最新多重共线性的检验与修正
多重共线性的检验方法

多重共线性的检验方法
多重共线性(multicollinearity)是指在回归模型中,自变量之间存在高度相关或线性相关的情况。
由于存在多重共线性,导致模型的解释能力降低,预测结果不可靠。
因此,需要对回归模型中自变量之间的关系进行检验和分析。
下面介绍几种多重共线性的检验方法。
1. 相关系数矩阵法。
计算自变量之间的相关系数矩阵,判断是否存在较高的相关系数。
相关系数矩阵主要分为Pearson 相关系数和Spearman 相关系数,其中Pearson 相关系数适用于连续变量之间的关系,Spearman 相关系数适用于序数类或等距类别的变量之间的关系。
2. 变量膨胀因子(VIF)法。
VIF 是判断某个自变量对其他自变量的回归系数影响的程度。
如果某个自变量的VIF 值超过10,就表示需要对其进行检验和分析。
3. 特征值检验法。
通过计算相关系数矩阵的特征值和特征向量,判断模型是否存在多重共线性。
如果某个特征值较小,就表示存在多重共线性。
4. 条件数检验法。
条件数是相邻特征值之比的平方根。
如果条件数大于30,就表示模型存在多重共线性。
综上所述,多重共线性的检验方法有多种,不同的检验方法可以互相验证,得到更加准确的判断结果。
在实际应用中,可以根据具体情况选择合适的方法进行多重共线性的检验。
多重共线性、异方差及自相关的检验和修正

计量经济学实验报告多重共线性、异方差及自相关的检验和修正——以财政收入模型为例经济学 1班一、引言财政收入是一国政府实现政府职能的基本保障,对国民经济的运行及社会的发展起着非凡的作用。
首先,它是一个国家各项收入得以实现的物质保证。
一个国家财政收入规模的大小通常是衡量其经济实力的重要标志。
其次,财政收入是国家对经济实行宏观调控的重要经济杠杆。
财政收入的增长情况关系着一个国家的经济的发展和社会的进步。
因此,研究财政收入的增长显得尤为重要。
二、数据及模型说明研究财政收入的影响因素离不开一些基本的经济变量。
回归变量的选择是建立回归模型的一个极为重要的问题。
如果遗漏了某些重要变量,回归方程的效果肯定不会好;而考虑过多的变量,不仅计算量增大许多,而且得到的回归方程稳定性也很差,直接影响到回归方程的应用。
通过经济理论对财政收入的解释以及对实践的观察,对财政收入影响的因素主要有农业增加值、工业增加值、建筑业增加值、总人口数、最终消费、受灾面积等等。
全部数据均来源于中华人民共和国国家统计局网站/具体数据见附录一。
为分析被解释变量财政收入(Y)和解释变量农业增加值(X1)、工业增加值(X2)、建筑业增加值(X3)、总人口(X4)、最终消费(X5)、受灾面积(X6)的关系。
作如下线性图(图1)。
图1可以看出Y、X1、X2、X3、X5基本都呈逐年增长的趋势,仅增长速率有所变动,而X4和X6在多数年份呈现水平波动,可能这两个自变量和因变量间不一定是线性关系。
可以初步建立回归模型如下:Y=α+β1*X1+β2*X2+β3*X3+β4*X4 +β5*X5+β6*X6 +U i 其中,U i为随机干扰项。
三、模型的检验及验证(一)多重共线性检验及修正利用Eviews5.0,做Y对X1、X2、X3、X4、X5和X6的回归,Eviews的最小二乘估计的回归结果如下表(表1)所示:表1Dependent Variable: YMethod: Least SquaresDate: 11/16/13 Time: 20:54Sample: 1990 2011Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 145188.0 26652.27 5.447488 0.0001X1 -0.972478 0.222703 -4.366701 0.0006X2 0.210089 0.068192 3.080851 0.0076X3 -0.100412 0.569465 -0.176327 0.8624X4 -1.268320 0.247725 -5.119870 0.0001X5 0.600205 0.130089 4.613794 0.0003X6 -0.007430 0.044233 -0.167964 0.8689R-squared 0.999306 Mean dependent var 27186.86Adjusted R-squared 0.999029 S.D. dependent var 28848.33S.E. of regression 899.0866 Akaike info criterion 16.69401Sum squared resid 12125351 Schwarz criterion 17.04116Log likelihood -176.6341 F-statistic 3600.848Durbin-Watson stat 1.825260 Prob(F-statistic) 0.000000 由上表的回归结果可见,,该模型可决系数R2=0.9993很高,F检验值3601,明显显著。
多重共线性的检验与修正

多重共线性的检验与修正【实验目的】掌握多重共线性的检验方法和补救措施。
【实验要求】选择习题4.7,运用EViews 软件进行解答。
【实验内容】一、 利用EViews 软件,输入654321,X X X X X X Y ,,,,, 等数据,采用这些数据对模型进行OLS 回归,结果如下表所示由此可见,该模型2R =0.9810,2R =0.9677可决系数很高,F 检验值73.8081,明显显著,但是当228.2)818()(025.02/=-=-t k n t α,不仅所有解释变量系数t 检验不显著,而且654321X X X X X X ,,,,,系数符号与预期相反,这表明它们之间很可能存在严重多重共线性;二、计算各解释变量的相关系数,的相关系数矩阵如下由相关系数矩阵可以看出,各解释变量相互之间相关系数较高,证实确实存在严重的多重共线性。
三、修正多重共线性采用逐步回归的办法,去检验和解决多重共线性问题。
分别做lny对lnxi(i=1……7)的一元回归,结果如下表:其中,加入lnx1的方程修正拟合度最大,以lnx1为基础,顺次加入其它变量逐步回归,结果如下表:这里说明:对于两个解释变量标准T 分布为:1312318302502.)(t )(n t .α/=-=-,加入各解释变量后,要么2R 下降,要么ln i X (i=1……7)参数的T 检验不显著,这说明765432,X X X X X X ,,,,引起严重多重共线性,应予以剔除。
最后,修正后的回归结果为:1ln 2359.01631.9ˆln X Y t+= T= (73.1914) (19.7895)2R =0.9607 2R =0.9583 F=391.6234 DW=0.5038 这说明,在其他因素不变的情况下,当国民总收入增加e 单位,能源消费标准煤总量增加2359.0e单位。
此案例存在问题是样本容量过小,其可靠性受到影响,如果增大样本容量,效果会好一些; 【练习解答】1) 所建立的对数线性多元回归模型为1ln 2359.01631.9ˆln X Y t+= 2) 会,从表中的解释变量比如“国民总收入”与“GDP ”的本身意义,我们知道这两个变量之间存在很大的联系;3)存在多重共线性,通过逐步回归方法:①简单线性回归分析,找出基本解释变量②逐步进行二次,三次回归分析,直到出现回归系数不显著或者变量系数符号与预期不相符,以及修正拟合度不高的情况,即可认为该解释变量会引起严重多重共线性,应予以剔除,最后得出所需要的回归模型。
【最新精选】多重共线性的检验和克服

