Bernese数据处理流程
Bernese处理数据前的准备工作(一)——建立项目和定义时段
在Bernese处理数据之前,首先要定义一个项目并激活为它当前使用项目,生成项目下的子目录,然后将数据文件拷贝进这些子目录中,还要收集并指定一些与项目有关的其它基础信息。从Bernese的5.0版本开始,用户还不得不为即将处理的数据选择处理时段。
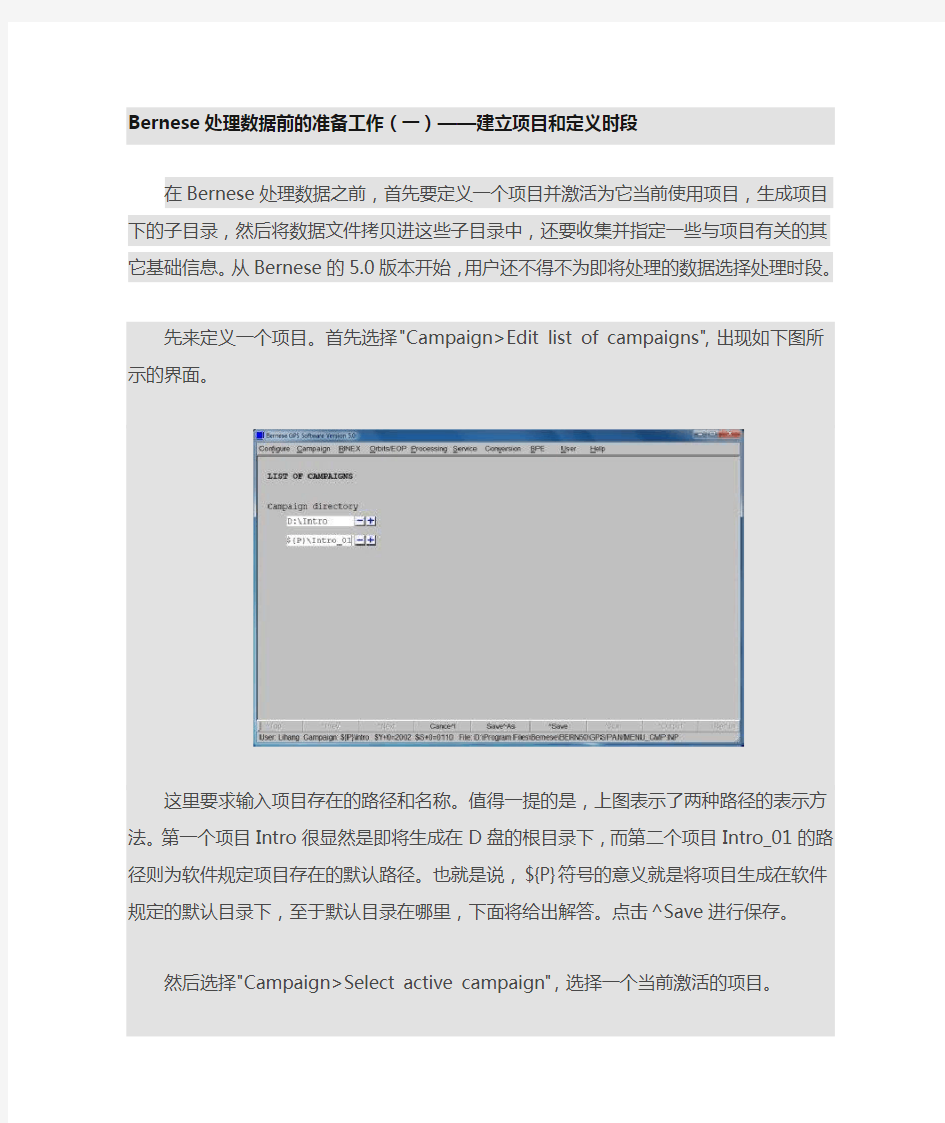
先来定义一个项目。首先选择"Campaign>Edit list of campaigns",出现如下图所示的界面。
这里要求输入项目存在的路径和名称。值得一提的是,上图表示了两种路径的表示方法。第一个项目Intro很显然是即将生成在D盘的根目录下,而第二个项目Intro_01的路径则为软件规定项目存在的默认路径。也就是说,${P}符号的意义就是将项目生成在软件规定的默认目录下,至于默认目录在哪里,下面将给出解答。点击^Save进行保存。
然后选择"Campaign>Select active campaign",选择一个当前激活的项目。
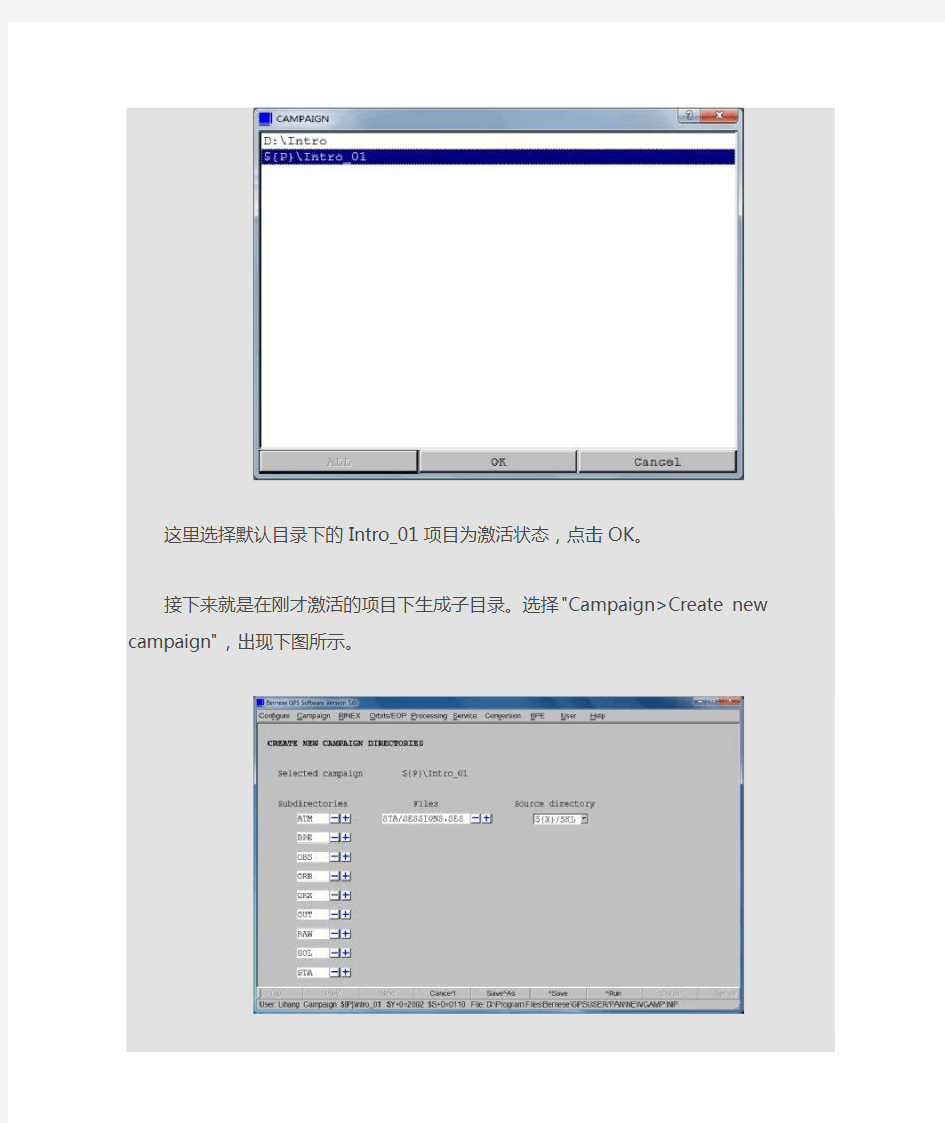
这里选择默认目录下的Intro_01项目为激活状态,点击OK。
接下来就是在刚才激活的项目下生成子目录。选择"Campaign>Create new campaign",出现下图所示。
这里左侧的一列即为项目下的子目录。点击^Run,然后找到Bernese软件安装目录下的"...\Bernese\GPSDATA"文件夹,就可以看到刚才新建的这个Intro_01项目,并且在项目文件夹内同时生成了和上图左侧一列相同的共9个同名文件夹。从这里可以看出,新建项目的默认路径就在"...\Bernese\GPSDATA"。至此,一个项目的新建过程完成。其中,这9个文件夹存放的内容分别为:
ATM:存放项目相关的大气层文件(例如电离层文件ION,电离层文件TRP)
BPE:存放BPE批处理时每一步骤完成的状态信息文件
OBS:存放Bernese的观测文件
ORB:存放跟轨道相关的文件(轨道文件、地球自转参数、卫星钟差文件等)
ORX:存放原始RINEX文件
OUT:存放输出文件
RAW:存放可用于计算的RINEX文件
SOL:存放结果文件(例如法方程文件,SINEX文件)
STA:存放项目相关的坐标和坐标信息文件等,项目时段信息表也在这里
接下来设置时段。时段是一段涵盖了所有即将处理的数据所处的时间段。也就是说,接下来所有处理的数据都要在这里所设置的时段以内。
首先选择"Campaign>Edit session table"将会出现时段表的编辑界面,如下所示。
需要说明的是,时段表的编辑界面默认是只会显示上图的第一行的。IDENTIFIER 这列表示的是时段的四位标识符,前三位是年积日,后一位如果为0,则表示时段为该天全天,时段表的默认状态就是0。这一行下面的由A~X共24个大写字母则是我手工添加进去的,每个代表一个小时。通过后两列的起始和结束历元可以自己指定特定的时段。这里对时段表的编辑,是为了下面的步骤选择时段做的准备工作。最后点击^Save保存修改。
选择"Configure>Set session/compute date",出现如下图选择时段的窗口。
这里将时间设置为2008年9月25日,点击Compute,就会将其对应的修正儒略日、GPS时和年积日计算出来。
Session Table一栏选择的是刚才编辑过了的时段表,这个文件在之前生成项目下的子目录时就自动生成了。这里的Session Char一栏里面填0,表示时段为2008年9月25日这一整天。同样的可以选择A~X或者自定义的其他字符,意义各不相同。
然后点击OK。之后会在软件界面下方状态栏出现下图所示。
这里的$Y+0和$S+0所对应的分别是年号和年积日号,说明刚才的设置已经生效。至此,时段信息也已经定义完成。
Bernese处理数据前的准备工作(二)——创建测站文件
上一篇介绍了Bernese处理数据前的准备工作之建立项目和定义时段,接下来要做的就是为创建测站文件了。对一些站文件,Bernese软件的"Campaign>Edit station files"菜单提供掩码形式的编辑。因为所有的站文件都是以ASCII形式存在的,所以用户可以用各种工具浏览并修改。创建测站文件的过程主要分为三个步骤:创建参考系/参考速度文件,创建测站信息文件和其他测站文件。
首先来说明如何创建参考系和参考速度文件。
在将要处理的项目中,如果任何站所处的参考系在ITRF中的精度都没有到达分米级别,那么建议在处理过程中至少加入一个项目所处地域附近的IGS跟踪站一并参与处理。也就是说,对于参与处理的项目,都必须建立相应的参考系和参考速度,对此用户可以从ITRF或者IGS参考框架选择与项目对应的SINEX文件。Bernese软件中的SNX2Q0
("Conversion>SINEX to normal equations")这个程序就是获取SINEX文件中的参考系和参考速度的,在使用之前必须先将SINEX文件拷贝到项目子目录SOL中去。
需要说明的是,ITRF参考框架最新为ITRF2000,用户可以到
“ftp://lareg.ensg.ign.fr/pub/itrf/itrf2000”下载相应的.SNX格式文件。IGS参考框架最新为IGS 00b,用户可以到“http://www.aiub.unibe.ch/download/BSWUSER50/STA”,选择下载IGS_00_R.CRD和IGS_00_R.VEL文件。这两个参考系和参考速度文件已经是Bernese标准格式了,可以直接拷贝到项目子目录STA路径下。
用"Campaign>Edit station files>Station coordinates/Station velocities"可以手动编辑修改参考系和
参考速度文件。官方建议这些文件仅含有先验参考系和参考速度达到1cm以上精度的测站,剩下的其他测站的信息则会在以后的PPP处理过程中再添加进去。
【实践】我在按上述方法下载了IGS_00_R.CRD和IGS_00_R.VEL这两个文件并拷贝到“...\Bernese\GPSDATA\Intro_01\STA”路径后,分别选择"Campaign>Edit station files>Station coordinates/Station velocities",按提示选择这两个文件,就会出现如下图所示的手动编辑参考系和参考速度文件的界面,这也就验证了上述操作步骤的正确性。
接下来是创建测站信息文件。有两点非常重要,一是确保处理过程中测站的名字正确;二是确保测站上接收机和天线型号以及天线高的正确。
登陆"ftp://ftp.unibe.ch/aiub/BSWUSER50/STA/",可以下载IGS.STA和EUREF.STA这两个文件。它们包含了IGS和EUREF跟踪站的测站信息文件,分别由IGS和EUREF 中心维护,由igs.snx和euref.snx文件转换而来。用户也可以自己下载.snx文件(例如"ftp://https://www.360docs.net/doc/b315001519.html,/pub/station/general/igs.snx"),然后将文件放到项目的SOL目录下,通过Bernese软件的SNX2STA程序("Conversion>SINEX to station information")来手动完成.snx文件到.STA文件的转换。
