8B10B编码法
8B/10B 編碼法
IEEE 802.3z gigabit Ethernet的實體層PCS 採用8B/10B 編碼法來改善資料在線路上傳送的特性。此編碼法保證在實體層傳送之位元串有足夠的訊號轉換頻率以便接收端能從中復原時序(clock recovery)。此種編碼亦大大的增加了偵測出一個或多個位元傳送錯誤的能力。除此之外,有些特殊的「群碼」(code_groups) 包含獨特而容易辨識的位元圖案也可以幫助接收端於位元串中達成「群碼對齊」(code_group alignment) 的工作。此8B/10B編碼法同時也具有以下重要的特性:高訊號轉換密度(high transition density), 長度限制編碼
(run-length-limited code), 以及直流平衡(DC-balanced)。圖7-22所示為
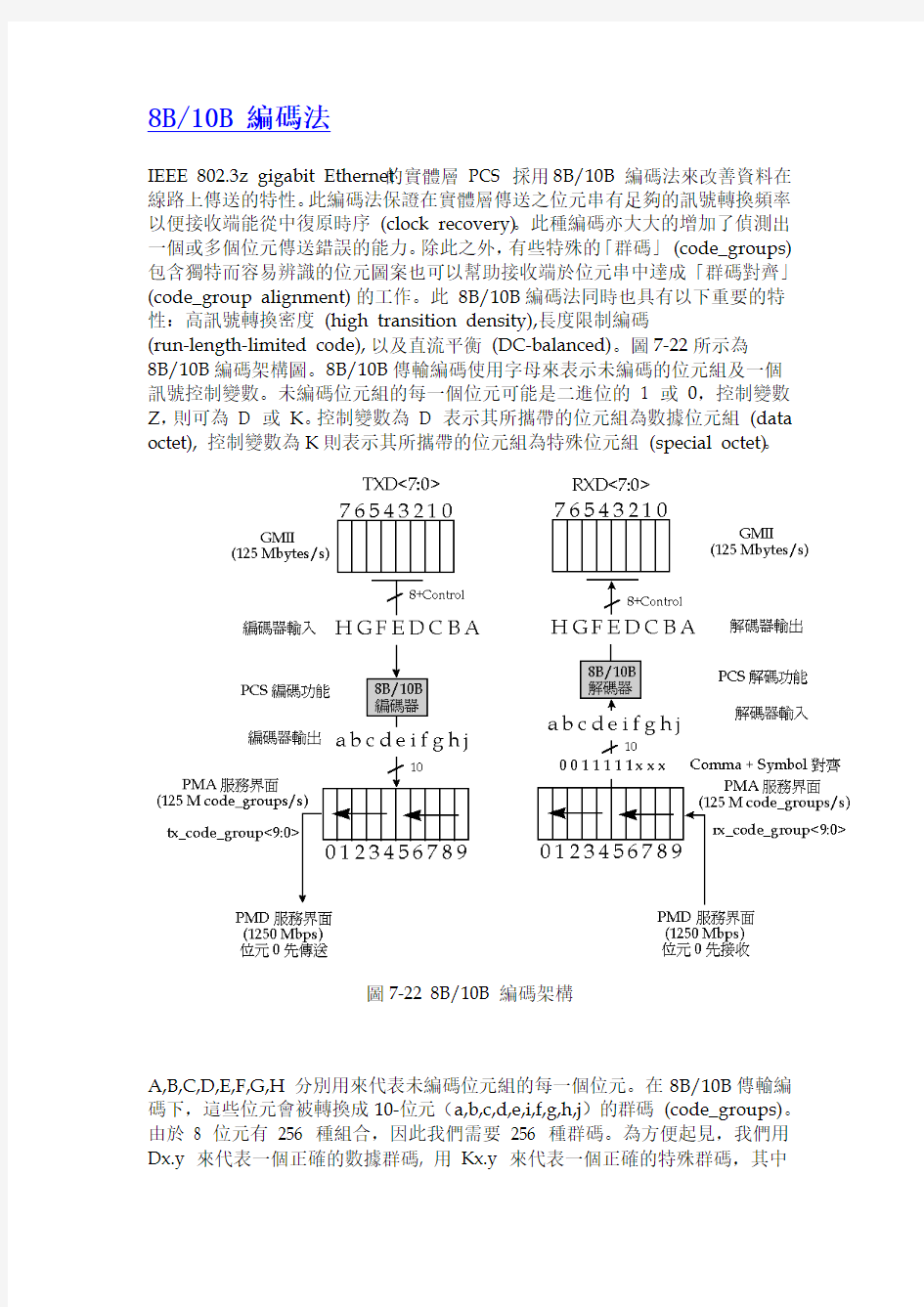
8B/10B編碼架構圖。8B/10B傳輸編碼使用字母來表示未編碼的位元組及一個訊號控制變數。未編碼位元組的每一個位元可能是二進位的 1 或0,控制變數Z,則可為D 或K。控制變數為D 表示其所攜帶的位元組為數據位元組(data octet), 控制變數為K則表示其所攜帶的位元組為特殊位元組(special octet)。
圖7-22 8B/10B 編碼架構
A,B,C,D,E,F,G,H 分別用來代表未編碼位元組的每一個位元。在8B/10B傳輸編碼下,這些位元會被轉換成10-位元(a,b,c,d,e,i,f,g,h,j)的群碼(code_groups)。由於8 位元有256 種組合,因此我們需要256 種群碼。為方便起見,我們用Dx.y 來代表一個正確的數據群碼, 用Kx.y 來代表一個正確的特殊群碼,其中
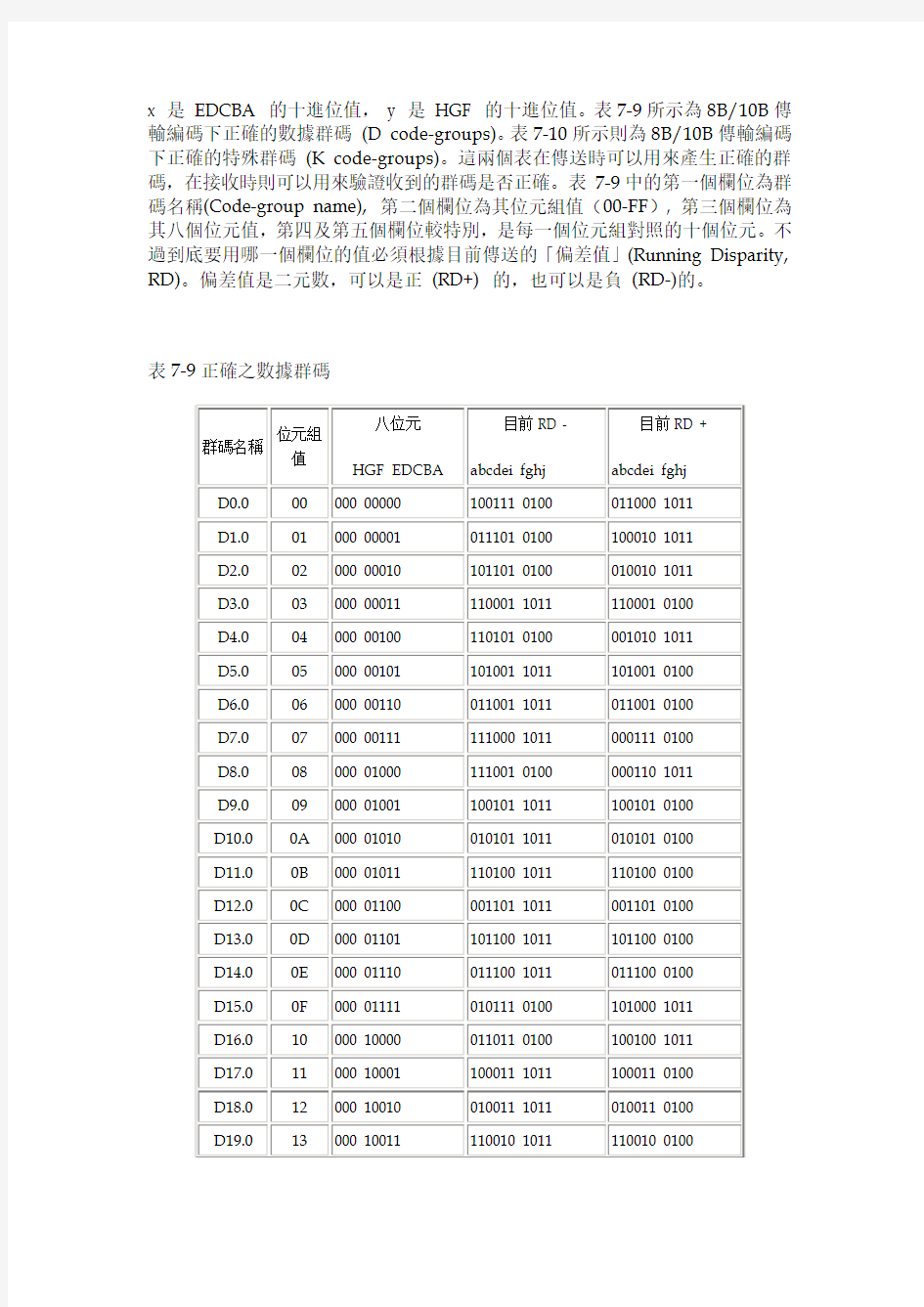
x 是EDCBA 的十進位值,y 是HGF 的十進位值。表7-9所示為8B/10B傳輸編碼下正確的數據群碼(D code-groups)。表7-10所示則為8B/10B傳輸編碼下正確的特殊群碼(K code-groups)。這兩個表在傳送時可以用來產生正確的群碼,在接收時則可以用來驗證收到的群碼是否正確。表7-9中的第一個欄位為群碼名稱(Code-group name), 第二個欄位為其位元組值(00-FF), 第三個欄位為其八個位元值,第四及第五個欄位較特別,是每一個位元組對照的十個位元。不過到底要用哪一個欄位的值必須根據目前傳送的「偏差值」(Running Disparity, RD)。偏差值是二元數,可以是正(RD+) 的,也可以是負(RD-)的。
表7-9正確之數據群碼
表7-9正確之數據群碼(續)
表7-9正確之數據群碼(續)
表7-9正確之數據群碼(續)
表7-9正確之數據群碼(續)
表7-9正確之數據群碼(續)
表7-9正確之數據群碼(續)
表7-9正確之數據群碼(續)
表7-9正確之數據群碼(續)
表7-9正確之數據群碼(續)
表7-9正確之數據群碼(續)
表7-9正確之數據群碼(續)
表7-10正確之特殊群碼
在傳送端,偏差值的初始值為負的。傳送器每傳送一個群碼就根據該群碼的內容重新計算一個新值。在接收端,偏差值的初始值可正可負。接收器每接收一個群碼就根據該群碼的內容重新計算一個新值。偏差值的計算原則如下所述。
一個群碼的偏差值的計算是以所謂的「子區塊」(sub-blocks) 為基礎。而所傳送(接收)的十位元中,前六個位元(abcdei)形成一個子區塊,後面四個位元(fghj)形成另一個子區塊。在六位元子區塊前的偏差值是前一個群碼的偏差值,在四位元子區塊前的偏差值是在六位元子區塊計算後的偏差值,群碼後的偏差值則是該群碼中四位元子區塊計算後的偏差值。子區塊偏差值的計算方式如下:
任何一個子區塊後的偏差值為正,如果該子區塊包含”1” 的數量大於“0” 的數量。如果是在一個值為000111 的六位元子區塊後,則偏差值仍然為正。相同的,如果是在一個值為0011 的四位元子區塊後,則偏差值仍然為正。
