单样本t检验

单样本t检验
(1)建立检验假设,确定检验标准
H0:μ=μ0=140g/L,即从事铅作业男性工人与正常成年男性的血红蛋白含量均数相等
H:μ≠μ0=140g/L,即从事铅作业男性工人与正常成年男性的血红蛋白含量均数不等
?=0.05
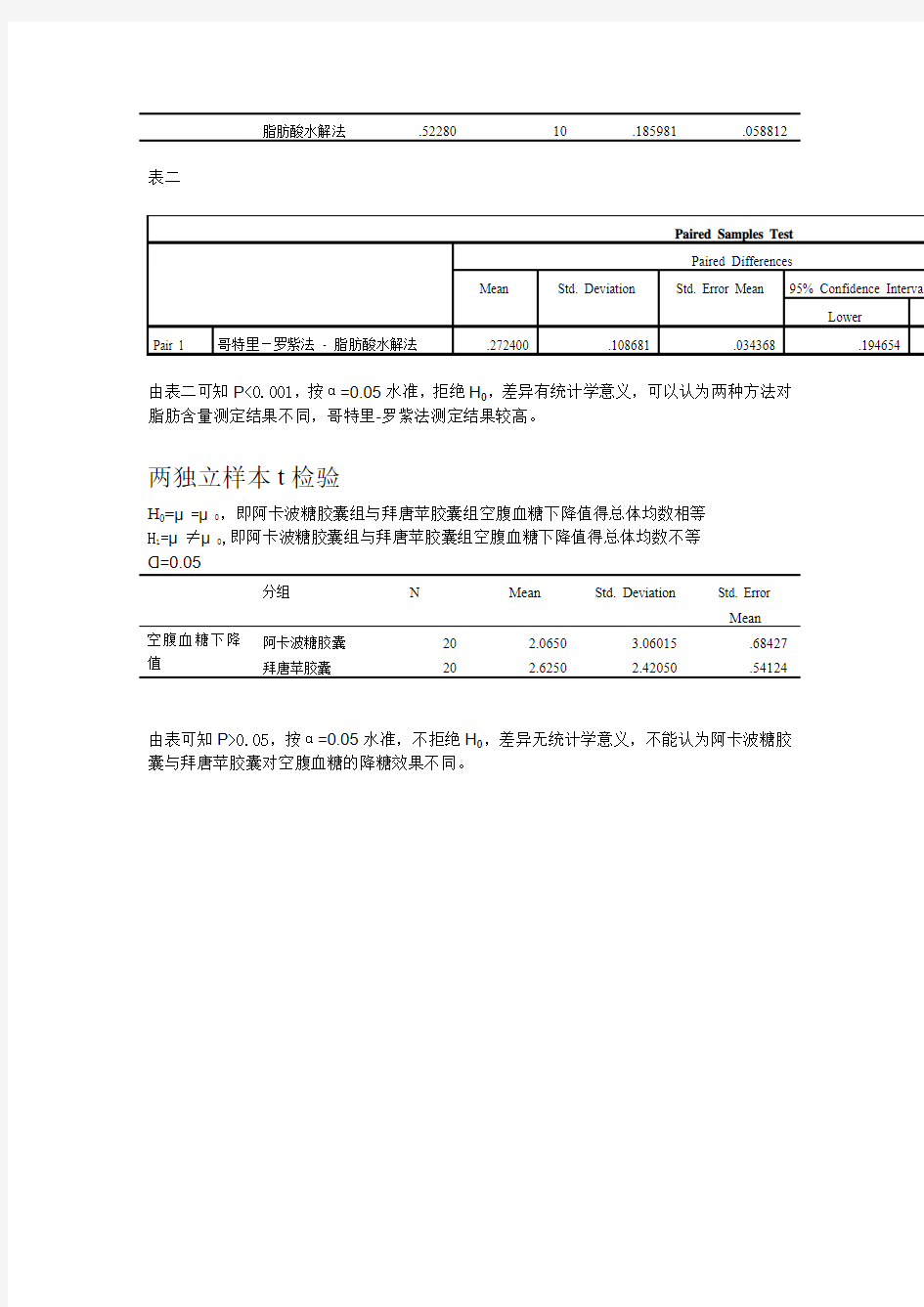
表一
N Mean Std. Deviation Std. Error Mean 血红蛋白含量36130.8325.741 4.290
表二
Test Value = 140
t df Sig.
