XPS数据分析方法

XPS数据分析
纵坐标:Intensity(cps)
横坐标:binding energy(eV)
除了氢氦元素,其他的元素都可以进行分析;先进行宽扫,确定样品有何种元素,再对该元素进行窄扫。该元素的不同键接方式都对应不同的峰,所以对元素窄扫的峰要进行分峰(分峰之前要进行调整基线)。如何分峰,不同的键接方式会对应不同的结合能。
第一步:先把元素的窄扫峰用origin画出来;
纵坐标:Intensity(cps)
横坐标:binding energy(eV)
第二步:调整基线;
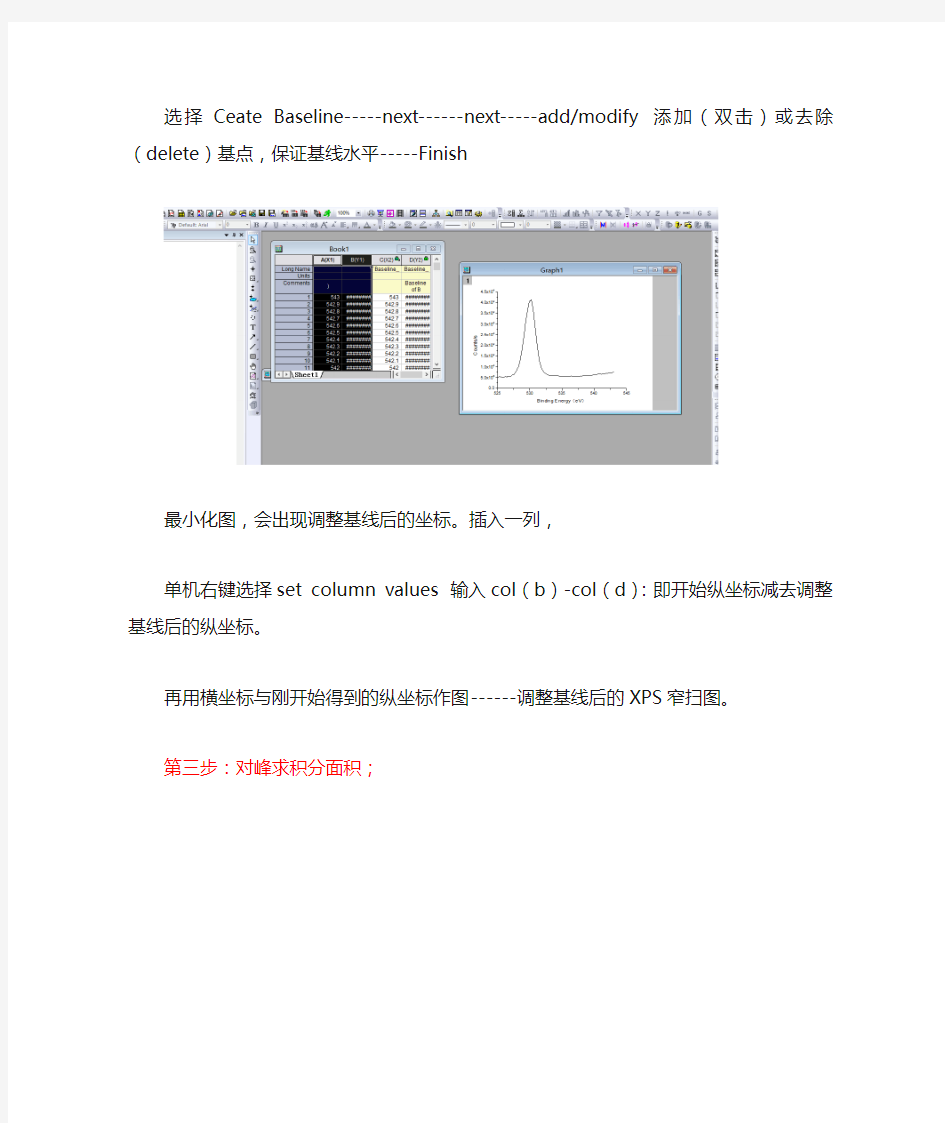
选择Ceate Baseline-----next------next-----add/modify添加(双击)或去除(delete)基点,保证基线水平-----Finish
最小化图,会出现调整基线后的坐标。插入一列,
单机右键选择set column values 输入col(b)-col(d):即开始纵坐标减去调整基线后的纵坐标。
再用横坐标与刚开始得到的纵坐标作图------调整基线后的XPS窄扫图。
第三步:对峰求积分面积;
选择integrate peaks-----next-------狂点------完成
即area为峰的面积。
第四步:分峰较难(有专门的分峰软件,origin也能分峰)
第五步:求组分元素比:
元素比等于:窄扫峰面积/XPS灵敏度因子(每一个元素的灵敏度因子不一致)
咱们这边西工大的XPS 设备选择的是铝板(AlK α)。
数据分析的思维技巧
数据分析的思维技巧 在我对数据分析有限的认识上(因为无知到没有认知),往往会看到一些秀技性的数据分析图表,以及好看的词云等等。年少无知的我,只想啪啪啪鼓掌伴随一声“卧槽,真牛逼”,然后在被秀了一脸后,并没有明白对方想说什么,空有一副好皮囊而没有灵魂。分析是为了给出偏好的,也是洗脑的一种重要手段,洗不洗的成功就要靠本事了。于是问题产生了,你的分析是为了干啥,通过哪几个角度达到哪几方面的目的。以下为我对几个技巧的认识想法: 一、象限法 就是划定几个坐标轴,让每一个数据在象限中找到自己的角色,比如打工这个事吧,就是要让你忙,就是要给你一堆事,于是重点出来了,这么多事孰重孰轻,孰急孰缓,跟打工皇帝学时间管理,事情要按照紧急程度和重要程度进行划分,以此给自己做事排序。 二、多维法 从个人理解来看,多维法和象限法联系紧密,无非就是象限法之间的界限清晰明显,多维法之间的维度不是严格意义的隔开,比如高度、富有、颜值,这到底算象限分类还是维度分类,或者说当象限多了,采用多维来理解效果更好,比如富有的家庭一般孩纸整体相对更高一些,维度与维度之间是有相对联系的,虽然不是那么绝对,但是也不是完全不相关。
但是多维法呢,正是由于维度与维度之间的关系,会导致整体维度情况和细分维度情况来看起来会有失真,最典型的例子是田忌赛马,上中下三个维度的马均是齐王更厉害,那么跑马结果田忌胜了。性别歧视在工作学习中经常会碰到,但是通过男女入取率判断性别歧视合适么,每个学院的女生录取率都高,但是整体入取率女生低的情况也不是不能出现,那么这到底是哪种性别歧视呢,数字不会骗人,但是分析洗脑会骗人,分析思维不对容易骗自己。为了解决辛普森悖论,可以通过切方块的方式,不断缩小分析的维度,不断深入挖掘,可以有效了解真实情况。 三、假设法 数据分析对下是有一系列材料做支撑,对上是为决策或了解情况提供支撑,只有下面有素材,才能为上面提供科学合理研判。那么问题出来了,如果没有材料做支撑,那怎么办。简单,没有条件那就为它创建条件嘛,我先假设一个基础,然后根据这个基础大肆分析,水平体现出来了,偏好结论也体现出来了,其实很多现实问题是没有那么多切实完整的基础资料的,有的就是一个感觉,有的就是一个偏好。这也是咨询圈常见的套路,虽然不是严格意义的1+1=2,但是可以严谨告诉别人1+1>1,而且面对那么多的未知,不将几个未知进行假设,如何区解决更多的未知。 四、指数法 一直觉得,指数法是一个装逼指数最高的方法,首先指数就已经狠专业了,在专业的基础上进行专业的分析,还有什么更专业的事情么。但是
XPS数据分析基本过程
XPS数据分析基本过程 定性分析 首先扫描全谱,由于荷电存在使结合能升高,因此要通过C结合能284.6eV 对全谱进行荷电校正,然后对感兴趣的元素扫描高分辨谱,将所得结果与标准图谱对照,由结合能确定元素种类,由化学位移确定元素得化学状态,为了是结果准确在每一次扫描得结果分别进行荷电校正。XPS谱图中化学位移的分析一般规律为: 1、原子失去价电子或因与电负性高的原子成键而显正电时,内层电子结合能升高。 2、原子获得电子而荷负电时,内层电子结合能减小。 3、氧化态越高,结合能越大。 4、价层发生某种变化时,所有内层电子化学位移相同。 5、对于XPS峰主量子数n小的壳层比n大的峰强,n相同的角量子数l大的峰强,n,l相同的j大的峰强。 定量分析 选取最强峰的面积或强度作为定量计算的基础,多采用灵敏度因子法,因为各元素产生光电子时的含量强度和含量不一定成正比,从而利用灵敏度因子对强度进行修正,其做法为:以峰边、背景的切线交点为准扣除背景,计算峰面积或峰强,然后分别除以相应元素的灵敏度因子法,就可得到各元素的相对含量,这个相对含量是原子个数相对含量即摩尔相对含量。 XPS图谱的分峰处理 由于在制备过程中外界条件不可能完全均匀一致,因而对于同一元素可能存在不同的化学态,而各化学态产生的峰又有可能相互重叠,这样就对定性、定量分析带来了不便,因而在进行数据分析时需要对可能存在重叠的峰进行分峰处理,目前有很多数据处理软件可以进行分峰运算,其原理都是利用高斯-洛沦兹函数,其中XPSpeak为一位台湾学者编写的程序,其采用图形用户界面(GUI),用于XPS分峰处理操作方便,简单易学。 XPSpeak运行后其界面为:
