新浪微博数据采集方法

https://www.360docs.net/doc/df16870602.html,
本文介绍使用八爪鱼采集微博数据-发布的全部微博为例
采集网站:
使用功能点:
●分页列表及详细信息提取
https://www.360docs.net/doc/df16870602.html,/tutorial/fylbxq7.aspx?t=1
●八爪鱼7.0教程——AJAX滚动教程
https://www.360docs.net/doc/df16870602.html,/tutorial/ajgd_7.aspx?t=1
●八爪鱼7.0教程——AJAX点击和翻页教程
https://www.360docs.net/doc/df16870602.html,/tutorial/ajaxdjfy_7.aspx?t=1 相关采集教程:
58同城信息采集
豆瓣电影短评采集
步骤1:创建采集任务
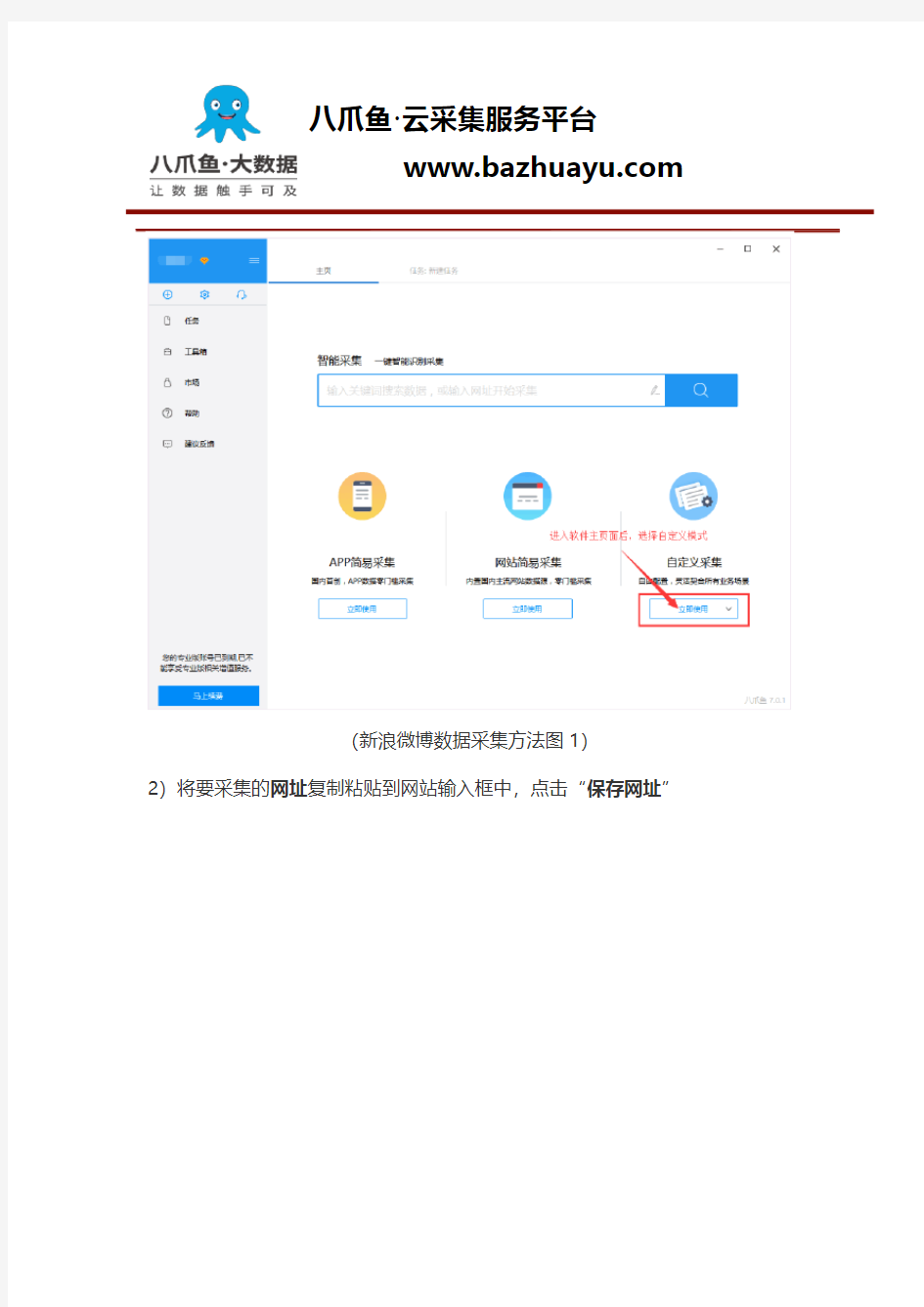
1)进入主界面,选择“自定义模式”
https://www.360docs.net/doc/df16870602.html,
2)将要采集的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/df16870602.html,
1)系统自动打开网页,进入微博页面。在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。将当前微博页面下拉至底部,出现“正在加载中,请稍后”的字样。等待约2秒,页面会有新的数据加载出来。经过2次下拉加载,页面达到最底部,出现“下一页”按钮
https://www.360docs.net/doc/df16870602.html,
(新浪微博数据采集方法图3)
“打开网页”步骤涉及Ajax下拉加载。打开“高级选项”,勾选“页面加载完成后向下滚动”,设置滚动次数为“4次”,每次间隔“3秒”,滚动方式为“直接滚动到底部”,最后点击“确定”
https://www.360docs.net/doc/df16870602.html,
(新浪微博数据采集方法图4)
注意,这里的滚动次数、间隔时间,需要针对网站进行设置,可根据相关功能点教程进行学习:
八爪鱼7.0教程——AJAX滚动教程
八爪鱼7.0教程——AJAX点击和翻页教程
https://www.360docs.net/doc/df16870602.html,/tutorial/ajaxdjfy_7.aspx?t=1
2)将页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”
https://www.360docs.net/doc/df16870602.html,
(新浪微博数据采集方法图5)
此步骤同样涉及了Ajax下拉加载。打开“高级选项”,勾选“页面加载完成后向下滚动”,设置滚动次数为“4次”,每次间隔“3秒”,滚动方式为“直接滚动到底部”,最后点击“确定”
https://www.360docs.net/doc/df16870602.html,
(新浪微博数据采集方法图6)
1)移动鼠标,选中页面里的第一条微博链接。选中后,系统会自动识别页面里的其他相似链接。在右侧操作提示框中,选择“选中全部”
https://www.360docs.net/doc/df16870602.html,
(新浪微博数据采集方法图7)2)选择“循环点击每个链接”,以创建一个列表循环
https://www.360docs.net/doc/df16870602.html,
1)在创建列表循环后,系统会自动点击第一条微博链接,进入微博详情页。点击需要的字段信息,在右侧的操作提示框中,选择“采集该元素的文本”。继续选择要采集的字段,选择“采集该元素的文本”
(新浪微博数据采集方法图9)
2)继续选中要采集的字段,这里选中了微博链接,在操作提示框中,选择“采集该链接的地址”。重复以上操作,直至需要的字段选择完成
https://www.360docs.net/doc/df16870602.html,
(新浪微博数据采集方法图10)
3)字段信息选择完成后,选中相应的字段,可以进行字段的自定义命名。完成后,点击左上角的“保存并启动”,启动采集任务
https://www.360docs.net/doc/df16870602.html,
(新浪微博数据采集方法图11)4)选择“启动本地采集”
https://www.360docs.net/doc/df16870602.html,
步骤5:数据采集及导出
1)采集完成后,会跳出提示,选择“导出数据”。选择“合适的导出方式”,将采集好微博发博数据导出
(新浪微博数据采集方法图13)
2)这里我们选择excel作为导出为格式,数据导出后如下图
https://www.360docs.net/doc/df16870602.html,
(新浪微博数据采集方法图14)
八爪鱼——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。
3、云采集,关机也可以。配置好采集任务后可关机,任务可在云端执行。庞大云采集集群24*7不间断运行,不用担心IP被封,网络中断。
4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的基本采集需求。同时设置了一些增值服务(如私有云),满足高端付费企业用户的需要。
https://www.360docs.net/doc/df16870602.html,
微博数据抓取方法详细步骤
https://www.360docs.net/doc/df16870602.html, 微博数据抓取方法详细步骤 很多朋友想要采集微博上面的有用信息,对于繁多的信息量,需要手动的复制,粘贴,修改格式吗?不用这么麻烦!教你一键收集海量数据。 本文介绍使用八爪鱼采集器简易模式采集抓取新浪微博的方法。 需要采集微博内容的,在网页简易模式界面里点击微博进去之后可以看到所有关于微博的规则信息,我们直接使用就可以的。 新浪微博数据抓取步骤1 采集在微博首页进关键词搜索后的信息以及发文者的关注量,粉丝数等(下图所示)即打开微博主页进行登录后输入关键词进行搜索,采集搜索到的内容以及进入发文者页面采集关注量,粉丝数,微博数。
