第六章 方差分析案例

第六章方差分析
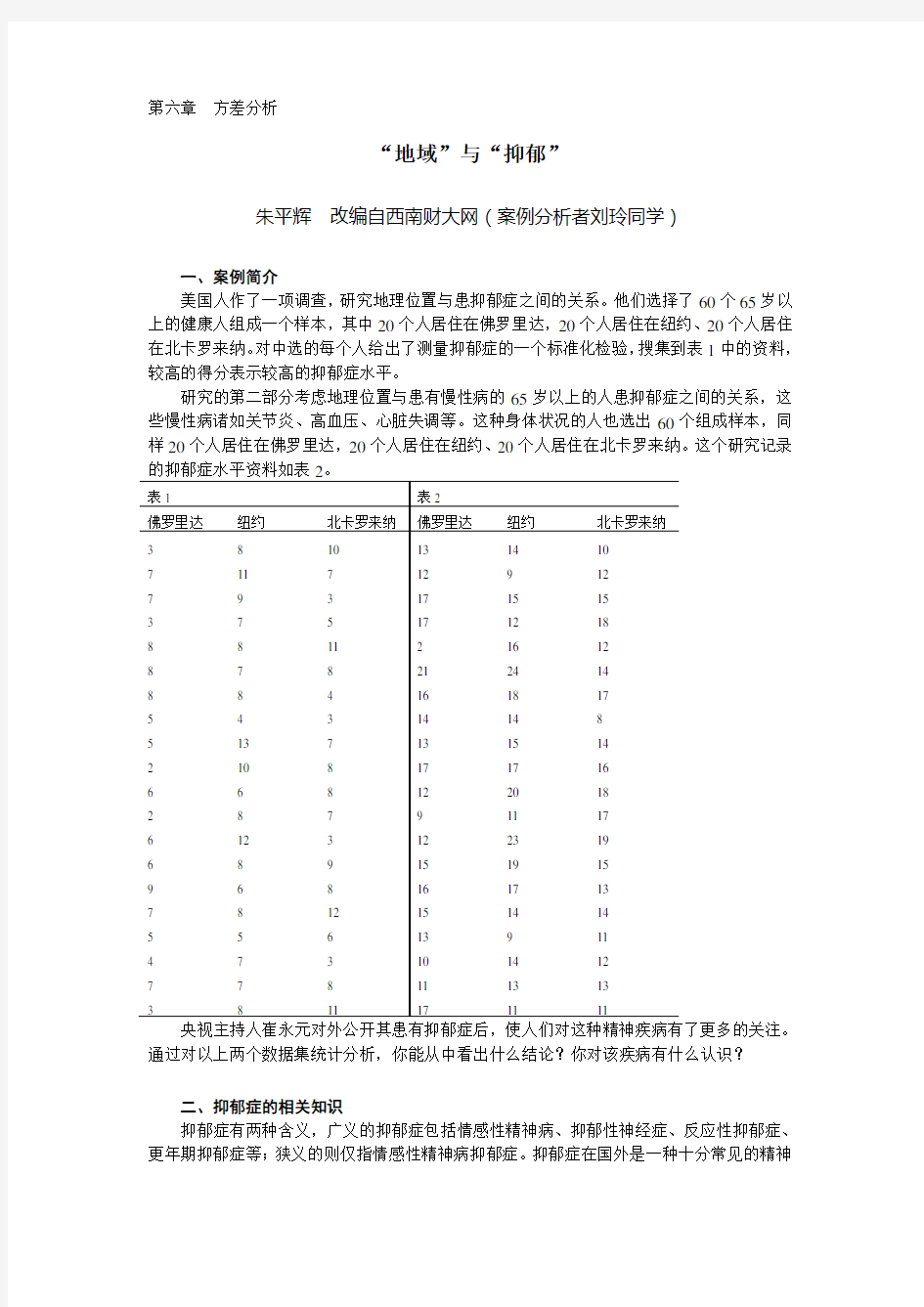
“地域”与“抑郁”
朱平辉改编自西南财大网(案例分析者刘玲同学)
一、案例简介
美国人作了一项调查,研究地理位置与患抑郁症之间的关系。他们选择了60个65岁以上的健康人组成一个样本,其中20个人居住在佛罗里达,20个人居住在纽约、20个人居住在北卡罗来纳。对中选的每个人给出了测量抑郁症的一个标准化检验,搜集到表1中的资料,较高的得分表示较高的抑郁症水平。
研究的第二部分考虑地理位置与患有慢性病的65岁以上的人患抑郁症之间的关系,这些慢性病诸如关节炎、高血压、心脏失调等。这种身体状况的人也选出60个组成样本,同样20个人居住在佛罗里达,20个人居住在纽约、20个人居住在北卡罗来纳。这个研究记录
央视主持人崔永元对外公开其患有抑郁症后,使人们对这种精神疾病有了更多的关注。通过对以上两个数据集统计分析,你能从中看出什么结论?你对该疾病有什么认识?
