钽电容知识总结(结构、工艺、参数、选型)
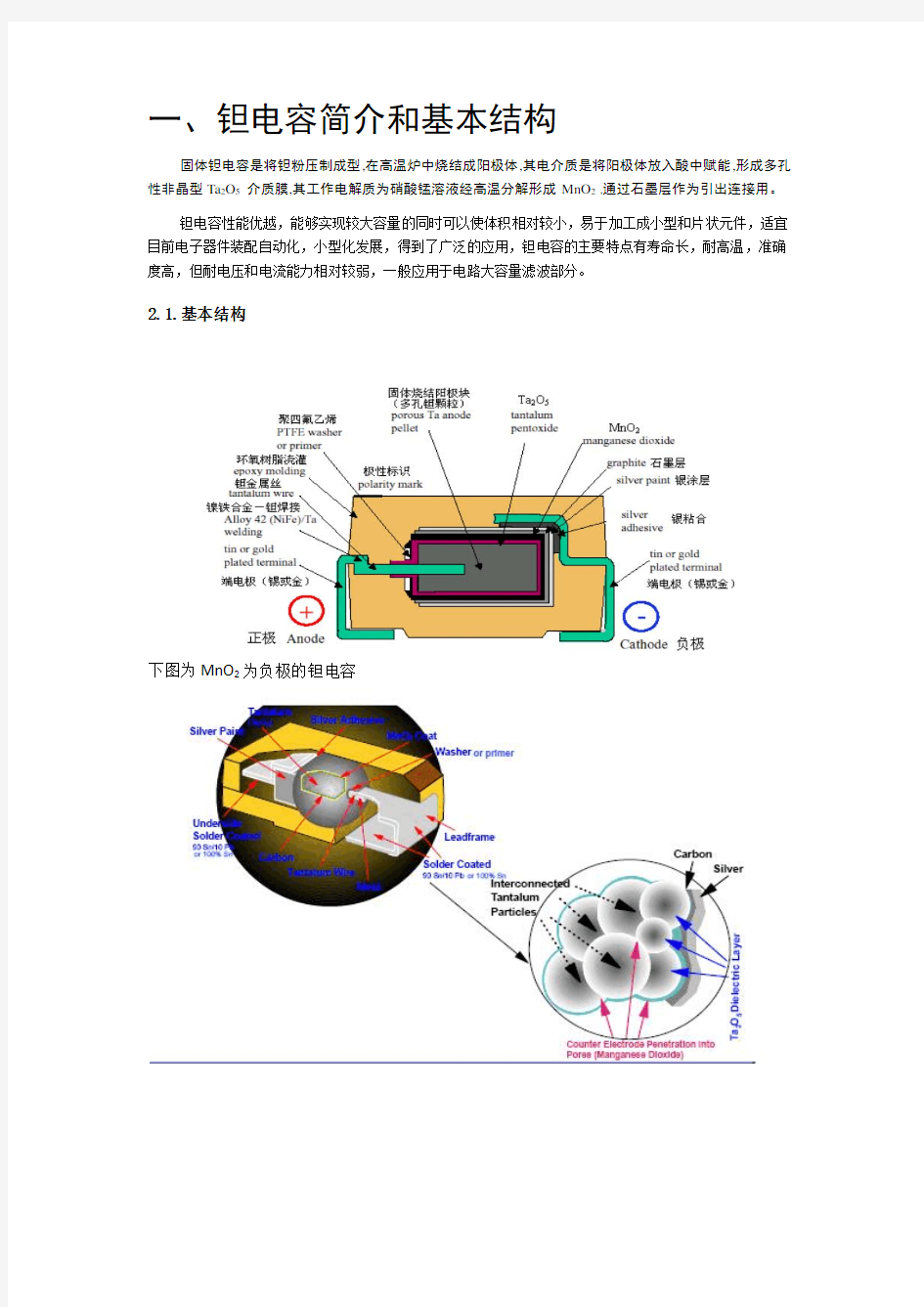
一、钽电容简介和基本结构
固体钽电容是将钽粉压制成型,在高温炉中烧结成阳极体,其电介质是将阳极体放入酸中赋能,形成多孔性非晶型Ta2O5介质膜,其工作电解质为硝酸锰溶液经高温分解形成MnO2 ,通过石墨层作为引出连接用。
钽电容性能优越,能够实现较大容量的同时可以使体积相对较小,易于加工成小型和片状元件,适宜目前电子器件装配自动化,小型化发展,得到了广泛的应用,钽电容的主要特点有寿命长,耐高温,准确度高,但耐电压和电流能力相对较弱,一般应用于电路大容量滤波部分。
2.1.基本结构
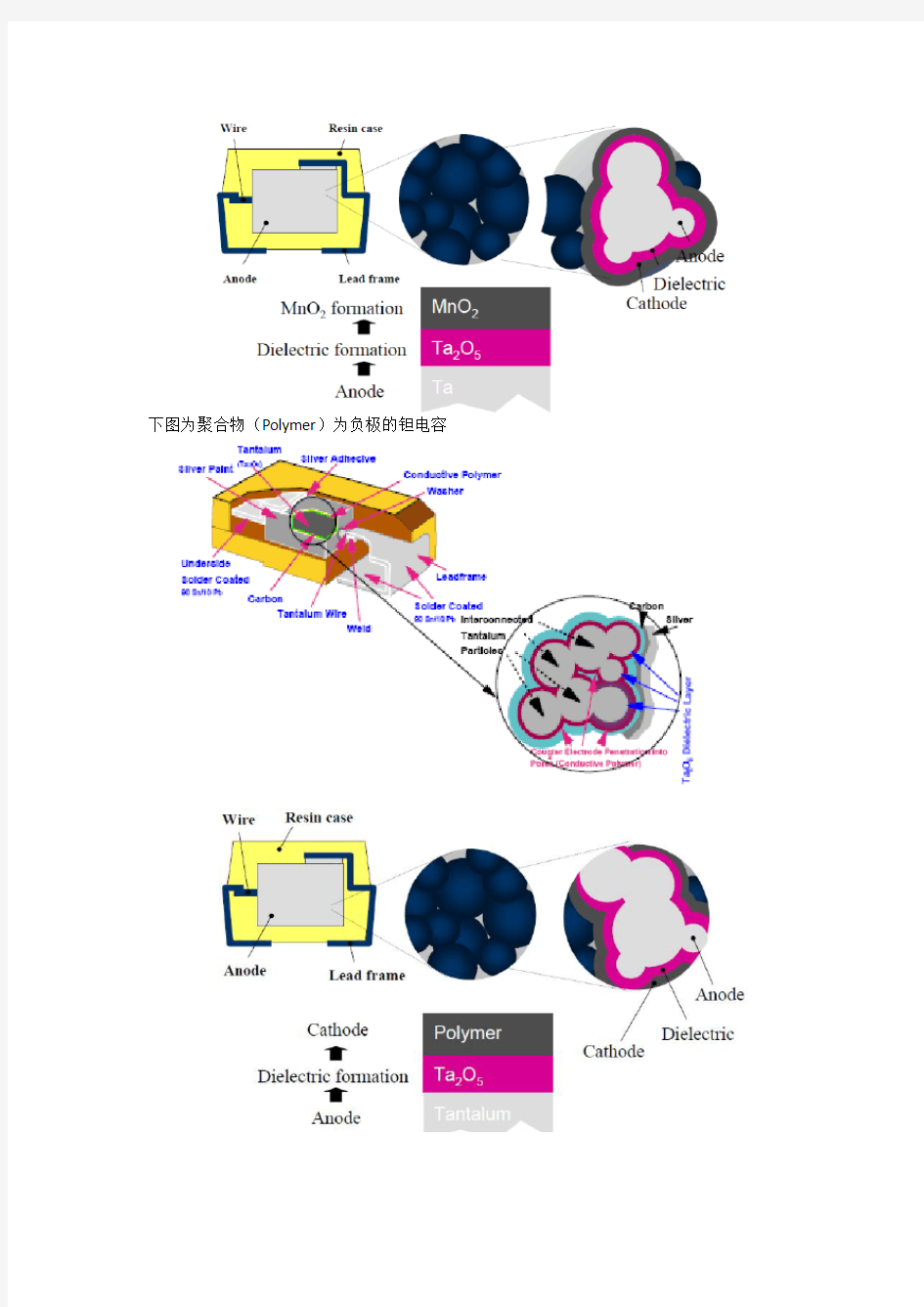
下图为MnO2为负极的钽电容
下图为聚合物(Polymer)为负极的钽电容
二、生产工艺
按照电解液的形态,钽电解电容有液体和固体钽电解电容之分,液体钽电解用量已经很少,本文仅介绍固体钽电解的生产工艺。
固体钽电解电容其介质材料是五氧化二钽;阳极是烧结形成的金属钽块,由
,目前最新的是采用聚合物作为负极材料,性钽丝引出,传统的负极是固态MnO
2
。
能优于MnO
2