XPS能谱数据处理
材料X射线光电子能谱数据处理及分峰的分析实例 例:将剂量为1 107ions/cm2,能量为45KeV的碳离子注入单晶硅中,然后在1100C 高分辨扫瞄谱退火2h进行热处理。对单晶硅试样进行XPS测试,试对其中的C 1s 进行解析,以确定各种可能存在的官能团。 分析过程: 1、在Origin中处理数据 图1
将实验数据用记事本打开,其中C 1s 表示的是C 1s 电子,299.4885表示起始结 合能,-0.2500表示结合能递减步长,81表示数据个数。从15842开始表示是光电子强度。从15842以下数据选中Copy到Excel软件B列中,为光电子强度数据列。同时将299.4885Copy到Excel软件A列中,并按照步长及个数生成结合能数据,见图2 图2 将生成的数据导入Origin软件中,见图3。
图3 谱图,检查谱此时以结合能作为横坐标,光电子强度作为纵坐标,绘出C 1s 图是否有尖峰,如果有,那是脉冲,应把它们去掉,方法为点Origin 软件中的Data-Move Data Points,然后按键盘上的↓或↑箭头去除脉冲。本例中的实验数据没有脉冲,无需进行此项工作。将column A和B中的值复制到一空的记事本 文档中(即成两列的格式,左边为结合能,右边为峰强),并存盘,见图4。
图4 2、打开XPS Peak,引入数据:点Data----Import (ASCII),引入所存数据, 则出现相应的XPS谱图,见图5、图6。
3、选择本底:点Background,因软件问题, High BE和Low BE的位置最好不改,否则无法再回到Origin,此时本底将连接这两点,Type可据实际情况选择,一般选择Shirley 类型,见图7。
【做计算 找华算】【干货】XPS数据的XPSPeak分峰以及Origin制图步骤
实验条件:样品用VG Scientific ESCALab220i-XL型光电子能谱仪分析。激发源为Al KαX射线,功率约300 W。分析时的基础真空为3×10-9 mbar。 电子结合能用污染碳的C1s峰(284.8 eV)校正。 X-ray photoelectron spectroscopy data were obtained with an ESCALab220i-XL electron spectrometer from VG Scientific using 300W AlKα radiat ion. The base pressure was about 3×10-9 mbar. The binding energies were referenced to the C1s line at 284.8 eV from adventitious carbon. 处理软件:Avantage 4.15 XPS数据考盘后的处理数据步骤 Origin作图: 1.open Excel文件,可以看到多组数据和谱图,一个sheet 对应一张谱图及 相应的数据(两列)。 2.将某一元素的两列数据直接拷贝到Origin中即可作出谱图。(注意:X轴 为结合能值,Y轴为每秒计数) 3. 如果某种元素有两种以上化学态,需要进行分峰处理时,按“XPS Peak 分峰步骤”进行。 XPS Peak分峰步骤 1.将所拷贝数据转换成所需格式:把所需拟合元素的数据引入Origin后,将column A和C中的值复制到一空的记事本文档中(即成两列的格式,左边为结合能,右边为峰强),并存盘。如要对数据进行去脉冲处理或截取其中一部分数据,需在Origin中做好处理。 2.打开XPS Peak,引入数据:点Data----Import(ASCII),引入所存数据,则出现相应的XPS谱图。 3.选择本底:点Background,在所出现的小框中的High BE和Low BE下方将出现本底的起始和终点位置(因软件问题,此位置最好不改,否则无法再回到Origin),本底将连接这两点,Type可据实际情况选择。确定好本底的位置后,回到TXT文本中将不在本底范围内的数据删除,然后保存。再重新Import ASCII。
人教版初中数学数据分析技巧及练习题附答案
人教版初中数学数据分析技巧及练习题附答案 一、选择题 1.如图是根据我市某天七个整点时的气温绘制成的统计图,则这七个整点时气温的中位数和众数分别是() A.中位数31,众数是22 B.中位数是22,众数是31 C.中位数是26,众数是22 D.中位数是22,众数是26 【答案】C 【解析】 【分析】 根据中位数,众数的定义即可判断. 【详解】 七个整点时数据为:22,22,23,26,28,30,31 所以中位数为26,众数为22 故选:C. 【点睛】 此题考查中位数,众数的定义,解题关键在于看懂图中数据 2.某校组织“国学经典”诵读比赛,参赛10名选手的得分情况如表所示: 分数/分80859095 人数/人3421 那么,这10名选手得分的中位数和众数分别是() A.85.5和80 B.85.5和85 C.85和82.5 D.85和85 【答案】D 【解析】 【分析】 众数是一组数据中出现次数最多的数据,注意众数可以不只一个; 找中位数要把数据按从小到大的顺序排列,位于最中间的一个数(或两个数的平均数)为中位数. 【详解】 数据85出现了4次,最多,故为众数;
