方和(R
e ):
21
?()n
e i i i
R C C ==?∑ 4-8
其中C i 为实测浓度,为拟合浓度,其二是拟合度r ?i
C 2; ∑∑
∑===??
=
n
1i 2i
n
1
i n
1
i 2i
i
2
i 2C
)C ?C (C r 4-9
其三是AIC(Akaike’s Information Criterion)值:
AIC=NlnR e +2P 4-10 式中N为实验数据的个数,P是所选模型参数的个数,R e 为加权残差平方和,P和R e 按下式计算
P=2n 4-11
4-12
∑=?=
n
1
i 2i
i
i
e )C ?C
(W R 式中n为指数项的个数,W i 为权重系数。权重系数可按下式计算: W i = 1 4-13 i i C 1
W =
4-14
2
i i C 1W =
4-15
目前比较公认的判别法是AIC 值法,该法被广泛地用于模型判别和选择。AIC 值越小,则可认为该模型拟合越好。在使用AIC 法选择模型时,应充分考虑到不同的权重系数对结果的影响,特别是当血药高低浓度悬殊比较大时应考虑采用加权法估算药动学参数。
四. 药动学参数的生理及临床意义
药动学参数(pharmacokinetic parameter)是反映药物在体内动态变化规律性的一些常数,如吸收、转运和消除速率常数、表观分布容积、消除半衰期等,通过这些参数来反映药物在体内经时过程的动力学特点及动态变化规律性。药动学参数是临床制订合理化给药方案的主要依据之一,根据药动学参数的特性,设计和制订安全有效的给药方案,包括给药剂量、给药间隔和最佳的给药途径等;针对
不同的生理病理状态,制定个体化给药方案,提高用药的安全有效性。此外,这些参数还有助于阐明药物作用的规律性,了解药物在体内的作用和毒性产生的物质基础。有些参数还是评价药物制剂质量的重要指标,在药剂学和新药的开发研究中常常被用于制剂的体内质量评价。下面简单介绍几种基本的和常用的药动学参数的生理学和临床意义。
1.药峰时间(t max )和药峰浓度(C max )
药物经血管外给药吸收后出现的血药浓度最大值称为药峰浓度,达到药峰浓度所需的时间为药峰时间,如图4-5所示。两者是反映药物在体内吸收速率的两
图4-5 血管外给药的血药浓度-时间曲线
个重要指标,常被用于制剂吸收速率的质量评价。与吸收速率常数相比它们能更直观和准确地反映出药物的吸收速率,因此更具有实际意义。药物的吸收速度快,则其峰浓度高,达峰时间短,反之亦然,如图4-6所示,图中A 、B 、C 三个制剂的吸收程度相似,但吸收速度不同,其中吸收速度A>B>C 。由此可见吸收速度是影响药物疗效或毒性的一个重要的因素。
血药浓度
时间
图4-6 制剂A 、B 和C 后的药-时曲线。
2.表观分布容积(apparent volume of distribution, V d )
表观分布容积是指药物在体内达到动态平衡时,体内药量与血药浓度相互关
系的一个比例常数,其本身不代表真实的容积,因此无直接的生理学意义,主要
反映药物在体内分布广窄的程度,其单位为L或L/kg。对于单室模型的药物而
言分布容积与体内药量X和血药浓度C之间存在下列关系:
X
V d= 4-16
C
药物的分布容积的大小取决于其脂溶性、膜通透性、组织分配系数及药物与
血浆蛋白等生物物质的结合率等因素。如药物的血浆蛋白结合率高,则其组织分
布较少,血药浓度高。我们可以根据体液的分布情况(见表4-2),由药物的分布
容积可以粗略地推测其在体内的大致分布情况。如一个药物的V d为3~5升左右,
那么这个药物可能主要分布于血液并与血浆蛋白大量结合,如双香豆素、苯妥英
钠和保泰松等;如一个药物的V d为10~20升左右,则说明这个药物主要分布于血
浆和细胞外液,这类药物往往不易通过细胞膜,因此无法进入细胞内液,如
溴化物和碘化物等;如一个药物的分布容积为40升,则这个药物可以分布于血
浆和细胞内、外液,表明其在体内的分布较广,如安替比林;有些药物的V d非常
大,可以达到100升以上,这一体积已远远地超过了体液的总容积,这类药物在
体内往往有特异性的组织分布,如硫喷妥钠具有较高的脂溶性,可以大量地分布
于脂肪组织,而I131可以大量地浓集于甲状腺,因而其分布容积也很大。由此可
见我们可以通过分布容积来了解药物在体内的分布情况。
3.消除速率常数(elimination rate constant, k)和消除半衰期(half life
time, t
)K是药物从体内消除的一个速率常数,而消除半衰期是指血药浓度1/2
下降一半所需的时间,两者都是反映药物从体内消除速度的常数,且存在倒数的
关系,由于后者比前者更为直观,故临床上多用t1/2来反映药物消除的快慢,它是
临床制定给药方案的主要依据之一。按一极消除的药物的半衰期和消除速率常数
之间的关系可用下式表示:
0.693
t 1/2 = 4-17 k
4.血药浓度曲线下面积(area under the curve, AUC) AUC 表示血药浓度-时间曲线下面积,它是评价药物吸收程度的一个重要指标,常被用于评价药物的吸收程度。AUC 可用梯形面积法按下式进行估算:
n
i-1i n
i i-1i=1C +C C AUC = (t -t ) +
2k
∑ 4-18
5.生物利用度(bioavailability,F) 生物利用度是指药物经血管外给药后,药物被吸收进入血液循环的速度和程度的一种量度,它是评价药物吸收程度的重要指标。生物利用度可以分为绝对生物利用度和相对生物利用度,前者主要用于比较两种给药途径的吸收差异,而后者主要用于比较两种制剂的吸收差异,可分别用下式表示:
AUC ext D iv
绝对生物利用度 F = × ×100% 4-19
AUC iv D ext
式中AUC iv 和AUC ext 分别为静注给药和血管外给药后的血药曲线下面积,
D iv 和D ext 分别为静注和血管外给药后的剂量。
AUC T D R
相对生物利用度 F = × ×100% 4-20 AUC R D T
式中AUC T 和AUC R 分别为服用受试制剂和参比制剂的血药曲线下面积,
D T 和D R 分别为受试制剂和参比制剂的剂量。
6.清除率(clearance,Cl) 是指在单位时间内,从体内消除的药物的表观分布容积数,其单位为L/h 或L/h/kg ,表示从血中清除药物的速率或效率,它是反映药物从体内消除的另一个重要的参数。清除率Cl 与消除速率常数k 和分布容积之间的关系可用下式表示:
Cl= k ? V d 4-21
第二节 一房室模型
一房室模型是一种最简单的房室模型,它把整个机体视为一个房室,药物进入体内后迅速分布于体液和全身各组织,并在体内各组织之间迅速达到动态平衡,药物在各组织之间的转运速率相同,但达到动态平衡后各组织部位的药量不一定相等,药物从体内按一级过程消除。静注给药后血药浓度-时间曲线呈现出典型的单指数函数的特征,即血药浓度的半对数与时间呈直线关系。这是一房室模型的重要的动力学特征。 一. 单剂量给药动力学 (一). 静注给药动力学 1.模型的建立及其动力学特征
一房室静注给药的模型见图4-7,血药浓度-时间曲线如图4-8所示。
X 0
图4-7 一房室模型静注给药模型示意图
l o g C
t
图4-8 一房室模型静注给血药浓度-时间曲线
图4-7中X 0为给药剂量,X 为体内药量,K 为一极消除速率常数,根据上述的模型,体内药量的变化速率可用下列微分方程表示:
dx
= -kx (4-22)
dt
4-22式经拉氏变换得4-23式,式中的s 为拉氏算子
X k X X s 0?=? (4-23)
4-23式经整理得
a
s X X 0
+=
(4-24)
4-24式经拉氏逆变换后得
X=X 0 e -kt
(4-25)
根据定义 : X=VC (4-26) 故可将体内药量变化的函数表达式改述为血药浓度与时间的关系式:
C = C 0 e -kt (4-27)
2.药动学参数的估算
将(4-27)式两边取对数得:
t 303.2k
C log C log 0?
