SVM习题集

SVM
1.判断题
(1) 在SVM训练好后,我们可以抛弃非支持向量的样本点,仍然可以对新样本进行分类。(T)
(2) SVM对噪声(如来自其他分布的噪声样本)鲁棒。(F)
2.简答题
现有一个点能被正确分类且远离决策边界。如果将该点加入到训练集,为什么SVM的决策边界不受其影响,而已经学好的logistic回归会受影响?
答:因为SVM采用的是hinge loss,当样本点被正确分类且远离决策边界时,SVM给该样本的权重为0,所以加入该样本决策边界不受影响。而logistic回归采用的是log损失,还是会给该样本一个小小的权重。
3.产生式模型和判别式模型。(30分,每小题10分)
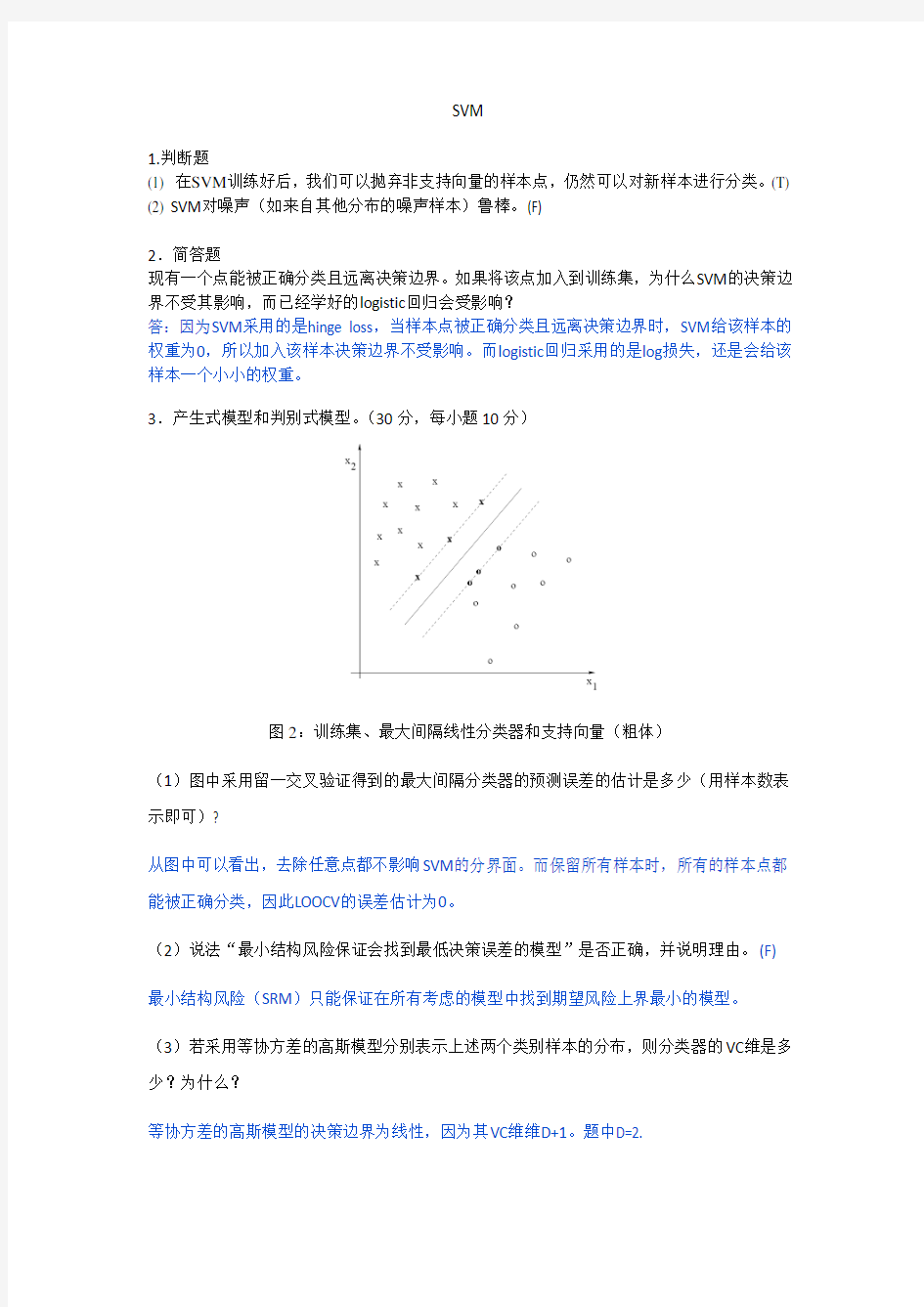
图2:训练集、最大间隔线性分类器和支持向量(粗体)
(1)图中采用留一交叉验证得到的最大间隔分类器的预测误差的估计是多少(用样本数表示即可)?