二、抑郁症的相关知识
抑郁症有两种含义,广义的抑郁症包括情感性精神病、抑郁性神经症、反应性抑郁症、更年期抑郁症等;狭义的则仅指情感性精神病抑郁症。抑郁症在国外是一种十分常见的精神
疾病,据报告,其患病率最高竟占人群的10%左右,而且社会经济情况较好的阶层,患病率越高。世界卫生组织预测,抑郁症将成为21世纪人类的主要杀手。全世界患有抑郁症的人数在不断增长,而抑郁症患者中有10—15%面临自杀的危险……引起抑郁症的原因有很多,为了了解地理位置对抑郁症是否有影响,我们做如下的案例分析:
三、地理位置与患抑郁症之间是否有关系
作为对65岁以上的人长期研究的一部分,在纽约洲北部地区的Wentworth医疗中心的社会学专家和内科医生进行了一项研究,以调查地理位置与患抑郁症之间的关系。选择了60个相当健康的人组成一个样本,其中20人居住在佛罗里达,20人居住在纽约,20人居住在北卡罗米纳。对中选的人给出了测量抑郁症的一个标准化实验,搜集到表1中的资料,较高的分表示较高的抑郁症水平。
研究的第二部分考虑地理位置与患有慢性病的65岁以上的人患抑郁症之间的关系,这些慢性病诸如关节炎、高血压、心脏失调等。这种状况的人也选出60个组成样本,同样20人居住在佛罗里达,20人居住在纽约,20人居住在北卡罗米纳。
要求根据所给的样本数据,做出以下管理报告:
描述统计学方法概括说明两部分研究的资料,关于抑郁症的得分,你的初步观测结果是什么?
对两个数据集使用方差分析方法,陈述每种情况下被检验的假设,你的结论是什么?
用推断法说明单个处理均值的合理性
讨论这个研究的推广和你认为有用的其他分析
四、有关统计方法
本案例是通过单因素的方差分析,对各个地区的抑郁症得分均值进行假设检验。分别检验地理位置对健康人群和慢性病患者是否有影响,以及影响程度,进而得出结论。
五、案例分析
首先:数据资料中的数据,并不能直接看出地区与患抑郁症之间有联系与否。我们可以根据所给的样本资料,得到以下信息:
(一)健康的被调查者中:佛罗里达地区平均得分=5.55
纽约地区平均得分=8
北卡罗米纳地区平均得分=7.05
(二)患抑郁症的被调查者中:佛罗里达地区平均得分=13.6
纽约地区平均得分=15.25
北卡罗米纳地区平均得分=13.95
(三)我们给出不同地区所有被调查者的平均得分情况
佛罗里达地区平均得分=9.575
纽约地区平均得分=11.625
北卡罗米纳地区平均得分=10.5
根据计算出的样本均值,给出相同地区不同健康状况下平均得分的比较图示以及不同地区所有被调查者的数据均值如图所示:
由以上图示,初步观测结论如下:
从同一地区来看,患慢性病的被调查者患抑郁症的水平明显高于健康者;
从地区差异来看,纽约地区患抑郁症的平均水平最高,北卡罗米纳次之,佛罗里达最低。
然后:为了进一步探讨地理位置与患抑郁症之间是否有显著关系,我们进行假设检验。该案例实质是检验不同水平下总体均值是否相等。我们把其他因素固定,只保留“地理位置”这个因素,来检验在不同地理位置,患抑郁症水平是否显著不同。
方差分析表如下所示:
方差分析:单因素方差分析
SUMMARY
组计数求和平均方差
佛罗里达40 383 9.575 26.55833
纽约40 465 11.625 24.13782
北卡罗米纳40 420 10.5 20.35897
方差分析
差异源SS Df MS F P-value F crit
组间84.31667 2 42.15833 1.779956 0.173182 3.073765
组内2771.15 117 23.68504
总计2855.467 119
从分析结果看,由于P值0.173182大于给定的显著性水平0.05,因此有充分的理由接受原假设,即不同地理位置下患抑郁症的测试平均水平相同,所以地理位置与抑郁症之间无显著性关系。
由表1数据资料,进行单因素方差分析如下表:
方差分析:单因素方差分析
SUMMARY
组计数求和平均方差
佛罗里达20 111 5.55 4.576316
纽约20 160 8 4.842105
北卡罗来纳20 141 7.05 8.05
方差分析
差异源SS df MS F P-value F crit
组间61.03333 2 30.51667 5.240886 0.00814 3.158846
组内331.9 57 5.822807
