spider简单的爬虫程序!!!经典
spider简单的爬虫程序
2008-10-10 16:29
spider简单的爬虫程序
1、基础准备
htmlparser
首页:https://www.360docs.net/doc/126240095.html,/projects/htmlparser/
下载:https://www.360docs.net/doc/126240095.html,/project/showfiles.php?group_id=24399
文件:htmlparser1_6_20060610.zip
cpdetector
首页:https://www.360docs.net/doc/126240095.html,/
下载:https://www.360docs.net/doc/126240095.html,/project/showfiles.php?group_id=114421
文件:cpdetector_eclipse_project_1.0.7.zip
spindle
首页:https://www.360docs.net/doc/126240095.html,/projects/spindle/(但是已经无法访问)
2 修改spindle代码得到的spider
简单的将URL打印出来了,解析的内容等等都没有处理
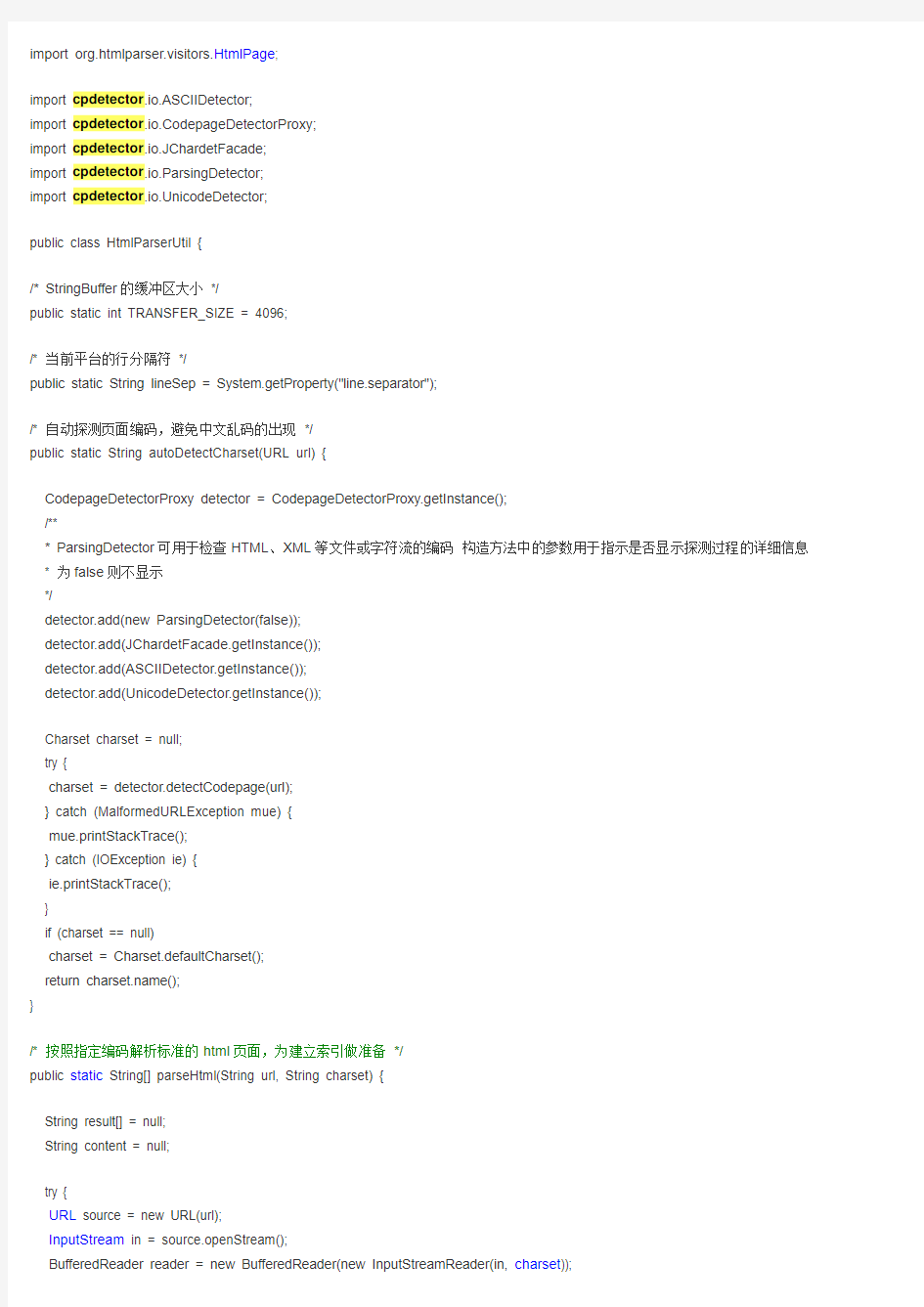
解析HTML的基类HtmlParserUtil.java
package https://www.360docs.net/doc/126240095.html,mons.utils.html;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.UnsupportedEncodingException;
import https://www.360docs.net/doc/126240095.html,.MalformedURLException;
import https://www.360docs.net/doc/126240095.html,.SocketException;
import https://www.360docs.net/doc/126240095.html,.SocketTimeoutException;
import https://www.360docs.net/doc/126240095.html,.URL;
import https://www.360docs.net/doc/126240095.html,.UnknownHostException;
import java.nio.charset.Charset;
import org.htmlparser.Parser;
import org.htmlparser.util.NodeList;
import org.htmlparser.util.ParserException;
import org.htmlparser.visitors.HtmlPage;
import cpdetector.io.ASCIIDetector;
import cpdetector.io.CodepageDetectorProxy;
import cpdetector.io.JChardetFacade;
import cpdetector.io.ParsingDetector;
import cpdetector.io.UnicodeDetector;
public class HtmlParserUtil {
/* StringBuffer的缓冲区大小*/
public static int TRANSFER_SIZE = 4096;
/* 当前平台的行分隔符*/
public static String lineSep = System.getProperty("line.separator");
/* 自动探测页面编码,避免中文乱码的出现*/
public static String autoDetectCharset(URL url) {
CodepageDetectorProxy detector = CodepageDetectorProxy.getInstance();
/**
* ParsingDetector可用于检查HTML、XML等文件或字符流的编码构造方法中的参数用于指示是否显示探测过程的详细信息* 为false则不显示
*/
detector.add(new ParsingDetector(false));
detector.add(JChardetFacade.getInstance());
detector.add(ASCIIDetector.getInstance());
detector.add(UnicodeDetector.getInstance());
Charset charset = null;
try {
charset = detector.detectCodepage(url);
} catch (MalformedURLException mue) {
mue.printStackTrace();
} catch (IOException ie) {
ie.printStackTrace();
}
if (charset == null)
charset = Charset.defaultCharset();
return https://www.360docs.net/doc/126240095.html,();
}
/* 按照指定编码解析标准的html页面,为建立索引做准备*/
public static String[] parseHtml(String url, String charset) {
String result[] = null;
String content = null;
try {
URL source = new URL(url);
InputStream in = source.openStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(in, charset));
String line = new String();
StringBuffer temp = new StringBuffer(TRANSFER_SIZE);
while ((line = reader.readLine()) != null) {
temp.append(line);
temp.append(lineSep);
}
reader.close();
in.close();
content = temp.toString();
} catch (UnsupportedEncodingException uee) {
uee.printStackTrace();
} catch (MalformedURLException mue) {
