的SPSS21使用教程哦
第21章spss21教程完整版

21.2.5 保存设置
单击如21-2中的“保存”按钮,则弹出如图21-9所示的对话框,各部分选项功能如 下所述。 1.保存变量选项栏 • 用于设置保存哪些变量。 • 终端节点编号:表示节点序号,此变量保存每个观测所属最终节点的序号。 • 预测值:此变量保存由模型预测的因变量值。 • 预测概率。 • 样本分配(训练/检验):样本类型,此变量记录单个观测是用于训练函数用于验证。 2.将树模型导出为XML选项 • 设置把模型格式输出到指定XML文件的选项。 • 培训样本:设置对训练样本的输出。 • 检验样本:设置对验证样本的输出。
21.2.14 利润设置
单击图21-16中的“利润”标签,则弹出如图21-18所示的对话框,用于设置预测分 类正确时的收益函数的参数。 ① 无:不使用收益函数。
② 设定选项栏:表示由用户自定义收益函数。 只有当分类因变量至少设置了两个值标签时,此选项栏才可用。收入表示 输入对当前行的值标签预测正确时的收入值;费用表示对当前行的值标签预测 正确时的消耗值;利润表示收益值。
② 节点性能选项栏:用于设置关于节点的统计信息。 • 摘要:摘要表格输出; • 按目标类别:对于定义了目标取值的分类因变量,此表包括得益比例、相应比例、 以节点或者百分比分组后的增量(Lift)值,对每个目标取值输出一个表格,对于连 续因变量和没有定义目标的分类因变量不作输出。 ③ 自变量选项栏:用于设置自变量的选项。 • 对模型的重要性:对于CART方法,把模型中的自变量按其重要性进行排序,对其他 算法无效; • 替代变量(按分割:对于CART和QUEST算法,如果模型有可替代的解决方案,就列 出所有可能的方案,对CHAID算法无效。 ④ 行下拉列表,用于指定节点信息表的显示方 式,可以选择终端节点、百分比和两者都是。 如果选择两者都是,则为因变量的每个目标取 值的输出两个表格。百分表按指定顺序依次显 示指定百分位处的累计值。 • 排序顺序:用于指定百分位表的显示顺序; • 百分比增量:在此指定百分位的递增间隔; • 显示累积统计:表示在每个最终节点表里 增加一列显示累计结果。
第15章spss21教程完整版

对应分析的基本原理
简单对应分析
Optimal Scaling过程
15.2 简单对应分析
15.2.1 对应分析过程
选择菜单“分析→降维→对应分析” 。 1.变量设置 • • • 行、列栏用于选入对应哪个分析的行变量和列变量。选入变量以后,单击“定义范 围”按钮则弹出如图15-2所示对话框。 最小值和最大值分别表示相应分类变量的最小值和最大值,此处只可以输入整数, 输入后单击“更新”按钮则进行确认。 类别约束栏用于设置分类变量取值的约束条件,其下列表框显示的是当前分类变量 的取值列表。选中框中的一个值,然后单击右侧的三个单选框设置其约束条件。 “无”表示不作任何的约束;“类别必须相等”表示等同约束,表示各类别必须有 相同的得分;“类别为补充型”表示增补约束,增补的种类不影响分析过程和种类 维数,但会在有效种类的定义空间里被描述。
4.选项设置 ① 补充对象栏,设置增补观测在数据集里的记录号,可以通过“更改”、“删除”按 钮进行更改或删除。 • 个案全距:指定第一个和最后一个,然后单击“添加”按钮加入到下面的增补列表; • 单个个案:设置特定的行号,单击“添加”按钮加入增补列表中。 ② 正态化方法栏,设置变量或者观测得分的正态化方法,如图15-24所示下拉菜单。 • 主要变量:相当于简单对应分析Column Principal方法; • 主要对象:相当于简单对应分析的Row Principal方法; • 对称:相当于简单对应分析的Symmetrical方法; • 因变量:相当于简单对应分析的Principal方法; • 设定:相当于简单对应分析的Custom方法。 ③ 标准栏,用来设置模型的拟合标准。“收敛性”用来 指定收敛的临界值;“最大迭代”用来指定的循环次数。 ④ 标注图栏,用来设置输出图形的显示方式。 • 变量标签或值标签:显示变量标签或变量值,其下 • 的标签长度的限制用来指定变量标签的最大长度; • 变量名称或值:显示变量名或变量值。 ⑤ 图维数栏,设置输出图形的维数,与图15-5的设置方法一样。 ⑥ 配置栏,用来设置从一个文件读入坐标的结构信息,单击“文件”按钮则选择文件。
第5章spss21教程完整版

• 百分差;
• 非整数权重:当频数因为加权而变成小数的时候,选择该项对频数进行取整,主 要包括5种取整方法。
⑨ 格式设置:单击“格式”按钮,弹出如图5-32所示的对话框,用于定义变量的排列 方式。
5.5.2 实例分析
1.参数设置 选择菜单“分析→描述→交叉表”,弹出如图5-34所示对话框,选择变量
⑤ 统计量设置:单击图5-15中的“统计量”按钮,则弹出如图5-16所示对话框, 此对话框用于设置各种需要计算的统计量。
描述性:计算一般的描述性统计量。输出均数、中位 数、众数、5%修正均数、标准误、方差、标准差、最小 值、最大值、全距、四分位全距、峰度系数、峰度系数的 标准误、偏度系数、偏度系数的标准误及指定的均数可信 区间。 M-估计量:描述集中趋势的统计量。 界外值:分别输出5个极大值和极小值。 百分位数:输出变量5%、10%、25%、50%、75%、90%、 95%分位数。 ⑥ 绘制设置:单击“绘制”按钮则弹出如图5-17所示对话框, 此对话框用于设置图形的各种特征。 箱图:定义箱图的输出。可以是按因子水平分组绘制,也 可以不分组,或者不绘制。 描述性:定义是否输出茎叶图和直方图; 带检验的正态图:选择是否进行正态检验,且是否输出 相应的Q-Q图。 伸展与级别Levene检验:当选入分组变量时,该功能才被激活,主要用于比较各组之
5.4 数据探索性分析过程
5.4.1 探索性过程的参数设置 选择菜单“分析→描述→探索”
① 变量列表选项栏:用于选入待分析的变量,可以选择的个变量。
② 因变量列表选项栏:用于选择分组变量,根据该变量取值不同,分组分析因 子列表中的变量。
③ 标注个案选项栏:选择标签变量。
④ 输出选项栏:用于定义输出结果,包括两者都、统计量,以及图,系统默认 为两者都。
spss使用教程