同样的,程序RNX2STA("RINEX>RINEX utilities>Extract station information")可以用来提取已经存放在项目RAW目录下的一系列RINEX的头文件信息,从而获取测站的信息文件。官方Manual建议用户用观测协议或者任何其他测站设置的描述来验证测站信息。
无论如何,在项目开始处理之前,要检查和修改好测站信息文件,可以通过"Campaign>Edit station files>Station information"来实现。测站信息文件中的内容定义了测站的名称(在所有测站文件中需要保持统一),观测仪器和天线偏心率(一定要在"Phase center eccentricity"文件中定义)等重要信息,因此一定要准备充分和正确。
【实践】这一部分我的实践如下。我先下载了IGS.STA和EUREF.STA这两个文件,放在了Intro_01项目的STA目录下,然后选择"Campaign>Edit station files>Station information",在弹出的对话框中分别选择IGS.STA和EUREF.STA,出现的界面如下。
这两张图分别显示的是IGS和EUREF跟踪站的相关信息。
然后,我到IGS的数据库下载了2008年9月25日,跟踪站wuhn的30s一天的数据文件wuhn2690.08o,将其放在RAW目录下,然后选择"RINEX>RINEX utilities>Extract station information",出现如下图所示的界面。
我在INPUT FILES一栏里面选择的是原始RINEX观测文件,并键入文件名,在RESULT FILES中为即将提取生成的.STA文件命名,在这里我同样命名为wuhan2690.STA。点击^Run 按钮后,会出现提示对话框,忽略它,继续点击主窗口右下角的^Output按钮,会出现从RNX 文件中提取出的STA文件的相关信息,这表明RNX2STA程序运行成功,如下图所示。
完成之后在STA文件夹内也会生成相应的wuhn0269.STA这个文件。
有的项目处理中,还需要一些其他的测站文件。
创建FIX文件——选择处理过程中的参考站。在"Campaign>Edit station files>Station selection lists"
中,如果选择之前在STA目录下的参考系文件IGS_00.CRD,也就意味着列表中包含了IGS 的参考站。
创建PLD文件——NUVEL模型中的构造板块分配。在"Campaign>Edit station files>Tectonic plate assignment"中可以进行操作。
利用"Campaign>Edit station files>Abbrevation table"可以来自定义处理过程中的测站名成为表单。
有时还需要建立海洋潮汐负荷等文件,这里不做详细讨论。
至此,关于Bernese开始数据处理前的文件准备工作完毕。
Bernese数据处理实例
本文将对Bernese进行非差和双差处理流程进行介绍和总结。
一、基本概述
操作系统:Windows 8
软件版本:Bernese GPS Software 5.0
中国境内选取10个IGS跟踪站:
bjfs,chan,guao,kunm,lhaz,shao,wuhn,xian,tnml,twtf
数据日期:2008年8月8日,对应的年积日为221,GPS周为1491+5。
二、数据准备
到ftp://https://www.360docs.net/doc/b315001519.html,/pub/gps/data/daily/2008/221/08o下载以上十个跟踪站的RINEX格式原始数据文件:bjfs2210.08o,chan2210.08o,guao2210.08o,
kunm2210.08o,lhaz2210.08o,shao2210.08o,wuhn2210.08o,xian2210.08o,tnml2210.08o,twtf2210.08o。
到ftp://https://www.360docs.net/doc/b315001519.html,/pub/gps/products/1491/下载对应当天的igs发布的精密星历文件、精密卫星钟差文件,以及对应该周的地球自转参数文件:igs14915.sp3、igs14915.clk、igs14917.erp(注:IGS格式的地球自转参数文件是以周为单位发布的,因此文件名的最后一位为7)。之后修改igs14917.erp文件的后缀为Bernese软件能识别的igs14917.iep格式。
到ftp://ftp.unibe.ch/aiub/CODE/2008/下载对应当天的电离层文件、对应该月的两个DCB文件:COD14915.ION、P1C10808.DCB和P1P20808.DCB。
三、建立项目
在软件界面以此点选Menu>Campaign>Edit list of campaigns,添加项目Olympic作为此次处理的项目名称,之后点击Save保存。
点选Menu>Campaign>Select active campaign,在弹出的窗口中选择刚才新建的Olympic项目为当前项目。
此时点OK之后会提示缺少处理所需的时段文件,先忽略它,因为马上设置时段就行了。
点选Menu>Configure>Set session/compute date,弹出设置时段窗口,在这里将处理时段设定为2008年8月8日,点击Compute,会将日期自动计算为其他几种常见格式。点击OK,此时会提示找不到SESSION文件,忽略它,马上生成项目子目录后就会生成默认的SESSION文件了。
点选Menu>Campaign>Create new campaign,点击Run,就会在Bernese软件目录下的GPSDATA文件下生成一个名为Olympic的项目文件夹,文件夹内会有一些子目录,这些子目录目前都是空的,除了之前提到过在STA文件夹下自动生成的SESSION文件。
至此,项目创建完成。
三、数据拷贝至项目下
将之前下载的10个RINEX格式的IGS跟踪站全天观测文件拷贝到Olympic目录的ORX 和RAW目录下,将精密星历文件igs14915.sp3、精密卫星钟差文件igs14915.clk、地球自转参数文件igs14917.iep,以及两个DCB文件P1C10808.DCB、P1P20808.DCB共五个文件一起放入ORB目录下。
四、创建和修改测站信息文件
点选Menu>RINEX>RINEX utilities>Extract station information,在弹出的窗口中,INPUT FILES一栏中选择那十个原始观测文件;RESULT FILES一栏,这里把输出的测站信息文件命名为08_221.STA。点击Run,就会从原始观测文件的头文件中提取测站名称、接收机和天线相关的信息,存储在Olympic\STA目录下的08_221.STA文件中。
之后找到08_221.STA文件,用记事本打开,修改TYPE 001: RENAMING OF STATIONS 下的内容,具体做法是将TYPE 002: STATION INFORMATION下的STATION NAME、FLG、FROM 和TO内容不做修改拷贝上去,之后的其他内容留空。如图所示。编辑完之后保存关闭。
