Accumulation distribution(累积 派发指标) MT4指标
Accumulation/distribution(累积/派发指标)
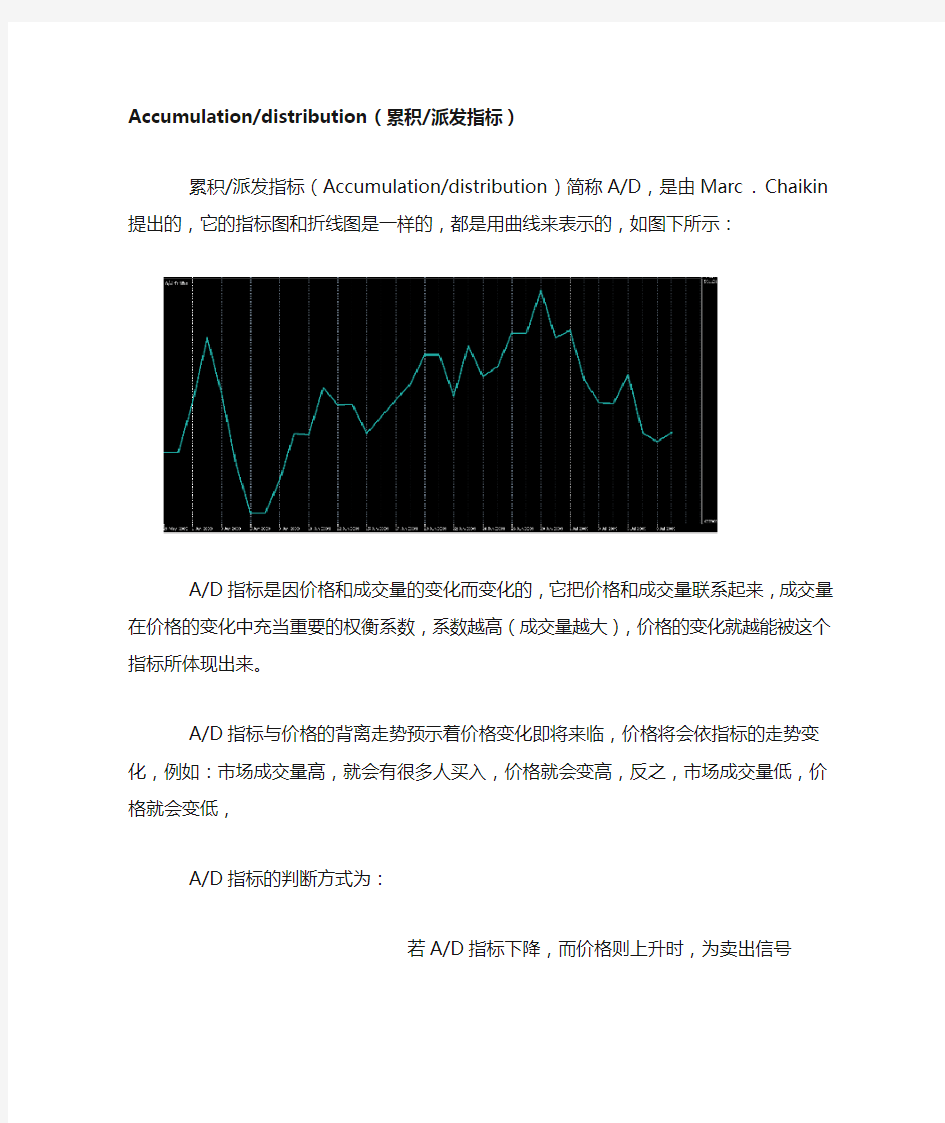
累积/派发指标(Accumulation/distribution)简称A/D,是由Marc . Chaikin提出的,它的指标图和折线图是一样的,都是用曲线来表示的,如图下所示:
A/D指标是因价格和成交量的变化而变化的,它把价格和成交量联系起来,成交量在价格的变化中充当重要的权衡系数,系数越高(成交量越大),价格的变化就越能被这个指标所体现出来。
A/D指标与价格的背离走势预示着价格变化即将来临,价格将会依指标的走势变化,例如:市场成交量高,就会有很多人买入,价格就会变高,反之,市场成交量低,价格就会变低,
A/D指标的判断方式为:
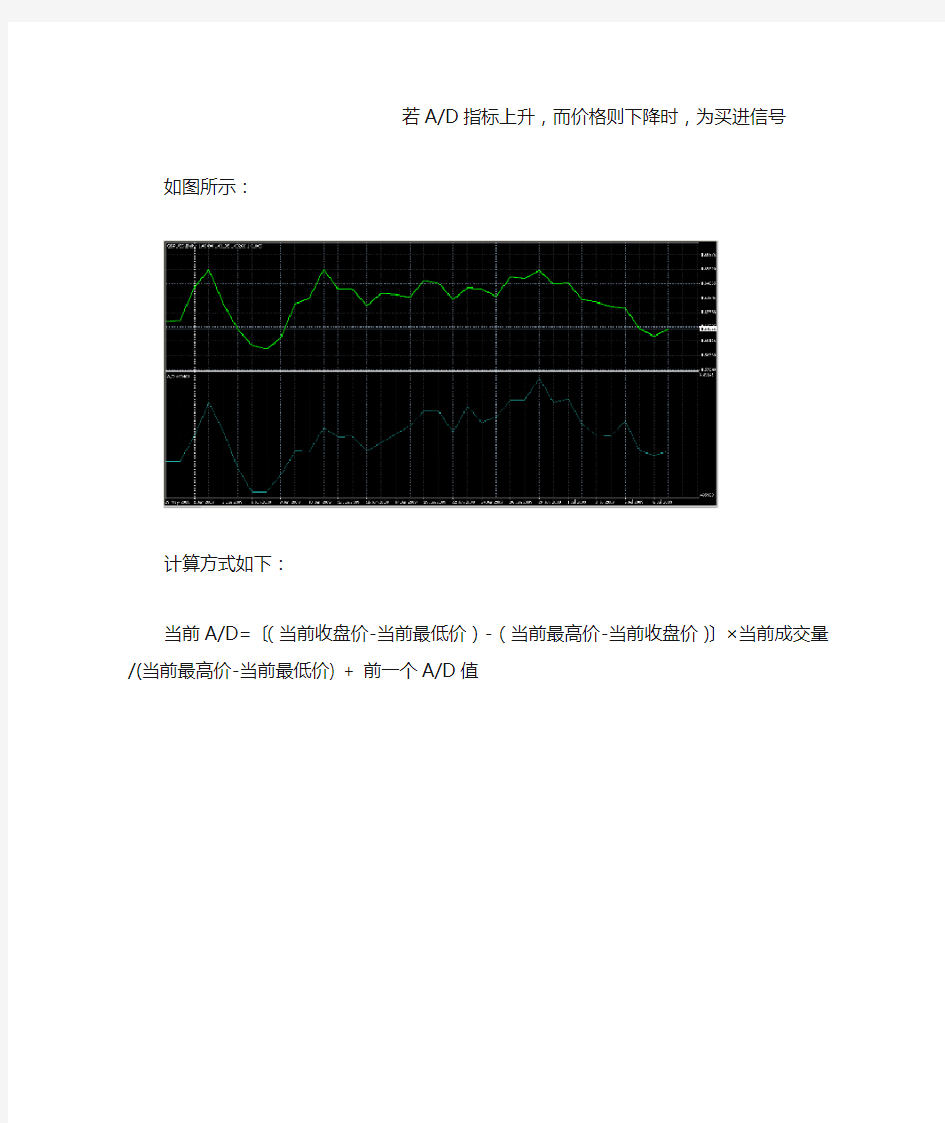
若A/D指标下降,而价格则上升时,为卖出信号
若A/D指标上升,而价格则下降时,为买进信号
如图所示:
计算方式如下:
当前A/D=〔(当前收盘价-当前最低价)-(当前最高价-当前收盘价)〕×当前成交量/(当前最高价-当前最低价) + 前一个A/D值
SPSS非参数检验之卡方检验
SPSS 中非参数检验之一:总体分布的卡方(Chi-square )检验 在得到一批样本数据后,人们往往希望从中得到样本所来自的总体的分布形态是否和某种特定分布相拟合。这可以通过绘制样本数据直方图的方法来进行粗略的判断。如果需要进行比较准确的判断,则需要使用非参数检验的方法。其中总体分布的卡方检验(也记为χ2检验)就是一种比较好的方法。 一、定义 总体分布的卡方检验适用于配合度检验,是根据样本数据的实际频数推断总 体分布与期望分布或理论分布是否有显著差异。它的零假设H0:样本来自的总体分布形态和期望分布或某一理论分布没有显著差异。 总体分布的卡方检验的原理是:如果从一个随机变量尤中随机抽取若干个观察样本,这些观察样本落在X 的k 个互不相交的子集中的观察频数服从一个多项分布,这个多项分布当k 趋于无穷时,就近似服从X 的总体分布。 因此,假设样本来自的总体服从某个期望分布或理论分布集的实际观察频数同时获得样本数据各子集的实际观察频数,并依据下面的公式计算统计量Q ()2 1 k i i i i O E Q E =-=∑ 其中,Oi 表示观察频数;Ei 表示期望频数或理论频数。可见Q 值越大,表示 观察频数和理论频数越不接近;Q 值越小,说明观察频数和理论频数越接近。SPSS 将自动计算Q 统计量,由于Q 统计量服从K-1个自由度的X 平方分布,因此SPSS 将根据X 平方分布表给出Q 统计量所对应的相伴概率值。 如果相伴概率小于或等于用户的显著性水平,则应拒绝零假设H0,认为样本来自的总体分布形态与期望分布或理论分布存在显著差异;如果相伴概率值大于显著性水平,则不能拒绝零假设HO ,认为样本来自的总体分布形态与期望分布或理论分布不存在显著差异。 因此,总体分布的卡方检验是一种吻合性检验,比较适用于一个因素的多项分类数据分析。总体分布的卡方检验的数据是实际收集到的样本数据,而非频数数据。 二、实例 某地一周内各日患忧郁症的人数分布如下表所示,请检验一周内各日人们忧
两独立样本t检验和非参数检验的实证分析