=
(4-28) 上述方程经线性回归即可求得该直线的斜率为-k/2.303,截距为logC 0,从其斜率我们可求得消除速率常数k ,从其截距我们可求得给药后瞬时间的血药浓度C 0。根据V 的定义可按下式求得分布容积:
0C
X
V =
(4-29)
根据消除半衰期的定义
C 0 k
log = log C 0 - t 1/2 (4-30)
2 2.303
故消除半衰期可按下式求得:
k
693.0t 2/1=
(4-31)
根据清除率的定义:
-dX/dt
Cl = (4-32) C
将4-22式代入上式,得:
KX
Cl = (4-33) C
将4-26式代入上式,得:
Cl = KV (4-34)
根据AUC 的定义
-kt 00
0 0C X C C e dt kv AUC dt k ∞
∞
===
=∫∫
(4-35) 从上式可以看出AUC 与给药剂量X 0成正比。 (二). 静脉滴注给药动力学 1.模型的建立及其动力学特征
静脉滴注亦称静脉输注,是药物以恒速静脉滴注给药的一种方式,血药浓度C随时间的增加而递增,直至达到稳态C ss ,其模型见图4-9:
K 0
图4-9 一房室模型静脉滴注给药模型示意图
图4-9中K 0为滴注速率,X为体内药量,K为一级消除速率常数。根据上述模型列出微分方程:
kX k dt
dX
0?= (4-36) 上式经拉氏变换后得
X k s /k X s 0?=
(4-37)
经整理得
()
k X s s k =
+ (4-38)
经拉氏逆变换后得
(1)kt k X e k ?=?
(4-39)
将X = VC 关系式代入后得
)e 1(Vk
k C kt 0
??=
(4-40) 药物以恒定速度静脉滴注给药后,其血药浓度-时间曲线如图4-10所示。从图4-10可以看出,达稳态前任一时间的血药农度均小于Css,因此任一时间点的
C 值可用Css 的某一分数来表示,即达坪分数,以fss 表示,则:
00/(1)/kt ss ss k kv e C f C k kv ??==
(4-41)
所以,
f ss = 1- e -kt
(4-42)
如以t 1/2的个数n 来表示时间,则上式变为
f ss = 1- e
-0.693n
(4-43)
两边取对数并整理得
n = -3.32 lg (1- f ss ) (4-44)
l o g C
图4-10 一房室模型静脉滴注给药血药浓度-时间曲线
从公式4-40和4-44及图4-10我们可看出静脉滴注给药的动力学特性: (1).血药浓度随时间递增,当t→∞时,e -kt →0,血药浓度达到稳态,稳态血药浓度C ss 可按下式估算。
Vk
k C 0ss =
(4-45)
(2).从4-20式可以看出,稳态水平高低取决于滴注速率,C ss 与k 0正比关系。 (3).达到稳态水平所需要的时间取决于药物的消除半衰期,而与滴注速率无关,当t=3.32t 1/2时,C=0.9C ss ,当t=6.64t 1/2时,C=0.99C ss ,即经3.32t 1/2即可达到坪水平的90%;经6.64t 1/2即可达到坪水平的99%。
(4).期望稳态水平确定后,滴注速率即可确定
k 0=C ss Vk
(4-46)
2.药动学参数的估算
静脉滴注给药的药动学参数估算方法有两种,其一是达稳态后停止滴注,估算药动学参数;其二是一是达稳态前停止滴注,估算药动学参数。 (1)达稳态后停止滴注
达稳态后停止滴注血药浓度变化可用下式表示
'
kt 0e Vk
k C ?= (4-47) 式中 t’为滴注结束后时间(post infusion time)
,两边取对数 k 0 kt’
logC = log - (4-48) VK 2.303
上述方程经线性回归即可求得该直线的斜率为-k/2.303,截距为logk 0/Vk,从其斜率我们可求得消除速率常数k,从其截距我们可求得分布容积V。 (2) 达稳态前停止滴注
达稳态前停止滴注后血药浓度变化可用下式表示
kt'kT 0
e )e 1(Vk
k C ???=
(4-49) 式中t’为滴注后时间,T 为滴注时间,两边取对数
k 0 kt’
logC = log (1-ek -kT
) - (4-50) KV 2.303
上述方程经线性回归,从其斜率我们可求得消除速率常数k,从其截距我们可求得分布容积V。
(三). 静脉注射加静脉滴注给药的动力学
临床上对于半衰期较长的药物采用静脉滴注给药时,欲达到期望的稳态水平需要较长的时间,为迅速达到该水平,并维持在该水平上,可采用滴注开始时给予静注负荷剂量(loading dose),要使血药浓度瞬时达到期望的C ss 水平,其负荷剂量X ss =C ss V,维持该水平所需要的滴注速率为k 0 = C ss Vk,则静脉注射加静脉滴注给药后体内药量变化的函数表达为:
)e 1(k
k e X X kt 0
kt ss ???+
= (4-51) 由式4-45式可知C ss V=
k
k 0
,故负荷剂量可按下式计算
k
k X 0ss
= (4-52) (四). 血管外途径给药动力学 1.模型的建立及其动力学特征
血管外给药一般指静脉以外的给药途径,包括口服、肌注和直肠等途径。血管外给药后,药物不直接进入血液循环系统,需经一个吸收过程方能进入血液循环系统。药物以一级过程从吸收部位吸收,血药浓度C随时间的增加而递增,直至达到血药浓度峰值C max ,而后药物按一级过程消除从体内消除。其模型如图4-11所示。
图4-11 一房室模型血管外给药模型示意图
图中X a 为吸收部位的药量,X为体内药量,ka一级吸收速率常数,k为一级消除速率常数。根据上述模型列出微分方程,其体内药量的变化速率的微分方程为:
kX X k dt
dX
a a ?= (4-53) 吸收部位药量的变化速率的微分方程为
a a a
X k dt
dX ?= (4-54) (4-53)式和(4-54)式经拉氏变换后得
0a a SX k X k X ?=? (4-55)
0a SX FX k X ?=?a a
(4-56)
式中体内药量的初始值为零,吸收部位的初始药量为FX 0,F为吸收分数,(4-55)
式和(4-56)式经整理得
()
a a
k X X s k =
+ (4-57)
)
k s (FX X a 0
a +=
(4-58)
将4-57式代入4-58式经整理得
)
k s )(k s (FX k X a 0
a ++=
(4-59)
经拉氏逆变换后得
)e e ()
k k (V FX k C kat kt a 0
a ????= (4-60)
药物按一级过程吸收药后,其血药浓度-时间曲线如图4-12所示。
l o g C
图4-12 一房室模型血管外给药后的血药浓度-时间曲线
从公式4-60和图4-12我们可以看出血管外给药的动力学特性:
(1).血药浓度-时间曲线为一条双指数曲线,这条双指数曲线可以看成是由两条具有相同截距的直线相减而成C=Ie -kt -Ie -kat ,其中
)
k k (V FX k I a a
a ?= (4-61) (2).在这条双指数曲线中因为k a >k,当t充分大时e -kat 先趋于零,即e -kat →0。
举例:
t(hr) ka=1 k=0.1 e -kat e -kt 1 0.3679 0.9050 2 0.1553 0.8187 3 0.0183 0.6783 4
0.0067
0.6065
(3).血药浓度-时间曲线可分为三相即:吸收分布相、平衡相和消除相。 2. 血管外给药的药动学参数估算
(1) 消除速率常数
根据前述的血管外给药的动力学特性,其药物动力学参数可采用残数法(method of residual)估算,当t充分大时e -kat 先趋于零即:e -kat →0,故当t充分大时4-60式变为
C=I 1e
-kt
(4-62)
两边取对数得
t 303
.2k
I log C log 1?
