https://www.360docs.net/doc/0d7540291.html,
对于做电商运营的朋友来说,阅读自身商品评论是一件必备的事情,有的时候商品评论文字很能会很多,不便于进行更精细的分析,那么有没有一款屏幕文字抓取工具,能够批量把这些商品评论文字抓取下来呢,答案是肯定的。下面以阿里巴巴商品评论抓取为例,为大家介绍屏幕文字抓取工具的使用方法。
采集网站:
使用功能点:
●AJAX点击和翻页
https://www.360docs.net/doc/0d7540291.html,/tutorial/ajaxdjfy_7.aspx?t=1
●分页列表及详细信息提取
https://www.360docs.net/doc/0d7540291.html,/tutorial/fylbxq7.aspx?t=1
●Xpath
https://www.360docs.net/doc/0d7540291.html,/search?query=XPath
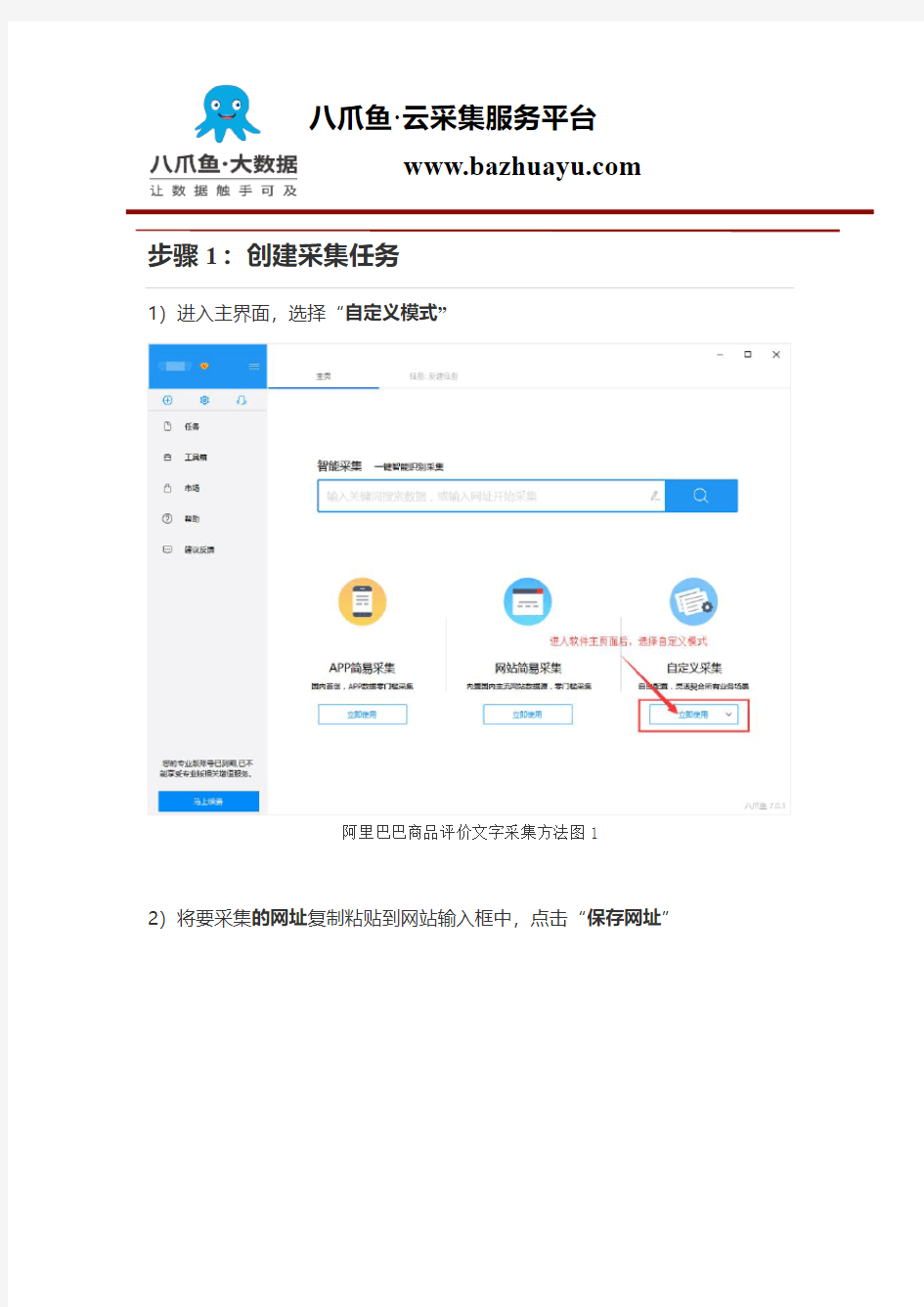
https://www.360docs.net/doc/0d7540291.html, 1)进入主界面,选择“自定义模式”
阿里巴巴商品评价文字采集方法图1
2)将要采集的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/0d7540291.html,
阿里巴巴商品评价文字采集方法图2
步骤2:创建翻页循环
1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。将页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”,以建立一个翻页循环
https://www.360docs.net/doc/0d7540291.html,
阿里巴巴商品评价文字采集方法图3
步骤3:创建列表循环
1)移动鼠标,选中页面里的第一条商品链接,接着再选中第2、3、4条商品链接。选中后,系统会自动识别页面里的其他相似链接。在右侧操作提示框中,选择“循环点击每个元素”,以创建一个列表循环
https://www.360docs.net/doc/0d7540291.html,
阿里巴巴商品评价文字采集方法图4
步骤4:提取商品信息
1)在创建列表循环后,系统会自动点击第一条商品链接,进入商品详情页。点击需要的字段信息,在右侧的操作提示框中,选择“采集该元素的文本”
https://www.360docs.net/doc/0d7540291.html,
阿里巴巴商品评价文字采集方法图5
2)继续点击要采集的字段,选择“采集该元素的文本”。采集的字段会自动添加到上方的数据编辑框中。选中相应的字段,可以进行字段的自定义命名
https://www.360docs.net/doc/0d7540291.html,
阿里巴巴商品评价文字采集方法图6
3)下拉页面并点击“评价”按钮,在操作提示框中,选择“点击该链接”
阿里巴巴商品评价文字采集方法图7
https://www.360docs.net/doc/0d7540291.html,
由于此网页涉及Ajax技术,我们需要进行一些高级选项的设置。选中“点击元素”步骤,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”
阿里巴巴商品评价文字采集方法图8
注:AJAX即延时加载、异步更新的一种脚本技术,通过在后台与服务器进行少量数据交换,可以在不重新加载整个网页的情况下,对网页的某部分进行更新。表现特征:a、点击网页中某个选项时,大部分网站的网址不会改变;b、网页不是完全加载,只是局部进行了数据加载,有所变化。
验证方式:点击操作后,在浏览器中,网址输入栏不会出现加载中的状态或者转圈状态。
https://www.360docs.net/doc/0d7540291.html,
1)点击“评价”按钮后,页面出现商品评价。下拉页面,找到并点击“下一页”按钮,选择“循环点击下一页”,以建立一个翻页循环
阿里巴巴商品评价文字采集方法图9
由于此网页涉及Ajax技术,我们选中“点击翻页”步骤,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”
https://www.360docs.net/doc/0d7540291.html,
阿里巴巴商品评价文字采集方法图10
2)选中页面中第一个评价区块,选择“选中子元素”
阿里巴巴商品评价文字采集方法图11
https://www.360docs.net/doc/0d7540291.html,
3)系统会自动识别出页面中的其他同类元素,在操作提示框中,选择“选中全部”,以建立一个列表循环
阿里巴巴商品评价文字采集方法图12
4)我们可以看到,页面中商品评价区块里的所有元素均被选中,变为绿色。右侧操作提示框中,出现字段预览表,将鼠标移到表头,点击垃圾桶图标,可删除不需要的字段。字段选择完成后,选择“采集以下数据”
https://www.360docs.net/doc/0d7540291.html,
阿里巴巴商品评价文字采集方法图13
5)字段选择完成后,选中相应的字段,可以进行字段的自定义命名
阿里巴巴商品评价文字采集方法图14
https://www.360docs.net/doc/0d7540291.html,
步骤5:调整流程图结构
回顾采集过程,操作思路是:打开要采集的网页>建立商品链接的翻页循环>建立商品链接的循环列表>点击商品链接,进入商品详情页>建立商品评价的翻页循环>建立商品评价的列表循环>提取评价
已有的流程图没有遵循此逻辑,我们需要手动调整一下流程图结构
1)选中整个“循环”步骤(商品链接的循环列表),将其拖入到第1个“循环翻页”步骤和到第2个“循环翻页”步骤之间
阿里巴巴商品评价文字采集方法图15
拖动完成后,位置如图
https://www.360docs.net/doc/0d7540291.html,
阿里巴巴商品评价文字采集方法图16
2)选中整个“循环翻页”步骤(商品评价的循环翻页),将其拖入到整个“循环”(商品链接的循环列表)步骤中