钽电解电容有引线式和贴片两种安装方式,其制造工艺大致相同,现在以片钽生产工艺
为例介绍如下。
一、生产工艺流程图
成型烧结试容检验组架赋能涂四氟被膜石墨银浆
上片点胶固化点焊模压固化切筋喷砂电镀打标志切边
漏电预测老化测试检验编带入库二、主要生产工序说明
(一)成型工序:
该工序目的是将钽粉与钽丝模压在一起并具有一定的形状,在成型过程中要给钽粉中加入一定比例的粘接剂。
1、什么要加粘接剂?
为了改善钽粉的流动性和成型性,避免粉重误差太大,另外避免钽粉堵塞模腔。
低比容粉流动性好可适当多加点粘接剂,高比容粉流动性差可适当少加点粘接剂。
2、加了太多或太少有什么影响?
如果太多:脱樟时,樟脑大量挥发,易导致钽坯开裂、断裂,瘦小的钽坯易导致弯曲。如果太少:起不到改善钽粉流动性的作用。拌好后的钽粉如果使用时间较长,因为樟脑是易挥发物品,可适量再加入一点粘和剂。樟脑的加入会导致钽粉中杂质含量增加,影响漏电。每天使用完毕,需将钽粉装入聚四氟乙烯瓶或真空袋内密封保存,以防樟脑挥发、钽粉中混入杂质、钽粉中吸附空气中的气体。
3、成型后不进行脱樟,可否直接放入烧结炉内进行烧结?
不行,因为樟脑是低温挥发物,如果直接放入烧结炉内进行烧结,挥发物会冷凝在炉膛、机械泵、扩散泵等排出管道内。
4、丝埋入深度太浅会有什么影响?