从图中可以看出,去除任意点都不影响SVM的分界面。而保留所有样本时,所有的样本点都能被正确分类,因此LOOCV的误差估计为0。
(2)说法“最小结构风险保证会找到最低决策误差的模型”是否正确,并说明理由。(F)
最小结构风险(SRM)只能保证在所有考虑的模型中找到期望风险上界最小的模型。
(3)若采用等协方差的高斯模型分别表示上述两个类别样本的分布,则分类器的VC维是多少?为什么?
等协方差的高斯模型的决策边界为线性,因为其VC维维D+1。题中D=2.
4、SVM 分类。(第1~5题各4分,第6题5分,共25分)
下图为采用不同核函数或不同的松弛因子得到的SVM 决策边界。但粗心的实验者忘记记录每个图形对应的模型和参数了。请你帮忙给下面每个模型标出正确的图形。
(1)、211min , s.t.2N
i i C ξ=??+ ?
??
∑w
()00, 1, 1,....,, T i i i y w i N ξξ≥+≥-=w x
其中0.1C =。 线性分类面,C 较小,
正则较大,||w||较小,Margin 较大, 支持向量较多(c )
(2)、211min , s.t.2N
i i C ξ=??+ ?
??
∑w
()00, 1, 1,....,, T i i i y w i N ξξ≥+≥-=w x
其中1C =。
线性分类面,C 较大,
正则较小,||w||较大,Margin 较小 支持向量的数目少(b )
(3)、()111
1max ,2N N N
i i j i j i j i i j y y k ααα===??- ???
∑∑∑x x
1
s.t. 0, 1,....,, 0N
i i i i C i N y αα=≤<==∑
其中()()2
,T T k '''=+x x x x x x 。
二次多项式核函数,决策边界为二次曲线 (d)
(4)、()1111max ,2N N N
i i j i j i j i i j y y k ααα===??- ?
??
∑∑∑x x 1
s.t. 0, 1,....,, 0N
i i i i C i N y αα=≤<==∑
其中()21,exp 2k ??''=-- ???
x x x x 。
RBF 核函数,决策边界为曲线, σ=1较大,曲线更平滑 (a)
(5)、()111
1max ,2N N N i i j i j i j i i j y y k ααα===??- ???
∑∑∑x x 1
s.t. 0, 1,....,, 0N
i i i i C i N y αα=≤<==∑
其中()()
2,exp k ''=--x x x x 。 RBF 核函数,决策边界为曲线, σ=sqrt(1/2)较小,曲线更弯曲 (e)
(6)考虑带松弛因子的线性
SVM
分类器:211min , s.t.
2N
i i C ξ=??+ ?
??
∑w ()00, 1, 1,....,, T i i i y w i N ξξ≥+≥-=w x 下面有一些关于某些变量随参数C 的增大而变化的表
述。如果表述总是成立,标示“是”;如果表述总是不成立,标示“否”;如果表述的正确性取决于C 增大的具体情况,标示“不一定”。
(1) 0w 不会增大 (不一定)
(2) ?w 增大
(不一定)
(3) ?w 不会减小
(是)
(4) 会有更多的训练样本被分错(否)
(5) 间隔(Margin)不会增大(是)
5、考虑带松弛因子的线性SVM 分类器:()2
T 011min , s.t. 1, 2N
i i i i i C y w i ξξ=??++≥-? ???