https://www.360docs.net/doc/0d7540291.html,
阿里巴巴商品评价文字采集方法图17
拖动完成后,位置如图
阿里巴巴商品评价文字采集方法图18
https://www.360docs.net/doc/0d7540291.html,
步骤6:修改Xpath
点击左上角的“保存并启动”,选择“启动本地采集”。采集过程中我们发现,采集的数据出现大量重复。
1)选中整个“循环翻页”步骤,打开“高级选项”,将单个元素列表中的这条Xpath://A[text()='下一页'],复制粘贴到火狐浏览器中的相应位置
阿里巴巴商品评价文字采集方法图19
Xpath:是一种路径查询语言,简单的说就是利用一个路径表达式找到我们需要的数据位置。
https://www.360docs.net/doc/0d7540291.html,
Xpath是用于XML中沿着路径查找数据用的,但是八爪鱼采集器内部有一套针对HTML的Xpath引擎,使得直接用XPATH就能精准的查找定位网页里面的数据。
2)在火狐浏览器中,我们发现,要采集的评论已经翻到最后一页(第11页)了的时候,使用此条Xpath://A[text()='下一页'],依旧能找到“下一页”按钮,即一直都可以点击这个按钮进行采集,循环无法结束
阿里巴巴商品评价文字采集方法图20
3)返回八爪鱼采集器,选择“自定义”
https://www.360docs.net/doc/0d7540291.html,
阿里巴巴商品评价文字采集方法图21
勾选“//A[@class='next']”
阿里巴巴商品评价文字采集方法图22
https://www.360docs.net/doc/0d7540291.html,
4)将修改后的Xpath://A[@class='next'],复制粘贴到火狐浏览器中。我们发现,当评论翻到第1-10页时,能够定位到“下一页”。当翻到最后一页(第11页)的时,不能定位到“下一页”。翻页死循环的问题得到解决
阿里巴巴商品评价文字采集方法图23
5)点击左上角的“保存并启动”,选择“启动本地采集”,再次启动采集任务
https://www.360docs.net/doc/0d7540291.html,
阿里巴巴商品评价文字采集方法图24
步骤7:数据采集及导出
1)采集完成后,会跳出提示,选择“导出数据”。选择“合适的导出方式”,将采集好的数据导出
从图片中读取文字、把图片转换成文本格式(用word附带功能就能做到)
超简单从图片中读取文字的方法(使用word自带软件) (全文原创,转载请注明版权。本文下载免费,如果对您有一定帮助,请在右边给予评价,这样有利于将本文档位于百度搜索结果的靠前位置,方便本方法的推广) 【本文将介绍读取图片中的文字、读取书中文字、读取PDF格式文件中的文字的方法】一、背景 看到图片中满是文字,而你又想把这些文字保存下来,怎么办? 日常读书,某篇文章写的极好,想把它分享到网络上,怎么办? 一个字一个字敲进电脑?太麻烦了。是不是希望有一种东西能自动识别读取这些文字? 是的,科技就是拿来偷懒的。 其实你们电脑中安装的word早就为你考虑过这些问题了,只是你还不知道。 二、方法 1、图片格式转换 只有特定格式的图片才能读取文字,所以要转换。大家常见的图片格式都是jpg,或者png,bmp等,用电脑自带的画图软件打开你要获取文字的图片(画图软件在开始——所有程序——附件中,win7用户直接右击图片,选择编辑,就默认使用画图软件打开图片),然后把图片另存为tiff格式。 (以我的win7画图为例。另存为tiff格式如下图) 2、打开读取文字的工具 开始——所有程序——Microsoft Office ——Microsoft Office工具——Microsoft Office Document Imaging(本文全部以office2003为例。另外,有些人
安装的是Office精简版,可能没有附带这个功能,那就需要添加安装一下,安装步骤见文末注释①) 3、导入tiff格式的图片 在Microsoft Office Document Imaging软件界面中,选择文件——导入,然后选择你刚才存放的tiff格式的图片,导入。
如何提取网页上不能复制的文字
如何提取网页上不能复制的文字 我们在浏览一些网页时会发现,有的网站可能出于保护版权的缘故,上面的文字是不能复制的。那么我们应该如何提取上面的文字呢?下面就教几种常用的方法给大家: 第一招 点击浏览器的“工具”—“internet选项”—“安全”—“自定义级别”,然后将脚本全部禁用,安F5刷新一下网页。这时候你就会发现之前不能复制的内容,现在都没有问题了!(提示:复制完想要的东西之后,记得吧禁用的脚本解禁,否则会影响正常浏览的) 第二招 这招说其实是最简单,但有时最麻烦的一招。直接右击然后“查看源文件”,在源文件代码中复制需要的文章。不过复制文章的时候会有很多用不着的符号和代码。是有些麻烦。 第三招 点击浏览器的“文件”菜单栏,选择“保存网页”然后点开保存的文件,下载下来想要的网页,然后用word文本打开就可以了! 第四招 打开想要下载的网页,然后把该网页另存到电脑上面,接着用记事本打开的方法打开!在记事本中找到(onpaste= “reture flase”不准粘贴oncopy=“reture flase;”不准复制oncut=“reture flase;”不准剪切onselectarst=“reture flase”不准选择)这句语句或者类似的代码,然后把这句代码去掉,body模块中的除外,然后保存记事本。接着双击打开刚才保存的记事本,这时候出现的文章就是可以复制的文章了 第五招 可以将网页截屏或是截图下来,再使用捷速图片文字识别软件,对网页上的文字进行识别,识别得到的文字可以保存为word,word中的文字可以随意的进行编辑或是其他操作。捷速图片文字识别软件的操作很简单,软件采用引导式界面,无需专业的技术知识,只要按软件提示点几下鼠标,就能轻松转扫描文件或PDF文件和图片文件。从兼容性来看,该软件可以适用于任何Windows操作系统,具有良好的系统兼容性,同时它能识别各类图片格式,如jpg,jpeg,bmp,gif,png等等,同时还能适用于pdf文件,文件的兼容性强。首先,我们将需要识别的图片准备好,将其采用直接拖曳或是点击“添加文件”将图片添加到软件中。然后,我们就可以开启识别程序,直接点击软件操作界面中的“识别”按钮,软件就开始自动对图片文字进行分析。最后,软件会将分析结果展示出来,与原文校对之后可以保存为word或是其他格式,这个根据需求进行操作。 个人还是比较建议使用捷速图片文字识别软件来进行识别网页文字,出错率较低,不需要多少专业的知识,而且速度快,方便快捷,就能轻松提取网页上不能复制的文字了。