= (4-63) 上述方程经线性回归即可从其斜率求得消除速率常数k 和I。 (2) 吸收速率常数
用4-62式减去4-60式:Ie -kt -I(e -kt -e -kat )=Ie -kat 得到剩余血药浓度函数表达式:
C r = I 2 e
-kat
(4-64)
将上式两边取对数得
t 303
.2k I log Cr log a
2?= (4-65)
上述方程经线性回归即可从其斜率求得吸收速率常数k a 和I 2。 (3)分布容积
分布容积可按下式估算
)
k k (I FX k V a 0
a ?=
(4-66)
(4)滞后时间(lag time)t 0
从理论上讲I 1=I 2,但实际上常常出现I 1≠I 2的现象,这是因为药物吸收前有一释放过程,然后才能被吸收,存在一个滞后时间,造成I位移,使I 1≠I 2,使I 1和I 2在t 0处相交。因为I 1e -kt 和在t t k 2a e I ?0处相交,故
(4-67) 0
a 0t k 2kt 1e I e I ??=0
()2
1
a
k k
t I e I ??=
(4-68)
两边取对数得
lnI 2/I 1=(k a -k)t 0
(4-69) )
k k (I /I ln t a 1
20?=
(4-70)
(5)药峰时间(t max )和药峰浓度(C max )
1)药峰时间
对进行一阶导数求极值,则t达到最大值t t k kt a Ie Ie C ???=max
0)e k ke (I dt
dc
max a max t k a kt =+?=?? (4-71)
max
max max ()a a kt k k t a t k k e e k e
???== (4-72)
两边取对数得
k k log k
k 303
.2t a a max =?=
(4-73)
2)药峰浓度
以t max 代入(57)式即可求得药峰浓度C max :
)e e (I C max a max t k kt max ???=
(4-74)
将max max
a k t k t a
k e e k ?=
?代入上式得到 )e k k
e (I C max max kt a
kt max ????
= (4-75)
经整理得
max
kt 0max e V
FX C ?=
(4-76)
二. 多剂量给药动力学
临床上有些药物如镇痛药、催眠药及止吐药等只需应用单剂量后即可获得期望的疗效,一般不必再次给药来维持其疗效时,这类药物常采用单剂量给药。但在临床实践中,许多疾病的药物治疗必须经重复多次给药方能达到预期的疗效。这类药物需按照一定的剂量、一定的给药间隔,经多次重复给药后才能使血药浓度保持在一定的有效浓度范围内,从而达到预期疗效。 1. 静注多剂量给药动力学
临床上为达到期望的疗效常常采用多剂量给药以维持有效的血药浓度。按一级过程处置的药物经连续多次给药后,血药浓度呈现出有规律的波动,如图4-13所示。对于一房室静注给药而言,如按等间隔和等剂量给药,则首次静注给药后,
C SS
C
图4-13 静注重复多次给药后的药时曲线。
体内的最大药量为(X 1)max ,经时间τ(给药间隔时间),给予第二次静注前的瞬间体内药量即为第一次给药的最小药量(X 1)min , 它们可用下列方程表示:
(X 1)max = X 0 (4-77)
(X 1)min = X 0 e -Kτ (4-78)
经时间间隔τ,给予第二次相同剂量的药物后体内的最大和最小药量分别为
(X 2)max = X 0 + X 0 e -Kτ = X 0 (1+ e -Kτ) (4-79) (X 2)min = X 0 (e -Kτ+ e -2Kτ) (4-80) 经时间间隔τ,给予第三次相同的剂量后体内的最大和最小药量为 (X 3)max = X 0 (1+e
-Kτ
+ e -2Kτ) (4-81)
(X 3)min = X 0 (e -Kτ+e -2Kτ+ e -3Kτ) (4-82) 依次类推,至第n 次,体内的最大和最小药量分别为
(X n )max = X 0 (1+e -Kτ+ e -2Kτ+ … + e -(n-1)Kτ) (4-83) (X n )min = X 0 (1+ e -Kτ+e -2Kτ+ e -3Kτ + … + e -(n-1)Kτ) e -Kτ (4-84) (1)多剂量函数
若设 r = (1+e -Kτ+ e -2Kτ+ … + e -(n-1)Kτ) (4-85) 将上式两边乘以e -Kτ则
r e -Kτ = (e -Kτ+ e -2Kτ+ e -3Kτ+ … + e -(n-1)Kτ+ e -nKτ) (4-86)
由4-85式减去4-86式得
数学建模中常见的十大模型
数学建模常用的十大算法==转 (2011-07-24 16:13:14) 转载▼ 1. 蒙特卡罗算法。该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟来检验自己模型的正确性,几乎是比赛时必用的方法。 2. 数据拟合、参数估计、插值等数据处理算法。比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用MA TLAB 作为工具。 3. 线性规划、整数规划、多元规划、二次规划等规划类算法。建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用Lindo、Lingo 软件求解。 4. 图论算法。这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,需要认真准备。 5. 动态规划、回溯搜索、分治算法、分支定界等计算机算法。这些算法是算法设计中比较常用的方法,竞赛中很多场合会用到。 6. 最优化理论的三大非经典算法:模拟退火算法、神经网络算法、遗传算法。这些问题是用来解决一些较困难的最优化问题的,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用。 7. 网格算法和穷举法。两者都是暴力搜索最优点的算法,在很多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具。 8. 一些连续数据离散化方法。很多问题都是实际来的,数据可以是连续的,而计算机只能处理离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的。 9. 数值分析算法。如果在比赛中采用高级语言进行编程的话,那些数值分析中常用的算法比如方程组求解、矩阵运算、函数积分等算法就需要额外编写库函数进行调用。 10. 图象处理算法。赛题中有一类问题与图形有关,即使问题与图形无关,论文中也会需要图片来说明问题,这些图形如何展示以及如何处理就是需要解决的问题,通常使用MA TLAB 进行处理。 以下将结合历年的竞赛题,对这十类算法进行详细地说明。 以下将结合历年的竞赛题,对这十类算法进行详细地说明。 2 十类算法的详细说明 2.1 蒙特卡罗算法 大多数建模赛题中都离不开计算机仿真,随机性模拟是非常常见的算法之一。 举个例子就是97 年的A 题,每个零件都有自己的标定值,也都有自己的容差等级,而求解最优的组合方案将要面对着的是一个极其复杂的公式和108 种容差选取方案,根本不可能去求解析解,那如何去找到最优的方案呢?随机性模拟搜索最优方案就是其中的一种方法,在每个零件可行的区间中按照正态分布随机的选取一个标定值和选取一个容差值作为一种方案,然后通过蒙特卡罗算法仿真出大量的方案,从中选取一个最佳的。另一个例子就是去年的彩票第二问,要求设计一种更好的方案,首先方案的优劣取决于很多复杂的因素,同样不可能刻画出一个模型进行求解,只能靠随机仿真模拟。 2.2 数据拟合、参数估计、插值等算法 数据拟合在很多赛题中有应用,与图形处理有关的问题很多与拟合有关系,一个例子就是98 年美国赛A 题,生物组织切片的三维插值处理,94 年A 题逢山开路,山体海拔高度的插值计算,还有吵的沸沸扬扬可能会考的“非典”问题也要用到数据拟合算法,观察数据的