钽丝易拔出,或者钽丝易松动,后道工序在钽丝受到引力后,易导致钽丝跟部漏
结构动力学心得汇总
结构动力学学习总结
通过对本课程的学习,感受颇深。我谈一下自己对这门课的理解: 一.结构动力学的基本概念和研究内容 随着经济的飞速发展,工程界对结构系统进行动力分析的要求日益提高。我国是个多地震的国家,保证多荷载作用下结构的安全、经济适用,是我们结构工程专业人员的基本任务。结构动力学研究结构系统在动力荷载作用下的位移和应力的分析原理和计算方法。它是振动力学的理论和方法在一些复杂工程问题中的综合应用和发展,是以改善结构系统在动力环境中的安全和可靠性为目的的。高老师讲课认真负责,结合实例,提高了教学效率,也便于我们学生寻找事物的内在联系。这门课的主要内容包括运动方程的建立、单自
由度体系、多自由度体系、无限自由度体系的动力学问题、随机振动、结构抗震计算及结构动力学的前沿研究课题。既有线性系统的计算,又有非线性系统的计算;既有确定性荷载作用下结构动力影响的计算,又有随机荷载作用下结构动力影响的随机振动问题;阻尼理论既有粘性阻尼计算,又有滞变阻尼、摩擦阻尼的计算,对结构工程最为突出的地震影响。 二.动力分析及荷载计算 1.动力计算的特点 动力荷载或动荷载是指荷载的大小、方向和作用位置随时间而变化的荷载。如果从荷载本身性质来看,绝大多数实际荷载都应属于动荷载。但是,如果荷载随时间变化得很慢,荷载对结构产生的影响与
静荷载相比相差甚微,这种荷载计算下的结构计算问题仍可以简化为静荷载作用下的结构计算问题。如果荷载不仅随时间变化,而且变化很快,荷载对结构产生的影响与静荷载相比相差较大,这种荷载作用下的结构计算问题就属于动力计算问题。 荷载变化的快与慢是相对与结构的固有周期而言的,确定一种随时间变化的荷载是否为动荷载,须将其本身的特征和结构的动力特性结合起来考虑才能决定。 在结构动力计算中,由于荷载时时间的函数,结构的影响也应是时间的函数。另外,结构中的内力不仅要平衡动力荷载,而且要平衡由于结构的变形加速度所引起的惯性力。结构的动力方程中除了动力荷载和弹簧力之外,还要引入因其质量产生的惯性力和耗散能量的阻尼力。而
(完整版)非常实用的数据结构知识点总结
数据结构知识点概括 第一章概论 数据就是指能够被计算机识别、存储和加工处理的信息的载体。 数据元素是数据的基本单位,可以由若干个数据项组成。数据项是具有独立含义的最小标识单位。 数据结构的定义: ·逻辑结构:从逻辑结构上描述数据,独立于计算机。·线性结构:一对一关系。 ·线性结构:多对多关系。 ·存储结构:是逻辑结构用计算机语言的实现。·顺序存储结构:如数组。 ·链式存储结构:如链表。 ·索引存储结构:·稠密索引:每个结点都有索引项。 ·稀疏索引:每组结点都有索引项。 ·散列存储结构:如散列表。 ·数据运算。 ·对数据的操作。定义在逻辑结构上,每种逻辑结构都有一个运算集合。 ·常用的有:检索、插入、删除、更新、排序。 数据类型:是一个值的集合以及在这些值上定义的一组操作的总称。 ·结构类型:由用户借助于描述机制定义,是导出类型。 抽象数据类型ADT:·是抽象数据的组织和与之的操作。相当于在概念层上描述问题。 ·优点是将数据和操作封装在一起实现了信息隐藏。 程序设计的实质是对实际问题选择一种好的数据结构,设计一个好的算法。算法取决于数据结构。 算法是一个良定义的计算过程,以一个或多个值输入,并以一个或多个值输出。 评价算法的好坏的因素:·算法是正确的; ·执行算法的时间; ·执行算法的存储空间(主要是辅助存储空间); ·算法易于理解、编码、调试。 时间复杂度:是某个算法的时间耗费,它是该算法所求解问题规模n的函数。 渐近时间复杂度:是指当问题规模趋向无穷大时,该算法时间复杂度的数量级。 评价一个算法的时间性能时,主要标准就是算法的渐近时间复杂度。 算法中语句的频度不仅与问题规模有关,还与输入实例中各元素的取值相关。 时间复杂度按数量级递增排列依次为:常数阶O(1)、对数阶O(log2n)、线性阶O(n)、线性对数阶O(nlog2n)、平方阶O (n^2)、立方阶O(n^3)、……k次方阶O(n^k)、指数阶O(2^n)。
结构动力学读书报告
《结构动力学》 读书报告
结构动力学读书报告 学习完本门课程和结合自身所学专业,我对本门课程内容的理解和在各方面的应用总结如下: 1. (1)结构动力学及其研究内容: 结构动力学是研究结构系统在动力荷载作用下的振动特性的一门科学技术,它是振动力学的理论和方法在一些复杂工程问题中的综合应用和发展,是以改善结构系统在动力环境中的安全和可靠性为目的的。本书的主要内容包括运动方程的建立、单自由度体系、多自由度体系、无限自由度体系的动力学问题、随机振动、结构抗震计算及结构动力学的前沿研究课题。 (2)主要理论分析 结构的质量是一连续的空间函数,因此结构的运动方程是一个含有空间坐标和时间的偏微分方程,只是对某些简单结构,这些方程才有可能直接求解。对于绝大多数实际结构,在工程分析中主要采用数值方法。作法是先把结构离散化成为一个具有有限自由度的数学模型,在确定载荷后,导出模型的运动方程,然后选用合适的方法求解。 (3)数学模型 将结构离散化的方法主要有以下三种:①集聚质量法:把结构的分布质量集聚于一系列离散的质点或块,而把结构本身看作是仅具有弹性性能的无质量系统。由于仅是这些质点或块才产生惯性力,故离散系统的运动方程只以这些质点的位移或块的位移和转动作为自由
度。对于大部分质量集中在若干离散点上的结构,这种方法特别有效。 ②广义位移法:假定结构在振动时的位形(偏离平衡位置的位移形态)可用一系列事先规定的容许位移函数fi (它们必须满足支承处的约束条件以及结构内部位移的连续性条件)之和来表示,例如,对于一维结构,它的位形u(x)可以近似地表为: @7710 二送 结构动力学 (1)式中的qj称为广义坐标,它表示相应位移函数的幅值。这样,离散系统的运动方程就以广义坐标作为自由度。对于质量分布比较均匀,形状规则且边界条件易于处理的结构,这种方法很有效。 ③有限元法:可以看作是分区的瑞利-里兹法,其要点是先把结构划 分成适当数量的区域(称为单元),然后对每一单元施行瑞利-里兹法。通常取单元边界上(有时也包括单元内部)若干个几何特征点(例如三角形的顶点、边中点等)处的广义位移qj作为广义坐标,并对每个广义坐标取相应的插值函数作为单元内部的位移函数(或称形状函数)。在这样的数学模型中,要求形状函数的组合在相邻单元的公共边界上满足位移连续条件。一般地说,有限元法是最灵活有效的离散化方法,它提供了既方便又可靠的理想化模型,并特别适合于用电子计算机进行分析,是目前最为流行的方法,已有不少专用的或通用的程序可供结构动力学分析之用。 (4)运动方程
金属工艺学重点知识点
属 工 -艺 学 第 五 版 上 强度:金属材料在里的作用下,抵抗塑性变形和断裂的能力。指标:屈服点(b s)、抗拉强度(b b)塑性:金属材料在力的作用下产生不可逆永久变形的能力。指标:伸长率(S)、断面收缩率( 3 硬度:金属材料表面抵抗局部变形,特别是塑性变形压痕、划痕的能力。 1布氏硬度:HBS (淬火钢球)。HBW (硬质合金球) 指标:-2洛氏硬度:HR (金刚石圆锥体、淬火钢球或硬质和金球) 3韦氏硬度 习题: 1什么是应力,什么是应变? 答:试样单位面积上的拉称为应力,试样单位长度上的伸长量称为应变。 5、下列符号所表示的力学性能指标名称和含义是什么?