网页图片提取方法
https://www.360docs.net/doc/0d7540291.html, 网页图片提取方法 对于新媒体运营来说,平日一定要注意积累图片素材,这样到写文案用的时候,才不会临时来照图片,耗费大量的时间。 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,以【图片采集】为例,教大家如何使用八爪鱼采集软件采集网络图片的方法。 1、图片采集 在八爪鱼中,采集图片有以下几大步 1、先采集网页图片的地址链接url 2、通过八爪鱼提供的专用图片批量下载工具将URL转化为图片 八爪鱼图片批量下载工具:https://https://www.360docs.net/doc/0d7540291.html,/s/1c2n60NI 2、常见应用情景 1)非瀑布流网站纯图片采集 采集示例:豆瓣网图片采集教程https://www.360docs.net/doc/0d7540291.html,/tutorial/tpcj-7 2)瀑布流网站纯图片采集 这类瀑布流网站的采集需要按下面的步骤对采集规则进行设置:
https://www.360docs.net/doc/0d7540291.html, ①点击采集规则打开网页步骤的高级选项; ②勾选页面加载完成后下滚动; ③填写滚动的次数及每次滚动的间隔; ④滚动方式设置为:直接滚动到底部; 完成上面的规则设置后,再对页面中图片的url进行采集 采集示例:百度网图片采集教程https://www.360docs.net/doc/0d7540291.html,/tutorial/bdpiccj 3)文章图文采集 需要将文章里的文字和图片都采集下来,一般有两种方法 方法1:判断条件,设置判断条件分别采集文字和图片 采集示例:https://www.360docs.net/doc/0d7540291.html,/tutorial/txnewscj 方法2:先整体采集文字,再循环采集图片 采集示例:https://www.360docs.net/doc/0d7540291.html,/tutorial/ucnewscj 3、教程目的 采集图片URL这个步骤,以上图片采集教程中都有详细说明,不再赘述。本文将重点讲解图片采集的采集技巧和注意事项。 4、采集图片URL操作步骤 以下演示一个采集图片URL的具体操作步骤,以百度图片url采集为例。不同的网站图片url会遇到不同的情况,请大家灵活处理。
教你如何复制网上的任何文字
教你如何复制网上的任何文字 朋友们在上网浏览一些网页时,可能会遇到过有些网页,随着时间的推移该地址也可能失效,无论你按住鼠标左键如何不停的拖动,都无法选中复制需要的文字。那是因为网站为了保密,对网页文件进行了加密,使用户无法通过选取的方法复制网页中的文字,采用“另存为”保存在硬盘中也无法复制其中的文字,是不是让人感觉无可奈何,而又心有不甘呢?下面,我就介绍几种方法来破解网上文字无法复制的问题: 方法1、先按CTRL+A键将网页全部选中,“复制”,然后从中选取需要的文字即可。 方法2、打开你想复制文字的网页,找到地址栏上面的工具栏,找到按钮,点一下右面那个向下的下拉箭头,你可以选择用Word、记事本、Excel编辑,我一般选择用Word,过一会就会出现一个Word文档,在里面找到自己需要复制的文字就可以复制了。 方法3、打开你想复制文字的网页,找到菜单栏中的→另存为(A)→就会出现下图→保存类型→点一下它右面的下拉箭头→选择→再点“保存”就可以了,然后找到该文本文件复制里面你想要的内容就可以了。 方法4、调用源文件查看文字。选择菜单“查看”,点击“源文件”,打开记事本就能看到网页的全部文字,选取你需要的即可。 方法5、点击IE的工具栏栏中的“工具/Internet”菜单,进入“安全”标签页,选择“自定义级别”,将所有脚本全部禁用然后按F5键刷新网页,然后你就会发现那些无法选取的文字就可以选取了。 方法6、下载安装一个SnagIt汉化破解版软件(找个不收费的),利用抓图软件SnagIt实现。SnagIt中有一个“文字捕获”功能,可以抓取屏幕中的文字,也可以用于抓取加密的网页文字。单击窗口中的“文字捕获”按钮,单击“输入”菜单,选择“区域”选项,最后单击“捕获”按钮,这时光标会变成带十字的手形图标,按下鼠标左键在网页中拖动选出你要复制的文本,松开鼠标后会弹出一个文本预览窗口,可以看到网页中的文字已经被复制到窗口中了。剩下的工作就好办了,把预览窗口中的文字复制到其他文本编辑器中即可,当然也可以直接在这个预览窗口中编辑修改后直接保存。 方法7、使用特殊的浏览器。如TouchNet Browser浏览器具有编辑网页功能,可以用它来复制所需文字。在“编辑”菜单中选择“编辑模式”,即可对网页文字进行选取。 注意:以上方法对某些网页并不都适用,朋友们可视情选用一种或几种配合使用,已达到我们复制网页文字的目的。
用Excel获取网页内容的方法