最简单的房室模型是一房室模型
最简单的房室模型是一房室模型。用一房室模型意味着将机体看成一个动力学单元,它适用于给药以后药物瞬即分布到血液、其它体液及各器官组织中,并达成动态平衡的情况。二房室模型是从动力学角度把机体设想为两部分,分别称为中央室和周边室。中央室一般包括血液及血流丰富的组织(如心、肝、肾、肺、脑、消化器官等),周边室一般指血流供应少,药物不易进入的组织(如肌肉、皮肤、脂肪、毛发等)。尽管经典房室模型在临床中已有广泛的应用,但是这种模型并不能描述组织间浓度差异较大的生理系统。对药理活性不高的药物而言,可以忽略房室之间的差异,但是对于具有高亲和力的药物,或对于某些组织具有毒性,有特殊的目标器官的药物,经典的房室模型就无法描述这种特殊的现象[1]。经典房室模型还存在着一些明显的缺点,如:分析结果依赖于房室模型的选择,而房室模型的选择带有一定的不确定性。同一种药物可用不同的房室模型来解释,相应的参数可以显著不同。因而,要判断哪一个模型最适宜,有时是困难的,甚至是不可能的。为了克服经典房室模型的缺点,近年来药物动力学研究继经典房室模型之后又提出了生理房室模型[2]。生理房室模型简称生理模型,是一种整体模型。它是根据生理学、生物化学和机体解剖学的知识,模拟机体循环系统的血液流向并将各器官或组织相互联结。每一房室代表一种或一组特殊器官或组织,每一器官或组织(房室)在实际血流速率和组织/血液分配系数以及药物性质的控制下遵循物质平衡原理进行药物运转。因此,生理模型可描述任何器官或组织内药物浓度的经时变化,以提供药物体内分布的资料,并可以模拟肝、肾等代谢、排泄功能,提供药物体内生物转化的资料,从而得到药物对靶器官作用的信息,有助于药物作用机理的探讨。依据生理房室模型药物动力学,通过模拟可以验证、补充和预测体内药量的经时变化规律。对新药研究开发、临床药物治疗均有理论指导意义和实用价值。 药动学通常用房室模拟人体,只要体内某些部位接受或消除药物的速率相似,即可归入一个房室。房室模型仅是进行药动学分析的一种抽象概念,并不一定代表某一特定解剖部位。把机体划分为一个或多个独立单元,可对药物在体内吸收、分布、消除的特性作出模式图,以建立数学模型,揭示其动态变化规律。 1,假设机体给药后,药物立即在全身各部位达到动态平衡,这时把整个机体视为一个房室,称为一室模型或单室模型。 2,假设药物进入机体后,瞬时就可在血液供应丰富的组织(如血液、肝、肾等)分布达到动态平衡,然后再在血液供应较少或血流较慢的组织(如脂肪、皮肤、骨骼等)分布达到动态平衡,此时可把这些组织分别称为中央室和周边室,即二室模型。 多数情况下二室模型能够准确地反映药物的体内过程特征,但一房室模型虽然准确性稍差,却比较简单,便于理解、推广、应用,且有些药物用单室模型处理已能满足要求,所以其重要性并不亚于二室模型。 第二章.目前的主要研究现状以及相应的文献、使用的方法和结论
新古典经济增长理论
新古典经济增长理论 新古典经济增长模型对我国经济发展的启示 王峰杰 【摘要】新古典经济增长模型使用可变技术系数的生产函数,认为在市场机制的作用下,宏观经济能够自动沿着充分就业轨迹增长。由于均衡增长率正好等于劳动增长率,在经济均衡增长时,人均产量将保持不变。可以通过提高生产技术水平、提高储蓄率与降低人口增长率等,增加人均产量。 【关键词】新古典经济增长模型资本广化资本深化人均产量 一、新古典经济增长模型 新古典经济增长模型假设: 第一,撇开政府与国际部门,为两部门经济。 第二,仅仅使用劳动与投入两种要素生产产品,且不存在技术进步,则总量生产函数为:Q=F(L,K)(1) 其中,Q表示总产量,L表示劳动,K表示资本。 第三,各种要素的边际报酬递减,即随着劳动与资本投入的增加,它们的边际产量(、)递减。 第四,规模报酬不变,即: (2) 令k表示资本—劳动比率,即k=KL,可得: Q=L?f(k),或QL=f(k)(3)
这就是新古典经济增长模型中的生产函数。与哈罗德经济增长模型中的生产函数不同,该生产函数中的资本—劳动比率(k)可以变动,因为人均产量(QL)就是人均资本量(k)的函数。 第五,每一时期的劳动(用L表示)按固定比率n增长,即: (4) 第六,不存在资本折旧,则投资(用I表示)会增加资本存量,即: (5) 第七,储蓄函数采取长期的形式,即S=s(Y)。其中,S表示储蓄,s表示储蓄率,即s=SY,Y表示实际产量或实际收入,等同于Q。 第八,经济均衡增长的条件为总需求等于总供给。在两部门经济中,经济均衡增长的条件就是投资等于储蓄,即: I=S(6) 从上述假定条件,可以推导出新古典经济增长模型的基本方程: (9)式就是新古典经济增长模型中的基本方程。该方程表示,从长期来看,储 蓄必然等于投资。一个社会由人均储蓄sf(k)转化而来的新资本分为两个部分:一 部分(nk)是为新增加的每个劳动力提供社会平均水平的资本量,称为“资本广化”;另一部分(dkdt)则用来增加人均资本拥有量,即为每个人配备更多的资本品,称为“资本深化”。也可以这样来理解:在两部门经济中,社会总产品扣除消费(C)以后,剩下的便是储蓄,储蓄转化为投资,投资所增加的资本存量,分成两部分,用于两种用途:一部分为新增加的劳动力提供社会平均水平的资本,另一部分用于增加人均资本拥有量。 经济均衡增长的条件是人均储蓄量等于“资本广化量”,“资本深化量”等于零,即: sf(k)=nk(10)
十大经典数学模型
1、蒙特卡罗算法(该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟来检验自己模型的正确性,是比赛时必用的方法) 2、数据拟合、参数估计、插值等数据处理算法(比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用Matlab作为工具) 3、线性规划、整数规划、多元规划、二次规划等规划类问题(建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用Lindo、Lingo软件实现) 4、图论算法(这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,需要认真准备) 5、动态规划、回溯搜索、分支定界等计算机算法(这些算法是算法设计中比较常用的方法,很多场合可以用到竞赛中) 6、最优化理论的三大非经典算法:模拟退火法、神经网络、遗传算法(这些问题是用来解决一些较困难的最优化问题的算法,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用)元胞自动机 7、网格算法和穷举法(网格算法和穷举法都是暴力搜索最优点的算法,在很多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具) 8、一些连续离散化方法(很多问题都是实际来的,数据可以是连续的,而计算机只认的是离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的) 9、数值分析算法(如果在比赛中采用高级语言进行编程的话,那一些数值分析中常用的算法比如方程组求解、矩阵运算、函数积分等算法就需要额外编写库函数进行调用) 10、图象处理算法(赛题中有一类问题与图形有关,即使与图形无关,论文中也应该要不乏图片的,这些图形如何展示以及如何处理就是需要解决的问题,通常使用Matlab进行处理) 以上为各类算法的大致介绍,下面的内容是详细讲解,原文措辞详略得当,虽然不是面面俱到,但是已经阐述了主要内容,简略之处还望大家多多讨论。 1、蒙特卡罗方法(MC)(Monte Carlo): 蒙特卡罗(Monte Carlo)方法,或称计算机随机模拟方法,是一种基于“随机数”的计算方法。这一方法源于美国在第二次世界大战进行研制原子弹的“曼哈顿计划”。该计划的主持人之一、数学家冯·诺伊曼用驰名世界的赌城—摩纳哥的Monte Carlo—来命名这种方法,为它蒙上了一层神秘色彩。 蒙特卡罗方法的基本原理及思想如下: 当所要求解的问题是某种事件出现的概率,或者是某个随机变量的期望值时,它们可以通过某种“试验”的方法,得到这种事件出现的频率,或者这个随机变数的平均值,并用它们作为问题的解。这就是蒙特卡罗方法的基本思想。蒙特卡罗方法通过抓住事物运动的几何数量和几何特征,利用数学方法来加以模拟,即进行一种数字模拟实验。它是以一个概率模型为基础,按照这个模型所描绘的过程,通过模拟实验的结果,作为问题的近似解。 可以把蒙特卡罗解题归结为三个主要步骤: 构造或描述概率过程;实现从已知概率分布抽样;建立各种估计量。 例:蒲丰氏问题 为了求得圆周率π值,在十九世纪后期,有很多人作了这样的试验:将长为2l的一根针任意投到地面上,用针与一组相间距离为2a( l<a)的平行线相交的频率代替概率P,再利用准确的关系式:
