序列相关的检验和修正

序列相关的检验及修正
例题:中国居民总量消费函数 数据:
年份 GDP CONS CPI TAX GDPC X Y 1978 1979 1980 1981 1982 1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006
1、 建立回归模型,模型的OLS 估计 t t t X Y μββ++=10 (1)录入数据
打开EViews6,点“File ”
“New ”“Workfile ”
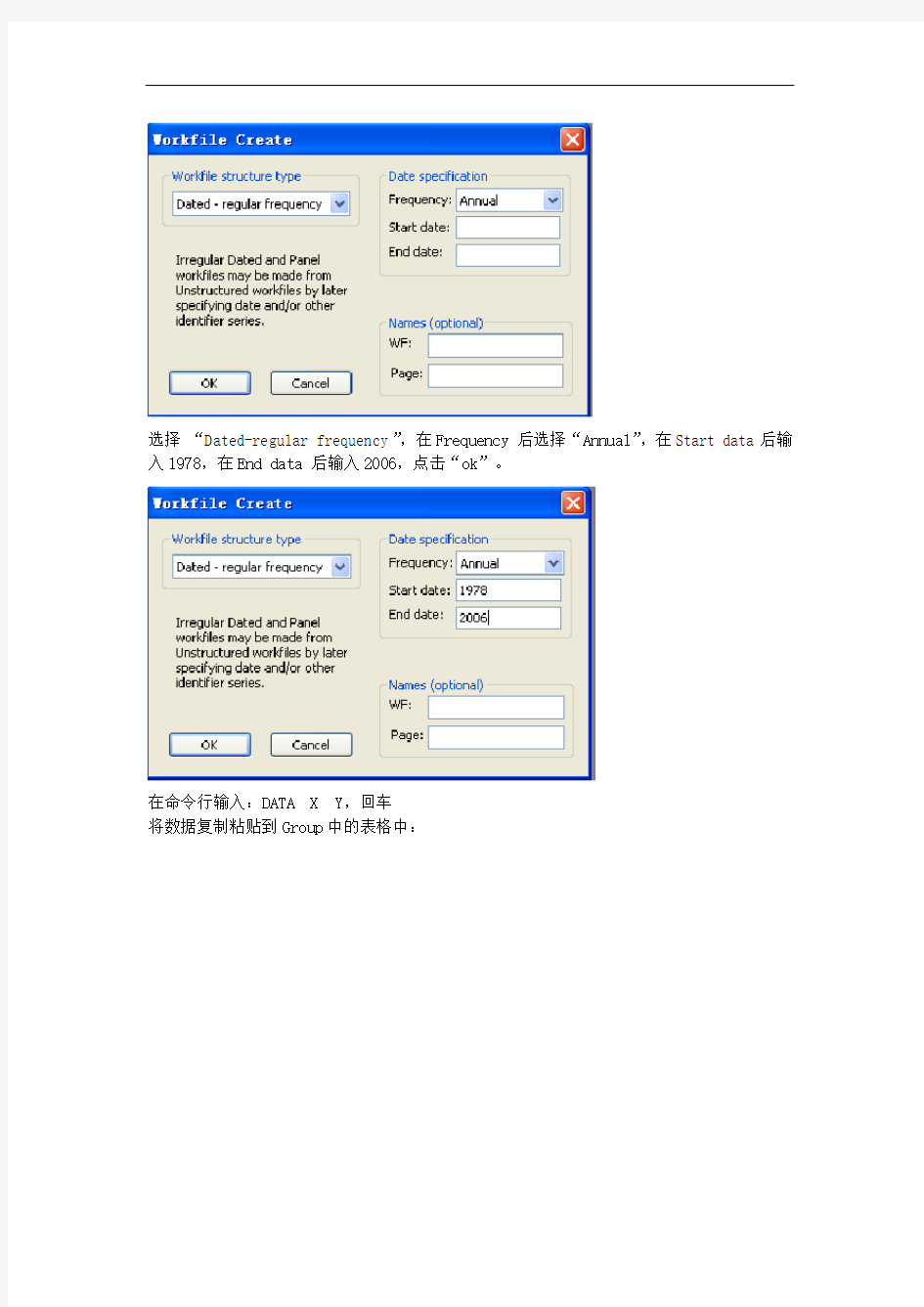
选择“Dated-regular frequency”,在Frequency 后选择“Annual”,在Start data后输入1978,在End data 后输入2006,点击“ok”。
在命令行输入:DATA X Y,回车
将数据复制粘贴到Group中的表格中:
(2)估计回归方程
在命令行输入命令:LS Y C X,回车
或者在主菜单中点“Quick”“Estimate Equation”,在Specification中输入 Y C X,点“确定”。得到如下输出:
写出估计结果:
X Y
4375.028.2091?+= () ()
2R = =2R F= .=
2、 序列相关的检验 (1) 图示检验法 作残差序列的时序图:
保存残差虚列: GENR E=RESID 作图: PLOT E
从图上可以看出,模型的最小二乘残差开始连续几期小于0,接着连续几期都大于0,这种模式的残差意味着模型可能存在正的序列相关性。
做t
e ~和1~-t e 的关系图: SCAT E(-1) E
-1,600
-1,200-800-4000400800
1,2001,6002,0002,400-4,000
-2,000
02,000
4,000
E
E (-1)
从上面的散点图可以看出,t e ~和1~-t e 之间可以拟合一个线性模型: t
e ~=t t e ερ+-1~ 且回归直线的斜率为正(>0),表明模型存在正的序列相关性。
(2)DW 检验
由OLS 估计的结果可知:.=。查DW 分布的临界值表,k=2,n=29时,L d =,U d =,显然0< (3)回归检验法 拟合模型:t e ~=t t e ερ+-1~,并运用OLS 估计模型:LS E E(-1) 得到如下结果: 写出回归结果: 1 ~949.0?~-=t t e e () 回归系数的t 统计量为,伴随概率P=<=,表明原模型存在一阶序列相关。 拟合模型:t e ~=t t t e e ερρ++--2211~~,并运用OLS 估计模型:LS E E(-1) E(-2) 得到如下结果: 写出回归结果: 2 1~864.0~659.1?~---=t t t e e e () 回归系数 和 的t 统计量分别为、,相应的伴随概率P=<=,表明原模型存在二阶 实验五自相关性 【实验目的】 掌握自相关性的检验与处理方法。 【实验内容】 利用表5-1资料,试建立我国城乡居民储蓄存款模型,并检验模型的自相关性。 【实验步骤】 一、回归模型的筛选 ⒈相关图分析 SCAT X Y 相关图表明,GDP指数与居民储蓄存款二者的曲线相关关系较为明显。现将函数初步设定为线性、双对数、对数、指数、二次多项式等不同形式,进而加以比较分析。 ⒉估计模型,利用LS命令分别建立以下模型 ⑴线性模型:LS Y C X t (-6.706) (13.862) = 2 R=0.9100 F=192.145 S.E=5030.809 ⑵双对数模型:GENR LNY=LOG(Y) GENR LNX=LOG(X) LS LNY C LNX t (-31.604) (64.189) = 2 R=0.9954 F=4120.223 S.E=0.1221 ⑶对数模型:LS Y C LNX =t (-6.501) (7.200) 2R =0.7318 F =51.8455 S.E =8685.043 ⑷指数模型:LS LNY C X =t (23.716) (14.939) 2R =0.9215 F =223.166 S.E =0.5049 ⑸二次多项式模型:GENR X2=X^2 LS Y C X X2 =t (3.747) (-8.235) (25.886) 2R =0.9976 F =3814.274 S.E =835.979 ⒊选择模型 比较以上模型,可见各模型回归系数的符号及数值较为合理。各解释变量及常数项都通过了t 检验,模型都较为显著。除了对数模型的拟合优度较低外,其余模型都具有高拟合优度,因此可以首先剔除对数模型。 比较各模型的残差分布表。线性模型的残差在较长时期内呈连续递减趋势而后又转为连续递增趋势,指数模型则大体相反,残差先呈连续递增趋势而后又转为连续递减趋势,因此,可以初步判断这两种函数形式设置是不当的。而且,这两个模型的拟合优度也较双对数模型和二次多项式模型低,所以又可舍弃线性模型和指数模型。双对数模型和二次多项式模型都具有很高的拟合优度,因而初步选定回归模型为这两个模型。 二、自相关性检验 ⒈DW 检验; ⑴双对数模型 因为n =21,k =1,取显著性水平α=0.05时,查表得L d =1.22, U d =1.42,而0<0.7062=DW 实验二序列相关性 【实验目的】 掌握序列相关性问题出现的来源、后果、检验及修正的原理,以及相关的Eviews操作方法。 【实验内容】 经济理论指出,商品进口主要由进口国的经济发展水平,以及商品进口价格指数与国内价格指数对比因素决定的。