第五章多元统计课件

第五章 假设检验与区间估计
5.1 假设检验概述
假设检验问题是统计推断的一类重要问题。在总体的分布函数完全未知或只知其形式、但不知其参数的情况,为了推断总体的某些求知特征,提出某些关于总体的假设。例如,提出总体服从正态分布的假设,又如,对于正态总体提出数据等于一个常数的假设等。我们可以根据样本对所提出的假设作出是接受,还是拒绝的决策。假设检验是作出这一决策的过程。
一、假设检验的步骤
处理假设检验的步骤如下: 1、根据实际问题的要求,提出原假设(Null Hypothesis )和备择假设(Alternative Hypothesis )。 2、给定显著性水平α以及样本容量n 。 3、确定检验统计量以及拒绝域的形式。
4、按照00(|P H H α≤拒绝为真)求出拒绝域。
5、取样,根据样本观测值作出决策,是接受原假设还是拒绝原假设。
二、假设检验的基本概念
1、两类错误
假设检验是根据一定概率显著水平对总体特征进行推断。否定了原假设,并不等于已证明原假设不真;接受了原假设,也不等于已证明原假设是真实的。
0H 0H 0H 0H 原假设在客观上只有两种可能性:真、假。样本值0H 12(,,,)n x x x 也只有两种可能性:属于拒绝域C、不属于拒绝域C。则在观察到样本值12(,,,)n x x x 时只可能有下列四种情况:
(1) 原假设为真,而样本值0H 12(,,,)n x x x 属于拒绝域C; (2) 原假设为真,而样本值0H 12(,,,)n x x x 不属于拒绝域C; (3) 原假设为假,而样本值0H 12(,,,)n x x x 属于拒绝域C; (4) 原假设为假,而样本值0H 12(,,,)n x x x 不属于拒绝域C;
显然在(2)、(3)情形下,对原假设的表态与客观实际相符。而在(1)、(4)情形下,表态犯了错误,即与客观实际不符。在情形(1)下出现的错误是把本来真实的看法进行了否定,这种“以真为假”的错误叫做第一类错误。在情形(4)下出现的错误是把本来虚假的看法接受下来,这种“以假为真”的错误叫做第二类错误。由于样本值有随机性,这两类错误一般难以避免。
0H 0H 0H 2、检验统计量
在参数假设检验中,用于假设检验问题的统计量称为检验统计量。在具体问题里,选择什么统计量作为检验统计量,需要考虑的因素与参数估计相同。
3、显著性检验
在描述假设检验时涉及在一个事先指定的显著性水平值α下拒绝原假设或不拒绝原假设,这
SAS 统计分析
就意味着要判断原假设的正确性。但在有些情况下,可以用P 值作为描述否定原假设的一个概括性度量。
P 值介于0和1之间。P 值越小越对原假设的真实性产生怀疑。如果(较小的)P 值表明统计量的值不可能合理地偶然取得,则应拒绝原假设;如果(较大的)P 值表明统计量的值在原假设 为真的条件下可能偶然地取到,就不能拒绝原假设(并不指可以接受原假设)。
检验法则:给定显著性水平值α(通常取为0.01,0.05,0.10),若P 值小于α,则拒绝原假设,否则表明没有充分的理由拒绝原假设。
通常的方法:先由显著性水平值和检验统计量确定一个拒绝域,若样本落在拒绝域内,则拒绝原假设。
4、参数方法与非参数方法
许多统计方法依赖于样本是来自正态分布总体的假设,而有些检验方法又依赖于样本来自其他分布的假设。这种依赖于某种分布假设的统计方法通常称为参数检验方法。
还有一些统计方法并不需要假设数据的分布类型这种不依赖数据分布类型的统计方法通常称为非参数检验方法。
5.2 正态性检验
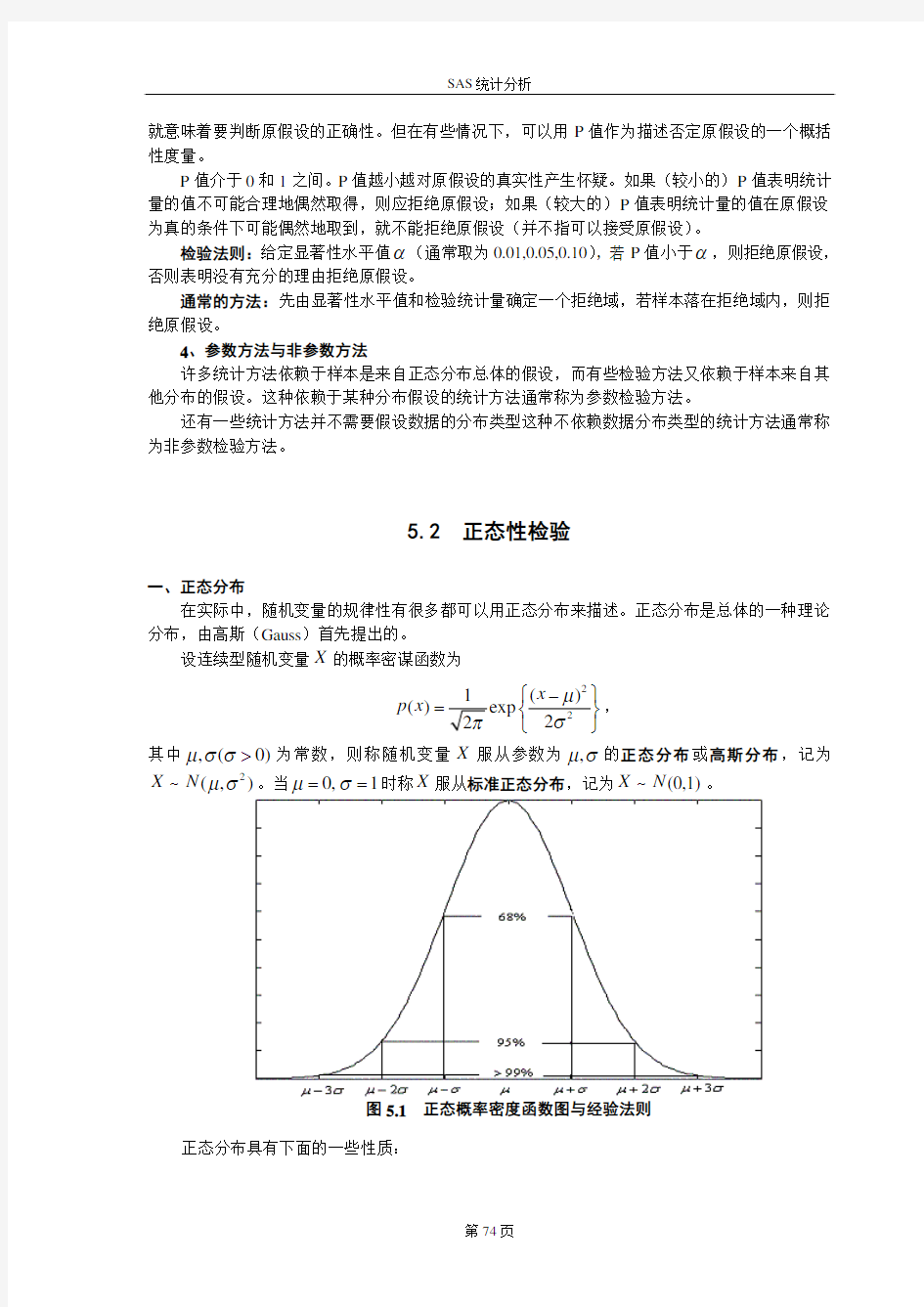
一、正态分布
在实际中,随机变量的规律性有很多都可以用正态分布来描述。正态分布是总体的一种理论分布,由高斯(Gauss )首先提出的。
设连续型随机变量X 的概率密谋函数为
2
()=p x , 其中,(0)μσσ>为常数,则称随机变量X 服从参数为,μσ的正态分布或高斯分布,记为
2(,)μσ~X N 。当0,1μσ==时称X 服从标准正态分布,记为。
(0,1)~X N
图5.1 正态概率密度函数图与经验法则
正态分布具有下面的一些性质:
假设检验与区间估计
(1) μ是位置参数,反映分布的具体位置;σ是刻度参数,反映分布的形状与大小,又称为形状参数。
(2) 正态分布的概率密度函数图是中间高、两边低、对称、光滑的“钟形”曲线。 (3) 正态分布的位置特征量均值、众数和中位数相等。
(4) 正态分布的偏度(Skewness )与峰度(Kurtosis )均为0。偏度是刻画总体分布是否对称,若偏度大于0,分布呈右偏的,若偏度小于0,分布呈左偏;峰度用于衡量分布的尾部轻重的特征量,若峰度大于0,分布呈重尾特征,若峰度小于,分布呈轻尾特征。
(5) 设2
(,)μσ~X N ,则
()68.26%μσμσ?<<+=P X ,即约的值落在距68%μ一个标准差σ的范围内。 (22)95.44%μσμσ?<<+=P X ,即约95%的值落在距μ两个标准差σ的范围内。 (33)99.74%μσμσ?<<+=P X ,即99%以上的值落在距μ三个标准差σ的范围内。 可以看出,尽管正态变量的取值范围是(,)?∞∞,但它的值落在(3,3)μσμσ?+内几乎是肯定的事。这就是人们常说的“3σ”法则,又称为经验法则。
二、正态性检验概述
正态性检验的方法有很多种,主要有:分布的拟合优度检验(卡方检验法与柯氏检验法)、直方图、偏峰检验法、QQ 图和PP 图检验法、W 检验法或经验分布函数的另一些检验法。还有稳定化PP 图也可进行分布的拟合检验。
在SAS 系统中,UNIV ARIATE 过程中,当样本容量小于2000时,SAS 还利用Shapiro-Wilks 的W 统计量来检验正态性。W 统计量是基于次序统计量线性组合平方的方差最优估计与通常校正平方和估计之比(介于0与1之间)。当样本来自正态总体,由样本构造的W 统计量的值应接近于1。W 的值过小是一种极端的情况,W 的值越小,则越表明数据不是来正态总体;Prob 时,采用Kolmogorov-Smirnov 的D 统计量,另外还有Cramer-von Mises 的W-Sq 统计量和 Anderson-Darling 的A-Sq 统计量。判断方法同W 统计量。 2000正态性检验可以用UNIV ARIATE 过程,其后加上选项NORMAL 。 语句格式为 PROC UNIV ARIATE V AR DATA =数据集名 NORMAL; 变量名; 运行上述过程生一些描述性统计量的值以及四个检验统计量的值及相应的P 值。 三、正态性的其它检验方法 1、偏度和峰度 依据正态分布的偏度和峰度均为0进行判定。 2、正态概率图 根据样本点在正态概率图(纸)上是否落在一条直线上进行判定。图中加号(+)均成一条直线,星号代表样本点。如果一个样本来自正态分布,则星号构成一条直线,因而将覆盖大多数的加号。正态概率图上加号越多,则认为样本值的分布偏离正态分布程度越大。(四种偏离情况:重尾,轻尾,左偏,右偏)。茎叶图及盒状图同样可以用于正态性的简单判定。 语句格式为: PROC UNIV ARIATE V AR DATA =数据集名 PLOT; 变量名; 3、直方图(条形图) 根据正态分布的概率密度呈钟形进行判定。 SAS统计分析语句格式为: PROC GCHART VBAR DATA=数据集名;变量名; 四、应用举例 例5.1:男子头颅的最大宽度的正态性检验 数据行中给出了84个伊特拉斯坎(Etruscan)人男子的头颅的最大宽度(mm)的数据,试 检验这些数据是否来自正态分布(取0.1 α=)。 SAS程序为: data ch5_1; input width @@; cards; 141 148 132 138 154 142 150 146 155 158 150 140 147 148 144 150 149 145 149 158 143 141 144 144 126 140 144 142 141 140 145 135 147 146 141 136 140 146 142 137 148 154 137 139 143 140 131 143 141 149 148 135 148 152 143 144 141 143 147 146 150 132 142 142 143 153 149 146 149 138 142 149 142 137 134 144 146 147 140 142 140 137 152 145 ; proc univariate data=ch5_1 normal; var width; proc univariate data=ch5_1 plot; var width; proc gchart data=ch5_1; vbar width/levels=12; run; 程序说明:第首先建立SAS数据集ch5_1,第一个UNIV ARIATE过程使用了选项NORMAL 表示进行正态性检验。第二个UNIV ARIATE过程使用了选项PLOT,表示可输出茎叶图、盒形图 和概率图。最后一个过程是GPLOT过程可输出直方图。 输出5.1.1 由UNIV ARIATE过程的NORMAL选项得到的正态性检验 正态性检验 检验 ----统计量---- -------P 值------- Shapiro-Wilk W 0.98901 Pr < W 0.7023 Kolmogorov-Smirnov D 0.085098 Pr > D 0.1364 Cramer-von Mises W-Sq 0.055499 Pr > W-Sq >0.2500 Anderson-Darling A-Sq 0.335623 Pr > A-Sq >0.2500 输出分析:第一个UNIV ARIATE过程加了选项NORMAL给出了正态性检验的统计量方法,可以输出四个检验统计量及相应的P值,从P值来看,四个值均大于给定的显著性水平值0.1 α=,故不能拒绝原假设,即该数据是来自正态分布的。