DB2_pureScale_的新特性介绍Group_Crash_Recovery

DB2 pureScale 的新特性介绍 -- Group Crash Recovery
武翠霞, 软件工程师, EMC
张玉颖, 软件工程师, IBM
简介:本文主要介绍了 DB2 pureScale 的结构,以及新特性 Group Crash Recovery ,并通过 DB2 V9.8 的实例进行了详细说明。
引言
DB2 V9.8(pureScale)最重要特性就是其高度的伸缩性,这是 DPF,HADR 所不能满足的。在 pureScale 中所有的数据都是在一个共享的地方存放,这点与DB2 for z/OS 的存储结构类似。
在 pureScale 中引入了 member 的概念,相当与 DPF 的 partition。一组member 的集合就是一个 Cluster(集群)。
在 pureScale 中还有 Cluster Facilitator,它来确保 cross member 数据的一致性,可以配置一个或者两个 CF。CF 的主要组件包括以下三部分。
?Global Buffer Pool (GBP) :保证集群上缓存中的共享数据页的一致性?Global Lock Manager (GLM) :保证集群上共享数据更改的一致性
?Shared Communications Area (SCA) :对 DB2 控制数据(比如:控制块,日志序列数(LSN))提供一致机制。
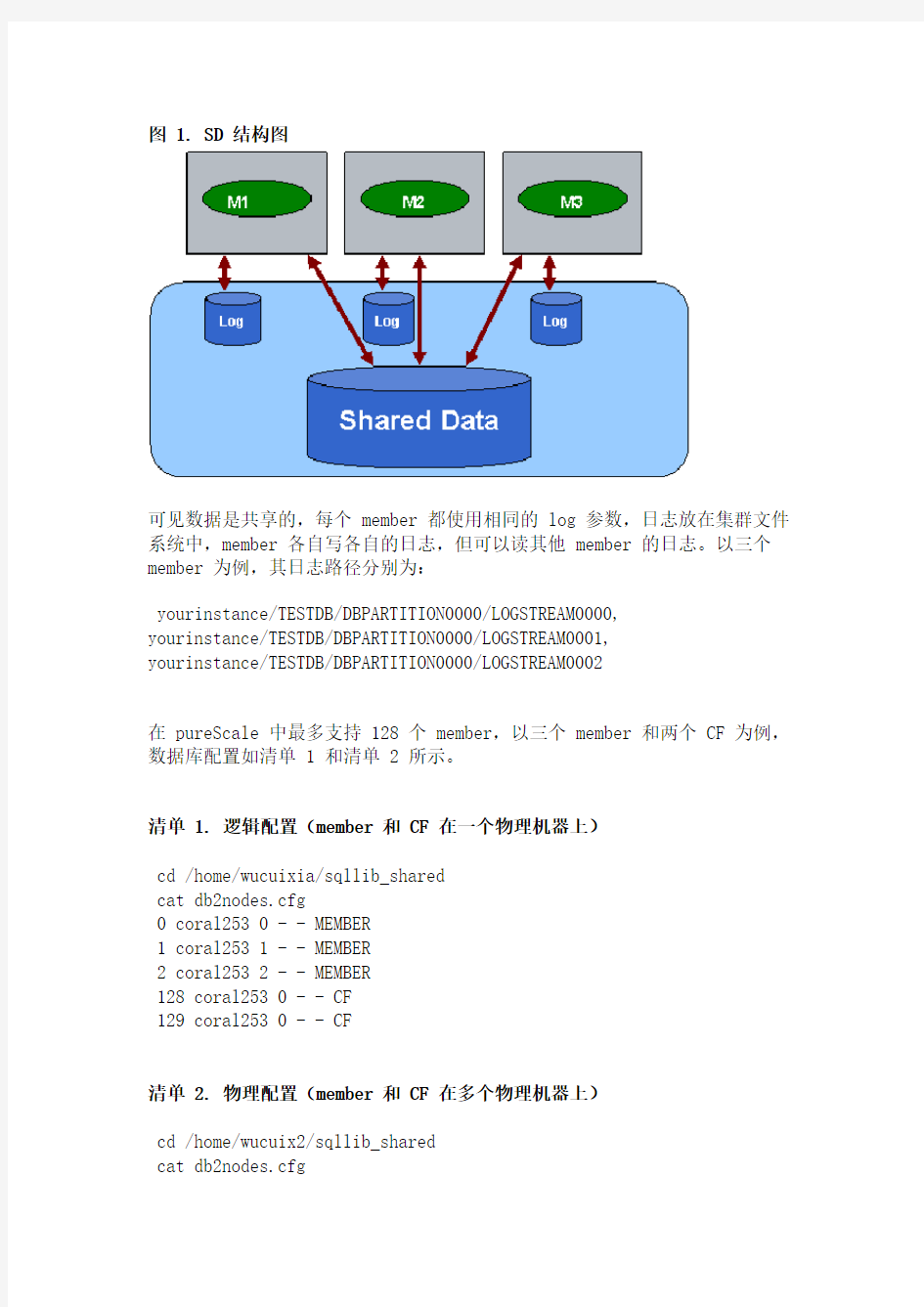
Shared Data 结构介绍
Shared Data(SD)是一种全新的数据存储方式。在这种方式中,所有的数据都是共享的,member1 可以读取 member2 的数据,但每个 member 只能在自己的日志路径上写日志。图 1 显示了 SD 结构。
图 1. SD 结构图
可见数据是共享的,每个 member 都使用相同的 log 参数,日志放在集群文件系统中,member 各自写各自的日志,但可以读其他 member 的日志。以三个member 为例,其日志路径分别为:
yourinstance/TESTDB/DBPARTITION0000/LOGSTREAM0000,
yourinstance/TESTDB/DBPARTITION0000/LOGSTREAM0001,
yourinstance/TESTDB/DBPARTITION0000/LOGSTREAM0002
在 pureScale 中最多支持 128 个 member,以三个 member 和两个 CF 为例,数据库配置如清单 1 和清单 2 所示。
清单 1. 逻辑配置(member 和 CF 在一个物理机器上)
cd /home/wucuixia/sqllib_shared
cat db2nodes.cfg
0 coral253 0 - - MEMBER
1 coral253 1 - - MEMBER
2 coral25
3 2 - - MEMBER
128 coral253 0 - - CF
129 coral253 0 - - CF
清单 2. 物理配置(member 和 CF 在多个物理机器上)
cd /home/wucuix2/sqllib_shared
cat db2nodes.cfg
0 coralxib14 0 - - MEMBER
1 coralxib15 0 - - MEMBER
2 coralxib16 0 - - MEMBER
128 coralxib17 0 - - CF
129 coralxib16 0 - - CF
Group Crash Recovery 介绍
DB2 现有的恢复方式有 HADR,Version Recovery,Crash Recovery,Rollforward Recovery,现在 Group/Member Crash Recovery 是 pureScale 引入的新的Crash Recovery。
在只有一个 CF 的情况下,如果 CF Down 掉了,就需要进行 Group Crash Recovery;如果 CF 正常工作,某一个或多个 member 不能工作,则需要进行Member Crash Recovery。如果有一个主 CF 和一个辅助 CF,在两种情况下需要进行 Group Crash Recovery。一种是如果锁双工运行,当主 CF 和辅助 CF 同时不能工作,或者主 CF 不能工作同时辅助 CF 未达到 peer 状态时,需要Group Crash Recovery;另一种情况是在锁非双工运行时,当主 CF 和辅助 CF 同时不能工作时需要 Group Crash Recovery。
本文主要介绍 Group Crash Recovery 新特性。在数据库中,Group Crash Recovery 可以在任何一个 member 上发生,并且只能在一个 member 上进行。如果不指定 member,默认是第一个 member,可以使用 export DB2NODE=2 来设定 member2, 然后连接数据库来触发 Group Crash Recovery。
在共享数据环境中,会有 Cluster Manager 的概念。它的一个职责是确保数据库是尽可能是一直可用的,这就包含了自动启动 Group Crash Recovery 的功能。因此只有 CM 出问题时,才需要手动执行 Group Crash Recovery。