龙源期刊网 https://www.360docs.net/doc/e27682804.html, 两独立样本t检验和非参数检验的实证分析作者:张家骥 来源:《经营者》2013年第11期 摘要:教学质量是靠具体课程完成,课程的建设是教学质量提升的重要环节和基本保证。本文简述了概率论与数理统计重点课程建设的必要性,重点在于对课程建设前后分层随机抽样得来的样本进行实证分析。实证分析主要从基本统计分析、参数检验、非参数检验三个大的方面进行,尤其是非参数检验方面,又具体利用了三种不同的检验法进行分析推断。 关键词:t检验;非参数检验;显著性水平;频数分析 概率论与数理统计是我国高等院校理工类、经济类、管理类各专业的一门重要公共基础课程,同时也是一门应用广泛,适用性强的工具课。此门课程的教学为学生的其他专业课及其将来毕业后的工作、继续深造等方面奠定必要的数学基础,而且对培养学生的逻辑思维能力、分析判断问题能力、统计观点、应用能力和创新能力均有着特殊而又重要的作用,是培养高素质综合型人才的重要保证。 笔者本身是东华理工大学理学院的一线教师,这两年来,同时在江西财经大学统计学院读研究生。在此期间,笔者主持的“概率论与数理统计”重点课程建设项目小组一直在努力的探索和研究,收获了一些成果。本文的主要目的是针对进行重点课程建设这几年来,对搜集到的学生该门课程的考试成绩从统计学的角度进行实证分析。尤其是从参数检验和非参数统计两个重要角度进行探究,论证这几年来进行课程建设是否让学生成绩取得了明显的提高。 本文数据来源于东华理工大学所有开设了概率论与数理统计课程的学院,分别收集了2010学年第二学期(即下半年)概率成绩和2012学年第二学期概率成绩。总共十个学院,进行分层随机抽样,对每个学院随机抽取10名学生,最终获到两组样本,每组各100个样本点。下面开始进行实证分析: 一、基本统计分析 对数据的分析首先从基本统计分析入手。通过基本统计分析,掌握数据的基本统计特征,同时迅速把握数据的总体分布形态。而基本统计分析往往先从频数分析开始,由于成绩数据均为定距型数据,直接采用频数分析不利于对其分布形态的把握,因此先对数据分组后再进行频数分析。SPSS频数分析的操作如下:选择菜单【Analyze】→【Descriptive】→【Frequencies】,结果如下: 从上面的统计表中可以看出,进行重点课程建设后,平均分有了明显的提高,而且从频数分布表可以看出,第3组第4组即中高分数段百分数有了明显提升。从数据的角度初步说明课程建设有效果,学生成绩明显改善。
非参数统计第4章 两独立样本的非参数检验
第四章 两独立样本的非参数检验 在单样本位置问题中,人们想要检验的是总体的中心是否等于一个已知的值.但在实际问题中,更受注意的往往是比较两个总体的位置参数;比如。两种训练方法中哪一种更出成绩,两种汽 油中哪一个污染更少,两种市场营销策略中那种更有效等等. 作为一个例子.我国沿海和非沿海省市区的人均国内生产总值(GDP)的1997年抽样数据如下(单位为元).沿海省市区为(Y1,Y2,…,Y12): 15044 12270 5345 7730 22275 8447 9455 8136 6834 9513 4081 5500 而非沿海的为对(x1,x2,…,x18): 5163 4220 4259 6468 3881 3715 4032 5122 4130 3763 2093 3715 2732 3313 2901 3748 3731 5167 人们想要知道沿海和非沿海省市区的人均GDP 的中位数是否一样.这就是检验两个总体的位置参数是否相等的问题. 