点选Campaign>Edit station files>Station information,选择打开08_221.STA文件,在Old station name一列添加“*+对应原来的名字”,如图所示。
之后点击Next,在这里需要注意的是,要正确选择处理时需用到的天线相位中心改正文件,这里由于采用的都是IGS跟踪站的数据,选择PHAS_IGS.REL文件,否则后面会提示天线类型不支持。之后点击Save进行保存。
https://www.360docs.net/doc/b315001519.html,/link?url=jdpvf9LA0pjDCJOxuqN1pomRj7cNSQdvg-uCu1hXIbwy88y uZ8MuWJGgtWCXHRDVBkHAjZzGhXcF2xOZ21BfDRRSi11DxkkKK6w2Be0ITK7
至此,测站信息文件的创建和修改完毕。
五、BPE(Bernese Processing Engine)批处理数据准备
将精密卫星钟差文件igs14915.clk拷贝至Olympic\OUT目录下,电离层文件
COD14915.ION拷贝至Olympic\ATM目录下。
从目录BERN50\GPS\DOC中拷贝EXAMPLE.CRD、EXAMPLE.BLQ、EXAMPLE.PLD、EXAMPLE.VEL 至Olympic\STA目录下,并将文件名分别改成08_221.CRD、08_221.BLQ、08_221.PLD、
08_221.VEL。
六、编辑批处理控制文件PCF(Processing Control File)
点选Menu>BPE>Edit process control file(PCF),这里选择PPP.PCF(精密单点定位)。
大数据处理流程的主要环节
大数据处理流程的主要环节 大数据处理流程主要包括数据收集、数据预处理、数据存储、数据处理与分析、数据展示/数据可视化、数据应用等环节,其中数据质量贯穿于整个大数据流程,每一个数据处理环节都会对大数据质量产生影响作用。通常,一个好的大数据产品要有大量的数据规模、快速的数据处理、精确的数据分析与预测、优秀的可视化图表以及简练易懂的结果解释,本节将基于以上环节分别分析不同阶段对大数据质量的影响及其关键影响因素。 一、数据收集 在数据收集过程中,数据源会影响大数据质量的真实性、完整性数据收集、一致性、准确性和安全性。对于Web数据,多采用网络爬虫方式进行收集,这需要对爬虫软件进行时间设置以保障收集到的数据时效性质量。比如可以利用八爪鱼爬虫软件的增值API设置,灵活控制采集任务的启动和停止。 二、数据预处理 大数据采集过程中通常有一个或多个数据源,这些数据源包括同构或异构的数据库、文件系统、服务接口等,易受到噪声数据、数据值缺失、数据冲突等影响,因此需首先对收集到的
大数据集合进行预处理,以保证大数据分析与预测结果的准确性与价值性。 大数据的预处理环节主要包括数据清理、数据集成、数据归约与数据转换等内容,可以大大提高大数据的总体质量,是大数据过程质量的体现。数据清理技术包括对数据的不一致检测、噪声数据的识别、数据过滤与修正等方面,有利于提高大数据的一致性、准确性、真实性和可用性等方面的质量; 数据集成则是将多个数据源的数据进行集成,从而形成集中、统一的数据库、数据立方体等,这一过程有利于提高大数据的完整性、一致性、安全性和可用性等方面质量; 数据归约是在不损害分析结果准确性的前提下降低数据集规模,使之简化,包括维归约、数据归约、数据抽样等技术,这一过程有利于提高大数据的价值密度,即提高大数据存储的价值性。 数据转换处理包括基于规则或元数据的转换、基于模型与学习的转换等技术,可通过转换实现数据统一,这一过程有利于提高大数据的一致性和可用性。 总之,数据预处理环节有利于提高大数据的一致性、准确性、真实性、可用性、完整性、安全性和价值性等方面质量,而大数据预处理中的相关技术是影响大数据过程质量的关键因素
气象站点数据插值处理流程
注:下面的为之前做的方法(7-以后不用做),里面的参数与现在的有出入,自己找到区域内站点,插值过程如下。 气象站点数据插值处理流程 1气象站点数据整理 Excel格式,第一行输入字段名称,包括站点名称、x经度(lon)、y纬度(lat)、平均气温、平均风速、相对湿度、平均日照时数。其中经纬度需换算为度的形式,其它数据换算为对应单位。 2excel气象数据转为shape格式的矢量点数据插值分析 (1)打开Arcgis,添加excel气象站点数据。打开LC_Ther10-11_16m合并_warp_裁剪BIL1.00_cj重采样6066_经纬度.img,打开边界.shp,三个应该能叠加在一起 (2)在arcgis内容列表中右键单击excel表,选择“显示XY数据”,设置X、Y字段为表中对应经-x、纬-y度字段,编辑坐标系,设置为气象站点经纬度获取时的坐标系,这里为地理坐标系WGS84。(图中错了,按上述,要不就换下一下XY对应的经纬度试一试看看形状对就可以了) (3)导出为shape格式的点数据。右键单击上一个步骤中新生成的事件图层,单击“数据-导出数据”。需注意导出数据的坐标系应选择“此图层的源数据”。
(4)设置Arcgis环境。在“地理处理”菜单下单击“环境”,在环境设置窗口中选择“处理范围”,选择一个处理好的遥感数据(LC_Ther10-11_16m合并_warp_裁剪BIL1.00_cj重采样6066_经纬度.img,主要是参考该遥感数据的行数和列数)。再选择“栅格分析”,按下图设置插值的分辨率为“0.0045”,掩膜文件设置为边界2/LC_Ther10-11_16m合并_warp_裁剪BIL1.00_cj重采样6066_经纬度.img。注意:生成出来的是否有坐标系,插值-环境-输出坐标系-与**相同 (5)气象站点数据插值。在toolbox中选择工具箱“Spatial Analyst————反距离权法”,默认12个数据参与运算,“Z值字段”分别选择平均风速、平均气温、相对湿度,直接输出,不要改输出路径名字。再导出数据。在差值分析界面最下栏也有环境,进去设置,注意经纬度显示位置是经纬度投影的投影坐标系,UTM不能用 (6)数据转换为image格式。上步骤中得到的插值栅格数据是Arcgis格式的栅格格式(grid格式),该格式envi识别不了。右键单击插值数据选择“数据—导出数据”,设置导出数据格式为image。 (7)再用envi claas 转换为UTM投影 (8)UTM 设置参数:datum:(原来为North America 1927)改为为WGS84, zone 49。 E: 719614.2770 N: 4100314.6180 X/Y PIXEL: 16.0 meter output x size: 8723 output y size: 6066
(完整版)管理信息系统数据流程图和业务流程图
