图像相似度文库
相似判定格式

相似判定格式【原创实用版】目录1.相似判定格式的定义和作用2.相似判定格式的分类3.相似判定格式的应用实例4.相似判定格式的优缺点5.相似判定格式的发展趋势正文一、相似判定格式的定义和作用相似判定格式,是一种用于判断两个或多个事物之间相似程度的方法。
在各个领域中,尤其是在计算机科学和人工智能领域,相似判定格式被广泛应用,以辅助人们快速、准确地找到具有相似特征的事物。
相似判定格式可以帮助我们更好地理解事物之间的关系,从而为决策和分析提供有力支持。
二、相似判定格式的分类相似判定格式可以根据不同的需求和应用场景,分为以下几类:1.文本相似判定格式:主要用于比较两个或多个文本之间的相似程度,如判断抄袭、评估文章质量等。
2.图像相似判定格式:主要用于比较两个或多个图像之间的相似程度,如图像识别、图像检索等。
3.音频相似判定格式:主要用于比较两个或多个音频之间的相似程度,如音乐识别、语音识别等。
4.视频相似判定格式:主要用于比较两个或多个视频之间的相似程度,如视频检索、内容识别等。
三、相似判定格式的应用实例相似判定格式在实际应用中具有广泛的应用价值,以下列举几个实例:1.实例一:文本相似判定格式在查重软件中的应用。
通过比较文章的相似程度,可以判断文章是否存在抄袭现象,从而确保学术论文、新闻报道等领域的原创性。
2.实例二:图像相似判定格式在图像识别中的应用。
通过比较两张图片的相似程度,可以实现图片检索、内容识别等功能,为图像处理领域提供有力支持。
3.实例三:音频相似判定格式在音乐识别中的应用。
通过比较两段音频的相似程度,可以实现音乐识别、歌曲推荐等功能,为用户提供个性化的音乐体验。
四、相似判定格式的优缺点相似判定格式具有一定的优点,同时也存在一定的局限性。
优点:1.相似判定格式具有较高的准确性,能够较好地判断事物之间的相似程度。
2.相似判定格式具有较强的普适性,可以应用于多种领域和场景。
局限性:1.相似判定格式受到数据质量和数量的影响,当数据质量不高或数量不足时,判断结果可能不准确。
相似度指标

相似度指标相似度是指两个或者多个对象之间的相似程度。
相似度是数据挖掘、自然语言处理、计算机视觉等领域中经常使用的重要指标。
相似度指标能够根据不同的应用环境和需求来选择不同的算法和模型,用来度量数据对象之间的相似程度。
本文将介绍一些常用的相似度指标。
1. 欧几里得距离欧几里得距离是指两个向量之间的距离,它是一个常用的相似度指标之一。
欧几里得距离用于评估两个向量之间的相似程度,计算公式为:$d(x,y)=\sqrt{\sum_{i=1}^n(x_i-y_i)^2}$其中,$x$ 和 $y$ 是两个向量,$n$ 是向量的维数,$x_i$ 和 $y_i$ 是向量中第$i$ 个分量的值。
2. 余弦相似度余弦相似度是指两个向量之间的夹角余弦值。
余弦相似度被广泛应用于自然语言处理和文本分析中,用于评估两个文本之间的相似程度。
计算公式为:$similarity=\frac{\sum_{i=1}^nx_iy_i}{\sqrt{\sum_{i=1}^nx_i^2}\sqrt{\sum_{i=1} ^ny_i^2}}$3. 皮尔逊相关系数皮尔逊相关系数是用于度量两个变量之间的线性相关性的一种统计量。
它适用于数据量较大的情况,计算公式为:4. Jaccard 相似系数$similarity=\frac{|A \cap B|}{|A \cup B|}$其中,$A$ 和 $B$ 是两个集合,$|A \cap B|$ 是两个集合中的交集元素数目,$|A \cup B|$ 是两个集合中的并集元素数目。
5. 汉明距离汉明距离是用于度量两个字符串之间的差异度的一种指标。
计算公式为:总结以上提到的相似度指标只是常见的一部分,还有其他的相似度指标,比如曼哈顿距离、编辑距离等等。
在选择相似度指标时,需要根据具体的应用需求和数据特点来选择适合的算法和模型。