https://www.360docs.net/doc/df16870602.html, 1、找到微博网页-关键词搜索规则然后点击立即使用 新浪微博数据抓取步骤2 2、简易模式中微博网页-关键词搜索的任务界面介绍 查看详情:点开可以看到示例网址 任务名:自定义任务名,默认为微博网页-关键词搜索 任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组用户名:请填写您的微博账号 密码:请填写微博账号的登录密码 关键词/搜索词:用于搜索的关键词,只支持填写一个 翻页次数:设置采集多少页,由于微博会封账号,限制翻页1-50页 将鼠标移动到?号图标和任务名顶部文字均可以查看详细的注释信息。示例数据:这个规则采集的所有字段信息。
https://www.360docs.net/doc/df16870602.html, 新浪微博数据抓取步骤3 3、任务设置示例 例如要采集与十九大相关的微博消息 在设置里如下图所示: 任务名:自定义任务名,也可以不设置按照默认的就行 任务组:自定义任务组,也可以不设置按照默认的就行 用户名:请填写您的微博账号,必填 密码:请填写微博账号的登录密码,必填 关键词/搜索词:用于搜索的关键词,此处填写“十九大” 翻页次数:设置采集多少页,此处设置2页 设置好之后点击保存
新浪微博数据抓取详细教程
https://www.360docs.net/doc/df16870602.html, 新浪微博数据抓取详细教程 本文介绍使用八爪鱼采集器简易模式采集抓取新浪微博的方法。 需要采集微博内容的,在网页简易模式界面里点击微博进去之后可以看到所有关于微博的规则信息,我们直接使用就可以的。 新浪微博数据抓取步骤1 采集在微博首页进关键词搜索后的信息以及发文者的关注量,粉丝数等(下图所示)即打开微博主页进行登录后输入关键词进行搜索,采集搜索到的内容以及进入发文者页面采集关注量,粉丝数,微博数。 1、找到微博网页-关键词搜索规则然后点击立即使用
https://www.360docs.net/doc/df16870602.html, 新浪微博数据抓取步骤2 2、 简易模式中微博网页-关键词搜索的任务界面介绍 查看详情:点开可以看到示例网址 任务名:自定义任务名,默认为微博网页-关键词搜索 任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组 用户名:请填写您的微博账号 密码:请填写微博账号的登录密码 关键词/搜索词:用于搜索的关键词,只支持填写一个 翻页次数: 设置采集多少页,由于微博会封账号,限制翻页1-50页 将鼠标移动到?号图标和任务名顶部文字均可以查看详细的注释信息。 示例数据:这个规则采集的所有字段信息。
https://www.360docs.net/doc/df16870602.html, 新浪微博数据抓取步骤3 3、任务设置示例 例如要采集与十九大相关的微博消息 在设置里如下图所示: 任务名:自定义任务名,也可以不设置按照默认的就行 任务组:自定义任务组,也可以不设置按照默认的就行 用户名:请填写您的微博账号,必填 密码:请填写微博账号的登录密码,必填 关键词/搜索词:用于搜索的关键词,此处填写“十九大” 翻页次数:设置采集多少页,此处设置2页 设置好之后点击保存
新浪微博博主信息采集方法以及详细步骤
https://www.360docs.net/doc/df16870602.html, 本文介绍使用八爪鱼7.0采集新浪微博博主信息的方法(以艺术分类为例)采集网站: 使用功能点: ●翻页元素设置 ●列表内容提取 相关采集教程: 新浪微博数据采集 豆瓣电影短评采集 搜狗微信文章采集 步骤1:创建采集任务 1)进入主界面选择,选择自定义模式
https://www.360docs.net/doc/df16870602.html, 微博博主信息采集方法以及详细步骤图1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 微博博主信息采集方法以及详细步骤图2
https://www.360docs.net/doc/df16870602.html, 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容 微博博主信息采集方法以及详细步骤图3 步骤2:设置翻页步骤 创建翻页循环,设置翻页元素 1)页面下拉到底部,找到“下一页”按钮,点击选择“循环点击下一页”
https://www.360docs.net/doc/df16870602.html, 微博博主信息采集方法以及详细步骤图4 2)设置翻页步骤:打开流程图,点击“循环翻页”步骤,在右侧点击“自定义” 微博博主信息采集方法以及详细步骤图5 注意:点击右上角的“流程”按钮,即可展现出可视化流程图。
https://www.360docs.net/doc/df16870602.html, 3)如图选择好翻页点击元素的xpath ,点击“确定”,完成翻页步骤的设置 微博博主信息采集方法以及详细步骤图 6 步骤3:采集博主信息 选中需要采集列表中的信息框,创建数据提取列表 1)如图,移动鼠标选中博主信息栏,右键点击,选择“选中子元素” 微博博主信息采集方法以及详细步骤图7
https://www.360docs.net/doc/df16870602.html, 2)然后点击“选中全部” 微博博主信息采集方法以及详细步骤图8 注意:鼠标点击“X”,即可删除不需要字段。 微博博主信息采集方法以及详细步骤图9
微博营销方法与技巧
微博营销规划
目录 一、微博营销的基本法则- 1 - 1)有趣-1- 2)互动-1- 3)真诚-1- 4)乐观开朗-2- 5)宽容-2- 6)个性魅力-2- 二、微博营销技巧总述- 3 - 1)微博的数量不在多而在精-3- 2)个性化的名称-3- 3)巧妙利用模板-4- 4)使用搜索检索,查看与自己相关的容-4- 5)定期更新微博信息-4- 6)善于回复粉丝们的评论-4- 7)#与的灵活运用-5- 8)学会使用私信-5-
9)确保信息真实与透明-5- 10)不能只发企业产品或广告容-5- 三、前期注册技巧- 6 - 1)账号的开通-6- 2)微博装修-6- 3)微博认证-7- 四、中期运营技巧- 7 - 1)运营-7- 1.容建设- 7 - 2.信息的采集和制作- 8 - 3.活动策划- 9 - 4.活动开展步骤- 10 - 2)推广-11- 1.站推广- 11 - 2.站外推广- 11 - 3)涨粉-12- 1.何从0粉丝运营到1000粉丝- 12 - 2.怎样增加粉丝量- 15 - 3.增加转发和互动- 17 - 4.实施中应注意的事项- 17 - 五、后期维护技巧- 18 - 1)客户管理-18- 2)商务合作-18- 3)运营日志-19- 4)数据分析-19- 1.日常报表- 20 -