第二UNIV ARIATE过程加了选项PLOT,给出了正态性检验的正态概率图,从图形可以看出基本呈一条直线,可以认为数据是服从正态分布的。最后使用了GCHART过程得到的直方图,结论也是一致的。 假设检验与区间估计 输出5.1.2 由UNIV ARIATE 过程的PLOT 选项得到的正态概率图 输出5.1.3 由GCHART 过程得到的直方图 5.3 单样本的t 检验 一、单样本的t 检验 设总体2 ~(,)μσX N ,其中2 ,μσ未知,假设检验问题为: 001:,:0μμμ=≠H H μ 不妨设00μ=,当00μ≠时,令0(1,2,,)μ=?= i i y x i n 。假设12(,,,)n x x x 是来自正 态总体X 的样本值, 使用统计量(1)=?~T t n t 作为检验统计量。由样本值计算统计量值 SAS 统计分析 及相应的P 值:(||||)=>P P T t 。并根据P 值的大小来判断以上的假设是否成立。当P 值小于显著性水平值α,则应否定以上的假设,即总体均值与0有显著性差异。否则认为总体均值μ与0没有显著性差异。利用SAS 进行t 检验主要有以下三种方法: 方法1:采用MEANS 过程 语句格式为: PROC MEANS V AR DATA=数据集名 MEAN STD STDERR PRT CLM; 变量名; 方法2:采用UNIV ARIATE 过程 语句格式为: PROC UNIV ARIATE V AR DATA=数据集名; 变量名; 方法2:采用TTEST 过程 语句格式为: PROC TTEST V AR DATA=数据集名; 变量名; 二、应用举例 例5.2:某种元件的寿命X (以小时计)服从正态分布,现测得16只元件的寿命如下: 159 280 101 212 224 379 179 264 222 362 168 250 149 260 485 170 问是否有理由认为元件的平均寿命等于225 (显著性水平值α为0.05)? SAS 程序为: data ch5_2; input x @@; y=x-225; cards ; 159 280 101 212 224 379 179 264 222 362 168 250 149 260 485 170 ; proc means data =ch5_2 mean std stderr prt; var y ; proc univariate data =ch5_2; var y; proc ttest data =ch5_2; var y; run ; 输出5.2.1 由MEANS 过程得到的检验 MEANS 过程 分析变量:y 均值 标准偏差 标准误差 Pr > |t| -------------------------------------------------------- 16.5000000 98.7258831 24.6814708 0.5140 -------------------------------------------------------- 假设检验与区间估计 输出5.2.2 由UNIV ARTIATE 过程得到的检验 UNIVARIATE 过程 位置检验: Mu0=0 检验 --统计量--- -------P 值------- 学生 t t 0.668518 Pr > |t| 0.5140 符号 M -1 Pr >= |M| 0.8036 符号秩 S 0.5 Pr >= |S| 0.9904 输出5.2.3 由TTEST 过程得到的检验 The TTEST Procedure T-Tests Variable DF t Value Pr > |t| y 15 0.67 0.5140 输出分析:由输出5.2.1可以看出P 值为0.5140,故平均寿命与225无显著性差异,由输出5.2.2和输出5.2.3得到的结论也是一致的。 5.4 两样本比较的统计检验 在进行两样本的统计检验之前,先做几件事情: (1) 用第四章中讲述的一些描述性统计分析SAS 过程(如MEANS ,UNIV ARIATE ,CHART )对两个样本进行概括和比较,以得出一个初步的结论:是否有差异。 (2) 确定两个样本是独立组还是成对组。 (3) 确定正态性是否满足。 在此基础上确定用什么统计量、哪一个SAS 过程去进行统计检验。概括起来有四种检验统计量。 表5.1 进行两组比较的统计检验 独立组 成对组 参数检验 (正态假设下) 两样本t 检验 成对差值t 检验 检验的类型 非参数检验 (非正态下) Wilcoxon 秩和检验 Wilcoxon 符号秩检验 一、两(独立)样本的t 检验 设2 2 12~(,),~(,)X N Y N μσμσ,其中2 12,,μμσ 均未知,假设检验问题为: 012112:,:H H μμδμμδ?=?≠,δ为已知常数 假设12(,,,)n x x x 和12(,,,)n y y y 分别是来自正态总体X 和Y 的样本值,使用t 统计量 T =22 21112)n n ?+22(1(1)2w n S n S S ?= +?,w S =。当为真时,。与单个总体的t 检验类似,我们可以得到相应的P 值。 0H 12~(2)T t n n +? SAS统计分析 两样本的t检验用于比较两个独立组的均值是否相等的一种参数检验,需要下面的三个假设:观测是独立的;每组的观测来自正态总体;两个独立组的方差(未知但相等)。若上述假设均满足,则可采用PROC TTEST进行两样本的t检验。 语句格式为: PROC TTEST CLASS V AR DATA=数据集名;变量名; 变量名; 例5.3:下表分别给出两个文学家马克·吐温(Mark Twain)的8篇小品文和斯诺特格拉斯(Snodgrass )的10篇小品文中由3个字母组成词的比例。 Mark Twain 0.225 0.262 0.2170.2400.2300.2290.2350.217 Snodgrass 0.209 0.205 0.1960.2100.2020.2070.2240.223 0.220 0.201 设两组数据分别来自正态总体,两样本相互独立。问两个作家所写的小品文中包含3个字母组成 的词的比例是否有显著性差异(显著性水平值取为0.05)? SAS程序为: data ch5_3; do i=1to2; input n; do j=1to n; input x @@; output; end; end; cards; 8 0.225 0.262 0.217 0.240 0.230 0.229 0.235 0.217 10 0.209 0.205 0.196 0.210 0.202 0.207 0.224 0.223 0.220 0.201 ; proc ttest data=ch5_3; class i; var x ; run; 输出5.3.1 由TTEST过程得到的t检验 The TTEST Procedure T-Tests Variable Method Variances DF t Value Pr > |t| x Pooled Equal 16 3.88 0.0013 x Satterthwaite Unequal 11.7 3.70 0.0032 假设检验与区间估计 输出5.3.2 由TTEST过程得到的方差齐性检验 Equality of Variances Variable Method Num DF Den DF F Value Pr > F x Folded F 7 9 2.27 0.2501 输出分析:由输出5.3.2给出了方差齐性检验,由于方差齐性检验的P值0.2501大于0.01,故认为两样本的方差相等,因而采用上面一行适合于两样本方差相等的T值,自由度DF和P值判别,由于P值0.0013大于0.01,故两样本的均值有显著差异,也即两个作家所写的小品文中3个字母组成的词的比例有显著性差异。如果方差齐性检验不能通过,则改用Unequal一行的近似t检验。 二、成对差值的t检验和Wilcoxon符号秩检验 有时为了比较两种产品,或两种仪器、两种方法等的差异,我们常在相同的条件下作对比试验,得到一批成对的观察值。然后分析观察数据作为推断。这种方法常称为逐对比较法。 成对差值的t检验是比较成对组的一种参数检验。一般假定:差值来自正态总体(方差未知);每对观测与其他对观测独立。此两个假设与单样本t检验的假设相同,因此成对数据(组)的比较利用它们的差值将问题转化为单样本的t检验问题。单样本的t检验直接用于对对组的检验,即可用MEANS过程、UNIV ARIATE过程或TTEST过程进行。 Wilcoxon符号秩检验是类似于成对差值t检验的一种非参数检验。Wilcoxon符号秩检验假设每对观测与其他对观测独立。Wilcoxon符号秩检验由UNIV ARIATE过程自动进行。一般地,要解释Wilcoxon符号秩检验的输出结果,看Pr >= |S|后面给出的值。如果此值小于给定的显著性水平,结论为两组有显著性差异,如果此P值大于显著性水平,结论是两组样本差异不明显例5.4:随机地选8个人,分别测量了他们在早晨起床时和晚上就寝时的身高(cm),得到以下数据: 序号 1 2 345 6 7 8早上 172168 180181160163 165 177晚上 172167 177179159161 166 175设各对数据的差是来自正态总体的样本,问是否可以认为早上的身高比晚上的身高要高(取显著性水平值α为0.05)? SAS程序为: data ch5_4; input x y @@; d=x-y; cards; 172 172 168 167 180 177 181 179 160 159 163 161 165 166 166 175 ; proc means data=ch5_4 mean std stderr t prt; var d; proc univariate data=ch5_4; var d; proc ttest data=ch5_4; var d; run; SAS统计分析 输出5.4.1 由MEANS过程得到的t检验 MEANS 过程 分析变量:d 均值 标准偏差 标准误差 t 值 Pr > |t| ------------------------------------------------------------------- 1.2500000 1.2817399 0.4531635 2.76 0.0282 ------------------------------------------------------------------- 输出分析:输出5.4.1至输出5.4.3容易看出学生t检验的P值(Pr > |t|)为0.0282<0.05,故认为早上的身高与晚上的身高有显著性差异。