答:b b:抗拉强度,材料抵抗断裂的最大应力。 (7 S :屈服强度,塑性材料抵抗塑性变形的最大应力。 6:条件屈服强度,脆性材料抵抗塑性变形的最大应力 7 -1 :疲劳强度,材料抵抗疲劳断裂的最大应力。 S:延伸率,衡量材料的塑性指标。 a k :冲击韧性,材料单位面积上吸收的冲击功。 HRC洛氏硬度,HBS压头为淬火钢球的布氏硬度。HBW压头为硬质合金球的布氏硬度。 过冷度:理论结晶温度与实际结晶温度之差。冷却速度越快,实际结晶温度越低,过冷度越大。纯金属的结晶包括晶核的形成和晶核的长大。 同一成分的金属,晶粒越细气强度、硬度越高,而且塑性和韧性也越好。 原因:晶粒越细,晶界越多,而晶界是一种原子排列向另一种原子排列的过度,晶界上的排列是犬牙交错的,变形是靠位错的变移或位移来实现的,晶界越多,要跃过的障碍越多。 M提高冷却速度,以增加晶核的数目。 J 2在金属浇注之前,向金属液中加入变质剂进行变质处理,以增加外来晶核,还可以采用热处理或塑性加工方法,使固态金属晶粒细化。 3采用机械、超声波振动,电磁搅拌等 合金:两种或两种以上的金属元素,或金属与非金属元素溶合在一起,构成具有金属特性的新物质。组成元素成为组员。 U、固溶体:溶质原子溶入溶剂晶格而保持溶剂晶格类型的金属晶体。 铁碳合金组织可分为:2、金属化合物:各组员按一定整数比结合而成、并具有金属性质的均匀物质 (渗 < 碳体) 3、机械混合物:结晶过程所形成的两相混合组织。
数据结构复习要点(整理版).docx
第一章数据结构概述 基本概念与术语 1.数据:数据是对客观事物的符号表示,在计算机科学中是指所有能输入到计算机中并被计算机程序所处理的符号的总称。 2. 数据元素:数据元素是数据的基本单位,是数据这个集合中的个体,也称之为元素,结点,顶点记录。 (补充:一个数据元素可由若干个数据项组成。数据项是数据的不可分割的最小单位。 ) 3.数据对象:数据对象是具有相同性质的数据元素的集合,是数据的一个子集。(有时候也 叫做属性。) 4.数据结构:数据结构是相互之间存在一种或多种特定关系的数据元素的集合。 (1)数据的逻辑结构:数据的逻辑结构是指数据元素之间存在的固有逻辑关系,常称为数据结构。 数据的逻辑结构是从数据元素之间存在的逻辑关系上描述数据与数据的存储无关,是独立于计算机的。 依据数据元素之间的关系,可以把数据的逻辑结构分成以下几种: 1. 集合:数据中的数据元素之间除了“同属于一个集合“的关系以外,没有其他关系。 2. 线性结构:结构中的数据元素之间存在“一对一“的关系。若结构为非空集合,则除了第一个元素之外,和最后一个元素之外,其他每个元素都只有一个直接前驱和一个直接后继。 3. 树形结构:结构中的数据元素之间存在“一对多“的关系。若数据为非空集,则除了第一个元素 (根)之外,其它每个数据元素都只有一个直接前驱,以及多个或零个直接后继。 4. 图状结构:结构中的数据元素存在“多对多”的关系。若结构为非空集,折每个数据可有多个(或零个)直接后继。 (2)数据的存储结构:数据元素及其关系在计算机内的表示称为数据的存储结构。想要计算机处理数据,就必须把数据的逻辑结构映射为数据的存储结构。逻辑结构可以映射为以下两种存储结构: 1. 顺序存储结构:把逻辑上相邻的数据元素存储在物理位置也相邻的存储单元中,借助元素在存储器中的相对位置来表示数据之间的逻辑关系。 2. 链式存储结构:借助指针表达数据元素之间的逻辑关系。不要求逻辑上相邻的数据元素物理位置上也相邻。 5. 时间复杂度分析:1.常量阶:算法的时间复杂度与问题规模n 无关系T(n)=O(1) 2. 线性阶:算法的时间复杂度与问题规模 n 成线性关系T(n)=O(n) 3. 平方阶和立方阶:一般为循环的嵌套,循环体最后条件为i++ 时间复杂度的大小比较: O(1)< O(log 2 n)< O(n )< O(n log 2 n)< O(n2)< O(n3)< O(2 n ) T p —荷载的周期 7/63 单自由度体系对周期荷载的反应 任意周期荷载作用下结构总的稳态反应为: 用复数Fourier 级数将周期荷载展开, 先计算单位复荷载e i ωj t 作用下,体系稳态反应的复幅值,设: 总的稳态反应为: 复频反应函数,也称为频响函数,传递函数 单位脉冲:作用时间很短,冲量等于1的荷载。 单位脉冲反应函数:单位脉冲作用下体系动力反应时程。 积分 时刻的一个单位脉冲作用在单自由体系上,使结构的质点获得一个单位冲量,在脉冲结束后,质点获得一个初速度: 由于脉冲作用时间很短,ε→0,质点的位移为零: 13/63 —Duhamel 积分无阻尼体系的单位脉冲反应函数为: 有阻尼体系的单位脉冲反应函数为: 、单位脉冲反应函数 单位脉冲及单位脉冲反应函数 15/63 在任意时间t 结构的反应,等的和: Duhamel 积分: 任意荷载作用下单自由度体系的反应等于作用于结构的外荷载与单位脉冲反应函数的卷积。 3.8.1时域分析方法—Duhamel 积分 无阻尼体系动力反应的Duhamel 积分公式: 阻尼体系动力反应的Duhamel 积分公式: 17/63杜哈曼积分法给出了计算线性SDOF体系在任意荷载作用下动力反应的一般解,适用于线弹性体系。 因为使用了叠加原理,因此杜哈曼积分法限于弹性范 速度和加速度的Fourier变换为: 21/63单自由度体系时域运动方程: 对时域运动方程两边同时进行Fourier 正变换,得单自由度体系频域运动方程: —Fourier 变换法频域解为: )—复频反应函数,i 是用来表示函数是一复数。