神经网络激活函数

激活函数是用来加入非线性因素的,因为线性模型的表达能力不够。
1.S形函数 ( Sigmoid Function )
该函数的导函数:
2.双极S形函数
该函数的导函数:
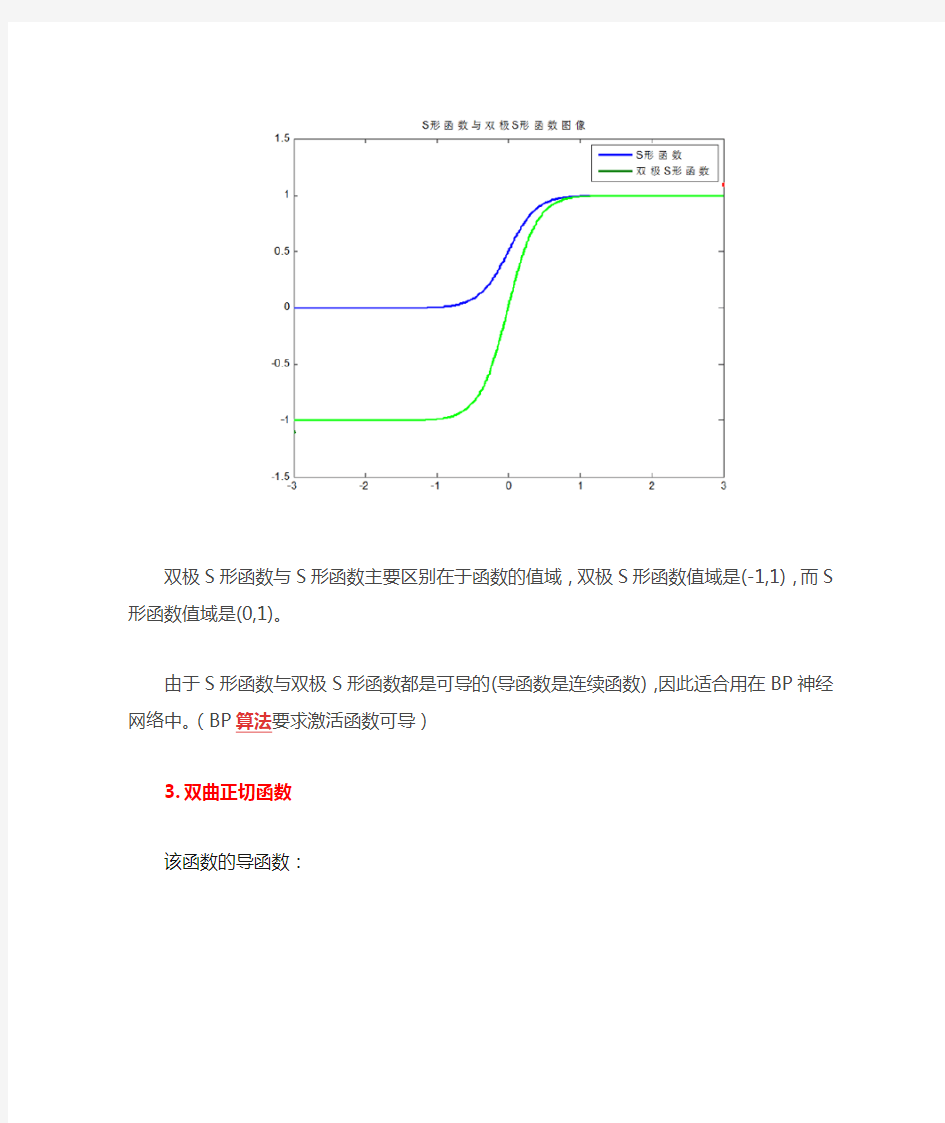
S形函数与双极S形函数的图像如下:
双极S形函数与S形函数主要区别在于函数的值域,双极S形函数值域是(-1,1),而S形函数值域是(0,1)。
由于S形函数与双极S形函数都是可导的(导函数是连续函数),因此适合用
3.双曲正切函数
该函数的导函数:
4.ReLu(Rectified Linear Units)函数
ReLU: g(x)=max(0,x)
该函数的导函数:
g(x)'=0或1
RELU取代sigmoid 和tanh函数的原因是在求解梯度下降时RELU的速度更快,在大数集下会节省训练的时间
在这里指出sigmoid和tanh是饱和非线性函数,而RELU是非饱和非线性函数。
5.PRELU激活函数
PReLU(Parametric Rectified Linear Unit), 顾名思义:带参数的ReLU。二者的定义和区别如下
图:
如果ai=0,那么PReLU退化为ReLU;如果ai是一个很小的固定值(如ai=0.01),则PReLU退化为Leaky ReLU(LReLU)。有实验证明,与ReLU相比,LReLU对最终的结果几乎没什么影响。
激活函数通常有如下一些性质:
?非线性:当激活函数是线性的时候,一个两层的神经网络就可以逼近基本上所有的函数了。但是,如果激活函数是恒等激活函数的时候(即f(x)=x),就不满足这个性质了,而且如果MLP使用的是恒等激活函数,那么其实整个网络跟单层神经网络是等价的。
?可微性:当优化方法是基于梯度的时候,这个性质是必须的。
?单调性:当激活函数是单调的时候,单层网络能够保证是凸函数。
?f(x)≈x:当激活函数满足这个性质的时候,如果参数的初始化是random的很小的值,那么神经网络的训练将会很高效;如果不满足这个性质,那么就需要很用心的去设置初始值。
?输出值的范围:当激活函数输出值是有限的时候,基于梯度的优化方法会更加稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是无限的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的learning rate.
Sigmoid
sigmoid 函数曾经被使用的很多,不过近年来,用它的人越来越少了。主要是因为它的一些缺点:
?Sigmoids saturate and kill gradients. (saturate 这个词怎么翻译?饱和?)sigmoid 有一个非常致命的缺点,当输入非常大或者非常小的时候(saturation),这些神经元的梯度是接近于0的,从图中可以看出梯度的趋势。所以,你需要尤其注意参数的初始值来尽量避免saturation的情况。如果你的初始值很大的话,大部分
神经元可能都会处在saturation的状态而把gradient kill掉,这会导致网络变的很难学习。
Sigmoid 的output 不是0均值. 这是不可取的,因为这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。产生的一个结果就是:如果数据进入神经元的时候是正的(e.g. x>0 elementwise in f=wTx+b),那么w计算出的梯度也会始终都是正的。当然了,如果你是按batch去训练,那么那个batch可能得到不同的信号,所以这个问题还是可以缓解一下的。因此,非0均值这个问题虽然会产生一些不好的影响,不过跟上面提到的kill gradients 问题相比还是要好很多的。
tanh
tanh是上图中的右图,可以看出,tanh跟sigmoid还是很像的,实际上,tanh是sigmoid的变形:
tanh(x)=2sigmoid(2x)?1
与sigmoid 不同的是,tanh是0均值的。因此,实际应用中,tanh会比sigmoid 更好(毕竟去粗取精了嘛)。
ReLU
近年来,ReLU变的越来越受欢迎。它的数学表达式如下:
f(x)=max(0,x)
很显然,从图左可以看出,输入信号<0时,输出都是0,>0 的情况下,输出等于输入。w是二维的情况下,使用ReLU之后的效果如下:
ReLU的优点:
?Krizhevsky et al.发现使用ReLU得到的SGD的收敛速度会比sigmoid/tanh快很多(看右图)。有人说这是因为它是linear,而且non-saturating
?相比于sigmoid/tanh,ReLU只需要一个阈值就可以得到激活值,而不用去算一大堆复杂的运算。
ReLU的缺点:当然ReLU也有缺点,就是训练的时候很”脆弱”,很容易就”die”
了. 什么意思呢?