而Wilcoxon符号秩检验的P值为0.0625,即早上的身高与晚上的身高无显著性差异。 输出5.4.2 由UNIV ARIATE过程得到的t检验 UNIVARIATE 过程 变量: d 位置检验: Mu0=0 检验 --统计量--- -------P 值------- 学生 t t 2.758386 Pr > |t| 0.0282 符号 M 2.5 Pr >= |M| 0.1250 符号秩 S 12 Pr >= |S| 0.0625 输出5.4.3 由TTEST过程得到的t检验 The TTEST Procedure T-Tests Variable DF t Value Pr > |t| d 7 2.76 0.0282 三、两(独立)样本的Wilcoxon秩和检验 两样本的Wilcoxon秩和检验用于比较两个独立组的一种非参数检验(又称Mann-Whitney U 检验)。此检验只需假定观测独立(正态性假设并不满足)。 NPAR1WAY过程是一个单因素的非参数过程,它分析变量的秩,计算几个相应的统计量,并检验一个变量的分布在不同组中具有相同的位置参数,或者检验在不同组中的变量具有相同的分布。NPAR1WAY过程要求数据是独立组的。 1、语句格式 PROC NPAY1WAY CLASS V AR BY 选项; 变量名; 变量名; 变量名; 2、语句说明 (1) 选项 DATA=数据集名:指定分析数据集名。 Wilcoxon:对数据进行Wilcoxon的秩和检验。对于两水平,即为wilcoxon的秩和检验;对于多水平,这是一个Kruskal-Wallis检验。 (2) CLASS语句 假设检验与区间估计 这个语句是必须的,它指定一个且只能指定一个分类变量。该变量用来识别数据中的各个类。Class变量可以数值变量,也可以是字符变量。 (3) BY语句 这个语句用来得到由BY变量定义的不同的观测组,并用NPAR1WAY过程分别进行分析。当然,使用BY变量之前,数据集需要先按BY变量排序。 (4) V AR语句 该语句命名要分析的响应变量或自变量。如果省略,则过程分析数据集中所有数值变量,除了CLASS变量以外。 例5.5:某机床厂某日从两台机器所加工的同一种零件中,分别抽若干个样品测量零件尺寸,得到如下数据: 第一台机器:6.2 5.7 6.5 6.0 6.6 6.3 5.8 5.7 6.0 6.0 5.8 6.0 第二台机器:5.6 5.9 5.6 5.7 5.8 6.0 5.5 5.7 5.5 α=)? 问这两台机器的加工精度是否有显著性差异(显著性水平值0.05 SAS程序为: data ch5_5; input engine$ x @@; cards; 1 6. 2 1 5.7 1 6.5 1 6.0 1 6.6 1 6. 3 1 5.8 1 5.7 1 6.0 1 6.0 1 5.8 1 6.0 2 5.6 2 5.9 2 5.6 2 5.7 2 5.8 2 6.0 2 5.5 2 5.7 2 5.5 ; proc npar1way data=ch5_5 wilcoxon; class engine; var x; run; 输出5.5.1 由NPAR1WAY过程得到的Wilcoxon检验 The NPAR1WAY Procedure Wilcoxon Scores (Rank Sums秩和) for Variable x Classified by Variable engine Sum of Expected Std Dev Mean engine N Scores Under H0 Under H0 Score ---------------------------------------------------------------------- 1 1 2 171.0 132.0 13.905806 14.250000 2 9 60.0 99.0 13.905806 6.666667 Average scores were used for ties. Wilcoxon Two-Sample Test Statistic 60.0000 ①Normal Approximation(正态近似) Z -2.7686 One-Sided Pr < Z 0.0028 Two-Sided Pr > |Z| 0.0056 ②t Approximation(t近似) One-Sided Pr < Z 0.0059 Two-Sided Pr > |Z| 0.0119 SAS 统计分析 Z includes a continuity correction of 0.5. Kruskal-Wallis Test ③Chi-Square 7.8657 DF 1 Pr > Chi-Square 0.0050 输出分析:一般地,解释Wilcoxon 秩和检验的输出结果主要看“Pr>|Z|”后面的P 值,如果此P 值大于预先给定的显著性水平,结论是两组的均值有显著性差异。如果此P 值大于预先给定的显著性水平,则两个组的均值无显著性差异。正态近似情况下①的双侧检验的P 值为0.0056,说明有显著性差异,在t 近似情况②与卡方检验③得到的结论也是一致的, 5.5 区间估计 对于一个未知量,人们在测量或计算时,常不以得到近似值为满足,还需要估计误差,即要求知道近似值的精确程度。例如,对于未知参数,除了求出它们的点估计外,还希望估计出一个范围,并希望知道这个范围包含参数真值的可信程度。这样的范围通常以区间的形式给出,同时还给出此区间包含参数真值的可信程度。这种形式的估计称为区间估计,这样的区间即所谓置信区间。 一、置信区间的基本概念 1、单个正态总体均值和标准差的区间估计 设总体2 ~(,)μσX N ,其中2 ,μσ未知。假设12(,,,)n x x x 是来自正态总体 X 的样本值, 则μ的1α?的置信区间为: /2/2[((x t n t n αα??+?, 其中是自由度为1/2(1t n α??)1n ?的 t 分布的上侧/2 α分位点。 σ的置信水平为1 α?的置信区间为: ?? , 其中是自由度为2 /2(1n αχ?)1n ?的2 χ分布的上侧/2α分位点。 2、两个正态总体均值差的区间估计 设2 2 12~(,),~(,)X N Y N μσμσ,其中2 12,,μμσ均未知,且两样本独立。12(,,,)n x x x 和 12(,,,)n y y y 分别是来自正态总体X 和Y 的样本值,则12μμ?的1α?的置信区间为: 利用MEANS 过程和TTEST 过程能够获得均值的区间估计,利用TTEST 过程可以方差的区 间估计。具体参见后面的应用举例。 假设检验与区间估计 二、应用举例 例5.6:有一大批糖果。现从中随机地取16袋,称得重量(以克计)如下: 506 508 499 503 504 510 497 512 514 505 493 496 506 502 509 496 假定它们来自某个正态总体,试求其均值和标准差的置信水平为95%的置信区间。 SAS程序为: data ch5_6; input x @@; cards; 506 508 499 503 504 510 497 512 514 505 493 496 506 502 509 496 ; proc means data=ch5_6 clm alpha=0.05; var x; proc ttest data=ch5_6 alpha=0.05; var x; run; 程序说明:MEANS过程可以得到均值的区间估计,后面选项alpha=0.05表示显著性水平,缺省值为0.05。TTEST过程可以得到均值和方差的区间估计。 输出5.6.1 由MEANS过程得到的均值的区间估计 MEANS 过程 分析变量:x 均值下限95% 均值上限95% 均值的置信限 均值的置信限 ---------------------------- 500.4451075 507.0548925 ---------------------------- 输出5.6.2 由TTEST过程得到的均值与方差的区间估计 The TTEST Procedure Lower CL Upper CL Lower CL Upper CL Variable N Mean Mean Mean Std Dev Std Dev Std Dev Std Err x 16 500.45 503.75 507.05 4.5816 6.2022 9.599 1.5505 输出分析:由输出5.6.1和输出5.6.2容易得到均值的95%的区间估计为(500.45,507.05),标准差的95%的区间估计为(4.5816,9.599)。 例5.7:有一大批随机地从A批导线中抽取4根,又从B批导线中抽取5根,测得电阻为:A批导线:0.143 0.142 0.143 0.137 B批导线:0.140 0.142 0.136 0.138 0.140 假设数据分别来自两个正态总体,且两样本独立,试求两样本均值差的95%的置信区间。 