Opencvpython图像处理-图像相似度计算
Opencvpython图像处理-图像相似度计算⼀、相关概念1. ⼀般我们⼈区分谁是谁,给物品分类,都是通过各种特征去辨别的,⽐如⿊长直、⼤⽩腿、樱桃唇、⽠⼦脸。
王⿇⼦脸上有⿇⼦,隔壁⽼王和⼉⼦很像,但是⼉⼦下巴涨了⼀颗痣和他妈⼀模⼀样,让你确定这是你⼉⼦。
还有其他物品、什么桌⼦带腿、镜⼦反光能在⾥⾯倒影出东西,各种各样的特征,我们通过学习、归纳,⾃然⽽然能够很快识别分类出新物品。
⽽没有学习训练过的机器就没办法了。
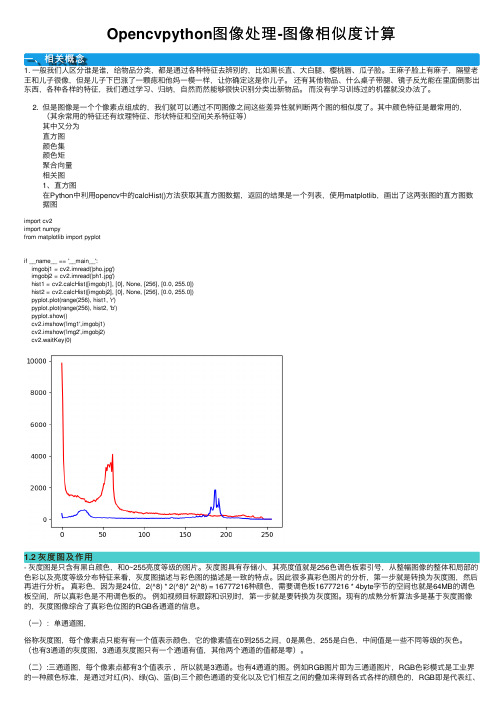
2. 但是图像是⼀个个像素点组成的,我们就可以通过不同图像之间这些差异性就判断两个图的相似度了。
其中颜⾊特征是最常⽤的,(其余常⽤的特征还有纹理特征、形状特征和空间关系特征等)其中⼜分为直⽅图颜⾊集颜⾊矩聚合向量相关图1、直⽅图在Python中利⽤opencv中的calcHist()⽅法获取其直⽅图数据,返回的结果是⼀个列表,使⽤matplotlib,画出了这两张图的直⽅图数据图import cv2import numpyfrom matplotlib import pyplotif __name__ == '__main__':imgobj1 = cv2.imread('pho.jpg')imgobj2 = cv2.imread('ph1.jpg')hist1 = cv2.calcHist([imgobj1], [0], None, [256], [0.0, 255.0])hist2 = cv2.calcHist([imgobj2], [0], None, [256], [0.0, 255.0])pyplot.plot(range(256), hist1, 'r')pyplot.plot(range(256), hist2, 'b')pyplot.show()cv2.imshow('img1',imgobj1)cv2.imshow('img2',imgobj2)cv2.waitKey(0)1.2 灰度图及作⽤- 灰度图是只含有⿊⽩颜⾊,和0~255亮度等级的图⽚。
【国家自然科学基金】_图像相似度_基金支持热词逐年推荐_【万方软件创新助手】_20140801

科研热词 相似度 图像检索 特征提取 概念相似度 图像匹配 颜色直方图 邻域评价 视频水印 脉冲噪声 聚类 粒子滤波 目标区域 深度 本体 属性 小波变换 基于内容的图像检索 图像配准 图像融合 图像分割 嗅觉可视化技术 信息隐藏 主成分分析 krawtchouk矩 鲁棒估计 骨架二叉树 食醋 食品工程 颜色量化 颜色相似度 颜色块 颜色信息熵 音频水印 非抽样contourlet变换 阵列噪声增强技术 采样点倒置 遗传粒子滤波器 连通像素标记 过分割 轮廓特征 轮廓对应 轨迹跟踪 车辆检测 跨媒体检索 距离不变性 贝叶斯滤波 语义相关度 语义 评价准则 角点检测 角度直方图 角度不变性
评价 计算机辅助诊断 视频语义挖掘 视频哈希 视觉跟踪 视觉关键词表 表情识别 行为识别 蛋白质组质谱数据 虹膜识别 色彩量化 自适应置乱 自适应概率统计模型 自相关 自主计算 自主单元 脆弱箕乱 能量曲线 肺癌 聚类中心 聚类 联合分类 置乱不变值 网页分割 网格化 维数约减 结构相似性 结构相似度(ssim) 纹理相似度 纹理特征 纹理分析 约束优化 红外图像 索引表 粒子群算法 简单线性图 第二代轮廓波变换 第一代轮廓波变换 窗口法 空间一致性 离散程度 磁共振成像 石材图像 短文本 知网 矢量中值滤波 相对熵 相似性传播聚类 相似度量度 相似度因子 相似度加权 相似关键帧 生物特征识别 生物测定学
