函数调用栈
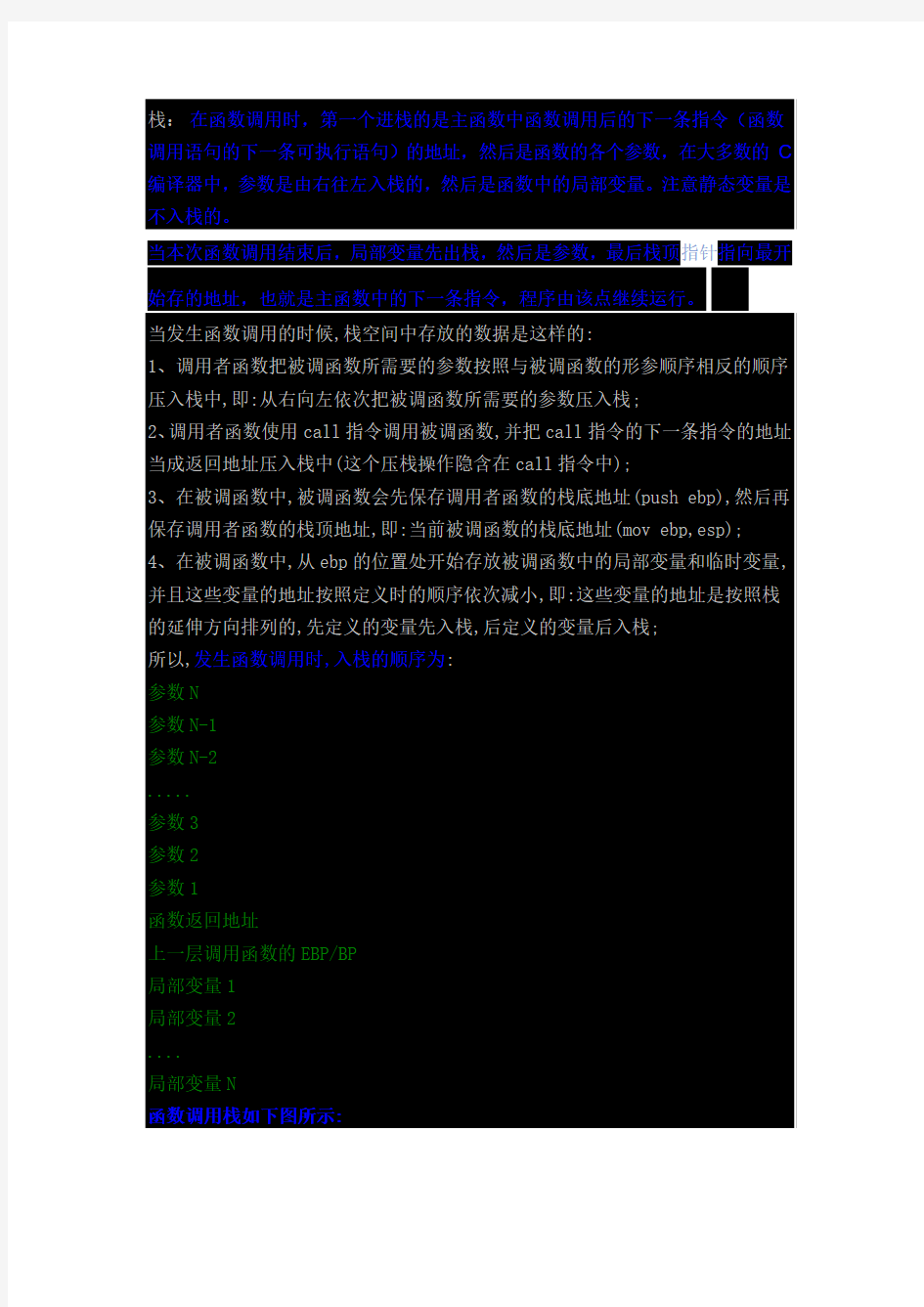

栈:在函数调用时,第一个进栈的是主函数中函数调用后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的C 编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
当发生函数调用的时候,栈空间中存放的数据是这样的:
1、调用者函数把被调函数所需要的参数按照与被调函数的形参顺序相反的顺序压入栈中,即:从右向左依次把被调函数所需要的参数压入栈;
2、调用者函数使用call指令调用被调函数,并把call指令的下一条指令的地址当成返回地址压入栈中(这个压栈操作隐含在call指令中);
3、在被调函数中,被调函数会先保存调用者函数的栈底地址(push ebp),然后再保存调用者函数的栈顶地址,即:当前被调函数的栈底地址(mov ebp,esp);
4、在被调函数中,从ebp的位置处开始存放被调函数中的局部变量和临时变量,并且这些变量的地址按照定义时的顺序依次减小,即:这些变量的地址是按照栈的延伸方向排列的,先定义的变量先入栈,后定义的变量后入栈;
所以,发生函数调用时,入栈的顺序为:
参数N
参数N-1
参数N-2
.....
参数3
参数2
参数1
函数返回地址
上一层调用函数的EBP/BP
局部变量1
局部变量2
....
局部变量N
函数调用栈如下图所示:
解释:
首先,将调用者函数的EBP入栈(push ebp),然后将调用者函数的栈顶指针ESP 赋值给被调函数的EBP(作为被调函数的栈底,mov ebp,esp),此时,EBP寄存器处于一个非常重要的位置,该寄存器中存放着一个地址(原EBP入栈后的栈顶),以该地址为基准,向上(栈底方向)能获取返回地址、参数值,向下(栈顶方向)能获取函数的局部变量值,而该地址处又存放着上一层函数调用时的EBP值;
一般而言,SS: [ebp+4]处为被调函数的返回地址,SS:[EBP+8]处为传递给被调函数的第一个参数(最后一个入栈的参数,此处假设其占用4字节内存)的
值,SS:[EBP-4]处为被调函数中的第一个局部变量,SS:[EBP]处为上一层EBP值;
由于EBP中的地址处总是"上一层函数调用时的EBP 值",而在每一层函数调用中,都能通过当时的EBP值"向上(栈底方向)能获取返回地址、参数值,向下(栈顶方向)能获取被调函数的局部变量值";
如此递归,就形成了函数调用栈;
函数内局部变量布局示例:
#include
#include
struct C
{
int a;
int b;
int c;
};
int test2(int x, int y, int z)
{
printf("hello,test2\n");
return 0;
}
int test(int x, int y, int z)
{
int a = 1;
int b = 2;
int c = 3;
struct C st;
printf("addr x = %u\n",(unsigned int)(&x));
printf("addr y = %u\n",(unsigned int)(&y));
printf("addr z = %u\n",(unsigned int)(&z));
printf("addr a = %u\n",(unsigned int)(&a));
printf("addr b = %u\n",(unsigned int)(&b));
printf("addr c = %u\n",(unsigned int)(&c));
printf("addr st = %u\n",(unsigned int)(&st));
printf("addr st.a = %u\n",(unsigned int)(&st.a));
printf("addr st.b = %u\n",(unsigned int)(&st.b));
printf("addr st.c = %u\n",(unsigned int)(&st.c)); return 0;
}
int main(int argc, char** argv)
{
int x = 1;
int y = 2;
int z = 3;
test(x,y,z);
printf("x = %d; y = %d; z = %d;\n", x,y,z); memset(&y, 0, 8);
printf("x = %d; y = %d; z = %d;\n", x,y,z); return 0;
}
打印输出如下:
addr x = 4288282272
addr y = 4288282276
addr z = 4288282280
addr a = 4288282260
addr b = 4288282256
addr c = 4288282252
addr st = 4288282240
addr st.a = 4288282240
addr st.b = 4288282244
addr st.c = 4288282248
a = 1;
b = 2;
c = 3;
a = 0;
b = 0;
c = 3;
示例效果图:
该图中的局部变量都是在该示例中定义的;
这个图片中反映的是一个典型的函数调用栈的内存布局;
访问函数的局部变量和访问函数参数的区别:
局部变量总是通过将ebp减去偏移量来访问,函数参数总是通过将ebp加上偏移量来访问。对于32位变量而言,第一个局部变量位于ebp-4,第二个位于ebp-8,以此类推,32位局部变量在栈中形成一个逆序数组;第一个函数参数位于ebp+8,第二个位于ebp+12,以此类推,32位函数参数在栈中形成一个正序数组。
汇编代码示例(1):
////////////////////////////////////////////////////////////////////
比如我们有这样一个C函数
#include
long test(int a,int b)
{
a = a + 1;
b = b + 100;
return a + b;
}
void main()
{
printf("%d",test(1000,2000));
}
写成32位汇编就是这样
;//////////////////////////////////////////////////////////////////////////////////////////////////////
.386
.model flat,stdcall ;这里我们用stdcall 就是函数参数压栈的时候从最后一个开始压,和被调用函数负责清栈
option casemap:none ;区分大小写
includelib msvcrt.lib ;这里是引入类库相当于#include