多重共线性的检验和克服一、实验目的掌握多重共线性的检验和处理方法二、实验原理判定系数检验法、解释变量相关系数矩阵法、逐步回归法三、实验步骤(一)创建新工作文件打开EViews ,执行以下步骤:点击File new workfile ,然后分别输入起始时间和结束时间(1983和2000),最后保存。
(二)输入数据表1 中国粮食生产函数模型年份y x1 x2 x3 x4 x51983 38728 1659.8 114047 16209.3 18022 31645.11984 40731 1739.8 112884 15264 19497 316851985 37911 1775.8 108845 22705.3 20913 30351.51986 39151 1930.6 110933 23656 22950 304671987 40208 1999.3 111268 20392.7 24836 308701988 39408 2141.5 110123 23944.7 26575 31455.71989 40755 2357.1 112205 24448.7 28067 32440.51990 44624 2590.3 113466 17819.3 28708 33330.41991 43529 2806.1 112314 27814 29389 34186.31992 44264 2930.2 110560 25894.7 30308 340371993 45649 3151.9 110509 23133 31817 33258.21994 44510 3317.9 109544 31383 33802 32690.31995 46662 3593.7 110060 22267 36118 32334.51996 50454 3827.9 112548 21233 38547 32260.41997 49417 3980.7 112912 30309 42016 32434.91998 51230 4083.7 113787 25181 45208 32626.41999 50839 4124.3 113161 26731 48996 32911.82000 46218 4146.4 108463 34374 52574 32797.5 其中:Y表示粮食产量,X1表示农业化肥施用量,X2表示粮食播种面积,X3表示成灾面积,X4表示农业机械总动力,X5表示农业劳动力。
多重共线性进行检验和补救

实验报告课程名称:实验项目名称:单方程线性回归模型中多重共线性的检验与补救院(系):专业班级:姓名:学号:实验地点:实验日期:年月日实验目的:掌握利用EViews软件对模型中存在的多重共线性进行检验和补救。
实验内容:1、多重共线性的检验1)简单相关系数法2)综合统计检验法3)观察个别偏回归系数估计值的符号4)Klein法则5)辅助回归法2、多重共线性的补救措施—逐步回归法实验方法、步骤和结果:一、建立工作文件并完成数据输入1、File---new---workfile2、Quick---Empty Group ----paste3、将ser01重命名为yser01重命名为x2ser01重命名为x3ser01重命名为x4ser01重命名为x5ser01重命名为x6二、作变量线性回归模型Quick---Estimate Equation三、多重共线性的检验(1)综合统计检验法由以上估计结果可知:F=282.6908,R^2=0.992278,X3=-0.733214,即F值较大与R^2的值较高,而系数估计值X3很小,故可知模型存在多重共线性。
(2)观察个别偏回归系数估计值的符号检验系数估计值,X3代表城镇居民人均旅游支出,X5代表公路里程数(万公里)X3 X5的符号应为正号,而由上图可知X3 X5的符号为负不合理,所以也可判断模型具有多重共线性。
(3)简单相关系数法1、将X2 X3 X4 X5 X6合并:open---as group2、点击上图的Wiew----correlations----common sample,得到以下相关系数矩阵:例如上图X2 5=0.962528, X26=0.952085, X36=0.910568均.>0.9,X32=0.857534 X34=0.864466, X35=0.847218, 均>0.8,大多数相关系数大于0.8,故可得:解释变量间存在严重的多重共线性。
多重共线性、异方差、自相关的检测与模型修正

多重共线性、异方差、自相关的检测与模型修正从《国家统计数据库》找到了自1978—2008年我国人均居民消费、人均国内生产总值、居民消费价格指数、前期人均居民消费、城镇居民人均可支配收入以及农村居民人均纯收入的官方数据。
以此来分析我国人均消费的影响因素以及它们具体是如何对消费产生影响的。
1978—2008年我国人均消费及其影响因素相关数据城镇居民农村居民人均居民人均国内居民消费前期人均年份人均可支人均纯收消费生产总值价格指数居民消费配收入入343 134 1978 184 381 100.7 165405 160 1979 208 419 101.9 184477 191 1980 238 463 107.5 208501 223 1981 264 492 102.5 238535 270 1982 288 528 102 264564 310 1983 316 583 102 288652 355 1984 361 695 102.7 316739 398 1985 446 858 109.3 361901 424 1986 497 963 106.5 4461002 463 1987 565 1112 107.3 4971180 545 1988 714 1366 111.8 5651373 602 1989 788 1519 118 7141510 686 1990 833 1644 103.1 7881701 709 1991 932 1893 103.4 8332027 784 1992 1116 2311 106.4 9322577 922 1993 1393 2998 114.7 11163496 1221 1994 1833 4044 124.1 13934283 1578 1995 2355 5046 117.1 18334839 1926 1996 2789 5846 108.3 23555160 2090 1997 3002 6420 102.8 27895425 2162 1998 3159 6796 99.2 30025854 2210 1999 3346 7159 98.6 31596280 2253 2000 3631 7858 100.4 33466859 2366 2001 3886 8622 100.7 36317703 2476 2002 4143 9398 99.2 38868472 2622 2003 4474 10542 101.2 41439422 2936 2004 5031 12336 103.9 447410493 3255 2005 5572 14053 101.8 503111759 3587 2006 6263 16165 101.5 557213786 4140 2007 7255 19524 104.8 626315781 4761 2008 8348 23648 105.9 7255来自《国家统计数据库》设定如下形式的计量经济模型1:=++++ Y,X,,,X,Xi33i24124其中,Y为人均居民消费 , X2为人均国内生产总值 , X3为居民消费价格指数 , X4为前期人均消费。
多重共线性的判断与修正

多重共线性的判断与修正一、多重共线性的判断1. 综合统计检验法LS Y C X1 X2 对模型进行OLS, 得到参数估计表(1) 当2,R F 很大,而回归系数的t 检验值小于临界值时,可判定该模型存在多重共线性。
(2) 当完全共线性存在时,模型的OLS 无法进行,Eviews 会提示:矩阵的逆(1()T X X -)不存在。
2. 简单相关系数检验法LS Y C X1 X2 对模型进行OLS, 得到参数估计表中的2R .点击:Quick/Group Statistics/Correlation在对话框中输入:X1 X2 , 点击OK, 即可得到简单相关系数矩阵检验:若存在 i j x x r 接近于1, 或 22,i j x x r R >,则说明,i j x x 之间存在着严重的相关性。
3. 辅助回归法(方差扩大因子法)设 121112...(1)(1)...j j k Xj X X X j X j Xk V ααααα-+=+++-+++++ (j ) LS Xj X1 X2…Xk 对(j) 进行OLS, 得到参数估计表检验:若表中 (2,1)F F k n k α>--+, 则可确定存在多重共线性。
或者(方差扩大因子法):计算211j jVIF R =-, (2j R 为以上方程的可决系数), 若10j VIF ≥, 则可确定存在多重共线性。
4. 逐步回归法1) 首先计算被解释变量对每个解释变量的回归方程,得到基本回归方程:LS Y C Xi OLS ,得到基本回归方程(i), i = 1,2,…,k2) 从这些基本回归方程中选出最合理的方程, 即,2R 取值最大,且t 检验显著。
比方说,0j Y Xj ββ=+3) 在这个选出的方程中增加新的解释变量, 再进行OLS 分析:LS Y C Xj Xi ( i= 1,2,…,j-1, j+1,…k)判断: 如果新加入的解释变量对2R 改进最大, 且每个系数又是t 统计显著,则保留这个新的解释变量。
检验多重共线性的方法

