编译原理实用教程(Tsu版电子教案)doc
第1章 编译系统概述
翻译系统(编译系统)、操作系统、数据库管理系统是计算机的三大系统软件。 1.1 程序设计语言的发展
机器语言汇编语言程序设计语言(高级语言)
例计算表达式3*16+2的值,实现该计算的机器语言程序、汇编语言程序和高级语言(C 语言)程序如下所示,该计算机的系统结构和汇编语言的使用方法详见本书第7章。
机器语言程序
汇编语言程序
高级语言程序
1.2 基本术语解释
㈠源语言和源程序 ㈡文本文件
㈢目标语言和目标程序 ㈣二进制文件 ㈤翻译程序
将源程序译成逻辑上等价的目标程序的程序,有二种翻译方式:编译和解释。 ①解释方式
以源程序作为输入,输入一句,解释执行一句,不产生完整的目标程序,相应的翻译程序称为解释程序,工作方式如下图所示:
解释、执行
源 解释程序 结 程 interpreter
果
序
输入数据
②编译方式
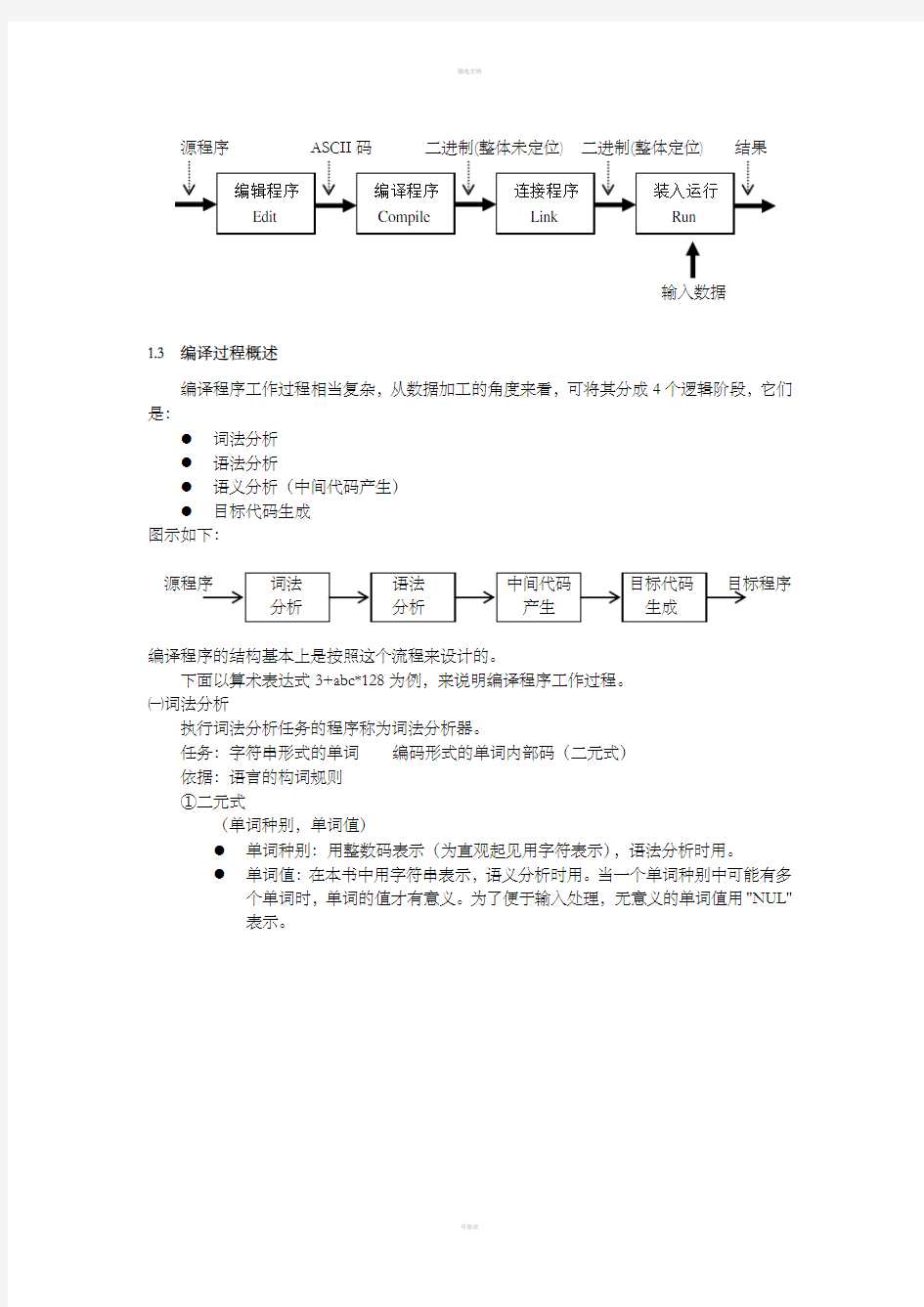
将源程序全部译为目标程序,该目标程序可在操作系统环境下直接执行,相应的翻译程序称为编译程序,工作方式如下图所示:
2203 //16进制 8210 2602 6101 1000 f000
Load R0,3
Mul R0,10 //10表示16 Load R1,2 Add R0,R1 Write R0 Halt
void main(void) //C 语言 {
cout<<3*16+2; }
输入数据
1.3 编译过程概述
编译程序工作过程相当复杂,从数据加工的角度来看,可将其分成4个逻辑阶段,它们
是:
● 词法分析 ● 语法分析
● 语义分析(中间代码产生) ● 目标代码生成 图示如下: 源程序 词法
语法 中间代码 目标代码 目标程序
分析
分析
产生
生成
编译程序的结构基本上是按照这个流程来设计的。
下面以算术表达式3+abc*128为例,来说明编译程序工作过程。 ㈠词法分析
执行词法分析任务的程序称为词法分析器。
任务:字符串形式的单词 编码形式的单词内部码(二元式) 依据:语言的构词规则 ①二元式
(单词种别,单词值)
● 单词种别:用整数码表示(为直观起见用字符表示),语法分析时用。
● 单词值:在本书中用字符串表示,语义分析时用。当一个单词种别中可能有多
个单词时,单词的值才有意义。为了便于输入处理,无意义的单词值用"NUL"表示。
编辑程序 Edit 编译程序 Compile 连接程序 Link 装入运行 Run
②二元式编码
('x',"3") ('+',"NUL") ('i',"abc") ('*', "NUL") ('x',"128")
㈡语法分析
执行语法分析任务的程序称为语法分析器。
任务:检查源程序的语法结构是否正确
依据:语言的语法规则
在语法分析时,算术表达式3+abc*128的语法结构应表示为x+i*x,语法分析器最终应识别出这是一个算术表达式,识别过程相当于建立一棵语法树。
<算术表达式>
<> + <项>
<项> <项* <>
<因子> <因子> x(整常数)
x(整常数)i(标识符)
㈢语义分析
执行语义分析任务的程序称为语义分析器或中间代码产生器。
任务:建立符号表和常数表,记录源程序中标识符属性和常数值,根据语言的语义规定生成中间代码。
依据:语言的语义内涵
语义分析(中间代码产生)主要工作为:语义正确性检查和语义翻译。
①语义正确性检查
例:
begin
real a;
integer a;
…………
end
语法正确,语义错误,除非语言允许变量性质可动态修改。
②语义翻译
1)说明语句的翻译
将标识符及其属性填入符号表。
2)执行语句的翻译
根据不同语句的语义,生成逻辑上等价的中间代码。
●中间代码
结构简单、意义明确的记号系统,非常接近机器指令,但又独立于具体机器。常用的中间代码有三元式和四元式。
表达式3+abc*128可译成如下四元式:
(*,&abc,&128,&T1)
(+,&3,&T1,&T2)
其中,&abc表示标识符abc在符号表中入口;T1和T2是在翻译过程中由编译程序引入的临时变量;而&128表示常数128在常数表中的地址。
●符号表
符号表用于记录源程序中出现的标识符,一个标识符往往具有一系列的语义值,它包括标识符的名称、标识符的种属、标识符的类型、标识符值的存放地址等等。每个标识符在符号表中有一项记录,用于记录标识符的各种语义值,而在四元式中填写的是标
内存地址符号名种属类型…………
未分配abc简单变量整型…………
未分配T1简单变量整型…………
未分配T2简单变量整型…………
●
常数表用于记录在源程序中出现的常数。假定,每个整常数在常数表中占2个字节,每个实常数在常数表中占4个字节。常数表的结构示意如下:
常数的二进制值
00000000-00000011(3)
00000000-01000000(128)
㈣目标代码生成
执行目标代码生成的程序称为目标代码生成器。
任务:中间代码目标代码(机器指令或汇编语言)
依据:目标机器的系统结构
上述算术表达式最终形成的汇编语言程序示意如下:
Load R0,abc
Mul R0,128
Store R0,T1
Load R0,3
Add R0,T1
Store R0,T2
1.4 出错处理
编译程序在工作过程中可发现源程序中各种错误,错误类型及对策简述如下:
㈠错误类型
●词法错误
●语法错误
●语义错误
㈡出错处理
●一旦发现错误,暂停编译程序工作,指出错误的地点和类型。
●在发现错误后,不中断编译程序工作。采取某些措施(例错误局部化),使得
源程序的编译工作可继续下去,尽可能发现源程序中比较多的错误。
1.5 编译程序的前端和后段
㈠编译程序前端
组成:词法分析器、语法分析器和中间代码产生器
特点:依赖于被编译的源语言,输出结果用中间代码描述,和目标机器无关。
㈡编译程序后端
组成:目标代码生成器
特点:和源语言无关,以中间代码形式的源程序为输入进行处理,输出结果依赖于目标机器。
1.6 编译程序的实现方式
㈠用机器指令或汇编语言手工编写
㈡用高级语言手工编写
㈢自编译方式
㈣自动构造
①词法分析器的自动构造
输入词法规则,编译结果为词法分析器,例LEX系统。
②语法分析器的自动构造
输入语法规则,编译结果为语法分析器,例YACC系统。
第2章词法分析
词法分析任务
2.1 词法分析器的设计考虑及手工构造
2.1.1 单词类型及二元式编码
㈠单词类型
基本字、标识符、常数、运算符、界符
㈡单词的性质
●个数确定和不确定
●单字符或多字符构成
㈢单词二元式编码
经词法分析后,单词用二元式(code,val) 表示。
●code表示单词的种别,用整数码表示,在语法分析时使用。
●val表示单词的值,在本书中用字符串表示,在语义分析时使用。
㈣编码原则
通常将标识符归为一种,常数按类型分种,基本字、运算符及界符采用一符一种。㈤实例
Begin/*S=2*3.14* R* R +2*3.14* R*H */
Real r,h,s;
s=2*3.14*r*(r+h)
End
根据单词二元式编码,上述程序的单词二元式序列应为:
('{',"NUL")
('c',"NUL")
('i',"r")
(',',"NUL")
('i',"h")
(',',"NUL")
('i', "s")
(';',"NUL")
('i', "s")
('=',"NUL")
('x', "2")
('*',"NUL")
('y', "3.14")
('*',"NUL")
('i', "r")
('*',"NUL")
('(',"NUL")
('i', "r")
('+',"NUL")
('i', "h")
(')',"NUL")
('}',"NUL")
2.1.2 源程序的输入及预处理
㈠源程序的输入
●分段读入处理(早期)
●全部读入后处理
设源程序如下所示,其中'\'为续行符。