第11章 新古典增长理论-索洛模型(讲义版)
第十一章 新古典增长理论——索洛模型(3) 本次授课框架: 总结波动理论,引出增长理论。 增长方程推导及对增长因素的讨论(包括索洛剩余) (1) 增长方程推导(总量形式),假设条件 (2) 人均形式生产函数 (3) 总量与人均量之间的关系 索洛稳态方程推导过程 (1) 索洛稳态定义 (2) 根据均衡条件的推导 (3) 稳态条件的存在性讨论(生产函数假设,INADA 条件) (4) 储蓄线和投资持平线(补偿线)相互关系的讨论解释稳态调整路径 比较静态分析 (1) 储蓄率增加情况 (2) 人口增长率增加情况 总结“新古典增长理论”的关键结论(影响总量、人均增长率的因素(结合储蓄率)与各国收入趋同论) 新古典增长理论评价 一、增长方程推导 假设生产函数: N N N K AF N N K AF N K K N K AF K N K AF K A A Y Y N K AF Y ???*+???* +?=?=),(),(),(),() ,( 假设 产品市场、要素市场完全竞争,规模收益不变1。根据欧拉定理: 1 对规模收益不变(Constant Return of Scale ,简称CRS )的理解。第一,经济规模足够大,以至于来自专业化分工的收益(gains from specialization )已不存在。当资本和劳动增加一倍时,只能重复原有的工作效率和工作方式,使产出翻倍而不能带来更多;第二,强调资本和劳动对产出的重要性,其他因素如自然资源的相对次要地位。本章的一道作业题也表明这种假设的合理性,自然资源对经济增长的制约阻碍在一定程度上是可以被逾越的。
总量表达式2 N N K K A A Y Y N K AF N N K AF N N K AF K N K AF K ?-+?+?=?-=??*=??* )1(1),(),() ,() ,(θθθθ 总量与人均量的关系 N N k k K K N N y y Y Y ?+?=??+?=? 人均量表达式 k k A A y y ?+?=?θ 索洛发现:技术进步、劳动供给增加和资本积累按此顺序是GDP 增长的重要决定因素,而技术进步和资本积累是人均GDP 增长的重要因素。在大部分历史中,两个重要的要素,当推资本积累3(实物与人力)与技术进步。我们对增长理论的研究重点集中于这两个因素。 索洛剩余 产出增长中不能通过资本积累和劳动投入来解释的部分,可以理解为技术进步(A A ?)带来的增长。A 4有时也被称作“全要素生产率”(TFP ),这是一个比“技术进步”更为中性的术语。实证研究表明: 技术进步在产出增长中的贡献大约为80%左右。由于产出和劳动、资 本投入可以直接观察到,而A 却不能,经济学家测量“索洛剩余” A 利用:])1[(K K N N Y Y A A ?+?--?=?θθ 二、稳态分析 2 在发达国家如美国,资本的收入份额θ是0.25,劳动的收入份额θ-1是0.75。这意味着,资本年增长率如果为3个百分点,导致产出增长率还不到1个百分点。 3 如果将资本进一步细化为实物资本和人力资本(H ),生产函数将转化为:),,(N H K AF Y =。曼昆、罗默等一篇颇有影响的文章指出,生产函数中实物资本K 、非熟练劳动力N 和人力资本H 的要素份额各占1/3。 4 A 被定义为“全要素生产率”的说法,只是针对),(N K AF Y =这种生产函数形式的,这种技术进步 类型在历史上也被称作“hicks-neutral ”(希克斯中性);如果生产函数形式为),(AN K F Y =,这是的技术进步被称作劳动增广型(labor-augmenting )技术进步或“harrod-neutral ”(哈罗德中性)。如果采用这种生产函数形式,也可以推导出类似的增长方程以及索洛稳态方程。
最经典的数学模型
最经典的数学模型 怎样得到最好的女孩子的数学模型 【关键词】怎样得到最好女孩子数学模型 由于老天爷在你的生命中安排的异性并不是同时出现任你挑选,因此无论你在何时选择结婚都是有机会成本的。 人们常常希望能够获得一个最可爱的人作为自己的伴侣。但是,由于老天爷在你的生命中安排的异性并不是同时出现任你挑选,因此无论你在何时选择结婚都是有机会成本的。也许你很早就结婚了,但是结婚之后却又不断发现还有不少更好更适合结婚的异性,这就是结婚太早的机会成本。那么,是不是晚一点结婚就可以避免这个问题呢?不是的!当结婚太晚,你错过最好的异性的可能性也就更大。那么,一个人究竟应采取什么样的策略才能最大可能地遇到最适合的异性,从而使结为伴侣的机会成本最低呢?我们不妨建立一个模型来考察。 假设你是一个男孩子,而老天爷在你20岁到30最之间安排了20位适合你的女孩子。这些女孩子都愿意作为你的伴侣,但是你只能选择其中的一位。对于你来说,这20位女孩子的质量是可以排序的,也就是说事后你可以对她们的质量排名,质量排第一的对你来说就是最好的,排第20的对你来说就是最差的。可惜的是,由于20位女孩不是同时出现在你的生命中,而是按时间先后出现,每出现一个你都要决定是否留下她或拒绝她。如果留下她则她成为你的伴侣,你将再没有权利选择后面的女孩子;如果拒绝她,则你还可以选择后面的女孩子,但是对前面已经拒绝的女孩子将没有机会从头再来。 20个女孩子的排名虽然可以在事后决定,但是在观察完20个女孩子之前,你并不知道全部女孩子的排名,你只知道已经观察过的女孩子谁比谁会更好。而且,上帝是完全随机地安排每个时间段出现的女孩子的,也就是说出现时间的先后与女孩子的质量是完全没有关系的。那么,你应该在什么时候决定接受一个女孩子,并且使得被接受那个女孩子属于最好女孩的概率最大呢? 当然,你完全可以在碰到第一个女孩子时就接受她。她确有可能刚好就是最好的,但也有可能是最差的。当你接触到第二个女孩子,你可以知道她和第一个女孩子谁更好,但却不知道她们与剩下的18个女孩比又如何——前两个分别是最差的、次差的概率当然有,但前两个刚好是最好的、次好的可能性也是存在的,其他的概率情况也是有的。看来,你要尽可能挑到最好的女孩做伴侣还真是费神哦。 现在让我们来设计几种挑选策略,以便在不确定性中尽可能找到最好的女孩子。 策略1:事先抽签,抽到第几个就第几个。比如,抽到第10位,那么第10个在你生命中出现的女孩就事前被确定为你的伴侣。而她刚好是最好的女孩之概率是多少呢?答案是1/20=0.05。这种策略使你有5%的可能性获得最好的女孩。这样的概率显然太小,很难发生。 策略2:把全部女孩分成前后两段,最先出现的10位均不接受,但了解了这10位女孩的质量,然后在后来出现的10位女孩当中,第一次碰到比以前都可爱的女孩子,就立马接受。这是一种等一等、看一看的策略。这样的策略中,你得到最好的女孩子的概率是
数据库原理第二章练习