在浏览网页时,你一定会不时看到一些需要保存的数据信息。这些信息或许是一个完整的表格,或许是一段文字,如果要保存这类信息,我们常用的方法就是拖动鼠标,选中这些信息,然后用Ctrl+C组合键复制文字,然后再保存到Word、Excel当中去。 这样的步骤算不上麻烦,但如果要求你在一个个内容丰富的大网页(比如新浪、网易、Sohu首页)中频繁地复制、粘贴,一定会让你感到疲劳和浪费时间。有什么好办法呢?用“Ctrl+A”全选后复制所有文字?粘贴后你会发现麻烦更大,因为所有文字都堆在一起了!下面,理睬教你一种方便的方法。 实例:抓取新浪首页不同位置内容 第一步:打开IE,访问理睬博客首页https://www.360docs.net/doc/0d7540291.html,/ 。 第二步:在网页左侧或右侧的空白处点击鼠标右键,在菜单中选择“导出到Microsoft Office Excel”。注意,不要在文字链接之间的空白处点右键,而是应该在完全没有任何网页内容的地方点右键。 第三步:这时Excel会启动,并出现一个“新建Web查询”的窗口。稍等片刻,等待这个窗口中显示出了完整网页,左下角会出现“完毕”字样。注意观察网页,你会发现网页被分割成了很多小的表格,每个表格的左上角有一个小的箭头标志。 第四步:双击窗口最上方标题栏,最大化窗口。依次找到要收藏的内容,然后按下该位置左上角的箭头,使它变成绿色的对勾。然后按下下方的“导入”按钮。 第五步:在弹出窗口中选择放置位置,然后按下“确定”按钮,文字、表格信息就可以自动导入Excel 了。字体格式、颜色自动处理为Excel默认的样式,表格也会被放到适当的单元格中。这样,就有效避免了直接复制粘贴网页造成一些无法识别的格式、链接信息加入网页,同时提高了导入速度。 你知道吗? 如何不将网页格式带入Office文档中? 当你在浏览器中复制一段内容,然后粘贴到Word、Excel中,会将一些网页格式直接照搬进来,这可能不是我们希望的,因为它会增大文件体积,也不利于加工整理。其实,你只要不用“Ctrl+V”来粘贴,而是选择Word、Excel中的“编辑→选择性粘贴→文本”来进行粘贴就可以了。
最方便的图片转换成文字的技巧
最方便的图片转换成文字的技巧 在我们网站更新的过程中,最好是更新一些原创的文章。很多人都已经想出了好的办法: 1、将正版的网上没有收录的文字,拍成照片,用软件转成文字。 2、将超星、书生上下载下来的网络上没有收录的书下载下来,截图后,用软件转成文字。 …… 无论使用什么样的方法,“用软件转成文字”是其中的一个重要的步骤。 很多人为此而苦恼…… 今天给大家介绍一种比较,方便又实惠。 具体步骤: 1、在电脑里安装WPS和AJViewer软件。 (WPS 是将图片转换成PDF文档的,AJViewer是转换的。) 具体的下载地址:(为了方便您查找,当然,你也可以百度查找)WPS :https://www.360docs.net/doc/0d7540291.html,/ AJViewer :https://www.360docs.net/doc/0d7540291.html,/soft/3688.html 2、安装好这两款软件。(这个应该大家都会的) 3、得到图片。(这个应该大家也会吧,一种方法用照相机拍,一种方法用截图,360,QQ都有截图功能。) 注意:照片效果越好,可以大大缩小转换文字的误差率
4、在wps中插入你的照片(打开WPS——插入菜单——图片——来自文件——选择照片——插入) 5、在WPS工具栏中,找到,点击后,弹出保存的路径,就得到了一个PDF文件。 6、打开AJViewer软件,然后在AJViewer中打开刚刚转换的PDF文件。 7、选择AJViewer中的,然后在需要的文字部分拖动鼠标画出虚线。 8、点击发送到word按钮,就可以转换成word文件了。可以编辑了。第7、8步骤图片如下:
要点提示: 1、照片一定要平整,最好对比强烈。(最关键的部分) 2、如果熟练的使用我的方法,用不了一分钟就可以转出若干的文字,
Java抓取网页内容三种方式
java抓取网页内容三种方式 2011-12-05 11:23 一、GetURL.java import java.io.*; import https://www.360docs.net/doc/0d7540291.html,.*; public class GetURL { public static void main(String[] args) { InputStream in = null; OutputStream out = null; try { // 检查命令行参数 if ((args.length != 1)&& (args.length != 2)) throw new IllegalArgumentException("Wrong number of args"); URL url = new URL(args[0]); //创建 URL in = url.openStream(); // 打开到这个URL的流 if (args.length == 2) // 创建一个适当的输出流 out = new FileOutputStream(args[1]); else out = System.out; // 复制字节到输出流 byte[] buffer = new byte[4096]; int bytes_read; while((bytes_read = in.read(buffer)) != -1) out.write(buffer, 0, bytes_read); } catch (Exception e) { System.err.println(e); System.err.println("Usage: java GetURL []"); } finally { //无论如何都要关闭流 try { in.close(); out.close(); } catch (Exception e) {} } } } 运行方法: C:\java>java GetURL http://127.0.0.1:8080/kj/index.html index.html 二、geturl.jsp
如何将图片(含WORD里的图片)中的文字转换成WORD文档
