Oracle 三种高可用方案原理介绍--解决方案
Oracle 三种高可用方案原理介绍
一、概述
Oracle因为是商用版本,所以高可用方案都已经非常成熟,主要有三种高可用方案,下边分别介绍一下。
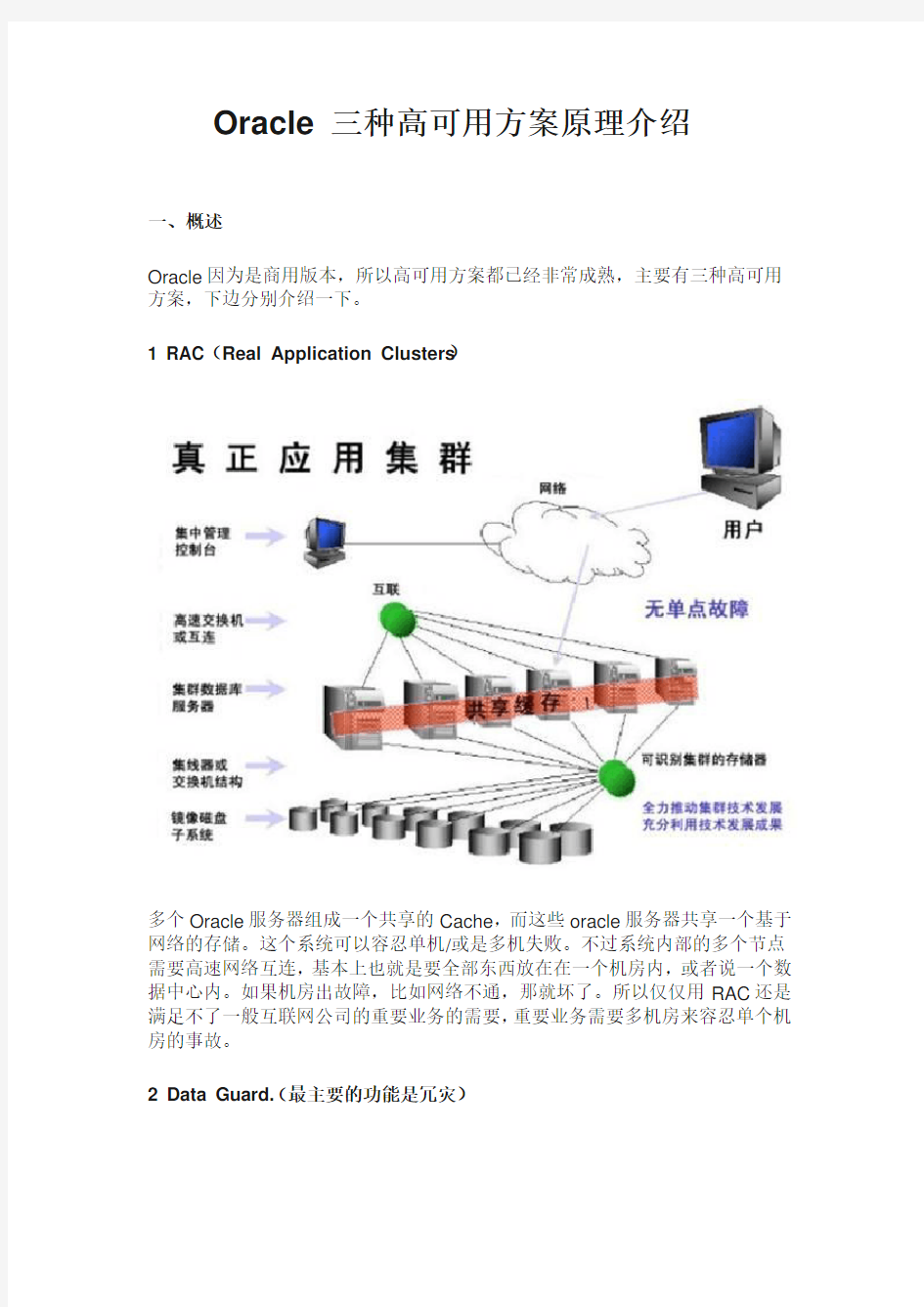
1 RAC(Real Application Clusters)
多个Oracle服务器组成一个共享的Cache,而这些oracle服务器共享一个基于网络的存储。这个系统可以容忍单机/或是多机失败。不过系统内部的多个节点需要高速网络互连,基本上也就是要全部东西放在在一个机房内,或者说一个数据中心内。如果机房出故障,比如网络不通,那就坏了。所以仅仅用RAC还是满足不了一般互联网公司的重要业务的需要,重要业务需要多机房来容忍单个机房的事故。