任何一個子區塊後的偏差值為負,如果該子區塊包含”1” 的數量小於“0” 的數量。如果是在一個值為111000 的六位元子區塊後,則偏差值仍然為負。相同的,如果是在一個值為1100 的四位元子區塊後,則偏差值仍然為負。
在其他狀況下(包含”1” 的數量等於“0” 的數量),則偏差值保持不變。
這裡值得注意的是,所有包含”1” 數量等於“0” 數量的子區塊都屬於無偏差。但是為了限制子區塊間”1” 數量與“0” 數量的差異值,8B/10B編碼法規定,000111 與0011 只能在該子區塊之前的偏差值為正時才能產生。相同的,111000 與1100 只能在該子區塊之前的偏差值為負時才能產生。
針對每一個位元組,其對應的群碼應參考表7-9或表7-10所產生。在選擇使用哪一行的群碼時,應該依據傳送端目前的偏差值。如果目前的偏差值為正,則選用最右邊欄位的群碼。如果目前的偏差值為負,則選用右邊第二個欄位的群碼。每傳送一個群碼都必須計算一個新的偏差值。
接收端在接收群碼時也是根據表7-9或表7-10來決定該群碼的正確性。當然,接收端目前的偏差值也必須考慮到。如果該群碼在表中存在,而且與接收端目前的偏差值符合,則該群碼為正確群碼,其相對的八位元也成功的被解碼出來。如果該群碼不在表中,則該群碼被認為是不正確的。但是無論接收群碼的正確性,該群碼仍必須用來產生一個新的偏差值。此新值成為驗證下一個接收群碼正確性時的偏差值。
在接收時發現一個不正確的群碼並不表示該群碼發生錯誤。不正確群碼可能肇因於先前的傳送錯誤,該錯誤改變了傳送位元串的偏差值,但是錯誤發生當時沒有檢查出來。錯誤群碼發生率通常與線路的位元錯誤率(bit-error-rate, BER) 成正比,計算群碼發生錯誤率也可用來監督線路的狀況。
為了傳送端與接收端間能達到位元與群碼之同步,8B/10B編碼法也規範了八種所謂的「順序集合」(Ordered-sets)。順序集合可以是只有一個特殊群碼,或特殊群碼與數據群碼的組合,如表7-11所示。順序集合可以包含一個,兩個,或四個群碼,但第一個群碼一定是一個特殊群碼。對於多群碼的順序集合,第二個群碼一定是一個數據群碼。此數據群碼用來區別其他的順序集合。
表7-11 順序集合
a: 代表Config-Reg 值的兩個數據群碼
在傳送端與接收端開始通訊之前,先用組態(Configuration) 順序集合來設定雙方的組態。在傳送一個訊框時則使用/S/, /T/ 碼來表示訊框的開始與結束。GMII介面如果沒有資料往下傳,則傳送端只傳送/I/ 碼。
表7-12, 7-13, 7-14 所示為8B/10B編碼法計算偏差值的範例。表7-12, 7-13的例子同時也舉出在接收時發現一個不正確的群碼並不表示該群碼發生錯誤的情形。表7-12的例子中,偏差值在群碼發生錯誤後的第二個群碼檢測出錯誤。表7-13的例子中,偏差值在群碼發生錯誤後的第一個群碼就檢測出錯誤。表7-14 的例子則顯示一個群碼發生一個位元的錯誤,而且該群碼就被檢查出不正確。此錯誤影響到下一個群碼,但在檢查出偏差值的錯誤後,遏止此錯誤的蔓延。
表7-12 偏差值計算與錯誤偵測範例(一)
a: 位元發生錯誤(1001 ? 1011)
b: 非零偏差的區塊應該交換其前後偏差值之極性(+ ? -)。
c: 無論接收群碼是否正確,偏差值仍須繼續計算。非零偏差的區塊可避免錯誤蔓延。表7-13 偏差值計算與錯誤偵測範例(二)
a: 位元發生錯誤(1001 ? 1011)
b: 非零偏差的區塊應該交換其前後偏差值之極性(+ ? -)。
表7-14 偏差值計算與錯誤偵測範例(三)
a: 位元發生錯誤(0110 ? 0111)
b: 非零偏差的區塊應該交換其前後偏差值之極性(- ? +)。
c: 非零偏差的區塊應該交換其前後偏差值之極性(+ ? -)。
d: 接收群碼在表7-9, 表7-10中找不到(檢查出錯誤群碼)。
e: 非零偏差的區塊可避免錯誤蔓延。
習題
7.1 請說明100BaseT 網路通訊協定架構。
7.2 請比較100Base4T 網路與100BaseX 網路的異同。
7.3 請說明100Base4T 網路如何利用四對雙絞線傳送訊框。
7.4 請說明為什麼100BaseT 網路不採用原來Ethernet 網路之編碼技術?7.5 何謂8B/6T 編碼法?100Base4T 網路如何利用此編碼法?