举个例子:一个非常大的梯度流过一个ReLU神经元,更新过参数之后,这个神经元再也不会对任何数据有激活现象了。
如果这个情况发生了,那么这个神经元的梯度就永远都会是0.
实际操作中,如果你的learning rate 很大,那么很有可能你网络中的40%的神经元都”dead”了。
当然,如果你设置了一个合适的较小的learning rate,这个问题发生的情况其实也不会太频繁。
Leaky-ReLU、P-ReLU、R-ReLU
Leaky ReLUs:就是用来解决这个“dying ReLU”的问题的。与ReLU不同的是:
f(x)=αx,(x<0)
f(x)=x,(x>=0)
这里的α是一个很小的常数。这样,即修正了数据分布,又保留了一些负轴的值,使得负轴信息不会全部丢失。
关于Leaky ReLU的效果,众说纷纭,没有清晰的定论。有些人做了实验发现Leaky ReLU表现的很好;有些实验则证明并不是这样。
Parametric ReLU:对于Leaky ReLU中的α,通常都是通过先验知识人工赋值的。然而可以观察到,损失函数对α的导数我们是可以求得的,可不可以将它作为一个参数进行训练呢?
Kaiming He的论文《Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification》指出,不仅可以训练,而且效果更好。公式非常简单,反向传播至未激活前的神经元的公式就不写了,很容易就能得到。对α的导数如下:
δyi / δα=0,(if yi>0),else=yi
原文说使用了Parametric ReLU后,最终效果比不用提高了1.03%. Randomized ReLU:
Randomized Leaky ReLU是leaky ReLU的random 版本(α是random的).
它首次试在kaggle的NDSB 比赛中被提出的。
核心思想就是,在训练过程中,α是从一个高斯分布U(l,u) 中随机出来的,然后再测试过程中进行修正(有点像dropout的用法)。
数学表示如下:
在测试阶段,把训练过程中所有的αij取个平均值。
Maxout
Maxout出现在ICML2013上,作者Goodfellow将maxout和dropout结合后,号称在MNIST, CIFAR-10, CIFAR-100, SVHN这4个数据上都取得了start-of-art的识别率。
Maxout公式如下:
fi(x)=maxj∈[1,k]zij
假设w是2维,那么有:
f(x)=max(wT1x+b1,wT2x+b2)
可以注意到,ReLU和Leaky ReLU都是它的一个变形(比如,w1,b1=0 的时候,就是ReLU).
Maxout的拟合能力是非常强的,它可以拟合任意的的凸函数。作者从数学的角度上也证明了这个结论,即只需2个maxout节点就可以拟合任意的凸函数了(相减),前提是”隐隐含层”节点的个数可以任意多.
所以,Maxout具有ReLU的优点(如:计算简单,不会saturation),同时又没有ReLU的一些缺点(如:容易Go die)。不过呢,还是有一些缺点的嘛:就是把参数double了。
怎么选择激活函数呢?
我觉得这种问题不可能有定论的吧,只能说是个人建议。
如果你使用ReLU,那么一定要小心设置learning rate,而且要注意不要让你的网络出现很多“dead” 神经元,如果这个问题不好解决,那么可以试试Leaky ReLU、PReLU或者Maxout.
友情提醒:最好不要用sigmoid,你可以试试tanh,不过可以预期它的效果会比不上ReLU和Maxout.
还有,通常来说,很少会把各种激活函数串起来在一个网络中使用的。
For the output units, you should choose an activation function suited to the distribution of the target values:
For binary (0/1) targets, the logistic function is an excellent choice (Jordan, 1995).
For categorical targets using 1-of-C coding, the softmax activation
function is the logical extension of the logistic function.
For continuous-valued targets with a bounded range, the logistic and tanh functions can be used, provided you either scale the outputs to the range
of the targets or scale the targets to the range of the output activation
function ("scaling" means multiplying by and adding appropriate
constants).
If the target values are positive but have no known upper bound, you can
use an exponential output activation function, but beware of overflow.
For continuous-valued targets with no known bounds, use the identity or "linear" activation function (which amounts to no activation function)
unless you have a very good reason to do otherwise.
Naming conventions.Notice that when we say N-layer neural network, we do not count the input layer. Therefore, a single-layer neural network describes a network with no hidden layers (input directly mapped to output). In that sense, you can sometimes hear people say that logistic regression or SVMs are simply a special case of single-layer Neural Networks. You may also hear these networks interchangeably referred to as “Artificial Neural Networks”(ANN) or “Multi-Layer Perceptrons”(MLP). Many people do not like the analogies between Neural Networks and real brains and prefer to refer to neurons as units.