检验多重共线性的方法多重共线性是指在多元回归模型中,自变量之间存在高度相关性,导致模型中的自变量之间互相冗余。
多重共线性会影响回归模型的稳定性和解释能力,降低模型的准确性和可靠性。
因此,检验多重共线性是进行多元回归分析中必不可少的一步。
本文将介绍常用的检验多重共线性的方法。
首先,我们可以通过计算自变量之间的相关系数矩阵来初步判断是否存在多重共线性。
相关系数矩阵包含了自变量之间的两两相关系数,如果相关系数高于0.7或者-0.7,就说明存在较强的线性相关性。
这种初步判断方法虽然简单,但并不可靠,因为它只是衡量了两两变量之间的线性相关关系,不能反映出多个变量的综合影响。
其次,我们可以利用方差膨胀因子(VIF)来检验多重共线性。
VIF是用来衡量自变量之间相关性的指标,计算方法是对每个自变量回归于其他自变量,得到残差平方和,并计算得到VIF值。
一般来说,VIF值大于10就表明存在较强的多重共线性。
但需要注意的是,VIF值受样本量的影响,样本量较小时,即使存在较强的相关性也不一定导致VIF值大于10。
此外,我们还可以利用特征值方法检验多重共线性。
特征值方法将相关系数矩阵进行特征值分解,得到矩阵的特征值和特征向量。
如果存在较强的多重共线性,那么相关系数矩阵的特征值将会非常小。
一般来说,特征值小于1表示存在多重共线性。
不过,特征值方法对于大样本量的数据集较为适用,对于小样本量的数据集可能会出现较大的误差。
除了上述方法,还可以通过偏回归系数的标准误差来检验多重共线性。
当自变量之间存在多重共线性时,偏回归系数的标准误差将会变得非常大,说明对自变量的估计不够精确。
通过计算偏回归系数的标准误差,我们可以判断自变量之间是否存在多重共线性。
此外,还可以通过将自变量进行逐步回归来检验多重共线性。
逐步回归是指将自变量逐个加入回归模型,根据自变量的显著性和增加的解释方差决定是否保留。
如果在逐步回归过程中,自变量的系数发生了剧烈变化或者不再显著,说明存在多重共线性。
多重共线性检验与修正

