编译原理词法分析和语法分析
词法分析
一、实验目的
设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验要求
2.1 待分析的简单的词法
(1)关键字:
begin if then while do end
所有的关键字都是小写。
(2)运算符和界符
:= + - * / < <= <> > >= = ; ( ) #
(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:
ID = letter (letter | digit)*
NUM = digit digit*
(4)空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
2.2 各种单词符号对应的种别码:
表2.1 各种单词符号对应的种别码
2.3 词法分析程序的功能:
输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;
token为存放的单词自身字符串;
sum为整型常数。
例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列:
(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)……
三、词法分析程序的算法思想:
算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
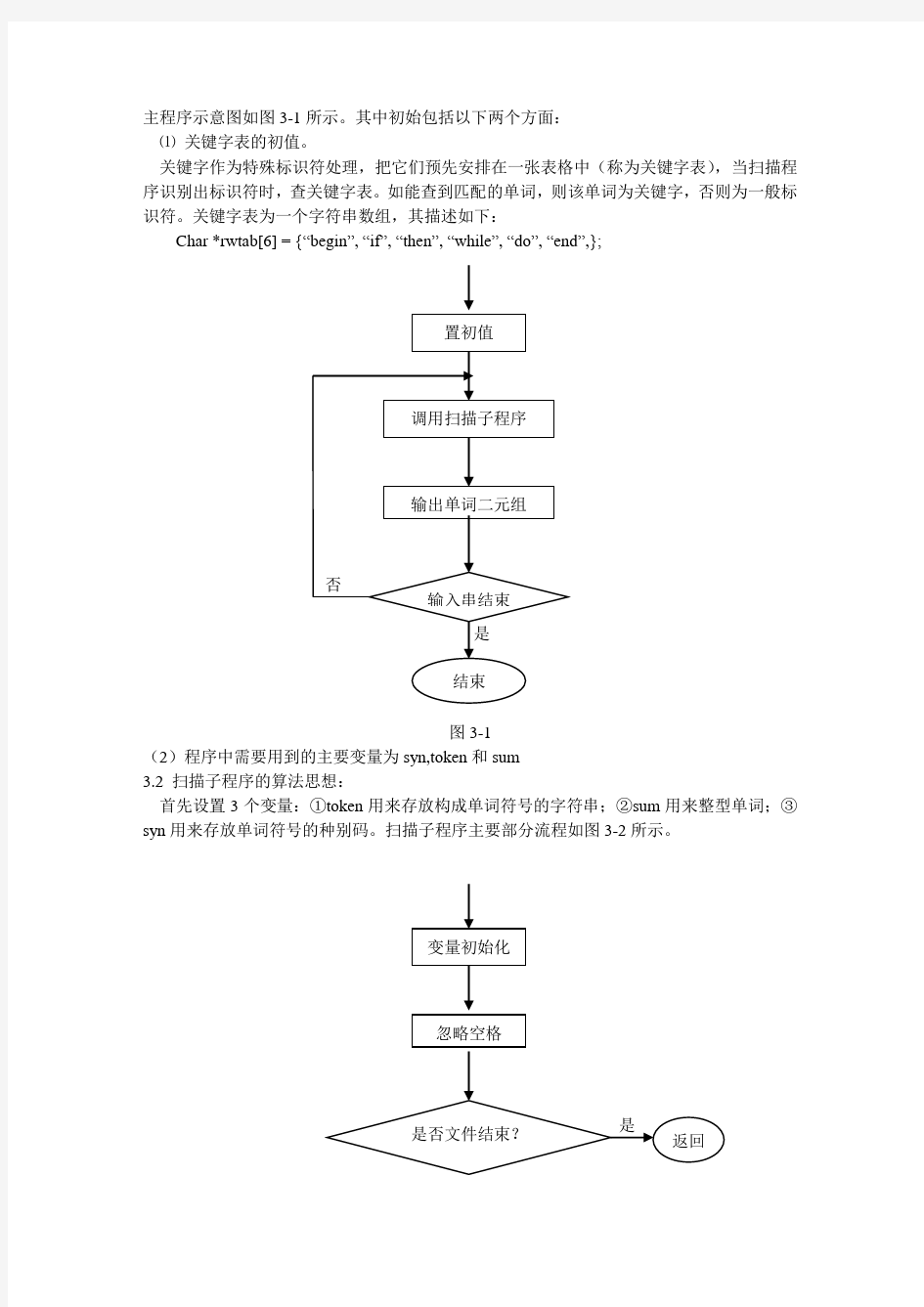
3.1 主程序示意图:
主程序示意图如图3-1所示。其中初始包括以下两个方面:
⑴关键字表的初值。
关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。如能查到匹配的单词,则该单词为关键字,否则为一般标识符。关键字表为一个字符串数组,其描述如下:
Char *rwtab[6] = {“begin”, “if”, “then”, “while”, “do”, “end”,};
图3-1
(2)程序中需要用到的主要变量为syn,token和sum
3.2 扫描子程序的算法思想:
首先设置3个变量:①token用来存放构成单词符号的字符串;②sum用来整型单词;③syn用来存放单词符号的种别码。扫描子程序主要部分流程如图3-2所示。
图3-2 四、词法分析程序的C语言程序源代码:
#include
#include
char prog[80],token[8],ch;
int syn,p,m,n,sum;
char *rwtab[6]={"begin","if","then","while","do","end"}; scaner();
main()
{p=0;
printf("\n please input a string(end with '#'):/n");
do{
scanf("%c",&ch);
prog[p++]=ch;
}while(ch!='#');
p=0;
do{
scaner();
switch(syn)
{case 11:printf("( %-10d%5d )\n",sum,syn);
break;
case -1:printf("you have input a wrong string\n");
getch();
exit(0);
default: printf("( %-10s%5d )\n",token,syn);
break;
}
}while(syn!=0);
getch();
}
scaner()
{ sum=0;
for(m=0;m<8;m++)token[m++]=NULL;
ch=prog[p++];
m=0;
while((ch==' ')||(ch=='\n'))ch=prog[p++];
if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A')))
{ while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) {token[m++]=ch;
ch=prog[p++];
}
p--;
syn=10;
for(n=0;n<6;n++)
if(strcmp(token,rwtab[n])==0)
{ syn=n+1;
break;
}
}
else if((ch>='0')&&(ch<='9'))
{ while((ch>='0')&&(ch<='9'))
{ sum=sum*10+ch-'0';
ch=prog[p++];
}
p--;
syn=11;
}
else switch(ch)
{ case '<':token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{ syn=22;
token[m++]=ch;
}
else
{ syn=20;
p--;
}
break;
case '>':token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{ syn=24;
token[m++]=ch;
}
else
{ syn=23;
p--;
}
break;
case '+': token[m++]=ch;
ch=prog[p++];
if(ch=='+')
{ syn=17;
token[m++]=ch;
}
else
{ syn=13;
p--;
}
break;
case '-':token[m++]=ch;
ch=prog[p++];
if(ch=='-')
{ syn=29;
token[m++]=ch;
}
else
{ syn=14;
p--;
}
break;
case '!':ch=prog[p++];
if(ch=='=')
{ syn=21;
token[m++]=ch;
}
else
{ syn=31;
}
break;
case '=':token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{ syn=25;
token[m++]=ch;
}
else
{ syn=18;
p--;
}
break;
case '*': syn=15;
token[m++]=ch;
break;
case '/': syn=16;
token[m++]=ch;
break;
case '(': syn=27;
token[m++]=ch;
break;
case ')': syn=28;
token[m++]=ch;
break;
case '{': syn=5;
token[m++]=ch;
break;
case '}': syn=6;
token[m++]=ch;
break;
case ';': syn=26;
token[m++]=ch;
break;
case '\"': syn=30;
token[m++]=ch;
break;
case '#': syn=0;
token[m++]=ch;
break;
case ':':syn=17;
token[m++]=ch;
default: syn=-1;
break;
}
token[m++]='\0';
}
五、结果分析:
输入begin x:=9: if x>9 then x:=2*x+1/3; end # 后经词法分析输出如下序列:(begin 1)(x 10)(:17)(= 18)(9 11)(;26)(if 2)……如图5-1所示:
图5-1
六、总结:
词法分析的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。通过本试验的完成,更加加深了对词法分析原理的理解。
语法分析
一、实验目的
编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析。
二、实验要求
利用C语言编制递归下降分析程序,并对简单语言进行语法分析。
2.1 待分析的简单语言的语法
用扩充的BNF表示如下:
⑴<程序>::=begin<语句串>end
⑵<语句串>::=<语句>{;<语句>}
⑶<语句>::=<赋值语句>
⑷<赋值语句>::=ID:=<表达式>
⑸<表达式>::=<项>{+<项> | -<项>}
⑹<项>::=<因子>{*<因子> | /<因子>
⑺<因子>::=ID | NUM | (<表达式>)
2.2 实验要求说明
输入单词串,以“#”结束,如果是文法正确的句子,则输出成功信息,打印“success”,否则输出“error”。
例如:
输入begin a:=9; x:=2*3; b:=a+x end #
输出success!
输入x:=a+b*c end #
输出error
2.3 语法分析程序的酸法思想
(1)主程序示意图如图2-1所示。
图2-1 语法分析主程序示意图
(2)递归下降分析程序示意图如图2-2所示。(3)语句串分析过程示意图如图2-3所示。
图2-3 语句串分析示意图
图2-2 递归下降分析程序示意图
(4)statement语句分析程序流程如图2-4、2-5、2-6、2-7所示。
图2-4 statement语句分析函数示意图图2-5 expression表达式分析函数示意图
图2-7 factor分析过程示意图
三、语法分析程序的C语言程序源代码:
#include "stdio.h"
#include "string.h"
char prog[100],token[8],ch;
char *rwtab[6]={"begin","if","then","while","do","end"};
int syn,p,m,n,sum;
int kk;
factor();
expression();
yucu();
term();
statement();
lrparser();
scaner();
main()
{
p=kk=0;
printf("\nplease input a string (end with '#'): \n");
do
{ scanf("%c",&ch);
prog[p++]=ch;
}while(ch!='#');
p=0;
scaner();
lrparser();
getch();
}
lrparser()
{
if(syn==1)
{
scaner(); /*读下一个单词符号*/
yucu(); /*调用yucu()函数;*/
if (syn==6)
{ scaner();
if ((syn==0)&&(kk==0))
printf("success!\n");
}
else { if(kk!=1) printf("the string haven't got a 'end'!\n");
kk=1;
}
}
else { printf("haven't got a 'begin'!\n");
kk=1;
}
return;
}
yucu()
{
statement(); /*调用函数statement();*/
while(syn==26)
{
scaner(); /*读下一个单词符号*/
if(syn!=6)
statement(); /*调用函数statement();*/
}
return;
}
statement()
{ if(syn==10)
{
scaner(); /*读下一个单词符号*/
if(syn==18)
{ scaner(); /*读下一个单词符号*/ expression(); /*调用函数statement();*/ }
else { printf("the sing ':=' is wrong!\n");
kk=1;
}
}
else { printf("wrong sentence!\n");
kk=1;
}
return;
}
expression()
{ term();
while((syn==13)||(syn==14))
{ scaner(); /*读下一个单词符号*/ term(); /*调用函数term();*/
}
return;
}
term()
{ factor();
while((syn==15)||(syn==16))
{ scaner(); /*读下一个单词符号*/ factor(); /*调用函数factor(); */ }
return;
}
factor()
{ if((syn==10)||(syn==11)) scaner();
else if(syn==27)
{ scaner(); /*读下一个单词符号*/
expression(); /*调用函数statement();*/ if(syn==28)
scaner(); /*读下一个单词符号*/
else { printf("the error on '('\n");
kk=1;
}
}
else { printf("the expression error!\n");
kk=1;
}
return;
}
scaner()
{ sum=0;
for(m=0;m<8;m++)token[m++]=NULL;
m=0;
ch=prog[p++];
while(ch==' ')ch=prog[p++];
if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A')))
{ while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) {token[m++]=ch;
ch=prog[p++];
}
p--;
syn=10;
token[m++]='\0';
for(n=0;n<6;n++)
if(strcmp(token,rwtab[n])==0)
{ syn=n+1;
break;
}
}
else if((ch>='0')&&(ch<='9'))
{ while((ch>='0')&&(ch<='9'))
{ sum=sum*10+ch-'0';
ch=prog[p++];
}
p--;
syn=11;
}
else switch(ch)
{ case '<':m=0;
ch=prog[p++];
if(ch=='>')
{ syn=21;
}
else if(ch=='=')
{ syn=22;
}
else
{ syn=20;
p--;
}
break;
case '>':m=0;
ch=prog[p++];
if(ch=='=')
{ syn=24;
}
else
{ syn=23;
p--;
}
break;
case ':':m=0;
ch=prog[p++];
if(ch=='=')
{ syn=18;
}
else
{ syn=17;
p--;
}
break;
case '+': syn=13; break;
case '-': syn=14; break;
case '*': syn=15;break;
case '/': syn=16;break;
case '(': syn=27;break;
case ')': syn=28;break;
case '=': syn=25;break;
case ';': syn=26;break;
case '#': syn=0;break;
default: syn=-1;break;