再利用Fourier 逆变换,即得到体系的位移解: 作Fourier 变换, 得到荷载的Fourier 谱P (ω)和复频反应函数到结构反应的频域解—Fourier 谱U (逆变换,由频域解U (ω)得到时域解u (t ): 在用频域法分析中涉及到两次Fourier 变换,均为无穷域积分,特别是Fourier 逆变换,被积函数是复数,有时涉及复杂的围道积分。 复习提纲 第一章数据结构概述 基本概念与术语(P3) 1.数据结构是一门研究非数值计算程序设计问题中计算机的操作对象以及他们之间的关系和操作的学科. 2.数据是用来描述现实世界的数字,字符,图像,声音,以及能够输入到计算机中并能被计算机识别的符号的集合 2.数据元素是数据的基本单位 3.数据对象相同性质的数据元素的集合 4.数据结构包括三方面内容:数据的逻辑结构.数据的存储结构.数据的操作. (1)数据的逻辑结构指数据元素之间固有的逻辑关系. (2)数据的存储结构指数据元素及其关系在计算机内的表示 ( 3 ) 数据的操作指在数据逻辑结构上定义的操作算法,如插入,删除等. 5.时间复杂度分析 -------------------------------------------------------------------------------------------------------------------- 1、名词解释:数据结构、二元组 2、根据数据元素之间关系的不同,数据的逻辑结构可以分为 集合、线性结构、树形结构和图状结构四种类型。 3、常见的数据存储结构一般有四种类型,它们分别是___顺序存储结构_____、___链式存储结构_____、___索引存储结构_____和___散列存储结构_____。 4、以下程序段的时间复杂度为___O(N2)_____。 int i,j,x; for(i=0;i 结构动力学课程学习总结 本学期我们开了《结构动力学》课程,作为结构工程专业的一名学生,《结构动力学》是我们的一门重要的基础课,所以同学们都认真的学习相关知识。《结构动力学》是研究结构体系在各种形式动荷载作用下动力学行为的一门技术学科。它是一门技术性很强的专业基础课程,涉及数学建模、演绎、计算方法、测试技术和数值模拟等多个研究领域,同时具有鲜明的工程与应用背景。学习该门学科的根本目的是为改善工程结构系统在动力环境中的安全和可靠性提供坚实的理论基础。通过该课程的学习,可以掌握动力学的基本规律,有助于在今后工程建设中减少振动危害。 对一般的内容,老师通常是让学生个人讲述所学内容,课前布置他们预习,授课时采用讨论式,先由一名学生主讲,老师纠正补充,加深讲解,同时回答其他同学提出的问题。对较难或较重要的内容,由教师直接讲解,最后大家共同讨论教材后面的思考题,以加深对相关知识点的理解。 通过本课程的学习,我们了解到:结构的动力计算与静力计算有很大的区别。静力计算是研究静荷载作用下的平衡问题。这时结构的质量不随时间快速运动,因而无惯性力。动力计算研究的是动荷载作用下的运动问题,这时结构的质量随时间快速运动,惯性力的作用成为必须考虑的重要问题。根据达朗伯原理,动力计算问题可以转化为静力平衡问题来处理。但是,这是一种形式上的平衡,是一种动平衡,是在引进惯性力的条件下的平衡。也就是说,在动力计算中,虽然形式上仍是是在列平衡方程,但是这里要注意两个问题:所考虑的力系中要包括惯性力这个新的力、考虑的是瞬间的平衡,荷载、内力等都是时间的函数。 我们首先学习了单自由度系统自由振动和受迫振动的概念,所以在学习多自由度系统和弹性体系的振动分析时,则重点学习后者的振动特点以及与前者的联系和区别,这样既节省了时间,又抓住了重点。由于多自由度系统振动分析的公式推导是以矩阵形式表达为基础的,我们开始学习时感到有点不适应,但是随着课程的进展,加上学过矩阵理论这门课后,我们自觉地体会到用矩阵形式表达非常有利于数值计算时的编程,从中也感受到数学知识的魅力和现代技术的优越性,这样就大大增强了我们学习的兴趣。 广西大学金属工艺学 复习重点 铸造 1金属工艺学是一门传授有关制造金属零件工艺方法的综合性技术基础课。是2铸造到今天为止仍然是毛坯生产的主要方法。是 3铸造生产中,最基本的工艺方法是离心铸造。否 4影响合金的流动性因素很多,但以化学成分的影响最为显著。是 5浇注温度过高,容易产生缩孔。是 6为防止热应力,冷铁应放在铸件薄壁处。否 7时效处理是为了消除铸件产生的微小缩松。否 8浇注温度越高,形成的缩孔体积就越大。是 9热应力使铸件薄壁处受压缩。是 10铸造中,手工造型可以做到三箱甚至四箱造型。是 二、单选题 1液态合金的流动性是以( 1)长度来衡量的. ①. 螺旋形试样②. 塔形试样 ③. 条形试样④. 梯形试样 2响合金的流动性的最显著的因素是(2 ) ①. 浇注温度②. 合金本身的化学成分 ③. 充型压力④. 铸型温度 3机器造型( 1) ①. 只能用两箱造型②. 只能用三箱造型 ③. 可以用两箱造型,也可以用三箱造型④. 可以多箱造型 4铸件的凝固方式有( 1) ①. 逐层凝固,糊状凝固,中间凝固②. 逐层凝固,分层凝固,中间凝固③. 糊状凝固,滞留凝固,分层凝固④. 过冷凝固,滞留凝固,过热凝固5缩孔通常是在(4) ①. 铸件的下部②. 铸件的中部 ③. 铸件的表面④. 铸件的上部 6(3 )不是铸造缺陷 ①. 缩松②. 冷裂 ③. 糊状凝固④. 浇不足 7浇注车床床身时,导轨面应该(1) ①. 放在下面②. 放在上面 ③. 放在侧面④. 可随意放置 8三箱造型比两箱造型更容易(2 ) ①. 产生缩孔和缩松②. 产生错箱和铸件长度尺寸的不精确 ③. 产生浇不足和冷隔④. 产生热应力和变形 9关于铸造,正确的说法是( 2) ①. 能加工出所有的机械零件②. 能制造出内腔形状复杂的零件 ③. 只能用铁水加工零件④. 砂型铸造可加工出很薄的零件 10关于热应力,正确的说法是(3 ) ①. 铸件浇注温度越高,热应力越大②. 