总计392.9333 59
从分析结果看,由于P值0.00814小于给定的显著性水平0.05,因此有理由拒绝原假设,即不同地理位置中患抑郁症的测试平均水平不相同,所以地理位置与抑郁症有关系。
同上,由表2中数据资料,进行方差分析可得下表:
方差分析:单因素方差分析
SUMMARY
组计数求和平均方差
佛罗里达20 272 13.6 15.83158
纽约20 305 15.25 17.03947
北卡罗来纳20 279 13.95 8.681579
方差分析
差异源SS df MS F P-value F crit
组间30.23333 2 15.11667 1.091387 0.342663 3.158846
组内789.5 57 13.85088
总计819.7333 59
从分析结果看,由于P值0.342663大于给定的显著性水平0.05,因此有充分的理由接受原假设,即不同地理位置下患抑郁症的测试平均水平相同,所以地理位置与抑郁症之间无显著性关系。
综上所述:人们的健康状况对其抑郁症水平有影响;不同的健康状况下,地理位置对抑郁症的影响也有不同,即地理位置对健康人群有显著性影响,而对慢性病患者没有显著性影响。
统计大家—Ronald . A. Fisher
改编自贾俊平《统计学》
Ronald . A ylmer . Fisher(1890-1962)出生于英国伦敦,在剑桥大学攻读数学和物理。他早年居无定所——在一家投资公司任过职,在加拿大的一个农场工作过,在英国的公立学校教过书。他对生物测定学产生了兴趣,而这一兴趣令他在1919年加入了位于Rothamstd 的一个世界著名的农业试验场。在那里,他负责对有关田间试验和天气记录的66年累积数据进行分类和再评估——在这个过程中他成为了20世纪的主导统计学家之一。早期他出版了开创新纪元的《Statistics Methods for Research Workers 》(1925),该书后来被翻译成各种语言并再版了14次,成为世界各地科研人员的“圣经”。其后还有两本同样深具影响的著作《The Genetic Theory of Natural Selection 》(1930)和《The Design of Experiments 》,前者是一本把达尔文进化论和孟德尔的遗传学融合到一起的大作。这些书的出版确立了Fisher 作为一名一流的统计学家的地位也确立了他作为一名一流的遗传学家的地位。实际上,在他晚年迁往澳大利亚之前,Fisher 先后在伦敦大学和剑桥大学长期担任优生学教授。
然而,上面所引用的作品仅仅是Fisher 诸多作品的一个开端。在近50年的时间里,他每两个月就发表一篇论文,而且绝大部分论文都开辟了新天地!因此,我们很难确定他的诸多贡献中哪一个才是最值得称颂的,也绝对没有可能用少许的篇幅来展示这位多产的学者是如何彻彻底底地纵横在统计学这一领域的。他是在实验中使用随机分组、拉丁方格、因子设计和混合设计的先驱者。之后,他推进了估计理论(并引入无偏性、一致性、有效性等概论),使相关、回归和方差(和协方差)分析发展成现在的状态。在Fisher 和William .S. Gosset 研究的基础上,人们才建立了小样本假设检验的综合理论。
不足为奇,Fisher 的一生获得了无数荣誉和奖励,他甚至于1952年被封为爵士。
下面通过一个简单的例子说明Fisher 解决统计问题的思路是如此的妙绝。
我们知道,方差分析中,当样本拒绝原假设时,只能认为各总体均值不全相等,但不能给出这种不相等到底出现在哪些总体之间。这需要进一步的多重比较,多重比较法有多种,其中Fisher 的最小显著差异方法,即LSD (least significant difference )法,是最为简单的方法。使用该方法进行检验的具体步骤是:
第一步:提出原假设:
01:,:i j i j
H H μμμμ=≠;
第二步:计算检验统计量:i j X X -; 第三步:计算LSD ,公式为:
LSD =
式中的
2
t α
为t 分布的临界值,自由度为n-k ,这里的k 是因素水平的个数。MSE 为组
内均方差。i n 和
j
n 为相应样本的容量。
第四步:根据显著性水平作出决策:如果i j X X ->LSD ,则拒绝H0,否则不拒绝之。 解决思路如此直接明了!