System.err.println("Invalid URL : " + url);
} catch (UnknownHostException uhe) {
System.err.println("UnknowHost : " + url);
} catch (SocketException se) {
System.err.println("Socket Error : " + se.getMessage() + " " + url);
} catch (SocketTimeoutException ste) {
System.err.println("Socket Connection Time Out : " + url);
} catch (FileNotFoundException fnfe) {
System.err.println("broken link "
+ ((FileNotFoundException) fnfe.getCause()).getMessage()
+ " ignored");
} catch (IOException ie) {
ie.printStackTrace();
}
if (content != null) {
Parser myParser = Parser.createParser(content, charset);
HtmlPage visitor = new HtmlPage(myParser);
try {
myParser.visitAllNodesWith(visitor);
String body = null;
String title = "Untitled";
if (visitor.getBody() != null) {
NodeList nodelist = visitor.getBody();
body = nodelist.asString().trim();
}
if (visitor.getTitle() != null){
title = visitor.getTitle();
}
result = new String[] { body, title };
} catch (ParserException pe) {
pe.printStackTrace();
}
}
return result;
}
}
多线程爬虫类HtmlCaptureRunner.java
package com.sillycat.api.thread.runner;
import java.io.FileNotFoundException;
import java.io.IOException;
import https://www.360docs.net/doc/126240095.html,.HttpURLConnection;
import https://www.360docs.net/doc/126240095.html,.MalformedURLException;
import https://www.360docs.net/doc/126240095.html,.SocketException;
import https://www.360docs.net/doc/126240095.html,.SocketTimeoutException;
import https://www.360docs.net/doc/126240095.html,.URL;
import https://www.360docs.net/doc/126240095.html,.UnknownHostException;
import java.util.ArrayList;
import java.util.HashSet;
import https://www.360docs.net/doc/126240095.html,mons.logging.Log;
import https://www.360docs.net/doc/126240095.html,mons.logging.LogFactory;
import org.htmlparser.Parser;
import org.htmlparser.PrototypicalNodeFactory;
import org.htmlparser.filters.AndFilter;
import org.htmlparser.filters.HasAttributeFilter;
import org.htmlparser.filters.NodeClassFilter;
import org.htmlparser.tags.BaseHrefTag;
import org.htmlparser.tags.FrameTag;
import org.htmlparser.tags.LinkTag;
import org.htmlparser.tags.MetaTag;
import org.htmlparser.util.EncodingChangeException;
import org.htmlparser.util.NodeIterator;
import org.htmlparser.util.NodeList;
import org.htmlparser.util.ParserException;
import https://www.360docs.net/doc/126240095.html,mons.utils.StringUtil;
import https://www.360docs.net/doc/126240095.html,mons.utils.html.HtmlParserUtil;
public class HtmlCaptureRunner implements Runnable {
public Log logger = LogFactory.getLog(getClass());
/* 基准(初始)URL */
protected String baseURL = null;
private String contentPath = null;
/**
* 待解析的URL地址集合,所有新检测到的链接均存放于此;解析时按照先入先出(First-In First-Out)法则线性取出*/
protected ArrayList URLs = new ArrayList();
/* 已存储的URL地址集合,避免链接的重复抓取*/
protected HashSet indexedURLs = new HashSet();
protected Parser parser = new Parser();;
/* 程序运行线程数,默认2个线程*/
protected int threads = 2;
/* 解析页面时的字符编码*/
protected String charset;
/* 基准端口*/
protected int basePort;