printf PROTO C:DWORD,:VARARG ;这个就是声明一下我们要用的函数头,到时候汇编程序会自动到msvcrt.lib里面找的了
;:VARARG 表后面的参数不确定因为C就是这样的printf(const char *, ...); ;这样的函数要注意不是被调用函数负责清栈因为它本身不知道有多少个参数;而是有调用者负责清栈下面会详细说明
.data
szTextFmt BYTE '%d',0 ;这个是用来类型转换的,跟C的一样,字符用字节类型
a dword 1000 ;假设
b dword 2000 ;处理数值都用双字没有int 跟long 的区别
;/////////////////////////////////////////////////////////////////////////////////////////
.code
_test proc ;A:DWORD,B:DWORD
push ebp
mov ebp,esp
mov eax,dword ptr ss:[ebp+8]
add eax,1
mov edx,dword ptr ss:[ebp+0Ch]
add edx,100
add eax,edx
pop ebp
retn 8
_test endp
_main proc
push dword ptr ds:b ;反汇编我们看到的b就不是b了而是一个[*****]数字dword ptr 就是我们在ds(数据段)把[*****]
;开始的一个双字长数值取出来
push dword ptr ds:a ;跟她对应的还有byte ptr ****就是取一个字节出来比如这样mov al,byte ptr ds:szTextFmt
;就把% 取出来而不包括d
call _test
push eax ;假设push eax的地址是×××××
push offset szTextFmt
call printf
add esp,8
ret
_main endp
end _main
汇编代码示例(2):
研究函数的调用过程
int bar(int c, int d)
{
int e = c + d;
return e;
int foo(int a, int b)
{
return bar(a, b);
}
int main(void)
{
foo(2, 3);
return 0;
}
如果在编译时加上-g选项(在第10 章gdb讲过-g选项),那么用objdump反汇编时可以把C代码和汇编代码穿插起来显示,这样C代码和汇编代码的对应关系看得更清楚。反汇编的结果很长,以下只列出我们关心的部分。
$ gcc main.c -g
$ objdump -dS a.out
...
08048394
int bar(int c, int d)
{
8048394: 55 push %ebp
8048395: 89 e5 mov %esp,%ebp
8048397: 83 ec 10 sub $0x10,%esp
int e = c + d;
804839a: 8b 55 0c mov 0xc(%ebp),%edx
804839d: 8b 45 08 mov 0x8(%ebp),%eax
80483a0: 01 d0 add %edx,%eax
80483a2: 89 45 fc mov %eax,-0x4(%ebp)
return e;
80483a5: 8b 45 fc mov -0x4(%ebp),%eax
80483a8: c9 leave
80483a9: c3 ret
080483aa
int foo(int a, int b)
{
80483aa: 55 push %ebp
80483ab: 89 e5 mov %esp,%ebp
80483ad: 83 ec 08 sub $0x8,%esp
return bar(a, b);
80483b0: 8b 45 0c mov 0xc(%ebp),%eax 80483b3: 89 44 24 04 mov %eax,0x4(%esp) 80483b7: 8b 45 08 mov 0x8(%ebp),%eax 80483ba: 89 04 24 mov %eax,(%esp)
80483bd: e8 d2 ff ff ff call 8048394
}
80483c2: c9 leave
80483c3: c3 ret
080483c4
int main(void)
{
80483c4: 8d 4c 24 04 lea 0x4(%esp),%ecx 80483c8: 83 e4 f0 and $0xfffffff0,%esp 80483cb: ff 71 fc pushl -0x4(%ecx)
80483ce: 55 push %ebp
80483cf: 89 e5 mov %esp,%ebp
80483d1: 51 push %ecx
80483d2: 83 ec 08 sub $0x8,%esp
foo(2, 3);
80483d5: c7 44 24 04 03 00 00 movl $0x3,0x4(%esp)
80483dc: 00
80483dd: c7 04 24 02 00 00 00 movl $0x2,(%esp)
80483e4: e8 c1 ff ff ff call 80483aa
return 0;
80483e9: b8 00 00 00 00 mov $0x0,%eax
}
80483ee: 83 c4 08 add $0x8,%esp
80483f1: 59 pop %ecx
80483f2: 5d pop %ebp
80483f3: 8d 61 fc lea -0x4(%ecx),%esp
80483f6: c3 ret
...
要查看编译后的汇编代码,其实还有一种办法是gcc -S main.c,这样只生成汇编代码main.s,而不生成二进制的目标文件。
整个程序的执行过程是main调用foo,foo调用bar,我们用gdb跟踪程序的执行,直到bar函数中的int e = c + d;语句执行完毕准备返回时,这时在gdb中打印函数栈帧。
(gdb) start
...
main () at main.c:14
14 foo(2, 3);
(gdb) s
foo (a=2, b=3) at main.c:9
9 return bar(a, b);
(gdb) s
bar (c=2, d=3) at main.c:3
3 int e = c + d;
(gdb) disassemble
Dump of assembler code for function bar:
0x08048394
0x08048395
0x08048397
0x0804839a
0x0804839d
0x080483a0
0x080483a2
0x080483a9
End of assembler dump.
