EXT2文件系统

ext2 文件系统格式
The Second Extended File System(ext2)文件系统是 Linux 系统中的标准 文件系统,是通过对 Minix 的文件系统进行扩展而得到的,其存取文件的性能 极好。 在 ext2 文件系统中,文件由 inode(包含有文件的所有信息)进行唯一标识。 一个文件可能对应多个文件名,只有在所有文件名都被删除后,该文件才会被 删除。此外,同一文件在磁盘中存放和被打开时所对应的 inode 是不同的,并 由内核负责同步。ext2 文件系统采用三级间接块来存储数据块指针,并以块 (block,默认为 1KB)为单位分配空间。其磁盘分配策略是尽可能将逻辑相 邻的文件分配到磁盘上物理相邻的块中, 并尽可能将碎片分配给尽量少的文件, 以从全局上提高性能。ext2 文件系统将同一目录下的文件(包括目录)尽可能 的放在同一个块组中,但目录则分布在各个块组中以实现负载均衡。在扩展文 件时,会尽量一次性扩展 8 个连续块给文件(以预留空间的形式实现)。
2.1. 总体存储布局 请点评
我们知道,一个磁盘可以划分成多个分区,每个分区必须先用格式化工具(例 如某种 mkfs 命令)格式化成某种格式的文件系统,然后才能存储文件,格式 化的过程会在磁盘上写一些管理存储布局的信息。 下图是一个磁盘分区格式化 成 ext2 文件系统后的存储布局。 图 1. ext2 文件系统的总体存储布局
文件系统中存储的最小单位是块(Block),一个块究竟多大是在格式化时确 定的,例如 mke2fs 的-b 选项可以设定块大小为 1024、2048 或 4096 字节。 而上图中启动块(Boot Block)的大小是确定的,就是 1KB,启动块是由 PC 标准规定的,用来存储磁盘分区信息和启动信息,任何文件系统都不能使用启 动块。 启动块之后才是 ext2 文件系统的开始, ext2 文件系统将整个分区划成若干 个同样大小的块组(Block Group),每个块组都由以下部分组成。
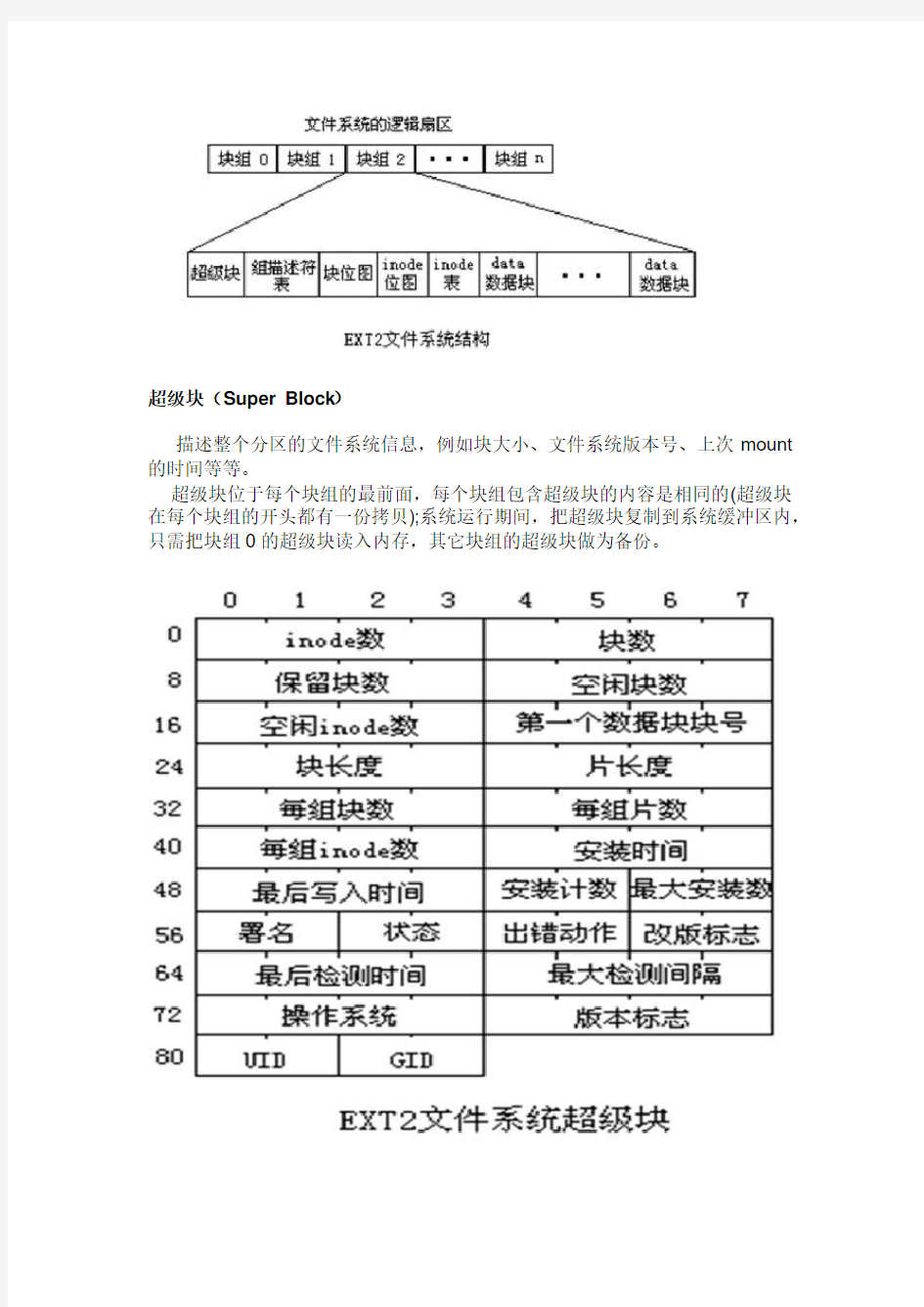
超级块(Super Block) 描述整个分区的文件系统信息,例如块大小、文件系统版本号、上次 mount 的时间等等。 超级块位于每个块组的最前面,每个块组包含超级块的内容是相同的(超级块 在每个块组的开头都有一份拷贝);系统运行期间,把超级块复制到系统缓冲区内, 只需把块组 0 的超级块读入内存,其它块组的超级块做为备份。
超级块的起始位置为其所在分区的第 1024 个字节,占用 1KB 的空间,其结构如下: struct ext2_super_block { __le32 s_inodes_count; // 文件系统中 inode 的总数 __le32 s_blocks_count; // 文件系统中块的总数 __le32 s_r_blocks_count; // 保留块的总数 __le32 s_free_blocks_count; // 未使用的块的总数(包括保留块) __le32 s_free_inodes_count; // 未使用的 inode 的总数 __le32 s_first_data_block; // 块 ID,在小于 1KB 的文件系统中为 0,大于 1KB 的文 件系统中为 1 __le32 s_log_block_size; // 用以计算块的大小(1024 算术左移该值即为块大小) __le32 s_log_frag_size; // 用以计算段大小(为正则 1024 算术左移该值,否则右移) __le32 s_blocks_per_group; // 每个块组中块的总数 __le32 s_frags_per_group; // 每个块组中段的总数 __le32 s_inodes_per_group; // 每个块组中 inode 的总数 __le32 s_mtime; // POSIX 中定义的文件系统装载时间 __le32 s_wtime; // POSIX 中定义的文件系统最近被写入的时间 __le16 s_mnt_count; // 最近一次完整校验后被装载的次数 __le16 s_max_mnt_count; // 在进行完整校验前还能被装载的次数 __le16 s_magic; // 文件系统标志,ext2 中为 0xEF53 __le16 s_state; // 文件系统的状态 __le16 s_errors; // 文件系统发生错误时驱动程序应该执行的操作 __le16 s_minor_rev_level; // 局部修订级别 __le32 s_lastcheck; // POSIX 中定义的文件系统最近一次检查的时间 __le32 s_checkinterval; // POSIX 中定义的文件系统最近检查的最大时间间隔 __le32 s_creator_os; // 生成该文件系统的操作系统 __le32 s_rev_level; // 修订级别 __le16 s_def_resuid; // 报留块的默认用户 ID __le16 s_def_resgid; // 保留块的默认组 ID // 仅用于使用动态 inode 大小的修订版(EXT2_DYNAMIC_REV) __le32 s_first_ino; // 标准文件的第一个可用 inode 的索引(非动态为 11) __le16 s_inode_size; // inode 结构的大小(非动态为 128) __le16 s_block_group_nr; // 保存此超级块的块组号 __le32 s_feature_compat; // 兼容特性掩码 __le32 s_feature_incompat; // 不兼容特性掩码 __le32 s_feature_ro_compat; // 只读特性掩码 __u8 s_uuid[16]; // 卷 ID,应尽可能使每个文件系统的格式唯一 char s_volume_name[16]; // 卷名(只能为 ISO-Latin-1 字符集,以'\0'结束) char s_last_mounted[64]; // 最近被安装的目录 __le32 s_algorithm_usage_bitmap; // 文件系统采用的压缩算法 // 仅在 EXT2_COMPAT_PREALLOC 标志被设置时有效 __u8 s_prealloc_blocks; // 预分配的块数 __u8 s_prealloc_dir_blocks; // 给目录预分配的块数 __u16 s_padding1;
// 仅在 EXT3_FEATURE_COMPAT_HAS_JOURNAL 标志被设置时有效,用以支持日志 __u8 s_journal_uuid[16]; // 日志超级块的卷 ID __u32 s_journal_inum; // 日志文件的 inode 数目 __u32 s_journal_dev; // 日志文件的设备数 __u32 s_last_orphan; // 要删除的 inode 列表的起始位置 __u32 s_hash_seed[4]; // HTREE 散列种子 __u8 s_def_hash_version; // 默认使用的散列函数 __u8 s_reserved_char_pad; __u16 s_reserved_word_pad; __le32 s_default_mount_opts; __le32 s_first_meta_bg; // 块组的第一个元块 __u32 s_reserved[190]; };
块组描述符表(GDT,Group Descriptor Table) 由很多块组描述符组成,整个分区分成多少个块组就对应有多少个块组描述 符。每个块组描述符(Group Descriptor)存储一个块组的描述信息,例如在这 个块组中从哪里开始是 inode 表,从哪里开始是数据块,空闲的 inode 和数据块 还有多少个等等。 和超级块类似,块组描述符表在每个块组的开头也都有一份拷 贝,这些信息是非常重要的,一旦超级块意外损坏就会丢失整个分区的数据,一 旦块组描述符意外损坏就会丢失整个块组的数据,因此它们都有多份拷贝。通常 内核只用到第 0 个块组中的拷贝,当执行 e2fsck 检查文件系统一致性时,第 0 个块组中的超级块和块组描述符表就会拷贝到其它块组, 这样当第 0 个块组的开 头意外损坏时就可以用其它拷贝来恢复,从而减少损失。