视频游动字幕 表面缺陷 融合规则 虹膜分类 蒙特卡罗方法 色彩畸变 自相似特征 脑出血ct图像 背景估计 聚类分析 聚类优化 统计模型 结构量化直方图 结构特征 纹理特征 纹理分析 纹理共生矩阵 红外图像 粗糙度 等温线 立体图像 空间拓扑关系 空间上下文 稳定特征 碎片拼合 碎片匹配 矩阵相似度 相空间重构 相关置信度 相关度 相似性度量 相似度量 直方图 目标跟踪 目标识别 目标检索 电能质量 电力系统 独特性 特性提取 特征的相似度计算 特征点提取 特征点 特征模板 特征异构 特征变换 炉衬蚀损 灰关联度 火焰图像 消歧 浮游生物 注水算法 汉字特征提取 模糊集
图像相似度计算

图像相似度计算图像相似度计算主要用于对于两幅图像之间内容的相似程度进行打分,根据分数的高低来判断图像内容的相近程度。
可以用于计算机视觉中的检测跟踪中目标位置的获取,根据已有模板在图像中找到一个与之最接近的区域。
然后一直跟着。
已有的一些算法比如BlobTracking,Meanshift,Camshift,粒子滤波等等也都是需要这方面的理论去支撑。
还有一方面就是基于图像内容的图像检索,也就是通常说的以图检图。
比如给你某一个人在海量的图像数据库中罗列出与之最匹配的一些图像,当然这项技术可能也会这样做,将图像抽象为几个特征值,比如Trace变换,图像哈希或者Sift特征向量等等,来根据数据库中存得这些特征匹配再返回相应的图像来提高效率。
下面就一些自己看到过的算法进行一些算法原理和效果上的介绍。
(1)直方图匹配。
比如有图像A和图像B,分别计算两幅图像的直方图,HistA,HistB,然后计算两个直方图的归一化相关系数(巴氏距离,直方图相交距离)等等。
这种思想是基于简单的数学上的向量之间的差异来进行图像相似程度的度量,这种方法是目前用的比较多的一种方法,第一,直方图能够很好的归一化,比如通常的256个bin条的。
那么两幅分辨率不同的图像可以直接通过计算直方图来计算相似度很方便。
而且计算量比较小。
这种方法的缺点:1、直方图反映的是图像像素灰度值的概率分布,比如灰度值为200的像素有多少个,但是对于这些像素原来的位置在直方图中并没有体现,所以图像的骨架,也就是图像内部到底存在什么样的物体,形状是什么,每一块的灰度分布式什么样的这些在直方图信息中是被省略掉得。
那么造成的一个问题就是,比如一个上黑下白的图像和上白下黑的图像其直方图分布是一模一样的,其相似度为100%。
2、两幅图像之间的距离度量,采用的是巴氏距离或者归一化相关系数,这种用分析数学向量的方法去分析图像本身就是一个很不好的办法。
3、就信息量的道理来说,采用一个数值来判断两幅图像的相似程度本身就是一个信息压缩的过程,那么两个256个元素的向量(假定直方图有256个bin条)的距离用一个数值表示那么肯定就会存在不准确性。
基于深度学习的图片相似度分析技术方案

基于深度学习的图片相似度分析技术方案一、引言随着数字图像数量的爆炸性增长,图片相似度分析成为了信息检索、电子商务、社交网络和数字版权管理等众多领域的关键技术。
传统的图片相似度分析方法主要基于像素级别的比较,对于光照、尺度、旋转等变化鲁棒性较差。
近年来,深度学习技术的发展为图片相似度分析提供了新的解决方案。
二、技术方案概述本技术方案提出了一种基于深度学习的图片相似度分析方法。
该方法采用卷积神经网络(CNN)提取图像特征,并使用余弦相似度度量图像之间的相似度。
具体而言,本技术方案包括以下步骤:1.数据预处理:对原始图像进行缩放、裁剪等操作,使其符合CNN模型的输入要求。
2.特征提取:使用预训练的CNN模型提取图像特征,得到一个固定长度的特征向量。
3.相似度计算:计算两个特征向量之间的余弦相似度,作为图像之间的相似度得分。
4.阈值判定:根据业务需求设定相似度阈值,判断两张图片是否相似。
三、技术方案细节1.数据预处理数据预处理阶段主要包括图像缩放、裁剪等操作,以便符合CNN 模型的输入要求。
具体而言,我们可以将原始图像缩放到统一大小(如256x256),然后进行中心裁剪或随机裁剪,得到一个固定大小的输入图像。
2.特征提取特征提取阶段使用预训练的CNN模型,如VGG16、ResNet50等,提取图像的特征。