1.采购部查询库存信息及用户需求,若商品的库存量不能满足用户的需要,则编制相应的采购订货单,并交送给供应商提出订货请求。供应商按订单要求发货给该公司采购部,并附上采购收货单。公司检验人员在验货后,发现货物不合格,将货物退回供应商,如果合格则送交库房。库房管理员再进一步审核货物是否合格,如果合格则登记流水帐和库存帐目,如果不合格则交由主管审核后退回供应商。 画出物资订货的业务流程图。(共10分) 2.在盘点管理流程中,库管员首先编制盘存报表并提交给仓库主管,仓库主管查询库存清单和盘点流水账,然后根据盘点规定进行审核,如果合格则提交合格盘存报表递交给库管员,由库管员更新库存清单和盘点流水账。如果不合格则由仓库主观返回不合格盘存报表给库管员重新查询数据进行盘点。根据以上情况画出业务流程图和数据流程图。(共15分)
3.“进书”主要指新书的验收、分类编号、填写、审核、入库。主要过程:书商将采购单和新书送采购员;采购员验收,如果不合格就退回,合格就送编目员;编目员按照国家标准进行的分类编号,填写包括书名,书号,作者、出版社等基本信息的入库单;库管员验收入库单和新书,如果合格就入库,并更新入库台帐;如果不合格就退回。“售书”的流程:顾客选定书籍后,收银员进行收费和开收费单,并更新销售台帐。顾客凭收费单可以将图书带离书店,书店保安审核合格后,放行,否则将让顾客到收银员处缴费。 画出“进书”和“售书”的数据流程图。 进书业务流程:
进书数据流程:
F3.2不合格采购单 售书业务流程:
售书数据流程:
4.背景:若库房里的货品由于自然或其他原因而破损,且不可用的,需进行报损处理,即这些货品清除出库房。具体报损流程如下: 由库房相关人员定期按库存计划编制需要对货物进行报损处理的报损清单,交给主管确认、审核。主管审核后确定清单上的货品必须报损,则进行报损处理,并根据报损清单登记流水帐,同时修改库存台帐;若报损单上的货品不符合报损要求,则将报损单退回库房。 试根据上述背景提供的信息,绘制出“报损”的业务流程图、数据流程图。 报损业务流程图:(10分) 业务流程图: 数据流程图:
气象资料业务系统(MDOS)操作平台业务流程汇总
气象资料业务系统(MDOS 操作平台业务流程一、地面自动站观测资料上传 按业务规定上传国家级测站实时地面气象分钟数据文件、小时数据文件、日数据文件、日照数据文件、 (辐射数据文件。 每日定时观测后, 登录 MDOS 平台查看本站数据完整性, 对缺测时次及时补传。 二、疑误信息处理与反馈 台站配置应值班手机,用于接收台站疑误信息短信;值班手机要保证 24小时开机,手机号码变动应及时向省级管理部门上报。 台站对疑误信息的反馈包括定时反馈、被动反馈和更正数据反馈。 (1定时反馈:在每日定时观测后,登录 MDOS 操作平台,查询本站国家站和区域站未处理疑误信息并反馈。保证疑误数据在下一次定时观测前完成反馈。 A:国家站数据质控信息处理——台站处理与反馈——台站未处理 B:区域站数据质控信息处理——台站处理与反馈——台站未处理 台站级数据处理:处理并反馈省级提交给台站的疑误查询信息。包括 3种处理流程: 流程 1:确认数据无误→处理完成。 流程 2:确认数据错误→修正(给出修改值→处理完成。流程 3:批量数据为缺测→处理完成。 (2被动反馈:收到疑误信息短信和电话后,实时登录 MDOS 操作平台反馈; 接到显性错误短信后, 先核对显性错误数据值, 检查相应观测仪器, 查明可能引起出现错误数据的原因, 并及时进行相关数据处理和观测仪器维护等工作。对省级转交台站
处理的疑误信息, 及时查明原因, 通过 MDOS 操作平台进行数据处理和反馈。台站在 收到疑误信息 12小时之内完成反馈。守班时段应急响应期间, 接收到疑误短信或电话后 1小时内进行反馈。 (3更正数据反馈:对台站本地更正过的数据要及时向省级进行反馈,更正报时效内的数据既可通过“ MDOS 数据查询与质疑”功能主动填报反馈, 也可发送更正报 进行修改;时效外的数据可通过 MDOS 平台的“数据查询与质疑”进行修改。 三、台站变动登记 包括变动信息登记(名称,台站号,级别,观测时间,机构,位置,要素, 仪器,障碍物,守班,其他 ,图像、观测记录和规范。 四、台站附加信息登记 (1备注信息登记,通过选择记录年月,事件类型,填入具体内容后,点击即可完成登记。 (2若该台站同一时间同一事件类型已经有记录内容,选择记录年月,事件类型后,具体内容文本框会显示已经填写登记的内容,用户可以直接修改后提交。 (3一般备注事件,本月天气气候概况,图像、观测记录和规范操作参照纪要信息登记方法。 五、产品下载与保存 A 、 J 文件在 MDOS 平台“功能菜单”中的“产品制作与数据服务”下的“ A 、 J 、 Y 文件管理”模块中下载。 每月 6号前将下载后的 A 、 J 文件上传至 10.79.3.18/xj/zdzh/目录下,上传后的文件如有变更请及时进行更新。
气象数据处理流程
气象数据处理流程1.数据下载 1.1.登录中国气象科学数据共享服务网 1.2.注册用户 1.3.选择地面气象资料 1.4.选择中国地面国际交换站日值数据 选择所需数据点击预览(本次气象数据为:降水量、日最高气温、日最低气温、平均湿度、辐射度、积雪厚度等;地区为:黑龙江省、吉林省、辽宁省、内蒙古) 下载数据并同时下载文档说明 1.5.网站数据粘贴并保存为TXT文档 2.建立属性库 2.1.存储后的TXT文档用Excel打开并将第一列按逗号分列 2.2.站点数据处理 2.2.1.由于站点数据为经纬度数据 为方便插值数据设置分辨率(1公里)减少投影变换次数,先将站点坐标转为大地坐标并添加X、Y列存储大地坐标值后将各项数据按照站点字段年月日合成总数据库 (注意:数据库存储为DBF3格式,个字段均为数值型坐标需设置小数位数) 为填补插值后北部和东部数据的空缺采用最邻近法将漠河北部、富锦东部补齐2点数据。
2.2.2.利用VBA程序 Sub we() i = 6 For j = 1 To 30 Windows("").Activate Rows("1:1").Select Field:=5, Criteria1:=i Field:=6, Criteria1:=j Windows("").Activate Rows("1:1").Select Windows("book" + CStr(j)).Activate Range("A1:n100").Select Range("I14").Activate ChDir "C:\Documents and Settings\王\桌面" Filename:="C:\Documents and Settings\王\桌面\6\" & InputBox("输入保存名", Title = "保存名字", "20070" + CStr(i) + "0" + CStr(j)), _ FileFormat:=xlDBF4, CreateBackup:=False SaveChanges:=True Next j End Sub 将数据库按照日期分为365个文件 3.建立回归模型增加点密度 由于现有的日辐射值数据不能覆盖东三省(如图),需要对现有数据建模分析,以增加气象数据各点密度。 已有数据10个太阳辐射站点,为了实现回归模型更好拟合效果,将10个样本全部作为回归参数。利用SPSS软件建模步骤:
简析大数据及其处理分析流程
昆明理工大学 空间数据库期末考察报告《简析大数据及其处理分析流程》 学院:国土资源工程学院 班级:测绘121 姓名:王易豪 学号:201210102179 任课教师:李刚