假定代表两个独立总体的随机样本(Y1,Y2,…,Y12)和(x1,x2,…,x18),则问题归结为检验它们总体的均值(或中位数)的差是否相等,或是否等于某个已知值.换言之,即检验 0H :021D =-μμ;1H : 021D ≠-μμ 0H :021D =-μμ;1H : 021D <-μμ 0H :021D =-μμ;1H : 021D >-μμ 在正态假定下,这些问题化为:)2(~11)(0-++ --= m n t m n s D y x t 2 ) ()(1 2 1 2 -+-+ -= ∑∑==n m y y x x S m i i n i i t 检验并不稳健,在不知总体分布时,应用t 检验时会有风险的。 3.1 Brown-Mood 中位数检验 令沿海地区的人均GDP 的中位数为M X ,而内地的为M Y 。零假设为 0H :y x M M =;1H : y x M M > 显然,在零假设下,中位数如果一样的话,它们共同的中位数,即这(12十18)=30个数的样 本中位数(记为此xy M ),应该对于每一列数据来说都处于中间位置.也就是说,(Y1,Y2,…,Y12) 和(x1,x2,…,x18)中大于或小于xy M 的样本点应该大致一样多,计算他们的混合样本中位数为
SPSS的参数检验和非参数检验
S P S S的参数检验和非 参数检验 公司内部档案编码:[OPPTR-OPPT28-OPPTL98-OPPNN08]
实验报告 SPSS的参数检验和非参数检验 学期:_2013__至2013_ 第_1_学期 课程名称:_数学建模专业:数学 实验项目__SPSS的参数检验和非参数检验实验成绩:_____ 一、实验目的及要求 熟练掌握t检验及其结果分析。熟练掌握单样本、两独立样本、多独立样本的非参数检验及各种方法的适用范围,能对结果给出准确分析。 二、实验内容 使用指定的数据按实验教材完成相关的操作。 1、给幼鼠喂以不同的饲料,用以下两种方法设计实验: 方式1:同一鼠喂不同的饲料所测得的体内钙留存量数据如下: 方式2:甲组有12只喂饲料1,乙组有9只喂饲料2,所测得的钙留存量数据如下:
请选用恰当方法对上述两种方式所获得的数据进行分析,研究不同饲料是否使幼鼠体内钙的留存量有显着不同。 2、为分析大众对牛奶品牌是否具有偏好,随机挑选超市收集其周一至 周六各天三种品牌牛奶的日销售额数据,如下表所示: 请选用恰当的非参数检验方法,以恰当形式组织上述数据进行分析,并说明分析结论。 实验报告附页 三、实验步骤 (一) 方式1: 1、打开SPSS软件,根据所给表格录入数据,建立数据文件; 2、选择菜单Analyze-Compare means-Paired-Samples T Test,出现窗口; 3、把检验变量饲料1,饲料2 选择到Paired Variables框,单击OK。方式2: 1、打开SPSS软件,根据所给表格录入数据,建立数据文件; 2、选择菜单Analyze-Compare means-Independent-Samples T Test,出现窗口 3、选择检验变量饲料到Test Variable(s)框中。 4、选择总体标志变量组号到Grouping Variables框中。 5、单击Define Groups按钮定义两总体的标志值1、2,单击OK。
非参数检验卡方检验实验报告
大理大学实验报告 课程名称生物医学统计分析 实验名称非参数检验(卡方检验) 专业班级 姓名 学号 实验日期 实验地点 2015—2016学年度第 2 学期