∑w w x 。
在下图中,0.1, 1, 10, 100C =,并且已经标出分界面和支持向量。请给每幅图标出最可能的C 的取值,并分析原因(20分)。
答:
()2
T 01, subject to 1, 2
i i i i i
C y w i ξξ+
+≥-?∑w w x 等价于
()2
T 01, subject to 1, 2i i i i i
y w i C
ξξ+
+≥-?∑w w x 所以2
2
1, ,
C ↑↑↓w w
,即margin 减小(当C 增大到一定程度时,Margin 不再变化),不
允许错分太多样本(对错分样本的惩罚大),支持向量(落在Margin 内的样本和错分的样本)的数目减少。
6. SVM
(1) 下面的情况,适合用原SVM 求解还是用对偶SVM 求解。 1) 特征变换将特征从D 维变换到无穷维。(对偶)
2) 特征变换将特征从D 维变换到2D 维,训练数据有上亿个并且线性可分。(原)
(2) 在线性可分情况下,在原问题形式化中怎样确定一个样本为支持向量?
在原问题中,给出了w ,w 0,支持向量满足:()
**01T
i i y w x +=w 。
7.SVM 和松弛因子。
考虑如图给出的训练样本,我们采用二次多项式做为核函数,松弛因子为C 。请对下列问题做出定性分析,并用一两句话给出原因。
(1) 当C →∞时,决策边界会变成什么样?
答:当C 很大时,错分样本的惩罚会非常大,因此模型会尽可能将样本分对。(记住这里决策边界为二次曲面)
C →∞ C →0
(2) 当C →0时,决策边界会变成什么样? 可以错分少量样本,但Margin 大
(3) 你认为上述两种情况,哪个在实际测试时效果会好些?
我们不能过于相信某个特定的样本,因此C →0的效果会好些,因为它最大化样本云团之间的Margin.
(4) 在图中增加一个点,使得当C →∞时,决策边界会不变。
能被原来的分类器正确分类,不会是支持向量。
(5) 在图中增加一个点,使得当C ∞时,该点会显著影响决策边界。
能被原来的分类器正确分类,不会是支持向量。
当C 很大时,错分样本的惩罚会非常大,因此增加一个不能被原来分类器正确分类的样本会影响决策边界。
8.对outlier 的敏感性。
我们知道在SVM 用于回归时,等价于采用ε不敏感的损失函数(如下图所示),即SVM 的目标为:
()()()2,,1
1?min ,2..0,0
N
i i
i i i i i i i i i C s t
y f y f ξξεξεξξξ+-+-
=+-
+-=++≤++≥--≥≥∑w ξξw w x x 。
课堂已经讨论L2损失对outliers 比较敏感,而L1损失和huber 损失相对不敏感些。 (1) 请说明为什么L2损失比较L1损失对outliers 更敏感。
Outlier 为离群点,因此其预测残差r 会比较大。L2损失为残差r 的平方r 2,L1损失为残差r 的绝对值|r|。当r>1时,r 2>|r|,从而L2损失在outliter 样本点的值会非常大,对结果影响更大。
(2) 请给出一个outlier 影响预测子的例子。
(3) 相比于L2损失和L1损失,分析SVM 的ε不敏感的损失函数对outliers 敏感性。
ε不敏感的损失函数对outliers 的敏感性更接近于L1损失,因此比L2损失更不敏感。初看起来,ε不敏感的损失函数在区间[-ε,ε]不施加惩罚,似乎比L1对outliers 更不敏感。但实际上outliers 对应的残差通常很大,所以不会落在区间[-ε,ε],所以ε不敏感的损失函数对outliers 的敏感性和L1损失相似。
(4) SVM 也等价于MAP 估计,则该MAP 估计对应的先验和似然是什么?