Maxout算法流程
1、算法概述
开始前我们先讲解什么叫maxout networks,等我们明白了什么叫maxout网络后,再对maxout的相理论意义做出解释。Maxout是深度学习网络中的一层网络,就像池化层、卷积层一样等,我们可以把maxout看成是网络的激活函数层,这个后面再讲解,本部分我们要先知道什么是maxout。我们假设网络某一层的输入特征向量为:X=(x1,x2,……xd),也就是我们输入是d个神经元。Maxout隐藏层每个神经元的计算公式如下:
上面的公式就是maxout隐藏层神经元i的计算公式。其中,k就是maxout层所需要的参数了,由我们人为设定大小。就像dropout一样,也有自己的参数p(每个神经元dropout概率),maxout的参数是k。公式中Z的计算公式为:
权重w是一个大小为(d,m,k)三维矩阵,b是一个大小为(m,k)的二维矩阵,这两个就是我们需要学习的参数。如果我们设定参数k=1,那么这个时候,网络就类似于以前我们所学普通的MLP网络。
我们可以这么理解,本来传统的MLP算法在第i层到第i+1层,参数只有一组,然而现在我们不怎么干了,我们在这一层同时训练n组参数,然后选择激活值最大的作为下一层神经元的激活值。下面还是用一个例子进行讲解,比较容易搞懂。为了简单起见,假设我们网络第i层有2个神经元x1、x2,第i+1层的神经元个数为1个,如下图所示:
(1)以前MLP的方法。我们要计算第i+1层,那个神经元的激活值的时候,传统的MLP计算公式就是:
z=W*X+b
out=f(z)
其中f就是我们所谓的激活函数,比如Sigmod、Relu、Tanh等。
(2)Maxout的方法。如果我们设置maxout的参数k=5,maxout层就如下所示:
相当于在每个输出神经元前面又多了一层。这一层有5个神经元,此时maxout 网络的输出计算公式为:
z1=w1*x+b1
z2=w2*x+b2
z3=w3*x+b3
z4=w4*x+b4
z5=w5*x+b5
out=max(z1,z2,z3,z4,z5)
所以这就是为什么采用maxout的时候,参数个数成k倍增加的原因。本来我们只需要一组参数就够了,采用maxout后,就需要有k组参数。
maxout激活函数,它具有如下性质:
1、maxout激活函数并不是一个固定的函数,不像Sigmod、Relu、Tanh等函数,是一个固定的函数方程
2、它是一个可学习的激活函数,因为我们W参数是学习变化的。
3、它是一个分段线性函数:
然而任何一个凸函数,都可以由线性分段函数进行逼近近似。其实我们可以把以前所学到的激活函数:relu、abs激活函数,看成是分成两段的线性函数,如下示意图所示:
maxout的拟合能力是非常强的,它可以拟合任意的的凸函数。最直观的解释就是任意的凸函数都可以由分段线性函数以任意精度拟合(学过高等数学应该能明白),而maxout又是取k个隐隐含层节点的最大值,这些”隐隐含层"节点也是线性的,所以在不同的取值范围下,最大值也可以看做是分段线性的(分段的个数与k值有关)
maxout是一个函数逼近器,对于一个标准的MLP网络来说,如果隐藏层的神经元足够多,那么理论上我们是可以逼近任意的函数的。类似的,对于maxout网络也是一个函数逼近器。
定理1:对于任意的一个连续分段线性函数g(v),我们可以找到两个凸的分段线性函数h1(v)、h2(v),使得这两个凸函数的差值为g(v):
(采用BP神经网络完成非线性函数的逼近)神经网络
控制系统仿真与模型处理设计报告 (采用BP神经网络完成非线性函数的逼近)
1、题目要求: (1)确定一种神经网络、网络结构参数和学习算法。 (2)选择适当的训练样本和检验样本,给出选取方法。 (3)训练网络使学习目标误差函数达到0.01,写出学习结束后的网络各参数,并绘制学习之前、第100次学习和学习结束后各期望输出曲线、实际输出曲线。绘制网络训练过程的目标误差函数曲线。 (4)验证网络的泛化能力,给出网络的泛化误差。绘制网络检验样本的期望输出曲线和网络输出曲线。 (5)分别改变神经网络的中间节点个数、改变网络的层数、改变学习算法进行比较实验,讨论系统的逼近情况,给出你自己的结论和看法。 2、设计方案: 在MATLAB中建立M文件下输入如下命令: x=[0:0.01:1]; y=2.2*power(x-0.25,2)+sin(5*pi*x); plot(x,y) xlabel('x'); ylabel('y'); title('非线性函数'); 得到如下图形,即所给的非线性函数曲线图:
构造一个1-7-1的BP神经网络,第一层为输入层,节点个数为1;第二层为隐层,节点个数为7;变换函数选正切s型函数(tansig);第三层为输出层,节点个数为1,输出层神经元传递函数为purelin函数。并且选Levenberg-Marquardt算法(trainlm)为BP网络的学习算法。对于该初始网络,我们选用sim()函数观察网络输出。继续在M函数中如下输入。 net=newff(minmax(x),[1,7,1],{'tansig','tansig','purelin'},'trainlm'); y1=sim(net,x); figure; plot(x,y,'b',x,y1,'r') title('期望输出与实际输出比较'); xlabel('t'); 则得到以下所示训练的BP网络期望输出与实际输出曲线比较: 应用函数train()对网络进行训练之前,需要预先设置训练参数。将最大训练次数为100次,训练精度设置为0.01,学习速度为0.01。 net.trainParam.epochs=100; net.trainParam.goal=0.001; net.trainParam.lr=0.01; net=train(net,x,y); y2=sim(net,x);
BP神经网络逼近非线性函数
BP神经网络逼近非线性函数3、试用BP神经网络逼近非线性函数 f(u) = )5.0 u(9.1 e+ - sin(10u) 其中,u∈[-0.5,0.5] 解题步骤: ①网络建立:使用“net=newff(minmax(x), [20, 1], {'tansig’,’ purelin' });,语句建立个前馈BP神经网络。该BP神经网络只含个隐含层,且神经元的个数为20。隐含层和输出层神经元的传递函数分别为tansig和pure-lin。其他参数默认。 ②网络训练:使用“net=train (net, x , y) ;”语句训练建立好的BP神经网络。当然在网络训练之前必须设置好训练参数。如设定训练时间为50个单位时间,训练目标的误差小于0.01,用“net.trainParam.epochs=50; net.train-Param.goal=0.01;”,语句实现。其他参数默认。 ③网络仿真:使用“y1=sim(net, x); y2=sim(net, x};”语句仿真训练前后的BP神经网络。 (2)程序如下: clear all; x=[-0.5:0.01:0.5]; y=exp(-1.9*(0.5+x)).*sin(10*x); net=newff(minmax(x),[20,1],{'tansig' 'purelin'}); y1=sim(net,x); %未训练网络的仿真结果net.trainParam.epochs=50; net.trainParam.goal=0.01; net=train(net,x,y); y2=sim(net,x); %训练后网络的仿真结果figure;
神经网络建模及Matlab中重要的BP网络函数