第二章关系数据库 一、选择题: 1、对于关系模型叙述错误的是。 A.建立在严格的数学理论、集合论和谓词演算公式基础之一 B.微机DBMS绝大部分采取关系数据模型 C.用二维表表示关系模型是其一大特点 D.不具有连接操作的DBMS也可以是关系数据库管理系统 2、关系模式的任何属性。 A.不可再分B.可再分 C.命名在该关系模式中可以不唯一D.以上都不是 3、在通常情况下,下面的表达中不可以作为关系数据库的关系的是。A.R1(学号,姓名,性别) B.R2(学号,姓名,班级号) C.R3(学号,姓名,宿舍号) D.R4(学号,姓名,简历) 4、关系数据库中的码是指。 A.能唯一关系的字段B.不能改动的专用保留字C.关键的很重要的字段D.能惟一表示元组的属性或属性集合 5、根据关系模式的完整性规则,一个关系中的“主码”。 A.不能有两个B.不能成为另外一个关系的外码 C.不允许为空D.可以取值 6、关系数据库中能唯一识别元组的那个属性称为。 A.唯一性的属性B.不能改动的保留字段C.关系元组的唯一性D.关键字段 7、在关系R(R#,RN,S#)和S(S#,SN,SD)中,R的主码是R#,S的主码是S#,则S#在R中称为。 A.外码B.候选码 C.主码D.超码 8、关系模型中,一个码是。 A.可由多个任意属性组成 B.至多由一个属性组成 C.可由一个或多个其值能唯一标识该关系模式中任意元组的属性组成D.以上都不是 9、一个关系数据库文件中的各条记录。 A.前后顺序不能任意颠倒,一定要按照输入的顺序排列 B.前后顺序可以任意颠倒,不影响库中的数据关系 C.前后顺序可以任意颠倒,但排列顺序不同,统计处理的结果可能不同D.前后顺序不能任意颠倒,一定要按照码段的顺序排列 10、关系数据库管理系统应能实现的专门关系运算包括。
(完整版)新古典经济增长模型对我国经济发展的启示
新古典经济增长模型对我国经济发展的启示 【摘要】新古典经济增长模型使用可变技术系数的生产函数,认为在市场机制的作用下,宏观经济能够自动沿着充分就业轨迹增长。由于均衡增长率正好等于劳动增长率,在经济均衡增长时,人均产量将保持不变。可以通过提高生产技术水平、提高储蓄率与降低人口增长率等,增加人均产量。 【关键词】新古典经济增长模型资本广化资本深化人均产量 一、新古典经济增长模型 新古典经济增长模型假设: 第一,撇开政府与国际部门,为两部门经济。 第二,仅仅使用劳动与投入两种要素生产产品,且不存在技术进步,则总量生产函数为:Q=F(L,K)(1) 其中,Q表示总产量,L表示劳动,K表示资本。 第三,各种要素的边际报酬递减,即随着劳动与资本投入的增加,它们的边际产量(MP L、MP K)递减。 第四,规模报酬不变,即: 令k表示资本—劳动比率,即k=KL,可得: Q=L?f(k),或QL=f(k)(3) 这就是新古典经济增长模型中的生产函数。与哈罗德经济增长模型中的生产函数不同,该生产函数中的资本—劳动比率(k)可以变动,因为人均产量(QL)就是人均资本量(k)的函数。 第五,每一时期的劳动(用L表示)按固定比率n增长,即: L t=L0e nt(4) 第六,不存在资本折旧,则投资(用I表示)会增加资本存量,即: 第七,储蓄函数采取长期的形式,即S=s(Y)。其中,S表示储蓄,s表示储蓄率,即s=SY,Y表示实际产量或实际收入,等同于Q。 第八,经济均衡增长的条件为总需求等于总供给。在两部门经济中,经济均衡增长的条件就是投资等于储蓄,即: I=S(6) 从上述假定条件,可以推导出新古典经济增长模型的基本方程: (9)式就是新古典经济增长模型中的基本方程。该方程表示,从长期来看,储蓄必然等于投资。一个社会由人均储蓄sf(k)转化而来的新资本分为两个部分:一部分(nk)是为新增加的每个劳动力提供社会平均水平的资本量,称为“资本广化”;另一部分(dkdt)则用来增加人均资本拥有量,即为每个人配备更多的资本品,称为“资本深化”。也可以这样来理解:在两部门经济中,社会总产品扣除消费(C)以后,剩下的便是储蓄,储蓄转化为投资,投资所增加的资本存量,分成两部分,用于两种用途:一部分为新增加的劳动力提供社会平均水平的资本,另一部分用于增加人均资本拥有量。 经济均衡增长的条件是人均储蓄量等于“资本广化量”,“资本深化量”等于零,即:sf(k)=nk(10) 在经济均衡增长时,收入、投资与资本均按劳动增长率或自然增长率n增长: (1)收入按n增长 当经济均衡增长时,由于QL=f(k),故人均资本量(k)不变,人均产量(f(k))也不变。但劳动力始终按固定比率n增长,为了保证人均产量不变,产量也必须按n增长。
房室模型的综述
房室模型的综述 1前言 神经系统可能是我们体内最复杂和最重要的系统。它负责传递有关肌肉运动和感官输入的信息,使我们能够与周围的世界互动并感知它们。神经系统主要由称为神经元的大量互连细胞网络组成。因此,对神经元的研究具有重要意义,因为了解神经元本身的性质有助于理解它们如何在更大的网络中协同工作。 1.1神经元解剖学 神经元可以分解为三个主要部分;躯体,树突和轴突。体细胞是神经元的主体,具有容纳细胞核的半透性细胞膜。树枝状结构形成一个巨大的树状结构,从躯体延伸出来。树突负责接收来自其他神经元的突触输入(神经递质)。神经元的轴突是长轴状结构,终止于轴突末端。轴突末端负责释放由其他神经元的树突所接收的神经递质。神经元图如图1所示。树突和轴突末端的大分支结构允许每个神经元与数千个其他神经元连接,形成大规模的通信网。神经元通过突触进行通信,突触由轴突终端中的电脉冲触发。轴突末端的电脉冲释放神经递质,该神经递质与另一神经元的树突上的受体位点结合。树突上的兴奋性神经递质的累积可以引起动作电位,这是跨细胞膜的电压的大的尖峰。该电脉冲可以沿树突移动到轴突终端,其中可以定位其他突触,允许信息在网络上传播。 1.2数学方法 为了捕获沿单个神经元的电脉冲传播的基本动态,可以使用数学方程。然而,神经元的复杂生理结构产生难以分析的方程式。跨越神经元细胞膜的潜在差异取决于空间和时间,因此生理上准确的神经元模型将受部分差异方程(PDE)控制。PDE难以通过分析和数值分析。为了克服这种困难,神经元可以通过称为区室化的过程离散化(图2)。当神经元被划分时,它被分解成称为隔室的不连续区段。 图1:神经元图。神经元的三个主要部分是体细胞,树突和轴突。 单个隔室没有空间依赖性,因此它们的电压仅取决于时间,这使得它们可以由普通的二元方程(ODE)控制。通常,对ODE系统的分析比PDE系统的分析容易得多。区室化过程允许使用空间独立的隔室对神经元进行建模。模型具有的隔室越多,其生理学上就越现实。然而,大隔室模型可能极难分析,因此可能难以揭
新古典经济增长理论
新古典经济增长模型对我国经济发展的启示 王峰杰 【摘要】新古典经济增长模型使用可变技术系数的生产函数,认为在市场机制的作用下,宏观经济能够自动沿着充分就业轨迹增长。由于均衡增长率正好等于劳动增长率,在经济均衡增长时,人均产量将保持不变。可以通过提高生产技术水平、提高储蓄率与降低人口增长率等,增加人均产量。 【关键词】新古典经济增长模型资本广化资本深化人均产量 一、新古典经济增长模型 新古典经济增长模型假设: 第一,撇开政府与国际部门,为两部门经济。 第二,仅仅使用劳动与投入两种要素生产产品,且不存在技术进步,则总量生产函数为:Q=F(L,K)(1) 其中,Q表示总产量,L表示劳动,K表示资本。 第三,各种要素的边际报酬递减,即随着劳动与资本投入的增加,它们的边际产量(MP L、MP K)递减。 第四,规模报酬不变,即: (2) 令k表示资本—劳动比率,即k=KL,可得: Q=L?f(k),或QL=f(k)(3)
这就是新古典经济增长模型中的生产函数。与哈罗德经济增长模型中的生产函数不同,该生产函数中的资本—劳动比率(k)可以变动,因为人均产量(QL)就是人均资本量(k)的函数。 第五,每一时期的劳动(用L表示)按固定比率n增长,即: (4) L t=L 0e nt 第六,不存在资本折旧,则投资(用I表示)会增加资本存量,即: (5) 第七,储蓄函数采取长期的形式,即S=s(Y)。其中,S表示储蓄,s表示储蓄率,即s=SY,Y表示实际产量或实际收入,等同于Q。 第八,经济均衡增长的条件为总需求等于总供给。在两部门经济中,经济均衡增长的条件就是投资等于储蓄,即: I=S(6) 从上述假定条件,可以推导出新古典经济增长模型的基本方程: (9)式就是新古典经济增长模型中的基本方程。该方程表示,从长期来看,储蓄必然等于投资。一个社会由人均储蓄sf(k)转化而来的新资本分为两个部分:一部分(nk)是为新增加的每个劳动力提供社会平均水平的资本量,称为“资本广化”;另一部分(dkdt)则用来增加人均资本拥有量,即为每个人配备更多的资本品,称为“资本深化”。也可以这样来理解:在两部门经济中,社会总产品扣除消费(C)以后,剩下的便是储蓄,储蓄转化为投资,投资所增加的资本存量,分成两部分,用于两种用途:一部分为新增加的劳动力提供社会平均水平的资本,另一部分用于增加人均资本拥有量。 经济均衡增长的条件是人均储蓄量等于“资本广化量”,“资本深化量”等于零,即: sf(k)=nk(10)