Fisher 的精确检验:精确概率法计算的卡方值(用于理论数E<5)。 不同的资料应选用不同的卡方计算方法。 例为2*2列联表,df=1,须用连续性校正公式,故采用“连续校正”行的统计结果。 X2=,P(Sig)=<,表明灭螨剂A组的杀螨率极显着高于灭螨剂B组。 例 表3 治疗方法* 治疗效果交叉制表 计数 治疗效果 123 合计 治疗方法11916540 21612836 31513735合计504120111 分析:表3是治疗方法* 治疗效果资料分析的列联表。 表4 卡方检验 X2值df渐进 Sig. (双侧) Pearson 卡方 1.428a4.839
似然比4.830线性和线性组合.5141.474 有效案例中的 N111 a. 0 单元格(.0%) 的期望计数少于 5。最小期望计数为。 分析:表4是卡方检验的结果。自由度df=4,表格下方的注解表明理论次数小于5的格子数为0,最小的理论次数为。各理论次数均大于5,无须进行连续性校正,因此可以采用第一行(Pearson 卡方)的检验结果,即 X2=,P=>,差异不显着,可以认为不同的治疗方法与治疗效果无关,即三种治疗方法对治疗效果的影响差异不显着。 例 表5 灌溉方式* 稻叶情况交叉制表 计数 稻叶情况 123 合计 灌溉方式114677160 2183913205 31521416182合计4813036547 分析:表5是灌溉方式* 稻叶情况资料分析的列联表。
方差分析与非参数检验
北京建筑大学 理学院信息与计算科学专业实验报告 课程名称《数据分析》实验名称方差分析与非参数检验实验地点基C-423 日期2017.3.30 (1)熟悉数据的基本统计与非参数检验分析方法; (2)熟悉撰写数据分析报告的方法; (3)熟悉常用的数据分析软件SPSS。 【实验要求】 根据各个题目的具体要求,完成实验报告。 【实验内容】 1、附件给出某年房屋价格的相关数据,请选用恰当的分析方法,对影响房屋价格的因素进行分析。(注意数据要调整成标准的格式,变量值、组别(字符变量转换成数值变量))(单因素方差分析选择其中两个因素、双因素方差分析选择其中任一对因素即可) 2、附件给出管理才能评分的相关数据,请选用恰当的分析方法,分析该评分数据是否服从正态分布。 3、附件给出了某体育比赛的两位裁判打分数据,请选用恰当的分析方法,检验该两组评分分布是否有显著差异。(注意数据要调整成标准的格式,变量值、组别) 4、附件给出了减肥茶数据,请选用恰当方法分析,检验该减肥茶是否对减肥有显著效果。(注意数据要调整成标准的格式,变量值、组别) 【分析报告】 1、对影响房屋价格的因素进行分析。(单因素方差分析选择其中两个因素、双因素方差分析选择其中任一对因素即可)。 表1-1(a) 装修状况对均价影响的单因素方差分析结果 均价 平方和df 均方 F 显著性 组间79.180 1 79.180 62.408 .000 组内230.914 182 1.269 总数310.094 183 表1-1(b) 所在区县对均价影响单因素方差分析结果 均价 平方和df 均方 F 显著性 组间91.919 3 30.640 25.279 .000 组内218.174 180 1.212 总数310.094 183 表1-1(a)是装修状况对均价影响的单因素方差分析结果。可以看到:观测变量均价的离差平方总和为310.094;如果仅考虑装修状况单个因素的影响,则均价总变差中,不同装修状况可解释的变差为79.180,抽样误差引起的变差为230.914,它们的方差分别为79.180和1.269,相除所得的F统计量的观测值为62.408,对应的概率P-值近似为0.