B e g i n/*S=2*3.14*R*R+2*3 .14*R*H*/\n\t R e a l r,h,s;\n \t s=2*3.\\n14*r*(r+h)\n E n d
\n\0\0…\0
㈡预处理
词法分析器通常由二个部分构成:
预处理程序
扫描器(单词识别程序)
①分成二部分的理由
②预处理主要工作
b e g i n r e a l r,h,s;s=
2*3.14*r*(r+h)e n d\0...\0
㈢预处理程序例
2.1.3 基本字的识别和超前搜索
程序设计语言单词以基本字识别最为困难,原因如下:
①有些语言对基本字不加保护,用户可用作普通标识符。
②基本字、用户定义的标识符和常数之间没有分隔符。
解决办法:
①所有基本字均为保留字(Reserved word),用户不得使用它们作为标识符。
②将空格、TAB和换行符视为界符。在基本字、用户定义的标识符和常数之间,若没有运算符或界符,则至少用一个空格(或TAB、换行符)加以分隔。
2.1.4 遍
㈠遍的基本概念
㈡遍引入的历史背景
㈢遍和编译程序的结构
2.1.5 状态转换图和词法分析器的手工构造
㈠引入状态转换图的必要性
㈡状态转换图基本概念及应用
例1,识别标识符的状态转换图如下所示:
字母数字
空格
①非字母数字*
例2,识别实常数和整常数的状态转换图如下所示:
空格数字数字
数字③小数点④非数字*
非数字非小数点
小数点* 数字
⑦数字⑧非数字*
非数字
×(出错)
例3,识别"#"、"+"和"++"的状态转换图。
空格
+ ⑩+
# 非+
*
㈢利用状态转换图识别单词
状态转换图每次只能识别一个单词,若源程序中有N个单词,则需使用状态转换图N次。设源程序为"x+++y#"('#'是预处理程序添加的),单词识别程序(扫描器)共使用状态转换图5次。
1)从初态0出发,读入'x'进入状态1,在状态1读入'+',进入终态2,识别出标识符
"x",退回'+';
2)从初态0出发,读入'+'进入状态10,在状态10读入'+',进入终态11,识别出运算
符"++";
3)从初态0出发,读入'+'进入状态10,在状态10读入'y',进入终态12,识别出运算
符"+",退回'y';
4)从初态0出发,读入'y'进入状态1,在状态1读入'#',进入终态2,识别出标识符
"y",退回'#';
5)从初态0出发,读入'#'进入状态13,识别出单词"#",识别出单词"#"意味着整个
源程序中字符处理完毕。
㈣根据状态转换图编制程序
2.2 正规式、自动机及词法分析器的自动生成
2.2.1 基本概念
㈠有穷字母表∑
符号有限集,它的每个元素称为字符。
㈡字(字符串)
∑上字符所构成的有限序列。
①空字
②∑*
③(集合的)积运算
④(集合的)闭包
⑤(集合的)正则闭包
2.2.2 正规式与正规集
㈠正规式和正规集的定义:
●ε和Φ是∑上的正规式,相应的正规集为{ε}、{}。
●若a∈∑,则a是正规式,相应正规集为{a}。
●若α、β为正规式,相应正规集分别记为L(α)和L(β),则α|β是正规式,其相应正
规集记为L(α|β),且令L(α|β)=L(α)∪L(β)。
●若α、β为正规式,相应正规集分别记为L(α)和L(β),则αβ(或α·β)是正规式,其
相应正规集记为L(αβ),且令L(αβ)=L(α)L(β)。正规式α自身的n次积αα…α是正规
式,记为αn,其相应正规集记为L(αn),显然L(αn)= L(α) n。
●若α为正规式,相应正规集记为L(α),则α*= α0|α1|α2|……|αn是正规式,规定α0 =
ε,其相应正规集记为L(α*),且令L(α*) =L(α) *。
●*·︱,可用园括号改变运算顺序。
㈡正规式相等原理
二个正规式是相等的,当且仅当二个正规式所表示的正规集是相等的。
㈢正规式满足下列关系
①交换律:α|β = β|α
②结合律:α|(β|γ) = (α|β)|γ,α(βγ) = (αβ) γ
③分配律:α(β|γ) = αβ|αγ,(β|γ)α = βα|γα
④εα = αε= α
2.2.3 确定有限自动机(DFA)
㈠DFA定义
一个确定有限自动机M是一个五元式
M = ( S,Σ,f,s0,Z )
●S是一个有限集,它的每一个元素称为状态。
●Σ是一个有穷字母表,它的每个元素称为一个输入字符。
●f是一个从S×Σ至S的映照,即,
f:S×Σ→S(单值函数)
例f (s i,a) = s j,表示当现行状态为s i,若输入字符为a,则转移到下一状态s j,s j称为s i的后继状态。
●s0∈S,是唯一的一个初态。
●Z S,是一个终态集。
㈡状态转换矩阵
㈢DFA M可用一个(确定的)状态转换图表示
㈣字α可为DFA M识别
2.2.4 非确定有限自动机(NFA)
㈠定义
一个非确定的有限自动机M是一个五元式
M=(S,Σ,f,S0,Z)
●S是一个有限集,它的每一个元素称为状态。
●Σ是一个有穷字母表,它的每个元素称为一个输入字符。
●f是一个从S×Σ*到S的子集映照,即,
f:S×Σ*→2S(多值函数)
2S表示幂集,若S={0,1},则2S ={{},{0},{1},{0,1}}。
●S0S,是一个非空初态集,即NFA的初态不一定唯一。
●Z S,是一个终态集。
㈡NFA M可用一个(非确定的)状态转换图表示
㈢字α可为NFA M识别
㈣DFA是NFA的特例
2.2.5正规式与确定有限自动机的等价性
对于Σ上的每个正规式V,存在一个Σ上的确定有限自动机M,便得L(V)=L(M)。
㈠V NFA
①将V表示成拓广NFA
②根据三条规则对V进行分裂,直至每条弧上的标记为Σ上的一个字符或ε。
㈡NFA DFA
①I的ε闭包
②I a
③NFA确定化算法
2.3 词法分析器的自动生成
输入正规式(构词规则),经自动生成器加工,其结果为DFA。
词法分析器
输入的输出
(正规式) 自动生成器(DFA)
㈠自动生成过程概述
①构造描述每个单词的正规式P i(1≤i≤N)。
②根据正规式P i构造NFA M i(1≤i≤N),假定初态均为0。在构造NFA M i的同时,逐步并且最终形成识别全部单词的NFA M。
③NFA M确定化
④重新标记,构造DFA M'。
㈡实例
㈢扫描器控制程序工作原理
第3章程序设计语言的语法描述
文法:对语言结构的定义和描述。
3.1 文法的引入
先讨论自然语言的文法。例:the big elephent ate a banana
㈠语法树
根据英语的语法,上述句子的语法结构可用图(语法树)表示如下:
<句子>
<> 谓语>
<冠词> <形容词> <名词> <动词> <直接宾语>
the big elephant ate <冠词> <名词>
a banana
①非叶结点称为语法单位,在形式语言中称为非终结符。
②处于根结点位置的结点又称为开始符号。
③叶结点称为单词符号,在形式语言中称为终结符。
㈡规则
可以通过建立一组规则,来描述上述句子的语法结构,规则在形式语言中称为产生式。上述英文句子可用下述规则来描述:
1.<句子>→<主语><谓语>
2.<主语>→<冠词><形容词><名词>
3.<冠词>→the| a
4.<形容词>→big
5.<名词>→elephant| banana
6.<谓语>→<动词><直接宾语>
7.<直接宾语>→<冠词><名词>
8.<动词>→ate
㈢由规则推导句子
可用规则来推导出句子。从开始符号出发,若能从规则推导出某符号串,则该符号串就是该文法的合法的句子,反之语法错误。
<句子><主语><谓语>
<冠词><形容词><名词><谓语>
the <形容词><名词><谓语>
the big <名词><谓语>
the big elephant <谓语>
the big elephant <动词><直接宾语>
the big elephant ate <直接宾语>
the big elephant ate <冠词><名词>