存放于超级块所在块的下一个块中。一个块组描述符的结构如下:
struct ext2_group_desc { __le32 bg_block_bitmap; // 块位图所在的第一个块的块 ID __le32 bg_inode_bitmap; // inode 位图所在的第一个块的块 ID __le32 bg_inode_table; // inode 表所在的第一个块的块 ID __le16 bg_free_blocks_count; // 块组中未使用的块数 __le16 bg_free_inodes_count; // 块组中未使用的 inode 数 __le16 bg_used_dirs_count; // 块组分配的目录的 inode 数 __le16 bg_pad; __le32 bg_reserved[3]; };
块位图(Block Bitmap) 一个块组中的块是这样利用的:数据块存储所有文件的数据,比如某个分区 的块大小是 1024 字节,某个文件是 2049 字节,那么就需要三个数据块来存, 即使第三个块只存了一个字节也需要占用一个整块;超级块、块组描述符表、块 位图、inode 位图、inode 表这几部分存储该块组的描述信息。那么如何知道哪 些块已经用来存储文件数据或其它描述信息, 哪些块仍然空闲可用呢?块位图就 是用来描述整个块组中哪些块已用哪些块空闲的,它本身占一个块,其中的每个 bit 代表本块组中的一个块,这个 bit 为 1 表示该块已用,这个 bit 为 0 表示该块 空闲可用。 为什么用 df 命令统计整个磁盘的已用空间非常快呢?因为只需要查看每个 块组的块位图即可,而不需要搜遍整个分区。相反,用 du 命令查看一个较大目 录的已用空间就非常慢,因为不可避免地要搜遍整个目录的所有文件。 与此相联系的另一个问题是:在格式化一个分区时究竟会划出多少个块组呢? 主要的限制在于块位图本身必须只占一个块。用 mke2fs 格式化时默认块大小是 1024 字节,可以用-b 参数指定块大小,现在设块大小指定为 b 字节,那么一个 块可以有 8b 个 bit,这样大小的一个块位图就可以表示 8b 个块的占用情况,因 此一个块组最多可以有 8b 个块,如果整个分区有 s 个块,那么就可以有 s/(8b) 个块组。格式化时可以用-g 参数指定一个块组有多少个块,但是通常不需要手 动指定,mke2fs 工具会计算出最优的数值。 inode 位图(inode Bitmap) 和块位图类似,本身占一个块,其中每个 bit 表示一个 inode 是否空闲可用。 inode 表(inode Table) 我们知道,一个文件除了数据需要存储之外,一些描述信息也需要存储,例 如文件类型(常规、目录、符号链接等),权限,文件大小,创建/修改/访问时
间等, 也就是 ls -l 命令看到的那些信息, 这些信息存在 inode 中而不是数据块中。 每个文件都有一个 inode,一个块组中的所有 inode 组成了 inode 表。 inode 表占多少个块在格式化时就要决定并写入块组描述符中,mke2fs 格式 化工具的默认策略是一个块组有多少个 8KB 就分配多少个 inode(每个 inode 占用多少字节?128 字节)。由于数据块占了整个块组的绝大部分,也可以近似 认为数据块有多少个 8KB 就分配多少个 inode, 换句话说, 如果平均每个文件的 大小是 8KB, 当分区存满的时候 inode 表会得到比较充分的利用, 数据块也不浪 费。 如果这个分区存的都是很大的文件 (比如电影) 则数据块用完的时候 inode , 会有一些浪费,如果这个分区存的都是很小的文件(比如源代码),则有可能数 据块还没用完 inode 就已经用完了,数据块可能有很大的浪费。如果用户在格式 化时能够对这个分区以后要存储的文件大小做一个预测,也可以用 mke2fs 的-i 参数手动指定每多少个字节分配一个 inode。
inode 表用于跟踪定位每个文件, 包括位置、 大小等 (但不包括文件名, 文件名包含于 dentry 结构中) ,一个块组只有一个 inode 表。一个 inode 的结构如下: struct ext2_inode { __le16 i_mode; // 文件格式和访问权限 __le16 i_uid; // 文件所有者 ID 的低 16 位 __le32 i_size; // 文件字节数 __le32 i_atime; // 文件上次被访问的时间 __le32 i_ctime; // 文件创建时间 __le32 i_mtime; // 文件被修改的时间 __le32 i_dtime; // 文件被删除的时间(如果存在则为 0) __le16 i_gid; // 文件所有组 ID 的低 16 位 __le16 i_links_count; // 此 inode 被连接的次数 __le32 i_blocks; // 文件已使用和保留的总块数(以 512B 为单位) __le32 i_flags; // 此 inode 访问数据时 ext2 的实现方式 union { struct { __le32 l_i_reserved1; // 保留 } linux1; struct { __le32 h_i_translator; // “翻译者”标签 } hurd1; struct { __le32 m_i_reserved1; // 保留 } masix1; } osd1; // 操作系统相关数据 __le32 i_block[EXT2_N_BLOCKS]; // 定位存储文件的块的数组,前 12 个为块号,第 13 个为一级间接块号,第 14 个为二级间接块号,第 15 个为三级间接块号 __le32 i_generation; // 用于 NFS 的文件版本 __le32 i_file_acl; // 包含扩展属性的块号,老版本中为 0 __le32 i_dir_acl; // 表示文件的“High Size”,老版本中为 0 __le32 i_faddr; // 文件最后一个段的地址
union { struct { __u8 l_i_frag; // 段号 __u8 l_i_fsize; // 段大小 __u16 i_pad1; __le16 l_i_uid_high; // 文件所有者 ID 的高 16 位 __le16 l_i_gid_high; // 文件所有组 ID 的高 16 位 __u32 l_i_reserved2; } linux2; struct { __u8 h_i_frag; // 段号 __u8 h_i_fsize; // 段大小 __le16 h_i_mode_high; __le16 h_i_uid_high; // 文件所有者 ID 的高 16 位 __le16 h_i_gid_high; // 文件所有组 ID 的高 16 位 __le32 h_i_author; } hurd2; struct { __u8 m_i_frag; // 段号 __u8 m_i_fsize; // 段大小 __u16 m_pad1; __u32 m_i_reserved2[2]; } masix2; } osd2; // 操作系统相关数据 };
inode 结构: inode 是 EXT2 基本构件,表示文件系统树型结构的节点。 EXT2 文件系统中的每个文件由一个 inode 描述,且只能由一个 inode 描述。 inode 与文件一起存放在外存,系统运行时,把 inode 写入内存建立映像,加
快文件系统速度。
数据块(Data Block) 根据不同的文件类型有以下几种情况
? ?
? ?