(gdb) si
0x0804839d 3 int e = c + d;
(gdb) si
0x080483a0 3 int e = c + d;
(gdb) si
0x080483a2 3 int e = c + d;
(gdb) si
4 return e;
(gdb) si
5 }
(gdb) bt
#0 bar (c=2, d=3) at main.c:5
#1 0x080483c2 in foo (a=2, b=3) at main.c:9 #2 0x080483e9 in main () at main.c:14 (gdb) info registers
eax 0x5 5
ecx 0xbff1c440 -1074674624
edx 0x3 3
ebx 0xb7fe6ff4 -1208061964
esp 0xbff1c3f4 0xbff1c3f4
ebp 0xbff1c404 0xbff1c404
esi 0x8048410 134513680
edi 0x80482e0 134513376
eip 0x80483a8 0x80483a8
eflags 0x200206 [ PF IF ID ]
cs 0x73 115
ss 0x7b 123
ds 0x7b 123
es 0x7b 123
fs 0x0 0
gs 0x33 51
(gdb) x/20 $esp
0xbff1c3f4: 0x00000000 0xbff1c6f7 0xb7efbdae 0x00000005
0xbff1c404: 0xbff1c414 0x080483c2 0x00000002 0x00000003
0xbff1c414: 0xbff1c428 0x080483e9 0x00000002 0x00000003
0xbff1c424: 0xbff1c440 0xbff1c498 0xb7ea3685 0x08048410
0xbff1c434: 0x080482e0 0xbff1c498 0xb7ea3685 0x00000001
(gdb)
这里又用到几个新的gdb命令。disassemble可以反汇编当前函数或者指定的函数,单独用disassemble命令是反汇编当前函数,如果disassemble命令后面跟函数名或地址则反汇编指定的函数。以前我们讲过step命令可以一行代码一行代码地单步调试,而这里用到的si命令可以一条指令一条指令地单步调试。info registers可以显示所有寄存器的当前值。在gdb中表示寄存器名时前面要加个$,例如p $esp可以打印esp寄存器的值,在上例中esp寄存器的值是0xbff1c3f4,所以x/20 $esp命令查看内存中从0xbff1c3f4地址开始的20个32位数。在执行程序时,操作系统为进程分配一块栈空间来保存函数栈帧,esp寄存器总是指向栈顶,在x86平台上这个栈是从高地址向低地址增长的,我们知道每次调用一个函数都要分配一个栈帧来保存参数和局部变量,现在我们详细分析这些数据在栈空间的布局,根据gdb的输出结果图示如下[29]:
图19.1. 函数栈帧
图中每个小方格表示4个字节的内存单元,例如b: 3这个小方格占的内存地址是0xbff1c420~0xbff1c423,我把地址写在每个小方格的下边界线上,是为了强调该地址是内存单元的起始地址。我们从main函数的这里开始看起:
foo(2, 3);
80483d5: c7 44 24 04 03 00 00 movl $0x3,0x4(%esp)
80483dc: 00
80483dd: c7 04 24 02 00 00 00 movl $0x2,(%esp)
80483e4: e8 c1 ff ff ff call 80483aa
return 0;
80483e9: b8 00 00 00 00 mov $0x0,%eax
要调用函数foo先要把参数准备好,第二个参数保存在esp+4指向的内存位置,第一个参数保存在esp指向的内存位置,可见参数是从右向左依次压栈的。然后执行call指令,这个指令有两个作用:
1. foo函数调用完之后要返回到call的下一条指令继续执行,所以把call的
下一条指令的地址0x80483e9压栈,同时把esp的值减4,esp的值现在是0xbff1c418。
2. 修改程序计数器eip,跳转到foo函数的开头执行。
现在看foo函数的汇编代码:
int foo(int a, int b)
{
80483aa: 55 push %ebp
80483ab: 89 e5 mov %esp,%ebp
80483ad: 83 ec 08 sub $0x8,%esp
push %ebp指令把ebp寄存器的值压栈,同时把esp的值减4。esp的值现在是
0xbff1c414,下一条指令把这个值传送给ebp寄存器。这两条指令合起来是把原来ebp的值保存在栈上,然后又给ebp赋了新值。在每个函数的栈帧中,ebp指向栈底,而esp指向栈顶,在函数执行过程中esp随着压栈和出栈操作随时变化,而ebp是不动的,函数的参数和局部变量都是通过ebp的值加上一个偏移量来访问,例如foo函数的参数a和b分别通过ebp+8和ebp+12来访问。所以下面的指令把参数a和b再次压栈,为调用bar函数做准备,然后把返回地址压栈,调用bar函数:
return bar(a, b);
80483b0: 8b 45 0c mov 0xc(%ebp),%eax
80483b3: 89 44 24 04 mov %eax,0x4(%esp)
80483b7: 8b 45 08 mov 0x8(%ebp),%eax
80483ba: 89 04 24 mov %eax,(%esp)
80483bd: e8 d2 ff ff ff call 8048394
现在看bar函数的指令:
int bar(int c, int d)
{
8048394: 55 push %ebp
8048395: 89 e5 mov %esp,%ebp
8048397: 83 ec 10 sub $0x10,%esp
int e = c + d;
804839a: 8b 55 0c mov 0xc(%ebp),%edx
804839d: 8b 45 08 mov 0x8(%ebp),%eax
80483a0: 01 d0 add %edx,%eax
80483a2: 89 45 fc mov %eax,-0x4(%ebp)
这次又把foo函数的ebp压栈保存,然后给ebp赋了新值,指向bar函数栈帧的栈底,通过ebp+8和ebp+12分别可以访问参数c和d。bar函数还有一个局部变量e,可以通过ebp-4来访问。所以后面几条指令的意思是把参数c和d取出来存在寄存器中做加法,计算结果保存在eax寄存器中,再把eax寄存器存回局部变量e的内存单元。
在gdb中可以用bt命令和frame命令查看每层栈帧上的参数和局部变量,现在可以解释它的工作原理了:如果我当前在bar函数中,我可以通过ebp找到bar 函数的参数和局部变量,也可以找到foo函数的ebp保存在栈上的值,有了foo 函数的ebp,又可以找到它的参数和局部变量,也可以找到main函数的ebp保存在栈上的值,因此各层函数栈帧通过保存在栈上的ebp的值串起来了。
现在看bar函数的返回指令:
return e;
80483a5: 8b 45 fc mov -0x4(%ebp),%eax