如果要手动启动 Group Crash Recovery,如果 AUTORESTART 参数为 ON, 可以使用 CONNECT TO 或者 ACTIVATE DATABASE 命令,如果 AUTORESTART 是 OFF, 则可以使用 RESTART DATABASE 命令。当 RESTART DATABASE, ACTIVATE DATABASE 或者 CONNECT TO 命令完成后,执行命令的 member 就可以接受新的请求,数据库也就可以使用了,但没有解决 in-doubt transaction 的数据页还是不能建立连接。
Group Crash Recovery 的特点
与以前版本的 Crash Recovery 相比,Group Crash Recovery 有以下几点不同:
可能从 log archive 中恢复文件
即使没有指定 infinite active logging,某些时候 Group Crash Recovery 仍然会从 log archive 中获取文件。比如当一个 member Down 掉了,并长时间没
有重新起动。这个 member 会保持这个恢复起点,如果其他活动的 member 的active log space 满了,这个时候又需要进行 Group Crash Recovery,在这种情况下,就会从 log archive 中获取文件日志。这和以前的 Crash Recovery 是不同的。以前只有在 infinite logging 情况下才会从 log archive 中恢复文件。
pseudo compensation log records 的概念
回滚自己未提交的事务日志是 compensation log records,在 Group Crash Recovery 中,一个 member 可以把其它 member 未提交的事务在自己的日志中进行回滚,这就是 pseudo compensation log records。
Group Crash Recovery 过程
出现不一致情况的数据库具备了 Group Crash Recovery 的触发条件,则 Group Crash Recovery 在某一个 member 上进行。Group Crash Recovery 在某一个member 发生时,数据库是 offline 状态,不能接受任何连接。如果其他 member 有请求,则数据库恢复后才能接受这些请求。
由于每个 member 只能维护自己的日志文件,并且可以更改数据库的任何对象,所以每个 member 上的日志文件可以包含任何一个对象的一个日志记录。日志文件在两个不同的 member 上可以有多个记录操作同一对象交叉出现的情况,因此,每个 member 上的日志文件必须汇合成正确的顺序,然后才能进行重新执行。Group Crash Recovery 需要调用汇合各个 member 上日志流的功能,这里注意汇合日志流是在内存中进行的。
在 Group Crash Recovery 进行中,先调用汇合日志流的功能把各个 member 的日志流汇合成一个日志流,然后用这个汇合后的日志流进行 redo 所有还没写到磁盘上的操作。
Redo 结束后,undo 没有提交的事务。undo 阶段不会涉及归并好的日志流,只从日志中读取相应的未提交记录。Compensation log records 是在 undo 阶段写入的,并且是写在当前执行 Group Crash Recovery 的 member 的日志中的。undo 和以前的 undo 有很大不同,做 Group Crash Recovery 的 member 会写pseudo compensation log records,即在自己的日志上写别的 member 未提交的事务。
Undo 结束后,数据库可以接受新的事务。如果有必要,还要进行 in-doubt 事务的处理来释放这些含有待处理 in-doubt 事务的数据页。
模拟发生 Group Crash Recovery 的实例
比如在创建 buffer pool,table space, table, index 等等数据操作中,如果有未提交的事务存在,此时发生 Crash CF,则在创新启动数据库,并试图进行
连接时,就会发生 Group Crash Recovery。以下举个最简单的例子来说明 Group Crash Recovery。清单 3 用来启动和创建数据库。
清单 3. 启动和建立数据库
=> db2start
03/04/2010 00:55:44 2 0 SQL1063N DB2START processing was successful. 03/04/2010 00:55:44 1 0 SQL1063N DB2START processing was successful. 03/04/2010 00:55:45 0 0 SQL1063N DB2START processing was successful. SQL1063N DB2START processing was successful.
=> db2 create db testdb
DB20000I The CREATE DATABASE command completed successfully.
