多个样本率的卡方检验及两两比较 之 spss 超简单

SPSS:多个样本率的卡方检验及两两比较
来自:医咖会
医咖会之前推送过“两个率的比较(卡方检验)及Fisher精确检验的SPSS教程”,小伙伴们都掌握了吗?如果不止两个分组,又该如何进行卡方检验以及之后的两两比较呢?来看详细教程吧!
1、问题与数据
某医生拟探讨药物以外的其他方法是否可降低患者的胆固醇浓度,如增强体育锻炼、减少体重及改善饮食习惯等。
该医生招募了150位高胆固醇、生活习惯差的受试者,并将其随机分成3组。其中一组给予降胆固醇药物,一组给予饮食干预,另一组给予运动干预。经过6个月的试验后,该医生重新测量受试者的胆固醇浓度,分为高和正常两类。
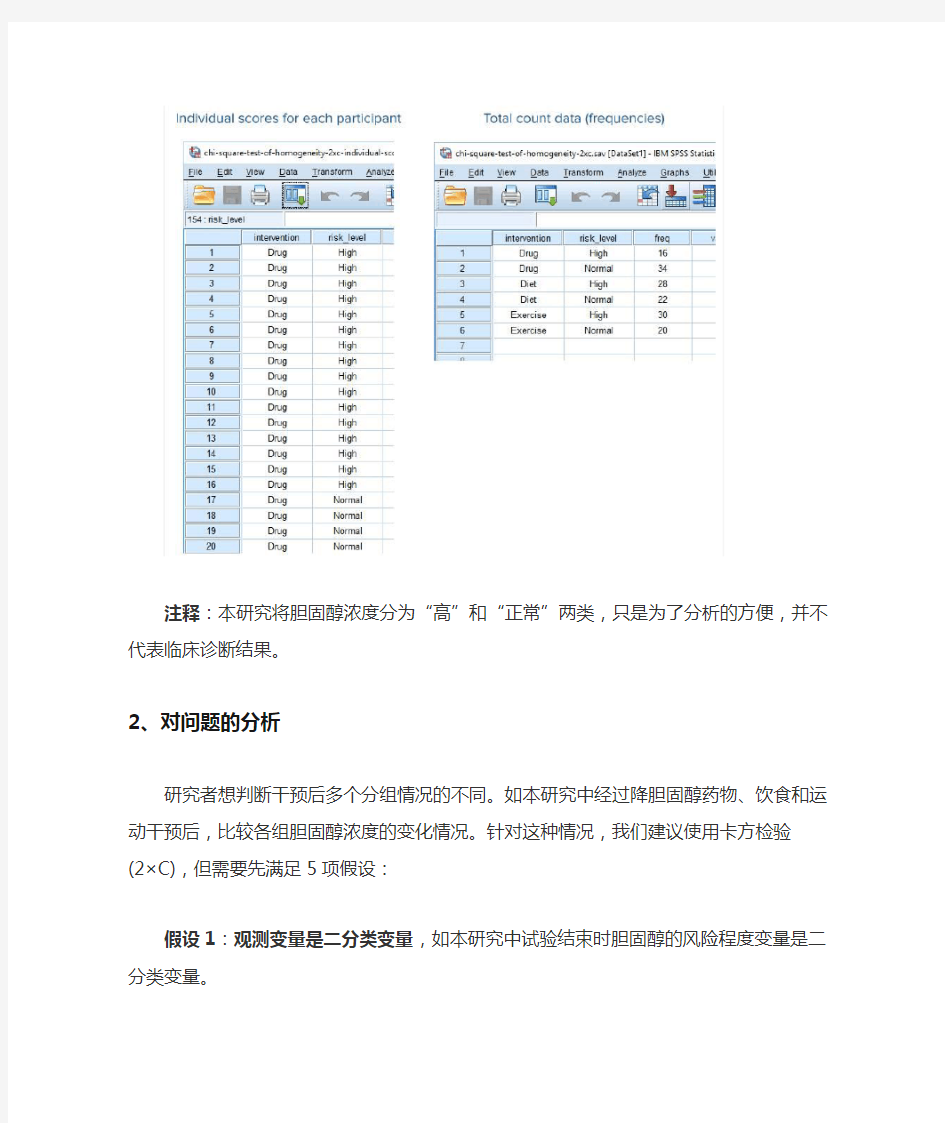
该医生收集了受试者接受的干预方法(intervention)和试验结束时胆固醇的风险程度(risk_level)等变量信息,并按照分类汇总整理,部分数据如下:
注释:本研究将胆固醇浓度分为“高”和“正常”两类,只是为了分析的方便,并不代表临床诊断结果。
2、对问题的分析
研究者想判断干预后多个分组情况的不同。如本研究中经过降胆固醇药物、饮食和运动干预后,比较各组胆固醇浓度的变化情况。针对这种情况,我们建议使用卡方检验(2×C),但需要先满足5项假设:
假设1:观测变量是二分类变量,如本研究中试验结束时胆固醇的风险程度变量是二分类变量。
假设2:存在多个分组(>2个),如本研究有3个不同的干预组。
假设3:具有相互独立的观测值,如本研究中各位受试者的信息都是独立的,不会相互干扰。
假设4:研究设计必须满足:(a) 样本具有代表性,如本研究在高胆固醇、生活习惯差的人群中随机抽取150位受试者;(b) 目的分组,可以是前瞻性的,也可以是回顾性的,如本研究中将受试者随机分成3组,分别给予降胆固醇药物、饮食和运动干预。
假设5:样本量足够大,最小的样本量要求为分析中的任一预测频数大于5。
经分析,本研究数据符合假设1-4,那么应该如何检验假设5,并进行卡方检验(2×C)呢?