(2-tailed)
Mean
Difference
95% Confidence Interval of
the Difference
Lower Upper
血红蛋白含
量
-2.13735.040-9.167-17.88-.46
(2)计算检验统计量
本例n=36,x=130.83g/L,S=25.74g/L,μ0=140g/L.按公式得
t=(130.83-140)÷(25.74/36)=-2.138,v=36-1=35
(3)确定P值,做出推断结论
以v=35,︱t︱=︱-2.138︱查表可知0.02 配对t检验 H0=μ=μ0,即两种方法的测定结果相等 H1=μ≠μ0,即两种方法的测定结果不等 ?=0.05 表一 Mean N Std. Deviation Std. Error Mean Pair 1哥特里-罗紫 法 .7952010.184362.058300 脂肪酸水解法.5228010.185981.058812 表二 Paired Samples Test Paired Differences Mean Std. Deviation Std. Error Mean 95% Confidence Interval Lower Pair 1 哥特里-罗紫法- 脂肪酸水解法.272400 .108681 .034368 .194654 由表二可知P<0.001,按ɑ=0.05水准,拒绝H0,差异有统计学意义,可以认为两种方法对 脂肪含量测定结果不同,哥特里-罗紫法测定结果较高。 两独立样本t检验 H0=μ=μ0,即阿卡波糖胶囊组与拜唐苹胶囊组空腹血糖下降值得总体均数相等 H1=μ≠μ0,即阿卡波糖胶囊组与拜唐苹胶囊组空腹血糖下降值得总体均数不等 ?=0.05 分组N Mean Std. Deviation Std. Error Mean 空腹血糖下降值阿卡波糖胶囊20 2.0650 3.06015.68427拜唐苹胶囊20 2.6250 2.42050.54124 由表可知P>0.05,按ɑ=0.05水准,不拒绝H0,差异无统计学意义,不能认为阿卡波糖胶囊与拜唐苹胶囊对空腹血糖的降糖效果不同。 例题7.5一家食品生产企业以生产袋装食品为主,每天的产量大约为8000袋左右。按规定每袋的重量应为100g。为对产品质量进行检测,企业质检部门经常要进行抽检,以分析 每袋重量是否符合要求。现从某天生产的一批食品中随机抽取25袋,测得每袋重量如表7—2所示。 表7—2 25袋食品的重量 112.5 101.0 103.0 102.0 110.5 102.6 107.5 95.0 108.8 115.6 100.0 123.5 102.0 101.6 102.2 116.6 95.4 97.8 108.6 105.0 136.8 102.8 101.5 98.4 93.3 已知产品重量的分布,且总体标准差为10g,试估计该天产品平均质量的置信区间,以为95%建立该种食品重量方差的置信区间。 解:已知δ=10,n=25,置信水平1-α=95%,Z x/2=1.96 案例处理摘要 案例 有效缺失合计 N 百分比N 百分比N 百分比 重量25 100.0% 0 .0% 25 100.0% 描述 统计量标准误 重量均值105.7600 1.93038 均值的95% 置信区间下限101.7759 上限109.7441 5% 修整均值104.8567 中值102.6000 方差93.159 标准差9.65190 极小值93.30 极大值136.80 范围43.50 四分位距9.15 偏度 1.627 .464 峰度 3.445 .902 重量 重量 Stem-and-Leaf Plot Frequency Stem & Leaf 1.00 9 . 3 4.00 9 . 5578 10.00 10 . 0111222223 4.00 10 . 5788 2.00 11 . 02 T检验 习题1.按规定苗木平均高达1.60m以上可以出圃,今在苗圃中随机抽取10株苗木,测定的苗木高度如下: 1.75 1.58 1.71 1.64 1.55 1.72 1.62 1.83 1.63 1.65 假设苗高服从正态分布,试问苗木平均高是否达到出圃要求?(要求α=0.05) 解:1)根据题意,提出:无效假设为:苗木的平均苗高为H0=1.6m; 备择假设为:苗木的平均苗高H A>1.6m; 2)定义变量:在spss软件中的“变量视图”中定义苗木苗高, 之后在“数据视图”中输入苗高数据; 3)分析过程 在spss软件上操作分析过程如下:分析——比较均值——单样本T检验——将定义苗高导入检验变量——检验值定义为1.6——单击选项将置信区间设为95%——确定输出如下: 表1.1:单个样本统计量 表1.2:单个样本检验 4)输出结果分析 由表1.1数据分析可知,变量苗木苗高的平均值为1.6680m,标 准差为0.0843,说明样本的离散程度较小,标准误为0.0267,说明抽样误差较小。 由表1.3数据分析可知,T检验值为2.55,样本自由度为9,t检验的双尾检验值为0.031<0.05,说明差异性显著,因此,否定无效假设H0,取备择假设H A。 根据题意,苗木的苗高服从正态分布,由以上分析知:在显著水平为0.05的水平上检验,苗木的平均苗高大于1.6m,符合出圃的要求。 习题2.从两个不同抚育措施育苗的苗圃中各以重复抽样的方式抽得样本如下: 样本1苗高(CM):52 58 71 48 57 62 73 68 65 56 样本2苗高(CM):56 75 69 82 74 63 58 64 78 77 66 73 设苗高服从正态分布且两个总体苗高方差相等(齐性),试以显著水平α=0.05检验两种抚育措施对苗高生长有无显著性影响。 解:1)根据题意提出:无效假设为H0:两种抚育措施对苗木生长没有显著的影响;备择假设H A:两种抚育措施对苗高生长影响显著; 2)在spss中的“变量视图”中定义变量“苗高1”,“抚育措施”,之后在“数据视图”中输入题中的苗高数据,及抚育措施,其中措施一定义为“1”措施二定义为“2”; 3)分析过程 在spss软件上操作分析过程如下:分析——比较变量——独立 第四章抽样误差与假设检验 练习题 一、单项选择题 1. 样本均数的标准误越小说明 A. 观察个体的变异越小 B. 观察个体的变异越大 C. 抽样误差越大 D. 由样本均数估计总体均数的可靠性越小 E. 由样本均数估计总体均数的可靠性越大 2. 抽样误差产生的原因是 A. 