宽度优先搜索算法

广度优先搜索
广度优先搜索
广度优先搜索类似于树的按层次遍历的过程。它和队有很多相似之处,运用了队的许多思想,其实就是对队的深入一步研究,它的基本操作和队列几乎一样。
三、队和广度优先搜索的运用
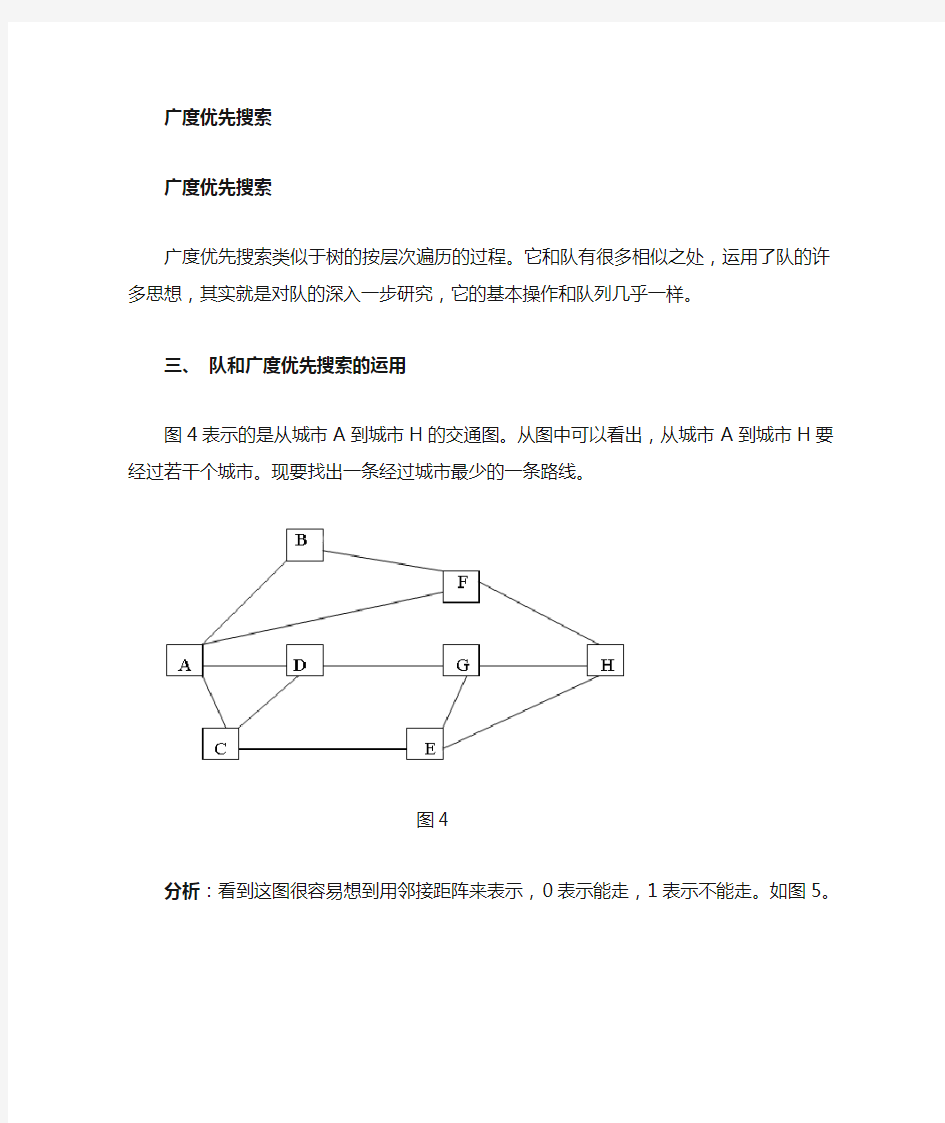
图4表示的是从城市A到城市H的交通图。从图中可以看出,从城市A到城市H要经过若干个城市。现要找出一条经过城市最少的一条路线。
图4
分析:看到这图很容易想到用邻接距阵来表示,0表示能走,1表示不能走。如图5。
图5
首先想到的是用队的思想。我们可以a记录搜索过程,a.city记录经过的城市,a.pre记录前趋元素,这样就可以倒推出最短线路。具体过程如
下:
(1)将城市A入队,队首0、队尾都为1。
(2)将队首所指的城市所有可直通的城市入队(如果这个城市在队中
出现过就不入队,可用一个集合来判断),将入队城市的pre指向队首的位置。然后将队首加1,得到新的队首城市。重复以上步骤,直到城市H入队为止。当搜到城市H时,搜索结束。利用pre可倒推出最少城市线路。
以下为参考程序:
const ju:array[1..8,1..8] of integer=((1,0,0,0,1,0,1,1),
(0,1,1,1,1,0,1,1),
(0,1,1,0,0,1,1,1),
(0,1,0,1,1,1,0,1),
(1,1,0,1,1,1,0,0),
(0,0,1,1,1,1,1,0),
(1,1,1,0,0,1,1,0),
(1,1,1,1,0,0,0,1));
type r=record {记录定义}
city:array[1..100] of char;
pre:array[1..100] of integer;
end;
var h,d,i:integer;
a:r;
s:set of 'A'..'H';
procedure out; {输出过程}
begin
write(a.city[d]);
repeat
d:=a.pre[d];
write('--',a.city[d]);
until a.pre[d]=0;
writeln;
halt;
end;
procedure doit;
begin
h:=0; d:=1;
a.city[1]:='A';
a.pre[1]:=0;
s:=['A'];
repeat {步骤2}
inc(h); {队首加一,出队}
for i:=1 to 8 do {搜索可直通的城市}
if (ju[ord(a.city[h])-64,i]=0)and
(not(chr(i+64) in s))then {判断城市是否走过}
begin
inc(d); {队尾加一,入队}
a.city[d]:=chr(64+i);
a.pre[d]:=h;
s:=s+[a.city[d]];
if a.city[d]='H' then out;
end;
until h=d;
writeln()
end;
begin {主程序}
doit;
end.