合金的收缩率越小,热应力越大 自考02331数据构造重点总结(最后修订) 第一章概论 1.瑞士计算机科学家沃思提出:算法+数据构造=程序。算法是对数据运算描述,而数据构造涉及逻辑构造和存储构造。由此可见,程序设计实质是针对实际问题选取一种好数据构造和设计一种好算法,而好算法在很大限度上取决于描述实际问题数据构造。 2.数据是信息载体。数据元素是数据基本单位。一种数据元素可以由若干个数据项构成,数据项是具备独立含义最小标记单位。数据对象是具备相似性质数据元素集合。 3.数据构造指是数据元素之间互有关系,即数据组织形式。 数据构造普通涉及如下三方面内容:数据逻辑构造、数据存储构造、数据运算 ①数据逻辑构造是从逻辑关系上描述数据,与数据元素存储构造无关,是独立于计算机。 数据逻辑构造分类:线性构造和非线性构造。 线性表是一种典型线性构造。栈、队列、串等都是线性构造。数组、广义表、树和图等数据构造都是非线性构造。 ②数据元素及其关系在计算机内存储方式,称为数据存储构造(物理构造)。 数据存储构造是逻辑构造用计算机语言实现,它依赖于计算机语言。 ③数据运算。最惯用检索、插入、删除、更新、排序等。 4.数据四种基本存储办法:顺序存储、链接存储、索引存储、散列存储 (1)顺序存储:普通借助程序设计语言数组描述。 (2)链接存储:普通借助于程序语言指针来描述。 (3)索引存储:索引表由若干索引项构成。核心字是能唯一标记一种元素一种或各种数据项组合。 (4)散列存储:该办法基本思想是:依照元素核心字直接计算出该元素存储地址。 5.算法必要满足5个准则:输入,0个或各种数据作为输入;输出,产生一种或各种输出;有穷性,算法执行有限步后结束;拟定性,每一条指令含义都明确;可行性,算法是可行。 算法与程序区别:程序必要依赖于计算机程序语言,而一种算法可用自然语言、计算机程序语言、数学语言或商定符号语言来描述。当前惯用描述算法语言有两类:类Pascal和类C。 6.评价算法优劣:算法"对的性"是一方面要考虑。此外,重要考虑如下三点: ①执行算法所耗费时间,即时间复杂性; ②执行算法所耗费存储空间,重要是辅助空间,即空间复杂性; ③算法应易于理解、易于编程,易于调试等,即可读性和可操作性。 第一篇金属材料材料导论 第一章金属材料的主要性能 第一节金属材料的力学性能 力学性能的定义:材料在外力作用下,表现出的性能。 一、强度与塑性 概念:应力;应变 拉伸实验 F( k· F ?L(mm) ?L e 1.强度: 定义:塑性变形、断裂的能力。 衡量指标:屈服强度、抗拉强度。 (1)屈服点: 定义:发生屈服现象时的应力。 公式:σs=F s/A o(MPa) (2)抗拉强度: 定义:最大应力值。 公式:σb=F b/A o 2.塑性: 定义:发生塑性变形,不破坏的能力。 衡量指标:伸长率、断面收缩率。 (1)伸长率: 定义: 公式:δ=(L1-L0)/L0×100% (2)断面收缩率: 定义: 公式:Ψ=(A0-A1)/A0×100% 总结:δ、Ψ越大,塑性越好,越易变形但不会断裂。 二、硬度 硬度: 定义:抵抗更硬物体压入的能力。 衡量:布氏硬度、洛氏硬度等。 1.布氏硬度:HB (1)应用范围:铸铁、有色金属、非金属材料。 (2)优缺点:精确、方便、材料限制、非成品检验和薄片。 2.洛氏硬度:HRC用的最多 一定锥形的金刚石(淬火钢球),在规定载荷和时间后,测出的压痕深度差即硬度的大小(表盘表示)。 (1)应用范围:钢及合金钢。 (2)优缺点:测成品、薄的工件,无材料限制,但不精确。 总结:数值越大,硬度越高。 第二章铁碳合金 第一节纯铁的晶体结构及其同素异晶转变 一、金属的结晶 结晶:液态金属凝结成固态金属的现象。 实际结晶温度-金属以实际冷却速度冷却结晶得到的结晶温度Tn。一、金属结晶的过冷现象: 金属的实际结晶温度总是低于理论结晶温度,Tn 结构力学知识点的归纳与总结 第一章 一、简化的原则 1. 结构体系的简化——分解成几个平面结构 2. 杆件的简化——其纵向轴线代替。 3. 杆件间连接的简化——结点通常简化为铰结点或刚结点 4. 结构与基础间连接的简化 结构与基础的连接区简化为支座。按受力特征,通常简化为: (1) 滚轴支座:只约束了竖向位移,允许水平移动和转动。提供竖向反力。在计算简图中用支杆表示。 (2) 铰支座:约束竖向和水平位移,只允许转动。提供两个反力。在计算简图中用两根相交的支杆表示。 (3) 定向支座:只允许沿一个方向平行滑动。提供反力矩和一个反力。在计算简图中用两根平行支杆表示。 (4) 固定支座:约束了所有位移。提供两个反力也一个反力矩。 5. 材料性质的简化——对组成各构件的材料一般都假设为连续的、均匀的、各向同性的、完全弹性或弹塑性的 6. 荷载的简化——集中荷载和分布荷载 §1-4 荷载的分类 一、按作用时间的久暂 荷载可分为恒载和活载 二、按荷载的作用范围 荷载可分为集中荷载和分布荷载 三、按荷载作用的性质 荷载可分为静力荷载和动力荷载 四、按荷载位置的变化 荷载可分为固定荷载和移动荷载 第二章几何构造分析 几何不变体系:体系的位置和形状是不能改变的讨论的前提:不考虑材料的应变 2.1.2 运动自由度S S:体系运动时可以独立改变的坐标的数目。 W:W= (各部件自由度总和 a )-(全部约束数总和) W=3m-(3g+2h+b) 或w=2j-b-r.注意:j与h的区别 约束:限制体系运动的装置 2.1.4 多余约束和非多余约束 不能减少体系自由度的约束叫多余约束。 能够减少体系自由度的约束叫非多余约束。 注意:多余约束与非多余约束是相对的,多余约束一般不是唯一指定的。 2.3.1 二元体法则 约束对象:结点 C 与刚片 约束条件:不共线的两链杆; 瞬变体系 §2-4 构造分析方法与例题 1. 