正交试验设计与方差分析在市场调查中的应用研究
朱建平
摘 要:本文主要通过正交试验设计分析,确定组成产品/服务各主要因素在消费者心目中的相对重要程度以及各因素的水平效应。并在此基础上,对产品/服务的市场前景进行预测。
关键词:正交试验设计极差分析方差分析水平效应
一、引言
我们知道,消费者在购买产品/服务时通常会考虑许多因素,如价格、品牌、款式以及产品的特有功能等。那么在这些因素当中,每个因素对消费者的重要程度如何?在同样的机会成本下,产品具有哪些因素水平最能贏得消费者的满意?我们试用正交试验设计理论来分析解决这类问题。
正交试验设计(简称正交设计或正交试验)是利用“正交表”进行科学地安排与分析多因素试验方法。它的优点是能在很多试验方案中挑选出代表性很强的少数试验方案,并通过对这少数方案的试验结果的分析,推断出影响试验结果的主要因素,同时还可作进一步的分析,得到比试验结果本身给出的还要多的有关各因素的信息。
二、实例分析
以下通过一个例子来说明正交试验设计理论在市场调查中的应用。
假设某电脑公司计划向市场推出一款中低档的电脑,定价在6000元左右,目前电脑市场上假设有两家竞争对手,一是联想,二是TCL。联想具有品牌优势,而TCL是目前电脑市场上的新秀,具有价格上的优势。那么这家电脑公司应采用什么样的产品配置才能贏得消费者的青睐?我们利用正交试验设计来分析这个问题。
1.确定因素与水平
根据以往的经验,电脑的价格、品牌以及处理器类型是影响消费者选购电脑的最主要因素。因此,我们决定选取价格、品牌、处理器类型为主要因素进行分析。
根据市场调查我们还了解到,目前市场上中低档电脑价格在5000—7000元之间。因此,可以考虑的定价为5000、6000、7000;处理器类型方面,目前较普遍的中低档电脑配置为赛扬333、赛扬400、PⅡ400。因此,最终选择的因素水平为:
其中:XX为该公司即将上市的新产品
2.正交设计
(34)安排试验,结果如下:
在本例中我们选用正交表L
9
3.数据收集
数据的收集方式是问卷调查,我们在问卷调查中作出这样的要求:
请您认真比较上述9种方案并给出相应的购买可能性得分。采用9分制,1表示完全不可能,9表示非常可能,打分区间[1 9]。
通过调查得到某一消费者对上述9种方案的评价如下:
4.确定因素的相对重要程度(极差分析) 引进记号:
ij k j i =第列上水平号为的各试验结果之和
1ij ij
k k s
=
其中s 为第j 列上水平号i 出现的次数
ij k j i 表示第列的因素取水平时进行试验所得试验结果的平均值
m ax ()m in ()
j ij ij i
i
j R k k R j =-称为第列的极差或其所在因素的极差
m ax()m in()
100%
(m ax()m in())
ij ij j ij
ij k k w k
k -=
?-∑
w j 表示第j 列所在因素在方案中的相对重要程度。计算结果列在表4上。 一般来说,各列的极差是不相等的,这就说明各因素的水平改变时对试验结果的影响是
不相同的。极差越大,说明这个因素的水平改变对试验结果的影响也越大,极差最大的那一列的因素,就是因素水平改变对试验结果影响最大的因素,也就是最主要因素。
对于上例,我们可以认为该消费者在购买电脑时,在上述的三个因素中考虑最多的是处理器,其次分别是价格、品牌。由w j 的定义式,我们可以把w j 理解为第j 个因素在消费者心目中的相对重要程度。也就是说,处理器在该消费者心目中的相对重要程度为44%,其次是价格32%、品牌24%。
5.统计检验(方差分析)
极差分析法的优点是方法简单、直观、计算量少。但极差分析法不能估计试验过程中以及试验结果测定中必然存在的误差的大小,因而不能真正区分某因素各水平所对应的试验结果的差异究竞是由于水平的改变所引起的,还是由于试验误差所引起的。为了弥补极差分析法的不足,现引入方差分析法。
利用正交表对试验结果进行方差分析的思想与步骤:先将数据(试验结果)的总偏差平方和分解为各因素以及误差的偏差平方和,然后求出F值,再用F检验法。
若用正交表L
n (r t),总的试验次数为n,试验结果为y
1
, y
2
,
……
y
n
,则数据的总偏差平
方和S
T
为:
2
2
222
111
()
n n n
T i i i
i i i
T
S y y y n y y
n
===
=-=-=-
∑∑∑
其中11