按大小排列第5和第6个数均是85,所以中位数是85. 故选:D. 【点睛】 本题主要考查了确定一组数据的中位数和众数的能力.一些学生往往对这个概念掌握不清楚,计算方法不明确而误选其它选项.注意找中位数的时候一定要先排好顺序,然后再根据奇数和偶数个来确定中位数,如果数据有奇数个,则正中间的数字即为所求.如果是偶数个则找中间两位数的平均数. 3.一组数据2,x,6,3,3,5的众数是3和5,则这组数据的中位数是() A.3 B.4 C.5 D.6 【答案】B 【解析】 【分析】 由众数的定义求出x=5,再根据中位数的定义即可解答. 【详解】 解:∵数据2,x,3,3,5的众数是3和5, ∴x=5, 则数据为2、3、3、5、5、6,这组数据为35 2 =4. 故答案为B. 【点睛】 本题主要考查众数和中位数,根据题意确定x的值以及求中位数的方法是解答本题的关键. 4.多多班长统计去年1~8月“书香校园”活动中全班同学的课外阅读数量(单位:本),绘制了如图折线统计图,下列说法正确的是() A.极差是47 B.众数是42 C.中位数是58 D.每月阅读数量超过40的有4个月 【答案】C 【解析】 【分析】 根据统计图可得出最大值和最小值,即可求得极差;出现次数最多的数据是众数;将这8
xps峰拟合规则及测试条件
n XPS Peak 软件拟合数据的简单步骤: 用excel 调入外部数据打开数据文件。1. Excel 中的数据转换成TXT 格式 从Excel 中的数据只选择要进行拟合的数据点,copy 至txt 文本中,即BD 两列数据,另存为*.txt 文件。 2.XPS Peak41中导入数据 打开xps peak 41分峰软件,在XPS Peak Fit 窗口中,从Data 菜单中选择Import (ASCII),即可将转换好的txt 文本导入,出现谱线
3.扣背底 在打开的Region 1窗口中,点击 Backgrond ,选择Boundary 的默认值,即不改变High BE 和Low BE 的位置,Type 一般选择Shirley 类型扣背底 4.加峰 选择Add Peak ,选择合适的Peak Type(如s,p,d,f),在Position 处选择希望的峰位,需固定时点fix 前的小方框,同时还可选半峰宽(FWHM )、峰面积等。各项中的constaints 可用来固定此峰与另一峰的关系。如W4f 中同一价态的W4f 7/2和W4f 5/2的峰位间距可固定为2.15eV ,峰面积比可固定为4:3等,对于% Lorentzian-Gaussian 选项中的fix 先去掉对勾,点击Accept 完成对该峰的设置。
n d n 点Delet e Peak 可去掉此峰。再选择Add Peak 可以增加新的峰,如此重复。注意:% Lorentzian-Gaussian 值最后固定为20%左右。 加峰界面 举例:对峰的限制constraints ,峰1的峰位=峰0峰位+1.5 5.拟合 选好所需拟合峰的个数及大致参数后,点XPS Peak Processing 中的Optimise All 进行拟合,观察拟合后总峰与原始峰的重合情况,如不好,可多次点Optimise All
XPS能谱数据处理方法
XPS 能谱数据处理 王博 吕晋军 齐尚奎 能谱数据转化成ASC 码文件后可以用EXCEL 、ORIGIN 等软件进行处理。这篇文章的目的是向大家介绍用ORIGIN 软件如何处理能谱数据,以及它的优势所在。 下面将分三部分介绍如何用ORIGIN 软件处理能谱数据:1、多元素谱图数据处理 2、剖面分析数据处理 3、复杂谱图的解叠 一、多元素谱图的处理: 1、将ASC 码文件用NOTEPAD 打开: 2、复制Y 轴数值。打开ORIGIN ,将Y 轴数据粘贴到B (Y ): 3、如图:点击工具栏plot ,选择line Y 轴数值 X 轴起始点 X 轴步长 采集的数据点总数 元素名称
4、出现下图:点击B(Y),再点击<->Y,使B(Y)成为Y轴数据。然后在“set X values”中输入起始值和步长。 5、点击OK,得到下图:
6、利用ORIGIN提供的工具可以方便的进行平滑、位移。 A.位移: 1)如图:选择analysis→translate→vertical或horizontal可以进行水平或垂直方向的位移。我们以水平位移为例进行讲解。 2)在图中双击峰顶,如图示(小窗口给出的是此点的X,Y值) 3)然后在图中单击其他位置找到合适的X值(小窗口给出的是红十字的X,Y值) 4)双击红十字的位置,峰顶就会位移到此处:
位移可以反复多次的进行,垂直方向的位移和水平方向的一样。 B、平滑 1)如图选择: 2)出现下面的小窗口
3)点击settings出现下面的界面(如果想用平滑后的代替原始的,选择”replace original”,如果想重新做图选”add to worksheet”,下面的数值不用改变) 4)点击operation,选择savizky-golay进行平滑。得到下图: 二、剖面分析数据处理: 1、用写字板打开ASC码文件,选取所需要的元素 元素名称 剖面分析中的CYCLE 数 起始值及步长 Y轴数据
如何自学数据分析方法介绍
如何自学数据分析方法介绍 如何自学数据分析方法介绍 想要成为数据分析师,最快需要七周?七周信不信? 这是一份数据分析师的入门指南,它包含七周的内容,Excel、 数据可视化、数据分析思维、数据库、统计学、业务、以及Python。 每一周的内容,都有两到三篇文章细致讲解,帮助新人们快速掌握。这七周的内容刚好涵盖了一位数据分析师需要掌握的基础体系,也是一位新人从零迈入数据大门的知识手册。 第一周:Excel 每一位数据分析师都脱离不开Excel。 Excel的学习分为两个部分。 掌握各类功能强大的函数,函数是一种负责输入和输出的神秘盒子。把各类数据输入,经过计算和转换输出我们想要的结果。 在SQL,Python以及R中,函数依旧是主角。掌握Excel的函数有助于后续的学习,因为你几乎在编程中能找到名字一样或者相近 的函数。 在「数据分析:常见的Excel函数全部涵盖在这里了」中,介绍了常用的Excel函数。 清洗处理类:trim、concatenate、replace、substitute、 left/right/mid、len/lenb、find、search、text 关联匹配类:lookup、vlookup、index、match、row、column、offset 逻辑运算类:if、and、or、is系列