对于常规文件,文件的数据存储在数据块中。 对于目录,该目录下的所有文件名和目录名存储在数据块中,注意文件名保 存在它所在目录的数据块中,除文件名之外,ls -l 命令看到的其它信息都保 存在该文件的 inode 中。注意这个概念:目录也是一种文件,是一种特殊类 型的文件。 对于符号链接, 如果目标路径名较短则直接保存在 inode 中以便更快地查找, 如果目标路径名较长则分配一个数据块来保存。 设备文件、FIFO 和 socket 等特殊文件没有数据块,设备文件的主设备号和 次设备号保存在 inode 中。
现在做几个小实验来理解这些概念。例如在 home 目录下 ls -l:
$ ls -l total 32 drwxr-xr-x 2008-10-25 drwxr-xr-x 2008-10-25 drwx-----2008-07-04
114 akaedu akaedu 12288 11:33 akaedu 114 ftp ftp 4096 10:30 ftp 2 root root 16384 05:58 lost+found
为什么各目录的大小都是 4096 的整数倍?因为这个分区的块大小是 4096,目 录的大小总是数据块的整数倍。 为什么有的目录大有的目录小?因为目录的数据 块保存着它下边所有文件和目录的名字,如果一个目录中的文件很多,一个块装 不下这么多文件名,就可能分配更多的数据块给这个目录。再比如:
$ ls -l /dev ... prw-r----- 1 syslog adm 2008-10-25 11:39 xconsole crw-rw-rw- 1 root root 2008-10-24 16:44 zero
0 1, 5
xconsole 文件的类型是 p(表示 pipe),是一个 FIFO 文件,后面会讲到它其实 是一块内核缓冲区的标识,不在磁盘上保存数据,因此没有数据块,文件大小是 0。zero 文件的类型是 c,表示字符设备文件,它代表内核中的一个设备驱动程 序,也没有数据块,原本应该写文件大小的地方写了 1, 5 这两个数字,表示主 设备号和次设备号,访问该文件时,内核根据设备号找到相应的驱动程序。再比 如:
$ touch hello $ ln -s ./hello halo $ ls -l total 0 lrwxrwxrwx 1 akaedu akaedu 7 2008-10-25 15:04 halo -> ./hello -rw-r--r-- 1 akaedu akaedu 0 2008-10-25 15:04 hello
文件 hello 是刚创建的,字节数为 0,符号链接文件 halo 指向 hello,字节数却 是 7,为什么呢?其实 7 就是“./hello”这 7 个字符,符号链接文件就保存着这 样一个路径名。再试试硬链接:
$ ln ./hello hello2
$ ls -l total 0 lrwxrwxrwx 1 akaedu akaedu 7 2008-10-25 15:04 halo -> ./hello -rw-r--r-- 2 akaedu akaedu 0 2008-10-25 15:04 hello -rw-r--r-- 2 akaedu akaedu 0 2008-10-25 15:04 hello2
hello2 和 hello 除了文件名不一样之外,别的属性都一模一样,并且 hello 的 属性发生了变化,第二栏的数字原本是 1,现在变成 2 了。从根本上说,hello 和 hello2 是同一个文件在文件系统中的两个名字,ls -l 第二栏的数字是硬链 接数, 表示一个文件在文件系统中有几个名字(这些名字可以保存在不同目录的 数据块中,或者说可以位于不同的路径下),硬链接数也保存在 inode 中。既然 是同一个文件, inode 当然只有一个, 所以用 ls -l 看它们的属性是一模一样的, 因为都是从这个 inode 里读出来的。再研究一下目录的硬链接数:
$ mkdir a $ mkdir a/b $ ls -ld a drwxr-xr-x 3 akaedu akaedu 4096 2008-10-25 16:15 a $ ls -la a total 20 drwxr-xr-x 3 akaedu akaedu 4096 2008-10-25 16:15 . drwxr-xr-x 115 akaedu akaedu 12288 2008-10-25 16:14 .. drwxr-xr-x 2 akaedu akaedu 4096 2008-10-25 16:15 b $ ls -la a/b total 8 drwxr-xr-x 2 akaedu akaedu 4096 2008-10-25 16:15 . drwxr-xr-x 3 akaedu akaedu 4096 2008-10-25 16:15 ..
首先创建目录 a,然后在它下面创建子目录 a/b。目录 a 的硬链接数是 3,这 3 个名字分别是当前目录下的 a, 目录下的.和 b 目录下的..。目录 b 的硬链接数 a 是 2,这两个名字分别是 a 目录下的 b 和 b 目录下的.。注意,目录的硬链接只 能这种方式创建,用 ln 命令可以创建目录的符号链接,但不能创建目录的硬链 接。
2.2. 实例剖析 请点评
如果要格式化一个分区来研究文件系统格式则必须有一个空闲的磁盘分区, 为了 方便实验, 我们把一个文件当作分区来格式化,然后分析这个文件中的数据来印 证上面所讲的要点。首先创建一个 1MB 的文件并清零:
$ dd if=/dev/zero of=fs count=256 bs=4K
我们知道 cp 命令可以把一个文件拷贝成另一个文件, dd 命令可以把一个文件 而 的一部分拷贝成另一个文件。这个命令的作用是把/dev/zero 文件开头的 1M (256×4K)字节拷贝成文件名为 fs 的文件。刚才我们看到/dev/zero 是一个 特殊的设备文件,它没有磁盘数据块,对它进行读操作传给设备号为 1, 5 的驱 动程序。/dev/zero 这个文件可以看作是无穷大的,不管从哪里开始读,读出来 的都是字节 0x00。因此这个命令拷贝了 1M 个 0x00 到 fs 文件。if 和 of 参数 表示输入文件和输出文件, count 和 bs 参数表示拷贝多少次, 每次拷多少字节。 做好之后对文件 fs 进行格式化,也就是把这个文件的数据块合起来看成一个 1MB 的磁盘分区,在这个分区上再划分出块组。
$ mke2fs fs mke2fs 1.40.2 (12-Jul-2007) fs is not a block special device. Proceed anyway? (y,n) (输入 y 回车) Filesystem label= OS type: Linux Block size=1024 (log=0) Fragment size=1024 (log=0) 128 inodes, 1024 blocks 51 blocks (4.98%) reserved for the super user First data block=1 Maximum filesystem blocks=1048576 1 block group 8192 blocks per group, 8192 fragments per group 128 inodes per group Writing inode tables: done Writing superblocks and filesystem accounting information: done This filesystem will be automatically checked every 27 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
格式化一个真正的分区应该指定块设备文件名,例如/dev/sda1,而这个 fs 是常 规文件而不是块设备文件, mke2fs 认为用户有可能是误操作了, 所以给出提示, 要求确认是否真的要格式化,输入 y 回车完成格式化。 现在 fs 的大小仍然是 1MB,但不再是全 0 了,其中已经有了块组和描述信息。 用 dumpe2fs 工具可以查看这个分区的超级块和块组描述符表中的信息:
$ dumpe2fs fs dumpe2fs 1.40.2 (12-Jul-2007) Filesystem volume name:
Last write time: Sun Dec 16 14:56:59 2007 Mount count: 0 Maximum mount count: 30 Last checked: Sun Dec 16 14:56:59 2007 Check interval: 15552000 (6 months) Next check after: Fri Jun 13 14:56:59 2008 Reserved blocks uid: 0 (user root) Reserved blocks gid: 0 (group root) First inode: 11 Inode size: 128 Default directory hash: tea Directory Hash Seed: 6d0e58bd-b9db-41ae-92b3-4563a02a5981
Group 0: (Blocks 1-1023) Primary superblock at 1, Group descriptors at 2-2 Reserved GDT blocks at 3-5 Block bitmap at 6 (+5), Inode bitmap at 7 (+6) Inode table at 8-23 (+7) 986 free blocks, 117 free inodes, 2 directories Free blocks: 38-1023 Free inodes: 12-128 128 inodes per group, 8 inodes per block, so: 16 blocks for inode table
根据上面讲过的知识简单计算一下, 块大小是 1024 字节, 1MB 的分区共有 1024 个块, 0 个块是启动块, 第 启动块之后才算 ext2 文件系统的开始, 因此 Group 0 占据第 1 个到第 1023 个块, 1023 个块。 共 块位图占一个块, 共有 1024×8=8192 个 bit,足够表示这 1023 个块了,因此只要一个块组就够了。默认是每 8KB 分 配一个 inode,因此 1MB 的分区对应 128 个 inode,这些数据都和 dumpe2fs 的 输出吻合。 用常规文件制作而成的文件系统也可以像磁盘分区一样 mount 到某个目录, 例如:
$ sudo mount -o loop fs /mnt $ cd /mnt/ $ ls -la total 17 drwxr-xr-x 3 akaedu akaedu 1024 2008-10-25 12:20 . drwxr-xr-x 21 root 2008-08-18 08:54 .. root 4096
drwx------ 2 root root 12288 2008-10-25 12:20 lost+found
-o loop 选项告诉 mount 这是一个常规文件而不是一个块设备文件。mount 会把 它的数据块中的数据当作分区格式来解释。 文件系统格式化之后在根目录下自动 生成三个子目录:.,..和 lost+found。其它子目录下的.表示当前目录,..表 示上一级目录, 而根目录的.和..都表示根目录本身。lost+found 目录由 e2fsck 工具使用,如果在检查磁盘时发现错误,就把有错误的块挂在这个目录下,因为 这些块不知道是谁的,找不到主,就放在这里“失物招领”了。 现在可以在/mnt 目录下添加删除文件,这些操作会自动保存到文件 fs 中。然后 把这个分区 umount 下来,以确保所有的改动都保存到文件中了。
$ sudo umount /mnt
注意, 下面的实验步骤是对新创建的文件系统做的,如果你在文件系统中添加删 除过文件, 跟着做下面的步骤时结果可能和我写的不太一样, 不过也不影响理解。 现在我们用二进制查看工具查看这个文件系统的所有字节,并且同 dumpe2fs 工 具的输出信息相比较,就可以很好地理解文件系统的存储布局了。
$ od -tx1 000000 00 * 000400 80 000410 75 ... -Ax fs 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 04 00 00 33 00 00 00 da 03 00 00 00 00 00 01 00 00 00 00 00 00 00 00 00 00 00
其中以*开头的行表示这一段数据全是零因此省略了。 下面详细分析 od 输出的信 息。
从 000000 开始的 1KB 是启动块,由于这不是一个真正的磁盘分区,启动块的 内容全部为零。 000400 到 0007ff 的 1KB 是超级块,对照着 dumpe2fs 的输出 从 信息,详细分析如下: 图 29.3. 超级块
超级块中从 0004d0 到末尾的 204 个字节是填充字节,保留未用,上图未画出。 注意,ext2 文件系统中各字段都是按小端存储的,如果把字节在文件中的位置 看作地址,那么靠近文件开头的是低地址,存低字节。各字段的位置、长度和含 义详见[ULK]。 从 000800 开始是块组描述符表,这个文件系统较小,只有一个块组描述符,对 照着 dumpe2fs 的输出信息分析如下:
... Group 0: (Blocks 1-1023) Primary superblock at 1, Group descriptors at 2-2 Reserved GDT blocks at 3-5
Block bitmap at 6 (+5), Inode bitmap at 7 (+6) Inode table at 8-23 (+7) 986 free blocks, 117 free inodes, 2 directories Free blocks: 38-1023 Free inodes: 12-128 ...