1
,
n n
i i
i i
y y T y
n
==
==
∑∑
因素A所引起的偏差平方和为:
2
222
2
111
()
r r r
A i i i i i i
i i i
T
S n y y n y n y n y
n
===
=-=-=
-
∑∑∑
其中r为因素A的水平数,i y为因素A的水平A i所对应的试验结果的平均值。计算S A
的公式也可用来计算误差e的偏差平方和S
e
。
F检验:检验因素A、B、C对试验结果有无显著影响。
设H
:a
1
=a
2
=a
3
=0
b
1
=b
2
=b
3
=0
c
1
=c
2
=c
3
=0
)
,
(
e
A
e
e
A
A
A
f
f
F
f
S
f
S
F→
=
其中A f称为A
S(或因素A)的自由度,有:
A
f= 因素A的水平数– 1 e
f称为
e
S(或误差)的自由度,有
e
f=(n – 1)–各因素的自由度之和。
给定显著性水平a=0.05进行F检验,结果因素B、C均显著,即因素B、C取不同水平
6.计算因素的水平效应
正交试验设计理论在市场调查中的应用目的并不是为了找出消费者的最佳方案,而是要在调查消费者对少数方案评价的基础上,预测该消费者对所有方案的评价。
要解决这个问题,我们首先要明确各个因素水平对于该消费者的效用,也就是该消费者对各个因素水平的满足程度。为此,我们先讨论“效应”的概念。 在一个因素的方差分析模型中,u i 表示第i 个水平所对应的总体均值,U 为理论总均值,定义a i =u i – U ,称为因素的第i 个水平效应。仿此来处理我们现在的问题,由于指定因素的第i 个水平的总体均值u i
及理论均值U 并不知道,我们只能用样本估计,因而定义: y k a iA i -= 称为因素A 的第i 水平效应。其中y 为正交表上所有试验指标的总平均。 终确定的各因素水平效应如下: 7.预测
利用表6所提供的信息,我们就可以预测该消费者对各种方案的评价。例如: 方案Ⅰ: XXP Ⅱ4006000
方案Ⅱ: 联想 赛扬333 5000 方案Ⅲ: TCL 赛扬400 7000
建立消费者效用函数U (方案)=构成该方案所有因素水平效应值之和。 U (Ⅰ)=–0.667+1.333 – 0.667= –0.001 U (Ⅱ)=1.333 – 2.333 +1.667= 0.667 U (Ⅲ)=–0.667+1.000 – 1.000= –0.667 U (Ⅱ)> U (Ⅰ)> U (Ⅲ),
理性的消费者总是追求效用最大化,因此我们可以认为该消费者对方案Ⅱ的评价优于方案Ⅰ、方案Ⅲ。
8.小结
在现实中,当面对众多选择的时候,消费者是在某种原则下进行购买决策的。本文试图通过正交试验设计分析把该原则用数量化的方法反映出来,并利用此原则预测消费者对其它方案的评价。通过这个简单的例子,可以很容易地推广到更多的因素、更多的因素水平。而对于更多的受访者,在计算出消费者心目中各因素的相对重要程度后通过聚类分析,可以将消费者划分为不同的消费群体,然后将这些群体作为同质个体处理。
三、用前景展望
正交试验设计分析在市场调查中的应用是对消费者购买决策的一种现实模拟。在实际的抉择过程中,由于价格等原因,消费者要对产品的多个因素进行综合考虑,往往要在满足一些要求的前提下牺牲部分其它因素,是一种对因素的权衡与折衷。通过正交试验设计分析,我们可以模拟出消费者的抉择行为,可以预测不同类型的人群抉择的结果。利用这些信息可
进行更深层次的市场研究。正交试验设计在市场研究中主要应用于以下几个领域: 1.新产品/服务开发和设计
2.市场细分:将因素相对重要性或水平效应值相似的消费者聚类,以找出市场划分,估计
不同目标市场的占有率。
3.利润分析:对产品/服务的利润进行分析,这个过程中可能会找出某一因素水平的组合,
虽然市场占有率较小,但可能是最有利可图的组合。
4.竞争分析:可以用正交试验设计的模拟操作预测某种产品/服务在各种竞争情景下可能获取的市场占有率。这种组合可能是市场上实际存在的,也有可能是虚拟的。根据可能的竞争情景构造组合投入到正交试验设计模型中,估计所有被调查者的选择行为,预测各模拟组合的市场占有率。
四、几点注意
在市场调查中应用正交试验设计进行分析时应注意以下几个方面:
1.将所有最主要的因素列入分析范围,但由于技术上的原因,因素的个数不能太多,一般为5—7个。因素的确定应尽可能精简。