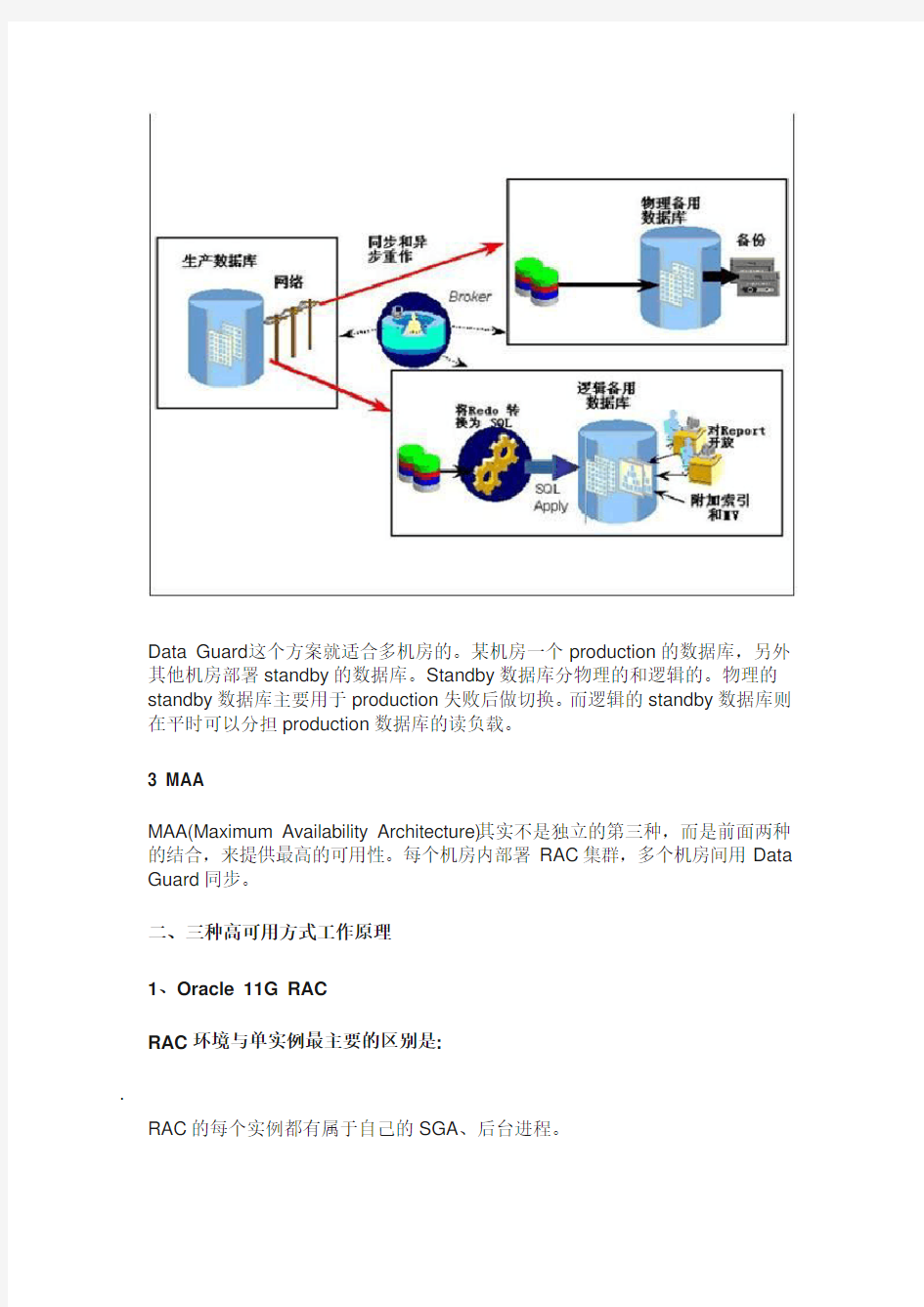
2 Data Guard.(最主要的功能是冗灾)
Data Guard这个方案就适合多机房的。某机房一个production的数据库,另外其他机房部署standby的数据库。Standby数据库分物理的和逻辑的。物理的standby数据库主要用于production失败后做切换。而逻辑的standby数据库则在平时可以分担production数据库的读负载。
3 MAA
MAA(Maximum Availability Architecture)其实不是独立的第三种,而是前面两种的结合,来提供最高的可用性。每个机房内部署RAC集群,多个机房间用Data Guard同步。
二、三种高可用方式工作原理
1、Oracle 11G RAC
RAC环境与单实例最主要的区别是:
.