7.6 何謂「直流迷失」(DC wander) 現象?100Base4T 網路如何解決此問題?
7.7 參考表7-1。請將下圖中A-L 位置填入適當字碼。
圖7-23
7.8 參考表7-1。請將下圖中A-L 位置填入適當字碼。
圖7-24
7.9 請說明100Base4T 編碼法中,EOS (End-of-Stream) 的使用方式。
7.10 請說明100Base4T 編碼法中,SOS (Start-of-Stream) 的使用方式。
7.11 何謂「近端串音」現象?100Base4T 網路如何解決此問題?
請說明Ether-Switch 的工作原理。
何謂「回壓」(backpressure) 技術?交換器如何使用技術?
何謂「延伸載波」(extended carrier) ? 請說明其工作原理與包含延伸載波之訊框格式。
何謂「訊爆」(frame bursting) ? 請說明其工作原理。
1000Mbps CSMA/CD 網路提供兩種網路模式:「傳輸系統模式一」(Transmission System Model 1, TSM-1),「傳輸系統模式二」(Transmission System Model 2, TSM-2)。請說明這兩種模式的特性為
何。
請說明TSM-2模式中,「最大路徑延遲」(Worst-case path delay value, PDV) 值如何計算。
請簡略說明Gigabit Ethernet採用之8B/10B編碼法工作原理。
請簡略說明8B/10B編碼法中「偏差值」(running disparity) 的目的與計算規則。參閱表7-9。請將下表中接收位元串及接收群碼空白部份填入正確內容。
7.21參閱表7-9。請將下表中接收位元串及接收群碼空白部份填入正確內容。
22參閱表7-9及表7-10。請將下表中接收位元串及接收群碼空白部份填入正確內容。
数据的编码与调制
数据的编码与调制 如前所述,网络中的通信信道可以分为模拟信道和数字信道,分别用于传输模拟信号和数字信号,而依赖于信道传输的数据也分为模拟数据与数字数据两类。为了正确地传输数据,必须对原始数据进行相应的编码或调制,将原始数据变成与信道传输特性相匹配的数字信号或模拟信号后,才能送入信道传输。如图6-20所示,数字数据经过数字编码后可以变成数字信号,经过数字调制(ASK、FSK、PSK)后可以成为模拟信号;而模拟数据经过脉冲编码调制(PCM)后可以变成数字信号,经过模拟调制(AM、FM、PM)后可以成为与模拟信道传输特性相匹配的模拟信号。 图6-20 数据的编码与调制示意图 6.3.1 数字数据的数字信号编码 利用数字通信信道直接传输数字信号的方法,称作数字信号的基带传输。而基带传输需要解决的两个问题是数字数据的数字信号编码方式及收发双方之间的信号同步。 在数字基带传输中,最常见的数据信号编码方式有不归零码、曼彻斯特编码和差分曼彻斯特编码3种。以数字数据011101001为例,采用这3种编码方式后,它的编码波形如图6-21所示。 1.不归零码(NRZ,Non-Return to Zero) NRZ码可以用低电平表示逻辑“0”,用高电平表示逻辑“1”。并且在发送NRZ码的同时,必须传送一个同步信号,以保持收发双方的时钟同步。 2.曼彻斯特编码(Manchester) 曼彻斯特编码的特点是每一位二进制信号的中间都有跳变,若从低电平跳变到高电平,就表示数字信号“1”;若从高电平跳变到低电平,就表示数字信号“0”。曼彻斯特编码的原则是:将每个比特的周期T分为前T/2和后T/2,前T/2取反码,后T/2取原码。 曼彻斯特编码的优点是每一个比特中间的跳变可以作为接收端的时钟信号,以保持接收端和
信息论与编码课程总结
信息论与编码 《信息论与编码》这门课程给我带了很深刻的感受。信息论是人类在通信工程实践之中总结发展而来的,它主要由通信技术、概率论、随机过程、数理统计等相结合而形成。它主要研究如何提高信息系统的可靠性、有效性、保密性和认证性,以使信息系统最优化。学习这门课程之后,我学到了很多知识,总结之后,主要有以下几个方面: 首先是基本概念。信息是指各个事物运动的状态及状态变化的方式。消息是指包括信息的语言、文字和图像等。信号是消息的物理体现,为了在信道上传输消息,就必须把消息加载到具有某种物理特性的信号上去。信号是信息的载荷子或载体。信息的基本概念在于它的不确定性,任何已确定的事物都不含有信息。信息的特征:(1)接收者在收到信息之前,对其内容是未知的。(2)信息是能使认识主体对某一事物的未知性或不确定性减少的有用知识。(3)信息可以产生,也可以消失,同时信息可以被携带、存储及处理。(4)信息是可以量度的,信息量有多少的差别。编码问题可分解为3类:信源编码、信道编 码、加密编码。= 理论上传输的最少信息量 编码效率实际需要的信息量。 接下来,学习信源,重点研究信源的统计特性和数学模型,以及各类离散信源的信息测度 —熵及其性质,从而引入信息理论的一些基本概念和重要结论。本章内容是香农信息论的基础。重点要掌握离散信源的自信息,信息熵(平均自信息量),条件熵,联合熵的的概念和求法及其它们之间的关系,离散无记忆的扩展信源的信息熵。另外要记住信源的数学模型。通过学习信源与信息熵的基本概念,了解了什么是无记忆信源。信源发出的序列的统计性质与时间的推移无关,是平稳的随机序列。当信源的记忆长度为m+1时,该时刻发出的符号与前m 个符号有关联性,而与更前面的符号无关,这种有记忆信源叫做m 阶马尔可夫信源。若上述条件概率与时间起点无关,则信源输出的符号序列可看成齐次马尔可夫链,这样的信源叫做齐次马尔可夫信源。之后学习了信息熵有关的计算,定义具有概率为 () i p x 的符号i x 的自信息量为:()log ()i i I x p x =-。自信息量具有下列特性:(1) ()1,()0i i p x I x ==(2)()0,()i i p x I x ==∞(3)非负性(4)单调递减性(5)可加 性。信源熵是在平均意义上来表征信源的总体特征,它是信源X 的 函数,一般写成H (X )。信源熵:()()log ()i i i H X p x p x =-∑,条件熵:(|)(,)log (|) i j i j ij H X Y p x y p x y =-∑联合 熵(|)(,)log (,)i j i j ij H X Y p x y p x y =-∑,联合熵 H(X,Y)与熵H(X)及条件熵H(Y|X)的关系: (,)()(|)()(|)H X Y H X H Y X H X H X Y =+=+。互信息: ,(|)(|)(;)(,)log ()(|)log () () j i j i i j i j i ij i j j j p y x p y x I X Y p x y p x p y x p y p y = = ∑ ∑ 。熵的性质:非负性,对称性,确定 性,极值性。 接下来接触到信道,知道了信道的分类,根据用户数可以分为,单用户和多用户;根
常用字符集编码详解:ASCII 、GB2312、GBK、GB18030、...