由于无法取得价格指数数据,我们主要研究中国商品进口与国内生产总值的关系。 以1978-2001年中国商品进口额与国内生产总值数据为例,练习检查和克服模型的序列相关性的操作方法。 【实验步骤】 一、建立线性回归模型 利用表中数据建立M 关于GDP 的散点图(SCAT GDP M )。 可以看到M 与GDP 呈现接近线性的正相关关系。 建立一个线性回归模型(LS M C GDP )。 即得到的回归式为: GDP M 0204.09058.152+= (3.32) (20.1) 9461.02=R D.W.=0.63 F=405 二、 进行序列相关性检验 1、 观察残差图 做出残差项与时间以及与滞后一期的残差项的折线图,可以看出随机项存在正序列相关性。 2、 用D.W.检验判断 由回归结果输出D.W.=0.628。若给定05.0=α,已知n=24,k=2,查D.W.检验上下界表可得,45.1,27.1==U L d d 。由于D.W.=0.628<1.27=L d ,故存在正自相关。 3、 用LM 检验判断 在估计窗口中选择Serial Correlation LM Test,设定滞后期Lag=1,得到LM 检验结果。 由于P值为0.0027,可以拒绝原假设,表明存在自相关。 4、用回归检验法判断 对初始估计结果得到的残差序列定义为E1,首先做一阶自回归(LS E1 E1(-1))。 经济计量分析实验报告 一、实验项目 自相关性的检验及修正 二、实验日期 2015.12.13 三、实验目的 对于国内旅游总花费的有关影响因素建立多元线性回归模型,对变量进行多重共线性的检验及修正后,对随机误差项进行异方差的检验和补救及自相关性的检验和修正。 四、实验内容 建立模型,对模型进行参数估计,对样本回归函数进行统计检验,以判定估计的可靠程度,包括拟合优度检验、方程总体线性的显著性检验、变量的显著性检验,以及参数的置信区间估计。 检验变量是否具有多重共线性并修正。 检验是否存在异方差并补救。 检验是否存在相关性并修正。 五、实验步骤 1、建立模型。 以国内旅游总花费Y 作为被解释变量,以年底总人口表示人口增长水平,以旅行社数量表示旅行社的发展情况,以城市公共交通运营数表示城市公共交通运行状况,以城乡居民储蓄存款年末增加值表示城乡居民储蓄存款增长水平。 2、模型设定为: t t t t t μβββββ+X +X +X +X +=Y 443322110t 其中:t Y — 国内旅游总花费(亿元) t 1X — 年底总人口(万人) t 2X — 旅行社数量(个) t 3X — 城市公共交通运营数(辆) t 4X — 城乡居民储蓄存款年末增加值(亿元) 3、对模型进行多重共线性检验。 4、检验异方差是否存在并补救。 5、检验自相关性是否存在并修正。 六、实验结果 消除多重共线性及排除异方差性之后的回归模型为:2382963.08388.301?X Y +-= 检验 I 、图示法 1、1-t e ,t e 散点图 -1,500 -1,000 -500 500 1,000 1,500 -2,000 -1,00001,0002,000 ET(-1) E T 大部分落在第Ⅰ,Ⅲ象限,表明随机误差项存在正自相关。 2、t e 折线图 -1,500 -1,000 -500 500 1,000 1,500 86 88 90 92 94 96 98 00 02 04 06 08 10 RESID Ⅱ、解析法 1、D-W 检验 案例三 ARIMA 模型的建立 一、实验目的 了解ARIMA 模型的特点和建模过程,了解AR ,MA 和ARIMA 模型三者之间的区别与联系,掌握如何利用自相关系数和偏自相关系数对ARIMA 模型进行识别,利用最小二乘法等方法对ARIMA 模型进行估计,利用信息准则对估计的ARIMA 模型进行诊断,以及如何利用ARIMA 模型进行预测。掌握在实证研究如何运用Eviews 软件进行ARIMA 模型的识别、诊断、估计和预测。 二、基本概念 所谓ARIMA 模型,是指将非平稳时间序列转化为平稳时间序列,然后将平稳的时间序列建立ARMA 模型。ARIMA 模型根据原序列是否平稳以及回归中所含部分的不同,包括移动平均过程(MA )、自回归过程(AR )、自回归移动平均过程(ARMA )以及ARIMA 过程。 在ARIMA 模型的识别过程中,我们主要用到两个工具:自相关函数ACF ,偏自相关函数PACF 以及它们各自的相关图。对于一个序列{}t X 而言,它的第j 阶自相关系数j ρ为它的j 阶自协方差除以方差,即j ρ=j 0γγ ,它是关于滞后期j 的函数,因此我们也称之为自相关函数,通常记ACF(j )。偏自相关函数PACF(j )度量了消除中间滞后项影响后两滞后变量之间的相关关系。 三、实验内容及要求 1、实验内容: (1)根据时序图的形状,采用相应的方法把非平稳序列平稳化; (2)对经过平稳化后的1950年到2007年中国进出口贸易总额数据运用经典B-J 方法论建立合适的ARIMA (,,p d q )模型,并能够利用此模型进行进出口贸易总额的预测。 2、实验要求: (1)深刻理解非平稳时间序列的概念和ARIMA 模型的建模思想; (2)如何通过观察自相关,偏自相关系数及其图形,利用最小二乘法,以及信息准则建立合适的ARIMA 模型;如何利用ARIMA 模型进行预测; (3)熟练掌握相关Eviews 操作,读懂模型参数估计结果。 