先从地基开始逐步组装 2.4.1 基本分析方法(1) 一. 先找第一个不变单元,逐步组装 1. 先从地基开始逐步组装 2. 先从内部开始,组成几个大刚片后,总组装 二. 去除二元体 2.4.3 约束等效代换 1. 曲(折)链杆等效为直链杆 2. 联结两刚片的两链杆等效代换为瞬铰 铸造将液态金属浇注到具有与零件形状、尺寸相适应的铸型型腔中,待其冷却凝固,以获得毛坯或零件的生产方法 液态合金的充型能力液态合金充满铸型型腔,获得形状完整、轮廓清晰铸件的能力 缩孔它是集中在铸件上部或最后凝固部位容积较大的孔洞。缩孔多呈倒圆锥形,内表面粗糙,通常隐藏在铸件的内层,但在某些情况下,可暴露在铸件的上表面,呈明显的凹坑。 缩松分散在铸件某区域内的细小缩孔,称为缩松。当缩松与缩孔的容积相同时,缩松的分布面积要比缩孔大得多。缩松的形成原因也是由于铸件最后凝固区域的收缩未能得到补足,或者,因合金呈糊状凝固,被树枝状晶体分隔开的小液体区难以得到补缩所致。 热应力它是由于铸件的壁厚不均匀、各部分的冷却速度不同,以致在同一时期内铸件各部分收缩不一致而引起的。 机械应力它是合金的固态收缩受到铸型或型芯的机械阻碍而形成的内应力 热裂热裂是在高温下形成的裂纹。其形状特征是:缝隙宽、形状曲折、缝内呈氧化色 结晶:金属的结晶就是金属液体转变为晶体的过程,亦即金属原子由无序到有序的排列过程。 热处理:就是将钢在固态下,通过加热、保温和冷却,以改变钢的组织,从而获得所需性能的工艺方法。 冷裂冷裂是在低温下形成的裂纹。其形状特征是:裂纹细小、呈连续直线状,有时缝内呈轻微的氧化色 可锻铸铁可锻铸铁又称为玛铁。它是将白口铸铁经石墨化退火而形 成的一种铸铁。 球墨铸铁球墨铸铁是上世纪40年代末发展起来的一种铸造合金, 它是向出炉的铁水中加入球化剂和孕育剂而得到的球状石墨铸铁。 起模斜度为了使模样(或型芯)便于从砂型(或芯盒)中取出,凡 垂直于分型面的立壁在制造模样时,必须留出一定的倾斜度(图2-36), 此倾斜度称为起模斜度。 熔模铸造用易熔材料制成模样,然后在模样上涂挂耐火材料,经硬 化之后,再将模样熔化以排出型外,从而获得无分型面的铸型。由于 模样广泛采用蜡质材料来制造,故又常将熔模铸造称为“失蜡铸造”。 金属型铸造将液态合金浇人金属铸型、以获得铸件的一种铸造方法。由于金属铸型可反复使用多次(几百次到几千次),故有永久型铸造之称 压力铸造简称压铸。它是在高压下(比压约为5~150MPa)将液态或半液态合金快速地压人金属铸型中,并在压力下凝固,以获得铸件的方法 离心铸造将液态合金浇人高速旋转(250~1500 r/min)的铸型,使金属液在离心力作用下充填铸型并结晶 利用金属在外力作用下所产生的塑性变形,来获得具有一定形状、尺寸和力学性能的原材料、毛坯或零件的生产方法,称为金属压力加工,又称金属塑性加工。轧制金属坯料在两个回转轧辊的孔隙中受压变形,以获得各种产品的加工方法。拉拔金属坯料被拉过拉拔模的模孔而变形的加工方法。 挤压金属坯料在挤压模内被挤出模孔而变形的加工方法。 锻造金属坯料在抵铁或锻模模膛内变形而获得产品的方法。 第一章概论 1.数据结构描述的是按照一定逻辑关系组织起来的待处理数据元素的表示及相关操作,涉及数据的逻辑结构、存储结构和运算 2.数据的逻辑结构是从具体问题抽象出来的数学模型,反映了事物的组成结构及事物之间的逻辑关系 可以用一组数据(结点集合K)以及这些数据之间的一组二元关系(关系集合R)来表示:(K, R) 结点集K是由有限个结点组成的集合,每一个结点代表一个数据或一组有明确结构的数据 关系集R是定义在集合K上的一组关系,其中每个关系r(r∈R)都是K×K上的二元关系 3.数据类型 a.基本数据类型 整数类型(integer)、实数类型(real)、布尔类型(boolean)、字符类型(char)、指针类型(pointer)b.复合数据类型 复合类型是由基本数据类型组合而成的数据类型;复合数据类型本身,又可参与定义结构更为复杂的结点类型 4.数据结构的分类:线性结构(一对一)、树型结构(一对多)、图结构(多对多) 5.四种基本存储映射方法:顺序、链接、索引、散列 6.算法的特性:通用性、有效性、确定性、有穷性 7.算法分析:目的是从解决同一个问题的不同算法中选择比较适合的一种,或者对原始算法进行改造、加工、使其优化 8.渐进算法分析 a.大Ο分析法:上限,表明最坏情况 b.Ω分析法:下限,表明最好情况 c.Θ分析法:当上限和下限相同时,表明平均情况 第二章线性表 1.线性结构的基本特征 a.集合中必存在唯一的一个“第一元素” b.集合中必存在唯一的一个“最后元素” c.除最后元素之外,均有唯一的后继 d.除第一元素之外,均有唯一的前驱 2.线性结构的基本特点:均匀性、有序性 3.顺序表 a.主要特性:元素的类型相同;元素顺序地存储在连续存储空间中,每一个元素唯一的索引值;使用常数作为向量长度 b. 线性表中任意元素的存储位置:Loc(ki) = Loc(k0) + i * L(设每个元素需占用L个存储单元) c. 线性表的优缺点: 优点:逻辑结构与存储结构一致;属于随机存取方式,即查找每个元素所花时间基本一样 缺点:空间难以扩充 d.检索:ASL=【Ο(1)】 e.插入:插入前检查是否满了,插入时插入处后的表需要复制【Ο(n)】 f.删除:删除前检查是否是空的,删除时直接覆盖就行了【Ο(n)】 4.链表 4.1单链表 a.特点:逻辑顺序与物理顺序有可能不一致;属于顺序存取的存储结构,即存取每个数据元素所花费的时间不相等 b.带头结点的怎么判定空表:head和tail指向单链表的头结点 c.链表的插入(q->next=p->next; p->next=q;)【Ο(n)】 d.