计算统计类:sum/sumif/sumifs、sumproduct、 count/countif/countifs、max、min、rank、rand/randbetween、averagea、quartile、stdev、substotal、int/round 时间序列类:year、month、weekday、weeknum、day、date、now、today、datedif 搜索能力是掌握Excel的不二窍门,工作中的任何问题都是可以找到答案。 第二部分是Excel中的工具。 在「数据分析:Excel技巧大揭秘」教程,介绍了Excel最具性 价比的几个技巧。包括数据透视表、格式转换、数组、条件格式、 自定义下拉菜单等。正是这些工具,才让Excel在分析领域经久不衰。 在大数据量的处理上,微软提供了Power系列,它和Excel嵌套,能应付百万级别的数据处理,弥补了Excel的不足。 Excel需要反复练习,实战教程「数据分析:手把手教你Excel 实战」,它通过网络上抓取的数据分析师薪资数据作为练习,总结 各类函数的使用。 除了上述要点,下面是附加的知识点,铺平数据分析师以后的道路。 了解单元格格式,数据分析师会和各种数据类型打交道,包括各类timestamp,date,string,int,bigint,char,factor, float等。 了解数组,以及相关应用(excel的数组挺难用),Python和R也会涉及到list,是核心概念之一。 了解函数,深入理解各种参数的作用。它会在学习Python中帮 助到你。 了解中文编码,UTF8、GBK、ASCII,这是数据分析师的坑点之一。
数据整理分析方法
数据梳理主要是指对数据的结构、内容和关系进行分析 大多数公司都存在数据问题。主要表现在数据难于管理,对于数据对象、关系、流程等难于控制。其次是数据的不一致性,数据异常、丢失、重复等,以及存在不符合业务规则的数据、孤立的数据等。 1数据结构分析 1元数据检验 元数据用于描述表格或者表格栏中的数据。数据梳理方法是对数据进行扫描并推断出相同的信息类型。 2模式匹配 一般情况下,模式匹配可确定字段中的数据值是否有预期的格式。 3基本统计 元数据分析、模式分析和基本统计是数据结构分析的主要方法,用来指示数据文件中潜在的结构问题。 2 数据分析 数据分析用于指示业务规则和数据的完整性。在分析了整个的数据表或数据栏之后,需要仔细地查看每个单独的数据元素。结构分析可以在公司数据中进行大范围扫描,并指出需要进一步研究的问题区域;数据分析可以更深入地确定哪些数据不精确、不完整和不清楚。 1标准化分析 2频率分布和外延分析 频率分布技术可以减少数据分析的工作量。这项技巧重点关注所要进一步调查的数据,辨别出不正确的数据值,还可以通过钻取技术做出更深层次的判断。 外延分析也可以帮助你查明问题数据。频率统计方法根据数据表现形式寻找数据的关联关系,而外延分析则是为检查出那些明显的不同于其它数据值的少量数据。外延分析可指示出一组数据的最高和最低的值。这一方法对于数值和字符数据都是非常实用的。 3业务规则的确认 3 数据关联分析 专业的流程模板和海量共享的流程图:[1] - 价值链图(EVC) - 常规流程图(Flowchart) - 事件过程链图(EPC) - 标准建模语言(UML) - BPMN2.0图 数据挖掘 数据挖掘又称数据库中的知识发现,是目前人工智能和数据库领域研究的热点问题, 所谓数据挖掘是指从数据库的大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平凡过程 利用数据挖掘进行数据分析常用的方法主要有分类、回归分析、聚类、关联规则、特征、变化和偏差分析、Web页挖掘等,它们分别从不同的角度对数据进行挖掘。 ①分类。分类是找出数据库中一组数据对象的共同特点并按照分类模式将其划分为
XPS Peak分峰步骤origin讲解学习
X P S P e a k分峰步骤 o r i g i n
实验条件:样品用VG Scientific ESCALab220i-XL型光电子能谱仪分析。激发源为AlKα X射线,功率约300 W。分析时的基础真空为3×10-9 mbar。电子结合能用污染碳的C1s峰(284.6 eV)校正。 X-ray photoelectron spectroscopy data were obtained with an ESCALab220i-XL electron spectrometer from VG Scientific using 300W AlKα radiation. The base pressure was about 3×10-9 mbar. The binding energies were referenced to the C1s line at 284.6 eV from adventitious carbon. XPS数据考盘后的处理数据步骤 数据是.TXT文件,凡是可以打开TXT文件的软件都可以使用。下面以origin5.0为例: 1.open文件,可以看到一列数据,找到Region 1(一个Region 对应一张谱 图)。 2.继续向下找到Kinetic Energy,其下面一个数据为动能起始值,即谱图 左侧第一个数据。用公式BE始=1486.6-KE始-?换算成结合能起始值,? 是一个常数值,即荷电位移,每个样品有一个值在邮件正文中给出。 3.再下面一个数据是步长值,如0.05或0.1或1,每张谱图间有可能不一 样。 4.继续向下8行,可以找到401或801这样的数,该数为通道数,即有401 或801个数据点。 5.再下面的数据开始两个数据是脉冲,把它们舍去,接下来的401或801 个数据都是Y轴数据,将它们copy到B(Y)。 6.X轴:点A(X),再点右键,然后点set column values,出现一个对话 框,在from中填1,在to中填401(通道数),在col(A)中填BE始- 0.05*(i-1),最后点do it。