2021/8/2
35
2.1 均值(Mean)和均值标准误差(S.E.mean)
2.11 统计学上的定义和计算公式
定义:均值(平均值、平均数)表示的是 某变量所有取值的集中趋势或平均水平。例如, 学生某门学科的平均成绩、公司员工的平均收 入、某班级学生的平均身高等。 计算公式如下。
2021/8/2
36
ห้องสมุดไป่ตู้
• 连续区域输入:用鼠标圈出一块地,在光 标所在单元格(白色那个)输入数据,再 Ctrl+回车,一气呵成。
2021/8/2
23
录入带有变量值标签的数据
在录入带有变量值标签的数据时,用户手 工输入的是实际的变量值,而屏幕上显示的是 与该变量对应的变量值标签。选中“Value Lables”的效
果
2021/8/2
• 4、analyze:SPSS软件统计分析功能的最核心部分。几乎所有的统计分析功能都可以 通过主菜单中的Analyze模块提供的各类过程来完成。
• 5、Transform:数据转换处理菜单,有关数值的计算、重新赋值、缺失值替代等; • 6、Statistics:统计菜单,有关一系列统计方法的应用; • 7、Graphs:作图菜单,有关统计图的制作; • 8、Utilities:用户选项菜单,有关命令解释、字体选择、文件信息、定义输出标题、窗
• 变量按测量精度可以分为定性变量、定序 变 量、定距变量和定比变量几种。SPSS 将其分为定距变量(Scale)、定序变量 (Ordinal)、定类变量(Nominal)。
• 定距变量:年龄、温度、重量、次数等, 包括连续变量和不连续变量。
• 定序变量:职称(高下)、程度(高低) 等。
• 定类变量:职业、性别等。
如何使用SPSS作数据分析

如何使用SPSS作数据分析SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,广泛应用于社会科学领域的数据分析。
本文将介绍如何使用SPSS进行数据分析的基本步骤和常用功能。
一、数据导入与清洗在使用SPSS进行数据分析之前,首先需要将数据导入软件,并对数据进行清洗,确保数据的准确性和完整性。
以下是数据导入与清洗的步骤:1. 打开SPSS软件,并创建一个新的数据文件。
2. 选择导入数据的方式,可以是从Excel、csv等格式导入,也可以手动输入数据。
3. 导入数据后,检查数据是否包含缺失值或异常值。
可以使用SPSS的数据清洗工具进行处理,比如删除缺失值或替代为合适的值。
4. 检查数据的变量类型,确保每个变量的类型正确,比如分类变量、连续变量等。
5. 对需要的变量进行重命名,并添加变量标签,便于后续分析的理解和解释。
二、数据描述统计分析数据描述统计是对数据的基本特征进行概括和描述的分析方法。
SPSS提供了丰富的数据描述统计功能,如均值、标准差、频数分布等。
以下是数据描述统计分析的步骤:1. 运行SPSS软件,打开已经导入并清洗好的数据文件。
2. 选择"统计"菜单下的"描述统计"选项。
3. 在弹出的对话框中,选择需要进行描述统计分析的变量,并选择所需的统计指标,如均值、标准差等。
4. 点击"确定"进行计算,SPSS将输出所选变量的描述统计结果,包括均值、标准差、中位数等。
三、相关性分析相关性分析用于衡量两个或多个变量之间的相关程度,常用于探究变量之间的关系。
SPSS提供了多种相关性分析方法,如皮尔逊相关系数、斯皮尔曼相关系数等。
以下是相关性分析的步骤:1. 打开已导入的数据文件。
2. 选择"分析"菜单下的"相关"选项。
3. 在弹出的对话框中,选择需要进行相关性分析的变量,并选择所需的相关系数方法。
2021年SPSS简明教程(绝对受用)

第一章 SPSS概览--数据分析实例详解欧阳光明(2021.03.07)希望了解SPSS 10.0版具体情况的朋友请参见本网站的。
例1.1 某克山病区测得11例克山病患者与13名健康人的血磷值(mmol/L)如下, 问该地急性克山病患者与健康人的血磷值是否不同(卫统第三版例4.8)?患者: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11健康人: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87解题流程如下:下面就按这几步依次讲解。
§1.1 数据的输入和保存1.1.1 SPSS的界面当打开SPSS后,展现在我们面前的界面如下:请将鼠标在上图中的各处停留,很快就会弹出相应部位的名称。
请注意窗口顶部显示为“SPSS for Windows Data Editor”,表明现在所看到的是SPSS的数据管理窗口。
这是一个典型的Windows软件界面,有菜单栏、工具栏。
特别的,工具栏下方的是数据栏,数据栏下方则是数据管理窗口的主界面。
该界面和EXCEL极为相似,由若干行和列组成,每行对应了一条记录,每列则对应了一个变量。
由于现在我们没有输入任何数据,所以行、列的标号都是灰色的。
请注意第一行第一列的单元格边框为深色,表明该数据单元格为当前单元格。
有的SPSS系统打开时会出现一个导航对话框,请单击右下方的Cancer按钮,即可进入上面的主界面。
1.1.2 定义变量该资料是定量资料,设计为成组设计,因此我们需要建立两个变量,一个变量代表血磷值,习惯上取名为X,另一个变量代表观察对象是健康人还是克山病人,习惯上取名为GROUP。
对数据的统计分析格式不太熟悉的朋友请先学习。
选择菜单Data==>Define Variable。
系统弹出定义变量对话框如下:该变量定义对话框在SPSS 10.0版中已被取消,这里的操作只适合9.0~7.0版的用户。
第16章spss21教程完整版