ASCII ASCII码是7位编码,编码范围是0x00-0x7F。ASCII字符集包括英文字母、阿拉伯数字和标点符号等字符。其中0x00-0x20和0x7F共33个控制字符。 只支持ASCII码的系统会忽略每个字节的最高位,只认为低7位是有效位。HZ字符编码就是早期为了在只支持7位ASCII系统中传输中文而设计的编码。早期很多邮件系统也只支持ASCII编码,为了传输中文邮件必须使用BASE64或者其他编码方式。 GB2312 GB2312是基于区位码设计的,区位码把编码表分为94个区,每个区对应94个位,每个字符的区号和位号组合起来就是该汉字的区位码。区位码一般用10进制数来表示,如1601就表示16区1位,对应的字符是“啊”。在区位码的区号和位号上分别加上0xA0就得到了GB2312编码。 区位码中01-09区是符号、数字区,16-87区是汉字区,10-15和88-94是未定义的空白区。它将收录的汉字分成两级:第一级是常用汉字计3755个,置于16-55区,按汉语拼音字母/笔形顺序排列;第二级汉字是次常用汉字计3008个,置于56-87区,按部首/笔画顺序排列。一级汉字是按照拼音排序的,这个就可以得到某个拼音在一级汉字区位中的范围,很多根据汉字可以得到拼音的程序就是根据这个原理编写的。 GB2312字符集中除常用简体汉字字符外还包括希腊字母、日文平假名及片假名字母、俄语西里尔字母等字符,未收录繁体中文汉字和一些生僻字。可以用繁体汉字测试某些系统是不是只支持GB2312编码。 GB2312的编码范围是0xA1A1-0x7E7E,去掉未定义的区域之后可以理解为实际编码范围是0xA1A1-0xF7FE。 EUC-CN可以理解为GB2312的别名,和GB2312完全相同。 区位码更应该认为是字符集的定义,定义了所收录的字符和字符位置,而GB2312及EUC-CN是实际计算机环境中支持这种字符集的编码。HZ和ISO- 2022-CN是对应区位码字符集的另外两种编码,都是用7位编码空间来支持汉字。区位码和GB2312编码的关系有点像Unicode和UTF-8。 GBK GBK编码是GB2312编码的超集,向下完全兼容GB2312,同时GBK收录了Unicode基本多文种平面中的所有CJK汉字。同GB2312一样,GBK也支持希腊字母、日文假名字母、俄语字母等字符,但不支持韩语中的表音字符(非汉字字符)。GBK还收录了GB2312不包含的汉字部首符号、竖排标点符号等字符。 GBK的整体编码范围是为0x8140-0xFEFE,不包括低字节是0×7F的组合。高字节范围是0×81-0xFE,低字节范围是0x40-7E和0x80-0xFE。
《信息论与编码》教学大纲
《信息论与编码》教学大纲 一课程简介 课程编号:04254002 课程名称:信息论与编码Informatics & Coding 课程类型:基础课必修课 学时:32 学分:2 开课学期:第六学期 开课对象:通信、电子专业 先修课程:概率论与数理统计、信号与系统、随机信号原理。 参考教材:信息论与编码,陈运,周亮,陈新,电子工业出版社,2002年8月 二课程性质、目的与任务 信息论在理论上指出了建立最佳编码、最佳调制和最佳接收方法的最佳系统的理论原则,它对通信体制和通信系统的研究具有指导意义。提高信息传输的可靠性和有效性始终是通信工作所追求的目标。因此,信息论与编码是从事通信、电子系统工程的有关工程技术人员都必须掌握的基本理论知识。 内容提要:本课程包括狭义相对论和提高通信可靠性的差错控制编码理论。信息论所研究的主要问题是在通信系统设计中如何实现有效性和可靠性。 三教学基本内容与基本要求 本课程总学时为32。其中理论教学为28,实验学时为4。 主要的理论教学内容包括:离散信源和连续信源的熵、条件熵、联合熵和平均互信息量的概念及性质;峰值功率受限和平均功率受限下的最大熵定理和连续信源熵的变换;变长码的霍夫曼编码方法,熟悉编码效率和平均码长的计算;最大后验概率准则和最大似然译码准则等。 实验内容主要包括:离散无记忆信道容量的迭代算法,循环码的编译码。 四教学内容与学时分配 第3章离散信源无失真编码
第6章网络信息论 (教学要求:A—熟练掌握;B—掌握;C—了解) 五实习、实验项目及学时分配 1.离散无记忆信道容量的迭代算法2学时 要求用Matlab编写计算离散信道容量的实用程序并调试成功,加深对信道容量的理解。 2.循环码的编译码2学时 要求用Matlab编写程序,用软件完成循环码的编译码算法。 六教学方法与手段 常规教学与多媒体教学相结合。
字符编码方式介绍及编码方式测试
第一部分编码方式介绍 一、编码: 美国标准信息交换标准码( , ) 在计算机内部,所有地信息最终都表示为一个二进制地字符串.每一个二进制位()有和两种状态.一个字节()共由八个二进制位来组成,共有种状态,从到. 阿拉伯数字、英文字母、标点符号等这些字符,怎么定义才能让计算机识别呢?因为计算机只识别二进制位和,所以以上这些字符就必须与二进制位(和)建立关系,才能让计算机识别. 年代初,计算机界制定了一套统一地字符编码,来表示字符与二进制位之间地关系.这种统一地字符编码就叫做编码.码一共规定了个字符地编码,比如空格是(二进制),大写地字母是(二进制).这个符号(包括个不能打印出来地控制符号),只占用了一个字节地后面位,最前面地位统一规定为. 在英语国家,个编码足以表达所有字符,但其它非英语国家,字符不是由英文字符组成,这样就需要增加编码以表达这些字符,对于超过个字符地编码被称为非编码.比如:在中国,我们用简体中文,字符编码方式为.个人收集整理勿做商业用途 二、编码: 看到上面地介绍后,我们了解了最早编码是码.它只用个二进制位来表示,由于那个时期生产地大多数计算机使用位大小地字节,因此用户不仅可以存放所有可能地字符,而且有整整一位空余下来.如果你技艺高超,可以将该位用做自己离奇地目地:中那个发暗地灯泡实际上设置这个高位,以指示一个单词中地最后一个字母,同时这也宣示了只能用于英语文本. 由于字节有多达位地空间,因此许多人在想:“呀!我们可以把之间地编码用做个人地应用目地.”问题在于,同时产生这种想法地人相当多,而且在之间地各个位置上应该存放什么这一问题上,真是仁者见仁智者见智.事实上,只要人们开始在美国以外地地方购买计算机,那么各种各样地不同字符集都会进入规划设计行列,并且各人都会根据自己地需要使用高位地个字符.如此一来,甚至在同语种地文档之间就不容易实现互换. 可被扩展,最优秀地扩展方案是,通常称之为.包括了足够地附加字符集来写基本地西欧语言. 最后,这个人参与地终于以标准地形式形成文件.在标准中,每个人都认同如何使用低端地个编码,这与相当一致.不过,根据所在国籍地不同,处理编码以上地字符有许多不同地方式.这些不同地系统称为代码页. 同时,甚至更为令人头疼地事情正在逐步上演,亚洲国家地字符表有成千上万个字符,这样地字符表是用位二进制无法表示地.该问题地解决通常有赖于称为(,双字节字符集)地繁杂字符系统. 不过,仍然需要指出一点,多数人还是姑且认为一个字节就是一个字符,以及一个字符就是个二进制位,并且只要确保不将字符串从一台计算机移植到另一台计算机,或者说一种以上地语言,那么这几乎总是可以凑合.当然,只要一进入,从一台计算机向另一台计算机移植字符串就成为家常便饭了,而各种复杂状况也随之呈现出来.令人欣慰地是,随即问世了.个人收集整理勿做商业用途 字符集(简称为),国际标准组织于年月成立工作组,针对各国文字、符号进行统一性编码.年美国跨国公司成立,并于年月与达成协议,采用同一编码字集.目前是采用位编码体系,其字符集内容与地()相同.于年月通过(),目前版本于公布,内容包含符号个,汉字个,韩文拼音个,造字区个,保留个,共计个.编码后地大小是一样地.例如一个英文字母"" 和一个汉字"好",编码后都是占用地空间大小是一样地,都是两个字节!个人收集整理勿做商业用途 可以用来表示所有语言地字符,而且是定长双字节(也有四字节地)编码,包括英文字