3、思维导图
4、SPSS操作
4.1 数据加权
在进行正式操作之前,我们需要先对数据加权,如下:(1)在主页面点击Data→Weight Cases
弹出下图:
(2)点击Weight cases by,激活Frequency Variable窗口
(3)将freq变量放入Frequency Variable栏
(4)点击OK
4.2 检验假设5
数据加权之后,我们要判断研究数据是否满足样本量要求,如下:(1)在主页面点击Analyze→Descriptive Statistics→Crosstabs
弹出下图:
(2)将变量intervention和risk_level分别放入Row(s)栏和Column(s)栏
(3)点击Statistics,弹出下图:
(4)点击Chi-square
(6)点击Counts栏中的Expected选项
经上述操作,SPSS输出预期频数结果如下:
该表显示,本研究最小的预测频数是24.7,大于5,满足假设5,具有足够的样本量。Chi-Square Tests 表格也对该结果做出提示,如下标注部分:
即在本研究中,没有小于5的预测频数,可以直接进行卡方检验(2×C)。那么,如果存在预测频数小于5的情况,我们应该怎么办呢?一般来说,如果预测频数小于5,就需要进行Fisher精确检验(2×C),我们将在后面推送的内容中向大家详细介绍。
4.3 卡方检验(2×C)的SPSS操作
(1)
弹出下图:
(2)
(3)
(4)
(5)点击Percentage栏中的Column选项
(6)
4.4 组间比较(1)
弹出下图:
(2)点击Cells,弹出下图:
(3)点击z-test栏中的Compare column proportions和Adjust p-values (Bonferroni method)选项
(4)
5、结果解释
5.1 统计描述
在进行卡方检验(2×C)的结果分析之前,我们需要先对研究数据有个基本的了解。SPSS 输出结果如下:
该表提示,本研究共有150位受试者,根据干预方式均分为3组。在试验结束时,药物干预组的50位受试者中有16位胆固醇浓度高,饮食干预组的50位受试者中有28位胆固醇浓度高,而运动干预组的50位受试者中有30位胆固醇浓度高,如下标注部分:
由此可见,药物干预比饮食或运动干预的疗效更好。同时,该表也提示,药物干预组的50位受试者中有34位胆固醇浓度下降,饮食干预组的50位受试者中有22位胆固醇浓度下降,而运动干预组的50位受试者中只有20位胆固醇浓度下降,如下标注部分:
但是,当各组样本量不同时,频数会误导人们对数据的理解。因此,我们推荐使用频率来分析结果,如下标注部分:
该表提示,药物干预组的50位受试者中68%胆固醇浓度下降,饮食干预组的50位受试者中44%胆固醇浓度下降,而运动干预组的50位受试者中只有40%胆固醇浓度下降,
提示药物干预比饮食和运动干预更有效。但是这种直接的数据比较可能受到抽样误差的影响,可信性不强,我们还需要进行统计学检验。
5.2 卡方检验(2×C)结果
本研究中任一预测频数均大于5,所以根据Chi-Square Tests表格分析各组的差别。SPSS输出检验结果如下:
卡方检验(2×C)结果显示χ2=9.175,P = 0.010,说明本研究中各组之间率的差值与0
的差异具有统计学意义,提示药物干预与饮食、运动干预在降低受试者胆固醇浓度的作用上存在不同。如果P>0.05,那么就说明各组之间率的差值与0的差异没有统计学意义,即不认为各组之间存在差异。
5.3 卡方检验(2×C)中的成对比较分析
如果卡方检验(2×C)的P<0.05,说明至少有两组之间的差异存在统计学意义。SPSS输出的risk_level * intervention Crosstabulation表格通过数字标记提示了两两比较的结果,如下标注部分:
大家可能会注意到,每组数据的标记相同(即上下两行的标记相同),那么我们只要知道组间标记的作用即可。
那么,risk_level * intervention Cross tabulation表格的标记是什么意思呢?第一种情况,各组间无差异,如下:
如上图,各组间标记一致,说明各组之间无差异。第二种情况,任意两组之间均存在差异,如下:
即每组标记字母均不相同,说明任意两组之间的差异均存在统计学意义。第三种情况,有些组之间存在差异,而另一些组之间的差异没有统计学意义,如下:
多个样本率地卡方检验及两两比较 之 spss 超简单
SPSS:多个样本率的卡方检验及两两比较来自:医咖会 医咖会之前推送过“两个率的比较(卡方检验)及Fisher精确检验的SPSS教程”,小伙伴们都掌握了吗?如果不止两个分组,又该如何进行卡方检验以及之后的两两比较呢?来看详细教程吧! 1、问题与数据 某医生拟探讨药物以外的其他方法是否可降低患者的胆固醇浓度,如增强体育锻炼、减少体重及改善饮食习惯等。 该医生招募了150位高胆固醇、生活习惯差的受试者,并将其随机分成3组。其中一组给予降胆固醇药物,一组给予饮食干预,另一组给予运动干预。经过6个月的试验后,该医生重新测量受试者的胆固醇浓度,分为高和正常两类。 该医生收集了受试者接受的干预方法(intervention)和试验结束时胆固醇的风险程度(risk_level)等变量信息,并按照分类汇总整理,部分数据如下: 注释:本研究将胆固醇浓度分为“高”和“正常”两类,只是为了分析的方便,并不代表临床诊断结果。
2、对问题的分析 研究者想判断干预后多个分组情况的不同。如本研究中经过降胆固醇药物、饮食和运动干预后,比较各组胆固醇浓度的变化情况。针对这种情况,我们建议使用卡方检验(2×C),但需要先满足5项假设: 假设1:观测变量是二分类变量,如本研究中试验结束时胆固醇的风险程度变量是二分类变量。 假设2:存在多个分组(>2个),如本研究有3个不同的干预组。 假设3:具有相互独立的观测值,如本研究中各位受试者的信息都是独立的,不会相互干扰。 假设4:研究设计必须满足:(a) 样本具有代表性,如本研究在高胆固醇、生活习惯差的人群中随机抽取150位受试者;(b) 目的分组,可以是前瞻性的,也可以是回顾性的,如本研究中将受试者随机分成3组,分别给予降胆固醇药物、饮食和运动干预。 假设5:样本量足够大,最小的样本量要求为分析中的任一预测频数大于5。 经分析,本研究数据符合假设1-4,那么应该如何检验假设5,并进行卡方检验(2×C)呢? 3、思维导图
SPSS—单样本T检验