四、实验指导 1、模型识别 (1)数据录入 打开Eviews 软件,选择“File”菜单中的“New --Workfile”选项,在“Workfile structure type ”栏选择“Dated –regular frequency ”,在“Date specification ”栏中分别选择“Annual ”(年数据) ,分别在起始年输入1950,终止年输入2007,点击ok ,见图3-1,这样就建立了一个工作文件。点击File/Import ,找到相应的Excel 数据集,导入即可。 实验实训报告 课程名称:计量经济学实验 开课学期:2012-2013学年第一学期 开课系(部):经济系 开课实验(训)室:数量经济分析实验室学生姓名: 专业班级: 学号: 重庆工商大学融智学院教务处制 实验题目 实验概述 【实验(训)目的及要求】 通过本实验,使学生掌握序列相关模型的检验方法、处理方法分析;熟悉图形法检验、掌握DW检验、掌握广义差分法处理序列相关。 【实验(训)原理】 如果对于不同的样本点,随机误差项之间不再是不相关的,而是存在某种相关性,则认为出现了序列相关性或自相关。对于存在序列相关性的模型主要采用广义差分法消除序列相关性,并对广义差分后的模型采用普通最小二乘法估计参数,并最终计算出原模型的参数。 实验内容 【实验(训)方案设计】 一、要求完成的实验内容 图形法检验;DW检验;LM检验;使用广义差分变换法进行序列相关的处理。 二、具体操作程序 1、图形法检验:(1)对模型进行回归分析(2)得到变量之间的残差趋势图和残差散点图(3)分析序列相关情况。 2、DW检验:(1)对模型进行回归分析(2)得到DW统计量(3)按照参数查DW表,建立分析区间(4)得到结论。 3、LM检验法:(1)对模型进行回归分析(2)选择LM检验的阶数(3)根据辅助回归结果判断是否存在序列相关。 4、广义差分法:如果原模型存在序列相关,使用广义差分法处理序列相关,并进一步估计原模型参数。 【实验(训)过程】(实验(训)步骤、记录、数据、分析) 一、模型设定 本例用1985-2003年农村居民人均收入和消费,建立中国农村居民的消费模型。模型的变量分别选择农村居民人均实际纯收入(X,单位:元)与农村居民人均实际消费性支出(Y,单位:元)。理论模型设定为: 1.序列相关性概述 或 对于模型 00 (,)()t t s t t s Cov E s μμμμ--=≠≠在其他假设仍成立的条件下,随机误差项序列相关意味着 ρ:自协方差系数(Coefficient of Autocovariance )或一阶自相关系数(First-order Coefficient of Autocorrelation ) 若E(μt μt -1)≠0 t =1,2,…,T 称为一阶序列相关,或自相关(Autocorrelation )自相关往往可写成如下形式: μt =ρμt -1+εt -1<ρ<1εt 是满足以下标准的OLS 假定的随机误差项: 2 000(),(),(,)t t t t s E Var Cov s εεσεε-===≠ 2.实际经济问题中的序列相关性 经济变量固有的惯性 大多数经济时间数据都有一个明显的特点:惯性,表现在时间序列不同时间的前后关联上。 模型设定的偏误所谓模型设定偏误(Specification error )是指所设定的模型“不正确”。主要表现在模型中丢掉了重要的解释变量或模型函数形式有偏误。数据的“编造” 在实际经济问题中,有些数据是通过已知数据生成的。因此,新生成的数据与原数据间就有了内在的联系,表现出序列相关性。 +++ 3.序列相关性的后果参数估计量非有效因为,在有效性证明中利用了即同方差性和互相独立性条件。而且,在大样本情况下,参数估计量也不具有渐近有效性。2()μμσ'=E X I +如果出现了序列相关性,估计的出现偏误(偏大 或偏小),t 检验失去意义。 ?βj S 变量的显著性检验中,构造了t 统计量 ??/ββ=j j t S +变量的显著性检验失去意义 实验2 自相关的检验与修正 一、实验目的: 掌握自相关模型的检验方法与处理方法.。 二、实验容及要求: 表1列出了1985-2007年中国农村居民人均纯收入与人均消费性支出的统计数据。 (1)利用OLS法建立中国农村居民人均消费性支出与人均纯收入的线性模型。 (2)检验模型是否存在自相关。 (3)如果存在自相关,试采用适当的方法加以消除。 表1 1985-2007年中国农村居民人均纯收入与人均消费性支出(单位:元) 实验如下: 首先对数据进行调整,将全年人均纯收入和全年人均消费性支出相应调整为全年实际人均纯收入和全年实际人均消费性支出。 图1 1、用OLS估计法估计参数 图2 图3 图4 从图4中可以看出,中国农村居民人均消费性支出与人均纯收入存在着显著的正相关关系。 估计回归方程: 从图3中可以得出,估计回归方程为: Y=56.21878+0.698928X t=(3.864210)(31.99973) R2=0.979904 F=1023.983 D.W.=0.409903 (1)图示法 图5 从图5中,可以看出残差的变化有系统模式,连续为正或连续为负,表示残差项存在一阶正自相关。 (2)DW检验 从图3中可以得到D.W.=0.409903,在显著水平去5%,n=23,k=2,d L=1.26, d U=1.44。此时0 计量经济学 自相关性检验实验报告 实验内容:自相关性检验 工业增加值主要由全社会固定资产投资决定。为了考察全社会固 定资产投资对工业增加值的影响,可使用如下模型:Y i = 1 β β+ i X; 其中,X表示全社会固定资产投资,Y表示工业增加值。下表列出了中国1998-2000的全社会固定资产投资X与工业增加值Y的统计数据。 