数字测图复习题
数字化测图复习题 一、填空题 1.广义的数字化测图又称为计算机成图主要包括:地面数字测图、地图数字化成图、航测数字测图和计算机地图制图。 2.数字测图的基本思想是将地面上的地形和地理要素转换为数字量,然后由电子计算机对其进行处理,得到内容丰富的电子地图。 3. 数字测图就是要实现丰富的地形信息、地理信息数字化和作业过程的自动化 或半自动化。 4. 计算机屏幕上能显示的图形软件给出了两种表示方式,即矢量图形和栅格图形,对应的图形数据称为矢量数据和栅格数据;数字测图中通常采用矢量数据结构和绘制矢量图形。 5.数字地形表达的方式可以分为两大类,即数学描述和图像描述。 6. 计算机地图制图过程中,制图的数据类型有三种:空间数据、属性数据和拓朴数据。而空间数据是所有数据的基础。 7. 绘图信息包括点的定位信息、连接信息、属性信息。 8.数字测图中描述地形点必须具备的三类信息为:点的三维坐标、测点的属性和测点的连接关系。 9.数字测图系统是以计算机为核心,在硬件和软件的支持下,对地形空间数据进行数据采集、输入、处 理、绘图、存储、输出、管理的测绘系统;它包括硬件和软件两个部分。 10.数字测图系统主要由数据输入、数据处理和图形输出三部分组成,其作业过程与使用的设备和软件、数据源及图形输出的目的有关。 11.数字测图系统可区分为现有地形图的数字化成图系统、基于影像的数字成图系统、地面数字测图系统。 12.数字测图的基本过程包括:数据采集、数据处理、图形输出。 13.在计算机外围设备中,鼠标、键盘、图形数字化仪和扫描仪,属于输入设备;
显示器、投影仪、打印机和绘图仪等,属于输出设备。 14.地面数字测图是利用全站仪或其它测量仪器在野外进行数字化地形数据采集在成图软件的支持下,通过计算机加工处理,获得数字地形图的方法,其实质是一种全解析机助测图方法。 15.目前我国主要采用数字化仪法、航测法和大地测量仪器法采集数据。前两者主要是室内作业采集数据,后者是野外采集数据。 16.测定点位是测量的基本工作,数据处理是数字测图的关键阶段。 17.数字化测图的特点为:点位精度高、自动化程度高、便于成果更新、增加了地图的表现力、方便成果的深加工利用、可以作为GIS的重要信息源。 18.数字测图作业模式粗分可区分为,数字测记式和电子平板两大作业模式。 19.由于软件设计者思路不同,使用的设备不同,数字测图有不同的作业模式。可区分为两大作业模式,即测记模式和电子平板模式。 20.测记法是一种盲式作业,电子平板法是一种明式作业。 21.把测定的碎部点实时地展绘在计算机屏幕(模拟测板)上,用软件的功能边测边绘,称为电子平板测图。 22.电子平板可区分为测站电子平板和镜站遥控电子平板。 23.全站仪是在电子经纬仪和电子测距技术基础上发展起来的一种智能化的测量仪器,是由电子测角、电子测距、电子计算机和数据存储单元等组成的三维坐标测量系统,测量结果能自动显示,并能与外围设备交换信息的多功能仪器,称为全站型电子速测仪(全站仪)。 24.全站仪的分类按结构形式可分为:组合式全站仪及整体式两种类型。 25.全站仪的基本结构包括光电测角系统、光电测距系统、双轴液体补偿装置和测量计算机系统。 26.目前,电子经纬仪的测角系统主要有三类:即编码度盘测角系统、增量式光栅度盘测角系统、以及动态光栅度盘测角系统。 27.脉冲法测距就是直接测定仪器所发射的脉冲信号往返于被测距离的传播时间而得到距离值。 28.相位法测距是通过测量含有测距信号的调制波在测线上往返传播所产生的相位移,间接地测定电磁波在测线上往返传播的时间,进而求得距离值。 29.实现图数转换的设备称为数字化仪;数字化仪分为两类:手扶跟踪数字化仪
信息论与编码总结
信息论与编码 1. 通信系统模型 信源—信源编码—加密—信道编码—信道—信道解码—解密—信源解码—信宿 | | | (加密密钥) 干扰源、窃听者 (解密秘钥) 信源:向通信系统提供消息的人或机器 信宿:接受消息的人或机器 信道:传递消息的通道,也是传送物理信号的设施 干扰源:整个系统中各个干扰的集中反映,表示消息在信道中传输受干扰情况 信源编码: 编码器:把信源发出的消息变换成代码组,同时压缩信源的冗余度,提高通信的有效性 (代码组 = 基带信号;无失真用于离散信源,限失真用于连续信源) 译码器:把信道译码器输出的代码组变换成信宿所需要的消息形式 基本途径:一是使各个符号尽可能互相独立,即解除相关性;二是使各个符号出现的概率尽可能相等,即概率均匀化 信道编码: 编码器:在信源编码器输出的代码组上增加监督码元,使之具有纠错或检错的能力,提高通信的可靠性 译码器:将落在纠检错范围内的错传码元检出或纠正 基本途径:增大码率或频带,即增大所需的信道容量 2. 自信息:()log ()X i i I x P x =-,或()log ()I x P x =- 表示随机事件的不确定度,或随机事件发生后给予观察者的信息量。 条件自信息://(/)log (/)X Y i j X Y i j I x y P x y =- 联合自信息:(,)log ()XY i j XY i j I x y P x y =- 3. 互信息:;(/) () (;)log log ()()()i j i j X Y i j i i j P x y P x y I x y P x P x P y == 信源的先验概率与信宿收到符号消息后计算信源各消息的后验概率的比值,表示由事件y 发生所得到的关于事件x 的信息量。 4. 信息熵:()()log ()i i i H X p x p x =-∑ 表示信源的平均不确定度,或信源输出的每个信源符号提供的平均信息量,或解除信源不确定度所需的信息量。 条件熵:,(/)()log (/)i j i j i j H X Y P x y P x y =- ∑ 联合熵:,()()log ()i j i j i j H XY P x y P x y =-∑ 5. 平均互信息:,()(;)()log ()() i j i j i j i j p x y I X Y p x y p x p y =∑
数字测图的作业方法
数字测图的作业模式是指数字化测图内外业作业方法、接口方式和流程的总称。 一般来说,数字测图的作业模式大致分为编码法、草图法、电子平板、原图数字化等几种。 1、编码法 编码法即利用成图系统的地形地物编码方案,在野外测图时不用画草图,只需将每一点的编码和相邻点的连接关系直接输入到全站仪或电子记录手簿中去,成图系统就会自动根据点的编码和连点信息进行图形生成,也称全要素编码法。 该方法的内外业工作量分配不合理,外业编码工作时大,点位关系复杂,容易输入错误编码。 编码法突出的优点是自动化程度较高,内业工作量相对较少,符合测量作业自动化的大趋势。但这种作业模式要求观测员熟悉编码,并在测站上随观测随输入。另外,当司镜员离测站较远时,观测者很难看清地物属性和连接关系,这就要求观测员与司镜员密切配合,相互交流反馈有关信息。其作业流程如下: 设站→观测输入编码→将数据输入微机→格式转换和编码识别→自动绘图→编辑修改→图幅整饰→图形输出 2、草图法 草图法是指在外业过程中只画草图就可以了,不用为每一点都赋予编码,也不用加注点的连接信息,使外业的工作量减到最少,当系统把所测的点展到计算机屏幕上之后,对照草图就可以在屏幕上直接进行编辑成图。 编码法和草图法成图模式无法实时显示和处理图形,图形信息很大程度上靠数据来体现,这就给测绘地面情况比较复杂的地形图、地籍图等带来困难。我们不难比较得出这样的结论:
以上两种方法中,全要素编码法外业编码复杂易出错但内业工作量相对较少,草图法的外业工作量最少,数据采集过程最简单,并且最不容易出错,但内业编辑工作量比较大,在一般的作业单位中应用较广。其工作流程如下: 设站→瞄准观测→将数据输入微机→(格式转换)编制编码→内业成图→编辑修改→图幅整饰→图形输出 3、电子平板测图系统 电子平板测图是利用电子平板测绘成图系统,把便携计算机与全站仪连接,与传统的平板视距法成图类似,用便携计算机替代了大平板,实时进行数据采集,数据处理与图形编辑,电子平板测绘系统是在传统数字化成图系统的基础上开发而成,其数据采集与图形处理在同一环境下完成,实时处理所测数据,具有现场直接生成地形图“即测即显,所见所得”等优点,但对阴雨天、暴晒或灰尘等条件难以适应。另外,把实地图形显示在屏幕上,操作员可根据实地信息直接成图,也可先把点展在图上,一站结束后再成图。在现场对某些实体作简单的编辑、修改,较复杂的工作可回到室内去做,最后通过绘图仪打印输出。其作业流程如下: 设站→观测数据通讯→便携机成图→编辑修改→图幅整饰→图形输出 4、原图数字化 如果已有大量的聚脂薄膜图,或者外业仍然采用平板测图,经纬仪+小平板测图方式,要使这些成果进入微机转化为数字化成果,就必须采用这种模式。进行数字化一般有两种方法,较早采用的是利用数字化仪将图纸矢量化到计算机中;而现在大多利用大幅面工程扫描仪借助扫描矢量化软件直接对扫描图纸进行矢量化,从而得到数字化图形文件。 总之,原图数字化的作业方法最大的优点是可以利用原有图纸,是原有测绘成果向数字化成果过渡的必经之路,同时也为传统测图与数字测图之间建立了密切的联系。便于对测绘人员进行合理分工,使人员、仪器设备得到合理配置。
(完整版)信息论与编码概念总结
第一章 1.通信系统的基本模型: 2.信息论研究内容:信源熵,信道容量,信息率失真函数,信源编码,信道编码,密码体制的安全性测度等等 第二章 1.自信息量:一个随机事件发生某一结果所带的信息量。 2.平均互信息量:两个离散随机事件集合X 和Y ,若其任意两件的互信息量为 I (Xi;Yj ),则其联合概率加权的统计平均值,称为两集合的平均互信息量,用I (X;Y )表示 3.熵功率:与一个连续信源具有相同熵的高斯信源的平均功率定义为熵功率。如果熵功率等于信源平均功率,表示信源没有剩余;熵功率和信源的平均功率相差越大,说明信源的剩余越大。所以信源平均功率和熵功率之差称为连续信源的剩余度。信源熵的相对率(信源效率):实际熵与最大熵的比值 信源冗余度: 0H H ∞=ηη ζ-=1
意义:针对最大熵而言,无用信息在其中所占的比例。 3.极限熵: 平均符号熵的N 取极限值,即原始信源不断发符号,符号间的统计关系延伸到无穷。 4. 5.离散信源和连续信源的最大熵定理。 离散无记忆信源,等概率分布时熵最大。 连续信源,峰值功率受限时,均匀分布的熵最大。 平均功率受限时,高斯分布的熵最大。 均值受限时,指数分布的熵最大 6.限平均功率的连续信源的最大熵功率: 称为平均符号熵。 定义:即无记忆有记忆N X H H X H N X H X NH X H X H X H N N N N N N )() ()()()()()(=≤∴≤≤
若一个连续信源输出信号的平均功率被限定为p ,则其输出信号幅度的概率密度分布是高斯分布时,信源有最大的熵,其值为 1log 22 ep π.对于N 维连续平稳信源来说,若其输出的N 维随机序列的协方差矩阵C 被限定,则N 维随机矢量为正态分布时信源 的熵最大,也就是N 维高斯信源的熵最大,其值为1log ||log 222N C e π+ 7.离散信源的无失真定长编码定理: 离散信源无失真编码的基本原理 原理图 说明: (1) 信源发出的消息:是多符号离散信源消息,长度为L,可以用L 次扩展信 源表示为: X L =(X 1X 2……X L ) 其中,每一位X i 都取自同一个原始信源符号集合(n 种符号): X={x 1,x 2,…x n } 则最多可以对应n L 条消息。 (2)信源编码后,编成的码序列长度为k,可以用k 次扩展信宿符号表示为: Y k =(Y 1Y 2……Y k ) 称为码字/码组 其中,每一位Y i 都取自同一个原始信宿符号集合: Y={y 1,y 2,…y m } 又叫信道基本符号集合(称为码元,且是m 进制的) 则最多可编成m k 个码序列,对应m k 条消息 定长编码:信源消息编成的码字长度k 是固定的。对应的编码定理称为定长信源编码定理。 变长编码:信源消息编成的码字长度k 是可变的。 8.离散信源的最佳变长编码定理 最佳变长编码定理:若信源有n 条消息,第i 条消息出现的概率为p i ,且 p 1>=p 2>=…>=p n ,且第i 条消息对应的码长为k i ,并有k 1<=k 2<=…<=k n
编码测量论文word版
第1章绪论 数字测图技术的应用与发展,极大地促进了测绘行业的自动化和现代化进程,使测量成果不仅有绘在纸上的地形图,还有方便传输、处理、共享的基础信息,即数字地图,它将为信息时代地理信息的应用发展提供最可靠的保障。数字化自动成图作业过程中,外业数据采集我校所用的设备有南方、尼康、徕卡和拓普康等仪器,内业成图用南方CASS 软件。面对众多的作业工具,如何组织好外业数据采集并且使外业数据能够顺利进入内业平台以提高作业效率,这是一个外业测绘者比较感兴趣的问题。众所周知,全野外数字化作业流程可以概括为图1-1。 图1-1 野外数字化作业流程 “简码记录法”,采取简洁的图形信息码表达地图信息,在采集地物坐标时同时输入图形信息码。“简码记录法”定位在不牺牲外业采集速度;不增加观测员记忆负担;以最精简的地物地形编码录入;替代野外人工绘制草图;减轻内业工作量。
第2章已有资料分析利用 2.1测区概况 黄河水利职业技术学院新校区位于开封市西北角,东临黄河大街,北临北环路,西邻夷山大街,东临东京大道,与河南大学比邻,新校区东西长782米,南北长985米,南侧有宽约80米的地下古城墙遗址,南侧有贯穿东西的城市绿化带。学校内部地势平坦,有教学楼,宿舍楼,食堂,绿化带,大小湖泊,篮球场,体育场,假山等。数字测图技术是黄河水利职业技术学院的省级精品课程,在开封市享有很高的知名度,学院测绘工程系应生产单位要求,着力发展工程测量学和数字测图学科,培养出更加优秀的毕业生,为国家的生产建设贡献力量。 2.2测区资料 (1)黄河水院新校区鸟瞰图2-1 (2)黄河水院新校区控制点分布示意图2-2 (3)黄河水院新校区控制点成果表(开封城建坐标系) (4)测区已知控制点成果表2-1 选用黄河水利职业技术学院两个E级GPS点H048、H033 作为已知控制点 表2-1 已知控制点
编码在大比例数字测图中的应用