链表的删除(q=p->next; p->next = q->next; delete q;)【Ο(n)】 e.不足:next仅指向后继,不能有效找到前驱 4.2双链表 a.增加前驱指针,弥补单链表的不足 b.带头结点的怎么判定空表:head和tail指向单链表的头结点 c.插入:(q->next = p->next; q->prev = p; p->next = q; q->next->prev = q;) d.删除:(p->prev->next = p->next; p->next->prev = p->prev; p->prev = p->next = NULL; delete p;) 4.3顺序表和链表的比较 4.3.1主要优点 a.顺序表的主要优点 没用使用指针,不用花费附加开销;线性表元素的读访问非常简洁便利 b.链表的主要优点 无需事先了解线性表的长度;允许线性表的长度有很大变化;能够适应经常插入删除内部元素的情况 4.3.2应用场合的选择 a.不宜使用顺序表的场合 经常插入删除时,不宜使用顺序表;线性表的最大长度也是一个重要因素 b.不宜使用链表的场合 当不经常插入删除时,不应选择链表;当指针的存储开销与整个结点内容所占空间相比其比例较大时,应该慎重选择 第三章栈与队列 1.栈 a.栈是一种限定仅在一端进行插入和删除操作的线性表;其特点后进先出;插入:入栈(压栈);删除:出栈(退栈);插入、删除一端被称为栈顶(浮动),另一端称为栈底(固定);实现分为顺序栈和链式栈两种 b.应用: 1)数制转换 while (N) { N%8入栈; N=N/8;} while (栈非空){ 出栈; 输出;} 2)括号匹配检验 不匹配情况:各类括号数量不同;嵌套关系不正确 算法: 逐一处理表达式中的每个字符ch: ch=非括号:不做任何处理 ch=左括号:入栈 ch=右括号:if (栈空) return false else { 出栈,检查匹配情况, if (不匹配) return false } 如果结束后,栈非空,返回false 3)表达式求值 3.1中缀表达式: 计算规则:先括号内,再括号外;同层按照优先级,即先乘*、除/,后加+、减-;相同优先级依据结合律,左结合律即为先左后右 3.2后缀表达式: <表达式> ::= <项><项> + | <项><项>-|<项> <项> ::= <因子><因子> * |<因子><因子>/|<因子> <因子> ::= <常数> ?<常数> ::= <数字>|<数字><常数> <数字> ∷= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 3.3中缀表达式转换为后缀表达式 InfixExp为中缀表达式,PostfixExp为后缀表 达式 初始化操作数栈OP,运算符栈OPND; OPND.push('#'); 读取InfixExp表达式的一项 操作数:直接输出到PostfixExp中; 操作符: 当‘(’:入OPND; 当‘)’:OPND此时若空,则出错;OPND若 非空,栈中元素依次弹出,输入PostfixExpz 中,直到遇到‘(’为止;若为‘(’,弹出即 可 当‘四则运算符’:循环(当栈非空且栈顶不是 ‘(’&& 当前运算符优先级>栈顶运算符优先 级),反复弹出栈顶运算符并输入到 PostfixExp中,再将当前运算符压入栈 3.4后缀表达式求值 初始化操作数栈OP; while (表达式没有处理完) { item = 读取表达式一项; 操作数:入栈OP; 运算符:退出两个操作数, 计算,并将结果入栈} c.递归使用的场合:定义是递归的;数据结构是 递归的;解决问题的方法是递归的 2.队列 a.若线性表的插入操作在一端进行,删除操作 在另一端进行,则称此线性表为队列 b.循环队列判断队满对空: 队空:front==rear;队满: (rear+1)%n==front 第五章二叉树 1.概念 a. 一个结点的子树的个数称为度数 b.二叉树的高度定义为二叉树中层数最大的叶 结点的层数加1 c.二叉树的深度定义为二叉树中层数最大的叶 结点的层数 d.如果一棵二叉树的任何结点,或者是树叶, 或者恰有两棵非空子树,则此二叉树称作满二 叉树 e.如果一颗二叉树最多只有最下面的两层结点 度数可以小于2;最下面一层的结点都集中在 该层最左边的位置上,则称此二叉树为完全二 叉树 f.当二叉树里出现空的子树时,就增加新的、特 殊的结点——空树叶组成扩充二叉树,扩充二 叉树是满二叉树 外部路径长度E:从扩充的二叉树的根到每个 外部结点(新增的空树叶)的路径长度之和 内部路径长度I:扩充的二叉树中从根到每个内 部结点(原来二叉树结点)的路径长度之和 2.性质 a. 二叉树的第i层(根为第0层,i≥0)最多有 2^i个结点 b. 深度为k的二叉树至多有2k+1-1个结点 c. 任何一颗二叉树,度为0的结点比度为2的 结点多一个。n0 = n2 + 1 d. 满二叉树定理:非空满二叉树树叶数等于其 分支结点数加1 e. 满二叉树定理推论:一个非空二叉树的空子 树(指针)数目等于其结点数加1 f. 有n个结点(n>0)的完全二叉树的高度为 ?log2(n+1)?,深度为?log2(n+1)?? g. 对于具有n个结点的完全二叉树,结点按层 次由左到右编号,则有: 1) 如果i = 0为根结点;如果i>0,其父结点 编号是(i-1)/2 2) 当2i+1结构动力学3-3w总结
数据结构复习提纲(整理)
结构动力学课程总结
广西大学金属工艺学复习重点教学教材
2021年自考02331数据结构重点总结最终修订
金属工艺学复习要点
结构力学知识点考点归纳与总结
金属工艺学(邓文英)经典知识点总结
大学数据结构期末知识点重点总结