一、估计回归方程 OLS法的估计结果如下: Y=668.0114+1.181861X (2.24039)(61.0963) R2=0.994936,R2=0.994669,SE=951.3388,D.W.=1.282353。 二、进行序列相关性检验 (1)图示检验法 通过残差与残差滞后一期的散点图可以判断,随机干扰项存在正序列相关性。 (2)回归检验法 一阶回归检验 e=0.356978e1-t+εt t 二阶回归检验 e=0.572433e1-t-0.607831e2-t+εt t 可见:该模型存在二阶序列相关。 (3)杜宾-瓦森(D.W)检验法 由OLS法的估计结果知:D.W.=1.282353。本例中,在5%的显 =1.22,著性水平下,解释变量个数为2,样本容量为21,查表得d l d u=1.42,而D.W.=1.282353,位于下限与上限之间,不能确定相关性。(4)拉格朗日乘数(LM)检验法 F-statistic 6.662380 Probability 0.007304 Test Equation: Dependent Variable: RESID Method: Least Squares Date: 12/26/09 Time: 22:55 X 0.005520 0.015408 0.358245 0.7246 RESID(-1) 0.578069 0.195306 2.959807 0.0088 Adjusted R-squared 0.340473 S.D. dependent var 927.2503 S.E. of regression 753.0318 Akaike info criterion 16.25574 Sum squared resid 9639967. Schwarz criterion 16.45469 Log likelihood -166.6852 F-statistic 4.441587 由上表可知:含二阶滞后残差项的辅助回归为: e=-35.61516+0.05520X+0.578069e1-t-0.617998e2-t t (-0.1507) (0.3582) (2.9598) (-3.0757) 序列相关的检验及修正 例题:中国居民总量消费函数 数据: 年份 GDP CONS CPI TAX GDPC X Y 1978 3605.6 1759.1 46.21 519.28 7802.6 6678.9 3806.8 1979 4092.6 2011.5 47.07 537.82 8694.7 7552.1 4273.4 1980 4592.9 2331.2 50.62 571.70 9073.3 7943.9 4605.3 1981 5008.8 2627.9 51.90 629.89 9650.9 8437.2 5063.4 1982 5590.0 2902.9 52.95 700.02 10557.1 9235.1 5482.3 1983 6216.2 3231.1 54.00 775.59 11511.5 10075.2 5983.5 1984 7362.7 3742.0 55.47 947.35 13273.3 11565.4 6746.0 1985 9076.7 4687.4 60.65 2040.79 14965.7 11600.8 7728.6 1986 10508.5 5302.1 64.57 2090.37 16274.6 13037.2 8211.4 1987 12277.4 6126.1 69.30 2140.36 17716.3 14627.8 8840.0 1988 15388.6 7868.1 82.30 2390.47 18698.2 15793.6 9560.3 1989 17311.3 8812.6 97.00 2727.40 17846.7 15034.9 9085.2 1990 19347.8 9450.9 100.00 2821.86 19347.8 16525.9 9450.9 1991 22577.4 10730.6 103.42 2990.17 21830.8 18939.5 10375.7 1992 27565.2 13000.1 110.03 3296.91 25052.4 22056.1 11815.1 1993 36938.1 16412.1 126.20 4255.30 29269.5 25897.6 13004.8 1994 50217.4 21844.2 156.65 5126.88 32057.1 28784.2 13944.6 1995 63216.9 28369.7 183.41 6038.04 34467.5 31175.4 15467.9 1996 74163.6 33955.9 198.66 6909.82 37331.9 33853.7 17092.5 1997 81658.5 36921.5 204.21 8234.04 39987.5 35955.4 18080.2 1998 86531.6 39229.3 202.59 9262.80 42712.7 38140.5 19363.9 1999 91125.0 41920.4 199.72 10682.58 45626.4 40277.6 20989.6 2000 98749.0 45854.6 200.55 12581.51 49239.1 42965.6 22864.4 2001 108972.4 49213.2 201.94 