RAC的每个实例都有属于自己的SGA、后台进程。
.
由于数据文件、控制文件共享于所有实例,所以必须放在共享存储中。
.
.
联机重做日志文件:只有一个实例可以写入,但是其他实例可以再回复和存档期间读取。
.
.
归档日志:属于该实例,但在介质恢复期间,其他实例需要访问所需的归档日志。
.
.
alter和trace日志:属于每个实例自己,其他实例不可读写。
.
RAC的主要组件包括:
? 共享磁盘系统
? Oracle集群件
? 集群互联
? Oracle内核组件
oracle集群件:
Oracle集群件能使节点能够互相通信,构成集群,从而这些节点能够像单个逻辑服务器那样整体运行。构成Oracle集群件的后台进程和服务是crsd、ocssd、oprocd、evmd和ons。Oracle集群件由CRS服务使用OCR和votingdisk进行管理。
OCR记录和维持集群及节点的成员资格信息,而votingdisk在通信故障时充当一个仲裁者。在集群运行期间,来自所有节点的一致性心跳信息都会发送给votingdisk。
CRS的组件包括,在Linux系统可以通过ps -ef来查看以下进程:
crs守护进程crsd
.
.
Oracle集群同步服务守护进程ocssd
.
.
事件管理器守护进程evmd
.
.
Oracle通知服务ons
.
集群就绪服务:
crsd为Oracle集群提供了高可用性的框架,并管理集群资源的状态:启动、停止、监视集群资源,并把发生故障的集群资源重定位到集群中的可用集群节点。
集群资源可以是网络资源,如虚拟IP、DB实例、侦听器等。在对集群资源采取任何动作之前,crsd进程都会获取OCR中存储的集群资源配置信息。crsd还使用ocr来维护集群资源配置文件盒状态。每个集群资源都有一个资源配置文件,它存储在OCR中。
集群同步服务:
ocssd提供节点之间的同步服务。它提供对节点成员关系的访问,并支持基本集群服务,包含集群组服务和集群锁定。ocssd的故障会导致计算机重新启动,以避免”脑裂“(如出现脑裂情况,集群的处理机制请看下面的votingdisk)。
注:”脑裂“ -- 集群环境网络链路不能互通,但这些实例仍然正常运作,每个实例都认为其他实例已经挂掉,并尝试接管所有权。在共享存储环境下,如果出现此现象就会发生数据不一致的严重情况。
事件管理进程:
Event Management (EVM): A background process that publishes events that Oracle Clusterware creates.一个发布Oracle集群事件产生的进程。
The background process that publishes Oracle Clusterware events. EVM scans the designated callout directory and runs all s in that directory when an event occurs.