图 29.4. 块组描述符
整个文件系统是 1MB, 每个块是 1KB, 应该有 1024 个块, 除去启动块还有 1023 个块,分别编号为 1-1023,它们全都属于 Group 0。其中,Block 1 是超级块, 接下来的块组描述符指出,块位图是 Block 6,因此中间的 Block 2-5 是块组描 述符表,其中 Block 3-5 保留未用。块组描述符还指出,inode 位图是 Block 7, inode 表是从 Block 8 开始的,那么 inode 表到哪个块结束呢?由于超级块中指 出每个块组有 128 个 inode, 每个 inode 的大小是 128 字节, 因此共占 16 个块, inode 表的范围是 Block 8-23。 从 Block 24 开始就是数据块了。块组描述符中指出,空闲的数据块有 986 个, 由于文件系统是新创建的, 空闲块是连续的 Block 38-1023, 用掉了前面的 Block 24-37。 从块位图中可以看出, 37 位 前 (前 4 个字节加最后一个字节的低 5 位) 都是 1,就表示 Block 1-37 已用:
001800 001810 * 001870 001880 * ff ff ff ff 1f 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 80 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff
在块位图中,Block 38-1023 对应的位都是 0(一直到 001870 那一行最后一个 字节的低 7 位),接下来的位已经超出了文件系统的空间,不管是 0 还是 1 都 没有意义。可见,块位图每个字节中的位应该按从低位到高位的顺序来看。以后 随着文件系统的使用和添加删除文件,块位图中的 1 就变得不连续了。
块组描述符指出,空闲的 inode 有 117 个,由于文件系统是新创建的,空闲的 inode 也是连续的,inode 编号从 1 到 128,空闲的 inode 编号从 12 到 128。从 inode 位图可以看出,前 11 位都是 1,表示前 11 个 inode 已用:
001c00 ff 07 00 00 00 00 00 00 00 00 00 00 00 00 00 00 001c10 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff *
以后随着文件系统的使用和添加删除文件,inode 位图中的 1 就变得不连续了。 001c00 这一行的 128 位就表示了所有 inode,因此下面的行不管是 0 还是 1 都 没有意义。已用的 11 个 inode 中,前 10 个 inode 是被 ext2 文件系统保留的, 其中第 2 个 inode 是根目录, 11 个 inode 是 lost+found 目录, 第 块组描述符也 指出该组有两个目录,就是根目录和 lost+found。 探索文件系统还有一个很有用的工具 debugfs,它提供一个命令行界面,可以对 文件系统做各种操作,例如查看信息、恢复数据、修正文件系统中的错误。下面 用 debugfs 打开 fs 文件,然后在提示符下输入 help 看看它都能做哪些事情:
$ debugfs fs debugfs 1.40.2 (12-Jul-2007) debugfs: help
在 debugfs 的提示符下输入 stat /命令,这时在新的一屏中显示根目录的 inode 信息:
Inode: 2 Type: directory Mode: 0755 Flags: 0x0 Generation: 0 User: 1000 Group: 1000 Size: 1024 File ACL: 0 Directory ACL: 0 Links: 3 Blockcount: 2 Fragment: Address: 0 Number: 0 Size: 0 ctime: 0x4764cc3b -- Sun Dec 16 14:56:59 2007 atime: 0x4764cc3b -- Sun Dec 16 14:56:59 2007 mtime: 0x4764cc3b -- Sun Dec 16 14:56:59 2007 BLOCKS: (0):24 TOTAL: 1
按 q 退出这一屏,然后用 quit 命令退出 debugfs:
debugfs: quit
把以上信息和 od 命令的输出对照起来分析: 图 29.5. 根目录的 inode
上图中的 st_mode 以八进制表示, 包含了文件类型和文件权限, 最高位的 4 表示 文件类型为目录(各种文件类型的编码详见 stat(2)),低位的 755 表示权限。 Size 是 1024,说明根目录现在只有一个数据块。Links 为 3 表示根目录有三个 硬链接,分别是根目录下的.和..,以及 lost+found 子目录下的..。注意,虽然 我们通常用/表示根目录, 但是并没有名为/的硬链接, 事实上, /是路径分隔符, 不能在文件名中出现。这里的 Blockcount 是以 512 字节为一个块来数的,并非 格式化文件系统时所指定的块大小,磁盘的最小读写单位称为扇区(Sector), 通常是 512 字节,所以 Blockcount 是磁盘的物理块数量,而非分区的逻辑块数 量。根目录数据块的位置由上图中的 Blocks[0]指出,也就是第 24 个块,它在 文件系统中的位置是 24×0x400=0x6000,从 od 命令的输出中找到 006000 地 址,它的格式是这样: 图 29.6. 根目录的数据块
目录的数据块由许多不定长的记录组成,每条记录描述该目录下的一个文件,在 上图中用框表示。第一条记录描述 inode 号为 2 的文件,也就是根目录本身,该 记录的总长度为 12 字节, 其中文件名的长度为 1 字节, 文件类型为 2 (见下表, 注意此处的文件类型编码和 st_mode 不一致),文件名是.。 表 29.1. 目录中的文件类型编码 编码 0 1 2 3 4 5 6 7 文件类型 Unknown Regular file Directory Character device Block device Named pipe Socket Symbolic link
第二条记录也是描述 inode 号为 2 的文件 (根目录) 该记录总长度为 12 字节, , 其中文件名的长度为 2 字节,文件类型为 2,文件名字符串是..。第三条记录一 直延续到该数据块的末尾,描述 inode 号为 11 的文件(lost+found 目录),该 记录的总长度为 1000 字节(和前面两条记录加起来是 1024 字节),文件类型 为 2,文件名字符串是 lost+found,后面全是 0 字节。如果要在根目录下创建 新的文件,可以把第三条记录截短,在原来的 0 字节处创建新的记录。如果该目 录下的文件名太多,一个数据块不够用,则会分配新的数据块,块编号会填充到 inode 的 Blocks[1]字段。 debugfs 也提供了 cd、ls 等命令,不需要 mount 就可以查看这个文件系统中的 目录,例如用 ls 查看根目录:
2 (12) . lost+found 2 (12) .. 11 (1000)
列出了 inode 号、记录长度和文件名,这些信息都是从根目录的数据块中读出来 的。
2.3. 数据块寻址 请点评
如果一个文件有多个数据块, 这些数据块很可能不是连续存放的,应该如何寻址 到每个块呢?根据上面的分析,根目录的数据块是通过其 inode 中的索引项
Blocks[0]找到的,事实上,这样的索引项一共有 15 个,从 Blocks[0]到 Blocks[14],每个索引项占 4 字节。前 12 个索引项都表示块编号,例如上面的 例子中 Blocks[0]字段保存着 24,就表示第 24 个块是该文件的数据块,如果块 大小是 1KB,这样可以表示从 0 字节到 12KB 的文件。如果剩下的三个索引项 Blocks[12]到 Blocks[14]也是这么用的,就只能表示最大 15KB 的文件了,这 是远远不够的,事实上,剩下的三个索引项都是间接索引。 索引项 Blocks[12]所指向的块并非数据块, 而是称为间接寻址块 (Indirect Block) , 其中存放的都是类似 Blocks[0]这种索引项,再由索引项指向数据块。设块大小 是 b,那么一个间接寻址块中可以存放 b/4 个索引项,指向 b/4 个数据块。所以 如果把 Blocks[0]到 Blocks[12]都用上,最多可以表示 b/4+12 个数据块,对于 块大小是 1K 的情况,最大可表示 268K 的文件。如下图所示,注意文件的数据 块编号是从 0 开始的,Blocks[0]指向第 0 个数据块,Blocks[11]指向第 11 个 数据块,Blocks[12]所指向的间接寻址块的第一个索引项指向第 12 个数据块, 依此类推。 图 29.7. 数据块的寻址
从上图可以看出,索引项 Blocks[13]指向两级的间接寻址块,最多可表示 (b/4)2+b/4+12 个数据块,对于 1K 的块大小最大可表示 64.26MB 的文件。索引 项 Blocks[14]指向三级的间接寻址块,最多可表示(b/4)3+(b/4)2+b/4+12 个数据 块,对于 1K 的块大小最大可表示 16.06GB 的文件。 可见,这种寻址方式对于访问不超过 12 个数据块的小文件是非常快的,访问文 件中的任意数据只需要两次读盘操作,一次读 inode(也就是读索引项)一次读 数据块。而访问大文件中的数据则需要最多五次读盘操作:inode、一级间接寻 址块、二级间接寻址块、三级间接寻址块、数据块。实际上,磁盘中的 inode 和 数据块往往已经被内核缓存了,读大文件的效率也不会太低。
操作系统课程设计-模拟文件系统
目录 第1章需求分析 (1) 第2章概要设计 (1) 系统的主要功能 (1) 系统模块功能结构 (1) 运行环境要求 (2) 数据结构设计 (2) 第3章详细设计 (3) 模块设计 (3) 算法流程图 (3) 第4章系统源代码 (4) 第5章系统测试及调试 (4) 运行结果及分析 (4) 系统测试结论 (5) 第6章总结与体会 (6) 第7章参考文献 (6) 附录 (7)