简析大数据及其处理分析流程 【摘要】大数据的规模和复杂度的增长超出了计算机软硬件能力增长的摩尔定律,对现有的IT架构以及计算能力带来了极大挑战,也为人们深度挖掘和充分利用大数据的大价值带来了巨大机遇。本文从大数据的概念特征、处理分析流程、大数据时代面临的挑战三个方面进行详细阐述,分析了大数据的产生背景,简述了大数据的基本概念。 【关键词】大数据;数据处理技术;数据分析 引言 大数据时代已经到来,而且数据量的增长趋势明显。据统计仅在2011 年,全球数据增量就达到了1.8ZB (即1.8 万亿GB)[1],相当于全世界每个人产生200GB 以上的数据,这些数据每天还在不断地产生。 而在中国,2013年中国产生的数据总量超过0.8ZB(相当于8亿TB),是2012年所产生的数据总量的2倍,相当于2009年全球的数据总量[2]。2014年中国所产生的数据则相当于2012 年产生数据总量的10倍,即超过8ZB,而全球产生的数据总量将超40ZB。数据量的爆发式增长督促我们快速迈入大数据时代。 全球知名的咨询公司麦肯锡(McKinsey)2011年6月份发布了一份关于大数据的详尽报告“Bigdata:The next frontier for innovation,competition,and productivity”[3],对大数据的影响、关键技术和应用领域等都进行了详尽的分析。进入2012年以来,大数据的关注度与日俱增。
数据流程图和业务流程图案例
数据流程图和业务流程图案例 1.采购部查询库存信息及用户需求,若商品的库存量不能满足用户的需要,则编制相应的采购订货单,并交送给供应商提出订货请求。供应商按订单要求发货给该公司采购部,并附上采购收货单。公司检验人员在验货后,发现货物不合格,将货物退回供应商,如果合格则送交库房。库房管理员再进一步审核货物是否合格,如果合格则登记流水帐和库存帐目,如果不合格则交由主管审核后退回供应商。 画出物资订货的业务流程图。 2.在盘点管理流程中,库管员首先编制盘存报表并提交给仓库主管,仓库主管查询库存清单和盘点流水账,然后根据盘点规定进行审核,如果合格则提交合格盘存报表递交给库管员,由库管员更新库存清单和盘点流水账。如果不合格则由仓库主观返回不合格盘存报表给库管员重新查询数据进行盘点。 根据以上情况画出业务流程图和数据流程图。
3.“进书”主要指新书的验收、分类编号、填写、审核、入库。主要过程:书商将采购单和新书送采购员;采购员验收,如果不合格就退回,合格就送编目员;编目员按照国家标准进行的分类编号,填写包括书名,书号,作者、出版社等基本信息的入库单;库管员验收入库单和新书,如果合格就入库,并更新入库台帐;如果不合格就退回。“售书”的流程:顾客选定书籍后,收银员进行收费和开收费单,并更新销售台帐。顾客凭收费单可以将图书带离书店,书店保安审核合格后,放行,否则将让顾客到收银员处缴费。 画出“进书”和“售书”的数据流程图。 进书业务流程: 书商采购单/新 书采购员 入库单退书单 编目员 合格新图 书 库管员 入库单 入库台帐 进书数据流程:
采购单审核 P3.1编目处理 p3.2入库单处理 p3.3供应商 F3.1采购单 F3.2不合格采购单 F3.3合格采购单F10入库单 F3.4不合格入库单 S2 图书库存情况存档 管理员 F9入库够书清单 F3.5合格入库清单 售书业务流程: 顾客 新书 收银员 收费单销售台帐 保安 未收费的 书 收费单/书 售书数据流程: 收费处理P1.1审核处理 P1.2E1顾客 F6购书单计划F1.1收费单 F1.2不合格收费单 S02S01S03S04图书库存情况存档 F4销售清单 图书销售存档 顾客需求图书情况存档 顾客基本情况存档 F4销售清单 F5顾客需求图书清单 F3顾客基本情况
气象数据处理流程
气象数据处理流程 1.数据下载 1.1. 登录中国气象科学数据共享服务网 1.2. 注册用户 1.3. 1.4. 辐射度、1.5. 2. 2.1. 2.2. 2.2.1. 为方便插值数据设置分辨率(1公里)减少投影变换次数,先将站点坐标转为大地坐标 并添加X、Y列存储大地坐标值后将各项数据按照站点字段年月日合成总数据库 (注意:数据库存储为DBF3格式,个字段均为数值型坐标需设置小数位数) 为填补插值后北部和东部数据的空缺采用最邻近法将漠河北部、富锦东部补齐2点数据。 2.2.2.利用VBA程序 Sub we() i = 6
For j = 1 To 30 Windows("chengle.dbf").Activate Rows("1:1").Select Selection.AutoFilter Selection.AutoFilter Field:=5, Criteria1:=i Selection.AutoFilter Field:=6, Criteria1:=j Cells.Select Selection.Copy Workbooks.Add ActiveSheet.Paste Windows("chengle.dbf").Activate ", Title = " 3. 利用 3.1. 3.2. 选择分析→回归→非线性回归 3.3. 将辐射值设为因变量 将经度(X)和纬度(Y)作为自变量,采用二次趋势面模型(f=b0+b1*x+b2*y+b3*x2+b4*x*y+b5*y2)进行回归,回归方法采用强迫引入法。 如图,在模型表达式中输入模型方程。 在参数中设置参数初始值
数据分析程序
数据分析程序流程图
数据分析程序 1 目的 确定收集和分析适当的数据,以证实质量管理体系的适宜性和有效性,评价和持续改进质量管理体系的有效性。 2 适用范围 本程序适用于烤烟生产服务全过程的数据分析。 3 工作职责 3.1 分管领导:负责数据分析结果的批准。 3.2 烟叶科:负责数据分析结果的审核。 3.3 相关部门:负责职责范围内数据的收集和分析。 4 工作程序 4.1 数据的分类 4.1.1 烟用物资采购发放数据:烟用物资盘点盘存、烟用物资需求、烟用物资采购、烟用物资发放、烟用物资分户发放、烟用物资供应商等相关数据。 4.1.2 烤烟生产收购销售数据。 4.1.3 烟叶挑选整理数据:烟叶挑选整理数据。 4.1.4 客户满意:烟厂(集团公司)和烟农满意度测量数据和其他反馈信息。 4.1.5 过程和质量监测数据:产购销过程各阶段检查数据及不合格项统计等。 4.1.6 持续改进数据。 4.2 数据的收集 4.2.1 烟用物资采购数据的收集 a) 烟草站于当年10月底对当年烟用物资使用情况进行收集,对库存情况进行盘点,并填写烟用物 资盘点情况统计表保存并送烟叶科; b) 储运科于当年10月底前将烟用物资库存情况进行盘点,送烟叶科; c) 储运站于当年挑选结束后对库存麻片、麻绳、缝口绳进行盘点,据次年生产需要,制定需求计 划表,送烟叶科。 d) 烟草站于当年10月底据次年生产需求填报烟用物资需求表,上报烟叶科,烟叶科据烟用物资需 求和库存盘点情况,拟定烟用物资需求计划,报公司烤烟生产分管领导批准; e) 烟叶科将物资采购情况形成汇总表,送财务科、报分管领导; f) 烟叶科形成烟用物资发放情况登记表,归档、备案; g) 烟草站形成烟用物资分户发放情况表,烟草站备案。 4.2.2 烤烟产购销数据的收集 a) 烟用物资采购数据收集完成后,由烟叶科填报《烟用物资采购情况汇总表》,于管理评审前上 报分管领导和经理。 b) 烤烟生产期间,烟草站每10天向烟叶科上报《烤烟生产情况统计表》,烟叶科汇总后定期上报 公司领导层。对所收集的进度报政府或上级部门时,必须由分管领导签字后才能送出。
管理信息系统数据流程图和业务流程图和E-R图.