}
}
四、结果分析:
输入begin a:=9; x:=2*3; b:=a+x end # 后输出success!如图4-1所示:
图4-1
输入x:=a+b*c end # 后输出error 如图4-2所示:
图4-2
五、总结:
通过本次试验,了解了语法分析的运行过程,主程序大致流程为:“置初值”→调用scaner 函数读下一个单词符号→调用IrParse→结束。递归下降分析的大致流程为:“先判断是否为begin”→不是则“出错处理”,若是则“调用scaner函数”→调用语句串分析函数→“判断是否为end”→不是则“出错处理”,若是则调用scaner函数→“判断syn=0&&kk=0是否成立”成立则说明分析成功打印出来。不成立则“出错处理”。
语义分析程序
#include "stdio.h"
#include "string.h"
char prog[100],token[8],ch;
char *rwtab[6]={"begin","if","then","while","do","end"};
int syn,p,m,n,sum,q;
int kk;
struct { char result1[8];
char ag11[8];
char op1[8];
char ag21[8];
} quad[20];
char *factor();
char *expression();
int yucu();
char *term();
int statement();
int lrparser();
char *newtemp();
scaner();
emit(char *result,char *ag1,char *op,char *ag2);
main()
{ int j;
q=p=kk=0;
printf("\nplease input a string (end with '#'): ");
do
{ scanf("%c",&ch);
prog[p++]=ch;
}while(ch!='#');
p=0;
scaner();
lrparser();
if(q>19)printf(" to long sentense!\n");
else for (j=0;j \n\n",quad[j].result1,quad[j].ag11,quad[j].op1,quad[j].ag21); getch(); } int lrparser() { int schain=0; kk=0; if (syn==1) { scaner(); schain=yucu(); if(syn==6) { scaner(); if((syn==0)&&(kk==0)) printf("Success!\n"); } else { if(kk!=1)printf("short of 'end' !\n"); kk=1; getch(); exit(0); } } else { printf("short of 'begin' !\n"); kk=1; getch(); exit(0); } return (schain); } int yucu() { int schain=0; schain=statement(); while(syn==26) { scaner(); schain=statement(); } return (schain); } int statement() { char tt[8],eplace[8]; int schain=0; if (syn==10) { strcpy(tt,token); scaner(); if(syn==18) { scaner(); strcpy(eplace,expression()); emit(tt,eplace,"",""); schain=0; } else { printf("short of sign ':=' !\n"); kk=1; getch(); exit(0); } return (schain); } } char *expression() { char *tp,*ep2,*eplace,*tt; tp=(char *)malloc(12); ep2=(char *)malloc(12); eplace=(char *)malloc(12); tt=(char *)malloc(12); strcpy(eplace,term()); while((syn==13)||(syn==14)) { if (syn==13)strcpy(tt,"+"); else strcpy(tt,"-"); scaner(); strcpy(ep2,term()); strcpy(tp,newtemp()); emit(tp,eplace,tt,ep2); strcpy(eplace,tp); } return (eplace); } char *term() { char *tp,*ep2,*eplace,*tt; tp=(char *)malloc(12); ep2=(char *)malloc(12); eplace=(char *)malloc(12); tt=(char *)malloc(12); strcpy(eplace,factor()); while((syn==15)||(syn==16)) { if (syn==15)strcpy(tt,"*"); else strcpy(tt,"/"); scaner(); strcpy(ep2,factor()); strcpy(tp,newtemp()); emit(tp,eplace,tt,ep2); strcpy(eplace,tp); } return (eplace); } char *factor() { char *fplace; fplace=(char *)malloc(12); strcpy(fplace,""); if(syn==10) { strcpy(fplace,token); scaner(); } else if(syn==11) { itoa(sum,fplace,10); scaner(); } else if(syn==27) { scaner(); fplace=expression(); if(syn==28) scaner(); else { printf("error on ')' !\n"); kk=1; getch(); exit(0); } } else { printf("error on '(' !\n"); kk=1; getch(); exit(0); } return (fplace); } char *newtemp() { char *p; char m[8]; p=(char *)malloc(8); kk++; itoa(kk,m,10); strcpy(p+1,m); p[0]='t'; return(p); } scaner() { sum=0; for(m=0;m<8;m++)token[m++]=NULL; m=0; ch=prog[p++]; while(ch==' ')ch=prog[p++]; if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))) { while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) {token[m++]=ch; ch=prog[p++]; } p--; syn=10; token[m++]='\0'; for(n=0;n<6;n++) 编译原理实验--词法分析器 实验一词法分析器设计 【实验目的】 1(熟悉词法分析的基本原理,词法分析的过程以及词法分析中要注意的问题。 