一、如果是单独的图片上有文字,可以转成TIF格式后用下面的办法: Microsoft Office 工具--->Microsoft Office Document Imaging,在里面点文件--->打开刚才的图片,工具--->将文本送到word就行了 二、如果WORD文档里有图片,图片上有文字,需要把上面的文字转成WORD格式的话可以试试这样做,特别适合WORD文档里多张图片的情况下用这种办法。 1、Microsoft Office 工具--->Microsoft Office Document Imaging,在里面导入有图片的那个word,然后选择工具-->将文本送到word就行了 2、经过试过后,有时有的图片好象不能直接象上面那样发送,可以先将WORD文档进行打印成mdi文档就可以了,而要打印成这文档就要先装Microsoft Office Document Imaging 打印机,一般正常情况下完全安装office 2003的话都应该自带装好了此打印机,否则可以参照以下进行: Microsoft Office Document Imaging 打印机安装: 首先自定义安装Office 2003,选择安装“Microsoft Office
Document Imaging”组件,完后在“打印机和传真”中会出现一个“Microsoft Office Document Imaging Writer Driver”的虚拟打印机,如果没有请试试如下方法: 控制面板→打印机和传真→添加打印机→下一步→选择“连接到此计算机的本地打印机”→取消勾选“自动检测并安装即插即用打印机”→下 一步→“使用以下端口”中选择“Microsoft Document Imaging Writer Port(Local)”→下一步→厂商选择“Generic”→打印机选择 “Generic/Text Only”→点击“下一步”直到完成。 右击刚添加的打印机→属性→高级→“驱动程序”选“Microsoft Office Document Image Writer”→应用→常规→打印首选项→高级→“输 出格式”选择“MDI”并勾选“压缩文档中的图像”→确定→“打印处理器”->选“ModiPrint”->“默认数据类型”选“RAW”->确定->确定
网络文字抓取工具使用方法
https://www.360docs.net/doc/0d7540291.html, 网络文字抓取工具使用方法 网页文字是网页中常见的一种内容,有些朋友在浏览网页的时候,可能会有批量采集网页内容的需求,比如你在浏览今日头条文章的时候,看到了某个栏目有很多高质量的文章,想批量采集下来,下面本文以采集今日头条为例,介绍网络文字抓取工具的使用方法。 采集网站: 使用功能点: ●Ajax滚动加载设置 ●列表内容提取 步骤1:创建采集任务
https://www.360docs.net/doc/0d7540291.html, 1)进入主界面选择,选择“自定义模式” 今日头条网络文字抓取工具使用步骤1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/0d7540291.html, 今日头条网络文字抓取工具使用步骤2 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容,即为今日头条最新发布的热点新闻。
https://www.360docs.net/doc/0d7540291.html, 今日头条网络文字抓取工具使用步骤3 步骤2:设置ajax页面加载时间 ●设置打开网页步骤的ajax滚动加载时间 ●找到翻页按钮,设置翻页循环 ●设置翻页步骤ajax下拉加载时间
https://www.360docs.net/doc/0d7540291.html, 1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定 今日头条网络文字抓取工具使用步骤4 注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量。
https://www.360docs.net/doc/0d7540291.html, 今日头条网络文字抓取工具使用步骤5 步骤3:采集新闻内容 创建数据提取列表 1)如图,移动鼠标选中评论列表的方框,右键点击,方框底色会变成绿色
网页内容如何批量提取
https://www.360docs.net/doc/0d7540291.html, 网页内容如何批量提取 网站上有许多优质的内容或者是文章,我们想批量采集下来慢慢研究,但内容太多,分布在不同的网站,这时如何才能高效、快速地把这些有价值的内容收集到一起呢? 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集】,以【新浪博客】为例,教大家如何使用八爪鱼采集软件采集新浪博客文章内容的方法。 采集网站: https://www.360docs.net/doc/0d7540291.html,/s/articlelist_1406314195_0_1.html 采集的内容包括:博客文章正文,标题,标签,分类,日期。 步骤1:创建新浪博客文章采集任务 1)进入主界面,选择“自定义采集”
https://www.360docs.net/doc/0d7540291.html, 2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/0d7540291.html, 步骤2:创建翻页循环
https://www.360docs.net/doc/0d7540291.html, 1)打开网页之后,打开右上角的流程按钮,使制作的流程可见状态。点击页面下方的“下一页”,如图,选择“循环点击单个链接”,翻页循环创建完成。(可在左上角流程中手动点击“循环翻页”和“点击翻页”几次,测试是否正常翻页。) 2)由于进入详情页时网页加载很慢,网址一直在转圈状态,无法立即执行下一个步骤,因此在“循环翻页”的高级选项里设置“ajax加载数据”,超时时间设置为5秒,点击“确定”。
https://www.360docs.net/doc/0d7540291.html, 步骤3:创建列表循环 1)鼠标点击列表目录中第一个博文,选择操作提示框中的“选中全部”。 2)鼠标点击“循环点击每个链接”,列表循环就创建完成,并进入到第一个循环项的详情页面。
《获取网页上的文字》教案