SAS程序为: data ch5_7; input class $ x @@; cards; a 0.143 a 0.142 a 0.143 a 0.137 b 0.140 b 0.142 b 0.136 b 0.138 b 0.140 SAS统计分析 ; proc ttest data=ch5_7; class class; run; 输出5.7.1 由MEANS过程得到的均值的区间估计 The TTEST Procedure Lower CL Upper CL Lower CL Upper CL Variable class N Mean Mean Mean Std Dev Std Dev Std Dev Std Err x a 4 0.1367 0.1413 0.1458 0.0016 0.0029 0.0107 0.0014 x b 5 0.1364 0.1392 0.142 0.0014 0.0023 0.0066 0.001 x Diff (1-2) -0.002 0.002 0.0061 0.0017 0.0026 0.0052 0.0017 输出分析:由输出5.7.1容易得到均值差的95%的区间估计为(-0.002,0.0061)。 习题五 1、某车间生产滚珠,随机抽取了50个产品,测得它们的直径为(以毫米计): 15.0 15.8 15.2 15.1 15.9 14.7 14.8 15.5 15.6 15.3 15.1 15.3 15.0 15.6 15.7 15.8 14.5 14.2 14.9 14.9 15.2 15.0 15.3 15.6 15.1 14.9 14.2 14.6 15.8 15.2 15.9 15.8 15.0 14.9 14.8 14.5 15.1 15.5 15.5 15.1 15.1 15.0 15.3 14.7 14.5 15.5 15.0 14.7 14.6 14.2 问:滚珠直径是否服从正态分布? 2、为了比较做鞋子后跟的两种材料的质量,选取15名男子(他们的生活条件各不相同)。每人穿 一双新鞋,其中一只是以材料A做成的,另一只是以材料B做成的,其厚度为10mm。过了一个 月再测厚度,得到数据如下: 材料A 6.6 7.0 8.3 8.2 5.2 9.3 7.9 8.5 7.8 7.5 6.1 8.9 6.1 9.4 9.1 材料B 7.4 5.4 8.8 8.0 6.8 9.1 6.3 7.5 7.0 6.5 4.4 7.7 4.2 9.4 9.1 设它们的差值是来自某个正态总体的样本,问是否可以认为材料A制成的后跟比材料B的耐穿? (显著性水平为0.05) 3、一化学家用两种不同的液体层析方法测量一种用煤制造的合成燃料的萘含量。取十份样品,每 一份分成两半:一半用标准的层析方法(STD)测量,另一种用高压液体层析方法(HP)测量,数据分 别为: HP 10.9 13.1 14.5 9.6 11.2 9.8 13.7 12.0 9.112.1 STD 14.0 12.9 16.2 10.2 12.4 12.0 14.8 11.8 9.7 14.7 假设它们的差值来自某个正态总体的样本,问两种液体层析方法是否有显著差异?(显著性水平为0.05) 假设检验与区间估计 4、十岁前的儿童学习游泳,在肌肉发育方面,较不学习游泳的人更为协调。这种情况是否在智能 测验中也有一定的效应?选出15孪生子,教孪生子中的一个学习游泳。到30岁时,这30个人由 三位专家组成的小组进行口头测验。结果产生下列智能记分: 游泳组86 49 77 63 59 99 77 83 67 73 78 74 86 73 69 非游泳组 85 53 70 60 53 84 79 85 65 70 72 70 88 71 60 问两组之间能否检验出智能的显著不同?显著性水平为0.05。 5、现已收集到两个城市A和B犯罪青年初犯的年龄样本如下: 城市A16 26 23 19 45 30 23 29 24 35 32 城市B15 25 17 40 22 27 21 20 18 16 14 31 试在5%的显著性水平下判定两个城市A,B的犯罪青年初犯的平均年龄之间是否有显著差异? 6、研究两组病人的胃液成分的试验。病人被分成两组:患胃溃疡的病人 (N) 与无胃溃疡的“正常”( Y )或对照组的病人。现要判断在5%显著性水平下两组的平均溶菌酶是否存在显著性差异。 数据如下表。 N 0.2 N 10.4 N 0.3N10.9N0.4N11.3N 1.1 N 12.4 N 2.0 N 16.2 N 2.1N17.6N 3.3N18.9N 3.8 N 20.7 N 4.5 N 24.0 N 4.8N25.4N 4.9N40.0N 5.0 N 42.2 N 5.3 N 50.0 N 7.5N60.0N9.8Y0.2Y 5.4 Y 0.3 Y 5.7 Y 0.4 Y 5.8Y0.7Y7.5Y 1.2Y 8.7 Y 1.5 Y 8.8 Y 1.5 Y 9.1Y 1.9Y10.3Y 2.0Y 15.6 Y 2.4 Y 16.1 Y 2.5 Y 16.5Y 2.8Y16.7Y 3.6Y 20.0 Y 4.8 Y 20.7 Y 4.8 Y 33.0 7、随机10个失眠患者,服用甲、乙两种安眠药,延长睡眠时间(小时)如下表所示。 患者编号 12345678910 甲药 1.90.8 1.10.1-0.1 4.4 5.5 1.6 4.6 3.4 乙药 0.7-1.6 -0.2-1.2-0.1 3.4 3.70.8 0 2.0 请回答下列问题: (1) 这两种安眠药的疗效有无显著性差异? (2) 并求出甲乙两种药延长睡眠时间差的99%的置信区间? 8、为了研究某种汽车轮胎的磨损特性,随机地选择16只轮胎,每只轮胎行驶到损坏为止。记录 行驶的路程(以公里计)如下: 41250 40187 43175 41010 39265 41872 42654 41287 38970 40200 42550 41096 40680 43500 39775 40400 首先对该数据进行正态性检验,再求汽车行驶平均路程的置信水平为0.95的单侧置信上限。 9、某天7个银行给出了它们的抵押贷款利率: 银行利率银行利率银行利率银行利率 BANKA 11 BANKB 10.5 BANKC 10.625 BANKD 10.5 BANKE 10.5 BANKF 10.625 BANKG 10.25 SAS统计分析 假定它们来自某个正态总体,试求其均值的置信水平为95%的置信区间。 10、设某种清漆的9个样品,其干燥时间(以小时计)分别为: 6.0 5.7 5.8 7.0 6.3 5.6 6.1 5.0 设干燥时间总体服从正态分布,求均值的置信水平为95%的置信区间? 11、下面给出两种型号的计算器充电以后所能使用的时间(以小时计): 型号A 5.5 5.6 6.3 4.6 5.3 5.0 6.2 5.8 5.1 5.2 5.9 型号B 3.8 4.3 4.2 4.0 4.9 4.5 5.2 4.8 4.5 3.9 3.7 4.6设样本独立且数据所属的两总体的密度至多差一个平移,试问能否认为型号A的计算器平均使用时间比型号B来得长(取显著性水平值为0.01)? 12、下面给出两个工人五天生产同一种产品每天生产的件数: 49 52 53 47 50 工人A 工人B56 48 58 46 55 设两样本独立且数据所属的两总体的密度至多差一个平移,问能否认为工人A、工人B平均每天完成的件数没有显著性差异(取显著性水平值为0.01)? 13、设从某河流内每月抽取一次水样,检验河水中汞的含量(以每克中含的微克量计),得到一年的数据如下: 月份123456789101112汞含量 2.3 2.7 2.5 3.2 3.8 3.6 2.8 2.5 3.4 3.7 4.2 3.5用秩方法检验河水的汞含量是否有上升的趋势? 14、设从两个不同的地区各取得某种植物的样品12个,测得植物中铁元素含量(以每克中含的微克量计)的数据如下: 地区A 11.5 18.6 7.6 18.211.416.519.210.111.2 9.0 14.015.3地区B 16.2 15.2 12.3 9.710.219.517.012.018.0 9.0 19.010.0假设已经知道这种植物中铁元素含量服从正态分布,且分布的方差不受地区影响,检验这两个地区该种植物中铁元素含量的分布是否相同? 15、假设用A、B两种饲料各喂猪10头,经一个喂养周期后,猪的增重(以千克计)如下表: A饲料20 24 32 31 28 17 25 19 24 30 B饲料27 29 27 38 38 27 35 29 31 36 请给出A、B两种饲料使猪平均增重的差的90%的置信区间。 第3章 多元正态总体的假设检验与方差分析 从本章开始,我们开始转入多元统计方法和统计模型的学习。统计学分析处理的对象是带有随机性的数据。按照随机排列、重复、局部控制、正交等原则设计一个试验,通过试验结果形成样本信息(通常以数据的形式),再根据样本进行统计推断,是自然科学和工程技术领域常用的一种研究方法。由于试验指标常为多个数量指标,故常设试验结果所形成的总体为多元正态总体,这是本章理论方法研究的出发点。 所谓统计推断就是根据从总体中观测到的部分数据对总体中我们感兴趣的未知部分作出推测,这种推测必然伴有某种程度的不确定性,需要用概率来表明其可靠程度。统计推断的任务是“观察现象,提取信息,建立模型,作出推断”。 统计推断有参数估计和假设检验两大类问题,其统计推断目的不同。参数估计问题回答诸如“未知参数θ的值有多大?”之类的问题,而假设检验回答诸如“未知参数θ的值是0θ吗?”之类的问题。本章主要讨论多元正态总体的假设检验方法及其实际应用,我们将对一元正态总体情形作一简单回顾,然后将介绍单个总体均值的推断, 两个总体均值的比较推断,多个总体均值的比较检验和协方差阵的推断等。 