2012-2013数据结构

浙江大学2012–2013学年秋学期
《数据结构基础》课程期末考试试卷(A) 课程号: 211C0020_,开课学院:_计算机科学与技术_
考试试卷:√A卷、B卷(请在选定项上打√)
考试形式:√闭、开卷(请在选定项上打√),允许带____无___入场考试日期: 2012 年 11 月 15 日,考试时间: 120 分钟
诚信考试,沉着应考,杜绝违纪。
考生姓名:学号:所属院系: _
Answer Sheet
NOTE: Please write your answers on the answer sheet.
注意:请将答案填写在答题纸上。
I. Please select the answer for the following problems. (20 points)
(1) Which one of the following statements is true as N grows?
a. For any x , N x grows faster than !N
b. 2)(log N grows faster than N
c. 2log N grows faster than 2)(log N
d. N grows faster than 2
)(log N N
(2) What is the time complexity of the following function that computes X N ?
long int Pow (long int X, unsigned int N) {
if (N == 0) return 1;
if (N == 1) return X;
if (IsEven(N)) /* IsEven(N) returns 1 if N is even, or 0 otherwise */
return Pow(X, N / 2) * Pow (X, N / 2);
else return Pow(X * X, N / 2) * X;
} a. O(N ) b. O(N log ) c. O(N N log ) d. O(N )
(3) Suppose that N integers are pushed into and popped out of a stack. The input sequence is 1, 2, …, N and the output sequence is p 1, p 2, …, p N . If p 2 = 2, then p i (i>2) must be .
a. i
b. i+2
c. N - i
d. cannot be determined
(4) What is the major difference among lists, stacks, and queues? a. Lists use pointers, and stacks and queues use arrays
b. Stacks and queues are lists with insertion/deletion constraints
c. Lists and queues can be implemented using circularly linked lists, but stacks cannot
d. Stacks and queues are linear structures while lists are not
(5) For an in-order threaded binary tree, if the pre-order and in-order traversal sequences are ABCDEF and CBAEDF respectively ,which pair nodes ’ right links are both threads?
a. A and B
b. B and D
c. C and D
d. B and E
(6) If N keys are hashed into the same slot, then to find these N keys, the minimum number of probes with linear probing is .
a. N-1
b. N
c. N(N+1)/2
d. N+1
(7) If an undirected graph with N vertices and E edges is represented by an adjacency matrix. How many zero elements are there in the matrix? a. E b. 2E c. N 2-E d. N 2-2E
(8) If a directed graph is stored by an upper-triangular adjacency matrix –- that is, all the elements below the main diagonal are zero. Then its topological order .
a. exists and must be unique
b. exists but may not be unique
c. does not exist
d. cannot be determined
(9)Sort a sequence of nine integers {4, 8, 3, 7, 9, 2, 10, 6, 5} by insertion sort. When 2 is moved to the first position, the number 8 must be at position (start from 1) .
a. 4
b. 5
c. 6
d. 7
(10)Let T be a tree of N nodes created by union-by-height without path compression, then the depth of the tree is
a. N/2
b. O(logN)
c. O(N2)
d. O(1)
II. Given the function descriptions of the following two (pseudo-code) programs, please fill in the blank lines. (21 points)
(1)Bubble sort is a simple sorting algorithm. Suppose we have a list of integers and want to sort them in ascending order. Bubble sort repeatedly scans the list from the head to the tail, and swaps two adjacent numbers if they are in the wrong order. Please complete the following program to implement bubble sort. (12 points)
struct node{
int value;
struct node *next;
/* some other fields */
}
struct node BubbleSort (struct node *h)
{/* h is the head pointer of the list with a dummy head node */
struct node *p, *q;
int flag_swap;
if (!h->next) return h;
do{
flag_swap = 0;
p = h;
while (p->next->next){
if (① ){
flag_swap++;
q = p->next;
② ;
③ ;
④ ;
}
else p = p->next;
}
} while (flag_swap > 0);
return h;
}
(2)The function is to perform Find as a Union/Find operation with path compression. (9 points)
SetType Find ( ElementType X, DisjSet S )
{
ElementType root, trail, lead;
for ( root = X; S[ root ] > 0; ① )
;
for ( trail = X; trail != root; ② ) {
lead = S[ trail ] ;
③ ;
}
return root ;
}
III. Please write or draw your answers for the following problems on the answer sheet. (44 points)
(1) A sorting algorithm is stable if for any keys K i = K j for i < j,
the corresponding records R i precedes R j in the sorted list.
(a)Is Heap Sort stable? Please give a proof if your answer is
“YES”, else please provide a counter example. (4 points)
(b)Is Quick Sort stable? Please give a proof if your answer is
“YES”, else please provide a counter example. (4 points)
(2)Given the adjacency list representation of a directed graph.
Suppose V1 is always the first vertex being visited. Please list
(a)the depth-first search sequence; (5 points)
(b)the breath-first search sequence; (5 points) and
(c)the strongly connected components. (3 points)
(3) A binary search tree is said to be of “type A”if all the keys
along the path from the root to any leaf node are in sorted order
(either ascending or descending).