15301.38 53962.8 46385.6 24370.2 2002 120350.3 52571.3 200.32 17636.45 60079.0 51274.9 26243.7 2003 136398.8 56834.4 202.73 20017.31 67281.0 57407.1 28034.5 2004 160280.4 63833.5 210.63 24165.68 76095.7 64622.7 30306.0 2005 188692.1 71217.5 214.42 28778.54 88001.2 74579.6 33214.0 2006 221170.5 80120.5 217.65 34809.72 101617.5 85624.1 36811.6 1、 建立回归模型,模型的OLS 估计 t t t X Y μββ++=10 (1)录入数据 打开EViews6,点“File ” “New ”“Workfile ” 重庆科技学院学生实验报告 五、实验记录与处理(数据、图表、计算等) 一、估计回归方程 工业增加值主要由全社会固定资产投资决定。为了考察全社会固定资产投资对工业 增加值的影响,可使用如下模型:Y i = 1 β β+ i X;其中,X表示全社会固定资产投资, Y表示工业增加值。下表列出了中国1998-2000的全社会固定资产投资X与工业增加值Y的统计数据。 单位:亿元年份固定资产投资X工业增加值Y年份固定资产投资X工业增加值Y 1980910.91996.519915594.58087.1 198********.419928080.110284.5 19821230.42162.3199313072.314143.8 19831430.12375.6199417042.119359.6 19841832.92789199520019.324718.3 19852543.23448.7199622913.529082.6 19863120.63967199724941.132412.1 19873791.74585.8199828406.233387.9 19884753.85777.2199929854.735087.2 19894410.46484200032917.739570.3 199045176858 由此实验结果可知模型估计结果为: Y=668.0114+1.181861X (2.24039)(61.0963) R2=0.994936,R2=0.994669,SE=951.3388,D.W.=1.282353。 二、序列相关性的检验 (1)图示检验法 通过残差与残差滞后一期的散点图可以判断,随机干扰项存在正序列相关性。 (2)回归检验法: 一阶回归检验 t e =0.356978e 1-t +εt 可见该模型存在一阶自相关 (3)D.W 检验法 由普通最小二乘法的估计结果知:D.W.=1.282353。在本例中,在5%的显著性水平下,解释变量个数为2,样本容量为21,查表得DL=1.22,DU=1.42,而D.W.=1.282353,DW 位于下限与上限之间,所以一阶序列相关性不能确定。 三、序列相关的补救 广义差分法估计模型 由D.W.=1.282353,得到一阶自相关系数的估计值ρ=1-DW/2=0.6412 则DY=Y-0.6412*Y(-1), DX=X-0.6412*X(-1);以DY 为因变量,DX 为解释变量,用OLS 法做回归模型,这样就生成了经过广义差分后的模型。 序列相关性检验(一)一元线性回归结果: Dependent Variable: Y Method: Least Squares Date: 06/01/12 Time: 14:16 Sample: 1981 2007 Included observations: 27 C 4276.362 1079.786 3.960380 0.0005 X 0.871668 0.029448 29.60012 0.0000 R-squared 0.972258 Mean dependent var 24869.44 Adjusted R-squared 0.971149 S.D. dependent var 25261.92 S.E. of regression 4290.920 Akaike info criterion 19.63758 Sum squared resid 4.60E+08 Schwarz criterion 19.73356 Log likelihood -263.1073 F-statistic 876.1668 Durbin-Watson stat 0.174669 Prob(F-statistic) 0.000000 (二)拉格朗日乘数检验: 含二阶残差项的回归结果: Breusch-Godfrey Serial Correlation LM Test: F-statistic 120.8648 Probability 0.000000 Obs*R-squared 24.65421 Probability 0.000004 Test Equation: Dependent Variable: RESID Method: Least Squares Variable Coefficient Std. Error t-Statistic Prob. C 361.5102 372.6461 0.970117 0.3421 X -0.025697 0.013222 -1.943398 0.0643 