3.1一元正态总体情形的回顾 一、 假设检验 在假设检验问题中通常有两个统计假设(简称假设),一个作为原假设(或称零假设),另一个作为备择假设(或称对立假设),分别记为0H 和1H 。 1、显著性检验 为便于表述,假定考虑假设检验问题:设1X ,2X ,…,n X 来自总体),(2 σμN 的样本,我们要检验假设 100:,:μμμμ≠=H H (3.1) 原假设0H 与备择假设1H 应相互排斥,两者有且只有一个正确。备择假设的意思是,一旦否定原假设0H ,我们就选择已准备的假设1H 。 当2 σ已知时,用统计量n X z σ μ -= 一、填空题: 1、多元统计分析是运用数理统计方法来研究解决多指标问题的理论和方法. 2、回归参数显著性检验是检验解释变量对被解释变量的影响是否著. 3、聚类分析就是分析如何对样品(或变量)进行量化分类的问题。通常聚类分析分为 Q型聚类和 R型聚类。 4、相应分析的主要目的是寻求列联表行因素A 和列因素B 的基本分析特征和它们的最优联立表示。 5、因子分析把每个原始变量分解为两部分因素:一部分为公共因子,另一部分为特殊因子。 6、若 () (,), P x N αμα ∑=1,2,3….n且相互独立,则样本均值向量x服从的分布 为_x~N(μ,Σ/n)_。 二、简答 1、简述典型变量与典型相关系数的概念,并说明典型相关分析的基本思想。 在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数。选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对,如此下去直到两组之间的相关性被提取完毕为止。被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。 2、简述相应分析的基本思想。 相应分析,是指对两个定性变量的多种水平进行分析。设有两组因素A和B,其中因素A包含r个水平,因素B包含c个水平。对这两组因素作随机抽样调查,得到一个rc的二维列联表,记为。要寻求列联表列因素A和行因素B的基本分析特征和最优列联表示。相应分析即是通过列联表的转换,使得因素A 和因素B 具有对等性,从而用相同的因子轴同时描述两个因素各个水平的情况。把两个因素的各个水平的状况同时反映到具有相同坐标轴的因子平面上,从而得到因素A 、B 的联系。 3、简述费希尔判别法的基本思想。 从k 个总体中抽取具有p 个指标的样品观测数据,借助方差分析的思想构造一个线性判别函数 系数: 确定的原则是使得总体之间区别最大,而使每个总体内部的离差最小。将新样品的p 个指标值代入线性判别函数式中求出 值,然后根据判别一定的规则,就可以判别新的样品属于哪个总体。 5、简述多元统计分析中协差阵检验的步骤 第一,提出待检验的假设 和H1; 第二,给出检验的统计量及其服从的分布; 第三,给定检验水平,查统计量的分布表,确定相应的临界值,从而得到否定域; 第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。 协差阵的检验 检验0=ΣΣ 0p H =ΣI : /2 /21exp 2np n e tr n λ???? =-?? ? ???? S S 00p H =≠ΣΣI : /2 /2**1exp 2np n e tr n λ???? =-?? ? ???? S S 多元统计分析(1) 题目:多兀统计分析知识点 研究生___________________________ 专业____________________________ 指导教师________________________ 完成日期2013年12月 目录 第一章绪论 (1) §.1什么是多元统计分析 (1) §.2多元统计分析能解决哪些实际问题 (2) §.3主要内容安排 (2) 第二章多元正态分布 (2) 弦.1基本概念 (2) 弦.2多元正态分布的定义及基本性质 (8) 1. (多元正态分布)定义 (9) 2?多元正态变量的基本性质 (10) §2.3多元正态分布的参数估计X =(X1,X2^|,X p) (11) 1?多元样本的概念及表示法 (12) 2. 多元样本的数值特征 (12) 3」和a 的最大似然估计及基本性质 (15) 4.Wishart 分布 (17) 第五章聚类分析 (18) §5.1什么是聚类分析 (18) §5.2距离和相似系数 (19) 1 ? Q—型聚类分析常用的距离和相似系数 (20) 2. .......................................................................................................................................... R 型聚类分析常用的距离和相似系数 (25) §5.3八种系统聚类方法 (26) 1. 最短距离法 (27) 2. 最长距离法 (30) 3. 中间距离法 (32) 4. 重心法 (35) 5. 类平均法 (37) 6. 可变类平均法 (38) 7. 可变法 (38) 8. 离差平方和法(Word方法) (38) 第六章判别分析 (39) 第三章 多元正态分布 多元正态分布是一元正态分布在多元情形下的直接推广,一元正态分布在统计学理论和应用方面有着十分重要的地位,同样,多元正态分布在多元统计学中也占有相当重要的地位。多元分析中的许多理论都是建立在多元正态分布基础上的,要学好多元统计分析,首先要熟悉多元正态分布及其性质。 第一节 一元统计分析中的有关概念 多元统计分析涉及到的都是随机向量或多个随机向量放在一起组成的随机矩阵,学习多元统计分析,首先要对随机向量和随机矩阵有所把握,为了学习的方便,先对一元统计分析中的有关概念和性质加以复习,并在此基础上推广给出多元统计分析中相应的概念和性质。 一、随机变量及概率分布函数 (一)随机变量 随机变量是随机事件的数量表现,可用X 、Y 等表示。随机变量X 有两个特点:一是取值的随机性,即事先不能够确定X 取哪个数值;二是取值的统计规律性,即完全可以确定X 取某个值或X 在某个区间取值的概率。 (二)随机变量的概率分布函数 随机变量X 的概率分布函数,简称为分布函数,其定义为: )()(x X P x F ≤= 随机变量有离散型随机变量和连续型随机变量,相对应的概率分布就有离散型概率分布和连续型概率分布。 1、离散型随机变量的概率分布 若随机变量X 在有限个或可列个值上取值,则称X 为离散型随机变量。 设X 为离散型随机变量,可能取值为1x ,2x ,…,取这些值的概率分别为1p ,2p ,…, 记为 k k p x X P ==)((Λ,2,1=k ) 称k k p x X P ==)((Λ,2,1=k )为离散型随机变量X 的概率分布。 离散型随机变量的概率分布具有两个性质: (1) 0≥k p ,Λ,2,1=k (2)11 =∑ ∞ =k k p 2、连续型随机变量的概率分布 若随机变量X 的分布函数可以表示为 dt t f x F x ?∞-=)()( 对一切R x ∈都成立,则称X 为连续型随机变量,称 )(x f 为X 的概率分布密度函数,简 多元统计分析第三章假设检验与方差分析 第3章 多元正态总体的假设检验与方差分析 从本章开始,我们开始转入多元统计方法和统计模型的学习。统计学分析处理的对象是带有随机性的数据。按照随机排列、重复、局部控制、正交等原则设计一个试验,通过试验结果形成样本信息(通常以数据的形式),再根据样本进行统计推断,是自然科学和工程技术领域常用的一种研究方法。由于试验指标常为多个数量指标,故常设试验结果所形成的总体为多元正态总体,这是本章理论方法研究的出发点。 所谓统计推断就是根据从总体中观测到的部分数据对总体中我们感兴趣的未知部分作出推测,这种推测必然伴有某种程度的不确定性,需要用概率来表明其可靠程度。统计推断的任务是“观察现象,提取信息,建立模型,作出推断”。 统计推断有参数估计和假设检验两大类问题,其统计推断目的不同。参数估计问题回答诸如“未知参数θ的值有多大?”之类的问题,而假设检验回答诸如“未知参数θ的值是0θ吗?”之类的问题。本章主要讨论多元正态总体的假设检验方法及其实际应用,我们将对一元正态总体情形作一简单回顾,然后将介绍单个总体均值的推断, 两个总体均值的比较推断,多个总体均值的比较检验和协方差阵的推断等。 3.1一元正态总体情形的回顾 一、 假设检验 在假设检验问题中通常有两个统计假设(简称假设),一个作为原假设(或称零假设),另一个作为备择假设(或称对立假设),分别记为0H 和1H 。 1、显著性检验 为便于表述,假定考虑假设检验问题:设1X ,2X ,…,n X 来自总体),(2 σμN 的样本,我们要检验假设 100:,:μμμμ≠=H H (3.1) 原假设0H 与备择假设1H 应相互排斥,两者有且只有一个正确。备择假设的意思是,一旦否定原假设0H ,我们就选择已准备的假设1H 。 当2 σ已知时,用统计量n X z σ μ -= 第三章多元统计分析 §4 聚类分析 分类是人类认识世界的方式,也是管理世界的有效手段。在科学研究中非常重要,许多科学的研究都是从分类研究出发的。没有分类就没有效率;没有分类,这个世界就没有秩序。瑞典博物学家林奈(Carl von Linnaeus, 1707-1778)因为对植物的分类成就被后人誉为“分类学之父”,后人评价说“上帝创世,林奈分类”——能与上帝的名字并列的人不多,另一个著名的科学家是牛顿。由此可见分类成果的重要性。最初分类都是定性了,后来随着科学的发展产生了定量分类技术,包括基于统计学的聚类方法和基于模糊数学的聚类技巧。本节主要讲述统计学意义的数字分类方法思想和过程。 1 聚类的分类 分类研究的成果的重要性决定了方法的重大实践意义。在任何一门语言的语法学中,都要对词词汇进行分类,词汇分类可以根据词性:名词,动词,形容词……;英文还可以根据首字母分类:ABCD……;汉字则还可以根据笔划,如此等等。