1. 采购部查询库存信息及用户需求, 若商品的库存量不能满足用户的需要, 则编制相应的采购订货单, 并交送给供应商提出订货请求。供应商按订单要求发货给该公司采购部, 并附上采购收货单。公司检验人员在验货后,发现货物不合格, 将货物退回供应商,如果合格则送交库房。库房管理员再进一步审核货物是否合格, 如果合格则登记流水帐和库存帐目, 如果不合格则交由主管审核后退回供应商。 画出物资订货的业务流程图。 (共 10分 2.在盘点管理流程中,库管员首先编制盘存报表并提交给仓库主管,仓库主管查询库存清单和盘点流水账,然后根据盘点规定进行审核,如果合格则提交合格盘存报表递交给库管员,由库管员更新库存清单和盘点流水账。如果不合格则由仓库主观返回不合格盘存报表给库管员重新查询数据进行盘点。 根据以上情况画出业务流程图和数据流程图。 (共 15分
3. “进书”主要指新书的验收、分类编号、填写、审核、入库。主要过程:书商将采购单和新书送采购员; 采购员验收,如果不合格就退回, 合格就送编目员;编目员按照国家标准进行的分类编号,填写包括书名,书号,作者、出版社等基本信息的入库单;库管员验收入库单和新书,如果合格就入库,并更新入库台帐;如果不合格就退回。“售书”的流程:顾客选定书籍后, 收银员进行收费和开收费单, 并更新销售台帐。顾客凭收费单可以将图书带离书店,书店保安审核合格后,放行,否则将让顾客到收银员处缴费。 画出“进书”和“售书”的数据流程图。 进书业务流程:
进书数据流程: F3.2不合格采购单售书业务流程:
售书数据流程: 4. 背景 :若库房里的货品由于自然或其他原因而破损,且不可用的,需进行报损处理, 即这些货品清除出库房。具体报损流程如下: 由库房相关人员定期按库存计划编制需要对货物进行报损处理的报损清单, 交给主管确认、审核。主管审核后确定清单上的货品必须报损,则进行报损处理, 并根据报损清单登记流水帐,同时修改库存台帐;若报损单上的货品不符合报损要求,则将报损单退回库房。
气象大数据资料
1 引言 在气象行业内部,气象数据的价值已经和正在被深入挖掘着。但是,不能将气象预报产品的社会化推广简单地认为就是“气象大数据的广泛应用”。 大数据实际上是一种混杂数据,气象大数据应该是指气象行业所拥有的以及锁接触到的全体数据,包括传统的气象数据和对外服务提供的影视音频资料、网页资料、预报文本以及地理位置相关数据、社会经济共享数据等等。 传统的”气象数据“,地面观测、气象卫星遥感、天气雷达和数值预报产品四类数据占数据总量的90%以上,基本的气象数据直接用途是气象业务、天气预报、气候预测以及气象服务。“大数据应用”与目前的气象服务有所不同,前者是气象数据的“深度应用”和“增值应用”,后者是既定业务数据加工产品的社会推广应用。 “大数据的核心就是预测”,这是《大数据时代》的作者舍恩伯格的名言。天气和气候系统是典型的非线性系统,无法通过运用简单的统计分析方法来对其进行准确的预报和预测。人们常说的南美丛林里一只蝴蝶扇动几下翅膀,会在几周后引发北美的一场暴风雪这一现象,形象地描绘了气象科学的复杂性。运用统计分析方法进行天气预报在数十年前便已被气象科学界否决了——也就是说,目前经典的大数据应用方法并不适用于天气预报业务。 现在,气象行业的公共服务职能越来越强,面向政府提供决策服务,面向公众提供气象预报预警服务,面向社会发展,应对气候发展节能减排。这些决策信息怎么来依赖于我们对气象数据的处理。
气象大数据应该在跨行业综合应用这一“增值应用”价值挖掘过程中焕发出的新的光芒。 2 大数据平台的基本构成 2.1 概述 “大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。 大数据技术的战略意义不在于掌握庞大的数据信息,而在于对这些含有意义的数据进行专业化处理。换言之,如果把大数据比作一种产业,那么这种产业实现盈利的关键,在于提高对数据的“加工能力”,通过“加工”实现数据的“增值”。 从技术上看,大数据与云计算的关系就像一枚硬币的正反面一样密不可分。大数据必然无法用单台的计算机进行处理,必须采用分布式架构。它的特色在于对海量数据进行分布式数据挖掘(SaaS),但它必须依托云计算的分布式处理、分布式数据库(PaaS)和云存储、虚拟化技术(IaaS)。 大数据可通过许多方式来存储、获取、处理和分析。每个大数据来源都有不同的特征,包括数据的频率、量、速度、类型和真实性。处理并存储大数据时,会涉及到更多维度,比如治理、安全性和策略。选择一种架构并构建合适的大数据解决方案极具挑战,因为需要考虑非常多的因素。 气象行业的数据情况则更为复杂,除了“机器生成”(可以理解为遥测、传感设备产生的观测数据,大量参与气象服务和共享的信息都以文本、图片、视频等多种形式存储,符合“大数据”的4V特点:Volume(大量)、Velocity(高速)、
业务流程图与数据流程图的比较知识讲解
业务流程图与数据流程图的比较
业务流程图与数据流程图的比较 一、业务流程图与数据流程图的区别 1. 描述对象不同 业务流程图的描述对象是某一具体的业务; 数据流程图的描述对象是数据流。 业务是指企业管理中必要且逻辑上相关的、为了完成某种管理功能的一系列相关的活动。在系统调研时, 通过了解组织结构和业务功能, 我们对系统的主要业务有了一个大概的认识。但由此我们得到的对业务的认识是静态的, 是由组织部门映射到业务的。而实际的业务是流动的, 我们称之为业务流程。一项完整的业务流程要涉及到多个部门和多项数据。例如, 生产业务要涉及从采购到财务, 到生产车间, 到库存等多个部门; 会产生从原料采购单, 应收付账款, 入库单等多项数据表单。因此, 在考察一项业务时我们应将该业务一系列的活动即整个过程为考察对象, 而不仅仅是某项单一的活动, 这样才能实现对业务的全面认识。将一项业务处理过程中的每一个步骤用图形来表示, 并把所有处理过程按一定的顺序都串起来就形成了业务流程图。如图 1 所示, 就是某公司物资管理的业务流程图。
数据流程图是对业务流程的进一步抽象与概括。抽象性表现在它完全舍去了具体的物质, 只剩下数据的流动、加工处理和存储; 概括性表现在它可以把各种不同业务处理过程联系起来,形成一个整体。从安东尼金字塔模型的角度来看, 业务流程图描述对象包括企业中的信息流、资金流和物流, 数据流程图则主要是对信息流的描述。此外, 数据流程图还要配合数据字典的说明, 对系统的逻辑模型进行完整和详细的描述。 2. 功能作用不同
业务流程图是一本用图形方式来反映实际业务处理过程的“流水帐”。绘制出这本流水帐对于开发者理顺和优化业务过程是很有帮助的。业务流程图的符号简单明了, 易于阅读和理解业务流程。绘制流程图的目的是为了分析业务流程, 在对现有业务流程进行分析的基础上进行业务流程重组, 产生新的更为合理的业务流程。通过除去不必要的、多余的业务环节; 合并重复的环节;增补缺少的必须的环节; 确定计算机系统要处理的环节等重要步骤, 在绘制流程图的过程中可以发现问题, 分析不足, 改进业务处理过程。 数据流程分析主要包括对信息的流动、传递、处理、存储等的分析。数据流程分析的目的就是要发现和解决数据流通中的问题, 这些问题有: 数据流程不畅, 前后数据不匹配, 数据处理过程不合理等。通过对这些问题的解决形成一个通畅的数据流程作为今后新系统的数据流程。数据流程图比起业务流程图更为抽象, 它舍弃了业务流程图中的一些物理实体, 更接近于信息系统的逻辑模型。对于较简单的业务, 我们可以省略其业务流程图直接绘制数据流程图。 3. 基本符号不同 (1)业务流程图的常用的基本符号有以下六种, 见图 2 所示。 (2)数据流程图的基本符号见图 3 所示