清单 4,5,6 分别是三个 member 上的操作。
清单 4. M1 执行事务
export DB2NODE=0
connect to testdb,
update command options using c off,
create table t1(a int,b int),
insert into t1 values(1, 2),
insert into t1 values(2, 4),
commit,
insert into t1 values(10, 20),
清单 5. M2 执行事务
export DB2NODE=1
connect to testdb,
update command options using c off,
insert into t1 values(3, 2),
insert into t1 values(4, 4),
commit,
insert into t1 values(20, 20),
清单 6. M3 执行事务
export DB2NODE=2
connect to testdb,
update command options using c off,
insert into t1 values(5, 2),
commit,
insert into t1 values(30, 20),
接下来产生触发 Group Crash Recovery 的条件,比如断电,这里我们使用killdbm。
清单 7. killdbm 命令
killdbm – killca
清单 8 来查询 Group Crash Recovery 后数据库表的结果。
清单 8. 查询结果
db2 => select * from t1
A B
----------- -----------
1 2
2 4
3 2
4 4
5 2
5 record(s) selected.
清单 9 显示了 db2diag 中关于 Group Crash Recovery 的信息。
清单 9. db2diag 的关于 Group Crash Recovery 的信息
2010-03-04-01.43.43.538263+480 I3980161E770 LEVEL: Info
PID : 17993 TID : 47441067895104 KTID : 18157
PROC : db2sysc 1
INSTANCE: wucuixia NODE : 001 DB : TESTDB
APPHDL : 1-55 APPID: *N1.DB2.100303174336
EDUID : 24 EDUNAME: db2agnti (TESTDB ) 1
FUNCTION: DB2 UDB, recovery manager, sqlpresr, probe:401 DATA #1 :
Group crash recovery started.
Recovery status for log stream 1
lowtranlsn: 000000000002E5C1
minbufflsn: 000000000002E5C4
headlsn: 000000000002E570
groupHeadLsn: 000000000002E570
groupMinBuffLSN: 000000000002E570
HeadExtentID: 0
GroupHeadExtentID: 0
nextLso: 4173825
nextLsn: 000000000002E56B
2010-03-04-01.43.43.547061+480 I3980932E771 LEVEL: Info PID : 17993 TID : 47441067895104 KTID : 18157
PROC : db2sysc 1
INSTANCE: wucuixia NODE : 001 DB : TESTDB
APPHDL : 1-55 APPID: *N1.DB2.100303174336
EDUID : 24 EDUNAME: db2agnti (TESTDB ) 1
FUNCTION: DB2 UDB, recovery manager, sqlpresr, probe:400 DATA #1 :
Group crash recovery started.
Recovery status for log stream 0
lowtranlsn: 000000000002E5BD
minbufflsn: 000000000002E5C4
headlsn: 000000000002E570
groupHeadLsn: 000000000002E570
groupMinBuffLSN: 000000000002E570
HeadExtentID: 0
GroupHeadExtentID: 0
nextLso: 36781825
nextLsn: 0000000000000000
2010-03-04-01.43.43.555777+480 I3981704E770 LEVEL: Info PID : 17993 TID : 47441067895104 KTID : 18157
PROC : db2sysc 1
INSTANCE: wucuixia NODE : 001 DB : TESTDB
APPHDL : 1-55 APPID: *N1.DB2.100303174336
EDUID : 24 EDUNAME: db2agnti (TESTDB ) 1
FUNCTION: DB2 UDB, recovery manager, sqlpresr, probe:402 DATA #1 :
Group crash recovery started.
Recovery status for log stream 2
minbufflsn: 000000000002E5C4
headlsn: 000000000002E570
groupHeadLsn: 000000000002E570
groupMinBuffLSN: 000000000002E570
HeadExtentID: 0
GroupHeadExtentID: 0
nextLso: 8347649
nextLsn: 0000000000000000
2010-03-04-01.43.43.608423+480 I3985671E797 LEVEL: Info PID : 17993 TID : 47441067895104 KTID : 18157
PROC : db2sysc 1
INSTANCE: wucuixia NODE : 001 DB : TESTDB
APPHDL : 1-55 APPID: *N1.DB2.100303174336
EDUID : 24 EDUNAME: db2agnti (TESTDB ) 1
FUNCTION: DB2 UDB, data protection services,
sqlpSetRecoveryStartingPoint, probe:101
DATA #1 :
Set recovery starting point.
Recovery status for log stream 1
lowtranlsn: 000000000002E570
minbufflsn: 000000000002E570
headlsn: 000000000002E570
groupHeadLsn: 000000000002E570
groupMinBuffLSN: 0000000000000000
HeadExtentID: 0
GroupHeadExtentID: 0
nextLso: 4173825
nextLsn: 000000000002E570
2010-03-04-01.43.43.626339+480 I3986469E798 LEVEL: Info PID : 17993 TID : 47441067895104 KTID : 18157
PROC : db2sysc 1
INSTANCE: wucuixia NODE : 001 DB : TESTDB
APPHDL : 1-55 APPID: *N1.DB2.100303174336
EDUID : 24 EDUNAME: db2agnti (TESTDB ) 1
FUNCTION: DB2 UDB, data protection services,
sqlpSetRecoveryStartingPoint, probe:100
DATA #1 :
Set recovery starting point.
Recovery status for log stream 0
lowtranlsn: 000000000002E570
headlsn: 000000000002E570
groupHeadLsn: 000000000002E570
groupMinBuffLSN: 0000000000000000
HeadExtentID: 0
GroupHeadExtentID: 0
nextLso: 36781825
nextLsn: 000000000002E570
2010-03-04-01.43.43.635045+480 I3987268E797 LEVEL: Info
PID : 17993 TID : 47441067895104 KTID : 18157
PROC : db2sysc 1
INSTANCE: wucuixia NODE : 001 DB : TESTDB
APPHDL : 1-55 APPID: *N1.DB2.100303174336
EDUID : 24 EDUNAME: db2agnti (TESTDB ) 1
FUNCTION: DB2 UDB, data protection services,
sqlpSetRecoveryStartingPoint, probe:102
DATA #1 :
Set recovery starting point.