2.活动分析- 21 - 3.粉丝分析- 24 - 5)团队建设-24- 1.团队构架- 24 - 2.成员考核- 25 - 六、需要注意的“雷区”- 25 - 1)雷区一:盲目跟风,微博是“万金油”?-25- 2)雷区二:未计划就执行,品牌形象难统一-26- 3)雷区三:忽视容本身,迷恋粉丝数增长-26- 4)雷区四:企业微博运营没有想象中那么容易-26- 七、微博营销中哪些不该做- 27 - 1)口水贴、生活贴-27- 2)刷屏-27- 3)频繁发广告-27- 4)频繁别人-28- 5)涉及政治及敏感话题-28-
微博爬虫抓取方法
https://www.360docs.net/doc/df16870602.html, 微博爬虫一天可以抓取多少条数据 微博是一个基于用户关系信息分享、传播以及获取的平台。用户可以通过WEB、WAP等各种客户端组建个人社区,以140字(包括标点符号)的文字更新信息,并实现即时分享。 微博作为一种分享和交流平台,十分更注重时效性和随意性。微博平台上产生了大量的数据。而在数据抓取领域,不同的爬虫工具能够抓取微博数据的效率是质量都是不一样的。 本文以八爪鱼这款爬虫工具为例,具体分析其抓取微博数据的效率和质量。 微博主要有三大类数据 一、博主信息抓取 采集网址:https://www.360docs.net/doc/df16870602.html,/1087030002_2975_2024_0 采集步骤:博主信息抓取步骤比较简单:打开要采集的网址>建立翻页循环(点击下一页)>建立循环列表(直接以博主信息区块建立循环列表)>采集并导出数据。 采集结果:一天(24小时)可采集上百万数据。
https://www.360docs.net/doc/df16870602.html, 微博爬虫一天可以抓取多少条数据图1 具体采集步骤,请参考以下教程:微博大号-艺术类博主信息采集 二、发布的微博抓取 采集网址: 采集步骤:这类数据抓取较为复杂,打开网页(打开某博主的微博主页,经过2次下拉加载,才会出现下一页按钮,因而需对步骤,进行Ajax下拉加载设置)>建立翻页循环(此步骤与打开网页步骤同理,当翻到第二页时,同样需要经过2次下来加载。因而也需要进行Ajax下拉加载设置)>建立循环列表(循环点击每条微博链接,以建立循环列表)>采集
https://www.360docs.net/doc/df16870602.html, 并导出数据(进入每条微博的详情页,采集所需的字段,如:博主ID、微博发布时间、微博来源、微博内容、评论数、转发数、点赞数)。 采集结果:一天(24小时)可采集上万的数据。 微博爬虫一天可以抓取多少条数据图2 具体采集步骤,请参考以下教程:新浪微博-发布的微博采集 三、微博评论采集 采集网址: https://https://www.360docs.net/doc/df16870602.html,/mdabao?is_search=0&visible=0&is_all=1&is_tag=0&profile_fty pe=1&page=1#feedtop 采集步骤:微博评论采集,采集规则也比较复杂。打开要采集的网页(打开某博主的微博主
微博内容提取
微博内容提取 摘要 随着近年来微博等社交软件的使用人数日益增多,微博的隐私发展也成为人们日益关注的问题,然而由于微博没有固定的格式约束使得在微博的研究过程中有一些无意义的“噪音”的干扰,本文主要是为了完成微博的“噪音”过滤问题,实现一个小软件,来将新浪微博等微博中下载到本地的微博来进行过滤,去除其中的噪音,提取出纯净的页面内容,主要工作包括以下几个方面: (1)字符串的查找函数与分割函数的实现。 (2)多个文件的查找的函数的实现。 (3)固定字符串的即表情“噪音”的过滤实现。 (4)具有一定正则文法的“噪音”的过滤实现。 关键字:中文微博,微博,过滤,噪音,正则
Microblogging content extraction Author: Liudi Tutor: Yangkexin Abstract With recent years the number of micro-blog using social software is increasing, the development of micro-blog privacy has become a growing concern,However, due to the micro blog there is no fixed format constraint makes the interference of some meaningless "noise" in the research process of micro blog. the purpose of this paper is to complete the "noise" micro-blog filtering problem, the realization of a small software, to be used for filtering the download to the Sina micro-blog micro-blog etc., remove the noise, extract the page content is pure, the main work includes the following aspects: (1) the search function and the function of the string segmentation. (2) the implementation of the search function for multiple files (3) the filter of the expression "noise" of the fixed string. (4) the filter of a certain regular grammar "noise" of the fixed string. Keywords: Chinese micro-blog,micro-blog,filtering ,noise ,regular
基于微博API的分布式抓取技术
