2013年山东科技大学数据结构与操作系统--真题及参考答案

《数据结构》部分
一、简答题(10分,每题5分)
1、数据元素之间的关系在计算机中的存储有几种表示方法?各有什么特点?(P6)
解:数据元素之间的关系在计算机中有四种不同的表示方法:
(1)顺序存储方法。数据元素顺序存放,每个结点只含有一个元素。存储位置反映数据元素间的逻辑关系。存储密度大,但有些操作(如插入、删除)效率较差。
(2)链式存储方法。每个结点除包含数据元素信息外还包含一组指针。指针反映数据元素间的逻辑关系。这种操作不要求存储空间连续,便于进行插入和删除等操作,但存储空间利用率较低。另外,由于逻辑上相邻的数据元素在存储空间上不一定相邻,所以不能对其进行随机存取。
(3)索引存储方法。除数据元素存储在一地址连续的内存空间外,尚需建立一个索引表。索引表中的索引指示结点的存储位置,兼有动态和静态特性。
(4)哈希(或散列)存储方法。通过哈希函数和解决冲突的方法,将关键字散列在连续的有限的地址空间内,并将哈希函数的值作为该数据元素的存储地址。其特点是存取速度快,只能按关键字随机存取,不能顺序存储,也不能折半存取。
2、对于堆排序法,快速排序法和归并排序法,若仅从节省存储空间考虑,则应该首先选取其中哪种方法?其次选取哪种方法?若仅考虑排序结果的稳定性,则应该选取其中哪种方法?若仅从平均情况下排序最快这一点考虑,则应该选取其中哪些方法?(P289)答:若只从存储空间考虑,则应首先选取堆排序方法,其次选取快速排序方法,最后选取归并排序方法;
若只从排序结果的稳定性考虑,则应选取归并排序方法;
若只从平均情况下最快考虑,则应选取快速排序方法;
若只从最坏情况下最快并且要节省内存考虑,则应选取堆排序方法。
二、应用题(55分)
1、证明:同一棵二叉树的所有叶子结点,在前序序列、中序序列以及后序序列中都按相同的相对位置出现(即先后顺序相同)。(8分)(例如先序abc,后序bca,中序bac。)(P128) 答:【答案】先序遍历是“根左右”,中序遍历是“左根右”,后序遍历是“左右根”。三种遍历中只是访问“根”结点的时机不同,对左右子树均是按左右顺序来遍历的,因此所有叶子都按相同的相对位置出现。
2、设有正文AADBAACACCDACACAAD,字符集为A,B,C,D,设计一套二进制编码,使得上述正文的编码最短。(10分)(P144;P148)
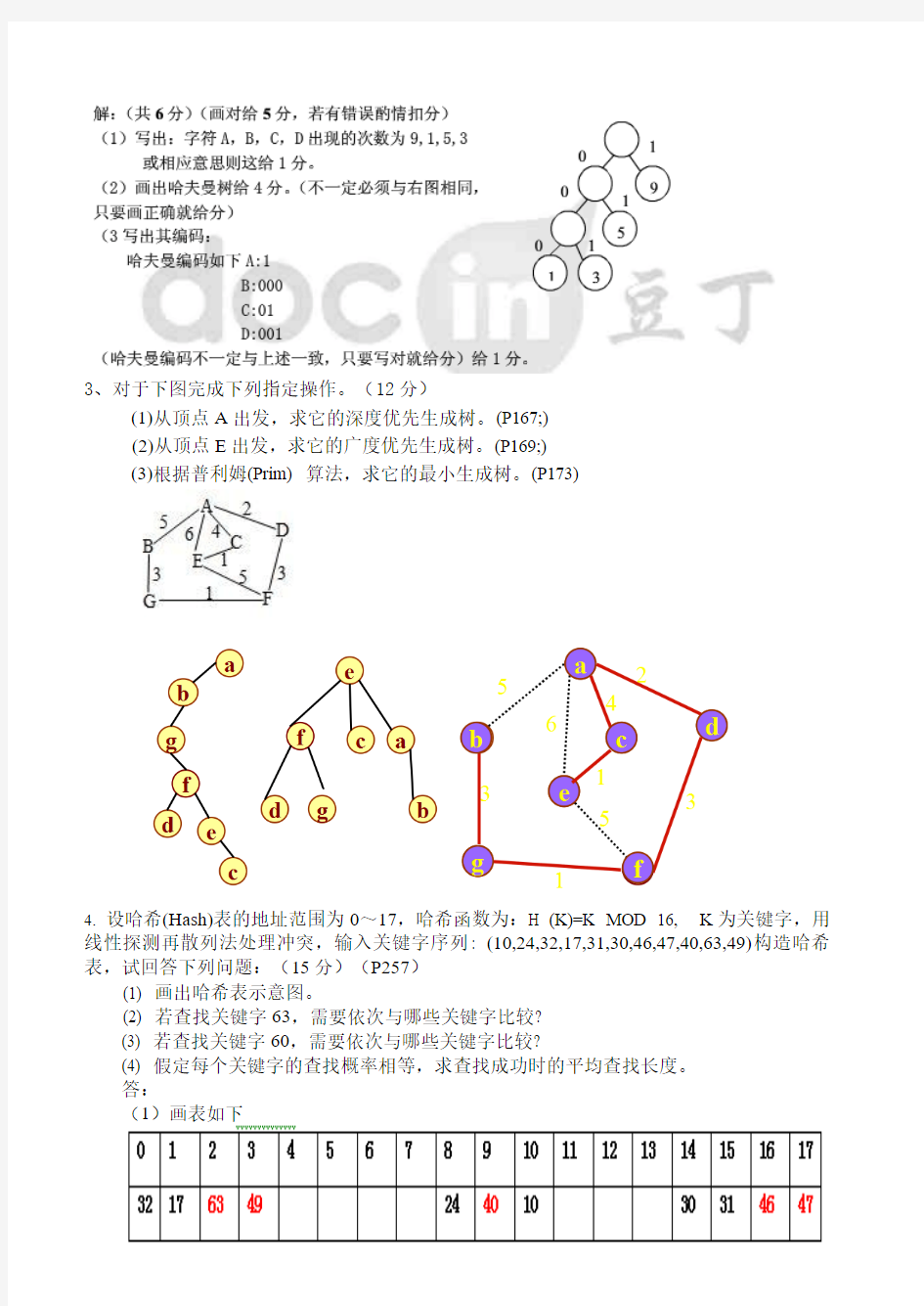
3、对于下图完成下列指定操作。(12分)
(1)从顶点A出发,求它的深度优先生成树。(P167;)
(2)从顶点E出发,求它的广度优先生成树。(P169;)
(3)根据普利姆(Prim) 算法,求它的最小生成树。(P173)
4.设哈希(Hash)表的地址范围为0~17,哈希函数为:H (K)=K MOD 16, K为关键字,用线性探测再散列法处理冲突,输入关键字序列: (10,24,32,17,31,30,46,47,40,63,49)构造哈希表,试回答下列问题:(15分)(P257)
(1) 画出哈希表示意图。
(2) 若查找关键字63,需要依次与哪些关键字比较?