Oracle通知服务:
在crs启动时会在每个集群节点上启动该进程。只要进群资源的状态发生改变,每个集群节点上的ons进程就会互相通信,并交换HA事件信息。crs触发这些HA事件,并将他们传到ons进程,然后ons进程将这一HA事件信息发布到中间层。为了在中间层使用ONS,对于任何一台主机,只要上面有需要与FAN集成的客户端应用程序,就需要再这台主机上安装ONS。应用程序会出于各种不同原因而使用这些高可用性事件,特别是用于快速检测故障。解决和发布高可用性事件的整个过程称为“快速应用程序通知FAN”。高可用性事件也可称为FAN 事件。
Oracle 11g r2的集群件启动进程:
在R2中Oracle引入了“Oracle高可用性服务”守护进程OHASD,它启动所有其他Oracle集群件守护进程。在安装GI期间,Oracle向/etc/inittab文件配置内容:
/etc/init.d/init.ohasd run >/dev/null 2>&1
Oracle集群注册表(ocr):
OCR文件是二进制文件,OCR存储Oracle集群件中所定义的全部集群资源的元数据、配置和状态信息。OCR必须能够给集群所有节点访问,所以在安装集群时需要配置好相关的权限。OCR用于引导css,提供端口信息等集群中的节点配置信息(可以理解为windows的注册表)。多数情况下OCR只提供只读操作,其他例如在节点新增和删除期间CSS用新的信息更新OCR。
OCR每4个小时会自动备份一次并保存一周,会循环进行覆盖。备份路径为$ORACLE_HOME/cdata/。
表决磁盘(votingdisk):
Votingdisk是一个共享磁盘,在操作期间可提供集群中的所有节点访问。votingdisk用作节点的集中引用,保存了节点之间的心跳信息。如果有任何节点不能ping表决磁盘,那么集群立即确认通信故障,将该节点从集群中剔除,以防止数据丢失。Votingdisk管理集群成员资格,并在节点之间发生通信故障时判断集群的所有权关系。对Votingdisk的管理应当对其进行镜像操作。
虚拟IP(vip):
vip的作用:当一个节点停机时,vip会被自动故障转移到其他节点之一,在此期间,获得vip的节点将重新向外部进行地质解析,指示vip的新mac地址,连接到这个vip的client将会立即发送一个重置数据包,这样客户端会获取这个错误消息,而不需要等待TCP超时值。
单一客户端访问名称(scan):
Oracle RAC 11g release 2 (11.2) introduces the Single Client Access Name (SCAN). SCAN is a domain name registered to at least one and up to three IP addresses, either in DNS or GNS. When using GNS and DHCP, Oracle Clusterware configures the VIP addresses for the SCAN name that is provided during cluster configuration.
The node VIP and the three SCAN VIPs are obtained from the DHCP server when using GNS. If a new server joins the cluster, then Oracle Clusterware dynamically obtains the required VIP address from the DHCP server, updates the cluster resource, and makes the server accessible through GNS. Example 1-1 shows the DNS entries that delegate a domain to the cluster.
Oracle内核组件:
OracleRAC环境中的Oracle内核组件是每个实例中的附加后台进程集合。缓冲区缓存和共享池在Oracle RAC换进中变为全局的,需要特殊处理才能做到无冲突、无损坏地管理资源。
全局缓存服务GCS和全局队列服务GES:
在这里可以回想在写Oracle体系结构的文时在单实例情况下Oracle对数据缓存和写入的过程,在RAC环境下,每个实例都有属于自己的SGA,那在这种情况下应该如果对数据进行有效管理呢,在rac中,一个节点的缓冲区缓存中可能包含了经常被另一个节点请求的数据,数据共享和交换的管理工作是由全局缓存服务(GCS)完成的。
全局资源目录GRD:
集群组中的所有资源构成一个集中的资源仓库,称为GRD,所有实例的资源加起来构成了GRD。GRD由两个服务管理,这两个服务分别为:GCS和GES,在Oracle并行服务器中这称为DLM(Distribute Lock Management)。
Oracle RAC后台进程:
OracleRAC进程包括oracle实例进程之外,还有RAC的进程。这些进程使节点之间的缓存保持一致。维持缓存一致性是RAC的重要部分。缓存一致性技术用于在不同节点上的不同oracle实例之间保持缓冲区多个副本的一致性。GCS管理确保在访问一个缓冲区缓存中某个数据块的主副本时,会与另一个缓冲区缓存中的数据块副本进行协调。这样就确保了一个缓冲区缓存中某个数据块的最新副本包含了系统中另一个实例对该数据块所做的全部修改而无论这些修改是否已经进行事务提交。
GRD管理所有资源的锁定或所有权,这些资源在OracleRAC中并不仅限于单一实例。GRD中GCS处理数据块,GES处理队列和其他全局资源。GCS和GES 使用以下进程来管理资源,RAC特有的这些进程和GRD写作,以支持缓存融合:
?