这些预训练模型在大量图像数据集上进行过训练,具有较强的泛化能力。
我们可以使用这些模型的全连接层输出作为图像的特征向量。
为了提高特征提取的效率,我们可以采用模型剪枝、知识蒸馏等技术对预训练模型进行压缩。
3.相似度计算相似度计算阶段采用余弦相似度作为度量标准。
余弦相似度通过计算两个特征向量之间的夹角余弦值来衡量它们之间的相似度。
具体公式如下:similarity = cos(θ) = A · B / (||A|| ||B||)其中,A和B是两个特征向量,·表示点积,||A||和||B||表示向量的模长。
相似图像的检测方法

相似图像的检测方法一、哈希算法哈希算法可对每张图像生成一个“指纹”(fingerprint)字符串,然后比较不同图像的指纹。
结果越接近,就说明图像越相似。
常用的哈希算法有三种:1.均值哈希算法(ahash)均值哈希算法就是利用图片的低频信息。
将图片缩小至8*8,总共64个像素。
这一步的作用是去除图片的细节,只保留结构、明暗等基本信息,摒弃不同尺寸、比例带来的图片差异。
将缩小后的图片,转为64级灰度。
计算所有64个像素的灰度平均值,将每个像素的灰度,与平均值进行比较。
大于或等于平均值,记为1;小于平均值,记为0。
将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图片的指纹。
均值哈希算法计算速度快,不受图片尺寸大小的影响,但是缺点就是对均值敏感,例如对图像进行伽马校正或直方图均衡就会影响均值,从而影响最终的hash值。
2.感知哈希算法(phash)感知哈希算法是一种比均值哈希算法更为健壮的算法,与均值哈希算法的区别在于感知哈希算法是通过DCT(离散余弦变换)来获取图片的低频信息。
先将图像缩小至32*32,并转化成灰度图像来简化DCT的计算量。
通过DCT变换,得到32*32的DCT系数矩阵,保留左上角的8*8的低频矩阵(这部分呈现了图片中的最低频率)。
再计算8*8矩阵的DCT的均值,然后将低频矩阵中大于等于DCT均值的设为”1”,小于DCT均值的设为“0”,组合在一起,就构成了一个64位的整数,组成了图像的指纹。
感知哈希算法能够避免伽马校正或颜色直方图被调整带来的影响。
对于变形程度在25%以内的图片也能精准识别。
3.差异值哈希算法(dhash)差异值哈希算法将图像收缩小至8*9,共72的像素点,然后把缩放后的图片转化为256阶的灰度图。
通过计算每行中相邻像素之间的差异,若左边的像素比右边的更亮,则记录为1,否则为0,共形成64个差异值,组成了图像的指纹。
相对于pHash,dHash的速度要快的多,相比aHash,dHash在效率几乎相同的情况下的效果要更好,它是基于渐变实现的。
OpenCV实战(1)——图像相似度算法(比对像素方差,感知哈希算法,模板匹配(OCR数字。。。

OpenCV实战(1)——图像相似度算法(⽐对像素⽅差,感知哈希算法,模板匹配(OCR数字。
如果需要处理的原图及代码,请移步⼩编的GitHub地址 传送门: 如果点击有误:https:///LeBron-Jian/ComputerVisionPractice 最近⼀段时间学习并做的都是对图像进⾏处理,其实⾃⼰也是新⼿,各种尝试,所以我这个门外汉想总结⼀下⾃⼰学习的东西,图像处理的流程。
但是动起笔来想总结,⼀下却不知道⾃⼰要写什么,那就把⾃⼰做过的相似图⽚搜索的流程整理⼀下,想到什么说什么吧。
⼀:图⽚相似度算法(对像素求⽅差并⽐对)的学习1.1 算法逻辑1.1.1 缩放图⽚ 将需要处理的图⽚所放到指定尺⼨,缩放后图⽚⼤⼩由图⽚的信息量和复杂度决定。
譬如,⼀些简单的图标之类图像包含的信息量少,复杂度低,可以缩放⼩⼀点。
风景等复杂场景信息量⼤,复杂度⾼就不能缩放太⼩,容易丢失重要信息。
根据⾃⼰需求,弹性的缩放。
在效率和准确度之间维持平衡。
1.1.2 灰度处理 通常对⽐图像相似度和颜⾊关系不是很⼤,所以处理为灰度图,减少后期计算的复杂度。