一、被调查学生对“云窗的打分值”总体平均值的推断: 1、以71个被调查学生为样本做T 检验 由表a 可知,71个观测的平均值为71.21,标准差为15,120,均值标准误为1.794。 表b 中,第二列是t 统计量的观测值为0.675,第三列是自由度n-1=70,第四列是t 统计量观测值的双尾概率p 值,第五列是样本均值与检验值的差(1.211),即t 统计量的分子部分,他除以表a 的均值标准误(1.794)后得到t 统计量的观测值0.675,第六列和第七列是总体均值与检验值差的95%的置信区间,为(67.63,74.79)。 对于研究的问题应采用双尾检验,因此比较 2α和2 p ,即比较α和p 。由于p 大于α(0.05),因此不能拒绝零假设,认为被调查学生对“云窗的打分值”总体平均值没有显著差异。有95%的把握认为总体均值在 67.63~74.79 分之间。70分包含在置信区间内,也证实了上述推断。
2、被调查学生对“云窗的打分值”的重抽样自举 表c Bootstrap 指定 采样方法简单箱图 样本数1000 置信区间度95.0% 置信区间类型百分位 由表c可知,自举过程执行1000次,随机数种子指定为默认值2000000,采样方法为简单箱图。 中均值的重抽样自举均值与实际样本均值的差为-0.12,1000个均值的标准差为1.82,由此得到的均值95%的置信区间为(67.18,74.46) 表e中没有给出双尾检验的概率p值,但是从检验的结果可知有95%的把握认为总体均值在 67.184~74.463之间。70包含在置信区间内。用更大的样本量再一次说明了被调查学生对“云窗的打分值”总体平均值没有显著差异。
SPSS单个样本T检验实验报告(一)
《统计学》实验分析报告 实验完成者 班级 2013级班 学号 实验时间 2015年6月5日 一、实验名称 假设检验——单个样本T检验 二、实验目的 掌握单样本t检验的基本原理和spss实现方法。 三、实验步骤 1、打开SPSS,选择输入数据; 2、由于已经有建好的数据,因此打开“电子元件抽验”; 3、在分析中选择比较均值,单样本t检验,将阻值添加到检验变量。 4、检验值为0.14,置信区间默认为95%,点击确定。 四、实验结果及分析 附件一:单个样本统计量表,给出了各个样本的均值,标准差和均值的标准误; 附件二:单个样本检验表,给出了各个样本的t值(t)、自由度(df)、P值(Sig.双尾)、均值差值、差值的95%可信区间 1、附件二——单个样本检验表中,第一批元件样本双尾T检验的显著性概率(Sig.(双侧)), Sig.=0.012<0.05,说明第一批元件的平均电阻与额定电阻值0.140有显著的差异。
2、由附件二同样可以看出,对于第二批和第三批元件,显著性概率分别为0.130与0.265均大于0.05,所以接受原假设,认为这两批元件的电阻与额定值无显著差异,即认为产品合乎质量要求; 3、综上,第一批元件不符合质量要求,第二、三批元件符合质量要求。 五、自评及问题 掌握了单样本t检验的基本原理和spss实现方法,熟悉SPSS软件操作和方法。通过检验得出结论的真否,能够更快更简单的检验数据,对数据的检验让我很快的了解该数据的代表性。 六、成绩 七、指导教师 田劲松 附件一、 单个样本统计量 N 均值 标准差 均值的标准误 第一批元件样本电阻值 15 .14200 .002673
多个样本率的卡方检验及两两比较之spss超简单
多个样本率的卡方检验及两两比较之s p s s超简单 The following text is amended on 12 November 2020.
S P S S:多个样本率的卡方检验及两两比较来自:医咖会 医咖会之前推送过“两个率的比较(卡方检验)及Fisher精确检验的SPSS教程”,小伙伴们都掌握了吗如果不止两个分组,又该如何进行卡方检验以及之后的两两比较呢来看详细教程吧! 1、问题与数据 某医生拟探讨药物以外的其他方法是否可降低患者的胆固醇浓度,如增强体育锻炼、减少体重及改善饮食习惯等。 该医生招募了150位高胆固醇、生活习惯差的受试者,并将其随机分成3组。其中一组给予降胆固醇药物,一组给予饮食干预,另一组给予运动干预。经过6个月的试验后,该医生重新测量受试者的胆固醇浓度,分为高和正常两类。 该医生收集了受试者接受的干预方法(intervention)和试验结束时胆固醇的风险程度(risk_level)等变量信息,并按照分类汇总整理,部分数据如下: 注释:本研究将胆固醇浓度分为“高”和“正常”两类,只是为了分析的方便,并不代表临床诊断结果。 2、对问题的分析 研究者想判断干预后多个分组情况的不同。如本研究中经过降胆固醇药物、饮食和运动干预后,比较各组胆固醇浓度的变化情况。针对这种情况,我们建议使用卡方检验 (2×C),但需要先满足5项假设:
假设1:观测变量是二分类变量,如本研究中试验结束时胆固醇的风险程度变量是二分类变量。 假设2:存在多个分组(>2个),如本研究有3个不同的干预组。 假设3:具有相互独立的观测值,如本研究中各位受试者的信息都是独立的,不会相互干扰。 假设4:研究设计必须满足:(a) 样本具有代表性,如本研究在高胆固醇、生活习惯差的人群中随机抽取150位受试者;(b) 目的分组,可以是前瞻性的,也可以是回顾性的,如本研究中将受试者随机分成3组,分别给予降胆固醇药物、饮食和运动干预。 假设5:样本量足够大,最小的样本量要求为分析中的任一预测频数大于5。 经分析,本研究数据符合假设1-4,那么应该如何检验假设5,并进行卡方检验(2×C)呢 3、思维导图 4、SPSS操作 数据加权 在进行正式操作之前,我们需要先对数据加权,如下: (1)在主页面点击Data→Weight Cases 弹出下图: (2)点击Weight cases by,激活Frequency Variable窗口
多个样本率的卡方检验及两两比较--之-spss-超简单教学文稿
多个样本率的卡方检验及两两比较--之-s p s s-超简单
SPSS:多个样本率的卡方检验及两两比较 来自:医咖会 医咖会之前推送过“两个率的比较(卡方检验)及Fisher精确检验的SPSS教程”,小伙伴们都掌握了吗?如果不止两个分组,又该如何进行卡方检验以及之后的两两比较呢?来看详细教程吧! 1、问题与数据 某医生拟探讨药物以外的其他方法是否可降低患者的胆固醇浓度,如增强体育锻炼、减少体重及改善饮食习惯等。 该医生招募了150位高胆固醇、生活习惯差的受试者,并将其随机分成3组。其中一组给予降胆固醇药物,一组给予饮食干预,另一组给予运动干预。经过6个月的试验后,该医生重新测量受试者的胆固醇浓度,分为高和正常两类。 该医生收集了受试者接受的干预方法(intervention)和试验结束时胆固醇的风险程度(risk_level)等变量信息,并按照分类汇总整理,部分数据如下:
注释:本研究将胆固醇浓度分为“高”和“正常”两类,只是为了分析的方便,并不代表临床诊断结果。 2、对问题的分析 研究者想判断干预后多个分组情况的不同。如本研究中经过降胆固醇药物、饮食和运动干预后,比较各组胆固醇浓度的变化情况。针对这种情况,我们建议使用卡方检验(2×C),但需要先满足5项假设: 假设1:观测变量是二分类变量,如本研究中试验结束时胆固醇的风险程度变量是二分类变量。 假设2:存在多个分组(>2个),如本研究有3个不同的干预组。 假设3:具有相互独立的观测值,如本研究中各位受试者的信息都是独立的,不会相互干扰。 假设4:研究设计必须满足:(a) 样本具有代表性,如本研究在高胆固醇、生活习惯差的人群中随机抽取150位受试者;(b) 目的分组,可以是前瞻性的,也可以是回顾性的,如本研究中将受试者随机分成3组,分别给予降胆固醇药物、饮食和运动干预。 假设5:样本量足够大,最小的样本量要求为分析中的任一预测频数大于5。 经分析,本研究数据符合假设1-4,那么应该如何检验假设5,并进行卡方检验(2×C)呢? 3、思维导图
多个样本率的卡方检验及两两比较之spss超简单
SPSS:多个样本率的卡方检验及两两比较 来自:医咖会 医咖会之前推送过“两个率的比较(卡方检验)及Fisher精确检验的SPSS教程”,小伙伴们都掌握了吗?如果不止两个分组,又该如何进行卡方检验以及之后的两两比较呢?来看详 细教程吧! 1、问题与数据 某医生拟探讨药物以外的其他方法是否可降低患者的胆固醇浓度,如增强体育锻炼、减少体重及改善饮食习惯等。 该医生招募了150位高胆固醇、生活习惯差的受试者,并将其随机分成3组。其中一组给予降胆固醇药物,一组给予饮食干预,另一组给予运动干预。经过6个月的试验后, 该医生重新测量受试者的胆固醇浓度,分为高和正常两类。 该医生收集了受试者接受的干预方法(intervention)和试验结束时胆固醇的风险程度(risk_level)等变量信息,并按照分类汇总整理,部分数据如下: 注释:本研究将胆固醇浓度分为“高”和“正常”两类,只是为了分析的方便,并不代表临 床诊断结果。
2、对问题的分析 研究者想判断干预后多个分组情况的不同。如本研究中经过降胆固醇药物、饮食和运动干预后,比较各组胆固醇浓度的变化情况。针对这种情况,我们建议使用卡方检验(2×C),但需要先满足5项假设: 假设1:观测变量是二分类变量,如本研究中试验结束时胆固醇的风险程度变量是二分 类变量。 假设2:存在多个分组(>2个),如本研究有3个不同的干预组。 假设3:具有相互独立的观测值,如本研究中各位受试者的信息都是独立的,不会相互 干扰。 假设4:研究设计必须满足:(a) 样本具有代表性,如本研究在高胆固醇、生活习惯差 的人群中随机抽取150位受试者;(b) 目的分组,可以是前瞻性的,也可以是回顾性的,如 本研究中将受试者随机分成3组,分别给予降胆固醇药物、饮食和运动干预。 假设5:样本量足够大,最小的样本量要求为分析中的任一预测频数大于5。 经分析,本研究数据符合假设1-4,那么应该如何检验假设5,并进行卡方检验(2×C)呢? 3、思维导图
spss 单样本t检验操作步骤
spss单样本t检验Analyze----compare Means----one sample T test 输入方式 实验数据 12 12 1 2 1 2 3 4 5 6 4 9 5 直接输入数据
Sig=0.000 差异显著
独立样本t检验(两组数据) Analyze-----compare Means----Independent-samples T test 输入方式 试验分组实验数据 1 12 1 13 1 12 1 12 1 1 1 1 2 2 2 2 2 2 2 2 2 两组数据个数可以不同
成组数据t检验 Analyze----compare Means-----paired-samples T test
单因素方差分析 Analyze---compare means----one-way ANOV A(analyze of variance)
Factor (因素)1 1 1 1 1 2 2 2 2 2 2 3 3 3 3(分组) Dependent List 试验数据 polynomial lines contrast---polynomial---Degree---linear post Hoc Multiple comparisons-----LSD(Duncan 邓肯检验) 先选方差齐性在结果中判断Sig 值?<0.05(差异显著)若不齐则进行数据转化。 数据输入 分组试验数据 1 12 1 13 1 13 1 1 2 2 2 2 2 2 3 3 3 3 3 3 4 4 4 4 4 4 双因素方差分析 Analyze-----General linear Model-----univariate Dependent Variable(因变因素)因别的数字变化而变化 Fixed Factor (固定因素) Random Factors(随机因素) Model-----custom-----Build Term---Interaction(交互作用)----Main effects(主因素) Contrast--- simple---first----change Plot Hoc----LSD (Duncan)
用SPSS19进行单样本T检验 截屏
用SPSS19进行单样本T检验(One -Sample T Test) 作者:邀月来源:博客园发布时间:2010-10-14 00:13 阅读:305 次原文链接[收藏] 在《0-1总体分布下的参数假设检验示例一(SPSS实现)》中,我们简要介绍了用SPSS 检验二项分布的参数。今天我们继续看看如何用SPSS进行单样本T检验(One -Sample T Test)。看例子: 例1:已知去年某市小学五年级学生400米的平均成绩是100秒,今年该市抽样测得60个五年级学生的400米成绩(数据见后面文件“CH6参检1小学生400米v提高.sav”),试检验该市五年级学生的400米平均成绩是否应为100秒(有无提高或下降)? 分析:此检验的假设是: H0:该市五年级学生的400米平均成绩是仍为100秒。 H1:该市五年级学生的400米平均成绩是不为100秒。 打开SPSS,读入数据