2(复习高级语言,进一步加强用高级语言来解决实际问题的能力。 3(通过完成词法分析程序,了解词法分析的过程。 【实验内容】 用C语言编写一个PL/0词法分析器,为语法语义分析提供单词,使之能把输入的字符 串形式的源程序分割成一个个单词符号传递给语法语义分析,并把分析结果(基本字, 运算符,标识符,常数以及界符)输出。 【实验流程图】 【实验步骤】 1(提取pl/0文件中基本字的源代码 while((ch=fgetc(stream))!='.') { int k=-1; char a[SIZE]; int s=0; while(ch>='a' && ch<='z'||ch>='A' && ch<='Z') { if(ch>='A' && ch<='Z') ch+=32; a[++k]=(char)ch; ch=fgetc(stream); } for(int m=0;m<=12&&k!=-1;m++) for(int n=0;n<=k;n++) { if(a[n]==wsym[m][n]) ++s; else s=0; if(s==(strlen(wsym[m]))) {printf("%s\t",wsym[m]);m=14;n=k+1;} } 2(提取pl/0文件中标识符的源代码 while((ch=fgetc(stream))!='.') { int k=-1; char a[SIZE]=" "; int s=0; while(ch>='a' && ch<='z'||ch>='A' && ch<='Z') { if(ch>='A' && ch<='Z') ch+=32; a[++k]=(char)ch; ch=fgetc(stream); } for(int m=0;m<=12&&k!=-1;m++) for(int n=0;n<=k;n++) { if(a[n]==wsym[m][n]) ++s; else s=0; if(s==(strlen(wsym[m]))) {m=14;n=k+1;} } if(m==13) for(m=0;a[m]!=NULL;m++) printf("%c ",a[m]); 编译原理实验报告实验名称:实验一编写词法分析程序 实验类型:验证型实验 指导教师:何中胜 专业班级:13软件四 姓名:丁越 学号: 电子邮箱: 实验地点:秋白楼B720 实验成绩: 日期:2016年3 月18 日 一、实验目的 通过设计、调试词法分析程序,实现从源程序中分出各种单词的方法;熟悉词法分析 程序所用的工具自动机,进一步理解自动机理论。掌握文法转换成自动机的技术及有穷自动机实现的方法。确定词法分析器的输出形式及标识符与关键字的区分方法。加深对课堂教学的理解;提高词法分析方法的实践能力。通过本实验,应达到以下目标: 1、掌握从源程序文件中读取有效字符的方法和产生源程序的内部表示文件的方法。 2、掌握词法分析的实现方法。 3、上机调试编出的词法分析程序。 二、实验过程 以编写PASCAL子集的词法分析程序为例 1.理论部分 (1)主程序设计考虑 主程序的说明部分为各种表格和变量安排空间。 数组 k为关键字表,每个数组元素存放一个关键字。采用定长的方式,较短的关键字 后面补空格。 P数组存放分界符。为了简单起见,分界符、算术运算符和关系运算符都放在 p表中 (编程时,还应建立算术运算符表和关系运算符表,并且各有类号),合并成一类。 id和ci数组分别存放标识符和常数。 instring数组为输入源程序的单词缓存。 outtoken记录为输出内部表示缓存。 还有一些为造表填表设置的变量。 主程序开始后,先以人工方式输入关键字,造 k表;再输入分界符等造p表。 主程序的工作部分设计成便于调试的循环结构。每个循环处理一个单词;接收键盘上 送来的一个单词;调用词法分析过程;输出每个单词的内部码。 ⑵词法分析过程考虑 将词法分析程序设计成独立一遍扫描源程序的结构。其流程图见图1-1。 图1-1 该过程取名为 lexical,它根据输入单词的第一个字符(有时还需读第二个字符),判断单词类,产生类号:以字符 k表示关键字;i表示标识符;c表示常数;p表示分界符;s表示运算符(编程时类号分别为 1,2,3,4,5)。 对于标识符和常数,需分别与标识符表和常数表中已登记的元素相比较,如表中已有 该元素,则记录其在表中的位置,如未出现过,将标识符按顺序填入数组id中,将常数 变为二进制形式存入数组中 ci中,并记录其在表中的位置。 lexical过程中嵌有两个小过程:一个名为getchar,其功能为从instring中按顺序取出一个字符,并将其指针pint加1;另一个名为error,当出现错误时,调用这个过程, 输出错误编号。 2.实践部分 编译原理课程设计Course Design of Compiling (课程代码3273526) 半期题目:词法和语法分析器 实验学期:大三第二学期 学生班级:2014级软件四班 学生学号:2014112218 学生姓名:何华均 任课教师:丁光耀 信息科学与技术学院 2017.6 课程设计1-C语言词法分析器 1.题目 C语言词法分析 2.内容 选一个能正常运行的c语言程序,以该程序出现的字符作为单词符号集,不用处理c语言的所有单词符号。 将解析到的单词符号对应的二元组输出到文件中保存 可以将扫描缓冲区与输入缓冲区合成一个缓冲区,一次性输入源程序后就可以进行预处理了 3.设计目的 掌握词法分析算法,设计、编制并调试一个词法分析程序,加深对词法分析原理的理解 4.设计环境(电脑语言环境) 语言环境:C语言 CPU:i7HQ6700 内存:8G 5.概要设计(单词符号表,状态转换图) 5.1词法分析器的结构 词法分析程序的功能: 输入:所给文法的源程序字符串。 输出:二元组(syn,token或sum)构成的序列。 词法分析程序可以单独为一个程序;也可以作为整个编译程序的一个子程序,当需要一个单词时,就调用此法分析子程序返回一个单词. 为便于程序实现,假设每个单词间都有界符或运算符或空格隔开,并引入下面的全局变量及子程序: 1) ch 存放最新读进的源程序字符 2) strToken 存放构成单词符号的字符串 3) Buffer 字符缓冲区 4)struct keyType 存放保留字的符号和种别 5.2待分析的简单词法 (1)保留字 break、case、char、const、int、do、while… (2)运算符和界符 = 、+、-、* 、/、%、,、;、(、)、?、# 5.3各种单词符号对应的种别码 编译技术 班级网络0802 学号3080610052姓名叶晨舟 指导老师朱玉全2011年 7 月 4 日 一、目的 编译技术是理论与实践并重的课程,而其实验课要综合运用一、二年级所学的多门课程的内容,用来完成一个小型编译程序。从而巩固和加强对词法分析、语法分析、语义分析、代码生成和报错处理等理论的认识和理解;培养学生对完整系统的独立分析和设计的能力,进一步培养学生的独立编程能力。 二、任务及要求 基本要求: 1.词法分析器产生下述小语言的单词序列 这个小语言的所有的单词符号,以及它们的种别编码和内部值如下表: 单词符号种别编码助记符内码值 DIM IF DO STOP END 标识符 常数(整)= + * ** , ( )1 2 3 4 5 6 7 8 9 10 11 12 13 14 $DIM $IF $DO $STOP $END $ID $INT $ASSIGN $PLUS $STAR $POWER $COMMA $LPAR $RPAR - - - - - - 内部字符串 标准二进形式 - - - - - - 对于这个小语言,有几点重要的限制: 首先,所有的关键字(如IF﹑WHILE等)都是“保留字”。