RESID(-1) 1.477525 0.193620 7.631049 0.0000 RESID(-2) -0.485298 0.229297 -2.116459 0.0453 R-squared 0.913119 Mean dependent var -2.29E-12 Adjusted R-squared 0.901787 S.D. dependent var 4207.593 S.E. of regression 1318.618 Akaike info criterion 17.34251 Sum squared resid 39991346 Schwarz criterion 17.53449 Log likelihood -230.1239 F-statistic 80.57655 Durbin-Watson stat 1.772240 Prob(F-statistic) 0.000000 案例一时间序列数据平稳性检验实验指导 一、实验目的: 理解经济时间序列存在的不平稳性,掌握对时间序列平稳性检验的步骤和各种方法,认识利用不平稳的序列进行建模所造成的影响。 二、基本概念: 如果一个随机过程的均值和方差在时间过程上都是常数,并且在任何两时期的协方差值仅依赖于该两个时期间的间隔,而不依赖于计算这个协方差的实际时间,就称它是宽平稳的。 时序图 ADF检验 PP检验 三、实验内容及要求: 1、实验内容: 用Eviews5.1来分析1964年到1999年中国纱产量的时间序列,主要内容: (1)、通过时序图看时间序列的平稳性,这个方法很直观,但比较粗糙; (2)、通过计算序列的自相关和偏自相关系数,根据平稳时间序列的性质观察其平稳性;(3)、进行纯随机性检验; (4)、平稳性的ADF检验; (5)、平稳性的pp检验。 2、实验要求: (1)理解不平稳的含义和影响; (2)熟悉对序列平稳化处理的各种方法; (2)对相应过程会熟练软件操作,对软件分析结果进行分析。 四、实验指导 (1)、绘制时间序列图 时序图可以大致看出序列的平稳性,平稳序列的时序图应该显示出序列始终围绕一个常数值波动,且波动的范围不大。如果观察序列的时序图显示出该序列有明显的趋势或周期,那它通常不是平稳序列,现以1964-1999年中国纱年产量序列(单位:万吨)来说明。 在EVIEWS中建立工作文件,在“Workfile structure type”栏中选择“Dated-regular frequency”,在右边的“Date specification”中输入起始年1964,终止年1999,点击ok则建立了工作文件。找到中国纱年产量序列的excel文件并导入命名该序列为sha,见图1-2。 图1-1 建立工作文件 1 Figure 1: Time series plot Athens University of Economics & Business V olatility Forecasting for Option Trading: Evaluating Estimators of Changes on Implied V olatilities George Lilianov, George Papadakis Graduate Program in Decision Sciences, Department of Management and Technolo gy, Athens University of Economics & Business, 47A Evelpidon & 33 Lefkados - Athens 113 62 - Greece 1. Introduction In this paper our goal is to find a reliable estimator of changes (first order differences) on implied volatilities on short maturity calls. We are using data from the Spanish Financial Futures Exchange (MEFF), containing historical intraday information of options on Index Futures on Ibex35, with sampling frequency at 60 minutes intervals and prediction interval one step ahead.. We examine three estimators of implied volatilities – a univariate time series (Box-Jenkins) model, a multivariate linear regression model and a multivariate backpropagation neural network model. Regarding the univariate model estimation, we firstly identify the significant lags upon which the model is specified as a second step. Then the model is estimated through regression and tested for adequacy with the Durbin-Watson