16.2 多维尺度分析
16.2.2 多维尺度分析过程的参数设置 选择菜单“分析→度量→多维尺度”,则弹出“进行多维尺度分析”对 话框,如图16-12所示。各个选择项的具体功能如下所述。 1.变量设置 如图16-12所示的左边变量框是待分析的变量框,选中变量后,单击按钮 即可 选入变量列表框。 ① 变量列表框,用于选入表示距离的分析变量。 ② 单个矩阵框,用于选入分组变量,分析时将会为每一组变量分别计算距离 矩阵,当选中“从数据创建距离”选项时才可用。
3.选项设置 单击图16-12中的“选项”按钮,则弹出如图16-16所示的“输出设置”对话框。 单击“继续”按钮则返回原界面。 • 组图:多维尺度分析图; • 个别主题图:为每位受试者分别输出分析图形; • 数据矩阵:输出每位受试者的数据矩阵; • 模型和选项摘要:输出分析所有的数据、模型、算法等信息。 (2)标准栏 • S应力收敛性:指定S-stress的最小改变量,默认值为0.001; • 最小S应力值:指定S-stress的最小值,默认值为0.005; • 最大迭代:指定最大的迭代次数。系统默认值为30。 (3)将小于“一个数”距离看作缺失值栏 • 此栏用于把距离小于某值的数据当做缺失值。
16.2.3 实例分析
1.参数设置 选择菜单“分析→度量→多维尺度”,则弹出“进行多维尺度分析”对话框,如 图16-18所示。选中除变量sourceid以外的15个变量到“变量”选项栏中。 选中“选项”按钮,则弹出如图16-19所示对话框,选中“组图”选项,然后单击 “继续”按钮返回主界面。
◆ 从数据创建距离选项:表示用户需要自行选择相识矩阵的计算方法。当数据比较复 杂、不可以直接用做距离矩阵时选择此项,表示从当前数据出发计算距离矩阵,单 击“度量”按钮,则弹出如图16-14所示的“度量”对话框。 • 度量标准栏:用于指定不相似度的测量方法; • 转换值栏:指定标准化转换的方法,这两部分的参数设置;
SPSS21使用教程(最新)

4
SPSS 应用软件试验指导手册
试验1 数据文件管理
一、试验目的与要求
通过本试验项目,使学生理解并掌握 SPSS 软件包有关数据文件创建和整理的 基本操作,学习如何将收集到的数据输入计算机,建成一个正确的 SPSS 数据文件, 并掌握如何对原始数据文件进行整理,包括数据查询,数据修改、删除,数据的排 序等等。
spss应用软件试验指导手册试验1数据文件管理一试验目的与要求通过本试验项目使学生理解并掌握spss软件包有关数据文件创建和整理的基本操作学习如何将收集到的数据输入计算机建成一个正确的spss数据文件并掌握如何对原始数据文件进行整理包括数据查询数据修改删除数据的排序等等
SPSS 应用软件试验指导手册
11
SPSS 应用软件试验指导手册
件进行合并,收集来的数据被放置在一个新的数据文件中。在 SPSS 中实现数据文 件横向合并的方法如下: 选择菜单【数据】→【合并文件】→【添加变量】,选择合并的数据文件,单击 “打开” ,弹出添加变量,如图 2.12 所示。
图 2.12
单击 Ok 执行合并命令。这样,两个数据文件将按观测的顺序一对一地横向 合并。 (5)数据拆分(Split File) 在进行统计分析时, 经常要对文件中的观测进行分组, 然后按组分别进行分析。 例如要求按性别不同分组。在 SPSS 中具体操作如下:
5
SPSS 应用软件试验指导手册
图 2.1 变量视窗
三、试验内容与步骤
1.创建一个数据文件 数据文件的创建分成三个步骤: (1)选择菜单 【文件】→【新建】→【数据】新建一个数据文件,进入数据 编辑窗口。窗口顶部标题为“PASW Statistics 数据编辑器” 。 (2)单击左下角【变量视窗】标签进入变量视图界面,根据试验的设计定义每 个变量类型。 (3)变量定义完成以后,单击【数据视窗】标签进入数据视窗界面,将每个具 体的变量值录入数据库单元格内。 2.读取外部数据 当前版本的 SPSS 可以很容易地读取 Excel 数据,步骤如下: (1)按【文件】→【打开】→【数据】的顺序使用菜单命令调出打开数据对话 框,在文件类型下拉列表中选择数据文件,如图 2.2 所示。
第1章spss21教程完整版

1.2 SPSS操作入门
运行图形化教程; 输入数据; 运行存在的查询文件; 新建数据库查询;
软件界面
行:表示观察 个体,由观察对 象的所有属性组 成; 列:表示变量, 一个变量是所有 观察对象的某个 属性的集合; 数据格:表示 对应观察对象的 某个属性的观察 值或者标签。
变量视图
文件位置
• 打开和保存对 话框的启动文 件夹。 会话日志:所 有运行的命令 将保存在一个 日志文件里, 包括附加模式 和覆盖模式两 种保存方式。
•
其他选项的设置
脚本的设置 多重归因 语法编辑器
1.3 帮助系统
主题选项; 教程选项; 个案研究; 统计辅导; 指令语法参考; SPSS社区。
货币
设定输入格式:用户定 义输出栏,可以设置5种 自定义的格式,分别命名 为CCA,CCB,CCC,CCD 和CCE。 所有值:设置数值的首 尾字符。 前缀,加入前 缀字符;后缀,加入后缀 字符。 负值:设置负数的首尾 字符。 小数分隔符。
输出
轮廓标签,设定输出 时是否使用标签。包 括设置变量标识栏和 设置变量值标识栏。 枢轴表标签,在要 点表格中,设定输出 表格时是否使用标签。
行:表示变量; 列:表示变量 的属性。
输出窗口
输出窗口包括两部分:左边为大纲 视图,右边为显示统计结果。 此结果可以作为输出文件进行保存。 输出窗口有自己的菜单栏,其大部 分菜单与主菜单相同,输出窗口的菜 单也可以执行所有的统计分析功能, 对数据文件进行分析,分析结果直接 显示在输出窗口。 程序中可以打开多个输出窗口,新 开的输出窗口按先后顺序分别标记为 输出1(output1),输出2(output2) 等。 双击输出窗口的生成图形可以进一 步对其进行编辑或修改。
第8章spss21教程完整版