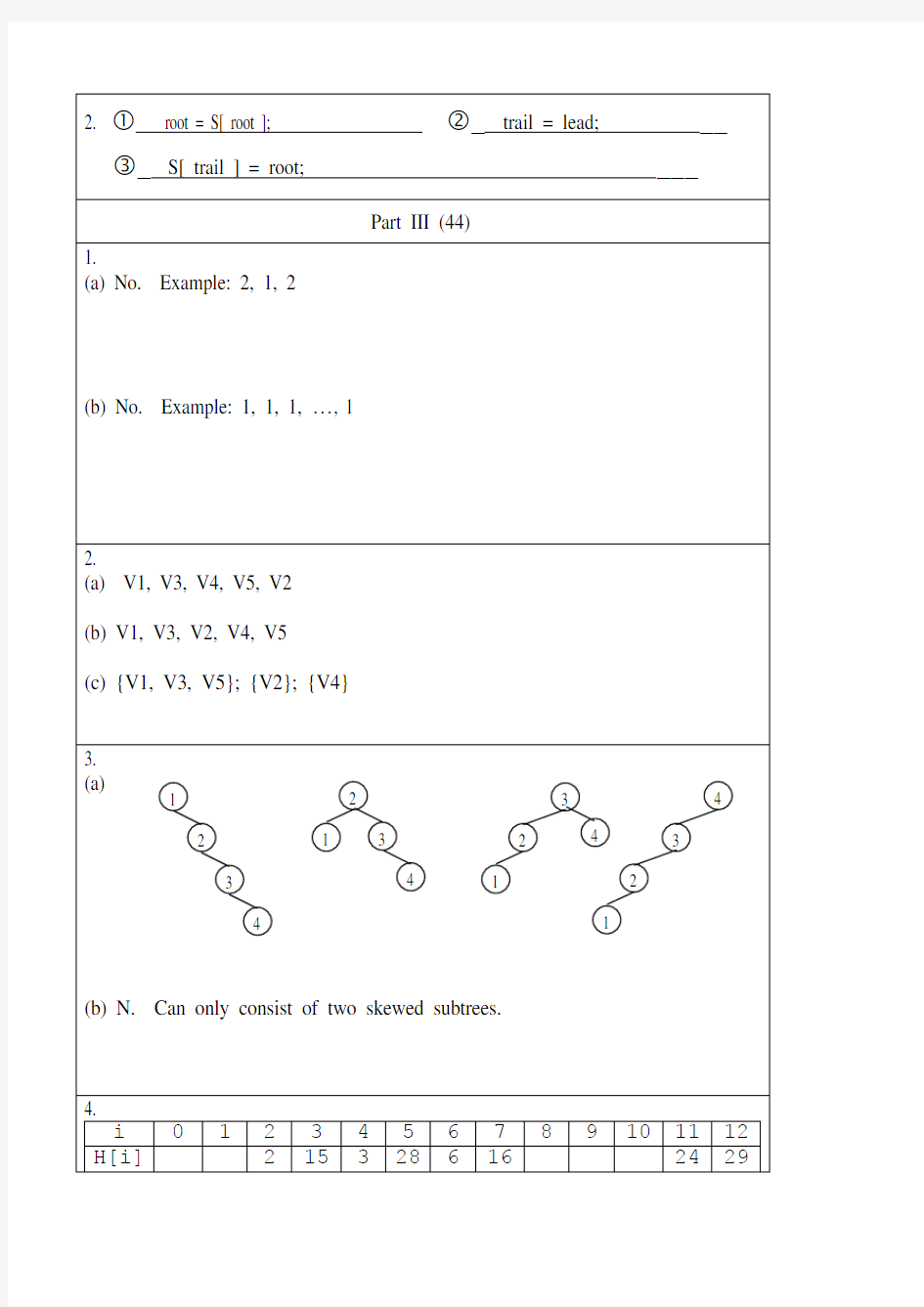
(a)Given four keys {1, 2, 3, 4}, please draw all the possible
binary search trees of type A. (4 points)
(b)In general, given N keys {1, 2, …, N}, how many different
binary search trees of type A can be constructed? (3 points)
(4)Given a hash table of size 13 and the hash function H(key) = key
mod 13. Assume that quadratic probing is used to solve collisions.
Please fill in the hash table with input numbers {2, 15, 3, 16, 6,
29, 24, 28}. (4 points)
(5)Given eight keys {1, 2, …, 8}. Please do the following:
(a)construct a complete binary tree which is also a binary search
tree; (5 points) and
(b)construct a min-heap out of the array which stores the
complete binary tree obtained from (a). Use BuildHeap with a
sequence of percolate-down’s. (4 points)
(c)Observe the keys on each level of the min-heap obtained from
(b). Is there a pattern of ordering? Is this true for more
general cases? (3 points)
IV. Given a tree represented by left-child-right-sibling structure, please describe an algorithm that counts the number of leaf nodes on every level.
(15 points)
数据库表结构设计参考
数据库表结构设计参考
表名外部单位表(DeptOut) 列名数据类型(精度范围)空/非空约束条件 外部单位ID 变长字符串(50) N 主键 类型变长字符串(50) N 单位名称变长字符串(255) N 单位简称变长字符串(50) 单位全称变长字符串(255) 交换类型变长字符串(50) N 交换、市机、直送、邮局单位邮编变长字符串(6) 单位标识(英文) 变长字符串(50) 排序号整型(4) 交换号变长字符串(50) 单位领导变长字符串(50) 单位电话变长字符串(50) 所属城市变长字符串(50) 单位地址变长字符串(255) 备注变长字符串(255) 补充说明该表记录数约3000条左右,一般不做修改。初始化记录。 表名外部单位子表(DeptOutSub) 列名数据类型(精度范围)空/非空约束条件 外部子单位ID 变长字符串(50) N 父ID 变长字符串(50) N 外键 单位名称变长字符串(255) N 单位编码变长字符串(50) 补充说明该表记录数一般很少 表名内部单位表(DeptIn) 列名数据类型(精度范围)空/非空约束条件 内部单位ID 变长字符串(50) N 主键 类型变长字符串(50) N 单位名称变长字符串(255) N 单位简称变长字符串(50) 单位全称变长字符串(255) 工作职责 排序号整型(4) 单位领导变长字符串(50) 单位电话(分机)变长字符串(50) 备注变长字符串(255)
补充说明该表记录数较小(100条以内),一般不做修改。维护一次后很少修改 表名内部单位子表(DeptInSub) 列名数据类型(精度范围)空/非空约束条件内部子单位ID 变长字符串(50) N 父ID 变长字符串(50) N 外键 单位名称变长字符串(255) N 单位编码变长字符串(50) 单位类型变长字符串(50) 领导、部门 排序号Int 补充说明该表记录数一般很少 表名省、直辖市表(Province) 列名数据类型(精度范围)空/非空约束条件ID 变长字符串(50) N 名称变长字符串(50) N 外键 投递号变长字符串(255) N 补充说明该表记录数固定 表名急件电话语音记录表(TelCall) 列名数据类型(精度范围)空/非空约束条件ID 变长字符串(50) N 发送部门变长字符串(50) N 接收部门变长字符串(50) N 拨打电话号码变长字符串(50) 拨打内容变长字符串(50) 呼叫次数Int 呼叫时间Datetime 补充说明该表对应功能不完善,最后考虑此表 表名摄像头图像记录表(ScreenShot) 列名数据类型(精度范围)空/非空约束条件ID 变长字符串(50) N 拍照时间Datetime N 取件人所属部门变长字符串(50) N 取件人用户名变长字符串(50) 取件人卡号变长字符串(50) 图片文件BLOB/Image
论非结构化数据库的应用
论非结构化数据库的应用 谭鑫(1101400114)随着网络技术和网络应用技术的飞快发展,完全基于Internet应用的非结构化数据库将成为继层次数据库、关系数据库之后的又一重点、热点技术。关系型数据库由于其严格的表格结构使其对图像、音频、视频等数据的处理存在着缺陷。这种无法用数字或统一的结构表示的信息,即通常意义上的多媒体信息统称为非结构化数据。随着网络技术的不断发展,在数据库应用领域中,非结构化数据的数据量日趋增大,非结构化数据库管理系统便应运而生。 非结构化数据库,即其字段长度可变,并且每个字段的记录又可以由可重复或不可重复的子字段构成的数据库。在其底层存储机制的变革基础上,采用先进的倒排档索引技术,从而实现了对于海量文献信息的快速全文检索的功能,并同时支持多种字段限定检索。对于多媒体信息的存储和管理,非结构化数据库系统采用外部文件方式,摈弃了传统关系型数据库采用二进制字段存储的方式,实现了对于图形、声音等多媒体信息的高效管理。