LMS 全局缓存服务进程(LMS是缓存融合中使用的一个进程。可以从数据块所在实例的缓冲区向请求实例的缓冲区缓存中传递数据块的一致性副本,而不需要进行磁盘写入。它还可以从LMD建立的服务器队列中获取请求,以执行所请求的锁操作。LMS进程管理队GCS资源的“锁管理服务器”请求,并将他们发送到一个由LMS进程处理的服务队列和全局锁的死锁检测,并监控锁对话的超时。
?
?
LMON 全局队列服务监控器(LMON是一个锁监控器进程,管理GES。)
?
?
LMD 全局队列服务守护进程(LMD是为GCS管理GES请求的守护进程。)
?
?
LCK0 实例队列进程(LCK0管理实例资源请求和对共享资源的跨实例调用操作。)
?
?
DIAG 诊断守护进程(DIAG用于RAC环境中一个实例的所有诊断需求。)
?
附上RAC集群启动图:
2、DG
Data Guard这个方案就适合多机房的。某机房一个production的数据库,另外其他机房部署standby的数据库。Standby数据库分物理的和逻辑的。物理的standby数据库主要用于production失败后做切换。而逻辑的standby数据库则在平时可以分担production数据库的读负载。
在Data Gurad 环境中,至少有两个数据库,一个处于Open 状态对外提供服务,这个数据库叫作Primary Database。第二个处于恢复状态,叫作Standby Database。运行时primary Database 对外提供服务,用户在Primary Database 上进行操作,操作被记录在联机日志和归档日志中,这些日志通过网络传递给
Standby Database。这个日志会在Standby Database 上重演,从而实现Primary Database 和Standby Database 的数据同步。
Oracle Data Gurad 对这一过程进一步的优化设计,使得日志的传递,恢复工作更加自动化,智能化,并且提供一系列参数和命令简化了DBA工作。
如果是可预见因素需要关闭Primary Database,比如软硬件升级,可以把Standby Database 切换为Primary Database 继续对外服务,这样即减少了服务停止时间,并且数据不会丢失。如果异常原因导致Primary Database 不可用,也可以把Standby Database 强制切换为Primary Database继续对外服务,这时数据损失成都和配置的数据保护级别有关系。因此Primary 和Standby 只是一个角色概念,并不固定在某个数据库中。
(一).Data Guard 架构
DG架构可以按照功能分成3个部分:
1)日志发送(Redo Send)
2)日志接收(Redo Receive)
3)日志应用(Redo Apply)
1. 日志发送(Redo Send)
Primary Database 运行过程中,会源源不断地产生Redo 日志,这些日志需要发送到Standy Database。这个发送动作可以由Primary Database 的LGWR 或者ARCH进程完成,不同的归档目的地可以使用不同的方法,但是对于一个目的地,只能选用一种方法。选择哪个进程对数据保护能力和系统可用性有很大区别。
1.1 使用ARCH 进程
1)Primary Database 不断产生Redo Log,这些日志被LGWR 进程写到联机日志。
2)当一组联机日志被写满后,会发生日志切换(Log Switch),并且会触发本地归档,本地归档位置是采用LOG_ARCHIVE_DEST_1='LOCATION=/path' 这种格式定义的。
如:alter system set log_archive_dest_1 = 'LOCATION=/u01/arch' scope=both;
3)完成本地归档后,联机日志就可以被覆盖重用。
4)ARCH 进程通过Net 把归档日志发送给Standby Database的RFS(Remote File Server)进程。
5)Standby Database 端的RFS 进程把接收的日志写入到归档日志。