8.4 游程检验
8.4.1 游程检验的参数设置
选择菜单“分析→非参数检验→旧对话框→游程”,则弹出如图8-16所示对话框。 ① 变量选择:如图8-16中左上角为待变量列表。 • 检验变量列表:检验变量选项框,用于放置检验变量,可以选入多个检验变量。 • 割点:断点设置选项,系统提供了4种方法,分别是中位数、均值、众数、设定。 ② 精确设置:与 检验设置对话框一致。 ③ 选项设置:与 检验设置对话框一致。
8.5.2 实例分析
1.参数设置 选择菜单“分析→非参数检验→旧对话框→1样本K-S检验”,则弹出如图8-22所示 对话框,选择变量Number of accidents past 5 years到“检验变量列表”选项栏,去掉 “常规”选项,选中“泊松”选项。
8.6 两独立样本分布位置检验
8.6.1 两独立样本分布位置检验的参数设置
8.9.2 实例分析
1.参数设置 在数据窗口中选择菜单“分析非参数检验→旧对话框 K个相关样本”,打开 “K个相关样本”对话框如图8-53所示。选中所有变量到“检验变量”选项栏中,然 后去掉Friedman选项,选中“Cochran”的Q选项栏。 然后单击图8-53中的“统计量”按钮,弹出如图8-54所示对话框,选中“描述性” 选项,并单击“继续”按钮返回主界面。
选择菜单“分析→非参数检验6→旧对话框→2个独立样本”。 ① 变量选择:如图8-28中左上角为待变量列表。 • 检验变量列表:检验变量选项框,用于放置检验变量,可以选入多个检验变量。 • 分组变量:分组变量框,用于设置分组变量,选入分组变量后,则激活其下的 “定义组”按钮,单击此按钮则弹出如图8-29所示对话框,可以在其中输入两个 分组的取值。 检验类型:选择检验方法。包括四种方法Mann-Whitney的U检验方 法、Moses极端反映检验法、Kolmogorov- Smirnov的Z检验法、Wald-Wolfowitz runs。 ② 精确设置:与 检验设置对话框一致。 ③ 选项设置:与 检验设置对话框一致。
spss入门基本操作ppt课件

Independent Samples Test
Levene's Test for Equality of Variances
t-test for Equality of Means
F Sig. t
95% Confidence
df
Sig. (2- Mean Std. Error tailed) Difference Difference
17
§1.3 按题目要求进行统计分析
下面我们要用SPSS来做成组设计两样本均数比较的t检验,选 择Analyze==>Compare Means==>Independent-Samples T test,系统弹出两样本t检验对话框如下:
18
将变量X选入test框内,变量group选入grouping框内,注意这时 下面的Define Groups按钮变黑,表示该按钮可用,单击它,系统 弹出比较组定义对话框如右图所示:
22
1.4.2 导出分析结果 文件倒是保存了,但问题还没有完全解决:我们从来写文章什么的 都用的是文字处理软件,尤其是WORD,可WORD不能直接读取 SPO格式的文件,怎么办呢?没关系,SPSS提供了将结果导出为纯 文本格式或网页格式的功能,在结果浏览窗口中选择菜单 File==>Export,系统会弹出Exprot Output对话框如下
现在,第一、第二列的名称均为深色显示,表明这两列已 经被定义为变量,其余各列的名称仍为灰色的“var”,表 示尚未使用。同样地,各行的标号也为灰色,表明现在还 未输入过数据,即该数据集内没有记录。
7
1.1.3 输入数据 在Data View中输入相应的数据,一个单元格输入一个数据, Group中输入1代表患者,2代表健康人。
《spss使用教程》课件

01
01
02
03
04
CHAPTER
SPSS在数据分析中的应用
描述市场状况
使用SPSS对市场数据进行统计分析,可以描述市场状况,了解市场趋势和消费者需求。
预测市场趋势
通过SPSS的预测模型,可以对市场趋势进行预测,帮助企业制定合理的营销策略。
竞争分析
利用SPSS对竞争对手进行分析,了解竞争对手的市场份额和营销策略,从而调整自身策略。
情感分析
数据收集
收集消费者对品牌的评价数据,包括品牌知名度、美誉度、忠诚度等。
因子分析
通过因子分析找出影响品牌形象的主要因素,为品牌定位和传播提供依据。
关联规则挖掘
挖掘品牌形象之间的关联规则,发现品牌形象之间的相互影响和关联。
通过SPSS分析品牌形象,了解品牌在消费者心中的认知和评价,为品牌管理和市场推广提供指导。
总结词
数据导入、整理数据
详细描述
在SPSS中,您需要先导入数据才能进行分析。数据可以来自多种来源,如Excel、CSV、数据库等。在导入数据后,您需要检查数据的完整性,并进行必要的整理,如删除重复项、处理缺失值等。
数据编码、数据标签化
总结词
对于某些变量,可能需要进行数据编码或标签化。例如,将分类变量(如性别)转换为数字代码,或将数字变量(如年龄)转换为更易于理解的标签(如儿童、青少年、成人)。
数据收集
收集消费者调查数据,包括消费者的基本信息、购买行为、产品评价等。
描述性统计分析
对数据进行描述性统计分析,如计算频数、均值、标准差等,了解数据的基本特征。
信度分析
通过信度分析检验问卷的一致性,确保数据可靠性。
因子分析
通过因子分析找出影响消费者行为的主要因素,简化数据结构。
spss使用说明