从结果中可以判断: 1、p=0.287>0.05,在5%的显著性水平上,不能拒绝假设H0。 2、95%的置信区间端点一正一负,必然覆盖总体均值。应该接受零假设(假设H0)。 这个结论出乎很多人的意料,因为样本均值明显下降了,105.38500000000003。实际上,那是因为有一个样本值为400秒,从而造成错觉的缘故。 再看一个更有趣的例子。 例1:已知去年某市小学五年级学生400米的平均成绩是100秒,今年该市抽样测得60个五年级学生的400米成绩(数据见后面文件“CH6参检1小学生400米v提高B.sav”),试检验该市五年级学生的400米平均成绩是否应为100秒(有无提高或下降)? 同上,打开SPSS,读入数据,结果:
(完整版)T检验F检验和卡方检验
什么是Z检验? Z检验是一般用于大样本(即样本容量大于30)平均值差异性检验的方法。它是用标准正态分布的理论来推断差异发生的概率,从而比较两个平均数>平均数的差异是否显著。 当已知标准差时,验证一组数的均值是否与某一期望值相等时,用Z检验。 Z检验的步骤 第一步:建立虚无假设,即先假定两个平均数之间没有显著差异。 第二步:计算统计量Z值,对于不同类型的问题选用不同的统计量计算方法。 1、如果检验一个样本平均数()与一个已知的总体平均数(μ0)的差异是否显著。其Z值计算公式为: 其中: 是检验样本的平均数; μ0是已知总体的平均数; S是样本的方差; n是样本容量。 2、如果检验来自两个的两组样本平均数的差异性,从而判断它们各自代表的总体的差异是否显著。其Z值计算公式为: 其中: 是样本1,样本2的平均数; S1,S2是样本1,样本2的标准差; n1,n2是样本1,样本2的容量。 第三步:比较计算所得Z值与理论Z值,推断发生的概率,依据Z值与差异显著性关系表作出判断。如下表所示: 第四步:根据是以上分析,结合具体情况,作出结论。 Z检验举例 某项教育技术实验,对实验组和控制组的前测和后测的数据分别如下表所示,比较两组前测和后测是否存在差异。 实验组和控制组的前测和后测数据表 前测实验组n1 = 50 S1a = 14
控制组n2 = 48 S2a = 16 后测实验组n1 = 50 S1b = 8 控制组n2 = 48 S2b = 14 由于n>30,属于大样本,所以采用Z检验。由于这是检验来自两个不同总体的两 个样本平均数,看它们各自代表的总体的差异是否显著,所以采用双总体的Z检验方法。 计算前要测Z的值: ∵|Z|=0.658<1.96 ∴ 前测两组差异不显著。 再计算后测Z的值: ∵|Z|= 2.16>1.96 ∴ 后测两组差异显著。 T检验,亦称student t检验(Student's t test),主要用于样本含量较小(例如n<30),总体标准差σ未知的正态分布资料。 t检验是对各回归系数的显著性所进行的检验,是指在多元回归分析中,检验回归系数是否为0的时候,先用F检验,考虑整体回归系数,再对每个系数是否为零进行t检验。t检验还可以用来检验样本为来自一元正态分布的总体的期望,即均值;和检验样本为来自二元正态分布的总体的期望是否相等) 目的:比较样本均数所代表的未知总体均数μ和已知总体均数μ0。 自由度:v=n –1 T检验注意事项 要有严密的抽样设计随机、均衡、可比 选用的检验方法必须符合其适用条件(注意:t检验的前提是资料服从正态分布) 单侧检验和双侧检验 单侧检验的界值小于双侧检验的界值,因此更容易拒绝,犯第Ⅰ错误的可能 性大。 假设检验的结论不能绝对化 不能拒绝H0,有可能是样本数量不够拒绝H0 ,有可能犯第Ⅰ类错误 正确理解P值与差别有无统计学意义P越小,不是说明实际差别越大,而 是说越有理由拒绝H0 ,越有理由说明两者有差异,差别有无统计学意义和有无 专业上的实际意义并不完全相同 假设检验和可信区间的关系结论具有一致性差异:提供的信息不同区间估计给出总体均值可能取值范围,但不给出确切的概率值,假设检验可以给出H 0成立与否的概率。 适用条件
spss操作独立样本T检验模板
例题:对某地区的山地和平原土壤中的磷含量的背景值各取了10个样品,数据如下所示: (单位:10-6),问山地与平原土壤中磷含量是否有显著性差异。( 25分) 1、本题中自变量个数等于2,且不是来自于同一组样本,故采用独立样本T检验 2、打开spss,在变量视图内定义变量,由题目可知,磷含量为“计量资料”,归类为“度量变量”,地形为计数资料,归类为“名义变量”,并对地形进行赋值,如图输入: 3、在数据视图内如下图输入数据: 4、独立样本T检验进行的假设: (1)数据必须为连续性数据; 2 2 ⑵方差齐性(可偏不齐,即(T 1 / (T 2 <3); (3)每组数据均服从正态分布 5、进行验证: (1)由题目可以看出,数据为连续型数据,满足; (2)此检验可于结果中查看; (3)首先,新建spss视图,重新输入变量进行探索队列,如下图所示:
将“山地”“平原”选入因变量列表,并于“绘图(T) ”中勾选“带检验的正态图”,操作步骤如下图所示: 根据正态性检验表的“ K-S检验”结果,由于样本内数据数量<30,故看Shapiro-Wilk 结果, 由于两者的sig均大于,故满足正态分布 *. a. Lilliefors 显著性校正 6、进行独立样本T检验: (1)依次点击“分析”-“比较平均值”-“独立样本T检验”,调出独立样本T检验对话框: ⑵将“磷含量”选入检验变量(T),将“地形”选入分组变量,然后定义组,于主页面中点 击“确定”,输出结果: 7、结果分析:
根据独立样本检验表的方差方程的Levene检验,F统计量的sig值<,否认方差相等的假设,认为方差不齐性,故参考第二行的t检验结果; 第二行t检验的双侧sig=>,即可认为在的显著性水平上,山地与平原土壤中磷含量
SPSS如何实现多个样本率多重比较
SPSS实现多组率的两两比较 多组率的比较是在医学研究中常常会遇到的问题,其通常被列为R×2表进行χ2检验,其结果仅能说明多个率间的差别有统计学意义,并不能对两两之间差别做出检验。而将其分割成2 ×2表虽可行两两比较,但不宜用独立四格表的显著界值。针对这个问题,本文就如何使用国际通用SPSS软件实现该方法,给出具体解决方案。 如图1一组病例资料。 拟对上述资料进行统计分析。 将上述资料按图2进行SPSS录入。 要求:将各组按观察率从小到大排列,本例有效率恰好已是升序排列,故无需再排序。经过交叉表对三组资料进行卡方检验后,具有统计学意义。下一步进行两两比较。