其高效性在图书馆信息资源中具体表现在: (1)非结构化数据库系统实现了对于变长字段、重复字段和子字段的定义、存储和管理,并且记录的数目、长度,字段数目与长度以及字段可重复次数均可不受限制,允许数据项具有多值性和可包含子字段,充分满足了图书馆建立文献数据库的特殊管理要求。 (2)图书馆资源载体类型较多,有纸制的载体,也有磁、光、电介质的载体。馆藏电子信息资源不仅包括TxT、DOC、EXCEL、PPT、PDF等流行的数据文件类型,而且还存有大量的图像、音频、视频等数据信息。图书馆资源既包括本地资源,又存在异地资源,既有国内资源,又存在国外资源,不同国别,不同地域的文献资料在数据著录格式上存在着差别。非结构化数据库采用面向对象技术不仅支持国际标准和国内标准格式,而且支持最新的SGML和XML格式,覆盖了多类型文档应用领域内几乎所有的文献数据类型。具有可扩展性,可以与其他元数据单元连接使用,不仅适合中文全文检索系统平台的应用,同时也符合国际数字图书馆标准化的发展趋势,便于与国际交流与接轨,这对于图书馆数据库标准化和数据交换与共享,起着极其重要的作用。 (3)在网络应用中,如何从浩瀚的信息海洋中查找到所需的信息,如何保证所查询信息的全面性和准确性,也是一个我们面临的问题。非结构化网络数据库系统通过其独特的索引技术和基于布尔检索表达式的查询检索算法,解决了基于字段级和数据库级的全文检索问题,用户可以针对数据库中特定的字段也可针对整个数据库进行全文检索,从而从数据库中检索出感兴趣的内容。非结构化数据库内嵌全文检索引擎,采用倒排档索引技术,不仅能够对整个字段进行查询,而且可以提供子字段、关键词、自由词、标引词、位置词和全文任意词的单项及组配检索。而且速度也非常快,一般不受文献量的影响,满足海量数据检索的需要。同时,非结构化数据库支持外挂文件的全文检索,其独特的外部文件支持能力使图书馆能轻松实现二次文献挂接全文的功能。 (4)非结构化数据库采用自然语言处理和人工智能技术,提供基于内容的检索和ANY词检索方式,并在检索中实现对于特定类目相关词的利用,大大提高了系统的查全率。同时非结构化数据库支持的禁用词,可以过滤掉一些没有检索意义的英文虚词,以提高查准率。作为网络应用,由于需要面对大量的用户群和
Egg非结构化数据库软件-设计说明书
产品概述 产品介绍 Egg是一个高性能、可扩展、并支持分布式存贮的非结构化数据库,同时也具备了部分非关系型数据库具备的结构化查询功能。该类型的数据库被广泛应用于搜索引擎、海量信息检索系统、音频视频管理系统等领域,成为这些领域中必不可少的一个组成部分。Egg是一个完全由C编写的,成熟的软件,并且是埃帕Cooling搜索引擎软件、Cooling云桌面平台软件、Cooling云输入法的重要组成部分,已经运用到了互联网、信息检索、数据挖掘、虚拟化等多个领域中。 行业背景 随着互联网的不断发展,搜索、云计算、WEB 2.0等全新的应用模式不断涌现出来。这些新应用都有着一些非常显著的特点,如:信息量巨大、信息结构化程度低、信息更新频度高、信息增长幅度大,并发访问频繁等。传统的关系型数据库,虽然能够胜任企业级别的信息管理,但在处理互联网级别的应用时,往往无法满足于以上的特点,暴露出了很多问题。 海量数据的高效存贮与访问要求 海量数据应用中最早,最典型的应用是搜索引擎;最有发展的是云计算;最流行的是WEB2.0中的SNS社区。 据CNNIC统计,截止2009年底,仅中国的网页数量就达到了336亿,较之2008年底,增长幅度接近100%。搜索引擎不光要存贮这些网页的基本信息,同时又要解决平均每天几千万网页的增长量。云计算、需要将原先用户端的应用、服务、数据移到服务端,利用服务端的计算、存贮、带宽、管理优势,提供相比传统桌面应用更有竞争力的服务方式。WEB 2.0中最主流的SNS社区,每天都要产生大量的用户动态信息,以Facebook为例,每月用户动态记录就达到2.5亿条;另如一些Web 门户,都已经达到上亿帐户数量。所有的此类应用中的存贮要求,都已经超过了关系型数据库可以容纳的范围。Google是最早采用了廉价硬件
进销存数据库表结构设计
1.帐类表(KIND) 无索引 序号中文名称英文名称类型备注 1 帐类编号K_SERIAL byte 2 帐类名称K_NAME text*10 本表系统自动建立,共划分为15种帐类,不可增删 帐类编号帐类名称备注 0 上期结存进货,不参加进货统计 1 购入进货,购入时必需输入供货单位名称 2 自制进货 3 投资转入进货 4 盘盈进货 5 领料出库,领料必需输入领料部门名称 6 调拨出库 7 报损出库 8 盘亏出库 9 退库对低值易耗品,在用品退为在用库存 10 直接报废对于低值易耗品,在用品转报废 11 领用对于低值易耗品,在用库存转在用 12 调拨对于低值易耗品,在用库存减少 13 报废对于低值易耗品,在用库存报废 14 直进直出进出库,购入与领料对库存无影响 2.物品表(GOODS) 序号索引名称索引域唯一? 主索引? 1 G_CODING +G_CODING Y N 2 G_SERIAL +G_SERIAL Y Y 序号中文名称英文名称类型备注 1 物品内部编号G_SERIAL INT->long 系统内部唯一标识该物品 2 物品编号G_CODING TEXT * 10 用户使用此编号访问物品 &3 物品名称G_NAME TEXT*40 非空 &4 物品单位G_UNIT TEXT*8 非空 &5 物品规格G_STATE TEXT*20
6 物品类别G_CLASS INT 取自表CLASS 7 备注G_REMARKS MEMO 8 最小库存量G_MIN CURRENCY 为零,即无最小库存 9 最大库存量G_MAX CURRENCY 为零,即无最大库存 10 库存数量G_QUANT CURRENCY 控制出库数量 11 虚拟库存数量G_VQUANT CURRENCY 出库时用 12 库存金额G_AMOUNT CURRENCY 3.类别表(CLASS) 序号索引名称索引域唯一? 主索引? 1 C_CODING +C_CODING Y N 2 C_SERIAL +C_SERIAL Y Y 序号中文名称英文名称类型备注 1 类别内部序号C_SERIAL INT 系统内部唯一标识该物品 2 类别编号C_CODING TEXT *10 用户使用该编号访问类别信息 3 类别名称C_NAME TEXT*20 非空 4 出库类型C_KIND BYTE 1.移动平均 2..先进先出 3.后进先出 4.实际计价 *5.月末平均 5 备注C_REMARKS MEMO *6 底标志C_BOTTOM BOOLEAN *7 类别级别C_LEVEL BYTE 4.供货单位、使用部门(DEPART) 序号索引名称索引域唯一? 主索引? 1 D_CODING +D_CODING Y N 2 D_SERIAL +D_SERIAL Y Y 序号中文名称英文名称类型备注 1 内部序号D_SERIAL INT 系统内部唯一标识该部门 >0 供货单位 =0 库房 <0 使用部门 2 单位编号D_CODING TEXT*10