statistic. As an additional step, we also test for ARCH-GA RCH effects, that is, for autocorrelation of squared residuals, and we specify and estimate an adequate model of volatility. In order to estimate an adequate multivariate model, we firstly regress the implied volatility against all 16 potentially significant factors (12 factors + 4 lags) and then we stepwise exclude the insignificant ones and repeat the process until the model is specified. Again the model is tested for existence of systematic error using the DW-stat. The third estimator is built upon a neural network, which uses the first 495 observations as an estimation dataset, the next 100 as validation dataset, and tests its forecast on the final 55 observations. Various combinations of hidden layers and hidden units are examined so that the best trade off between generalization error and training error is made. After comparing the three estimators on the basis of their ability to best explain changes of implied volatility, we examine the economic implications of having an adequate model for predicting implied volatility. We assume that the forecasts are used as the criterion to buy or sell a call option following the rule th at Δoption_price= ? Δimplied_volatility. Finally, hourly and cumulative profit results of each estimator are calculated and compared using graphical representation, variance, standard deviation and the Sharpe ratio. 2. Univariate Time Series Estimator As we plot the first 595 observations of the data we can see that all the series seems stationary, i.e. there is no noticeable trend and the mean seems to be constant (Figure 1). We need to examine the autocorrelation in the time series in order to determine the strength of association between the current and the lagged values of the price changes in implied volatility. As we can see on Figure 2 the autocorrelations are not persistently large and so we can conclude 实验2自相关的检验与修正 、实验目的: 掌握自相关模型的检验方法与处理方法.。 、实验内容及要求: 表1列出了1985—2007年中国农村居民人均纯收入与人均消费性支出的统计数据。 (1)利用OLS法建立中国农村居民人均消费性支出与人均纯收入的线性模型。 (2)检验模型是否存在自相关。 (3)如果存在自相关,试采用适当的方法加以消除。 