the big elephant ate a <名词>
the big elephant ate a banana
上述推导可简单表示为:
<句子>the big elephant ate a banana。
值得注意的是用上述规则可推导出多个句子,因存在推导
<句子>the big banana ate an elephant
故the big banana ate an elephant也是文法的一个合法的句子。但意义是荒谬的,也就是说句子的语义是错误的。
一个语法正确的句子不能保证其语义是正确的,故一个句子是否正确,需要进行语法和语义两方面检查。
㈣递归规则和递归文法
①递归定义
②递归规则(直接递归)
③间接递归
④递归文法
利用递归文法我们可以用有穷的规则来描述无穷的语言,这不但解决了语言的定义问题,而且使得对语言的语法检查成为可能。
例:定义无符号整数。
①不采用递归规则,描述无符号整数全体就要使用无穷多条的规则。
<无符号整数>→<数字>|<数字><数字>|<数字><数字><数字>|…
<数字>→0|1|2|3|4|5|6|7|8|9|0
②采用递归规则,描述无符号整数全体仅需12条规则。
<无符号整数>→<无符号整数><数字>|<数字> N→ND|D
<数字>→0|1|2|3|4|5|6|7|8|9|0 D→0|1|2|3|4|5|6|7|8|9|0例1:无符号整数1
N D1
例2:无符号整数23
N ND DD2D23
例3:无符号整数456
N ND NDD DDD4DD45D456
3.2 上下文无关文法
形式语言的奠基人乔姆斯基将文法分为4种类型,它们是:
●短语文法(0型文法)
●上下文有关文法(1型文法)
●上下文无关文法(2型文法)
●正规文法(3型文法)
这四种文法在形式语言中都有严格的定义。但对于程序设计语言来说,上下文无关文法已经够用了,上下文无关文法有足够的能力描述大多数现今使用的程序设计语言的语法结构。以后,“文法”一词若无特别说明,则指“上下文无关文法”。
㈠文法和语言
一个文法G是一个四元式(V T,V N,S,V P),其中
●V T是一个终结符的非空有限集,终结符通常用小写字母表示。
●V N是一个非终结符的非空有限集,非终结符通常用大写字母表示。
●S是一个特殊的非终结符(S∈V N),称为开始符号。
●V P是一个产生式(规则)的有限集合,每个产生式的形式是A→α,其中A∈V N,
α∈(V T∪V N)*。
例:
G=(V T,V N,S,V P)
V T={+,*,(,),i}
V N={E}
S=E
V P={E→E+E,E→E*E,E→(E),E→i }
可简记为:
G:E→E+E|E*E| (E)|i
根据上述文法,可推导出任何仅包含加乘的算术表达式。
㈡基本术语
①直接推出和直接归约
②推导和归约
③句型
④句子
⑤语言
⑥等价文法
⑦最左推导和最右推导
㈢文法的二义性
①语法树
我们可以用一个有向图表示一个句型的推导,这种表示称为语法树。
在一般情况下,某一句型不论其推导过程如何,其最终形成的语法树是相同的,故语法树是不同推导过程的共性抽象。若仅进行最左(右)推导,则语法树和最左(右)推导等价。
②二义文法
某些文法的句型的推导可能对应一棵以上的语法树,或存在一个以上的最左(右)推导。
例:已知文法G:E→E+E|E*E|(E)|i和句子i+i*i,该句子存在二个最左(右)推导,即二棵语法树。
语法树1(先形成+后形成*)
E
E + E
* E i
i i
语法树2(先形成*后形成+)
E
E * E
i E + E
i i
句子i+i*i的二个最左推导序列:
E E+E i+E i+E*E i+i*E i+i*i
E E*E E+E*E i+E*E i+i*E i+i*i
句子i+i*i的二个最右推导序列:
E E+E E+E*E E+E*i E+i*i i+i*i
E E*E E*i E+E*i E+i*i i+i*i
二义文法:若一个文法所产生的语言中,只要存在一个句子,它有二个最左推导,或有二个最右推导,或句子的推导对应两棵语法树,则称该文法为二义文法。
③二义文法的利用和处理
●根据条件修改文法,语言不变。
●根据条件修改编译程序的某一部分,文法保持不变(详见第四、五章)。
编译原理课程设计
《编译原理》课程设计大纲 课程编号: 课程名称:编译原理/Compiler Principles 周数/学分:1周/1学分 先修课程:高级程序设计语言、汇编语言、离散数学、数据结构 适用专业:计算机科学与技术专业、软件工程专业 开课学院,系或教研室:计算机科学与技术学院 一、课程设计的目的 课程设计是对学生的一种全面综合训练,是与课堂听讲、自学和练习相辅相成的必不可少的一个教学环节。通常,设计题中的问题比平时的练习题要复杂,也更接近实际。编译原理这门课程安排的课程设计的目的是旨在要求学生进一步巩固课堂上所学的理论知识,深化理解和灵活掌握教学内容,选择合适的数据逻辑结构表示问题,然后编制算法和程序完成设计要求,从而进一步培养学生独立思考问题、分析问题、解决实际问题的动手能力。 要求学生在上机前应认真做好各种准备工作,熟悉机器的操作系统和语言的集成环境,独立完成算法编制和程序代码的编写。 设计时间: 开发工具: (1) DOS环境下使用Turbo C; (2) Windows环境下使用Visual C++ 。 (3) 其它熟悉语言。 二、课程设计的内容和要求 设计题一:算术表达式的语法分析及语义分析程序设计。 1.目的
通过设计、编制、调试一个算术表达式的语法及语义分析程序,加深对语法及语义分析原理的理解,并实现词法分析程序对单词序列的词 法检查和分析。 2.设计内容及要求: 算术表达式的文法: 〈无符号整数〉∷= 〈数字〉{〈数字〉} 〈标志符〉∷= 〈字母〉{〈字母〉|〈数字〉} 〈表达式〉∷= [+|-]〈项〉{〈加法运算符〉〈项〉} 〈项〉∷= 〈因子〉{〈乘法运算符〉〈因子〉} 〈因子〉∷= 〈标志符〉|〈无符号整数〉|‘(’〈表达式〉‘)’ 〈加法运算符〉∷= +|- 〈乘法运算符〉∷= *|/ (1) 分别选择递归下降法、算符优先分析法(或简单优 先法)完成以上任务,中间代码选用逆波兰式。 (2) 分别选择LL(1)、LR法完成以上任务,中间代码选 用四元式。 (3) 写出算术表达式的符合分析方法要求的文法,给出 分析方法的思想,完成分析程序设计。 (4) 编制好分析程序后,设计若干用例,上机测试并通 过所设计的分析程序。 设计题二:简单计算器的设计 1.目的 通过设计、编制、调试一个简单计算器程序,加深对语法及语 义分析原理的理解,并实现词法分析程序对单词序列的词法检 查和分析。 2.设计内容及要求 算术表达式的文法:
编译原理(清华大学第2版)课后习题答案
第三章 N=>D=> {0,1,2,3,4,5,6,7,8,9} N=>ND=>NDD L={a |a(0|1|3..|9)n且 n>=1} (0|1|3..|9)n且 n>=1 {ab,} a n b n n>=1 第6题. (1) <表达式> => <项> => <因子> => i (2) <表达式> => <项> => <因子> => (<表达式>) => (<项>) => (<因子>)=>(i) (3) <表达式> => <项> => <项>*<因子> => <因子>*<因子> =i*i (4) <表达式> => <表达式> + <项> => <项>+<项> => <项>*<因子>+<项> => <因子>*<因子>+<项> => <因子>*<因子>+<因子> = i*i+i (5) <表达式> => <表达式>+<项>=><项>+<项> => <因子>+<项>=i+<项> => i+<因子> => i+(<表达式>) => i+(<表达式>+<项>) => i+(<因子>+<因子>) => i+(i+i) (6) <表达式> => <表达式>+<项> => <项>+<项> => <因子>+<项> => i+<项> => i+<项>*<因子> => i+<因子>*<因子> = i+i*i 第7题