所谓的保留字的意思是,用户不得使用它们作为自己定义的标示符。例如,下面的写法是绝对禁止的: IF(5)=x 其次,由于把关键字作为保留字,故可以把关键字作为一类特殊标示符来处理。也就是说,对于关键字不专设对应的转换图。但把它们(及其种别编码)预先安排在一张表格中(此表叫作保留字表)。当转换图识别出一个标识符时,就去查对这张表,确定它是否为一个关键字。 再次,如果关键字、标识符和常数之间没有确定的运算符或界符作间隔,则必须至少用一个空白符作间隔(此时,空白符不再是完全没有意义的了)。例如,一个条件语句应写为 实验1-3 《编译原理》S语言词法分析程序设计方案 一、实验目的 了解词法分析程序的两种设计方法之一:根据状态转换图直接编程的方式; 二、实验内容 1.根据状态转换图直接编程 编写一个词法分析程序,它从左到右逐个字符的对源程序进行扫描,产生一个个的单词的二元式,形成二元式(记号)流文件输出。在此,词法分析程序作为单独的一遍,如下图所示。 具体任务有: (1)组织源程序的输入 (2)拼出单词并查找其类别编号,形成二元式输出,得到单词流文件 (3)删除注释、空格和无用符号 (4)发现并定位词法错误,需要输出错误的位置在源程序中的第几行。将错误信息输出到屏幕上。 (5)对于普通标识符和常量,分别建立标识符表和常量表(使用线性表存储),当遇到一个标识符或常量时,查找标识符表或常量表,若存在,则返回位置,否则返回0并且填写符号表或常量表。 标识符表结构:变量名,类型(整型、实型、字符型),分配的数据区地址 注:词法分析阶段只填写变量名,其它部分在语法分析、语义分析、代码生成等阶段逐步填入。 常量表结构:常量名,常量值 三、实验要求 1.能对任何S语言源程序进行分析 在运行词法分析程序时,应该用问答形式输入要被分析的S源语言程序的文件名,然后对该程序完成词法分析任务。 2.能检查并处理某些词法分析错误 词法分析程序能给出的错误信息包括:总的出错个数,每个错误所在的行号,错误的编号及错误信息。 本实验要求处理以下两种错误(编号分别为1,2): 1:非法字符:单词表中不存在的字符处理为非法字符,处理方式是删除该字符,给出错误信息,“某某字符非法”。 2:源程序文件结束而注释未结束。注释格式为:/* …… */ 四、保留字和特殊符号表 编译技术实验报告 实验题目:词法分析 学院:信息学院 专业:计算机科学与技术学号: 姓名: 一、实验目的 (1)理解词法分析的功能; (2)理解词法分析的实现方法; 二、实验内容 PL0的文法如下 …< >?为非终结符。 …::=? 该符号的左部由右部定义,可读作“定义为”。 …|? 表示…或?,为左部可由多个右部定义。 …{ }? 表示花括号内的语法成分可以重复。在不加上下界时可重复0到任意次 数,有上下界时可重复次数的限制。 …[ ]? 表示方括号内的成分为任选项。 …( )? 表示圆括号内的成分优先。 上述符号为“元符号”,文法用上述符号作为文法符号时需要用引号…?括起。 〈程序〉∷=〈分程序〉. 〈分程序〉∷= [〈变量说明部分〉][〈过程说明部分〉]〈语句〉 〈变量说明部分〉∷=V AR〈标识符〉{,〈标识符〉}:INTEGER; 〈无符号整数〉∷=〈数字〉{〈数字〉} 〈标识符〉∷=〈字母〉{〈字母〉|〈数字〉} 〈过程说明部分〉∷=〈过程首部〉〈分程序〉{;〈过程说明部分〉}; 〈过程首部〉∷=PROCEDURE〈标识符〉; 〈语句〉∷=〈赋值语句〉|〈条件语句〉|〈过程调用语句〉|〈读语句〉|〈写语句〉|〈复合语句〉|〈空〉 〈赋值语句〉∷=〈标识符〉∶=〈表达式〉 〈复合语句〉∷=BEGIN〈语句〉{;〈语句〉}END 〈条件〉∷=〈表达式〉〈关系运算符〉〈表达式〉 〈表达式〉∷=〈项〉{〈加法运算符〉〈项〉} 〈项〉∷=〈因子〉{〈乘法运算符〉〈因子〉} 〈因子〉∷=〈标识符〉|〈无符号整数〉|'('〈表达式〉')' 〈加法运算符〉∷=+|- 〈乘法运算符〉∷=* 〈关系运算符〉∷=<>|=|<|<=|>|>= 〈条件语句〉∷=IF〈条件〉THEN〈语句〉 〈字母〉∷=a|b|…|X|Y|Z 〈数字〉∷=0|1|2|…|8|9 实现PL0的词法分析 实验二语法分析器 一、实验目的 通过完成预测分析法的语法分析程序,了解预测分析法和递归子程序法的区别和联系。使学生了解语法分析的功能,掌握语法分析程序设计的原理和构造方法,训练学生掌握开发应用程序的基本方法。有利于提高学生的专业素质,为培养适应社会多方面需要的能力。 二、实验内容 ◆根据某一文法编制调试LL (1 )分析程序,以便对任意输入的符号串 进行分析。 ◆构造预测分析表,并利用分析表和一个栈来实现对上述程序设计语言的分 析程序。 ◆分析法的功能是利用LL(1)控制程序根据显示栈栈顶内容、向前看符号 以及LL(1)分析表,对输入符号串自上而下的分析过程。 三、LL(1)分析法实验设计思想及算法 ◆模块结构: (1)定义部分:定义常量、变量、数据结构。 (2)初始化:设立LL(1)分析表、初始化变量空间(包括堆栈、结构体、数组、临时变量等); (3)控制部分:从键盘输入一个表达式符号串; (4)利用LL(1)分析算法进行表达式处理:根据LL(1)分析表对表达式符号串进行堆栈(或其他)操作,输出分析结果,如果遇到错误则显示错误信息。 四、实验要求 1、编程时注意编程风格:空行的使用、注释的使用、缩进的使用等。 2、如果遇到错误的表达式,应输出错误提示信息。 3、对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)E->TG (2)G->+TG|—TG (3)G->ε (4)T->FS (5)S->*FS|/FS (6)S->ε (7)F->(E) (8)F->i 输出的格式如下: 五、实验源程序 LL1.java import java.awt.*; import java.awt.event.*; import javax.swing.*; import javax.swing.table.DefaultTableModel; import java.sql.*; import java.util.Vector; public class LL1 extends JFrame implements ActionListener { /** * */ private static final long serialVersionUID = 1L; JTextField tf1; JTextField tf2; JLabel l; JButton b0; JPanel p1,p2,p3; JTextArea t1,t2,t3; JButton b1,b2,b3; 词法分析 一、实验目的 设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。 二、实验要求 2.1 待分析的简单的词法 (1)关键字: begin if then while do end 所有的关键字都是小写。 (2)运算符和界符 : = + - * / < <= <> > >= = ; ( ) # (3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义: ID = letter (letter | digit)* NUM = digit digit* (4)空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。 2.2 各种单词符号对应的种别码: 输入:所给文法的源程序字符串。 