俄歇电子能谱分析原理及方法
俄歇电子能谱分析原理及方法 XXX 【摘要】近年来,俄歇电子能谱(AES)分析方法发展迅速,它具有很多的优点,比如分析速度快、精度高、需要样品少等等,也因此在很多研究领域的表面分析中都得到了广泛的应用。可以不夸张的说,这个技术为表面物理和化学定量分析奠定了基础。本文主要是介绍俄歇电子能谱分析的主要原理及其在科学研究中的主要应用,旨在让读者对俄歇电子能谱有一个初步的了解。 关键词:俄歇电子能谱;表面物理;化学分析。 前言 近些年来,俄歇电子能谱分析发展如火如荼,在各个领域都有很抢眼的表现。目前有很多的人在研究,将俄歇电子分析技术应用到电子碰撞以及微纳尺度加工等高技术领域,俄歇电子能谱分析方法表现出强大的生命力,同目前已为很人熟悉和赞赏的强有力的分析仪器电子探针相比俄歇电子能仪可能有几个独到之处:( 1 )能分析固体表面薄到只有几分之一原子层内的化学元素组成,这里说的“表面”指的不只是固体的自然表面,也指固体内颗粒的分界面,(2)俄歇电子谱的精细结构中包含有许多化学信自,借此可以推断原子的价态;( 3 )除氢和氦外所有元素都可以分析,特别是分析轻元素最为有利;(4)利用低能电子衍射装置和俄歇能谱分析器相结合的仪器(“LEED一Au-ger”装置),有可能从得到的数据资料中分晶体表面的结构,推断原子在晶胞中的位置。因此,俄歇电子能谱仪作为固体材料分析的一个重要工具,近年来发展很快,研究成果不断出现于最新的文献中。本文主要是想要综合论述俄歇电子能谱的分析方法,以及概述它在各方面的应用。[1] [1]《俄歇电子能谱仪及其应用》许自图 正文 一、俄歇电子能谱分析的原理
1.1俄歇电子能谱发现的历史 1925年法国科学家俄歇在威尔逊云室中首次观察到了俄歇电子的轨迹,并且他正确的解释了俄歇电子产生的过程,为了纪念他,就用他的名字命名了这种物理现象。到了1953年,兰德才从二次电子能量分布曲线中第一次辨识出这种电子的电子谱线,但是由于俄歇电子谱线强度较低,所以当时检测还比较困难。到了1968年,哈里斯应用微分法和锁相放大器,才解决了如何检测俄歇电子信号的问题,也由此发展了俄歇电子能谱仪。俄歇电子能谱仪不仅可以作为元素的组分分析仪器,还可以检测化学环境信息。咋很多的领域都得到了应用,比如基础物理,应用表面科学等等。 1.2俄歇效应 当一束具有一定能量的电子束(一次电子)射到固体表面的时候,原子对电子产生了弹性散射和非弹性散射。非弹性散射使得电子和原子之间发生了能量的转移,发出X-射线以及二次电子。这个时候如果在固体表面安装一个接受电子的探测器,就可以得到反射电子的数目(强度)按能量分布的电子能谱曲线。 图1 入射电子在固体中激发出的二次电子能谱 俄歇电子是指外壳层电子填补内壳层空穴所释放出来的能量激发了外壳层的另外一电子,并且使得它脱离原子核,逃逸出固体表面的电子,这个过程被俄歇发现,所以称为俄歇电子。
XPS分峰的分析实例复习过程
XPS分峰的分析实例
材料X射线光电子能谱数据处理及分峰的分析实例 例:将剂量为1107ions/cm2,能量为45KeV的碳离子注入单晶硅中,然后在1100C退火2h进行热处理。对单晶硅试样进行XPS测试,试对其中的C1s高分辨扫瞄谱进行解析,以确定各种可能存在的官能团。 分析过程: 1、在Origin中处理数据 图1 将实验数据用记事本打开,其中C1s表示的是C1s电子,299.4885表示起始结合能,-0.2500表示结合能递减步长,81表示数据个数。从15842开始表示
是光电子强度。从15842以下数据选中Copy到Excel软件B列中,为光电子强度数据列。同时将299.4885Copy到Excel软件A列中,并按照步长及个数生成结合能数据,见图 2 图2 将生成的数据导入Origin软件中,见图3。
图3 此时以结合能作为横坐标,光电子强度作为纵坐标,绘出C1s谱图,检查谱图是否有尖峰,如果有,那是脉冲,应把它们去掉,方法为点Origin 软件中的Data-Move Data Points,然后按键盘上的或箭头去除脉冲。本例中的实验数据没有脉冲,无需进行此项工作。将column A和B中的值复制到一空的记事本文档中(即成两列的格式,左边为结合能,右边为峰强),并存盘,见图 4。
图4 2、打开XPS Peak,引入数据:点Data--Import(ASCII),引入所存数据, 则出现相应的XPS谱图,见图5、图6
3、选择本底:点Background,因软件问题, High BE和Low BE的位置最好不改,否则无法再回到Origin,此时本底将连接这两点,Type可据实际情况选择,一般选择Shirley 类型,见图7。
XPS数据处理步骤_北京科技大学
Generated by Foxit PDF Creator ? Foxit Software https://www.360docs.net/doc/e88976507.html, For evaluation only.