操作步骤 ①权变量:由于“数据”变量中数据并非真正的每条记录数据,而是频数资料,所以要加权, 其步骤如下:Data→Weight Case→选择⊙weight case by单选按钮→将“数据”变量添加到Frequency Variable框内→OK。 ②选择记录:根据杜养志法,需分别将G1组与第Gi ( i = 2, 3, ??k)组进行非独立2 ×2表, 步骤如下:Data→Select Case→选择⊙If condition is satisfied单选按钮→点击其下方的If??按钮→在右上方框体内录入引号内的内容:“行变量= 1 or行变量= i”( i根据所比的具体组的序数而定) →continue→OK。
③卡方检验: Analyze →Descrip tive Statisics →Crosstable→将“行变量”放入Row框体 中→将“列变量”放入column框体中→Statisics→选择Chi - square→continue→OK。 ④重复选择记录步骤,选择新的比较组,再行卡方检验,直到所有组均与G1比较过为止。
多个样本率的卡方检验及两两比较之spss超简单教学内容
多个样本率的卡方检验及两两比较之s p s s 超简单
SPSS :多个样本率的卡方检验及两两比 较 来自:医咖会 医咖会之前推送过两个率的比较(卡方检验)及Fisher精确检验的SPSS教程”小伙伴们都掌握了吗?如果不止两个分组,又该如何进行卡方检验以及之后的两两比较呢?来看详细教程吧! 1、问题与数据 某医生拟探讨药物以外的其他方法是否可降低患者的胆固醇浓度,如增强体育锻炼、减少体重及改善饮食习惯等。 该医生招募了150位高胆固醇、生活习惯差的受试者,并将其随机分成3 组。其中一组给予降胆固醇药物,一组给予饮食干预,另一组给予运动干预。经过6个月的试验后,该医生重新测量受试者的胆固醇浓度,分为高和正常两类。 该医生收集了受试者接受的干预方法(intervention )和试验结束时胆固醇的风险程度(risk_level )等变量信息,并按照分类汇总整理,部分数据如下: Individual scores for eocr parrtdp^ni qu sre-tesi-crf-lrz m =i^ neiiry-riLi.c-3 ndn-icfualkscG flic flain Tnanaorm 押出倍 Total coum (frequencies) Bl g chi - [DuatiaSeLl] - IBM SPSS Statkti
注释:本研究将胆固醇浓度分为高”和正常”5类,只是为了分析的方便, 并不代表临床诊断结果。 2、对问题的分析 研究者想判断干预后多个分组情况的不同。如本研究中经过降胆固醇药物、饮食和运动干预后,比较各组胆固醇浓度的变化情况。针对这种情况,我们建议使用卡方检验(2 >€),但需要先满足5项假设: 假设1 :观测变量是二分类变量,如本研究中试验结束时胆固醇的风险程度变量是二分类变量。 假设2:存在多个分组(>2个),如本研究有3个不同的干预组。 假设3 :具有相互独立的观测值,如本研究中各位受试者的信息都是独立的,不会相互干扰。 假设4:研究设计必须满足:(a)样本具有代表性,如本研究在高胆固醇、生活习惯差的人群中随机抽取150位受试者;(b)目的分组,可以是前瞻性的,也可以是回顾性的,如本研究中将受试者随机分成3组,分别给予降胆固 醇药物、饮食和运动干预。 假设5:样本量足够大,最小的样本量要求为分析中的任一预测频数大于5。 经分析,本研究数据符合假设1-4,那么应该如何检验假设5,并进行卡方检验(2 >C)呢? 3、思维导图
SPSS 比较均值 独立样本T检验 案例分析
SPSS-比较均值-独立样本T检验案例解析 2011-08-26 14:55 在使用SPSS进行单样本T检验时,很多人都会问,如果数据不符合正太分布,那还能够进行T检验吗?而大样本,我们一般会认为它是符合正太分布的,在鈡型图看来,正太分布,基本左右是对称的,一般具备两个参数,数学期望和标准方差,即:N(p, Q) 如果你的样本数非常少,一般需要进行正太分布检验,检验的方法网上很多,我就不说了 下面以“雄性老鼠和雌性老鼠分别注射了某种毒素,经过观察分析,进行随机取样,查看最终老鼠是否活着。 问题:很多人认为,雄性老鼠和雌性老鼠分别注射毒液后,雌性老鼠存活下来的数量会比雄性老鼠多? 我们将通过进行统计分析来认证这个假设是否成立。 下面进行参数设置:a 代表:雄性老鼠 b代表:雌性老鼠 tim 代表:生存时间,即指经过多长时间后,去查看结果 0 代表:结果死亡 1 代表:结果活着 随机抽取的样本,如下所示:
打开SPSS- 分析---检验均值---独立样本T检验,如下图所示:
将你要分析的变量,移入右边的框内,再将你要进行分组的变量移入“分组变量”框内,“组别group()里面的两个参数,不能够随意设置,必须要跟样本里面的数字一致 点击确定后,分析结果,如下所示: 从组统计量可以看出,雄性老鼠的存活下来的均值为0.73,但是雌性老鼠存活下来的均值为1.00,很明显,雌性老是存活下来的个数明显比雄性老鼠多,但是一般我们不看这个结果,为什么?因为样本不够大,如果将样本升至10000个?也许这个均值将会发生变化,不具备统计学意义, 我们一般只看独立样本检验的结果。 独立样本检验,提供了两种方法:levene检验和均值T检验两种方法 Levene检验主要用来检验原假设条件是否成立,(即:假设方差相等和方差不相等两种情况)如果SIG>0.05,证明假设成立,不能够拒绝原假设,如果 SIG<0.05,证明假设不成立,拒绝原假设。 进行levene检验结果判断是第一步,从上图,可以看出 sig<0.05 方差相等的假设不成立,所以看第二行,方差不相等的情况 sig=0.082>0.05 即说明 P 值大于显著性水平,不应该拒绝原假设:即指:雌性老鼠和雄性老鼠在注射毒液后,存活下来的个数没有显著的差异
多个样本率的卡方检验及两两比较之 spss 超简单