《获取网页上的文字》教案 一、教案背景 通过本课教学培养学生综合应用信息技术及网络资源的能力,同时引导学生学会运用搜索引擎(如:百度)为学习和信息处理服务。 二、教学课题 小学四年级学生经历了几年的小学学习生活,积累了一定的学习经验,能有自己的见解和认识。他们都应具备一定的信息技术,能进行基本的文件及文件夹的操作;会进行基本的文字、图像处理;有一定的互联网应用技能。 本课使学生掌握利用搜索引擎搜索图片的方法。引导学生知识迁移,学生尝试操作相结合的方式,学会搜索网页,保存网页中文字以及复制文件。 三、教材分析 本课是在信息技术教材四年级上册《获取网页中的文字》一课的内容。目的在于进一步培养学生学习信息技术的兴趣和能力;提升学生的信息素养;培养学生敢于去探索与搜索网页,保存网页中文字。 四、教学方法 演示讲授、引导启发和学生讨论尝试、合作学习。 五、教学过程 (一)导入
出示可爱的小动物图片。 教师提问:你认识这些小动物吗?知道这些小动物图片是哪找来的吗?想不想到网上找到这些可爱的小动物,更加深入的了解它们呢? (二)新课 1.搜索网页 用关键字搜索网页可以引导学生进行知识迁移。 2.保存网页中文字(教师演示) 提醒学生注意观察保存类型选什么——文本文件*.TXT。如果要保存网页中的部分文字,可以先选定网页中需要的文字进行复制,粘贴在记事本中,最后保存。 (1)打开搜索引擎网站,如百度,输入“大熊猫”,然后单击“百度一下”按钮。 (2)找到相关的信息,选择自己最感兴趣的词条,进入相关网页,单击网页中的“大熊猫百度百科、大熊猫吧”等链接。 (3)在进入的新闻页面中单击“文件”菜单下的“另存为”选项。(4)在弹出的对话框中填入文件名,将保存的类型设置为“文本文件”,最后单击“保存” (5)从“桌面”上打开文本文件“大熊猫百度百科”,这就是我们保存下来的网页。 学生观看演示并认真听讲学生模仿自行操作练习 3.复制文件或文件夹
php获取网页内容方法
1.file_get_contents获取网页内容 2.curl获取网页内容 3.fopen->fread->fclose获取网页内容
网页文字抓取器使用方法
https://www.360docs.net/doc/0d7540291.html, 网页文字抓取器使用方法 市面上有很多的网页文字抓取器小工具,但是真正强大又好用的真心没几个,一般我们都是利用网页文字抓取器来轻松抓取和复制那些可见的网页文字内容,甚至是哪些页面上的内容被大面积的广告盖住看不到的网页,网页文字抓取器都可以帮你把想要的网页文字内容给抓取下来,就是这么神奇。 今天就给大家介绍一款免费网页文字抓取器抓取本文介绍使用八爪鱼采集新浪博客文章的方法。 采集网站: https://www.360docs.net/doc/0d7540291.html,/s/articlelist_1406314195_0_1.html 采集的内容包括:博客文章正文,标题,标签,分类,日期。 步骤1:创建新浪博客文章采集任务 1)进入主界面,选择“自定义采集”
https://www.360docs.net/doc/0d7540291.html, 2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/0d7540291.html, 步骤2:创建翻页循环 1)打开网页之后,打开右上角的流程按钮,使制作的流程可见状态。点击页面下方的“下一页”,如图,选择“循环点击单个链接”,翻页循环创建完成。(可在左上角流程中手动点击“循环翻页”和“点击翻页”几次,测试是否正常翻页。)
https://www.360docs.net/doc/0d7540291.html, 2)由于进入详情页时网页加载很慢,网址一直在转圈状态,无法立即执行下一个步骤,因此在“循环翻页”的高级选项里设置“ajax 加载数据”,超时时间设置为5秒,点击“确定”。
https://www.360docs.net/doc/0d7540291.html, 步骤3:创建列表循环 1)鼠标点击列表目录中第一个博文,选择操作提示框中的“选中全部”。
图片转文字的两种方法
在日常的工作中最害怕什么呢?害怕上级下达整理图片文件文 字或者是把文件文字输入到word文档中的任务,因为没有便捷的出来方法,导致我们在整理文字的时候浪费了很多时间,下面小编分享一个图片转文字的方法。 这个方法是利用迅捷OCR文字识别软件进行的,识别图片文字很简单,直接把带有文字的图片添加到文字识别工具中,点击识别就可以啦。当我们在整理文件文字的时候,需要增加一步操作,将文件拍成图片保存到电脑中,然后进行识别,便可以轻松实现图片转文字了,让我们的工作效率迅速提升。 图片转文字方法一(PC端): 第一步:在电脑打开OCR文字识别软件,关闭提示窗口,点击左边功能栏中的“极速识别”功能,进入识别页面;
第二步:点击页面上方的“添加文件”按钮,通过此按钮把需要识别的文字图片添加进去,请注意图片的格式哦; 第三步:图片转文字可以转换成word或者是TXT文档文字,可以根据自己的需求在右边选择文件的“识别效果”;
第四步:点击右下角的“一键识别”按钮,开始实现图片转文字; 第五步:想快速的查看识别成功的图片文字,点击操作下面的“打开文件”按钮,便可以直接打开文档了。
图片转文字方法二(移动端): 1:在手机里找到如下的工具,然后在可以看到在首页有【图片识别】【拍照识别】两个主要功能
2:选择任何一种方式,都能快速实现纸质文档转电子档,这里以【图片识别】为例:点击【图片识别】自动跳转自手机相册,选择事先准备好的需要识别文字内容的图片——【完成】
3:选择好图片以后会出现一个批量处理的页面,在此看一下转化的图片是否正确,然后点击立即识别。
js 爬虫如何实现网页数据抓取
https://www.360docs.net/doc/0d7540291.html, js 爬虫如何实现网页数据抓取 互联网Web 就是一个巨大无比的数据库,但是这个数据库没有一个像SQL 语言可以直接获取里面的数据,因为更多时候Web 是供肉眼阅读和操作的。如果要让机器在Web 取得数据,那往往就是我们所说的“爬虫”了。有很多语言可以写爬虫,本文就和大家聊聊如何用js实现网页数据的抓取。 Js抓取网页数据主要思路和原理 在根节点document中监听所有需要抓取的事件 在元素事件传递中,捕获阶段获取事件信息,进行埋点 通过getBoundingClientRect() 方法可获取元素的大小和位置 通过stopPropagation() 方法禁止事件继续传递,控制触发元素事件 在冒泡阶段获取数据,保存数据 通过settimeout异步执行数据统计获取,避免影响页面原有内容 Js抓取流程图如下