X射线光电子能谱 数据处理
北京科技大学 冶金生态楼109 冯 婷 2011.3
Generated by Foxit PDF Creator ? Foxit Software https://www.360docs.net/doc/e88976507.html, For evaluation only.
Content 1 2 3 4
仪器型号及主要参数 元素组成鉴别 元素定量分析 元素化学态分析
Generated by Foxit PDF Creator ? Foxit Software https://www.360docs.net/doc/e88976507.html, For evaluation only.
Content 1
仪器型号及主要参数
Generated by Foxit PDF Creator ? Foxit Software https://www.360docs.net/doc/e88976507.html, For evaluation only.
仪器型号及参数
X射线光电子能谱仪型号: AXIS ULTRADLD(岛津集团
Kratos公司生产)
X射线源:单色化Al靶, Al Kα hυ=1486.6eV 样品分析区域:700μm×300μm 信息采样深度:无机材料<5nm,有机材料<10nm X射线工作功率:一般为150W
XPS峰拟合步骤及规则
XPS峰拟合步骤及规则 (2010-05-26 10:47:46) 转载▼ 标签: 分类:穿越博士 杂谈 1.原始数据的处理:A,与C1s比较标准化数据:将excel表格中的C1s数据的最高点对应的结合能与标准C1s结合能(一般为284.6)比较,算差值+(-)α;将需拟合元素(如Ir)的结合能-(+)α,得标准化数据。注:若得到的C1s不平滑,先怀疑是否测试过程出现问题。若无测试问题,数据可信,将C1s进行拟合得到一个最高点(可用XPSPEAK, origin等)。拟合元素结合能-(+)α最好拷贝到另个excel中处理,得标准化数据。B,转化成TXT:将标准化数据拷贝到TXT文本中(两列就足够了) 2.下载安装XPS拟合处理软件https://www.360docs.net/doc/e88976507.html,.hk/%7Esurface/XPSPEAK/ 3.数据输入:运行XPSPEAK41,点data>Import(ASCII)>*.txt (转换好的标准化数据),得谱线。 4.背景扣除:点Background,调high 和low BE的值,一般用Shirley背景扣除。注:基线不能高于需拟合的曲线。 5.加峰:A,查需拟合元素标准结合能值https://www.360docs.net/doc/e88976507.html,/xps/;Search Menu>Retrieve Data for a Selected Element>Binding Energy >元素;查需拟合元素分裂能Doublet Separation >元素;B,加峰选Add Peak,选合适的Peak Type(如s,p,d,f),Position处选希望的峰位(参考所查标准结合能值),需固定时点fix前的小方框,否则所有Fix选项都不要选。各项中的constaints可用来固定此峰与另一峰的关系,如Ir4f中同一价态的Ir4f7/2和Ir4f5/2的峰位间距可固定为2.98eV,峰面积比可固定为4:3等。点击Optimise Peak对峰进行优化,最后点击Accept完成对该峰的设置。点Delete Peak可去掉此峰。再选择Add Peak可以增加新的峰,如此重复。注:1)对p、d、f的次能级强度比是一定的,p3/2:p1/2=2:1;d5/2:d3/2=3:2,f7/2:f5/2=4:3;2)对有能级分裂的能级(p、d、f),分裂的两个轨道间的距离也基本上是固定的,如同一价态的Ir4f7/2和Ir4f5/2之间的距离为2.98eV左右。 6.优化:分别点Peak Processing窗口总的Region Peaks下方的0、1、2等,可查看每个峰的参数,此时XPS峰中变红的曲线为被选中的峰;观察拟合后总峰与原始峰的重合情况,如对拟合不满,可重新改变参数,再Optimise All。 7.保存和输出:A,点Save XPS可存为.xps的图,点Open XPS可打开这副图,并可编辑;B,点
数据分析的方法与技巧
数据分析技巧和方法 1.数据分析必须遵循的原则 数据分析是为了验证假设的问题,提供必要的数据验证 数据分析是为了挖掘更多的问题,并找到深层次的原因 不能为了做数据分析而做数据分析 2.数据分析的步骤 数据分析有极广泛的应用范围。典型的数据分析可能包含以下三个步: 1、探索性数据分析,当数据刚取得时,可能杂乱无章,看不出规律,通过作图、造表、用各种形式的方程拟合,计算某些特征量等手段探索规律性的可能形式,即往什么方向和用何种方式去寻找和揭示隐含在数据中的规律性。 2、模型选定分析,在探索性分析的基础上提出一类或几类可能的模型,然后通过进一步的分析从中挑选一定的模型。 3、推断分析,通常使用数理统计方法对所定模型或估计的可靠程度和精确程度作出推断。 数据分析过程实施 数据分析过程的主要活动由识别信息需求、收集数据、分析数据、评价并改进数据分析的有效性组成。 一、识别信息需求 识别信息需求是确保数据分析过程有效性的首要条件,可以为收