第1章需求分析 通过模拟文件系统的实现,深入理解操作系统中文件系统的理论知识, 加深对教材中的重要算法的理解。同时通过编程实现这些算法,更好地掌握操作系统的原理及实现方法,提高综合运用各专业课知识的能力;掌握操作系统结构、实现机理和各种典型算法,系统地了解操作系统的设计和实现思路,并了解操作系统的发展动向和趋势。 模拟二级文件管理系统的课程设计目的是通过研究Linux的文件系统结构,模拟设计一个简单的二级文件系统,第一级为主目录文件,第二级为用户文件。 第2章概要设计 系统的主要功能 1) 系统运行时根据输入的用户数目创建主目录 2) 能够实现下列命令: Login 用户登录 Create 建立文件 Read 读取文件 Write 写入文件 Delete 删除文件 Mkdir 建立目录 Cd 切换目录 Logout 退出登录 系统模块功能结构
运行环境要求 操作系统windows xp ,开发工具vc++ 数据结构设计 用户结构:账号与密码结构 typedef struct users { char name[8]; char pwd[10]; }users; 本系统有8个默认的用户名,前面是用户名,后面为密码,用户登陆时只要输入正确便可进入系统,否则提示失败要求重新输入。 users usrarray[8] = { "usr1","usr1", "usr2","usr2", "usr3","usr3", "usr4","usr4",
Ext2数据块分配
Ext2数据块分配 跟索引节点一样,Ext2也对磁盘数据块进行分配与释放。在详细分析相关代码之前,先引出两个重要的预备,一个是数据块寻址,一个是文件的洞 1 数据块寻址 每个非空的普通文件都由一组数据块组成。这些块或者由文件内的相对位置(它们的文件块号)来标识,或者由磁盘分区内的位置(它们的逻辑块号)来标识。 从文件内的偏移量f 导出相应数据块的逻辑块号需要两个 步骤: 1. 从偏移量f导出文件的块号,即在偏移量f处的字符所在的块索引。 2. 把文件的块号转化为相应的逻辑块号。 因为Unix文件不包含任何控制字符,因此,导出文件的第f 个字符所在的文件块号当容易的,只是用f除以文件系统块
的大小,并取整即可。 例如,让我们假定块的大小为4KB。如果f小于4096,那么这个字符就在文件的第一数据块中,其文件的块号为O。如果f等于或大于4096而小于8192,则这个字符就在文件块号为1的数据块中,以此类推。 得到了文件的块号是第一步。但是,由于Ext2文件的数据块在磁盘上不必是相邻的,因此把文件的块号转化为相应的逻辑块号可不是这么直截了当的了。 因此,Ext2文件系统必须提供一种方法,用这种方法可以在磁盘上建立每个文件块号与相应逻辑块号之间的关系。在索引节点内部部分实现了这种映射(回到了 AT&T Unix的早期版本)。这种映射也涉及一些包含额外指针的专用块,这些块用来处理大型文件的索引节点的扩展。 ext2磁盘索引节点ext2_inode的i_block字段是一个有EXT2_N_BLOCKS个元素且包含逻辑块号的数组。在下面的讨论中, 我们假定EXT2_N_BLOCKS的默认值为15(实际上到2.6.18这个值都一直是15)。如图所示,这个数组表示一个大型数据结构的初始化部分。
spring配置文件各个属性详解
spring配置文件各个属性详解 分类:spring 2012-08-09 11:25 9316人阅读评论(2) 收藏举报springaophibernateattributesxhtmlwebsphere 目录(?)[+]一、引用外部属性文件
Linux 0.1.1文件系统的源码阅读
Linux 0.11文件系统的源码阅读总结 1.minix文件系统 对于linux 0.11内核的文件系统的开发,Linus主要参考了Andrew S.Tanenbaum 所写的《MINIX操作系统设计与实现》,使用的是其中的1.0版本的MINIX文件系统。而高速缓冲区的工作原理参见M.J.Bach的《UNIX操作系统设计》第三章内容。 通过对源代码的分析,我们可以将minix文件系统分为四个部分,如下如1-1。 ●高速缓冲区的管理程序。主要实现了对硬盘等块设备进行数据高速存取的函数。 ●文件系统的底层通用函数。包括文件索引节点的管理、磁盘数据块的分配和释放 以及文件名与i节点的转换算法。 ●有关对文件中的数据进行读写操作的函数。包括字符设备、块设备、管道、常规 文件的读写操作,由read_write.c函数进行总调度。 ●涉及到文件的系统调用接口的实现,这里主要涉及文件的打开、关闭、创建以及 文件目录等系统调用,分布在namei和inode等文件中。 图1-1 文件系统四部分之间关系图
1.1超级块 首先我们了解一下MINIX文件系统的组成,主要包括六部分。对于一个360K软盘,其各部分的分布如下图1-2所示: 图 1-2 建有MINIX文件系统的一个360K软盘中文件系统各部分的布局示意图 注释1:硬盘的一个扇区是512B,而文件系统的数据块正好是两个扇区。 注释2:引导块是计算机自动加电启动时可由ROM BIOS自动读入得执行代码和数据。 注释3:逻辑块一般是数据块的2幂次方倍数。MINIX文件系统的逻辑块和数据块同等大小 对于硬盘块设备,通常会划分几个分区,每个分区所存放的不同的文件系统。硬盘的第一个扇区是主引导扇区,其中存放着硬盘引导程序和分区表信息。分区表中得信息指明了硬盘上每个分区的类型、在硬盘中其实位置参数和结束位置参数以及占用的扇区总数。其结构如下图1-3所示。 图1-3 硬盘设备上的分区和文件系统 对于可以建立不同的多个文件系统的硬盘设备来说,minix文件系统引入超级块进行管理硬盘的文件系统结构信息。其结构如下图1-4所示。其中,s_ninodes表示设备上得i节点总数,s_nzones表示设备上的逻辑块为单位的总逻辑块数。s_imap_blocks 和s_zmap_blocks分别表示i节点位图和逻辑块位图所占用的磁盘块数。 s_firstdatazone表示设备上数据区开始处占用的第一个逻辑块块号。s_log_zone_size 是使用2为底的对数表示的每个逻辑块包含的磁盘块数。对于MINIX1.0文件系统该值为0,因此其逻辑块的大小就等于磁盘块大小。s_magic是文件系统魔幻数,用以指明文件系统的类型。对于MINIX1.0文件系统,它的魔幻数是0x137f。
认识文件系统
认识文件系统 物联网学院平震宇
文件系统 文件系统是一套实现了数据的存储、分级组织、访问和获取等操作的抽象数据类型,一种存储和组织计算机文件和数据的方法,它使得对其访问和查找变得容易。 Linux 最早的文件系统是Minix,但是专门为Linux 设计的文件系统——扩展文件系统第二版 (EXT2)被设计出来并添加到Linux中,这对Linux产生了重大影响。EXT2文件系统功能强大、易扩充、性能上进行了全面优化,也是所有Linux发布和安装的标准文件系统类型。
虚拟文件系统 Linux支持ext,ext2,xia,minix,umsdos,msdes,fat32 ,ntfs,proc,stub,ncp,hpfs,affs 以及 ufs 等多种文件系统。 Linux 对所有的文件系统采用统一的文件界面,用户通过文件的操作界面来实现对不同文件系统的操作。对于用户来说,我们不要去关心不同文件系统的具体操作过程,而只是对一个虚拟的文件操作界面来进行操作,这个操作界面就是 Linux 的虚拟文件系统(VFS ) 。 VFS 作为 Linux内核中的一个软件层,用于给用户空间的程序提供文件系统接口,同时也提供了内核中的一个抽象功能,允许不同的文件系统很好地共存。VFS 使 Linux 同时安装、支持许多不同类型的文件系统成为可能。VFS 拥有关于各种特殊文件系统的公共界面,如超级块、inode、文件操作函数入口等。实际文件系统的细节,统一由 VFS 的公共界面来索引,它们对系统核心和用户进程来说是透明的。
Linux上有许多可用的文件系统。每个文件系统都有其特定的用途,以便于特定用户解决不同的问题。 ?要求文件系统在频繁的文件操作(例如,新建,删 除,截断)下能够保持较高的读写性能,要求低碎 片化。 ?Linux下的日志文件系统能保持数据的完整性,但消 耗过多系统资源,的弱点使之不能成为嵌入式系统中 的主流应用。并且这些都是专门为硬盘这类的存储 设备优化,对于flash这类的存储介质并不适用。
iec61850规约SCL文件属性详解
SCL文件属性详解 目录
0 前言 (5) 1 术语 (5) 2 概述 (5) 2.1SCL语言介绍 (5) 2.2SCL文件分类 (6) 3 工程实施过程 (8) 3.1公共部分 (8) 3.2我们监控与我们装置 (8) 3.3我们监控与外厂家装置 (8) 3.4我们装置与外厂家监控 (9) 4 文件错误验证规则 (9) 4.1验证规则概述 (9) 4.2语法验证细则 (9) 4.2.1 SCL节点 (9) 4.2.2 Header节点 (10) 4.2.3 History节点 (10) 4.2.4 Hitem节点 (10) 4.2.5 Communication节点 (11) 4.2.6 SubNetwork节点 (11) 4.2.7 BitRate节点 (11) 4.2.8 ConnectedAP节点 (11) 4.2.9 Address节点 (12) 4.2.10 P节点 (12) 4.2.11 GSE节点 (12) 4.2.12 MinTime、MaxTime节点 (12) 4.2.13 SMV节点 (12) 4.2.14 PhysConn节点 (13) 4.2.15 IED节点 (13) 4.2.16 Services节点 (14) 4.2.17 DynAssociation节点 (14) 4.2.18 SettingGroups节点 (14) 4.2.19 GetDirectory节点 (15) 4.2.20 GetDataObjectDefinition节点 (15) 4.2.21 DataObjectDirectory节点 (15) 4.2.22 GetDataSetValue节点 (15) 4.2.23 SetDataSetValue节点 (15) 4.2.24 DataSetDirectory节点 (15) 4.2.25 ConfDataSet节点 (15) 4.2.26 DynDataSet节点 (15) 4.2.27 ReadWrite节点 (16) 4.2.28 TimerActivatedControl节点 (16) 4.2.29 ConfReportControl节点 (16)
iec61850icd模型文件属性详解
ICD模型文件属性详解 目录