神经网络建模及Matlab中重要的BP网络函数一、神经组织的基本特征 1.细胞体是一个基本的初等信号处理器,轴突是信号的输出通路,树突是信号的输入通路。信号从一个神经细胞经过突触传递到另一个细胞。 2.不同的神经元之间有不同的作用强度,称为联接强度。当某细胞收到信号时,它的电位发生变化,如果电位超过某一阈值时,该细胞处于激发态,否则处于抑制状态。 3.两神经元之间的联接强度随其激发与抑制行为相关性的时间平均值正比变化,也就是说神经元之间的联接强度不是一成不变的。这就是生物学上的Hebb律。
∑t j ij t S w )(二、人工神经元的M-P 模型(McCulloch 、Pitts,1943) 1.构造一个模拟生物神经组织的人工神经网络的三要素: (1).对单个神经元给出定义; (2).定义网络结构:决定神经元数量及连接方式; (3).给出一种方法,决定神经元之间的联接强度。 2.M-P 模型 其中,t 表示时间 S i (t)表示第i 个神经元在t 时刻的状态,S i (t)=1表示处于激发态,S i (t)=0表示处于抑制态 w ij 表示第j 个神经元到第i 个神经元的联接强度,称之为权,可正可负 表示第i 个神经元在t 时刻所接收到的所有信号的线性迭加。 μi 表示神经元i 的阈值, 可以在模型中增加一个S k (t)=1神经元k ,并且w ik =-μi ,则阈值可归并到和号中去。 注: 1.M-P 神经元虽然简单,但可以完成任何计算。 2.神经元的状态可以取[0,1]中的连续值,如用以下函数代替θ(x): ???<≥=-=+∑0 0011x x x t S w t S i j j ij i )() )(()(θμθ
BP神经网络在Matlab函数逼近中的应用
燕山大学 模式识别与智能系统导论 题目:BP网络在函数逼近中的应用 专业:控制工程 姓名: X X X 学号:
一BP神经网络及其原理............................................................ - 1 - 1.1 BP神经网络定义............................................................. - 1 - 1.2 BP神经网络模型及其基本原理..................................... - 1 - 1.3 BP神经网络的主要功能................................................. - 3 - 1.4 BP网络的优点以及局限性............................................. - 3 - 二基于MATLAB的BP神经网络工具箱函数 ........................ - 6 - 2.1 BP网络创建函数............................................................. - 7 - 2.2 神经元上的传递函数...................................................... - 7 - 2.3 BP网络学习函数............................................................. - 8 - 2.4 BP网络训练函数............................................................. - 9 - 三BP网络在函数逼近中的应用.............................................. - 10 - 3.1 问题的提出.................................................................... - 10 - 3.2 基于BP神经网络逼近函数......................................... - 10 - 3.3 不同频率下的逼近效果................................................ - 14 - 3.4 讨论................................................................................ - 17 -
神经网络作业(函数逼近)
智能控制理论及应用作业 1资料查询 BP 神经网络的主要应用: 人脸识别、风电功率预测、短时交通流混沌预测、高炉熔渣粘度预测、汇率预测、价格预测、函数逼近等 Rbf神经网络的主要应用: 函数逼近、短时交通流预测、模式识别、降水预测、民航客运量预测、遥感影像分析、声纹识别、语言识别、人脸识别、车牌识别、汇率预测 Hopfield网络应用: 车牌识别、图像识别、遥感影像分类、字母识别、交通标志识别、优化计算中的应用、联想记忆存储器的实现、 2 BP编程算法: 2.1 利用样本训练一个BP网络 注:此程序自李国勇书中学习而来 程序部分: function [ output_args ] = bp( input_args ) %UNTITLED Summary of this function goes here % Detailed explanation goes here %此设计为两层BP神经网络,3输入,3隐含层节点,两个输出 %初始化部分: lr=0.05; %%需要给定学习速率 error_goal=0.001; %期望的误差 max_epoch=100000; %训练的最大步长 a=0.9; %惯性系数 Oi=0; Ok=0; %给两组输入,以及目标输出: X=[1 1 1;-1 -1 1;1 -1 1;]; %随便给一组输入输入,训练BP网络
T=[1 1 1 ;1 1 1]; %X=-1:0.1:1; %输入范围 %T=sin(pi*X); %X=[] q=3; %隐含层的节点数自己定义,在此给3个 %初始化 [M,N]=size(X); %输入节点个数为M,N为样本数 [L,N]=size(T); %输出节点个数为L wij=rand(q,M); %先给定加权系数一组随机值 wki=rand(L,q); wij0=zeros(size(wij)); %加权系数矩阵的初始值 wki0=zeros(size(wki)); for epoch=1:max_epoch %计算开始 NETi=wij*X; %各个隐含层的净输入 for j=1:N for i=1:q Oi(i,j)=2/(1+exp(-NETi(i,j)))-1; %再输入作用下,隐含层的输出 end end NETk=wki*Oi; %各个输出层的净输入 for i=1:N for k=1:L Ok(k,i)=2/(1+exp(-NETk(k,i)))-1; %在输入作用下,输出层的输出end end E=((T-Ok)'*(T-Ok))/2; %性能指标函数,就是误差 if(E 1. 数据预处理 在训练神经网络前一般需要对数据进行预处理,一种重要的预处理手段是归一化处理。下面简要介绍归一化处理的原理与方法。 (1) 什么是归一化? 数据归一化,就是将数据映射到[0,1]或[-1,1]区间或更小的区间,比如 (0.1,0.9) 。 (2) 为什么要归一化处理? <1>输入数据的单位不一样,有些数据的范围可能特别大,导致的结果是神经网络收敛慢、训练时间长。 <2>数据范围大的输入在模式分类中的作用可能会偏大,而数据范围小的输入作用就可能会偏小。 <3>由于神经网络输出层的激活函数的值域是有限制的,因此需要将网络训练的目标数据映射到激活函数的值域。例如神经网络的输出层若采用S形激活函数,由于S形函数的值域限制在(0,1),也就是说神经网络的输出只能限制在(0,1),所以训练数据的输出就要归一化到[0,1]区间。 <4>S形激活函数在(0,1)区间以外区域很平缓,区分度太小。例如S形函数f(X)在参数a=1时,f(100)与f(5)只相差0.0067。 (3) 归一化算法 一种简单而快速的归一化算法是线性转换算法。线性转换算法常见有两种形式: <1> y = ( x - min )/( max - min ) 其中min为x的最小值,max为x的最大值,输入向量为x,归一化后的输出向量为y 。上式将数据归一化到[ 0 , 1 ]区间,当激活函数采用S形函数时(值域为(0,1))时这条式子适用。 <2> y = 2 * ( x - min ) / ( max - min ) - 1 这条公式将数据归一化到[ -1 , 1 ] 区间。当激活函数采用双极S形函数(值域为(-1,1))时这条式子适用。 (4) Matlab数据归一化处理函数 Matlab中归一化处理数据可以采用premnmx ,postmnmx ,tramnmx 这3个函数。 <1> premnmx 语法:[pn,minp,maxp,tn,mint,maxt] = premnmx(p,t) 参数: pn:p矩阵按行归一化后的矩阵 minp,maxp:p矩阵每一行的最小值,最大值 第一节、神经网络基本原理 1. 人工神经元( Artificial Neuron )模型 人工神经元是神经网络的基本元素,其原理可以用下图表示: 图1. 人工神经元模型 图中x1~xn是从其他神经元传来的输入信号,wij表示表示从神经元j 到神经元i的连接权值,θ表示一个阈值( threshold ),或称为偏置( bias )。则神经元i的输出与输入的关系表示为: 图中yi表示神经元i的输出,函数f称为激活函数( Activation Function )或转移函数( Transfer Function ) ,net称为净激活(net activation)。若将阈值看成是神经元i的一个输入x0的权重wi0,则上面的式子可以简化为: 若用X表示输入向量,用W表示权重向量,即: X = [ x0 , x1 , x2 , ....... , xn ] 则神经元的输出可以表示为向量相乘的形式: 若神经元的净激活net为正,称该神经元处于激活状态或兴奋状态(fire),若净激活net为负,则称神经元处于抑制状态。 图1中的这种“阈值加权和”的神经元模型称为M-P模型 ( McCulloch-Pitts Model ),也称为神经网络的一个处理单元( PE, Processing Element )。 2. 常用激活函数 激活函数的选择是构建神经网络过程中的重要环节,下面简要介绍常用的激活函数。 (1) 线性函数( Liner Function ) (2) 斜面函数( Ramp Function ) (3) 阈值函数( Threshold Function ) 图2 . 阈值函数图像 以上3个激活函数都是线性函数,下面介绍两个常用的非线性激活函数。 (4) S形函数( Sigmoid Function ) 该函数的导函数: (5) 双极S形函数 神经网络算法详解 第0节、引例 本文以Fisher的Iris数据集作为神经网络程序的测试数据集。Iris数据集可以在https://www.360docs.net/doc/cc9646687.html,/wiki/Iris_flower_data_set 找到。这里简要介绍一下Iris数据集: 有一批Iris花,已知这批Iris花可分为3个品种,现需要对其进行分类。不同品种的Iris花的花萼长度、花萼宽度、花瓣长度、花瓣宽度会有差异。我们现有一批已知品种的Iris花的花萼长度、花萼宽度、花瓣长度、花瓣宽度的数据。 一种解决方法是用已有的数据训练一个神经网络用作分类器。 如果你只想用C#或Matlab快速实现神经网络来解决你手头上的问题,或者已经了解神经网络基本原理,请直接跳到第二节——神经网络实现。 第一节、神经网络基本原理 1. 人工神经元( Artificial Neuron )模型 人工神经元是神经网络的基本元素,其原理可以用下图表示: 图1. 人工神经元模型 图中x1~xn是从其他神经元传来的输入信号,wij表示表示从神经元j到神经元i的连接权值,θ表示一个阈值( threshold ),或称为偏置( bias )。则神经元i的输出与输入的关系表示为: 图中yi表示神经元i的输出,函数f称为激活函数 ( Activation Function )或转移函数( Transfer Function ) ,net称为净激活(net activation)。若将阈值看成是神经元i的一个输入x0的权重wi0,则上面的式子可以简化为: 若用X表示输入向量,用W表示权重向量,即: X = [ x0 , x1 , x2 , ....... , xn ] 则神经元的输出可以表示为向量相乘的形式: 若神经元的净激活net为正,称该神经元处于激活状态或兴奋状态(fire),若净激活net 为负,则称神经元处于抑制状态。 图1中的这种“阈值加权和”的神经元模型称为M-P模型 ( McCulloch-Pitts Model ),也称为神经网络的一个处理单元( PE, Processing Element )。 2. 常用激活函数 激活函数的选择是构建神经网络过程中的重要环节,下面简要介绍常用的激活函数。 (1) 线性函数 ( Liner Function ) (2) 斜面函数 ( Ramp Function ) (3) 阈值函数 ( Threshold Function ) 浅谈神经网络 先从回归(Regression)问题说起。我在本吧已经看到不少人提到如果想实现强AI,就必须让机器学会观察并总结规律的言论。具体地说,要让机器观察什么是圆的,什么是方的,区分各种颜色和形状,然后根据这些特征对某种事物进行分类或预测。其实这就是回归问题。 如何解决回归问题?我们用眼睛看到某样东西,可以一下子看出它的一些基本特征。可是计算机呢?它看到的只是一堆数字而已,因此要让机器从事物的特征中找到规律,其实是一个如何在数字中找规律的问题。 例:假如有一串数字,已知前六个是1、3、5、7,9,11,请问第七个是几? 你一眼能看出来,是13。对,这串数字之间有明显的数学规律,都是奇数,而且是按顺序排列的。 那么这个呢?前六个是0.14、0.57、1.29、2.29、3.57、5.14,请问第七个是几? 这个就不那么容易看出来了吧!我们把这几个数字在坐标轴上标识一下,可以看到如下图形: 用曲线连接这几个点,延着曲线的走势,可以推算出第七个数字——7。 由此可见,回归问题其实是个曲线拟合(Curve Fitting)问题。那么究竟该如何拟合?机器不 可能像你一样,凭感觉随手画一下就拟合了,它必须要通过某种算法才行。 假设有一堆按一定规律分布的样本点,下面我以拟合直线为例,说说这种算法的原理。 其实很简单,先随意画一条直线,然后不断旋转它。每转一下,就分别计算一下每个样本点和直线上对应点的距离(误差),求出所有点的误差之和。这样不断旋转,当误差之和达到最小时,停止旋转。说得再复杂点,在旋转的过程中,还要不断平移这条直线,这样不断调整,直到误差最小时为止。这种方法就是著名的梯度下降法(Gradient Descent)。为什么是梯度下降呢?在旋转的过程中,当误差越来越小时,旋转或移动的量也跟着逐渐变小,当误差小于某个很小的数,例如0.0001时,我们就可以收工(收敛, Converge)了。啰嗦一句,如果随便转,转过头了再往回转,那就不是梯度下降法。 我们知道,直线的公式是y=kx+b,k代表斜率,b代表偏移值(y轴上的截距)。也就是说,k 可以控制直线的旋转角度,b可以控制直线的移动。强调一下,梯度下降法的实质是不断的修改k、b这两个参数值,使最终的误差达到最小。 求误差时使用累加(直线点-样本点)^2,这样比直接求差距累加(直线点-样本点) 的效果要好。这种利用最小化误差的平方和来解决回归问题的方法叫最小二乘法(Least Square Method)。 