非结构化数据管理系统
非结构化数据管理系统 1 范围 本标准规定了非结构化数据管理系统的功能性要求和质量要求。 本标准适用于非结构化数据管理系统产品的研制、开发和测试。 2 符合性 对于非结构化数据管理系统是否符合本标准的规定如下: a)非结构化数据管理系统若满足本标准基本要求中的所有要求,则称其满足本标准的基本要求; b)非结构化数据管理系统在满足所有基本要求的前提下,若满足某部分扩展要求,则称其满足本 标准的基本要求和该部分扩展要求; c)非结构化数据管理系统若满足本标准基本要求和扩展要求中的所有要求,则称其满足本标准的 所有要求。 3 规范性引用文件 下列文件对于本文件的应用是必不可少的。凡是注日期的引用文件,仅注日期的版本适用于本文件。凡是不注日期的引用文件,其最新版本(包括所有的修改单)适用于本文件。 GB 18030—2005 信息技术中文编码字符集 GB/T AAAAA-AAAA 非结构化数据访问接口规范 4 术语和定义 下列术语和定义适用于本文件。 4.1 非结构化数据unstructured data 没有明确结构约束的数据,如文本、图像、音频、视频等。 4.2 非结构化数据管理系统unstructured data management system 对非结构化数据进行管理、操作的大型基础软件,提供非结构化数据存储、特征抽取、索引、查询等管理功能。 5 缩略语 下列缩略语适用于本文件。 IDF:逆向文件频率 (Inverse Document Frequency) MFCC:梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient)
PB:千万亿字节(Peta Byte) SIFT:尺度不变特征转换(Scale-invariant Feature Transform) TF:词频 (Term Frequency) 6 功能性要求 6.1 总体要求 非结构化数据管理系统的总体要求如下: a)应包括存储与计算设施、存储管理、特征抽取、索引管理、查询处理、访问接口、管理工具七 个基本组成部分; b)宜包括转换加载、分析挖掘、可视展现三个扩展组成部分。 6.2 存储与计算设施 6.2.1 基本要求 存储与计算设施基本要求如下: a)应支持磁盘、磁盘阵列、内存存储、键值存储、关系型存储、分布式文件系统等一种或多种存 储设施; b)应支持单机、并行计算集群、分布式计算集群等一种或多种计算设施。 6.2.2 扩展要求 无。 6.3 存储管理 6.3.1 基本要求 存储管理基本要求如下: a)应提供涵盖原始数据、基本属性、底层特征、语义特征的概念层存储建模功能; b)应提供逻辑层的存储建模功能; c)支持整型、浮点型、布尔型、字符串、日期、日期时间、二进制块等基本数据类型; d)支持向量、矩阵、关联等数据类型; e)应支持根据建好的逻辑层存储模型创建存储实例; f)应支持在创建好的存储实例上插入、修改、删除非结构化数据; g)应支持删除存储实例; h)应支持非结构化数据操作的原子性。 6.3.2 扩展要求 存储管理扩展要求如下: a)应支持全局事务的定义并保证事务的原子性、一致性、隔离性和持久性; b)应支持数据类型的多值结构和层次结构; c)应支持在不同的存储设施上创建存储实例并实现自动映射; d)应支持PB级数据存储。 6.4 特征抽取
数据库结构设计
一、数据库结构设计步骤 二、需求分析 三、概念结构设计 四、逻辑结构设计 五、数据库物理设计 数据库结构设计 一、数据库结构设计步骤 一般可将数据库结构设计分为四个阶段,即需求分析、概念结构设计、逻辑结构设计和物理设计。 下面各节分别介绍各阶段设计内容和具体方法。 二、需求分析 需求分析的任务是具体了解应用环境,了解与分析用户对数据和数据处理的需求,对应用系统的性能的要求,提出新系统的目标,为第二阶段、第三阶段的设计奠定基础。一般需求分析的操作步骤如下所述。 1.了解组织、人员的构成 子系统的划分常常以现有组织系统为基础,再进行整合,而新系统首先必须达到的目的是尽可能地完成当前系统中有关信息方面的工作,在原有系统中,信息处理总是由具体人来实施的。我们要了解组织结构情况、相互之间信息沟通关系、数据(包括各种报告、报表、凭证、单据)往来联系情况。 具体弄清各个数据的名称,产生的时间与传递所需时间与周期,数据量的大小,所涉及(传送)的范围,使用数据的权限要求,数据处理过程中容易发生的问题及其影响,各个部门所希望获得的数据的情况等。 然后了解每个人对每一具体数据处理的过程,基本数据元素来源于哪些地方、获取的途径、处理的要求、数据的用途,进而弄清数据的构成、数据元素的类型、性质、算法、取值范围、相互关系。 在上述调查基础上,首先画出组织机构及工作职能图。我们以一个学校的基层单位——某大学一个系的管理为例来简要说明。 系的组织机构及工作职能如图7.1所示。
图7.1 系管理体系结构图 作为管理层经常需要的信息和工作有: .查询老师个人基本情况及打印相应内容 .查询与统计科研项目情况及相关报表 .查询与统计论文著作情况及相关报表 .上级部门及其他部门来文管理与查询(要求能全文检索) .系部发文管理 .任务下达、检查及管理 .信件、通知的收发及管理 .日程安排调度及管理 .设备仪器计划及管理 .设备入库与库存情况管理与查询 .设备借还领用管理及相应报表 .耗材计划与领发管理及相应统计报表 .图书管理及借还情况查询 .学生毕业设计文档管理 .专业与班组编制与查询 .教学文档管理及查询(安排与检查,包括课表、考试日程安排、监考安排等).学生成绩管理与查询和统计 .教师、学生、实验室课表管理及查询 .学生基本情况管理与查询(包括社会活动、奖惩、家庭情况及学校校友管理)
SQL数据库修改表结构
S Q L数据库修改表结构-CAL-FENGHAI-(2020YEAR-YICAI)_JINGBIAN