如果显著性水平α为0.05,由于概率P-值小于显著性水平α,应拒绝原假设,认为不同装修状况对均价的平均值产生了显著影响,不同装修状况对均价的影响效应不全为0。 表1-1(b)是所在区县对均价影响单因素方差分析结果。可以看到:如果仅考虑所在区县单个因素的影响,则均价总变差310.094中不同所在区县可解释的变差为91.919,抽样误差引起的变差为218.174,
两个独立样本的非参数检验方法有4种
两个独立样本的非参数检验方法有4种 曼-惠特尼U检验(Mann—whitney U) 两个独立的曼-惠特尼U检验可用于对两个总体分布的比较判断。其零假设是两组独立样本来自的总体分布无显著差异。曼-惠特尼U检验通过对两组样本平均秩的研究来实现推断秩简单的说就是变量值排序的名次。 两个独立样本的K-S检验 K-S检验不仅能够检验单个总体的分布是否与某一理论分布差异显著,还能够检验两个总体的分布是否存在显著差异,其零假设是两组独立样本来自的两个总体的分布无显著差异。 两个独立样本K-S检验的基本思想与前面讨论的单样本K-S检验的基本思路大体一致。主要差别在于:这里是以变量值的秩作为分析对象,而非变量值本身。其基本思路如下: ①首先,将这两组样本混合并按升序排序。 ②然后分别计算两组样本秩的累计频数和累计频率。 ③最后,计算累计频率之差,得到秩的差值序列并得到D统计量(同单样本K-S检验,但无需修正)。 两独立样本的游程检验 单样本游程检验用来检验变量值的出现是否随机,而两个独立变量游程检验则用来检验两个独立样本来自的两个总体的分布是否存在显著差异。其零假设是两组独立样本来自的两个总体的分布无显著差异。 两独立样本的游程检验与单样本游程检验的基本思想相同,不同的是计算游程数的方法。两独立样本的游程检验中,又程数依赖于变量的秩。 步骤如下:首先,将两组样本混合并按升序排列,在变量值排序的同时,对应的组标记值也会随之重新排列。 然后,对组标记只序列按前面讨论的游程的方法计算游程数容易理解:如果两总体的分布存在较大的差距,那么游程数会相对比较少,如果游程数比较大,则应是两组样本充分混合的结果,那么总体的分布不会存在显著差异。 再次,根据游程数据计算Z统计量,该统计量近似服从正态分布。 极端反应检验 极端反应检验从另一个角度检验两独立样本所来自的两个总体分布是否存在显著差异。其零假设是来两独立样本来自的两个总体分布无显著差异。 极端反应检验的基本思想是将一组样本作为控制样本,另一组样本作为实验样本。以控制样本作为对照,检验实验样本相对于控制样本是否出现极端反应。如果试验样本没有出现极端反应,则认为两总体分布无显著差异,反之,则总体分布存在显著差异。 第1 页共1 页
SPSS的参数检验和非参数检验
实验二 SPSS的参数检验和非参数检验 (验证性实验 4学时) 1、目的要求:熟练掌握t检验及其结果分析。熟练掌握单样本、两独立 样本、多独立样本的非参数检验及各种方法的适用范围,能对结果给 出准确分析。 2、实验内容:使用指定的数据按实验教材完成相关的操作。 3、主要仪器设备:计算机。 练习: 1、给幼鼠喂以不同的饲料,用以下两种方法设计实验: 鼠体内钙的留存量有显著不同。 2、为分析大众对牛奶品牌是否具有偏好,随机挑选超市收集其周一至周六各天 并说明分析结论。 1 参数检验概述 假设检验的基本思想 .事先对总体参数或分布形式作出某种假设,然后利用样本信息来判断原假设是否成立; .采用逻辑上的反证法,依据统计上的小概率原理。