编码在大比例数字测图中的应用 发表时间:2014-12-23T14:07:44.093Z 来源:《价值工程》2014年第9月下旬供稿作者:刘宏光 [导读] 这个小程序的应用完全依据的是输入全站仪的属性代码,那么内业成图自动化的程度,完全取决于外业编码输入的正确与否刘宏光LIU Hong-guang曰朱俊鹏ZHU Jun-peng曰刘海辰LIU Hai-chen(天津市勘察院,天津300191)(Tianjin Institute of Geotechnical Investigation & Surveying,Tianjin 300191,China) 摘要院使用全站仪野外数字测图是一项需要相互协作的团体作业过程,本文主要介绍一种编码的方法来解决这个问题。利用新方法采集外业数据的时候只需要两个人,不需要绘草图,不仅减少了外业的工作量,最重要的是内业基本实现全自动化,解决了高程点坐标、图层、线型及连接关系等问题,大大减轻了内业人员成图编辑的工作量。 Abstract院The use of total station field digital mapping is a group work process that needs cooperation, this paper mainly introduces akind of coding method to solve this problem. When using the new method to collect field surveying data, only two personnel are needed, andthey don't need to draw the sketch, which reduces the workload of the field surveying, the most importantly, basically realizes the fullautomation of the indoor work, solves the problems of elevation point coordinates, layer, linear, and connection relationship etc, and greatlyreduces the workload of mapping editor of field surveying personnel.关键词院数字测图;编码;全站仪;野外数据采集Key words 院digital mapping;coding;total station;field data collection中图分类号院P208 文献标识码院A 文章编号院1006-4311(2014)27-0203-04 0 引言全站仪数字测图已经成为野外测图中常用的作业方式。它方便、快捷、测量精度高。通常作业时需要几名作业员相互配合:跑棱镜,操作全站仪,绘草图或者是记属性。 外业草图是内业成图编辑的重要依据,它记录了点号的属性和连向,全站仪记录了点号的坐标。作业时我们发现当外业采集的点比较多的时候,这种方式的弊端就很明显。 绘制草图变得比较复杂,内业编辑相当麻烦,特别是点位密集的地方草图往往很难表示清楚,只能依据点位属性和记忆来绘图,往往需要再次甚至多次到实地核实才能搞清楚。我们在发现了这种弊端以后尝试对作业流程进行改进,本文主要就是介绍一种利用编码数字测图内业自动成图的方法。新方法外业数据采集的时候只需要两个人,不需要绘草图,外业的工作量减少了,最重要的是内业基本实现全自动化,包括高程点坐标、图层、线型及连接关系都解决了,大大减轻了内业人员的成图编辑。 1 实现方法及主要内容目前大部分的内业绘图软件,如广州SCS、南方CASS等都是支持编码测图的,但这是不够的,自动化的程度不高,并且操作全站仪的时候输入属性是会耽误一定时间的。我们用的方法是用属性解决全部的问题。除了点的属性,还把图层、线型和连接关系都解决了。全站仪中,属性可以用数字代码或英文字母代码来表示,英文字母比较直观,数字比较简单。在徕卡全站仪中,用数字代码输入的速度非常快,基本上不耽误什么时间,并且数字都可以自己定义。这里为了说明比较直观,就用字母代码来表示。我们是在广州SCS 的环境下来实现的。用两个文件来定义测量的碎步点,一个是图层文件,一个是地物的定义。这两个文件都是开放式的,自己可以按照规定的格式根据自己的需要定制。这里就用我们平时工作使用的规定做一个简单的说明。 程序的实现分为如下四个阶段:淤准备阶段,该阶段读取图层和地物的规定文件,根据规定的文件新建相应的图层,读取外业实测数据文件,获取每个实测点的XYZ 坐标值,为后续图形绘制做好充分的准备。于分析阶段,该阶段主要通过缩写编码分析地物为一般点、高程点、图根点、块、线、文字等,从而确定其绘制方式。盂绘制阶段,根据上一步中分析的地形绘制方式来具体绘制地物。榆结果反馈阶段,根据绘制的情况反馈用户绘制成功与否,如果不成功,具体哪些点失败,需要反馈用户一个详细的列表。
数字测图软件总结(全面版)
数字测图系统(Digital Surveying and Mapping System是以计算机为核心,以全站性电子速测仪、GPS、数字摄影测量仪、数字化仪等为数据采集工具,在外接输入、输出设备软、硬件的支持下,对地形的数字空间数据进行采集、输入、成图、绘图、输出、管理的测绘系统。 数字化测图的优点 1.数字化测图使大比例尺测图走向自动化 数字测图的自动化效率高,劳动强度小,错误(读、记、展)率小,绘得的地形图精确、美观、规范。 2.数字化测图使大比例尺测图走向数字化 数字信息可供传输、处理、共享 自动提取面积、方位、坐标、距离 为CAD、GIS提供基础空间信息 进行分层、放大、裁剪等处理 局部更新速度快 3.数字化测图使大比例尺测图实现了高精度 白纸测图有精度损失:图上0.1mm,比例尺为1:1000,最好精度为10cm。 蓝晒、图纸变形等误差一般精度为0.3mm,和原测距精度一致 数字测图无损失地记录了外业测绘数据。 4.数字化测图使大比例尺测图进入新时期 测图作业过程发生了很大的变化 控制测量、碎部测量的一步法 分图幅作业到地物整体测量,计算机自动分幅。 数字化测图的特点为:点位精度高、自动化程度高、便于图件更新、可以作为GIS的重要信息源、增加了地图的表现力、方便成果的深加工利用。 数字测图的作业过程 明确任务,调查测区 编写技术设计书 地形控制测量 地形测图 地形图的编辑、整饰与输出 质量检查与验收 编写技术总结,提交有关资料 组织、管理、人员、业务技术 大比例尺数字测图技术设计的内容 1、任务概述 2、测区情况,实地踏勘,了解测区地形特点考察图根控制的布设条件 3、已有资料及其分析需要的测绘资料:控制点,已有地形图 4、技术方案的设计 5、组织与劳动计划 6、仪器配备及供应计划 6、财务预算 7、检查验收计划以及安全措施等。 数字测图中地形点的描述必须具备3类信息: (1)测点的三维坐标(点号);
CDMA语音编码和信道编码总结