输出:
H-F--A
图的深度优先遍历算法课程设计报告
合肥学院 计算机科学与技术系 课程设计报告 2013~2014学年第二学期 课程数据结构与算法 课程设计名称图的深度优先遍历算法的实现 学生姓名陈琳 学号1204091022 专业班级软件工程 指导教师何立新 2014 年9 月 一:问题分析和任务定义 涉及到数据结构遍会涉及到对应存储方法的遍历问题。本次程序采用邻接表的存储方法,并且以深度优先实现遍历的过程得到其遍历序列。
深度优先遍历图的方法是,从图中某顶点v 出发: (1)访问顶点v ; (2)依次从v 的未被访问的邻接点出发,对图进行深度优先遍历;直至图中和v 有路径相通的顶点都被访问; (3)若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行深度优先遍历,直到图中所有顶点均被访问过为止。 二:数据结构的选择和概要设计 设计流程如图: 图1 设计流程 利用一维数组创建邻接表,同时还需要一个一维数组来存储顶点信息。之后利用创建的邻接表来创建图,最后用深度优先的方法来实现遍历。 图 2 原始图 1.从0开始,首先找到0的关联顶点3 2.由3出发,找到1;由1出发,没有关联的顶点。 3.回到3,从3出发,找到2;由2出发,没有关联的顶点。 4.回到4,出4出发,找到1,因为1已经被访问过了,所以不访问。
所以最后顺序是0,3,1,2,4 三:详细设计和编码 1.创建邻接表和图 void CreateALGraph (ALGraph* G) //建立邻接表函数. { int i,j,k,s; char y; EdgeNode* p; //工作指针. printf("请输入图的顶点数n与边数e(以逗号做分隔符):\n"); scanf("%d,%d",&(G->n),&(G->e)); scanf("%c",&y); //用y来接收回车符. for(s=0;s
深度优先与广度优先
深度优先与广度优先 (一)深度优先搜索的特点是:(1)从上面几个实例看出,可以用深度优先搜索的方法处理的题目是各种各样的。有的搜索深度是已知和固定的,如例题2-4,2-5,2-6;有的是未知的,如例题2- 7、例题2-8;有的搜索深度是有限制的,但达到目标的深度是不定的。但也看到,无论问题的内容和性质以及求解要求如何不同,它们的程序结构都是相同的,即都是深度优先算法(一)和深度优先算法 (二)中描述的算法结构,不相同的仅仅是存储结点数据结构和产生规则以及输出要求。(2)深度优先搜索法有递归以及非递归两种设计方法。一般的,当搜索深度较小、问题递归方式比较明显时,用递归方法设计好,它可以使得程序结构更简捷易懂。当搜索深度较大时,如例题2- 5、2-6。当数据量较大时,由于系统堆栈容量的限制,递归容易产生溢出,用非递归方法设计比较好。(3)深度优先搜索方法有广义和狭义两种理解。广义的理解是,只要最新产生的结点(即深度最大的结点)先进行扩展的方法,就称为深度优先搜索方法。在这种理解情况下,深度优先搜索算法有全部保留和不全部保留产生的结点的两种情况。而狭义的理解是,仅仅只保留全部产生结点的算法。本书取前一种广义的理解。不保留全部结点
的算法属于一般的回溯算法范畴。保留全部结点的算法,实际上是在数据库中产生一个结点之间的搜索树,因此也属于图搜索算法的范畴。(4)不保留全部结点的深度优先搜索法,由于把扩展望的结点从数据库中弹出删除,这样,一般在数据库中存储的结点数就是深度值,因此它占用的空间较少,所以,当搜索树的结点较多,用其他方法易产生内存溢出时,深度优先搜索不失为一种有效的算法。(5)从输出结果可看出,深度优先搜索找到的第一个解并不一定是最优解。例如例题2-8得最优解为13,但第一个解却是17。如果要求出最优解的话,一种方法将是后面要介绍的动态规划法,另一种方法是修改原算法:把原输出过程的地方改为记录过程,即记录达到当前目标的路径和相应的路程值,并与前面已记录的值进行比较,保留其中最优的,等全部搜索完成后,才把保留的最优解输出。 二、广度优先搜索法的显著特点是:(1)在产生新的子结点时,深度越小的结点越先得到扩展,即先产生它的子结点。为使算法便于实现,存放结点的数据库一般用队列的结构。(2)无论问题性质如何不同,利用广度优先搜索法解题的基本算法是相同的,但数据库中每一结点内容,产生式规则,根据不同的问题,有不同的内容和结构,就是同一问题也可以有不同的表示方法。(3)当结点到跟结点的费用(有的书称为耗散值)和结点的深度成正比时,特别是当每一结点到根结点的费用等于深度时,用广度优先法得到的解是最优解,但如果不成正比,则得到的解不一
广度优先搜索训练题