多重共线性检验与修正数据来源:《中国统计年鉴2014》12-10、4-3、12-4、12-5、12-8、Eviews操作:1、基本操作:(1)录入数据:命令:data y l m f a ir(y代表粮食产量,l代表第一产业劳动力数量,m代表农业机械总动力,f代表化肥施用量,a代表农作物总播种面积,ir为有效灌溉面积/农作总播种面积得出的灌溉率)(2)做线性回归:命令:LS y c l m f a ir2、检验多重共线性(1)方差膨胀因子判断法在生成的线性回归eq01中,view—coefficient diagnostics—variance inflation factors看生成表格中的Centered VIF,发现L、M、F、A、IR的方差膨胀因子都很大,说明存在严重多重共线性。
(eg:L的Centered VIF指以L为因变量,M、A、F、IR为自变量所做出的辅助回归的判定系数R²,然后1/1-R²得出的值。
)(由课本内容可知,当完全不共线性时,VIF=1;完全共线性时,VIF=正无穷)(2)相关系数矩阵判断法命令:cor l m f a ir这个是通过看各个解释变量之间的相关系数来判断是否存在多重共线性的。
可以看到大多数解释变量之间两两相关系数都大于0.9。
相关系数极大说明解释变量之间存在很高的相关性,因而也就很可能存在共线性。
3、修正多重共线性(1)逐步回归排除引起共线性的变量①菜单栏操作在生成的线性回归eq01中,Estimate—Method—STEPLS接下来会出现两个框框,上面的框框是固定住不做逐步回归的变量,一般设定为y和c下面的框框是需要进行逐步回归选择是否剔除的变量,这里填入l m f a ir 然后出来一个新的表格,这个表格已经自动选择了可以保留的变量l a f,剔除了m ir②命令栏操作命令:STEPLS y c @ l m f a ir这条命令其实和菜单栏操作的意思一样,stepls代表采用逐步回归方法,@前的y、c代表固定不做逐步回归的变量,@后的l、m、f、a、ir代表要做逐步回归的变量出来的结果和菜单栏操作的结果是一样的。
EViews计量经济学实验报告-多重共线性的诊断与修正
时间 地点 实验题目 多重共线性的诊断与修正一、实验目的与要求:要求目的:1、对多元线性回归模型的多重共线性的诊断;2、对多元线性回归模型的多重共线性的修正。
二、实验内容根据书上第四章引子“农业的发展反而会减少财政收入”,1978-2007年的财政收入,农业增加值,工业增加值,建筑业增加值等数据,运用EV 软件,做回归分析,判断是否存在多重共线性,以及修正。
三、实验过程:(实践过程、实践所有参数与指标、理论依据说明等)(一)模型设定及其估计经分析,影响财政收入的主要因素,除了农业增加值,工业增加值,建筑业增加值以外,还可能与总人口等因素有关。
研究“农业的发展反而会减少财政收入”这个问题。
设定如下形式的计量经济模型:i Y =1β+2β2X +3β3X +4β4X +5β5X +6β6X +7β7X +i μ其中,i Y 为财政收入CS/亿元;2X 为农业增加值NZ/亿元;3X 为工业增加值GZ/亿元;4X 为建筑业增加值JZZ/亿元;5X 为总人口TPOP/万人;6X 为最终消费CUM/亿元;7X 为受灾面积SZM/千公顷。
图1: 1978~2007年财政收入及其影响因素数据年份财政收入CS/亿元 农业增加值NZ/亿元 工业增加值GZ/亿元 建筑业增加值JZZ/亿元总人口TPOP/万人最终消费CUM/亿元受灾面积SZM/千公顷 1978 1132.3 1027.5 1607 138.2 96259 2239.1 50790 1979 1146.4 1270.2 1769.7 143.8 97542 2633.7 39370 1980 1159.9 1371.6 1996.5 195.5 98705 3007.9 44526 1981 1175.8 1559.5 2048.4 207.1 100072 3361.5 39790 1982 1212.3 1777.4 2162.3 220.7 101654 3714.8 33130 1983 1367 1978.4 2375.6 270.6 103008 4126.4 34710 1984 1642.9 2316.1 2789 316.7 104357 4846.3 31890 1985 2004.8 2564.4 3448.7 417.9 105851 5986.3 44365 1986 2122 2788.7 3967 525.7 107507 6821.8 47140 1987 2199.4 3233 4585.8 665.8 109300 7804.6 42090 1988 2357.2 3865.4 5777.2 810 111026 9839.5 50870 1989 2664.9 4265.9 6484 794 112704 11164.2 46991 1990 2937.1 5062 6858 859.4 114333 12090.5 38474 1991 3149.48 5342.2 8087.1 1015.1 115823 14091.9 55472 1992 3483.37 5866.6 10284.5 1415 117171 17203.3 51333 1993 4348.95 6963.8 14188 2266.5 118517 21899.9 48829 19945218.1 9572.7 19480.7 2964.7 11985029242.2550431995 6242.2 12135.8 24950.6 3728.8 121121 36748.2 45821 1996 7407.99 14015.4 29447.6 4387.4 122389 43919.5 46989 1997 8651.14 14441.9 32921.4 4621.6 123626 48140.6 53429 1998 9875.95 14817.6 34018.4 4985.8 124761 51588.2 50145 1999 11444.08 14770 35861.5 5172.1 125786 55636.9 49981 2000 13395.23 14944.7 40036 5522.3 126743 61516 54688 2001 16386.04 15781.3 43580.6 5931.7 127627 66878.3 52215 2002 18903.64 16537 47431.3 6465.5 128453 71691.2 47119 2003 21715.25 17381.7 54945.5 7490.8 129227 77449.5 54506 2004 26396.47 21412.7 65210 8694.3 129988 87032.9 37106 2005 31649.29 22420 76912.9 10133.8 130756 96918.1 38818 2006 38760.2 24040 91310.9 11851.1 131448 110595.3 41091 2007 51321.78 28095 107367.2 14014.1 132129 128444.6 48992利用EV 软件,生成i Y 、2X 、3X 、4X 、5X 、6X 、7X 等数据,采用这些数据对模型进行OLS 回归。
计量经济学实验五-多重共线性的检验与修正
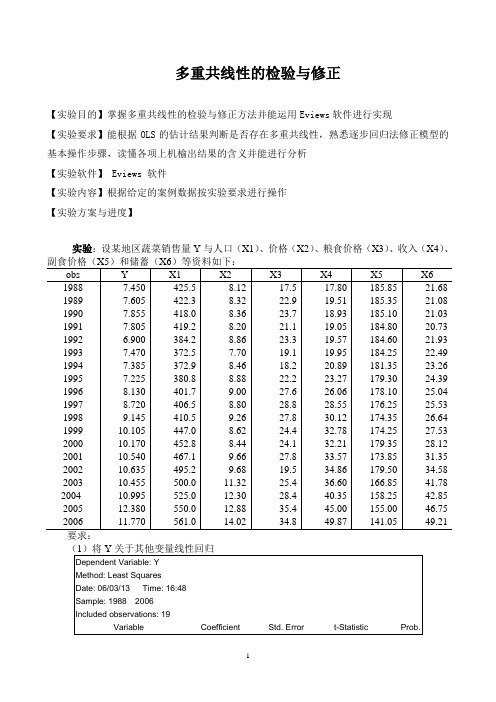
多重共线性的检验与修正【实验目的】掌握多重共线性的检验与修正方法并能运用Eviews软件进行实现【实验要求】能根据OLS的估计结果判断是否存在多重共线性,熟悉逐步回归法修正模型的基本操作步骤,读懂各项上机榆出结果的含义并能进行分析【实验软件】 Eviews 软件【实验内容】根据给定的案例数据按实验要求进行操作【实验方案与进度】实验:设某地区蔬菜销售量Y与人口(X1)、价格(X2)、粮食价格(X3)、收入(X4)、副食价格(X5)和储蓄(X6)等资料如下:obs Y X1 X2 X3 X4 X5 X6 1988 7.450 425.5 8.12 17.5 17.80 185.85 21.68 1989 7.605 422.3 8.32 22.9 19.51 185.35 21.08 1990 7.855 418.0 8.36 23.7 18.93 185.10 21.03 1991 7.805 419.2 8.20 21.1 19.05 184.80 20.73 1992 6.900 384.2 8.86 23.3 19.57 184.60 21.93 1993 7.470 372.5 7.70 19.1 19.95 184.25 22.49 1994 7.385 372.9 8.46 18.2 20.89 181.35 23.26 1995 7.225 380.8 8.88 22.2 23.27 179.30 24.39 1996 8.130 401.7 9.00 27.6 26.06 178.10 25.04 1997 8.720 406.5 8.80 28.8 28.55 176.25 25.53 1998 9.145 410.5 9.26 27.8 30.12 174.35 26.64 1999 10.105 447.0 8.62 24.4 32.78 174.25 27.53 2000 10.170 452.8 8.44 24.1 32.21 179.35 28.12 2001 10.540 467.1 9.66 27.8 33.57 173.85 31.35 2002 10.635 495.2 9.68 19.5 34.86 179.50 34.58 2003 10.455 500.0 11.32 25.4 36.60 166.85 41.78 2004 10.995 525.0 12.30 28.4 40.35 158.25 42.85 2005 12.380 550.0 12.88 35.4 45.00 155.00 46.75 2006 11.770 561.0 14.02 34.8 49.87 141.05 49.21 要求:(1)将Y关于其他变量线性回归Dependent Variable: YMethod: Least SquaresDate: 06/03/13 Time: 16:48Sample: 1988 2006Included observations: 19Variable Coefficient Std. Error t-Statistic Prob.C -1.530260 6.006901 -0.254750 0.8032 X1 0.014649 0.002923 5.012107 0.0003 X2 -0.702775 0.254521 -2.761169 0.0172 X3 0.060321 0.027575 2.187545 0.0492 X4 0.119825 0.036991 3.239290 0.0071 X5 0.018081 0.026022 0.694816 0.5004 X60.0922660.0542651.7003020.1148 R-squared0.986169 Mean dependent var 9.091579 Adjusted R-squared 0.979254 S.D. dependent var 1.717935 S.E. of regression 0.247442 Akaike info criterion 0.322027 Sum squared resid 0.734730 Schwarz criterion 0.669979 Log likelihood 3.940740 F-statistic 142.6067 Durbin-Watson stat2.292164 Prob(F-statistic)0.000000123456-1.5300.0150.7030.0600.120.0180.092t t t t t t t t Y X X X X X X u =+-+++++ (2)经济意义检验:与预期符号相符 (3)方程线性显著性检验由(1)表中的数据可知F 统计量的值为142.6067,查表得0.05(6,1F =3,显然142.6067>0.05(6,12)F =3,说明方程具有线性显著性。
计量经济学实验五 多重共线性的检验与修正 完成版

习题CPI 。
资料来源:《中国统计年鉴》,中国统计出版社2000年、2004年。
请考虑下列模型:i t t t u CPI GDP Y ++=ln ln ln 321βββ+ (1)利用表中数据估计此模型的参数。
解:ln 3.6489 1.796ln 1.2075ln t t t Y GDP CPI =--+t= (-11.32) (9.93) (-3.415)20.988770.6.0.1124R F S E ===(2)你认为数据中有多重共线性吗?多重共线性的检验 1)综合统计检验法若 在OLS 法下:R 2与F 值较大,但t 检验值较小,则可能存在多重共线性。
2)简单相关系数检验在Eviews 软件命令窗口中键入:COR GDP CPI或在包含所有解释变量的数组窗口中点击View\Correlations ,其结果如图所示。
由相关系数矩阵可以看出,解释变量之间的相关系数均为0.93以上,即解释变量之间是高度相关的。
GDP CPI GDP 1.000000 0.941303 CPI 0.9413031.0000003)判定系数检验法当解释变量多余两个且变量之间呈现出较复杂的相关关系时,可以通过建立辅助回归模型来检验多重共线性。
在Eviews 软件命令窗口中键入:LS GDP C CPI得到相应的回归结果,分析方程对应的F 值和T 值,来检验这些变量间是否相关以及相关联程度。
对应的回归结果如下图所示。
上述回归方程的F 检验值非常显著,方程回归系数的T 检验值表明:GDP 与CPI 的T 检验值较大,变量之间相关。
(3)进行以下回归:i t t i t t i t t v CPI C C GDP v CPI B B Y v GDP A A Y 321221121ln ln ln ln ln ln ++=+=+=++根据这些回归你能对数据中多重共线性的性质说些什么?解:进行ls 检验,得到如下的三个结果:ln 3.745 1.187ln t t Y GDP =-+t= (-9.143) (30.6594)20.981939.999.0.1434R F S E ===ln 3.39 2.254ln t t Y CPI =-+t= (-4.064) (14.63)20.922213.93.0.2918R F S E ===ln 0.1439 1.9273ln t t GDP CPI =+t= (0.334) (24.21)20.97586.337.0.15R F S E ===数据中多重共线性的性质:单个解释变量也可以解释被解释变量,但是本题的两个解释变量之间的相关性较大,若在同一个线性方程中使用就会造成多重共线性。
多重共线性验证及修正