样本不是随机抽取 B. 测量不准确 C. 资料不是正态分布 D. 个体差异 E. 统计指标选择不当 3. 对于正偏态分布的的总体, 当样本含量足够大时, 样本均数的分布近似为 A. 正偏态分布 B. 负偏态分布 C. 正态分布 D. t分布 E. 标准正态分布 4. 假设检验的目的是 A. 检验参数估计的准确度 B. 检验样本统计量是否不同 C. 检验样本统计量与总体参数是否不同 D. 检验总体参数是否不同 E. 检验样本的P值是否为小概率 5. 根据样本资料算得健康成人白细胞计数的95%可信区间为7.2×109/L~ 9.1×109/L,其含义是 A. 估计总体中有95%的观察值在此范围内 B. 总体均数在该区间的概率为95% C. 样本中有95%的观察值在此范围内 D. 该区间包含样本均数的可能性为95% E. 该区间包含总体均数的可能性为95% 答案:E D C D E 二、计算与分析 1.为了解某地区小学生血红蛋白含量的平均水平,现随机抽取该地小学生450人,算得其血红蛋白平均数为101.4g/L,标准差为1.5g/L,试计算该地小学生血红蛋白平均数的95%可信区间。 [参考答案] 样本含量为450,属于大样本,可采用正态近似的方法计算可信区间。 101.4 X=, 1.5 S=,450 n=,0.07 X S=== 95%可信区间为 下限: /2.101.4 1.960.07101.26 X X u S α=-?= -(g/L) 上限: /2.101.4 1.960.07101.54 X X u S α +=+?=(g/L) 即该地成年男子红细胞总体均数的95%可信区间为101.26g/L~101.54g/L。 2.研究高胆固醇是否有家庭聚集性,已知正常儿童的总胆固醇平均水平是175mg/dl,现测得100名曾患心脏病且胆固醇高的子代儿童的胆固醇平均水平为207.5mg/dl,标准差为30mg/dl。问题: ①如何衡量这100名儿童总胆固醇样本平均数的抽样误差? ②估计100名儿童的胆固醇平均水平的95%可信区间; ③根据可信区间判断高胆固醇是否有家庭聚集性,并说明理由。 [参考答案] ①均数的标准误可以用来衡量样本均数的抽样误差大小,即 30 S=mg/dl,100 n= 3.0 X S=== ②样本含量为100,属于大样本,可采用正态近似的方法计算可信区间。 207.5 X=,30 S=,100 n=,3 X S=,则95%可信区间为 下限: /2.207.5 1.963201.62 X X u S α=-?= -(mg/dl) 独立样本的T检验 (independent-samples T T est) 对于相互独立的两个来自正态总体的样本,利用独立样本的T 检验来检验这两个样本的均值和方差是否来源于同一总体。在SPSS 中,独立样本的T检验由“Independent-Sample T Test”过程来完成。 例:双语教师的英语水平有高低之分,他们(她们)所教的学生对双语教学的态度是否有显著差异? 例题分析: ——研究目的:寻找差异 ——自变量:双语教师的英语水平(ordinal data等级变量),有两个水平:;level1低水平,level2 高水平 ——因变量:学生的双语教学态度(interval data等距变量) SPSS操作步骤 ·Analyze→Compare Means→Independent Samples T Test ·Click the 双语教学态度to the column of “Test V ariable(s)” and the 教师英语水平分组to the column of “Grouping variable” ·Click the button of “Define Groups…” and put the group numbers “1” and “3” into Group 1 and Group 2, and “Continue” back, then “OK”. 结果在论文中的呈现方式 独立样本T检验结果显示,双语教师的英语水平不同,其所教学生对双语教学的态度有显著差异(t=-3,249, df=72, p<0.05)。双语教师英语水平较低所教的学生,他们对双语教学态度的得分也显著低于英语水平较高的双语教师所教的学生(MD=-0.65)。这可能是因为…… 练习:文科生和理科生对双语教学的态度是否有显著差异? 配对样本T检验(Paired-samples T Test) 配对样本T检验,用于检验两个相关的样本(配对资料)是否来自具有相同均值的总体。 例:本次调查中,学生对自己英语能力水平和英语知识水平的评价之间是否有显著差异? 例题分析: ——研究目的:寻找差异 ——自变量:学生的评价对象(norminal data定类数据),有两个水平:level1对自身英语能力水平的评价,level2对自身英语知识水平的评价。 ——因变量:学生自身英语能力和知识的评价分数 spss单样本t检验Analyze----compare Means----one sample T test 输入方式 实验数据 12 12 1 2 1 2 3 4 5 6 4 9 5 直接输入数据 Sig=0.000 差异显著 独立样本t检验(两组数据) Analyze-----compare Means----Independent-samples T test 输入方式 试验分组实验数据 1 12 1 13 1 12 1 12 1 1 1 1 2 2 2 2 2 2 2 2 2 两组数据个数可以不同 成组数据t检验 Analyze----compare Means-----paired-samples T test 单因素方差分析 Analyze---compare means----one-way ANOV A(analyze of variance) Factor (因素)1 1 1 1 1 2 2 2 2 2 2 3 3 3 3(分组) Dependent List 试验数据 polynomial lines contrast---polynomial---Degree---linear post Hoc Multiple comparisons-----LSD(Duncan 邓肯检验) 先选方差齐性在结果中判断Sig 值?<0.05(差异显著)若不齐则进行数据转化。 