SQL数据库修改表结构 修改表结构包括: 增加字段、删除字段、增加约束、删除约束、修改缺省值、修改字段数据类型、重命名字段、重命名表。 所有这些动作都是用 ALTER TABLE 命令执行的。 1、增加字段 ALTER TABLE products ADD description text; 你也可以同时在该字段上定义约束,使用通常的语法: ALTER TABLE products ADD description text CHECK (description <> ''); 实际上,所有在CREATE TABLE里描述的可以应用于字段之选项都可以在这里使用。不过,我们要注意的是缺省值必须满足给出的约束,否则ADD 将会失败。另外,你可以在你正确填充了新字段的数值之后再增加约束(见下文)。 2、删除字段 要删除一个字段,使用下面这样的命令: ALTER TABLE products DROP COLUMN description; 不管字段里有啥数据,都会消失。和这个字段相关的约束也会被删除。不过,如果这个字段被另外一个表的外键所引用,PostgreSQL 则不会隐含地删除该约束。你可以通过使用 CASCADE 来授权删除任何依赖该字段的东西:ALTER TABLE products DROP COLUMN description CASCADE; 3、增加约束 要增加一个约束,使用表约束语法。比如: ALTER TABLE products ADD CHECK (name <> ''); ALTER TABLE products ADD CONSTRAINT some_name UNIQUE (product_no); ALTER TABLE products ADD FOREIGN KEY (product_group_id) REFERENCES product_groups; ALTER TABLE Teacher add constraint df_sex default('男') for sex 要增加一个不能写成表约束的非空约束,使用下面语法: ALTER TABLE products ALTER COLUMN product_no SET NOT NULL; 这个约束将立即进行检查,所以表在添加约束之前必须符合约束条件。 4、删除约束 要删除一个约束,你需要知道它的名字。如果你给了它一个名字,那么事情就好办了。否则系统会分配一个生成的名字,这样你就需要把它找出来
Oracle非结构化数据解决方案
Oracle数据库11g管理非结构化数据 (2) 一、引言 (2) 二、在ORACLE 中管理非结构化数据的优势 (3) 三、打破了原来处理非结构化数据的“性能障碍” (4) 3.1 Oracle SecureFiles (4) 3.2 SecureFiles 中的存储优化 (5) 四、专用数据类型和数据结构 (6) 4.1 Oracle XML DB (6) 4.2 Oracle Text (7) 4.3 Oracle Spatial (8) 4.4 RDF、OWL 和语义数据库管理 (9) 4.5 Oracle Multimedia (9) 4.6 Oracle DICOM 医学内容管理 (9) 五结论 (10)
Oracle数据库11g管理非结构化数据 一、引言 公司、企业以及其他机构使用的绝大部分信息都可归类为非结构化数据。 非结构化数据是计算机或人生成的信息,其中的数据并不一定遵循标准的数据结构(如模式定义规范的行和列),若没有人或计算机的翻译,则很难理解这些数据。常见的非结构化数据有文档、多媒体内容、地图和地理信息、人造卫星和医学影像,还有Web 内容,如HTML。 根据数据的创建方式和使用方式的不同,非结构化数据的管理方法大不相同。 1.大量数据分布于桌面办公系统(如文档、电子表格和演示文稿)、专门的工作站和设备 (如地理空间分析系统和医学捕获和分析系统)上。 2.政府、学术界和企业中数TB 的文档存档和数字库。 3.生命科学和制药研究中使用的影像数据银行和库。 4.公共部门、国防、电信、公用事业和能源地理空间数据仓库应用程序。 5.集成的运营系统,包括零售、保险、卫生保健、政府和公共安全系统中的业务或健康记 录、位置和项目数据以及相关音频、视频和图像信息。 6.学术、制药以及智能研究和发现等应用领域中使用的语义 数据(三元组)。 自数据库管理系统引入后,数据库技术就一直用于解决管理大量非结构化数据时所遇到的特有问题。通常通过“基于指针的”方法使用数据库对存储在文件中的文档、影像和媒体内容进行编目和引用。为了在数据库表内存储非结构化数据,二进制大对象(或简称为BLOB)作为容器使用已经数十年了。除了简单的BLOB 外,多年以来,Oracle 数据库一直通过运算符合并智能数据类型和优化数据结构,以分析和操作XML 文档、多媒体内容、文本和地理空间信息。由于有了Oracle 数据库11g,Oracle 再次在非结构化数据管理领域开辟出一片新天地:大幅提升了通过数据库管理系统原生支持的非结构化数据的性能、安全性以及类型。
数据库表结构设计参考
数据库表结构设计参考. )表名外部单位表(DeptOut 约束条件非空空数据类型(精度范围) /列名外部单位ID N 变长字符串(50) 主键 N 变长字符串类型 (50)
N 单位名称(255) 变长字符串 (50) 单位简称变长字符变长字符(255)单位全交换类交换、市机、直送、邮变长字符(50)N (6)单位邮变长字符 变长字符(50))单位标英整排序(4) (50)交换变长字符变长字符(50)单位领 变长字符单位电(50) 变长字符所属城(50) 变长字符(255)单位地 备(255) 变长字符 补充说300条左右,一般不做修改。初始化记录该表记录数 表外部单位子表DeptOutSu 数据类型(精度范围列非约束条 变长字符(50)外部子单IDN 外ID变长字符(50)N单位名N变长字符(255) 变长字符单位编(50) 该表记录数一般很补充说 表内部单位表DeptI
数据类型(精度范围非列约束条IDN(50)变长字符主内部单类N变长字符(50) (255)变长字符N单位名 (50)变长字符单位简 变长字符单位全(255) 工作职 排序整(4) 单位领导(50) 变长字符串 (50) 单位电话(分机)变长字符串 (255) 变长字符串备注. 条以内),一般不做修改。维护一次后很少修改补充说明该表记录数较小(100 内部单位子表(DeptInSub)表名 约束条件数据类型(精度范围)空列名/非空 (50) N 变长字符串内部子单位ID 变长字符串(50) 父ID N 外键 (255) 单位名称 N 变长字符变长字符(50)单位编领导、部变长字符(50)单位类 Int 排序 该表记录数一般很补充说 省、直辖市表Provinc表
数据库结构分类