同岭回归类似,先验为0均值得高斯分布,但方差为2C ,同时各维独立,即
()()0,2j
p C =∏w N ,
似然函数在区间[-ε,ε]为常数,其他地方为Laplace 分布:
()()
10
22|,1exp 22T T y p y y otherwise
εεε?
-≤??+=?
?---?+?
w x w x w x
9. 多个数据源的SVM
假设你在两天内用两个不同的仪器收集了两批数据,你觉得数据集1标签的可信度为数据集2的两倍。 我们分别用(){}
1
11
,N i
i
i y ==
x D 表示数据集1,(){}
2
21
,N i
i
i v ==
u D 表示数据集2,数据集1的松弛
因子表示为ξ,数据集2的松弛因子表示ζ,二者的Lagrange 乘子分别表示为α和β。 关于怎样处理这两批数据,你的朋友们给出了不同的建议。 张三:将数据集1的松弛惩罚乘以2,因此优化问题为:
(){}(){}{}{}11
2
,,11
T 01T 02121min 22subject to
1, 1,2.,,,,, 1, 1,2.,,,,,
0, 1,2.,,,,, 0, 1,2.,,,,,
N N i j i j i i i j j j i j C C y w i N v w j N i N j N ξ?ξ?ξ?ξ?==+++≥-?∈+≥-?∈≥?∈≥?∈∑∑w w w x w u
李四:将数据集1的Lagrange 乘子乘以2,因此优化问题为:
{}{}121112
22
1
2
1
1
11
11
11
121
1
1max 22αα,2α,,2subject to
20, 1,2.,,,,, 0, 1,2.,,,,,
20
N N N N N N N N i j i j i j i j i j i j i j
i j i j i j i j i j i j i j i j N N i i
j
j
i j C C y y y v v v c i N c j N y v
αββββαβαβ==========+---≥≥?∈≥≥?∈+=∑∑∑∑∑∑∑∑∑∑α,β
x x x u u u
王五:将数据集1的数据点复制一份(即数据集1中的每个样本点变成2个),然后照常处理。
问题:请说明上述处理是否等价(得到的分界面相同)。
解:我们从张三的建议的对偶表示开始,即
()()()
()()
{}{}12
1
2
12
2
011
T
T
001
1
1
1
121,,,,22 11subject to
1,2.,,,,, 1,2.,,,,,
0, 0, 0N N i j
i j N N N N i i i i i i i i i i i i
i i i i i j i L w C C y w v w e f i N j N e ξ?αξβ?ξ?αβ=======++-+-+-+-+---?∈?∈≥≥≥∑∑∑∑∑∑αβe,f w w w x w u (){}(){}()()T 01T 02T
0T 0, 0
1, 1,2.,,,,, 1, 1,2.,,,,, 0, 0
10,10
j i i i j j j i i j j i i i i j j j j f y w i N v w j N e f y w v w ξ?ξ?αξβ?≥+≥-?∈+≥-?∈==??+-+=????+-+=??w x w u w x w u
优化0,,w e,f w ,目标函数对0,,w e,f w 求导等于0,
12
110N N i i i i i i i i L y v αβ*
==?=?=+?∑∑w x u w ,(1) 1211
000N N i i i i i i L
y v w αβ==?=?+=?∑∑, (2) 02i i i
L
C e αξ?=?=-?, (3) 0i i i
L
C f β??=?=-?, (4) 由于有约束0, 0, 0, 0 i j i j e f αβ≥≥≥≥,公式(3)(4)变成 20, 0,
i j c c αβ≥≥≥≥。
将上述公式代入L ,消除0,,,i j w ξ?w ,得到对偶表示:
(
){}{}1
2
1112
22
1
2
111111
11121
111,αα,α,,22subject to
20, 1,2.,,,,, 0, 1,2.,,,,,
20
N N N N N N N N i j i j i j i j i j i j i j i j i j i j
i j i j i j i j i j N N i i
j
j
i j L C C y y y v v v c i N c j N y v