spss使用说明SPSS使用说明1、简介1.1 SPSS的定义SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,被广泛应用于社会科学、市场调研、医学研究和其他领域的数据分析。
1.2 SPSS的功能- 数据清洗和处理- 描述性统计分析- 假设检验- 回归分析- 方差分析- 因子分析- 聚类分析等2、安装和设置2.1 和安装SPSS软件2.2 设置SPSS的语言和界面2.3 建立和管理数据文件夹3、数据输入和编辑3.1 手动输入数据3.2 导入外部数据文件3.3 数据变量的类型和属性设置 3.4 数据缺失值处理3.5 数据标准化和转换4、数据清洗和预处理4.1 数据的筛选和排序4.2 数据的去重和重复值处理 4.3 数据的缺失值填补4.4 异常值处理4.5 数据的合并和拆分4.6 数据的抽样和分层抽样5、描述性统计分析5.1 数据摘要统计量5.2 频数分布表和直方图 5.3 中心趋势度量5.4 离散程度度量5.5 相关分析5.6 拟合曲线和回归分析6、假设检验6.1 统计假设和显著性水平 6.2 单样本t检验6.3 相依样本t检验6.4 独立样本t检验6.5 方差分析6.6 卡方检验6.7 相关性检验7、高级统计分析7.1 回归分析7.2 非参数检验7.3 因子分析7.4 线性判别分析7.5 生存分析7.6 聚类分析8、图表和报告8.1 绘制数据图表8.2 编制统计报告8.3 导出和共享结果附件:本文档提供以下附件,供参考和进一步学习使用:- 示例数据文件- 示例数据分析报告法律名词及注释:1、著作权:指著作权法所规定的对作品享有的权利,包括复制、发行、表演、展览、广播、摄制、改编、翻译等权利。
2、商标:指商标法所保护的标志,用于区分不同商品和服务源自于不同商家的标识。
3、法律责任:指因使用SPSS软件而带来的任何法律风险或责任,用户需自行承担。
spss21中文安装与破解
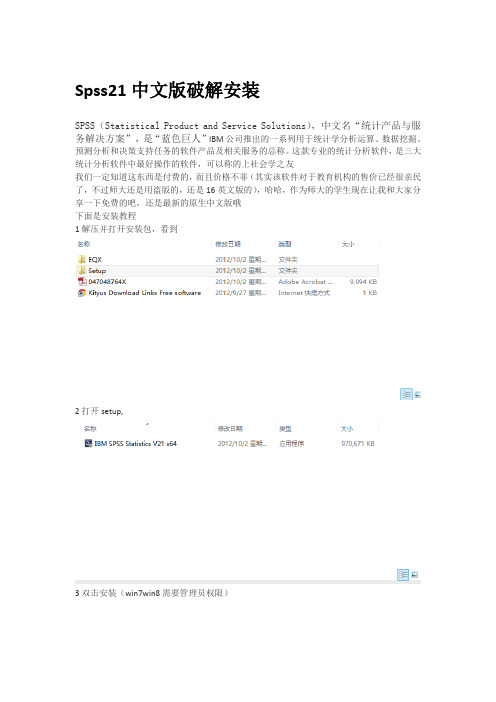
Spss21中文版破解安装SPSS(Statistical Product and Service Solutions),中文名“统计产品与服务解决方案”,是“蓝色巨人”IBM公司推出的一系列用于统计学分析运算、数据挖掘、预测分析和决策支持任务的软件产品及相关服务的总称。
这款专业的统计分析软件,是三大统计分析软件中最好操作的软件,可以称的上社会学之友我们一定知道这东西是付费的,而且价格不菲(其实该软件对于教育机构的售价已经很亲民了,不过师大还是用盗版的,还是16英文版的),哈哈,作为师大的学生现在让我和大家分享一下免费的吧,还是最新的原生中文版哦下面是安装教程1解压并打开安装包,看到2打开setup,3双击安装(win7win8需要管理员权限)3 4下一步注,这里可以选择语言,点击语言前方的图标,选择在本机运行即可,这里默认简体中文,你觉得汉字好看些,也可以选择繁体中文,可多选注:在这里,可以更改一下安装目录,不要放在c盘,造成C盘压力上大2——3分钟后,就安装完毕了不要着急,首次运行软件时会有激活提示,先关掉软件打开安装包中EQX文件,接下来就是见证的时刻1将EQX中的"lservrc"(屏蔽命令)复制到安装目录文件夹里,也就是我刚才更改安装目录后的文件夹2然后打开“许可证授权向导”也就是这个图标,非win8可以在开始菜单里找到3输入授权密码QA3AW8U62Z4ZWTSPV44VXI65P59OLE547WHIQVZYWLARL9JEYQEGDUBLH8Z3ZCJAL3FLXMS98V 95TSDYI7FOEXUPRR看到“许可证到期日期:无”了吗,我们成功了,打开SPSS,让他为你服务吧谢谢,谢谢spss的三位斯坦福的前辈,谢谢IBM。
第22章spss21教程完整版