在生物学中,将生物划分为:界,门,纲,目,科,属,种。例如白菜(种)属于油菜属、十字花科、十字花目、双子叶植物纲、被子植物亚门、种子植物门、植物界;老虎(种)则属于猫属、猫科、食肉目、哺乳动物纲、脊椎动物亚门、脊索动物门、动物界。这样,整个世界的生物就可以建立一个等级谱系,根据这个谱系,我们可以比较容易地判断那些生物已经认识了,哪些生物尚未发现,哪些生物已经灭绝了。如果发现了新的生物,就可以方便地将其归类。在天文学中,天体可以根据视觉区域分类,也可以根据发光性质与光谱特征进行分类。在地理学中,城市既可以根据地域空间分类,也可以根据城市的职能进行分类。 表3-3-1 各种生物在分类学上的位置举例 位置白菜虎 界植物界动物界 门种子植物门脊索动物门 亚门被子植物亚门脊椎动物亚门 纲双子叶植物纲哺乳动物纲 目十字花目食肉目 科十字花科猫科 属油菜属猫属 种白菜虎 当我们走进一家图书馆,如果它们的图书没有分类编目,我们要找到一本图书与大海捞针没有什么区别。分类的方式也会影响工作的效率。书店的图书一般根据科学门类进行分类摆设,但有一段时间一家书店改为按照出版单位进行分类排列,结果读者很难找到所需图书,这家原本效益挺好的书店很快收到了消极影响。 早期的分类,一般根据事物的属性与特征进行划分,属于定性分类的范畴。随着人们认识的深入和研究对象复杂程度的增加,单纯的定性分类方法就不能满足要求了,于是产生了定量分类技术,即所谓数字分类。本节要讲述的就是根据多个指标进行数字分类的一种多元 应用多元统计分析 课程报告 班级专业:_ 市调0901 _ 学号: 2009***** __ 姓名:__ CYQ _____ 成绩:______________ 2010年10月7日 我国部分城市主要经济指标统计 ——官方与民间数据差异分析 一、引言 经济指标是反映一定社会经济现象数量方面的名称及其数值。本题主要经济指标包括人均GDP 1x (元)、人均工业产值2x (元)、客运总量3x (万人)、货运总量4x (万吨)、5x (亿元)、固定资产投资总额6x (亿元)、在岗职工占总人口的比例7x (%)、在岗职工人均工资额8x (元)、城乡居民年底储蓄余额9x (亿元)。所以我们借助这一指标体系对我国部分城市的主要经济指标进行分析。 二、数据分析 过程 1. 在SPSS 窗口中选择Analyze→Classify→Hierachical Cluster ,调出系统聚类分析主界面,并将变量X 1~X 5移入Variables 框中。在Cluster 栏中选择Cases 单选按钮,即对样品进行聚类(若选择Variables ,则对变量进行聚类)。在Display 栏中选择Statistics 和Plots 复选框,这样在结果输出窗口中可以同时得到聚类结果统计量和统计图。 2. 点击Statistics按钮,设置在结果输出窗口中给出的聚类分析统计 量。这里我们选择系统默认值,点击Continue按钮,返回主界面。 3. 点击Plots按钮,设置结果输出窗口中给出的聚类分析统计图。选 中Dendrogram复选框和Icicle栏中的None单选按钮,即只给出聚类树形图,而不给出冰柱图。单击Continue按钮,返回主界面。 4. 点击Method按钮,设置系统聚类的方法选项。这里我们仍然均沿 用系统默认选项。单击Continue按钮,返回主界面。 5. 点击Save按钮,指定保存在数据文件中的用于表明聚类结果的新 变量。None表示不保存任何新变量;Single solution表示生成一 3-8假定人体尺寸有这样的一般规律,身高(X 1),胸围(X 2)和上半臂围(X 3)的平均尺寸比例是6:4:1,假设()()1,,X n αα=L 为来自总体()123=,,X X X X '的随机样本,并设()~,X N μ∑。试利用表3.4中男婴这一数据来检验其身高、胸围和上半臂围这三个尺寸变量是否符合这一规律(写出假设H 0,并导出检验统计量)。 解:设32,~(,),~(,)Y CX X N Y N C C C μμ'=∑∑。 121231233106,,,,,014C X X X μμμμμμμ??-?? ? == ? ?-?? ? ??其中,分别为 的样本均值。则检验三个变量是否符合规律的假设为 0212:,:H C O H C O μμ=≠。 检验统计量为 2 1(1)1~(1,1) (3,6)(1)(1) n p F T F p n p p n n p ---+= --+==--, 由样本值计算得:=(82,60.2,14.5)X ',及 15840.2 2.5=40.215.86 6.552.5 6.559.5A ?? ? ? ??? , 2-1(1)()()()=47.1434T n n CX CAC CX ''=-, 221(1)12 =18.8574(1)(1)5 n p F T T n p ---+= ?=--, 对给定显著性水平=0.05α,利用软件SAS9.3进行检验时,首先计算p 值: p =P {F ≥18.8574}=0.0091948。 因为p 值=0.0091948<0.05,故否定0H ,即认为这组男婴数据与人类的一般规律不一致。在这种情况下,可能犯第一类错误·且犯第一类错误的概率为0.05。 SAS 程序及结果如下: prociml ; n=6;p=3; x={7860.616.5, 7658.112.5, 9263.214.5, 815914, 8160.815.5, 8459.514 }; m0={00,00}; c={10 -6,01 -4}; ln={[6]1}; x0=(ln*x)`/n; print x0; mm=i(6)-j(6,6,1)/n; a=x`*mm*x; a1=inv(c*a*c`); a2=c*x0; dd=a2`*a1*a2; d2=dd*(n-1); t2=n*d2; f=(n+1-p)*t2/((n-1)*(p-1)); print x0 a d2 t2 f; p0=1-probf(f,p-1,n-p+1); fa=finv(0.95,2,4); print p0; run ; 应用多元统计分析课后答案 第五章 聚类分析 判别分析和聚类分析有何区别 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 对样品和变量进行聚类分析时, 所构造的统计量分别是什么简要说明为什么这样构造 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1 ()() p q q ij ik jk k d q X X ==-∑ q 取不同值,分为 (1)绝对距离(1q =) 1 (1)p ij ik jk k d X X ==-∑ (2)欧氏距离(2q =) 21/2 1 (2)() p ij ik jk k d X X ==-∑ (3)切比雪夫距离(q =∞) 1()max ij ik jk k p d X X ≤≤∞=- (二)马氏距离 (三)兰氏距离 对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性进行衡量。 将变量看作p 维空间的向量,一般用 (一)夹角余弦 (二)相关系数 在进行系统聚类时,不同类间距离计算方法有何区别选择距离公式应遵循哪些原则 答: 设d ij 表示样品X i 与X j 之间距离,用D ij 表示类G i 与G j 之间的距离。 (1). 最短距离法 ,min i k j r kr ij X G X G D d ∈∈= min{,}kp kq D D = (2)最长距离法 ,max i p j q pq ij X G X G D d ∈∈= 21 ()()()ij i j i j d M -'=--X X ΣX X 11()p ik jk ij k ik jk X X d L p X X =-=+∑ cos p ik jk ij X X θ= ∑ ()() p ik i jk j ij X X X X r --= ∑ ij G X G X ij d D j j i i ∈∈= ,min 东北三省经济发展水平 及影响因素因子分析 摘要:东北三省在我国属经济欠发达地区,对于这个资源丰富、地理位置占有绝对优势的地区来讲,这是一个可悲的现象。东北三省有着太多的共同点,但又有着各自的特点,这对于东北三省发挥各自的优势以及进行经济合作都是非常有利的。作为东北土生土长的孩子,很希望能为家乡的经济发展献计献策,贡献一份自己的力量。本文通过对部分经济指标进行因子分析,判断出造成东北三省经济差距的潜在因素及三省各自的优势,并给出东北三省发挥各自优势以及共同合作的建议。 关键词:经济比较,东北三省,因子分析 (一)前言 改革开放以来,我国的经济发展取得了举世瞩目的成就,综合国力日益增强,人民生活水平也显著提高,我国各个省的经济发展水平也都随着国力的增强而提高。但是,各个省的经济发展速度并不是同步的,导致省域经济发展水平不同,而且差距有日趋扩大的趋势。区域经济发展的不平衡性是世界经济、世界各国各地区经济发展中普遍存在的现象。就全世界而言,表现为发达国家与发展中国家之间的差距;就我国,则表现为东西部差距。这种不平衡发展会影响国民经济整体素质的提高以及国民经济的协调发展,关系到整个现代化的进程。在这种情况下,比较各省域的经济发展水平,明确各省域经济在整个国民经济中的位置,分析各省域的优势与劣势,对于各省域制定其最优发展策略以及对国家制定区域经济协调发展政策都有重大的意义。 在各地区的经济蓬勃发展的同时,东北三省经济日益相对落后,已成为制约中国经济跃上新台阶、实现工业化与现代化的瓶颈。在中华人民共和国历史上,东北三省经济曾有过令人刮目相看的成就与辉煌。直到1978 年,东北三省的人均GDP 仅次于京、津、沪3 大直辖市,在全国处于领先地位。但是,从上个世纪90 年代开始,东北三省经济发展明显落后了。