如果有特殊需求则保留图像⾊彩。
1.1.3 计算平均值 此处开始,与传统的哈希算法不同:分别依次计算图像每⾏像素点的平均值,记录每⾏像素点的平均值。
每⼀个平均值对应着⼀⾏的特征。
1.1.4 计算⽅差 对得到的所有平均值进⾏计算⽅差,得到的⽅差就是图像的特征值。
⽅差可以很好的反应每⾏像素特征的波动,既记录了图⽚的主要信息。
1.1.5 ⽐较⽅差 经过上⾯的计算之后,每张图都会⽣成⼀个特征值(⽅差)。
到此,⽐较图像相似度就是⽐较图像⽣成⽅差的接近成程度。
⼀组数据⽅差的⼤⼩可以判断稳定性,多组数据⽅差的接近程度可以反应数据波动的接近程度。
我们不关注⽅差的⼤⼩,只关注两个⽅差的差值的⼤⼩。
⽅差差值越⼩图像越相似!1.2 代码:import cv2import matplotlib.pyplot as plt#计算⽅差def getss(list):#计算平均值avg=sum(list)/len(list)#定义⽅差变量ss,初值为0ss=0#计算⽅差for l in list:ss+=(l-avg)*(l-avg)/len(list)#返回⽅差return ss#获取每⾏像素平均值def getdiff(img):#定义边长Sidelength=30#缩放图像img=cv2.resize(img,(Sidelength,Sidelength),interpolation=cv2.INTER_CUBIC)#灰度处理gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#avglist列表保存每⾏像素平均值avglist=[]#计算每⾏均值,保存到avglist列表for i in range(Sidelength):avg=sum(gray[i])/len(gray[i])avglist.append(avg)#返回avglist平均值return avglist#读取测试图⽚img1=cv2.imread("james.jpg")diff1=getdiff(img1)print('img1:',getss(diff1))#读取测试图⽚img11=cv2.imread("durant.jpg")diff11=getdiff(img11)print('img11:',getss(diff11))ss1=getss(diff1)ss2=getss(diff11)print("两张照⽚的⽅差为:%s"%(abs(ss1-ss2))) x=range(30)plt.figure("avg")plt.plot(x,diff1,marker="*",label="$jiames$") plt.plot(x,diff11,marker="*",label="$durant$") plt.title("avg")plt.legend()plt.show()cv2.waitKey(0)cv2.destroyAllWindows() 两张原图: 图像结果如下:img1: 357.03162469135805img11: 202.56193703703704两张照⽚的⽅差为:154.469687654321 实验环境开始设置了图⽚像素值,⽽且进⾏灰度化处理,此⽅法⽐对图像相似对不同的图⽚⽅差很⼤,结果很明显,但是对⽐⽐较相似,特别相似的图⽚不适应。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
闲言碎语
才疏学浅,只把计算图像相似度的一个基本算法的基本实现方式给罗列了出来,以至于在最后自己测评的时候也大发感慨,这个算法有点不靠谱。
不管怎么样,这个算法有时候还是有用的,所以还是列出来跟大家伙一起分享分享~~
PS:图像处理这一块博大精深,个人偶尔发现了点东西拿来分享。
说的不好的地方,写得太糟的地方,诸位准备扔砖头还望淡定,淡定~~
基本知识介绍
颜色直方图