表1 1985 —2007年中国农村居民人均纯收入与人均消费性支出(单位:元) 年份 全年人均纯收入 (现价)全年人均消费性支 出 (现价) 消费价格指数 (1985=100) 1985397.6317.42100 1986423.8357106.1 1987462.6398.3112.7 1988544.9476.7132.4 1989601.5535.4157.9 1990686.3584.63165.1 1991708.6619.8168.9 1992784659.8176.8 1993921.6769.7201 199412211016.81248 19951577.71310.36291.4 19961923.11572.1314.4 19972090.11617.15322.3 199821621590.33319.1 19992214.31577.42314.3 20002253.41670314 20012366.41741316.5 20022475.61834315.2 20032622.241943.3320.2 20042936.42185335.6 20053254.932555343 200635872829348.1 序列相关性的检验与修正 案例:书本P115进口与国内生产总值的关系。 一检验 准备工作:建立工作文件,导入数据。采用OLS方法建立进口方程。在命令框输入: equation Eq01.ls m c gdp 建立残差序列 在命令框输入: series e=resid 建立残差序列的滞后一期序列 在命令框输入: series e_lag1=resid(-1) 方法1:利用两个残差序列画图、观察。 方法2:查看回归方程的DW值=0.628,存在序列相关。方法3:LM检验 在命令框输入: equation Eq02.ls e c gdp e(-1) e(-2) 在命令框输入:Scalar lm1= @obs(e(-2))*eq02.@r2 可得LM1=15.006 在命令框输入:scalar chi1=@qchisq(0.95,2) 可得chi1=5.99 可以判定模型存在2阶序列相关。 简便方法:在方程eq01窗口中点击View/Residual Test/Series Correlation LM Test,并选择滞后期为2,则会得到如下图所示的信息。 注:LM计算结果与上面有差异,因为这里的辅助回归所采用的resid(-1)、resid(-2)的缺失值用0补齐。 检验是否存在更高阶的序列相关。继续在命令框输入: equation Eq03.ls e c gdp e(-1) e(-2) e(-3) 在命令框输入:Scalar lm2= @obs(e(-3))*eq03.@r2 可得LM2=14.58 在命令框输入:scalar chi2=@qchisq(0.95,3) 可得chi2=7.185 仍然存在序列相关性,但由于e(-3)的参数不显著,可认为不存在3阶序列相关。在方程eq01窗口中点击View/Residual Test/Series Correlation LM Test,并选择滞后期为3,则会得到如下图所示的信息。 显然,LM检验的结果拒绝原假设(无序列相关),表明存在序列相关性。 二序列相关性的修正与补救 广义差分法就是广义最小二乘法(GLS),但损失了部分样本观测值,损失的数量依赖于序列相关性的阶数(如一阶序列相关,至少损失1个样本值)。 在实际操作中,往往基于广义差分法完成估计。根据随机扰动项相关系数估计方法的不同,可以分为C-O迭代法和Durbin两步法。 (1)Durbin两步法 第一步,估计随机扰动项的相关系数 根据前面检验可知存在二阶序列相关,因此设定方程为 实验四自相关检验与修正 【实验目的】 1.掌握自相关模型的检验及处理方法。 2.要求掌握自相关模型的图形法检验、DW 检验,与科克伦—奥克特迭代法对自相关修正。 【实验内容】 1.检测进口额模型121i i i Y X u ββ=++和实际利用外资模型122i i i Y X u ββ=++的自相关性(显著性水平=0.05α); 2.检验模型中存在的问题,并采取科克伦—奥克特迭代法和德宾两步法的补救措施予以处理。 表1 1985-2003年中国实际GDP 、进口额和实际利用FDI 1. (1)检测进口额模型121i i i Y X u ββ=++的自相关性检验 导入数据,使用普通最小二乘法估计进口额模型得: 11^ 6149.340.17330x Y += Se=(6378.162) (0.188499) t=(2.717147) (19.18235) 941171.02=R F=367.9624 DW=0.54247 对样本量为25,一个解释变量的模型,5%显著水平,差DW 表可知, =L d 1.288,=L d 1.454,模型中DW <L d ,显然进口额模型中有自相关。所有需要采取补救措施。 (2)检验实际利用外资模型122i i i Y X u ββ=++的自相关性 导入数据,使用普通最小二乘法估计进口额模型得: 2^ 214305.3935.13112x Y +-= Se=(14550.15) (4.049664) t=(-0.901183) (9.665753) =2R 0.802451 F=93.42679 DW=0.17648 对样本量为25,一个解释变量的模型,5%显著水平,差DW 表可知,=L d 1.288,=L d 1.454,, 模型中DW <L d ,显然进口额模型中有自相关。所有需要采取补救措施。 2.eviews自相关性检验
Eviews序列相关性实验报告
计量经济学--自相关性的检验及修正
试验一异方差的检验与修正-时间序列分析
实验报告:序列相关模型的检验和处理教师使用范文
序列相关性检验(上)
自相关地检验与修正
计量经济学自相关性检验实验报告
序列相关的检验和修正
计量经济学序列相关性实验分析
时间序列相关性检验-自相关
时间序列数据平稳性检验实验指导
[16]时间序列的自相关检验 - 论文选读:序列相关性的ACF与PACF验证
自相关的检验与修正
序列相关性的检验与修正(精)
实验四自相关检验与修正