新古典增长理论与新增长理论之间的区别和联系
新古典增长理论与新增长理论之间的区别和联系 经济增长(economic growth)就是社会物质财富不断增加的过程,是一般社会再生产动态过程的共性实质。它代表的是一国潜在的GDP或国民产出的增加。对于一个国家而言,经济增长是宏观经济中衡量一个国家经济状况的重要指标。无庸置疑,没有谁不希望经济增长,但是,用什么方法实现经济增长,人们却有不同的看法。一些经济学家强调投资的重要性,还有一些人则提倡提高劳工素质。 长期以来,经济学家们一直致力于研究经济增长中各种决定因素的相对重要性,从而提出了种种经济增长理论。诞生于20世纪早期的新古典增长理论对世界经济产生了重大影响,随着近年来新的经济现象的不断出现,新古典增长理论在某些方面的局限性日益明显,于是,新经济增长理论产生了。 在接下来的讨论中,我们将对这两种经济增长理论进行简要的比较。 ◎新古典主义增长理论 新古典增长理论(neoclassical growth theory)是人均实际GDP的增长是由于技术变革引起人均资本增加的储蓄和投资水平的观点。如果技术进步停止,增长就结束。 一、代表人物 新古典经济增长理论的创立者是美国的经济学家、MIT的罗伯特·索洛(Robert M. Solow)以及英国的经济学家斯旺(Swan)。早在1956年,他们就分别提出了他们的经济增长模型。但是剑桥大学的弗兰克·拉姆(Frank Ramsey)在上世纪20年代就第一次提出了这种理论后来,英国经济学家米德又进一步发展了新古典经济增长理论,并对其作了系统的研究。美国的经济学家萨缪尔森(Paul A. Samuelson)等在他们的经济增长理论中也提出了与索洛基本相同的观点。 二、假定条件 索落在其著作中提出了以下假设: (1)萨伊定理:供给可以创造自身的需求。 (2)I=S,即储蓄永远等于投资。 (3)工资取决于劳动的边际生产力,利息取决于资本的边际生产力。 由以上假定条件,可以得出一个结论:社会上不会出现失业和通货膨胀。
数学建模的经典模板
一、摘要 内容: (1)用1、2句话说明原问题中要解决的问题; (2)建立了什么模型(在数学上属于什么类型),建模的思想(思路),模型特点;(3)算法思想(求解思路),特色; (4)主要结果(数值结果,结论);(回答题目的全部“问题”) (5)模型优点,结果检验;模型检验,灵敏度分析,有无改进,推广 要求 (1)特色和创新之处必须在这里强调; (2)长度 (3)要确保准确、简明、条理、清晰、突出特色和创新点; 二、问题的提出 内容: 用自己的语言阐述背景,条件,要求;重点列出‘问题’也即要求; 要求: (1)不是题目的完整拷贝 (2)根据自己的理解,用自己的语言清楚简明的阐述背景、条件和要求; 三、条件假设 内容 (1)根据题目中的条件做出假设 (2)根据题目中的要求做出假设; 要求 (1)合理性最重要; (2)假设合理且全面,但不欣赏罗列大量的无关假设,关键性假设不能缺; (3)合理假设作用: 简化问题,明确问题,限定模型的适用范围 四、符号约定 五、问题分析 1.名词解释 2.问题的背景分析 3.问题分析 六、模型建立 抽象要求
(1)模型的主要类别:初等模型、微分方程模型、差分方程模型、概率模型、统计预测模型、优化模型、决策模型、图论模型等 (2)几种常见的建模目的:(对应相对(1)的方法) 描述或解释现实世界的各类现象,常采用机理型分析方法,探索研究对象的内在规律性; 预测感兴趣的时间爱你是否会发生,或者事物的房展趋势,常采用数理统计或模拟的方法; 优化管理、决策或者控制事物,需要合理地定义可量化的评价指标及评价方法; (3)建模过程常见的几个要点: 模型的整体设计、合理的假设、建立数学结构、建立数学表达式; (4)模型的要求: 明确、合理、简洁、具有一般性; 例如:有些论文不给出明确的模型,只是就赛题所给的特殊情况,用凑得方法给出结果,虽然结果大致对,但缺乏一般性,不是建模的正确思路;((与第三点对应))(5)鼓励创新,特别欣赏独树一帜、标新立异,但要合理 (6)避免出现罗列一系列的模型,又不做评价的现象; 具体要求: (1)基本模型:首先要有数学模型:数学公式、方案等;基本模型,要求完整,正确,简明 (2)简化模型:要明确说明,简化思想,依据;简化后的模型尽可能给出; 七、模型求解 每一块内容包括:计算方法设计或选择、算法设计或选择、算法思想依据、步骤及实现、计算框图、所采用的软件名称 写作要求: 1、需要建立数学命题时:命题叙述要符合数学命题的表述规范,尽可能论证严密 2、需要说明计算方法或算法的原理、思想、依据、步骤。若采用现有软件,说明采用此软件的理由,软件名称 3、计算过程,中间结果可要可不要的,不要列出 4、设法算出合理的数值结果 5、最终数值结果的正确性或合理性是第一位的 6、对数值结果或模拟结果进行必要的检验。结果不正确、不合理、或误差大时,分析原因,对算法、计算方法、或模型进行修正、改进 7、题目中要求回答的问题,数值结果,结论,须一一列出 8、列数据问题:考虑是否需要列出多组数据,或额外数据对数据进行比较、分析,为各种方案的提出提供依据 9、结果表示:要集中,一目了然,直观,便于比较分析 ▲数值结果表示:精心设计表格;可能的话,用图形图表形式 ▲求解方案,用图示更好 10、必要时对问题解答,作定性或规律性的讨论。最后结论要明确
1.评述新古典增长理论。
1.评述新古典增长理论 答:(1)新古典增长理论放弃了哈罗德-多马模型中关于资本和劳动不可替代的假设。模型的假设前提大致是:①全社会只生产一种产品;②储蓄函数为S =sY ,s 是作为参数的储蓄,且0社会的人均储蓄量在用于为新增人口n 配备人均资本所需要的资本量nk 后仍有余额,则意 味着每个人都可以继续增加人均资本量,即K >0。 这表明,人均资本量将会进一步增加,从而缩小储 蓄与新增人口配备资本的需要量之间的差距。相反, 如果()sf K nK <,意味着现在的储蓄不够为新增人 口配备资本,从而人均资本倾向于下降。因此,当K =0时,经济实现稳定增长。在稳定增长状态下,人均产量保持不变,因而经济将会以人口增长率增长。新古典增长模型图形如图8—l 。 从新古典增长模型中可以得出结论,经济可以以人口增长率实现稳定增长。 此外,模型也包含着促进人均收入增加的政策含义。事实上,实现人均产出量增加有三 种途径:一是提高总产量,即提高技术水平;二是提高储蓄率;三是降低人口出生率。这对图8—1 新古典增长模型
第2章信息与数据模型
数据库系统原理及MySQL应用教程(第2版) 课后习题参考答案 第2章信息与数据模型 1. 信息的三种世界分别是:信息的现实世界、信息世界和信息的计算机世界。 这3个领域是由客观到认识、由认识到使用管理的3个不同层次,后一领域是前一领域的抽象描述。信息的三种世界描述: 2.也称信息模型,按用户的观点对数据和信息建模,主要用于数据库设计。3.实体:客观存在的实体事物。 实体型:用实体类型名和所有属性来共同表示同一类实体。 实体集:同一类型实体的集合 属性:实体所具有的某一特性 码:可以唯一标识一个实体的属性集 E-R图:E-R图也称实体-联系图(Entity Relationship Diagram),提供了表示实体类型、属性和联系的方法,用来描述现实世界的概念模型。 4. 转换原则:一个实体转换为一个关系模式。实体的属性就是关系的属性。 联系类型的转换: 1).若实体间联系是1∶1,可以在两个实体类型转换成的两个关系模式中任意一个关系模式中加入另一个关系模式的码和联系类型的属性。 2.)若实体间的联系是1∶n,则在n 端实体类型转换成的关系模式中加入 1端实体类型的码和联系类型的属性。 3.)若实体间联系是m∶n,则将联系类型也转换成关系模式,其属性为两