1、层次数据库结构 层次数据库结构将数据通过一对多或父结点对子结点的方式组织起来。一个层次数据库中,根表或父表位于一个类似于树形结构的最上方,它的子表中包含相关数据。层次数据库模型的结构就像是一棵倒转的树。 优点: ?快速的数据查询 ?便于管理数据的完整性 缺点: ?用户必须十分熟悉数据库结构 ?需要存储冗余数据 2、网状数据库结构 网状数据库结构是用连接指令或指针来组织数据的方式。数据间为多对多的关系。矢量数据描述时多用这种数据结构。 优点: ?快速的数据访问 ?用户可以从任何表开始访问其他表数据 ?便于开发更复杂的查询来检索数据 缺点: ?不便于数据库结构的修改 ?数据库结构的修改将直接影响访问数据库的应用程序 ?用户必须掌握数据库结构 3、关系数据库结构 这就目前最流行的数据库结构了。数据存储的主要载体是表,或相关数据组。有一对一、一对多、多对多三种表关系。表关联是通过引用完整性定义的,这是通过主码和外码(主键或外键)约束条件实现的。
优点: ?数据访问非常快 ?便于修改数据库结构 ?逻辑化表示数据,因此用户不需要知道数据是如何存储的 ?容易设计复杂的数据查询来检索数据 ?容易实现数据完整性 ?数据通常具有更高的准确性 ?支持标准SQL语言 缺点: ?很多情况下,必须将多个表的不同数据关联起来实现数据查询 ?用户必须熟悉表之间的关联关系 ?用户必须掌握SQL语言 4、面向对象数据库结构 它允许用对象的概念来定义与关系数据库交互。值得注意的是面向对象数据库设计思想与面向对象数据库管理系统理论不能混为一谈。前者是数据库用户定义数据库模式的思路,后者是数据库管理程序的思路。 面向对象数据库中有两个基本的结构:对象和字面量。对象是一种具有标识的数据结构,这些数据结构可以用来标识对象之间的相互关系。字面量是与对象相关的值,它没有标识符。 优点: ?程序员只需要掌握面向对象的概念,而不要掌握与面向对象概念以及关系数据库有关的存储 ?对象具有继承性,可以从其他对象继承属性集 ?大量应用软件的处理工作可以自动完成 ?从理论上说,更容易管理对象 ?面向对象数据模型与面向对象编程工具更兼容 缺点:
产品表与分类表数据库设计
原文地址:https://www.360docs.net/doc/3e2065210.html,/index.php/archives/95/ 问题的提出:网上商城对产品进行了很多分类,不同的分类产品又有不同的属性,比如,电脑的属性有:CUP,内存,主板,硬盘等等,服装的属性有:布料,尺寸,颜色等等,那么产品表以及产品分类表应该如何设计才能满足不同类型产品的区别呢? 解决方案: 1、产品分类表的设计 第一种设计思路:使用树形结构,递归的形式,可以对产品进行N级分类,只要你喜欢,树形结构在数据库的设计中经常用到,比如功能菜单表等。以下是一个简单的产品分类表。 说明:上级类别ID为该表的外键,并关联到本级类别ID,这样就可以对产进行N级分类了,这种设计思想十分灵活,是无限分类中最常用到的。 第二种设计思路:定义N个类别表,并对他们进行关联,如图:
说明:这种设计在项目中没有人会使用它,因为产品的分类是不固定的,很难在数据库设计的时候确定类别表的个数,很不灵活。不过省分城市分类有用这样子的设计 2、产品表的设计 第一种设计思路:直接在产品表预留N个字段,用到的时候直接插入数据,如图 可行性:会产生很多字段的冗余,并且不知道到底需要多少个字段,数据类型也不能确定,可行性比较低,但是这种设计也有它的优点,就是表的数量少,其他的优点我实在找不出来了,所以,在项目中这种设计思想也不会用到。 第二种设计思路:在提及这种设计思路前,首先得了解数据表可以分为两种结构,一种是横表,也就是我们经常用到的表结构,另外一种是纵表,这种结构平时我们用到的表少,所以我也是今天通过请教别人才知有这种表结构的。什么是纵表,它有哪些优点和缺点呢?通过两张图片对比来了解或许会更清楚 横表的结构: 纵表的结构: 可以看出横表的优点是很直观,它是根据现行业务逻辑定制,设计简单,易操作,缺点是当业务逻辑发生拓展时,大多情况下要更改表的结构。纵表的数据让人看
数据库技术发展的新方向-非结构化数据
数据库技术发展的新方向——非机构化数据 1 什么是非结构化数据库 在信息社会,所有信息大体上可以分为两类:一类信息能够用数据或统一的结构加以表示,我们称之为结构化数据,如数字、符号;另一类信息根本无法用数字或者统一的结构表示,如文本、图像、声音乃至网页等,我们称之为非结构化数据。非结构化数据包括结构化数据,但又不止是结构化数据;结构化数据属于非结向化数据,是非结构化数据的特例。 所谓非结构化数据库,是指数据库的变长记录由若干不可重复和可重复的字段组成,而每个字段又可由若干不可重复和可重复的子字段组成。简单的说,非结构化数据库就是字段数和字段长度可变的数据库。 2 为什么需要非结构化数据库 传统关系数据库,通过引入数学领域的关系模型及关系代数和关系演算,经过几十年的应用和发展,奠定了自己的优势。但随着网络的发展,关系数据库越来越显示出不足的一面。到了20世纪90年代,当关系数据库还满足于用户连接到大型主机上的数据库进行联机检索时,因特网的出现已经可以把超文本文件传送到用户的浏览器里了。起初,WWW只支持较简单的文挡,随着应用需求的不断提高和技术的发展,它不仅可以支持文字、图形、图像、声音等多媒体信息,还可以支持一些较为复杂的对象,比如电子表棉对象。但随着数据量的增大,显然只靠静态页面就捉襟见肘了。让页面动起来的想法由此应运而生,这时迫切需要数据库在动态页面中扮演主角。 而此前,关系数据库要么限于桌面,用文件方式的共享来实现局域网内的使用;要么是使用各种关系数据库厂商开发的专用客户端软件和工具。尽管ODBC,JDBC,OLE DB等解决了不同数据库之间的接口,但是我们可以说关系数据库从设计之初并没有也不可能考虑到以HTTP为基础、HTML为文件格式的因特网的需求.只是在因特网出现后才作出相应的调整,因此关系数据库在基于因特网应用时由于结构模型等原因的限制,不能与因特网完全融合,需在因特网与数据库之间加人大量的中间件,从而在无形中加大了数据库基于网络应用的难度。同时,由于关系数据库从一开始就没有考虑网络时代的应用需求,因而对于网络环境下WWW 应用,如各种非结构化文挡信息、多媒体信息以及全文检索需求显得有些力不从心。虽然后来关系数据库对于这些需求作出了一些适应性调整,如增加数据库的面向对象成分以增加处理多种复杂数据类型的能力,增加各种中间件以扩展基于WWW应用能力,但对于网络环境下WWW应用不可或缺的检索效率、全文检索能力等却无法解决。关系数据库的基于中间件的解决方案又给WWW应用带来了新的网络瓶颈,应用服务器端由于与数据库频繁交互,因其本身的效率和数据库检索的效率造成WWW应用在服务器端的阻塞。 非结构化数据库就是针对关系数据库模型过于简单,不便表达复杂的嵌套需要以及支持数据类型有限等局限,从数据模型入手而提出的全面基于因特网应用的新型数据库理论。非结构化数据库主要是针对非结构化数据应运而生的,与目前流行的关系数据库相比,其最大区别在于它突破了关系数据库结构定义不易改变和数据定长的限制,支持重复字段、子字段以及变长字段并实现了对变长数据和重复字段进行处理和数据项的变长存储管理,在处理连续信息(包括全文信息)