问题到此使似乎就已经解决了,可是我们需要一种适应于各种曲线拟合的方法,所以还需要继续深入研究。 我们根据拟合直线不断旋转的角度(斜率)和拟合的误差画一条函数曲线,如图: 神经网络作业(函数逼近) 智能控制理论及应用作业 1资料查询 BP 神经网络的主要应用: 人脸识别、风电功率预测、短时交通流混沌预测、高炉熔渣粘度预测、汇率预测、价格预测、函数逼近等 Rbf神经网络的主要应用: 函数逼近、短时交通流预测、模式识别、降水预测、民航客运量预测、遥感影像分析、声纹识别、语言识别、人脸识别、车牌识别、汇率预测 Hopfield网络应用: 车牌识别、图像识别、遥感影像分类、字母识别、交通标志识别、优化计算中的应用、联想记忆存储器的实现、 2 BP编程算法: T=[1 1 1 ;1 1 1]; %X=-1:0.1:1; %输入范围 %T=sin(pi*X); %X=[] q=3; %隐含层的节点数自己定义,在此给3个 %初始化 [M,N]=size(X); %输入节点个数为M,N为样本数 [L,N]=size(T); %输出节点个数为L wij=rand(q,M); %先给定加权系数一组随机值 wki=rand(L,q); wij0=zeros(size(wij)); %加权系数矩阵的初始值 wki0=zeros(size(wki)); for epoch=1:max_epoch %计算开始 NETi=wij*X; %各个隐含层的净输入 for j=1:N for i=1:q Oi(i,j)=2/(1+exp(-NETi(i,j)))-1; %再输入作用下,隐含层的输出 end end NETk=wki*Oi; %各个输出层的净输入 for i=1:N for k=1:L Ok(k,i)=2/(1+exp(-NETk(k,i)))-1; %在输入作用下,输出层的输出 end end E=((T-Ok)'*(T-Ok))/2; %性能指标函数,就是误差 if(E 关于误差函数的深入研究姓名:李宏成 学号:6720130345 摘要 我写这篇文章的目的意在补充老师上课中遗留的一些问题以及我自身对神经网络中误差函数的一些看法。文章涉及到hebb学习规则中误差函数推导过程,非线性传输函数中误差函数推导过程以及感知机的误差函数证明。如有不足之处,敬请谅解。 1.Hebb 学习规则中误差函数的推导过程 首先,在推导过程中我们首先要问问自己为什么我们要选择最小二乘?有许多东西都可以被优化,为什么我们要选择这样的指标(()() ∑=-= m i T P W T W F 1 2 )? 其次,理论的推导过程是以有监督hebb 学习规则为前提,采用的传输函数是类似于线性联想器的purelin 函数。此函数为一过原点且斜率为1的直线,因此整个系统的输出结果就可以直接认为是该系统的净输入。 在这里,我们先定义如下几个基本参数 m 表示训练的样本数目 p 表示输入变量 a 表示实际输出 w 表示权值参数 于是()a p ,就构成了一个训练样本,更一般的() () ()( )p a p i i ,表示第i 列训练样本集。所以, 我们可以用如下表达式来表述成我们所预想的结果: ()n n p w p w p w p a +++=...1100 (1.1) 为了突出权值在实际输出函数()p a 中的作用和更具有真实性质,以上式(1.1)子我们可以改写成: ()B p w p w p w p a n n w ++++=...1100 (1.2) 其中B 是一个偏置项,你可以把偏置项看成是对未建模事物产生的效应的一种估测。我们举个例子,购买房屋时我们主要是考虑房子每平米的价格,地理位置等主要特征(这里所指的权值),也许房子还有其它的特征比如说朝向,楼层高度,是否有电梯等因素。 用矩阵形式表示(1.2)可以改写成: () ()()()()i i T i i i n i i w b p W b p w p a +=+∑==1 (1.3) 现在我们假设偏置项() i b 服从均值为0,方差为2 ?的高斯分布,那么它的概率密度函数可以表示为: () () ()() ()()()( )? ?? ? ? ?--=???? ??-=22 222exp 212exp 21σσπσσπi T i w i i p W p a b b f (1.4) 观察等式(1.4)的右半部分,我们不难看出输出项() i w a 服从均值为() i T P W ,方差为2 ?的高 斯分布。这里假设不同输入对应的偏置项() i p 是彼此独立同分布的,这意味着它们都服从均值和方差完全相同的高斯分布。现在我们定义一个似然性函数: ()()()() ??? ? ? ?--=???? ??-=22 222exp 21 2exp 21σσπσσπP W p a B W L T w (1.5) bp神经网络及matlab实现 分类:算法学习2012-06-20 20:56 66399人阅读评论(28) 收藏举报网络matlab算法functionnetworkinput 本文主要内容包括:(1) 介绍神经网络基本原理,(2) https://www.360docs.net/doc/cc9646687.html,实现前向神经网络的方法,(3) Matlab实现前向神经网络的方法。 第0节、引例 本文以Fisher的Iris数据集作为神经网络程序的测试数据集。Iris数据集可以在https://www.360docs.net/doc/cc9646687.html,/wiki/Iris_flower_data_set 找到。这里简要介绍一下Iris数据集: 有一批Iris花,已知这批Iris花可分为3个品种,现需要对其进行分类。不同品种的Iris花的花萼长度、花萼宽度、花瓣长度、花瓣宽度会有差异。我们现有一批已知品种的Iris花的花萼长度、花萼宽度、花瓣长度、花瓣宽度的数据。 一种解决方法是用已有的数据训练一个神经网络用作分类器。 如果你只想用C#或Matlab快速实现神经网络来解决你手头上的问题,或者已经了解神经网络基本原理,请直接跳到第二节——神经网络实现。 第一节、神经网络基本原理 1. 人工神经元( Artificial Neuron )模型 人工神经元是神经网络的基本元素,其原理可以用下图表示: 图1. 人工神经元模型 图中x1~xn是从其他神经元传来的输入信号,wij表示表示从神经元j到神经元i的连接权值,θ表示一个阈值( threshold ),或称为偏置( bias )。则神经元i的输出与输入的关系表示为: 图中yi表示神经元i的输出,函数f称为激活函数 ( Activation Function )或转移函数( Transfer Function ) ,net称为净激活(net activation)。若将阈值看成是神经元i的一个输入x0的权重wi0,则上面的式子可以简化为: 若用X表示输入向量,用W表示权重向量,即: X = [ x0 , x1 , x2 , ....... , xn ] 应用BP神经网络逼近非线性函 一、实验要求 1、逼近的非线性函数选取为y=sin(x1)+cos(x2),其中有两个自变量即x1,x2,一个因变量即y。 2、逼近误差<5%,即:应用测试数据对网络进行测试时,神经网络的输出与期望值的最大误差的绝对值小于期望值的5%。 3、学习方法为经典的BP算法或改进形式的BP算法,鼓励采用改进形式的BP算法。 4、不允许采用matlab中现有的关于神经网络建立、学习、仿真的任何函数及命令。 二、实验基本原理 2.1 神经网络概述 BP神经网络是一种多层前馈神经网络,该网络的主要特点是信号前向传播,误差反向传播。在前向传递中,输入信号从输入层经隐含层逐层处理,直至输出层。每一层的神经元状态只影响下一层神经元状态。如果输出层得不到期望输出,则转入反向传播,根据预判误差调整网络权值和阈值,从而使BP神经网络预测输出不断逼近期望输出。BP神经网络的拓扑结构如图所示。 