1.变量 • 因变量:用于选入因变量; • 因子:用于选入因变量; • 协变量:用于设置协变量; • 协变量重标度:用于设置协变量的标度,其下拉菜单中有四个选择项,分别是标准 化、Normalized、调整,以及None。 2.分区 单击图22-3中的“分区”标签,则弹出如图22-4所示的对话框。 ① 变量:用于存放待分析的变量。 ② 分区数据集:用于设置分区数据集, 有两个选项。 • 根据个案的相对数量随机分配个案: 根据个案的相对数量随机的分配个案, 其下的选项栏有分区、相对数量、培训、 检验、支持、总计。 • 使用分区变量分配个案:使用分区变 量分配个案,其下的分区变量表示分区 变量。
3.选项设置 单击图22-11中的“选项”标签,则弹出如图22-13所示的对话框各部分组成如下所 述。 • 用户缺失值。 • ① 指定如何使用因子及类别因变量的用户缺失值处理个案。其下有两个选项即 • 排除; • 包括。 • ② 具有用户缺失值协变量或者尺度因变量的个案始终被视为无效
22.3 实例分析
第二十二章 神经网络
神经网络的概述
SPSS神经网络模型的参数设置 实例分析
22.2 SPSS神经网络模型的设置
22.2.1 多层感知器(MLP)的设置
选择菜单“分析→神经网络→多层感知器”,则弹出如图22-3所示的对话框,此对话框 用于设置多层感知器的各种参数。此界面中共有8个标签,即Variables(变量)、 Partitions(分区)、Architecture(体系结构)、Training(培训)、Output(输出)、 Save(保存)、Export(导出)、Options(选项)。
4.培训 单击图22-5中的“培训”标签,则弹出如图22-6所示的对话框。 ① 培训类型。 • 批处理; • 在线; • 袖珍型批处理,选择此项后激活其下的选项栏,自动计算表示自动计算;设定表示 拥护自定义,在其下的记录数选项栏中填入记录数。 ② 优化算法。 • 调整的共轭梯度法; • 梯度下降法。 ③ 培训选项。 • 初始Lambda值; • 初始的Sigma值; • 初始的中心点; • 间隔偏移量。
SPSS软件的基本操作教程

选择所有数据
随机选取数据
用过滤器变量 选取数据
数据的选择
根据逻辑关系表 达式选择数据
数据文件的编辑
在给定范围(日期、时间 或个案号等)内选择数据
删除个案
剔除个案(斜杠)
数据文件的编辑
数据的选择(逻辑关系表达式举例)
选择男性并且年龄大于等于35 岁且小于等于74岁的个案
数据的加权
数据文件的编辑
加权是一种通过人为方法来调节样本或数据大小的方法, 在样本分析和科学评价中经常用到。所谓加权,就是给被加权 对象乘上一个系数。
撤消等,以及系统参数设置 View:选择显示状态条、工具栏、网格线、变量标签、变量
视图及字体设置等 Data: 实现文件级别的数据管理,如记录排序、记录拆分、
记录筛选、合并文件等 Transform:实现变量级别的数据管理,如计算新变量、变
量值的分组合并、连续变量的可视化分段等
SPSS菜单栏
Analyze:SPSS的重点菜单项,涵盖各种主要统计分析功能 Graphs:绘制各种普通统计图及交互式统计图,如直方图、
变量的相关操作
• 变量名(Name)的定名规则 • 变量类型(Type) • 变量宽度(Width)和小数位数(Decimal) • 变量标签(Label) • 变量赋值(Value) • 变量缺失值的定义(Missing) • 列宽(Column)和位置(Align) • 度量类型(Measure)
数据的合并
数据文件的编辑
对于存在某种联系的两个数据文件,可以用SPSS的合并功能 将它们按照一定的方式进行合并。
SPSS提供了两种方式来合并数据文件的数据:个案合并(Add Cases)和变量合并(Add Variables)。
第3章spss21教程完整版(精品课件)

数据文件保存
选择菜单“文件(File)→保存(Save)”SPSS可以将数据保存为SPSS (*.sav)、Excel(*.xls)、dBASE(*.dbf)、ASCII(*.dat,*txt)等数据文件形 式。在弹出的“保存文件”对话框里,指定保存路径,输入文件名,确定数 据类型,最后单击“保存(save)”按钮。
LAG(variable,ncases)
(变量名,自 然数n)
数值型函数
MAX(ivalue,value[,…])
(变量名,变 量名,…)
数值型函数
MEAN(numexpr,numexpr,…)
(变量名,变 量名,…)
数值型函数
MIN(value,value[,…])
(变量名,变 量名,…)
数值型函数
编辑变量
1、 名称(Name)选项 用于输入字符(汉字和
英文)作为变量的名称,如 不输入名称, 系统依次默 认为“var00001”, “var00002”,“var00003”
变量名应遵循下列原则: 在SPSS21.0中没有限制。 首字符必须是字母或汉字,不能以下划线“_”或圆点“.”结尾。 变量名不能有空格或某些特殊符号,如“!?*”等。 变量名不能与SPSS的关键字相同,即不能用ALL、AND、BY、EQ、GT、LE等。
9.对齐(Align)选项 对齐方式:有左中右三种数据显示方式。
10.度量标准(Measure)选项 度量标准:按度量精度将变量分为定量变量、等级变量和定性变量。 该选项仅用于统计绘图时坐标轴变量的区分,以及决策树模块的变量 定义。定量变量,如虫口数、死亡率等;等级变量,如防治效果的好、 不好等;定性变量,如害虫抗药性发生低抗、中抗和高抗。
11.角色选项 角色包括输入、目标,两者都是无分区拆分。
SPSS基本操作步骤详解