6)Standby Database 端的MRP(Managed Recovery Process)进程(Redo Apply)或者LSP 进程(SQL Apply)在Standby Database上应用这些日志,进而同步数据。
用ARCH模式传输不写Standby Redologs,直接保存成归档文件存放于Standby 端。
说明:
逻辑Standby接收后将其转换成SQL语句,在Standby数据库上执行SQL语句实现同步,这种方式叫SQL Apply。
物理Standby接收完Primary数据库生成的REDO数据后,以介质恢复的方式实现同步,这种方式也叫Redo Apply。
注意:创建逻辑Standby数据库要先创建一个物理Standby数据库,然后再将其转换成逻辑Standby数据库。
使用ARCH进程传递最大问题在于:Primary Database 只有在发生归档时才会发送日志到Standby Database。如果Primary Database 异常宕机,联机日志中的Redo 内容就会丢失,因此使用ARCH 进程无法避免数据丢失的问题,要想避免数据丢失,就必须使用LGWR,而使用LGWR 又分SYNC(同步)和ASYNC(异步)两种方式。
在缺省方式下,Primary Database使用的是ARCH进程,参数设置如下:alter system set log_archive_dest_2 = 'SERVICE=ST' scope=both;
1.2 使用LGWR 进程的SYNC 方式
1)Primary Database 产生的Redo 日志要同时写道日志文件和网络。也就是说LGWR进程把日志写到本地日志文件的同时还要发送给本地的LNSn进程(Network Server Process),再由LNSn(LGWR Network Server process)进程把日志通过网络发送给远程的目的地,每个远程目的地对应一个LNS进程,多个LNS进程能够并行工作。
oracle人力资源管理系统全球案例分享1.doc
oracle人力资源管理系统全球案例分享1 人力资源管理系统全球案例分享 提交人: 提交日期:2005-01 版本号:V1.0 目录 一提交背景(2) 二案例分享(2) 2.1案例一:英国国际健康服务公司(N A TIONAL H EALTH S ERVICE) (2) 2.1.1客户与项目背景(2) 2.1.2技术参考(2) 2.2案例二:英国电信(B RITISH T ELECOM) (6) 2.2.1客户与项目背景(6) 2.2.2项目过程及现状(7) 3.2案例三:甲骨文公司全球(O RACLE C O.G LOBAL) (8) 3.2.1项目背景(8)
3.2.2技术参考(8) 一提交背景 基于对中国网络通信集团ERP管理信息系统二期工程的理解及中国网络通信集团较关注的“Oracle应用系统优秀性能展现”一议题,现提供如下全球案例。 如下案例的运行性能受控于每一项目中的具体情况,仅供参考。 二案例分享 2.1案例一:英国国际健康服务公司(N a t i o n a l H e a l t h S e r v i c e) 2.1.1客户与项目背景 National Health Service Co. 英国国际健康服务公司,成立于1948年。(医疗保健行业)在全球拥有超过600家的分支机构,120万名员工。是全欧洲最大的跨国集团组织。 人力资源管理信息系统采用了Oracle HRMS 解决方案中的:核心人力资源,薪酬福利,自助式人力资源和学习管理模块。系统建设体系构架采用了“大集中”方式,即全球搭建一个“Instance”。 2.1.2技术参考 系统配置目标
Oracle人力资源