Recovery status for log stream 2
lowtranlsn: 000000000002E570
minbufflsn: 000000000002E570
headlsn: 000000000002E570
groupHeadLsn: 000000000002E570
groupMinBuffLSN: 0000000000000000
HeadExtentID: 0
GroupHeadExtentID: 0
nextLso: 8347649
nextLsn: 000000000002E570
2010-03-04-01.43.47.247910+480 E4053435E467 LEVEL: Info
PID : 17993 TID : 47441067895104 KTID : 18157
PROC : db2sysc 1
INSTANCE: wucuixia NODE : 001 DB : TESTDB
APPHDL : 1-55 APPID: *N1.DB2.100303174336
EDUID : 24
EDUNAME: db2agnti (TESTDB ) 1
FUNCTION: DB2 UDB, recovery manager, sqlpresr, probe:3110
MESSAGE : ADM1528I Group crash recovery has completed successfully.
2010-03-04-01.43.47.262001+480 I4053903E478 LEVEL: Info
PID : 17993
TID : 47441067895104 KTID : 18157
PROC : db2sysc 1
INSTANCE: wucuixia NODE : 001 DB : TESTDB
APPHDL : 1-55 APPID: *N1.DB2.100303174336
EDUID : 24 EDUNAME: db2agnti (TESTDB ) 1
FUNCTION: DB2 UDB, recovery manager, sqlpresr, probe:3170
DATA #1 :
Crash recovery completed. Next LSN is 000000000002E5CB
结束语
本文简单的对 DB2 pureScale 的结构进行了描述,并重点介绍了新特性 Group Crash Recovery 新特性,并使用 DB2 V9.8 做了简单的实例说明。
Oracle数据库11g新特性:安全性
Oracle数据库11g新特性:安全性 默认口令 2006 年,OTN 发布了我撰写的一系列题为“安全保护项目:一种分阶段的数据库基础架构保护方法”的文章。在这些文章中,我讨论了如何应对常见的安全挑战(如用户使用默认口令)以及如何扫描您的数据库以查找这些用户。 对我而言很不幸的是,您可能已经忘记了我文章中的那一部分。Oracle 数据库11g 现在提供一种快速识别使用默认口令的用户的方法。该方法实施起来极为简单,只需检查单个数据字典视图:D BA_USERS_WITH_DEFPWD.(注意,DBA_ 是一个标准前缀,它不仅包含使用默认口令的DBA 用户。)您可以执行以下命令来识别这些用户: 输出如下:
由于SCOTT 使用了默认口令TIGER,因此您会看到他出现在上面的清单中。使用下面的语句进行更改: 现在,如果您查看该视图: 您就不会在该清单中看到SCOTT 了。就这么简单! 区分大小写的口令 在版本11g 之前的Oracle 数据库中,用户口令是不区分大小写的。例如:
这种安排为支付卡行业(PCI)数据安全标准之类的标准带来了问题,这些标准要求口令区分大小写。 该问题得到了解决,在Oracle 数据库11g 中,口令也可以区分大小写。通过DBCA 创建数据库时,系统会提示您是否希望升级到“新的安全标准”,其中之一就是区分大小写的口令。如果您接受该标准,口令在创建时的大小写状态将被记录下来。假如您接受了新标准,相应的操作结果如下: 注意对“tiger”和“TIGER”的不同处理方式。 现在,您的某些应用程序可能无法立刻传递大小写正确的口令。典型示例是用户输入表单:很多表单在接受口令时不会进行大小写转换。然而,在Oracle 数据库11g中,这种登录方式可能会失败,除非用户以区分大小写格式输入口令,或者开发人员对应用程序进行了修改,使其能够进行大小写转换(这一点不可能迅速实现)。 不过,如果您希望的话,仍然可以通过更改系统参数SEC_CASE_SENSITIVE_LOGON 恢复到不区分大小写的状态,如以下示例所示。
Oracle数据库12c各版本介绍及功能比较
Oracle Database 12c版本介绍 Oracle Database 12c有三种版本,提供多种企业版选件来满足客户对各种领域(性能和可用性、安全性和合规性、数据仓储和分析、非结构化数据和可管理性)的特定需求。 Oracle Database 12c标准版1 企业级的性能和安全性 Oracle Database 12c标准版1经过了优化,适用于部署在小型企业、各类业务部门和分散的分支机构环境中。该版本可在单个服务器上运行,最多支持两个插槽。Oracle Database 12c标准版1可以在包括Windows、Linux和Unix 在内的所有Oracle支持的操作系统上使用。 概述 ●快速安装和配置,具有内置的自动化管理 ●适用于所有类型的数据和所有应用 ●公认的性能、可靠性、安全性和可扩展性 ●使用通用代码库,可无缝升级到Oracle Database 12c标准版或Oracle Database 12c企业版 优势 ●以极低的每用户180美元起步(最少5个用户) ●以企业级性能、安全性、可用性和可扩展性支持所有业务应用 ●可运行于Windows、Linux和Unix操作系统 ●通过自动化的自我管理功能轻松管理 ●借助Oracle Application Express、Oracle SQL Developer和Oracle 面向Windows的数据访问组件简化应用开发 Oracle Database 12c标准版 经济实惠、功能全面的数据库 Oracle Database 12c标准版是面向中型企业的一个经济实惠、功能全面的数据管理解决方案。该版本中包含一个可插拔数据库用于插入云端,还包含Oracle真正应用集群用于实现企业级可用性,并且可随您的业务增长而轻松扩展。