2.各因素的水平应尽量符合实际情况,因为被调查者是在给定的因素水平的条件下做出评价的。若不限于给定的水平,有可能会得到截然不同的分析结果。另外,各因素水平应尽可能平衡。
3.消费者是根据构成产品/服务的多个因素水平来进行理解和作出理性评价的。因此,数据的收集应该在确保受访者能够对各因素及因素水平完整理解的条件下进行。
4.在对水平效应进行分析时,应注意不同因素的水平效应的比较是没有意义的。我们不能说该消费者对联想品牌的偏好程度大于对赛扬400的偏好。但我们可以这样说,在其它因素水平相同的情况下,若选择TCL、赛扬400和联想、赛扬333,该消费者可能更偏爱前者。因为前两个因素水平的效应值和为0.333(–0.667+1.000)大于后两个因素水平效应值的和–1.000(1.333–2.333)。在正交试验设计分析中,消费者对方案的评价是一个相对的概念。因此,水平效应值的解释也是相对的。
第五章 统计学习题集 假设检验 第六章 方差分析
第五章 假设检验 第六章 方差分析 1、某厂生产一种产品,原月产量服从)14,75(N 。设备更新后,为了考察产量是否提高,抽查了6个月的产量,其平均产量为78。问在显著水平5%条件下,设备是否值得更新? 2、某工厂对所生产的产品进行质量检验,规定:次品率不得超过0.01,方可出厂。现从一批产品中随机抽查80件,发现次品2件。试问在0.05的显著水平下,这批产品是否可以出厂? 3、已知某种电子元件的使用寿命服从标准差为100小时的正态分布,要求平均寿命不得低于1000小时。现在从一批这种电子元件中随机抽取25件,测得平均寿命为950小时。试在0.02 的显著性水平下,检验这批元件是否合格. 4、在正常生产情况下,某厂生产的无缝钢管的内径服从均值为54mm 、 标准差为0.9mm 的正态分布。某日从当天生产的产品中随机抽取10根,测得内径分别为:53.8,54.0,55.1,54.2,52.1,54.2,55.0,55.8,55.4,55.5(单位:mm )。试检验该日产品生产是否正常(α=5%)。 5、某专家认为A 地男孩入学率明显高于女孩,小学男女学生比例至少是6:4。从A 地小学中随机抽取400个学生的调查结果是:男生258人,女生142人.问当α=5%时,调查结果是否支持该专家的观点? 6、某饮料厂生产一种新型饮料,其颜色有四种分别为:橘黃色、粉色、绿色、和无色透明。随机从5家商场收集了前一期其销售量,数据如下表: 数据计算结果如下: 组间平方和为76.8445,组内平方和为39.084。问饮料的颜色是否对产品的销售量产生显著的影响? {66.8)3,16(05.0=F ,24.3)16,3(05.0=F ,29.5)16,3(01.0=F ,69.26)3,16(01.0=F }
第六章--spss的方差分析
第六章spss的方差分析 1、入户推销有五种方法。某大公司想比较这五种方法有无显著的效果差异,设计了一项实验。从应聘人员中尚无推销经验的人员中随机挑选一部分人,并随机地将他们分为五个组,每组用一种推销方法培训。一段时期后得到他们在一个月内的推销额,如下表所示: 1)请利用单因素方差分析方法分析这五种推销方式是否存在显著差异。 2)绘制各组的均值对比图,并利用LSD方法进行多重比较检验。 原假设:这五种推销方式是否存在显著差异。 步骤:建立SPSS数据→分析→比较均值→单因素→因变量导入销售额→变量导入方式→选项→选择方差同质性检验、均值图→选择LSD方法检验→确定 表6-1 方差齐性检验 销售额 Levene 统计量df1 df2 显著性 2.048 4 30 .113 表6-2 分析:sig值为0.00<0.05,故拒绝原假设,认为这五种销售方式中存在显著差异。 (2)多重比较:
分析:有表6-3可以看出,多重比较中sig值均小于0,05,所以拒绝原假设,认为五种推销方法存在显著差异均值图也可以看出均值对比图的曲折比较大,进一步验证了结论。 2、为研究某种降血压药的适用特点,在五类具有不同临床特征的高血压患者中随机挑选了若干志愿者进行对比试验,并获得了服用该降压药后的血压变化数据。现对该数据进行单因素方差分析,所得部分分析结果如下表所示。 1)请根据表格数据说明以上分析是否满足方差分析的前提要求,为什么? 2)请填写表中空缺部分的数据结果,并说明该降压药对不同组患者的降压效果是否存在显著差异。 3)如果该降压药对不同组患者的降压效果存在显著差异,那么该降压药更适合哪组患者?1)图表中可以看出,在方差齐性检验中,sig值为0.001,小于0.05,故拒绝原假设,所以方差不齐。2)表中空缺补充: ANOVA 销售量 平方和df 均方 F 显著性 组间1104.128 4 276.032 11.403 .000 组内1524.990 6324.206 总数2629.118 67