2 单样本的T检验 2.1检验目的: ?检验单个变量的均值是否与给定的常数(总体均值)之间是否存在显著差异。如:分析学生的IQ平均分是否为100分;大学生考研率是否为5%。 ?要求样本来自的总体服从或近似服从正态分布。 2.2 单样本T检验的实现思路 ?提出原假设: ?计算检验统计量和概率P值 ●给定显著性水平与p值做比较:如果p值小于显著性水平,小概率事件在 一次实验中发生,则我们应该拒绝原假设,反之就不能拒绝原假设。 2.3 单样本t检验的基本操作步骤 1、选择选项Analyze-Compare means-One-Samples T test,出现窗口: 2、在Test Value框中输入检验值。 3、单击Option按钮定义其他选项。Option选项用来指定缺失值的处理方法。其中,Exclude cases analysis by analysis表示计算时涉及的变量上有缺失值,则剔除在该变量上为缺失值的个案;Exclude cases listwise表示剔除所有在任意变量上含有缺失值的个案后再进行分析。可见,较第二种方式,第一种处理方式较充分地利用了样本数据。在后面的分析方法中,SPSS对缺失值的处理方法与此相同,不再赘述。另外,还可以输出默认95%的置信区间。 至此,SPSS将自动计算t统计量和对应的概率p值。 3 两独立样本的T检验 3.1 两独立样本T检验的目的 ?利用来自两个总体的独立样本,推断两个总体的均值是否存在显著性差异; ?两独立样本的样本容量可以相等,也可以不相等; ?样本来自的总体服从或近似服从正态分布。 方差齐性检验(Levene F方法): ?计算两组样本的均值 ●计算各个样本与本组均值的平均离差绝对值; ●利用单因素方差分析推断两独立总体平均离差绝对值是否有显著差异。 ●在对两独立样本进行T检验时,两组样本方差相等和不等时使用的计算t 值的公式不同,所以首先进行方差F检验。用户需要根据F检验的结果自己判断选择t检验输出中的哪个结果,得出最后结论。如果推断两总体方差相等则看方差相等的T检验值和P值,如果推断两总体方差不相等则看方差不相等的T检验值和P值。 3.2 两独立样本T检验的实现思路 ?提出原假设:两总体均值不存在显著差异: ●计算统计量和P值:首先利用F检验确定两个总体的方差是否相等;然后 再选择合适的T统计量计算观测值和概率P值; ●根据显著性水平和概率P值进行统计决策。 3.3 两独立样本t检验的基本操作步骤 进行两独立样本t检验之前,正确地组织数据是一个非常关键的任务。SPSS 要求将两组样本数据存放在一个SPSS变量中,同时,为区分哪些样本来自哪个
SPSS的参数检验和非参数检验
实验报告SPSS的参数检验和非参数检验 学期:_2013__至2013_ 第_1_学期 课程名称:_数学建模专业:数学 实验项目__SPSS的参数检验和非参数检验实验成绩:_____ 一、实验目的及要求 熟练掌握t检验及其结果分析。熟练掌握单样本、两独立样本、多独立样本的非参数检验及各种方法的适用范围,能对结果给出准确分析。 二、实验内容 使用指定的数据按实验教材完成相关的操作。 1、给幼鼠喂以不同的饲料,用以下两种方法设计实验: 鼠体内钙的留存量有显著不同。 2、为分析大众对牛奶品牌是否具有偏好,随机挑选超市收集其周一至周六各天 并说明分析结论。 实验报告附页