(3) 若查找关键字60,需要依次与哪些关键字比较?
(4) 假定每个关键字的查找概率相等,求查找成功时的平均查找长度。
答:
(1)画表如下
(2)查找63,首先要与H(63)=63%16=15号单元内容比较,即63 vs 31 ,no;
然后顺移,与46,47,32,17,63相比,一共比较了6次!
(3)查找60,首先要与H(60)=60%16=12号单元内容比较,但因为12号单元为空(应当有空标记),所以应当只比较这一次即可。
(4)对于黑色数据元素,各比较1次;共6次;
对红色元素则各不相同,要统计移位的位数。“63”需要6次,“49”需要3次,“40”需要2次,“46”需要3次,“47”需要3次,
ASL=1/11(6+2+3×3)=17/11≈1.55
5.奇偶交换排序如下所述:对于初始序列A[1],A[2],…,A[n],第一趟对所有奇数i(1<=i (1) 分析这种排序方法的结束条件。 (2) 写出用这种排序方法对35,70,33,65,24,21,33进行排序时,每一趟的结果。 【解答】 (1) 排序结束条件为,连续的第奇数趟排序和第偶数趟排序都没有交换。 (2) 第一趟奇数:35,70,33,65,21,24,33 第二趟偶数:35,33,70,21,65,24,33 第三趟奇数:33,35,21,70,24,65,33 第四趟偶数:33,21,35,24,70,33,65 第五趟奇数:21,33,24,35,33,70,65 第六趟偶数:21,24,33,33,35,65,70 第七趟奇数:21,24,33,33,35,65,70(无交换) 第八趟偶数:21,24,33,33,35,65,70(无交换) 结束 三、算法设计题(25分) 答题要求: ①用自然语言说明所采用算法的思想; ②给出每个算法所需的数据结构定义,并做必要说明; ③用C语言写出对应的算法程序,并做必要的注释。 1、编程实现单链表的就地逆置(额外存储空间只能使用指针)。 (10分) 答: void reverse(LinkList &L)//单链表的就地逆置 { p=L->next; if(p==NULL || p->next==NULL) return OK;//空表和表中只有一个结点时,不用逆置。 while(p->next!=NULL) { q= p->next; p->next=q->next; //删除结点q,但未释放 q->next=L->next; L->next=q; //将q插入头结点之后 } return OK; }//reverse 2、二叉树采用二叉链表存储结构,设计算法统计二叉树的深度(二叉树的最大层数)和宽度(二叉树中所有层中结点的最大个数)。(15分) 标准答案: ①求树的高度 思想:对非空二叉树,其深度等于左子树的最大深度加1。 Int Depth(BinTree *T) { int dep1,dep2; if(T==Null) return(0); else { dep1=Depth(T->lchild); dep2=Depth(T->rchild); if(dep1>dep2) return(dep1+1); else return(dep2+1); } } ②求树的宽度 思想:按层遍历二叉树,采用一个队列q,让根结点入队列,最后出队列,若有左右子树,则左右子树根结点入队列,如此反复,直到队列为空。 int Width(BinTree *T) { int front=-1,rear=-1;/*队列初始化*/ int flag=0,count=0,p; /* p用于指向树中层的最右边的结点,标志flag记录层中结点数的最大值。*/ if(T!=Null) { rear++; q[rear]=T; flag=1; p=rear; } while(front { front++; T=q[front]; if(T->lchild!=Null) { rear++; q[rear]=T->lchild; count++; } if(T->rchild!=Null) { rear++; q[rear]=T->rchild; count++; } if(front==p) /* 当前层已遍历完毕*/ { if(flag flag=count; count=0; p=rear; /* p指向下一层最右边的结点*/ } } /* endwhile*/ return (flag); } 《操作系统部分》 一:简单题(共27分) 1:操作系统的四个基本特征是什么?并请分析它们之间的关系。(本小题3分)(P15) 答:操作系统的特征有并发,共享,虚拟和异步性.它们的关系如下: (1)并发和共享是操作系统最基本的特征.为了提高计算机资源的利用率,操作系统必然要采用多道程序设计技术,使多个程序共享系统的资源,并发的执行. (2)并发和共享互为存在的条件.一方面,资源的共享以程序(进程)的并发执行 为条件,若系统不允许程序并发执行,自然不存在资源的共享问题;另一方面,若系统不能对资源共享实施有效管理,协调好各个进程对共享资源的访问,也必将影响到程序的并发执行,甚至根本无法并发执行. (3)虚拟以并发和共享为前提条件.为了使并发进程能更方便,更有效地共享资源,操作系统经常采用多种虚拟技术来在逻辑上增加CPU和设备的数量以及存储器的容量,从而解决众多并发进程对有限的系统资源的竞争问题. (4)异步性是并发和共享的必然结果.操作系统允许多个并发进程共享资源,相互合作,使得每个进程的运行过程受到其他进程的制约,不再"一气呵成",这必然导致异步性特征的产生. 2:请简述进程和程序的差异、进程和线程的差异。(本小题6分)(P37;P72) (定义: 一程序只是一组指令的有序集合, 二进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,是系统进行资源分配和调度的一个独立单位; 三线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),一个线程可以创建和撤销另一个线程;) 进程和程序区别和联系 (1)程序只是一组指令的有序集合,它本身没有任何运行的含义,它只是一个静态的实体。而进程则不同,它是程序在某个数据集上的执行。进程是一个动态的实体,它有自己的生命周期。反映了一个程序在一定的数据集上运行的全部动态过程。 (2)进程和程序并不是一一对应的,一个程序执行在不同的数据集上就成为不同的进程,可以用进程控制块来唯一地标识每个进程。而这一点正是程序无法做到的,由于程序没有和数据产生直接的联系,既使是执行不同的数据的程序,他们的指令的集合依然是一样的,所以无法唯一地标识出这些运行于不同数据集上的程序。