0 前言 (5) 1 术语 (5) 2 概述 (5) 2.1SCL语言介绍 (5) 2.2SCL文件分类 (6) 3 工程实施过程 (8) 3.1公共部分 (8) 3.2我们监控与我们装置 (8) 3.3我们监控与外厂家装置 (8) 3.4我们装置与外厂家监控 (9) 4 文件错误验证规则 (9) 4.1验证规则概述 (9) 4.2语法验证细则 (9) 4.2.1 SCL节点 (9) 4.2.2 Header节点 (10) 4.2.3 History节点 (10) 4.2.4 Hitem节点 (10) 4.2.5 Communication节点 (11) 4.2.6 SubNetwork节点 (11) 4.2.7 BitRate节点 (11) 4.2.8 ConnectedAP节点 (11) 4.2.9 Address节点 (12) 4.2.10 P节点 (12) 4.2.11 GSE节点 (12) 4.2.12 MinTime、MaxTime节点 (12) 4.2.13 SMV节点 (12) 4.2.14 PhysConn节点 (13) 4.2.15 IED节点 (13) 4.2.16 Services节点 (14) 4.2.17 DynAssociation节点 (14) 4.2.18 SettingGroups节点 (14) 4.2.19 GetDirectory节点 (15) 4.2.20 GetDataObjectDefinition节点 (15) 4.2.21 DataObjectDirectory节点 (15) 4.2.22 GetDataSetValue节点 (15) 4.2.23 SetDataSetValue节点 (15) 4.2.24 DataSetDirectory节点 (15) 4.2.25 ConfDataSet节点 (15) 4.2.26 DynDataSet节点 (15) 4.2.27 ReadWrite节点 (16) 4.2.28 TimerActivatedControl节点 (16) 4.2.29 ConfReportControl节点 (16)
Ext3文件系统
EXT3文件系统 EXT2和EXT3是许多Linux操作系统发行版本的默认文件系统。EXT基于UFS,是一种快速、稳定的文件系统。 随着Linux系统在关键业务中的应用,Linux文件系统的弱点也渐渐显露出来了;其中EXT2文件系统是非日志式文件系统,这在关键行业的应用是一个致命的弱点,EXT3文件系统弥补了这一缺点。 EXT3文件系统是直接从EXT2文件系统发展而来,目前EXT3文件系统已经非常稳定可靠。它完全兼容EXT2文件系统。用户可以平滑地过渡到一个日志功能健全的文件系统中来。这实际上了也是EXT3日志文件系统初始设计的初衷。 Ext3文件系统属于一种日志文件系统,是对Ext2系统的扩展。Ext3系统兼容Ext2文件系统,二者之间的相互转换并不复杂。 Ext2是 GNU/Linux 系统中标准的文件系统,其簇快取层的优良设计使得Ext2系统存取文件的性能非常好,尤其是针对中小型的文件更显优势。 Ext3是一种日志式文件系统,日志文件系统比传统的文件系统安全,因为它用独立的日志文件跟踪磁盘内容的变化。就像关系型数据库(RDBMS),日志文件系统可以用事务处理的方式,提交或撤消文件系统的变化。由于文件系统都有快取层参与运作,不使用时必须将文件系统卸下,以便将快取层的资料写回磁盘中。因此每当系统要关机时,必须将其所有的文件系统全部关闭后才能进行关机。 如果在文件系统尚未关闭前就关机 (如停电) 时,下次重开机后会造成文件系统的资料不一致,故(所以)这时必须做文件系统的重整工作,将不一致与错误的地方修复。然而这一重整的工作是相当耗时的,特别是容量大的文件系统,而且也不能百分之百保证所有的资料都不会流失。 为了克服此问题,使用(便出现了)所谓的日志式文件系统 (Journal File System) 。此类文件系统最大的特色是,它会将整个磁盘的写入动作完整记录在磁盘的某个区域上,以便有需要时可以回溯追踪。 由于资料的写入动作包含许多的细节,如改变文件标头资料、搜寻磁盘可写入空间、一个个写入资料区段等等,每一个细节进行到一半若被中断,就会造成文件系统的不一致,因而需要重整。 然而在日志式文件系统中,由于详细纪录了每个细节,故当在某个过程中被中断时,系统可以根据这些记录直接回溯并重整被中断的部分,而不必花时间去检查其他的部分,故重整的工作速度相当快,几乎不需要花时间。 EXT3日志文件系统的特点 1、高可用性 系统使用了EXT3文件系统后,即使在非正常关机后,系统也不需要检查文件系统。宕机发生后,恢复EXT3文件系统的时间只要数十秒钟。 2、数据的完整性: EXT3文件系统能够极大地提高文件系统的完整性,避免了意外宕机对文件系统的破
文件属性详解
linux中各种文件类型 普通文件(- regular file) (1)文本文件。文件中的内容是由文本构成的,文本指的是ASCII码字符。文件里的内容本质上都是数字(不管什么文件内容本质上都是数字,因为计算机中本身就只有1和0),而文本文件中的数字本身应该被理解为这个数字对应的ASCII码。常见的.c 文件, .h文件 .txt文件等都是文本文件。文本文件的好处就是可以被人轻松读懂和编写。所以说文本文件天生就是为人类发明的。 (2)二进制文件。二进制文件中存储的本质上也是数字,只不过这些数字并不是文字的编码数字,而是就是真正的数字。常见的可执行程序文件(gcc编译生成的a.out,arm-linux-gcc编译连接生成的.bin)都是二进制文件。 (3)对比:从本质上来看(就是刨除文件属性和内容的理解)文本文件和二进制文件并没有任何区别。都是一个文件里面存放了数字。区别是理解方式不同,如果把这些数字就当作数字处理则就是二进制文件,如果把这些数字按照某种编码格式去解码成文本字符,则就是文本文件。 (4)我们如何知道一个文件是文件文件还是二进制文件?在linux系统层面是不区分这两个的(譬如之前学过的open、read、write等方法操作文件文件和二进制文件时一点区别都没有),所以我们无法从文件本身准确知道文件属于哪种,我们只能本来就知道这个文件的类型然后用这种类型的用法去用他。有时候会用一些后缀名来人为的标记文件的类型。 (5)使用文本文件时,常规用法就是用文本文件编辑器去打开它、编辑它。常见的文本文件编辑器如vim、gedit、notepad++、SourceInsight等,我们用这些文本文件编辑器去打开文件的时候,编辑器会read读出文件二进制数字内容,然后按照编码格式去解码将其还原成文字展现给我们。如果用文本文件编辑器去打开一个二进制文件会如何?这时候编辑器就以为这个二进制文件还是文本文件然后试图去将其解码成文字,但是解码过程很多数字并不对应有意义的文字所以成了乱码。 (6)反过来用二进制阅读工具去读取文本文件会怎么样?得出的就是文本文字所对应的二进制的编码。 目录文件(d directory) (1)目录就是文件夹,文件夹在linux中也是一种文件,不过是特殊文件。用vi打开一个文件夹就能看到,文件夹其实也是一种特殊文件,里面存的内容包括这个文件的路径,还有文件夹里面的文件列表。 (2)但是文件夹这种文件比较特殊,本身并不适合用普通的方式来读写。linux中是使用特殊的一些API来专门读写文件夹的。 字符设备文件(c character) 块设备文件(b block) (1)设备文件对应的是硬件设备,也就是说这个文件虽然在文件系统中存在,但是并不是真正存在于硬盘上的一个文件,而是文件系统虚拟制造出来的(叫虚拟文件系统,如/dev /sys /proc等) (2)虚拟文件系统中的文件大多数不能或者说不用直接读写的,而是用一些特殊的API产生或者使用的,具体在驱动阶段会详解。 管道文件(p pipe) 套接字文件(s socket) 符号链接文件(l link)
stm32sdiofatfs文件系统源码分析
、概述 1、目的 在移植之前,先将源代码大概的阅读一遍,主要是了解文件系统的结构、 各个函数的功能和接口、与移植相关的代码等等。 2、准备工作 在官方网站下载了0.07c 版本的源代码,利用记事本进行阅读。 二、源代码的结构 1、源代码组成 源代码压缩包解压后,共两个文件夹,doc是说明,src里就是代码。src文件夹里共五个文件和一个文件夹。文件夹是option,还有OOreadme.txt、 diskio.c、diskio.h、ff.c、ff.h、integer.h。对比网上的文章,版本已经不同了,已经没有所谓的tff.c 和tff.h 了,估计现在都采用条件编译解决这个问题了,当然文件更少,可能编译选项可能越复杂。 2、00readme.txt 的说明 Low level disk I/O module is not included in this archive because the FatFs module is only a generic file system layer and not depend on any specific storage device. You have to provide a low level disk I/O module that written to control your storage device .主要是说不包含底层10代码,这是个通用文 件系统可以在各种介质上使用。我们移植时针对具体存储设备提供底层代码。 接下来做了版权声明-可以自由使用和传播。 然后对版本的变迁做了说明。 3、源代码阅读次序
先读integer.h,了解所用的数据类型,然后是ff.h, 了解文件系统所用的数据结构和各种函数声明,然后是diskio.h,了解与介质相关的数据结构和操作函数。再把ff.c和diskio.c两个文件所实现的函数大致扫描一遍。最后根据用户应用层程序调用函数的次序仔细阅读相关代码。 三、源代码阅读 1、integer.h 头文件 这个文件主要是类型声明。以下是部分代码。 typedef intINT; typedef unsigned int UINT; typedef signed charCHAR;/* These types must be 8-bit integer */ 都是用typedef 做类型定义。移植时可以修改这部分代码,特别是某些定义与你所在工程的类型定义有冲突的时候。 2、ff.h 头文件 以下是部分代码的分析 #include “ intege使用i n teger.h 的类型定义 #ifndef _FATFS #define _FATFS 0x007版本号007c, 0.07c #define _WORD_ACCESS 0如//果定义为1,则可以使用word 访问。 中间有一些看着说明很容易弄清楚意思。这里就不例举了。 #define _CODE_PAGE 936 /* The _CODE_PAGE specifies the OEM code page to be used on the target system. /936 -Simplified Chinese GBK (DBCS, OEM, WindoW跟据这个中国应该是936.