第9题 语法树 s s s* s s+a a a 推导: S=>SS*=>SS+S*=>aa+a* 11. 推导:E=>E+T=>E+T*F 语法树: E +T * 短语: T*F E+T*F 直接短语: T*F 句柄: T*F 12.
北京邮电大学《编译原理与技术》课程教学大纲
《编译原理与技术》课程教学大纲 一、课程编号:1311020 二、课程名称:编译原理与技术(64学时) Compiler Principle and Technology 三、课程教学目的 通过本课程的学习,使学生了解并掌握程序设计语言的编译程序的设计原理与实现技术,了解编译程序的构造方法;加深学生对高级程序设计语言的理解,做到触类旁通;使学生体会到其他专业基础知识如算法与数据结构、程序设计、操作系统、形式语言与自动机、计算机组成原理、汇编语言、软件工程等综合应用,对计算机的软硬件工作原理建立比较深刻的理解,提高学生的专业素养,使学生能够利用所学的理论知识解决实际问题,培养学生分析问题、解决问题的能力。 四、课程教学基本要求 1.了解编译的基本概念和步骤,编译程序的基本组成、结构、编译环境等基本概念。 2.掌握词法分析的原理、词法分析程序的设计和实现方法。 3.掌握语法分析的原理和实现技术、简单的语法分析程序的设计和实现。 4.掌握语法制导翻译技术。 5.理解利用语法制导翻译技术进行语义分析、中间代码生成的实现。 6.理解程序运行环境、代码生成相关的基本概念和实现方法。 7.了解代码优化技术的基本概念和方法。 五、教学内容及学时分配(含实验) 第一章编译概述2学时 1.翻译和解释 2.编译的阶段 3.编译程序的前后处理器(预处理器、汇编程序、连接装配程序)第二章词法分析4学时 1.词法分析器的作用 2.词法分析器的输入与输出 3.记号的描述与识别 4.词法分析程序的设计与实现 5*.软件工具LEX(规格说明、工作原理)
1.语法分析器的作用 2.自顶向下分析(预测分析器、非递归的预测分析器) 3.自底向上分析(规范归约、移进-归约方法实现) 4.LR分析器(模型及工作过程、SLR(1)分析器、LR(1)分析器、LALR(1)分析器)5.LR分析方法对二义文法的应用 6*.软件工具YACC (规格说明、二义性处理) 第四章语法制导翻译技术8学时 1.语法制导定义与翻译方案 2.S属性定义的自底向上翻译 3.L属性的自顶向下翻译 4.L属性的自底向上翻译 第五章语义分析4学时 1.语义分析的概念 2.符号表的组织与管理 3.类型检查(类型表达式、类型等价) 4.简单类型检查器的说明(语言说明、确定标识符的类型、表达式及语句的类型检查) 5*.类型检查有关的其他主题(函数和运算符的重载、类型转换、多态函数) 第六章运行环境6学时 1.程序运行时的存储组织 2.存储分配策略(静态存储分配、栈式存储分配、堆式存储分配) 3.访问非局部名字 4.参数传递方式 第七章中间代码生成6学时 1.中间代码形式 2.赋值语句的翻译 3.布尔表达式的翻译 4.控制语句的翻译 5.过程调用语句的翻译
编译原理教程课西安电子科大出版社第三版后习题答案——第二章
第二章 词法分析 2.1 完成下列选择题: (1) 词法分析器的输出结果是 。 a. 单词的种别编码 b. 单词在符号表中的位置 c. 单词的种别编码和自身值 d. 单词自身值 (2) 正规式M1和M2等价是指 。 a. M1和M2的状态数相等 b. M1和M2的有向边条数相等 c. M1和M2所识别的语言集相等 d. M1和M2状态数和有向边条数相等 (3) DFA M(见图2-1)接受的字集为 。 a. 以0开头的二进制数组成的集合 b. 以0结尾的二进制数组成的集合 c. 含奇数个0的二进制数组成的集合 d. 含偶数个0的二进制数组成的集合 【解答】 (1) c (2) c (3) d 图2-1 习题2.1的DFA M 2.2 什么是扫描器?扫描器的功能是什么? 【解答】 扫描器就是词法分析器,它接受输入的源程序,对源程序进行词法分析并识别出一个个单词符号,其输出结果是单词符号,供语法分析器使用。通常是把词法分析器作为一个子程序,每当词法分析器需要一个单词符号时就调用这个子程序。每次调用时,词法分析器就从输入串中识别出一个单词符号交给语法分析器。 2.3 设M=({x,y}, {a,b}, f, x, {y})为一非确定的有限自动机,其中f 定义如下: f(x,a)={x,y} f{x,b}={y} f(y,a)=Φ f{y,b}={x,y} 试构造相应的确定有限自动机M ′。 【解答】 对照自动机的定义M=(S,Σ,f,So,Z),由f 的定义可知f(x,a)、f(y,b)均为多值函数,因此M 是一非确定有限自动机。 先画出NFA M 相应的状态图,如图2-2所示。 图2-2 习题2.3的NFA M 用子集法构造状态转换矩阵,如表 表2-1 状态转换矩阵 1b a
编译原理课程设计报告_LL(1)分析过程模拟
课程设计(论文)任务书 软件学院学院软件工程专业07-1班 一、课程设计(论文)题目LL(1)分析过程模拟 二、课程设计(论文)工作自 2010 年 6 月 22日起至 2010 年 6月 28 日止。 三、课程设计(论文) 地点: 四、课程设计(论文)内容要求: 1.本课程设计的目的 (1)使学生掌握LL(1)模块的基本工作原理; (2)培养学生基本掌握LL(1)分析的基本思路和方法; (3)使学生掌握LL(1)的调试; (4)培养学生分析、解决问题的能力; (5)提高学生的科技论文写作能力。 2.课程设计的任务及要求 1)基本要求: (1)分析LL(1)模块的工作原理; (2)提出程序的设计方案; (3)对所设计程序进行调试。 2)创新要求: 在基本要求达到后,可进行创新设计,如改算法效率。 3)课程设计论文编写要求 (1)要按照书稿的规格打印誊写课程设计论文 (2)论文包括目录、绪论、正文、小结、参考文献、附录等 (3)课程设计论文装订按学校的统一要求完成 4)答辩与评分标准: (1)完成原理分析:20分; (2)完成设计过程(含翻译):40分; (3)完成调试:20分;
(4)回答问题:20分。 5)参考文献: (1)张素琴,吕映芝,蒋维杜,戴桂兰.编译原理(第2版).清华大学出版社 (2)丁振凡.《Java语言实用教程》北京邮电大学出版社 6)课程设计进度安排 内容天数地点 构思及收集资料2图书馆 编程与调试4实验室 撰写论文1图书馆、实验室 学生签名: 2009 年6 月22 日 课程设计(论文)评审意见 (1)完成原理分析(20分):优()、良()、中()、一般()、差();(2)设计分析(20分):优()、良()、中()、一般()、差();(3)完成调试(20分):优()、良()、中()、一般()、差();(4)翻译能力(20分):优()、良()、中()、一般()、差();(5)回答问题(20分):优()、良()、中()、一般()、差();(6)格式规范性及考勤是否降等级:是()、否() 评阅人:职称: 年月日
编译原理_第三版_课后答案