论文选读:中国货币需求的因素分析钟瑜王桢黄琦珍内容摘要:本文以宏观货币需求理论为基础,引入收入和利率两个解释变量,利用计量经济学的方法,分析货币需求与这两者的关系.从中国的实际情况出发,在利用年度数据分析的基础上,又引入九十年代中期到目前为止的季度数据着重分析利率对货币需求的影响,从而将经济理论和中国现实情况结合进行分析.关键字:货币需求利率一经济理论阐述凯恩斯在传统的货币数量论和现金余额说的基础上,考虑了货币的交易职能和货币的价值贮藏职能,提出了自己的货币需求理论。
他认为人们之所以持有货币是处于三个动机:交易动机,预防动机和投机动机,从而相应地形成了货币的交易需求,预防需求和投机需求。
随着经济的发展,交易与收入和支出往往在时间上不一致,人们为了应付日常的购买而持有一定量的货币即构成了货币的交易需求。
而人们为了应付一些意外开支而持有的货币即为货币的预防需求。
这两种需求都来源于货币的交易媒介职能。
在影响交易动机和预防动机的众多因素中,货币收入起着决定作用,并且收入与货币的交易需求和预防需求成正方向变化。
而货币的投机需求则是为了应付有价证券市场上价格的变化,从而获利。
这一货币需求来源于货币的价值贮藏职能。
人们总是根据对利率变动的预期持有一定量的货币,以在有利时机购买债券进行投机获利,因而,货币的投机需求与利率成反方向变化。
凯恩斯根据对人们持有货币的心理动机的分析,将货币需求分为两个部分:货币的交易需求和预防需求L1(Y)和货币的投机需求L2(r), 从而提出了他的货币需求函数:L=L1(Y)+L2(r),其中,L代表对货币的需求,Y代表收入,r代表利率.在凯恩斯的货币需求理论的基础上,后凯恩斯主义对其进行了发展。
美国经济学家汉森将商品市场和货币市场结合起来建立了IS-LM模型,认为货币的交易需求不仅受到收入的影响,而且受到利率的影响。
这是由于利率的变化会影响投资,进而影响收入,最终影响对货币的交易需求。
(整理)多重共线性的检验与修正

附件二:实验报告格式(首页)山东轻工业学院实验报告成绩课程名称计量经济学指导教师实验日期 2013-5-25 院(系)商学院专业班级实验地点二机房学生姓名学号同组人无实验项目名称多重共线性的检验与修正一、实验目的和要求掌握Eviews软件的操作和多重共线性的检验与修正二、实验原理Eviews软件的操作和多重共线性的检验修正方法三、主要仪器设备、试剂或材料Eviews软件,计算机四、实验方法与步骤(1)准备工作:建立工作文件,并输入数据:CREATE EX-7-1 A 1974 1981;TATA Y X1 X2 X3 X4 X5 ;(2)OLS估计:LS Y C X1 X2 X3 X4 X5;(3)计算简单相关系数COR X1 X2 X3 X4 X5 ;(4)多重共线性的解决LS Y C X1;LS Y C X2;LS Y C X3;LS Y C X4;LS Y C X5;LS Y C X1 X3;LS Y C X1 X3 X2;LS Y C X1 X3 X4;LS Y C X1 X3 X5;五、实验数据记录、处理及结果分析(1)建立工作组,输入以下数据:98.45 560.20 153.20 6.53 1.23 1.89100.70 603.11 190.00 9.12 1.30 2.03102.80 668.05 240.30 8.10 1.80 2.71133.95 715.47 301.12 10.10 2.09 3.00140.13 724.27 361.00 10.93 2.39 3.29143.11 736.13 420.00 11.85 3.90 5.24146.15 748.91 491.76 12.28 5.13 6.83144.60 760.32 501.00 13.50 5.47 8.36148.94 774.92 529.20 15.29 6.09 10.07158.55 785.30 552.72 18.10 7.97 12.57169.68 795.50 771.16 19.61 10.18 15.12162.14 804.80 811.80 17.22 11.79 18.25170.09 814.94 988.43 18.60 11.54 20.59178.69 828.73 1094.65 23.53 11.68 23.37 (2)OLS估计Dependent Variable: YMethod: Least SquaresDate: 05/25/13 Time: 11:10Sample: 1974 1987Included observations: 14Variable Coefficient Std. Error t-Statistic Prob.C -3.496563 30.00659 -0.116526 0.9101X1 0.125330 0.059139 2.119245 0.0669X2 0.073667 0.037877 1.944897 0.0877X3 2.677589 1.257293 2.129646 0.0658X4 3.453448 2.450850 1.409082 0.1965X5 -4.491117 2.214862 -2.027719 0.0771R-squared 0.970442 Mean dependent var 142.7129Adjusted R-squared 0.951968 S.D. dependent var 26.09805S.E. of regression 5.719686 Akaike info criterion 6.623232Sum squared resid 261.7185 Schwarz criterion 6.897114Log likelihood -40.36262 F-statistic 52.53086Durbin-Watson stat 1.972755 Prob(F-statistic) 0.000007用Eviews进行最小二乘估计得,Yˆ=-3.497+0.125X1+0.074X2+2.678X3+3.453X4-4.491X5(-0.1) (2.1) (1.9) (2.1) (1.4) (-2.0)R2=0.970, 2R=0.952, DW=1.97, F=52.53其中括号内的数字是t值。
多重共线性问题的几种解决方法【最新】