αββββαβαβ===========+---≥≥?∈≥≥?∈+=∑∑∑∑∑∑∑∑∑∑αβx x x u u u 可以看出,这和下面李四的建议不同。
{}{}1
2
1
1
1
2
22
1
2
1
1
11
11
11
121
1
1max 22αα,2α,,2subject to
20, 1,2.,,,,, 0, 1,2.,,,,,
20
N N N N N N N N i j i j i j i j i j i j i j
i j i j i j i j i j i j i j i j N N i i
j
j
i j C C y y y v v v c i N c j N y v
αββββαβαβ==========+---≥≥?∈≥≥?∈+=∑∑∑∑∑∑∑∑∑∑α,β
x x x u u u 。
王五的建议如下,
111
2
,,111
1min 2N N N i i j i i j C C C ξ?ξξ?===+++∑∑∑w w ,
和张三的建议相同,即张三= 王五。
(完整word版)支持向量机(SVM)原理及应用概述分析
支持向量机(SVM )原理及应用 一、SVM 的产生与发展 自1995年Vapnik (瓦普尼克)在统计学习理论的基础上提出SVM 作为模式识别的新方法之后,SVM 一直倍受关注。同年,Vapnik 和Cortes 提出软间隔(soft margin)SVM ,通过引进松弛变量i ξ度量数据i x 的误分类(分类出现错误时i ξ大于0),同时在目标函数中增加一个分量用来惩罚非零松弛变量(即代价函数),SVM 的寻优过程即是大的分隔间距和小的误差补偿之间的平衡过程;1996年,Vapnik 等人又提出支持向量回归 (Support Vector Regression ,SVR)的方法用于解决拟合问题。SVR 同SVM 的出发点都是寻找最优超平面(注:一维空间为点;二维空间为线;三维空间为面;高维空间为超平面。),但SVR 的目的不是找到两种数据的分割平面,而是找到能准确预测数据分布的平面,两者最终都转换为最优化问题的求解;1998年,Weston 等人根据SVM 原理提出了用于解决多类分类的SVM 方法(Multi-Class Support Vector Machines ,Multi-SVM),通过将多类分类转化成二类分类,将SVM 应用于多分类问题的判断:此外,在SVM 算法的基本框架下,研究者针对不同的方面提出了很多相关的改进算法。例如,Suykens 提出的最小二乘支持向量机 (Least Square Support Vector Machine ,LS —SVM)算法,Joachims 等人提出的SVM-1ight ,张学工提出的中心支持向量机 (Central Support Vector Machine ,CSVM),Scholkoph 和Smola 基于二次规划提出的v-SVM 等。此后,台湾大学林智仁(Lin Chih-Jen)教授等对SVM 的典型应用进行总结,并设计开发出较为完善的SVM 工具包,也就是LIBSVM(A Library for Support Vector Machines)。LIBSVM 是一个通用的SVM 软件包,可以解决分类、回归以及分布估计等问题。 二、支持向量机原理 SVM 方法是20世纪90年代初Vapnik 等人根据统计学习理论提出的一种新的机器学习方法,它以结构风险最小化原则为理论基础,通过适当地选择函数子集及该子集中的判别函数,使学习机器的实际风险达到最小,保证了通过有限训练样本得到的小误差分类器,对独立测试集的测试误差仍然较小。 支持向量机的基本思想:首先,在线性可分情况下,在原空间寻找两类样本的最优分类超平面。在线性不可分的情况下,加入了松弛变量进行分析,通过使用非线性映射将低维输
svm使用详解
1.文件中数据格式 label index1:value1 index2:value2 ... Label在分类中表示类别标识,在预测中表示对应的目标值 Index表示特征的序号,一般从1开始,依次增大 Value表示每个特征的值 例如: 3 1:0.122000 2:0.792000 3 1:0.144000 2:0.750000 3 1:0.194000 2:0.658000 3 1:0.244000 2:0.540000 3 1:0.328000 2:0.404000 3 1:0.402000 2:0.356000 3 1:0.490000 2:0.384000 3 1:0.548000 2:0.436000 数据文件准备好后,可以用一个python程序检查格式是否正确,这个程序在下载的libsvm文件夹的子文件夹tools下,叫checkdata.py,用法:在windows命令行中先移动到checkdata.py所在文件夹下,输入:checkdata.py 你要检查的文件完整路径(包含文件名) 回车后会提示是否正确。