S P S S:多个样本率的卡方检验及两两比较来自:医咖会 医咖会之前推送过“两个率的比较(卡方检验)及Fisher精确检验的SPSS教程”,小伙伴们都掌握了吗?如果不止两个分组,又该如何进行卡方检验以及之后的两两比较呢?来看详细教程吧! 1、问题与数据 某医生拟探讨药物以外的其他方法是否可降低患者的胆固醇浓度,如增强体育锻炼、减少体重及改善饮食习惯等。 该医生招募了150位高胆固醇、生活习惯差的受试者,并将其随机分成3组。其中一组给予降胆固醇药物,一组给予饮食干预,另一组给予运动干预。经过6个月的试验后,该医生重新测量受试者的胆固醇浓度,分为高和正常两类。 该医生收集了受试者接受的干预方法(intervention)和试验结束时胆固醇的风险程度(risk_level)等变量信息,并按照分类汇总整理,部分数据如下: 注释:本研究将胆固醇浓度分为“高”和“正常”两类,只是为了分析的方便,并不代表临床诊断结果。 2、对问题的分析 研究者想判断干预后多个分组情况的不同。如本研究中经过降胆固醇药物、饮食和运动干预后,比较各组胆固醇浓度的变化情况。针对这种情况,我们建议使用卡方检验(2×C),但需要先满足5项假设:
假设1:观测变量是二分类变量,如本研究中试验结束时胆固醇的风险程度变量是二分类变量。 假设2:存在多个分组(>2个),如本研究有3个不同的干预组。 假设3:具有相互独立的观测值,如本研究中各位受试者的信息都是独立的,不会相互干扰。 假设4:研究设计必须满足:(a) 样本具有代表性,如本研究在高胆固醇、生活习惯差的人群中随机抽取150位受试者;(b) 目的分组,可以是前瞻性的,也可以是回顾性的,如本研究中将受试者随机分成3组,分别给予降胆固醇药物、饮食和运动干预。 假设5:样本量足够大,最小的样本量要求为分析中的任一预测频数大于5。 经分析,本研究数据符合假设1-4,那么应该如何检验假设5,并进行卡方检验(2×C)呢? 3、思维导图 4、SPSS操作 4.1 数据加权 在进行正式操作之前,我们需要先对数据加权,如下: (1)在主页面点击Data→Weight Cases 弹出下图: (2)点击Weight cases by,激活Frequency Variable窗口
8.2 多个独立样本R×C列联表资料的卡方检验
第八章c 2 检验 二、多个独立样本R×C列联表资料的c 2 检验
表 8-5 三种不同治疗方法治疗慢性支气管炎的疗效组别 有效 无效 合计 有效率% A 药 35 5 40 87.50 B 药 20 10 30 66.67 C 药 7 25 32 21.88 合计62 40 102 60.78 (24.31) ( ) A T T c - = ? 2 22 2 11 (1)32.74 R C i j i j i j A n n m c == =-= ?? 2.1 频率的比较
表 8-5 三种不同治疗方法治疗慢性支气管炎的疗效 组别 有效 无效 合计 有效率% A 药 35 5 40 87.50 B 药 20 10 30 66.67 C 药 7 25 32 21.88 合计62 40 102 60.78 2.1 多个独立样本频率的比较 (24.31) ( ) A T T c - = ? 2 22 2 11 (1)32.74 R C i j i j i j A n n m c == =-= ?? c 2 (A, B ) =4.419,P =0.036,P ’=0.108
2.2 独立样本频率的比较 表 8-6 儿童急性白血病患者与成年人急性白血病患者的血型分布 分组A 型 B 型 O 型 AB 型合计 儿童30 38 32 12 112 成人19 30 19 9 77 合计49 68 51 21 189 c 2 0.75,3 =1.21,P >0.75 2 2 11 (1)0.695 R C i j i j i j A n n m c == =- = ??
两独立样本T检验---SPSS操作详解
两独立样本T检验-SPSS操作详解 为了解某一新药降血压的效果,将28名高血压患者随机分为实验组和对照组,实验组采用新药,对照组采用常规药,测得治疗前后的血压变化,问新药是否优于常规药? 编号 1 2 3 4 5 6 7 8 9 10 11 新药前102 100 92 98 118 100 100 92 126 117 109 后90 90 85 90 114 95 86 88 102 92 98 编号 1 2 3 4 5 6 7 8 9 10 11 常规 前98 110 109 94 110 92 95 90 108 90 110 药 后100 103 105 98 109 95 94 88 104 85 110 变量1设置:name-group , decimals-0 , label-分组, value-(1=新药,2=常规药) 变量2设置:name-value , decimals-0 , label-血压下降值 2 输入数据---血压差=用药前血压-用药后血压 3 单击菜单栏analyze/compare means/independent-samples t test 4 将血压下降值调入test variables下矩形框 5 将分组(group)调入grouping variable 下矩形框 6单击define groups…定义分组group1为1 定义group2为2 单击continue 7 options选项默认 8 bootstrap选项默认 9 单击OK 输出结果 10 结果界面 11 结果解释 表1表示两独立样本t检验基本统计量-group statistics 表2表示两独立样本t检验结果,方差方程的levene检验(Levene’s Test for
多个样本率的卡方检验及两两比较--之-spss-超简单
SPSS:多个样本率的卡方检验及两两比 较 来自:医咖会 医咖会之前推送过“两个率的比较(卡方检验)及Fisher精确检验的SPSS教程”,小伙伴们都掌握了吗?如果不止两个分组,又该如何进行卡方检验以及之后的两两比较呢?来 看详细教程吧! 1、问题与数据 某医生拟探讨药物以外的其他方法是否可降低患者的胆固醇浓度,如增强体育锻炼、 减少体重及改善饮食习惯等。 该医生招募了150位高胆固醇、生活习惯差的受试者,并将其随机分成3组。其中一组给予降胆固醇药物,一组给予饮食干预,另一组给予运动干预。经过6个月的试验后,该医生重新测量受试者的胆固醇浓度,分为高和正常两类。 该医生收集了受试者接受的干预方法(intervention)和试验结束时胆固醇的风险程度(risk_level)等变量信息,并按照分类汇总整理,部分数据如下:
注释:本研究将胆固醇浓度分为“高”和“正常”两类,只是为了分析的方便,并不代表临 床诊断结果。 2、对问题的分析 研究者想判断干预后多个分组情况的不同。如本研究中经过降胆固醇药物、饮食和运 动干预后,比较各组胆固醇浓度的变化情况。针对这种情况,我们建议使用卡方检验 (2×C),但需要先满足5项假设: 假设1:观测变量是二分类变量,如本研究中试验结束时胆固醇的风险程度变量是二 分类变量。 假设2:存在多个分组(>2个),如本研究有3个不同的干预组。 假设3:具有相互独立的观测值,如本研究中各位受试者的信息都是独立的,不会相 互干扰。 假设4:研究设计必须满足:(a) 样本具有代表性,如本研究在高胆固醇、生活习惯差 的人群中随机抽取150位受试者;(b) 目的分组,可以是前瞻性的,也可以是回顾性的, 如本研究中将受试者随机分成3组,分别给予降胆固醇药物、饮食和运动干预。 假设5:样本量足够大,最小的样本量要求为分析中的任一预测频数大于5。 经分析,本研究数据符合假设1-4,那么应该如何检验假设5,并进行卡方检验(2×C)呢? 3、思维导图
多个样本率的卡方检验及两两比较之spss超简单
多个样本率的卡方检验及两两比较之s p s s超简 单 文件排版存档编号:[UYTR-OUPT28-KBNTL98-UYNN208]
S P S S:多个样本率的卡方检验及两两比较来自:医咖会 医咖会之前推送过“两个率的比较(卡方检验)及Fisher精确检验的SPSS教程”,小伙伴们都掌握了吗如果不止两个分组,又该如何进行卡方检验以及之后的两两比较呢来看详细教程吧! 1、问题与数据 某医生拟探讨药物以外的其他方法是否可降低患者的胆固醇浓度,如增强体育锻炼、减少体重及改善饮食习惯等。 该医生招募了150位高胆固醇、生活习惯差的受试者,并将其随机分成3组。其中一组给予降胆固醇药物,一组给予饮食干预,另一组给予运动干预。经过6个月的试验后,该医生重新测量受试者的胆固醇浓度,分为高和正常两类。 该医生收集了受试者接受的干预方法(intervention)和试验结束时胆固醇的风险程度(risk_level)等变量信息,并按照分类汇总整理,部分数据如下:注释:本研究将胆固醇浓度分为“高”和“正常”两类,只是为了分析的方便,并不代表临床诊断结果。 2、对问题的分析 研究者想判断干预后多个分组情况的不同。如本研究中经过降胆固醇药物、饮食和运动干预后,比较各组胆固醇浓度的变化情况。针对这种情况,我们建议使用卡方检验(2×C),但需要先满足5项假设:
假设1:观测变量是二分类变量,如本研究中试验结束时胆固醇的风险程度变量是二分类变量。 假设2:存在多个分组(>2个),如本研究有3个不同的干预组。 假设3:具有相互独立的观测值,如本研究中各位受试者的信息都是独立的,不会相互干扰。 假设4:研究设计必须满足:(a) 样本具有代表性,如本研究在高胆固醇、生活习惯差的人群中随机抽取150位受试者;(b) 目的分组,可以是前瞻性的,也可以是回顾性的,如本研究中将受试者随机分成3组,分别给予降胆固醇药物、饮食和运动干预。 假设5:样本量足够大,最小的样本量要求为分析中的任一预测频数大于5。 经分析,本研究数据符合假设1-4,那么应该如何检验假设5,并进行卡方检验(2×C)呢 3、思维导图 4、SPSS操作 数据加权 在进行正式操作之前,我们需要先对数据加权,如下: (1)在主页面点击Data→Weight Cases 弹出下图:
用SPSS进行单样本T检验(One -Sample T Test)
用SPSS进行单样本T检验(One -Sample T Test) 在《0-1总体分布下的参数假设检验示例一(SPSS实现)》中,我们简要介绍了用SPSS 检验二项分布的参数。今天我们继续看看如何用SPSS进行单样本T检验(One -Sample T Test)。看例子: 例1:已知去年某市小学五年级学生400米的平均成绩是100秒,今年该市抽样测得60个五年级学生的400米成绩(数据见后面文件“CH6参检1小学生400米v提高.sav”),试检验该市五年级学生的400米平均成绩是否应为100秒(有无提高或下降)? 分析:此检验的假设是: H0:该市五年级学生的400米平均成绩是仍为100秒。 H1:该市五年级学生的400米平均成绩是不为100秒。 打开SPSS,读入数据
从结果中可以判断: 1、p=0.287>0.05,在5%的显著性水平上,不能拒绝假设H0。 2、95%的置信区间端点一正一负,必然覆盖总体均值。应该接受零假设(假设H0)。 这个结论出乎很多人的意料,因为样本均值明显下降了,105.38500000000003。实际上,那是因为有一个样本值为400秒,从而造成错觉的缘故。 再看一个更有趣的例子。 例1:已知去年某市小学五年级学生400米的平均成绩是100秒,今年该市抽样测得60个五年级学生的400米成绩(数据见后面文件“CH6参检1小学生400米v提高B.sav”),试检验该市五年级学生的400米平均成绩是否应为100秒(有无提高或下降)? 同上,打开SPSS,读入数据,结果: 从结果中判断: t统计值的显著性概率为0.005小于1%,在1%犯错误的水平上拒绝零假设。可以认为,今年该市五年级学生的400米平均成绩明显下降了。
SPSS独立单样本t检验方法
SPSS独立单样本t检验方法(independent-samples t Test)又叫两样本t检验, 要将两组独立的数据进行差异性比较,这属于两样本t检验,这是实验中常用的一种检验方法,下面是基本操作方法。 以低浓度组与对照组比较为例进行说明: 操作步骤: 1.输入独立样本数据(变量1和变量2都可以做数据项)
2.选用程序 从菜单选择Analysize——Compare Mean——Independent-samples t Test,打开对话框,分别将数据变量组和组别变量组对应的var转入右边对应的空白框中,数据变量组转到Test Variable(s),组别变量组转到Grouping Variable
转入后,在定义组别, 点击Difine Groups…按钮,出现如下对话框,然后输入对应的组别号,在这个例子中,group1是用1来表示的,group2使用2表示的。因此,分别输入1和2,再点击Continue按钮。
点击continue按钮后出现如下对话框,再点击OK,这样独立样本T检验程序定义完成。 3.结果分析 在第二步最后点击OK后,软件的分析结果就会出现,如下图,红框里就是要的数据。 经Levene’s方差齐性检验,F=4.655,而P=0.045<0.5,认为两组总体方差是齐的,就看两样本t检验的第一横列的值(也就是跟F同列的值):t=1.353,P=0.193,按P=0.05水准,P>0.05,则两样本物显著性差异,P<0.05,有显著性差异,P<0.01时,两样本有极大差异。 如果F的P>0.5,则认为两样本总体方差不齐,则看第二横列的值,t检验的P值分析同上。