一般来说,一个进程肯定有一个与之对应的程序,而且只有一个。而一个程序有可能没有与之对应的进程(因为它没有执行),也有可能有多个进程与之对应(运行在几个不同的数据集上)。 (3)进程还具有并发性和交往性,这也与程序的封闭性不同。 进程与线程区别与联系 (1)划分尺度:线程更小,所以多线程程序并发性更高; (2)资源分配:进程是资源分配的基本单位,同一进程内多个线程共享其资源; (3)地址空间:进程拥有独立的地址空间,同一进程内多个线程共享其资源; (4)处理器调度:线程是处理器调度的基本单位; (5)执行:每个线程都有一个程序运行的入口,顺序执行序列和程序的出口,但线程不能单独执行,必须组成进程,一个进程至少有一个主线程。简而言之,一个程序至少有一个进程,一个进程至少有一个线程。 3:处理死锁的基本方法有哪几种?并请分析它们的优缺点。(本小题4分)(P105) (1)预防死锁---事先预防法破坏一个或几个产生死锁的必要条件。 实现简单,常用资源利用率和系统吞吐量低; (2)避免死锁---事先预防法利用算法动态分配资源防止系统进入不安全状态。 实现较难,资源利用率和系统吞吐量较高; (3)检测死锁---允许运行中发生死锁及时检测到死锁及其有关进程和资源; 实现很难,资源利用率和系统吞吐量高。 (4)解除死锁---与检测死锁配套使用,挂起或撤销相关进程,回收资源并重新分配检测和解除。 实现很难,资源利用率和系统吞吐量高。 4:“根据链接时间的不同,可把链接分为三种”,请问是哪三种?并请分析DLL 方式的优点。(本小题4分)(程序的链接P120;P121) 静态链接,装入时动态链接,运行时动态链接。 (DLL是Dynamic Link Library的缩写,意为动态链接库。在Windows中,许多应用程序并不是一个完整的可执行文件,它们被分割成一些相对独立的动态链接库,即DLL文件,放置于系统中。当我们执行某一个程序时,相应的DLL文件就会被调用。一个应用程序可有多个DLL 文件,一个DLL文件也可能被几个应用程序所共用,这样的DLL文件被称为共享DLL文件。)DLL方式的优点: (1)便于修改和更新。 (2)便于实现对目标模块的共享。 5:什么是SPOOLING技术?一个SPOOLING系统主要由哪几部分组成?(本小题4分)(P190) SPOOLing是Simultaneous Peripheral Operation On-Line (即外部设备联机并行操作)的缩写,它是关于慢速字符设备如何与计算机主机交换信息的一种技术,通常称为“假脱机技术”。 1、输入井输出井 2、输入缓冲区和输出缓冲区 3、输入SPi和输出SPo (参考资料:SPOOLing技术如何使一台打印机虚拟成多台打印机? 答:将一台独享打印机改造为可供多个用户共享的打印机,是应用SPOOLing 技术的典型实例。具体做法是:系统对于用户的打印输出,并不真正把打印机分配给该用户进程,而是先在输出井中申请一个空闲盘块区,并将要打印的数据送入其中;然后为用户申请并填写请求打印表,将该表挂到请求打印队列上。若打印机空闲,输出程序从请求打印队首取表,将要打印的数据从输出井传送到内存缓冲区,再进行打印,直到打印队列为空。) 6:连续分配、链接分配和索引分配是外存管理中常用的分配方式。请分析三者的优点和缺点。(本小题6分) 连续分配(P214) 优点:(1)顺序访问容易(2)顺序访问速度快 缺点:(1)要求有连续的存储空间(2)必须事先知道文件的长度 链接分配(P215) 优点:(1)不需要分配连续的空间(2)消除了外部碎片(3)可动态分配盘块,无需事先知道文件的大小。(4)文件增删改方便 缺点:(1)对随机访问低效(2)可靠性较差(3)存在内部碎片 索引分配(P221) 优点:(1)支持直接访问(2)不会产生外部碎片 缺点:(1)可能花费较多的外存空间 二:算法和计算题(共33分) 1:设A、B两进程共用一个缓冲区Q进行通信,A向Q写入信息,B则从Q读出信息。为了保证进程A、B之间的通信顺利进行,某同学设计了一个如下图所示的算法,该算法使用一个信号量S进行进程A、B之间的同步。请问,该算法是否正确?若有错,请指出原因并予以改正。(本题10分)(生产者-消费者问题P58) 解:这个算法不对。 因为A、B两进程共用一个缓冲区Q,如果A先运行,且信息数量足够多,那么缓冲区Q中的信息就会发生后面的冲掉前面的,造成信息丢失,B就不能从Q中读出完整的信息。 进行改正:A、B两进程要同步使用缓冲区Q。为此,设立两个信号量:empty表示缓冲区Q为空,初值为1; full表示缓冲区Q为满,初值为0。 算法框图如图所示。 2:某虚拟存储器的用户空间共有32个页面,每页1KB,而主存为16KB。假定某时刻系统为用户的第0、1、2、3页分配的物理块号为5、10、4、7,而该用户作业的长度为6页。请问:(本题总计10分)(提示:请注意逻辑地址是由哪两部分组成的)(虚拟存储器P141) 1)十六进制的逻辑地址(也称为虚拟地址)0A5C对应的物理地址是什么? (2分) (P130) 2)如果要访问的十六进制的逻辑地址是103C ,那么会出现什么现象?操作系统是如何处理这种现象的,并请说明处理过程。(6分)(P145) 缺页中断就是要访问的页不在主存,需要操作系统将其调入主存后再进行访问。在这个时候,被内存映射的文件实际上成了一个分页交换文件。 缺页中断作为中断,它们同样需要经历诸如保护cpu 环境、分析中断原因、转入缺页中断处理程序进行处理、恢复cpu 环境等几个步骤。 3)如果要访问的十六进制的逻辑地址是1A5C ,那么会出现什么现象? (2分) 3:假设磁盘有200个磁道,磁盘请求队列中都是随机请求,它们按照到达的次序分别处于55、58、39、18、90、160、150、38、184号磁道上,当前磁头在100号磁道上,并向磁道号增加的方向移动。请给出按着FCFS 、SSTF 算法进行磁盘调度时的次序,并计算平均寻道长度。(本题7分)(P194) 分析:FCFS 算法按进程请求访问磁盘的先后次序进行服务;SSTF 算法优先为距离当前磁头所在磁道最近的请求进行服务;SCAN 算法则优先为在磁头当前移动方向上、与当前磁头所在磁道最近的请求进行服务;CSAN 算法类似于SCAN 算法,但它规定磁头只能作单向移动。 答:磁盘调度的次序以及它们的平均寻、道长度如表6.1所示。 表6.1磁盘调度的次序以及平均寻道时间 4:随着CPU速度的不断提升,IO设备的速度逐渐成为系统性能的瓶颈之一。请分析、说明现代操作系统是如何缓解这一问题的,并列举多个解决方案。