编译 原理 课后题答案 第二章 P36-6 (1) L G ()1是0~9组成的数字串 (2) 最左推导: N ND NDD NDDD DDDD DDD DD D N ND DD D N ND NDD DDD DD D ??????????????????0010120127334 556568 最右推导: N ND N ND N ND N D N ND N D N ND N ND N D ??????????????????77272712712701274434 886868568 P36-7 G(S) O N O D N S O AO A AD N →→→→→1357924680||||||||||| P36-8 文法: E T E T E T T F T F T F F E i →+-→→|||*|/()| 最左推导: E E T T T F T i T i T F i F F i i F i i i E T T F F F i F i E i E T i T T i F T i i T i i F i i i ?+?+?+?+?+?+?+?+??????+?+?+?+?+?+********()*()*()*()*()*()*() 最右推导:
E E T E T F E T i E F i E i i T i i F i i i i i E T F T F F F E F E T F E F F E i F T i F F i F i i i i i ?+?+?+?+?+?+?+?+?????+?+?+?+?+?+?+**********()*()*()*()*()*()*()*() 语法树:/******************************** E E F T E + T F F T +i i i E E F T E -T F F T -i i i E E F T +T F F T i i i *i+i+i i-i-i i+i*i *****************/ P36-9 句子iiiei 有两个语法树: S iSeS iSei iiSei iiiei S iS iiSeS iiSei iiiei ???????? P36-10 /************** ) (|)(|S T T TS S →→ ***************/ P36-11 /*************** L1: ε ||cC C ab aAb A AC S →→→ L2:
编译原理结课论文
目录
1.绪论 概述 “编译原理”是一门研究设计和构造编译程序原理课程,是计算机各专业的一门重要的专业课。编译原理这门课程蕴含着计算机学科中解决问题的思路和解决问题的方法,对应用软件和系统软件的设计与开发有一定的启发和指导作用。“编译原理”是一门实践性很强的课程,要掌握这门课程中的思想,就必须要把所学到的知识应用于实践当中。而课程设计是将理论与实践相互联系的一种重要方式。 设计目的 课程设计是对学生的一种全面综合素质训练,是与课堂听讲、自学和练习相辅相成的必不可少的一个教学环节。通常,设计题中的问题比平时的练习题要复杂很多,但也更接近实际。编译原理这门课程安排的课程设计的目的是旨在要求学生进一步巩固课堂上所学的理论知识,深化理解和灵活掌握教学内容,选择合适的数据逻辑结构解决问题,然后编制算法和程序完成设计要求,从而进一步培养学生独立思考问题、分析问题、解决实际问题的能力。 设计题目及要求 基于这个学期所学习的内容以及自己所掌握到的知识,本次我所要设计的题目是赋值语句的四元式生成。
要求: (1)设计语法制导生成赋值语句的四元式的算法; (2)编写代码并上机调试运行通过; (3)输入一赋值语句; (4)输出相应的表达式的四元式; 2.背景知识 语法制导翻译方法 语法制导翻译的方法就是为每个产生式配上一个翻译子程序(称语义动作或语义子程序),并在语法分析的同时执行这些子程序。语义动作是为产生式赋予具体意义的手段,它一方面指出了一个产生式所产生的符号串的意义,另一方面又按照这种意义规定了生成某种中间代码应做哪些基本动作。在语法分析的过程中,当一个产生式获得匹配(对于自顶向下分析)或用于规约(对于自底向上分析)时,此产生式相应的语义子程序就进入工作,完成既定的翻译任务。语法制导翻译分为自底向上语法制导翻译和自顶向下语法制导翻译。 属性文法 属性文法是编译技术中用来说明程序语言语义的工具,也是当前实际应用中比较流行的一种语义描述方法。属性是指与文法符号的类型和值等有关的一些信息,在编译中用属性描述处理对象的特征。属性文法是一种
编译原理课程设计报告(一个完整的编译器)
编译原理程序设计报告 一个简单文法的编译器的设计与实现专业班级:计算机1406班 组长姓名:宋世波 组长学号: 20143753 指导教师:肖桐 2016年12月
设计分工 组长学号及姓名:宋世波20143753 分工:文法及数据结构设计 词法分析 语法分析(LL1) 基于DAG的中间代码优化 部分目标代码生成 组员1学号及姓名:黄润华20143740 分工:中间代码生成(LR0) 部分目标代码生成 组员2学号及姓名:孙何奇20143754 分工:符号表组织 部分目标代码生成
摘要 编译器是将便于人编写,阅读,维护的高级计算机语言翻译为计算机能解读、运行的低阶机器语言的程序。编译是从源代码(通常为高阶语言)到能直接被计算机或虚拟机执行的目标代码(通常为低阶语言或机器语言)的翻译过程。 一.编译器的概述 1.编译器的概念 编译器是将便于人编写,阅读,维护的高级计算机语言翻译为计算机能解读、运行的低阶机器语言的程序。编译器将原始程序作为输入,翻译产生使用目标语言的等价程序。源代码一般为高阶语言如Pascal、C++、Java 等,而目标语言则是汇编语言或目标机器的目标代码,有时也称作机器代码。 2.编译器的种类 编译器可以生成用来在与编译器本身所在的计算机和操作系统(平台)相同的环境下运行的目标代码,这种编译器又叫做“本地”编译器。另外,编译器也可以生成用来在其它平台上运行的目标代码,这种编译器又叫做交叉编译器。交叉编译器在生成新的硬件平台时非常有用。“源码到源码编译器”是指用一种高阶语言作为输入,输出也是高阶语言的编译器。例如: 自动并行化编译器经常采用一种高阶语言作为输入,转换其中的代码,并用并行代码注释对它进行注释(如OpenMP)或者用语
编译原理教程课后习题答案——第四章
第四章语义分析和中间代码生成 4.1 完成下列选择题: (1) 四元式之间的联系是通过实现的。 a. 指示器 b. 临时变量 c. 符号表 d. 程序变量 (2) 间接三元式表示法的优点为。 a. 采用间接码表,便于优化处理 b. 节省存储空间,不便于表的修改 c. 便于优化处理,节省存储空间 d. 节省存储空间,不便于优化处理 (3) 表达式(┐A∨B)∧(C∨D)的逆波兰表示为。 a. ┐AB∨∧CD∨ b. A┐B∨CD∨∧ c. AB∨┐CD∨∧ d. A┐B∨∧CD∨ (4) 有一语法制导翻译如下所示: S→bAb {print″1″} A→(B {print″2″} A→a {print″3″} B→Aa) {print″4″} 若输入序列为b(((aa)a)a)b,且采用自下而上的分析方法,则输出序列为。a. 32224441 b. 34242421 c. 12424243 d. 34442212 【解答】 (1) b (2) a (3) b (4) b 4.2 何谓“语法制导翻译”?试给出用语法制导翻译生成中间代码的要点,并用一简例予以说明。 【解答】语法制导翻译(SDTS)直观上说就是为每个产生式配上一个翻译子程序(称语义动作或语义子程序),并且在语法分析的同时执行这些子程序。也即在语法分析过程中,当一个产生式获得匹配(对于自上而下分析)或用于归约(对于自下而上分析)时,此产生式相应的语义子程序进入工作,完成既定的翻译任务。 用语法制导翻译(SDTS)生成中间代码的要点如下: (1) 按语法成分的实际处理顺序生成,即按语义要求生成中间代码。 (2) 注意地址返填问题。 (3) 不要遗漏必要的处理,如无条件跳转等。 例如下面的程序段: if (i>0) a=i+e-b*d; else a=0; 在生成中间代码时,条件“i>0”为假的转移地址无法确定,而要等到处理“else”时方可确定,这时就存在一个地址返填问题。此外,按语义要求,当处理完(i>0)后的语句(即“i>0”为真时执行的语句)时,则应转出当前的if语句,也即此时应加入一条无条件跳转指令,并且这个转移地址也需要待处理完else之后的语句后方可获得,就是说同样存在着地址返填问题。对于赋值语句a=i+e-b*d,其处理顺序(也即生成中间代码顺序)是先生成i+e的代码,再生成b*d的中间代码,最后才产生“-”运算的中间代码,这种顺序不能颠倒。 4.3 令S.val为文法G[S]生成的二进制数的值,例如对输入串101.101,则S.val= 5.625。按照语法制导翻译方法的思想,给出计算S.val的相应的语义规则,G(S)如下: G[S]: S→L.L|L