数据输入 分组试验数据 1 12 1 13 1 13 1 1 2 2 2 2 2 2 3 3 3 3 3 3 4 4 4 4 4 4 双因素方差分析 Analyze-----General linear Model-----univariate Dependent Variable(因变因素)因别的数字变化而变化 Fixed Factor (固定因素) Random Factors(随机因素) Model-----custom-----Build Term---Interaction(交互作用)----Main effects(主因素) Contrast--- simple---first----change Plot Hoc----LSD (Duncan) 教育统计学t检验练习内部编号:(YUUT-TBBY-MMUT-URRUY-UOOY-DBUYI-0128) 实验报告实验名称:t 检验成绩: 实验日期: 2011年10月31日实验报告日期:2011年11 月日 林虹 一、实验目的 (1)掌握单一样本t检验。 (2)掌握相关样本t检验 (3)掌握独立样本t检验 二、实验设备 (1)微机 (2)SPSS for Windows 统计软件包 三、实验内容: 1.某市统一考试的数学平均成绩为75分,某校一个班的成绩见表4-1。问该班的 成绩与全市平均成绩的差异显着吗 表4-1 学生的数学成绩 12345678910111213141516 编 号 成96977560926483769097829887568960 号 68747055858656716577566092548780 成 绩 2.某物理教师在教学中发现,在课堂物理教学中采用“先讲规则(物理的定理或 法则),再举例题讲解规则的具体应用”与采用“先讲例题,再概括出解题规则”这两种教学方法的教学效果似乎不同。为了验证他的这个经验性发现是否属实,他选择了两个近似相等的班级进行教学实验。进行教学实验时的教学内容、教学时间和教学地点等无关变量他都做了严格的控制,分别采用“例-规” 法与“规-例”法对两个班的学生进行物理教学,然后,两个班的被试都进行同样的物理知识测验。测验成绩按“5分制”进行评定。两组被试的测验成绩见数据文件data4-02。请用SPSS,通过适当的统计分析方法,检验这两种教学方法的教学效果是否存在实质性差别。 3.某幼儿园分别在儿童入园时和入园一年后对他们进行了“比奈智力测验”,测 验结果见数据文件data4-03。请问,儿童入园一年后的智商有明显的变化吗(例题) 4.某心理学工作者以大学生为被试,以“正性”和“负性”两种面部表情模式的 照片为实验材料,测量被试对“正性”和“负性”面部表情识别的时间,测验结果见数据文件data4-04。请用SPSS中适当的统计分析方法检验两种面部表情模式对大学生识别面部表情的时间是否存在明显的影响。 5.某小学教师分别采用“集中学习”与“分散学习”两种方式教两个小学二年级 班级的学生学习相同的汉字,两个班学生的学习成绩见data4-05。请问哪种学习方式效果更好 6.某省语文高考平均成绩为78分,某学校的成绩见data4-06。请问该校考生的 平均成绩与全省平均成绩之间的差异显着吗 ** 用SPSS19进行单样本T检验(One -Sample T Test) 作者:邀月来源:博客园发布时间:2010-10-14 00:13 阅读:305 次原文链接[收藏] 在《0-1总体分布下的参数假设检验示例一(SPSS实现)》中,我们简要介绍了用SPSS 检验二项分布的参数。今天我们继续看看如何用SPSS进行单样本T检验(One -Sample T Test)。看例子: 例1:已知去年某市小学五年级学生400米的平均成绩是100秒,今年该市抽样测得60个五年级学生的400米成绩(数据见后面文件“CH6参检1小学生400米v提高.sav”),试检验该市五年级学生的400米平均成绩是否应为100秒(有无提高或下降)? 分析:此检验的假设是: H0:该市五年级学生的400米平均成绩是仍为100秒。 H1:该市五年级学生的400米平均成绩是不为100秒。 打开SPSS,读入数据 从结果中可以判断: 1、p=0.287>0.05,在5%的显著性水平上,不能拒绝假设H0。 2、95%的置信区间端点一正一负,必然覆盖总体均值。应该接受零假设(假设H0)。 这个结论出乎很多人的意料,因为样本均值明显下降了,105.38500000000003。实际上,那是因为有一个样本值为400秒,从而造成错觉的缘故。 再看一个更有趣的例子。 例1:已知去年某市小学五年级学生400米的平均成绩是100秒,今年该市抽样测得60个五年级学生的400米成绩(数据见后面文件“CH6参检1小学生400米v提高B.sav”),试检验该市五年级学生的400米平均成绩是否应为100秒(有无提高或下降)? 同上,打开SPSS,读入数据,结果: 单一样本的T检验 如果已知总体均数,进行样本均数与总体均数之间的差异显著性检验属于单一样本的T 检验。在SPSS中,单一样本的T检验由“One-Sample T Test”过程来完成。 [例子] 有一种新型农药防治柑桔红蜘蛛,进行了9个小区的实验,其防治效果为: 95%,92%,88%,92%,93%,95%,89%,98%,92% 与原用农药的防治效果90%比较,分析其效果是否高于原用农药。该数据保存在“DATA4-2.SA V”文件中。 1)准备分析数据 在数据编辑窗口输入分析的数据,如图4-4所示。或者打开需要分析的数据文件“DATA4-2.SA V”。 图4-4 数据窗口 2)启动分析过程 在SPSS主菜单选中“Analyze→Compare Means→One-Sample T Test”,打开单一样本T 检验主对话框,如图4-5。 图4-5 单一样本T检验变量选择窗 3)设置分析变量 设置检验变量:从左边的变量列表中选中“防治效果”变量后,点击中部的右拉按钮后,这个变量就进入到检验分析“Test Variable(s):”框里,用户可以从左边变量列表里选择一个或多个变量进行分析。 输入检验值:在“Test Variable(s)”输入栏里,输入用于比较检验的均值:在本例中为90。 4)设置其他参数 单击“Options”按钮,打开设置检验的置信度和缺失值对话框。 在“Confidence Interval :”框输入置信度水平,系统默认为95%。 在“Missing Values”栏里选择缺失值处理方式: 5)提交执行 输入完成后,在过程主窗口中单击“OK”按钮,SPSS 输出分析结果如表4-3和表4-4。 