数据库表结构文档
数据库表结构文档 1 表名 USERS (系统用户) 主键 USERID 序号字段名称字段说明类型位数属性备注 1 USERID 用户账号 Int 非空主键,自增 2 LOGINNAME 登陆账户 Varchar 32 非空唯一键 3 USERNAME 用户姓名 Varchar 32 非空 4 PASSWORD 登陆口令 Varchar 32 非空 5 FLAG 用户状态 Varchar 1 6 非空 1、正常2、退休 3、离职 6 ROLEID 角色账号 SmallInt 短整型 2 表名 PERSONALDATA (用户个人基本信息) 主键 USERID 序号字段名称字段说明类型位数属性备注 1 USERID 用户账号 Int 非空主键,与USERS一 对一 2 IDCARD 身份证 Varchar 20 可空 3 USERNAME 用户姓名 Varchar 32 可空允许冗余,提高查 询性能 4 SEX 用户性别 Nchar 1 可空一个汉字,check约 束在(男,女) 5 BIRTH 出生年月Varchar 20 可空数据库中日期都设 日计为字符串,方便 操作,以下一样 6 CALLBE 职称系列 Varchar 16 可空与BASEDATAS表 关联 7 CALLCONCRETELY 职称具体 Varchar 16 可空与BASEDATAS表 关联
现职称任职8 NOWCALLDATE Varchar 20 可空 时间 9 LONGEVITY 资历 Varchar 16 可空与BASEDATAS表 关联 10 NOWSTATION 现岗位 Varchar 16 可空与BASEDATAS表 关联 11 NSENGAGETIME 现岗位聘Varchar 20 可空 任时间 12 BELONGTOCOLLEGE 所属学院 Varchar 16 可空与BASEDATAS表 关联 13 BELONGTODEPARTMENT 所属部门 Varchar 16 可空与BASEDATAS表关联 14 POLITYVISAGE 政治面貌 Varchar 16 可空与BASEDATAS表 关联 15 ATTENDJOBTIME 参加工作Varchar 20 可空 时间 16 FINALSTUDY 最后学历 Varchar 16 可空与BASEDATAS表 关联 17 FINALDEGREE 最后学位 Varchar 16 可空与BASEDATAS表 关联 18 FINALSDDEMO 最后学历Text 可空 学位说明 19 IDENTITYS 身份 Varchar 16 可空与BASEDATAS表 关联(教学人员和 非教学人员) 20 CALLDETAIL 职称详细 Varchar 可空与BASEDATAS表 关联 21 FILLINTIME 填入时间 Varchar 20 可空 22 FINALMODIFYTIME 最后修改Varchar 20 可空 时间 23 CHECKSTATE 审核状态 Varchar 16 非空与BASEDATAS表 关联(1、已审核2、 未审核3、已作废) 24 CHECKUSER 审核人 Int 可空领导对个人资料进
非结构化数据管理:ERP力不从心 ECM接力
对于国内相当多的企业来说,ECM这个概念还比较陌生,但提起ERP,很多人都耳熟能详。 事实上,ERP是以数据库管理为核心的,而ECM是以非结构化数据管理为核心。凯德云M-Files是由美国M-Files公司开发的软件产品,主要用于企业内容管理(ECM)、文档管理(EDM)、质量管理、知识管理、项目协同。 调查显示,企业中80%的数据是以非结构化的形式存在的,例如电子邮件、报表、办公文档、扫描文件、网页等,而这些非结构化数据往往散落在企业的各种应用系统中,无法得到统一的管理,更惶谈从中挖掘出价值。 ERP与ECM的关联 在廖强(EMC中国区副总裁、内容管理及归档事业部大中华区总经理)看来,现在非结构化数据的管理需求产生了,实际上就是一个很自然的过程,跟以前ERP比较的话,内容管理与ERP同等重要,内容管理是管着80%的非结构化信息,ERP管理着20%的结构化信息。其次从复杂性来讲,因为ERP牵涉了管理的方方面面,内容管理却没有那么复杂。从投资来讲,大家都在讲收益率,企业现在实际上逐渐地认识到内容管理的重要性。这几年内容管理逐渐地跟ERP、CRM,包括银行的核心系统,包括电信的计费系统等成为企业信息化的新重点。也就是说,随着内容管理逐渐地深入客户的核心业务,对企业的工作效率、收益、信息安全等都将得到提高。 ECM已进入第三代 IDC在2008年上半年针对中国企业所做的一项调查显示,在受调查的434个最终用户中,接近60%的用户表示有计划投资内容管理软件。而在2007年的类似调查中,这一比例还只有30%多。这一结果表示,内容管理在组织中的优先级大大提高。IDC分析认为,用户渴望投资内容管理解决方案,主要有两方面的原因:一是日益增长的法规要求;二是通过内容管理功能更好地优化、自动化纸质业务流程。 廖强分析说,综合当今内容管理市场,内容管理解决方案可以分为三代。 第一代是小型供应商提供单点解决方案,主要用于解决零碎的业务问题,例如光盘系统管理、记录管理、Web内容管理、数字资产管理、工作流/BPM管理等。第一代内容管理的特点是有众多小型技术公司,每个公司都使用专门构建的应用程序解决一些零碎的业务问题。 第二代是中型供应商在单点解决方案的基础上,提供较为全面的内容管理功能套件。第二代内容管理是由整合驱动的,在这一阶段,中型公司纷纷展开收购,并开始构建成套的内容管理应用程序。这是一个从单点产品到内容管理套件的变化过程,许多公司都是从点入手,而逐渐架构起较为完善的内容管理解决方案。但在这个过程中,内容管理底层平台的健壮性和面向应用的灵活性及可扩展性往往被忽视。 前两代内容管理带来的问题是:各个系统之间往往会形成信息孤岛的现象。而且,当应用出现变化时,需要对各个单点产品逐一修改,不能快速满足应用变化速度。 在第三代内容管理中,内容管理正逐渐成为企业信息基础架构的一部分;企业对内容管理的需求,已并不满足于应用某些点的产品去实现特定业务的管理,而是需要一个高性能、高可扩展性、能支持企业业务快速发展并能满足企业业务变化需求的内容管理平台。 开放性成长 任何一个软件公司的理想是要做到能够尽量满足客户的最终需要,但这很难实现,主要原因是需求的复杂度,很难有一个企业所提供的软件产品能够适应各式各样的不同需求。 廖强介绍说,Documentum平台一直以来就不是自行运转,Documentum平台一定跟结构化结合在一起。比如在国内某银行的应用,像有一套贷款审批,因为它要审核你的原始的资质,你的房产证等,这些都需要EPR系统与Documentum。从我们整个的发展方向来看,ECM是关注着技术性、扩展性、高性能,可对接性,希望把自己的开发能力提供给整个社