1引言 近年来,社交网络的发展引人注目,参考文献[1]介绍了社交网络的发展现状及趋势。目前,约有一半的中国网民通过社交网络沟通交流、分享信息,社交网络已成为覆盖用户最广、传播影响最大、商业价值最高的Web2.0业务。微博作为一种便捷的媒体交互平台,在全球范围内吸引了数亿用户,已成为人们进行信息交流的重要媒介,用户可以通过微博进行信息记录和交流、娱乐消遣以及社会交往等[2]。 Twitter自2006年由Williams E等人联合推出以来,发展迅猛。Twitter作为一种结合社会化网络和微型博客的新型Web2.0应用形式正风靡国外,其应用涉及商业、新闻教育等社会领域,已成为网络舆论中最具有影响力的一种[3]。 基于微博API的分布式抓取技术 陈舜华1,王晓彤1,郝志峰1,蔡瑞初1,肖晓军2,卢宇2 (1.广东工业大学计算机学院广州510006;2.广州优亿信息科技有限公司广州510630) 摘要:随着微博用户的迅猛增长,越来越多的人希望从用户的行为和微博内容中挖掘有趣的模式。针对如何对微博数据进行有效合理的采集,提出了基于微博API的分布式抓取技术,通过模拟微博登录自动授权,合理控制API的调用频次,结合任务分配控制器高效地获取微博数据。该分布式抓取技术还结合时间触发和内存数据库技术实现重复控制,避免了数据的重复爬取和重复存储,提高了系统的性能。本分布式抓取技术具有可扩展性高、任务分配明确、效率高、多种爬取策略适应不同的爬取需求等特点。新浪微博数据爬取实例验证了该技术的可行性。 关键词:新浪微博;爬取策略;分布式爬取;微博API doi:10.3969/j.issn.1000-0801.2013.08.025 A Distributed Data-Crawling Technology for Microblog API Chen Shunhua1,Wang Xiaotong1,Hao Zhifeng1,Cai Ruichu1,Xiao Xiaojun2,Lu Yu2 (1.School of Computers,Guangdong University of Technology,Guangzhou510006,China; 2.Guangzhou Useease Information Technology Co.,Ltd.,Guangzhou510630,China) Abstract:As more and more users begin to use microblog,people eagerly want to dig interesting patterns from the microblog data.How to efficiently collect data from the service provider is one of the main challenges.To address this issue,a distributed crawling solution based on microblog API was present.The distributed crawling solution simulates microblog login,automatically gets authorized,and control the invoked frequency of the API with a task controller.A time trigger method with memory database was also proposed to avoid extra trivial data duplication and improve efficiency of the system.In the distributed framework,the crawling tasks can be assigned to distributed clients independently,which ensures the high scalability and flexibility of the crawling procedure.The feasibility of the crawler technology according to Sina microblog instance was verified. Key words:Sina microblog,crawling strategy,distributed crawl,microblog API 运营创新论坛 146
微信文章抓取工具详细使用方法
https://www.360docs.net/doc/df16870602.html, 微信文章抓取工具详细使用方法 如今越来越多的优质内容发布在微信公众号中,面对这些内容,有些朋友就有采集下来的需求,下面为大家介绍使用八爪鱼抓取工具去抓取采集微信文章信息。 抓取的内容包括:微信文章标题、微信文章关键词、微信文章部分内容展示、微信所属公众号、微信文章发布时间、微信文章URL等字段数据。 采集网站:https://www.360docs.net/doc/df16870602.html,/ 步骤1:创建采集任务 1)进入主界面,选择“自定义模式”
https://www.360docs.net/doc/df16870602.html, 微信文章抓取工具详细使用步骤1 2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/df16870602.html, 微信文章抓取工具详细使用步骤2 步骤2:创建翻页循环 1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。点击页面中的文章搜索框,在右侧的操作提示框中,选择“输入文字”
https://www.360docs.net/doc/df16870602.html, 微信文章抓取工具详细使用步骤3 2)输入要搜索的文章信息,这里以搜索“八爪鱼大数据”为例,输入完成后,点击“确定”按钮 微信文章抓取工具详细使用步骤4
https://www.360docs.net/doc/df16870602.html, 3)“八爪鱼大数据”会自动填充到搜索框,点击“搜文章”按钮,在操作提示框中,选择“点击该按钮” 微信文章抓取工具详细使用步骤5 4)页面中出现了 “八爪鱼大数据”的文章搜索结果。将结果页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”