大数据数据分析方法、数据处理流程实战案例
数据分析方法、数据处理流程实战案例 大数据时代,我们人人都逐渐开始用数据的眼光来看待每一个事情、事物。确实,数据的直观明了传达出来的信息让人一下子就能领略且毫无疑点,不过前提是数据本身的真实性和准确度要有保证。今天就来和大家分享一下关于数据分析方法、数据处理流程的实战案例,让大家对于数据分析师这个岗位的工作内容有更多的理解和认识,让可以趁机了解了解咱们平时看似轻松便捷的数据可视化的背后都是有多专业的流程在支撑着。 一、大数据思维 在2011年、2012年大数据概念火了之后,可以说这几年许多传统企业也好,互联网企业也好,都把自己的业务给大数据靠一靠,并且提的比较多的大数据思维。 那么大数据思维是怎么回事?我们来看两个例子: 案例1:输入法 首先,我们来看一下输入法的例子。 我2001年上大学,那时用的输入法比较多的是智能ABC,还有微软拼音,还有五笔。那时候的输入法比现在来说要慢的很多,许多时候输一个词都要选好几次,去选词还是调整才能把这个字打出来,效率是非常低的。 到了2002年,2003年出了一种新的输出法——紫光拼音,感觉真的很快,键盘没有按下去字就已经跳出来了。但是,后来很快发现紫光拼音输入法也有它的问题,比如当时互联网发展已经比较快了,会经常出现一些新的词汇,这些词汇在它的词库里没有的话,就很难敲出来这个词。
在2006年左右,搜狗输入法出现了。搜狗输入法基于搜狗本身是一个搜索,它积累了一些用户输入的检索词这些数据,用户用输入法时候产生的这些词的信息,将它们进行统计分析,把一些新的词汇逐步添加到词库里去,通过云的方式进行管理。 比如,去年流行一个词叫“然并卵”,这样的一个词如果用传统的方式,因为它是一个重新构造的词,在输入法是没办法通过拼音“ran bing luan”直接把它找出来的。然而,在大数据思维下那就不一样了,换句话说,我们先不知道有这么一个词汇,但是我们发现有许多人在输入了这个词汇,于是,我们可以通过统计发现最近新出现的一个高频词汇,把它加到司库里面并更新给所有人,大家在使用的时候可以直接找到这个词了。 案例2:地图 再来看一个地图的案例,在这种电脑地图、手机地图出现之前,我们都是用纸质的地图。这种地图差不多就是一年要换一版,因为许多地址可能变了,并且在纸质地图上肯定是看不出来,从一个地方到另外一个地方怎么走是最好的?中间是不是堵车?这些都是有需要有经验的各种司机才能判断出来。 在有了百度地图这样的产品就要好很多,比如:它能告诉你这条路当前是不是堵的?或者说能告诉你半个小时之后它是不是堵的?它是不是可以预测路况情况? 此外,你去一个地方它可以给你规划另一条路线,这些就是因为它采集到许多数据。比如:大家在用百度地图的时候,有GPS地位信息,基于你这个位置的移动信息,就可以知道路的拥堵情况。另外,他可以收集到很多用户使用的情况,可以跟交管局或者其他部门来采集一些其他摄像头、地面的传感器采集的车辆的数量的数据,就可以做这样的判断了。
anusplin软件操作说明及气象数据处理
气象数据处理方法:spss和Excel 一、下载原始txt数据中的经纬度处理:将度分处理成度,Excel处 理 首先除以100,处理成小数格式,这里第一个实际是52度58分, 在Excel中用公式:=LEFT(O2,FIND(".",O2)-1)+RIGHT(O2,LEN(O2)-FIND(".",O2))/60 需注意: 当为整数时,值为空,这时需查找出来手动修改,或者将经纬度这一列的小数位改成两位再试试,可能好使(这个我没尝试) 第二步: 将经纬度转换成投影坐标,在arcgis实现 将Excel中的点导入arcgis,给定坐标系为wgs84地理坐标,然后投影转换成自己定义的等面积的albers投影(因为anusplina软件需要投影坐标,这里转换成自己需要的坐标系)
第三步:spss处理 将下载的txt数据导入spss之后,编辑变量属性,删掉不需要的列,然后将最后需要的那些变量进行数据重组 本实验下载的数据是日均温数据,全国800+个站点2012年366天的数据。相当于有800+ * 366行数据 1.变量 变量属性:变量属性这里的设置决定了在SPLINA这个模块中输入数据的格式,本实验spss处理的气象数据的格式统一用这个:(A5,2F18.6,F8.2,F8.2),一共5列。 即:台站号,字符串,5位; 经纬度:都是浮点型,18位,6个小数位 海拔:浮点型,8位,2个小数位 日均温:浮点型,8位,2个小数位
2.数据重组,将个案重组成变量: 后几步都默认就行: 重组之后结果:变成了800+行,370列,就相当于数据变成了:行代表每个站点,列是代表每一天的数据。
气象数据质量控制方法
数据质量控制方法 1. 数据质量检查的内容 地面气象要素上传文件的各要素值的质量控制以实时检查为主,检查内容包括气候学界限值检查、气候极值检查、数据内部一致性检查和数据时间一致性检查。 (1)气候学界限值检查:指从气候学的角度不可能发生的要素值,观测记录应在气候学界限值之内的检查 (2)气候极值检查:指气象记录是否是超气候极值的检查。气候极值是指在固定地点的气象台站在一定的时间范围内出现概率很小的气象记录 (3)内部一致性检查:指同一时间观测的气象要素记录之间的关系必须符合一定规律的检查 (4)时间一致性检查:指对气象记录变化是否在一定的时间范围内变化具有特定的规律的检查
内部一致性 内部一致性对地面观测数据而言,即为要素间一致性,它是基于一个观测点内同一时刻所测得的要素之间或多或少有点相关的事实,对某些有物理特征关联的气象要素间是否一致进行检测。例如:水汽压、露点温度与气温和相对湿度的一致性,海平面气压与本站气压和气温的一致性,小时内极值出现时间只能是从本小时内 时间一致性 大多数气象要素(除风、降水量和蒸发量外)都是连续变化的,它们随时间的变化应该是连续的,在一定的时间间隔,同一要素的前后波动应是在一定范围内。建立各要素的每分钟和每小时的最大变化值表
数据质量检查流程及质量控制码的确定 数据质量检查的顺序是:气候学界限值检查、气候极值检查、内部一致性检查、时间一致性检查 (1)与气候学界限值比较,观测记录不在气候学界限值范围内的,其数据定性为错误,数据作缺测处理,质量控制码为6 (2)与该月累年极端值比较,观测记录不在气候极值范围内的,其数据定性为“可疑”,质量控制码为1 (3)用气温、相对湿度计算水汽压、露点温度,用本站气压计算海平面气压,计算值应与观测记录一致,若不一致时,用计算值代替观测值。代替后的观测值按正确对待,相应质量控制码为6,若原数据为缺测,相应质量控制码为8 (4)小时内极值出现时间不在本小时内时,出现时间按缺测处理,质量控制码为6 (5)当前小时值与前一小时值比较,超过小时最大变化值的,该当前值定性为“可疑”,质量控制码为1,此值参与下一小时的比较 (6)本站气压、气温、相对湿度、最大风速、极大风速、地面温度、草面温度的小时极值与该小时内的极值出现时间的分钟值应该一致。出现极值与分钟值矛盾时,该时极值定性为“可疑”,质量控制码为1。出现时间与记录时间矛盾时,出现时间按缺测处理,质量控制码为6 (7)小时降水量与小时内分钟降水量之和不相等时,在没有人工干预时,将分钟降水量全部定性为“可疑”,质量控制码为1;若进行人工干预,能够确定正确值,则用正确值代替小时降水量或分钟降水量,质量控制码为6,小时值正确但不能给出正确的分钟值时,可将
数据流程与业务流程的区别