/* 基准主机*/
protected String baseHost;
/* 是否存储,默认true */
protected boolean justDatabase = true;
/* 检测索引中是否存在当前URL信息,避免重复抓取*/
protected boolean isRepeatedCheck = false;
public HtmlCaptureRunner() {
PrototypicalNodeFactory factory = new PrototypicalNodeFactory();
factory.registerTag(new LocalLinkTag());
factory.registerTag(new LocalFrameTag());
factory.registerTag(new LocalBaseHrefTag());
parser.setNodeFactory(factory);
}
public void capture() {
URLs.clear();
URLs.add(getBaseURL());
int responseCode = 0;
String contentType = "";
try {
HttpURLConnection uc = (HttpURLConnection) new URL(baseURL)
.openConnection();
responseCode = uc.getResponseCode();
contentType = uc.getContentType();
} catch (MalformedURLException mue) {
logger.error("Invalid URL : " + getBaseURL());
} catch (UnknownHostException uhe) {
logger.error("UnknowHost : " + getBaseURL());
} catch (SocketException se) {
logger.error("Socket Error : " + se.getMessage() + " "
+ getBaseURL());
} catch (IOException ie) {
logger.error("IOException : " + ie);
}
if (responseCode == HttpURLConnection.HTTP_OK && contentType.startsWith("text/html")) { try {
charset = HtmlParserUtil.autoDetectCharset(new URL(baseURL));
basePort = new URL(baseURL).getPort();
baseHost = new URL(baseURL).getHost();
if (charset.equals("windows-1252"))
charset = "GBK";
long start = System.currentTimeMillis();
ArrayList threadList = new ArrayList();
for (int i = 0; i < threads; i++) {
Thread t = new Thread(this, "Spider Thread #" + (i + 1));
t.start();
threadList.add(t);
}
while (threadList.size() > 0) {
Thread child = (Thread) threadList.remove(0);
try {
child.join();
} catch (InterruptedException ie) {
logger.error("InterruptedException : " + ie);
}
}
// for (int i = 0; i < threads; i++) {
// threadPool.getThreadPoolExcutor().execute(new
// Thread(this,"Spider Thread #" + (i + 1)));
// }
long elapsed = System.currentTimeMillis() - start;
https://www.360docs.net/doc/126240095.html,("Finished in " + (elapsed / 1000) + " seconds");
https://www.360docs.net/doc/126240095.html,("The Count of the Links Captured is "
+ indexedURLs.size());
} catch (MalformedURLException e) {
e.printStackTrace();
}
}
}
public void run() {
String url;
while ((url = dequeueURL()) != null) {
if (justDatabase) {
process(url);
}
}
threads--;
}
/**
* 处理单独的URL地址,解析页面并加入到lucene索引中;通过自动探测页面编码保证抓取工作的顺利执行*/
protected void process(String url) {
String result[];
String content = null;
String title = null;
result = HtmlParserUtil.parseHtml(url, charset);
content = result[0];
title = result[1];
if (content != null && content.trim().length() > 0) {
// content
System.out.println(url);
// title
// DateTools.timeToString(System.currentTimeMillis() }
}
/* 从URL队列mPages里取出单个的URL */
public synchronized String dequeueURL() {
while (true)
if (URLs.size() > 0) {
String url = (String) URLs.remove(0);
indexedURLs.add(url);
if (isToBeCaptured(url)) {
NodeList list;
try {
int bookmark = URLs.size();
/* 获取页面所有节点*/
parser.setURL(url);
try {
list = new NodeList();