广度优先搜索训练题 一、奇怪的电梯 源程序名LIFT.PAS 可执行文件名 LIFT.EXE 输入文件名 LIFT.IN 输出文件名 LIFT.OUT 呵呵,有一天我做了一个梦,梦见了一种很奇怪的电梯。大楼的每一层楼都可以停电梯,而且第i层楼(1<=i<=N)上有一个数字Ki(0<=Ki<=N)。电梯只有四个按钮:开,关,上,下。上下的层数等于当前楼层上的那个数字。当然,如果不能满足要求,相应的按钮就会失灵。例如:3 3 1 2 5代表了Ki(K1=3,K2=3,……),从一楼开始。在一楼,按“上”可以到4楼,按“下”是不起作用的,因为没有-2楼。那么,从A楼到B楼至少要按几次按钮呢? 输入 输入文件共有二行,第一行为三个用空格隔开的正整数,表示N,A,B(1≤N≤200, 1≤A,B≤N),第二行为N个用空格隔开的正整数,表示Ki。 输出 输出文件仅一行,即最少按键次数,若无法到达,则输出-1。 样例 LIFT.IN 5 1 5 3 3 1 2 5 LIFT.OUT 3 二、字串变换 [问题描述]: 已知有两个字串 A$, B$ 及一组字串变换的规则(至多6个规则): A1$ -> B1$ A2$ -> B2$ 规则的含义为:在 A$中的子串 A1$ 可以变换为 B1$、A2$ 可以变换为B2$ …。例如:A$='abcd' B$='xyz' 变换规则为: ‘abc’->‘xu’‘ud’->‘y’‘y’->‘yz’ 则此时,A$ 可以经过一系列的变换变为 B$,其变换的过程为:‘abcd’->‘xud’->‘xy’->‘xyz’ 共进行了三次变换,使得 A$ 变换为B$。 [输入]: 键盘输人文件名。文件格式如下: A$ B$ A1$ B1$ \
算法设计:深度优先遍历和广度优先遍历
算法设计:深度优先遍历和广度优先遍历实现 深度优先遍历过程 1、图的遍历 和树的遍历类似,图的遍历也是从某个顶点出发,沿着某条搜索路径对图中每个顶点各做一次且仅做一次访问。它是许多图的算法的基础。 深度优先遍历和广度优先遍历是最为重要的两种遍历图的方法。它们对无向图和有向图均适用。 以下假定遍历过程中访问顶点的操作是简单地输出顶点。 2、布尔向量visited[0 ..n-1] 的设置图中任一顶点都可能和其它顶点相邻接。在访问了某顶点之后,又可能顺着某条回路又回到了该顶点。为了避免重复访问同一个顶点,必须记住每个已访问的顶点。为此,可设一布尔向量visited[0 ..n-1] ,其初值为假,一旦访问了顶点Vi 之后,便将visited[i] 置为真。 深度优先遍历(Depth-First Traversal) 1.图的深度优先遍历的递归定义 假设给定图G的初态是所有顶点均未曾访问过。在G中任选一顶点V为初始出发 点(源点),则深度优先遍历可定义如下:首先访问出发点V ,并将其标记为已访问过;然后依次从V出发搜索V的每个邻接点W。若W未曾访问过,则以W为新的出发点继续进行深度优先遍历,直至图中所有和源点V 有路径相通的顶点(亦称为从源点可达的顶点)均已被访问为止。若此时图中仍有未访问的顶点,则另选一个尚未访问的顶点作为新的源点重复上述过程,直至图中所有顶点均已被访问为止。 图的深度优先遍历类似于树的前序遍历。采用的搜索方法的特点是尽可能先对纵深方向进行搜索。这种搜索方法称为深度优先搜索(Depth-First Search) 。相应地,用此方法遍历图就很自然地称之为图的深度优先遍历。 2、深度优先搜索的过程 设x 是当前被访问顶点,在对x 做过访问标记后,选择一条从x 出发的未检测过的
图的深度优先遍历实验报告
一.实验目的 熟悉图的存储结构,掌握用单链表存储数据元素信息和数据元素之间的关系的信息的方法,并能运用图的深度优先搜索遍历一个图,对其输出。 二.实验原理 深度优先搜索遍历是树的先根遍历的推广。假设初始状态时图中所有顶点未曾访问,则深度优先搜索可从图中某个顶点v出发,访问此顶点,然后依次从v的未被访问的邻接点出发深度优先遍历图,直至图中所有与v有路径相通的顶点都被访问到;若此时图中尚有顶点未被访问,则另选图中一个未曾访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。 图的邻接表的存储表示: #define MAX_VERTEX_NUM 20 #define MAXNAME 10 typedef char VertexType[MAXNAME]; typedef struct ArcNode{ int adjvex; struct ArcNode *nextarc; }ArcNode; typedef struct VNode{ VertexType data; ArcNode *firstarc;
}VNode,AdjList[MAX_VERTEX_NUM]; typedef struct{ AdjList vertices; int vexnum,arcnum; int kind; }ALGraph; 三.实验内容 编写LocateVex函数,Create函数,print函数,main函数,输入要构造的图的相关信息,得到其邻接表并输出显示。 四。实验步骤 1)结构体定义,预定义,全局变量定义。 #include"stdio.h" #include"stdlib.h" #include"string.h" #define FALSE 0 #define TRUE 1 #define MAX 20 typedef int Boolean; #define MAX_VERTEX_NUM 20
答深度优先搜索算法的特点是