Oracle 人力资源 无论你经营的是私营企业,还是国有企业,Oracle?人力资源(HR )软件都是可以帮助您优化使 用人力资产的强大工具。它使企业能够采用结构化的方法来吸引、保留、发展和使用具备所需要的关键能力和知识的人才,从而提高应对新挑战的能力。Oracle 人力资源软件是Oracle 电子商务套件的一部分,后者是为协同工作而设计的管理软件集成套件。 Oracle 人力资源软件是全面集成的Oracle HRMS 管理软件套件的一个关键组件,该套件包括Oracle 人力资源、Oracle 薪酬管理、Oracle 自助式人力资源、Oracle 工时与人工、Oracle 网上招聘、Oracle HR 智能、Oracle 网上学习EBS 、Oracle 高级福利和Oracle 劳动力分配。 Oracle 人力资源软件还提供了在整个电子商务套件中所利用的劳动力信息的基础,以支持诸如专业服务自动化、销售激励管理、资产分配、财务管理以及审批等流程。Oracle 人力资源软件为超过30个国家和地区提供了本地化的扩充,包括适合每个国家和地区的法律和文化的功能。 使人力适应企业的目标 随着在全球动态商务环境中优化使用人力的要求不断提高,企业正迅速采纳新的电子商务实践,以便在日益激烈的竞争环境中获得成功。这些实践使企业能够协调人力与企业目标,并系统地培养和奖励可作为战略资源的人才。通过基于互联网的各种协作功能,Oracle 能够做到这一点。 企业能够: z 使用为帮助建立企业组织结构而设计的各种工具来 快速实现工作、岗位、级别和等级的设置。 z 创建和管理不断发展的企业结构;通过大规模改造企 业结构、薪酬体系和劳动条款,快速重新分配人力以实现新的目标。 z 使用长期工、短期合同工和临时工管理灵活的工作安 排,为新的项目以适当的成本和技能水平快速安排人力。 z 确定当前以及未来的工作能力需求, 通过职业发展分
甲骨文人力资源管理软件薪酬管理解决方案
Oracle人力资源管理软件薪酬管理解决方案 描述: 人力资源管理逐渐成为职场“显学”,使企业从传统的“管人事”迅速向“管绩效”迈进,人力资源管理软件取代传统的管理模式,推动企业业务的高效发展。那么今天和大家一起探讨一下:Oracle人力资源管理软件如何解决薪酬管理呢? 正文: 人力资源管理逐渐成为职场“显学”,使企业从传统的“管人事”迅速向“管绩效”迈进,人力资源管理软件取代传统的管理模式,推动企业业务的高效发展。那么今天和大家一起探讨一下:Oracle人力资源管理软件如何解决薪酬管理呢? Oracle HCM Cloud劳动力报酬管理提供了一个最完整的劳动力报酬解决方案. 包括基本工资、奖金以及股票期权等,能够真正实现按照绩效付薪的管理。 Oracle HCM Cloud劳动力报酬管理通过对总体薪酬战略上的计划、分配和沟通可以使企业吸引、激励和保留企业所需的人才,是市场上提供最全面完整的劳动力报酬解决解决方案。与人才管理的整合能够为企业实现按绩效付薪提供强有力的支持。通过最佳的数据分析以及对一个或者一组员工在同一时刻的整体报酬视图,无论他们不同地点或者报酬组成,可以使企业做出更好的决策。 ?消除集成问题,提供市场上最全面完整的报酬解决方案 作为一个全面的人才资本管理应用一部分Oracle HCM Cloud劳动力报酬管理提供无缝的系统集成和在报酬计划流程管理中更好的用户体验。通过连接核心人力资源中的员工记录、安全构架和组织层级,可以使经理为其团队提供安全的预算分发和分配,所有这些都包含在一个可配置的审批流程中。通过与甲骨文绩效管理的集成,可以使经理查看
员工的绩效整体视图,从而实现按绩效付薪的报酬管理。甲骨文劳动力报酬管理为经理提供了一个浏览员工报酬历史、经理建议、绩效得分和绩效文档以及潜力和职位薪酬范围的统一入口。经理可以访问交互式的报告、多视图的整体报酬建议参考,使经理可以分析不同维度的数据。一旦整体报酬计划流程完毕,这些更改将自动反应在财务和薪酬系统中。 ?全球化统一管理员工整体报酬 Oracle HCM Cloud劳动力报酬管理允许经理在一组员工中分配整体报酬情况,无论他们不同的地点、不同币种、不同的业务单元或者不同的报酬项目。包括年度薪资调整、晋升薪资调整、一次性薪资调整、奖金以及股票等多种报酬组成,可以使经理在同一时刻浏览整体报酬视图或者进行更改。例如,在同一视图的基础上,为美国员工输入股票授予情况和英国员工一次性的国际代理费用。嵌入式的分析可以提供内部和外部的比较、统计分析、报酬历史情况以及当前预算占用情况的整体视图,使经理可以容易地做出更好的决策支持达成业务目标。可以输入和查看支持当地币种或者特定统一币种的报酬信息。一个可配置的、支持全球化审批流程的报酬管理确保经理在审批时可以获取他所需要的全部信息,从而保证了决策的准确性。