由于中国改革开放首先从东南沿海地区起步,各种优惠政策首先在那里实施,外国资本及先进技术与管理方法最先从那里引入,因而东南沿海地区经济快速增长。尤其是自1992 年春天起,在邓小平南巡讲话精神的鼓舞下,中国经济发展战略的重点更是明显地移向东南沿海地区,资本、技术和人才一并“东南飞”。而此时,东北三省几乎被冷落、被担负大量沉重包袱的国企所拖累、被落后且严重失衡的产业结构所困扰,发展步伐日益趋缓。可以肯定地讲,东北三省经济若不振兴,中国的工业化与现代化必然大受影响,甚至难以实现。因此,振兴东北三省经济是当今中国经济发展的大局,是全国人民的根本利益所在。 我是一名土生土长的黑龙江人,虽然对家乡充满了无限的热爱,但也深知家乡的经济水平处在全国相对落后的位置。而黑龙江作为全国位置最东北的一个省,作为东北三省这个整体的重要组成部分,对于整个东北的发展也起到至关重要的作用。因此,我通过对本文的创作,对东北三省的经济进行综合的比较和分析,得到三个省各自的优势和劣势,为其各自的发展和东北三省彼此间的合作提出合理的意见和建议,希望能够为东北三省的经济发展提供一定的帮助。 第三章 多元正态分布 多元正态分布是一元正态分布在多元情形下的直接推广,一元正态分布在统计学理论和应用方面有着十分重要的地位,同样,多元正态分布在多元统计学中也占有相当重要的地位。多元分析中的许多理论都是建立在多元正态分布基础上的,要学好多元统计分析,首先要熟悉多元正态分布及其性质。 第一节 一元统计分析中的有关概念 多元统计分析涉及到的都是随机向量或多个随机向量放在一起组成的随机矩阵,学习多元统计分析,首先要对随机向量和随机矩阵有所把握,为了学习的方便,先对一元统计分析中的有关概念和性质加以复习,并在此基础上推广给出多元统计分析中相应的概念和性质。 一、随机变量及概率分布函数 (一)随机变量 随机变量是随机事件的数量表现,可用X 、Y 等表示。随机变量X 有两个特点:一是取值的随机性,即事先不能够确定X 取哪个数值;二是取值的统计规律性,即完全可以确定X 取某个值或X 在某个区间取值的概率。 (二)随机变量的概率分布函数 随机变量X 的概率分布函数,简称为分布函数,其定义为: )()(x X P x F ≤= 随机变量有离散型随机变量和连续型随机变量,相对应的概率分布就有离散型概率分布和连续型概率分布。 1、离散型随机变量的概率分布 若随机变量X 在有限个或可列个值上取值,则称X 为离散型随机变量。 设X 为离散型随机变量,可能取值为1x ,2x ,…,取这些值的概率分别为1p ,2p , …,记为 k k p x X P ==)(( ,2,1=k ) 称k k p x X P ==)(( ,2,1=k )为离散型随机变量X 的概率分布。 离散型随机变量的概率分布具有两个性质: (1) 0≥k p , ,2,1=k (2)11 =∑∞ =k k p 2、连续型随机变量的概率分布 若随机变量X 的分布函数可以表示为 dt t f x F x ?∞-=)()( 对一切R x ∈都成立,则称X 为连续型随机变量,称 )(x f 为X 的概率分布密度函数,简 1 简述欧氏距离与马氏距离的区别和联系。 答: 设p 维空间中的两点X =和Y =。则欧氏距离为。欧氏距离的局限有①在多元数据分析中,其度量不合理。②会受到实际问题中量纲的影响。 设X,Y 是来自均值向量为,协方差为的总体G 中的p 维样本。则马氏距离为D(X,Y)=。当即单位阵时,D(X,Y)==即欧氏距离。 因此,在一定程度上,欧氏距离是马氏距离的特殊情况,马氏距离是欧氏距离的推广。 2 试述判别分析的实质。 答:判别分析就是希望利用已经测得的变量数据,找出一种判别函数,使得这一函数具有某种最优性质,能把属于不同类别的样本点尽可能地区别开来。设R1,R2,…,Rk 是p 维空间R p 的k 个子集,如果它们互不相交,且它们的和集为,则称为的一个划分。判别分析问题实质上就是在某种意义上,以最优的性质对p 维空间构造一个“划分”,这个“划分”就构成了一个判别规则。 3 简述距离判别法的基本思想和方法。 答:距离判别问题分为①两个总体的距离判别问题和②多个总体的判别问题。其基本思想都是分别计算样本与各个总体的距离(马氏距离),将距离近的判别为一类。 ①两个总体的距离判别问题 设有协方差矩阵∑相等的两个总体G 1和G 2,其均值分别是μ1和μ2,对于一个新的样品X , 要判断它来自哪个总体。计算新样品X 到两个总体的马氏距离D 2(X ,G 1)和D 2 (X ,G 2),则 X ,D 2(X ,G 1)D 2 (X ,G 2) X ,D 2(X ,G 1)>D 2 (X ,G 2, 具体分析, 2212(,)(,) D G D G -X X 111122111111 111222********* ()()()() 2(2)2()-----------''=-----''''''=-+--+'''=-+-X μΣX μX μΣX μX ΣX X ΣμμΣμX ΣX X ΣμμΣμX ΣμμμΣμμΣμ11211212112122()()() 2() 22()2() ---''=-++-' +? ?=--- ?? ?''=--=--X ΣμμμμΣμμμμX ΣμμX μααX μ 记()()W '=-X αX μ则判别规则为 X ,W(X) X ,W(X)<0 ②多个总体的判别问题。 设有k 个总体k G G G ,,,21 ,其均值和协方差矩阵分别是k μμμ,,,21 和k ΣΣΣ,,,21 ,且ΣΣΣΣ====k 21。计算样本到每个总体的马氏距离,到哪个总体的距离最小就属于哪个总体。 具体分析,2 1 (,)()()D G ααα-'=--X X μΣX μ 第五章 聚类分析 5.1 判别分析和聚类分析有何区别? 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 5.2 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 5.3 对样品和变量进行聚类分析时, 所构造的统计量分别是什么?简要说明为什么这样构造? 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1 ()() p q q ij ik jk k d q X X ==-∑ q 取不同值,分为 (1)绝对距离(1q =) 1 (1)p ij ik jk k d X X ==-∑ (2)欧氏距离(2q =) 21/2 1 (2)() p i j i k j k k d X X ==-∑ (3)切比雪夫距离(q =∞) 1()max ij ik jk k p d X X ≤≤∞=- (二)马氏距离 (三)兰氏距离 对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性进行衡量。 2 1()()()ij i j i j d M -'=--X X ΣX X 11()p ik jk ij k ik jk X X d L p X X =-= +∑ 第三章 因子分析 一、填空题 1. 因子分析是把每个原始变量分解为两部分因素,一部分是_公共因子____,另一部分为2.变量共同度是指因子载荷矩阵中___变量所在行元素平方和______。 3.公共因子方差与特殊因子方差之和为__1_____。 二、简答题 1.能否将因子旋转的技术用于主成分分析,使主成分有更鲜明的实际背景。不能,用了就是因子分析,旋转之后不叫主成分(这一句就行),公因子的方差不等于特征值,因此不能旋转。 三、计算题 在一次调查中调查了消费者对一种玩具熊6个方面的评价:COLOUR (颜色)、 SOFTNESS (柔软度)、STYLE (外观)、VALUE (价值)、ROBUST (耐用性)、SAFETY (安全性)。对数据进行因子分析的部分结果如下,因子分析中采用了主成分方法,因子系数矩阵采用方差最大旋转。根据结果回答下列问题: (1)变量之间的相关系数表如下。根据表中的数据分析因子分析方法的适用性。适合,因为其中数据有较大的 (2)因子分析中为什么要进行因子旋转?通过因子旋转,可以使每个变量只在一个公共因子上有较大的载荷,因此因子分析模型是适用的 (3)旋转后的因子载荷矩阵如下,分析各个因子的含义。用F1、F2表示两个因子,写出用公共因子表示的COLOUR 变量的表达式。 前三个描述外观,即外观因子 后三个(价值,耐用型 实用性)使用因子 Colour=0.950F1+后边数的F2 (4)什么是因子得分?因子得分有何作用?在因子分析中,得出公共因子后,可以根据原始变量计算出各个样本(个体)在每个因子上的得分,称为因子得分,因子得分可以有多种求解方法,计算出因子得分后,可以把各个因子作为新的变量用于其他分析,也可以来进行综合评价等。 应用多元统计分析 1 课程介绍 多元统计分析(简称多元分析)是统计学的一个重要分支.它是应用数理统计学来研究多变量(多指标)问题的理论和方法; 它是一元统计学的推广和发展. 多元统计分析是一门具有很强应用性的课程;它在自然科学和社会科学等各个领域中得到广泛的应用;它包括了很多非常有用的数据处理方法. 第一章绪论 第二章多元正态分布及参数的估计第三章多元正态总体参数的假设检验 第四章回归分析--第五章判别分析第六章聚类分析 第七章主成分分析 第八章因子分析 第九章对应分析方法 第十章典型相关分析第十一章偏最小二乘回归分析 本课程的内容多变量分析(数据结构简化)分类方法两组变量的相关分析基础理论两组变量的相依分析 使用的教材 普通高等教育”十一五”国家级教材 北京大学数学教学系列丛书 本科生 数学基础课教材 应用多元统计分析(北京大学出版社,高惠璇,2006.10) 参考书(一) 1. 实用多元统计分析(方开泰,1989,见参考文献[1]) 2. 多元统计分析引论(张尧庭,方开泰, 2003,见[2]) 3. 实用多元统计分析(王学仁,1990 ,见[6]) 4. 