https://www.360docs.net/doc/df16870602.html, 微信文章抓取工具详细使用步骤6 步骤3:创建列表循环并提取数据 1)移动鼠标,选中页面里第一篇文章的区块。系统会识别此区块中的子元素,在操作提示框中,选择“选中子元素”
知乎回答采集方法
https://www.360docs.net/doc/df16870602.html, 知乎回答采集方法 本文介绍使用八爪鱼采集知乎回答的方法 采集网站:https://https://www.360docs.net/doc/df16870602.html,/question/29727952 规则下载: 使用功能点: ●分页列表信息采集 https://www.360docs.net/doc/df16870602.html,/tutorialdetail-1/fylb-70.html ●AJAX点击和翻页教程 https://www.360docs.net/doc/df16870602.html,/tutorial/ajaxdjfy_7.aspx?t=1 步骤1:创建采集任务 1)进入主界面,选择“自定义模式”
https://www.360docs.net/doc/df16870602.html, 知乎回答采集方法图1 2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/df16870602.html, 知乎回答采集方法图2 步骤2:创建翻页循环 1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。点击问题,在操作提示框中,选择“采集该元素的文本”
https://www.360docs.net/doc/df16870602.html, 知乎回答采集方法图3 2)将页面下拉到底部,点击“查看更多回答”按钮,在右侧的操作提示框中,选择“更多操作”
https://www.360docs.net/doc/df16870602.html, 知乎回答采集方法图4 选择“循环点击单个按钮”
https://www.360docs.net/doc/df16870602.html, 知乎回答采集方法图5 我们发现,系统自动打开要采集的网页,进入知乎问题回答区。经过一次自动下拉加载,此页面达到最底部,出现“查看更多回答”按钮。因而,我们在执行翻页操作前,需等待网页完全加载出来,即需要设置执行前等待 选中整个“循环翻页”步骤,打开高级选项,设置执行前等待为“3秒”,然后点击 “确定”
网络爬虫开题报告doc
网络爬虫开题报告 篇一:毕设开题报告及开题报告分析 开题报告如何写 注意点 1.一、对指导教师下达的课题任务的学习与理解 这部分主要是阐述做本课题的重要意义 2.二、阅读文献资料进行调研的综述 这部分就是对课题相关的研究的综述落脚于本课题解决了那些关键问题 3.三、根据任务书的任务及文件调研结果,初步拟定执行实施的方案(含具体进度计划) 这部分重点写具体实现的技术路线方案的具体实施方法和步骤了,具体进度计划只是附在后面的东西不是重点南京邮电大学通达学院毕业设计(论文)开题报告文献[5] 基于信息数据分析的微博研究综述[J];研究微博信息数据的分析,在这类研究中,大多数以微博消息传播的三大构件---微博消息、用户、用户关系为研究对象。以微博消息传播和微博成员组织为主要研究内容,目的在于发祥微博中用户、消息传博、热点话题、用户关系网络等的规律。基于微博信息数据分析的研究近年来在国内外都取得了很多成果,掌握了微博中的大量特征。该文献从微博消息传播三大构件的角度,对当前基于信息数据分析的微博研究
进行系统梳理,提出微博信息传播三大构件的概念,归纳了此类研究的主要研究内容及方法。 对于大多用户提出的与主题或领域相关的查询需求,传统的通用搜索引擎往往不能提供令人满意的结果网页。为了克服通用搜索引擎的以上不足,提出了面向主题的聚焦爬虫的研究。文献[6]综述了聚焦爬虫技术的研究。其中介绍并分析了聚焦爬虫中的关键技术:抓取目标定义与描述,网页分析算法和网页分析策略,并根据网络拓扑、网页数据内容、用户行为等方面将各种网页分析算法做了分类和比较。聚焦爬虫能够克服通用爬虫的不足之处。 文献[7]首先介绍了网络爬虫工作原理,传统网络爬虫的实现过程,并对网络爬虫中使用的关键技术进行了研究,包括网页搜索策略、URL去重算法、网页分析技术、更新策略等。然后针对微博的特点和Ajax技术的实现方法,指出传统网络爬虫的不足,以及信息抓取的技术难点,深入分析了现有的基于Ajax的网络爬虫的最新技术——通过模拟浏览器行为,触发JavaScript事件(如click, onmouseover等),解析JavaScript脚本,动态更新网页DOM树,抽取网页中的有效信息。最后,详细论述了面向SNS网络爬虫系统的设计方案,整(转载自:https://www.360docs.net/doc/df16870602.html, 小草范文网:网络爬虫开题报告)体构架,以及各功能模块的具体实现。面向微博的网络爬虫系统的实现是以新浪微博作为抓取的
新浪微博营销策略和时间规划
新浪微博营销策略和时间规划 一、微博营销策略和时间规划 营销策略 (1)根据不同的时期设置不同的标签,永远让系统搜索结果处在第一页,提高曝光率, 吸引眼球; (2)创造有意义的体验和互动,人们才会和你进行交流,成为你的粉丝,对你的广播进 行关注; (3)主动搜索主题相关话题,主动去与用户互动,发展新的粉丝, 与老粉丝经常交流,稳定粉丝群,提高粉丝的忠诚度; (4)善用大众热门话题如#地震#,因为它适合微博的每个人,并且回应时事热点,增加微博的社会实事参与度,贴近广大微博用户的生活; (5)话题:我+营销对象(用中英文对照),这种方式的营销是种双赢的模式,粉丝愿 意接受,并当做时尚潮流热点欣然接受,作为版主,不仅可以盈利也可以凸显我的微博——时尚英语,这一主题,与此同时,企业也可以借此宣传产品,扩大知名度,和用户群体; (6)有规律地对微博进行更新,每天5~10条,保证微博的信息不被用户的其他广播覆 盖掉,但是一小时内不要连发两条,以免消息泛滥,得不到收听用户的重视; (7)上班或上学、午休、下午四点后、晚上8点,抓住这些用户微博在线高峰发帖时间,增加广播的阅读量,转发量以及爆帖的几率; (8)使微博信息的内容有连载性,连载会显著提高粉丝的活跃度,例如按四季的划分连 续发帖,或是星座的顺序轮流广播。增加粉丝的对该系列的广播的关注; (9)不要关注超过50个人,哪怕有100万的粉丝,这样才会显得我的微博的专业性和话语的权威性,以便得到粉丝的认同; (10)定期举办活动,能够带来快速的粉丝增长,或是加话题展开讨论,亲近粉丝增加其忠诚度。 二、内容策略 1.微博内容与企业相关 微博内容可以使企业的产品、服务、活动、文化等,让粉丝能够通过企业发展状况和最 新动态,增加品牌亲和感。