习题 3 1、答:深度优先搜索算法的特点是 ①一般不能保证找到最优解; ②当深度限制不合理时,可能找不到解,可以将算法改为可变深度限制; ③方法与问题无关,具有通用性; ④属于图搜索方法。 宽度优先搜索算法的特点是 ①当问题有解时,一定能找到解; ②当问题为单位耗散值,并且问题有解时,一定能找到最优解; ③效率低; ④方法与问题无关,具有通用性; ⑤属于图搜索方法。 2、答:在决定生成子状态的最优次序时,应该采用深度进行衡量,使深度大的 结点优先扩展。 3、答:(1)深度优先 (2)深度优先 (3)宽度优先 (4)宽度优先 (5)宽度优先 4、答:如果把一个皇后放在棋盘的某个位置后,它所影响的棋盘位置数少,那 么给以后放皇后留下的余地就大,找到解的可能性也大;反之留下的余地就小,找到解的可能性也小。 并不是任何启发函数对搜索都是有用的。 6、讨论一个启发函数h在搜索期间可以得到改善的几种方法。 7、答:最短路径为ACEBDA,其耗散值为15。 8、解:(1)(S,O,S0,G) S:3个黑色板和3个白色板在7个空格中的任何一种布局都是一个状态。 O:①一块板移入相邻的空格; ②一块板相隔1块其他的板跳入空格; ③一块板相隔2块其他的板跳入空格。 S0: B B B W W W G: W W W B B B W W W B B B W W W B B B
W W W B B B W W W B B B W W W B B B W W W B B B (2)1401231231234567333377 =???????????=?P P P (3)定义启发函数h 为每一白色板左边的黑色板数的和。 显然,)()(n h n h *≤,所以该算法具有可采纳性。 又,?? ?≤-=),()()(0)(j i i j n n c n h n h t h ,所以该启发函数h 满足单调限制条件。 9、解: ((( ),( )),( ),(( ),( ))) ((S,( )),( ),(( ),( ))) ((A,( )),( ),(( ),( ))) ((A,S),( ),(( ),( ))) ((A,A),( ),(( ),( ))) ((A),( ),(( ),( ))) (S,( ),(( ),( ))) (A,( ),(( ),( ))) (A,S,(( ),( ))) (A,A,(( ),( ))) (A,(( ),( )))
八数码宽度优先搜索
/*程序利用C++程序设计语言,在VC6.0下采用宽度优先的搜索方式, 成功的解决了八数码问题。程序中把OPEN表和CLOSED表用队列的方式存储, 大大地提高了效率,开始的时候要输入目标状态和起始状态,由于在宽度优先搜索的情况下,搜索过程中所走过的状态是不确定且很庞大的,所以程序 最后输出宽度优先情况下最少步数的搜索过程以及程序运行所需要的时间*/ #include "iostream" #include "stdio.h" #include "stdlib.h" #include "time.h" #include "string.h" #include 有两种常用的方法可用来搜索图:即深度优先搜索和广度优先搜索。它们最终都会到达所有 连通的顶点。深度优先搜索通过栈来实现,而广度优先搜索通过队列来实现。 深度优先搜索: 深度优先搜索就是在搜索树的每一层始终先只扩展一个子节点,不断地向纵深前进直到不能再前进(到达叶子节点或受到深度限制)时,才从当前节点返回到上一级节点,沿另一方向又继续前进。这种方法的搜索树是从树根开始一枝一枝逐渐形成的。 下面图中的数字显示了深度优先搜索顶点被访问的顺序。 "* ■ J 严-* 4 t C '4 --------------------------------- --- _ 为了实现深度优先搜索,首先选择一个起始顶点并需要遵守三个规则: (1) 如果可能,访问一个邻接的未访问顶点,标记它,并把它放入栈中。 (2) 当不能执行规则1时,如果栈不空,就从栈中弹出一个顶点。 (3) 如果不能执行规则1和规则2,就完成了整个搜索过程。 广度优先搜索: 在深度优先搜索算法中,是深度越大的结点越先得到扩展。如果在搜索中把算法改为按结点的层次进行搜索,本层的结点没有搜索处理完时,不能对下层结点进行处理,即深度越小的结点越先得到扩展,也就是说先产生的结点先得以扩展处理,这种搜索算法称为广度优先搜索法。 在深度优先搜索中,算法表现得好像要尽快地远离起始点似的。相反,在广度优先搜索中, 算法好像要尽可能地靠近起始点。它首先访问起始顶点的所有邻接点,然后再访问较远的区 域。它是用队列来实现的。 下面图中的数字显示了广度优先搜索顶点被访问的顺序。 实现广度优先搜索,也要遵守三个规则: ⑴ 访问下一个未来访问的邻接点,这个顶点必须是当前顶点的邻接点,标记它,并把它插入到队列中。(2)如果因为已经没有未访问顶点而不能执行规则1 图的广度优先搜索的应用 ◆内容提要 广度优先搜索是分层次搜索,广泛应用于求解问题的最短路径、最少步骤、最优方法等方面。本讲座就最短路径问题、分酒问题、八数码问题三个典型的范例,从问题分析、算法、数据结构等多方面进行了讨论,从而形成图的广度优先搜索解决问题的模式,通过本讲座的学习,能明白什么样的问题可以采用或转化为图的广度优先搜索来解决。