(本题6分)(SPOOLing技术?P189;多通道?;这个真不会,看书总结) 山东大学数据库实验答案2—8 CREATE TABLE test2_01 AS SELECT SID, NAME FROM pub.STUDENT WHERE sid NOT IN ( SELECT sid FROM pub.STUDENT_COURSE ) CREATE TABLE test2_02 AS SELECT SID, NAME FROM PUB.STUDENT WHERE SID IN ( SELECT DISTINCT SID FROM PUB.STUDENT_COURSE WHERE CID IN ( SELECT CID FROM PUB.STUDENT_COURSE WHERE SID='200900130417' ) ) CREATE TABLE test2_03 AS select SID,NAME from PUB.STUDENT where SID in ( select distinct SID from PUB.STUDENT_COURSE where CID in (select CID from PUB.COURSE where FCID='300002') ) CREATE TABLE test2_04 AS select SID,NAME from PUB.STUDENT where SID in ( select distinct SID from PUB.STUDENT_COURSE where CID in (select CID from PUB.COURSE where NAME='操作系统') intersect select distinct SID from PUB.STUDENT_COURSE where CID in (select CID from PUB.COURSE where NAME='数据结构') ) create table test2_05 as with valid_stu(sid,name) as ( select SID,NAME from PUB.STUDENT where AGE=20 and SID in (select SID from PUB.STUDENT_COURSE) ) select sid,name as name,ROUND(avg(score)) as avg_score,sum(score) as sum_score from PUB.STUDENT_COURSE natural join valid_stu where SID in (select SID from valid_stu) group by SID,NAME create table test2_06 as .. ;.. 第一章 概论 1.数据结构描述的是按照一定逻辑关系组织起来的待处理数据元素的表示及相关操作,涉及数据的逻辑结构、存储结构和运算 2.数据的逻辑结构是从具体问题抽象出来的数学模型,反映了事物的组成结构及事物之间的逻辑关系 可以用一组数据(结点集合K )以及这些数据之间的 一组二元关系(关系集合R )来表示:(K, R) 结点集K 是由有限个结点组成的集合,每一个结点代表一个数据或一组有明确结构的数据 关系集R 是定义在集合K 上的一组关系,其中每个关系r (r ∈R )都是K ×K 上的二元关系 3.数据类型 a.基本数据类型 整数类型(integer)、实数类型(real)、布尔类型(boolean)、字符类型(char )、指针类型(pointer ) b.复合数据类型 复合类型是由基本数据类型组合而成的数据类型;复合数据类型本身,又可参与定义结构更为复杂的结点类型 4.数据结构的分类:线性结构(一对一)、树型结构(一对多)、图结构(多对多) 5.四种基本存储映射方法:顺序、链接、索引、散列 6.算法的特性:通用性、有效性、确定性、有穷性 7.算法分析:目的是从解决同一个问题的不同算法中选择比较适合的一种,或者对原始算法进行改造、加工、使其优化 8.渐进算法分析 a .大Ο分析法:上限,表明最坏情况 b .Ω分析法:下限,表明最好情况 c .Θ分析法:当上限和下限相同时,表明平均情况 第二章 线性表 1.线性结构的基本特征 a.集合中必存在唯一的一个“第一元素” b.集合中必存在唯一的一个“最后元素” c.除最后元素之外,均有唯一的后继 d.除第一元素之外,均有唯一的前驱 2.线性结构的基本特点:均匀性、有序性 3.顺序表 a.主要特性:元素的类型相同;元素顺序地存储在连续存储空间中,每一个元素唯一的索引值;使用常数作为向量长度 b. 线性表中任意元素的存储位置:Loc(ki) = Loc(k0) + i * L (设每个元素需占用L 个存储单元) c. 线性表的优缺点: 优点:逻辑结构与存储结构一致;属于随机存取方式,即查找每个元素所花时间基本一样 缺点:空间难以扩充 d.检索:ASL=【Ο(1)】 e .插入:插入前检查是否满了,插入时插入处后的表需要复制【Ο(n )】 f.删除:删除前检查是否是空的,删除时直接覆盖就行了【Ο(n )】 4.链表 4.1单链表 a.特点:逻辑顺序与物理顺序有可能不一致;属于顺序存取的存储结构,即存取每个数据元素所花费的时间不相等 b.带头结点的怎么判定空表:head 和tail 指向单链表的头结点 c.链表的插入(q->next=p->next; p->next=q;)【Ο(n )】 d.链表的删除(q=p->next; p->next = q->next; delete q;)【Ο(n )】 e.不足:next 仅指向后继,不能有效找到前驱 4.2双链表 a.增加前驱指针,弥补单链表的不足 b.带头结点的怎么判定空表:head 和tail 指向单链表的头结点 c.插入:(q->next = p->next; q->prev = p; p->next = q; q->next->prev = q;) d.删除:(p->prev->next = p->next; p->next->prev = p->prev; p->prev = p->next = NULL; delete p;) 4.3顺序表和链表的比较 4.3.1主要优点 a.顺序表的主要优点 没用使用指针,不用花费附加开销;线性表元素的读访问非常简洁便利 b.链表的主要优点 无需事先了解线性表的长度;允许线性表的长度有很大变化;能够适应经常插入删除内部元素的情况 4.3.2应用场合的选择 a.