新浪微博运营方案执行计划
新浪微博运营计划方案 一、发布计划 发布时间: 周一至周二、周五: 1、中阿淘、中阿购微博11点各发1条微博 2、中阿淘、中阿购微博17点各发1条微博 周三至周四: 1、中阿淘、中阿购微博10点各发1条微博
2、中阿淘、中阿购微博11点各发1条微博 3、中阿淘、中阿购微博14点各发1条微博 4、中阿淘、中阿购微博17点各发1条微博 二、发布内容: 1、时效性(占25%):电商及网购相关新闻和社会热点话题 2、知识性(占45%):有关产品、品牌、电商、网购、互联网等实用性知识 3、趣味性(占20%):笑话、趣味图、视频等 4、活动(占5%):促销活动信息 注:多用一些幽默、流行网络语,更容易引起共鸣,可以在结尾提出互动性问题或诱导转发评论语言。 三、活动计划 1、微博自发活动手段: 方法一:有奖转发。 发布中阿淘进口产品及品牌推荐介绍或促销抢购活动,粉丝们转发+评论或+@好友就有机会中奖 (@的数量要求10个或以上)。奖品尽量以实物为宜,可选几款进口产品做为奖励。 方法二:有奖征集。 常见的有奖征集主题有广告语、段子、祝福语、创意点子等等。调动用户兴趣来参与,并通过获得奖品可能性的系列性“诱导”,从而吸引参与。 方法三:有奖竞猜。
有奖竞猜是揭晓谜底或答案,最后抽奖。这里面包括猜图,还有猜文字、猜结果、猜价格等方式。 方法四:有奖调查。 有奖调查目前应用的也不多,主要用于收集用户的反馈意见,一般不是直接以宣传或销售为目的。要求粉丝回答问题,并转发和回复微博后就可以有机会参与抽奖。 2、微博网络活动: 有赞绑定微博,发布有赞代付产品活动页面链接,通过粉丝们转发+评论或+@好友就可以让朋友参加代付产品的活动。 3、网络热点活动: 关注网络热点,发起讨论活动。 注意: 1)活动主题要鲜明可与与节假日配合,活动有理 2)活动规则简单明了,门槛放低 3)活动发布时间选在早9-10点或晚上7点以后 4)活动中注意维护和互动 活动备案: 1、任何在微博上没有通过官方活动平台发起的活动,如转发抽奖等,均需向站 方备案; 2、备案方式:私信@微博客服选择“自助服务—活动备案”,提供活动持续时 间、抽奖方式、奖品发放时间等相关信息。 四、互动计划 主动关注目标粉丝 目标粉丝:1、关企业微博活跃的粉丝
基于新浪微博的用户信息爬虫及分析
目录 摘要 ............................................................................................................................................................. I Abstract ........................................................................................................................................................... II 1 引言 . (3) 1.1 选题背景与意义 (3) 1.2 系统开发工具 (3) 1.2.1 vs 2008 (3) 1.2.2 oracle 11g (3) 1.2.3 boost库 (3) 1.2.4 GZIP压缩算法函数库 (3) 1.2.5 JSON格式文件转换函数库 (4) 2 系统需求分析与设计 (5) 2.1 系统需求 (5) 2.1.1 名词说明 (5) 2.1.2 系统功能需求说明 (5) 2.1.3 系统总体功能设计 (7) 2.2 系统数据库构建 (9) 2.2.1 数据库设计 (9) 2.2.2 数据库详细设计 (9) 3 系统详细设计与实现 (12) 3.1 爬虫系统详细设计 (12) 3.1.1 HTTP请求数据包 (12) 3.1.2 HTTP返回数据包 (13) 3.1.3 数据分析与提取 (13) 3.1.4 AnaData类 (13) 3.1.5 数据入库 (15) 3.2服务端详细设计 (16) 3.3客户端详细设计 (17) 3.3.1 登录页面 (17) 3.3.2 注册新用户和忘记密码页面 (18) 3.3.3 用户关注列表查询界面 (19) 3.3.4 微博用户标签分类查询 (20) 3.3.4 发布微博并@列表框中的微博用户昵称 (20) 3.3.5 微博用户昵称模糊搜索 (21) 3.3.6 微博用户微博查询 (21) 4 系统部署与测试 (22) 4.1 系统部署图 (22) 4.2 系统测试 (22) 5 结束语 (29) 参考文献 (30) 致谢 (31)
2.2-微博数据获取处理平台
基于云计算的 微博数据获取分析平台 朱廷劭 中国科学院心理研究所计算网络心理实验室 目录 2016‐7‐14中国科学院大学, University of Chinese Academy of Sciences2 目录 2016‐7‐14中国科学院大学, University of Chinese Academy of Sciences3
平台概述?微博信息概况 2016‐7‐14 中国科学院大学, University of Chinese Academy of Sciences 4 我国网民数已以逾6亿(含移动客户端) 在新浪微博(我国最大的开放社会媒体)上: 日均活跃用户数约7660万月活跃用户数约1.67亿社会媒体兴起,用户在社会媒体上 获取信息、表达自我、进行互动… 数据即行为的记录 社会媒体→在线心理学实验室 平台概述?平台信息概况 2016‐7‐14中国科学院大学, University of Chinese Academy of Sciences 5 传统数据技术已经无法满足海量微博数据的处理要求,而云计算技术可以非常高效的可以非常高效的完成对海量数据的存储和计算任务。 采集 传输处理 存储分析 展示 虚拟化、云计算虚拟化平台: ?基于vSphere,提供实验室私有云 ?虚拟化计算资源(CPU、Memory): 28 * (12*2.1GHz CPU + 128GB Memory) ?虚拟化存储资源(外接存储):5 * 27.3 TB ?网络资源(内网、外网): 8Gbps、20Mbps ?提供便捷的资源管理 目录 2016‐7‐14中国科学院大学, University of Chinese Academy of Sciences 6