6)结果与分析 表4-3 单一样本的统计量列表 One-Sample Statistics Test Value = 90 95% Confidence Interval of the Difference t df Sig .(2-tailed )Mean Difference Lower Upper 防治效果 2.596 8 .032 2.6667 .29755.0359 表4-4 均值的检验结果 One-Sample Test 在表4-4中,各项的意义分别为:t T 统计量;df 自由度;Sig (2-ailed )双尾T 检验的显著性概率;Mean Difference 检验值和实际值的差;95%Confidence Interval of the Difference 具有95%置信度的范围。 实验报告实验名称:t 检验成绩: 实验日期: 2011年10月31日实验报告日期:2011年11 月日 林虹 一、实验目的 (1)掌握单一样本t检验。 (2)掌握相关样本t检验 (3)掌握独立样本t检验 二、实验设备 (1)微机 (2)SPSS for Windows V17.0统计软件包 三、实验内容: 1.某市统一考试的数学平均成绩为75分,某校一个班的成绩见表4-1。 问该班的成绩与全市平均成绩的差异显着吗? 表4-1 学生的数学成绩 12345678910111213141516编 号 成 96977560926483769097829887568960绩 编 17181920212223242526272829303132号 成 68747055858656716577566092548780绩 2.某物理教师在教学中发现,在课堂物理教学中采用“先讲规则(物理的 定理或法则),再举例题讲解规则的具体应用”与采用“先讲例题,再概括出解题规则”这两种教学方法的教学效果似乎不同。为了验证他的这个经验性发现是否属实,他选择了两个近似相等的班级进行教学实验。进行教学实验时的教学内容、教学时间和教学地点等无关变量他都做了严格的控制,分别采用“例-规”法与“规-例”法对两个班的学生进行物理教学,然后,两个班的被试都进行同样的物理知识测验。测验成绩按“5分制”进行评定。两组被试的测验成绩见数据文件data4-02。 请用SPSS,通过适当的统计分析方法,检验这两种教学方法的教学效果是否存在实质性差别。 3.某幼儿园分别在儿童入园时和入园一年后对他们进行了“比奈智力测 验”,测验结果见数据文件data4-03。请问,儿童入园一年后的智商有明显的变化吗? (例题) 4.某心理学工作者以大学生为被试,以“正性”和“负性”两种面部表情 模式的照片为实验材料,测量被试对“正性”和“负性”面部表情识别的时间,测验结果见数据文件data4-04。请用SPSS中适当的统计分析方法检验两种面部表情模式对大学生识别面部表情的时间是否存在明显的影响。 5.某小学教师分别采用“集中学习”与“分散学习”两种方式教两个小学 t检验有单样本t检验,配对t检验和两样本t检验。 单样本t检验:是用样本均数代表的未知总体均数和已知总体均数进行比较,来观察此组样本与总体的差异性。 配对t检验:是采用配对设计方法观察以下几种情形,1,两个同质受试对象分别接受两种不同的处理;2,同一受试对象接受两种不同的处理;3,同一受试对象处理前后。 u检验:t检验和就是统计量为t,u的假设检验,两者均是常见的假设检验方法。当样本含量n较大时,样本均数符合正态分布,故可用u检验进行分析。当样本含量n小时,若观察值x符合正态分布,则用t检验(因此时样本均数符合t分布),当x为未知分布时应采用秩和检验。 F检验又叫方差齐性检验。在两样本t检验中要用到F检验。 从两研究总体中随机抽取样本,要对这两个样本进行比较的时候,首先要判断两总体方差是否相同,即方差齐性。若两总体方差相等,则直接用t检验,若不等,可采用t'检验或变量变换或秩和检验等方法。 其中要判断两总体方差是否相等,就可以用F检验。 简单的说就是检验两个样本的方差是否有显著性差异这是选择何种T检验(等方差双样本检验,异方差双样本检验)的前提条件。 在t检验中,如果是比较大于小于之类的就用单侧检验,等于之类的问题就用双侧检验。 卡方检验 是对两个或两个以上率(构成比)进行比较的统计方法,在临床和医学实验中应用十分广泛,特别是临床科研中许多资料是记数资料,就需要用到卡方检验。 方差分析 用方差分析比较多个样本均数,可有效地控制第一类错误。方差分析(analysis of variance,ANOV A)由英国统计学家,以F命名其统计量,故方差分析又称F检验。 其目的是推断两组或多组资料的总体均数是否相同,检验两个或多个样本均数的差异是否有统计学意义。我们要学习的主要内容包括 单因素方差分析即完全随机设计或成组设计的方差分析(one-way ANOVA): 用途:用于完全随机设计的多个样本均数间的比较,其统计推断是推断各样本所代表的各总体均数是否相等。完全随机设计(completely random design)不考虑个体差异的影响,仅涉及一个处理因素,但可以有两个或多个水平,所以亦称单因素实验设计。在实验研究中按随机化原则将受试对象随机分配到一个处理因素的多个水平中去,然后观察各组的试验效应;在观察研究(调查)中按某个研究因素的不同水平分组,比较该因素的效应。 两因素方差分析即配伍组设计的方差分析(two-way ANOV A): 用途:用于随机区组设计的多个样本均数比较,其统计推断是推断各样本所代表的各总体均数是否相等。随机区组设计考虑了个体差异的影响,可分析处理因素和个体差异对实验效应的影响,所以又称两因素实验设计,比完全随机设计的检验效率高。该设计是将受试对象先按配比条件配成配伍组(如动物实验时,可按同窝别、同性别、体重相近进行配伍),每个配伍组有三个或三个以上受试对象,再按随机化原则分别将各配伍组中的受试对象分配到各个处理组。值得注意的是,同一受试对象不同时间(或部位)重复多次测量所得到的资料称为重复测量数据(repeated measurement data),对该类资料不能应用随机区组设计的两因素方差分析进行处理,需用重复测量数据的方差分析。 方差分析的条件之一为方差齐,即各总体方差相等。因此在方差分析之前,应首先检验各样本的方差是否具有齐性。常用方差齐性检验(test for homogeneity of variance)推断各总体方差是否相等。本节将介绍多个样本的方差齐性检验,本法由Bartlett于1937年提出,称Bartlett 法。