2.对数据进行归一化。 该过程要用到libsvm软件包中的svm-scale.exe Svm-scale用法: 用法:svmscale [-l lower] [-u upper] [-y y_lower y_upper] [-s save_filename] [-r restore_filename] filename (缺省值: lower = -1,upper = 1,没有对y进行缩放) 其中, -l:数据下限标记;lower:缩放后数据下限; -u:数据上限标记;upper:缩放后数据上限; -y:是否对目标值同时进行缩放;y_lower为下限值,y_upper 为上限值;(回归需要对目标进行缩放,因此该参数可以设定为–y -1 1 ) -s save_filename:表示将缩放的规则保存为文件save_filename; -r restore_filename:表示将缩放规则文件restore_filename载入后按此缩放; filename:待缩放的数据文件(要求满足前面所述的格式)。 数据集的缩放结果在此情况下通过DOS窗口输出,当然也可以通过DOS的文件重定向符号“>”将结果另存为指定的文件。该文件中的参数可用于最后面对目标值的反归一化。反归一化的公式为:
svm核函数matlab
clear all; clc; N=35; %样本个数 NN1=4; %预测样本数 %********************随机选择初始训练样本及确定预测样本******************************* x=[]; y=[]; index=randperm(N); %随机排序N个序列 index=sort(index); gama=23.411; %正则化参数 deita=0.0698; %核参数值 %thita=; %核参数值 %*********构造感知机核函数************************************* %for i=1:N % x1=x(:,index(i)); % for j=1:N % x2=x(:,index(j)); % K(i,j)=tanh(deita*(x1'*x2)+thita); % end %end %*********构造径向基核函数************************************** for i=1:N x1=x(:,index(i)); for j=1:N x2=x(:,index(j)); x12=x1-x2; K(i,j)=exp(-(x12'*x12)/2/(deita*deita)); End End %*********构造多项式核函数**************************************** %for i=1:N % x1=x(:,index(i)); % for j=1:N % x2=x(:,index(j)); % K(i,j)=(1+x1'*x2)^(deita); % end %end %*********构造核矩阵************************************ for i=1:N-NN1 for j=1:N-NN1 omeiga1(i,j)=K(i,j); end end
支持向量机(SVM)算法推导及其分类的算法实现
支持向量机算法推导及其分类的算法实现 摘要:本文从线性分类问题开始逐步的叙述支持向量机思想的形成,并提供相应的推导过程。简述核函数的概念,以及kernel在SVM算法中的核心地位。介绍松弛变量引入的SVM算法原因,提出软间隔线性分类法。概括SVM分别在一对一和一对多分类问题中应用。基于SVM在一对多问题中的不足,提出SVM 的改进版本DAG SVM。 Abstract:This article begins with a linear classification problem, Gradually discuss formation of SVM, and their derivation. Description the concept of kernel function, and the core position in SVM algorithm. Describes the reasons for the introduction of slack variables, and propose soft-margin linear classification. Summary the application of SVM in one-to-one and one-to-many linear classification. Based on SVM shortage in one-to-many problems, an improved version which called DAG SVM was put forward. 关键字:SVM、线性分类、核函数、松弛变量、DAG SVM 1. SVM的简介 支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。支持向量机方法是建立在统计学习理论的VC 维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度,Accuracy)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折衷,以期获得最好的推广能力。 对于SVM的基本特点,小样本,并不是样本的绝对数量少,而是与问题的复杂度比起来,SVM算法要求的样本数是相对比较少的。非线性,是指SVM擅长处理样本数据线性不可分的情况,主要通过松弛变量和核函数实现,是SVM 的精髓。高维模式识别是指样本维数很高,通过SVM建立的分类器却很简洁,只包含落在边界上的支持向量。
SVM方法步骤
SVM 方法步骤 彭海娟 2010-1-29 看了一些文档和程序,大体总结出SVM 的步骤,了解了计算过程,再看相关文档就比较容易懂了。 1. 准备工作 1) 确立分类器个数 一般都事先确定分类器的个数,当然,如有必要,可在训练过程中增加分类器的个数。分类器指的是将样本中分几个类型,比如我们从样本中需要识别出:车辆、行人、非车并非人,则分类器的个数是3。 分类器的个数用k 2) 图像库建立 SVM 方法需要建立一个比较大的样本集,也就是图像库,这个样本集不仅仅包括正样本,还需要有一定数量的负样本。通常样本越多越好,但不是绝对的。 设样本数为S 3) ROI 提取 对所有样本中的可能包含目标的区域(比如车辆区域)手动或自动提取出来,此时包括正样本中的目标区域,也包括负样本中类似车辆特征的区域或者说干扰区域。 4) ROI 预处理 包括背景去除,图像滤波,或者是边缘增强,二值化等预处理。预处理的方法视特征的选取而定。 5) 特征向量确定 描述一个目标,打算用什么特征,用几个特征,给出每个特征的标示方法以及总的特征数,也就是常说的特征向量的维数。 对于车辆识别,可用的特征如:车辆区域的灰度均值、灰度方差、对称性、信息熵、傅里叶描述子等等。 设特征向量的维数是L 。 6) 特征提取 确定采取的特征向量之后,对样本集中所有经过预处理之后的ROI 区域进行特征提取,也就是说计算每个ROI 区域的所有特征值,并将其保存。 7) 特征向量的归一化 常用的归一化方法是:先对相同的特征(每个特征向量分别归一化)进行排序,然后根据特征的最大值和最小值重新计算特征值。 8) 核的选定 SVM 的构造主要依赖于核函数的选择,由于不适当的核函数可能会导致很差的分类结果,并且目前尚没有有效的学习使用何种核函数比较好,只能通过实验结果确定采用哪种核函数比较好。训练的目标不同,核函数也会不同。 核函数其实就是采用什么样的模型描述样本中目标特征向量之间的关系。如常用的核函数:Gauss 函数 2 1),(21x x x p e x x k --= 对样本的训练就是计算p 矩阵,然后得出描述目标的模板和代表元。 2. 训练 训练就是根据选定的核函数对样本集的所有特征向量进行计算,构造一个使样本可分的
svm为什么需要核函数