如何做好用户运营-新浪微博运营经理金璞总结
运营篇 开源:如何提高注册用户量 关键词:开源注册转化 在开放注册渠道、提高用户注册量上,所有产品都不遗余力,想尽办法抢入口,然后再提高转化率。 一,绑定注册带来更多用户 经过多年发展,互联网产品的注册渠道比较成熟,除了产品自身的注册入口外,还会有和一些站外产品合作、商业推广、绑定注册的渠道。前两种方式已经非常成熟,最后一种方式的应用也非常广泛,对于新出炉或者用户规模小的产品来说是个傍大款的好方式。 绑定注册,就是在其他产品上注册的用户,通过授权也被认为是已注册用户。这种注册方式可以大幅降低获得用户的成本。例如目前常见的第三方应用登录页面,提示可用新浪微 博、QQ、MSN等账号直接登录,就是一种绑定授权的方式。这种方式可以快速增加用户规模。 正所谓“没有永远的朋友,只有永远的利益”,就算你的产品和某集团的某个产品是直接竞争对手,你的产品一样可以和该集团的其他产品有合作机会。只要找到双方共赢的切入点,合作自是水到渠成。 二,如何做好注册转化 注册引导是用户注册进来后的重要环节,是教育用户的第一过程。注册转化是一个让产品经理感到很头疼的细节活。 通常,我们需要通过引导流程告诉用户我们的产品是什么、核心价值是什么、能够为你提供什么服务、你应该怎么用这个产品来满足你的需求等等。产品在注册引导环节会分几步来告诉用户以上内容。用户只有完全通过注册引导流程,到达产品使用界面,才算真正从注册用户转化成为一个真正的用户。 然而这个过程的流失相当严重:从数据统计来看,每增加一步注册引导,将会让注册转化成功率下降10%。成功注册的用户经过了5步的注册引导,基本上就只剩下一半了。但是如 果注册引导流程不做,很难再找到合适的机会让用户能全面了解产品,那么用户因为不知道怎么用而流失掉的概率又会大大增加。 因此,我们需要考虑如何平衡,一方面考虑充分介绍产品功能,一方面防止用户流失。
微博数据采集方法
https://www.360docs.net/doc/df16870602.html, 微博上面有很多我们想要收集的信息,有没有什么简单的方法做到一键收集提取呢。当然是有的,本文介绍使用八爪鱼7.0采集新浪微博数据的方法,供大家学习参考。 采集网站: https://https://www.360docs.net/doc/df16870602.html,/1875781361/FhuTqwUjk?from=page_1005051875781361_profile&wvr=6&m od=weibotime&type=comment#_rnd1503315170479 使用功能点: ●Ajax滚动加载设置 ●分页列表详情页内容提取 步骤1:创建采集任务 1)进入主界面选择,选择自定义模式
https://www.360docs.net/doc/df16870602.html, 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 采集新浪微博数据图2 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容
https://www.360docs.net/doc/df16870602.html, 采集新浪微博数据图3 步骤2:设置ajax页面加载时间 ●设置打开网页步骤的ajax滚动加载时间 ●找到翻页按钮,设置翻页循环 ●设置翻页步骤ajax下拉加载时间 1)在页面打开后,当下拉页面时,会发现页面有新的数据在进行加载
https://www.360docs.net/doc/df16870602.html, 采集新浪微博数据图4 所以需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定 采集新浪微博数据图5 2)将页面下拉到底部,找到下一页按钮,鼠标点击,在右侧操作提示框中,
网站数据抓取能抓取哪些数据
https://www.360docs.net/doc/df16870602.html, 网站数据抓取能抓取哪些数据 互联网数据爆发式增长,且这些数据大多是开放的。通过在线的方式,所有人均可访问和获取这些数据,即网页上直接可见的数据,99%都是可以抓取的。 详细到具体网站,可抓取IT橘子和36Kr的各公司的投融资数据;可抓取知乎/微博/微信等平台的内容;可抓取天猫/淘宝/京东/淘宝等电商的评论及销售数据;可抓取58同城/安居客/Q房网/搜房网上的房源信息;可抓取大众点评/美团网等网站的用户消费和评价;可抓取拉勾网/中华英才/智联招聘/大街网的职位信息...... 网站数据是为我们的需要服务的,先确定好自己的需求,然后选择目标网站,通过写代码/网站数据抓取工具的方式,抓取数据即可。以下是一个八爪鱼采集今日头条网站的完整示例。示例中采集的是今日头条-热点下的新闻标题、新闻来源、发布时间。 采集网站: https://https://www.360docs.net/doc/df16870602.html,/ch/news_hot/ 步骤1:创建采集任务 1)进入主界面选择,选择“自定义模式”
https://www.360docs.net/doc/df16870602.html, 网站数据抓取能抓取哪些数据图1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 网站数据抓取能抓取哪些数据图2
https://www.360docs.net/doc/df16870602.html, 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容 网站数据抓取能抓取哪些数据图3 步骤2:设置ajax页面加载时间 ●设置打开网页步骤的ajax滚动加载时间 ●找到翻页按钮,设置翻页循环 ●设置翻页步骤ajax下拉加载时间
https://www.360docs.net/doc/df16870602.html, 1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定 网站数据抓取能抓取哪些数据图4 注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量
基于Python的新浪微博爬虫研究
龙源期刊网 https://www.360docs.net/doc/df16870602.html, 基于Python的新浪微博爬虫研究 作者:吴剑兰 来源:《无线互联科技》2015年第06期 摘要:对比新浪提供的API及传统的爬虫方式获取微博的优缺点,采用模拟登陆和网页解析技术,将获取的信息存入数据库中并进行分析。基于Python设计实现了新浪微博爬虫程序,可以根据指定的关键词获取相应的微博内容及用户信息。 关键词:新浪微博;Python;爬虫 0 引言 自2009年8月新浪推出微博业务以来,微博逐渐地进入人们的日常生活中。越来越多的人开始加入到社交网络中,与他人互动。继新浪之后,腾讯、网易等也相继推出微博业务,但新浪做为国内微博界的“元老”,仍是广泛受到人们的欢迎。如今,新浪微博用户已达5亿多人。 随着使用人数的直线上升,带来的是信息量的急剧膨胀。每天都有数以万计的信息在奔流。微博通过点赞,转发,评论功能将个人的声音快速放大到社会空间,将个人的行为放大成为社会行为。作为网络新媒体的代表,微博用户产生的大量微博数据以及用户之间的互粉,转发等关系作为真实社会关系的一种写照,为社会网络研究提供了绝佳的研究数据。基于微博的数据研究已成为当今社会科学和计算机科学研究的重点。 1 新浪API API接口使用较为方便,通过一个接口就可以很方便得获取所需的信息,而无须了解具体实现过程。但是新版的新浪API接口却有着很大的限制。最主要的一点,如果要想获得某人的微博个人信息和发表的微博内容,就必须得到对方的授权许可。 新浪API使用OAuth2.0授权机制。授权流程如图1所示。 其中Client指第三方应用,Resource Owner指用户,Authorization Server是我们的授权服务器,ResourceServer是API月艮务器。 首先应用需要先引导用户到某个地址,用户授权后得到access token,然后使用获取的access token来调用API,以此来得到用户的信息和微博的内容。Access_token相当于是令牌,持有相应的令牌才能得到所需。除此以外,access token还有授权有效期,对于测试应用来说 只有一天的时间。
微博页面用户信息抓取采集方法
https://www.360docs.net/doc/df16870602.html, 微博页面用户信息抓取采集方法 本文介绍使用八爪鱼采集器简易模式采集抓取微博页面用户信息的方法。 需要采集微博内容的,在网页简易模式界面里点击微博进去之后可以看到所有关于微博的规则信息,我们直接使用就可以的。 微博页面用户信息抓取步骤1 批量采集微博每个用户界面的信息(下图所示)即在博主个人主页的信息 1、找到微博用户页面信息采集任务然后点击立即使用
https://www.360docs.net/doc/df16870602.html, 微博页面用户信息抓取步骤2 2、简易采集中微博用户页面信息采集的任务界面介绍 查看详情:点开可以看到示例网址; 任务名:自定义任务名,默认为微博用户页面信息采集; 任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组; 网址:用于填写博主个人主页的网址,可以填写多个,用回车分隔,一行一个,将鼠标移动到?号图标和任务名顶部文字均可以查看详细的注释信息; 示例数据:这个规则采集的所有字段信息。
https://www.360docs.net/doc/df16870602.html, 微博页面用户信息抓取步骤3 3、任务设置示例 例如要采集与相关的微博消息 在设置里如下图所示: 任务名:自定义任务名,也可以不设置按照默认的就行 任务组:自定义任务组,也可以不设置按照默认的就行 网址:从浏览器中直接复制博主个人主页的网址,此处以“人民日报”和“雷军”为例。示例网址:https://www.360docs.net/doc/df16870602.html,/rmrb?is_all=1 https://www.360docs.net/doc/df16870602.html,/leijun?refer_flag=1001030103_&is_all=1 设置好之后点击保存
https://www.360docs.net/doc/df16870602.html, 微博页面用户信息抓取步骤4 保存之后会出现开始采集的按钮 微博页面用户信息抓取步骤5
新浪微博运营计划方案三篇
新浪微博运营计划方案三篇篇一:新浪微博运营计划方案 一、发布计划 发布时间: 周一至周二、周五:
1、XX、XX微博11点各发1条微博 2、XX、XX微博17点各发1条微博 周三至周四: 1、XX、XX微博10点各发1条微博 2、XX、XX微博11点各发1条微博 3、XX、XX微博14点各发1条微博 4、XX、XX微博17点各发1条微博 二、发布内容: 1、时效性(占25%):电商及网购相关新闻和社会热点话题 2、知识性(占45%):有关产品、品牌、电商、网购、互联网等实用性知识 3、趣味性(占20%):笑话、趣味图、视频等 4、活动(占5%):促销活动信息 注:多用一些幽默、流行网络语,更容易引起共鸣,可以在结尾提出互动性问题或诱导转发评论语言。 三、活动计划 1、微博自发活动手段: 方法一:有奖转发。 发布XX进口产品及品牌推荐介绍或促销抢购活动,粉丝们转发+评论或+@好友就有机会中奖 (@的数量要求10个或以上)。奖品尽量以实物为宜,可选几款进口产品做为奖励。 方法二:有奖征集。 常见的有奖征集主题有广告语、段子、祝福语、创意点子等等。调动用户兴趣来
参与,并通过获得奖品可能性的系列性“诱导”,从而吸引参与。 方法三:有奖竞猜。 有奖竞猜是揭晓谜底或答案,最后抽奖。这里面包括猜图,还有猜文字、猜结果、猜价格等方式。 方法四:有奖调查。 有奖调查目前应用的也不多,主要用于收集用户的反馈意见,一般不是直接以宣传或销售为目的。要求粉丝回答问题,并转发和回复微博后就可以有机会参与抽奖。 2、微博网络活动: 有赞绑定微博,发布有赞代付产品活动页面链接,通过粉丝们转发+评论或+@好友就可以让朋友参加代付产品的活动。 3、网络热点活动: 关注网络热点,发起讨论活动。 注意: 1)活动主题要鲜明可与节假日配合,活动有理 2)活动规则简单明了,门槛放低 3)活动发布时间选在早9-10点或晚上7点以后 4)活动中注意维护和互动 活动备案: 1、任何在微博上没有通过官方活动平台发起的活动,如转发抽奖等,均需向站方备案;