在讨论过程中,还同时对同一问题进行了深层次的探讨,进一步寻求解决问题的最优方案。 ◆知识讲解和实例分析 和深度优先搜索一样,图的广度优先搜索也有广泛的用途。由于广度优先搜索是分层次搜索的,即先将所有与上一层顶点相邻接的顶点搜索完之后,再继续往下搜索与该层的所有邻接而又没有访问过的顶点。故此,当某一层的结点出现目标结点时,这时所进行的步骤是最少的。所以,图的广度优先搜索广泛应用于求解问题的最短路径、最少步骤、最优方法等方面。 本次讲座就几个典型的范例来说明图的广度优先搜索的应用。 先给出图的广度优先搜索法的算法描述: F:=0;r:=1;L[r]:=初始值; H:=1;w:=1;bb:=true; While bb do begin H:=h+1;g[h]:=r+1; For I:=1 to w do Begin F:=f+1; For t:=1 to 操作数do Begin ⑴m:=L[f]; {出队列}; ⑵判断t操作对m结点的相邻结点进行操作;能则设标记bj:=0,并生成新结点;不能,则设标记bj:=1; if bj:=0 then {表示有新结点生成} begin for k:=1 to g[h]-1 do if L[k]=新结点then {判断新扩展的结点是否以前出现过} begin bj:=1;k:=g[h]-1 第3章作业题参考答案 2.综述图搜索的方式和策略。 答:用计算机来实现图的搜索,有两种最基本的方式:树式搜索和线式搜索。 树式搜索就是在搜索过程中记录所经过的所有节点和边。 线式搜索就是在搜索过程中只记录那些当前认为是处在所找路径上的节点和边。线式搜索的基本方式又可分为不回溯和可回溯的的两种。 图搜索的策略可分为:盲目搜索和启发式搜索。 盲目搜索就是无向导的搜索。树式盲目搜索就是穷举式搜索。 而线式盲目搜索,对于不回溯的就是随机碰撞式搜索,对于回溯的则也是穷举式搜索。 启发式搜索则是利用“启发性信息”引导的搜索。启发式搜索又可分为许多不同的策略,如全局择优、局部择优、最佳图搜索等。 5.(供参考)解:引入一个三元组(q0,q1,q2)来描述总状态,开状态 为0,关状态为1,全部可能的状态为: Q0=(0,0,0) ; Q1=(0,0,1); Q2=(0,1,0) Q3=(0,1,1) ; Q4=(1,0,0); Q5=(1,0,1) Q6=(1,1,0) ; Q7=(1,1,1)。 翻动琴键的操作抽象为改变上述状态的算子,即F ={a, b, c} a:把第一个琴键q0翻转一次 b:把第二个琴键q1翻转一次 c:把第三个琴键q2翻转一次 问题的状态空间为<{Q5},{Q0 Q7}, {a, b, c}> 问题的状态空间图如下页所示:从状态空间图,我们可以找到Q5到Q7为3的两条路径,而找不到Q5到Q0为3的路径,因此,初始状态“关、开、关”连按三次琴键后只会出现“关、关、关”的状态。 6.解:用四元组(f 、w 、s 、g)表示状态, f 代表农夫,w 代表狼,s 代表羊,g 代表菜,其中每个元素都可为0或1,用0表示在左 (0,0, (1,0,(0,0,(0,1,(1,1,(1,0,(0,1, (1,1, a c a b a c a b c b b c “八”数码问题的宽度优先搜索与深度优先 搜索 我在观看视频和查看大学课本及网上搜索等资料才对“八”数码问题有了更进一步的了解和认识。 一、“八”数码问题的宽度优先搜索 步骤如下: 1、判断初始节点是否为目标节点,若初始节点是目标节点则搜索过程结束;若不是则转到第2步; 2、由初始节点向第1层扩展,得到3个节点:2、 3、4;得到一个节点即判断该节点是否为目标节点,若是则搜索过程结束;若2、3、4节点均不是目标节点则转到第3步; 3、从第1层的第1个节点向第2层扩展,得到节点5;从第1层的第2个节点向第2层扩展,得到3个节点:6、7、8;从第1层的第3个节点向第2层扩展得到节点9;得到一个节点即判断该节点是否为目标节点,若是则搜索过程结束;若6、7、8、9节点均不是目标节点则转到第4步; 4、按照上述方法对下一层的节点进行扩展,搜索目标节点;直至搜索到目标节点为止。 二、“八”数码问题的深度优先搜索 步骤如下: 1、设置深度界限,假设为5; 2、判断初始节点是否为目标节点,若初始节点是目标节点则搜索过程结束;若不是则转到第2步; 3、由初始节点向第1层扩展,得到节点2,判断节点2是否为目标节点;若是则搜索过程结束;若不是,则将节点2向第2层扩展,得到节点3; 4、判断节点3是否为目标节点,若是则搜索过程结束;若不是则将节点3向第3层扩展,得到节点4; 5、判断节点4是否为目标节点,若是则搜索过程结束;若不是则将节点4向第4层扩展,得到节点5; 6、判断节点5是否为目标节点,若是则搜索过程结束;若不是则结束此轮搜索,返回到第2层,将节点3向第3层扩展得到节点6; 7、判断节点6是否为目标节点,若是则搜索过程结束;若不是则将节点6向第4层扩展,得到节点7; 8、判断节点7是否为目标节点,若是则结束搜索过程;若不是则将节点6向第4层扩展得到节点8; 9、依次类推,知道得到目标节点为止。 三、上述两种搜索策略的比较 在宽度优先搜索过程中,扩展到第26个节点时找到了目标节点;而在深度优先搜索过程中,扩展到第18个节点时得到了目标节点。 