不宜使用顺序表的场合 经常插入删除时,不宜使用顺序表;线性表的最大长度也是一个重要因素 b.不宜使用链表的场合 当不经常插入删除时,不应选择链表;当指针的存储开销与整个结点内容所占空间相 比其比例较大时,应该慎重选择 第三章 栈与队列 1.栈 a.栈是一种限定仅在一端进行插入和删除操作的线性表;其特点后进先出;插入:入栈(压栈);删除:出栈(退栈);插入、删除一端被称为栈顶(浮动),另一端称为栈底(固定);实现分为顺序栈和链式栈两种 b.应用: 1)数制转换 while (N) { N%8入栈; N=N/8;} while (栈非空){ 出栈; 输出;} 2)括号匹配检验 不匹配情况:各类括号数量不同;嵌套关系不正确 算法: 逐一处理表达式中的每个字符ch : ch=非括号:不做任何处理 ch=左括号:入栈 ch=右括号:if (栈空) return false else { 出栈,检查匹配情况, if (不匹配) return false } 如果结束后,栈非空,返回false 3)表达式求值 3.1中缀表达式: 计算规则:先括号内,再括号外;同层按照优先级,即先乘*、除/,后加+、减-;相同优先级依据结合律,左结合律即为先左后右 3.2后缀表达式: <表达式> ::= <项><项> + | <项> <项>-|<项> <项> ::= <因子><因子> * |<因子><因子>/|<因子> <因子> ::= <常数> ? <常数> ::= <数字>|<数字><常数> <数字> ∷= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 3.3中缀表达式转换为后缀表达式 InfixExp 为中缀表达式,PostfixExp 为后缀表达式 初始化操作数栈OP ,运算符栈OPND ;OPND.push('#'); 读取InfixExp 表达式的一项 操作数:直接输出到PostfixExp 中; 操作符: 当‘(’:入OPND; 当‘)’:OPND 此时若空,则出错;OPND 若非空,栈中元 素依次弹出,输入PostfixExpz 中,直到遇到‘(’为止;若 为‘(’,弹出即可 当‘四则运算符’:循环(当栈非空且栈顶不是‘(’&& 当前运算符优先级>栈顶运算符优先级),反复弹出栈顶运 算符并输入到PostfixExp 中,再将当前运算符压入栈 3.4后缀表达式求值 初始化操作数栈OP ; while (表达式没有处理完) { item = 读取表达式一项; 操作数:入栈OP ; 运算符:退出两个操作数, 计算,并将结果入栈} c.递归使用的场合:定义是递归的;数据结构是递归的;解决问题的方法是递归的 2.队列 a.若线性表的插入操作在一端进行,删除操作在另一端进行,则称此线性表为队列 b.循环队列判断队满对空: 队空:front==rear ;队满:(rear+1)%n==front 第五章 二叉树 1.概念 a. 一个结点的子树的个数称为度数 b.二叉树的高度定义为二叉树中层数最大的叶结点的层数加1 c.二叉树的深度定义为二叉树中层数最大的叶结点的层数 d.如果一棵二叉树的任何结点,或者是树叶,或者恰有两棵非空子树,则此二叉树称作满二叉树 e.如果一颗二叉树最多只有最下面的两层结点度数可以小于2;最下面一层的结点都集中在该层最左边的位置上,则称此二叉树为完全二叉树 f.当二叉树里出现空的子树时,就增加新的、特殊的结点——空树叶组成扩充二叉树,扩充二叉树是满二叉树 外部路径长度E :从扩充的二叉树的根到每个外部结点(新增的空树叶)的路径长度之和 内部路径长度I :扩充的二叉树中从根到每个内部结点(原来二叉树结点)的路径长度之和 2.性质 a. 二叉树的第i 层(根为第0层,i ≥0)最多有2^i 个结点 b. 深度为k 的二叉树至多有2k+1-1个结点 c. 任何一颗二叉树,度为0的结点比度为2的结点多一个。n0 = n2 + 1 d. 满二叉树定理:非空满二叉树树叶数等于其分支结点数加1 e. 满二叉树定理推论:一个非空二叉树的空子树(指针)数目等于其结点数加1 f. 有n 个结点(n>0)的完全二叉树的高度为?log2(n+1)?,深度为?log2(n+1)?? g. 对于具有n 个结点的完全二叉树,结点按层次由左到右编号,则有: 1) 如果i = 0为根结点;如果i>0,其父结点编号是 (i-1)/2 2) 当2i+1 1.二分搜索一个14个数的数组,查找A[4]所经过的元素有____. 2.一个序列先入栈,再出栈,出栈元素加入队列,生成一个新的顺序(已给出),则栈结构最少需要能保存几个元素_______. 3.一个5000个元素的数据需要排序,在堆排序,基数排序,快速排序里,要求速度最快,选哪一个______. 4.n个结点的m序B树,有____个外部节点。一个5序B树有53个结点,该B树至少有___ 层。 5.已给出一个K=11的散列表已有三个元素,再插入两个元素,则这两个元素的位置是________. 6.已给出一个无序数组,选第一个元素作为基点,快排一趟之后的顺序为____________________. 7.一个图已给3条边,再添加一条边,使其有唯一的拓扑序列,添加的边是_______,拓扑序列为____________. 8已给出一个序列,初始化为最小堆____________________。 1.跳表和散列,分别搜索最小元素写出思想和时间复杂度。 2.已给出一个序列,写出建立A VL树的过程,及删除某一个元素后的结果。 3.已给出一个有向图,写出对应的邻接表,根据Dijkstra算法写出某个顶点到其余各顶点的最短路径。 4.已给出一颗公式化描述的二叉树,画出二叉树并写出前中后序列及转化成森林。 5.无向图用公式化描述,为简化,用数组M表示上三角矩阵。写出A[i,j]到M的映射关系,说明如何求任意顶点i的度。 6.6个有序的序列,20 30 40 60 70 100 通过5次两两合并,生成一个有序的序列,求最少次数的合并过程。 1.删除链表形式的二叉搜索树的最大元素,写出思想,算法实现,时间复杂度。 2.邻接链表表示的图写出算法判断是否存在V->U的路径,以及思想。 2017年数据结构期末考试题及答案 一、选择题(共计50分,每题2分,共25题) 1 ?在数据结构中,从逻辑上可以把数据结构分为 C 。 A. 动态结构和静态结构B?紧凑结构和非紧凑结构 C.线性结构和非线性结构 D .内部结构和外部结构 2?数据结构在计算机内存中的表示是指 A ° A. 数据的存储结构 B.数据结构 C.数据的逻辑结构 D .数据元 素之间的关系 3.在数据结构中,与所使用的计算机无关的是数据的 A 结构。 