多重共线性问题的几种解决方法在多元线性回归模型经典假设中,其重要假定之一是回归模型的解释变量之间不存在线性关系,也就是说,解释变量X1,X2,……,X k中的任何一个都不能是其他解释变量的线性组合。
如果违背这一假定,即线性回归模型中某一个解释变量与其他解释变量间存在线性关系,就称线性回归模型中存在多重共线性。
多重共线性违背了解释变量间不相关的古典假设,将给普通最小二乘法带来严重后果。
这里,我们总结了8个处理多重共线性问题的可用方法,大家在遇到多重共线性问题时可作参考:1、保留重要解释变量,去掉次要或可替代解释变量2、用相对数变量替代绝对数变量3、差分法4、逐步回归分析5、主成份分析6、偏最小二乘回归7、岭回归8、增加样本容量这次我们主要研究逐步回归分析方法是如何处理多重共线性问题的。
逐步回归分析方法的基本思想是通过相关系数r、拟合优度R2和标准误差三个方面综合判断一系列回归方程的优劣,从而得到最优回归方程。
具体方法分为两步:第一步,先将被解释变量y对每个解释变量作简单回归:对每一个回归方程进行统计检验分析(相关系数r、拟合优度R2和标准误差),并结合经济理论分析选出最优回归方程,也称为基本回归方程。
第二步,将其他解释变量逐一引入到基本回归方程中,建立一系列回归方程,根据每个新加的解释变量的标准差和复相关系数来考察其对每个回归系数的影响,一般根据如下标准进行分类判别:1.如果新引进的解释变量使R2得到提高,而其他参数回归系数在统计上和经济理论上仍然合理,则认为这个新引入的变量对回归模型是有利的,可以作为解释变量予以保留。
2.如果新引进的解释变量对R2改进不明显,对其他回归系数也没有多大影响,则不必保留在回归模型中。
3.如果新引进的解释变量不仅改变了R2,而且对其他回归系数的数值或符号具有明显影响,则认为该解释变量为不利变量,引进后会使回归模型出现多重共线性问题。
不利变量未必是多余的,如果它可能对被解释变量是不可缺少的,则不能简单舍弃,而是应研究改善模型的形式,寻找更符合实际的模型,重新进行估计。
4-2多重共线性的检验和补救措施

多重共线性的检验和补救措施
一、多重共线性的检验
1. 相关系数检验法
● 只有两个解释变量时:用二者相关系数判断。 ● 两个以上解释变量时:可用两两变量的相关系数。 ● 一般地,如果每两个解释变量的相关系数大于0.8,表明存在着较严 重的多重共线性。 ● 简单相关系数只是多重共线性的充分条件,不是必要条件。 ● 在有多个解释变量时,较低的相关系数也可能存在较严重多重共线性。
4.逐步回归法
● 例2:比率变换
●
=+
+
+
● 财政收入( 税收总额(
),财政支出( )
+ ),国内生产总值(
),
● 将总量指标变为相对指标,建立模型:
●
=+
+
+
4.逐步回归法
● 逐步回归既是判断是否存在多重共线性的方法,也是解决多重共线 性的方法。 ● 逐步回归法的具体步骤如下: ● 先用被解释变量对每一个解释变量做简单回归,得到每一个回归方程的
● 经验表明,当VIF≥10,说明该解释变量与其余解释变量之间有严重的 多重共线性。
4.逐步回归检测法
● 基本思想:将变量逐个的引入模型,每引入一个解释变量后,都要观 察可决系数的变化,进行F检验,并对已经选入的解释变量逐个进行t 检验。
如果引入新变量后,可决系数显著改善,并且原来的解释变量的显著性 不变化,说明新变量是独立解释变量。KtKt3 Nhomakorabea变换模型形式
● 对存在多重共线性的变量,进行对数变换、一阶差分变换、比率变换等, 有时可减轻多重共线性的影响。
● 例1:对于时间序列数据可采用差分法降低多重共线性。
=+
+
多重共线性的检验方法

多重共线性的检验方法多重共线性是指独立变量之间存在高度相关性的情况,它会对回归分析的结果产生严重影响,使得模型的稳定性和可靠性受到威胁。
因此,对于多重共线性的检验方法具有重要意义。
本文将介绍多重共线性的检验方法,以帮助读者更好地理解和应对多重共线性问题。
1. 方差膨胀因子(VIF)。
方差膨胀因子是一种常用的多重共线性检验方法。
它通过计算每个自变量的VIF值来判断是否存在多重共线性。
VIF值越大,说明变量之间的相关性越强,一般认为当VIF值大于10时,就存在较为严重的多重共线性问题。
2. 特征值和条件数。
特征值和条件数也是常用的多重共线性检验方法。
通过计算自变量矩阵的特征值和条件数,可以判断模型中是否存在多重共线性。
特征值接近0或条件数非常大时,就需要警惕多重共线性的问题。
3. 相关系数和散点图。
除了定量的方法,还可以通过观察自变量之间的相关系数和绘制散点图来初步判断是否存在多重共线性。
如果自变量之间的相关系数接近1或-1,或者在散点图中出现明显的线性关系,就可能存在多重共线性。
4. 主成分分析。
主成分分析是一种通过降维的方法来解决多重共线性问题的技术。
通过将高度相关的自变量进行主成分提取,可以减少自变量之间的相关性,从而解决多重共线性的问题。
5. 变量膨胀因子(VIF)。
变量膨胀因子是一种用于判断单个自变量是否存在多重共线性的方法。
通过计算每个自变量的VIF值,可以判断该变量是否受到其他自变量的影响,从而判断是否存在多重共线性。
总结。
多重共线性是回归分析中常见的问题,它会对模型的稳定性和可靠性造成严重影响。
因此,及早发现并解决多重共线性问题至关重要。
本文介绍了多重共线性的常用检验方法,包括方差膨胀因子、特征值和条件数、相关系数和散点图、主成分分析以及变量膨胀因子。
通过合理运用这些方法,可以有效地检验和应对多重共线性问题,提高回归分析的准确性和可靠性。
希望本文能够帮助读者更好地理解和解决多重共线性问题,提升数据分析的水平和能力。
Eviews多重共线性检验及补救

Eviews多重共线性检验及补救Eviews多重共线性检验及补救关键词:eviews多重共线性、eviews多重共线性操作、多重共线性检验、eviews判断多重共线性⽬的:1、正确使⽤EVIEWS2、能根据计算结果进⾏多重共线性检验和出现多重共线性时的补救。
3、数据为demo data2实例:我国钢材供应量分析(多重共线性检验及补救)通过分析我国改⾰开放以来(1978-1997)钢材供应量的历史资料,可以建⽴⼀个单⼀⽅程模型。
根据理论及对现实情况的认识,影响我国钢材供应量Y(万吨)的主要因素有:原油产量X1(万吨),⽣铁产量X2(万吨),原煤产量X3(万吨),电⼒产量X4(亿千⽡⼩时),固定资产投资X5(亿元),国内⽣产总值X6(亿元),铁路运输量X7(万吨)。
设模型的函数形式为:⼀、运⽤OLS估计法对上式中参数进⾏估计,EVIEWS操作步骤为:1、在FILE菜单中选择NEW-WORKFILE,输⼊起⽌时间。
2、在主窗⼝菜单选QUICK-EMPTY GROUP,在编辑数据区输⼊Y X1 X2 X3 X4 X5 X6 X7所对应的数据。
3、在主窗⼝菜单选在QUICK-ESTIMATE EQUATION,对参数做OSL估计,输出结果见下表:Variable Coefficient Std. Error t-Statistic Prob.C139.2362718.24930.1938550.8495X1-0.0519540.090753-0.5724830.5776X20.1275320.1324660.9627510.3547X3-24.2942797.48792-0.2492030.8074X40.8632830.186798 4.6214750.0006X50.3309140.105592 3.1338890.0086X6-0.0700150.025490-2.7467550.0177X70.0023050.0190870.1207800.9059R-squared0.999222 Mean dependent var5153.350Adjusted R-0.998768 S.D. dependent var2511.950squaredS.E. of regression88.17626 Akaike info criterion12.08573Sum squared resid93300.63 Schwarz criterion12.48402Log likelihood-112.8573 F-statistic2201.081Durbin-Watson1.703427 Prob(F-statistic)0.000000statY = 139.2361608 – 0.0519********X1 + 0.1275320853*X2 – 24.294272*X3 +0.8632825292*X4 + 0.330913843*X5 – 0.07001518918*X6 + 0.002305379405*X7⼆、分析由F=2201.081>F0.05(7,12)=2.91(显著性⽔平a=0.05),表明模型从整体上看钢材供应量与解释变量之间线性关系显著。
多重共线性问题的定义和影响多重共线性问题的检验和解决方法