集数据、分析数据提供清晰的目标。识别信息需求是管理者的职责管理者应根据决策和过程控制的需求,提出对信息的需求。就过程控制而言,管理者应识别需求要利用那些信息支持评审过程输入、过程输出、资源配置的合理性、过程活动的优化方案和过程异常变异的发现。 二、收集数据 有目的的收集数据,是确保数据分析过程有效的基础。组织需要对收集数据的内容、渠道、方法进行策划。策划时应考虑: ①将识别的需求转化为具体的要求,如评价供方时,需要收集的数据可能包括其过程能力、测量系统不确定度等相关数据; ②明确由谁在何时何处,通过何种渠道和方法收集数据; ③记录表应便于使用; ④采取有效措施,防止数据丢失和虚假数据对系统的干扰。 三、分析数据 分析数据是将收集的数据通过加工、整理和分析、使其转化为信息,通常用方法有: 老七种工具,即排列图、因果图、分层法、调查表、散步图、直方图、控制图; 新七种工具,即关联图、系统图、矩阵图、KJ法、计划评审技术、PDPC法、矩阵数据图; 四、数据分析过程的改进 数据分析是质量管理体系的基础。组织的管理者应在适当时,通过对以下问题的分析,评估其有效性:
XPS能谱数据处理
XPS能谱数据处理 材料,射线光电子能谱数据处理及分峰的分析实例 72例:将剂量为1,10ions/cm,能量为45KeV的碳离子注入单晶硅中,然后在1100C退火2h进行热处理。对单晶硅试样进行XPS测试,试对其中的C高分辨扫瞄谱1s进行解析,以确定各种可能存在的官能团。 分析过程: 1、在Origin中处理数据 图1 将实验数据用记事本打开,其中C表示的是C电子,299.4885表示起始结 1s1s 0.2500表示结合能递减步长,81表示数据个数。从15842开始表示是光合能,- 电子强度。从15842以下数据选中Copy到Excel软件B列中,为光电子强度数据列。同时将299.4885Copy到Excel软件A列中,并按照步长及个数生成结合能数据,见图2
图2 将生成的数据导入Origin软件中,见图3。 图3 此时以结合能作为横坐标,光电子强度作为纵坐标,绘出C谱图,检查谱1s 图是否有尖峰,如果有,那是脉冲,应把它们去掉,方法为点Origin 软件中的Data-Move Data Points,然后按键盘上的,或,箭头去除脉冲。本例中的实验数据没有脉冲,无需进行此项工作。将column A和B中的值复制到一空的记事本文档中(即成两列的格式,左边为结合能,右边为峰强),并存盘,见图4。
图4 2、打开XPS Peak,引入数据:点Data----Import (ASCII),引入所存数据,则出现相应的XPS谱图,见图5、图6。 3、选择本底:点Background,因软件问题, High BE和Low BE的位置最
好不改,否则无法再回到Origin,此时本底将连接这两点,Type可据实际情况选择,一般选择Shirley 类型,见图7。 图7 4、加峰: 点Add peak,出现小框,在Peak Type处选择s、p、d、f等峰类型(一般选s),在Position处选择希望的峰位,需固定时则点fix前小方框,同法还可选半峰宽(FWHM)、峰面积等。各项中的constraints可用来固定此峰与另一峰的关系。点Delete peak可去掉此峰。然后再点Add peak选第二个峰,如此重复。 在选择初始峰位时,如果有前人做过相似的实验,可以查到相应价键对应的峰位最好。但是如果这种实验方法比较新,前人没有做过相似的,就先用标准的峰位为初始值。最优化所有的峰位,然后看峰位位置的变化。 本例中加了三个峰,C元素注入单晶硅后可能形成C-C、C-Si和C-H三个价键。根据这三个价键对应的结合能确定其初始峰位,然后添加。具体过程见图8、9、10。
XPS数据分析方法及分峰软件
XPS数据分析方法及分峰软件 定性分析 首先扫描全谱,由于荷电存在使结合能升高,因此要通过C结合能289.6eV对全谱进行荷电校正,然后对感兴趣的元素扫描高分辨谱,将所得结果与标准图谱对照,由结合能确定元素种类,由化学位移确定元素得化学状态,为了是结果准确在每一次扫描得结果分别进行荷电校正。XPS谱图中化学位移的分析一般规律为: 1、原子失去价电子或因与电负性高的原子成键而显正电时,内层电子结合能升高。 2、原子获得电子而荷负电时,内层电子结合能减小。 3、氧化态越高,结合能越大。 4、价层发生某种变化时,所有内层电子化学位移相同。 5、对于XPS峰主量子数n小的壳层比n大的峰强,n相同的角量子数l大的峰强,n,l相同的j大的峰强。 定量分析 选取最强峰的面积或强度作为定量计算的基础,多采用灵敏度因子法,因为各元素产生光电子时的含量强度和含量不一定成正比,从而利用灵敏度因子对强度进行修正,其做法为:以峰边、背景的切线交点为准扣除背景,计算峰面积或峰强,然后分别除以相应元素的灵敏度因子法,就可得到各元素的相对含量,这个相对含量是原子个数相对含量即摩尔相对含量。 XPS图谱的分峰处理 由于在制备过程中外界条件不可能完全均匀一致,因而对于同一元素可能存在不同的化学态,而各化学态产生的峰又有可能相互重叠,这样就对定性、定量分析带来了不便,因而在进行数据分析时需要对可能存在重叠的峰进行分峰处理,目前有很多数据处理软件可以进行分峰运算,其原理都是利用高斯-洛沦兹函数,其中XPSpeak为一位台湾学者编写的程序,其采用图形用户界面(GUI),用于XPS分峰处理操作方便,简单易学。 上面的窗口主要用于图形显示,即原始数据图谱、分离的峰、拟和的峰都将在此窗口中显示,在主菜单栏中Data中选择打开的数据类型,由于不同的设备输出的数据格式不同,所以一般需要将原始数据转换成Ascii格式;在进行分峰处理前需要扣除背景,在Background菜单中选择扣除背景的参数;在Add Peak菜单中选择增加峰的参数如峰位、峰面积、半峰宽等。
XPS分峰的分析实例复习过程
X P S分峰的分析实例
材料X射线光电子能谱数据处理及分峰的分析实例 例:将剂量为1 107ions/cm2,能量为45KeV的碳离子注入单晶硅中,然后在 1100C退火2h进行热处理。对单晶硅试样进行XPS测试,试对其中的C 1s 高分辨扫瞄谱进行解析,以确定各种可能存在的官能团。 分析过程: 1、在Origin中处理数据 图1 将实验数据用记事本打开,其中C 1s 表示的是C 1s 电子,299.4885表示起始 结合能,-0.2500表示结合能递减步长,81表示数据个数。从15842开始表示
是光电子强度。从15842以下数据选中Copy到Excel软件B列中,为光电子强度数据列。同时将299.4885Copy到Excel软件A列中,并按照步长及个数生成结合能数据,见图2 图2 将生成的数据导入Origin软件中,见图3。
图3 此时以结合能作为横坐标,光电子强度作为纵坐标,绘出C1s谱图,检查谱图是否有尖峰,如果有,那是脉冲,应把它们去掉,方法为点Origin 软件中的Data-Move Data Points,然后按键盘上的↓或↑箭头去除脉冲。本例中的实验数据没有脉冲,无需进行此项工作。将column A和B中的值复制到一空的记事本文档中(即成两列的格式,左边为结合能,右边为峰强),并存盘,见图4。
图4 2、打开XPS Peak,引入数据:点Data--Import(ASCII),引入所存数据, 则出现相应的XPS谱图,见图5、图6
3、选择本底:点Background,因软件问题, High BE和Low BE的位置最好不改,否则无法再回到Origin,此时本底将连接这两点,Type可据实际情况选择,一般选择Shirley 类型,见图7。
(完整版)xps峰拟合规则及测试条件
XPS Peak软件拟合数据的简单步骤: 用excel调入外部数据打开数据文件。 1. Excel中的数据转换成TXT格式 从Excel中的数据只选择要进行拟合的数据点,copy至txt文本中,即BD两列数据,另存为*.txt文件。 2.XPS Peak41中导入数据 打开xps peak 41分峰软件,在XPS Peak Fit窗口中,从Data菜单中选择Import (ASCII),即可将转换好的txt文本导入,出现谱线
3.扣背底 在打开的Region 1窗口中,点击 Backgrond,选择Boundary的默认值,即不改变High BE和Low BE的位置,Type一般选择Shirley类型扣背底 4.加峰 选择Add Peak,选择合适的Peak Type(如s,p,d,f),在Position处选择希望的峰位,需固定时点fix前的小方框,同时还可选半峰宽(FWHM)、峰面积等。各项中的constaints可用来固定此峰与另一峰的关系。如W4f中同一价态的 W4f7/2和W4f5/2的峰位间距可固定为2.15eV,峰面积比可固定为4:3等,对于% Lorentzian-Gaussian选项中的fix先去掉对勾,点击Accept完成对该峰的设
置。点Delete Peak可去掉此峰。再选择Add Peak可以增加新的峰,如此重复。注意:% Lorentzian-Gaussian值最后固定为20%左右。 加峰界面 举例:对峰的限制constraints,峰1的峰位=峰0峰位+1.5 5.拟合 选好所需拟合峰的个数及大致参数后,点XPS Peak Processing中的Optimise All进行拟合,观察拟合后总峰与原始峰的重合情况,如不好,可多次点Optimise All
XPS能谱处理数据的方法(中国科学院)
XPS 能谱数据处理 能谱数据转化成ASC 码文件后可以用EXCEL 、ORIGIN 等软件进行处理。这篇文章的目的是向大家介绍用ORIGIN 软件如何处理能谱数据,以及它的优势所在。 下面将分三部分介绍如何用ORIGIN 软件处理能谱数据:1、多元素谱图数据处理 2、剖面分析数据处理 3、复杂谱图的解叠 一、多元素谱图的处理: 1、将ASC 码文件用NOTEPAD 打开: 2、复制Y 轴数值。打开ORIGIN ,将Y 轴数据粘贴到B (Y ): Y 轴数值 X 轴起始点 X 轴步长 采集的数据点总数 元素名称
3、如图:点击工具栏plot,选择line 4、出现下图:点击B(Y),再点击<->Y,使B(Y)成为Y轴数据。然后在“set X values”中输入起始值和步长。 5、点击OK,得到下图:
6、利用ORIGIN提供的工具可以方便的进行平滑、位移。 A.位移: 1)如图:选择analysis→translate→vertical或horizontal可以进行水平或垂直方向的位移。我们以水平位移为例进行讲解。 2)在图中双击峰顶,如图示(小窗口给出的是此点的X,Y值) 3)然后在图中单击其他位置找到合适的X值(小窗口给出的是红十字的X,Y值) 4)双击红十字的位置,峰顶就会位移到此处:
位移可以反复多次的进行,垂直方向的位移和水平方向的一样。 B、平滑 1)如图选择: 2)出现下面的小窗口
3)点击settings出现下面的界面(如果想用平滑后的代替原始的,选择”replace original”,如果想重新做图选”add to worksheet”,下面的数值不用改变) 4)点击operation,选择savizky-golay进行平滑。得到下图: 二、剖面分析数据处理: 1、用写字板打开ASC码文件,选取所需要的元素 元素名称 剖面分析中的CYCLE 数 起始值及步长 Y轴数据