A. 逻辑B?存储 C.逻辑和存储 D.物理 4 .在存储数据时,通常不仅要存储各数据元素的值,而且还要存储 C ° A.数据的处理方法B?数据元素的类型 C.数据元素之间的关系 D.数据的存储方法 5. 在决定选取何种存储结构时,一般不考虑 A ° A.各结点的值如何B?结点个数的多少 C?对数据有哪些运算 D.所用的编程语言实现这种结构是否方便。 6. 以下说法正确的是D ° A. 数据项是数据的基本单位 B. 数据元素是数据的最小单位 C. 数据结构是带结构的数据项的集合 D. —些表面上很不相同的数据可以有相同的逻辑结构 7. 在以下的叙述中,正确的是B ° A. 线性表的顺序存储结构优于链表存储结构 B. 二维数组是其数据元素为线性表的线性表 C?栈的操作方式是先进先出 D.队列的操作方式是先进后出 8. 通常要求同一逻辑结构中的所有数据元素具有相同的特性,这意味着 A. 数据元素具有同一特点 B. 不仅数据元素所包含的数据项的个数要相同,而且对应的数据项的类型要一致 C. 每个数据元素都一样 D. 数据元素所包含的数据项的个数要相等 9 ?链表不具备的特点是 A 。 A.可随机访问任一结点 B.插入删除不需要移动元素 C?不必事先估计存储空间 D.所需空间与其长度成正比 10. 若某表最常用的操作是在最后一个结点之后插入一个结点或删除最后一 个结点,则采用 D 存储方式最节省运算时间。 A.单链表B ?给出表头指针的单循环链表 C.双链表D ?带头结点 的双循环链表 11. 需要分配较大空间,插入和删除不需要移动元素的线性表,其存储结构是 B 。 A.单链表B .静态链表 C.线性链表 D .顺序存储结构 12 .非空的循环单链表head的尾结点(由p所指向)满足C 。 A. p—>next 一NULL B. p — NULL C. p—>next == head D. p = = head 13 .在循环双链表的p所指的结点之前插入s所指结点的操作是 D 。 A .p—> prior-> prior=s B .p—> prior-> n ext=s C.s —> prior—> n ext = s D.s —> prior—> prior = s 14 .栈和队列的共同点是C 。 A.都是先进后出 B .都是先进先出 C.只允许在端点处插入和删除元素 D .没有共同点 数据库实验(一) 熟悉环境、建立/删除表、插入数据 Drop table 表名 update dbtest set test=1 select * from dbscore 1.教师信息(教师编号、姓名、性别、年龄、院系名称) test1_teacher:tid char 6 not null、name varchar 10 not null、sex char 2、age int、dname varchar 10。 根据教师名称建立一个索引。 1、create table test1_teacher( tid char(6) primary key, name varchar(10) not null, sex char(2), age int, dname varchar(10) ) 2.学生信息(学生编号、姓名、性别、年龄、出生日期、院系名称、班级)test1_student:sid char 12 not null、name varchar 10 not null、sex char 2、age int、birthday date(oracle的date类型是包含时间信息的,时间信息全部为零)、dname varchar 10、class varchar(10)。 根据姓名建立一个索引。 2、create table test1_student( sid char(12) primary key, name varchar(10) not null, sex char(2), age int, birthday date, dname varchar(10), class varchar(10) ) 3.课程信息(课程编号、课程名称、先行课编号、学分) test1_course:cid char 6 not null、name varchar 10 not null、fcid char 6、credit numeric 2,1(其中2代表总长度,1代表小数点后面长度)。 根据课程名建立一个索引。 3、create table test1_course( cid char(6) primary key, name varchar(10) not null, fcid char(6), credit numeric(2,1) ) 4.学生选课信息(学号、课程号、成绩、教师编号) test1_student_course:sid char 12 not null、cid char 6 not null、 score numeric 5,1(其中5代表总长度,1代表小数点后面长度)、tid char 6。 4、 create table test1_student_course( sid char(12) , cid char(6) , score numeric(5,1), tid char(6), primary key(sid,cid), 一、选择(2’×15=30’) 1.若长度为n的线性表采用顺序存储结构,在其第i个位置插入一个新元素的算法的时 间复杂度为( ) A.O(0) B.O(1) C.O(n) D.O(n2) 2.用不带头结点的单链表存储队列时,其队头指针指向队头结点,其队尾指针指向队尾 结点,则在进行删除操作时( ) A.仅修改队头指针 B.仅修改队尾指针 C.队头、队尾指针都不修改 D.队头、队尾指针都可能要修改 3.设栈S和队列Q的初始状态均为空,元素a,b,c,d,e,f,g依次进入栈S,若每个元素出栈 后立即进入队列Q,且7个元素出队的顺序是b,d,c,f,e,a,g,则栈S的容量至少是( ) A.1 B.2 C.3 D.4 4.对n(n≥2)个权值均不相同的字符构成哈夫曼树,关于该树的叙述中,错误的是( ) A.该树一定是一棵完全二叉树 B.树中一定没有度为1的结点 C.树中两个权值最小的结点一定是兄弟结点 D.树中任一非叶结点的权值一定不小于下一层任一结点的权值 5.一棵二叉树的前序遍历序列为ABCDEFG,它的中序遍历序列可能是( ) A.CABDEFG B.ABCDEFG C.DACEFBG D.ADCFEG 6.下列线索二叉树中(用虚线表示线索),符合后序线索二叉树定义的是( D) 7.