多重共线性问题的定义和影响多重共线性问题的检验和解决方法多重共线性问题的定义和影响,多重共线性问题的检验和解决方法多重共线性问题是指在统计分析中,使用多个解释变量来预测一个响应变量时,这些解释变量之间存在高度相关性的情况。
共线性是指两个或多个自变量之间存在线性相关性,而多重共线性则是指两个或多个自变量之间存在高度的线性相关性。
多重共线性问题会给数据分析带来一系列影响。
首先,多重共线性会导致统计分析不准确。
在回归分析中,多重共线性会降低解释变量的显著性和稳定性,使得回归系数估计的标准误差变大,从而降低模型的准确性。
其次,多重共线性会使得解释变量的效果被混淆。
如果多个解释变量之间存在高度的线性相关性,那么无法确定每个解释变量对响应变量的独立贡献,从而使得解释变量之间的效果被混淆。
此外,多重共线性还会导致解释变量的解释力度下降。
当解释变量之间存在高度的线性相关性时,其中一个解释变量的变化可以通过其他相关的解释变量来解释,从而降低了该解释变量对响应变量的独立解释力度。
为了检验和解决多重共线性问题,有几种方法可以采用。
首先,可以通过方差膨胀因子(VIF)来判断解释变量之间的相关性。
VIF是用来度量解释变量之间线性相关性强度的指标,其计算公式为:VIFi = 1 / (1 - R2i)其中,VIFi代表第i个解释变量的方差膨胀因子,R2i代表模型中除去第i个解释变量后,其他解释变量对第i个解释变量的线性回归拟合优度。
根据VIF的大小,可以判断解释变量之间是否存在多重共线性。
通常来说,如果某个解释变量的VIF大于10或15,那么可以认为该解释变量与其他解释变量存在显著的多重共线性问题。
其次,可以通过主成分分析(PCA)来降低多重共线性的影响。
PCA是一种降维技术,可以将高维的解释变量压缩成低维的主成分,从而减少解释变量之间的相关性。
通过PCA,可以得到一组新的解释变量,这些新的解释变量之间无相关性,并且能够保留原始解释变量的主要信息。
(完整版)多重共线性检验与修正
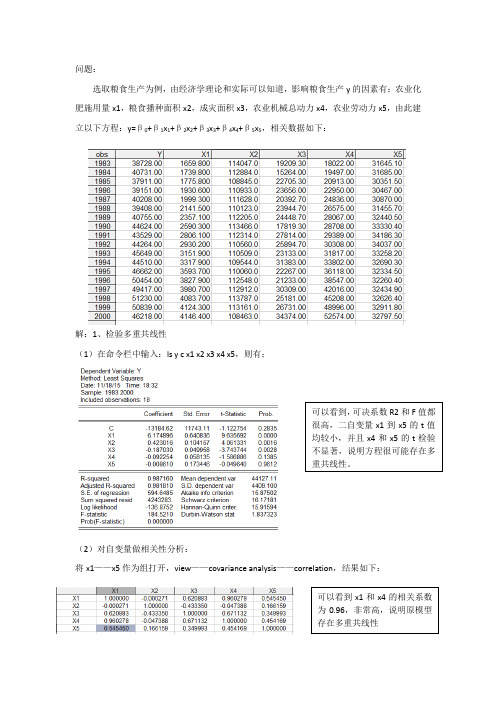
问题:选取粮食生产为例,由经济学理论和实际可以知道,影响粮食生产y的因素有:农业化肥施用量x1,粮食播种面积x2,成灾面积x3,农业机械总动力x4,农业劳动力x5,由此建立以下方程:y=β0+β1x1+β2x2+β3x3+β4x4+β5x5,相关数据如下:解:1、检验多重共线性(1)在命令栏中输入:ls y c x1 x2 x3 x4 x5,则有;可以看到,可决系数R2和F值都很高,二自变量x1到x5的t值均较小,并且x4和x5的t检验不显著,说明方程很可能存在多重共线性。
(2)对自变量做相关性分析:将x1——x5作为组打开,view——covariance analysis——correlation,结果如下:可以看到x1和x4的相关系数为0.96,非常高,说明原模型存在多重共线性2、多重共线性的修正 (1)逐步回归法第一步:首先确定一个基准的解释变量,即从x1,x2,x3,x4,x5中选择解释y 的最好的一个建立基准模型。
分别用x1,x2,x3,x4,x5对y 求回归,结果如下:在基准模型的基础上,逐步将x2,x3等加入到模型中, 加入x2,结果:从上面5个输出结果可以知道,y 对x1的可决系数R2=0.89(最高),因此选择第一个方程作为基准回归模型。
即: Y = 30867.31062 + 4.576114592* x1再加入x3,结果:再加入x4,结果:拟合优度R2=0.961395,显著提高;并且参数符号符合经济常识,且均显著。
所以将模型修改为:Y= -44174.52+ 4.576460*x1+ 0.672680*x2拟合优度R2=0.984174,显著提高;并且参数符号符合经济常识(成灾面积越大,粮食产量越低),且均显著。
所以将模型修改为:Y=-12559.35+5.271306*x1+0.417257*x2-0.212103*x3拟合优度R2=0.987158,虽然比上一次拟合提高了;但是变量x4的系数为-0.091271,符号不符合经济常识(农业机械总动力越高,粮食产量越高),并且x4的t检验不显著。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
多重共线性的检验与修正附件二:实验报告格式(首页)山东轻工业学院实验报告成绩课程名称计量经济学指导教师实验日期 2013-5-25 院(系)商学院专业班级实验地点二机房学生姓名学号同组人无实验项目名称多重共线性的检验与修正一、实验目的和要求掌握Eviews软件的操作和多重共线性的检验与修正二、实验原理Eviews软件的操作和多重共线性的检验修正方法三、主要仪器设备、试剂或材料Eviews软件,计算机四、实验方法与步骤(1)准备工作:建立工作文件,并输入数据:CREATE EX-7-1 A 1974 1981;TATA Y X1 X2 X3 X4 X5 ;(2)OLS估计:LS Y C X1 X2 X3 X4 X5;(3)计算简单相关系数COR X1 X2 X3 X4 X5 ;(4)多重共线性的解决LS Y C X1;LS Y C X2;LS Y C X3;LS Y C X4;LS Y C X5;LS Y C X1 X3;LS Y C X1 X3 X2;LS Y C X1 X3 X4;LS Y C X1 X3 X5;五、实验数据记录、处理及结果分析(1)建立工作组,输入以下数据:98.45 560.20 153.20 6.53 1.23 1.89100.70 603.11 190.00 9.12 1.30 2.03102.80 668.05 240.30 8.10 1.80 2.71133.95 715.47 301.12 10.10 2.09 3.00140.13 724.27 361.00 10.93 2.39 3.29143.11 736.13 420.00 11.85 3.90 5.24146.15 748.91 491.76 12.28 5.13 6.83144.60 760.32 501.00 13.50 5.47 8.36148.94 774.92 529.20 15.29 6.09 10.07158.55 785.30 552.72 18.10 7.97 12.57169.68 795.50 771.16 19.61 10.18 15.12162.14 804.80 811.80 17.22 11.79 18.25170.09 814.94 988.43 18.60 11.54 20.59178.69 828.73 1094.65 23.53 11.68 23.37(2)OLS估计Dependent Variable: YMethod: Least SquaresDate: 05/25/13 Time: 11:10Sample: 1974 1987Included observations: 14Variable Coefficient Std. Error t-Statistic Prob.C -3.496563 30.00659 -0.116526 0.9101X1 0.125330 0.059139 2.119245 0.0669X2 0.073667 0.037877 1.944897 0.0877X3 2.677589 1.257293 2.129646 0.0658X4 3.453448 2.450850 1.409082 0.1965X5 -4.491117 2.214862 -2.027719 0.0771R-squared 0.970442 Mean dependent var 142.7129Adjusted R-squared 0.951968 S.D. dependent var 26.09805S.E. of regression 5.719686 Akaike info criterion 6.623232Sum squared resid 261.7185 Schwarz criterion 6.897114Log likelihood -40.36262 F-statistic 52.53086Durbin-Watson stat 1.972755 Prob(F-statistic) 0.000007用Eviews进行最小二乘估计得,Yˆ=-3.497+0.125X1+0.074X2+2.678X3+3.453X4-4.491X5(-0.1) (2.1) (1.9) (2.1) (1.4) (-2.0)R2=0.970, 2R=0.952, DW=1.97, F=52.53其中括号内的数字是t值。
给定显著水平α=0.05,回归系数估计值都没有显著性。
查F 分布表,得临界值为F0.05(5,8)=3.69,故F=52.53>3.69,回归方程显著。