SQL ANYWHERE 12四大关键新特性
SQL ANYWHERE 12四大关键新特性 当前,移动应用浪潮正以迅猛的速度席卷着世界的每个角落。尤其,移动应用正越来越多地出现在企业关键业务的各个环节——办公、销售、物流、财务、客服、流程管理等等。但与此同时,众多的系统平台和移动设备、广泛的移动应用也给企业数据管理带来了全新的挑战。据Kelton Research近期发布的一份调查结果显示,在受访的IT经理中,90%的受访者计划在2011年实施全新的移动应用,其中接近一半的IT 经理认为成功管理移动应用将成为他们的首要任务。面对移动应用的多样化、分散化给企业数据管理带来的巨大压力,企业迫切需要一个功能强大的、安全可靠的移动数据管理解决方案来帮其分忧。 事实上,作为企业移动化领域的公认领导者,Sybase推出的移动数据管理和同步解决方案——SQL Anywhere已经满足了企业移动数据管理的诸多要求。借助这一解决方案,移动员工可立刻通过智能电话或其它移动设备随时随地访问公司的后台数据,提高工作效率。 SQL Anywhere介绍 SQL Anywhere是Sybase公司推出的一款能够提供数据管理和企业数据交换技术的综合程序包,它可以帮助工作人员为服务器环境、桌面环境、移动环境以及远程办公环境快速开发由数据库驱动的应用程序,并能为开发人员提供处理复杂前端环境的技术、支持他们更轻松地架构应用程序的底层数据管理、同步、安全和远程支持。 2010年,SQL Anywhere两度创新——3月,Sybase推出具备先进的空间数据功能的全新版本,7月,Sybase推出SQL Anywhere? 12,该版本拥有新的、重要的增强功能,包括支持空间数据的存储和同步、支持iPhone设备和大型同步环境,以及全新的自我管理特性。优化的SQL Anywhere适用于那些对现场IT支持要求很少或甚至无要求、在传统数据中心环境之外运行的任务关键型数据库应用。这一版本的推出使得Sybase成为业界首家为iPhone、Blackberry和Windows Mobile智能手机设备提供数据库和同步支持的数据库供应商,也是首家在移动数据库和同步平台中提供空间数据支持的供应商。 对于在传统的数据中心之外运行的应用来说,SQL Anywhere是领先的数据管理和企业同步解决方案。从一开始,SQL Anywhere就被设计成具备企业级功能、开箱即用的高性能和强大同步能力的数据库解决方案,能实施成为网络、嵌入式以及移动环境中的任务关键型数据库。 传承了简单易用、自我管理和轻松嵌入的特质,最新版本的SQL Anywhere 12持续深化这些特质,并在开发人员生产力、高性能的开箱即用、可扩展性和监控和高级数据同步方面提供了关键的新特性,以及添加到MobiLink和UltraLite中的技术新功能。 SQL Anywhere 12四大关键新特性之一——提升开发者效率 最新版本的数据库和同步解决方案——SQL Anywhere 12新增了包括空间数据在内的诸多新功能和新选项,比如空间查看器、空间数据类型、方法、构造器和函数、空间向导等,这些功能使其在SQL Anywhere 数据库、UltraLite数据库以及MobiLink同步技术中支持空间数据,大大地提升了开发人员的工作效率。 空间数据
Oracle 12C优化器的巨大变化,上生产必读(上)
Oracle 12C优化器的巨大变化,上生产必读(上) 序言 优化器是Oracle数据库最吸引人的部件之一,因为它对每一个SQL语句的处理都必不可少。优化器为每个SQL语句确定最有效的执行计划,这是基于给定的查询的结构,可用的关于底层对象的统计信息,以及所有与优化器和执行相关的特性。 随着每个新版本的发布,优化器都会进化,利用新功能以及新的统计信息来生成更好的执行计划。随着对查询优化的新的自适应方法的引入,Oracle 12c数据库把这种进化更推上了一个台阶。 这份白皮书介绍了在Oracle 12c数据库中与优化器和统计相关的所有新特性并且提供了简单的,可再现的例子,使得你能够更容易地熟悉它们。它还概括了已有的功能是如何被增强以改善性能和易管理性。 优化器和统计信息新特性 1、自适应查询优化 到目前为止,Oracle 12c数据库中最大的变化是自适应查询优化。自适应查询优化是这样的一组功能,它使得优化器能够对执行计划进行实时调整,并且发现能够导致更佳的统计信息的额外信息。当现有的统计信息不足以产生一个优化的计划,这种新方法是极其有用的。自适应查询优化包括两个方面:自适应计划,它着重于改善一个查询的初次执行;自适应统计信息,它为后续的执行提供了额外的信息。 (图1. 自适应查询优化功能的组件) 2、自适应计划
自适应计划使得优化器能够延迟产生一个语句的最终计划,直到执行的时候才决定。优化器在它所选择的计划(缺省计划)中植入统计收集器,从而在运行的时候,它能够判断自己的基数估算与计划的操作所实际看到的行数是否有很大的偏差。如果有显著的区别,那么这个计划或者计划的一部分在SQL语句的首次执行就能够被自动调整来避免不理想的性能。 3、自适应的连接方式 通过为计划中的某些分支预先确定多个子计划,优化器能够实时调整连接方式。例如,在图2中优化器的初始计划(缺省计划)为order_items 和 product_info 之间的连接选定的是嵌套循环连接,通过对product_info表的索引读取。另一个可选的子计划也同时被确定,它允许优化器将连接方式切换到哈希连接。在候选计划中product_info是通过全表扫描来读取的。 在执行的时候,统计收集器收集了关于这次执行的信息,并且将一部分进入到子计划的数据行缓存起来。在这个例子中,统计收集器监控并缓存了对order_items的全表扫描。基于它在统计收集器中看到的信息,优化器会最终确定采用哪个子计划。在这个例子中,哈希连接被选为最终计划,因为来自order_items表的行数大于优化器最初的估计。 在优化器选择了最终计划之后,统计收集器停止收集统计信息以及对数据行的缓存,而仅仅是传递数据。在子游标随后的执行中,优化器禁止了数据缓存,并且选择了同一个最终计划。目前的优化器能够从嵌套连接切换到哈希连接,反之亦然。可是,如果初始选中的连接方法是排序合并连接,则自适应不会发生。 (图2. 自适应执行计划确定Order_items 和 Prod_info 表之间的连接) 在缺省情况下,explain plan命令只会显示优化器选定的初始(缺省)计划。而 DBMS_XPLAN.DISPLAY_CURSOR只显示查询所用的最终计划。