端实体类型的码加上联系类型的属性,而码为两端实体码的组合。 5 A 6 D 7 C 8 D 9 A 10 A 11 B 12 C 13 B 14 A 15 C 16 C 17 D 18 A 19 C 20 B 21 A 22A 23 A 24 A 25(1)B (2)D (3)C (4)A 23 (1)D (2)C (3)C (4)B 27 答: (1)学生与课程联系类型是多对多联系。 (2)课程与教师的联系类型是多对多联系。 (3)学生与教师的联系类型是一对多联系。 (4)完善本题E-R图的结果如下图所示。 28 (1)
数学建模典型例题
一、人体重变化 某人的食量是10467焦/天,最基本新陈代谢要自动消耗其中的5038焦/天。每天的体育运动消耗热量大约是69焦/(千克?天)乘以他的体重(千克)。假设以脂肪形式贮存的热量100% 地有效,而1千克脂肪含热量41868焦。试研究此人体重随时间变化的规律。 一、问题分析 人体重W(t)随时间t变化是由于消耗量和吸收量的差值所引起的,假设人体重随时间的变化是连续变化过程,因此可以通过研究在△t时间内体重W的变化值列出微分方程。 二、模型假设 1、以脂肪形式贮存的热量100%有效 2、当补充能量多于消耗能量时,多余能量以脂肪形式贮存 3、假设体重的变化是一个连续函数 4、初始体重为W0 三、模型建立 假设在△t时间内: 体重的变化量为W(t+△t)-W(t); 身体一天内的热量的剩余为(10467-5038-69*W(t)) 将其乘以△t即为一小段时间内剩下的热量; 转换成微分方程为:d[W(t+△t)-W(t)]=(10467-5038-69*W(t))dt; 四、模型求解 d(5429-69W)/(5429-69W)=-69dt/41686 W(0)=W0 解得: 5429-69W=(5429-69W0)e(-69t/41686) 即: W(t)=5429/69-(5429-69W0)/5429e(-69t/41686) 当t趋于无穷时,w=81; 二、投资策略模型 一、问题重述 一家公司要投资一个车队并尝试着决定保留汽车时间的最佳方案。5年后,它将卖出所有剩余汽车并让一家外围公司提供运输。在策划下一个5年计划时,这家公司评估在年i 的开始买进汽车并在年j的开始卖出汽车,将有净成本a ij(购入价减去折旧加上运营和维修成本)ij
02第二章数据模型(答案)
第二章数据模型 一、单项选择题 1、按照传统的数据模型分类,数据库系统可分为三种类型( B )。 A、大型、中型和小型 B、层次、网状和关系 C、西文、中文和兼容 D、数据、图形和多媒体 2、在概念模型中,客观存在并可以相互区别的事物称为( C )。 A、物体 B、物质 C、实体 D、个体 3、用树型结构来表示实体之间联系的模型称为( A )。 A、层次模型 B、关系模型 C、运算模型 D、网状模型 4、按照数据模型划分,ACCESS是一个( A )。 A、关系型数据库管理系统 B、网状型数据库管理系统 C、层次型数据库管理系统 D、混合型数据库管理系统 5、关系数据模型用( C )结构表示实体和实体间的联系。 A、树型 B、网状 C、二维表 D、对象 6、E-R图中用( C )表示实体间的联系。 A、矩形 B、正方形 C、菱形 D、椭圆形 7、实体间的联系存在着( D )。 A、1:1联系 B、1:n联系 C、m:n联系 D、1:1、1:n(n:1)和m:n 8、一个公司可以接纳多名职员参加工作,但每个职员只能在一个公司工作,从公 司到职员之间的联系类型是( D )。 A、多对多 B、一对一 C、多对一 D、一对多 9、E-R方法的三要素是( C )。 A、实体、属性、实体集 B、实体、码、关系 C、实体、属性、关系 D、实体、域、码 10、E-R表示法是设计( A )常用的方法。 A、概念模型 B、数据库逻辑结构设计模型 C、数据库物理结构设计模型 D、都可以 11、Access基于( C )数据模型。 A、层次 B、网状 C、关系 D、面向对象 12、E-R图在数据库设计中被广泛使用,椭圆表示( C )。 A、实体 B、实体的主键 C、实体的属性 D、实体间的联系 13、常见的数据模型有( C )。 A、面向对象、空间数据模型和NoSQL B、实体、属性和联系 C、层次、网状和关系 D、矩形、椭圆形和菱形 二、判断题 1、关系模型是目前最常用的数据模型。√ 2、概念模型的表示与系统采用的数据模型有关。× 3、同类实体的集合称为实体型。× 4、在E-R图中,用矩形表示实体、椭圆形表示实体的属性。√
数学建模中常见的十大模型
数学建模中常见的十大 模型 集团标准化工作小组 #Q8QGGQT-GX8G08Q8-GNQGJ8-MHHGN#
数学建模常用的十大算法==转 (2011-07-24 16:13:14) 1. 蒙特卡罗算法。该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟来检验自己模型的正确性,几乎是比赛时必用的方法。 2. 数据拟合、参数估计、插值等数据处理算法。比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用MATLAB 作为工具。 3. 线性规划、整数规划、多元规划、二次规划等规划类算法。建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用Lindo、Lingo 软件求解。 4. 图论算法。这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,需要认真准备。 5. 动态规划、回溯搜索、分治算法、分支定界等计算机算法。这些算法是算法设计中比较常用的方法,竞赛中很多场合会用到。 6. 最优化理论的三大非经典算法:模拟退火算法、神经网络算法、遗传算法。这些问题是用来解决一些较困难的最优化问题的,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用。 7. 网格算法和穷举法。两者都是暴力搜索最优点的算法,在很多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具。
8. 一些连续数据离散化方法。很多问题都是实际来的,数据可以是连续的,而计算机只能处理离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的。 9. 数值分析算法。如果在比赛中采用高级语言进行编程的话,那些数值分析中常用的算法比如方程组求解、矩阵运算、函数积分等算法就需要额外编写库函数进行调用。 10. 图象处理算法。赛题中有一类问题与图形有关,即使问题与图形无关,论文中也会需要图片来说明问题,这些图形如何展示以及如何处理就是需要解决的问题,通常使用MATLAB 进行处理。 以下将结合历年的竞赛题,对这十类算法进行详细地说明。 以下将结合历年的竞赛题,对这十类算法进行详细地说明。 2 十类算法的详细说明 蒙特卡罗算法 大多数建模赛题中都离不开计算机仿真,随机性模拟是非常常见的算法之一。 举个例子就是97 年的A 题,每个零件都有自己的标定值,也都有自己的容差等级,而求解最优的组合方案将要面对着的是一个极其复杂的公式和108 种容差选取方案,根本不可能去求解析解,那如何去找到最优的方案呢随机性模拟搜索最优方案就是其中的一种方法,在每个零件可行的区间中按照正态分布随机的选取一个标定值和选取一个容差值作为一种方案,然后通过蒙特卡罗算法仿真出大量的方案,从中选取一个最佳的。另一个例子就是去年的彩票第二问,要求设计一种更好的方案,首先方案的优劣取决于很多复杂的因素,同样不可能刻画出一个模型进行求解,只能靠随机仿真模拟。