Ext2格式分析
Ext2格式分析 1、Ext2磁盘数据结构 任何Ext2分区中的第一个块从不受Ext2文件系统的管理,因为这一块是为分区的引导扇区所保留的。Ext2分区的其余部分被分成块组(block group),每个块组的分布图如图所示。正如你从图中所看到的,一些数据结构正好可以放在一块中,而另一些可能需要更多的块。在Ext2文件系统中的所有块组大小相同并被顺序存放,因此,内核可以从块组的整数索引很容易地得到磁盘中一个块组的位置: 由于内核尽可能地把属于同一个文件的数据块存放在同一块组中,所以块组减少了文件碎片。块组中的每个块包含下列信息之一: 1.文件系统的超级块的一个拷贝 2.一组块组描述符的拷贝 3.一个数据块位图 4.一个索引节点位图 5.一个索引节点表 6.属于文件的一大块数据,即数据块 如果一个块中不包含任何有意义的信息,就说这个块是空闲的。 从上图中可以看出,超级块与组描述符被复制到每个块组中。 其实呢,只有块组0中所包含超级块和组描述符才由内核使用,而其余的超级块和组描述符都保持不变;事实上,内核甚至不考虑它们。当e2fsck程序对Ext2文件系统的状态执行一致性检查时,就引用存放在块组0中的超级块和组描述符,然后把它们拷贝到其他所有的块组中。如果出现数据损坏,并且块组0 中的主超级块和主描述符变为无效,那么,系
统管理员就可以命令e2fsck引用存放在某个块组(除了第一个块组)中的超级块和组描述符的旧拷贝。通常情况下,这些多余的拷贝所存放的信息足以让e2fsck把Ext2分区带回到一个一致的状态。 那么有多少块组呢?这取决于分区的大小和块的大小。其主要限制在于块位图,因为块位图必须存放在一个单独的块中。块位图用来标识一个组中块的占用和空闲状况。所以,每组中至多可以有8×b个块,b是以字节为单位的块大小。例如,一个块是 1024 Byte,那么,一个块的位图就有8192个位,一个块组正好就对应8192个块(位图中的一个bit描述一个块)。 Ext2超块(super Block) Ext2超块中包含了描叙文件系统基本尺寸和形态的信息,是用定义在include/Linux /ext2_fs.h中ext2_supe_block数据结构描述的。文件系统管理器利用它们来使用和维护文件系统。通常安装文件系统时只读取数据块组0中的超块,但是为防止文件系统被破坏,每个数据块组都包含了它的拷贝。超块中的主要信息如下: Magic Number:文件系统安装软件用来检验是否是一个真正的EXl2文件系统超块。当前Exl2版本中为0xEF53。 Block Size:以字节记数的文件系统块大小,如1024字节。 Blocks per Group:每个组中块数目。当文件系统创建时此块大小被固定下来。 Free Blocks:文件系统中的空闲块数。 Free Inodes:文件系统中空闲Inode数。 First Inode:文件系统中第一个Inode号。EX配根文件系统中第一个Inode将是指向‘/’目录的人口。 ExT2组描述符(Group Descript) 每个数据块组都拥有一个描叙结构的组描叙符,它是定义在include/Linux/ext2一fs.h中的ext2一group—desc结构。组描叙符放置在一起形成了组描叙符表。每个数据块组在超块拷贝后包含整个组描叙符表。象超块一样,所有数据块组中的组描叙符表被复制到每个数据块组中以防文件系统崩溃。EX配文件系统仅使用第一个拷贝(在数据块组0中)。组描叙符主要包含以下信息: Blocks Bitm印:对应此数据块组的块分配位图的块号,在块分配和回收时使用。 Inode Bitmap:对应此数据块组的Inode分配位图的块号,在Inode分配和回收时使用。 Inode Table:对应数据块组的Inode表的起始块号。每个Inode用下面的EX佗Inode 结构来表示。
传奇DBC数据库变量详细解释传奇DB文件详解
本文档由:www.haosf.bz整理 传奇DBC数据库变量详细解释传奇DB文件详解: MagicDB:是你所修炼的法术和各种技能. (1)MagID 技能代号 (2)MagName 技能名称 (3)Effect Type 效果类型(使用技能时角色的动作效果) (4)Effect 效果(技能产生的动画效果) (5)Spell 每次耗用魔法值 (6)Power 基本威力 (7)MaxPower 最大威力 (8)DefSpell 升级后增加的每次耗用魔法值 (9)DefPower 升级后增加的威力 (10)DefMaxPower 升级后增加的最大威力 (11)Job 职业(0-战士,1-法师,2-道士) (12)NeedL1 1级技能所需等级 (13)L1Train 1级技能修炼所需经验 (14)NeedL2 2级技能所需等级 (15)L2Train 2级技能修炼所需经验 (16)NeedL3 3级技能所需等级 (17)L3Train 3级技能修炼所需经验 (18)Delay 技能延迟时间 (19)Descr 备注 EffectType 效果类型(使用技能时角色的动作效果)代码 0 基础剑术Fencing/精神力战法SpiritSword/攻杀剑术Slaying/刺杀剑术Thrusting/半月弯刀HalfMoon/烈火剑法FlamingSword/野蛮冲撞ShoulderDash 1 火球术Fireball/大火球GreatFireBal 2 治愈术Healing/施毒术Poisoning/诱惑之光Eshock/爆裂火焰FireBang/心灵启示Revelation/群体治愈术MassHealing/圣言术TurnUndead/冰咆哮IceStorm 4 抗拒火环Repulsion/召唤骷髅SummonSkele/隐身术Hiding/瞬息移动Teleport/火墙FireWall/地狱雷光ThunderStorm/召唤神兽SummonShinsu/魔法MagicShield 5 地狱火Hellfire 6 疾光电影Lightning 7 雷电术ThunderBolt 8 灵魂火符SoulFireBall/集体隐身术MassHiding 9 幽灵盾SoulShield/神圣战甲术BlessedArmou 10 困魔咒TrapHexagon Effect 效果(技能产生的动画效果)代码 0 基础剑术Fencing 精神力战法SpiritSword 1 火球术Fireball 2 治愈术Healing 3 大火球GreatFireBal 4 施毒术Poisoning
文件系统结构分析
文件系统结构分析 1嵌入式文件系统 1.1嵌入式文件系统体系结构 在嵌入式系统中,文件系统是嵌入式系统的一个组成模块,它是作为系统的一个 可加载选项提供给用户,由用户决定是否需要加载它。同时,它还需要满足结构紧 凑、代码量小、支持多种存储设备、可伸缩、可剪裁、可移植等特点。基于上面的要 求,嵌入式文件系统在设计和实现时就要把它作为一个独立的模块来整体考虑。特别 是对文件系统内部资源的管理要做到独立性。 由于嵌入式文件系统是作为嵌入式系统的一个可选加载项提供给用户的,当 用户针对其应用的特殊要求对嵌入式系统进行配置时没有选择加载文件系统,但 是用户还是需要使用到系统I/O。由于这种情况的出现就决定了嵌入式系统中的文件 系统不再具有I/O设备的管理功能。系统I/O的管理和使用接口的提供将由 I/O管理 模块完成,文件系统作为一个独立的自包含模块存在。 基于以上考虑,嵌入式文件系统的体系结构如图1所示。 1卩 硬件 图1嵌入式文件系统体系结构 在嵌入式文件系统的最上层是文件系统 API。文件系统的一切功能都是通过这一层提供给用户的。同时,在整个文件系统中也只有这一层对用户是可见的。 在这一层中所提供的所有功能接口都将严格的遵循 POSIX标准。 文件系统核心层是实现文件系统主要功能的模块。在这一层中,文件系统要把
用户的功能操作转化成对文件系统的抽象对象的操作。这些操作将通过下面的功能模块最终落实到物理介质上面。如果文件系统需要支持多种具体的文件系统格式的话,这一层还可以进一步细分成虚拟文件系统和逻辑文件系统。 块高速缓存的存在是为了提高文件系统的性能。在这一层中缓存着以前访问过的块设备数据。文件系统通过一定的算法来高效的管理这些数据,以提高缓冲的性能。同时,它的存在使下层的数据操作对上层的文件操作透明,提高了文件系统的模块性。 1.2 嵌入式文件系统体系的功能与特点 文件系统是操作系统的重要组成部分,用于控制对存储设备的存取。它提供对文件和目录的分层组织形式、数据缓冲(对于实时系统,允许绕过缓冲)以及对文件存取权限的控制。 嵌入式系统所使用的文件系统除了要提供通用文件系统的功能外,还由于嵌入式操作系统的特殊性而具有其自身的一些特点。嵌入式文件系统的设计应该满足如下目标: 1.实现按名存取。和桌面操作系统类似,用户对文件的操作是通过其“文件名”来完成的。因此,用户只需知道待操作文件的文件名,就可以方便的访问数据,而不必关心文件在物理设备上是如何存放的,以及如何对文件的打开、关闭操作进行处理等细节。所有与文件相关的管理工作都由文件系统组件隐式完成。 2.与实时系统相适应。嵌入式应用大多数都具有实时性需求。实时系统不仅 要求计算结果地准确无误,而且要求特定的指令要在限定的时间内完成,这就对文件系统提出了很高的要求。在通用操作系统中,往往采取分页和虚拟存储器管理的机制来满足规定的指令时间。然而嵌入式实时操作系统一般都不具有虚拟存储器管理机制,且各种外部设备的性能差异较大,控制文件系统的实时性变得非常困难。为了尽可能提高文件系统的实时性,除了选取高速存储介质作为嵌入式系统的外设外,还应该根据设备的特点设置一定大小的高速缓冲,以提高数据存取的相应速度。 3.支持多任务环境。面对日益复杂的计算环境,应用常常采取“分而治之” 的方法,将解决方案划分为多个任务,每个任务完成相对单一的功能。实时操作系统的设计目标之一就是对多任务的支持。从应用的层面上看,多任务可以对文件进行并发读操作,在实时内核进程间同步与通信机制支持下进行写操作。此外,文件系统内部实现也应该具备较好的可重入性,即利用同步机制对全局数据结构 进行必要的保护。 4.支持多种逻辑文件系统标准。随着操作系统技术的发展,出现了多种成熟的桌面文件系统标准,如 Windows下的FAT系列,Linux中的ext系列等。将这些成熟标