https://www.360docs.net/doc/0d7540291.html, 第一步:分析要爬的网站:包括是否需要登陆、点击下一页的网址变化、下拉刷新的网址变化等等 第二步:根据第一步的分析,想好爬这个网站的思路 第三步:爬好所需的内容保存 爬虫过程中用到的一些包:
https://www.360docs.net/doc/0d7540291.html, (1)const request = require('superagent'); // 处理get post put delete head 请求轻量接http请求库,模仿浏览器登陆 (2)const cheerio = require('cheerio'); // 加载html (3)const fs = require('fs'); // 加载文件系统模块将数据存到一个文件中的时候会用到 fs.writeFile('saveFiles/zybl.txt', content, (error1) => { // 将文件存起来文件路径要存的内容错误 if (error1) throw error1; // console.log(' text save '); }); this.files = fs.mkdir('saveFiles/simuwang/xlsx/第' + this.page + '页/', (e rror) => { if (error) throw error; }); //创建新的文件夹 //向新的文件夹里面创建新的文件 const writeStream = fs.createWriteStream('saveFiles/simuwang/xlsx/'
如何抓取网页文字
如何抓取网页文字 第一种情况,出现“ 版权所有、严禁复制!”。这是由于网页文件中被加入了如下代码( 破解方法(先选中目标,然后在目标上按下鼠标右键,此时会弹出提示窗口,这时不要松开右键,将鼠标指针移到提示窗口的“确定”按钮上,然后按下左键。现在松开鼠标左键,限制窗口被关闭了,再将鼠标移到目标上松开鼠标右键,弹出了鼠标右键菜单,限制取消了?第二种情况,出现“添加到收藏夹”的。破解方法如下: 在目标上点鼠标右键,出现添加到收藏夹的窗口,这时不要松开右键,也不要移动鼠标,而是使用键盘的TAB键,移动焦点到取消按钮上,按下空格键,这时窗口就消失了,松开右键后,我们熟悉的右键菜单又出现了。 第三种情况,超链接无法用鼠标右键弹出“在新窗口中打开”菜单的。这时用上面的两种方法无法破解,看看我这一招:在超链接上点鼠标右键,弹出窗口,这时不要松开右键,按键盘上的空格键,窗口消失了,这时松开右键,右键菜单又出现了,选择其中的“在新窗口中打开”就可以了。第四种情况,在浏览器中点击“查看”菜单上的“源文件”命令,这样就可以看到html源代码了。不过如果网页使用了框架,你就只能看到框架页面的代码,此方法就不灵了,我们还可以按Shift+F10或按动键盘上与右手边的Ctrl键紧挨着的那个
键,都可以轻松的破解上面这种对鼠标右键的屏蔽。 第五种情况,最近在某网页中又遇一新的屏蔽方法,使用上面这些破解方法无效。关键代码如下( 在屏蔽鼠标右键的页面中点右键,出现警告窗口,此时不要松开右键,用左手按键盘上的ALT+F4组合键,这时提示窗口就被我们关闭了,松开鼠标右键,还是没有反应?想当初这招可是“百发百中”的?现在居然也不管用了?它既然能用javascript限制我们使用鼠标右键,我们就应该能用javascript来破解它? 仔细看看上面的代码,关键是这句 (“document.oncontextmenu=stop”,如果我们能让其中的“stop”失效不就成功的破解了吗;让我们来试试,具体方法 是( 在浏览器地址栏中键入 “java_s:alert(document.oncontextmenu='')”,输入时不要输入双引号!,此时会弹出个对话框,点击“确定”按钮,然后再对着你的目标,图片或文字!点击鼠标右键就可以看到弹出菜单了?第六种情况,网页中的鼠标右键锁定是基 于javascript的基础实现的?以下有个很方便的方法就可以 破掉它?在网址中输入 (void(document.body.oncontextmenu=null) 按一下回 车键,页面没反应?但是你按一下右键,看看是不是可以打开了?1/3页同样的原理也可以破解掉页面的“防复制”,“防选取”等限制?韵率谴耄?br /> 选取
有没有图片转文字的免费软件
推荐2个非常好用的OCR文字识别工具,识别速度快准确度高,不管是手写体、印刷体还是表格,统统都不在话下。 第一个不仅免费还不用下载,第二个功能强大。 1、微信小程序——迅捷文字识别 迅捷文字小程序的话呢,可以直接使用,不需要下载到手机上,而且是免费的。 功能方面的话,一些基础的功能都是有的。 可以上传图片进行识别,或者是直接选择微信聊天中的图片进行识别,这个还是很方便的。 也可以直接拍照识别,拍照识别的话能够识别手写体、文档和表格。
使用步骤基本上都是一样的,上传图片或者拍照,调整选框选中自己需要识别的区域,然后进行识别就好了。 识别结果会自动排版,基本上不用自己调整,如果文字识多的话可能显示的不完整,往下滑查看未显示文字就好了。 识别出来的文字可以直接复制,或者导出Word、PDF文档,又或者是直接发给微信好友。 手写体的话只要不是自己很潦草的话,基本上都能识别出来。
2、手机APP——迅捷文字识别 迅捷文字识别APP比小程序的功能更加丰富一下。 文字识别的支持表格识别、上传图片识别、拍照识别、证件扫描和拍照翻译,其中拍照识别能够多张图片连拍,更加方便一些。 拍照视图的时候可以选择手写体或者印刷体,这样识别更加精准一些。 识别步骤基本都是差不多的,识别出来的文字可以直接复制、翻译、导出和直接保存,保存格式也比小程序丰富一些,可以保存为TXT、Word、PDF或者图片的形式。
还有校对功能可以使用,打开时候,上半部分就是你上传的图片或者是拍的图片,下半部分是识别歘来的结果,就可以比对是否正确了,在同一个页面校对还是很快的。 还有文本翻译功能,支持二十多种语言翻译,翻译出来的内容也可以直接复制或者保存的。