该检验方法所计算的统计量服从分布。 第四章:定量资料的参数估计与假设检验基础1抽样与抽样误差 抽样方法本身所引起的误差。当由总体中随机地抽取样本时,哪个样本被抽到是随机的,由所抽到的样本得到的样本指标x与总体指标μ之间偏差,称为实际抽样误差。当总体相当大时,可能被抽取的样本非常多,不可能列出所有的实际抽样误差,而用平均抽样误差来表征各样本实际抽样误差的平均水平。 σx=σ/ Sx=S/ 2t分布 t分布曲线形态与n(确切地说与自由度v)大小有关。与标准正态分布曲线相比,自由度v越小,t分布曲线愈平坦,曲线中间愈低,曲线双侧尾部翘得愈高;自由度v愈大,t分布曲线愈接近正态分布曲线,当自由度v=∞时,t分布曲线为标准正态分布曲线。 t=X-u/Sx=X-u/(S/),V=N-1 正态分布(normaldistribution)是数理统计中的一种重要的理论分布,是许多统计方法的理论基础。正态分布有两个参数,μ和σ,决定了正态分布的位置和形态。为了应用方便,常将一般的正态变量X通过u变换[(X-μ)/σ]转化成标准正态变量u,以使原来各种形态的正态分布都转换为μ=0,σ=1的标准正态分布(standardnormaldistribution),亦称u分布。 根据中心极限定理,通过上述的抽样模拟试验表明,在正态分布总体中以固定n,抽取若干个样本时,样本均数的分布仍服从正态分布,即N(μ,σ)。所以,对样本均数的分布进行u 变换,也可变换为标准正态分布N(0,1) 由于在实际工作中,往往σ是未知的,常用s作为σ的估计值,为了与u变换区别,称为t变换,统计量t值的分布称为t分布。 假设X服从标准正态分布N(0,1),Y服从χ2(n)分布,那么Z=X/sqrt(Y/n)的分布称为自由度为n的t分布,记为Z~t(n)。 特征: 1.以0为中心,左右对称的单峰分布; MINITAB 协助白皮书 本书包括一系列文章,解释了 Minitab 统计人员为制定在 Minitab 统计软件的“协助”中使用的方法和数据检查所开展的研究。 单样本 t 检验 概述 单样本 t 检验用于估计检验过程的平均值并将该平均值与目标值进行比较。该检验操作起来 比较可靠,因为当样本大小适中时,它对正态性假设极不敏感。根据大多数统计教材中的内容,单样本 t 检验和平均值的 t 置信区间适合任何大小为 30 或以上的样本。 在本文中,我们介绍了对这个针对至少 30 个样本单位的一般规则进行评估的模拟方法。我们的模拟重点关注非正态性对单样本 t 检验产生的影响。我们也希望评估异常数据对检验结果 的影响。 根据我们的研究,“协助”会自动对您的数据进行以下检查并在“报告卡”中显示研究结果:?异常数据 ?正态性(样本量是否足够大,因此正态性不是问题?) ?样本量 有关单样本 t 检验方法的一般信息,请参见 Arnold (1990), Casella and Berger (1990), Moore and McCabe (1993), and Srivastava (1958)。 注意:本文中的研究结果也适用于“协助”中的配对 t 检验,因为配对 t 检验对配对差异样本应用单样本 t 检验方法。 https://www.360docs.net/doc/c514044172.html, 数据检查 异常数据 异常数据是非常大或非常小的数据值,也称为异常值。异常数据会对分析结果产生巨大的影响。当样本量较小时,异常数据会影响发现具有重要统计意义的结果的概率。异常数据可以表明数据收集问题,或者由您正在研究的过程的异常表现产生的问题。这些数据点往往值得研究,应尽可能予以更正。 目标 我们想要制定一种方法来检查相对于总体样本而言,非常大或非常小的数据值,这可能会影响分析的结果。 方法 我们制定了一种方法,用于根据 Hoaglin, Iglewicz, and Tukey (1986) 所述的方法检查异 常数据,以确定箱线图中的异常值。 结果 如果某个数据点超出分布范围下限或上限 1.5 倍的四分位范围,“协助”将该数据点识别为 异常数据点。上、下四分位数分别是数据的第 25 个和第 75 个百分位数。四分位范围是两个四分位数之间的差异。即使有多个异常值,这种方法也能正常使用,因为它可以检测到每一个具体的异常值。 当检查异常数据时,单样本检验的“协助报告卡”会显示以下状态指标: 没有异常数据点。 至少有一个异常数据点,可能会影响检验结果。 正态性 单样本 t 检验根据总体呈正态分布的假设推导出来。幸运的是,当样本量足够大时,即使数 据不呈正态分布,此方法也同样有效。 目标 我们想要确定非正态性对检验的 I 类和 II 类错误的影响,以提供有关样本量和正态性的指南。 第三章习题 安庆师范学院 胡云峰 3.1对某地区的6名2周岁男婴的身高、胸围、上半臂进行测量。得样本数据如表3.1所示。 假设男婴的测量数据X (a )(a=1,…,6)来自正态总体N 3(μ,∑)的随机样本。根据以往的资料,该地区城市2周岁男婴的这三项的均值向量μ0=(90,58,16)’,试检验该地区农村男婴与城市男婴是否有相同的均值向量。 表3.1某地区农村2周岁男婴的体格测量数据 男婴身高(X 1)cm 胸围身高(X 2)cm 上半臂围身高(X 3)cm 17860.616.527658.112.539263.2 14.54815914581 60.815.568459.5 14 解 1.预备知识∑未知时均值向量的检验:H 0:μ=μ0H 1:μ≠μ0 H 0成立时 122 )(0,) (1)(1,) ()'((1)))()'()(,1) (1)1(,) (1)P P X N n S W n n X n S X n X S X T p n n p T F P n p n p μμμμμ---∑--∑??∴----=-----+∴ -- 当 2 (,)(1) n p T F p n p p n α-≥--或者22T T α≥拒绝0 H 当 2 (,)(1) n p T F p n p p n α-<--或者22T T α<接受0 H 这里2 (1) (, )p n T F p n p n p αα-= --2.根据预备知识用matlab 实现本例题算样本协方差和均值 程序x=[7860.616.5;7658.112.5;9263.214.5;8159.014.0;8160.815.5;8459.514.0];[n,p]=size(x);i=1:1:n; xjunzhi=(1/n)*sum(x(i,:));y=rand(p,n);for j=1:1:n T 检验分为三种方法 T 检验分为三种方法: 1. 