(3)计算简单相关系数COR X1 X2 X3 X4 X5 ;X1 X2 X3 X4 X5X1 1 0.866551867279170.8822931086064990.852*******193940.821305444858646X2 0.86655186727917 10.9458956983200270.9647730220121920.98253206329193X3 0.88229310860.9458956983 1 0.94050582080.948361346406499 20027 23996 95427X4 0.852*******193940.9647730220121920.940505820823996 10.98197917741363X5 0.8213054448586460.982532063291930.9483613464954270.98197917741363 1 r12=0.867, r13=0.882,r14=0.852, r15=0.821,r23=0.946, r24=0.965,r25=0.983, r34=0.941,r35=0.948, r45=0.982可见解释变量之间是高度相关的。
(4)多重共线性的解决, 采用Frisch法。
&1.对Y关于X1,X2,X3,X4,X5作最小二乘回归:1) LS Y C X1Dependent Variable: YMethod: Least SquaresDate: 05/25/13 Time: 11:12Sample: 1974 1987Included observations: 14Variable Coefficient Std. Error t-Statistic Prob.C -90.92074 19.32929 -4.703781 0.0005X1 0.316925 0.026081 12.15161 0.0000R-squared 0.924841 Mean dependent var 142.7129Adjusted R-squared 0.918578 S.D. dependent var 26.09805S.E. of regression 7.446964 Akaike info criterion 6.985054Sum squared resid 665.4873 Schwarz criterion 7.076347Log likelihood -46.89537 F-statistic 147.6617Durbin-Watson stat 1.536885 Prob(F-statistic) 0.000000得回归方程为:Yˆ=-90.921+0.317X1(-4.7)(12.2)R2=0.925, 2R=0.919, DW=1.537, F=147.6192) LS Y C X2Dependent Variable: YMethod: Least SquaresDate: 05/25/13 Time: 11:14Sample: 1974 1987Included observations: 14Variable Coefficient Std. Error t-Statistic Prob.C 99.61349 6.431242 15.48900 0.0000X2 0.081470 0.010738 7.587119 0.0000R-squared 0.827498 Mean dependent var 142.7129Adjusted R-squared 0.813123 S.D. dependent var 26.09805S.E. of regression 11.28200 Akaike info criterion 7.815858Sum squared resid 1527.403 Schwarz criterion 7.907152Log likelihood -52.71101 F-statistic 57.56437Durbin-Watson stat 0.638969 Prob(F-statistic) 0.000006 得回归方程为:Yˆ=99.614+0.0815X2(15.5)(7.6)R2=0.828, 2R=0.813, DW=0.639,F=57.5643)LS Y C X3Dependent Variable: YMethod: Least SquaresDate: 05/25/13 Time: 11:14Sample: 1974 1987Included observations: 14Variable Coefficient Std. Error t-Statistic Prob.C 74.64824 8.288989 9.005711 0.0000X3 4.892712 0.563578 8.681514 0.0000 R-squared 0.862651 Mean dependent var 142.7129Adjusted R-squared 0.851205 S.D. dependent var 26.09805S.E. of regression 10.06704 Akaike info criterion 7.587974Sum squared resid 1216.144 Schwarz criterion 7.679268Log likelihood -51.11582 F-statistic 75.36868Durbin-Watson stat 0.813884 Prob(F-statistic) 0.000002 得回归方程为:Yˆ=74.648+4.893X3(9.0)(8.7)R2=0.863, 2R=0.851, DW=0.814,F=75.3694) LS Y C X4Dependent Variable: YMethod: Least SquaresDate: 05/25/13 Time: 11:15Sample: 1974 1987Included observations: 14Variable Coefficient Std. Error t-Statistic Prob.C 108.8647 5.934330 18.34490 0.0000X4 5.739752 0.838756 6.843175 0.0000R-squared 0.796019 Mean dependent var 142.7129Adjusted R-squared 0.779021 S.D. dependent var 26.09805S.E. of regression 12.26828 Akaike info criterion 7.983475Sum squared resid 1806.129 Schwarz criterion 8.074769Log likelihood -53.88433 F-statistic 46.82904Durbin-Watson stat 0.769006 Prob(F-statistic) 0.000018 得回归方程为:Yˆ=108.865+5.740X4(18.3)(6.8)R2=0.796, 2R=0.779, DW=0.769,F=46.8295) LS Y C X5Dependent Variable: YMethod: Least SquaresDate: 05/25/13 Time: 11:16Sample: 1974 1987Included observations: 14Variable Coefficient Std. Error t-Statistic Prob.C 113.3747 6.077133 18.65596 0.0000X5 3.080811 0.512300 6.013688 0.0001 R-squared 0.750854 Mean dependent var 142.7129Adjusted R-squared 0.730091 S.D. dependent var 26.09805S.E. of regression 13.55865 Akaike info criterion 8.183490Sum squared resid 2206.044 Schwarz criterion 8.274784Log likelihood -55.28443 F-statistic 36.16444Durbin-Watson stat 0.593639 Prob(F-statistic) 0.000061 得回归方程为:Yˆ=113.375+3.081X5(18.7)(6.0)R2=0.75, 2R=0.73, DW=0.59,F=36.16选第一个方程为基本回归方程。