}
80483a8: c9 leave
80483a9: c3 ret
bar函数有一个int型的返回值,这个返回值是通过eax寄存器传递的,所以首先把e的值读到eax寄存器中。然后执行leave指令,这个指令是函数开头的push %ebp和mov %esp,%ebp的逆操作:
1. 把ebp的值赋给esp,现在esp的值是0xbff1c404。
2. 现在esp所指向的栈顶保存着foo函数栈帧的ebp,把这个值恢复给ebp,
同时esp增加4,esp的值变成0xbff1c408。
最后是ret指令,它是call指令的逆操作:
1. 现在esp所指向的栈顶保存着返回地址,把这个值恢复给eip,同时esp
增加4,esp的值变成0xbff1c40c。
2. 修改了程序计数器eip,因此跳转到返回地址0x80483c2继续执行。
地址0x80483c2处是foo函数的返回指令:
80483c2: c9 leave
80483c3: c3 ret
重复同样的过程,又返回到了main函数。注意函数调用和返回过程中的这些规则:
1. 参数压栈传递,并且是从右向左依次压栈。
2. ebp总是指向当前栈帧的栈底。
3. 返回值通过eax寄存器传递。
这些规则并不是体系结构所强加的,ebp寄存器并不是必须这么用,函数的参数和返回值也不是必须这么传,只是操作系统和编译器选择了以这样的方式实现C代码中的函数调用,这称为Calling Convention,Calling Convention是操作系统二进制接口规范(ABI,Application Binary Interface)的一部分。
linux C用户态调试追踪函数调用堆栈以及定位段错误
linux C用户态调试追踪函数调用堆栈以及定位段错误 一般察看函数运行时堆栈的方法是使用GDB(bt命令)之类的外部调试器,但是,有些时候为了分析程序的BUG,(主要针对长时间运行程序的分析),在程序出错时打印出函数的调用堆栈是非常有用的。 在glibc头文件"execinfo.h"中声明了三个函数用于获取当前线程的函数调用堆栈。 int backtrace(void **buffer,int size) 该函数用于获取当前线程的调用堆栈,获取的信息将会被存放在buffer中,它是一个指针列表。参数size 用来指定buffer中可以保存多少个void* 元素。函数返回值是实际获取的指针个数,最大不超过size大小 在buffer中的指针实际是从堆栈中获取的返回地址,每一个堆栈框架有一个返回地址 注意:某些编译器的优化选项对获取正确的调用堆栈有干扰,另外内联函数没有堆栈框架;删除框架指针也会导致无法正确解析堆栈内容 char ** backtrace_symbols (void *const *buffer, int size) backtrace_symbols将从backtrace函数获取的信息转化为一个字符串数组. 参数buffer应该是从backtrace函数获取的指针数组,size是该数组中的元素个数(backtrace的返回值) 函数返回值是一个指向字符串数组的指针,它的大小同buffer相同.每个字符串包含了一个相对于buffer中对应元素的可打印信息.它包括函数名,函数的偏移地址,和实际的返回地址 现在,只有使用ELF二进制格式的程序才能获取函数名称和偏移地址.在其他系统,只有16进制的返回地址能被获取.另外,你可能需要传递相应的符号给链接器,以能支持函数名功能(比如,在使用GNU ld链接器的系统中,你需要传递(-rdynamic),-rdynamic可用来通知链接器将所有符号添加到动态符号表中,如果你的链接器支持-rdynamic的话,建议将其加上!) 该函数的返回值是通过malloc函数申请的空间,因此调用者必须使用free函数来释放指针. 注意:如果不能为字符串获取足够的空间函数的返回值将会为NULL void backtrace_symbols_fd (void *const *buffer, int size, int fd)
C++函数调用过程深入分析
函数调用过程分析 刘兵QQ: 44452114 E-mail: liubing2000@https://www.360docs.net/doc/c19949478.html, 0. 引言 函数调用的过程实际上也就是一个中断的过程,那么C++中到底是怎样实现一个函数的调用的呢?参数入栈、函数跳转、保护现场、回复现场等又是怎样实现的呢?本文将对函数调用的过程进行深入的分析和详细解释,并在VC 6.0环境下进行演示。分析不到位或者存在错误的地方请批评指正,请与作者联系。 首先对三个常用的寄存器做一下说明,EIP是指令指针,即指向下一条即将执行的指令的地址;EBP 为基址指针,常用来指向栈底;ESP为栈指针,常用来指向栈顶。 看下面这个简单的程序并在VC 6.0中查看并分析汇编代码。 图1 1. 函数调用 g_func函数调用的汇编代码如图2: 图2 首先是三条push指令,分别将三个参数压入栈中,可以发现参数的压栈顺序是从右向左的。这时我们可以查看栈中的数据验证一下。如图3所示,从右边的实时寄存器表中我们可以看到ESP(栈顶指针)值为0x0012FEF0,然后从中间的内存表中找到内存地址0x0012FEF0处,我们可以看到内存中依次存储了0x00000001(即参数1),0x00000002(即参数2),0x00000003(即参数3),即此时栈顶存储的是三个参数值,说明压栈成功。 图3
然后可以看到call指令跳转到地址0x00401005,那么该地址处是什么呢?我们继续跟踪一下,在图4中我们看到这里又是一条跳转指令,跳转到0x00401030。我们再看一下地址0x00401030处,在图5中可以看到这才是真正的g_func函数,0x00401030是该函数的起始地址,这样就实现了到g_func函数的跳转。 图4 图5 2. 保存现场 此时我们再来查看一下栈中的数据,如图6所示,此时的ESP(栈顶)值为0x0012FEEC,在内存表中我们可以看到栈顶存放的是0x00401093,下面还是前面压栈的参数1,2,3,也就是执行了call指令后,系统默认的往栈中压入了一个数据(0x00401093),那么它究竟是什么呢?我们再看到图3,call指令后面一条指令的地址就是0x00401093,实际上就是函数调用结束后需要继续执行的指令地址,函数返回后会跳转到该地址。这也就是我们常说的函数中断前的“保护现场”。这一过程是编译器隐含完成的,实际上是将EIP(指令指针)压栈,即隐含执行了一条push eip指令,在中断函数返回时再从栈中弹出该值到EIP,程序继续往下执行。 图6 继续往下看,进入g_func函数后的第一条指令是push ebp,即将ebp入栈。因为每一个函数都有自己的栈区域,所以栈基址也是不一样的。现在进入了一个中断函数,函数执行过程中也需要ebp寄存器,而在进入函数之前的main函数的ebp值怎么办呢?为了不被覆盖,将它压入栈中保存。 下一条mov ebp, esp 将此时的栈顶地址作为该函数的栈基址,确定g_func函数的栈区域(ebp为栈底,
C语言函数参数入栈的理解分析
先来看这样一段程序: [cpp]view plain copy print? 1.#include
2.#include
Excel中三个查找引用函数的用法(十分有用)