单一样本t 检验(One-sample t test ),是用来比较一组数据的平均值和一个数值有无差异。例如,你选取了5个人,测定了他们的身高,要看这五个人的身高平均值是否高于、低于还是等于1.70m ,就需要用这个检验方法。 2. 配对样本t 检验(paired-samples t test ),是用来看一组样本在处理前后的平均值有无差异。比如,你选取了5个人,分别在饭前和饭后测量了他们的体重,想检测吃饭对他们的体重有无影响,就需要用这个t 检验。 注意,配对样本t 检验要求严格配对,也就是说,每一个人的饭前体重和饭后体重构成一对。 3. 独立样本t 检验(independent t test ),是用来看两组数据的平均值有无差异。比如,你选取了5男5女,想看男女之间身高有无差异,这样,男的一组,女的一组,这两个组之间的身高平均值的大小比较可用这种方法。 总之,选取哪种t 检验方法是由你的数据特点和你的结果要求来决定的。 t 检验会计算出一个统计量来,这个统计量就是t 值, spss 根据这个t 值来计算sig 值。因此,你可以认为t 值是一个中间过程产生的数据,不必理他,你只需要看sig 值就可以了。sig 值是一个最终值,也是t 检验的最重要的值。 上海神州培训中心 SPSS 培训 sig 值的意思就是显著性(significance ),它的意思是说,平均值是在百分之几的几率上相等的。 一般将这个sig 值与0.05相比较,如果它大于0.05,说明平均值在大于5%的几率上是相等的,而在小于95%的几率上不相等。我们认为平均值相等的几率还是比较大的,说明差异是不显著的,从而认为两组数据之间平均值是相等的。 如果它小于0.05,说明平均值在小于5%的几率上是相等的,而在大于95%的几率上不相等。我们认为平均值相等的几率还是比较小的,说明差异是显著的,从而认为两组数据之间平均值是不相等的。 (二)t 检验 当总体呈正态分布,如果总体标准差未知,而且样本容量n <30,那么这时一切可能的样本平均数与总体平均数的离差统计量呈t 分布。 t 检验是用t 分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。t 检验分为单总体t 检验和双总体t 检验。 1.单总体t 检验 单总体t 检验是检验一个样本平均数与一已知的总体平均数的差异是否显 著。当总体分布是正态分布,如总体标准差σ未知且样本容量n <30,那么样本平均数与总体平均数的离差统计量呈t 分布。检验统计量为: X t μ σ-= 。 如果样本是属于大样本(n >30)也可写成: 独立样本T检验要求被比较的两个样本彼此独立,既没有配对关系,要求两个样本均来自正态分布,要求均值是对于检验有意义的描述统计量。 例如:男性和女性的工资均值比较 分析——比较均值——独立样本T检验。 分析身高大于等于155厘米与身高小于155的两组男生的体重和肺活量均值之间是否有显着性差异。 基本信息的描述 方差齐次性检验(详见下面第二个例题)和T检验的计算结果。从sig(双侧)栏数据可以看出,无论两组体重还是肺活量,方差均是齐的,均选择假设方差相等一行数据进行分析得出结论。 体重T检验结果,sig(双侧)=,小于,拒绝原假设。两组均值之差的99%上、下限均为正值,也说明两组体重均值之差与0的差异显着。由此可以得出结论,按身高分组的两组体重均值差异,在统计学上高度显着。 肺活量T检验的结果,sig(双侧)=,大于,。两组均值之差的上下限为一个正值,一个负值,也说明差值的99%上下限与0的差异不显着。由此可以得出结论,按身高分组烦人两组肺活量均值差异在99%水平上不显着,均值差异是由抽样误差引起的。 以性别作为分组变量,比较当前工资salary变量的均值 方差齐性检验(levene检验)结果,F值为,显着性概率为p<,因此结论是 两组方差差异显着,及方差不齐。在下面的T 检验结果中应该选择假设方差不相等一行的数据作为本例的T检验的结果数据,另一航是假设方差相等的T检验的据算数据,不取这个结果。 T的值 sig 两组均值差异为.平均现工资女的低于男的. 差值的标准误为 差分的95%的置信区间在-18003~-12816之间,不包括0,也说明两组均值之差与0有显着差异。 结论:从T 检验的P的值为<,和均值之差值的95%置信区间不包括0都能得出,女雇员现工资明显低于男雇员,茶差异有统计学意义。 习题1.按规定苗木平均高达1.60m以上可以出圃,今在苗圃中随机抽取10株苗木,测定的苗木高度如下: 1.75,1.58,1.71,1.64,1.55,1.72,1.62,1.83,1.63,1.65 假设苗高服从正态分布,试问苗木平均高是否达到出圃要求?(要求α=0.05) 答:1、假设H0<=1.6m,H1>1.6m 2、定义变量,输入数据 定义变量“苗高”,各属性如图所示: 输入数据,如图所示: 3、分析过程: 分析——比较均值——单样本T检验——在检验变量中加入 “苗高”变量——检验值输入1.6——选项中置信区间为95% ——继续——确定 4、输出结果分析 结果分析如图所示: 样本容量为N =10,均值为 1.67,自由度df=9,显著性水平 sig.=0.031 。因为0.01 < sig.=0.031 <0.05,在α=0.05水平上有显著性差异,结论受实验误差影响的可能性较小,所以推翻原假设H0<=1.6m,接受备择假设H1>1.6m,即苗木平均高达到出圃要求。习题2.从两个不同抚育措施育苗的苗圃中各以重复抽样的方式抽得样本如下: 样本1苗高(CM):52,58,71,48,57,62,73,68,65,56 样本2苗高(CM):56,75,69,82,74,63,58,64,78,77,66,73 设苗高服从正态分布且两个总体苗高方差相等(齐性),是以显著水平α=0.05检验两种抚育措施对苗高生长有无显著性影响。 答:1、假设H0为两种抚育措施对苗高生长无显著性影响,H1为两种抚育措施对苗高生长有显著性影响。 2、定义变量,输入数据 定义变量“苗高1”和“抚育措施”,各属性如图所示: 输入数据,如图所示: 3、分析过程: 分析——比较均值——独立样本T检验——在检验 变量中加入“苗高1”变量,在分组变量中加入“抚 育措施”变量,定义组选择使用指定值,组1输入1, 组2 输入2——继续——确定 4、输出结果分析 第三章习题 安庆师范学院 胡云峰 3.1对某地区的6名2周岁男婴的身高、胸围、上半臂进行测量。