for (NodeIterator e = parser.elements(); e
.hasMoreNodes();)
list.add(e.nextNode());
} catch (EncodingChangeException ece) {
/* 解码出错的异常处理*/
parser.reset();
list = new NodeList();
for (NodeIterator e = parser.elements(); e
.hasMoreNodes();)
list.add(e.nextNode());
}
/**
* 依据https://www.360docs.net/doc/126240095.html,/wc/meta-user.html处理* Robots tag
*/
NodeList robots = list
.extractAllNodesThatMatch(
new AndFilter(new NodeClassFilter(
MetaTag.class),
new HasAttributeFilter("name",
"robots")), true);
if (0 != robots.size()) {
MetaTag robot = (MetaTag) robots.elementAt(0);
String content = robot.getAttribute("content")
.toLowerCase();
if ((-1 != content.indexOf("none"))
|| (-1 != content.indexOf("nofollow")))
for (int i = bookmark; i < URLs.size(); i++)
URLs.remove(i);
}
} catch (ParserException pe) {
logger.error("ParserException : " + pe);
}
return url;
}
} else {
threads--;
if (threads > 0) {
try {
wait();
threads++;
} catch (InterruptedException ie) {
logger.error("InterruptedException : " + ie);
}
} else {
notifyAll();
return null;
}
}
}
private boolean isHTML(String url) {
if (!url.endsWith(".html")) {
return false;
}
if (StringUtil.isNotBlank(contentPath)) {
if (!url.startsWith(baseURL + "/" + contentPath)) {
return false;
}
}
return true;
}
/**
* 判断提取到的链接是否符合解析条件;标准为Port及Host与基准URL相同且类型为text/html或text/plain */
public boolean isToBeCaptured(String url) {
boolean flag = false;
HttpURLConnection uc = null;
int responseCode = 0;
String contentType = "";
String host = "";
int port = 0;
try {
URL source = new URL(url);
String protocol = source.getProtocol();
if (protocol != null && protocol.equals("http")) {
host = source.getHost();
port = source.getPort();
uc = (HttpURLConnection) source.openConnection();
uc.setConnectTimeout(8000);
responseCode = uc.getResponseCode();
contentType = uc.getContentType();
}
} catch (MalformedURLException mue) {
logger.error("Invalid URL : " + url);
} catch (UnknownHostException uhe) {
logger.error("UnknowHost : " + url);
} catch (SocketException se) {
logger.error("Socket Error : " + se.getMessage() + " " + url);
} catch (SocketTimeoutException ste) {
logger.error("Socket Connection Time Out : " + url);
} catch (FileNotFoundException fnfe) {
logger.error("broken link " + url + " ignored");
} catch (IOException ie) {
logger.error("IOException : " + ie);
}
if (port == basePort
&& responseCode == HttpURLConnection.HTTP_OK
&& host.equals(baseHost)
&& (contentType.startsWith("text/html") || contentType
.startsWith("text/plain")))
flag = true;
return flag;
}
class LocalLinkTag extends LinkTag {
public void doSemanticAction() {
String link = getLink();
if (link.endsWith("/"))
link = link.substring(0, link.length() - 1);
int pos = link.indexOf("#");
if (pos != -1)
link = link.substring(0, pos);
/* 将链接加入到处理队列中*/
if (!(indexedURLs.contains(link) || URLs.contains(link))) {
if (isHTML(link)) {
URLs.add(link);
}
}
setLink(link);
}
/**
* Frame tag that rewrites the SRC URLs. The SRC URLs are mapped to local * targets if they match the source.