SPSS基本操作步骤详解本文采用SPSS21.0版本,其它版本操作步骤大体相同一、基本步骤(一)检查数据在进行项目分析或统计分析之前,要检核输入的数据文件有无错误,即检核missing。
例,“XX量表”采用Likert scale五点量表式填答,每个题项的数据只有五个水平:1,2,3,4,5。
1.执行次数分布表的程序Analyze(分析)→Descriptive statistics(描述统计)→将题项变量【例,a1—a10】键入至Variables(变量)框中→Frequencies(频率)→Statistics(统计量)→Minimum (最小值)、Maximum(最大值)→Continue(继续)→OK(确定)2.执行描述统计量的程序Analyze(分析)→(描述统计)→将题项变量【例,a1—a10】键入至Variables(变量)框中→Descriptives(描述)→Options(选项)→Minimum(最小值)、Maximum(最大值)【此处一般为默认状态即可】→Continue(继续)→OK(确定)(二)反项计分若是分析的预试量表中没有反向题,则此操作步骤可以省略;量表或问卷题中如果有反向题,则在进行题项加总之前将反向题反向计分,否则测量分数所表示的意义刚好相反。
例,“XX量表”采用Likert scale五点量表式填答,反向题重向编码计分:1→5,2→4,3→3【可不写】,4→2,5→1。
Transform(转换)→Recode into same Variables(重新编码为相同变量)→将要反向的题目键入至Variables(变量)框中【例,a1,a3,a5】→Old and new values(旧值和新值)→在左边Old value—value中键入1,在右边New value—value中键入5,Add (添加)→……依次进行此步骤……在左边Old value—value中键入5,在右边New value —value中键入1,Add(添加)→Continue(继续)→OK(确定)【注意不同量表计分方式不同,因而反向编码计分也不同,常见的有四点量表、五点量表和六点量表等】(三)题项加总量表题项加总的目的在于便于进行观察值得高低分组。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SPSS工具简介最新统计要与大量的数据打交道,涉及繁杂的计算和图表绘制。
现代的数据分析工作如果离开统计软件几乎是无法正常开展。
在准确理解和掌握了各种统计方法原理之后,再来掌握几种统计分析软件的实际操作,是十分必要的。
常见的统计软件有SAS,SPSS,MINITAB,EXCEL等。
这些统计软件的功能和作用大同小异,各自有所侧重。
其中的SAS和SPSS是目前在大型企业、各类院校以及科研机构中较为流行的两种统计软件。
特别是SPSS,其界面友好、功能强大、易学、易用,包含了几乎全部尖端的统计分析方法,具备完善的数据定义、操作管理和开放的数据接口以及灵活而美观的统计图表制作。
SPSS在各类院校以及科研机构中更为流行。
SPSS(Statistical Product and Service Solutions,意为统计产品与服务解决方案)。
自20世纪60年代SPSS诞生以来,为适应各种操作系统平台的要求经历了多次版本更新,各种版本的SPSS for Windows大同小异,在本试验课程中我们选择PASW Statistics 20.0作为统计分析应用试验活动的工具。
1.SPSS的运行模式SPSS主要有三种运行模式:(1)批处理模式这种模式把已编写好的程序(语句程序)存为一个文件,提交给[开始]菜单上[SPSS for Windows]→[Production Mode Facility]程序运行。
(2)完全窗口菜单运行模式这种模式通过选择窗口菜单和对话框完成各种操作。
用户无须学会编程,简单易用。
(3)程序运行模式这种模式是在语句(Syntax)窗口中直接运行编写好的程序或者在脚本(script)窗口中运行脚本程序的一种运行方式。
这种模式要求掌握SPSS的语句或脚本语言。
本试验指导手册为初学者提供入门试验教程,采用“完全窗口菜单运行模式”。
2.SPSS的启动(1)在windows[开始]→[程序]→[PASW],在它的次级菜单中单击“SPSS 12.0 for Windows”即可启动SPSS软件,进入SPSS for Windows对话框,如图1.1,图1.2所示。
图1.1 SPSS启动图1.1 PASW Statistics 启动对话框3.SPSS软件的退出SPSS软件的退出方法与其他Windows应用程序相同,有两种常用的退出方法:♦按的顺序使用菜单命令退出程序。
♦直接单击SPSS窗口右上角的“关闭”按钮,回答系统提出的是否存盘的问题之后即可安全退出程序。
4.SPSS的主要窗口介绍SPSS 软件运行过程中会出现多个界面,各个界面用处不同。
其中,最主要的界面有三个:数据编辑窗口、结果输出窗口和语句窗口。
(1) 数据编辑窗口启动SPSS 后看到的第一个窗口便是数据编辑窗口,如图1.3所示。
在数据编辑窗口中可以进行数据的录入、编辑以及变量属性的定义和编辑,是SPSS 的基本界面。
主要由以下几部分构成:标题栏、菜单栏、工具栏、编辑栏、变量名栏、观测序号、窗口切换标签、状态栏。
图1.3 数据浏览界面♦ 标题栏:显示数据编辑的数据文件名。
♦ 菜单栏:通过对这些菜单的选择,用户可以进行几乎所有的SPSS 操作。
关于菜单的详细的操作步骤将在后续实验内容中分别介绍。
为了方便用户操作,SPSS 软件把菜单项中常用的命令放到了工具栏里。
当鼠标停留在某个工具栏按钮上时,会自动跳出一个文本框,提示当前按钮的功能。
另外,如果用户对系统预设的工具栏设置不满意,也可以用[视图]→[工具栏] →[设定]命令对工具栏按钮进行定义。
♦ 编辑栏:可以输入数据,以使它显示在内容区指定的方格里。
♦ 变量名栏:列出了数据文件中所包含变量的变量名菜单栏工具栏编辑栏观测序号 变量名栏窗口切换标签状态栏标题栏♦观测序号:列出了数据文件中的所有观测值。
观测的个数通常与样本容量的大小一致。
♦窗口切换标签:用于“数据视图”和“变量视图”的切换。
即数据浏览窗口与变量浏览窗口。
数据浏览窗口用于样本数据的查看、录入和修改。
变量浏览窗口用于变量属性定义的输入和修改。
♦状态栏:用于说明显示SPSS当前的运行状态。