在Excel中,我们经常会需要从某些工作表中查询有关的数据复制到另一个工作表中。比如我们需要把学生几次考试成绩从不同的工作表中汇总到一个新的工作表中,而这几个工作表中的参考人数及排列顺序是不完全相同的,并不能直接复制粘贴。此时,如果使用Excel的VLOOKUP、INDEX或者OFFSET函数就可以使这个问题变得非常简单。我们以Excel 2007为例。 图1 假定各成绩工作表如图 1所示。B列为,需要汇总的项目“总分”及“名次”位于H列和I列(即从B列开始的第7列和第8列)。而汇总表则如图2所示,A列为列,C、D两列分别为要汇总过来的第一次考试成绩的总分和名次。其它各次成绩依次向后排列。
图2 一、 VLOOKUP函数 我们可以在“综合”工作表的C3单元格输入公式“=VLOOKUP($B3,第1次!$B$1:$I$92,7,FALSE)”,回车后就可以将第一位同学第一次考试的总分汇总过来了。 把C3单元格公式复制到D3单元格,并将公式中第三个参数“7”改成“8”,回车后,就可以得到该同学第一次考试名次。 选中C3:D3这两个单元格,向下拖动填充句柄到最后就可以得到全部同学的总分及名次了。是不是很简单呀?如图3所示。
VLOOKUP函数的用法是这样的:VLOOKUP(参数1,参数2,参数3,参数4)。“参数1”是“要查找谁?”本例中B3单元格,那就是要查找B3单元格中显示的人名。“参数2”是“在哪里查找?”本例中“第1次!$B$1:$I$92”就是告诉Excel在“第1次”工作表的B1:I92单元格区域进行查找。“参数3”是“找第几列的数据?”本例中的“7”就是指从“第1次”工作表的B列开始起,第7列的数据,即H列。本例中“参数4”即“FALSE”是指查询方式为只查询精确匹配值。 该公式先在“第1次”工作表的B!:I92单元格区域的第一列(即B1:B92单元格区域)查找B3单元格数据,找到后,返回该数据所在行从B列起第7列(H列)的数据。所以,将参数3改成“8”以后,则可以返回I列的数据。 由此可以看出,使用VLOOKUP函数时,参数1的数据必须在参数2区域的第一列中。否则是不可以查找的。 二、INDEX函数 某些情况下,VLOOKUP函数可能会无用武之地,如图4所示。“综合”工作表中,列放到了A 列,而B列要求返回该同学所在的班级。但我们看前面的工作表就知道了,“班级”列是位于“”列前面的。所以,此时我们不可能使用VLOOKUP函数来查找该同学的班级。而INDEX函数就正可以一试身手。
程序调试技巧之调用堆栈
调试技巧之调用堆栈 在计算机科学中,Callstack是指存放某个程序的正在运行的函数的信息的栈。Call stack由stack frames组成,每个stack frame对应于一个未完成运行的函数。 在当今流行的计算机体系架构中,大部分计算机的参数传递,局部变量的分配和释放都是通过操纵程序栈来实现的。栈用来传递函数参数,存储返回值信息,保存寄存器以供恢复调用前处理机状态。每次调用一个函数,都要为该次调用的函数实例分配栈空间。为单个函数分配的那部分栈空间就叫做stack frame,也就是说,stack frame这个说法主要是为了描述函数调用关系的。 Stackframe组织方式的重要性和作用体现在两个方面:第一,它使调用者和被调用者达成某种约定。这个约定定义了函数调用时函数参数的传递方式,函数返回值的返回方式,寄存器如何在调用者和被调用者之间进行共享;第二,它定义了被调用者如何使用它自己的stack frame来完成局部变量的存储和使用。 简单介绍 调试是程序开发者必备技巧。如果不会调试,自己写的程序一旦出问题,往往无从下手。本人总结10年使用VC经验,对调试技巧做一个粗浅的介绍。希望对大家有所帮助。 今天简单的介绍介绍调用堆栈。调用堆栈在我的专栏的文章VC调试入门提了一下,但是没有详细介绍。 首先介绍一下什么叫调用堆栈:假设我们有几个函数,分别是function1,function2,function3,funtion4,且function1调用function2,function2调用function3,function3调用function4。在function4运行过程中,我们可以从线程当前堆栈中了解到调用他的那几个函数分别是谁。把函数的顺序关系看,function4、function3、function2、function1呈现出一种“堆栈”的特征,最后被调用的函数出现在最上方。因此称呼这种关系为调用堆栈(callstack)。 当故障发生时,如果程序被中断,我们基本上只可以看到最后出错的函数。利用call stack,我们可以知道当出错函数被谁调用的时候出错。这样一层层的看上去,有时可以猜测出错误的原因。常见的这种中断时ASSERT宏导致的中断。 在程序被中断时,debug工具条的右侧倒数第二个按钮一般是callstack按钮,这个按钮被按下后,你就可以看到当前的调用堆栈。
C语言函数调用规定
在C语言中,假设我们有这样的一个函数: int function(int a,int b) 调用时只要用result = function(1,2)这样的方式就可以使用这个函数。但是,当高级语言被编译成计算机可以识别的机器码时,有一个问题就凸现出来:在CPU中,计算机没有办法知道一个函数调用需要多少个、什么样的参数,也没有硬件可以保存这些参数。也就是说,计算机不知道怎么给这个函数传递参数,传递参数的工作必须由函数调用者和函数本身来协调。为此,计算机提供了一种被称为栈的数据结构来支持参数传递。 栈是一种先进后出的数据结构,栈有一个存储区、一个栈顶指针。栈顶指针指向堆栈中第一个可用的数据项(被称为栈顶)。用户可以在栈顶上方向栈中加入数据,这个操作被称为压栈(Push),压栈以后,栈顶自动变成新加入数据项的位置,栈顶指针也随之修改。用户也可以从堆栈中取走栈顶,称为弹出栈(pop),弹出栈后,栈顶下的一个元素变成栈顶,栈顶指针随之修改。 函数调用时,调用者依次把参数压栈,然后调用函数,函数被调用以后,在堆栈中取得数据,并进行计算。函数计算结束以后,或者调用者、或者函数本身修改堆栈,使堆栈恢复原装。 在参数传递中,有两个很重要的问题必须得到明确说明: 当参数个数多于一个时,按照什么顺序把参数压入堆栈 函数调用后,由谁来把堆栈恢复原装 在高级语言中,通过函数调用约定来说明这两个问题。常见的调用约定有:stdcall cdecl fastcall thiscall naked call stdcall调用约定 stdcall很多时候被称为pascal调用约定,因为pascal是早期很常见的一种教学用计算机程序设计语言,其语法严谨,使用的函数调用约定就是stdcall.在Microsoft C++系列的C/C++编译器中,常常用PASCAL宏来声明这个调用约定,类似的宏还有WINAPI和CALLBACK. stdcall调用约定声明的语法为(以前文的那个函数为例): int __stdcall function(int a,int b) stdcall的调用约定意味着:1)参数从右向左压入堆栈,2)函数自身修改堆栈3)函数名自动加前导的下划线,后面紧跟一个@符号,其后紧跟着参数的尺寸 以上述这个函数为例,参数b首先被压栈,然后是参数a,函数调用function(1,2)调用处翻译成汇编语言将变成: push 2 第二个参数入栈 push 1 第一个参数入栈 call function 调用参数,注意此时自动把cs:eip入栈 而对于函数自身,则可以翻译为: push ebp 保存ebp寄存器,该寄存器将用来保存堆栈的栈顶指针,可以在函数退出时恢复 mov ebp,esp 保存堆栈指针
C语言函数调用栈
C语言函数调用栈(一) 程序的执行过程可看作连续的函数调用。当一个函数执行完毕时,程序要回到调用指令的下一条指令(紧接call指令)处继续执行。函数调用过程通常使用堆栈实现,每个用户态进程对 应一个调用栈结构(call stack)。编译器使用堆栈传递函数参数、保存返回地址、临时保存寄 存器原有值(即函数调用的上下文)以备恢复以及存储本地局部变量。 不同处理器和编译器的堆栈布局、函数调用方法都可能不同,但堆栈的基本概念是一样 的。 1 寄存器分配 寄存器是处理器加工数据或运行程序的重要载体,用于存放程序执行中用到的数据和指令。因此函数调用栈的实现与处理器寄存器组密切相关。 Intel 32位体系结构(简称IA32)处理器包含8个四字节寄存器,如下图所示: 图1 IA32处理器寄存器 最初的8086中寄存器是16位,每个都有特殊用途,寄存器名城反映其不同用途。由于 IA32平台采用平面寻址模式,对特殊寄存器的需求大大降低,但由于历史原因,这些寄存 器名称被保留下来。在大多数情况下,上图所示的前6个寄存器均可作为通用寄存器使用。某些指令可能以固定的寄存器作为源寄存器或目的寄存器,如一些特殊的算术操作指令 imull/mull/cltd/idivl/divl要求一个参数必须在%eax中,其运算结果存放在%edx(higher 32-bit)和%eax (lower32-bit)中;又如函数返回值通常保存在%eax中,等等。为避免兼容性问题,ABI规范对这组通用寄存器的具体作用加以定义(如图中所示)。 对于寄存器%eax、%ebx、%ecx和%edx,各自可作为两个独立的16位寄存器使用,而低16位寄存器还可继续分为两个独立的8位寄存器使用。编译器会根据操作数大小选择合 适的寄存器来生成汇编代码。在汇编语言层面,这组通用寄存器以%e(AT&T语法)或直接以e(Intel语法)开头来引用,例如mov $5, %eax或mov eax, 5表示将立即数5赋值给寄存器%eax。 在x86处理器中,EIP(Instruction Pointer)是指令寄存器,指向处理器下条等待执行的指
C语言函数调用规定[试题]
C语言函数调用规定[试题] 在C语言中~假设我们有这样的一个函数: int function,int a~int b, 调用时只要用result = function,1~2,这样的方式就可以使用这个函数。但是~当高级语言被编译成计算机可以识别的机器码时~有一个问题就凸现出来:在CPU中~计算机没有办法知道一个函数调用需要多少个、什么样的参数~也没有硬件可以保存这些参数。也就是说~计算机不知道怎么给这个函数传递参数~传递参数的工作必须由函数调用者和函数本身来协调。为此~计算机提供了一种被称为栈的数据结构来支持参数传递。 栈是一种先进后出的数据结构~栈有一个存储区、一个栈顶指针。栈顶指针指向堆栈中第一个可用的数据项,被称为栈顶,。用户可以在栈顶上方向栈中加入数据~这个操作被称为压栈,Push,~压栈以后~栈顶自动变成新加入数据项的位置~栈顶指针也随之修改。用户也可以从堆栈中取走栈顶~称为弹出栈,pop,~弹出栈后~栈顶下的一个元素变成栈顶~栈顶指针随之修改。 函数调用时~调用者依次把参数压栈~然后调用函数~函数被调用以后~在堆栈中取得数据~并进行计算。函数计算结束以后~或者调用者、或者函数本身修改堆栈~使堆栈恢复原装。 在参数传递中~有两个很重要的问题必须得到明确说明: 当参数个数多于一个时~按照什么顺序把参数压入堆栈 函数调用后~由谁来把堆栈恢复原装 在高级语言中~通过函数调用约定来说明这两个问题。常见的调用约定有: stdcall cdecl
fastcall thiscall naked call stdcall调用约定 stdcall很多时候被称为pascal调用约定~因为pascal是早期很常见的一种 教学用计算机程序设计语言~其语法严谨~使用的函数调用约定就是stdcall.在Microsoft C++系列的C/C++编译器中~常常用PASCAL宏来声明这个调用约定~类似的宏还有WINAPI和CALLBACK. stdcall调用约定声明的语法为,以前文的那个函数为例,: int __stdcall function,int a~int b, stdcall的调用约定意味着:1,参数从右向左压入堆栈~2,函数自身修改堆栈 3,函数名自动加前导的下划线~后面紧跟一个@符号~其后紧跟着参数的尺寸以上述这个函数为例~参数b首先被压栈~然后是参数a~函数调用 function,1~2,调用处翻译成汇编语言将变成: push 2 第二个参数入栈 push 1 第一个参数入栈 call function 调用参数~注意此时自动把cs:eip入栈 而对于函数自身~则可以翻译为: push ebp 保存ebp寄存器~该寄存器将用来保存堆栈的栈顶指针~可以在函 数退出时恢复 mov ebp~esp 保存堆栈指针 mov eax~[ebp + 8H] 堆栈中ebp指向位置之前依次保存有ebp~cs:eip~a~b~ebp +8指向a add eax~[ebp + 0CH] 堆栈中ebp + 12处保存了b
C语言函数调用参数传递栈详解
C语言调用函数过程详解 Sunny.man 1.使用环境: gcc 版本4.1.2 20071124 (Red Hat 4.1.2-42) 2.示例源代码 int foo(int a,int b) { int a1=0x123; return a1+a+b; } int main() { foo(2,3); return 0; } 3.运行程序 命令:gdb a.out Start Disassemble 4.汇编函数清单 4.1main函数的汇编 0x0804836c
函数调用规范
函数调用规范 当高级语言函数被编译成机器码时,有一个问题就必须解决:因为CPU没有办法知道一个函数调用需要多少个、什么样的参数。即计算机不知道怎么给这个函数传递参数,传递参数的工作必须由函数调用者和函数本身来协调。为此,计算机提供了一种被称为栈的数据结构来支持参数传递。 函数调用时,调用者依次把参数压栈,然后调用函数,函数被调用以后,在堆栈中取得数据,并进行计算。函数计算结束以后,或者调用者、或者函数本身修改堆栈,使堆栈恢复原状。在参数传递中,有两个很重要的问题必须得到明确说明: 1) 当参数个数多于一个时,按照什么顺序把参数压入堆栈; 2) 函数调用后,由谁来把堆栈恢复原状。 3)函数的返回值放在什么地方 在高级语言中,通过函数调用规范(Calling Conventions)来说明这两个问题。常见的调用规范有: stdcall cdecl fastcall thiscall naked call stdcall调用规范 stdcall很多时候被称为pascal调用规范,因为pascal是早期很常见的一种教学用计算机程序设计语言,其语法严谨,使用的函数调用约定是stdcall。在Microsoft C++系列的C/C++编译器中,常常用PASCAL宏来声明这个调用约定,类似的宏还有WINAPI和CALLBACK。 stdcall调用规范声明的语法为: int __stdcall function(int a,int b) stdcall的调用约定意味着: 1)参数从右向左压入堆栈;
2)函数自身修改堆栈; 3) 函数名自动加前导的下划线,后面紧跟一个@符号,其后紧跟着参数的 尺寸。 以上述这个函数为例,参数b首先被压栈,然后是参数a,函数调用function(1,2)调用处翻译成汇编语言将变成: push 2 第二个参数入栈 push 1 第一个参数入栈 call function 调用参数,注意此时自动把cs:eip入栈 而对于函数自身,则可以翻译为: push ebp 保存ebp寄存器,该寄存器将用来保存堆栈的栈 顶指针,可以在函数退出时恢复 mov ebp,esp 保存堆栈指针 mov eax,[ebp + 8H] 堆栈中ebp指向位置之前依次保存有 ebp,cs:eip,a,b,ebp +8指向a add eax,[ebp + 0CH] 堆栈中ebp + 12处保存了b mov esp,ebp 恢复esp pop ebp ret 8 而在编译时,这个函数的名字被翻译成_function@8 注意不同编译器会插入自己的汇编代码以提供编译的通用性,但是大体代码如此。其中在函数开始处保留esp到ebp中,在函数结束恢复是编译器常用的方法。 从函数调用看,2和1依次被push进堆栈,而在函数中又通过相对于ebp(即刚进函数时的堆栈指针)的偏移量存取参数。函数结束后,ret 8表示清理8个字节的堆栈,函数自己恢复了堆栈。
函数调用有哪几种方式
函数调用有哪几种方式 我们知道在进行函数调用时,有几种调用方法,主要分为C式,Pascal式.在C和C++中 C式调用是缺省的,类的成员函数缺省调用为_stdcall。二者是有区别的,下面我们用 实例说明一下:(还有thiscall和fastcall) 1. __cdecl :C和C++缺省调用方式 C 调用约定(即用__cdecl 关键字说明)按从右至左的顺序压参数入栈,由调用者把 参数弹出栈。对于传送参数的内存栈是由调用者来维护的(正因为如此,实现可变参数 的函数只能使用该调用约定)。另外,在函数名修饰约定方面也有所不同。 _cdecl 是C 和C++ 程序缺省的调用方式。每一个调用它的函数都包含清空堆栈的 代码,所以产生的可执行文件大小会比调用_stdcall 函数的大。函数采用从右到左的 压栈方式。VC 将函数编译后会在函数名前面加上下划线前缀。它是MFC 缺省调用约 定。 例子: void Input( int &m,int &n); 以下是相应的汇编代码: 00401068 lea eax,[ebp-8] ;取[ebp-8]地址(ebp-8),存到eax 0040106B push eax ;然后压栈 0040106C lea ecx,[ebp-4] ;取[ebp-4]地址(ebp-4),存到ecx 0040106F push ecx ;然后压栈 00401070 call @ILT+5(Input) (0040100a);然后调用Input函数 00401075 add esp,8 ;恢复栈 从以上调用Input函数的过程可以看出:在调用此函数之前,首先压栈ebp-8,然后压栈ebp-4,然后调用函数Input,最后Input函数调用结束后,利用esp+8恢复栈。由 此可见,在C语言调用中默认的函数修饰_cdecl,由主调用函数进行参数压栈并且恢复 堆栈。 下面看一下:地址ebp-8和ebp-4是什么? 在VC的VIEW下选debug windows,然后选Registers,显示寄存器变量值,然后在选debug windows下面的Memory,输入ebp-8的值和ebp-4的值(或直接输入ebp-8和-4), 看一下这两个地址实际存储的是什么值,实际上是变量n 的地址(ebp-8),m的地址(ebp-4),由此可以看出:在主调用函数中进行实参的压栈并且顺序是从右到左。另外,
[CC++] 函数调用的栈分配
[C/C++] 函数调用的栈分配 压栈,跳转到被调函数的入口点。 进入被调函数时,函数将esp减去相应字节数获取局部变量存储空间。被调函数返回(ret)时,将esp加上相应字节数,归还栈空间,弹出主调函数压在栈中的代码执行指针(eip),跳回主调函数。再由主调函数恢复到调用前的栈。 为了访问函数局部变量,必须有方法定位每一个变量。变量相对于栈顶esp的位置在进入函数体时就已确定,但是由于esp会在函数执行期变动,所以将esp 的值保存在ebp中,并事先将原ebp的值压栈保存,以声明中的顺序(即压栈的相反顺序)来确定偏移量。 访问函数的局部变量和访问函数参数的区别: 局部变量总是通过将ebp减去偏移量来访问,函数参数总是通过将ebp加上偏移量来访问。对于32位变量而言,第一个局部变量位于ebp-4,第二个位于ebp-8,以此类推,32位局部变量在栈中形成一个逆序数组;第一个函数参数位于ebp+8,第二个位于ebp+12,以此类推,32位函数参数在栈中形成一个正序数组。 函数的返回值不同于函数参数,可以通过寄存器传递。如果返回值类型可以放入32位变量,比如int、short、char、指针等类型,将通过eax寄存器传递。如果返回值类型是64位变量,如_int64,则通过edx+eax传递,edx存储高32位,eax存储低32位。如果返回值是浮点类型,如float和double,通过专用的浮点数寄存器栈的栈顶返回。如果返回值类型是struct或class类型,编译器将通过隐式修改函数的签名,以引用型参数的形式传回。由于函数返回值通过寄存器返回,不需要空间分配等操作,所以返回值的代价很低。基于这个原因,C89规范中约定,不写明返回值类型的函数,返回值类型默认为int。这一规则与现行的C++语法相违背,因为C++中,不写明返回值类型的函数返回值类型为void,表示不返回值。这种语法不兼容性是为了加强C++的类型安全,但同时也带来了一些代码兼容性问题。 代码示例 VarType Func (Arg1, Arg2, Arg3, ... ArgN) { VarType Var1, Var2, Var3, ...VarN; //... return VarN; } 假设sizeof(VarType) = 4(DWORD), 则一次函数调用汇编代码示例为: 调用方代码: push ArgN ; 依次逆序压入调用参数 push ... push Arg1 call Func_Address ; 压入当前EIP后跳转 跳转至被调方代码:
函数调用过程分析
1. 函数调用过程分析
1. 函数调用
我们用下面的代码来研究函数调用的过程。 例 19.1. 研究函数的调用过程
int bar(int c, int d) { int e = c + d; return e; }
int foo(int a, int b) { return bar(a, b); }
int main(void) { foo(2, 3); return 0; }
如果在编译时加上-g 选项(在第 10 章 gdb 讲过-g 选项),那么用 objdump 反汇编时可以把 C 代 码和汇编代码穿插起来显示,这样 C 代码和汇编代码的对应关系看得更清楚。反汇编的结果很长, 以下只列出我们关心的部分。
$ gcc main.c -g $ objdump -dS a.out ...