三、实验步骤 (一) 方式1: 1、打开SPSS软件,根据所给表格录入数据,建立数据文件; 2、选择菜单Analyze-Compare means-Paired-Samples T Test,出现窗口; 3、把检验变量饲料1,饲料2 选择到Paired Variables框,单击OK。 方式2: 1、打开SPSS软件,根据所给表格录入数据,建立数据文件; 2、选择菜单Analyze-Compare means-Independent-Samples T Test,出现窗口 3、选择检验变量饲料到Test Variable(s)框中。 4、选择总体标志变量组号到Grouping Variables框中。 5、单击Define Groups按钮定义两总体的标志值1、2,单击OK。 (二) 1、打开SPSS软件,根据所给表格录入数据,建立数据文件; 2、选择菜单Analyze->Nonparametric->k Independent sample 3、选择待检验的若干变量入包装1,包装2,包装3到Test Variable(s)框中; 4、选择推广的平均秩检验(Friedman检验),单击OK。 四、实验结果分析与评价 (一): 方式1: 由上表知:两配对变量饲料1和饲料2对应的概率p值为0.108>0.05通过了检验,可以认为两配对变量饲料1和饲料2无相关关系。 由上表知:吃饲料1和饲料2的幼鼠分别有9人,其中喂以饲料1的9只幼鼠体内平均钙留存量为32.578;而喂以饲料2的9只幼鼠体内平均钙留存量为34.267。
两个独立样本的非参数检验方法
两个独立样本的非参数检验方法 两个独立样本的费参数检验正是对总体分布不甚了解的情况下,通过对两组独立样本的分析来推断样本来自的两个总体的分布是否存在显著差异的方法。 一、曼-惠特尼U检验 两个独立的曼-惠特尼U检验可用于对两个总体分布的比较判断。其零假设是两组独立样本来自的总体分布无显著差异。曼-惠特尼U检验通过对两组样本平均秩的研究来实现推断秩简单的说就是变量值排序的名次。 二、两个独立样本的K-S检验 K-S检验不仅能够检验单个总体的分布是否与某一理论分布差异显著,还能够检验两个总体的分布是否存在显著差异,其零假设是两组独立样本来自的两个总体的分布无显著差异。 两个独立样本K-S检验的基本思想与前面讨论的单样本K-S检验的基本思路大体一致。这里是以变量值的秩作为分析对象,而非变量值本身。其基本思路如下: ①首先,将这两组样本混合并按升序排序。 ②然后分别计算两组样本秩的累计频数和累计频率。 ③最后,计算累计频率之差,得到秩的差值序列并得到D统计量(同单样本K-S检验,但无需修正)。 三、两独立样本的游程检验 单样本游程检验用来检验变量值的出现是否随机,而两个独立变量游程检验则用来检验两个独立样本来自的两个总体的分布是否存在显著差异。其零假设是两组独立样本来自的两个总体的分布无显著差异。 两独立样本的游程检验与单样本游程检验的基本思想相同,不同的是计算游程数的方法。两独立样本的游程检验中,又程数依赖于变量的秩。 步骤如下:首先,将两组样本混合并按升序排列,在变量值排序的同时,对应的组标记值也会随之重新排列。 然后,对组标记只序列按前面讨论的游程的方法计算游程数容易理解:如果
参数检验和非参数检验