题目: 图的深度优先遍历算法 一、实验题目 前序遍历二叉树 二、实验目的 ⑴掌握图的逻辑结构; ⑵掌握图的邻接矩阵存储结构; ⑶验证图的邻接矩阵存储及其深度优先遍历操作的实现。 三、实验内容与实现 ⑴建立无向图的邻接矩阵存储; ⑵对建立的无向图,进行深度优先遍历;实验实现 #include typedef struct EdgeNode { int adjvex; struct EdgeNode *next; }EdgeNode; typedef struct VertexNode { VertexType data; EdgeNode *firstedge; }VertexNode,AdjList[MaxVex]; typedef struct Graph{ AdjList adjList; int numVertexes,numEdges; }Graph,*GraphAdjList; typedef struct LoopQueue{ int data[MaxVex]; int front,rear; }LoopQueue,*Queue; void initQueue(Queue &Q){ Q->front=Q->rear=0; } Bool QueueEmpty(Queue &Q){ if(Q->front == Q->rear){ return TRUE; }else{ return FALSE; } } Bool QueueFull(Queue &Q){ if((Q->rear+1)%MaxVex == Q->front){ return TRUE; }else{ return FALSE; } } void EnQueue(Queue &Q,int e){ if(!QueueFull(Q)){ Q->data[Q->rear] = e; 一、深度优先搜索和广度优先搜索的深入讨论 (一)深度优先搜索的特点是: (1)从上面几个实例看出,可以用深度优先搜索的方法处理的题目是各种各样的。有的搜索深度是已知和固定的,如例题2-4,2-5,2-6;有的是未知的,如例题2-7、例题2-8;有的搜索深度是有限制的,但达到目标的深度是不定的。 但也看到,无论问题的内容和性质以及求解要求如何不同,它们的程序结构都是相同的,即都是深度优先算法(一)和深度优先算法(二)中描述的算法结构,不相同的仅仅是存储结点数据结构和产生规则以及输出要求。 (2)深度优先搜索法有递归以及非递归两种设计方法。一般的,当搜索深度较小、问题递归方式比较明显时,用递归方法设计好,它可以使得程序结构更简捷易懂。当搜索深度较大时,如例题2-5、2-6。当数据量较大时,由于系统堆栈容量的限制,递归容易产生溢出,用非递归方法设计比较好。 (3)深度优先搜索方法有广义和狭义两种理解。广义的理解是,只要最新产生的结点(即深度最大的结点)先进行扩展的方法,就称为深度优先搜索方法。在这种理解情况下,深度优先搜索算法有全部保留和不全部保留产生的结点的两种情况。而狭义的理解是,仅仅只保留全部产生结点的算法。本书取前一种广义的理解。不保留全部结点的算法属于一般的回溯算法范畴。保留全部结点的算法,实际上是在数据库中产生一个结点之间的搜索树,因此也属于图搜索算法的范畴。 (4)不保留全部结点的深度优先搜索法,由于把扩展望的结点从数据库中弹出删除,这样,一般在数据库中存储的结点数就是深度值,因此它占用的空间较少,所以,当搜索树的结点较多,用其他方法易产生内存溢出时,深度优先搜索不失为一种有效的算法。 (5)从输出结果可看出,深度优先搜索找到的第一个解并不一定是最优解。例如例题2-8得最优解为13,但第一个解却是17。 如果要求出最优解的话,一种方法将是后面要介绍的动态规划法,另一种方法是修改原算法:把原输出过程的地方改为记录过程,即记录达到当前目标的路径和相应的路程值,并与前面已记录的值进行比较,保留其中最优的,等全部搜索完成后,才把保留的最优解输出。 二、广度优先搜索法的显著特点是: (1)在产生新的子结点时,深度越小的结点越先得到扩展,即先产生它的子结点。为使算法便于实现,存放结点的数据库一般用队列的结构。 (2)无论问题性质如何不同,利用广度优先搜索法解题的基本算法是相同的,但数据库中每一结点内容,产生式规则,根据不同的问题,有不同的内容和结构,就是同一问题也可以有不同的表示方法。 (3)当结点到跟结点的费用(有的书称为耗散值)和结点的深度成正比时,特别是当每一结点到根结点的费用等于深度时,用广度优先法得到的解是最优解,但如果不成正比,则得到的解不一定是最优解。这一类问题要求出最优解,一种方法是使用后面要介绍的其他方法求解,另外一种方法是改进前面深度(或广度)优先搜索算法:找到一个目标后,不是立即退出,而是记录下目标结点的路径和费用,如果有多个目标结点,就加以比较,留下较优的结点。把所有可能的路径都搜索完后,才输出记录的最优路径。 (4)广度优先搜索算法,一般需要存储产生的所有结点,占的存储空间要比深度优先大得多,因此程序设计中,必须考虑溢出和节省内存空间得问题。 (5)比较深度优先和广度优先两种搜索法,广度优先搜索法一般无回溯操作,即入栈和出栈的操作,所以运行速度比深度优先搜索算法法要快些。 广度优先搜索 广度优先搜索 广度优先搜索类似于树的按层次遍历的过程。它和队有很多相似之处,运用了队的许多思想,其实就是对队的深入一步研究,它的基本操作和队列几乎一样。 三、队和广度优先搜索的运用 图4表示的是从城市A到城市H的交通图。从图中可以看出,从城市A到城市H要经过若干个城市。现要找出一条经过城市最少的一条路线。 图4 分析:看到这图很容易想到用邻接距阵来表示,0表示能走,1表示不能走。如图5。 图5 首先想到的是用队的思想。我们可以a记录搜索过程,a.city记录经过的城市,a.pre记录前趋元素,这样就可以倒推出最短线路。具体过程如 下: (1)将城市A入队,队首0、队尾都为1。 (2)将队首所指的城市所有可直通的城市入队(如果这个城市在队中 出现过就不入队,可用一个集合来判断),将入队城市的pre指向队首的位置。然后将队首加1,得到新的队首城市。重复以上步骤,直到城市H入队为止。当搜到城市H时,搜索结束。利用pre可倒推出最少城市线路。 以下为参考程序: const ju:array[1..8,1..8] of integer=((1,0,0,0,1,0,1,1), (0,1,1,1,1,0,1,1), (0,1,1,0,0,1,1,1), (0,1,0,1,1,1,0,1), (1,1,0,1,1,1,0,0), (0,0,1,1,1,1,1,0), (1,1,1,0,0,1,1,0), (1,1,1,1,0,0,0,1)); type r=record {记录定义} city:array[1..100] of char; pre:array[1..100] of integer; end; var h,d,i:integer; a:r; s:set of 'A'..'H'; procedure out; {输出过程} begin write(a.city[d]); repeat d:=a.pre[d]; write('--',a.city[d]); until a.pre[d]=0; writeln; halt; end; procedure doit; begin h:=0; d:=1; a.city[1]:='A'; a.pre[1]:=0; s:=['A']; repeat {步骤2} inc(h); {队首加一,出队} for i:=1 to 8 do {搜索可直通的城市} if (ju[ord(a.city[h])-64,i]=0)and (not(chr(i+64) in s))then {判断城市是否走过} begin inc(d); {队尾加一,入队} Y 八数码问题 具体思路: 宽度优先算法实现过程 (1)把起始节点放到OPEN表中; (2)如果OPEN是个空表,则没有解,失败退出;否则继续; (3)把第一个节点从OPEN表中移除,并把它放入CLOSED的扩展节点表中; (4)扩展节点n。如果没有后继节点,则转向(2) (5)把n的所有后继结点放到OPEN表末端,并提供从这些后继结点回到n的指针; (6)如果n的任意一个后继结点是目标节点,则找到一个解答,成功退出,否则转向(2)。 深度优先实现过程 (1)把起始节点S放入未扩展节点OPEN表中。如果此节点为一目标节点,则得到一个解;(2)如果OPEN为一空表,则失败退出; (3)把第一个节点从OPEN表移到CLOSED表; (4)如果节点n的深度等于最大深度,则转向(2); (5)扩展节点n,产生其全部后裔,并把它们放入OPEN表的前头。如果没有后裔,则转向(2); (6)如果后继结点中有任一个目标节点,则得到一个解,成功退出,否则转向(2)。 方法 一:用C语言实现 #include 华北水利水电学院数据结构实验报告 20 10 ~20 11 学年第一学期2008级计算机专业 班级:107学号:200810702姓名:王文波 实验四图的应用 一、实验目的: 1.掌握图的存储结构及其构造方法 2.掌握图的两种遍历算法及其执行过程 二、实验内容: 以邻接矩阵或邻接表为存储结构,以用户指定的顶点为起始点,实现无向连通图的深度优先及广度优先搜索遍历,并输出遍历的结点序列。 提示:首先,根据用户输入的顶点总数和边数,构造无向图,然后以用户输入的顶点为起始点,进行深度优先和广度优先遍历,并输出遍历的结果。 三、实验要求: 1.各班学号为单号的同学采用邻接矩阵实现,学号为双号的同学采用邻接表实现。 2.C/ C++完成算法设计和程序设计并上机调试通过。 3.撰写实验报告,提供实验结果和数据。 4.写出算法设计小结和心得。 