*/
class LocalFrameTag extends FrameTag {
public void doSemanticAction() {
String link = getFrameLocation();
if (link.endsWith("/"))
link = link.substring(0, link.length() - 1);
int pos = link.indexOf("#");
if (pos != -1)
link = link.substring(0, pos);
/* 将链接加入到处理队列中*/
if (!(indexedURLs.contains(link) || URLs.contains(link))) {
if (isHTML(link)) {
URLs.add(link);
}
}
setFrameLocation(link);
}
}
/**
* Base tag that doesn't show. The toHtml() method is overridden to return
* an empty string, effectively shutting off the base reference.
*/
class LocalBaseHrefTag extends BaseHrefTag {
public String toHtml() {
return ("");
}
}
public String getBaseURL() {
return baseURL;
}
public void setBaseURL(String baseURL) {
this.baseURL = baseURL;
}
public int getThreads() {
return threads;
}
public void setThreads(int threads) {
this.threads = threads;
}
public String getCharset() {
return charset;
public void setCharset(String charset) {
this.charset = charset;
}
public int getBasePort() {
return basePort;
}
public void setBasePort(int basePort) {
this.basePort = basePort;
}
public String getBaseHost() {
return baseHost;
}
public void setBaseHost(String baseHost) {
this.baseHost = baseHost;
}
public boolean isJustDatabase() {
return justDatabase;
}
public void setJustDatabase(boolean justDatabase) {
this.justDatabase = justDatabase;
}
public String getContentPath() {
return contentPath;
}
public void setContentPath(String contentPath) {
this.contentPath = contentPath;
}
}
spring上的配置文件applicationContext-bean.xml:
class="com.sillycat.api.thread.runner.HtmlCaptureRunner" >
class="com.sillycat.api.thread.runner.HtmlCaptureRunner" >
easySearch.properties配置文件:
#==========================================
# spider configration
#=========================================
product.contentPath=product
product.base.port=80
product.base.url=https://www.360docs.net/doc/126240095.html,
product.base.code=UTF-8
product.base.threads=3
message.contentPath=message
message.base.port=80
message.base.url=https://www.360docs.net/doc/126240095.html,
message.base.code=UTF-8
message.base.threads=3
单元测试类HtmlRunnerTest.java文件:
package com.sillycat.api.thread;
import https://www.360docs.net/doc/126240095.html,mons.base.BaseManagerTest;
import com.sillycat.api.thread.runner.HtmlCaptureRunner;
public class HtmlRunnerTest extends BaseManagerTest {
private HtmlCaptureRunner productCapture;
private HtmlCaptureRunner messageCapture;
protected void setUp() throws Exception {
super.setUp();
productCapture = (HtmlCaptureRunner) appContext.getBean("productCapture");
messageCapture = (HtmlCaptureRunner) appContext.getBean("messageCapture"); }
protected void tearDown() throws Exception {
super.tearDown();
}
public void testDumy() {
assertTrue(true);
}
public void ntestProductCapture() {
productCapture.capture();
}
public void testMessageCapture(){ messageCapture.capture();
}
}