颜色直方图是在许多图像检索系统中被广泛采用的颜色特征,它所描述的是不同色彩在整幅图像中所占的比例,而并不关心每种色彩所处的空间位置,即无法描述图像中的对象或物体。
颜色直方图特别适用于描述那些难以进行自动分割的图像。
灰度直方图
灰度直方图是灰度级的函数,它表示图像中具有每种灰度级的像素的个数,反映图像中每种灰度出现的频率。
灰度直方图的横坐标是灰度级,纵坐标是该灰度级出现的频率,是图像的最基本的统计特征。
本文中即是使用灰度直方图来计算图片相似度,关于算法那一块也不赘言了,毕竟图像学图形学,直方图我是门儿都不懂,我也不准备打肿脸充胖子,只想实现一个最基本的算法,然后从最直观的角度看看这个算法的有效性,仅此而已。
算法实现
诸位看官休怪笔者囫囵吞枣,浅尝辄止的学习态度。
额毕竟是因兴趣而来,于此方面并无半点基础(当然,除了知道RGB是啥玩意儿——这还幸亏当年计算机图形学的老师是个Super美女,因此多上了几节课的缘故),更谈不上半点造诣,看官莫怪莫怪,且忍住怒气,是走是留,小生不敢有半点阻拦~~
大致步骤如下:
1,将图像转换成相同大小,以有利于计算出相像的直方图来
2,计算转化后的灰度直方图
3,利用XX公式,得到直方图相似度的定量度量
4,输出这些不知道有用没用的相似度结果数据
代码实现
步骤1,将图像转化成相同大小,我们暂且转化成256 X 256吧。
public Bitmap Resize(string imageFile, string newImageFile)
{
img = Image.FromFile(imageFile);
Bitmap imgOutput = new Bitmap(img, 256, 256);
imgOutput.Save(newImageFile,
System.Drawing.Imaging.ImageFormat.Jpeg);
imgOutput.Dispose();
return (Bitmap)Image.FromFile(newImageFile);
}
这部分代码很好懂,imageFile为原始图片的完整路径,newImageFile为强转大小后的256 X 256图片的路径,为了“赛”后可以看到我们转化出来的图片长啥样,所以我就把它
保存到了本地了,以至于有了上面略显丑陋的代码。
步骤2,计算图像的直方图
public int[] GetHisogram(Bitmap img)
{
BitmapData data = img.LockBits( new System.Drawing.Rectangle( 0 , 0 , img.Width , img.Height ), ImageLockMode.ReadWrite , PixelFormat.Format24bppRgb ); int[ ] histogram = new int[ 256 ];
unsafe
{
byte* ptr = ( byte* )data.Scan0;
int remain = data.Stride - data.Width * 3;
for( int i = 0 ; i < histogram.Length ; i ++ ) histogram[ i ] = 0;
for( int i = 0 ; i < data.Height ; i ++ )
{
for( int j = 0 ; j < data.Width ; j ++ ) {
int mean = ptr[ 0 ] + ptr[ 1 ] + ptr[ 2 ];
mean /= 3;
histogram[ mean ] ++;
ptr += 3;
}
ptr += remain;
}
}
img.UnlockBits( data );
return histogram;
}
这段就是惊天地泣鬼神的灰度直方图计算方法,里面的弯弯绕还是留给诸位自己去掺和。
步骤3,计算直方图相似度度量
这一步骤的法宝在于这个:
Sim(G,S)= 其中G,S为直方图,N 为颜色空间样点数
为了大家少敲两行字儿,也给出一堆乱七八糟的代码:
//计算相减后的绝对值
private float GetAbs(int firstNum, int secondNum)
{
float abs = Math.Abs((float)firstNum - (float)secondNum);
float result = Math.Max(firstNum, secondNum);
if (result == 0)
result = 1;
return abs / result;
}
//最终计算结果
public float GetResult(int[] firstNum, int[] scondNum)
{
if (firstNum.Length != scondNum.Length)
{
return 0;
}
else
{
float result = 0;
int j = firstNum.Length;
for (int i = 0; i < j; i++)
{
result += 1 - GetAbs(firstNum[i], scondNum[i]);
Console.WriteLine(i + "----" + result);
}
return result/j;
}
}
步骤4,输出
这个……诸位爱怎么输出就怎么输出吧。
直接Console也好,七彩命令行输出也罢,亦或者保存到文本文件中留作纪念啦啦,诸位“好自为之”~~
算法测评
真对不住大家,忘了跟大家说,我也不是一个专业的算法测评人员,但是作为一个半拉子测试人员免不了手痒痒想要看看这个算法到底有多大能耐,就拿出几张图片出来验验货吧。
以下是算法测评结果。
以下部分内容话带调侃,绝无恶意,开开玩笑,娱乐大众~~
路人甲
路人乙
图像相似度
恶搞点评
100%
里面什么都没有!?
恭喜你,如果你看不出来这是两张白底图片,那么你还真是小白,因为你连自家人都认不出来啊~~
100%
天下乌鸦一般黑,这个算法在这一点上立场还算坚定,表现不错~
100%
碰到Win7也不动心,意志坚定地给出了100%的正确答案。
这算法比我意志坚定多了,我可是win7刚出来个7000就装了,还一直用到现在,不过确实好用~~
88.84%
明明很不一样的“我”跟“你”摆在那里,怎么就相似度这么高咧??
难道,“我”,“你”都认不出来??
哦,我忘了,这两张图片的大背景是一样的,难怪……
16.08%
MS跟Apple这么水火不相容?
【均使用默认桌面~~】
50.64%
终于了解了Jack跟Rose不能在一起的真正原因:
不是爱的不够深,也不是泰坦尼克号沉了,用老妈的话说“没有‘夫妻’相”
——还是老妈这个过来人老道~~
99.21%
哇,太不可思议了,竟然是这样。
这算法这样“黑”“白”不分??
我得向Jack跟Rose的忠实Fans道歉了,上面的话是一时失言~~祝他们俩白头偕老,下辈子千万别做船了,坐船也不出海,出海也不去北极,……
经过我略显玩世不恭的测评活动,说实话,我对这个算法是相当的失望,尤其是最后一次对比中的结果,目前情绪低落中。
这倒不是说这算法的一无是处,应该是我或者某些前辈用错了地方,个人觉得算法使用的局限性太大,也或许是我的期望值太高了吧。
后记
开始看到这玩意儿的时候觉得这玩意儿很简单啊,可是一想不对劲,没有这么容易的事情,要不Google,MS这些大牛们做了这么久还没有像样的玩意儿出来。
果不其然,为了多了解一点相关的内容,我不得不Google了一下,觉得那些术语完全不知所云,看不懂啊;看来我得祭出我一般不使用的大杀器了——百度一搜。
嘿,还真找出来了一堆东西,比Google 上面的看起来容易多了,可是打开链接进去瞅瞅,发现还是非我当前能力之所及。
没学到东
西,但是好歹还是了解了一点皮毛上的皮毛。
全文完
诸位看官若觉得讲得没有意义,浪费了你的时间,那就权当作冷笑话听听缓解一下紧张的神经~~。