统计学教案习题05方差分析
第五章 方差分析 一、教学大纲要求 (一)掌握内容 1.方差分析基本思想 (1) 多组计量资料总变异的分解,组间变异和组内变异的概念。 (2) 多组均数比较的检验假设和F 值的意义。 (3) 方差分析的使用条件。 2.常见实验设计资料的方差分析 (1)完全随机设计的单因素方差分析:适用的资料类型、总变异分解(包括自由度的分解)、方差分析的计算、方差分析表。 (2)随机区组设计资料的两因素方差分析:适用的资料类型、总变异分解(包括自由度的分解)、方差分析的计算、方差分析表。 (3)多个样本均数间的多重比较方法: LSD-t 检验法;Dunnett-t 检验法;SNK-q 检验法。 (二)熟悉内容 多组资料的方差齐性检验、变量变换方法。 (三)了解内容 两因素析因设计方差分析、重复测量设计资料的方差分析。 二、教学内容精要 (一) 方差分析的基本思想 1. 基本思想 方差分析(analysis of variance ,ANOV A )的基本思想就是根据资料的设计类型,即变异的不同来源将全部观察值总的离均差平方和(sum of squares of deviations from mean ,SS )和自由度分解为两个或多个部分,除随机误差外,其余每个部分的变异可由某个因素的作用(或某几个因素的交互作用)加以解释,如各组均数的变异SS 组间可由处理因素的作用加以解释。通过各变异来源的均方和误差均方比值的大小,借助F 分布作出统计推断,判断各因素对各组均数有无影响。 2.分析三种变异 (1)组间变异:各处理组均数之间不尽相同,这种变异叫做组间变异(variation among groups ),组间变异反映了处理因素的作用(处理确有作用时 ),也包括了随机误差( 包括个体差异及测定误差 ), 其大小可用组间均方(MS 组 间 )表示,即 MS 组间= 组间组间ν/SS , 其中,SS 组间= 21 )(x x n k i i i -∑= ,组间ν=k -1为组间自由度。k 表示处理组数。 (2)组内变异:各处理组内部观察值之间不尽相同,这种变异叫做组内变异(variation within groups),组内变异反映了随机误差的作用,其大小可用组内均方 (组内MS ) 表示, 组内组内组内ν/SS MS = ,其中∑∑==?? ? ???-=k i n j i ij i x x SS 112)(组内 , k N -=组内ν,为组内均方自由度。 (3)总变异:所有观察值之间的变异(不分组),这种变异叫做总变异(total variation)。其大小可用全体数据的方差表示, 也称总均方(MS 总 )。按方差的计算方法,MS 总= 总总ν/SS ,其中SS 总=211 )(∑∑==-k i n j ij i x x , k 为处理组数,i n 为第i 组例数,总ν=N -1为总的自由度, N 表示总例数。 (二)方差分析的使用条件 (1) 各样本是相互独立的随机样本,且来自正态分布总体。 (2) 各样本的总体方差相等,即方差齐性(homoscedasticity)。 (三)不同设计资料的方差分析 1.完全随机设计的单因素方差分析 (1)资料类型:完全随机设计(completely random design)是将受试对象完全随机地分配到各个处理组。设计因素
第六章方差分析