08048394
int e = c + d; 804839a: 804839d: 80483a0: 80483a2: 8b 55 0c 8b 45 08 01 d0 89 45 fc mov mov add mov 0xc(%ebp),%edx 0x8(%ebp),%eax %edx,%eax %eax,-0x4(%ebp)
return e; 80483a5: } 80483a8: 80483a9: c9 c3 leave ret 8b 45 fc mov -0x4(%ebp),%eax
080483aa
int foo(int a, int b) { 80483aa: 80483ab: 80483ad: 55 89 e5 83 ec 08 push mov sub %ebp %esp,%ebp $0x8,%esp
return bar(a, b); 80483b0: 80483b3: 80483b7: 8b 45 0c 89 44 24 04 8b 45 08 mov mov mov 0xc(%ebp),%eax %eax,0x4(%esp) 0x8(%ebp),%eax
函数的调用规则
函数的调用规则(__cdecl,__stdcall,__fastcall,_pascal) 关于函数的调用规则(调用约定),大多数时候是不需要了解的,但是如果需要跨语言的编程,比如VC写的dll要delphi调用,则需要了解。 microsoft的vc默认的是__cdecl方式,而windows API则是__stdcall,如果用vc开发dll 给其他语言用,则应该指定__stdcall方式。堆栈由谁清除这个很重要,如果是要写汇编函数给C 调用,一定要小心堆栈的清除工作,如果是__cdecl方式的函数,则函数本身(如果不用汇编写)则不需要关心保存参数的堆栈的清除,但是如果是__stdcall的规则,一定要在函数退出(ret)前恢复堆栈。 1.__cdecl 所谓的C调用规则。按从右至左的顺序压参数入栈,由调用者把参数弹出栈。切记:对于传送参数的内存栈是由调用者来维护的。返回值在EAX中因此,对于象printf这样变参数的函数必须用这种规则。编译器在编译的时候对这种调用规则的函数生成修饰名的饿时候,仅在输出函数名前加上一个下划线前缀,格式为_functionname。 2.__stdcall 按从右至左的顺序压参数入栈,由被调用者把参数弹出栈。_stdcall是Pascal程序的缺省调用方式,通常用于Win32 Api中,切记:函数自己在退出时清空堆栈,返回值在EAX中。__stdcall调用约定在输出函数名前加上一个下划线前缀,后面加上一个“@”符号和其参数的字节数,格式为_functionname@number。如函数int func(int a, double b)的修饰名是_func@12。 3.__fastcall __fastcall调用的主要特点就是快,因为它是通过寄存器来传送参数的(实际上,它用ECX和EDX 传送前两个双字(DWORD)或更小的参数,剩下的参数仍旧自右向左压栈传送,被调用的函数在返回前清理传送参数的内存栈)。__fastcall调用约定在输出函数名前加上一个“@”符号,后面也是一个“@”符号和其参数的字节数,格式为@functionname@number。这个和__stdcall很象,唯一差别就是头两个参数通过寄存器传送。注意通过寄存器传送的两个参数是从左向右的,即第一个参数进ECX,第2个进EDX,其他参数是从右向左的入stack。返回仍然通过EAX. 4.__pascal 这种规则从左向右传递参数,通过EAX返回,堆栈由被调用者清除 5.__thiscall 仅仅应用于"C++"成员函数。this指针存放于CX寄存器,参数从右到左压。thiscall不是关键词,因此不能被程序员指定 名字修饰约定: 1、修饰名(Decoration name):"C"或者"C++"函数在内部(编译和链接)通过修饰名识别 2、C编译时函数名修饰约定规则: __stdcall调用约定在输出函数名前加上一个下划线前缀,后面加上一个"@"符号和其参数的字节数,格式为_functionname@number,例如:function(int a, int b),其修饰名为:_function@8 __cdecl调用约定仅在输出函数名前加上一个下划线前缀,格式为_functionname。 __fastcall调用约定在输出函数名前加上一个"@"符号,后面也是一个"@"符号和其参数的字节数,格式为@functionname@number。 3、C++编译时函数名修饰约定规则: __stdcall调用约定:
函数调用
杨振平
●函数定义后,并不能自动执行,必须通过函数调用来实现函数的功能。 ●函数调用,即控制执行某个函数。 ●C++中,主函数可以调用其它子函数,而其它函数之间也可以相互调用。 ●在本节中,我们将介绍一下内容: ?函数调用的格式 ?参数的传递方式 ?为形参指定默认值 ?数组名作函数参数 ?结构体变量作函数参数
函数调用的一般格式: <函数名>(<实际参数表>)//有参调用 或<函数名>()//无参调用 其中: ●<函数名>为要使用的函数的名字。 ●<实际参数表>是以逗号分隔的实参列表,必须放在一对圆括号中。 <实参表>与<形参表>中参数的个数、类型和次序应保持一致。 ●当调用无参函数时,函数名后的圆括号不能省略。
1.实参的几种形式 ●形参为简单类型变量,对应的实参可以是:常量,变量及表达式。 ●形参为数组,对应的实参为数组(名)。 ●形参为结构类型,对应的实参为结构类型变量。 如:调用已知三边求三角形面积的函数Area。 double Area(double,double,double); //函数声明 cout< 2.函数调用的形式 (1)函数调用作为一个独立的语句(用于无返回值的函数)调用的形式为: 函数名(实参表);或函数名(); 如:调用print_char函数(用户定义的无返回值函数)。 print_char(‘*’,6); //连续显示6个‘*’字符。 分析函数调用关系图(call graph)的几种方法 绘制函数调用关系图对理解大型程序大有帮助。我想大家都有过一边读源码(并在头脑中维护一个调用栈),一边在纸上画函数调用关系,然后整理成图的经历。如果运气好一点,借助调试器的单步跟踪功能和call stack窗口,能节约一些脑力。不过如果要分析的是脚本语言的代码,那多半只好老老实实用第一种方法了。如果在读代码之前,手边就有一份调用图,岂不妙哉?下面举出我知道的几种免费的分析C/C++函数调用关系的工具。 函数调用关系图(call graph)是图(graph),而且是有向图,多半还是无环图(无圈图)——如果代码中没有直接或间接的递归的话。Graphviz是专门绘制有向图和无向图的工具,所以很多call graph分析工具都以它为后端(back end)。那么前端呢?就看各家各显神通了。 调用图的分析分析大致可分为“静态”和“动态”两种,所谓静态分析是指在不运行待分析的程序的前提下进行分析,那么动态分析自然就是记录程序实际运行时的函数调用情况了。 静态分析又有两种方法,一是分析源码,二是分析编译后的目标文件。 分析源码获得的调用图的质量取决于分析工具对编程语言的理解程度,比如能不能找出正确的C++重载函数。Doxygen是源码文档化工具,也能绘制调用图,它似乎是自己分析源码获得函数调用关系的。GNU cflow也是类似的工具,不过它似乎偏重分析流程图(flowchart)。 对编程语言的理解程度最好的当然是编译器了,所以有人想出给编译器打补丁,让它在编译时顺便记录函数调用关系。CodeViz(其灵感来自Martin Devera (Devik) 的工具)就属于此类,它(1.0.9版)给GCC 3.4.1打了个补丁。另外一个工具egypt的思路更巧妙,不用大动干戈地给编译器打补丁,而是让编译器自己dump出调用关系,然后分析分析,交给Graphviz去绘图。不过也有人另起炉灶,自己写个C语言编译器(ncc),专门分析调用图,勇气可嘉。不如要是对C++语言也这么干,成本不免太高了。分析C++的调用图,还是借助编译器比较实在。 分析目标文件听起来挺高深,其实不然,反汇编的工作交给binutils的objdump 去做,只要分析一下反汇编出来的文本文件就行了。下面是Cygwin下objdump -d a.exe的部分结果: 00401050 <_main>: 401050: 55 p Win32环境下函数调用的堆栈之研究 1.背景说明 由于阅读《Q版缓冲区溢出教程》的需要理解和掌握栈的相关知识,故而使用VC 6.0工具来研究win32环境下函数调用时具体的栈操作。 阅读本文建议先看结论,大概了解相关概念,再看第4节,更易于理解。 2.C原程序 主函数main()和子函数func1都定义了不同类型的局部变量, 并且子函数定义了两个以上(包括两个)的参数. 这样实例源代码可以较充分地说明各种情况。在本实例没有体现的情况, 建议另外添加代码来运行分析。 #include 3.汇编代码 在VC中,按F10进入DEBUG模式。右键弹出菜单,选择“Go To Disassembly”,则显示C源程序的相应汇编代码。注意:这里的汇编代码是DEBUG模式的,与RELEASE模式的汇编代码会有所不同,但我们将要研究的问题。下面的代码完全摘自VC中,未作任何修改。由此可见,子函数存储区(低址)和主函数存储区(高址)之间还有一些空白区。函数中调用的其他库函数存储在更高的地址,具体情况在实践在查看。 ……(前面省略) --- F:\QBufOverflow\rptBugDlgBox\rptBugDialogBox.c -------------------- 1: #include 分析函数调用关系图(call graph)的几种方法
Win32环境下函数调用的堆栈之研究