CDMA的语音编码与信道编码 摘要:随着3G移动通信技术的逐步实现以及移动通信与互联网的融合,全球正迅速步入移动信息时代。CDMA已被广泛接纳为第三代移动通信的核心技术之一,它具有优越的性能。本文主要介绍CDMA中常用的语音编码技术与信道技术。 关键词:语音编码信道编码受激励线性编码码激励线性预测编码矢量和激励线性预测编码编码器解码器卷积码 1 CDMA中的语音编码技术 语音编码为信源编码,是将模拟信号转变为数字信号,然后在信道中传输。在数字移动通信中,语音编码技术具有相当关键的作用,高质量低速率的话音编码技术与高效率数字调制技术相结合,可以为数字移动网提供高于模拟移动网的系统容量。目前,国际上语音编码技术的研究方向有两个:降低话音编码速率和提高话音质量。 1.1 语音编码技术的分类 语音编码技术有三种类型:波形编码、参量编码和混合编码。 ●波形编码:是在时域上对模拟话音的电压波形按一定的速率抽样,再将 幅度量化,对每个量化点用代码表示。解码是相反过程,将接收的数字 序列经解码和滤波后恢复成模拟信号。波形编码能提供很好的话音质 量,但编码信号的速率较高,一般应用在信号带宽要求不高的通信中。 脉冲编码调制(PCM)和增量调制(ΔM)常见的波形编码,其编码速率 在16~64kbps。 ●参量编码:又称声源编码,是以发音模型作基础,从模拟话音提取各个 特征参量并进行量化编码,可实现低速率语音编码,达到2~4.8kbps。 但话音质量只能达到中等。 ●混合编码:是将波形编码和参量编码结合起来,既有波形编码的高质量 优点又有参量编码的低速率优点。其压缩比达到4~16kbps。泛欧GSM 系统的规则脉冲激励-长期预测编码(RPE-LTP)就是混合编码方案。1.2 CDMA的语音编码
UTF-8编码的详细讲解
什么是UTF-8? 首先 UCS 和 Unicode 只是分配整数给字符的编码表. 现在存在好几种将一串字符表示为一串字节的方法. 最显而易见的两种方法是将 Unicode 文本存储为 2 个或 4 个字节序列的串. 这两种方法的正式名称分别为 UCS-2 和 UCS-4. 除非另外指定, 否则大多数的字节都是这样的(Bigendian convention). 将一个 ASCII 或 Latin-1 的文件转换成 UCS-2 只需简单地在每个 ASCII 字节前插入 0x00. 如果要转换成 UCS-4, 则必须在每个 ASCII 字节前插入三个 0x00. 在 Unix 下使用 UCS-2 (或 UCS-4) 会导致非常严重的问题. 用这些编码的字符串会包含一些特殊的字符, 比如’\0’或’/’, 它们在文件名和其他 C 库函数参数里都有特别的含义. 另外, 大多数使用 ASCII 文件的 UNIX 下的工具, 如果不进行重大修改是无法读取 16 位的字符的. 基于这些原因, 在文件名, 文本文件, 环境变量等地方, UCS-2 不适合作为 Unicode 的外部编码. 在 ISO 10646-1 Annex R 和 RFC 2279 里定义的 UTF-8 编码没有这些问题. 它是在 Unix 风格的操作系统下使用 Unicode 的明显的方法. UTF-8 and Unicode FAQ by Markus Kuhn 中国LINUX论坛翻译小组 xLoneStar[译] 2000年2月 这篇文章说明了在 POSIX 系统 (Linux,Unix) 上使用 Unicode/UTF-8 所需要的信息. 在将来不远的几年里, Unicode 已经很接近于取代 ASCII 与 Latin-1 编码的位置了. 它不仅允许你处理处理事实上存在于地球上的任何语言文字, 而且提供了一个全面的数学与技术符号集, 因此可以简化科学信息交换. UTF-8 编码提供了一种简便而向后兼容的方法, 使得那种完全围绕 ASCII 设计的操作系统, 比如 Unix, 也可以使用 Unicode. UTF-8 就是 Unix, Linux 已经类似的系统使用 Unicode 的方式. 现在是你了解它的时候了. 什么是 UCS 和 ISO 10646? 国际标准 ISO 10646 定义了通用字符集 (Universal Character Set, UCS). UCS 是所有其他字符集标准的一个超集. 它保证与其他字符集是双向兼容的. 就是说, 如果你将任何文本字符串翻译到 UCS格式, 然后再翻译回原编码, 你不会丢失任何信息. UCS 包含了用于表达所有已知语言的字符. 不仅包括拉丁语,希腊语, 斯拉夫语,希伯来语,阿拉伯语,亚美尼亚语和乔治亚语的描述, 还包括中文, 日文和韩文这样的象形文字, 以及平假名, 片假名, 孟加拉语, 旁遮普语果鲁穆奇字符(Gurmukhi), 泰米尔语, 印.埃纳德语(Kannada), Malayalam, 泰国语, 老挝语, 汉语拼音(Bopomofo), Hangul, Devangari, Gujarati, Oriya, Telugu 以及其他数也数不清的语. 对于还没有加入的语言, 由于正在研究怎样在计算机中最好地编码它们, 因而最终它们都将被加入. 这些语言包括 Tibetian, 高棉语, Runic(古代北欧文字), 埃塞俄比亚语, 其他象形文字, 以及各种各样的印-欧语系的语言, 还包括挑选出来的艺术语言比如 Tengwar, Cirth 和克林贡语(Klingon). UCS 还包括大量的图形的, 印刷用的, 数学用的和科学用的符号, 包括所有由 TeX, Postscript, MS-DOS,MS-Windows, Macintosh, OCR 字体, 以及许多其他字处理和出版系统提供的字符. ISO 10646 定义了一个 31 位的字符集. 然而, 在这巨大的编码空间中, 迄今为止只分配了前 65534 个码位 (0x0000 到 0xFFFD). 这个 UCS 的 16位子集称为基本多语言面 (Basic Multilingual Plane, BMP). 将被编码在 16 位 BMP 以外的字符都属于非常特殊的字符(比如象形文字), 且只有专家在历史和科学领域里才会
信息论与编码实验报告材料
实验报告 课程名称:信息论与编码姓名: 系:专 业:年 级:学 号:指导教 师:职 称:
年月日 目录 实验一信源熵值的计算 (1) 实验二Huffman 信源编码. (5) 实验三Shannon 编码 (9) 实验四信道容量的迭代算法 (12) 实验五率失真函数 (15) 实验六差错控制方法 (20) 实验七汉明编码 (22)
实验一信源熵值的计算 、实验目的 1 进一步熟悉信源熵值的计算 2 熟悉Matlab 编程 、实验原理 熵(平均自信息)的计算公式 q q 1 H(x) p i log2 p i log2 p i i 1 p i i 1 MATLAB实现:HX sum( x.* log2( x));或者h h x(i)* log 2 (x(i )) 流程:第一步:打开一个名为“ nan311”的TXT文档,读入一篇英文文章存入一个数组temp,为了程序准确性将所读内容转存到另一个数组S,计算该数组中每个字母与空格的出现次数( 遇到小写字母都将其转化为大写字母进行计数) ,每出现一次该字符的计数器+1;第二步:计算信源总大小计算出每个字母和空格出现的概率;最后,通过统计数据和信息熵公式计算出所求信源熵值(本程序中单位为奈特nat )。 程序流程图: 三、实验内容 1、写出计算自信息量的Matlab 程序 2、已知:信源符号为英文字母(不区分大小写)和空格输入:一篇英文的信源文档。输出:给出该信源文档的中各个字母与空格的概率分布,以及该信源的熵。 四、实验环境 Microsoft Windows 7
五、编码程序 #include"stdio.h" #include