SPSS被打开时,将会显示“PASW Statistics Processor”的提示信息。
(2)结果输出窗口在SPSS中大多数统计分析结果都将以表和图的形式在结果观察窗口中显示。
窗口右边部分显示统计分析结果,左边是导航窗口,用来显示输出结果的目录,可以通过单击目录来展开右边窗口中的统计分析结果。
当用户对数据进行某项统计分析,结果输出窗口将被自动调出。
当然,用户也可以通过双击后缀名为.spo的SPSS 输出结果文件来打开该窗口。
试验1 数据文件管理一、试验目的与要求通过本试验项目,使学生理解并掌握SPSS软件包有关数据文件创建和整理的基本操作,学习如何将收集到的数据输入计算机,建成一个正确的SPSS数据文件,并掌握如何对原始数据文件进行整理,包括数据查询,数据修改、删除,数据的排序等等。
二、试验原理SPSS数据文件是一种结构性数据文件,由数据的结构和数据的内容两部分构成,也可以说由变量和观测两部分构成。
一个典型的SPSS数据文件如表2.1 所示。
表2.1 SPSS数据文件结构SPSS变量的属性SPSS中的变量共有10个属性,分别是变量名(Name)、变量类型(Type)、长度(Width)、小数点位置(Decimals)、变量名标签(Label)、变量名值标签(Value)、缺失值(Missing)、数据列的显示宽度(Columns)、对其方式(Align)和度量尺度(Measure)。
定义一个变量至少要定义它的两个属性,即变量名和变量类型,其他属性可以暂时采用系统默认值,待以后分析过程中如果有需要再对其进行设置。
在spss数据编辑窗口中单击“变量视窗”标签,进入变量视窗界面(如图2.1所示)即可对变量的各个属性进行设置。
图2.1 变量视窗三、试验内容与步骤1.创建一个数据文件数据文件的创建分成三个步骤:(1)选择菜单【文件】→【新建】→【数据】新建一个数据文件,进入数据编辑窗口。
窗口顶部标题为“PASW Statistics数据编辑器”。
(2)单击左下角【变量视窗】标签进入变量视图界面,根据试验的设计定义每个变量类型。
(3)变量定义完成以后,单击【数据视窗】标签进入数据视窗界面,将每个具体的变量值录入数据库单元格内。
2.读取外部数据当前版本的SPSS可以很容易地读取Excel数据,步骤如下:(1)按【文件】→【打开】→【数据】的顺序使用菜单命令调出打开数据对话框,在文件类型下拉列表中选择数据文件,如图2.2所示。
图2.2 Open File对话框(2)选择要打开的Excel文件,单击“打开”按钮,调出打开Excel数据源对话框,如图2.3所示。
对话框中各选项的意义如下:工作表下拉列表:选择被读取数据所在的Excel工作表。
范围输入框:用于限制被读取数据在Excel工作表中的位置。
图2.3 Open Excel Data Source对话框3.数据编辑在SPSS中,对数据进行基本编辑操作的功能集中在Edit和Data菜单中。
4.SPSS数据的保存SPSS数据录入并编辑整理完成以后应及时保存,以防数据丢失。
保存数据文件可以通过【文件】→【保存】或者【文件】→【另存为】菜单方式来执行。
在数据保存对话框(如图2.5所示)中根据不同要求进行SPSS数据保存。
图2.5 SPSS数据的保存5. 数据整理在SPSS中,数据整理的功能主要集中在【数据】和【转换】两个主菜单下。
(1)数据排序(Sort Case)对数据按照某一个或多个变量的大小排序将有利于对数据的总体浏览,基本操作说明如下:选择菜单【数据】→【排列个案】,打开对话框,如图2.7所示。
(2)抽样(Select Case)在统计分析中,有时不需要对所有的观测进行分析,而可能只对某些特定的对象有兴趣。
利用SPSS的Select Case命令可以实现这种样本筛选的功能。
以SPSS安装配套数据文件Growth study.sav为例,选择年龄大于10的观测,基本操作说明图2.7 排列个案对话框如下:♦打开数据文件Growth study.sav,选择【数据】→【选择个案】命令,打开对话框,如图2.8图2.8 选择个案对话框♦指定抽样的方式:【全部个案】不进行筛选;【如果条件满足】按指定条件进行筛选。
本例设置:产品数量>150,如图2.9所示;图2.9 选择个案对话框设置完成以后,点击continue,进入下一步。
♦确定未被选择的观测的处理方法,这里选择默认选项【过滤掉未选定的个案】。
♦单击ok进行筛选,结果如图2.10图2.10 选择个案的结果(3)增加个案的数据合并(【合并文件】→【添加个案】)将新数据文件中的观测合并到原数据文件中,在SPSS中实现数据文件纵向合并的方法如下:选择菜单【数据】→【合并文件】→【添加个案】,如图2.11,选择需要追加的数据文件,单击打开按钮,弹出Add Cases对话框,如图2.12。
图2.11 选择个体数据来源的文件图2.12 选择变量(4)增加变量的数据合并(【合并文件】→【添加变量】)增加变量时指把两个或多个数据文件实现横向对接。
例如将不同课程的成绩文件进行合并,收集来的数据被放置在一个新的数据文件中。
在SPSS中实现数据文件横向合并的方法如下:选择菜单【数据】→【合并文件】→【添加变量】,选择合并的数据文件,单击“打开”,弹出添加变量,如图2.12所示。
图2.12♦单击Ok执行合并命令。
这样,两个数据文件将按观测的顺序一对一地横向合并。
(5)数据拆分(Split File)在进行统计分析时,经常要对文件中的观测进行分组,然后按组分别进行分析。
例如要求按性别不同分组。
在SPSS中具体操作如下:♦选择菜单【数据】→【分割文件】,打开对话框,如图2.13所示。
图2.13 分割文件对话框♦选择拆分数据后,输出结果的排列方式,该对话框提供了3种方式:对全部观测进行分析,不进行拆分;在输出结果种将各组的分析结果放在一起进行比较;按组排列输出结果,即单独显示每一分组的分析结果。
♦选择分组变量♦选择数据的排序方式♦单击ok按钮,执行操作(6)计算新变量在对数据文件中的数据进行统计分析的过程中,为了更有效地处理数据和反映事务的本质,有时需要对数据文件中的变量加工产生新的变量。
比如经常需要把几个变量加总或取加权平均数,SPSS中通过【计算】菜单命令来产生这样的新变量,其步骤如下:♦选择菜单【转换】→【计算变量】,打开对话框,如图2.14所示。
图2.14 Compute Variable对话框♦在目标变量输入框中输入生成的新变量的变量名。