2.2 BP神经网络训练步骤 BP神经网络预测前首先要训练网络,通过训练使网络具有联想记忆和预测能力。BP神经网络的训练过程包括以下几个步骤。 步骤1:网络初始化。根据系统输入输出序列(X,Y)确定网络输入层节点数n、隐含层节点数l、输出层节点数m,初始化输入层、隐含层和输出层神经元之间的连接权值ωij,ωjk,初始化隐含层阈值a,输出层阈值b,给定学习速率和神经元激励函数。 步骤2:隐含层输出计算。根据输入变量X,输入层和隐含层间连接权值ωij 以及隐含层阈值a,计算隐含层输出H。 j 1 (a )n j ij i i H f x ω==-∑ j=1,2,…,l 式中,l 为隐含层节点数,f 为隐含层激励函数,该函数有多种形式,一般选取为1 (x)1x f e -=+ 步骤3:输出层输出计算。根据隐含层输出H ,连接权值ωjk 和阈值b ,计算BP 神经 网络预测输出O 。 1 l k j jk k j O H b ω==-∑ k=1,2,…,m 步骤4:误差计算。根据网络预测输出O 和期望输出Y ,计算网络预测误差e 。 k k k e Y O =- k=1,2,…,m 步骤5:权值更新。根据网络预测误差e 更新网络连接权值ωij ,ωjk 1 (1)x(i)m ij ij j j jk k k H H e ωωηω==+-∑ i=1,2,…,n j=1,2,…,l jk jk j k H e ωωη=+ j=1,2,…,l k=1,2,…,m 步骤6:阈值更新。根据网络预测误差e 更新网络节点阈值a ,b 。 1 (1)m j j j j jk k k a a H H e ηω==+-∑ j=1,2,…,l k k k b b e =+ k=1,2,…,m 步骤7:判断算法迭代是否结束,若没有结束,返回步骤2。 2.3 附加动量法 经典BP 神经网络采用梯度修正法作为权值和阈值的学习算法,从网络预测误差的负梯 度方向修正权值和阈值,没有考虑以前经验的积累,学习过程收敛缓慢。对于这个问题,可以采用附加动量法来解决,带附加动量的算法学习公式为 [](k)(k 1)(k)a (k 1)(k 2)ωωωωω=-+?+--- 式中,ω(k),ω(k-1),ω(k-2)分别为k ,k-1,k-2时刻的权值;a 为动量学习率,一般取值为0.95。 MATLAB 神经网络工具箱函数 说明:本文档中所列出的函数适用于 MATLAB5.3以上版本, 为了简明起见, 只列出了函数名, 若需要进一步的说明,请参阅 MATLAB 的帮助文档。 1. 网络创建函数 newp 创建感知器网络 newlind 设计一线性层 newlin 创建一线性层 newff 创建一前馈 BP 网络 newcf 创建一多层前馈 BP 网络 newfftd 创建一前馈输入延迟 BP 网络 newrb 设计一径向基网络 newrbe 设计一严格的径向基网络 newgrnn 设计一广义回归神经网络 newpnn 设计一概率神经网络 newc 创建一竞争层 newsom 创建一自组织特征映射 newhop 创建一 Hopfield 递归网络 newelm 创建一 Elman 递归网络 2. 网络应用函数 sim 仿真一个神经网络 init 初始化一个神经网络 adapt 神经网络的自适应化 train 训练一个神经网络 3. 权函数 dotprod 权函数的点积 ddotprod 权函数点积的导数 dist Euclidean 距离权函数normprod 规范点积权函数negdist Negative 距离权函数mandist Manhattan 距离权函数linkdist Link 距离权函数 4. 网络输入函数 netsum 网络输入函数的求和dnetsum 网络输入函数求和的导数5. 传递函数 hardlim 硬限幅传递函数hardlims 对称硬限幅传递函数purelin 线性传递函数 tansig 正切 S 型传递函数 logsig 对数 S 型传递函数 dpurelin 线性传递函数的导数 dtansig 正切 S 型传递函数的导数dlogsig 对数 S 型传递函数的导数compet 竞争传递函数 radbas 径向基传递函数 satlins 对称饱和线性传递函数 6. 初始化函数 initlay 层与层之间的网络初始化函数initwb 阈值与权值的初始化函数initzero 零权/阈值的初始化函数 initnw Nguyen_Widrow层的初始化函数initcon Conscience 阈值的初始化函数midpoint 中点权值初始化函数 7. 性能分析函数 mae 均值绝对误差性能分析函数 mse 均方差性能分析函数 msereg 均方差 w/reg性能分析函数 有关BP神经网络参数的一些学习经验 1、BP网络的激活函数必须是处处可微的。 2、S型激活函数所划分的区域是一个非线性的超平面组成的区域,它是比较柔和、光滑的任意界面,因而它的分类比线性划分精确、合理,这种网络的容错性较好。另一个重要特点是由于激活函数是连续可微的,它可以严格利用梯度法进行推算。 3、一般情况下BP网络结构均是在隐含层采用S型激活函数,而输出层采用线性激活函数。 4、动手编写网络的程序设计之前,需要确定神经网络的结构,其中包括以下内容:网络的层数、每层的神经元数、每层的激活函数。 5、trainbp.m提供了两层和三层的BP训练程序,用户可以根据程序来选取不同的参数。 6、神经网络具有泛化性能,但是该性能只能对被训练的输入/输出对在最大值范围内的数据有效,即网络具有内插植特性,不具有外插植特性,超出最大训练的输入必将产生大的输出误差。 7、理论上已经证明:具有偏差和至少一个S型隐含层加上一个线性输出层网络,能够逼近任何有理函数。 8、隐含层层数的经验选择:对于线性问题一般可以采用感知器或自适应网络来解决,而不采用非线性网络,因为单层不能发挥出非线性激活函数的特长;非线性问题,一般采用两层或两层以上的隐含层,但是误差精度的提高实际上也可以通过增加隐含层中的神经元数目获得,其训练效果也比增加层数更容易观察和调整,所以一般情况下,应优先考虑增加隐含层中的神经元数。 9、隐含层的神经元数的经验确定:通过对不同神经元数进行训练对比,然后适当的增加一点余量。 10、初始权值的经验选取:威得罗等人分析了两层网络是如何对一个函数进行训练后。提出一种选定初值的策略:选择权值的量级为S1的r次方,其中S1为第一层神经元数目。利用他们的方法可以在较少的训练次数下得到满意的训练结果。在Matlab工具箱中可以采用nwlog.m和nwtan.m来初始化隐含层权值W1和B1。其方法仅需要使用在第一层隐含层初始值的选取上,后面层的初始值仍然采用(-1,1)之间的随机数。 11、学习速率的经验选择:一般情况下倾向于选取较小的学习速率以保证系统的稳定性,学习速率的选取范围在0.01~0.8之间。 12、期望误差的选取:一般情况下,作为对比,可以同时对两个不同的期望误差值的网络进行训练,最后通过综合因素的考虑来确定其中一个网络。 13、采用附加动量法使反向传播减少了网络在误差表面陷入低谷的可能性有助于减少训练时间。Matlab工具箱中提供的trainbpm.m可以训练一层直至三层的带有附加动量因子的反向传播网络。 14、太大的学习速率导致学习的不稳定,太小值又导致极长的训练时间。自适应学习速率通过保证稳定训练的前提下,达到了合理的高速率,可以减少训练时间。Matlab工具箱中带有自适应学习速率进行反向传播训练的函数为trainbpa.m,它可以训练至三层网络。 15、可以将动量法和自适应学习速率结合起来利用两方面的优点,这个技术已经编入函数trainbpx.m中。 入门 | 了解神经网络,你需要知道的名词都在这里 近日,Mate Labs 联合创始人兼 CTO 在 Medium 上撰文《Everything you need to know about Neural Networks》,从神经元到 Epoch,扼要介绍了神经网络的主要核心术语。 