第六章方差分析 一、方差分析(Analysis of variance,ANOVA): 又叫变量分析,是英国著名统计学家R . A . Fisher于20世纪提出的。它是用以检验两个或多个均数间差异的假设检验方法。它是一类特定情况下的统计假设检验,或者说是平均数差异显著性检验的一种引伸。方差分析的基本功能:对多组样本平均数差异的显著性进行检验 二、对多个处理进行平均数差异显著性检验时,采用t检验法的缺点: (1)检验过程烦琐。 (2)无统一的试验误差,误差估计的精确性和检验的灵敏性低。 (3)推断的可靠性低,检验时犯α错误概率大。 三、试验指标(experimental index): 为衡量试验结果的好坏和处理效应的高低,在实验中具体测定的性状或观测的项目称为试验指标。常用的试验指标有:身高、体重、日增重、酶活性、DNA含量等等。 四、试验因素( experimental factor): 试验中所研究的影响试验指标的因素叫试验因素。当试验中考察的因素只有一个时,称为单因素试验;若同时研究两个或两个以上因素对试验指标的影响时,则称为两因素或多因素试验。 五、因素水平(level of factor): 试验因素所处的某种特定状态或数量等级称为因素水平,简称水平。如研究3个品种奶牛产奶量的高低,这3个品种就是奶牛品种这个试验因素的3个水平。 六、试验处理(treatment): 事先设计好的实施在实验单位上的具体项目就叫试验处理。如进行饲料的比较试验时,实施在试验单位上的具体项目就是具体饲喂哪一种饲料。 七、试验单位( experimental unit ): 在实验中能接受不同试验处理的独立的试验载体叫试验单位。一只小白鼠,一条鱼,一定面积的小麦等都可以作为实验单位。 八、重复(repetition): 在实验中,将一个处理实施在两个或两个以上的试验单位上,称为处理有重复;一处理实施的试验单位数称为处理的重复数。例如,用某种饲料喂4头猪,就说这个处理(饲料)有4个重复。 第一节方差分析的基本原理 方差:又叫均方,是标准差的平方,是表示变异的量。在一个多处理试验中,可以得出一系列不同的观测值。 观测值不同的原因:处理效应(treatment effect):处理不同引起;试验误差:试验过程中偶然性因素的干扰和测量误差所致。
第六章 方差分析
第六章方差分析 方差的计算公式 ()2 2 1 x X S n - = - ∑ 【离均差平方和:()2 x X - ∑;分母为自由度:n-1】 第一节方差分析的基本思想 用途:检验3组及以上总体均数是否相等。通过分析处理组均数之间的差别,推论它们所代表的k个总体均数间是否存在差别,或k个处理组间的差别是否具有统计学意义。 = 组间变异+ 组内变异 SS总 组内。 F= MS组间/ MS组内 如果:各样本均数来自同一总体(H0: ),即各组均数之间无差别。 则:组间变异与组内变异均只能反映随机误差,此时:F 值应接近1。 反之,若各样本均数不是来自同一总体,组间变异应较大,F 值将明显大于1,则不能认为组间的变异仅反映随机误差,也就是认为处理因素有作用。 F值要到多大才有统计学意义呢? 在各样本来自正态总体,各样本所来自的总体方差相等的假定之下,当H0成立时,检验统计量F 服从自由度ν组间=k-1,ν组内=N-k的F 分布,表示为:F ~ F (ν组间, ν组内) 可由F界值表查出在某一α水准下F分布的单尾界值F α。当F < F(ν组间, ν组内), P> α。 方差分析的基本思想 1·根据资料的设计类型,将全部观察值总的离均差平方和及自由度分解为两个或多个部分, 2·除随机误差(如SS组内)外,其余每个部分的变异(如SS组间)可由某个因素的作用(或某几个因素的交互作用,如A因素×B因素)加以解释。 3·通过比较不同变异来源的均方,借助F分布作出统计推断,从而了解该因素对观测指标有无影响。方差分析对数据的基本假设(方差分析的应用条件) 1·任何两个观察值之间均不相关 2·每一水平下的观察值均来自正态总体 3·各总体方差相等,即方差齐性(homogeneity of variance) 第二节完全随机设计资料的单因素方差分析 1·在实验研究中,将受试对象随机分配到一个研究因素的多个水平中去,然后观察实验效应。 如将30名乙型脑炎患者随机分为三组,分别用单克隆抗体、胸腺肽和利巴韦林三种药物治疗(药物这个研究因素分为3个水平),观察治疗后的退热时间。 2·在观察研究中,按某个因素的不同水平分组,比较该因素的效应。 如比较糖尿病患者,IGT异常和正常人的载脂蛋白有无差别(人群这个研究因素分为3个水平)。 一、完全随机设计 如何分组:可以利用随机数字表(医学统计中的研究设计介绍) 二、变异分解: 例:某社区随机抽取了30名糖尿病患者(11例),IGT异常(9例)和正常人(10例)进行载脂蛋白(mg/dL)测定,问三种人的载脂蛋白有无差别? 1.完全随机设计方差分析中变异的分解 总变异= 组间变异+ 组内变异 2. 分析计算步骤建立检验假设和确定检验水准