编译原理课后答案
第二章 2.3叙述由下列正规式描述的语言 (a) 0(0|1)*0 在字母表{0, 1}上,以0开头和结尾的长度至少是2的01 串 (b) ((ε|0)1*)* 在字母表{0, 1}上,所有的01串,包括空串 (c) (0|1)*0(0|1)(0|1) 在字母表{0, 1}上,倒数第三位是0的01串 (d) 0*10*10*10* 在字母表{0, 1}上,含有3个1的01串 (e) (00|11)*((01|10)(00|11)*(01|10)(00|11)*)* 在字母表{0, 1}上,含有偶数个0和偶数个1的01串 2.4为下列语言写正规定义 C语言的注释,即以 /* 开始和以 */ 结束的任意字符串,但它的任何前缀(本身除外)不以 */ 结尾。 [解答] other → a | b | … other指除了*以外C语言中的其它字符 other1 → a | b | … other1指除了*和/以外C语言中的其它字符 comment → /* other* (* ** other1 other*)* ** */ (f) 由偶数个0和偶数个1构成的所有0和1的串。 [解答]由题目分析可知,一个符号串由0和1组成,则0和1的个数只能有四种情况: x 偶数个0和偶数个1(用状态0表示); x 偶数个0和奇数个1(用状态1表示); x 奇数个0和偶数个1(用状态2表示); x 奇数个0和奇数个1(用状态3表示);所以, x 状态0(偶数个0和偶数个1)读入1,则0和1的数目变为:偶数个0和奇数个1(状态1) x 状态0(偶数个0和偶数个1)读入0,则0和1的数目变为:奇数个0和偶数个1(状态2) x 状态1(偶数个0和奇数个1)读入1,则0和1的数目变为:偶数个0和偶数个1(状态0) x 状态1(偶数个0和奇数个1)读入0,则0和1的数目变为:奇数个0和奇数个1(状态3) x 状态2(奇数个0和偶数个1)读入1,则0和1的数目变为:奇数个0和奇数个1(状态3) x 状态2(奇数个0和偶数个1)读入0,则0和1的数目变为:偶数个0和偶数个1(状态0) x 状态3(奇数个0和奇数个1)读入1,则0和1的数目变为:奇数个0和偶数个1(状态2) x 状态3(奇数个0和奇数个1)读入0,则0和1的数目变为:偶数个0和奇数个1(状态1) 因为,所求为由偶数个0和偶数个1构成的所有0和1的串,故状态0既为初始状态又为终结状态,其状态转换图: 由此可以写出其正规文法为: S0 → 1S1 | 0S2 | ε S1 → 1S0 | 0S3 | 1 S2 → 1S3 | 0S0 | 0 S3 → 1S2 | 0S1 在不考虑S0 →ε产生式的情况下,可以将文法变形为: S0 = 1S1 + 0S2 S1 = 1S0 + 0S3 + 1 S2 = 1S3 + 0S0 + 0 S3 = 1S2 + 0S1 所以: S0 = (00|11) S0 + (01|10) S3 + 11 + 00 (1) S3 = (00|11) S3 + (01|10) S0 + 01 + 10 (2) 解(2)式得: S3 = (00|11)* ((01|10) S0 + (01|10)) 代入(1)式得: S0 = (00|11) S0 + (01|10) (00|11)*((01|10) S0 + (01|10)) + (00|11) => S0 = ((00|11) + (01|10) (00| 11)*(01|10))S0 + (01|10) (00|11)*(01|10) + (00|11) => S0 = ((00|11)|(01|10) (00|11)*(01|10))*((00|1
编译原理课后习题答案-清华大学-第二版
第1章引论 第1题 解释下列术语: (1)编译程序 (2)源程序 (3)目标程序 (4)编译程序的前端 (5)后端 (6)遍 答案: (1) 编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。 (2) 源程序:源语言编写的程序称为源程序。 (3) 目标程序:目标语言书写的程序称为目标程序。 (4) 编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶 段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符 号表管理等工作。 (5) 后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。 (6) 遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。 第2题 一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。 答案: 一个典型的编译程序通常包含8个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。其各部分的主要功能简述如下。 词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。 语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。 语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。 表格管理程序:负责建立、填写和查找等一系列表格工作。表格的作用是记录源程序的各类信息和编译各阶段的进展情况,编译的每个阶段所需信息多数都从表格中读取,产生的中间结果都记录在相应的表格中。可以说整个编译过程就是造表、查表的工作过程。需要指出的是,这里的“表格管理程序”并不意味着它就是一个独立的表格管理模块,而是指编译程序具有的表格管理功能。 错误处理程序:处理和校正源程序中存在的词法、语法和语义错误。当编译程序发现源程序中的错误时,错误处理程序负责报告出错的位置和错误性质等信息,同时对发现的错误进行适当的校正(修复),目的是使编译程序能够继续向下进行分析和处理。 注意:如果问编译程序有哪些主要构成成分,只要回答六部分就可以。如果搞不清楚,就回答八部分。 第3题 何谓翻译程序、编译程序和解释程序?它们三者之间有何种关系? 答案: 翻译程序是指将用某种语言编写的程序转换成另一种语言形式的程序的程序,如编译程序和汇编程序等。 编译程序是把用高级语言编写的源程序转换(加工)成与之等价的另一种用低级语言编写的目标程序的翻译程序。 解释程序是解释、执行高级语言源程序的程序。解释方式一般分为两种:一种方式是,源程序功能的实现完全由解释程序承担和完成,即每读出源程序的一条语句的第一个单词,则依据这个单词把控制转移到实现这条语句功能的程序部分,该部分负责完成这条语句的功
编译原理课程设计