用友T数据库表结构表
用友软件T3 用友通数据库表结构、表名 fa_Control 30_ 记录互斥fa_Departments 07_ 部门fa_Depreciations 11_ 折旧方法 fa_DeprList 34_ 折旧日志fa_DeprTransactions 19_ 折旧fa_DeprVoucherMain 23_ 折旧分配凭证主表fa_DeprVouchers 24_ 折旧分配凭证 fa_DeprVouchers_pre 24_ 折旧分配凭证_准备fa_Dictionary 12_ 常用参照字典 fa_EvaluateMain 21_ 评估单主表 fa_EvaluateVouchers 22_ 评估单fa_Items 12_ 项目fa_ItemsManual 32_ 自定义项目 fa_ItemsOfModel 14_ 对应各样式的项目 fa_ItemsOfQuery 35_ 查询项目fa_Log 33_ 日志fa_Models 13_ 样式fa_Msg 29_ 信息 fa_Objects 03_ 对象表fa_Operators 02_ 操作员fa_Origins 09_ 增减方式fa_QueryFilters 05_ 查询条件fa_Querys 04_ 查询 fa_ReportTemp fa_Status 10_ 使用状况 fa_Total 31_ 汇总表Accessaries 成套件表AccInformation 账套参数表Ap_AlarmSet 单位报警分类设置表Ap_BillAge 账龄区间表 Ap_Cancel 核销情况表Ap_CancelNo 生成自动序号Ap_CloseBill 收付款结算表Ap_CtrlCode 控制科目设置表Ap_Detail 应收/ 付明细账 AP_DispSet 查询显示列设置表Ap_InputCode 入账科目表Ap_InvCode 存货科目设置表 Ap_Lock 操作互斥表 Ap_MyTableSet 查询条件存储表 Ap_Note 票据登记簿 Ap_Note_Sub 票据登记簿结算表 Ap_SStyleCode 结算方式科目表 Ap_Sum应收/ 付总账表 Ap_Vouch 应付/ 收单主表 Ap_Vouchs 应付/ 收单主表的关联表 Ap_VouchType 单据类型表 Ar_BadAge 坏账计提账龄期间表 Ar_BadPara 坏账计提参数表 ArrivalVouch 到货单、质检单主表ArrivalVouchs 到货单、质检单子表AssemVouch 组装、拆卸、形态转换单主表
数据库设计中英文术语表
数据库设计中英文术语表 June 27, 2004, In Focus on 索引 A B C D E F G H I J K L M N O P Q R S T U V W X Y Z 正文 1.Access method(访问方法):此步骤包括从文件中存储和检索记录。 2.Alias(别名):某属性的另一个名字。在SQL中,可以用别名替换表名。 3.Alternate keys(备用键,ER/关系模型):在实体/表中没有被选为主健的候选键。 4.Anomalies(异常)参见更新异常(update anomalies) 5.Application design(应用程序设计):数据库应用程序生命周期的一个阶段,包括设 计用户界面以及使用和处理数据库的应用程序。 6.Attribute(属性)(关系模型):属性是关系中命名的列。 7.Attribute(属性)(ER模型):实体或关系中的一个性质。 8.Attribute inheritance(属性继承):子类成员可以拥有其特有的属性,并且继承那些 与超类有关的属性的过程。 9.Base table(基本表):一个命名的表,其记录物理的存储在数据库中。 10.Binary relationship(二元关系):一个ER术语,用于描述两个实体间的关系。例如, panch Has Staff。 11.Bottom-up approach(自底向上方法):用于数据库设计,一种设计方法学,他从标 识每个设计组建开始,然后将这些组件聚合成一个大的单元。在数据库设计中,可以从表示属性开始底层设计,然后将这些属性组合在一起构成代表实体和关系的表。 12.Business rules(业务规则):由用户或数据库的管理者指定的附加规则。 13.Candidate key(候选键,ER关系模型):仅包含唯一标识实体所必须得最小数量的 属性/列的超键。 14.Cardinality(基数):描述每个参与实体的可能的关系数目。 15.Centralized approach(集中化方法,用于数据库设计):将每个用户试图的需求合并 成新数据库应用程序的一个需求集合 16.Chasm trap(深坑陷阱):假设实体间存在一根,但某些实体间不存在通路。 17.Client(客户端):向一个或多个服务器请求服务的软件应用程序。 18.Clustering field(群集字段):记录总的任何用于群集(集合)航记录的非键字段, 这些行在这个字段上有相同的值。 19.Clustering index(群集索引):在文件的群集字段上定义的索引。一个文件最多有一 个主索引或一个群集索引。 20.Column(列):参加属性(attribute)。 https://www.360docs.net/doc/3e2065210.html,plex relationship(复杂关系):度数大于2的关系。 https://www.360docs.net/doc/3e2065210.html,posite attribute(复合属性):由多个简单组件组成的属性。 https://www.360docs.net/doc/3e2065210.html,posite key(复合键):包含多个列的主健。 24.Concurrency control(并发控制):在多用户环境下同时执行多个十五并保证数据完 整性的一个DBMS服务。