可复制网上任何文字的方法
可复制网上任何文字的方法 在上网浏览一些网页时,可能会遇到过有些网页,随着时间的推移该地址也可能失效,无论你按住鼠标左键如何不停的拖动,都无法选中复制需要的文字。那是因为网站为了保密,对网页文件进行了加密,使用户无法通过选取的方法复制网页中的文字,采用“另存为”保存在硬盘中也无法复制其中的文字,让人感觉无可奈何,而又心有不甘呢?对此迎春从网络引用几种方法来破解网上文字无法复制的问题。 方法步骤 方法1、先按CTRL+A键将网页全部选中,“复制”,然后从中选取需要的文字即可。 方法2、打开你想复制文字的网页,找到地址栏上面的工具栏,找到按钮,点一下右面那个向下的下拉箭头,你可以选择用Word、记事本、Excel编辑,我一般选择用Word,过一会就会出现一个Word文档,在里面找到自己需要复制的文字就可以复制了。 方法3、打开你想复制文字的网页,找到菜单栏中的→另存为(A)→就会出现下图→保存类型→点一下它右面的下拉箭头→选择→再点“保存”就可以了,然后找到该文本文件复制里面你想要的内容就可以了。 方法4、调用源文件查看文字。选择菜单“查看”,点击“源文件”,打开记事本就能看到网页的全部文字,选取你需要的即可。 方法5、点击IE的工具栏栏中的“工具/Internet”菜单,进入“安全”标签页,选择“自定义级别”,将所有脚本全部禁用然后按F5键刷新网页,然后你就会发现那些无法选取的文字就可以选取了。 方法6、下载安装一个SnagIt汉化破解版软件(找个不收费的),利用抓图软件SnagIt 实现。SnagIt中有一个“文字捕获”功能,可以抓取屏幕中的文字,也可以用于抓取加密的网页文字。单击窗口中的“文字捕获”按钮,单击“输入”菜单,选择“区域”选项,最后单击“捕获”按钮,这时光标会变成带十字的手形图标,按下鼠标左键在网页中拖动选出你要复制的文本,松开鼠标后会弹出一个文本预览窗口,可以看到网页中的文字已经被复制到窗口中了。剩下的工作就好办了,把预览窗口中的文字复制到其他文本编辑器中即可,当然也可以直接在这个预览窗口中编辑修改后直接保存。 方法7、使用特殊的浏览器。如TouchNet Browser浏览器具有编辑网页功能,可以用它来复制所需文字。在“编辑”菜单中选择“编辑模式”,即可对网页文字进行选取。 注意:以上方法对某些网页并不都适用,朋友们可视情选用一种或几种配合使用,已达到我们复制网页文字的目的。
如何快速提取网页文字
https://www.360docs.net/doc/0d7540291.html, 如何快速提取网页文字 我们在浏览网页时,有时候需要将网页上的一些文字内容复制下来,保存到本地电脑或者数据库中,手工复制粘贴费时费力,效率又低,这时我们可以借助网页文字采集器来轻松提取网页上可见的文字内容,甚至是那些被大面积的广告覆盖看不到的文字内容,网页文字采集器都可以帮你把想要的网页文字内容给提取出来,简单方便,又大大的提升了效率。 下面就为大家介绍一款免费好用的网页文字采集器来提取网页文字。本文以使用八爪鱼采集器采集新浪博客文章为例子,为大家详细讲解如何快速提取网页文字。 采集网站: https://www.360docs.net/doc/0d7540291.html,/s/articlelist_1406314195_0_1.html 采集的内容包括:博客文章正文,标题,标签,分类,日期。 步骤1:创建新浪博客文章采集任务 1)进入主界面,选择“自定义采集”
https://www.360docs.net/doc/0d7540291.html, 2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/0d7540291.html, 步骤2:创建翻页循环 1)打开网页之后,打开右上角的流程按钮,使制作的流程可见状态。点击页面下方的“下一页”,如图,选择“循环点击单个链接”,翻页循环创建完成。(可在左上角流程中手动点击“循环翻页”和“点击翻页”几次,测试是否正常翻页。)
https://www.360docs.net/doc/0d7540291.html, 2)由于进入详情页时网页加载很慢,网址一直在转圈状态,无法立即执行下一个步骤,因此在“循环翻页”的高级选项里设置“ajax 加载数据”,超时时间设置为5秒,点击“确定”。
https://www.360docs.net/doc/0d7540291.html, 步骤3:创建列表循环 1)鼠标点击列表目录中第一个博文,选择操作提示框中的“选中全部”。
抓取网页数据工具的内容获取方式
抓取网页数据工具的内容获取方式 抓取网页数据的工具火车采集器在获取内容时,需要对数据内容的标签进行编辑定义,在火车采集器V9中对数据内容标签进行编辑定义,从而获取数据的方法有三类:A).从源码中获取数据B).生成固定格式的数据C).已有标签组合,下面分别讲解下具体的含义。 A).从源码中获取数据:可精确地设置标签的来源是从默认页的源码、返回头信息和网页地址中,或者是分页、循环分块、多页中。其源码提取的方式包括:前后截取、正则提取、正文提取、Xpath提取,JSON 提取五种,后面详细示范。 B).生成固定格式的数据:可生成固定的字符串、系统时间、随机字符串、随机数字、系统时间戳,随机抽取信息。 C).已有标签组合:可通过组合已有的标签,来生成新的标签内容。 其中最常用的是从源码中获取数据,其对应的五种获取方式的操作如下: A.a).前后截取 通过设置开始字符串和结束字符串,来获取中间的字符,可以在开始和结束字符串中设置通配符(*)。比如一段源代码为“
标题”,那么其中的标题就是我们需要的内容,我们在火车采集器V9中写作: A.b).正则提取 支持两种正则,一个纯正则,一个参数正则。 先介绍纯正则,举个例子,如:前字符串(?
[\s\S]*?)后字符串,这个正则其实效果跟前后截取一样,如需要获取全部代码,则为^(?[\s\S]*?)$ ,此功能运用需有一定的正则基础。 关于参数正则,是通过参数组合,来生成内容。比如说要匹配标题为“新用户注册”和作者“神秘嘉宾”,代码如下: