实用统计学

第六章动态分析
动态分析,也称为时间序列分析或时间数列分析、动态数列分析,是根据时间序列资料,分析数据的平均水平和社会经济发展变化的速度,包括动态分析和动态平均分析两个方面。
第一节动态对比分析
动态对比分析,就是通过前后不同时间上数据值的对比研究,分析社会经济的发展变化情况。动态对比分析包括增长量分析和增长速度分析。
一、增长量分析
增长量就是报告期与基期数据值之差,表示报告期比基期增减的绝对差额,计算方法为:
增长量=报告期数据值﹣基期数据值(时期数、相对数、平均数)
=报告期末数据值﹣基期末数据值(时点数)
根据选择基期的不同,增长量分析可计算的增长量有环比、定基比和年距比三种。
(一)环比增长量
每期以上一期为基期计算的增长量称为环比增长量,说明每期比上期增减的数量,举例见表6-1.
(二)定比增长量
定比增长量,就是每期均以前一固定基期计算的增长量,表示若干期以来的累计增长量。由于对比的基期固定,所以称定比增长量或定基增长量。举例如表6-1。(以2001年为固定基期)
(三)同比增长量
本年与上年同期对比计算的增长量称为同比增长量,也称年距增长量。例如本年7月份销售额为50万元,上年7月份销售额为40万元,则本年7 月份的同比增长量为10万元。再如本年1—7月实现利润30万元,上年1—7月实现利润25万元,则本年1—7月同比增长量为5万元。同比增长量一般用于分析具有季节性变化规律的经济现象的增减变动,与上年同期对比,季节条件相同,这才具有可比性,分析的结论才有说服力。例如若以7月份与6月份对比,如果7月份是旺季,6月份是淡季,7月比6月的增长就是季节因素造成的,而不能说明7月份比6月经营业绩增加了。
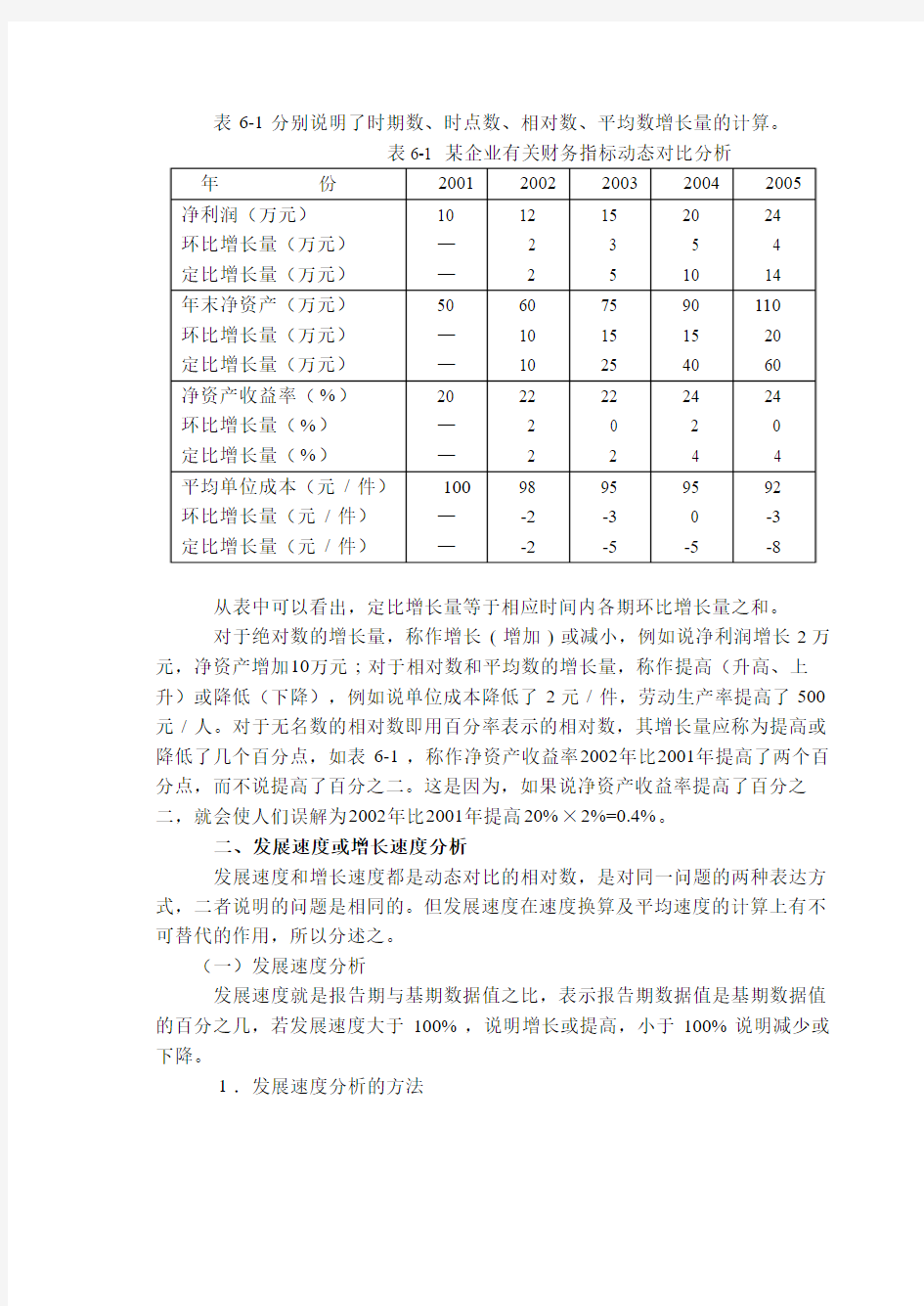
表6-1分别说明了时期数、时点数、相对数、平均数增长量的计算。
从表中可以看出,定比增长量等于相应时间内各期环比增长量之和。
对于绝对数的增长量,称作增长(增加)或减小,例如说净利润增长2万元,净资产增加10万元;对于相对数和平均数的增长量,称作提高(升高、上升)或降低(下降),例如说单位成本降低了2元/件,劳动生产率提高了500元/人。对于无名数的相对数即用百分率表示的相对数,其增长量应称为提高或降低了几个百分点,如表6-1,称作净资产收益率2002年比2001年提高了两个百分点,而不说提高了百分之二。这是因为,如果说净资产收益率提高了百分之二,就会使人们误解为2002年比2001年提高20%×2%=0.4%。
二、发展速度或增长速度分析
发展速度和增长速度都是动态对比的相对数,是对同一问题的两种表达方式,二者说明的问题是相同的。但发展速度在速度换算及平均速度的计算上有不可替代的作用,所以分述之。
(一)发展速度分析
发展速度就是报告期与基期数据值之比,表示报告期数据值是基期数据值的百分之几,若发展速度大于100%,说明增长或提高,小于100%说明减少或下降。
1.发展速度分析的方法
发展速度=
基期(或期末)数据值
值
报告期(求期末)数据×100%
根据基期选择的不同,发展速度与增长量一样,也有环比、定比、同比三
种形式。
(1)环比发展速度 环比发展速度就是每期与上期对比计算的发展速
度,表示每期比上期的变化速度,举例如表6-2。
(2)定比发展速度 定比发展速度就是各期以同一固定基期计算的发展
速度,表示几期累计总发展速度,也称定基发展速度,举例如表6-2。
(3)同比发展速度 同比发展速度就是本年与上年同期对比计算的发展
速度,表示本年比上年同期的发展变化速度。同比发展速度分析用于有季节变化的经济现象。
表6-2分别说明了时期数、时点数、相对数、平均数发展速度的计算方
法。
2.环比发展速度与定比发展速度之间的关系及其应用 (1)环比发展速度与定比发展速度之间的关系 环比发展速度与定比发展速度之间的关系为:
定比发展速度=环比发展速度之积
若用1
a 、2a 、3a 、……n a 表示各期数据值,则环比发展速度与定
比发展速度之间的关系可表示为:
a a n =
01a a ×12a a ×23a a ×34a a
×……×1
n n a a 此关系式也是对上述关系的证明。 以表6-2净利润发展速度为例:
150%=120%×125%
200%=120%×125%×133%
240%=120%×125%×133%×120% (2)环比发展速度与定比发展速度关系的应用
上述环比发展速度与定比发展速度之间的关系,可进一步推广为:
0a a n =0a a i ×i
j a a ×j n
a a
(i 、j 为任意两期数据值)
即: 间隔n 期的总(定比)发展速度=各阶段发展速度之积 根据这一推广关系,可有以下两种应用: ① 根据分阶段发展速度推算总发展速度
[例6-1]某地GDP 指标2005年为2000年的150%,如果2010年可以达到
2005年的180%,那么2010年的GDP 将是2000年的百分之几?
此例就是根据两个五年的分阶段发展速度推算10年的总发展速度,计算如
下:
2010年比2000年的总发展速度=150%×180%=270% 即2010年的GDP 将是2000年的270%。 ② 根据总发展速度推算分阶段发展速度
这种应用是上述关系式的逆运算,即用总发展速度除以某一阶段的发展速
度等于另一阶段的发展速度。
[例6-2]某地区计划目标为2010年的GDP 要比2000年翻两翻,已知2005年
已是2000年的150%,那么后五年应达到多高的发展速度才能实现翻两翻的目标?
此例就是根据10年的总发展速度推算后五年分阶段发展速度的问题。计算
如下:
后五年的总发展速度=
%
150%
400=267%
即后五年的总发展速度,也就是2010年应达到2005年的267%,才能实现翻两翻的目标。
(二)增长速度分析
增长速度就是增长量与基期数据值之比,即增减比率,它表示报告期比基期增长(或减少)了百分之几,比率为正为增长(提高)比率为负为减少(降低)。增长速度是发展速度高于或低于100%的部分。
1.
增长速度的分析方法
增长速度=
%100?-基期数据值基期数据值
报告期数据值
=
%100?基期数据值
增长量
=发展速度
100%
根据基期选择的不同,增长速度分析也有环比、定比、同比三种形式 (1)环比增长速度 环比增长速度就是每期比上期的增长速度,表示逐
期的增长,举例如表6-3。
(2) 定比增长速度 定比增长速度就是各期比同一基期计算的增长速
度,表示几期的累计总增长速度,也称定基增长速度,举例如表6-3。(以2001年为固定基期)
(3)同比增长速度 同比增长速度就是本年与上年同期对比计算的增长
速度,适用于有季节变化的经济现象,分析原理与同比增长量相同。
表6-3分别说明了时期数、时点数、相对数、平均数增长速度的分析计算
方法。
增长速度的表达方法即增减比率的表达方法,绝对数称为增长或减少;相
对数和平均数称为提高或降低。
2.环比增长速度与定比增长速度的换算及应用 (1)环比增长速度与定比增长速度的换算
定比增长速度不等于环比增长速度之积,因而二者不能直接换算。但增长
速度与发展速度可以互化,我们可以利用发展速度比与定比之间的关系进行间接换算。
由于: 增长速度=发展速度-100% 发展速度=增长速度+100% 所以: 定比增长速度=
%100%)100(-+环比增长速度π
[例6-3] 某企业产品销售额2001年比2000年增长5%,2002年比2001年增
长10%,2003年比2002年增长8%,2004年比2003年增长12%,2005年比2004年增长15%,那么2005年比2000年增长百分之几?
2005年比2000年增长速度=(5%+100%)×(10%+100%)×
(8%+100%)×(12%+100%)×(15%+100%)-100%
=60.7% (2)环比增长速度与定比增长速度关系的应用
将环比增长速度与定比增长速度的换算关系推广,可得出: 间隔n 期的总增长速度=
%100%)100(-+各阶段增长速度π
根据推广关系式,可有以下两种应用: ①根据分阶段增长速度推算总增长速度
[例6-4] 某地区2000年GDP 为20亿元,2005年比2000年增长了50%,“十
一五”计划2010年比2005年增长率100%,那么2010年的GDP 将达到多少亿元?
本例是根据两个五年的增长速度推算10年的总增长速度,计算如下:
10年总增长速度=(50%+100%)×(100%+100%)-100% =150%×200%-100%
=300%-100%=200% 2010年的GDP=20×(1+200%)=60(亿元)
②根据总增长速度推算分阶段增长速度 根据上述推广关系式可得出: 某阶段增长速度=
%100%
100%
100-++已知阶段增长速度总增长速度
[例6-5]某市“十一五”计划五年间(2006—2010年)工业总产值增长一
倍,已知2006年比2005年增长了10%,预计2007年可比2006年增长20%,那么2010年应比2007年增长百分几才能完成计划目标?
本例是根据总增长速度推算分阶段增长速度的问题,计算如下:
2010年比2007年的增长速度=
%100%100%20%100%10%
100%100-+?++)
()(
=
%100%
132%
200- =51.5%
第二节
动态平均分析
一.平均增长量
(一)平均增长量的概念
平均增长量就是环比增长量的平均数,表示平均每期比上期增长(或减
少)了多少。在研究经济现象在某一阶段的发展过程时,就需要计算平均增长量。
(二)平均增长量的计算 平均增长量的计算方法为:
平均增长量=增长期数
环比增长量之和
=增长期数
定比增长量
例如表6-1中,净利润的年平均增长量为: 平均增长量=44532+++ =4
14
=3.5(万元)
即每年平均增长3.5万元。 二.平均增长速度
(一)平均增长速度的概念
平均增长速度是环比增长速度的平均数,即指平均每期比上期的增长速度。在动态分析中,为了研究一个阶段的发展速度快慢,就需要计算这一阶段的平均增长(或递减)速度。
(二)平均增长速度的计算
平均增长速度,要通过计算平均发展速度间接计算,平均增长速度的计算原理为:
平均增长速度=平均发展速度-100%
计算平均发展速度时,根据问题的性质和要求不同,有两种不同的计算方法。
1.几何平均法
几何平均法也称水平法,是用开方的方法计算平均发展速度的方法。一般情况下,都适用几何平均法计算平均发展速度。为了说明几何平均法的计算原理,我们从一个实例开始。
[例6-6]某市2005年工业总产值为10亿元,“十一五”计划到2010年达到20亿元,问“十一五”计划期间年平均增长百分之几才能完成计划?
设:年平均发展速度为x。
照此平均发展速度推算,则:
2006年工业总产值=10x?=10x
2007年工业总产值=10x x?=102x
2008年工业总产值=102x x?=103x
2009年工业总产值=103x x?=104x
2010年工业总产值=104x x?=105x
根据问题要求,可得下式:
105x=20
20
解之得:x=5
10
=
5
%200=114.87%
年平均增长速度=114.87%-100%=14.87% 即年平均增长14.87%才能完成计划。
由本例可以看出,平均发展速度等于总发展速度开年数次方。 由本例可推出一般:
若已知基期数据值为0a ,n 期后达到的数据值为n
a ,平均每期发展速
度为x 。则:
1a =0a x 2
a = 0a x x ?= 0a 2x
3a = 0a 2x x ?= 0
a 3x
…… n
a = 0a n x
所以: x =
n
n
a a 0
即: 平均发展速度=
n
n 期的总发展速度间隔
平均增长速度=平均发展速度-100% 此即平均增长速度的计算公式。
事实上,由于总发展速度等于环比发展速度的乘积,若以1
x 、2x 、
3x ……n x 表示各期环比发展速度,则平均发展速度理应为:
x =
n
n x x x x 321??
也是对平均发展速度计算方法的解释。
[例6-7] 某企业2001年至2005年销售额的环比增长速度依次为:5%、
6%、10%、8%、9%,计算年平均增长速度。
五年总发展速度=(5%+100%)×(6%+100%)×(10%+100%)×
(8%+100%)×(9%+100%)
=144.12%
平均发展速度=
5
%
12.144=107.58%
平均增长速度=107.58%-100%=7.58%
[例6-8]某地区“九五”计划期间财政收入2000年比1995年增长了50%,
“十五”计划的2005年比2000年增长了90%,试计算10年来财政收入年平均增长百分之几。
10年总发展速度=(50%+100%)×(100%+90%)=285%
平均发展速度=
10
%285=111.04%
平均增长速度=111.04%-100%=11.04%
[例6-9] 某企业产品销售量2000年为200万件,2005年为500万件,计算
销售量年平均增长速度。
5年总发展速度=200
500=250%
平均发展速度=
5
%250=120.11%
平均增长速度=120.11%—100%=20.11%
[例6-10]某企业产品成本3年来降低了20%,问平均每年降低百分之
几?
3年总发展速度=﹣20%+100%=80% 平均发展速度=
3
%
80=92.83%
平均增长速度=92.83—100%=﹣7.17%
即平均每年降低7.17%。
[例6-11] 某公司计划目标为3年净利润翻一番,那么平均每年必须增长
百分之几才能实现?
3年总发展速度=200% 平均发展速度=
3
%200=126%
平均增长速度=126%-100%=26%
即平均每年增长26%才能实现目标。 2.代数平均法
代数平均法也称累计法,是用解方程计算平均发展速度的方法。代数平均法适用于那些影响长远、注重累计效果的现象的平均发展速度分析,如基本建设投资、人才培养、造林、对文化教育事业投资等。其他情况,如果要求累计数,也可用代数平均法。
为了说明代数平均法的原理,我们再从一个实例开始研究。
[例6-12] 某地区2005年公路建设投资为10亿元,“十一五”计划2006年至2010年5年累计公路建设投75亿元,那么投资年平均增长百分之几才能完成计划目标?
设:年投资平均发展速度为x。
按此平均发展速度推算,“十一五”期间各年投资额应为:
2006年投资额=10x?=10x
2007年投资额=10x x?=102x
2008年投资额=102x x?=103x
2009年投资额=103x x?=104x
2010年投资额=104x x?=105x 根据计划要求,可得下列方程式:
10x+102x+103x+104x+105x=75
75
化简得:x+2x+3x+4x+5x=
10
解此方程,x的正根即为平均发展速度,再减去100%就是平均增长速度。
然而求解高次方程是非常困难的,于是人们编出了《平均增长速度查对表》(见附录一),从表中可以直接查出平均增长速度的值。本例查出的平均增长速度为13.8%。
由本例可推出一般:
a,n期内要求累计达到∑a,平均发展速度为x。
已知基期数据值为
则:
1
a = 0a x
2
a = 0a x x
?=
0a 2
x
3
a = 0a 2
x x ?= 0a 3x
……
n a = 0a n
x 0a x
+ 0a 2
x
+0a 3
x
+……0a n
x
=
∑a
方程式为: x +2
x
+3
x +……n
x =
a a ∑
查《平均增长速度查对表》的方法为:先计算出总发展速度
a a
∑的值,再
根据年数n 和总发展速度即可查出平均增长速度的值。如上例:
总发展速度=10
75
=750% 年数=5年
从表中可查出平均增长速度为13.8%。 (三)应用平均增长速度进行预测 1. 根据平均增长速度预测未来
根据平均发展速度的计算公式: x =
n
n
a a 0
可推出:
a a n
=n x
n
a =0
a
n
x
即由平均发展速度推出总发展速度,进而可推算出未来某期的数据值
n a 。
[例6-13]某地区2005年人口为50万人,预计未来10年人口年自然增长率
可控制在2%左右,试预测2015年的人口将达到多少万人?
未来10年人口总发展速度=10
%100%2)(+=121.9% 2015年人口数=50×121.9%=60.9(万人)
2. 根据既定目标和平均增长速度预测实现目标所需时间 根据: x =
n
n
a a 0 则: lg x =
n
1(lg n a -lg 0
a )
n =
x
a a n lg lg lg 0
-
[例6-14]某地区本年人均GDP 为1000美元,按全面小康目标人均GDP 要
达到3000美元,按目前的发展速度预计,人均GDP 年平均增长速度为7%左右,试预测多少年后可实现全面小康目标?
已知: 10000=a 3000=n a x =107%
n =
07
.1lg 1000lg 3000lg -=0294.03
477.3-=16(年)
即16年后可实现小康目标。
三.序时平均数
序时平均数,就是时间序列各期数据值的平均数。如平均日产量、平均年
产值、月平均销售额、存货平均库存量、年资产平均余额等。序时平均数是经济管理中常用的分析数据。
序时平均数数的计算,因数据的种类不同而不同,绝对数与相对数、平均
数的序时平均数计算方法不同,绝对数中的时期数与时点数的序时平均数的计算方法也不同。下面就分别讲述各种不同数据的序时平均数计算方法。
(一)绝对数的序时平均数计算 1.时期数的序时平均数计算
时期数的序时平均数就是各期数据值的简单平均,计算方法为: 序时平均数=
期数
各期数据值之和
[例6-15]某商业企业全年各月销售额资料如表6-4。
表6-4
单位:万元
月平均销售额=
12
8
9121112991010121110+++++++++++
=12
123
=10.25(万元)
2.时点数的序时平均数计算
时点数是表示某个时点上存在的数量,时点数的序时平均数就是指一定时
期内各个时点上数据值的平均数,即平均每个时点上存在的数量。在经济生活中,时点通常是指“日”,即一日为一时点。所以,时点数的序时平均数就是指平均每日存在的数量。
在计算时点数的序时平均数时,由于所掌握时点资料的详细程度不同,采
用的计算方法也有差异,分为连续时点资料和间断时点资料两种情况。
(1)连续时点资料的序时平均数计算
所谓连续时点资料,就是指掌握了一定时期内每日存在数据值,这是时点
资料最详细、最理想的状况,依此计算的序时平均数也最精确的。
在经济生活中,属于连续时点资料的例子如:银行存款余额、固定资产余
额、企业职工人数、借款余额等。银行活期存款由于有日记帐,因而掌握每日余额;定期存款、固定资产余额、借款额、职工人数等是由于变动很少,那一日发生变动是有记录的,没有变动的日子则维持原数量不变,所以等于每日存在的数量均已知,都是掌握的。
连续时点资料序时平均数的基本计算方法:
序时平均数=
当期日数
每日时点值之和
连续时点资料又根据是否每日变动,分为逐日变动资料和分段变动资料两
种。
①逐日变动时点资料序时平均数的计算 这种情况下,用基本公式计算即可。
[例6-16]某企业某月银行活期存款帐户每日余额如表6-5。试计算本月
平均存款余额,再据以计算本月存款利息(存款月利率为0.2%)。
每日存款余额合计=301000+302000+……351000=9658000
本月平均存款余额=
30
9658000=321933.33(元)
本月存款利息=321933.33×0.2%=643.87 ②分段变动时点资料序时平均数的计算
有些时点数资料并不是每日变动,而是相隔一段时间才有变动,我们称为
分段变动时点资料。如固定资产余额、借款余额、企业职工人数等,它们相隔一 表6-5
单位:元
段时间才会有变动,这样,计算其平均余额、平均人数就不必逐日相加,可以简化计算。
[例6-17]某企业6月初有职工500人,9日增加5人,20日减小2人。
当月工资总额300000元。要求计算当月平均职工人数,并据以计算当月职工平均工资额。
根据本月人数变动情况,可整理为表6-6
表6-6 由于本月职工人数只变动了两次,这样就将本月职工人数分为三段,每段
若干日人数相同。因此,每日人数合计就不必逐日相加,而采用下式加权平均计算:
本月平均职工人数=
3011503115058500?+?+?=30
15088
=(人)9.502
本月职工平均工资=(元)54.59649
.502300000
=
[例6-18]某企业一固定资产投资项目向银行借款,年初借款余额为50万
元;按借款合同,3月1日借入100万元,7月1日借入150万元,10月1日借入200万元。全年共支付借款利息15元。要求计算全年平均借款余额,并据以计算平均利率,作为会计核算资本化利息的资本化率。(为简化计算,每月均按30天计算) 平均借款余额=
(万元)3.258360
90
500903001201506050=?+?+?+?
或=
)(3.25812
3
50033004150250万元=?+?+?+? 平均利率=
%8.53
.25815
= [例6-19]某工业企业年初固定资产净值为500万元,4月初新购设备50
万元,10月初报废设备价值10万元,12月初报废设备价值2万元。为进行固定资产利用效益分析,请计算本年固定资产平均占用额。 固定资产平均占用=
(万元)535360
30
5386054018055090500=?+?+?+?
或
=
(万元)
535360
30
2901027050360500=?-?-?+? 由以上各例可以总结出分段变动时点资料序时平均数的计算公式为: 序时平均数=当期日数
存在日数阶段时点数∑?
=当期总天数
减少日至期末天数减少数增加日至期末天数增加数当期总天数期初数∑∑?-?+?
(2)间断时点资料的序时平均数计算
在经济管理工作中,大量的时点资料为间断资料,也就是说多数情况下并
不完全掌握每日时点值,只掌握期初或期末那一天的时点值,因而时点资料是间断的。为什么会出现这种结果呢?这是因为如果我们要掌握每日时点数值,就会大大增加会计、统计核算的工作量,是不经济和不现实的。比如要掌握每日企业
资产余额,就得每天结帐并编制资产负债表;要掌握每日人口资料,就得每日计算编制人口报表,这显然是做不到的。因此,在实践中,为了减少工作量,许多时点现象只在期末(月本或年末)提供或登记其现存的数量,这就形成了间断时点资料,如人口、社会劳动力人数、物资库存量、资产余额、负债余额等,均属此类。
在计算间断时点资料的序时平均数时,又分为时点值之间间隔相等和不相
等两种情况。
①间隔相等的时点资料序时平均数的计算
在正常情况下,时点资料都是间隔相等的,如资产负债表按月编报,人口
每年年末报告,劳动力人数每月填报。
间断时点资料序时平均数的计算原理是:假定相邻两个时点间的数值变化
是均匀的,因而以相邻两时点数值的中间值作为其间隔期内的每日平均值,然后再将各间隔期内每日平均值与间隔期内日数的乘积相加,即可得到每日时点值之和,再除以当期总日数,就可计算出一定时期内时点数的平均数。由于这种算法带有假定性,所以计算出的序时平均数是近似值。下面举例说明其计算方法。
[例6-20]某商业企业一季度商品库存额资料如表6-7。 表6-7
计算一季度商品平均库存。(为简化计算,每月均按30天计) 将表6-7资料用图表示如下:
50 70 60 80
1月 2月 3月
第一步,假定库存额月初到月末的变化是逐日均匀变化的,则每月的月内
日平均库存额分别为:
1月份日平均库存额=
(万元)60270
50=+ 2月份日平均库存额=(万元)652
60
70=+
3月份日平均库存额=(万元)702
80
60=+ 第二步,计算各月日库存额之和:
1月份日库存额合计=60×30 2月份库存额合计=65×30 3月份库存额合计=70×30 第三步,计算一季度每日库存额合计:
1季度每日库存额合计=60×30+65×30+70×30=5850
(万元)
第四步,计算一季度日平均库存额: 1季度平均库存额=(万元)6590
5850
= 将以上步骤综合起来即为: 1季度平均库存额
=90
30280
6030260703027050?++?++?+
=3
280
602607027050+++++
=65(万元) 由上例可推出间断时点资料序时平均数计算的一般方法: 设1
a 、2a 、3a 、……n a 依次为各个时点数值,相邻两个时点间的
间隔日数依次为1
f 、2f 、……1-n f ,用图表示如下:
1
a 2
a 3
a 4
a 1-n a
n a
……
1
f 2
f 3f
1-n f
全期时点数的序时平均数为:
a =
1
3211
134323212
12222---++++?++?++?++?+n n n n f f f f f a a f a a f a a f a a 当时点间间隔相等时,则1f =2
f =3
f =1
-=n f ,此时:
a =
1
1
114313212
1)12222f n f a a f a a f a a f a a n n -?++?++?++?+-( =1
2
2221
43322
1-++?+++++-n a a a a a a a a n n
化简得:
a =1
2
214321
-++++++-n a a a a a a n n
上式即为间隔相等的时点资料序时平均数的计算公式。
[例6-21]某企业某年资产总额资料如表6-8,为了财务分析的需要,要
求计算全年平均资产总额。 平均资产总额
=12
21301301201021049810510095110801002
90+
+++++++++++ =104.5(万元)
在粗略计算的情况下,也可以只用年初、年末数计算,如本例:
平均资产总额=
2
13090+=110(万元)
只用年初、年末数计算的办法,仅适用于各月末时点数值差异不大的情
形,若各月末时点数值差异较大时,此法计算的结果误差太大,故不宜采用。
表6-8
②间隔不等的时点资料序时平均数的计算
在少数情况下,可能因为核算不健全或不定期调查,缺乏某些时点资料,
就造成了时点资料的间隔不相等。此时,计算公式就不能化简,于是,间隔不等的时点资料的序时平均计算公式就是:
a =
1
3211
134323212
12222---++++?++?++?++?+n n n n f f f f f a a f a a f a a f a a [例6-22] 某企业全年各月末存货资产余额资料如表6-9,缺少几月数
字,试据以计算全年存货平均余额。
表6-9
单位:万元
存货平均余额
=
360
60212
10302109902986028930291160211123021210?++?++?++?++?++?++?+=
12
2212
10121093298228912911221112121210?++?++?++?++?++?++?+=8.9(万元)
(二)相对数和平均数的序时平均数计算
相对数和平均数的序时平均数计算,不同于绝对数的序时平均数计算,它
不能根据自身来计算,而是要用产生它的分子、分母两个绝对数的序时平均数来计算。由于相对数和平均数(静态)都是由两个绝对数相除产生的,具有相同的产生方式,所以其序时平均数的计算方法是相同的。
统计学原理常用公式汇总
2.加权算术平均数 X =- X h X 3调和平均数: 式中: m = Xf , f X 统计学原理常用公式汇总 第2章统计整理 a ) 组距=上限—下限 b ) 组中值=(上限+下限)—2 c ) 缺下限开口组组中值=上限-1/2邻组组距 d ) 缺上限开口组组中值=下限+1/2邻组组距 e ) 组数k=1+3.322Lg n n 为数据个数 第3章综合指标 i. 相对指标 1.结构相对指标=各组(或部分)总量/总体总量 2?比例相对指标=总体中某一部分数值/总体中另一部分数值 3?比较相对指标=甲单位某指标值/乙单位同类指标值 4. 强度相对指标=某种现象总量指标/另一个有联系而性质不 同的现象总量指标 5. 计划完成程度相对指标=实际数/计划数 =实际完成程度(%) /计划规定的完成程度(%) ii. 平均指标 1.简单算术平均数:; 丄 iii. 标志变动度 1.全距=最大标志值-最小标志值 加权 或 ? f ? Xf ? Xf
3.标准差系数:”= iiii抽样推 断 1.抽样平均误差: 重复抽样: p(1 P) n 不重复抽样: 2 ( 1 2.抽样极限误差 3.重复抽样条件下: 平均数抽样时必要的样本数目 n 成数抽样时必要的样本数目不重复抽样条件下: t2 2 2- x t2P(1 p) 平均数抽样时必要的样本数目第4 章动态数列分析一、平均发展水平的计算方法:(1)由总量指标动态数列计算序时平均数 ①由时期数列计算 a a n Nt2 2 N 2x t2 2 ②由时点数列计算 在间断时点数列的条件下计算: 若间断的间隔相等,则米用“首末折半法”计算。公式为: 1 1 a i a2 a n a. 1 a 2—— n 1 若间断的间隔不等,则应以间隔数为权数进行加权平均计算。公式为:
统计学三大分布与正态分布的关系
统计学三大分布与正态分布的关系[1] 张柏林 41060045 理实1002班 摘要:本文首先将介绍2χ分布,t 分布,F 分布和正态分布的定义及基本性质, 然后用理论说明2χ分布,t 分布,F 分布与正态分布的关系,并且利用数学软件MATLAB 来验证之. 1. 三大分布函数[2] 1.12χ分布 2()n χ分布是一种连续型随机变量的概率分布。这个分布是由别奈梅 (Benayme)、赫尔默特(Helmert)、皮尔逊分别于1858年、1876年、1900年所发现,它是由正态分布派生出来的,主要用于列联表检验。 定义:若随机变量12n ,,X X …X 相互独立,且都来自正态总体01N (,) ,则称统计量2222 12n =+X X χ++…X 为 服从自由度为n 的2χ分布,记为22~()n χχ. 2χ分布的概率密度函数为 122210(;),2()200n x n x e x n f x n x --?≥??=Γ???? ,2χ分布的密度函数图形是一个只取非负值 的偏态分布,如下图.
卡方分布具有如下基本性质: 性质1:22(()),(())2E n n D n n χχ==; 性质2:若221122(),()X n X n χχ==,12,X X 相互独立,则21212~()X X n n χ++; 性质3:2 n χ→∞→时,( n )正态分布; 性质4:设)(~2 2n αχχ,对给定的实数 ),10(<<αα称满足条件: αχχαχα==>? +∞ ) (222 )()}({n dx x f n P 的点)(2 n α χ为)(2n χ分布的水平α的上侧分位数. 简称为上侧α分位数. 对不同的α与n , 分位数的值已经编制成表供查用. 2()n χ分布的上α分位数 1.2t 分布 t 分布也称为学生分布,是由英国统计学家戈赛特在1908年“student”的笔名首次发表的,这个分布在数理统计中也占有重要的位置. 定义:设2 ~0~X N χ(,1),Y (n ),,X Y 相互独立,,则称统计量 T = 服从自由度为n 的t 分布,记为~()T t n . t 分布的密度函数为
常用医学统计学方法汇总
选择合适的统计学方法 1连续性资料 1.1 两组独立样本比较 1.1.1 资料符合正态分布,且两组方差齐性,直接采用t检验。 1.1.2 资料不符合正态分布,(1)可进行数据转换,如对数转换等,使之服从正态分布,然后对转换后的数据采用t检验;(2)采用非参数检验,如Wilcoxon检验。 1.1.3 资料方差不齐,(1)采用Satterthwate 的t’检验;(2)采用非参数检验,如Wilcoxon检验。 1.2 两组配对样本的比较 1.2.1 两组差值服从正态分布,采用配对t检验。 1.2.2 两组差值不服从正态分布,采用wilcoxon的符号配对秩和检验。 1.3 多组完全随机样本比较 1.3.1资料符合正态分布,且各组方差齐性,直接采用完全随机的方差分析。如果检验结果为有统计学意义,则进一步作两两比较,两两比较的方法有LSD检验,Bonferroni法,tukey 法,Scheffe法,SNK法等。 1.3.2资料不符合正态分布,或各组方差不齐,则采用非参数检验的Kruscal-Wallis法。如果检验结果为有统计学意义,则进一步作两两比较,一般采用Bonferroni法校正P值,然后用成组的Wilcoxon检验。 1.4 多组随机区组样本比较 1.4.1资料符合正态分布,且各组方差齐性,直接采用随机区组的方差分析。如果检验结果为有统计学意义,则进一步作两两比较,两两比较的方法有LSD检验,Bonferroni法,tukey 法,Scheffe法,SNK法等。 1.4.2资料不符合正态分布,或各组方差不齐,则采用非参数检验的Fridman检验法。如果检验结果为有统计学意义,则进一步作两两比较,一般采用Bonferroni法校正P值,然后用符号配对的Wilcoxon检验。 ****需要注意的问题: (1)一般来说,如果是大样本,比如各组例数大于50,可以不作正态性检验,直接采用t 检验或方差分析。因为统计学上有中心极限定理,假定大样本是服从正态分布的。 (2)当进行多组比较时,最容易犯的错误是仅比较其中的两组,而不顾其他组,这样作容易增大犯假阳性错误的概率。正确的做法应该是,先作总的各组间的比较,如果总的来说差别有统计学意义,然后才能作其中任意两组的比较,这些两两比较有特定的统计方法,如上面提到的LSD检验,Bonferroni法,tukey法,Scheffe法,SNK法等。**绝不能对其中的两
统计学常用公式汇总 (2)
统计学常用公式汇总 项目三 统计数据的整理与显示 组距=上限-下限 a) 组中值=(上限+下限)÷2 b) 缺下限开口组组中值=上限-邻组组距/2 c) 缺上限开口组组中值=下限+1/2邻组组距 例 按完成净产值分组(万元) 10以下 缺下限: 组中值=10—10/2=5 10—20 组中值=(10+20)/2=15 20—30 组中值=(20+30)/2=25 30—40 组中值=(30+40)/2=35 40—70 组中值=(40+70)/2=55 70以上 缺上限:组中值=70+30/2=85 项目四 统计描述 i. 相对指标 1. 结构相对指标=各组(或部分)总量/总体总量 2. 比例相对指标=总体中某一部分数值/总体中另一部分数值 3、 比较相对指标=甲单位某指标值/乙单位同类指标值 4、 动态相对指标=报告期数值/基期数值 5、 强度相对指标=某种现象总量指标/另一个有联系而性质不同的现 象总量指标 6、 计划完成程度相对指标K =计划数实际数 =% %计划规定的完成程度实际完成程度 7、 计划完成程度(提高率):K=%10011?++计划提高百分数 实际提高百分数 计划完成程度(降低率):K=%10011?--计划提高百分数 实际提高百分数 ii. 平均指标 1、简单算术平均数: 2、加权算术平均数 或
iii. 变异指标 1. 全距=最大标志值-最小标志值 2、标准差: 简单σ= ; 加权 σ= 成数的标准差(1) p p p σ=- 3、标准差系数: 项目五 时间序列的构成分析 一、平均发展水平的计算方法: (1)由总量指标动态数列计算序时平均数 ①由时期数列计算 n a a ∑= ②由时点数列计算 在连续时点数列的条件下计算(判断标志按日登记):∑∑=f af a 在间断时点数列的条件下计算(判断标志按月/季度/年等登记): 若间断的间隔相等,则采用“首末折半法”计算。公式为: 1 212 1121-++++=-n a a a a a n n 若间断的间隔不等,则应以间隔数为权数进行加权平均计算。公式为: ∑ --++++++=f f a a f a a f a a a n n n 11232121222 (2) (选用)由相对指标或平均指标动态数列计算序时平均数 基本公式为: b a c = 式中:c 代表相对指标或平均指标动态数列的序时平均数; a 代表分子数列的序时平均数; b 代表分母数列的序时平均数;
BIM 考试试题库 案例分析
BIM 应用案例分析试卷 1 一、单选题 施工图设计主要工作可按工作类型分为两个阶段为(): A.建筑设计+结构设计 B.模型设计+标注出图 C.模型设计+模型计算 D.建筑设计+机电设计 2.不属于按照工程建设程序分类的招标方式有() A.建设项目前期咨询招投标 B.勘察设计招标 C.材料设备采购招标 D.专项工程承包招标 的用途决定了 BIM 模型细节的精度,同时仅靠一个 BIM 工具并 不能完成所有的工作,所以目前业内主要采用()BIM 模型的方法。 A.分布式 B.统一式 C.协调式 D.时效式 4.下列措施项目中,应参阅施工技术方案进行列项的事()。 A.施工排水降水 淘宝店铺: 1 QQ群:7
微信公众号:111考试 B.文明安全施工 C.材料二次搬运 D.环境保护 5.以下哪一项不是 BIM 技术在施工阶段应用?() A.施工 BIM—3D 协调 B.可视化最佳施工方案 C.工程量自动统计 D.设备监控应急与维护 6.通风与空调系统经平衡调整后,各风口的总风量与设计风量的允许偏差不应大于() % % % % 7.结构(),是用于绘制结构梁板柱之钢筋、标注钢筋代号和布筋范围、钢筋量注释等内容。 A.布置平面 B.配筋平面 C.模板平面 D.基础平面 淘宝店铺: 2
QQ群:7 微信公众号:111考试 8.导入 CAD 图纸进入 revit 时,如何定位图纸() A.中心到中心 B.中心到圆点 C.圆点到圆点 D.圆点到中心 9.对于物业管理部门,包含建筑工程信息的竣工模型的用途是:() A.发现原始设计图纸中的问题,并利用模型进行管线综合排布调整。 B.导入物业运维管理系统中将模型和建筑物关联进行整体管理管控。 C.对综合管线模型直接布置支吊架模型并进行校核计算。 D.通过机电模型和建筑模型的配合,进行孔洞预留。 10.下面哪些不是特指桥梁 BIM 构件库模板构件的分类? A.桥墩 B.承台 C.基础 D.桥面 11.下面哪一项不是三维协同设计的优势? A.设计效率增加 B.多专业协同 C.便于变更设计
统计学原理常用公式汇总
统计学原理常用公式汇总 第2章统计整理 a)组距=上限-下限 b)组中值=(上限+下限)÷2 c)缺下限开口组组中值=上限-1/2邻组组距 d)缺上限开口组组中值=下限+1/2邻组组距 e)组数k=1+3.322Lg n n为数据个数 第3章综合指标 i.相对指标 1.结构相对指标=各组(或部分)总量/总体总量 2.比例相对指标=总体中某一部分数值/总体中另一部分数值 3.比较相对指标=甲单位某指标值/乙单位同类指标值 4.强度相对指标=某种现象总量指标/另一个有联系而性质不 同的现象总量指标 5.计划完成程度相对指标=实际数/计划数 =实际完成程度(%)/计划规定的完成程度(%) ii.平均指标 1.简单算术平均数: 2.加权算术平均数或 3调和平均数: ? ? = f X f X h 1 1 式中:, h Xf Xf m X X m f Xf X X m m Xf f X ==== == ??? ??? iii.标志变动度 1.全距=最大标志值-最小标志值 2.标准差: 简单σ= ;加权σ=
3.标准差系数: iiii 抽样推断 1. 抽样平均误差: 重复抽样: n x σ μ= n p p p ) 1(-= μ 不重复抽样: )1(2 N n n x - = σμ 2.抽样极限误差 x x t μ=? 3.重复抽样条件下: 平均数抽样时必要的样本数目 2 22x t n ?= σ 成数抽样时必要的样本数目2 2)1(p p p t n ?-= 不重复抽样条件下: 平均数抽样时必要的样本数目 2222 2σσt N Nt n x +?= 第4章 动态数列分析 一、平均发展水平的计算方法: (1)由总量指标动态数列计算序时平均数 ①由时期数列计算 n a a ∑= ②由时点数列计算 在间断时点数列的条件下计算: 若间断的间隔相等,则采用“首末折半法”计算。公式为: 1 212 11 21-++++=-n a a a a a n n Λ 若间断的间隔不等,则应以间隔数为权数进行加权平均计算。公式为:
案例分析报告常见框架与工具详细
商业案例分析的常见框架与工具 1.Strategy 1.1市场进入类 ?公司宏观环境:PEST(政治、经济、社会、技术) ?公司微观环境:SWOT分析、波特五力模型 ?市场情况分析:市场趋势、市场规模、市场份额、市场壁垒等 ?利益相关方分析:公司、供应商、经销商、顾客、竞争对手、大众 ?3C战略三角 ?市场细分(定位目标客户群;Niche Market) - 地理细分:国家、地区、城市、农村、气候、地形 - 人口细分:年龄、性别、职业、收入、教育、家庭人口、家庭类型、家庭生命周期、国籍、民族、宗教、社会阶层 - 心理细分:社会阶层、生活方式、个性 - 行为细分:时机、追求利益、使用者地位、产品使用率、忠诚程度、购买准备阶段、态度 ?风险预测与防范 1.2行业分析类 ?市场:市场规模、市场细分、产品需求/趋势分析、客户需求;BCG Matrix ?竞争:竞争对手的经济情况、产品差异化、市场整合度、产业集中度 ?顾客/供应商关系:谈判能力、替代者、评估垂直整合 ?进入/离开的障碍:对新加入者的反应、经济规模、预测学习曲线、研究政府调控 ?资金:主要资金来源、产业风险因素、成本变化趋势 1.3新产品引入类 ?营销调研数据分析 ?收入预测:时间推导、可比公司推导 ?产品生命周期 ?产品战略:4P, 4C, STP, 安索夫矩阵 ?市场营销战略:以消费者为核心的整合营销,关注各触点,并有所创新 ?物流条件:存储、运输 2.Operation 2.1市场容量扩张类:竞争对手、消费者、自身(广义3C理论) 2.2利润改善类:利润减少的两种可能 ?成本上升:固定成本/可变成本 - 固定成本过高:更新设备?削减产能?降低管理者/一般员工工资? - 可变成本过高:降低原材料价格?更换供应商?降低工资?裁员? - 成本结构是否合理? - 产能利用是否合理(闲置率)? ?销售额下降:4P(价格过高?产品品质?分销渠道?促销效果?) 2.3产品营销类(接近于“新产品引入类”) 2.4产品定价类 ?以成本为基础的定价:成本加成定价、以目标利润(盈亏平衡)定价 ?以价值为基础定价
三大抽样分布
三大抽样分布 众所周知,在概率论中有二项分布、正态分布、泊松分布着三大分布,而统计学中也有三大抽样分布,分别是x2 分布、t布和F分布。这三大抽样分布的发现正好是现代统计学的形成时期,对于以参数统计推断为主要内容的现代统计学理论的形成有着重要意义。X2分布的发现来源于Kad Pears0n创立X2拟合优度理论的过程,而t分布的发现来源于Gosset小样本理论的创立过程,F分布则是来源于Fisher创立方差分析理论的过程。 三大抽样分布的研究意义 c.R.Rao曾经说过“在终极的分析中,一切知识都是历史,在抽象的意义下,一切科学都是数学,在理性的基础上,所有的判断都是统计学。”这句话一语道破统计学的重要性。三大抽样分布在统计学理论中占据着重要地位,由此可见,研究三大抽样分布对于科学研究有着重要意义。在实际工作中,统计工作者对于三大抽样分布的研究必不可少,通过研究三大抽样分布的产生、发展和完善,能够充分了解三大抽样分布理论的重要性。具体到统计学三大分布,对于三大分布理论的研究,能够在充分吸收前人研究成果的基础上不断进行理论创新,从而推动科学技术的进步。纵观所有的科技进步,无一不是在充分研究前人成果的基础上发展而来的研究统计学三大抽样分布,对于我国社会经济发展有着重要的推动作用。三大抽样分布产生于19世纪末20世纪初,在统计学的发展过程中,每一次新的分析统计数据概率模型的发现,统计学理论都会发生一次重大飞跃。为此,要想研究三大抽样分布,就应该对其发展过程进行研究。统计量是样本的函数,是随机变量,有其概率分布,统计量的分布称为抽样分布。 X2分布 x2的早期发展 由于受到中心极限定理和正态误差理论的影响,正态分布一直在统计学中占据重要地位。在很多数学家和哲学家心目中,正态分布是唯一可用的分析和解释统计数据的方法。但是随着时代的发展,一些学者开始对正态性提出了质疑,随后,在多位科学家的试验验证下,正态分布与实际数据拟合不好的情况日渐凸显出来,科学家纷纷开始研究比正态分布范围更广的分布类型,波那个人产生了偏态分布,其中,x2就是最早的偏态分布最早引入偏态分布的是JamesClerk Maxwel,他在研究气体分子运动的过程中引入了X2分布。1891年,X2分布首次被作为统计量的分布导出。Pizzetti在求线性 模型最小二乘估计残差平方和的分布时,通过富氏分析法得出了X2的分布。随着时代的发展,正态分布理论的局限更加明显,更加推动了偏态分布的发展。KarlPearson是对偏态分布贡献最大的人,成为了一代统计学巨人。按照他的观点,统计学应该把在模型基础上对观测数据进行有效预测作为基本任务,所以他开创了一族曲线对观测数据进行拟合,使得分布拟台数据的应用范围进一步扩大。 X2模型
(完整word版)统计学三大分布与正态分布的关系
统计学三大分布与正态分布的关系 [1] 张柏林 41060045 理实1002班 摘要:本文首先将介绍 2分布,t 分布,F 分布和正态分布的定义及基本性质, 然后 用理论说明2分布,t 分布,F 分布与正态分布的关系,并且利用数学软件 MATLAB 来验证之. 1.三大分布函数[2] 1.1 2分布 2(n )分布是一种连续型随机变量的概率分布。这个分布是由别奈梅 (Benayme )赫尔默特(Helmert )、皮尔逊分别于1858年、1876年、1900年所发 现,它是由正态分布派生出来的,主要用于列联表检验。 定义:若随机变量X 1,X 2,…X n 相互独立,且都来自正态总体 N (0,,),则称 统计量 2 =x ; X ;…+X ;为服从自由度为n 的2分布,记为 2 2 ~ (n ). 2 分布的概率密度函数为 1 x e 2 x 0 J x 0 其中伽玛函数(X ) e t t x 1dt,x 0, 2 分布的密度函数图形是一个只取非负值 的偏态分布,如下图? x 2 n 2° f(x; n)
2(n2) ,X!,X2相互独立,则X! X2~ 2g n2); 性质3: n 时,2(n) 正态分布; 性质4:设2~ 2(n),对给定的实数 (0 1),称满足条件: P{ 2 2(n)} 2(、f(x)dx (n) 的点2(n)为2(n)分布的水平的上侧分位数. 简称为上侧分位数.对不同的与n,分位 数的值已经编制成表供查 分布,是由英国统计学家戈赛特在1908年“student的'笔名 布在数理统计中也占有重要的位置. 1), Y?2(n), X,Y相互独立,,则称统计量T —X VY/ n 分布,记为T~t( n). 为 性质1: E( 2(n)) n,D( 2(n)) 2n ; 性质2:若X! 2(nJ,X2
统计学常用分布及其分位数
§1、4 常用得分布及其分位数 1、 卡平方分布 卡平方分布、t 分布及F 分布都就是由正态分布所导出得分布,它们与正态分布一起,就是试验统计中常用得分布。 当X 1、X 2、… 、Xn 相互独立且都服从N(0,1)时,Z=∑i i X 2 得分布称为自由度等于n 得2χ分布,记作Z ~2χ(n),它得分布 密度 p(z )=??? ????>??? ??Γ--,,00,2212122其他z e x n z n n 式中得??? ??Γ2n =u d e u u n ?∞+--012,称为Gamma 函数,且()1Γ=1, ?? ? ??Γ21=π。2χ分布就是非对称分布,具有可加性,即当Y 与Z 相互独立,且Y ~2χ(n ),Z ~2χ(m ),则Y+Z ~2χ(n+m )。 证明: 先令X 1、X 2、…、X n 、X n+1、X n+2、…、 X n+m 相互独立且都服从N(0,1),再根据2χ分布得定义以及上述随机变量得相互独立性,令 Y=X 21+X 22+…+X 2n ,Z=X 21+n +X 22+n +…+X 2m n +, Y+Z= X 21+X 22+…+X 2n + X 21+n +X 22+n +…+X 2m n +, 即可得到Y+Z ~2χ(n +m )。 2、 t 分布 若X 与Y 相互独立,且 X ~N(0,1),Y ~2χ(n ),则Z =n Y X 得分布称为自由度等于n 得t 分布,记作Z ~ t (n ),它得分布密度 P(z)=)()(221n n n ΓΓ+2121+-???? ??+n n z 。 请注意:t 分布得分布密度也就是偶函数,且当n>30时,t
统计学三大分布及正态分布的关系
统计学三大分布与正态分布的关系 [1] 张柏林 41060045 理实1002班 摘要:本文首先将介绍2χ分布,t 分布,F 分布和正态分布的定义及基本性质, 然后用理论说明2χ分布,t 分布,F 分布与正态分布的关系,并且利用数学软件MATLAB 来验证之. 1.三大分布函数[2] 1.12χ分布 2()n χ分布是一种连续型随机变量的概率分布。这个分布是由别奈梅(Benayme)、赫尔默特(Helmert)、皮尔逊分别于1858年、1876年、1900年所发现,它是由正态分布派生出来的,主要用于列联表检验。 定义:若随机变量12n ,,X X …X 相互独立,且都来自正态总体01N (,) ,则称统计量222 212n =+X X χ++…X 为服从自由度为n 的2χ分布, 记为22~()n χχ. 2χ分布的概率密度函数为 122210(;),2()200n x n x e x n f x n x --?≥??=Γ???? ,2χ分布的密度函数图形是一个只取非负值的偏态分布,如下图.
卡方分布具有如下基本性质: 性质1:22(()),(())2E n n D n n χχ==; 性质2:若221122(),()X n X n χχ==,12,X X 相互独立,则21212~()X X n n χ++; 性质3:2 n χ→∞→时,( n )正态分布; 性质4:设)(~2 2n α χχ,对给定的实数),10(<<αα称满足条 件:αχχα χα ==>?+∞ ) (2 22)()}({n dx x f n P 的点)(2 n α χ为)(2n χ分布的水平α的上侧分位数. 简称为上侧α分位数. 对不同的α与n , 分位数的值已经编制成表供查 用. 2()n χ分布的上α分位数 1.2t 分布 t 分布也称为学生分布,是由英国统计学家戈赛特在1908年“student ”的笔名 首次发表的,这个分布在数理统计中也占有重要的位置. 定义:设2 ~0~X N χ(,1),Y (n ),,X Y 相互独立,,则称统计量/T Y n = 服从自由度为n 的t 分布,记为~()T t n .
统计学原理公式及应用
《统计学原理》常用公式汇总及计算题目分析 第一部分常用公式 第三章统计整理 a)组距=上限-下限 b)组中值=(上限+下限)÷2 c)缺下限开口组组中值=上限-1/2邻组组距 d)缺上限开口组组中值=下限+1/2邻组组距 第四章综合指标 i.相对指标 1.结构相对指标=各组(或部分)总量/总体总量 2.比例相对指标=总体中某一部分数值/总体中另一部分数值 3.比较相对指标=甲单位某指标值/乙单位同类指标值 4.强度相对指标=某种现象总量指标/另一个有联系而性质不同的现象 总量指标 5.计划完成程度相对指标=实际数/计划数 =实际完成程度(%)/计划规定的完成程度(%) ii.平均指标
1.简单算术平均数: 2.加权算术平均数或 iii.变异指标 1.全距=最大标志值-最小标志值 2.标准差: 简单σ= ;加权σ= 3.标准差系数: 第五章抽样估计 1.平均误差: 重复抽样: 不重复抽样: 2.抽样极限误差 3.重复抽样条件下: 平均数抽样时必要的样本数目
成数抽样时必要的样本数目 4.不重复抽样条件下: 平均数抽样时必要的样本数目 第七章相关分析 1.相关系数 2.配合回归方程y=a+bx 3.估计标准误: 第八章指数分数 一、综合指数的计算与分析 (1)数量指标指数
此公式的计算结果说明复杂现象总体数量指标综合变动的方向和程度。 (-) 此差额说明由于数量指标的变动对价值量指标影响的绝对额。 (2)质量指标指数 此公式的计算结果说明复杂现象总体质量指标综合变动的方向和程度。 (-) 此差额说明由于质量指标的变动对价值量指标影响的绝对额。 加权算术平均数指数= 加权调和平均数指数= (3)复杂现象总体总量指标变动的因素分析 相对数变动分析: = × 绝对值变动分析:
案例分析常用的方法
介绍的主要方法有六种,分别为: 1、对比分析法:将A公司和B公司进行对比、 2、外部因素评价模型(EFE)分析、 3、内部因素评价模型(IFE)分析、 4、swot分析方法、 5、三种竞争力分析方法、 6、五种力量模型分析。 对比分析法是最常用,简单的方法,将一个管理混乱、运营机制有问题的公司和一个管理有序、运营良好的公司进行对比,观察他们在组织结构上、资源配置上有什么不同,就可以看出明显的差别。在将这些差别和既定的管理理论相对照,便能发掘出这些差异背后所蕴含的管理学实质。企业管理中经常进行案例分析,将A和B公司进行对比,发现一些不同。各种现象的对比是千差万别的,最重要的是透过现象分析背后的管理学实质。所以说,只有表面现象的对比是远远不够的,更需要有理论分析。 外部因素评价模型(EFE)和内部因素评价模型(IFE)分析来源于战略管理中的环境分析。因为任何事物的发展都要受到周边环境的影响,这里的环境是广义的环境,不仅指外部环境,还指企业内部的环境。通常我们将企业的内部环境称作企业的禀赋,可以看作是企业资源的初始值。公司战略管理的基本控制模式由两大因素决定:外部不可控因素和内部可控因素。其中公司的外部不可控因素主要包括:政府、合作伙伴(如银行、投资商、供应商)、顾客(客户)、公众压力集团(如新闻媒体、消费者协会、宗教团体)、竞争者,除此之外,社会文化、政治、法律、经济、技术和自然等因素都将制约着公司的生存和发展。由此分析,外部不可控因素对公司来说是机会与威胁并存。公司如何趋利避险,在外部因素中发现机会、把握机会、利用机会,洞悉威胁、规避风险,对于公司来说是生死攸关的大事。在瞬息万变的动态市场中,公司是否有快速反应(应变)的能力,是否有迅速适应市场变化的能力,是否有创新变革的能力,决定着公司是否有可持续发展的潜力。公司的内部可控因素主要包括:技术、资金、人力资源和拥有的信息,除此之外,公司文化和公司精神又是公司战略制定和战略发展中不可或缺的重要部分。一个公司制定公司战略必须与公司文化背景相联。内部可控因素可以充分彰显出公司的优势与劣势或弱点。从而知己知彼,扬长避短,发挥自身的竞争优势,确定公司的战略发展方向和目标,使目标、资源和战略三者达到最佳匹配。公司通过对外部机会、风险以及内部优势、劣势的综合加权分析(借助外部因素评价矩阵[EFE]以及内部因素评价矩阵[IFE]),确立公司长期战略发展目标,制定公司发展战略。再将公司目标、资源与所制定的战略相比较,找出并建立外部与内部重要因素相匹配的有效的备选战略(借助SWOT矩阵、SPACE矩阵、BCG矩阵、IE矩阵及大战略矩阵),通过定量战略计划矩阵(QSPM)对若干备选战略的吸引力总分数的比较,确定公司最有效、最可能成功的战略。然后制定公司可量化的、具体的年度目标,围绕着已确立的目标,合理的进行各项资源的配置(如人、财、物方面的配置和调度),并有效地实施战略,最后是对已实施的战略进行控制、反馈与评价。这是最后一项工作,也是极重要的工作。往往一些战略的挫败很大部分是在实施战略的过程中,缺乏严格的控制机制和绩效考核标准所导致的。充分与及时的反馈是有效战略评价的基石,在快速而剧烈变化的环境中,公司的战略经受着巨大的挑战。通过战略评价决策矩阵,可以清晰地了解公司现行战略与实际的目标实现进程,
统计学常用分布
二项分布(,)B n p n 为试验次数,p 为每次成功概率 {}x x n x n p X x C p q -== 其中1p q += (),()E X np Var X npq == ()()tX t n E e q pe =+其中t -¥<<¥ 解释:n 重贝努里实验中正好成功x 次的概率 几何分布()Geo p p 为成功概率 ()x P X x pq == 2(),()E X q p Var X q p == ()(1),ln tX t E e p qe t q =-<- 解释:n 重贝努里实验中首次成功正好在第x+1次 负二项分布(,),1NB k p k >,k 为成功次数,01p <<,p 为成功概率 1{}x k x k x P X x C p q +-== 2(),()E X kq p Var X kq p == ()(),ln 1tX k t p E e t q qe =<-- 解释:贝努里实验系列中第k 次成功正好出现在第x +k 次实验上地概率 泊松分布()P l {},0! x P X x e x l l l -==> (),()E X Var X l l == (1)()t tX e E e e l -=,t -¥<<¥ 解释:贝努里概型中的实验次数很大,但每次成功的概率很小,平均成功次数接近于常数
均匀分布(,)U a b 1 (),X f x a x b b a =<<-;(),X x a F x a x b b a -=<<- 2 ()(),()212a b b a E X Var X +-== 11 ()(1)()r r r b a E X r b a ++-=+- 正态分布2(,)N m s 2 1) 2()x X f x m s -- = 2(),()E X Var X m s == 22 1 2()t t tX E e e m s += 对数正态分布2log (,)N m s 2 1 ln () 2()x X f x m s --=2 221 22(),()(1)E X e Var X e e m m s s ++==- 22 1 2()t t t E X e m s += 解释:如果X~2log (,)N m s ,则logX ~2(,)N m s 指数分布()Exp l ()x X f x e l l -=,()1x X F x e l -=- 21 1 (),()E X Var X l l == (1) ()r r r E X l G += 1()(1,X t M t t l l -=-<
统计学常用公式汇总
《统计学原理》常用公式汇总 组距=上限-下限组中值=(上限+下限)÷2 缺下限开口组组中值=上限-1/2邻组组距缺上限开口组组中值=下限+1/2邻组组距 111平均指标 1.简单算术平均数: 2.加权算术平均数 或 iii.变异指标 1.全距=最大标志值-最小标志值 2.标准差: 简单σ= ;加权σ= 3.标准差系数: 第五章抽样估计 1.平均误差:重复抽样: 不重复抽样: 2.抽样极限误差 3.重复抽样条件下:平均 数抽样时必要的样本数目 成数抽样时必要的样本数目 4.不重复抽样条件下:平均数抽样时必要的样本数目 第七章相关分析 1.相关系数 2.配合回归方程y=a+bx
3.估计标准误: 第八章指数分数一、综合指数的计算与分析 (1)数量指标指数 此公式的计算结果说明复杂现象总体数量指标综合变动的方向和程度。 ( - ) 此差额说明由于数量指标的变动对价值量指标影响的绝对额。 (2)质量指标指数 此公式的计算结果说明复杂现象总体质量指标综合变动的方向和程度。 ( - ) 此差额说明由于质量指标的变动对价值量指标影响的绝对额。 加权算术平均数指数= 加权调和平均数指数= (3)复杂现象总体总量指标变动的因素分析 相对数变动分析: = × 绝对值变动分析: - = ( - )×( - ) 第九章动态数列分析 一、平均发展水平的计算方法:
(1)由总量指标动态数列计算序时平均数 ①由时期数列计算 ②由时点数列计算 在间断时点数列的条件下计算: a.若间断的间隔相等,则采用“首末折半法”计算。公式为: b.若间断的间隔不等,则应以间隔数为权数进行加权平均计算。公式为: (2)由相对指标或平均指标动态数列计算序时平均数 基本公式为: 式中:代表相对指标或平均指标动态数列的序时平均数; 代表分子数列的序时平均数; 代表分母数列的序时平均数; 逐期增长量之和累积增长量 二. 平均增长量=─────────=───────── 逐期增长量的个数逐期增长量的个数 (1)计算平均发展速度的公式为: (2)平均增长速度的计算 平均增长速度=平均发展速度-1(100%)
统计学公式汇总
统计学公式汇总 Document number:NOCG-YUNOO-BUYTT-UU986-1986UT
统计学原理常用公式汇总第三章统计整理 a)组距=上限-下限 b)组中值=(上限+下限)÷2 c)缺下限开口组组中值=上限-1/2邻组组距 d)缺上限开口组组中值=下限+1/2邻组组距
第四章综合指标 i.相对指标 1.结构相对指标=各组(或部分)总量/总体总量 2.比例相对指标=总体中某一部分数值/总体中另一部分数值 3.比较相对指标=甲单位某指标值/乙单位同类指标值 4.强度相对指标=某种现象总量指标/另一个有联系而性质不同的现象总量指 标 5.计划完成程度相对指标=实际数/计划数 =实际完成程度(%)/计划规定的完成程度(%) ii.平均指标 1.简单算术平均数: 2.加权算术平均数或 iii.变异指标 1.全距=最大标志值-最小标志值 2.标准差: 简单σ= ;加权σ= 3.标准差系数:
第五章 抽样推断 1. 抽样平均误差: 重复抽样: n x σ μ= n p p p ) 1(-= μ 不重复抽样: )1(2 N n n x - = σμ 2.抽样极限误差 x x t μ=? 3.重复抽样条件下: 平均数抽样时必要的样本数目 2 22x t n ?= σ 成数抽样时必要的样本数目2 2) 1(p p p t n ?-= 不重复抽样条件下:平均数抽样时必要的样本数目 2222 2σσt N Nt n x +?=
第七章 相关分析 1.相关系数 [][ ] ∑∑∑∑∑∑∑---= 2 2 2 2 ) ()(y y n x x n y x xy n γ 2.配合回归方程 y=a+bx ∑∑∑∑∑--= 2 2 ) (x x n y x xy n b x b y a -= 3.估计标准误:2 2 ---= ∑∑∑n xy b y a y s y
高中常见数学模型案例(最新整理)
高中常见数学模型案例 中华人民共和国教育部2003年4月制定的普通高中《数学课程标准》中明确指出:“数学探究、数学建模、数学文化是贯穿于整个高中数学课程的重要内容”,“数学建模是数学学习的一种新的方式,它为学生提供了自主学习的空间,有助于学生体验数学在解决问题中的价值和作用,体验数学与日常生活和其他学科的联系,体验综合运用知识和方法解决实际问题的过程,增强应用意识;有助于激发学生学习数学的兴趣,发展学生的创新意识和实践能力。”教材中常见模型有如下几种: 一、函数模型 用函数的观点解决实际问题是中学数学中最重要的、最常用的方法。函数模型与方法在处理实际问题中的广泛运用,两个变量或几个变量,凡能找到它们之间的联系,并用数学形式表示出来,建立起一个函数关系(数学模型),然后运用函数的有关知识去解决实际问题,这些都属于函数模型的范畴。 1、正比例、反比例函数问题 例1:某商人购货,进价已按原价a 扣去25%,他希望对货物订一新价,以便按新价让利销售后仍可获得售价25%的纯利,则此商人经营者中货物的件数x 与按新价让利总额y 之间的函数关系是___________。 分析:欲求货物数x 与按新价让利总额y 之间的函数关系式,关键是要弄清原价、进价、新价之间的关系。 若设新价为b ,则售价为b (1-20%),因为原价为a ,所以进价为a (1-25%) 解:依题意,有化简得,所以25.0)2.01()25.01()2.01(?-=---b a b a b 4 5=,即x a bx y ??==2.0452.0+ ∈=N x x a y ,4 2、一次函数问题 例2:某人开汽车以60km/h 的速度从A 地到150km 远处的B 地,在B 地停留1h 后,再以50km/h 的速度返回A 地,把汽车离开A 地的路x (km )表示为时间t (h )的函数,并画出函数的图像。 分析:根据路程=速度×时间,可得出路程x 和时间t 得函数关系式x (t );同样,可列出v(t)的关系式。要注意v(t)是一个矢量,从B 地返回时速度为负值,重点应注意如何画这两个函数的图像,要知道这两个函数所反映的变化关系是不一样的。 解:汽车离开A 地的距离x km 与时间t h 之间的关系式是:,图略。 ?? ???∈--∈∈=]5.6,5.3(),5.3(50150]5.3,5.2(,150]5.2,0[,60t t t t t x 速度vkm/h 与时间t h 的函数关系式是:,图略。 ?? ???∈-∈∈=)5.6,5.3[,50)5.3,5.2[,0)5.2,0[,60t t t v 3、二次函数问题 例3:有L 米长的钢材,要做成如图所示的窗架,上半部分为半圆,下半部分为六个全等小矩形组成的矩形,试问小矩形的长、宽比为多少时,窗所通过的光线最多,并具体标出窗框面积的最大值。
统计学三大分布与正态分布的差异
申请大学学士学位论文 大学 学士学位论文 统计学三大分布与正态分布的差异年级专业: 学生: 指导教师:
统计学三大分布与正态分布的差异 中文摘要 统计学是应用数学的一个分支,主要通过利用概率论建立数学模型,收集所观察系统的数据,进行量化的分析、总结,并进而进行推断和预测,为相关决策者提供依据和参考。它被广泛的应用在各门学科之上,从物理和社会科学到人文科学,甚至被用来工商业及政府的情报决策之上。而对数据的分析过程中就需要利用到数据的分布来研究分类。 在实际遇到的许多随机现象都服从或近似服从正态分布。而由正态分布构造的三大分布在实际中有广泛的应用,因为这三大分布不仅有明确的背景,而且其抽样分布的密度函数有明显表达式,研究三大分布与正态分布有助于研究实际事例,比如经济安全与金融保险领域、人口统计等。 本文讨论了三大分布与正态分布,并将它们之间的密度函数进行比较说明. 第二章介绍了正态分布的定义、性质,三大分布的定义、性质。 第三章介绍了正态分布与三大分布的密度函数,并将它们之间的密度函数进行比较关键词:正态分布;三大分布;密度函数 The Difference between the Three Statistical Distributions and the Normal Distribution Abstract Statistics is a branch of applied mathematics, the mathematical models are mainly established by the probability and statistics theory based on the collecting
统计学名词解释
名词解释 1.统计学:是应用概率论和数理统计的基本原理和方法,研究数据的收集、整 理、分析、表达和解释的一门科学。 2.医学统计学:是应用统计学的基本原理和方法,研究医学及其有关领域数据 信息的搜集整理、分析、表达和解释的一门科学。 3.抽样:是从研那个研究总体抽取少量有代表性的个体,称为抽样。 4.统计推断:是根据已知的样本信息来推断未知的总体,是统计分析的目的, 包括参数估计和假设检验。 5.总体:是根据研究目的确定的同质研究对象的全体。 6.概率:是随机事件发生可能性大小的数值度量。 7.同质:是指所研究的观察对象具有某些相同的性质或特征。 8.变异:是同质个体的某项指标之间的差异,即个体差异。 9.正态分布:频数分布的高峰在中间,两端基本对称,逐步减少,这种分布称 为近似正态分布,如果两端完全对称则称为正态分布。 10.医学参考值范围:又称正常值范围,医学上常将包括绝大多数正常人的某指 标值的波动范围称为该指标的正常值范围。 11.动态数列(dynamic series):是按照一定的时间顺序,将一系列描述某事 物的统计指标依次排列起来,观察和比较该事物在时间上的变化和发展趋势,这些统计指标可以为绝对数、相对数或平均数。 12.人口金字塔:将人口的性别与年龄资料结合起来以图形的方式表达人口的性 别与年龄结构,以年龄为纵轴,人口百分比为横轴,左侧为男,右侧为女,两个对应的直方图,其形似金字塔。 13.负担系数(dependency ratio):又称抚养比或抚养系数,是指人口中非劳 动年龄人数与劳动年龄人数之比。 14.标准化死亡比(SMR):实际死亡人数与期望死亡人数之比称为标准化死亡比。
贾俊平《统计学》(第5版)课后习题-第6章 统计量及其抽样分布【圣才出品】
第6章 统计量及其抽样分布一、思考题 1.什么是统计量?为什么要引进统计量?统计量中为什么不含任何未知参数? 答:(1)设12n X X X ,, …,是从总体X 中抽取的容量为n 的一个样本,如果由此 样本构造一个函数12()n T X X X ,,…,,不依赖于任何未知参数,则称函数12()n T X X X ,,…,是一个统计量。 (2)在实际应用中,当从某总体中抽取一个样本后,并不能直接应用它去对总体的有关性质和特征进行推断,这是因为样本虽然是从总体中获取的代表,含有总体性质的信息,但仍较分散。为了使统计推断成为可能,首先必须把分散在样本中关心的信息集中起来,针对不同的研究目的,构造不同的样本函数。 (3)统计量是样本的一个函数。由样本构造具体的统计量,实际上是对样本所含的总体信息按某种要求进行加工处理,把分散在样本中的信息集中到统计量的取值上,不同的统计推断问题要求构造不同的统计量,所以统计量不包含未知参数。 2.判断下列样本函数哪些是统计量?哪些不是统计量? 1121021210310410()/10 min() T X X X T X X X T X T X μ μσ =+++==-=-…,,…,()/答:统计量中不能含有未知参数,故1T 、2T 是统计量,3T 、4T 不是统计量。
3.什么是次序统计量? 答:设12n X X X ,, …,是从总体X 中抽取的一个样本,()i X 称为第i 个次序统计量,它是样本 12()n X X X ,,…,满足如下条件的函数:每当样本得到一组观测值12X X ,,…,n X 时,其由小到大的排序 (1)(2)()()i n X X X X ≤≤≤≤≤……中,第i 个值()i X 就作为次序统计量()i X 的观测值,而(1)(2)()n X X X ,,…,称为次序统计量,其中(1)X 和()n X 分别为最小和最大次序统计量。 4.什么是充分统计量? 答:在统计学中,假如一个统计量能把含在样本中有关总体的信息一点都不损失地提取出来,那对保证后边的统计推断质量具有重要意义。统计量加工过程中一点信息都不损失的统计量通常称为充分统计量。 5.什么是自由度? 答:统计学上的自由度是指当以样本的统计量来估计总体的参数时,样本中独立或能自由变化的变量的个数。 6.简述2 χ分布、t 分布、F 分布及正态分布之间的关系。答:(1)随机变量X 1,X 2,… X n 相互独立,且都服从标准正态分布,则它们的平方和21 n i i X =∑服从自由度为n 的2 χ分布。(2)随机变量X 服从标准正态分布,Y 服从自由度为n 的2 χ分布,且X 与Y 独立,