一.单因素方差分析(one-way ANOVA),用于完全随机设计的多个样本均数间的比较,其统计推断是推断各样本所代表的各总体均数是否相等。 完全随机设计(completely random design)不考虑个体差异的影响,仅涉及一个处理因素,但可以有两个或多个水平,所以亦称单因素实验设计。在实验研究中按随机化原则将受试对象随机分配到一个处理因素的多个水平中去,然后观察各组的试验效应;在观察研究(调查)中按某个研究因素的不同水平分组,比较该因素的效应。 二. T检验,亦称student t检验(Student's t test),主要用于样本含量较小(例如n<30),总体标准差σ未知的正态分布资料。t检验是用t分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。它与Z检验、卡方检验并列。 t检验 t检验分为单总体检验和双总体检验。 单总体t检验时检验一个样本平均数与一个已知的总体平均数的差异是否显著。当总体分布是正态分布,如总体标准差未知且样本容量小于30,那么样本平均数与总体平均数的离差统计量呈t分布。 单总体t检验统计量为: 双总体t检验是检验两个样本平均数与其各自所代表的总体的差异是否显著。双总体t 检验又分为两种情况,一是独立样本t检验,一是配对样本t检验。 独立样本t检验统计量为:
S1 和S2 为两样本方差;n1 和n2 为两样本容量。(上面的公式是1/n1 + 1/n2 不是减!) 配对样本t检验统计量为: t检验的适用条件 (1) 已知一个总体均数; (2) 可得到一个样本均数及该样本标准差; (3) 样本来自正态或近似正态总体。 t检验步骤 以单总体t检验为例说明: 问题:难产儿出生体重n=35,X拔=3.42,S =0.40,一般婴儿出生体重μ0=3.30(大规模调查获得),问相同否? 解:1.建立假设、确定检验水准α H0:μ = μ0 (无效假设,null hypothesis) H1:μ≠μ0(备择假设,alternative hypothesis,) 双侧检验,检验水准:α=0.05 2.计算检验统计量
非参数检验 SPSS操作
非参数检验的SPSS操作 前面一章介绍的二项分布的比率检验、配合度检验——卡方检验和1-Sample K-S检验等都属于非参数检验。这一节我们主要结合前面参数假设检验一章讲过的t检验以及方差分析一章讲过的方差分析,来进一步分析,当参数检验的前提条件不满足时,两个样本和多个样本平均数差异的SPSS操作方法。 一、两个独立样本的差异显著性检验 两独立样本的的差异显著性检验只有在满足如下条件时才能进行T检验:变量为正态分布的连续测量数据。若数据不满足这样的条件,强行进行T检验容易造成错误的结论。在数据不能满足这种参数检验的条件下,我们可以选择非参数检验方法进行。与两独立样本差异显著性检验相对应的方法可以在SPSS主菜单Analyze / Nonparametric Tests / 2 Independent Samples…中得到。 1.数据 采用本章第一节中例2的数据(数据文件“9-4-1.sav”),具体介绍操作过程。 2.理论分析 对于数据文件9-4-1.sav中的数据,目的是检验男女生之间注意稳定性是否存在显著差异,注意稳定性测量的结果虽然是测量数据但是从总体上来看不满足正态分布的前提假设,另外不同性别的学生可以看成是两组独立的样本,因此对上述资料的检验可以用非参数的独立样本的检验方法。 2.操作过程 (1)在SPSS主菜单中选择Analyze / Nonparametric Tests / 2 Independent Samples…得到两个独立样本非参数检验的主对话框(图9-1),把因变量atten选入到检验变量表列(Test Independent-Sample