输出:二元组(syn,token或sum)构成的序列。 其中:syn为单词种别码; token为存放的单词自身字符串; sum为整型常数。 例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列: (1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)…… 三、词法分析程序的算法思想: 算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。 3.1 主程序示意图: 主程序示意图如图3-1所示。其中初始包括以下两个方面: ⑴关键字表的初值。 关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。如能查到匹配的单词,则该单词为关键字,否则为一般标识符。关键字表为一个字符串数组,其描述如下: Char *rwtab[6] = {“begin”, “if”, “then”, “while”, “do”, “end”,}; 图3-1 (2)程序中需要用到的主要变量为syn,token和sum 3.2 扫描子程序的算法思想: 首先设置3个变量:①token用来存放构成单词符号的字符串;②sum用来整型单词;③syn用来存放单词符号的种别码。扫描子程序主要部分流程如图3-2所示。 . 编译原理实验专业:13级网络工程 语法分析器1 一、实现方法描述 所给文法为G【E】; E->TE’ E’->+TE’|空 T->FT’ T’->*FT’|空 F->i|(E) 递归子程序法: 首先计算出五个非终结符的first集合follow集,然后根据五个产生式定义了五个函数。定义字符数组vocabulary来存储输入的句子,字符指针ch指向vocabulary。从非终结符E函数出发,如果首字符属于E的first集,则依次进入T函数和E’函数,开始递归调用。在每个函数中,都要判断指针所指字符是否属于该非终结符的first集,属于则根据产生式进入下一个函数进行调用,若first集中有空字符,还要判断是否属于该非终结符的follow集。以分号作为结束符。 二、实现代码 头文件shiyan3.h #include #include int a=0; cout<<"按1结束程序"< 编译原理 C语言词法分析器 一、实验题目 编制并调试C词法分析程序。 a.txt源代码: ?main() { int sum=0 ,it=1;/* Variable declaration*/ if (sum==1) it++; else it=it+2; }? 设计其词法分析程序,能识别出所有的关键字、标识符、常数、运算符(包括复合运算符,如++)、界符;能过滤掉源程序中的注释、空格、制表符、换行符;并且能够对一些词法规则的错误进行必要的处理,如:标识符只能由字母、数字和下划线组成,且第一个字符必须为字母或下划线。实验要求:要给出所分析语言的词法说明,相应的状态转换图,单词的种别编码方案,词法分析程序的主要算法思想等。 二、实验目的 1、理解词法分析在编译程序中的作用; 2、掌握词法分析程序的实现方法和技术; 3、加深对有穷自动机模型的理解。 三、主要函数 四、设计 1.主函数void main ( ) 2. 初始化函数void load ( ) 3. 保留字及标识符判断函数void char_search(char *word) 4. 整数类型判断函数void inta_search(char *word) 5. 浮点类型判断函数void intb_search(char *word) 6. 字符串常量判断函数void cc_search(char *word) 7. 字符常量判断函数void c_search(char *word) 同4、5函数图 8.主扫描函数void scan ( ) 五、关键代码 #include 词法分析器实验报告 一、实验目的 选择一种编程语言实现简单的词法分析程序,设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。 二、实验要求 待分析的简单的词法 (1)关键字: begin if then while do end 所有的关键字都是小写。 (2)运算符和界符 : = + - * / < <= <> > >= = ; ( ) # (3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义: ID = letter (letter | digit)* NUM = digit digit* (4)空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。 各种单词符号对应的种别码: 表各种单词符号对应的种别码 词法分析程序的功能: 输入:所给文法的源程序字符串。 输出:二元组(syn,token或sum)构成的序列。 其中:syn为单词种别码; token为存放的单词自身字符串; sum为整型常数。 例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列: (1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)…… 三、词法分析程序的算法思想: 算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根 据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。 主程序示意图: 主程序示意图如图3-1所示。其中初始包括以下两个方面: ⑴关键字表的初值。 关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。如能查到匹配的单词,则该单词为关键字,否则为一般标识符。关键字表为一个字符串数组,其描述如下: Char *rwtab[6] = {“begin”, “if”, “then”, “while”, “do”, “end”,}; 图3-1 (2)程序中需要用到的主要变量为syn,token和sum 扫描子程序的算法思想: 首先设置3个变量:①token用来存放构成单词符号的字符串;②sum用来整型单词;③syn 用来存放单词符号的种别码。扫描子程序主要部分流程如图3-2所示。 编译原理实验报告 实验一 一、实验名称:词法分析器的设计 二、实验目的:1,词法分析器能够识别简单语言的单词符号 2,识别出并输出简单语言的基本字.标示符.无符号整数.运算符.和界符。 三、实验要求:给出一个简单语言单词符号的种别编码词法分析器 四、实验原理: 1、词法分析程序的算法思想 算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。 2、程序流程图 (1 (2)扫描子程序 3 五、实验内容: 1、实验分析 编写程序时,先定义几个全局变量a[]、token[](均为字符串数组),c,s( char型),i,j,k(int型),a[]用来存放输入的字符串,token[]另一个则用来帮助识别单词符号,s用来表示正在分析的字符。字符串输入之后,逐个分析输入字符,判断其是否‘#’,若是表示字符串输入分析完毕,结束分析程序,若否则通过int digit(char c)、int letter(char c)判断其是数字,字符还是算术符,分别为用以判断数字或字符的情况,算术符的判断可以在switch语句中进行,还要通过函数int lookup(char token[])来判断标识符和保留字。 