Oracle 11G新特性--ASM 增强 说明
一. ASM 快速镜像再同步(ASMFast Mirror Resync) 1.1 无ASM快速镜像再同步时 每当ASM 无法向分配给某个磁盘的区执行写入操作时,就会使该磁盘脱机,同时会在其它磁盘上至少写入一个此区(ASM 数据区)的镜像副本(如果相应的磁盘组使用了ASM 冗余)。 使用OracleDatabase 10g 时,ASM 会假定脱机磁盘只包含过时数据,因此不再从此类磁盘中读取数据。磁盘脱机后不久,ASM 就会使用冗余区副本在磁盘组中的剩余磁盘上重新创建分配给磁盘的区(ASM 数据区),将脱机的磁盘从磁盘组中删除。此进程是一项开销相对较大的操作,可能要花费几小时来完成。 如果磁盘故障只是临时性的(如电缆、主机总线适配器、控制器故障或磁盘的电源中断),则必须在临时故障修复后重新添加磁盘。但是,将删除的磁盘重新添加回磁盘组还需要将区(ASM 数据区)迁回磁盘,因此增加了成本。
1.2 ASM 快速镜像再同步 1.2.1 概述 ASM 快速镜像再同步会显著减少重新同步临时故障磁盘所需的时间。如果某个磁盘因临时故障而脱机,ASM 将跟踪在中断期间发生修改的区。临时故障被修复后,ASM 可以快速 地仅重新同步在中断期间受到影响的ASM 磁盘区。此功能假定受到影响的ASM磁盘内容未发生损坏或修改。 某个ASM 磁盘路径出现故障时,如果您已设置了相应磁盘组的DISK_REPAIR_TIME 属性,则ASM 磁盘会脱机,但不会被删除。此属性的设置确定了ASM 可容忍的磁盘中断持续时间;如果中断在此时间范围内,则修复完成后仍可重新同步。 注:跟踪机制对每个已修改的区使用一个位,这样可确保跟踪机制非常高效。 1.2.2 设置ASM 快速镜像再同步 请按磁盘组设置此功能。可以在创建磁盘组后使用ALTER DISKGROUP 命令完成此操作。使用一个类似以下命令的命令启用ASM 快速镜像再同步:
ORACLE 12C新特性
ORACLE 12C新特性——CDB与PDB Oracle 12C引入了CDB与PDB的新特性,在ORACLE 12C数据库引入的多租用户环境(Multitenant Environment)中,允许一个数据库容器(CDB)承载多个可插拔数据库(PDB)。CDB全称为Container Database,中文翻译为数据库容器,PDB全称为Pluggable Database,即可插拔数据库。在ORACLE 12C之前,实例与数据库是一对一或多对一关系(RAC):即一个实例只能与一个数据库相关联,数据库可以被多个实例所加载。而实例与数据库不可能是一对多的关系。当进入ORACLE 12C后,实例与数据库可以是一对多的关系。下面是官方文档关于CDB与PDB的关系图。 其实大家如果对SQL SERVER比较熟悉的话,这种CDB与PDB是不是感觉和SQL SERVER的单实例多数据库架构是一回事呢。像PDB$SEED可以看成是master、msdb等系统数据库,PDBS可以看成用户创建的数据库。而可插拔的概念与SQL SERVER中的用户数据库的分离、附加其实就是那么一回事。看来ORACLE也“抄袭”了一把SQL SERVER的概念,只是改头换面的包装了一番。 CDB组件(Components of a CDB) 一个CDB数据库容器包含了下面一些组件: ROOT组件 ROOT又叫CDB$ROOT, 存储着ORACLE提供的元数据和Common User,元数据的一个例子是ORACLE提供的PL/SQL包的源代码,Common User 是指在每个容器中都存在的用户。 SEED组件
Oracle 数据库12c新特性总结
Oracle 数据库 12c 新特性总结
导读:本系列文章是 Oracle ACE 总监 Syed Jaffer Hussain 对 Oracle 数据库 12c 的一些 新特性总结,包括数据库管理、RMAN、高可用性以及性能调优等内容。 关键词:Oracle 数据库 12c RMAN PGA 限制 不可见字段
【TechTarget 中国原创】 编者按:甲骨文公司近日正式发布了新版旗舰级数
据库 Oracle Database 12c,在 TechTarget 数据库网站之前的一些报道中,我 们曾对 12c 的一些新特性进行了介绍(参考:尝鲜 Oracle Database 12c 的十 二大新特性)而随着产品正式 GA,相关技术文档也披露了更多关于 12c 数据库 的细节。本系列文章是 Oracle ACE 总监 Syed Jaffer Hussain 对 Oracle 数据 库 12c 的一些新特性总结,包括数据库管理、RMAN、高可用性以及性能调优 等内容。
Oracle 数据库 12c 新特性总结(一)
在第一部分中,我们将介绍: 1. 在线迁移活跃的数据文件 2. 表分区或子分区的在线迁移 3. 不可见字段 4. 相同字段上的多重索引 5. DDL 日志 6. 临时 undo
7. 新的备份用户特权 8. 如何在 RMAN 中执行 SQL 语句 9. RMAN 中的表级别恢复 10. PGA 的大小限制问题
1. 在线重命名和重新定位活跃数据文件
不同于以往的版本,在 Oracle 数据库 12c R1 版本中对数据文件的迁移或 重命名不再需要太多繁琐的步骤,即把表空间置为只读模式,接下来是对数据文 件进行离线操作。 在 12c R1 中, 可以使用 ALTER DATABASE MOVE DATAFILE 这样的 SQL 语句对数据文件进行在线重命名和移动。而当此数据文件正在传输 时,终端用户可以执行查询,DML 以及 DDL 方面的任务。另外,数据文件可以 在存储设备间迁移,如从非 ASM 迁移至 ASM,反之亦然。 重命名数据文件:
SQL> ALTER DATABASE MOVE DATAFILE '/u00/data/users01.dbf' TO '/u00/data/u sers_01.dbf';
从非 ASM 迁移数据文件至 ASM:
SQL> ALTER DATABASE MOVE DATAFILE '/u00/data/users_01.dbf' TO '+DG_DATA ';
将数据文件从一个 ASM 磁盘群组迁移至另一个 ASM 磁盘群组:
SQL> ALTER DATABASE MOVE DATAFILE '+DG_DATA/DBNAME/DATAFILE/users_0 1.dbf ' TO '+DG_DATA_02';
Oracle 12C RAC集群原理与管理实战
Oracle 12C RAC集群原理与管理实战 Oracle 集群(也叫Oracle RAC)推出已经很多年了,其技术本来比较复杂,再加上12C中的新概念,难上加难!我们正是想给你首先介绍12C RAC的基本概念,接着做几个完整的实验,通过实验,加深你对12C概念的理解。12C RAC涉及很多技术(主机、网络设备、存储、操作系统、clusterware、Oracle database软件),通过本课的学习,你将彻底的明白12C RAC的原理,并能够独立动手安装和运维Oracle 12C RAC。 课程大纲: 第一课:大型数据库高可用性解决方案与集群 什么是高可用性 Oracle高可用性解决方案概述 DB2高可用性解决方案概述 MySQL高可用性解决方案概述 什么是集群 使用ORACLE RAC 的优势-集群和可伸缩性 平衡的I/O 吞吐量 使用RAC 实现并行执行 集群件的体系结构和服务 Oracle ASM自动存储管理 ASM的关键功能和优点 ASM和Grid Infrastructure 第二课:Oracle RAC 12c的新特性 Flex集群和Flex ASM介绍 Flex集群架构 Flex集群的扩展性和可用性 第三课:Oracle 12c RAC 硬件构成 集群总体硬件结构图 小型机介绍
X86服务器介绍 网络设备介绍 存储设备介绍(DAS,NAS、SAN) RAC One Node 单实例高可用性 可识别集群的存储解决方案 Oracle 集群文件系统 第四课:Oracle 12c RAC 软件构成 Oracle Clusterware 资料档案库(OCR) CSS 表决磁盘功能 Oracle 本地注册表和高可用性 Oracle Clusterware 初始化 控制Oracle Clusterware 验证Oracle Clusterware 的状态 集群文件系统OCFS 网络文件系统NFS 自动存储管理ASM VIP SCAN VIP 第五课:Oracle 12C RAC安装环境准备(一)安装环境说明 DHCP配置(在192.168.0.88) DNS(Bind)配置(在192.168.0.88) 第六课:Oracle 12C RAC安装环境准备(二)创建用户和组,并创建相应目录 系统配置和准备 准备共享存储 配置裸设备 第七课:Grid Infrastructure 安装
Oracle数据库c各版本介绍及功能比较
OracleDatabase12c版本介绍 OracleDatabase12c?有三种版本,提供多种企业版选件来满足客户对各种领域(性能和可用性、安全性和合规性、数据仓储和分析、非结构化数据和可管理性)的特定需求。 OracleDatabase12c?标准版1 企业级的性能和安全性 OracleDatabase12c?标准版1经过了优化,适用于部署在小型企业、各类业务部门和分散的分支机构环境中。该版本可在单个服务器上运行,最多支持两个插槽。OracleDatabase12c?标准版1可以在包括Windows、Linux和Unix在内的所有Oracle支持的操作系统上使用。 概述 ●快速安装和配置,具有内置的自动化管理 ●适用于所有类型的数据和所有应用 ●公认的性能、可靠性、安全性和可扩展性 ●使用通用代码库,可无缝升级到OracleDatabase12c?标准版或 OracleDatabase12c?企业版 优势 ●以极低的每用户180美元起步(最少5个用户) ●以企业级性能、安全性、可用性和可扩展性支持所有业务应用 ●可运行于Windows、Linux和Unix操作系统 ●通过自动化的自我管理功能轻松管理 ●借助OracleApplicationExpress、OracleSQLDeveloper和Oracle面向 Windows的数据访问组件简化应用开发 OracleDatabase12c?标准版 经济实惠、功能全面的数据库 OracleDatabase12c?标准版是面向中型企业的一个经济实惠、功能全面的数据管理解决方案。该版本中包含一个可插拔数据库用于插入云端,还包含Oracle 真正应用集群用于实现企业级可用性,并且可随您的业务增长而轻松扩展。
ORACLE 11G 新特性ADR
Oracle 11g 新特性 ADR ADR 主目录 既然所有的焦点都集中于数据库的诊断能力,那么 Oracle 数据库是不是应该存储以结构化方式组织的所有跟踪文件、日志文件等等?在 Oracle 数据库 11g 中确实如此。自动诊断信息库 (ADR) 文件位于一个指定为诊断目标(或 ADR 基目录)的常用目录下的目录中。该目录由初始化参数 (diagnostic_dest) 设置。默认情况下,它设置为 $ORACLE_BASE,但是您可以将其显式设置为某些独占目录。(但是不建议这样做。)该目录下有一个 diag 子目录,您将在这个子目录中发现存储诊断文件的子目录。 ADR 存储所有组件(ASM、CRS、监听器等)的日志和跟踪文件,包括数据库本身的日志和跟踪文件。这使您可以方便地在一个位置查找特定的日志。 在 ADR 基目录中,可以有多个 ADR 主目录,每个组件和实例一个。例如,如果服务器有两个 Oracle 实例,则有两个 ADR 主目录。下面是数据库实例的 ADR 主目录的目录结构。 目录名称<在 DIAGNOSTIC_DEST 参数中提到的目录> →diag →rdbms →<数据库名称> →<实例名称> →alert →cdump →hm →incident →<所有事件目录存在这里> →incpkg 说明 XML 格式的警报日志存储在这里。核心转储存储在这里,相当于早期版本中的core_dump_dest。运行情况监视对多个组件运行检查,它在这里存储某些文件。所有事件转储都存储在这里。每个事件存储在一个不同的目录中,这些目录都存储在这里。当您打包事件时(在本文中可以了解打包),某些支持文件存
实践实战:在PoC中的Oracle 12c优化器参数推荐(含PPT)
实践实战:在PoC中的Oracle 12c优化器参数推荐(含PPT) 最近,Oracle数据库优化器的产品经理 Nigel Bayliss 发布了一篇文档,介绍:Setting up the Oracle Optimizer for PoCs - 在PoC测试中优化器参数的设置和调节。优化器是Oracle 数据库的核心组件,我们一起来看一看12c 有哪些优化器的变化。 关注本公众号回复关键字:Internals 即可获得本文PPT(SettingUp..),同时附送了一系列的精彩PPT学习资源。 首先,作者描述了POC 测试的基本原则,遵循KISS 原则(Keep it Simple Stupid),从一个尽可能简单的基线开始;优先考虑稳定性和一致性;通过测试掌控变化;持续向前: 首先,在Oracle 12cR1中,Oracle 引入了一个重要的新特性:自适应查询优化器- Adaptive Query Optimization,该特性的主要功能有两个:
对SQL的执行计划进行运行时(run-time)调整,(也就是在SQL执行过程 中,具备动态改变执行计划的能力); ? ? 在SQL执行过程中,动态统计和发现新的统计信息,以实现更佳的执行计 划; ? 通过这个特性的描述,我们可以知道,当现有统计数据不足以生成最佳计划时,自适应查询优化器会很有用;当然相反方向是,如果我们数据库中执行计划是稳定的、优化的、满足需要的,那么这个新的特性对我们就基本不需要。 下图展示了这个新特性的两个路径:自适应执行计划、自适应统计信息。在12.1版本中,是否启用自适应优化器参数由初始化参数optimizer_adaptive_features决定。 基于在执行过程中获得的真实统计信息,优化器动态调整执行计划的能力可以极大地提高查询性能。 下图展示了一个最常见的场景,基于静态统计信息,Oracle选择了Nest Loop的执行计划,当执行中动态统计信息(自适应统计信息)被收集之后,SQL的执行计划自动变更为Hash Join 的执行方式。
Oracle12c入门
Oracle 12c入门第一讲: Oracle 12c基本体系结构(1) 摘要: DataBi独家发布Oracle 12C 入门系列Oracle 12c基本结构简介,将容器数据库和传统的非容器数据库放在同一个server上比对,很容易概括出Oracle公司即将推出的Oracle 12c容器数据库和可插拔式数据库的基本架构。... ... https://www.360docs.net/doc/d712825853.html, 独家发布Oracle 12c入门系列第一讲: Oracle 12c基本结构简介 将容器数据库和传统的非容器数据库放在同一个server上比对,很容易概括出Oracle公司即将推出的Oracle 12c容器数据库和可插拔式数据库的基本架构。 从文件角度: 在图示存储设备上保存着5个数据库的文件:分别是PDBA、PDBB、PDBC、CDB1和NDB。其中PDBA、PDBB、PDBC均属于容器数据库CDB1的可插拔式数据库,NDB 则为传统的非容器数据库。所以也可以这样描述:只有两个数据库CDB1和NDB 保存在存储设备上。 从实例角度: 在图示服务器节点上,运行着两个实例:分别是icdb1和i1,对应的数据库分别是CDB1和NDB。可以清楚地看到只有容器数据库和非容器数据库才有对应的
实例,可插拔式数据库PDBA、PDBB和PDBC共用容器数据库的实例—icdb1,并没有自身对应的实例。 从服务角度: 传统的非容器数据库可以通过实例名或服务名链接,但是可插拔式数据库只能通过服务名链接。至于容器数据库,就像一个非容器数据库一样,同样可以通过实例名或服务名链接。 这些基本概念是深入理解容器数据库的基础。
Oracle 12c入门第二讲: Oracle 12c体系结构 (2) 摘要: 在一个Oracle database 12c server上通过容器数据库集中三个应用的数据。其数据分别被部署到三个可插拔式数据库中. 在一个database server上通过容器数据库集中三个应用的数据。其数据分别被部署到三个可插拔式数据库中,名为App1、App2和App3: 图片上展示的是一个容器数据库,其内包含4个容器:Root容器和三个可插拔式数据库。每个可插拔式数据库为特定应用提供数据,它们既可以被三个不同的DBA管理也能够由一个容器数据库DBA统一管理,即用户SYS。 用户SYS在这种架构中是典型的“通用”用户,SYS可以登录在全部4个容器上,并且具备SYSDBA权限。 可插拔式数据库的一种定义是:一系列Schema的集合,从用户和应用看来是一个逻辑上独立的数据库。但是在物理角度上,实例和所有数据库文件都是属于容器数据库的。 通过将非容器数据库作为可插拔式数据库“插入”容器数据库,很容易实现数据集中。容器数据库避免了以下结构不必要的冗余: a. 后台进程
ORACLE 12C新特性——CDB与PDB 进阶干货
Oracle 12C引入了CDB与PDB的新特性,在ORACLE 12C数据库引入的多租用户环境(Multitenant Environment)中,允许一个数据库容器(CDB)承载多个可插拔数据库(PDB)。CDB全称为Container Database,中文翻译为数据库容器,PDB全称为Pluggable Database,即可插拔数据库。在ORACLE 12C之前,实例与数据库是一对一或多对一关系(RAC):即一个实例只能与一个数据库相关联,数据库可以被多个实例所加载。而实例与数据库不可能是一对多的关系。当进入ORACLE 12C后,实例与数据库可以是一对多的关系。下面是官方文档关于CDB与PDB的关系图。 CDB组件(Components of a CDB) 一个CDB数据库容器包含了下面一些组件: ROOT组件 ROOT又叫CDB$ROOT, 存储着ORACLE提供的元数据和Common User,元数据的一个例子是ORACLE提供的PL/SQL包的源代码,Common User 是指在每个容器中都存在的用户。 SEED组件 Seed又叫PDB$SEED,这个是你创建PDBS数据库的模板,你不能在Seed中添加或修改一个对象。一个CDB中有且只能有一个Seed. 这个感念,个人感觉非常类似SQL SERVER 中的model数据库。 PDBS CDB中可以有一个或多个PDBS,PDBS向后兼容,可以像以前在数据库中那样操作PDBS,这里指大多数常规操作。 这些组件中的每一个都可以被称为一个容器。因此,ROOT(根)是一个容器,Seed(种子)是一个容器,每个PDB是一个容器。每个容器在CDB中都有一个独一无二的的ID和名称。 南京宝云教育