数据流程与业务流程的区别.txt21春暖花会开!如果你曾经历过冬天,那么你就会有春色!如果你有着信念,那么春天一定会遥远;如果你正在付出,那么总有一天你会拥有花开满圆。 一、不同之处 1. 描述对象不同 业务流程图的描述对象是某一具体的业务; 数据流程图的描述对象是数据流。 业务是指企业管理中必要且逻辑上相关的、为了完成某种管理功能的一系列相关的活动。在系统调研时, 通过了解组织结构和业务功能, 我们对系统的主要业务有了一个大概的认识。但由此我们得到的对业务的认识是静态的, 是由组织部门映射到业务的。而实际的业务是鞫 ? 我们称之为业务流程。一项完整的业务流程要涉及到多个部门和多项数据。例如, 生产 业务要涉及从采购到财务, 到生产车间, 到库存等多个部门; 会产生从原料采购单, 应收付账款, 入库单等多项数据表单。因此, 在考察一项业务时我们应将该业务一系列的活动即整个过程为考察对象, 而不仅仅是某项单一的活动, 这样才能实现对业务的全面认识。将一项业务处理过程中的每一个步骤用图形来表示, 并把所有处理过程按一定的顺序都串起来就形成了业务流程图。如图 1 所示, 就是某公司物资管理的业务流程图。 数据流程图是对业务流程的进一步抽象与概括。抽象性表现在它完全舍去了具体的物质, 只剩下数据的流动、加工处理和存储; 概括性表现在它可以把各种不同业务处理过程联系起来,形成一个整体。从安东尼金字塔模型的角度来看, 业务流程图描述对象包括企业中的信息流、资金流和物流, 数据流程图则主要是对信息流的描述。此外, 数据流程图还要配合数据字典的说明, 对系统的逻辑模型进行完整和详细的描述。 2. 功能作用不同 业务流程图是一本用图形方式来反映实际业务处理过程的“流水帐”。绘制出这本流水帐对于开发者理顺和优化业务过程是很有帮助的。业务流程图的符号简单明了, 易于阅读和理解业务流程。绘制流程图的目的是为了分析业务流程, 在对现有业务流程进行分析的基础上进行业务流程重组, 产生新的更为合理的业务流程。通过除去不必要的、多余的业务环节; 合并重复的环节; 增补缺少的必须的环节; 确定计算机系统要处理的环节等重要步骤, 在绘制流程图的过程中可以发现问题, 分析不足, 改进业务处理过程。 数据流程分析主要包括对信息的流动、传递、处理、存储等的分析。数据流程分析的目的就是要发现和解决数据流通中的问题, 这些问题有: 数据流程不畅, 前后数据不匹配, 数据处理过程不合理等。通过对这些问题的解决形成一个通畅的数据流程作为今后新系统的数据流程。数据流程图比起业务流程图更为抽象, 它舍弃了业务流程图中的一些物理实体, 更接近于信息系统的逻辑模型。对于较简单的业务, 我们可以省略其业务流程图直接绘制数据流程图。 3. 基本符号不同
大数据处理培训:大数据处理流程
大数据处理培训:大数据处理流程 生活在数据裸奔的时代,普通人在喊着如何保护自己的隐私数据,黑心人在策划着如何出售个人信息,而有心人则在思考如何处理大数据,数据的处理分几个步骤,全部完成之后才能获得大智慧。 大数据处理流程完成的智慧之路: 第一个步骤叫数据的收集。 首先得有数据,数据的收集有两个方式: 第一个方式是拿,专业点的说法叫抓取或者爬取。例如搜索引擎就是这么做的:它把网上的所有的信息都下载到它的数据中心,然后你一搜才能搜出来。比如你去搜索的时候,结果会是一个列表,这个列表为什么会在搜索引擎的公司里面?就是因为他把数据都拿下来了,但是你一点链接,点出来这个网站就不在搜索引擎它们公司了。比如说新浪有个新闻,你拿百度搜出来,你不点的时候,那一页在百度数据中心,一点出来的网页就是在新浪的数据中心了。 第二个方式是推送,有很多终端可以帮我收集数据。比如说小米手环,可以
将你每天跑步的数据,心跳的数据,睡眠的数据都上传到数据中心里面。 第二个步骤是数据的传输。 一般会通过队列方式进行,因为数据量实在是太大了,数据必须经过处理才会有用。可系统处理不过来,只好排好队,慢慢处理。 第三个步骤是数据的存储。 现在数据就是金钱,掌握了数据就相当于掌握了钱。要不然网站怎么知道你想买什么?就是因为它有你历史的交易的数据,这个信息可不能给别人,十分宝贵,所以需要存储下来。 第四个步骤是数据的处理和分析。 上面存储的数据是原始数据,原始数据多是杂乱无章的,有很多垃圾数据在里面,因而需要清洗和过滤,得到一些高质量的数据。对于高质量的数据,就可以进行分析,从而对数据进行分类,或者发现数据之间的相互关系,得到知识。 比如盛传的沃尔玛超市的啤酒和尿布的故事,就是通过对人们的购买数据进行分析,发现了男人一般买尿布的时候,会同时购买啤酒,这样就发现了啤酒和尿布之间的相互关系,获得知识,然后应用到实践中,将啤酒和尿布的柜台弄的很近,就获得了智慧。 第五个步骤是对于数据的检索和挖掘。 检索就是搜索,所谓外事不决问Google,内事不决问百度。内外两大搜索引擎都是将分析后的数据放入搜索引擎,因此人们想寻找信息的时候,一搜就有了。 另外就是挖掘,仅仅搜索出来已经不能满足人们的要求了,还需要从信息中挖掘出相互的关系。比如财经搜索,当搜索某个公司股票的时候,该公司的高管
文档-气象站点数据插值处理流程
气象站点数据插值处理流程 1气象站点数据整理 Excel格式,第一行输入字段名称,包括站点名称、x经度(lon)、y纬度(lat)、平均气温、平均风速、相对湿度、平均日照时数。其中经纬度需换算为度的形式,其它数据换算为对应单位。 2excel气象数据转为shape格式的矢量点数据插值分析 (1)打开Arcgis,添加excel气象站点数据。打开LC_Ther10-11_16m合并_warp_裁剪BIL1.00_cj重采样6066_经纬度.img,打开边界.shp,三个应该能叠加在一起 (2)在arcgis内容列表中右键单击excel表,选择“显示XY数据”,设置X、Y字段为表中对应经、纬度字段,编辑坐标系,设置为气象站点经纬度获取时的坐标系,这里为地理坐标系WGS84。 (3)导出为shape格式的点数据。右键单击上一个步骤中新生成的事件图层,单击“数据-导出数据”。需注意导出数据的坐标系应选择“此图层的源数据”。 (4)设置Arcgis环境。在“地理处理”菜单下单击“环境”,在环境设置窗口中选择“处理范围”,选择一个处理好的遥感数据(LC_Ther10-11_16m合并_warp_裁剪BIL1.00_cj重采样6066_经纬度.img,主要是参考该遥感数据的行数和列数)。再选
择“栅格分析”,按下图设置插值的分辨率为“0.0045”,掩膜文件设置为边界2/LC_Ther10-11_16m合并_warp_裁剪BIL1.00_cj重采样6066_经纬度.img。注意:生成出来的是否有坐标系,插值-环境-输出坐标系-与**相同 (5)气象站点数据插值。在toolbox中选择工具箱“Spatial Analyst————反距离权法”,默认12个数据参与运算,“Z值字段”分别选择平均风速、平均气温、相对湿度,直接输出,不要改输出路径名字。再导出数据。在差值分析界面最下栏也有环境,进去设置,注意经纬度显示位置是经纬度投影的投影坐标系,UTM不能用 (6)数据转换为image格式。上步骤中得到的插值栅格数据是Arcgis格式的栅格格式(grid格式),该格式envi识别不了。右键单击插值数据选择“数据—导出数据”,设置导出数据格式为image。 (7)再用envi claas 转换为UTM投影 (8)UTM 设置参数:datum:(原来为North America 1927)改为为WGS84, zone 49。 E: 719614.2770 N: 4100314.6180 X/Y PIXEL: 16.0 meter output x size: 8723 output y size: 6066