下面关于二分查找的叙述正确的是( ) A.表必须有序,表可以顺序方式存储,也可以链表方式存储 B.表必须有序,且表中数据必须是整型,实型或字符型 C.表必须有序,而且只能从小到大排列 D.表必须有序,且表只能以顺序方式存储 8.下列排序算法中,在每一趟都能选出一个元素放到其最终位置上,并且其时间性能受 数据初始特性影响的是( ) A.直接插入排序 B.快速排序 C.直接选择排序 D.堆排序 9.下列关于无向连通图特性的叙述中,正确的是( ) I.所有顶点的度之和为偶数 II.边数大于顶点个数减1 《数据结构》模拟卷 一、选择题 1.在一个长度为n的顺序表的任一位置插入一个新元素的渐进时间复杂度为(A )。 A. O(n) B. O(n/2) C. O(1) D. O(n2) 2.带头结点的单链表first为空的判定条件是:(B )。 A. first == NULL; B. first->link == NULL; C. first->link == first; D. first != NULL; 3. 从逻辑上可以把数据结构分为(C )两大类。 A.动态结构、静态结构B.顺序结构、链式结构 C.线性结构、非线性结构D.初等结构、构造型结构 4.在系统实现递归调用时需利用递归工作记录保存实际参数的值。在传值参数情形,需为 对应形式参数分配空间,以存放实际参数的副本;在引用参数情形,需保存实际参数的( D ),在被调用程序中可直接操纵实际参数。 A. 空间 B. 副本 C. 返回地址 D. 地址 5. 以下数据结构中,哪一个是线性结构(D )。 A.广义表 B. 二叉树 C. 稀疏矩阵 D. 串 6. 以下属于逻辑结构的是(C )。 A.顺序表 B. 哈希表 C.有序表 D. 单链表 7.对于长度为9的有序顺序表,若采用折半搜索,在等概率情况下搜索成功的平均搜索长 度为( C )的值除以9。 A. 20 B. 18 C. 25 D. 22 8.在有向图中每个顶点的度等于该顶点的( C )。 A. 入度 B. 出度 C. 入度与出度之和 D. 入度与出度之差 9.在基于排序码比较的排序算法中,( C )算法的最坏情况下的时间复杂度不高于 O(nlog2n)。 A. 起泡排序 B. 希尔排序 C. 归并排序 D. 快速排序 10.当α的值较小时,散列存储通常比其他存储方式具有( B )的查找速度。 A. 较慢 B. 较快 C. 相同 D.不同 二、填空题 1.二维数组是一种非线性结构,其中的每一个数组元素最多有___2___个直接前驱(或直 接后继)。 2.将一个n阶三对角矩阵A的三条对角线上的元素按行压缩存放于一个一维数组B中, A[0][0]存放于B[0]中。对于任意给定数组元素B[K],它应是A中第_「(K+1)/3」_行的元素。 3.链表对于数据元素的插入和删除不需移动结点,只需改变相关结点的_指针__域的值。 4.在一个链式栈中,若栈顶指针等于NULL则为__空栈__。 5.主程序第一次调用递归函数被称为外部调用,递归函数自己调用自己被称为内部调用, 它们都需要利用栈保存调用后的__返回___地址。 6.在一棵树中,_叶子_结点没有后继结点。 7.一棵树的广义表表示为a (b (c, d (e, f), g (h) ), i (j, k (x, y) ) ),结点f的层数为__3__。假定 根结点的层数为0。 8.在一棵AVL树(高度平衡的二叉搜索树)中,每个结点的左子树高度与右子树高度之差 的绝对值不超过__1____。 9.n (n﹥0) 个顶点的无向图最多有_n(n-1)/2__条边,最少有___0___条边。 10.在索引存储中,若一个索引项对应数据对象表中的一个表项(记录),则称此索引为_ 稠密_索引,若对应数据对象表中的若干个表项,则称此索引为__稀疏__索引。 三、判断题 1.数组是一种复杂的数据结构,数组元素之间的关系既不是线性的也不是树形的(对) 2.链式存储在插入和删除时需要保持物理存储空间的顺序分配,不需要保持数据元素之间 的逻辑顺序(错) 3.在用循环单链表表示的链式队列中,可以不设队头指针,仅在链尾设置队尾指针(对) 山东大学操作系统实验报告4进程同步实验 计算机科学与技术学院实验报告 实验题目:实验四、进程同步实验学号: 日期:20120409 班级:计基地12 姓名: 实验目的: 加深对并发协作进程同步与互斥概念的理解,观察和体验并发进程同步与互斥 操作的效果,分析与研究经典进程同步与互斥问题的实际解决方案。了解 Linux 系统中 IPC 进程同步工具的用法,练习并发协作进程的同步与互斥操作的编程与调试技术。 实验内容: 抽烟者问题。假设一个系统中有三个抽烟者进程,每个抽烟者不断地卷烟并抽烟。抽烟者卷起并抽掉一颗烟需要有三种材料:烟草、纸和胶水。一个抽烟者有烟草,一个有纸,另一个有胶水。系统中还有两个供应者进程,它们无限地供应所有三种材料,但每次仅轮流提供三种材料中的两种。得到缺失的两种材料的抽烟者在卷起并抽掉一颗烟后会发信号通知供应者,让它继续提供另外的两种材料。这一过程重复进行。请用以上介绍的 IPC 同步机制编程,实现该问题要求的功能。 硬件环境: 处理器:Intel? Core?i3-2350M CPU @ 2.30GHz ×4 图形:Intel? Sandybridge Mobile x86/MMX/SSE2 内存:4G 操作系统:32位 磁盘:20.1 GB 软件环境: ubuntu13.04 实验步骤: (1)新建定义了producer和consumer共用的IPC函数原型和变量的ipc.h文件。 (2)新建ipc.c文件,编写producer和consumer 共用的IPC的具体相应函数。 (3)新建Producer文件,首先定义producer 的一些行为,利用系统调用,建立共享内存区域,设定其长度并获取共享内存的首地址。然后设定生产者互斥与同步的信号灯,并为他们设置相应的初值。当有生产者进程在运行而其他生产者请求时,相应的信号灯就会阻止他,当共享内存区域已满时,信号等也会提示生产者不能再往共享内存中放入内容。 (4)新建Consumer文件,定义consumer的一些行为,利用系统调用来创建共享内存区域,并设定他的长度并获取共享内存的首地址。然后设定消费者互斥与同步的信号灯,并为他们设置相应的初值。当有消费进程在运行而其他消费者请求时,相应的信号灯就会阻止它,当共享内存区域已空时,信号等也会提示生产者不能再从共享内存中取出相应的内容。 运行的消费者应该与相应的生产者对应起来,只有这样运行结果才会正确。 山大网络教育《数据结构》(-C-卷) 《数据结构》模拟卷 一、单项选择题 1.