得样本数据如表3.1所示。 假设男婴的测量数据X (a )(a=1,…,6)来自正态总体N 3(μ,∑) 的随机样本。根据以往的资料,该地区城市2周岁男婴的这三项的均值向量μ0=(90,58,16)’,试检验该地区农村男婴与城市男婴是否有相同的均值向量。 表3.1 某地区农村2周岁男婴的体格测量数据 解 1.预备知识 ∑未知时均值向量的检验: H 0:μ=μ0 H 1:μ≠μ0 H 0成立时 122)(0,)(1)(1,) ()'((1)))()'()(,1)(1)1(,) (1)P P X N n S W n n X n S X n X S X T p n n p T F P n p n p μμμμμ---∑--∑??∴----=-----+∴-- 当 2 (,)(1) n p T F p n p p n α-≥--或者22T T α≥拒绝0H 当 2 (,)(1) n p T F p n p p n α-<--或者22T T α<接受0H 这里2 (1) (, )p n T F p n p n p αα-= -- 2.根据预备知识用matlab 实现本例题 算样本协方差和均值 程序x=[78 60.6 16.5;76 58.1 12.5;92 63.2 14.5;81 59.0 14.0;81 60.8 15.5;84 59.5 14.0]; [n,p]=size(x); i=1:1:n; xjunzhi=(1/n)*sum(x(i,:)); y=rand(p,n); for j=1:1:n 【案例1】有12名接种卡介苗的儿童,八周后用两批不同的结核菌素,一批是标准结核菌素,一批是新制结核菌素,分别注射在儿童的前臂,两种结核菌素的皮肤浸润平均直径(mm)如表5-1所示。某医生计算标准品与新制品的差值,均数3.25cm,故认为新制结核菌素的皮肤浸润直径比标准结核菌素的小。 【问题】 (1)该医生的结论是否正确?为什么? (2)问两种结核菌素的反应性有无差别? 表112名儿童分别接种结核菌素的皮肤浸润结果(m m) 编号标准品新制品差值d 112.010.02.0 214.510.04.5 315.512.53.0 412.013.0-1.0 513.010.03.0 612.05.56.5 710.58.52.0 87.56.51.0 99.05.53.5 1015.08.07.0 1113.06.56.5 1210.59.51.0 【案例2】为比较两种方法对乳酸饮料中脂肪含量测定结果是否不同,随机抽取了10份乳酸饮料制品,分别用脂肪酸水解法和哥特里-罗紫法测定其结果如表3-5第(1)~(3)栏。问两法测定结果是否不同? 表2 两种方法对乳酸饮料中脂肪含量的测定结果(%) 编号(1) 哥特里-罗紫法 (2) 脂肪酸水解法 (3) 差值d (4)=(2) (3) 1 0.840 0.580 0.260 2 0.591 0.509 0.082 3 0.67 4 0.500 0.174 4 0.632 0.316 0.316 5 0.687 0.337 0.350 6 0.978 0.51 7 0.461 7 0.750 0.454 0.296 8 0.730 0.512 0.218 9 1.200 0.997 0.203 10 0.870 0.506 0.364 2.724 【案例3】某研究者为比较耳垂血和手指血的白细胞数,调查12名成年人,同时采取耳垂血和手指血见下表,试比较两者的白细胞数有无不同。 表成人耳垂血和手指血白细胞数(10g/L) 编号耳垂血手指血 单样本t检验 (1)建立检验假设,确定检验标准 H0:μ=μ0=140g/L,即从事铅作业男性工人与正常成年男性的血红蛋白含量均数相等 H:μ≠μ0=140g/L,即从事铅作业男性工人与正常成年男性的血红蛋白含量均数不等 ?=0.05 表一 N Mean Std. Deviation Std. Error Mean 血红蛋白含量36130.8325.741 4.290 表二 Test Value = 140 t df Sig. (2-tailed) Mean Difference 95% Confidence Interval of the Difference Lower Upper 血红蛋白含 量 -2.13735.040-9.167-17.88-.46 (2)计算检验统计量 本例n=36,x=130.83g/L,S=25.74g/L,μ0=140g/L.按公式得 t=(130.83-140)÷(25.74/36)=-2.138,v=36-1=35 (3)确定P值,做出推断结论 以v=35,︱t︱=︱-2.138︱查表可知0.02 脂肪酸水解法.5228010.185981.058812 表二 Paired Samples Test Paired Differences Mean Std. Deviation Std. Error Mean 95% Confidence Interval Lower Pair 1 哥特里-罗紫法- 脂肪酸水解法.272400 .108681 .034368 .194654 由表二可知P<0.001,按ɑ=0.05水准,拒绝H0,差异有统计学意义,可以认为两种方法对 脂肪含量测定结果不同,哥特里-罗紫法测定结果较高。 两独立样本t检验 H0=μ=μ0,即阿卡波糖胶囊组与拜唐苹胶囊组空腹血糖下降值得总体均数相等 H1=μ≠μ0,即阿卡波糖胶囊组与拜唐苹胶囊组空腹血糖下降值得总体均数不等 ?=0.05 分组N Mean Std. Deviation Std. Error Mean 空腹血糖下降值阿卡波糖胶囊20 2.0650 3.06015.68427拜唐苹胶囊20 2.6250 2.42050.54124 由表可知P>0.05,按ɑ=0.05水准,不拒绝H0,差异无统计学意义,不能认为阿卡波糖胶囊与拜唐苹胶囊对空腹血糖的降糖效果不同。t检验习题及答案
T检验例题
医药数理统计第六章习题(检验假设和t检验)
三种常用的T检验
spss 单样本t检验操作步骤
教育统计学t检验练习
用SPSS19进行单样本T检验 截屏
单一样本的T检验
教育统计学t检验练习
t检验有单样本t检验
t检验的与习题
单样本t检验
matlab与单样本t检验
t检验及公式96725
独立样本T检验
单样本T检验
matlab与单样本t检验
42配对样本t检验例题
单样本t检验