svm为什么需要核函数 本来自己想写这个内容,但是看到了一篇网上的文章,觉得写得很好,这样我就不自己写了,直接转载人家的。我在两处加粗红了,我觉得这两处理解了,就理解了svm中kernel的作用。 1.原来在二维空间中一个线性不可分的问题,映射到四维空间后,变成了线性可分的!因此这也形成了我们最初想解决线性不可分问题的基本思路——向高维空间转化,使其变得线性可分。 2.转化最关键的部分就在于找到x到y的映射方法。遗憾的是,如何找到这个映射,没有系统性的方法(也就是说,纯靠猜和凑)。 3.我们其实只关心那个高维空间里内积的值,那个值算出来了,分类结果就算出来了。 4.核函数的基本作用就是接受两个低维空间里的向量,能够计算出经过某个变换后在高维空间里的向量内积值。 列一下常用核函数: 线性核函数: 多项式核函数: 高斯核函数: 核函数: 下面便是转载的部分: 转载地址:https://www.360docs.net/doc/da9784772.html,/zhenandaci/archive/2009/03/06/258288.html 生存?还是毁灭?——哈姆雷特 可分?还是不可分?——支持向量机 之前一直在讨论的线性分类器,器如其名(汗,这是什么说法啊),只能对线性可分的样本做处理。如果提供的样本线性不可分,结果很简单,线性分类器的求解程序会无限循环,永远也解不出来。这必然使得它的适用范围大大缩小,而它的很多优点我们实在不原意放弃,怎么办呢?是否有某种方法,让线性不可分的数据变得线性可分呢? 有!其思想说来也简单,来用一个二维平面中的分类问题作例子,你一看就会明白。事先声明,下面这个例子是网络早就有的,我一时找不到原作者的正确信息,在此借用,并加进了我自己的解说而已。 例子是下面这张图: 我们把横轴上端点a和b之间红色部分里的所有点定为正类,两边的黑色部分里的点定为负类。试问能找到一个线性函数把两类正确分开么?不能,因为二维空间里的线性函数就是指直线,显然找不到符合条件的直线。
SVM通俗讲解
SVM(Support Vector Machine) 支持向量机相关理论介绍 基于数据的机器学习是现代智能技术中的重要方面,研究从观测数据(样本)出发寻找规律,利用这些规律对未来数据或无法观测的数据进行预测。迄今为止,关于机器学习还没有一种被共同接受的理论框架,关于其实现方法大致可以分为三种[3]: 第一种是经典的(参数)统计估计方法。包括模式识别、神经网络等在内,现有机器学习方法共同的重要理论基础之一是统计学。参数方法正是基于传统统计学的,在这种方法中,参数的相关形式是已知的,训练样本用来估计参数的值。这种方法有很大的局限性。 首先,它需要已知样本分布形式,这需要花费很大代价,还有,传统统计学研究的是样本数目趋于无穷大时的渐近理论,现有学习方法也多是基于此假设。但在实际问题中,样本数往往是有限的,因此一些理论上很优秀的学习方法实际中表现却可能不尽人意。 第二种方法是经验非线性方法,如人工神经网络(ANN)。这种方法利用已知样本建立非线性模型,克服了传统参数估计方法的困难。但是,这种方法缺乏一种统一的数学理论。与传统统计学相比,统计学习理论(Statistical Learning Theory或SLT)是一种专门研究小样本情况下机器学习规律的理论。该理论针对小样本统计问题建立了一套新的理论体系,在这种体系下的统计推理规则不仅考虑了对渐近性能的要求,而且追求在现有有限信息的条件下得到最优结果。V. Vapnik等人从六、七十年代开始致力于此方面研究,到九十年代中期,随着其理论的不断发展和成熟,也由于神经网络等学习方法在理论上缺乏实质性进展,统计学习理论开始受到越来越广泛的重视。 统计学习理论的一个核心概念就是VC维(VC Dimension)概念,它是描述函数集或学习机器的复杂性或者说是学习能力(Capacity of the machine)的一个重要指标,在此概念基础上发展出了一系列关于统计学习的一致性(Consistency)、收敛速度、推广性能(Generalization Performance)等的重要结论。 统计学习理论是建立在一套较坚实的理论基础之上的,为解决有限样本学习问题提供了一个统一的框架。它能将很多现有方法纳入其中,有望帮助解决许多原来难以解决的问题(比如神经网络结构选择问题、局部极小点问题等); 同时,这一理论基础上发展了一种新的通用学习方法──支持向量机(Support Vector Machine或SVM),已初步表现出很多优于已有方法的性能。一些学者认为,SLT和SVM正在成为继神经网络研究之后新的研究热点,并将推动机器学习理论和技术有重大的发展。 支持向量机方法是建立在统计学习理论的VC维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度,Accuracy)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折衷,以期获得最好的推广能力(Generalizatin Ability)。支持向量机方法的几个主要优点