2 实验词法分析器源程序: #include 信息工程学院实验报告(2010 ~2011 学年度第一学期) 姓名:柳冠天 学号:2081908318 班级:083 词法分析 一、实验目的 设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。 二、实验要求 2.1 待分析的简单的词法 (1)关键字: begin if then while do end 所有的关键字都是小写。 (2)运算符和界符 := + - * / < <= <> > >= = ; ( ) # (3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义: ID = letter (letter | digit)* NUM = digit digit* (4)空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。 2.2 各种单词符号对应的种别码: 表2.1 各种单词符号对应的种别码 2.3 词法分析程序的功能: 输入:所给文法的源程序字符串。 输出:二元组(syn,token或sum)构成的序列。 其中:syn为单词种别码; token为存放的单词自身字符串; sum为整型常数。 例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列: (1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)…… 三、词法分析程序的算法思想: 算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。 3.1 主程序示意图: 编译原理实验报告 实验名称:编写语法分析分析器实验类型: 指导教师: 专业班级: 学号: 电子邮件: 实验地点: 实验成绩: 一、实验目的 通过设计、编制、调试一个典型的语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,进一步掌握常用的语法分析方法。 1、选择最有代表性的语法分析方法,如LL(1) 语法分析程序、算符优先分析程序和LR分析分析程序,至少选一题。 2、选择对各种常见程序语言都用的语法结构,如赋值语句(尤指表达式)作为分析对象,并且与所选语法分析方法要比较贴切。 二、实验过程 编写算符优先分析器。要求: (a)根据算符优先分析算法,编写一个分析对象的语法分析程序。读者可根据自己的能力选择以下三项(由易到难)之一作为分析算法中的输入: Ⅰ:通过构造算符优先关系表,设计编制并调试一个算法优先分析程序Ⅱ:输入FIRSTVT,LASTVT集合,由程序自动生成该文法的算符优先关系矩阵。 Ⅲ:输入已知文法,由程序自动生成该文法的算符优先关系矩阵。(b)程序具有通用性,即所编制的语法分析程序能够使用于不同文法以及各种输入单词串,并能判断该文法是否为算符文法和算符优先文法。 (c)有运行实例。对于输入的一个文法和一个单词串,所编制的语法分析程序应能正确地判断,此单词串是否为该文法的句子,并要求输出分析过程。 三、实验结果 算符优先分析器: 测试数据:E->E+T|T T->T*F|F F->(E)|i 实验结果:(输入串为i+i*i+i) 四、讨论与分析 自下而上分析技术-算符优先分析法: 算符文法:一个上下无关文法G,如果没有且没有P→..QR...(P ,Q ,R属于非终结符),则G是一个算符文法。 FIRSTVT集构造 1、若有产生式P →a...或P →Qa...,则a∈FIRSTVT(P)。 2、若有产生式P→...,则FIRSTVT(R)包含在FIRSTVT(P)中。由优先性低于的定义和firstVT集合的定义可以得出:若存在某个产生式:…P…,则对所有:b∈firstVT(P)都有:a≦b。 构造优先关系表: 1、如果每个非终结符的FIRSTVT和LASTVT集均已知,则可构造优先关系表。 2、若产生式右部有...aP...的形式,则对于每个b∈FIRSTVT(P)都有 《编译原理》 课程设计 院系信息科学与技术学院 专业软件工程 年级 2011级 学号 20112723 姓名林苾湲 西南交通大学信息科学与技术学院 2013年 12月 目录 课程设计1 词法分析器 (2) 1.1 设计题目 (2) 1.2 设计容 (2) 1.3 设计目的 (2) 1.4 设计环境 (2) 1.5 需求分析 (2) 1.6 概要设计 (2) 1.7 详细设计 (4) 1.8 编程调试 (5) 1.9 测试 (11) 1.10 结束语 (13) 课程设计2 赋值语句的解释程序设计 (14) 2.1 设计题目 (14) 2.2 设计容 (14) 2.3 设计目的 (14) 2.4 设计环境 (14) 2.5 需求分析 (15) 2.6 概要设计 (16) 2.7 详细设计 (16) 2.8 编程调试 (24) 2.9 测试 (24) 2.10 结束语 (25) 课程设计一词法分析器设计 一、设计题目 手工设计c语言的词法分析器(可以是c语言的子集)。 二、设计容 处理c语言源程序,过滤掉无用符号,判断源程序中单词的合法性,并分解出正确的单词,以二元组形式存放在文件中。 三、设计目的 了解高级语言单词的分类,了解状态图以及如何表示并识别单词规则,掌握状态图到识别程序的编程。 四、设计环境 该课程设计包括的硬件和软件条件如下: 4.1.硬件 (1)Intel Core Duo CPU P8700 (2)存4G 4.2.软件 (1)Window 7 32位操作系统 (2)Microsoft Visual Studio c#开发平台 4.3.编程语言 C#语言 五、需求分析 5.1.源程序的预处理:源程序中,存在许多编辑用的符号,他们对程序逻辑功能无任何影响。例如:回车,换行,多余空白符,注释行等。在词法分析之前,首先要先剔除掉这些符号,使得词法分析更为简单。 5.2.单词符号的识别并判断单词的合法性:将每个单词符号进行不同类别的划分。单词符号可以划分成5中。 (1)标识符:用户自己定义的名字,常量名,变量名和过程名。 (2)常数:各种类型的常数。 (3) 保留字(关键字):如if、else、while、int、float等。 (4) 运算符:如+、-、*、<、>、=等。 (5)界符:如逗号、分号、括号等。 5.3.将所有合法的单词符号转化为便于计算机处理的二元组形式:(单词分类号,单词自身值);以图形化界面显示出来。 5.4.可选择性地将结果保存到文件中。 六、概要设计 6.1.数据类型 6.1.1.单词的分类:本词法分析器演示的是C语言的一个子集,故字符集如下: 编译原理实验报告 实验一 实验题目:词法分析 指导老师:任姚鹏 专业班级:计算机科学与技术系网络工程方向1002班姓名:xxxx 2013年 4月13日 实验类型__验证性__ 实验室_软件实验室三__ 一、实验项目的目的和任务: 了解和掌握词法分析的方法,编程实现给定源语言程序的词法分析器,并利用该分析器扫描源语言程序的字符串,按照给定的词法规则,识别出单词符号作为输出,发现其中的词法错误。 二、实验内容: 1.设计一个简单的程序设计语言(语言中有若干运算符和分界符;有若干关健字;若干标识符及若干常数) 2.确定编译中使用的表格、词法分析器的输出形式、标识符与关键字的区分方法。 3.把词法分析器设计成一个独立的过程。 三、实验要求: 1.从键盘上输入源程序; 2.处理各单词,计算个单词的值和类型; 3.输出个单词名、单词的值和类型。 四、实验代码 #include 一、实验目的 了解词法分析程序的两种设计方法:1.