先简要分析一下语法分析的大致流程: 当有句子要进行处理时,首先要对其进行词法分析来分解出该句子中的每个符号,然后将该句子按照算符优先算法压入归约栈中,如果可以顺利归约,则说明这是一个合法的句子,否则该句子非法。 这里有一个需要考虑的地方,就是如何进行归约。由于文法已经给定,所以我们考虑设计一个文法表,文法表中的内容就是可归约串的种别码的顺序,比如v=E可以表示为9,1,13。这样的话当我们要进行一次归约时,只用按顺序存储最左素短语中符号的种别码,然后拿这个种别码序列与文法表进行匹配,就可知道当前归约需要执行哪些操作。 还有一点需要注意,就是如何对一个表达式进行求值。这里需要我们设计一个二元组的变量名表,这个变量名表可以根据变量的名称来返回变量的数据。变量名表的具体设计见详细设计部分。 由于是简化分析,所以这个程序只考虑整数的处理。 有了上面的分析,可以构造出算符优先分析算法的流程图,如下图所示。
详细设计 (1)词法分析部分 由于词法分析的内容在课程设计1中已经介绍,并且这次的状态转换图与课程设计1中的非常相似,所以这里就不过多介绍。(2)优先关系表 在程序中我们用一个二维数组priTable[][]来存储算符间的优先关系。priTable[a][b]=1表示a>b; 。priTable[a][b]=0表示a=b; 。priTable[a][b]=-1表示a 编译原理课程设计报告 设计题目编译代码生成器设计 学生姓名 班级 学号 指导老师 成绩 一、课程设计的目的 编译原理课程兼有很强的理论性和实践性,是计算机专业的一门非常重要的专业基础课程,它在系统软件中占有十分重要的地位,是计算机专业学生的一门主修课。为了让学生能够更好地掌握编译原理的基本理论和编译程序构造的基本方法和技巧,融会贯通本课程所学专业理论知识,提高他们的软件设计能力,特设定该课程的课程设计,通过设计一个简单的PASCAL语言(EL语言)的编译程序,提高学生设计程序的能力,加深对编译理论知识的理解与应用。 二、课程设计的要求 1、明确课程设计任务,复习编译理论知识,查阅复印相关的编译资料。 2、按要求完成课程设计内容,课程设计报告要求文字和图表工整、思路清晰、算法正 确。 3、写出完整的算法框架。 4、编写完整的编译程序。 三、课程设计的内容 课程设计是一项综合性实践环节,是对平时实验的一个补充,课程设计内容包括课程的主要理论知识,但由于编译的知识量较复杂而且综合性较强,因而对一个完整的编译程序不适合平时实验。通过课程设计可以达到综合设计编译程序的目的。本课程的课程设计要求学生编写一个完整的编译程序,包括词法分析器、语法分析器以及实现对简单程序设计语言中的逻辑运算表达式、算术运算表达式、赋值语句、IF语句、While语句以及do…while语句进行编译,并生成中间代码和直接生汇编指令的代码生成器。 四、总体设计方案及详细设计 总体设计方案: 1.总体模块 主程序 词法分析程序语法分析 程序 中间代码 生成程序 2. 表2.1 各种单词符号对应的种别码 单词符号种别码单词符号种别码bgin 1 :17 If 2 := 18 Then 3 < 20 wile 4 <> 21 do 5 <= 22 end 6 > 23 lettet(letter|digit)* 10 >= 24 dight dight* 11 = 25 + 13 ;26 —14 ( 27 * 15 ) 28 / 16 # 0 详细设计: 4.1界面导入设计 (1)一共三个选项: ①choice 1--------cifafenxi ②choice 2--------yufafenxi ③choice 3--------zhongjiandaima (2)界面演示 图一 编译原理简明教程答案 【篇一:8000 份课程课后习题答案与大家分享~~】 > 还有很多,可以去课后答案网 (/bbs )查找。 ################## 【公共基础课-答案】 #################### 新视野大学英语读写教程答案(全) 【khdaw 】 /bbs/viewthread.php?tid=108fromuid=1429267 概率论与数理统 计教程(茆诗松著) 高等教育出版社课后答案 /bbs/viewthread.php?tid=234fromuid=1429267 高等数学(第五 版)含上下册高等教育出版社课后答案 d.php?tid=29fromuid=1429267 新视野英语听力原文及答案课后答 案 【khdaw 】 /bbs/viewthread.php?tid=586fromuid=1429267 线性代数(同济 大学应用数学系著) 高等教育出版社课后答案 /bbs/viewthread.php?tid=31fromuid=1429267 21 世纪大学英语 第3 册(1-4)答案 【khdaw 】 /bbs/viewthread.php?tid=285fromuid=1429267 概率与数理统计 第二,三版(浙江大学盛骤谢式千潘承毅著) 高等教育出版社课后答案 d.php?tid=32fromuid=1429267 复变函数全解及导学[西安交大第四版] 【khdaw 】 /bbs/viewthread.php?tid=142fromuid=1429267 大学英语精读第 三版2 册课后习题答案 /bbs/viewthread.php?tid=411fromuid=1429267 线性代数(第二版) 习题答案 /bbs/viewthread.php?tid=97fromuid=1429267 21 世纪(第三册) 课后答案及课文翻译(5-8)【khdaw 】 /bbs/viewthread.php?tid=365fromuid=1429267 大学英语精读第 2 册课文翻译(上外) 第 1 章引论 第1 题 解释下列术语: (1)编译程序 (2)源程序 (3)目标程序 (4)编译程序的前端 (5)后端 (6)遍 答案: (1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。 (2)源程序:源语言编写的程序称为源程序。 (3)目标程序:目标语言书写的程序称为目标程序。 (4)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶 段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符 号表管理等工作。 (5)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。 (6)遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。 第2 题 一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。 答案: 一个典型的编译程序通常包含8个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。其各部分的主要功能简述如下。 词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。 语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。 语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。 中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。 中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。 《编译原理》课程论文 编译程序是现代计算机系统的基本组成部分之一,而且多数计算机系统都配有不止一个高级语言的编译程序,对有些高级语言甚至配置了几个不同性能的编译程序。从功能上讲,一个编译程序就是一个语言翻译程序。语言翻译程序把一种源语言书写的程序翻译成另一种目标语言的等价程序,所以总的说编译程序是一种翻译程序,其源程序是高级语言,目标语言程序是低级语言。 