数据结构是()。 A.一种数据类型 B.数据的存储结构 C.一组性质相同的数据元素的集合 D.相互之间存在一种或多种特定关系的数据元素的集合 2.算法分析的目的是( B )。 A.辨别数据结构的合理性 B.评价算法的效率 C.研究算法中输入与输出的关系 D.鉴别算法的可读性 3.在线性表的下列运算中,不.改变数据元素之间结构关系的运算是( D )。 A.插入B.删除 C.排序D.定位 4.若进栈序列为1,2,3,4,5,6,且进栈和出栈可以穿插进行,则可能出现的出栈序列为( B )。 A.3,2,6,1,4,5 B.3,4,2,1,6,5 C.1,2,5,3,4,6 D.5,6,4,2,3,1 5.设串sl=″Data Structures with Java″,s2=″it″,则子串定位函数index(s1,s2)的值为( D )。 A.15 B.16 C.17 D.18 6.二维数组A[8][9]按行优先顺序存储,若数组元素A[2][3]的存储地址为1087,A[4][7]的存储地址为1153,则数组元素A[6][7]的存储地址为( A )。 A.1207 B.1209 C.1211 D.1213 7.在按层次遍历二叉树的算法中,需要借助的辅助数据结构是( A )。 A.队列B.栈 C.线性表D.有序表 8.在任意一棵二叉树的前序序列和后序序列中,各叶子之间的相对次序关系( B )。A.不一定相同B.都相同 C.都不相同D.互为逆序 9.若采用孩子兄弟链表作为树的存储结构,则树的后序遍历应采用二叉树的( C )。 安徽大学2014-2015学年第一学期《数据结构》期末考试试卷(A卷) (含参考答案) 一、单项选择题(本大题共15小题,第小题2分,共30分)在每小题列出的四个选项中只有一 个符合题目要求,请将其代码填在题后的括号内。错选或未选均无分。 1. 算法必须具备输入、输出和[ C ] A. 计算方法 B. 排序方法 C.解决问题的有限运算步骤 D. 程序设计方法 2. 有n个节点的顺序表中,算法的时间复杂度是O(1)的操作是[ A ] A.访问第i个节点(1≤i≤n) B.在第i个节点后插入一个新节点(1≤i≤n) C.删除第i个节点(1≤i≤n) D.将n个节点从小到大排序 3.单链表的存储密度[ C] A.大于1 B. 等于1 C.小于1 D. 不能确定 4. 循环队列SQ的存储空间是数组d[m],队头、队尾指针分别是front和rear,则执行出队后其头指针front值是[ D ] A.front=front+1 B. front=(front+1)%(m-1) C. front=(front-1)%m D. front=(front+1)%m 5. 在一个具有n个结点的有序单链表中插入一个新结点并仍然保持有序的时间复杂度是 [ B ] A. O(1) B. O(n) C. O(n2) D. O(nlogn) 6 设二维数组A[0..m-1][0..n-1]按行优先顺序存储,则元素A[i][j]的地址为 [ B ] A.LOC(A[0][0])+(i*m+j) B.LOC(A[0][0])+(i*n+j) C.LOC(A[0][0])+[(i-1)*n+j-1] D. LOC(A[0][0])+[(i-1)*m+j-1] 7.设将整数1,2,3,4,5依次进栈,最后都出栈,出栈可以在任何时刻(只要栈不空)进行,则出栈序列不可能是[ B] A.23415 B. 54132 C.23145 D. 15432 2005年-2006学年第二学期“数据结构”考试试题(A) 姓名学号(序号)_ 答案隐藏班号 要求:所有的题目的解答均写在答题纸上(每张答题纸上要写清楚姓名、班号和学号),需写清楚题目的序号。每张答题纸都要写上姓名和序号。 一、单项选择题(每小题2分,共20分) 1.数据的运算a 。 A.效率与采用何种存储结构有关 B.是根据存储结构来定义的 C.有算术运算和关系运算两大类 D.必须用程序设计语言来描述 答:A。 2. 链表不具备的特点是 a 。 A.可随机访问任一结点 B.插入删除不需要移动元素 C.不必事先估计存储空间 D.所需空间与其长度成正比 答:参见本节要点3。本题答案为:A。 3. 在顺序表中删除一个元素的时间复杂度为 c 。 A.O(1) B.O(log2n) C.O(n) D.O(n2) 答:C。 4.以下线性表的存储结构中具有随机存取功能的是 d 。 A. 不带头结点的单链表 B. 带头结点的单链表 C. 循环双链表 D. 顺序表 解 D。 5. 一个栈的进栈序列是a,b,c,d,e,则栈的不可能的输出序列是 c 。 A.edcba B.decba C.dceab D.abcde 答:C。 6. 循环队列qu的队空条件是 d 。 A. (qu.rear+1)%MaxSize==(qu.front+1)%MaxSize B. (qu.rear+1)%MaxSize==qu.front+1 C.(qu.rear+1)%MaxSize==qu.front D.qu.rear==qu.front 答:D。 7. 两个串相等必有串长度相等且 b 。 A.串的各位置字符任意 B.串中各位置字符均对应相等 C.两个串含有相同的字符 D.两个所含字符任意 答:B。 8. 用直接插入排序对下面四个序列进行递增排序,元素比较次数最少的是c 。 A.94,32,40,90,80,46,21,69 B.32,40,21,46,69,94,90, 80 C.21,32,46,40,80,69,90,94 D.90,69,80,46,21,32,94, 40 答:C。 9. 以下序列不是堆(大根或小根)的是 d 。 A.{100,85,98,77,80,60,82,40,20,10,66} B.{100,98,85,82,80, 77,66,60,40,20,10} C.{10,20,40,60,66,77,80,82,85,98,100} D.{100,85,40,77,80, 60,66,98,82,10,20}山东大学数据库实验答案2—8
大学数据结构期末知识点重点总结(考试专用)
山东大学软件学院2014-2015数据结构真题
2017年数据结构期末考试题及答案A
山东大学《数据库系统》上机实验答案 详细整理 2013最新版
大连理工大学软件学院2014数据结构期末考试)
山东大学网络教育《数据结构》( A 卷)
山东大学操作系统实验报告4进程同步实验
山大网络教育《数据结构》(-C-卷)
安徽大学2014数据结构期末考试试卷(A卷)
数据结构期末考试试题含答案