应用多元分析(王学民,1999 ,见[8]) 5. 实用统计方法与SAS系统(高惠璇,2001, 见[3]) 6. 多元统计分析(于秀林,1999 ,见[9]) 7. 多元统计方法(周光亚,1988 ,见[28]) 8. 多元分析(英. M . 肯德尔,1983 ,见[15]) 9. SAS系统使用手册等资料(1994-1998 ,见[17]-[21]) 参考书(二) (1) An Introduction to Multivariate Statistical Analysis(Anderson 1984 ,见[22]) (2) Applied Multivariate Statistical Analysis( Richard A.Johnson and Dean W.Wichern 4th ed 1998) 中译本:实用多元统计分析(陆璇译2001 ,见[5])(3) Linear Statistical Inference and Its Applications (C.R.Rao 1973) 中译本:线性统计推断及其应用(C.R.劳1987 ,见[25]) 第七章因子分析 7.1 试述因子分析与主成分分析的联系与区别。 答:因子分析与主成分分析的联系是:①两种分析方法都是一种降维、 简化数据的技术。② 两种分析的求解过程是类似的, 都是从一 个协方差阵出发,利用特征值、特征向量求解。因 子分析可以说是主成分分析的姐妹篇, 析也可以说成是主成分分析的逆问题。 分析可以说是将原指标给予分解、演绎。 因子分析与主成分分析的主要区别是: 变换到变异程度大的方向上为止, 在变量去提炼潜在因子的过程。 子模型。 7.2 因子分析主要可应用于哪些方面? 答:因子分析是一种通过显在变量测评潜在变量, 通过具体指标测评抽象因子的统计分析方 法。目前因子分析在心理学、社会学、经济学等学科中都有重要的应用。具体来说,①因子 分析可以用于分类。如用考试分数将学生的学习状况予以分类; 用空气中各种成分的比例对 空气的优劣予以分类等等②因子分析可以用于探索潜在因素。 即是探索未能观察的或不能观 测的的潜在因素是什么,起的作用如何等。对我们进一步研究与探讨指示方向。 在社会调查 分析中十分常用。③因子分析的另一个作用是用于时空分解。 如研究几个不同地点的不同日 期的气象状况,就用因子分析将时间因素引起的变化和空间因素引起的变化分离开来从而判 断各自的影响和变化规律。 简述因子模型X = 中载荷矩阵A 的统计意义。 对于因子模型 Xi =aiiFi +ai2F2+ill + aijFj +H)+aimFm +:^ i =12111, P X i 与F j 的协方差为: m Cov(X i , F j ) =Cov(2: k=1 m = Cov(2 a ik F k ,F j )+Cov(知 F j ) 将主成分分析向前推进一步便导致因子分析。 因子分 如杲说主成分分析是将原指标综合、 归纳,那么因子 主成分分析本质上是一种线性变换,将原始坐标 突出数据变异的方向, 归纳重要信息。而因子分析是从显 此外,主成分分析不需要构造分析模型而因子分析要构造因 7.3 答: 「a ii a i2 a 21 a 22 III ill [a pi a p2 a 2m III a p m J = (A i ,A 2,H|,A m ) 因子载荷阵为A = II I il l 主成分分析 6.1 试述主成分分析的基本思想。 答:我们处理的问题多是多指标变量问题,由于多个变量之间往往存在着一定程度的相关性,人们希望能通过线性组合的方式从这些指标中尽可能快的提取信息。当第一个组合不能提取止。这就是主成分分析的基本思想。 6.2 主成分分析的作用体现在何处? 答:一般说来,在主成分分析适用的场合,用较少的主成分就可以得到较多的信息量。以各个主成分为分量,就得到一个更低维的随机向量;主成分分析的作用就是在降低数据“维数” 6.3 简述主成分分析中累积贡献率的具体含义。 答:主成分分析把p 个原始变量12,, ,p X X X 的总方差()tr Σ分解成了p 个相互独立的变量p 个主成分的,忽略 一些带有较小方差的主成分将不会给总方差带来太大的影响。这里我们()m p <个主成分,则称11 p m m k k k k ψλλ ===∑∑ 为主成分1,,m Y Y 的累计贡献率,累计贡献率表明1,,m Y Y 综合12,, ,p X X X 的能力。通常取m ,使得累计贡 献率达到一个较高的百分数(如85%以上)。 答:这个说法是正确的。 即原变量方差之和等于新的变量的方差之和 6.5 试述根据协差阵进行主成分分析和根据相关阵进行主成分分析的区别。 答:从相关阵求得的主成分与协差阵求得的主成分一般情况是不相同的。从协方差矩阵出发的,其结果受变量单位的影响。主成分倾向于多归纳方差大的变量的信息,对于方差小的变量就可能体现得不够,也存在“大数吃小数”的问题。实际表明,这种差异有时很大。我 6.6 已知X =( )’的协差阵为 试进行主成分分析。 解:=0 计算得 当 时 , 同理,计算得 时, 易知 相互正交 单位化向量得, 应用多元统计分析期末试卷 重庆文理学院试卷 2011,2012学年第一学期期末考试 承担单位: 数学与统计学院 课程名称: 《应用多元统计分析》 试卷类别: 考试形式:开卷考试时间:14教学周至16教学周适用层次: 本科适用专业: 数学与应用数学(金融方向)2009级1,2班 题号一二三四五六七八九十总分 得分 阅卷须知:阅卷用红色墨水笔书写,小题得分写在相应小题题号前,用正分表示;大题得分登录在对应的分数框内;考试课程应集体阅卷,流水作业. 考试说明及要求: 《应用多元统计分析》课程采用课程论文的形式对学生进行考试。要求学生利用所学的多元统计分析的基本方法和参考其它文献资料撰写一篇3000字以上的课程论文。具体要求如下: 一、学生可以选择以下七个方向中的一个或者多种进行写作,学生可以结合实际问题,进行数据的收集(包括自己制作问卷调查表,网上下载数据等),利用以下的七个方向进行写作。学生亦可自己拟定选题,选题要与所学课程的理论与方法联系紧密,能利用所学的知识研究某一实际问题(10分)。 (1)均值向量的检验; (2)聚类分析; (3)判别分析; (4)主成分分析; (5)因子分析; 密封线 (6)对应分析和频数分析; (7)典型相关分析。 二、只写中文摘要。摘要能简明扼要地阐明研究的内容、方法和主要结论等(5分)。三、论文结构要合理,层次分明,逻辑性强,重点突出,前后连贯,能形成有机整体(5分)。 四、论文的观点要与论证统一,论据充分严密,数据处理分析方法恰当,模型能通过各种理论检验(25分)。系(院): 专业: 年级及班级: 姓名: 学号: . 错误~未定义“自动图文集”词条。 《应用多元统计分析》考试形式:开卷五、论文的观点和材料要统一,数据要真实可靠(表明出处),数据与所研究的问题要一致,数据要能满足建模的要求,模型的结果能够支撑所论述的观点(25分)。六、论文能充分体现对所学课程知识的综合运用能力。理论方法上不能有知识性错误(25分)。 七、论文的文本格式要规范,字号(小四字体)、行距前后一致,数学公式,图表要排版整齐,图表要标明图(表)题,重要数学式子、图表应统一编号,参考文献录入要符合规范标准(5分)。 论文题目: [摘要]: [关键词]: 参考文献: 错误~未定义“自动图文集”词条。 第三章 3.1 试述多元统计分析中的各种均值向量和协差阵检验的基本思想和步骤。 其基本思想和步骤均可归纳为: 答: 第一,提出待检验的假设错误!未找到引用源。和H1; 第二,给出检验的统计量及其服从的分布; 第三,给定检验水平,查统计量的分布表,确定相应的临值,从而得到否定域; 第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。 均值向量的检验: 统计量 拒绝域 在单一变量中 当2 σ已知 X z = /2||z z α> 当2 σ未知 X t = /2||(1)t t n α>- (2 21 1()1n i i S X X n ==--∑作为2σ的估计量) 一个正态总体00H =μμ: 协差阵Σ已知 212000()()~()T n p χ-'=--X μΣX μ 22 0T αχ> 协差阵Σ未知 2(1)1~(,)(1)n p T F p n p n p --+-- 2 (1)n p T F n p α->- (2 00(1))]T n -'=---X μS X μ) 两个正态总体012H =μμ: 有共同已知协差阵 2 120()()~()n m T p n m χ-?'= --+X Y ΣX Y 22 0T αχ> 有共同未知协差阵 2 (2)1~(,1)(2)n m p F T F p n m p n m p +--+=+--+- F F α> (其中 21 (2)))T n m -'??=+---???? X Y S X Y ) 协差阵不等m n = -1()~(,)n p n F F p n p p -'= -Z S Z F F α> 协差阵不等m n ≠ 1()~(,)n p n F F p n p p -'=--Z S Z F F α> 多个正态总体k H μμμ=== 210:多元统计分析第三章假设检验与方差分析
应用多元统计分析试题及答案
多元统计分析知识点多元统计分析课件
多元统计分析-第三章 多元正态分布
最新多元统计分析第三章 假设检验与方差分析
第三章 多元统计分析(3)
应用多元统计分析应用报告(DOC)
应用多元统计分析SAS作业第三章
应用多元统计分析课后答案
应用多元统计分析论文
多元统计分析-第三章 多元正态分布
应用多元统计分析考试要点
应用多元统计分析习题解答_聚类分析
多元统计分析第三章
多元统计分析
应用多元统计分析习题解答因子分析
应用多元统计分析习题解答-主成分分析
应用多元统计分析期末试卷
应用多元统计分析课后答案_朱建平版