理解什么是人工智能,以及机器学习和深度学习如何影响它,是一种不同凡响的体验。在 Mate Labs 我们有一群自学有成的工程师,希望本文能够分享一些学习的经验和捷径,帮助机器学习入门者理解一些核心术语的意义。 神经元(节点)—神经网络的基本单元,它包括特定数量的输入和一个偏置值。当一个信号(值)输入,它乘以一个权重值。如果一个神经元有 4 个输入,则有 4 个可在训练中调节的权重值。 神经网络中一个神经元的运算 连接—它负责连接同层或两层之间的神经元,一个连接总是带有一个权重值。训练的目标是更新这一权重值以降低损失(误差)。 偏置(Offset)—它是神经元的额外输入,值总是 1,并有自己的连接权重。这确保即使当所有输入为 0 时,神经元中也存在一个激活函数。 激活函数(迁移函数)—激活函数负责为神经网络引入非线性特征。它把值压缩到一个更小范围,即一个Sigmoid 激活函数的值区间为 [0,1]。深度学习中有很多激活函数,ReLU、SeLU 、TanH 较 Sigmoid 更为常用。更多激活函数,请参见《一文概览深度学习中的激活函数》。 各种激活函数 基本的神经网络设计 输入层—神经网络的第一层。它接收输入信号(值)并将其传递至下一层,但不对输入信号(值)执行任何运算。它没有自己的权重值和偏置值。我们的网络中有 4 个输入信号 x1、x2、x3、x4。 隐藏层—隐藏层的神经元(节点)通过不同方式转换输入数据。一个隐藏层是一个垂直堆栈的神经元集。下面的图像有 5 个隐藏层,第 1 个隐藏层有 4 个神经元(节点),第 2 个 5 个神经元,第 3 个 6 个神经元,第 4个 4 个神经元,第 5 个 3 个神经元。最后一个隐藏层把值传递给输出层。隐藏层中所有的神经元彼此连接,下一层的每个神经元也是同样情况,从而我们得到一个全连接的隐藏层。 输出层—它是神经网络的最后一层,接收来自最后一个隐藏层的输入。通过它我们可以得到合理范围内的理想数值。该神经网络的输出层有 3 个神经元,分别输出 y1、y2、y3。 输入形状—它是我们传递到输入层的输入矩阵的形状。我们的神经网络的输入层有 4 个神经元,它预计 1 个样本中的 4 个值。该网络的理想输入形状是 (1, 4, 1),如果我们一次馈送它一个样本。如果我们馈送 100 个样本,输入形状将是 (100, 4, 1)。不同的库预计有不同格式的形状。 权重(参数)—权重表征不同单元之间连接的强度。如果从节点 1 到节点 2 的权重有较大量级,即意味着神将元 1 对神经元 2 有较大的影响力。一个权重降低了输入值的重要性。权重近于 0 意味着改变这一输入将不会改变输出。负权重意味着增加这一输入将会降低输出。权重决定着输入对输出的影响力。 前向传播 前向传播—它是把输入值馈送至神经网络的过程,并获得一个我们称之为预测值的输出。有时我们也把前向传播称为推断。当我们馈送输入值到神经网络的第一层时,它不执行任何运算。第二层接收第一层的值,接着执行乘法、加法和激活运算,然后传递至下一层。后续的层重复相同过程,最后我们从最后一层获得输出值。 1 神经网络学习笔记 发表于2016/4/14 22:41:51 3754人阅读 分类: machine-learning 2 神经网络 3 sigmoid函数 sigmoid函数是一种常见的挤压函数,其将较大范围的输入挤压到(0,1)区间内,其函数的表达式与形状如下图所示: 该函数常被用于分类模型,因为其具有很好的一个特性f′(x)=f(x)(1?f (x))。这个函数也会被用于下面的神经网络模型中做激活函数。 4 M-P神经元模型 生物的神经网络系统中,最简单最基本的结构是神经元。每个神经元都是接受其他多个神经元传入的信号,然后将这些信号汇总成总信号,对比总信号与阈值,如果超过阈值,则产生兴奋信号并输出出去,如果低于阈值,则处于抑制状态。McCulloch在1 943年将该过程抽象成如下图所示的简单模型: 该模型称为“M-P神经元模型”。通过上图我们可以知道,当前神经元的输入是来自其他 n个神经元的带权值的输出,而激活函数f()是一个如下图所示的阶跃函数 我们可以看到当总的输入小于阈值的时候,神经元处于抑制状态,输出为0,而当总输入大于阈值,则神经元被激活为兴奋状态,输出1。但是我们发现该函数是不连续且不光滑的,使用起来会很不方便,因此在实际应用中常常使用sigmoid函数代替阶跃函数做神经元的激活函数。 5 感知器模型 感知器模型,是一种最简单的神经网络模型结构,其网络结构包括输入层与输出层两层,如下图所示: 其为具有两个输入神经元,一个输出神经元的感知器模型。我们知道该模型是可以做 与或非运算的。这是因为如果我们要做与或非运算,那么对于输入x1,x2来说,其取值只能是0或1,而我们的输出y=f(∑2i=1ωi x i?θ),如果要做与运算,那令阈值ω1=1,ω2=1,θ=2,则只有在x1=1,x2=1的时候才能激活输出层神经元,输出1,其余情况均输出0。同样,如果做或运算,那令阈值ω1=1,ω2=1,θ=1,则只要有一个输入x i=1,即可激活输出神经元, 输出1,如果对x1做非运算,那么可以令阈值ω1=?0.6,ω2=0,θ= 神经网络近似函数 题目: 采用神经网络逼近下列函数: 双极值型算例 9655 .0,537.0] 3,0[2/)3)(89.22.3()(max max 2==∈-+--=f x x x x x x x f 最优值 解: )(x f 的实际图如下: 神经网络训练前: 应用newff()函数建立BP 网络结构。隐层神经元数目n 可以改变,暂设为n=5,输出层有一个神经元。选择隐层和输出层神经元传递函数分别为tansig 函数和purelin 函数,网络训练的算 法采用Levenberg – Marquardt算法trainlm。 因为使用newff( )函数建立函数网络时,权值和阈值的初始化是随机的,所以网络输出结构很差,根本达不到函数逼近的目的,每次运行的结果也不同。 神经网络训练后 应用train()函数对网络进行训练之前,需要预先设置网络训练参数。将训练时间设置为500,训练精度设置为0.001,其余参数使用缺省值。训练后得到的误差变化过程如下所示。 由上图可知,逼近结果未达到目标,为此我们增加神经元数目n=20; 仿真结果如下: 至此,神经网络逼近结果符合要求。 下图是训练时间图: 从以上结果可以看出,网络训练速度很快,很快就达到了要求的精度0.001。 结论: 1.n 取不同的值对函数逼近的效果有很大的影响。改变BP 网络隐层神经元的数目,可以改变BP 神经网络对于函数的逼近效果。隐层神经元数目越多,则BP 网络逼近非线性函数的能力越强。(左边n=3,右边n=20) 2.不同的精度要求,对函数的逼近效果也不同。精度要求越高,逼近效果越好。 (左边精度为0.01,右边为0.001) 程序文本: clear all; x=[0:0.001:3]; y=-x.*(x.*x-3.2*x+2.89).*(x-3)/2.0; net=newff(minmax(x),[5,1],{'tansig''purelin'},'trainlm'); y1=sim(net,x); %神经网络训练前 net.trainParam.epochs=500; net.trainParam.goal=0.001; net=train(net,x,y);BP神经网络的Matlab语法要点
神经网络
神经网络算法详解
浅谈神经网络分析解析
神经网络作业(函数逼近)
神经网络误差函数大全
bp神经网络及matlab实现
BP神经网络逼近非线性函数
Matlab神经网络工具箱函数.
有关BP神经网络参数的一些学习经验
了解神经网络,你需要知道的名词都在这里
神经网络学习笔记
神经网络逼近函数