四、程序源代码: #include { int nData; QueueNode* next; }; struct QueueList { QueueNode* front; QueueNode* rear; }; void EnQueue(QueueList* Q,int e) { QueueNode *q=new QueueNode; q->nData=e; q->next=NULL; if(Q==NULL) return; if(Q->rear==NULL) Q->front=Q->rear=q; else { Q->rear->next=q; Q->rear=Q->rear->next; } } void DeQueue(QueueList* Q,int* e) { if (Q==NULL) return; if (Q->front==Q->rear) { *e=Q->front->nData; Q->front=Q->rear=NULL; } else { *e=Q->front->nData; Q->front=Q->front->next; } } //创建图 void CreatAdjList(Graph* G) { int i,j,k; edgenode* p1; edgenode* p2; *问题描述: 建立图的存储结构(图的类型可以是有向图、无向图、有向网、无向网,学生可以任选两种类型),能够输入图的顶点和边的信息,并存储到相应存储结构中,而后输出图的邻接矩阵。 1、邻接矩阵表示法: 设G=(V,E)是一个图,其中V={V1,V2,V3…,Vn}。G的邻接矩阵是一个他有下述性质的n阶方阵: 1,若(Vi,Vj)∈E 或 若图中每个顶点只含一个编号i(1≤i≤vnum),则只需一个二维数组表示图的邻接矩阵。此时存储结构可简单说明如下: type adjmatrix=array[1..vnum,1..vnum]of adj; 利用邻接矩阵很容易判定任意两个顶点之间是否有边(或弧)相联,并容易求得各个顶点的度。 对于无向图,顶点Vi的度是邻接矩阵中第i行元素之和,即 n n D(Vi)=∑A[i,j](或∑A[i,j]) j=1 i=1 对于有向图,顶点Vi的出度OD(Vi)为邻接矩阵第i行元素之和,顶点Vi 的入度ID(Vi)为第i列元素之和。即 n n OD(Vi)=∑A[i,j],OD(Vi)=∑A[j,i]) j=1j=1 用邻接矩阵也可以表示带权图,只要令 Wij, 若 #include 广度优先搜索实例 【例题】八数码难题(Eight-puzzle)。在3X3的棋盘上,摆有 8个棋子,在每个棋子上标有1~8中的某一数字。棋盘中留有一个空格。空格周围的棋子可以移到空格中。要求解的问题是,给出一种初始布局(初始状态)和目标布局(目标状态),找到一种最少步骤的移动方法,实现从初始布局到目标布局的转变。初始状态和目标状态如下: 初始状态目标状态 2 8 3 1 2 3 1 6 4 8 4 7 5 7 6 5 求解本题我们可以分3步进行。 问题分析: 由的解于题目要找是达到目标的最少步骤,因此可以这样来设计解题的方法: 初始状态为搜索的出发点,把移动一步后的布局全部找到,检查是否有达到目标的布局,如果没有,再从这些移动一步的布局出发,找出移动两步后的所有布局,再判断是否有达到目标的。依此类推,一直到某布局为目标状态为止,输出结果。由于是按移动步数从少到多产生新布局的,所以找到的第一个目标一定是移动步数最少的一个,也就是最优解。 建立产生式系统: (1) 综合数据库。用3X3的二维数组来表示棋盘的布局比较直观。我们用Ch[i,j]表示第i 行第j列格子上放的棋子数字,空格则用0来表示。为了编程方便,还需存储下面3个数据:该布局的空格位置(Si,Sj);初始布局到该布局的步数,即深度dep;以及该布局的上一布局,即父结点的位置(pnt)。这样数据库每一个元素应该是由上述几个数据组成的记录。 在程序中,定义组成数据库元素的记录型为: Type node=record ch:array[1..3,1..3] of byte;{存放某种棋盘布局} si,sj:byte; {记录此布局中空格位置} dep,pnt:byte; end; 因为新产生的结点深度(从初始布局到该结点的步数)一般要比数据库中原有的结点深度大(或相等)。按广度优先搜索的算法,深度大(步数多)的结点后扩展,所以新产生的结点应放在数据库的后面。而当前扩展的结点从数据库前面选取,即处理时是按结点产生的先后次序进行扩展。这样广度优先搜索的数据库结构采用队列的结构形式较合适。我们用记录数组data来表示数据库,并设置两个指针:Head为队列的首指针,tail为队列的尾指针。(2) 产生规则。原规则规定空格周围的棋子可以向空格移动。但如果换一种角度观察,也可看作空格向上、下、左、右4个位置移动,这样处理更便于编程。设空格位置在(Si,sj),则有4条规则: ①空格向上移动: if si-1>=1 then ch[si,sj]:=ch[si-1,sj];ch[si-1,sj]:=0 ②空格向下移动: if si+1<=3 then [si,sj]:=ch[si+1,sj];ch[si+1,sj]:=0广度优先搜索和深度优先搜索
图的广度优先搜索的应用
代价树如下图所示分别给出宽度优先及深度优先搜索策略-Read
“八”数码问题的宽度优先搜索与深度优先搜索
数据结构实验报告图的深度优先遍历算法
深度优先搜索和广度优先搜索的深入讨论
宽度优先搜索算法
深度宽度优先搜索 - 八数码
图的深度优先遍历和广度优先遍历
邻接矩阵表示图深度广度优先遍历
图的深度优先搜索,广度优先搜索,代码
广度优先搜索 实例