编译程序完成从源程序到目标程序的翻译工作,是一个复杂的整体的过程。从概念上来讲,一个编译程序的整个工作过程是划分成几个阶段进行的,每个阶段将源程序的一种表示形式转换成另一种表示形式,各个阶段进行的操作在逻辑上是紧密连接在一起的。一般一个编译过程是词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成。 编写编译器的原理和技术具有十分普遍的意义,以至于在每个计算机工作者的职业生涯中,本书中的原理和技术都会反复用到。在这本书中,向我们介绍了文法的概念,在讲词法分析的章节中讲述了构造一个有穷自动机的方法,以及如何将一个不确定的有穷自动机转化成确定的有穷自动机和有穷自动机的最小化等方法。 词法分析相对来说比较简单。可能是词法分析程序本身实现起来很简单吧,很多没有学过编译原理的人也同样可以写出各种各样的词法分析程序。不过编译原理在讲解词法分析的时候,重点把正则表达式和自动机原理加了进来,然后以一种十分标准的方式来讲解词法分析程序的产生。这样的做法道理很明显,就是要让词法分析从程序上升到理论的地步。 词法分析中的重点是有穷自动机DFA的生成以及DFA和正规式与正规文法的关系。还要熟练掌握NFA转换为DFA的方法及DFA的化简。 词法分析的核心应该是构建DFA,最后维护一个状态转移表。通过转态转移的结果来识别词性。DFA的思想和字典树很像。NFA通过求每个状态的闭包后构造出的自动机与DFA等价。正则表达式闭包,连接,或三种操作都有相应的NFA与其等价。所以正则表达式==NFA==DFA。DFA状态最小化算法化简DFA。LL(1)文法主要就是根据FIRST集判断向哪条路径走,来避免回溯;LR(0)文法构造项 《编译原理》教学大纲 课程编号:070183A 课程类型:□通识教育必修课□通识教育选修课 □专业必修课□专业选修课 □√学科基础课 总学时:48 讲课学时:32 实验(上机)学时:16 学分:3 适用对象:(专业名称)计算机科学与技术 先修课程:程序设计基础(C)、离散数学、数据结构 一、教学目标 本课程是首都经济贸易大学信息学院计算机科学与技术专业的核心课程。设置本课程的目的在于系统地向学生介绍编译系统的结构、工作原理以及编译程序各组成部分的设计原理,使学生通过本课程的学习之后,掌握编译理论和方法的基本知识,为从事计算机软件开发工作及理论研究工作打下坚实的基础。 目标1:掌握程序编译的理论和方法。 目标2:能够构造简单的编译相关程序。 目标3:为学生将来在软件研发工作等打下坚实的基础。 二、教学内容及其与毕业要求的对应关系 该课程的主要教学内容包括:编译基本概念,文法概论,限自动机与词法分,自顶向下的语法分析,自底向上的语法分析,语法制导及中间代码生成,代码优化,目标代码生成等,系统地向学生介绍编译系统的结构、工作原理以及编译程序各组成部。重点讲授词法分析、语法分析和语义分析三个部分,精讲语法分析, 重点内容采用理论与上机实践相结合的方法讲授。 在多功能教室中采用电子教案,授课时运用原理讲授与课程设计相结合的教学方法,充分调动学生在解决问题过程中主动学习和深入研究的积极性。注重实践,并在此过程中引入学科新知识、新动态,提高授课质量,提高课堂活跃度。 要求学生对高级语言有较深的了解,对计算机原理等基础知识掌握良好。由于本门课程授课专业性强等特点,布置适当的笔头作业,并以上机实验等方法,加强学生对此门课程的理解。 本课程与毕业要求的第2条、第3条和第4条有密切的关系,可以帮助达成此三条毕业要求,更好的完成计算机科学与技术培养方案的执行。 三、各教学环节学时分配 教学课时分配 四、教学内容 第一章绪论 第一节什么叫编译程序 第二节编译过程概述 《编译原理》课程实验报告(临时) 题目 专业 班级 学号 姓名 指导教师 华东理工大学软件与管理信息学院 2006年9月22日 一.实验题目 二.实验成员 组长名字写在第一个,每个同学完成的基本任务是什么。 三.实验内容 本学期的编译实验内容是使用编译构造工具实现一个扩充PL0语言的编译器。 扩充PL0语言是在PL0语言的基础上增加对整型一维数组的支持、扩充IF-THEN-ELSE 条件语句、增加REPEA T语句、支持带参数的过程和增加注释,如下所示:(1)整型一维数组,数组的定义格式为: V AR <数组标识名>(<下界>:<上界>) ●其中上界和下界可以是整数或者常量标识名。 ●访问数组元素的时候,数组下标是整型的表达式,包括整数、常量或者变量和 它们的组合。例如,假设a是常量,b是整型变量,c是数组,这些访问方式 都应该可以使用:c(1),c(a),c(b),c(b+c(1))。 (2)扩充条件语句,格式为: <条件语句>::= IF <条件>THEN <语句>[ELSE <语句>] (3)增加REPEA T语句,格式为: <重复语句> ::= REPEAT <语句> UNTIL <条件> (4) 支持带参数(传值参数)的过程,定义和调用形式如下: <过程首部>::= PROCEDURE <标识符> [‘(’<形式参数>{, <形式参数>}‘)’] ; <过程调用语句> ::= CALL <标识符>[‘(’<传值参数> {,<传值参数> }‘)’] (5) 注释 单行注释以{ 开始,以} 结束,注释内容不包括{和}. 完整的扩充PL0语言的EBNF范式见实验提供的文档所示。下文所说的PL0语言,如果不加说明,就是特指扩充PL0语言。 本实验实现的PL0语言编译器,输入是PL0源语言程序,输出是一个栈式机的汇编语言(PCODE)程序,然后解释执行。如图1所示。 图1 编译程序的功能 1.2 计算机执行用高级语言编写的程序有哪些途径?它们之间的主要区别是什么? 【解答】计算机执行用高级语言编写的程序主要有两种途径:解释和编译。在解释方式下,翻译程序事先并不采用将高级语言程序全部翻译成机器代码程序,然后执行这个机器代码程序的方法,而是每读入一条源程序的语句,就将其解释(翻译)成对应其功能的机器代码语句串并执行,而所翻译的机器代码语句串在该语句执行后并不保留,最后再读入下一条源程序语句,并解释执行。这种方法是按源程序中语句的动态执行顺序逐句解释(翻译)执行的,如果一语句处于一循环体中,则每次循环执行到该语句时,都要将其翻译成机器代码后再执行。在编译方式下,高级语言程序的执行是分两步进行的:第一步首先将高级语言程序全部翻译成机器代码程序,第二步才是执行这个机器代码程序。因此,编译对源程序的处理是先翻译,后执行。从执行速度上看,编译型的高级语言比解释型的高级语言要快,但解释方式下的人机界面比编译型好,便于程序调试。这两种途径的主要区别在于:解释方式下不生成目标代码程序,而编译方式下生成目标代码程序。 1.3 请画出编译程序的总框图。如果你是一个编译程序的总设计师,设计编译程序时应当考虑哪些问题? 【解答】编译程序总框图如图所示。 作为一个编译程序的总设计师,首先要深刻理解被编 译的源语言其语法及语义;其次,要充分掌握目标指令的 功能及特点,如果目标语言是机器指令,还要搞清楚机器 的硬件结构以及操作系统的功能;第三,对编译的方法及 使用的软件工具也必须准确化。总之,总设计师在设计编 译程序时必须估量系统功能要求、硬件设备及软件工具等 诸因素对编译程序构造的影响等。 2.2 什么是扫描器?扫描器的功能是什么? 【解答】扫描器就是词法分析器,它接受输入的源程序,对源程序进行词法分析并识别出一个个单词符号,其输出结果是单词符号,供语法分析器使用。通常是把词法分析器作为一个子程序,每当词法分析器需要一个单词符号时就调用这个子程序。每次调用时,词法分析器就从输入串中识别出一个单词符号交给语法分析器。编译原理课程设计 C语言编译器的实现
编译原理简明教程答案.doc
编译原理课后习题答案+清华大学出版社第二版
编译原理论文
编译原理-大纲
《编译原理》课程
编译原理教程课后答案