Dreamweaver里标签及属性详解
《》 Dreamweaver里标签及属性的详细解释 Dreamweaver标签库可以帮助我们轻松的找到所需的标签,并根据列出的属性参数使用它,常用的HTML标签和属性解释, 请搜索"常用的HTML标签和属性". 基本结构标签: ,表示该文件为HTML文件
,包含文件的标题,使用的脚本,样式定义等,换行标志
,分段标志 ,采用黑体字 ,采用斜体字
,水平画线
ext2文件系统
ext2文件系统 总体存储布局 我们知道,一个磁盘可以划分成多个分区,每个分区必须先用格式化工具(例如某种mkfs命令)格式化成某种格式的文件系统,然后才能存储文件,格式化的过程会在磁盘上写一些管理存储布局的信息。下图是一个磁盘分区格式化成ext2文件系统后的存储布局。 图 29.2. ext2文件系统的总体存储布局 文件系统中存储的最小单位是块(Block),一个块究竟多大是在格式化时确定的,例如mke2fs 的-b选项可以设定块大小为1024、2048或4096字节。而上图中启动块(Boot Block)的大小是确定的,就是1KB,启动块是由PC标准规定的,用来存储磁盘分区信息和启动信息,任何文件系统都不能使用启动块。启动块之后才是ext2文件系统的开始,ext2文件系统将整个分区划成若干个同样大小的块组(Block Group),每个块组都由以下部分组成。 超级块(Super Block) 描述整个分区的文件系统信息,例如块大小、文件系统版本号、上次mount的时间等等。超级块在每个块组的开头都有一份拷贝。 块组描述符表(GDT,Group Descriptor Table) 由很多块组描述符组成,整个分区分成多少个块组就对应有多少个块组描述符。每个块组描述符(Group Descriptor)存储一个块组的描述信息,例如在这个块组中从哪里开始是inode表,从哪里开始是数据块,空闲的inode和数据块还有多少个等等。和超级块类似,块组描述符表在每个块组的开头也都有一份拷贝,这些信息是非常重要的,一旦超级块意外损坏就会丢失整个分区的数据,一旦块组描述符意外损坏就会丢失整个块组的数据,因此它们都有多份拷贝。通常内核只用到第0个块组中的拷贝,当执行e2fsck检查文件系统一致性时,第0个块组中的超级块和块组描述符表就会拷贝到其它块组,这样当第0个块组的开头意外损坏时就可以用其它拷贝来恢复,从而减少损失。 块位图(Block Bitmap) 一个块组中的块是这样利用的:数据块(Data Block)存储所有文件的数据,比如某个分区的块大小是1024字节,某个文件是2049字节,那么就需要三个数据块来存,即使第三个块只存了一
Java class文件格式之属性详解
Java class文件格式之属性详解 Code属性 code属性是方法的一个最重要的属性。因为它里面存放的是方法的字节码指令,除此之外还存放了和操作数栈,局部变量相关的信息。所有不是抽象的方法,都必须在method_info中的attributes中有一个Code属性。下面是Code 属性的结构,为了更直观的展示Code属性和method_info的包含关系,特意画出了method_info: 下面依次介绍code属性中的各个部分。 attribute_name_index指向常量池中的一个CONSTANT_Utf8_info ,这个CONSTANT_Utf8_info 中存放的是当前属性的名字“Code” 。
attribute_length给出了当前Code属性的长度(不包括前六字节)。 max_stack指定当前方法被执行引擎执行的时候,在栈帧中需要分配的操作数栈的大小。 max_locals指定当前方法被执行引擎执行的时候,在栈帧中需要分配的局部表量表的大小。注意,这个数字并不是局部变量的个数,因为根据局部变量的作用域不同,在执行到一个局部变量以外时,下一个局部变量可以重用上一个局部变量的空间(每个局部变量在局部变量表中占用一个或两个Slot)。方法中的局部变量包括方法的参数,方法的默认参数this,方法体中定义的变量,catch语句中的异常对象。关于执行引擎的相关内容会在后面的博客中讲到。 code_length指定该方法的字节码的长度,class文件中每条字节码占一个字节。 code存放字节码指令本身,它的长度是code_length个字节。 exception_table_length指定异常表的大小 exception_table就是所谓的异常表,它是对方法体中try-catch_finally的描述。exception_table可以看做是一个数组,每个数组项是一个exception_info结构,一般来说每个catch块对应一个exception_info,编译器也可能会为当前方法生成一些exception_info。 exception_info的结构如下(为了直观的显示exception_info, exception_table和Code属性的关系,画出了Code属性,的话读者就会更清楚各个数据项之间的位置关系和包含关系):
ext2文件系统删除后的恢复
ext2文件系统下数据进行数据恢复 摘要 ext2文件系统下数据进行数据恢复 --------------------------------------------------------------------- 本系的 BBS 系统真是多灾多难 (嗯 .... 其实是因为我的疏忽,才会这么多灾多难 ....) ,继这几日系统时间不正确,造成许多人的 ID 被误砍后,又一次因系统设定上的问题,将 BBS 的重要备份档给杀了。这件事是学弟发现后告诉我的,当我上站来一见到他的mail, 当真是欲哭无泪,差点没去撞墙。 那时已是周六晚 11:00 左右,我一边想着要编一套说辞向大家解释无法替大家进行数据恢复旧信件与设定了,一边还在想是否能够挽回局面。大家知道, UNIX like 的系统是很难像 M$ 的系统一样,做到 undelete 的,所有网管前辈都曾再三警告我们,要小心! 小心! 砍档之前三思而后行,砍了之后再后悔也没用。虽然我已渐渐做到砍档三思而后行,但之次误砍事件是系统在背景中定时执行的,等到我找出原因时已是数据被砍后一个多小时。我凭着一点点的印象,想起在网络上,有人讨论过在 Linux ext2 filesystem中 undelete 的可能性,但我所见到的多半是负面的答案,但好象真的有人做过这件事,于是我第一个所做的,就是马上将该数据原来所在的 partition mount成 read-only, 禁止任何的写入动作,不是怕再有数据被误砍 (因为已没什么可砍的了) ,而是怕有新数据写进来,新资料可能会覆盖到旧资料原本存在的磁区 (block) 。我们现在唯一个指望,就是企图将数据原来存在的磁区一个个找回来,并且「希望」这些磁区上的旧资料都还在,然后将这些磁区串成一个数据。终于被我找到了!! 原来这方面的技术文件就存在我自己的系统中 :-)) /usr/doc/HOWTO/mini/Ext2fs-Undeletion.gz 于是我就按照这份文件的指示一步步来,总算将一个长达 8MB 的压缩档数据恢复了 99%, 还有一个长达 1.1 MB 的压缩档完整无缺地救了回来。感谢上帝、 Linux 的设计者、写那篇文件的作者、曾经讨论过此技术的人、以及 Linux 如此优秀的 ext2 filesystem, 让我有机会抢救过去。现在,我将我的抢救步骤做一个整理让大家参考,希望有派得上用场的时候 (喔! 不,最好是希望大家永远不要有机会用到以下的步数 :-))) 在此严正声明!! 写这篇文章的目的,是给那些处于万不得已情况下的人们,有一个挽回的机会,并不意味着从此我们就可以大意,砍档不需要三思。前面提到,我有一个数据无法100% 救回,事实上,长达 8MB 的数据能救回 99% 已是幸运中的幸运,一般的情况下若能救回 70% - 80% 已经要愉笑了。所以,不要指望 undelete 能救回一切。预防胜于治疗! 请大