根据状态转换图直接编程的方式;2.利用DFA 编写通用的词法分析程序。 二、实验内容及要求 1.根据状态转换图直接编程 编写一个词法分析程序,它从左到右逐个字符的对源程序进行扫描,产生一个个的单词的二元式,形成二元式(记号)流文件输出。在此,词法分析程序作为单独的一遍,如下图所示。 具体任务有: (1)组织源程序的输入 (2)拼出单词并查找其类别编号,形成二元式输出,得到单词流文件 (3)删除注释、空格和无用符号 (4)发现并定位词法错误,需要输出错误的位置在源程序中的第几行。将错误信息输出到屏幕上。 (5)对于普通标识符和常量,分别建立标识符表和常量表(使用线性表存储),当遇到一个标识符或常量时,查找标识符表或常量表,若存在,则返回位置,否则返回0并且填写符号表或常量表。 标识符表结构:变量名,类型(整型、实型、字符型),分配的数据区地址 注:词法分析阶段只填写变量名,其它部分在语法分析、语义分析、代码生成等阶段逐步填入。 常量表结构:常量名,常量值 2.编写DFA模拟程序 算法如下: DFA(S=S0,MOVE[][],F[],ALPHABET[]) /*S为状态,初值为DFA的初态,MOVE[][]为状态转换矩阵,F[] 为终态集,ALPHABET[] 为字母表,其中的字母顺序与MOVE[][] 中列标题的字母顺序一致。*/ { Char Wordbuffer[10]=“”//单词缓冲区置空 Nextchar=getchar();//读 i=0; while(nextchar!=NULL)//NULL代表此类单词 { if (nextcha r!∈ALPHABET[]){ERROR(“非法字符”),return(“非法字符”);} S=MOVE[S][nextchar] //下一状态 if(S=NULL)return(“不接受”);//下一状态为空,不能识别,单词错误 wordbuffer[i]=nextchar ;//保存单词符号 i++; nextchar=getchar(); } Wordbuffer[i]=‘\0’; 编译原理词法分析程序实现实验报告实验一词法分析程序实现 一、实验内容 选取无符号数的算术四则运算中的各类单词为识别对象,要求将其中的各个单词识别出来。输入:由无符号数和+,,,*,/, ( , ) 构成的算术表达式,如 1.5E+2,100。输出:对识别出的每一单词均单行输出其类别码(无符号数的值暂不要求计算)。二、设计部分 因为需要选取无符号数的算术四则运算中的各类单词为识别对象,要求将其中的各个单词识别出来,而其中的关键则为无符号数的识别,它不仅包括了一般情况下的整数和小数,还有以E为底数的指数运算,其中关于词法分析的无符号数的识别过程流程图如下: 输入字符p指向第一个字符 符号识别*p=+||-||*||/ YYNN*p=0~9*p=E*p=0~9||"." N无效符号Y *p=“.”GOTO 2 GOTO 1 GOTO 1: NY无符号数GOTO 1*p=0~9*p='/0' YN P++NNP++*p=E*p='+'||'-' YY P++P++continue YY *p=0~9*p=0~9 NN 无符号数无符号数 P++P++ continuecontinue GOTO 2: GOTO 2 *p=Econtinue Y 无符号数 P++ continue 三、源程序代码部分 #include 昆明理工大学信息工程与自动化学院学生实验报告 (2011 —2012 学年第 1 学期) 课程名称:编译原理开课实验室: 445 2011年 12 月 19日年级、专业、 班 计科093 学号200910405310 姓名孙浩川成绩 实验项目名称语法分析器指导教师严馨 教 师评语 该同学是否了解实验原理: A.了解□ B.基本了解□ C.不了解□ 该同学的实验能力: A.强□ B.中等□ C.差□ 该同学的实验是否达到要求: A.达到□ B.基本达到□ C.未达到□ 实验报告是否规范: A.规范□ B.基本规范□ C.不规范□ 实验过程是否详细记录: A.详细□ B.一般□ C.没有□ 教师签名: 年月日 一、实验目的及内容 实验目的:编制一个语法分析程序,实现对词法分析程序所提供的单词序列进行语法检 查和结构分析。 实验内容:在上机(一)词法分析的基础上,采用递归子程序法或其他适合的语法分析方法,实现其语法分析程序。要求编译后能检查出语法错误。 已知待分析的C语言子集的语法,用EBNF表示如下: <程序>→main()<语句块> <语句块> →‘{’<语句串>‘}’ <语句串> → <语句> {; <语句> }; <语句> → <赋值语句> |<条件语句>|<循环语句> <赋值语句>→ID=<表达式> <条件语句>→if‘(‘条件’)’<语句块> <循环语句>→while’(‘<条件>’)‘<语句块> <条件> → <表达式><关系运算符> <表达式> <表达式> →<项>{+<项>|-<项>} <项> → <因子> {* <因子> |/ <因子>} <因子> →ID|NUM| ‘(’<表达式>‘)’ <关系运算符> →<|<=|>|>=|==|!= 二、实验原理及基本技术路线图(方框原理图或程序流程图) 南华大学 计算机科学与技术学院实验报告 (2018~2019学年度第二学期) 课程名称编译原理 实验名称词法分析器的设计与 实现 姓名学号 专业班级 地点教师 1.实验目的及要求 实验目的 加深对词法分析器的工作过程的理解;加强对词法分析方法的掌握;能够采用一种编程语言实现简单的词法分析程序;能够使用自己编写的分析程序对简单的程序段进行词法分析。 实验要求 1.对单词的构词规则有明确的定义; 2.编写的分析程序能够正确识别源程序中的单词符号; 3.识别出的单词以<种别码,值>的形式保存在符号表中,正确设计和维护 符号表; 4.对于源程序中的词法错误,能够做出简单的错误处理,给出简单的错误 提示,保证顺利完成整个源程序的词法分析; 2.实验步骤 1.词法分析规则 <标识符>::=<字母>|<标识符><字母>|<标识符><数字> <常数>::=<数字>|<数字序列><数字> <数字序列>::=<数字序列><数字>|<数字>|<.> <字母>::=a|b|c|……|x|y|z <数字>::=0|1|2|3|4|5|6|7|8|9 <运算符>::=<关系运算符>|<算术运算符>|<逻辑运算符>|<位运算符>|<赋值运算符> <算数运算符>::=+|-|*|/|...|-- <关系运算符>::=<|>|!=|>=|<=|== <逻辑运算符>::=&&| || |! <位运算符>::=&| | |! <赋值运算符>::==|+=|-=|/=|*= <分界符>::=,|;|(|)|{|}|:| // |/**/ <保留字>::=main|if|else|while|do|for|...|void编译原理实验--词法分析器
编译原理实验报告实验一编写词法分析程序
编译原理课程设计-词法语法分析器
编译原理词法分析器语法分析器实验报告
实验1-3-《编译原理》词法分析程序设计方案
编译原理实验词法分析实验报告
编译原理 语法分析器 (java完美运行版)(精选.)
编译原理词法分析和语法分析报告+代码(C语言版)
编译原理实验报告(语法分析器)
编译原理C语言词法分析器
编译原理词法分析实验报告
编译原理实验报告(词法分析器语法分析器)
编译原理词法分析和语法分析报告+代码(C语言版)
编译原理-语法分析-算符优先文法分析器
编译原理词法分析器语法分析课程设计报告书
编译原理实验(词法分析)
编译原理词法分析器
编译原理词法分析程序实现实验报告
昆明理工大学 编译原理 实验二 语法分析器
编译原理实验-词法分析器的设计与实现.docx